Распознавание лиц: программа с пошаговой инструкцией и описанием. Распознавания лиц алгоритм
Создание собственной системы распознавания лиц
Распознавание лиц – это последняя тенденция, когда дело доходит до аутентификации пользователей. Недавно Apple выпустила свой новый iPhone X, который использует идентификатор лица для аутентификации пользователей. OnePlus 5 скоро получит функцию Face Unlock от theOnePlus 5T. И Baidu использует распознавание лиц вместо удостоверений личности, чтобы позволить своим сотрудникам войти в их офисы. Эти приложения могут показаться волшебными для многих людей. Но в этой статье мы стремимся демистифицировать предмет, обучая вас, как сделать свою собственную упрощенную версию системы распознавания лиц в Python.
Задний план
Прежде чем мы перейдем к деталям реализации, я хочу обсудить детали FaceNet. Какую сеть мы будем использовать в нашей системе.

FaceNet
FaceNet – это нейронная сеть, которая изучает сопоставление изображений лица с компактным евклидовым пространством, где расстояния соответствуют мере сходства лица. То есть, более похожие два изображения лица – это меньшее расстояние между ними.
Триплетная потеря
FaceNet использует отдельный метод потерь, называемый Triplet Loss, для вычисления потерь. Triplet Loss минимизирует расстояние между якорем и положительным, изображения, которые содержат идентичность и максимизирует расстояние между якорем и отрицательным изображения, которые содержат разные идентичности.
Сиамские сети
FaceNet – это сиамская сеть. Сиамская сеть – это тип нейронной сетевой архитектуры, которая учится различать два входа. Это позволяет им узнать, какие изображения похожи, а какие нет. Эти изображения могут содержать лица.

Сиамские сети состоят из двух идентичных нейронных сетей, каждая из которых имеет одинаковые точные веса. Во-первых, каждая сеть принимает одно из двух входных изображений в качестве входных данных. Затем выходы последних слоев каждой сети отправляются функции, которая определяет, содержат ли изображения одинаковые идентификаторы.
В FaceNet это делается путем вычисления расстояния между двумя выходами.
Реализация
Теперь, когда мы выяснили теорию, мы можем перейти прямо к реализации.В нашей реализации мы будем использовать Keras и Tensorflow. Кроме того, мы используем две вспомогательные файлы , которые взаимодействиют с сетью FaceNet:
- fr_utils.py содержит функции для подачи изображений в сеть и получения кодирования изображений;
- inception_blocks_v2.py содержит функции для подготовки и компиляции сети FaceNet
Компиляция сети FaceNet
Первое, что нам нужно сделать, это собрать сеть FaceNet, чтобы мы могли использовать ее для нашей системы распознавания лиц.
Мы начнем с инициализации нашей сети с входной формой (3, 96, 96). Это означает, что каналы Red-Green-Blue (RGB) являются первым измерением объема изображения, подаваемого в сеть. И все изображения, которые подаются в сеть, должны быть 96×96 пикселей.

Если вы не знакомы с любой функцией Tensorflow, используемой для выполнения расчета, я бы рекомендовал прочитать документацию, так как это улучшит ваше понимание кода.Как только у нас есть функция потерь, мы можем скомпилировать нашу модель распознавания лиц с помощью Keras. И мы будем использовать оптимизатор Адама, чтобы минимизировать потери, рассчитанные функцией Triplet Loss.
Подготовка базы данных
Теперь, когда мы собрали FaceNet, мы собираемся подготовить базу данных тех людей, которых хотим, чтобы наша система распознала. Мы будем использовать все изображения, содержащиеся в нашем каталоге изображений, для нашей базы данных отдельных лиц. Для каждого изображения мы преобразуем данные изображения в кодировку 128 чисел с плавающей запятой. Мы делаем это, вызывая функцию img_path_to_encoding. Функция принимает путь к изображению и передает изображение в нашу сеть распознавания лиц. Затем он возвращает вывод из сети, который, оказывается, является кодировкой изображения.
Как только мы добавили кодировку для каждого изображения в нашу базу данных, наша система может, наконец, начать распознавать людей!
Признание лица
Как обсуждалось ранее, FaceNet обучается минимизировать расстояние между изображениями одного и того же человека и максимизировать расстояние между изображениями разных лиц. Наша реализация использует эту информацию для определения того, кем, по-видимому, является новое изображение, поданное в нашу систему.

Функция обрабатывает изображение с помощью FaceNet и возвращает кодировку изображения. Теперь, когда у нас есть кодировка, мы можем найти человека, к которому, скорее всего, принадлежит изображение.Чтобы найти человека, мы просматриваем нашу базу данных и вычисляем расстояние между нашим новым изображением и каждым человеком в базе данных. В качестве наиболее вероятного кандидата выбирается человек с самым низким расстоянием до нового изображения.
Наконец, мы должны определить, содержит ли изображение кандидата и новое изображение одно и то же лицо. Поскольку к концу нашего цикла мы определили только наиболее вероятного человека.
Создание системы с использованием распознавания лиц.
Теперь, когда мы знаем подробности о том, как мы распознаем человека, использующего алгоритм распознавания лиц, мы можем начать с ним некоторое удовольствие.
