Фотограф нашел профили случайно встреченных людей во «Вконтакте» через нейросеть. Поиск по фото нейросеть
Распознавание лиц по фото онлайн

Сегодня есть специальные приложения для смартфонов и ПК, которые позволяют узнать о человеке основную информацию по фотографии. Некоторые из них перекочевали в онлайн-приложения, что даёт возможность производить быстрый поиск людей в сети, имеющих похожую внешность. Хотя точность в определённых случаях оставляет желать лучшего.
Работа сервисов по распознаванию лиц
Распознавание происходит при помощи встроенной нейросети, которая быстро ищет похожие фотографии по определённым признакам, изначально самым базовым, например, по весу изображения, его разрешению и т. д. Исходя из данной особенности, у вас в результатах поиска могут появиться ссылки на профили/сайты совершенно не того человека, который изображён на фото, но, к счастью, такое случается крайне редко. Обычно находятся люди со схожей внешностью или похожей обстановкой на фото (например, если плохо видно лица).
При работе с сервисами по поиску фотографий желательно не загружать фото, где находятся несколько человек в фокусе. В таком случае вы вряд ли получите адекватный результат.
Дополнительно нужно учесть, что если вы хотите по фотографии человека найти его профиль во Вконтакте, то стоит помнить, что в настройках приватности этой социальной сети пользователь может поставить галочки напротив определённых пунктов, из-за чего его страницу не смогут сканировать поисковые роботы и просматривать пользователи, не зарегистрированные в VK. Если у нужного вам человека выставлены таковые настройки приватности, то найти его страницу по фото будет очень сложно.
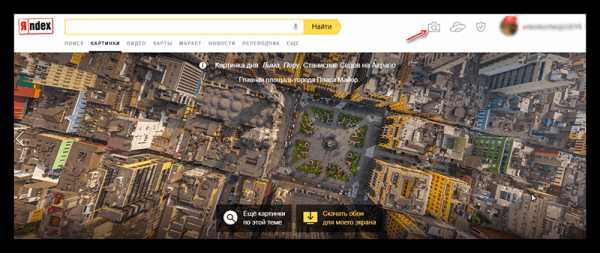
Способ 1: Яндекс Картинки
Использование поисковиков может показаться немного неудобным, так как на одно изображение может выйти несколько ссылок, где оно когда-либо использовалось. Однако если вам нужно найти как можно больше информации о человеке, используя только его фотографию, то лучше воспользоваться подобным методом. Яндекс – это российская поисковая система, которая неплохо производит поиск в русскоязычном сегменте интернета.
Перейти на Яндекс Картинки
Инструкция по поиску через данный сервис выглядит так:
- На главной странице нажмите на иконку поиска по фотографии. Она выглядит как лупа на фоне фотоаппарата. Находится в верхнем меню, в правой части экрана.
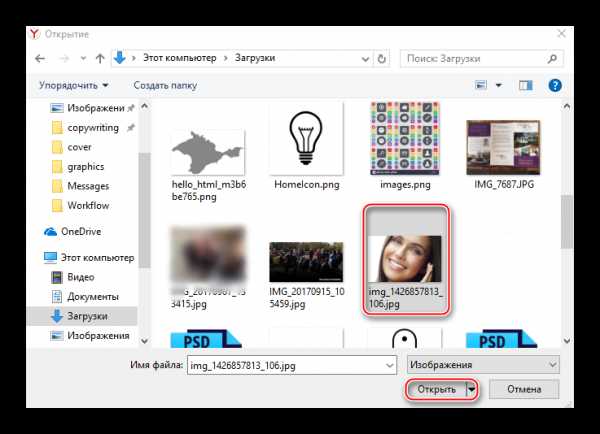
- Поиск можно осуществить по URL-адресу картинки (ссылке в интернете) или используя кнопку загрузки изображения с компьютера. Инструкция будет рассмотрена на последнем примере.
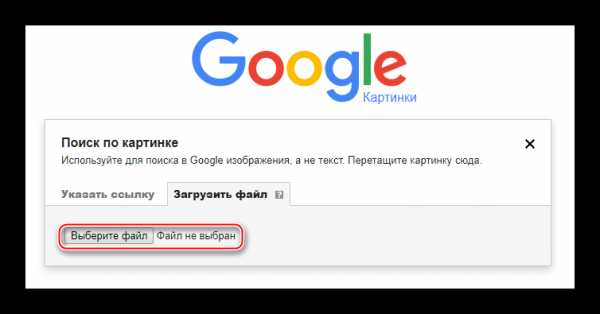
- При нажатии на «Выберите файл» открывается окошко, где указывается путь к изображению на компьютере.
