Сколько операций в секунду современный компьютер может выводить? Сколько операций в секунду выполняет компьютер
Сколько операций в секунду современный компьютер может выводить?
Если уже вы начали говорить о количестве операций в секунду, то могу сказать, что в этом случае мощность компьютеров меряется в flops, т.е в количестве операций с плавающей точкой в секунду (по простому что-то типа обычного десятичного числа, в форме типо 51,1535434 ). Почему именно числа с плавающей точной объяснять не буду, т.к. читать курс компьютерной арифметики нет желания :)
Для действительно огромных вычислений уже давно люди создали и до сих пор разрабатывают все более мощные "суперкомпьютеры". Их используют в специфических целях, например для прогноза погоды, моделирования ядерных взрывов, к примеру установив суперкомпьютер в систему водоснабжения, можно сделать так, что он будет проводить мониторинг, анализировать полученные данные и будет выявлять вероятные проблемы еще задолго до их возникновения.
На сегодняшний день самым мощным суперкомпьютером( ru.wikipedia.org/wiki/Суперком... ) является Jaguar( ru.wikipedia.org/wiki/Jaguar_(суперкомпьютер) ), его производительность( top500.org/lists/2009/11/press... ) 1.75 petaflop/s, а максимально теоретически возможная 2,3 петафлопс (приставка пета это *10^15, т.е. 1 750 000 000 000 000 операций с плавающей точкой в 1 секунду).
Только в случае суперкомпьютеров такое измерение производительности не всегда является корректным, т.к. количество операция в секунду зависит от типа задачи выполняемой этим компьютером, возможен такой вариант, что суперкомпьютеру для выполнения задачи нужно часто обращаться к периферийным устройствам(например проводить какой-то мониторинг, как с системой водоснабжения) или считывать, или записывать много информации, тогда у него явно будет производительность, измеряемая в флопсах ниже, т.к. это не основная его цель.
Современный настольный компьютер имеет производительность порядка 0.1 Терафлопс. Но если говорить об обычных, настольных компьютерах, то здесь тоже количество операций в секунду не всегда решающий фактор, т.к. если компьютер предназначен для игр, то ему более важна производительность видеокарты, а не процессора. И опятьже это зависит от задачи, поставленной компьютеру. Серверные компьютерыы будут быстрее в этом плане, т.к. обычно напичканы более дорогими игрушками, да они и созданы для таких вещей. Сегодня при желании можно в компьютер поставить 2 восьмиядерных процессора (core i7).
vorum.ru
Как и зачем мерить FLOPSы / Блог компании Intel / Хабр
Давайте сначала немного разберемся с терминами и определениями. Итак, FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Здесь используется слово «вычислительных», так как микропроцессор умеет выполнять и другие инструкции с такими операндами, например, загрузку из памяти. Такие операции не несут полезной вычислительной нагрузки и поэтому не учитываются.
Значение FLOPS, опубликованное для конкретной системы, – это характеристика прежде всего самого компьютера, а не программы. Ее можно получить двумя способами – теоретическим и практическим. Теоретически мы знаем сколько микропроцессоров в системе и сколько исполняемых устройств с плавающей точкой в каждом процессоре. Все они могут работать одновременно и начинать работу над следующей инструкцией в конвеере каждый цикл. Поэтому для подсчета теоретического максимума для данной системы нам нужно только перемножить все эти величины с частотой процессора – получим количество FP операций в секунду. Все просто, но такими оценками пользуются, разве что заявляя в прессе о будущих планах по построению суперкомпьютера.
Практическое измерение заключается в запуске бенчмарка Linpack. Бенчмарк осуществляет операцию умножения матрицы на матрицу несколько десятков раз и вычисляет усредненное значение времени выполнения теста. Так как количество FP операций в имплементации алгоритма известно заранее, то разделив одно значение на другое, получим искомое FLOPS. Библиотека Intel MKL (Math Kernel Library) содержит пакет LAPAСK, — пакет библиотек для решения задач линейной алгебры. Бенчмарк построен на основе этого пакета. Cчитается, что его эффективность находится на уровне 90% от теоретически возможной, что позволяет бенчмарку считаться «эталонным измерением». Отдельно Intel Optimized LINPACK Benchmark для Windows, Linux и MacOS можно качать здесь, либо взять в директории composerxe/mkl/benchmarks, если у вас установлена Intel Parallel Studio XE.
Очевидно, что разработчики высокопроизводительных приложений хотели бы оценить эффективность имплементации своих алгоритмов, используя показатель FLOPS, но уже померянный для своего приложения. Сравнение измеренного FLOPS с «эталонным» дает представление о том, насколько далека производительность их алгоритма от идеальной и каков теоретический потенциал ее улучшения. Для этого всего-навсего нужно знать минимальное количество FP операций, требуемое для выполнения алгоритма, и точно измерить время выполнения программы (ну или ее части, выполняющей оцениваемый алгоритм). Такие результаты, наряду с измерениями характеристик шины памяти, нужны для того, чтобы понять, где реализация алгоритма упирается в возможности аппаратной системы и что является лимитирующим фактором: пропускная способность памяти, задержки передачи данных, производительность алгоритма, либо системы.
Ну а теперь давайте покопаемся в деталях, в которых, как известно, все зло. У нас есть три оценки/измерения FLOPS: теоретическая, бенчмарк и программа. Рассмотрим особенности вычисления FLOPS для каждого случая.
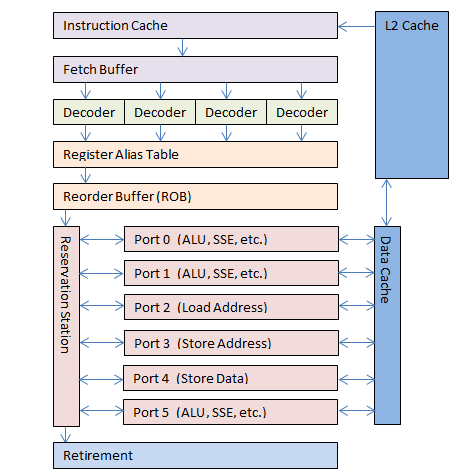
Теоретическая оценка FLOPS для системы Чтобы понять, как подсчитывается количество одновременных операций в процессоре, давайте взглянем на устройство блока out-of-order в конвеере процессора Intel Sandy Bridge.
Здесь у нас 6 портов к вычислительным устройствам, при этом, за один цикл (или такт процессора) диспетчером может быть назначено на выполнение до 6 микроопераций: 3 операции с памятью и 3 вычислительные. Одновременно могут выполняться одна операция умножения (MUL) и одна сложения (ADD), как в блоках x87 FP, так и в SSE, либо AVX. С учетом ширины SIMD регистров 256 бит мы может получить следующие результаты:
8 MUL (32-bit) и 8 ADD (32-bit): 16 SP FLOP/cycle, то есть 16 операций с плавающей точкой одинарной точности за один такт. 4 MUL (64-bit) и 4 ADD (64-bit): 8 DP FLOP/cycle, то есть 8 операций с плавающей точкой двойной точности за один такт.
Теоретическое пиковое значение FLOPS для доступного мне 1-сокетного Xeon E3-1275 (4 cores @ 3.574GHz) составляет: 16 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 228 GFLOPS SP 8 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 114 GFLOPS DP
Запуск бенчмарка Linpack Запускам бенчмарк из пакета Intel MKL на системе и получаем следующие результаты (порезано для удобства просмотра):
Здесь нужно сказать, как именно учитываются FP операции в бенчмарке. Как уже упоминалось, тест заранее «знает» количество операций MUL и ADD, которые необходимы для перемножения матриц. В упрощенном представлении: производится решение системы линейных уравнений Ax=b (несколько тысяч штук) путем перемножения плотных матриц действительных чисел (real8) размером MxK, а количество операций сложения и умножения, необходимых для реализации алгоритма, считается (для симметричной матрицы) Nflop = 2*(M^3)+(M^2). Вычисления производятся для чисел с двойной точностью, как и для большинства бенчмарков. Сколько операций с плавающей точкой действительно выполняется в реализации алгоритма, пользователей не волнует, хотя они догадываются, что больше. Это связано с тем, что выполняется декомпозиция матриц по блокам и преобразование (факторизация) для достижения максимальной производительности алгоритма на вычислительной платформе. То есть нам нужно запомнить, что на самом деле значение физических FLOPS занижено за счет неучитывания лишних операций преобразования и вспомогательных операций типа сдвигов.