В репозитории Github, с которым я связался в начале этой статьи, приведена демонстрация, в которой используется веб-камера для переноски видеокадров для нашего алгоритма распознавания лиц. Как только алгоритм распознает человека в кадре, демо воспроизводит звуковое сообщение, которое приветствует пользователя, используя имя своего изображения в базе данных.
Вывод
Теперь вы должны быть знакомы с тем, как работают системы распознавания лиц и как сделать свою собственную упрощенную систему распознавания лиц, используя предварительно подготовленную версию сети FaceNet в python!
Если вы хотите поиграть с демонстрацией в репозитории Github и добавить изображения людей, которых вы знаете, тогда вперед и разветвите репозиторий.
Поужинайте с демонстрацией и поразите всех своих друзей своим удивительным знанием распознавания лица!
genapilot.ru
Алгоритмы распознавания лиц наконец-то превзошли человеческое зрение
Системы машинного зрения значительно усовершенствовались в последние годы. Особенно бурный прогресс — в распознавании лиц. Оно и понятно, ведь это самое коммерчески перспективное применение технологии. В идеальных условиях освещения, при одинаковом положении в кадре и одинаковом выражении лиц точность алгоритмов уже давно превосходит человеческую. Но реальный мир не идеален. Люди носят шляпы и очки, кривляются, меняют прически и отворачиваются от объектива. Поэтому разработчики упорно решают проблему распознавания лиц на произвольных фотографиях, хотя бы с той же точностью, что и человек.
В качестве тестовой базы для проверки новых алгоритмов в этой области стандартно используется база Labelled Faces in the Wild, состоящая из 13 000 фотографий почти 6000 известных людей, собранных по всему интернету. Сравнивая произвольные пары фотографий, люди легко находят соответствия или несоответствия и дают верный ответ, в среднем, в 97,53% случаев. Программы никогда не могли приблизиться к такому результату. До сегодняшнего дня.
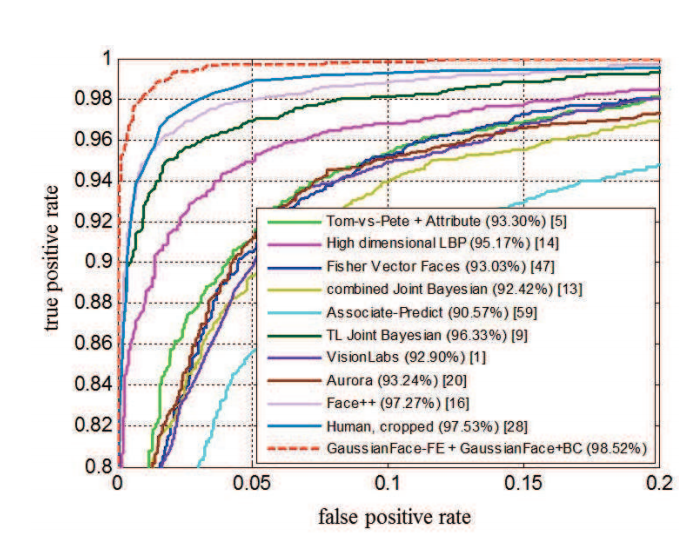 Результат различных алгоритмов и человеческого зрения при решении задач Labelled Faces in the Wild
Результат различных алгоритмов и человеческого зрения при решении задач Labelled Faces in the Wild
Ученые из Китайского университета Гонконга утверждают, что их программа впервые превзошла этот показатель. Разработанный алгоритм GaussianFace нормализует все лица на фотографиях, преобразуя их во фронтальное изображение 150х120 пикселов, по пяти базовым опорным точкам: расположение обоих глаз, носа и уголков рта. Затем изображение разделяется на несколько перекрывающихся фрагментов 25х25 пикселов, которые сравниваются по отдельности. После тренировки на большом количестве картинок из четырех других баз данных, в том числе Multi-PIE и Life Photos, программа GaussianFace проходит тесты Labelled Faces in the Wild с показателем 98,52%.
Теперь перед разработчиками встают задачи по совершенствованию распознавания лиц в более сложных ситуациях. Люди могут использовать многочисленные подсказки, например, конфигурацию шеи и плеч. Программы тоже должны этому научиться.
Оценка качества алгоритмов распознавания лиц
Привет!
Мы, в компании NtechLab, занимаемся исследованиями и разработкой продуктов в области распознавания лиц. В процессе внедрения наших решений мы часто сталкиваемся с тем, что заказчики не очень ясно представляют себе требования к точности алгоритма, поэтому и тестирование того или иного решения для их задачи даётся с трудом. Чтобы исправить ситуацию, мы разработали краткое пособие, описывающее основные метрики и подходы к тестированию, которыми хотелось бы поделиться с сообществом Хабра.

В последнее время распознавание лиц вызывает все больше интереса со стороны коммерческого сектора и государства. Однако корректное измерение точности работы таких систем – задача непростая и содержит массу нюансов. К нам постоянно обращаются с запросами на тестирование нашей технологии и пилотными проектами на ее основе, и мы заметили, что часто возникают вопросы с терминологией и методами тестирования алгоритмов применительно к бизнес-задачам. В результате для решения задачи могут быть выбраны неподходящие инструменты, что приводит к финансовым потерям или недополученной прибыли. Мы решили опубликовать эту заметку, чтобы помочь людям освоиться в среде специализированных терминов и сырых данных, окружающих технологии распознавания лиц. Нам хотелось рассказать об основных понятиях в этой области простым и понятным языком. Надеемся, это позволит людям технического и предпринимательского склада говорить на одном языке, лучше понимать сценарии использования распознавания лиц в реальном мире и принимать решения, подтвержденные данными.