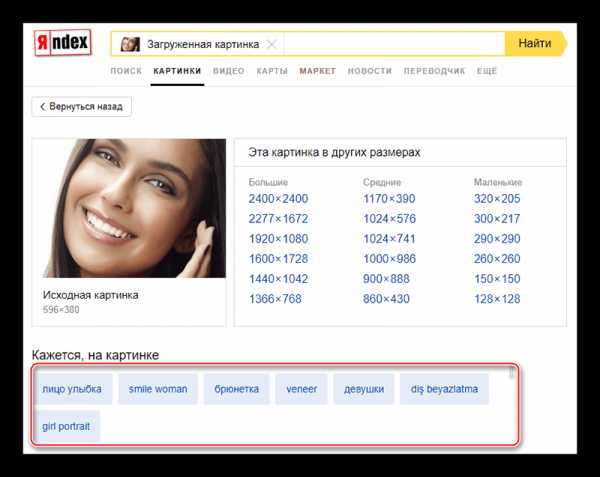
- Подождите некоторое время, пока картинка полностью не загрузится. В верхней части выдачи будет показана эта же картинка, но здесь вы сможете просмотреть её в других размерах. Данный блок нам не интересен.
- Ниже вы можете посмотреть теги, которые применимы к загруженному изображению. Используя их, можно найти похожие картинки, но это в поиске информации по конкретной личности вряд ли поможет.
- Далее находится блок с похожими фотографиями. Он может оказаться вам полезен, так как в нём по определённому алгоритму подбираются похожие фотографии. Рассмотрим поиск по этому блоку. Если в первых похожих картинках вы не увидели нужное фото, то нажмите «Ещё похожие».
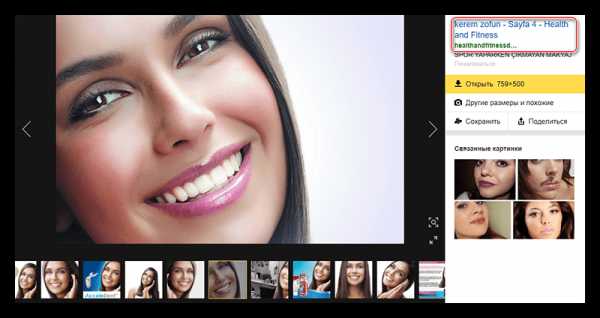
- Откроется новая страница, где будут все схожие фото. Предположим, вы нашли ту фотографию, которая вам нужна. Кликните по ней, чтобы её увеличить и узнать подробную информацию.
- Здесь обратите внимание на правый блок слайдера. В нём можно найти ещё похожие фотографии, открыть эту в полном размере, а главное — перейти на сайт, где она размещена.
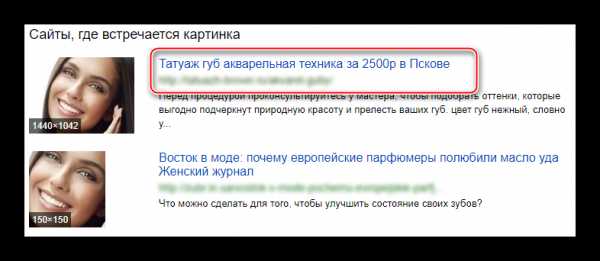
- Вместо блока с похожими фото (6-й шаг), можно пролистать страницу чуть ниже, и увидеть на каких сайтах размещено именно то изображение, которое вы загрузили. Данный блок называется «Сайты, где встречается картинка».
- Для перехода на интересующий сайт нажмите по ссылке или оглавлению. Не стоит переходить на сайты с сомнительными именами.

Если вы оказались недовольны результатом поиска, то можете воспользоваться следующими способами.
Способ 2: Google Images
По факту – это аналог Яндекс Картинок от международной корпорации Google. Алгоритмы, которые применяются здесь, чем-то похожи на те, что у конкурента. Однако у Гугл Картинок есть весомое преимущество – он лучше ищет похожие фотографии на иностранных сайтах, что Яндекс делает не совсем корректно. Это преимущество может стать и недостатком, если вам нужно найти человека в рунете, в этом случае рекомендуется использовать первый и третий способы.
Перейти на Google Images
Инструкция выглядит следующим образом:
- Перейдя на сайт, в строке поиска нажмите на иконку фотоаппарата.
- Выберите вариант загрузки: либо укажите ссылку, либо закачайте изображение с компьютера. Для переключения между вариантами загрузки просто нажмите на одну из надписей в верхней части окошка. В данном случае будет рассмотрен поиск по изображению, которое загружено с компьютера.