Оценка FLOPS программы Чтобы исследовать соизмеримые результаты, в качестве нашего высокопроизводительного приложения будем использовать пример перемножения матриц, сделанный «своими руками», то есть без помощи математических гуру из команды разработчиков MKL Performance Library. Пример реализации перемножения матриц, написанный на языке С, можно найти в директории Samples пакета Intel VTune Amplifier XE. Воспользуемся формулой Nflop=2*(M^3) для подсчета FP операций (исходя из базового алгоритма перемножения матриц) и померим время выполнения перемножения для случая алгоритма multiply3 при размере симметричных матриц M=4096. Для того, чтобы получить эффективный код, используем опции оптимизации –O3 (агрессивная оптимизация циклов) и –xavx (использовать инструкции AVX) С-компилятора Intel для того, чтобы сгенерировались векторные SIMD-инструкции для исполнительных устройств AVX. Компилятор нам поможет узнать, векторизовался ли цикл перемножения матрицы. Для этого укажем опцию –vec-report3. В результатах компиляции видим сообщения оптимизатора: «LOOP WAS VECTORIZED» напротив строки с телом внутреннего цикла в файле multiply.c.
На всякий случай проверим, какие инструкции сгенерированы компилятором для цикла перемножения.$icl –g –O3 –xavx –S По тэгу __tag_value_multiply3 ищем нужный цикл — инструкции правильные.
$vi muliply3.s
Результат выполнения программы (~7 секунд)
нам дает следующее значение FLOPS = 2*4096*4096*4096/7[s] = 19.6 GFLOPS Результат, конечно, очень далек от того, что получается в Linpack, что объясняется исключительно квалификционной пропастью между автором статьи и разработчиками библиотеки MKL.
Ну, а теперь дессерт! Собственно то, ради чего я затеял свое исследование этой, вроде бы скучной и давно избитой, темы. Новый метод измерения FLOPS.
Измерение FLOPS программы Существуют задачи в линейной алгебре, программную имплементацию решения которых очень сложно оценить в количестве FP операций, в том смысле, что нахождение такой оценки само является нетривиальной математической задачей. И тут мы, что называется, приехали. Как считать FLOPS для программы? Есть два пути, оба экспериментальных: трудный, дающий точный результат, и легкий, но обеспечивающий приблизительную оценку. В первом случае нам придется взять некую базовую программную имплементацию решения задачи, скомпилировать ее в ассемблерные инструкции и, выполнив их на симуляторе процессора, посчитать количество FP операций. Звучит так, что резко хочется пойти легким, но недостоверным путем. Тем более, что если ветвление исполнения задачи будет зависеть от входных данных, то вся точность оценки сразу поставится под сомнение.
Идея легкого пути состоит в следующем. Почему бы не спросить сам процессор, сколько он выполнил FP инструкций. Процессорный конвеер, конечно же, об этом не ведает. Зато у нас есть счетчики производительности (PMU – вот тут про них интересно), которые умеют считать, сколько микроопераций было выполнено на том или ином вычислительном блоке. С такими счетчиками умеет работать VTune Amplifier XE.
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
- Создаем новый проект и указываем в качестве target application наше приложение matrix.
- Выбираем профиль Lightweight Hotspots (который использует технологию сэмплирования счетчиков процессора Hadware Event-based Sampling) и копируем его для создания пользовательского профиля. Обзываем его My FLOPS Analysis.
- Редактируем профиль, добавляем туда новые процессорные счетчики событий процессора Sandy Bridge (Events). На них остановимся чуть подробнее. В их названии зашифрованы исполнительные устройства (x87, SSE, AVX) и тип данных, над которыми выполнялась операция. Каждый такт процессора счетчики складывают количество вычислительных операций, назначенных на исполнение. На всякий случай мы добавили счетчики на все возможные операции с FP:
- FP_COMP_OPS_EXE. SSE_PACKED_DOUBLE – векторы (PACKED) данных двойной точности (DOUBLE)
- FP_COMP_OPS_EXE. SSE_PACKED_SINGLE – векторы данных одинарной точности
- FP_COMP_OPS_EXE. SSE_SCALAR_DOUBLE – скалярые DP
- FP_COMP_OPS_EXE. SSE_ SCALAR _SINGLE – скалярные SP
- SIMD_FP_256.PACKED_DOUBLE – векторы AVX данных DP
- SIMD_FP_256.PACKED_SINGLE – векторы AVX данных SP
- FP_COMP_OPS_EXE.x87 – скалярые данные x87
Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE. Удостоверимся, что данные события собраны для нашего цикла в функции multiply3 (переключившись в Source View):
FLOPS = 4 *34.6Gops/7s = 19.7 GFlops Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.
habr.com
О лживых постах в ВК или сколько операций в секунду выполняет мозг человека / Хабр
Для измерения вычислительной мощности компьютеров используется единица измерения, называемая флопс (flops, flop/s). Флопс показывает, сколько операций с плавающей запятой выполняет компьютер за одну секунду. Кроме того, для измерения вычислительной мощности используется такое понятие, как тактовая частота. Тактовая частота процессора показывает, какое количество основных операций выполняет процессор в секунду, и измеряется в герцах. Основная операция, выполняемая процессором, может включать в себя множество операций с плавающей запятой, поэтому результаты измерения в флопсах и герцах различаются. Если вы найдете у себя на рабочем столе иконку «Мой компьютер», кликните по ней правой копкой мыши, в выпадающем меню откроете свойства, то истина для вас откроется. Найдите в открывшемся окне заголовок «Ситема», и там, напротив слова «процессор» будет указана тактовая частота вашего процессора. Скорее всего она будет иметь такой вид: «2.10 GHz». Число может незначительно отличаться. Так вот, 1 GHz — это 1000000000 герц, или один миллиард операций в секунду. Из этого следует, что при тактовой частоте 2.10 гигагерца проц выполняет 2100000000 операций в секунду. Это конечно побольше, чем 1016. При измерении в флопсах число возрастет в несколько раз.
Идем дальше. Суперкомпьютер Titan компании Cray inc. имеет приблизительную вычислительную мощность 20 петафлопс. 1 петафлопс равен 10^15 флопс. Можете сами подсчитать, какое получится число и сколько у него нулей. Как сказал один поэт: «Это ж долбануться...»
Теперь о головном мозге. Тут все не так просто, как с компьютерами. На современном этапе развития нейробиологии довольно трудно подсчитать вычислительную мощность мозга, и сравнить его с компьютером. Однако и так понятно, что мы не можем выполнять те же операции, что выполняет наш ноутбук с такой же скоростью и в таких же объемах. Очевидно, что комп мощнее, да? А вот и нет.
Давайте разберемся подробнее, как он работает.
Мозг — это биологическая нейронная сеть. Нейронная сеть состоит из нейронов, (в случае с мозгом — это клетки мозга), каждый из которых связан с другими нейронами. Место связи нейронов называется синапсом. Через синапс от одного нейрона передается химический или электрический импульс другому нейрону. Количество нейронов в головном мозге человека примерно равно 100000000000 (ста миллиардам). Данные в из разных источников немного различаются, но в целом картина схожа. Каждый из этих нейронов имеет от 7000 до 10000 синапсов. В среднем, через один синапс проходит 10 импульсов в секунду, т.е. мы имеем тактовую частоту 10 герц на одну синоптическую связь. А теперь занимательная математика: 100000000000 нейронов мы умножаем на 10000 их синоптических связей и умножаем все это на 10 герц. Мы получаем число с шестнадцатью нолями после единицы, а иначе 10^16. Так вот откуда взялось загадочное число 1016. Видимо оно просто трансформировалось в ходе бесконечного перепоста из паблика в паблик. И оказывается, что наш мозг имеет бОльшую вычислительную мощность, чем суперкомпьютер Titan. В конечном итоге автор поста о 1016 операциях в секунду был прав.
habr.com
FLOPS - это... Что такое FLOPS?
FLOPS (также flops, flop/s, флопс или флоп/с) (акроним от англ. FLoating-point Operations Per Second, произносится как флопс) — внесистемная единица, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Существуют разногласия насчёт того, допустимо ли использовать слово FLOP, и что оно может означать. Некоторые считают, что FLOP и FLOPS — синонимы, другие же полагают, что FLOP (или flop или флоп, от англ. FLoating point OPeration) — это просто количество операций с плавающей запятой (например, требуемое для исполнения данной программы).Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от FLOPS, образуемые путём использования кратных приставок системы СИ.