Задачи распознавания лиц
Распознаванием лиц часто называют набор различных задач, например, детектирование лица на фотографии или в видеопотоке, определение пола и возраста, поиск нужного человека среди множества изображений или проверка того, что на двух изображениях один и тот же человек. В этой статье мы остановимся на последних двух задачах и будем их называть, соответственно, идентификация и верификация. Для решения этих задач из изображений извлекаются специальные дескрипторы, или векторы признаков. В этом случае задача идентификации сводится к поиску ближайшего вектора признаков, а верификацию можно реализовать с помощью простого порога расстояний между векторами. Комбинируя эти два действия, можно идентифицировать человека среди набора изображений или принимать решение о том, что его нет среди этих изображений. Такая процедура называется open-set identification (идентификацией на открытом множестве), см. Рис.1.
 Рис.1 Open-set identification
Рис.1 Open-set identification
Для количественной оценки схожести лиц можно использовать расстояние в пространстве векторов признаков. Часто выбирают евклидово или косинусное расстояние, но существуют и другие, более сложные, подходы. Конкретная функция расстояния часто поставляется в составе продукта по распознаванию лиц. Идентификация и верификация возвращают разные результаты и, соответственно, разные метрики применяются для оценки их качества. Мы подробно рассмотрим метрики качества в последующих разделах. Помимо выбора адекватной метрики, для оценки точности алгоритма понадобится размеченный набор изображений (датасет).
Оценка точности
Датасеты
Почти всё современное ПО для распознавания лиц построено на машинном обучении. Алгоритмы обучаются на больших датасетах (наборах данных) с размеченными изображениями. И качество, и природа этих датасетов оказывают существенное влияние на точность. Чем лучше исходные данные, тем лучше алгоритм будет справляться с поставленной задачей.
Естественный способ проверить, что точность алгоритма распознавания лиц соответствует ожиданиям, это измерить точность на отдельном тестовом датасете. Очень важно правильно выбрать этот датасет. В идеальном случае организации стоит обзавестись собственным набором данных, максимально похожим на те изображения, с которыми система будет работать при эксплуатации. Обратите внимание на камеру, условия съемки, возраст, пол и национальность людей, которые попадут в тестовый датасет. Чем более похож тестовый датасет на реальные данные, тем более достоверными будут результаты тестирования. Поэтому часто имеет смысл потратить время и средства для сбора и разметки своего набора данных. Если же это, по какой-то причине, не представляется возможным, можно воспользоваться публичными датасетами, например, LFW и MegaFace. LFW содержит только 6000 пар изображений лиц и не подходит для многих реальных сценариев: в частности, на этом датасете невозможно измерить достаточно низкие уровни ошибок, как мы покажем далее. Датасет MegaFace содержит намного больше изображений и подходит для тестирования алгоритмов распознавания лиц на больших масштабах. Однако и обучающее, и тестовое множество изображений MegaFace’a есть в открытом доступе, поэтому использовать его для тестирования следует с осторожностью.
Альтернативный вариант заключается в использовании результатов тестирования третьим лицом. Такие тестирования проводятся квалифицированными специалистами на больших закрытых датасетах, и их результатам можно доверять. Одним из примеров может служить NIST Face Recognition Vendor Test Ongoing. Это тест, проводимый Национальным Институтом Стандартов и Технологий (NIST) при Министерстве торговли США. “Минус” данного подхода заключается в том, что датасет организации, проводящей тестирование, может существенно отличаться от интересующего сценария использования.
Переобучение
Как мы говорили, машинное обучение лежит в основе современного ПО для распознавания лиц. Одним из распространенных феноменов машинного обучения является т.н. переобучение. Проявляется он в том, что алгоритм показывает хорошие результаты на данных, которые использовались при обучении, но результаты на новых данных получаются значительно хуже.
Рассмотрим конкретный пример: представим себе клиента, который хочет установить пропускную систему с распознаванием лиц. Для этих целей он собирает набор фотографий людей, которым будет разрешен доступ, и обучает алгоритм отличать их от других людей. На испытаниях система показывает хорошие результаты и внедряется в эксплуатацию. Через некоторое время список людей с допуском решают расширить и обнаруживается, что система отказывает новым людям в доступе. Алгоритм тестировался на тех же данных, что и обучался, и никто не проводил измерения точности на новых фотографиях. Это, конечно, утрированный пример, но он позволяет понять проблему.
В некоторых случаях переобучение проявляется не так явно. Допустим, алгоритм обучался на изображениях людей, где превалировала определенная этническая группа. При применении такого алгоритма к лицам другой национальности его точность наверняка упадет. Излишне оптимистичная оценка точности работы алгоритма из-за неправильно проведенного тестирования – очень распространенная ошибка. Всегда следует тестировать алгоритм на новых данных, которые ему предстоит обрабатывать в реальном применении, а не на тех данных, на которых проводилось обучение.