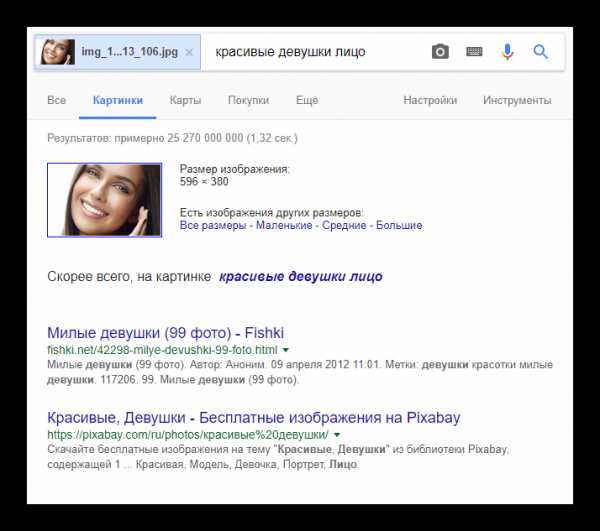
- Откроется страница с результатами. Здесь, как и в Яндексе, в первом блоке вы можете просмотреть это же изображение, но в других размерах. Под этим блоком находится пара тегов, подходящих по смыслу, и пара сайтов, где есть такая же картинка.
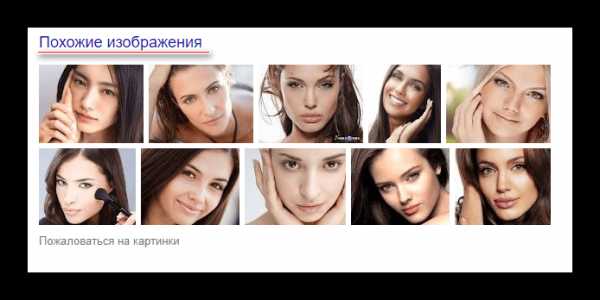
- В данном случае рекомендуется рассмотреть подробнее блок «Похожие изображения». Нажмите на заголовок блока, чтобы увидеть больше похожих картинок.
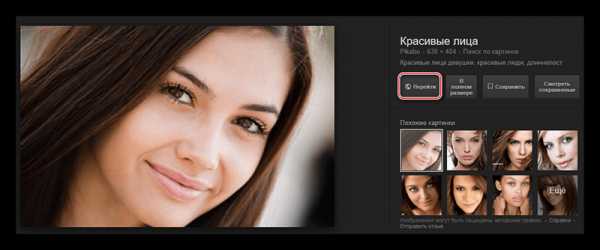
- Найдите нужное изображение и кликните по нему. Откроется слайдер по аналогии с Яндекс Картинками. Здесь вы также можете посмотреть это изображение в разных размерах, найти ещё похожие, перейти на сайт, где оно размещено. Для перехода на сайт-источник нужно нажать на кнопку «Перейти» или кликнуть по заголовку в верхней правой части слайдера.
- Дополнительно вам может быть интересен блок «Страницы с подходящим изображением». Тут всё аналогично с Яндексом – просто набор сайтов, где встречается точно такое же изображение.
Такой вариант может сработать хуже, чем прошлый. Желающим найти человека, зарегистрированного ВК, подойдет следующий сервис, специализирующийся на узком поиске.
Способ 3: FindFace
Изначально FindFace был приложением для смартфонов, сейчас же есть полноценный онлайн-сервис, который помогает найти пользователей во Вконтакте, используя фотографию с этим человеком. Со своей задачей сервис справляется безупречно, но у него есть один серьёзный недостаток – он ищет только в социальной сети Вконтакте, поэтому, если вы хотели бы найти какого-либо человека по фото на других сайтах, то такой сервис вряд ли идеально подойдёт.
Перейти на FindFace
Инструкция в данном способе будет выглядеть так:
- Перейдя на сайт, нажмите на кнопку «Найти одинаковых». Не забудьте поставить галочку напротив «Согласен с пользовательским соглашением».
- Откроется специальное окно, где сервис попросит разрешение доступа к определённым пунктам в вашем профиле в социальной сети Вконтакте. Если же вы не авторизованы/зарегистрированы там, то вам придётся это сделать и разрешить доступ, иначе дальнейшее использование сервиса будет невозможным.
- Изначально будет доступно только 30 поисков, чтобы получить больше, нужно будет приобрести Premium-аккаунт. Его можно купить или получить, пригласив 10 друзей. Для разовых поисков возможностей бесплатного аккаунта вполне хватит.
- В блок «Загрузите фотографию» перетащите фото с компьютера или используйте стандартный способ загрузки через системный проводник.
- Поиск займёт от нескольких секунд до одной минуты. Всё зависит от того, как много людей будет обнаружено и какая скорость вашего интернета. На странице выдачи вы можете просмотреть результаты.
- Ещё можно настроить дополнительные параметры, дабы сократить число возможных вариантов – указать пол (обычно определяется автоматически), возраст, место проживания, статус семейного положения. Однако если вы будете искать человека, применив ещё эти параметры, то вам придётся нажать на кнопку «Новый поиск», следовательно, ещё один доступный поиск пропадёт.