Флопс как мера производительности
Как и большинство других показателей производительности, данная величина определяется путём запуска на испытуемом компьютере тестовой программы, которая решает задачу с известным количеством операций и подсчитывает время, за которое она была решена. Наиболее популярным тестом производительности на сегодняшний день является программа Linpack, используемая, в том числе, при составлении рейтинга суперкомпьютеров TOP500.
Одним из важнейших достоинств показателя флопс является то, что он до некоторых пределов может быть истолкован как абсолютная величина и вычислен теоретически, в то время как большинство других популярных мер являются относительными и позволяют оценить испытуемую систему лишь в сравнении с рядом других. Эта особенность даёт возможность использовать для оценки результаты работы различных алгоритмов, а также оценить производительность вычислительных систем, которые ещё не существуют или находятся в разработке.
Границы применимости
Несмотря на кажущуюся однозначность, в реальности флопс является достаточно плохой мерой производительности, поскольку неоднозначным является уже само его определение. Под «операцией с плавающей запятой» может скрываться масса разных понятий, не говоря уже о том, что существенную роль в данных вычислениях играет разрядность операндов, которая также нигде не оговаривается. Кроме того, величина флопс подвержена влиянию очень многих факторов, напрямую не связанных с производительностью вычислительного модуля, таких как: пропускная способность каналов связи с окружением процессора, производительность основной памяти и синхронность работы кэш-памяти разных уровней.
Всё это, в конечном итоге, приводит к тому, что результаты, полученные на одном и том же компьютере при помощи разных программ, могут существенным образом отличаться, более того, с каждым новым испытанием разные результаты можно получить при использовании одного алгоритма. Отчасти эта проблема решается соглашением об использовании единообразных тестовых программ (той же LINPACK) с усреднением результатов, но со временем возможности компьютеров «перерастают» рамки принятого теста и он начинает давать искусственно заниженные результаты, поскольку не задействует новейшие возможности вычислительных устройств. А к некоторым системам общепринятые тесты вообще не могут быть применены, в результате чего вопрос об их производительности остаётся открытым.
Так, например, 24 июня 2006 года общественности был представлен суперкомпьютер MDGrape-3, разработанный в японском исследовательском институте RIKEN (Йокогама), с рекордной теоретической производительностью в 1 Пфлопс. Однако данный компьютер не является компьютером общего назначения и приспособлен для решения узкого спектра конкретных задач, в то время как стандартный тест LINPACK на нём выполнить невозможно в силу особенностей его архитектуры.
Также высокую производительность на специфичных задачах показывают графические процессоры современных видеокарт и игровые приставки. К примеру, заявленная производительность игровой приставки Xbox 360 составляет 1 Тфлопс, а приставки PlayStation 3 и вовсе 2 Тфлопс, что ставит их в один ряд с суперкомпьютерами начального уровня. Столь высокие показатели объясняются тем, что указана производительность над числами 32-битного формата[1][2], тогда как для суперкомпьютеров обычно указывают производительность на 64-разрядных данных[3][4]. Кроме того, данные приставки и видео-процессоры рассчитаны на операции с трёхмерной графикой, хорошо поддающиеся распараллеливанию, однако эти процессоры не в состоянии выполнять многие задачи общего назначения, и их производительность сложно оценить классическим тестом LINPACK[5] и тяжело сравнить с другими системами.
Причины широкого распространения
Несмотря на большое число существенных недостатков, показатель флопс продолжает с успехом использоваться для оценки производительности, базируясь на результатах теста LINPACK. Причины такой популярности обусловлены, во-первых, тем, что флопс, как говорилось выше, является абсолютной величиной. А во-вторых, очень многие задачи инженерной и научной практики в конечном итоге сводятся к решению систем линейных алгебраических уравнений, а тест LINPACK как раз и базируется на измерении скорости решения таких систем. Кроме того, подавляющее большинство компьютеров (включая суперкомпьютеры) построены по классической архитектуре с использованием стандартных процессоров, что позволяет использовать общепринятые тесты с большой достоверностью.
Для подсчета максимального количества FLOPS для процессора нужно учитывать, что современные процессоры в каждом своём ядре содержат несколько исполнительных блоков каждого типа (в том числе и для операций с плавающей точкой), работающих параллельно, и могут выполнять более одной инструкции за такт. Данная особенность архитектуры называется суперскалярность и впервые появилась ещё в самом первом процессоре Pentium в 1993 году. Современное ядро Intel Core 2 так же является суперскалярным и содержит 2 устройства вычислений над 64-битными числами с плавающей запятой, которые могут завершать по 2 связанные операции (умножение и последующее сложение, MAC) в каждый такт, теоретически позволяющих достичь пиковой производительности до 4-х операций за 1 такт в каждом ядре[6][7]. Таким образом, для процессора, имеющего в своём составе 4 ядра (Core 2 Quad) и работающего на частоте 3.5ГГц, теоретический предел производительности составляет 4х4х3.5=56 гигафлопс, а для процессора, имеющего 2 ядра (Core 2 Duo) и работающего на частоте 3ГГц — 2х4х3=24 гигафлопс, что хорошо согласуется с практическими результатами, полученными на тесте LINPACK. Типичная производительность теста LINPACK составляет 80-95 % от теоретического максимума.
Обзор производительности реальных систем
Из-за высокого разброса результатов теста LINPACK, приведены примерные величины, полученные путём усреднения показателей на основе информации из разных источников. Производительность игровых приставок и распределённых систем (имеющих узкую специализацию и не поддерживающих тест LINPACK) приведена в справочных целях в соответствии с числами, заявленными их разработчиками. Более точные результаты с указанием параметров конкретных систем можно получить, например, на сайте The Performance Database Server.
Суперкомпьютеры
- Компьютер ЭНИАК, построенный в 1946 году, при массе 27 т и энергопотреблении 150 кВт, обеспечивал производительность в 300 флопс
- IBM 709 (1957) — 5 Кфлопс
Планы:
- Fujitsu FX-10 (2012) — 23 Пфлопс
- Intel планирует к 2020 году создать суперкомпьютер производительностью 4 Эфлопс[13]
- По личному мнению Ректора МГУ Садовничего, высказанного в октябре 2011 года, в МГУ через пару лет (к 2014 году) может появиться суперкомпьютер производительностью до 10 Эфлопс[14] В декабре появилось сообщение о начале проектирования 10 ПФлопс компьютера для МГУ[15].
- К 2018—2020 годам планируется увеличить мощность суперкомпьютера Саровского ядерного центра до 1 эксафлопс[16].
Процессоры персональных компьютеров
- AMD Athlon 64 2,211 ГГц (2003) — 8 Гфлопс[17]
- AMD Athlon 64 X2 4200+ 2,2 ГГц (2006) — 13.2 Гфлопс
- Intel Core 2 Duo 2,4 ГГц (2006) — 19,2 Гфлопс[18]
- AMD Athlon II X4 640 (ADX640W) 3.0 ГГц (2010) — 37.39 Гфлопс
- Intel Core 2 Quad Q8300 2,5 ГГц — 40 Гфлопс[19]
- Intel Core i7-975 XE 3,33 ГГц (2009) — 53.328 Гфлопс[20]
- CPU AMD Phenom II X6 1075T (HDT75TFB) 3.0 ГГц/6core/ 3+6Мб/125 Вт/4000 МГц Socket AM3 — 55.6094 Гфлопс[21]
- Intel Core i5-2500K 3.3-3.7 ГГц (2011) — 105,6-118 Гфлопс[22]
- Intel Atom[уточнить] — 2,1 Гфлопс
Карманные компьютеры
- КПК на основе процессора Samsung S3C2440 400 МГц (архитектура ARM9) — 1,3 Мфлопс
- Intel XScale PXA270 520 МГц — 1,6 Мфлопс
- Intel XScale PXA270 624 МГц — 2 Мфлопс
- Samsung Exynos 4210 2х1600 МГц — 84 Мфлопс
Распределённые системы
Данные приведены по состоянию на 26 июля 2011 года
- Bitcoin — более 161.9 Пфлопс одинарной точности (оценочно, так как bitcoin не использует операций с плавающей точкой[23])[24]
- Folding@home — более 6,5 Пфлопс[25]
- BOINC — более 6,1 Пфлопс[26]
- SETI@home — более 549 Тфлопс[27]
- Einstein@Home — более 490 Тфлопс[28]
- Rosetta@home — более 105 Тфлопс[29]
Игровые приставки
Указаны операции с плавающей точкой над 32-разрядными данными
GPU-процессоры
Теоретическая производительность (FMA; гигафлопсы):
Человек и калькулятор
Калькулятор не случайно попал в одну категорию вместе с человеком, поскольку хотя он и является электронным устройством, содержащим процессор, память и устройства ввода/вывода, режим его работы кардинально отличается от режима работы компьютера. Калькулятор выполняет одну операцию за другой с той скоростью, с какой их запрашивает человек-оператор. Время, проходящее между операциями, определяется возможностями человека и существенно превышает время, которое затрачивается непосредственно на вычисления. Можно сказать, что в среднем производительность обычного карманного калькулятора составляет 10 флопс.