Резюмируя вышесказанное, составим список рекомендаций: не используйте данные, на которых обучался алгоритм при тестировании, используйте специальный закрытый датасет для тестирования. Если это невозможно и вы собираетесь воспользоваться публичным датасетом, убедитесь, что вендор не использовал его в процессе обучения и/или настройки алгоритма. Изучите датасет перед тестированием, подумайте, насколько он близок к тем данным, которые будут поступать при эксплуатации системы.
Метрики
После выбора датасета, следует определиться с метрикой, которая будет использоваться для оценки результатов. В общем случае метрика – это функция, которая принимает на вход результаты работы алгоритма (идентификации или верификации), а на выходе возвращает число, которое соответствует качеству работы алгоритма на конкретном датасете. Использование одного числа для количественного сравнения разных алгоритмов или вендоров позволяет сжато представлять результаты тестирования и облегчает процесс принятия решений. В этом разделе мы рассмотрим метрики, наиболее часто применяемые в распознавании лиц, и обсудим их значение с точки зрения бизнеса.
Верификация
Верификацию лиц можно рассматривать как процесс принятия бинарного решения: “да” (два изображения принадлежат одному человеку), “нет” (на паре фотографий изображены разные люди). Прежде чем разбираться с метриками верификации, полезно понять, как мы можем классифицировать ошибки в подобных задачах. Учитывая, что есть 2 возможных ответа алгоритма и 2 варианта истинного положения вещей, всего возможно 4 исхода:
 Рис. 2 Типы ошибок. Цвет фона кодирует истинное отношение между картинками (синий означает “принять”, желтый – “отвергнуть”), цвет рамки соответствует предсказанию алгоритма (синий – “принять”, желтый – “отвергнуть”
Рис. 2 Типы ошибок. Цвет фона кодирует истинное отношение между картинками (синий означает “принять”, желтый – “отвергнуть”), цвет рамки соответствует предсказанию алгоритма (синий – “принять”, желтый – “отвергнуть”

В таблице выше столбцы соответствуют решению алгоритма (синий – принять, желтый – отвергнуть), строки соответствуют истинным значениям (кодируются теми же цветами). Правильные ответы алгоритма отмечены зеленым фоном, ошибочные – красным.
Из этих исходов два соответствуют правильным ответам алгоритма, а два – ошибкам первого и второго рода соответственно. Ошибки первого рода называют «false accept», «false positive» или «false match» (неверно принято), а ошибки второго рода – «false reject», «false negative» или «false non-match» (неверно отвергнуто).
Просуммировав количество ошибок разного рода среди пар изображений в датасете и поделив их на количество пар, мы получим false accept rate (FAR) и false reject rate (FRR). В случае с системой контроля доступа «false positive» соответствует предоставлению доступа человеку, для которого этот доступ не предусмотрен, в то время как «false negative» означает, что система ошибочно отказала в доступе авторизованной персоне. Эти ошибки имеют разную стоимость с точки зрения бизнеса и поэтому рассматриваются отдельно. В примере с контролем доступа «false negative» приводит к тому, что сотруднику службы безопасности надо перепроверить пропуск сотрудника. Предоставление неавторизованного доступа потенциальному нарушителю (false positive) может привести к гораздо худшим последствиям.
Учитывая, что ошибки разного рода связаны с различными рисками, производители ПО для распознавания лиц зачастую дают возможность настроить алгоритм так, чтобы минимизировать один из типов ошибок. Для этого алгоритм возвращает не бинарное значение, а вещественное число, отражающее уверенность алгоритма в своем решении. В таком случае пользователь может самостоятельно выбрать порог и зафиксировать уровень ошибок на определенных значениях.
Для примера рассмотрим «игрушечный» датасет из трех изображений. Пусть изображения 1 и 2 принадлежат одному и тому же человеку, а изображение 3 кому-то еще. Допустим, что программа оценила свою уверенность для каждой из трех пар следующим образом:
Мы специально выбрали значения таким образом, чтобы ни один порог не классифицировал все три пары правильно. В частности, любой порог ниже 0.6 приведет к двум false accept (для пар 2-3 и 1-3). Разумеется, такой результат можно улучшить.
Выбор порога из диапазона от 0.6 до 0.85 приведет к тому, что пара 1-3 будет отвергнута, пара 1-2 по-прежнему будет приниматься, а 2-3 будет ложно приниматься. Если увеличить порог до 0.85-0.9, то пара 1-2 станет ложно отвергаться. Значения порога выше 0.9 приведут к двум true reject (пары 1-3 и 2-3) и одному false reject (1-2). Таким образом, лучшими вариантами выглядят пороги из диапазона 0.6-0.85 (один false accept 2-3) и порог выше 0.9 (приводит к false reject 1-2). Какое значение выбрать в качестве финального, зависит от стоимости ошибок разных типов. В этом примере порог варьируется в широких диапазонах, это связано, в первую очередь, с очень маленьких размеров датасетом и с тем, как мы выбрали значения уверенности алгоритма. Для больших, применяемых для реальных задач датасетов, получились бы существенно более точные значения порога. Зачастую вендоры ПО для распознавания лиц поставляют значения порога по умолчанию для разных FAR, которые вычисляются похожим образом на собственных датасетах вендора.
