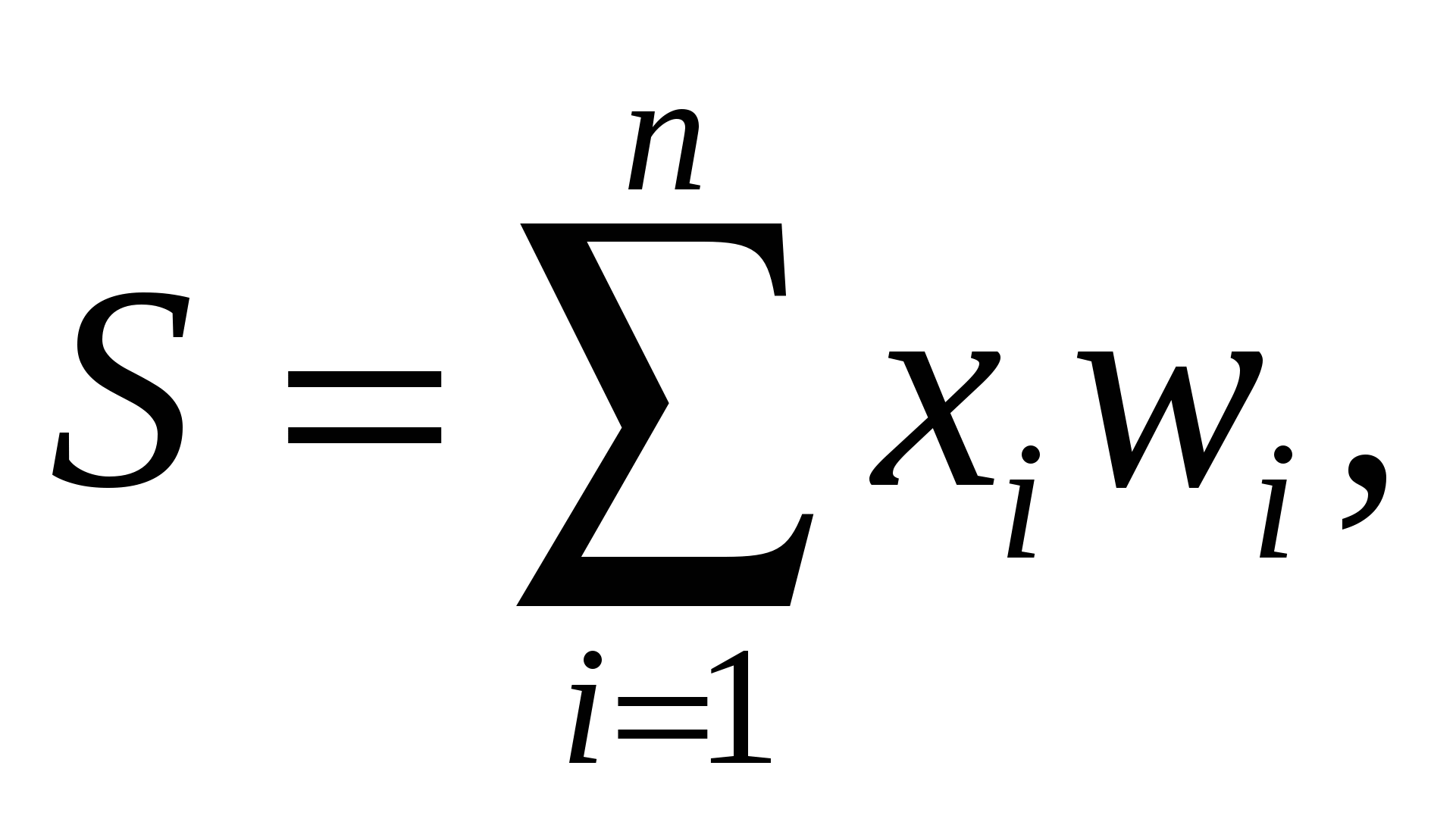Когнитивная система IBM Watson: принципы работы с естественным языком. Суперкомпьютер ватсон
Watson: искусственный интеллект IBM пять лет спустя
На дворе стоял 2012 год, и искусственный интеллект Watson разработки IBM был на гребне своей славы. Он победил двух многократных чемпионов игры Jeopardy! (наш аналог — «Своя игра») в 2011 году, и мир был в шоке. Это была первая широкая и успешная демонстрация компьютера, обрабатывающего естественный язык. И благодаря победе в игре, Watson стал популярнее HAL 9000, хоть и не надолго. Позже, в 2012 году, IBM объявила одного из крупнейших практических партнеров Watson — Кливлендскую клинику, которая захотела включить эту систему в свое дело врачей.
Используя Watson для синтеза огромных сумм данных и создания основанных на фактических данных гипотез, появилась надежда, что система поможет врачам и студентам более точно диагностировать заболевание и выбирать лучшие планы лечения для пациентов.
С тех пор прошло четыре года. Как мы знаем, искусственный интеллект должен учиться быстро. Что изменилось для Watson с тех пор?
Долгая дорога доктора Ватсона
Под капотом Watson всегда был (и остается) программным продуктом DeepQA. Если простыми словами, DeepQA — это сложная архитектура программного обеспечения, которая анализирует, размышляет и отвечает на контент, который скармливают Watson. В 2012 году система работала на 80-терафлопсовом компьютере — машине, способной производить 80 000 000 000 000 операций в секунду — расположенном в Йорктаун Хайтсе, штат Нью-Йорк, с серверами в небольшой комнатке.
IBM считала, что Watson может стать «сверхспособной Siri для бизнеса», и он стал. Сегодня он обозначен как когнитивный компьютер для бизнеса. Или, если точнее, «платформа для когнитивного бизнеса».
Вот чем стал Watson: платформой.
Как и обещалось, Watson 2012 года получил мощное обновление. Он уменьшился в размерах, от большой спальни до четырех коробок из-под пиццы, и теперь доступен в облаке на планшете и смартфоне. Система на 240% продуктивнее своего предшественника и может обрабатывать 28 типов (или модулей) данных, по сравнению с 5, которые были раньше.
В 2013 году IBM открыла исходный код API Watson и теперь предлагает IBM Bluemix, комплексную облачную платформу для сторонних разработчиков для создания и запуска приложений на основе внушительных вычислительных возможностей Watson.