Человек, пользуясь лишь ручкой и бумагой, выполняет операции с плавающей запятой очень медленно и часто с большой ошибкой. Говоря о производительности нашего вычислительного аппарата, придётся использовать такие единицы как миллифлопс и даже микрофлопс.
См. также
Примечания
- ↑ http://ixbtlabs.com/articles3/video/rv670-part1-page1.html floating-point ALUs .. support for FP32 precision
- ↑ http://insidehpc.com/2009/07/01/personal-gpu-supercomputer-for-the-contrarian-puts-4-tflops-in-1u/ these are single precision GPU peak numbers
- ↑ http://www.top500.org/faq/what_hpl_benchmark HPL is a software package that solves a dense linear system in double precision (64 bits)
- ↑ [1] [2] HPL Faq entries for precision
- ↑ Exploiting the Performance of 32 bit FP Arithmetic in Obtaining 64 bit Accuracy (Revisiting Iterative Refinement for Linear Systems)
- ↑ SSE, SSE2 & SSE3 max throughput: 4 Flop / cycle
- ↑ The net result is that you can now process 2 DP adds and 2 DP multiplies per clock, or 4 FLOPS per cycle. (DP)
- ↑ 1 2 [ http://24gadget.ru/gallery/index/slider/3128/12 Суперкомпьютер Fujitsu K] (рус.)
- ↑ IBM создала самый мощный суперкомпьютер в мире (рус.), Lenta.ru, 9 июня 2008 года
- ↑ Японский суперкомпьютер обогнал по производительности китайский (рус.)
- ↑ Lawrence Livermore’s Sequoia Supercomputer Towers above the Rest in Latest TOP500 List (англ.)
- ↑ Agam Shah (IDG News), Titan supercomputer hits 20 petaflops of processing power // PCWorld, Computers, Oct 29, 2012 (англ.)
- ↑ Intel планирует увеличить мощность суперкомпьютеров в 500 раз к 2020 г. (рус.)
- ↑ Сверхмощный суперкомпьютер может появиться в МГУ в ближайшие годы (рус.) «Я думаю, что в ближайшие год-два в Московском университете будет создан супервычислитель уже эксафлопсной скорости, до 10 эксафлопс (10 тысяч петафлопс).»
- ↑ Последователь Ломоносова
- ↑ Мощность суперкомпьютера в Сарове может достигнуть максимума к 2020 г. РИА Новости (23 февраля 2012). Архивировано из первоисточника 31 мая 2012. Проверено 24 февраля 2012.
- ↑ iXBT: Факты и предположения об архитектуре AMD Opteron и Athlon 64
- ↑ http://download.intel.com/support/processors/core2duo/sb/core_E6000.pdf (pdf) «E6600 2.40 GHz 19.20» GFlops
- ↑ http://download.intel.com/support/processors/core2quad/sb/core_Q8000.pdf (pdf) «Q8300 4 MB 1333 MHz 2.5 GHz 75833 40.00»
- ↑ http://download.intel.com/support/processors/corei7ee/sb/core_i7-900_d_x.pdf (pdf) «i7-975 Base 3.33 GHz, 101101 CTP, 53.328 GFLOPS»
- ↑ НИКС: Сводные таблицы тестирования Intel Linpack x64 Решение системы из 10000 уравнений
- ↑ [3] http://www.intel.com/support/processors/sb/CS-032815.htm
- ↑ bitcoin выполняет вычисления хеш функции sha256, каждое из которых оценивается в 6350 операций над целыми числами или в 12700 операций над 32-битными плавающими числами http://forum.bitcoin.org/index.php?topic=4689.0
- ↑ Bitcoin Watch
- ↑ Folding@Home
- ↑ BOINC
- ↑ BOINCstats:SETI@home
- ↑ BOINCstats:Einstein@Home
- ↑ BOINCstats:Rosetta@home
- ↑ PSP Specs Revealed Processing speed, polygon rate and lots more. // IGN Entertainment, 2003. «PSP CPU CORE…FPU, VFPU (Vector Unit) @ 2.6GFlops»
- ↑ SONY COMPUTER ENTERTAINMENT INC. TO LAUNCH ITS NEXT GENERATION COMPUTER ENTERTAINMENT SYSTEM, PLAYSTATION®3 IN SPRING 2006 (англ.)
- ↑ Update: How many FLOPS are in game consoles? | TG Daily
- ↑ 1 2 Сравнительная таблица графических карт NVIDIA GeForce
- ↑ 1 2 3 Сравнительные таблицы графических карт AMD (ATI) Radeon
Ссылки
dic.academic.ru
Тфлопс - это... Что такое Тфлопс?
FLOPS (или flops или flop/s)(акроним от англ. Floating point Operations Per Second, произносится как флопс) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от FLOPS, образуемые путём использования стандартных приставок системы СИ.
Флопс как мера производительности
Как и большинство других показателей производительности, данная величина определяется путём запуска на испытуемом компьютере тестовой программы, которая решает задачу с известным количеством операций и подсчитывает время, за которое она была решена. Наиболее популярным тестом производительности на сегодняшний день является программа LINPACK, используемая, в том числе, при составлении рейтинга суперкомпьютеров TOP500.
Одним из важнейших достоинств показателя флопс является то, что он до некоторых пределов может быть истолкован как абсолютная величина и вычислен теоретически, в то время как большинство других популярных мер являются относительными и позволяют оценить испытуемую систему лишь в сравнении с рядом других. Эта особенность даёт возможность использовать для оценки результаты работы различных алгоритмов, а также оценить производительность вычислительных систем, которые ещё не существуют или находятся в разработке.
Границы применимости
Несмотря на кажущуюся однозначность, в реальности флопс является достаточно плохой мерой производительности, поскольку неоднозначным является уже само его определение. Под «операцией с плавающей запятой» может скрываться масса разных понятий, не говоря уже о том, что существенную роль в данных вычислениях играет разрядность операндов, которая также нигде не оговаривается. Кроме того, величина флопс подвержена влиянию очень многих факторов, напрямую не связанных с производительностью вычислительного модуля, таких как: пропускная способность каналов связи с окружением процессора, производительность основной памяти и синхронность работы кэш-памяти разных уровней.
Всё это, в конечном итоге, приводит к тому, что результаты, полученные на одном и том же компьютере при помощи разных программ, могут существенным образом отличаться, более того, с каждым новым испытанием разные результаты можно получить при использовании одного алгоритма. Отчасти эта проблема решается соглашением об использовании однообразных тестовых программ (той же LINPACK) с осреднением результатов, но со временем возможности компьютеров «перерастают» рамки принятого теста и он начинает давать искусственно заниженные результаты, поскольку не задействует новейшие возможности вычислительных устройств. А к некоторым системам общепринятые тесты вообще не могут быть применены, в результате чего вопрос об их производительности остаётся открытым.
Так, например, 24 июня 2006 года общественности был представлен суперкомпьютер Йокогама), с рекордной теоретической производительностью в 1 Пфлопс. Однако данный компьютер не является компьютером общего назначения и приспособлен для решения узкого спектра конкретных задач, в то время как стандартный тест LINPACK на нём выполнить невозможно в силу особенностей его архитектуры.
Также, высокую производительность на специфичных задачах показывают графические процессоры современных видеокарт и игровые приставки. К примеру, заявленная производительность игровой приставки Xbox 360 составляет 1 Тфлопс, а приставки PlayStation 3 и вовсе 2 Тфлопс, что ставит их в один ряд с суперкомпьютерами начального уровня. Столь высокие показатели обеспечиваются тем, что операции с трёхмерной графикой, которые они в основном выполняют, очень хорошо поддаются распараллеливанию, что с успехом используется в графических процессорах. Однако эти процессоры не в состоянии выполнять большинство задач общего назначения, и их производительность не поддаётся оценке теста LINPACK и сравнению с другими системами.