Также нетрудно заметить, что по мере того как интересующий FAR снижается, требуется все больше и больше положительных пар изображений, чтобы точно вычислить значение порога. Так, для FAR=0.001 нужно по меньшей мере 1000 пар, а для FAR= потребуется уже 1 миллион пар. Собрать и разметить такой датасет непросто, поэтому клиентам, заинтересованным в низких значениях FAR, имеет смысл обратить внимание на публичные бенчмарки, такие как NIST Face Recognition Vendor Test или MegaFace. К последнему следует относиться с осторожностью, так как и обучающая, и тестовая выборки доступны всем желающим, что может привести к излишне оптимистичной оценке точности (см. раздел «Переобучение»).
потребуется уже 1 миллион пар. Собрать и разметить такой датасет непросто, поэтому клиентам, заинтересованным в низких значениях FAR, имеет смысл обратить внимание на публичные бенчмарки, такие как NIST Face Recognition Vendor Test или MegaFace. К последнему следует относиться с осторожностью, так как и обучающая, и тестовая выборки доступны всем желающим, что может привести к излишне оптимистичной оценке точности (см. раздел «Переобучение»).
Типы ошибок различаются по связанной с ними стоимости, и у клиента есть способ смещать баланс в сторону тех или иных ошибок. Для этого надо рассмотреть широкий диапазон значений порога. Удобный способ визуализации точности алгоритма при разных значениях FAR заключается в построении ROC-кривых (англ. receiver operating characteristic, рабочая характеристика приёмника).
Давайте разберемся, как строятся и анализируются ROC-кривые. Уверенность алгоритма (а следовательно, и порог) принимают значения из фиксированного интервала. Другими словами, эти величины ограничены сверху и снизу. Предположим, что это интервал от 0 до 1. Теперь мы можем измерить количество ошибок, варьируя значение порога от 0 до 1 с небольшим шагом. Так, для каждого значения порога мы получим значения FAR и TAR (true accept rate). Далее мы будет рисовать каждую точку так, чтобы FAR соответствовал оси абсцисс, а TAR – оси ординат.
 Рис.3 Пример ROC-кривой
Рис.3 Пример ROC-кривой
Легко заметить, что первая точка будет иметь координаты 1,1. При пороге равном 0 мы принимаем все пары и не отвергаем ни одной. Аналогично, последняя точка будет 0,0: при пороге 1 мы не принимаем ни одной пары и отвергаем все пары. В остальных точках кривая обычно выпуклая. Также можно заметить, что наихудшая кривая лежит примерно на диагонали графика и соответствует случайному угадыванию исхода. С другой стороны, наилучшая возможная кривая образует треугольник с вершинами (0,0) (0,1) и (1,1). Но на датасетах разумного размера такое трудно встретить.
 Рис.4 ROC-кривые NIST FRVT
Рис.4 ROC-кривые NIST FRVT
Можно построить подобие RОС-кривых с различными метриками/ошибками на оси. Рассмотрим, например, рисунок 4. На нем видно, что организаторы NIST FRVT по оси Y нарисовали FRR (на рисунке – False non-match rate), а по оси X – FAR (на рисунке – False match rate). В данном конкретном случае лучшие результаты достигнуты кривыми, которые расположены ниже и смещены влево, что соответствует низким показателям FRR и FAR. Поэтому стоит обращать внимание на то, какие величины отложены по осям.
Такой график позволяет легко судить о точности алгоритма при заданном FAR: достаточно найти точку на кривой с координатой Х равной нужному FAR и соответствующее значение TAR. «Качество» ROC-кривой также можно оценить одним числом, для этого надо посчитать площадь под ней. При этом лучшее возможное значение будет 1, а значение 0.5 соответствует случайному угадыванию. Такое число называют ROC AUC (Area Under Curve). Однако следует заметить, что ROC AUC неявно предполагает, что ошибки первого и второго рода однозначны, что не всегда так. В случае если цена ошибок различается, следует обратить внимание на форму кривой и те области, где FAR соответствует бизнес-требованиям.
Идентификация
Второй популярной задачей распознавания лиц является идентификация, или поиск человека среди набора изображений. Результаты поиска сортируются по уверенности алгоритма, и наиболее вероятные совпадения попадают в начало списка. В зависимости от того, присутствует или нет искомый человек в поисковой базе, идентификацию разделяют на две подкатегории: closed-set идентификация (известно, что искомый человек есть в базе) и open-set идентификация (искомого человека может не быть в базе).
Точность (accuracy) является надежной и понятной метрикой для closed-set идентификации. По сути, точность измеряет количество раз, когда нужная персона была среди результатов поиска.
Как это работает на практике? Давайте разбираться. Начнем с формулировки бизнес-требований. Допустим, у нас есть веб-страница, которая может разместить десять результатов поиска. Нам нужно измерить количество раз, которое искомый человек попадает в первые десять ответов алгоритма. Такое число называется Top-N точностью (в данном конкретном случае N равно 10).