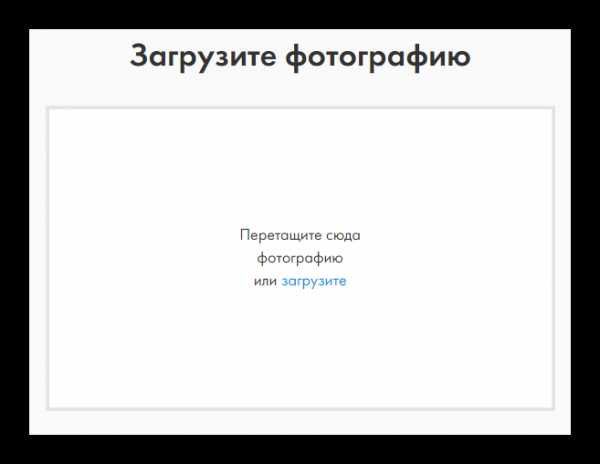
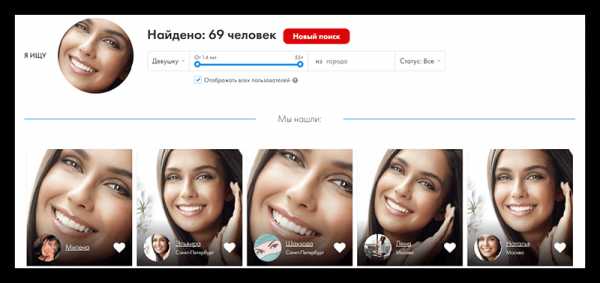
К сожалению, сейчас нет идеальных сервисов в свободном доступе по поиску человека по фотографии, которые могли бы найти всю информацию о человеке в сети.
Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет lumpics.ru
На этом сайте вы можете загрузить фотографию, которую хотите обработать, и получить неожиданный шедевр
Эти изображения, похожие и на фотографии, и на картины, создали пользователи российского сайта Ostagram с помощью техники инцепционизм (Inceptionism), которая совмещает технологии и искусство. Чтобы создать единую необычную картину, разные изображения объединяются с помощью нейронных сетей.
Нейронная сеть представляет собой вычислительную модель, основанную на структуре биологической нейронной сети. Обычное программное обеспечение работает в соответствии со строгими параметрами, но искусственные нейронные сети обладают способностью «обучаться», подпитываясь новыми данными с течением времени.
Программное обеспечение DeepDream находит и усиливает закономерности в изображениях с помощью процесса под названием алгоритмическая парейдолия. Чтобы получить собственное художественное произведение, посетите Ostagram. Примеры работ предлагаем посмотреть ниже:


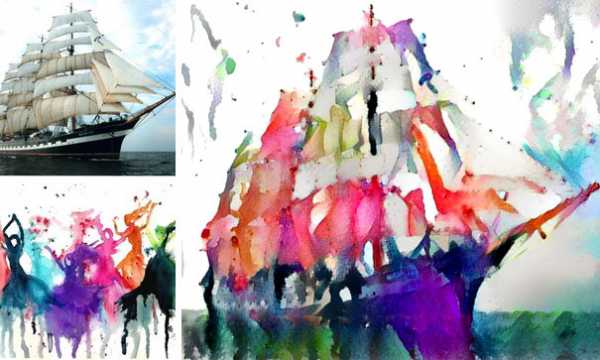
































cameralabs.org
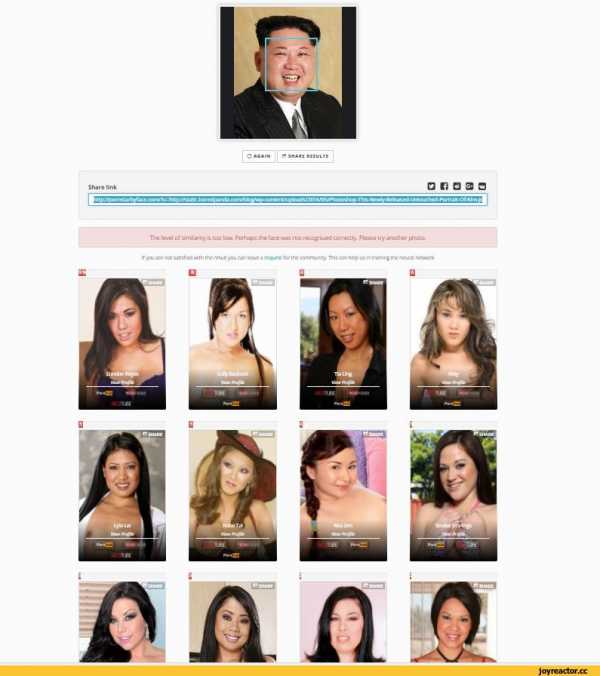
Сервис поиска похожих порноактрис по фотографии, построенный на…: allanhan
Сервис поиска похожих порноактрис по фотографии, построенный на глубоких нейронных сетяхМы с коллегами занимаемся изучением нейронных сетей. Одному из нас пришла в голову идея исполнить мечту из юношества... В общем мы создали сервис на основе нейронных сетей по поиску похожих (или реальных) порноактрис по фотографии любой тян. http://PornStarByFace.com Мы только стартовали и стараемся улучшать алгоритм распознания и подбора. Главная сложность - кол-во актрис в БД. Их приходится забивать и тестировать вручную. Пытались автоматизировать, но тогда качество распознания падает. Решили оставить "ручной" труд и проверку, не хотим терять качество в угоду кол-ву. Алгорит постоянно улучшаем и стабильно добовляем новых девушек. В общем такой вот ресурс =) будем стараться делать его все более и более качественным. Надеемся нас не внесут в реестр запрещенных ) P.S. если кому интересна техническая часть, то все написано на языке C# и с использованием библиотек OpenCV.  |
Отличный коммент!