Но один из самых больших шагов, которые проделал Watson к своему нынешнему состоянию, произошел в 2014 году, когда IBM инвестировала 1 миллиард долларов в IBM Watson Group, большой отдел, посвященный работе Watson, на 2000 сотрудников.
В этот момент «доктор Ватсон» вышел из яслей стартапа и стал чувствовать себя значительно увереннее. В некотором смысле он стал «как IMB в каждом аспекте».
Перенесемся в 2016 год: сегодня Watson предлагает больше корпоративных сервисов и решений, чем могло бы уместиться в этой статье, — советник по финансам, автоматизированный представитель по обслуживанию клиентов, поисков — что бы вы ни назвали, Watson это умеет, скорее всего.
По мере развития технологии, стоящей за суперкомпьютером 2012 года, развивалось и позиционирование IBM Watson. И в большей степени это позиционирование касалось медицины.
Встречайте доктора Ватсона
Сегодня задачи Watson в сфере здравоохранения определяет новый отдел под названием Watson Health. Это был стратегический шаг, поскольку со времен подключения Кливлендской клиники в 2012 году с Watson завязалось много похожих партнеров.
В 2014 году, например, IBM анонсировала, что онкологи могут использовать Watson для сбора геномических и медицинских данных и разработки более персонализированного лечения. Watson мог, наконец, позволить онкологам «загружать отпечаток ДНК опухоли пациента, который покажет, какие гены мутировали; и Watson может просеивать тысячи мутаций и определять, какие из них вызвали опухоль, после чего настраивать точную схему лечения».
Не так давно Университет Токио использовал Watson для постановки правильного диагноза 60-летнего пациента с лейкемией за счет сопоставления генетических данных миллионов исследовательских работ на тему рака. Это впечатляющий пример, но пока сложно говорить о похожем применении в каждой сфере медицины.
Хотя IBM удвоила силу Watson и добилась определенного успеха, сделать его практическим во всех смыслах этого слова еще только предстоит. В прошлом году Брэндон Кейм из IEEE Spectrum изложил несколько верных причин, почему «доктору Ватсону» еще только предстоит стать настоящим доктором.
«IBM Watson прошел долгий путь, но его прогресс сравнительно с ожиданиями «мгновенного врыва» делает его достижения менее значимыми, — пишет Кейм. — Медицинский искусственный интеллект сейчас сравним с персональными компьютерами 1970-х. Применение искусственного интеллекта в сфере здравоохранения созреет через годы».
Сложные проблемы в системе здравоохранения вроде качества данных также мешают Watson. Электронные медицинские данные часто заполняются с ошибками и изначально оцифровываются для хранения, а не для поиска в них данных. Наконец, обучение Watson представляет собой изнурительный процесс, особенно потому, что дело касается человеческих жизней.
Поиск быстрых ответов на проблемы пациентов имеет мало чего общего с игрой. Watson придется научиться думать, как хороший врач. То есть ему придется находить правильные фрагменты данных, взвешивать доказательства и делать точные выводы.
Чтобы Watson продолжал прогрессировать, ему также придется идти в ногу с современными достижениями в области ИИ. Самым большим изменением с 2012 года стал рост глубокого обучения — метода ИИ, при котором программа самообучается, используя огромные наборы помеченных данных.
Например, преемник Watson, игровой ИИ AlphaGo от Google, представляет собой программу глубокого обучения, которая научилась играть в го лучше всех в мире.
Очевидно, IBM в курсе, что такое глубокое обучение. В прошлом году она рассказала, что также интегрирует подход глубокого обучения в Watson.
Огромные бюджеты посвящаются эволюции следующего поколения чат-ботов и виртуальных ассистентов, и в этом завязаны самые крупные игроки — включая Google и Facebook. Остается лишь вопрос времени, пока «доктор Ватсон» не станет доступен широкому числу пользователей, может, и под другим именем.
hi-news.ru
IBM Watson: на что способен самый известный суперкомпьютер
Что такое суперкомпьютер
Современные суперкомпьютеры – это несколько серверных компьютеров, объединенных в сеть. Скорость их вычислений измеряется в петафлопсах.
- 1 петафлопс = 1015 операций в секунду
Средняя производительность головного мозга человека — 20 петафлопс. Всего несколько суперкомпьютеров в мире имеют большую производительность, но при этом ни один из них не может заменить человеческий мозг.
В настоящее время в мире существуют несколько сотен суперкомпьютеров. Самые мощные попадают в ежегодный рейтинг ТОП-500. В 2016 году этот рейтинг возглавил китайский Sunway TaihuLight. До этого три года лидерство удерживал тоже китайский компьютер Tianhe-2. У компании IBM в этом рейтинге два суперкомпьютера: Mira и Sequoia. Последний в 2012 году был лидером, а сейчас занимает четвертое место.
Андрей Филатов (генеральный директор IBM в России и странах СНГ) о когнитивных технологияхDr. Watson — самый известный суперкомпьютер
Главное достоинство Watson в том, что он понимает вопросы на естественном языке и отвечает на них, анализируя данные. В 2011 году Watson выиграл у людей в телевикторине Jeopardy! (российский аналог — «Своя игра»).
Watson — это набор технологий применения, которые называются «облачными сервисами». Активнее всего Watson применяется в медицине, помогая диагностировать и лечить рак. В его памяти содержится более 600 000 медицинских заключений. Также он используется в финансовой сфере, юриспруденции, гостиничном бизнесе и многих других отраслях. Более того, даже способен поддержать беседу со знаменитостями.
Области применения IBM Watson
Образование. Школы в США тестируют Teacher Advisor with Watson — когнитивный инструмент, который предлагает советы по улучшению учебных планов и персонализации программ обучения.
Наука. Компания Johnson & Johnson использует Watson для того, чтобы анализировать научную литературу. Из колоссального количества материалов он выбирает необходимые для исследования, и исследование можно проводить намного быстрее и эффективнее.
Безопасность труда. Производитель прокатной стали North Star BlueScope Steel собирается использовать систему Watson Internet of Things, чтобы создать решения по защите рабочих в экстремальных ситуациях. Также рабочие будут носить устройства для сбора и обработки данных. При возникновении опасных для людей условий сведения будут сразу же отправляться руководству North Star.
Кибербезопасность. Киберпреступники взламывают информационные системы предприятий, а потом продают доступ к ним в «чёрном» интернете. Если в одной части земного шара произошёл сбой или мошенничество, система Watson позволит предупредить других пользователей этой системы.