Причины широкого распространения
Несмотря на большое число существенных недостатков, показатель флопс продолжает с успехом использоваться для оценки производительности, базируясь на результатах теста LINPACK. Причины такой популярности обусловлены, во-первых, тем, что флопс, как говорилось выше, является абсолютной величиной. А, во-вторых, очень многие задачи инженерной и научной практики, в конечном итоге, сводятся к решению систем линейных алгебраических уравнений, а тест LINPACK как раз и базируется на измерении скорости решения таких систем. Кроме того, подавляющее большинство компьютеров (включая суперкомпьютеры), построены по классической архитектуре с использованием стандартных процессоров, что позволяет использовать общепринятые тесты с большой достоверностью. Как показано на процессорах Intel Core 2 Quad Q9450 2.66ГГц @3.5ГГц и Intel Core 2 Duo E8400 3000 МГц (2008) программа LINPACK не использует решения алгебраических выражений, так как любая операция не может идти быстрее, чем 1 такт процессора. Так для процессоров Intel Core 2 Quad один такт требует один-два герца. Так как для задач с плавающей запятой: деление/умножение, сложение/вычитание — требуется намного больше одного такта, то видно, что выдать 48 Гигафлопс и 18,5 гигафлопса соответственно данные процессоры не могли. Часто вместо операции деления с плавающей запятой используется загрузка данных в режиме ДМА из оперативной памяти в стек процессора. Так работает программа LINPACK в некоторых тестах, но, строго говоря, результат не является значением флопс.
Примечание: замечание о невозможности выполнения более одной операции за такт абсолютно некорректно, так как все современные процессоры в каждом своем ядре содержат несколько исполнительных блоков каждого типа (в том числе и для операций с плавающей точкой) работающих параллельно и могут выполнять более одной инструкции за такт. Данная особенность архитектуры называется суперскалярность и впервые появилась еще в самом первом процессоре
Обзор производительности реальных систем
Из-за высокого разброса результатов теста LINPACK, приведены примерные величины, полученные путём осреднения показателей на основе информации из разных источников. Производительность игровых приставок и распределённых систем (имеющих узкую специализацию и не поддерживающих тест LINPACK) приведена в справочных целях в соответствии с числами, заявленными их разработчиками. Более точные результаты с указанием параметров конкретных систем можно получить, например, на сайте The Performance Database Server.
Суперкомпьютеры
- Компьютер ЭНИАК, построенный в 1946 году, при массе 27 т и энергопотреблении 150 кВт, обеспечивал производительность в 300 флопс
- IBM 709 (1957) — 5 кфлопс
- БЭСМ-6 (1968) — 1 Мфлопс (операций деления)
- Cray-1 (1974) — 160 Мфлопс
- БЭСМ-6 на базе Эльбрус-1К2 (1980-х) — 6 Мфлопс (операций деления)
- Cray Y-MP (1988) — 2,3 Гфлопс
- ASCI Red (1993) — 1 Тфлопс
- Blue Gene/L (2006) — 478,2 Тфлопс
- Jaguar (суперкомпьютер) (2008) — 1,059 Пфлопс
- IBM Roadrunner (2008) — 1,105 Пфлопс [1]
- IBM Sequoia (2012) — 20 Пфлопс [2]
Персональные компьютеры
Процессоры
- Intel Core 2 Duo E8400 3.0ГГц (2008) — 18.6 Гфлопс При использовании стандартной версии LINPACK 10
- Intel Core 2 Duo E8400 3.0ГГц @4.0ГГц (2008) — 25 Гфлопс (LINPACK Benchmark 10.0 64-бит) в Windows Vista x64 Ultimate SP1
- Intel Core 2 Quad Q9450 2.66ГГц @3.5ГГц — 48 ГФлопс (LINPACK Benchmark 10.0 64-бит) в Windows 2003sp2 x64
Карманные компьютеры
Распределённые системы
Данные приведены по состоянию на 23 июня 2008 года
Игровые приставки
- Dreamcast — 1,4 Мфлопс
- Xbox — 6,3 Гфлопс
- PlayStation 2 — 6,2 Гфлопс
- Sony PlayStation Portable — 2,6 Мфлопс
- Gamecube — 10,5 Мфлопс
- Microsoft Xbox 360 — 1 Тфлопс
- Sony PlayStation 3 — 2 Тфлопс [8]
Человек и калькулятор
Калькулятор неслучайно попал в одну категорию вместе с человеком, поскольку, хотя он и является электронным устройством, содержащим процессор, память и устройства ввода/вывода, режим его работы кардинально отличается от режима работы компьютера. Калькулятор выполняет одну операцию за другой с той скоростью, с какой их запрашивает человек-оператор. Время, проходящее между операциями, определяется возможностями человека и существенно превышает время, которое затрачивается непосредственно на вычисления. Можно сказать, что в среднем производительность обычного карманного калькулятора составляет 10 флопс.
Человек, пользуясь лишь ручкой и бумагой, выполняет операции с плавающей запятой очень медленно и, часто, с большой ошибкой. Говоря о производительности нашего вычислительного аппарата, придётся использовать такие единицы как миллифлопс и даже микрофлопс. Тем не менее, мозг человека в реальном времени может выполнять столь сложные операции как синтез и распознавание речи и образов, координацию в пространстве и множество других, недоступных пока даже самым мощным суперкомпьютерам.
Примечания
- ↑ IBM создала самый мощный суперкомпьютер в мире(рус.), Lenta.ru, 9 июня 2008 года
- ↑ IBM создаст мощнейший суперкомпьютер(рус.)
- ↑ При использовании нестандартной версии LINPACK BENCHMARK 2007 года, реализующей все преимущества 64-битного процессора, это число поднимается до 1 Гфлопс
- ↑ Folding@Home
- ↑ BOINC
- ↑ SETI at home
- ↑ Einstein@Home — Server Status
- ↑ SONY COMPUTER ENTERTAINMENT INC. TO LAUNCH ITS NEXT GENERATION COMPUTER ENTERTAINMENT SYSTEM, PLAYSTATION®3 IN SPRING 2006(англ.)
См. также
Ссылки
Wikimedia Foundation. 2010.
dic.academic.ru
MIPS (GIPS- giga- миллиард операций в секунду)
Определения
Архитектура Вычислительной системы: АЛУ, ДК, СОЗУ=Регистры PC-prgram counter- счетчик (указатель) инструкций
Процессор (устройство, отвечающее за выполнение арифметических, логических и операций управления, записанных в машинном коде
Микропроце́ссор —процессор реализованный в виде одной микросхемы[1] или комплекта из нескольких специализированных микросхем[2] (в противоположность реализации процессора в виде электрической схемы на элементной базе общего назначения или в виде программной модели).
Первые микропроцессоры появились в 1970-х и применялись в электронных калькуляторах, в них использовалась двоично-десятичная арифметика 4-х битных слов. Вскоре их стали встраивать и в другие устройства, например терминалы, принтеры и различную автоматику. Доступные 8-битные микропроцессоры с 16-битной адресацией позволили в середине 1970-х создать первые бытовые микрокомпьютеры.
Разместив целый ЦПУ на одном чипе сверxбольшой интеграции удалось значительно снизить его стоимость. Несмотря на скромное начало, непрерывное увеличение сложности микропроцессоров привело к почти полному устареванию других форм компьютеров (см. историю вычислительной
техники), в настоящее время один или несколько микропроцессоров используются в качестве вычислительного элемента во всём, от мельчайших встраиваемых систем и мобильных устройств до огромных мейнфреймов и суперкомпьютеров.
С начала 1970-х широко известно, что рост мощности микропроцессоров следует закону Мура, который утверждает что число транзисторов на интегральной микросхеме удваивается каждые 18 месяцев. В конце 1990-х главным препятствием для разработки новых микропроцессоров стало тепловыделение (TDP) из-за утечек тока и других факторов[3].
Некоторые авторы относят к микропроцессорам только устройства, реализованные строго на одной микросхеме. Такое определение расходится как с академическими источниками[4], так и с коммерческой практикой (например, варианты микропроцессоров Intel и AMD в корпусах типа SECC и подобных, такие как Pentium II — были реализованы на нескольких микросхемах- называемых микропроцессорным комплектом).