PhotoHint http://pics.livejournal.com/igrick/pic/000r1edq
allanhan.livejournal.com
Нейронная сеть, которая верстает сайты по картинке — Будущее на vc.ru
Прошёл почти год с того момента, как на GitHub опубликовали алгоритм pix2code. И вот ребята из FloydHub на его основе создали нейронную сеть для вёрстки страниц, которую уже можно запустить самому.
Работа алгоритма делится на три этапа:
1. Нейронной сети передаётся картинка-исходник в формате JPEG 2. Алгоритм конвертирует элементы в HTML- и CSS-код 3. На выходе получается свёрстанная версияЧтобы получить такой результат, разработчики скармливали алгоритму скриншоты и присваивали определённые HTML-теги, в итоге получился датасет, с помощью которого можно генерировать шаблонные сайты. Ниже будут примеры.
Пример датасетаАлгоритм учится предсказывать соответствующие HTML-теги, последовательно «изучая» изображение на входе. Когда алгоритм предсказывает следующий тег разметки, он получает скриншот и все «правильные» теги HTML-разметки для этого элемента.
Примеры:
- 250 циклов работы алгоритма;
- 350 циклов работы алгоритма;
- 450 циклов работы алгоритма;
- 550 циклов работы алгоритма.
Везде выше можно посмотреть пример исходного кода, сгенерированного нейронной сетью, а вот оригинальный сайт, скриншоты которого скармливали алгоритму.
Если вы вдруг фронтенд-инженер (я нет), поделитесь в комментариях: как вам код, сгенерированный алгоритмом?
Более техническое описание проекта доступно по ссылке, а ноутбук для запуска в Jupyter лежит тут.
#инструменты #будущее #нейросетьдня
vc.ru
Нейросети с легкостью найдут вас в соцсетях (3 фото) » Триникси
Почти 6 лет назад, летом 2010 года я гулял по Невскому с фотоаппаратом. Ко мне подошли две случайные девочки и попросили сфотографировать. Лето, солнце, у всех хорошее настроение, почему нет — сделал кадр и пошел гулять дальше. Когда разбирал дома фоточки, оказалось что снимок вышел забавный и неплохо бы его отдать. Но отдать невозможно, контактами мы не обменялись, поэтому фото я забросил в архив и забыл. На всякий случай даже написал пост про это, хотя было без шансов кого-то найти.
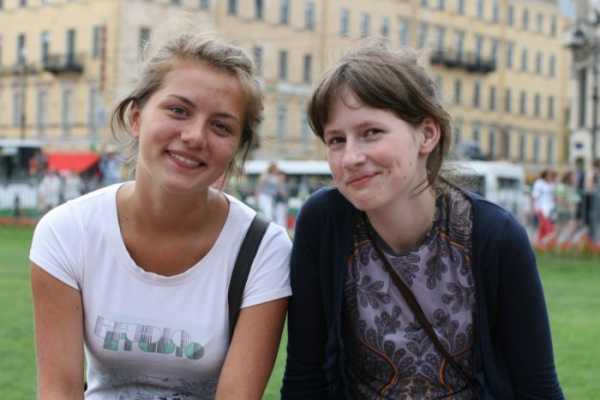
Шли годы, менялись ноутбуки, волшебным образом архив со старыми фото смог пережить несколько жестких дисков и переехал на новый ноут. Вчера я разбирал архивы и снова наткнулся на это фото. Я и раньше перебирал архивы и каждый раз думал что это забавно, но зачем я храню эту фотку, я же никогда не смогу ее отдать. Наверно фото напоминало мне о прогулке тем летом, хранил ее для памяти о настроении — что можно вот так просто быть беззаботным, счастливым, гулять и фотографировать людей вокруг. Короче, фото я не удалял и каждый раз думал что было бы прикольно как-нибудь ее отдать. Так бы все и продолжалось, если бы не одно обстоятельство. Чумовые российские программисты создали охерительно крутой алгоритм и сделали то, чего раньше никто никогда до них в РФ не делал — прогнали через него все-все-все фотографии, которые были в открытом доступе ВКонтакте и натренировали нейросетку на распознавание лиц. Создали для каждого человека цифровой отпечаток лица на основе его открытых фотографий. И месяц назад они запустили в открытом доступе сервис, который находит профили людей ВКонтакте по фотографии. Как в шпионском кино, только пользоваться может каждый.