Медицина. Университет Северной Каролины и ещё 12 центров по изучению онкологических заболеваний используют Watson для анализа ДНК пациентов, чтобы затем вырабатывать персонализированные методики лечения.
Ни один врач не в состоянии проанализировать такую огромную выборку информации, только компьютер
Первая в России демонстрация работы платформы Watson ConversationПолную версию видео смотрите на Malina.am
hi-tech.mail.ru
Watson
-
 Hi-News.ru
Hi-News.ru
- Исследования
- IBM Watson выдавал «небезопасные и неправильные» рекомендации по лечению рака
Внутренние документы компании IBM показывают, что эксперты-медики, работающие с суперкомпьютером Watson, обнаружили «многочисленные примеры небезопасных и неправильных рекомендаций по лечению», используя программное обеспечение, сообщает Stat News. Из документов стало понятно, что продукт выдает «зачастую неточные» предположения, что вызывает «серьезные вопросы к процессу создания содержимого и к технологиям в его основе».
Читать далее →
-
Hi-News.ru
- Темы
- Медицина
- Watson: искусственный интеллект IBM пять лет спустя
На дворе стоял 2012 год, и искусственный интеллект Watson разработки IBM был на гребне своей славы. Он победил двух многократных чемпионов игры Jeopardy! (наш аналог — «Своя игра») в 2011 году, и мир был в шоке. Это была первая широкая и успешная демонстрация компьютера, обрабатывающего естественный язык. И благодаря победе в игре, Watson стал популярнее HAL 9000, хоть и не надолго. Позже, в 2012 году, IBM объявила одного из крупнейших практических партнеров Watson — Кливлендскую клинику, которая захотела включить эту систему в свое дело врачей.
Читать далее →
-
Hi-News.ru
- Технологии
- Искусственный интеллект попытается решить проблемы человечества
В последнее время Интернет захлестнула истерия и всеобщая паника касательно мрачного будущего, которое ждёт нас всех, если искусственный интеллект вдруг разовьётся до уровня, когда человечество станет для него обузой. Неужели всё действительно настолько плохо, как нам рассказывали в фильмах «Космическая одиссея 2001» и «Терминатор»? Организаторы фонда поддержки революционных инноваций XPRIZE так не считают, именно поэтому они организовали конкурс на выявление самого полезного для людей и максимально дружелюбного искусственного интеллекта.
Читать далее →
-
Hi-News.ru
- Темы
- Компьютеры
- Суперкомпьютер IBM поможет стать роботу Pepper ещё умнее
Мы уже неоднократно рассказывали вам о роботе Pepper, созданном стараниями компаний SoftBank и Aldebaran Electronics. Также вы наверняка слышали о суперкомпьютере Watson, разработанном специалистами корпорации IBM. Pepper изначально проектировался для того, чтобы общаться с людьми на понятном им языке и быть подспорьем в самых разных областях. Разработчики робота планируют использовать мощность суперкомпьютера Watson для того, чтобы сделать своё детище ещё более похожим на настоящего человека в общении.
Читать далее →
-
- Темы
- Технологии
- Суперкомпьютер Watson поможет бороться с онкологическими заболеваниями
Мы уже неоднократно рассказывали вам о суперкомпьютере Watson, созданном инженерами корпорации IBM. Какие только роли этот компьютер не примерял на себя: он был поваром, продавцом-консультантом и даже одержал победу в телевикторине. Не так давно мощности Watson пустили в новое для него русло – он занялся здравоохранением. Теперь суперкомпьютер будет помогать анализировать раковые опухоли, чтобы найти и рассчитать для пациентов максимально эффективный набор лечебных препаратов.
Читать далее →
-
Hi-News.ru
- Темы
- Гаджеты
- Суперкомпьютер IBM Watson занялся здравоохранением
Суперкомпьютер Watson, названный так в честь основателя корпорации IBM Томаса Уотсона, примерял на себя много самых разных ролей. Он был кулинаром, продавцом-консультантом, изучал наши твиты и даже принял участие в телевикторине, где выиграл 1 миллион долларов, заняв первое место. Но у его создателей всегда были куда более амбициозные планы. К примеру, сделать Watson самым опытным и эффективным консультантом в области здравоохранения.
Читать далее →
-
Hi-News.ru
- Темы
- Исследования
- Искусственный интеллект: насколько умные машины нам нужны?
Искусственный интеллект уже стал фактом в некоторых финансовых и транспортных сегментах, и по мере его распространения в других сферах мы все больше хотим убедиться, что контролируем его, а не наоборот. От «Космической Одиссеи 2001 года» до «Бегущего по лезвию», от «Робокопа» до «Матрицы», когда люди имеют дело с искусственным интеллектом, они неизбежно сталкиваются с мрачной фантазией кинематографистов. Последний фильм Спайка Джонса «Она» и грядущий «Из машины» Алекса Гарленда уже посвящаются творениям искусственного интеллекта, живущим среди нас. Тест Тьюринга выходит на передний план, а мы все так же не можем определить основное отличие чипов и кода от плоти и крови.
Читать далее →
-
Hi-News.ru
- Темы
- Компьютеры
- Суперкомпьютер Watson читает все ваши твиты
Twitter и IBM заключили партнерское соглашение, которое поможет предпринимателям узнать, что о них думают простые обыватели в социальных сетях. Новые инструменты позволят коммерческим компаниям эффективно манипулировать общественным мнением. Очевидно, что без суперкомпьютера здесь не обошлось.
Читать далее →
-
Hi-News.ru
- Темы
- Компьютеры
- Суперкомпьютер Watson пробует себя в роли кулинара
Суперкомпьютер с программой искусственного интеллекта Watson от компании IBM уже пробовал себя в роли продавца-консультанта, а также принимал участие в школьной викторине. А как же насчет других профессий? Оказывается, суперкомпьютер может генерировать кулинарные рецепты для поваров.
Читать далее →
-
Hi-News.ru
- Темы
- Технологии
- IBM купила стилиста для суперкомпьютера «Уотсон»
Группа Watson корпорации IBM купила австралийскую стартап-фирму Cognea, которая специализируется на разработке виртуальных помощников для корпоративных клиентов, таких как банковские колл-центры. Сообщение об этом появилось в блоге IBM в понедельник. Эти усилия вписываются в представление IBM о когнитивной эре вычислений, где машины способны общаться с человеком на одном языке. Некоторые уже выразили опасения по этому поводу.