Для каждого испытания мы определяем изображение человека, которого будем искать, и галерею, в которой будем искать, так, чтобы галерея содержала хотя бы еще одно изображение этого человека. Мы просматриваем первые десять результатов работы алгоритма поиска и проверяем, есть ли среди них искомый человек. Чтобы получить точность, следует просуммировать все испытания, в которых искомый человек был в результатах поиска, и поделить на общее число испытаний.
 Рис 5. Пример идентификации. В этом примере искомый человек появляется в позиции 2, поэтому точность Top-1 равна 0, а Top-2 и далее равна 1.
Рис 5. Пример идентификации. В этом примере искомый человек появляется в позиции 2, поэтому точность Top-1 равна 0, а Top-2 и далее равна 1.
Open-set идентификация состоит из поиска людей, наиболее похожих на искомое изображение, и определения, является ли кто-то из них искомым человеком на основании уверенности алгоритма. Open-set идентификацию можно рассматривать как комбинацию closed-set идентификации и верификации, поэтому на этой задаче можно применять все те же метрики, что и в задаче верификации. Также нетрудно заметить, что open-set идентификацию можно свести к попарным сравнениям искомого изображения со всеми изображениями из галереи. На практике это не используется из соображений скорости вычислений. ПО для распознавания лиц часто поставляется с быстрыми алгоритмами поиска, которые могут находить среди миллионов лиц похожие за миллисекунды. Попарные сравнения заняли бы намного больше времени.
Практические примеры
В качестве иллюстрации давайте рассмотрим несколько распространенных ситуаций и подходов к тестированию алгоритмов распознавания лиц.
Розничный магазин
Допустим, что средний по размеру розничный магазин хочет улучшить свою программу лояльности или уменьшить количество краж. Забавно, но с точки зрения распознавания лиц это примерно одно и то же. Главная задача этого проекта заключается в том, чтобы как можно раньше идентифицировать постоянного покупателя или злоумышленника по изображению с камеры и передать эту информацию продавцу или сотруднику службы безопасности.
Пусть программа лояльности охватывает 100 клиентов. Данную задачу можно рассматривать как пример open-set идентификации. Оценив расходы, отдел маркетинга пришел в выводу, что приемлемый уровень ошибки – принимать одного посетителя за постоянного покупателя за день. Если в день магазин посещает 1000 посетителей, каждый из которых должен быть сверен со списком 100 постоянных клиентов, то необходимый FAR составит  .
.
Определившись с допустимым уровнем ошибки, следует выбрать подходящий датасет для тестирования. Хорошим вариантом было бы разместить камеру в подходящем месте (вендоры могут помочь с конкретным устройством и расположением). Сопоставив транзакции держателей карт постоянного покупателя с изображениями с камеры и проведя ручную фильтрацию, сотрудники магазина могут собрать набор позитивных пар. Также имеет смысл собрать набор изображений случайных посетителей (по одному изображению на человека). Общее количество изображений должно примерно соответствовать количеству посетителей магазина в день. Объединив оба набора, можно получить датасет как «позитивных», так и «негативных» пар.
Для проверки желаемой точности должно хватить около тысячи «позитивных» пар. Комбинируя различных постоянных клиентов и случайных посетителей, можно собрать около 100 000 «негативных» пар.
Следующим шагом будет запустить (или попросить вендора запустить) ПО и получить уверенность алгоритма для каждой пары из датасета. Когда это будет сделано, можно построить ROC-кривую и удостовериться, что количество правильно идентифицированных постоянных клиентов при FAR= соответствует бизнес-требованиям.
соответствует бизнес-требованиям.
E-Gate в аэропорту
Современные аэропорты обслуживают десятки миллионов пассажиров в год, а процедуру паспортного контроля ежедневно проходит около 300 000 человек. Автоматизация этого процесса позволит существенно сократить расходы. С другой стороны, пропустить нарушителя крайне нежелательно, и администрация аэропорта хочет минимизировать риск такого события. FAR= соответствует десяти нарушителям в год и кажется разумным в этой ситуации. Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
соответствует десяти нарушителям в год и кажется разумным в этой ситуации. Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
Таргетированная почтовая рассылка
До сих пор мы рассматривали примеры, в которых заказчик был заинтересован в низких FAR, однако это не всегда так. Представим себе оборудованный камерой рекламный стенд в крупном торговом центре. Торговый центр имеет собственную программу лояльности и хотел бы идентифицировать ее участников, остановившихся у стенда. Далее этим покупателям можно было бы рассылать таргетированные письма со скидками и интересными предложениями на основании того, что их заинтересовало на стенде.
Допустим, что эксплуатация такой системы обходится в 10 $, при этом около 1000 посетителей в день останавливаются у стенда. Отдел маркетинга оценил прибыль от каждого таргетированного email в 0.0105 $. Нам хотелось бы идентифицировать как можно больше постоянных покупателей и не слишком беспокоить остальных. Чтобы такая рассылка окупилась, точность должна быть равна затратам на стенд, поделенным на количество посетителей и ожидаемый доход от каждого письма. Для нашего примера точность равна  . Администрация торгового центра могла бы собрать датасет способом, описанным в разделе «Розничный магазин», и измерить точность, как описано в разделе «Идентификация». На основании результатов тестирования можно принимать решение, получится ли извлечь ожидаемую выгоду с помощью системы распознавания лиц.