В настоящее время, в связи с очень незначительным распространением процессоров, не являющихся микропроцессорами, в бытовой лексике термины «микропроцессор» и «процессор» практически равнозначны.
Микроконтроллер- процессор с ОЗУ и ПЗУ и широким набором контроллеров, в том числе переферийных, и специализированных процессоров, реализованный в виде одной микросхемы. Центральный (управляющий) процессор обычно средней производительности, меньшей чем у микропроцессоров того-же уровня технологии. Его основная задача управлять конроллерами и другими спецпроцессорами (DSP)
Параметры МП
Архитектура
Разрядность процессора (32х 64х 86х – разрядность внутренних регистров. Разрядность команд).
Система команд, семейство
Тактовая частота процессора
Быстродействие (интегральный параметр- MIPS=MOPS/FLOPS
Параметры Внешней(их) шины(шиш) и интрерфейсов –разрядность, частота (FBUS)
Напряжение питания (или несколько)
Энергопотребление, удельное потребление Вт/флоры, Вт/операцию,Гфлопс/Вт тип теплоотвода
Корпус (тип корпуса по ISO=размеры, кол и тип выводов)
Показатель производительности Гфлопс/ГГц
MIPS (GIPS- giga- миллиард операций в секунду)
MIPS(англ. Million Instructions Per Second) — единица измерения быстродействия, равная одному миллиону инструкций в секунду. Если указано быстродействие в MIPS, то, как правило, оно показывает, сколько миллионов инструкций в секунду выполняет процессор в некотором синтетическом тесте.
BogoMIPS(от англ. bogus (поддельный) и MIPS — англ. Millions of Instructions Per Second) — в ядре Линукс ненаучный способ измерения производительности компьютера, предназначенный для калибровки внутренних циклов. Термин изобрёл Линус Торвальдс в 1993. BogoMIPS шутливо определяется как «сколько миллионов раз в секунду компьютер может абсолютно ничего не делать».
Причина возникновения такой величины в том, что для работы с некоторыми видами оборудования ядру системы требуются короткие временны́е задержки, которые реализуются в форме пустых циклов.
Чтобы узнать, сколько именно раз надо повторять пустой цикл, необходимо выяснить скорость его выполнения на данной машине — именно для этого используется BogoMIPS.
FLOPS
FLOPS(или flopsили flop/s)(акроним от англ. Floating point Operations Per Second, произносится как флопс) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от FLOPS, образуемые путём использования стандартных приставок системы СИ.
Флопс как мера производительности
Производительность суперкомпьютеров
Название год FLOPS
Флопс 1941 100
килофлопс 1949 10³
Мегафлопс 1964 106
Гигафлопс 1987 109
Терафлопс 1997 1012
Петафлопс 2008 1015
эксафлопс − 1018
зеттафлопс − 1021
йоттафлопс − 1024
ксерафлопс − 1027
Как и большинство других показателей производительности, данная величина определяется путём запуска на испытуемом компьютере тестовой программы, которая решает задачу с известным количеством операций и подсчитывает время, за которое она была решена. Наиболее популярным тестом производительности на сегодняшний день является программа LINPACK, используемая, в том числе, при составлении рейтинга суперкомпьютеров TOP500.
Одним из важнейших достоинств показателя флопс является то, что он до некоторых пределов может быть истолкован как абсолютная величина и вычислен теоретически, в то время как большинство других популярных мер являются относительными и позволяют оценить испытуемую систему лишь в сравнении с рядом других. Эта особенность даёт возможность использовать для оценки результаты работы различных алгоритмов, а также оценить производительность вычислительных систем, которые ещё не существуют или находятся в разработке.
Границы применимости
Несмотря на кажущуюся однозначность, в реальности флопс является достаточно плохой мерой производительности, поскольку неоднозначным является уже само его определение. Под «операцией с плавающей запятой» может скрываться масса разных понятий, не говоря уже о том, что существенную роль в данных вычислениях играет разрядность операндов, которая также нигде не оговаривается.
Кроме того, величина флопс подвержена влиянию очень многих факторов, напрямую не связанных с производительностью вычислительного модуля, таких как: пропускная способность каналов связи с окружением процессора, производительность основной памяти и синхронность работы кэш-памяти разных уровней.
Всё это, в конечном итоге, приводит к тому, что результаты, полученные на одном и том же компьютере при помощи разных программ, могут существенным образом отличаться, более того, с каждым новым испытанием разные результаты можно получить при использовании одного алгоритма. Отчасти эта проблема решается соглашением об использовании однообразных тестовых программ (той же LINPACK) с усреднением результатов, но со временем возможности компьютеров «перерастают» рамки принятого теста и он начинает давать искусственно заниженные результаты,
поскольку не задействует новейшие возможности вычислительных устройств. А к некоторым системам общепринятые тесты вообще не могут быть применены, в результате чего вопрос об их производительности остаётся открытым.
Так, например, 24 июня 2006 года общественности был представлен суперкомпьютер MDGrape-3, разработанный в японском исследовательском институте RIKEN (Йокогама), с рекордной теоретической производительностью в 1 Пфлопс. Однако данный компьютер не является компьютером общего назначения и приспособлен для решения узкого спектра конкретных задач, в то время как стандартный тест LINPACK на нём выполнить невозможно в силу особенностей его архитектуры.
Также, высокую производительность на специфичных задачах показывают графические процессоры современных видеокарт и игровые приставки. К примеру, заявленная производительность игровой приставки Xbox 360 составляет 1 Тфлопс, а приставки PlayStation 3 и вовсе 2 Тфлопс, что ставит их в один ряд с суперкомпьютерами начального уровня. Столь высокие показатели объясняются тем, что указана производительность над числами 32-битного формата[1][2], тогда как для суперкомпьютеров обычно указывают производительность на 64-разрядных данных[3][4]. Кроме того, данные приставки и
видео-процессоры рассчитаны на операции с трёхмерной графикой, хорошо поддающиеся
распараллеливанию, однако эти процессоры не в состоянии выполнять многие задачи общего назначения, и их производительность сложно оценить классическим тестом LINPACK[5] и тяжело сравнить с другими системами.
Суперкомпьютеры
• Компьютер ЭНИАК, построенный в 1946 году, при массе 27 т и энергопотреблении 150 кВт, обеспечивал производительность в 300 флопс
• IBM 709 (1957) — 5 кфлопс
• БЭСМ-6 (1968) — 1 Мфлопс (операций деления)
• Cray-1 (1974) — 160 Мфлопс
• БЭСМ-6 на базе Эльбрус-1К2 (1980-х) — 6 Мфлопс (операций деления)
• Эльбрус-2 (1984) — 125 Мфлопс
• Cray Y-MP (1988) — 2,3 Гфлопс
• Электроника СС БИС (1991) — 500 Мфлопс
• ASCI Red (1993) — 1 Тфлопс
• Blue Gene/L (2006) — 478,2 Тфлопс
• Jaguar (суперкомпьютер) (2008) — 1,059 Пфлопс
• IBM Roadrunner (2008) — 1,105 Пфлопс [7]
• IBM Sequoia (2012) — 20 Пфлопс [8]
Персональные компьютеры
• IBM PC/XT (1983) — 6,9 кфлопс
• ПК на основе процессора Intel 80386 (1985) с тактовой частотой 40 МГц — 0,6 Мфлопс
• Intel Pentium 75 МГц (1993) — 7,5 Мфлопс
• Intel Pentium II 300 МГц (1997) — 50 Мфлопс
• Intel Pentium III 1 ГГц (1999) — 320 Мфлопс
• AMD Athlon 64 2,211 ГГц (2003) — 840 Мфлопс[9]
• Intel Core 2 Duo 2,4 ГГц (2006) — 1,3 Гфлопс
Вычислительные
комплексы России Эльбрус 3М Эльбрус 4 Эльбрус 5 Эльбрус 6 Эльбрус 7 (Компания ЗАО МЦСТ- физтех МГУ)
Год выпуска 2007 2011 2013 2016 2019
Производительностть
процессора (Гфлп) 4,8 19,2 64 256 768
Количество
процессоров
на сервере 2 16 64 64 64
Производительность
сервера (Гфлп) 9,6 300 4000 16000 49000
Количество серверов
в комплексе 64
Производительность
комплекса (Тфлп) 0,6 19 256 1000 3000
Процессоры
• Intel Core 2 Duo E7300 2.66ГГц — 19.34 Гфлопс При использовании (SiSoftware Sandra Pro Home 2009.SP3) Windows XP sp3
• Intel Core 2 Duo E8400 3.0ГГц (2008) — 18.6 Гфлопс При использовании стандартной версии LINPACK 10
• Intel Core 2 Duo E8400 3.0ГГц @4.0ГГц (2008) — 25 Гфлопс (LINPACK Benchmark 10.0 64-бит) в Windows Vista x64 Ultimate SP1
• Intel Core 2 Quad Q9450 2.66ГГц @3.5ГГц — 48 ГФлопс (LINPACK Benchmark 10.0 64-бит) в Windows 2003sp2 x64
Название МП Эльбрус Эльбрус 2С Эльбрус 4С Эльбрус 8С Эльбрус 16С
Год выпуска 2007 2010 2012 2015 2018
Техн. норма (нм) 130 90 65 45 32
Частота (Мгц) 300 600 1000 2000 3000
Производительность
МП (Гфлп) 4,8 19,2 64 256 768
Мощность (Вт) 6 16 25
Карманные компьютеры
• КПК на основе процессора Samsung S3C2440 400 МГц (архитектура ARM9) — 1,3 Мфлопс
• Intel XScale PXA270 520 МГц — 1,6 Мфлопс
• Intel XScale PXA270 624 МГц — 2 Мфлопс
Примечание:Приведенные процессоры не имеют аппаратной поддержки вычислений с плавающей
точкой. Более современные процессоры этого класса (I.MX31, OMAP-Lx) с аппаратным FPU имеют на
2 десятичных порядка большую производительность.