Читать далее →
-
Hi-News.ru
- Темы
- Технологии
- Искусственный интеллект IBM собрался в школу
Студенты из семи лучших американских университетов информатики получат шанс испытать искусственный интеллект суперкомпьютера, прославившегося в телевикторине Jeopardy. Они смогут сделать это ближайшей осенью.
Читать далее →
-
Hi-News.ru
- Темы
- Технологии
- Суперкомпьютер Watson станет продавцом-консультантом
Суперкомпьютер Watson, принадлежащий корпорации IBM, уже неоднократно примерял на себя самые разные роли. Он уже был доктором, генетиком, экономистом и даже шеф-поваром. Теперь же ему предстоит освоить профессию продавца-консультанта.Читать далее →
-
Hi-News.ru
- Темы
- Технологии
- #MWC | IBM призвала разработчиков мобильных приложений использовать искусственный интеллект
Руководство IBM в ходе выставки Mobile World Congress объявило конкурс среди разработчиков на создание мобильных приложений на когнитивной платформе Watson. Цель данной инициативы — привлечь внимание девелоперов к суперкомпьютеру Watson с искусственным интеллектом.
Читать далее →
-
Hi-News.ru
- Темы
- Технологии
- IBM инвестирует 1 миллиард долларов в суперкомпьютер
IBM заявила, что собирается инвестировать более 1 миллиарда долларов в создание нового подразделения, которое займется развитием Watson («Уотсон»). Технологическая корпорация намерена извлечь как можно больше прибыли от использования возможностей суперкомпьютера, в прошлом соревновавшегося в телевизионной игре-викторине Jeopardy с «живыми» людьми.
Читать далее →
-
Hi-News.ru
- Темы
- Компьютеры
- IBM несет искусственный интеллект в массы
Компания IBM открывает публичный доступ к искусственному интеллекту суперкомпьютера Watson. Начиная с 2014 года, разработчики программного обеспечения смогут создавать «умные» онлайн-сервисы и приложения, пишет газета Financial Times. Двумя месяцами ранее ученые впервые открыли доступ к квантовому компьютеру.
Читать далее →
-
Hi-News.ru
- Темы
- Компьютеры
- IBM представила Институт когнитивных систем
На прошлой неделе IBM открыла «эпоху когнитивных вычислений» на коллоквиуме, посвященном когнитивных системам (CSC), который состоялся в Нью-Йорке. Компания представила новоиспеченный Институт когнитивных систем, который стал результат усилий нескольких университетов, исследовательских институтов и клиентов IBM. В списке первых — Университета Карнеги-Меллона (CMU), Массачусетский технологический институт (MIT), Нью-Йоркский университет (NYU) и Политехнический институт Ренсселера (RPI).
Читать далее →
-
Hi-News.ru
- Темы
- Бизнес и аналитика
- Watson от IBM может свергнуть Google с поискового трона
Если вы думаете, что Google — лучший в мире поисковик (не говоря уж о «Яндексе»), то очень скоро вы можете серьезно ошибиться. Пока одни развлекают людей, другие просто делают мегамонстров: например, Watson в исполнении IBM. Помимо того, что IBM и так известна в корпоративном сегменте и ориентацией на бэкенд, а не фронтенд, ее собственный чемпион Jeopardy может выдать вам молниеносный ответ на любой вопрос.
Читать далее →
hi-news.ru
Суперкомпьютер IBM Watson победил в телевикторине Jeopardy (российский аналог — Своя игра): luckyea77
Участие в «Jeopardy!»
В феврале 2011 года для проверки возможностей Уотсона он принял участие в телешоу Jeopardy! (российский аналог — Своя игра). Его соперниками были Брэд Раттер — обладатель самого большого выигрыша в программе, и Кен Дженнингс — рекордсмен по длительности беспроигрышной серии. Уотсон одержал победу, получив 1 миллион долларов, в то время, как Дженнингс и Раттер получили, соответственно, по 300 и 200 тысяч.
Платформа
Уотсон состоит из 90 серверов Power7 750, каждый из которых содержит по 4 восьмиядерных процессора POWER7. Суммарная оперативная память Уотсона более 15 терабайт.
Система имела доступ к 200 миллионам страниц структурированной и неструктурированной информации объемом в 4 терабайта, включая полный текст Википедии. Во время игры Уотсон не имел доступа к интернету.
Будущее проекта
IBM совместно с Nuance Communications планирует в ближайшие два года разработать продукт, направленный на помощь в диагностировании и лечении пациентов. Также рассматриваются возможности использования в других сферах, таких как оценка политик страхования или эффективности энергопотребления.
История Watson началась в 2006 году, когда Дэвид Феруччи, старший менеджер отделения IBM по семантическому анализу, занялся тестированием одного из самых мощных суперкомпьютеров компании, занимавшего одну из верхних строчек 500 самых производительных машин мира. Феруччи решил попробовать, насколько эффективно машина будет справляться с задачами, поставленными "естественным языком", и предложил ей ответить на 500 вопросов, заданных в уже состоявшихся программах Jeopardy! Результаты оказались катастрофическими: по сравнению с живыми игроками, машина недостаточно быстро "нажимала на кнопку" (то есть была готова к ответу), а в случае, когда она всё-таки могла конкурировать с людьми, количество правильных ответов не превышало 15%
Феруччи заинтересовался причинами такого поведения суперкомпьютера и в итоге в 2007 году смог убедить руководство IBM дать ему команду из 15 человек и от 3 до 5 лет на создание эффективной автоматической системы, способной отвечать на неформализованные вопросы. Такая система пригодилась бы всевозможным колл-центрам, справочным и любым другим службам, обслуживающим клиентов. У IBM уже был успешный опыт создания машины, способной поспорить с интеллектом человека – речь идёт о суперкомпьютере Deep Blue, который в 1997 году победил чемпиона мира по шахматам Гарри Каспарова. Эта победа сделала большую рекламу IBM, но коммерческого применения подобной установке найти так и не удалось. В случае же с системой автоматических ответов на вопросы коммерческий потенциал вполне очевиден.