. Администрация торгового центра могла бы собрать датасет способом, описанным в разделе «Розничный магазин», и измерить точность, как описано в разделе «Идентификация». На основании результатов тестирования можно принимать решение, получится ли извлечь ожидаемую выгоду с помощью системы распознавания лиц.
Поддержка видео
В этой заметке мы обсуждали преимущественно работу с изображениями и почти не касались потокового видео. Видео можно рассматривать как последовательность статичных изображений, поэтому метрики и подходы к тестированию точности на изображениях применимы и к видео. Стоит отметить, что обработка потокового видео гораздо более затратна с точки зрения производимых вычислений и накладывает дополнительные ограничения на все этапы распознавания лиц. При работе с видео следует проводить отдельное тестирование производительности, поэтому детали этого процесса не затрагиваются в настоящем тексте.
Частые ошибки
В этом разделе мы хотели бы перечислить распространенные проблемы и ошибки, которые встречаются при тестировании ПО для распознавания лиц, и дать рекомендации, как их избежать.
Тестирование на датасете недостаточного размера
Всегда следует быть аккуратным при выборе датасета для тестирования алгоритмов распознавания лиц. Одним из важнейших свойств датасета является его размер. Размер датасета нужно выбирать, исходя из требований бизнеса и значений FAR/TAR. «Игрушечные» датасеты из нескольких изображений людей из вашего офиса дадут возможность «поиграть» с алгоритмом, измерить его производительность или протестировать нестандартные ситуации, но на их основании нельзя делать выводы о точности алгоритма. Для тестирования точности следует использовать датасеты разумных размеров.
Тестирование при единственном значении порога
Иногда люди тестируют алгоритм распознавания лиц при одном фиксированном пороге (часто выбранном производителем «по умолчанию») и принимают во внимание лишь один тип ошибок. Это неправильно, так как значения порога «по умолчанию» у разных вендоров различаются или выбираются на основе различных значений FAR или TAR. При тестировании следует обращать внимание на оба типа ошибок.
Сравнение результатов на разных датасетах
Датасеты различаются по размерам, качеству и сложности, поэтому результаты работы алгоритмов на разных датасетах невозможно сравнивать. Можно запросто отказаться от лучшего решения только потому, что оно тестировалось на более сложном, чем у конкурента, датасете.
Делать выводы на основе тестирования на единственном датасете
Следует стараться проводить тестирование на нескольких наборах данных. При выборе единственного публичного датасета нельзя быть уверенным, что он не использовался при обучении или настройке алгоритма. В этом случае точность алгоритма будет переоценена. К счастью, вероятность этого события можно снизить, сравнив результаты на разных датасетах.
Выводы
В этой заметке мы описали основные составные части тестирования алгоритмов распознавания лиц: наборы данных, задачи, соответствующие метрики и распространенные сценарии.
Конечно, это далеко не всё, что хотелось бы рассказать о тестировании, и наилучший порядок действий может отличаться при многочисленных исключительных сценариях (команда NtechLab с радостью поможет с ними разобраться). Но мы очень надеемся, что этот текст поможет правильно спланировать тестирование алгоритма, оценить его сильные и слабые стороны и интерпретировать метрики качества с точки зрения бизнес-задач.
Автор: NtechLab
Источник
www.pvsm.ru
Анализ существующих подходов к распознаванию лиц - Распознавание образов
Несмотря на большое разнообразие представленных алгоритмов, можно выделить общую структуру процесса распознавания лиц:
Общий процесс обработки изображения лица при распознавании
На первом этапе производится детектирование и локализация лица на изображении. На этапе распознавания производится выравнивание изображения лица (геометрическое и яркостное), вычисление признаков и непосредственно распознавание – сравнение вычисленных признаков с заложенными в базу данных эталонами. Основным отличием всех представленных алгоритмов будет вычисление признаков и сравнение их совокупностей между собой.
1. Метод гибкого сравнения на графах (Elastic graph matching) [13].
Суть метода сводится к эластичному сопоставлению графов, описывающих изображения лиц. Лица представлены в виде графов со взвешенными вершинами и ребрами. На этапе распознавания один из графов – эталонный – остается неизменным, в то время как другой деформируется с целью наилучшей подгонки к первому. В подобных системах распознавания графы могут представлять собой как прямоугольную решетку, так и структуру, образованную характерными (антропометрическими) точками лица.
а)
б)
Пример структуры графа для распознавания лиц: а) регулярная решетка б) граф на основе антропометрических точек лица.
В вершинах графа вычисляются значения признаков, чаще всего используют комплексные значения фильтров Габора или их упорядоченных наборов – Габоровских вейвлет (строи Габора), которые вычисляются в некоторой локальной области вершины графа локально путем свертки значений яркости пикселей с фильтрами Габора.