Архитектура фон Неймана
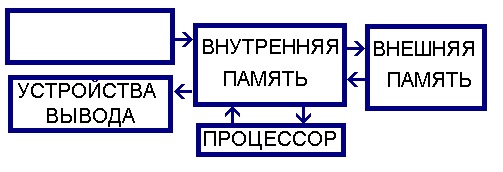
Архитектура фон Неймана(англ. Von Neumann architecture) — широко известный принцип
совместного хранения программ и данных в памяти компьютера. Вычислительные системы такого
рода часто обозначают термином «Машина фон Неймана», однако, соответствие этих понятий не
всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают
физическое отделение процессорного модуля от устройств хранения программ и данных.
Принципы фон Неймана
В 1946 году группа учёных во главе с Джоном фон Нейманом (Герман Голдстайн, Артур Беркс) опубликовали статью «Предварительное рассмотрение логической конструкции Электронно-вычислительного устройства». В статье обосновывалось использование двоичной системы для представления данных в ЭВМ (преимущественно для технической реализации, простота выполнения арифметических и логических операций. До этого машины хранили данные в десятеричном виде)[1], выдвигалась идея использования программами общей памяти. Имя фон Неймана было достаточно широко известно в науке того времени, что отодвинуло на второй план его соавторов, и данные идеи получили название «Принципы фон Неймана».
1. Принцип использования двоичной системы счисления для представления данных и команд.
2. Принцип программного управления.
Программа состоит из набора команд, которые выполняются процессором друг за
другом в определенной последовательности.
3. Принцип однородности памяти.
Как программы (команды), так и данные хранятся в одной и той же памяти (и
кодируются в одной и той же системе счисления — чаще всего двоичной). Над
командами можно выполнять такие же действия, как и над данными.
4. Принцип адресуемости памяти.
Структурно основная память состоит из пронумерованных ячеек; процессору в
произвольный момент времени доступна любая ячейка.
5. Принцип последовательного программного управления
Все команды располагаются в памяти и выполняются последовательно, одна после
завершения другой.
6. Принцип условного перехода.
Сам принцип был сформулирован задолго до фон Неймана Адой Лавлейз и Чарльзом
Бебиджем, однко он добавлен в общую архитектуру.
Компьютеры, построенные на этих принципах, относят к типу фоннеймановских.
Гарвардская Архитектура

Гарвардская архитектура— архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана Говардом Эйкеном в конце 1930-х годов в Гарвардском университете.
Дело в том, что, судя по опыту использования МПС для управления различными объектами, для реализации большинства алгоритмов управления такие преимущества фон-неймановской архитектуры как гибкость и универсальность не имеют большого значения. Анализ реальных программ управления показал, что необходимый объем памяти данных МК, используемый для хранения промежуточных результатов, как правило, на порядок меньше требуемого объема памяти программ. В этих условиях
использование единого адресного пространства приводило к увеличению формата команд за счет увеличения числа разрядов для адресации операндов. Применение отдельной небольшой по объему памяти данных способствовало сокращению длины команд и ускорению поиска информации в памяти данных.
Кроме того, гарвардская архитектура обеспечивает потенциально более высокую скорость
выполнения программы по сравнению с фон-неймановской за счет возможности реализации параллельных операций. Выборка следующей команды может происходить одновременно с выполнением предыдущей, и нет необходимости останавливать процессор на время выборки команды.
Этот метод реализации операций позволяет обеспечивать выполнение различных команд за одинаковое число тактов, что дает возможность более просто определить время выполнения циклов и критичных участков программы.
Большинство производителей современных 8-разрядных МК используют гарвардскую архитектуру.
История
В 30-х годах правительство США поручило Гарвардскому и Принстонскому университетам разработать архитектуру компьютера для военно-морской артиллерии. Победила разработка Принстонского университета (более известная как архитектура фон Неймана, названная так по имени разработчика, первым предоставившего отчет об архитектуре), так как она была проще в реализации.
Гарвардская архитектура не использовалась вплоть до конца 70-х годов.
Использование
Первым компьютером, в котором была использована идея гарвардской архитектуры, был Марк I.
Гарвардская архитектура используется в ПЛК и микроконтроллерах, таких, как Atmel AVR, Intel 4004,
Intel 8051.
В Intel(фон-Неймановская)-архитектуре:
"+", "-" - 3 такта
знаковые "+", "-" - 4 такта
"*", ":" - 5 тактов
знаковые "*",":" - 6 тактов
В Гарвардской архитек-ре:
"+", "-" - 2 такта
знаковые "+", "-" - 3 такта
"*", ":" - 3 такта
знаковые "*",":" - 4 такта
Для примера: вот такая операция z=a+b*c в микропроцессоре фон-неймановской архитектуры выполниться за
8-10 тактов, а в микропроцессоре гарвардской архитектуры - за 4-5 тактов.__
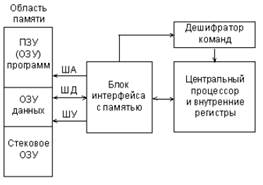
Конвейеры
Первоначальный 8086 процессор имеет 14 регистров, которые используются до сих пор. Четыре регистра общего назначения – AX, BX, CX и DX. Четыре сегментных регистра, которые используют для облегчения работы с указателями – CS (Code Segment), DS (Data Segment), ES (Extra Segment) и SS (Stack Segment). Четыре индексных регистра, которые указывают на различные адреса в памяти – SI (Source Index), DI (Destination Index), BP (Base Pointer) и SP (Stack Pointer). Один регистр содержит битовые флаги. И, наконец, регистр IP (Instruction Pointer).
IP регистр – это указатель с особой функцией, его задача указывать на следующую инструкцию, которая подлежит исполнению.
Все процессоры в x86 семействе следуют одному и тому же принципу. Сначала они следуют указателю на инструкцию и декодируют следующую команду по этому адресу. После декодирования следует этап выполнения этой инструкции. Некоторые инструкции читают из памяти или пишут в нее, другие производят вычисления, сравнения или другую работу. Когда работа окончена, команда проходит через этап отставки (retire stage) и IP начинает указывать на следующую инструкцию.
Конвейер-способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций, выполняемых в единицу времени), технология, используемая при разработке компьютеров и других цифровых электронных устройств.
Простой пятиуровневый конвейер в RISC-процессорах.
· 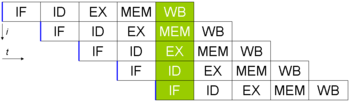 IF (англ. Instruction Fetch) — получение инструкции,
IF (англ. Instruction Fetch) — получение инструкции,
· ID (англ. Instruction Decode) — раскодирование (получение) инструкции,
· EX (англ. Execute) — выполнение,
· MEM (англ. Memory access) — доступ к памяти,
· WB (англ. Register write back) — запись в регистр.