Принципиальное отличие Watson от Deep Blue заключается в том, что если шахматный автомат имеет дело со строго логическими правилами игры, то машина, распознающая "естественную речь", сталкивается в куда более сложными правилами языка и многочисленными искажениями и отклонениями от них. Но самая большая сложность заключается в том, что люди, сами того не осознавая, общаются в рамках своего культурного и социального контекста. В разговорной речи полно намёков, аллюзий и коннотаций, отсылок к неким общим для конкретной общественной среды фактам, понятиям и явлениям. В их числе и религиозные представления, и политические убеждения, и всевозможные произведения искусства – от книг и картин до кинофильмов и компьютерных игр.
Для эффективной обработки подобной информации используются статистические алгоритмы, позволяющие путём анализа самых разнообразных документов устанавливать связь разных понятий друг с другом. Проще говоря, она определяет, какие слова чаще всего употребляются вместе. К примеру, "Кремль" чаще связан со словами "Россия", "Москва", чуть реже с "Казань", "Нижний Новгород", ещё реже – с "собор", "икона"" и т.п. Хотя эти алгоритмы известны давным-давно, полноценно применять их стало возможно лишь в последнее десятилетие – после кардинального роста производительности вычислительной техники и снижения стоимости накопителей для хранения огромных массивов данных.
Команда Феруччи загружает в память IBM Watson миллионы всевозможных документов – учебники, энциклопедии, справочники, художественную и религиозную литературу. Для анализа вопросов одновременно используется более сотни алгоритмов, предлагающих сотни возможных решений. Затем другие алгоритмы оценивают достоверность потенциальных ответов, отсеивая невозможные в силу объективных причин (например, несоответствия даты события и лет жизни действующих лиц) и маловероятные. Чем больше будет получено одинаковых ответов, тем выше вероятность, что они правильны – в процессе игры, на табло выводится рейтинг из нескольких самых вероятных ответов, помимо чаще всего встречающегося.
К 2008 году IBM Watson переместился из разряда "неудачников" на верхние строчки так называемого "облака победителей", состоящего из людей, в 50% случаев успевающих первыми нажать кнопку, сигнализирующую о готовности к ответу и затем в 85-95% случаев дающих правильный ответ. В IBM даже договорились с продюсерами Jeopardy о проведении осенью 2010 года специальной серии игр с участием Watson и победителей прошлых лет. Для подготовки к этим играм (то есть фактически для совершенствования алгоритмов) был воссоздан примерный интерьер студии викторины и стали проводиться испытания с участием живых игроков и ведущего. При этом, как и полагается, "Ватсон" даёт свои ответы вслух синтезированным компьютерным голосом, чем немало веселит присутствующих.
В ходе "тренировок" выяснился занятный факт: несмотря не весь потенциал Watson, он может не только выигрывать большинство игр, но и проигрывать более половины из них. Причин несколько: от "его величества случая" (возможны ситуации, когда соперник может выиграть, просто повышая ставки, оставив машину банкротом) до специфики правил. Как ни странно, но человек способен быстрее нажать на кнопку, чем машина, и это связано с правилами игры, которые менять нельзя.
Дело в том, что каждый вопрос выводится на экран и зачитывается ведущим, причём нажать на кнопку можно только после окончания чтения вопроса. Watson получает текст вопроса в электронном виде одновременно с его выводом на экран, но даже при этом он не успевает прийти к готовому решению быстрее человека. Пока ведущий читает вопрос, на что уходит шесть-семь секунд, опытный игрок уже может оценить свои шансы дать правильный ответ и готов нажать на кнопку за какие-то десятки миллисекунд. На последующий ответ правила отводят ещё пять секунд.
Нажимая на кнопку, человек рискует: если он не даст правильный ответ на вопрос за 100 единиц, его виртуальный счёт опустеет на ту же сумму. Компьютер не склонен рисковать и выдаёт ответы только после проведения всех расчётов и только в том случае, если у него достаточно сведений для оценки достоверности и вероятности того, что этот ответ правильный. Как это выглядит в процессе игры, можно увидеть на видеролике. Рискуя, живой игрок может выиграть благодаря тому, что вспомнит нужный ответ за имеющиеся в его распоряжении 11-12 секунд.
В чуть более формализованной ситуации, чем телевикторина, алгоритмы Watson способны дать куда более предсказуемые и точные ответы. В частности, глава исследовательского подразделения IBM Джон Келли намерен создать медицинскую версию этого устройства под неофициальным названием Watson M.D. Такая система помогла бы врачам быстро принимать правильные решения с учётом огромного множества данных о пациенте, которые физически невозможно всегда удерживать в памяти. "Ватсон" вполне может заменить живых операционистов в компьютерных и телефонных службах в розничной торговле, в банковской сфере и на транспорте.
Стоимость системы класса IBM Watson на сегодняшний день может составить несколько миллионов долларов, поскольку для её работы требуется по крайней мере один суперкомпьютер IBM за миллион долларов. Келли считает, что в ближайшие десять лет подобная технология может быть реализована на гораздо более дешёвом сервере, а в перспективе такая программа будет работать на компьютере не дороже современного ноутбука.
Знающие английский язык могут сразиться с IBM Watson онлайн на сайте The New York Times.
Суперкомпьютер IBM Watson планируют использовать в службах техподдержки вместо живых операторов. Однако все эти задачи связаны скорее с нахождением правильного ответа на запросы пользователей на базе известной информации. В IBM считают, что настоящий искусственный интеллект должен уметь находить творческие решения, создавать и изобретать новое, а не только анализировать старое.
Для развития креативных способностей Ватсона его создатели выбрали кулинарное искусство. Это весьма удобный испытательный полигон: приготовление пищи — очень «человеческий», интуитивный процесс, слабо поддающийся алгоритмизации и стандартизации. А оценить результат способен любой человек с улицы. Миндально-шоколадное печенье в испанском стиле, клубничный десерт по-эквадорски, помидоры гриль на гренках с шафраном — эти и другие блюда, созданные Ватсоном, уже были приготовлены и с удовольствием съедены в ходе экспериментов. А пару недель назад был опубликован препринт статьи с описанием алгоритмов и математических моделей, которые Ватсон использует для создания оригинальных рецептов.
Любое творческое решение должно одновременно удовлетворять двум критериям — быть новым и быть качественным. Новизны добиться относительно легко, просто комбинируя ингредиенты и приёмы обработки. А вот с качеством дело обстоит намного сложнее. Научить компьютер понимать, каким будет вкус, аромат, фактура и внешний вид блюда, чрезвычайно трудно.