Без особых надежд, ради фана, я попытал счастья и загрузил туда эту фотку. Я знал что сервис работает очень хорошо, но не рассчитывал что алгоритмы справятся соотнести цифровые образы лиц из древнего снимка с новыми фотографиями человека, который за 6 лет просто обязан был неузнаваемо сильно измениться, все люди взрослеют. Даже человек не справляется с этой задачей. Я сам не справился! Когда мне показали аватары найденных профилей, я решил что алгоритм промахнулся. Но на всякий случай внимательно просмотрел оба профиля, которые сервис предложил как наиболее похожих на людей с фотографии.И эти профили оказались друг у друга в друзьях! Спустя почти 6 лет они получили свой снимок. Это просто афигительно. Я и мечтать не мог что доживу до таких технологий в открытом доступе.

Эта история может вызвать приступ паранойи. Вы верно поняли, теперь любой человек на улице может вас сфотографировать и сразу увидеть ваше имя и всю открытую информацию про вас. Но не спешите скрывать все фотографии из публичного доступа и удалять аватары. Уже поздно!Профили уже проиндексированы. Вас уже любой человек найдёт по фотографии. То, что вы скроете новые фотографии (и даже старые), не спасёт вас от цифрового слепка в базе данных таких сервисов.Но даже если бы можно было закрыться от всех таких сервисов, вы не сможете убежать от прогресса. Мы вели публичную активность в интернете уже много лет, это должно было неизбежно случиться. Появление такого сервиса было вопросом времени. И будущее настало, оно сейчас.
Отсюда
trinixy.ru
Нейронные сети: практическое применение / Хабр

Наталия Ефремова погружает публику в специфику практического использования нейросетей. Это — расшифровка доклада Highload++.
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace. Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning. В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами — дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
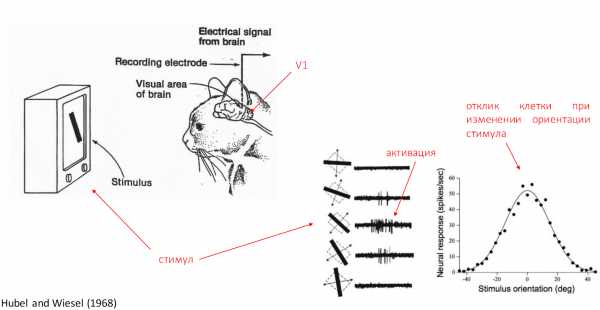
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств — это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле — это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.
Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.
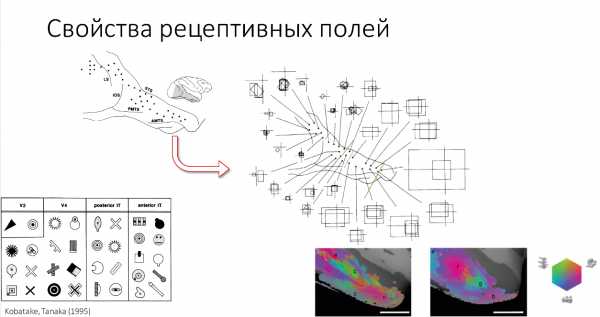
Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex'a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон — это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
До того, как мы научились это применять к компьютерному зрению — в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга — нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.
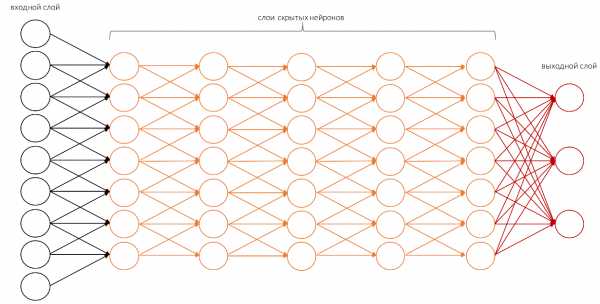
В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей — как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х — это наше входное изображение, Y — это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.