Вертикальная ось — последовательные независимые инструкции, горизонтальная — время. Зелёная колонка описывает состояние процессора в один момент времени, в ней самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция — только в процессе чтения.
Пример: Сумма А+B=C.
Эта инструкция суммирует значения, находящиеся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C.
1. Загрузка в А из регистра1
2. Загрузка в В из регистра2
3. Сложение А и В в С
4. Результат С в регистр3
Преимущества:
1. Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
2. Некоторые комбинационные логические элементы, такие, как сумматоры или умножители, могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
Недостатки:
1. Бесконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще, и он дешевле для изготовления.
2. Задержка инструкций в бесконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
3. У бесконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
4. Конвеерный пузырь (ступор конвейера)- ситуация, которая следующие за первой команды ждут, пока первая не пройдет этапы исполнения и записи результата. И только после этого вторая команда могла продолжить путь по конвейеру.
Процессор i486 имел 5-уровневый конвейер – загрузка (Fetch), основное декодирование (D1), вторичное декодирование или трансляция (D2), выполнение (EX), запись результата в регистры и память (WB). Каждый этап конвейера мог содержать по инструкции.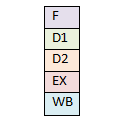
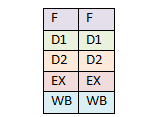
Суперскалярный конвейер i486.
В процессорах 486 использовался конвейер с ядром с внеочередным исполнением.
Далее в Pentium появилось использование параллельных суперскалярных конвееров.
Определения
Архитектура Вычислительной системы: АЛУ, ДК, СОЗУ=Регистры PC-prgram counter- счетчик (указатель) инструкций
Процессор (устройство, отвечающее за выполнение арифметических, логических и операций управления, записанных в машинном коде
Микропроце́ссор —процессор реализованный в виде одной микросхемы[1] или комплекта из нескольких специализированных микросхем[2] (в противоположность реализации процессора в виде электрической схемы на элементной базе общего назначения или в виде программной модели).
Первые микропроцессоры появились в 1970-х и применялись в электронных калькуляторах, в них использовалась двоично-десятичная арифметика 4-х битных слов. Вскоре их стали встраивать и в другие устройства, например терминалы, принтеры и различную автоматику. Доступные 8-битные микропроцессоры с 16-битной адресацией позволили в середине 1970-х создать первые бытовые микрокомпьютеры.
Разместив целый ЦПУ на одном чипе сверxбольшой интеграции удалось значительно снизить его стоимость. Несмотря на скромное начало, непрерывное увеличение сложности микропроцессоров привело к почти полному устареванию других форм компьютеров (см. историю вычислительной
техники), в настоящее время один или несколько микропроцессоров используются в качестве вычислительного элемента во всём, от мельчайших встраиваемых систем и мобильных устройств до огромных мейнфреймов и суперкомпьютеров.
С начала 1970-х широко известно, что рост мощности микропроцессоров следует закону Мура, который утверждает что число транзисторов на интегральной микросхеме удваивается каждые 18 месяцев. В конце 1990-х главным препятствием для разработки новых микропроцессоров стало тепловыделение (TDP) из-за утечек тока и других факторов[3].
Некоторые авторы относят к микропроцессорам только устройства, реализованные строго на одной микросхеме. Такое определение расходится как с академическими источниками[4], так и с коммерческой практикой (например, варианты микропроцессоров Intel и AMD в корпусах типа SECC и подобных, такие как Pentium II — были реализованы на нескольких микросхемах- называемых микропроцессорным комплектом).
В настоящее время, в связи с очень незначительным распространением процессоров, не являющихся микропроцессорами, в бытовой лексике термины «микропроцессор» и «процессор» практически равнозначны.
Микроконтроллер- процессор с ОЗУ и ПЗУ и широким набором контроллеров, в том числе переферийных, и специализированных процессоров, реализованный в виде одной микросхемы. Центральный (управляющий) процессор обычно средней производительности, меньшей чем у микропроцессоров того-же уровня технологии. Его основная задача управлять конроллерами и другими спецпроцессорами (DSP)
Параметры МП
Архитектура
Разрядность процессора (32х 64х 86х – разрядность внутренних регистров. Разрядность команд).
Система команд, семейство
Тактовая частота процессора
Быстродействие (интегральный параметр- MIPS=MOPS/FLOPS
Параметры Внешней(их) шины(шиш) и интрерфейсов –разрядность, частота (FBUS)
Напряжение питания (или несколько)
Энергопотребление, удельное потребление Вт/флоры, Вт/операцию,Гфлопс/Вт тип теплоотвода
Корпус (тип корпуса по ISO=размеры, кол и тип выводов)
Показатель производительности Гфлопс/ГГц
MIPS (GIPS- giga- миллиард операций в секунду)
MIPS(англ. Million Instructions Per Second) — единица измерения быстродействия, равная одному миллиону инструкций в секунду. Если указано быстродействие в MIPS, то, как правило, оно показывает, сколько миллионов инструкций в секунду выполняет процессор в некотором синтетическом тесте.
BogoMIPS(от англ. bogus (поддельный) и MIPS — англ. Millions of Instructions Per Second) — в ядре Линукс ненаучный способ измерения производительности компьютера, предназначенный для калибровки внутренних циклов. Термин изобрёл Линус Торвальдс в 1993. BogoMIPS шутливо определяется как «сколько миллионов раз в секунду компьютер может абсолютно ничего не делать».
Причина возникновения такой величины в том, что для работы с некоторыми видами оборудования ядру системы требуются короткие временны́е задержки, которые реализуются в форме пустых циклов.
Чтобы узнать, сколько именно раз надо повторять пустой цикл, необходимо выяснить скорость его выполнения на данной машине — именно для этого используется BogoMIPS.
FLOPS
FLOPS(или flopsили flop/s)(акроним от англ. Floating point Operations Per Second, произносится как флопс) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.
Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от FLOPS, образуемые путём использования стандартных приставок системы СИ.
infopedia.su
Сколько операций в секунду современный компьютер может выводить?
Если уже вы начали говорить о количестве операций в секунду, то могу сказать, что в этом случае мощность компьютеров меряется в flops, т.е в количестве операций с плавающей точкой в секунду (по простому что-то типа обычного десятичного числа, в форме типо 51,1535434 ). Почему именно числа с плавающей точной объяснять не буду, т.к. читать курс компьютерной арифметики нет желания :)
Для действительно огромных вычислений уже давно люди создали и до сих пор разрабатывают все более мощные "суперкомпьютеры". Их используют в специфических целях, например для прогноза погоды, моделирования ядерных взрывов, к примеру установив суперкомпьютер в систему водоснабжения, можно сделать так, что он будет проводить мониторинг, анализировать полученные данные и будет выявлять вероятные проблемы еще задолго до их возникновения.
На сегодняшний день самым мощным суперкомпьютером( ru.wikipedia.org/wiki/Суперком... ) является Jaguar( ru.wikipedia.org/wiki/Jaguar_(суперкомпьютер) ), его производительность( top500.org/lists/2009/11/press... ) 1.75 petaflop/s, а максимально теоретически возможная 2,3 петафлопс (приставка пета это *10^15, т.е. 1 750 000 000 000 000 операций с плавающей точкой в 1 секунду).
Только в случае суперкомпьютеров такое измерение производительности не всегда является корректным, т.к. количество операция в секунду зависит от типа задачи выполняемой этим компьютером, возможен такой вариант, что суперкомпьютеру для выполнения задачи нужно часто обращаться к периферийным устройствам(например проводить какой-то мониторинг, как с системой водоснабжения) или считывать, или записывать много информации, тогда у него явно будет производительность, измеряемая в флопсах ниже, т.к. это не основная его цель.
Современный настольный компьютер имеет производительность порядка 0.1 Терафлопс. Но если говорить об обычных, настольных компьютерах, то здесь тоже количество операций в секунду не всегда решающий фактор, т.к. если компьютер предназначен для игр, то ему более важна производительность видеокарты, а не процессора. И опятьже это зависит от задачи, поставленной компьютеру. Серверные компьютерыы будут быстрее в этом плане, т.к. обычно напичканы более дорогими игрушками, да они и созданы для таких вещей. Сегодня при желании можно в компьютер поставить 2 восьмиядерных процессора (core i7).
vorum.ru