Исходными данными для Ватсона послужили несколько миллионов рецептов, собранных в интернете. Он были пропущены через проверенные алгоритмы обработки естественного языка, которые использовались для победы в викторине и для обучения Ватсона медицине. Из Википедии была извлечена информация о типичных ингредиентах и приёмах обработки, характерных для кухонь разных народов мира. Наконец, Ватсон получил основательные знания в химии и физиологии восприятия человеком вкуса и запаха.
Новые рецепты генерировались на основе существующих с помощью генетического алгоритма, в качестве функции приспособленности использовались значения новизны, приятности и сочетаемости.
Математическая модель оценки новизны рецепта основана на теореме Байеса, был использован так называемый подход "байесова удивления", изначально разработанный для моделирования поведения зрителя при просмотре видео. В двух словах суть метода состоит в том, что измеряется различие между априорной и постериорной вероятностью встретить некое сочетание продуктов в пространстве рецептов при добавлении в него нового. Так, сочетания орехов с шоколадом или горчицы с сосисками являются совершенно банальными и не вызывает почти никакого изменения вероятностей разных сочетаний. А вот сосиски в шоколаде повлияют на эти вероятности гораздо более существенно.
Для оценки приятности использовалась в основном химия. Зная химический состав продуктов и порядок их смешивания и обработки, компьютер вычислял, какие вещества будут определять вкус и запах блюда. Интересно, что запах оказался намного более важным, чем вкус блюда. Наше восприятие вкуса очень сильно связано с запахом и ароматом. Человек различает всего несколько базовых вкусов — кислый, сладкий солёный, горький. В разных культурах выделяют ещё несколько базовых вкусов, например терпкий или умами. А вот разнообразие запахов гораздо больше и они не сводятся к простым базовым сочетаниям.
Наконец, оценка сочетаемости продуктов также опиралась на серьёзную научную базу, в частности, на совместное исследование американских и британских учёных "Сети ароматов и принципы сочетания продуктов", в котором было проанализировано около 50 000 рецептов и построены карты сочетаемости продуктов, характерные для кухонь разных регионов.
В результате было создано приложение, в котором можно задать набор продуктов, национальный стиль и разновидность блюда, после чего Ватсон выдавал набор рецептов, которые можно упорядочить по степени новизны, приятности и сочетаемости. Кроме отдельных блюд, Ватсон умеет создавать целые меню, добиваясь разнообразия и правильных сочетаний блюд благодаря использованию тематического моделирования. Это способ построения модели коллекции текстовых документов, который разбивает коллекцию на темы и определяет к какой теме относится каждый документ. Ватсон применяет эту модель к рецептам — в качестве ключевых слов выступают отдельные ингредиенты, в качестве документов — сами рецепты.
По словам Лава Варшни, одного из авторов методики моделирования творческих способностей, компания уже обсуждает вопрос применения Ватсона с несколькими крупными производителями продуктов и парфюмерии.
Суперкомпьютер IBM Watson победил в телевикторине Jeopardy (российский аналог — Своя игра)
Смотрите также:Робот QboРобот NAOЮмор на кремниевой основеПередачи и документальные фильмы о роботахБеспилотный автомобиль
luckyea77.livejournal.com
принципы работы с естественным языком / Блог компании IBM / Хабр
IBM Watson — одна из первых когнитивных систем в мире. Эта система умеет очень многое, благодаря чему возможности Watson используются во многих сферах — от кулинарии до предсказания аварий в населенных пунктах. В общем-то, большинство возможностей Watson не являются чем-то уникальным, но в комплексе все эти возможности представляют собой весьма мощный инструмент для решения разнообразных вопросов.
Например — распознавание естественного языка, динамическое обучение системы, построение и оценка гипотез. Все это позволило IBM Watson научиться давать прямые корректные ответы (с высокой степенью достоверности) на вопросы оператора. При этом когнитивная система умеет использовать для работы большие массивы глобальных неструктурированных данных, Big Data. Каковы основные принципы работы IBM Watson с языком? Об этом — в продолжении.
Основные сложности распознавания естественного языка
Для человека язык — это средство выражения мысли. Мы используем язык для передачи своего мнения, каких-либо данных и сведений. Можем делать прогнозы и формировать теории. Именно язык — краеугольный камень нашего сознания. При этом, вот парадокс, язык человека очень неточный.Многие термины — нелогичны, и компьютерным системам понять нас бывает очень сложно. Например, как может быть тонким голос? Как можно сгореть со стыда? Для машины это — проблема, для человека же — вполне обыденная вещь. Дело в том, что для правильного ответа на вопрос во многих случаях необходимо учитывать имеющийся контекст. При отсутствии достаточной фактической информации трудно правильно ответить на вопрос, даже если вы можете найти точный ответ на элементы вопроса в буквальном смысле.
Обработка естественного языка — начало
Многие компьютерные системы способны анализировать язык, но при этом проводится поверхностный анализ. Это может иметь смысл, например, для того, чтобы поставить статистически обоснованную оценку тенденций в изменении эмоций на больших массивах информации. Здесь точность передачи информации не слишком важна, поскольку если даже если предположить, что число ошибочно-позитивных результатов примерно равно числу ошибочно-негативных результатов, то они компенсируют друг друга.Но если значение имеют все случаи, то системы, которые работают с поверхностным анализом языка, уже не могут нормально делать свою работу. Ярким примером сказанному может быть задача для голосового помощника любого из мобильных устройств. Если сказать «найди мне пиццу», то помощник выведет список пиццерий. Если же сказать «не ищи мне пиццу в Мадриде», например, система все равно будет искать. Такие системы работают, идентифицируя некоторые ключевые слова и используя определенный набор правил. Результат может быть точным в заданной системе правил, но неправильным.