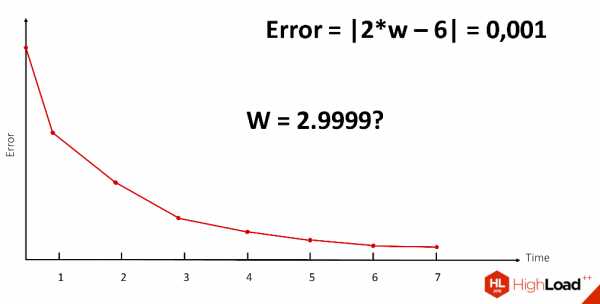
Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.
Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.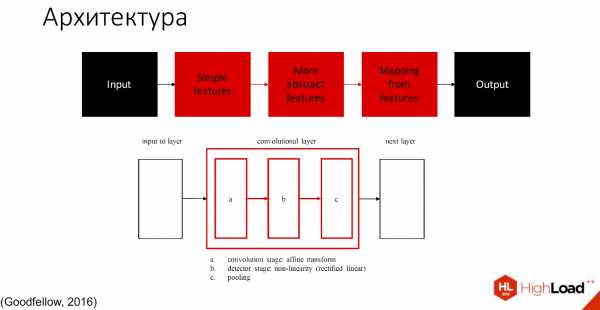
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений — один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.
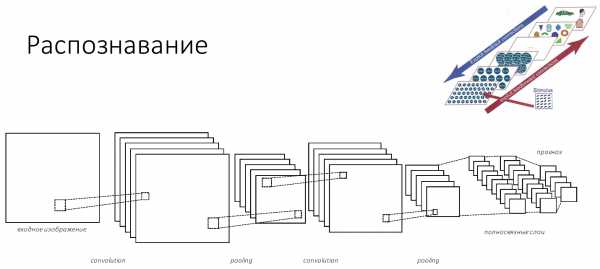
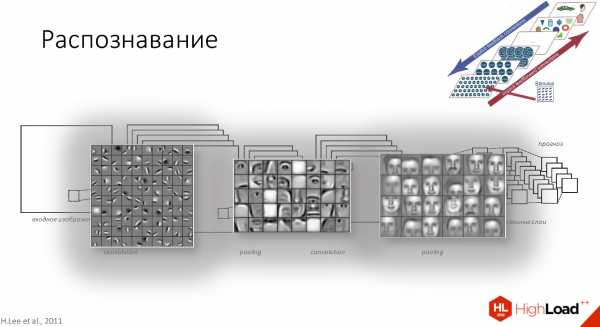
Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP — многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.
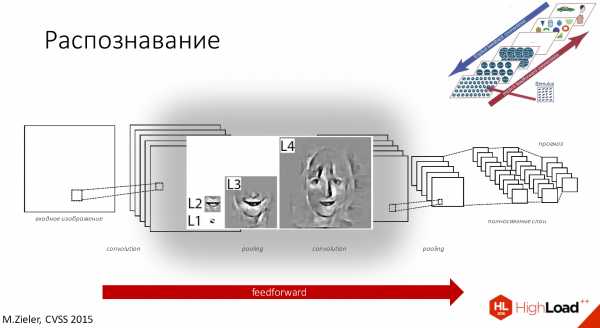
Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.
С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети — это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Их на самом деле не так много, они относятся к трём классам. Среди них — такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.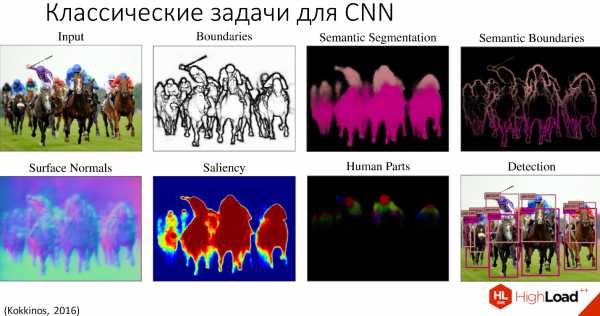
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ — это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания — это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ — это выделение границ, разбитых на классы.
- Выделение частей тела человека.
- И самая высокоуровневая задача — распознавание самих объектов, которое мы сейчас рассмотрим на примере распознавания лиц.
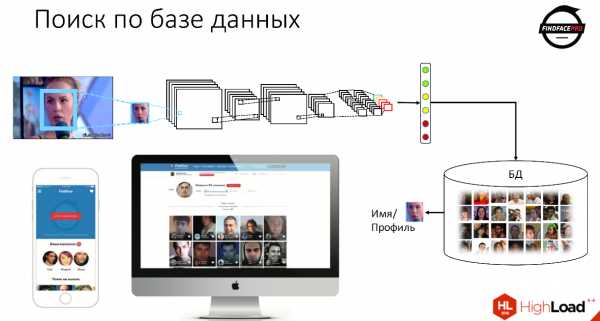
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль — всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace — это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый — это идентификация, поиск лица по базе данных. Второе — это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection — это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям — нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition — аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду — после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке — одной из самых простых эмоций — есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.