Глубокая обработка естественного языка
Для того, чтобы научить систему анализировать сложные смысловые конструкции, с учетом эмоций и прочих факторов, специалисты использовали глубокую обработку естественного языка. А именно — вопросно-ответную систему контентной аналитики (Deep Question*Answering, DeepQA). Если требуется большая точность, то приходится использовать дополнительные методы обработки естественного языка. IBM Watson — система глубокой обработки естественного языка. При анализе определенного вопроса, для того, чтобы дать правильный ответ, система старается оценить как можно более обширный контекст. При этом используется не только информация вопроса, но и данные базы знаний. Создание системы, способной провести глубокую обработку естественного языка, позволило решить и другую проблему — анализ огромного количества информации, которая генерируется ежедневно. Это неструктурированная информация, вроде твитов, сообщений социальных сетей, отчеты, статьи и прочее. IBM Watson научился использовать все это для решения задач, поставленных человеком.Когнитивная система IBM Watson
Watson — это уже иной уровень вычислительных возможностей. Система умеет разделять определенные высказывания на естественном языке и находить связи между этими высказываниями. При этом Watson справляется с задачей, во многих случаях, даже лучше человека, при этом обработка данных идет гораздо быстрее, работа ведется с гораздо большими объемами — человек на такое просто неспособен.Основные характеристики когнитивной системы
Система работает в таком порядке:1. Получив вопрос, Watson выполняет его синтаксический анализ, чтобы выделить основные особенности вопроса.
2. Система генерирует ряд гипотез, просматривая корпус в поисках фраз, которые с некоторой долей вероятности могут содержать необходимый ответ. Для того чтобы вести эффективный поиск в потоках неструктурированной информации, нужны совершенно другие вычислительные возможности * их называют когнитивными системами. (не очень понимаю последнее предложение и роль звёздочки)
3. Система выполняет глубокое сравнение языка вопроса и языка каждого из возможных вариантов ответа, применяя различные алгоритмы логического вывода.
Это трудный этап. Существуют сотни алгоритмов логического вывода, и все они выполняют разные сравнения. Например, одни выполняют поиск совпадающих терминов и синонимов, вторые рассматривают временные и пространственные особенности, тогда как третьи анализируют подходящие источники контекстуальной информации.
4. Каждый алгоритм логического вывода выставляет одну или несколько оценок, показывающих, в какой степени возможный ответ следует из вопроса, в той области, которая рассматривается данным алгоритмом.
5. Каждой полученной оценке затем присваивается весовой коэффициент по статистической модели, которая фиксирует, насколько успешно справился алгоритм с выявлением логических связей между двумя аналогичными фразами из этой области в “период обучения” Watson. Эта статистическая модель может быть использована впоследствии для определения общего уровня уверенности системы Watson в том, что возможный вариант ответа следует из вопроса.
6. Watson повторяет процесс для каждого возможного варианта ответа до тех пор, пока не найдет ответы, которые будут иметь больше шансов оказаться правильными, чем остальные.
Как уже говорилось выше, для правильного ответа на вопрос системе необходимо обращаться к дополнительным источникам данных. Это могут быть учебники, мануалы, FAQ, новости и все прочее. Watson за считанные секунды обрабатывает огромные массивы информации для получения правильного ответа. При этом найденное содержимое тоже проверяется, отсеиваются устаревшие и бесполезные данные.
Элементы когнитивной системы
Общий смысл текста Watson выводит из полученной информации, из дополнительной базы. При этом используется заголовок документа, часть текста документа или весь текст.
Когнитивные системы, их способы сбора, запоминания и извлечения информации схожи с тем, как анализирует информацию человек. При этом когнитивные системы могут передавать информацию и действовать. Вот примеры поведенческих конструктов, которые используются в этом случае:
— способность создавать и проверять гипотезы; — способность разбивать на составляющие и строить логические выводы о языке; — способность извлекать и оценивать полезную информацию (такую как даты, местоположения и характеристики).
Без этих способностей ни компьютер, ни человек не смогут определить правильную взаимосвязь между вопросами и ответами. Когнитивные процессы более высокого порядка могут достичь высокого уровня понимания, ориентируясь на основные способы поведения. Для того чтобы понять что-то, мы должны уметь разделить информацию на более мелкие элементы, которые достаточно хорошо упорядочены на рассматриваемом уровне. Физические процессы у человека протекают совсем не так, как процессы в космическом масштабе или на уровне элементарных частиц. Так же и когнитивные системы предназначены для работы на уровне человека, хотя они представляют огромное множество людей.
В связи с этим понимание языка начинается с понимания более простых правил языка – не только формальной грамматики, но и неформальных соглашений, которые наблюдаются в повседневном использовании.
Зачем все это?
Сейчас когнитивная система IBM Watson, благодаря многолетнему обучению и совершенствованию, может выполнять работу в самых разных сферах. Здесь и медицина, и кулинария, и лингвистика, и решение бизнес-задач с задачами научными.
Изначально у специалистов был выбор — сделать систему универсальной или специализированной. У каждого из вариантов есть свои достоинства и недостатки, но выбор был сделан в сторону универсальности.
Компания уже много раз убедилась в правильности совершенного выбора — перед IBM Watson открылось огромное количество возможностей. Например, когнитивная система помогает найти индивидуальный метод лечения раковых заболеваний, или составить оригинальнейший рецепт, или наладить бизнес-процесс в компании. Множество проблем решено, но еще больше только предстоит решить.
habr.com
Суперкомпьютер IBM Watson усвоил знания 2-го курса медицинского вуза
На другом фронте дата-майнинга IBM демонстрирует ещё более значительные успехи. Разработчики суперкомпьютера IBM Watson (который способен отвечать на вопросы, разбираясь в массиве неструктурированных данных) продолжают накачивать его БД медицинской информацией. По их словам, уже сейчас компьютер усвоил всю информацию, которую должен знать студент медицинского колледжа. И это только начало обучения. Вполне возможно, что разработчиков IBM Watson вдохновляет сериал «Доктор Хаус». Из этого фильма широкие массы впервые смогли узнать, как работает врач-диагност. Мы видим, что его работа исключительно формальна и напоминает интеллектуальную головоломку, а ведь IBM Watson является чемпионом в интеллектуальном шоу Jeopardy — игре, где нужно быстро отвечать на вопросы (российским клоном является «Своя игра»). Компьютер гораздо лучше человека приспособлен для решения таких головоломок, потому что здесь требуется широкая эрудиция и очень глубокие познания. В то же время обыкновенные врачи отлично диагностируют часто встречающиеся болезни (список 100 самых распространённых диагнозов), но если встречается что-то необычное, то у врача обычно не хватает ни опыта, ни знаний.
Сейчас IBM Watson приспосабливают для ответа на вопросы вроде «Чем болен данный пациент с данным набором симптомов и данной историей болезни?», снабжая его всей необходимой информацией для этого. При постановке диагнозов IBM Watson использует тот же самый алгоритм ответов на вопросы, что и в игре Jeopardy.
Консультантом IBM в данном проекте является д-р Элиот Сигал (Eliot Siegal) из Мэрилендского университета. Он уже был свидетелем создания подобных программ для диагностики болезней в 70-е и 80-е годы, но все они были неудачными, пишет журнал Forbes.
Полтора года назад д-р Сигал помог программистам из IBM определить круг медицинских журналов и учебников, необходимых компьютеру для обучения на первое время, а также на какие вопросы его нужно учить отвечать для начала. Watson начал читать издания из национальной медицинской базы PubMed и десятки учебников. Вскоре он уже смог отвечать на вопросы на текстах и экзаменах, которые сдают студенты медицинского колледжа. Разумеется, ни один студент не смог бы усвоить такой же объём информации, поэтому IBM Watson здесь был вне конкурса.
Затем Watson начал пробовать решать известные клинико-патологические головоломки, которые публикуются в каждом номере журнала New England Journal of Medicine. Обучение происходит таким же образом, как на первом этапе, когда компьютер всё лучше и лучше отвечал на вопросы Jeopardy, пока не достиг чемпионского уровня среди людей. Так и здесь, точность диагнозов IBM Watson постепенно растёт.
Следующий этап обучения будет более сложным. В компьютер загрузят записи с историями болезней пациентов, так что Watson получит сведения о тех методах лечения, которые в реальности применялись на практике, и об их эффективности. Потом нужно пополнить его базу подробными массивами данных по отдельным болезням, например, по лейкемии — такие записи ведутся в медицинских институтах, которые специализируются на изучении той или иной болезни.
Хотя сейчас компьютеры широко используются в качестве справочных инструментов для постановки диагнозов, но IBM Watson — это система совершенно иного уровня. В перспективе IBM Watson должен стать идеальным врачом-диагностом, который путём анализа симптомов и истории болезни пациента способен поставить диагноз и назначить самое вероятное лечение.
По прогнозу разработчиков, через три-пять лет Watson будет готов для первых пилотных тестов по лечению реальных пациентов, а через 8–10 лет эти компьютеры могут найти широкое применение в больницах в качестве диагностического инструмента.
Дополнительную информацию о применении IBM Watson в медицине и дополнительную литературу можно найти здесь.
habr.com
IBM и его суперкомпьютер
Сегодня стартует серия статей о компаниях, которые внесли значительный вклад в развитие разработок в области искусственного интеллекта. Сегодня речь пойдет об IBM и легендарной разработке Watson.
IBM
International Business Machines (IBM) — крупнейшая американская компания, занимающаяся производством аппаратного и программного обеспечения. IBM одна из первых начала заниматься разработками в области искусственного интеллекта (ИИ). В настоящее время компания является не только одним из лидеров в этой сфере, но и оказывает значительную финансовую помощь молодым, перспективным компаниям в сфере ИИ.
История основания
История IBM начинается с изобретения статистического табулятора, прибора для ускоренной обработки результатов переписи населения. Идею использования для этой цели перфокарт подсказал высокопоставленный чиновник Джон Шоу Биллингс, а реализовал ее молодой американский изобретатель, Герман Холлерит, будущий основатель IBM (и будущий зять Биллингса). К слову, в 1890 году, изобретение Холлерита, позволило сократить сроки обработки результатов переписи с восьми лет до одного года. Так появилась предшественница IBM — компания Tabulating Machine Company. В 1943 началась эра компьютеров IBM. Начиная со знаменитого «Марк I» (1941), способного выполнять три операции, IBM прошла сложный путь до создания своего выдающегося IBM Watson, способного понимать вопросы, сформулированные на естественном языке, и находить на них ответы в своей базе данных.
Суперкомпьютер IBM
Работа над IBM Watson началась в 2007 году. Задача изначально состояла в том, чтобы создать компьютер, который смог бы понимать естественный язык и отвечать на вопросы в режиме реального времени. Уже в начале 2011 года на американской телевикторине Jeopardy (Русский аналог «Своя игра») Watson в трех выпусках программы обыграл рекордсменов игры Кена Дженнингса, одержавшего до этого 74 победы, и Брэда Руттера, заработавшего за все время своего участия сумму в 3,2 млн. долларов. Компьютер не оставил соперникам ни единого шанса на победу. Благодаря высокой скорости реакции, компьютер быстрее всех «нажимал на кнопку». «Знание», которые продемонстрировал суперкомпьютер, были получены путем индексации огромного числа текстов на его жестком диске. Особо следует отметить тот факт, что во время испытания компьютер не был подключен к интернету!
Профессии Watson
Доктор
Самая значимая область применения суперкомпьютера Watson — здравоохранение. В настоящее время более 15 крупных американских клиник и лечебных учреждений используют программу IBM Watson Health, с помощью которой врачи могут задать свой вопрос суперкомпьютеру. Watson способен проанализировать огромное количество данных и поставить правильный диагноз. Он умеет выдвигать гипотезы, самообучаться. Отметим также, что в будущем IBM планирует выпуск устройств, наблюдающих за работой человеческого мозга в режиме реального времени с помощью чипов-имплантов TrueNorth. Благодаря этой технологии станет возможна идентификация приближающихся эпилептических приступов.
Продавец-консультант
Ещё одна отрасль, которую освоил суперкомпьютер — это торговля. Уотсон запрограммирован отвечать на вопросы посетителей интернет — магазина. Он может рекомендовать лучшие варианты покупки, к примеру, посоветовать выбор одежды исходя из погодных условий, типа местности и цели использования. Планируется использовать подобных продавцов при помощи мобильных устройств.
Повар
Данный проект был разработан совместно с редакцией знаменитого кулинарного журнала Bon Appetit. Компьютеру была предоставлена огромная база данных, содержащая 9000 различных рецептов. Watson генерирует свои рецепты исходя из собственной «фантазии», учитывая, однако, вкусовые предпочтения человека. В будущем планируется запустить приложение для домашних поваров.
Аналитик
Watson будет собирать, систематизировать и анализировать информацию, полученную из социальной сети Twitter. Суперкомпьютер сможет собрать мнения людей о той или иной компании, также он может прогнозировать будущий спрос на товары, учитывая, например, время года.
neuronus.com