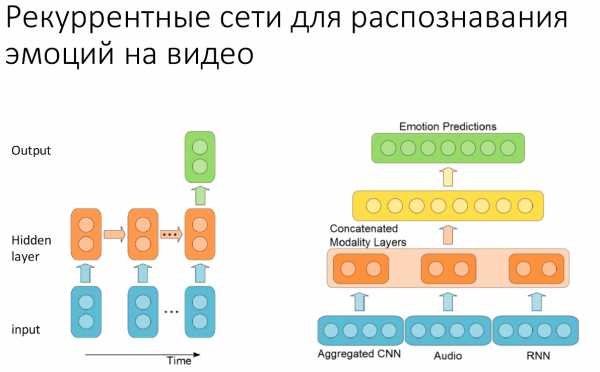
В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа — это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически — мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение — это максимально быстрый исход игры с максимально большим счетом.
Справа вверху — последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым — нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память — то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.
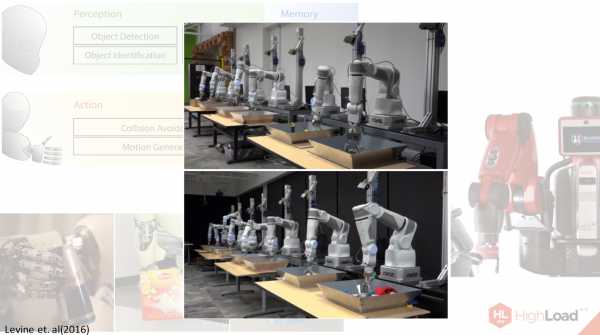
Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных — это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet'е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите — самый последний кадр — реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги — все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить — семантическая сегментация 3D изображений в медицине. Вообще medical imaging — это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали — ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах — вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.
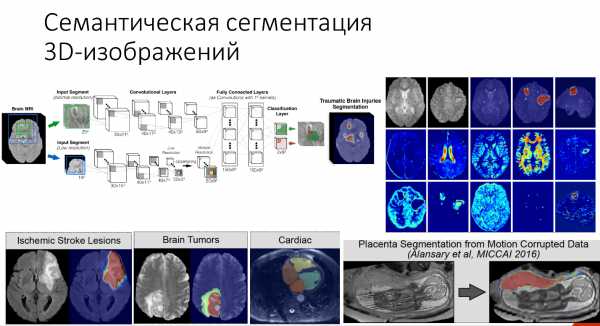
Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
Доклад: Нейронные сети — практическое применение.
habr.com
Фотограф нашел профили случайно встреченных людей во «Вконтакте» через нейросеть
Фотограф из Санкт-Петербурга Егор Цветков успешно использовал нейросетевой поиск по фото, чтобы найти во «ВКонтакте» профили случайно встреченных в московском метро людей.
«В проекте YOUR FACE IS BIG DATA («Твое лицо – это большие данные» – прим. Rusbase) я фотографировал людей, сидевших передо мной в вагоне метро, а потом искал их в социальных сетях с помощью общедоступного программного обеспечения. Таким образом я узнавал многое о жизни человека, не вступая в личный контакт, и мог сопоставить реальный образ с интернет-репрезентацией», – приводятся слова Цветкова на сайте Bird In Flight.
Сообщается, что Цветков использовал российское приложение FindFace, в основе которого лежит алгоритм по поиску профилей во «ВКонтакте» по заранее проиндексированной базе фото из соцсети.
«Развитие технологий отбирает у властных структур монополию на идентификацию человека по фото/видео и передаёт эту возможность буквально любому заинтересованному. Не подозревая об этом, люди продолжают придерживаться привычных моделей поведения, закрываясь на публике и открываясь в социальных сетях», – написал Цветков на Bird in Flight.

© Фото Егора Цветкова

© Фото Егора Цветкова

© Фото Егора Цветкова
Напомним, сервис FindFace был разработан российской компанией N-Tech.Lab. Ранее лежащая в основе этого приложения нейросеть FaceN обошла продукт команды Google на конкурсе алгоритмов по распознаванию лиц The MegaFace Benchmark.
Сейчас FindFace работает только с данными «ВКонтакте», однако в перспективе компания планирует сделать сервис доступным и для других соцсетей. Подробнее о FindFace можно прочитать здесь.
Если у вас есть новости, пишите на [email protected]. Мы читаем все письма.Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
rb.ru