Набор (банк, jet) фильтров Габора
Пример свертки изображения лица с двумя фильтрами Габора
Ребра графа взвешиваются расстояниями между смежными вершинами. Различие (расстояние, дискриминационная характеристика) между двумя графами вычисляется при помощи некоторой ценовой функции деформации, учитывающей как различие между значениями признаков, вычисленными в вершинах, так и степень деформации ребер графа.Деформация графа происходит путем смещения каждой из его вершин на некоторое расстояние в определённых направлениях относительно ее исходного местоположения и выбора такой ее позиции, при которой разница между значениями признаков (откликов фильтров Габора) в вершине деформируемого графа и соответствующей ей вершине эталонного графа будет минимальной. Данная операция выполняется поочередно для всех вершин графа до тех пор, пока не будет достигнуто наименьшее суммарное различие между признаками деформируемого и эталонного графов. Значение ценовой функции деформации при таком положении деформируемого графа и будет являться мерой различия между входным изображением лица и эталонным графом. Данная «релаксационная» процедура деформации должна выполняться для всех эталонных лиц, заложенных в базу данных системы. Результат распознавания системы – эталон с наилучшим значением ценовой функции деформации.
Пример деформации графа в виде регулярной решетки
В отдельных публикациях указывается 95-97%-ая эффективность распознавания даже при наличии различных эмоциональных выражениях и изменении ракурса лица до 15 градусов. Однако разработчики систем эластичного сравнения на графах ссылаются на высокую вычислительную стоимость данного подхода. Например, для сравнения входного изображения лица с 87 эталонными тратилось приблизительно 25 секунд при работе на параллельной ЭВМ с 23 транспьютерами [15] (Примечание: публикация датирована 1993 годом). В других публикациях по данной тематике время либо не указывается, либо говорится, что оно велико.
Недостатки: высокая вычислительная сложность процедуры распознавания. Низкая технологичность при запоминании новых эталонов. Линейная зависимость времени работы от размера базы данных лиц.
2. Нейронные сети
В настоящее время существует около десятка разновидности нейронных сетей (НС). Одним из самых широко используемых вариантов являться сеть, построенная на многослойном перцептроне, которая позволяет классифицировать поданное на вход изображение/сигнал в соответствии с предварительной настройкой/обучением сети.Обучаются нейронные сети на наборе обучающих примеров. Суть обучения сводится к настройке весов межнейронных связей в процессе решения оптимизационной задачи методом градиентного спуска. В процессе обучения НС происходит автоматическое извлечение ключевых признаков, определение их важности и построение взаимосвязей между ними. Предполагается, что обученная НС сможет применить опыт, полученный в процессе обучения, на неизвестные образы за счет обобщающих способностей. Наилучшие результаты в области распознавания лиц (по результатам анализа публикаций) показала Convolutional Neural Network или сверточная нейронная сеть (далее – СНС) [29-31], которая является логическим развитием идей таких архитектур НС как когнитрона и неокогнитрона. Успех обусловлен возможностью учета двумерной топологии изображения, в отличие от многослойного перцептрона. Отличительными особенностями СНС являются локальные рецепторные поля (обеспечивают локальную двумерную связность нейронов), общие веса (обеспечивают детектирование некоторых черт в любом месте изображения) и иерархическая организация с пространственными сэмплингом (spatial subsampling). Благодаря этим нововведениям СНС обеспечивает частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям.
Схематичное изображение архитектуры сверточной нейронной сети
Тестирование СНС на базе данных ORL, содержащей изображения лиц с небольшими изменениями освещения, масштаба, пространственных поворотов, положения и различными эмоциями, показало 96% точность распознавания. Свое развитие СНС получили в разработке DeepFace [47], которую приобрел Facebook для распознавания лиц пользователей своей соцсети. Все особенности архитектуры носят закрытый характер.
Принцип работы DeepFace
Недостатки нейронных сетей: добавление нового эталонного лица в базу данных требует полного переобучения сети на всем имеющемся наборе (достаточно длительная процедура, в зависимости от размера выборки от 1 часа до нескольких дней). Проблемы математического характера, связанные с обучением: попадание в локальный оптимум, выбор оптимального шага оптимизации, переобучение и т. д. Трудно формализуемый этап выбора архитектуры сети (количество нейронов, слоев, характер связей). Обобщая все вышесказанное, можно заключить, что НС – «черный ящик» с трудно интерпретируемыми результатами работы.
3. Скрытые Марковские модели (СММ, HMM)
Одним из статистических методов распознавания лиц являются скрытые Марковские модели (СММ) с дискретным временем [32-34]. СММ используют статистические свойства сигналов и учитывают непосредственно их пространственные характеристики. Элементами модели являются: множество скрытых состояний, множество наблюдаемых состояний, матрица переходных вероятностей, начальная вероятность состояний. Каждому соответствует своя Марковская модель. При распознавании объекта проверяются сгенерированные для заданной базы объектов Марковские модели и ищется максимальная из наблюдаемых вероятность того, что последовательность наблюдений для данного объекта сгенерирована соответствующей моделью.На сегодняшний день не удалось найти примера коммерческого применения СММ для распознавания лиц.
Недостатки: — необходимо подбирать параметры модели для каждой базы данных;— СММ не обладает различающей способностью, то есть алгоритм обучения только максимизирует отклик каждого изображения на свою модель, но не минимизирует отклик на другие модели.
4. Метод главных компонент или principal component analysis (PCA) [11]
Одним из наиболее известных и проработанных является метод главных компонент (principal component analysis, PCA), основанный на преобразовании Карунена-Лоева. Первоначально метод главных компонент начал применяться в статистике для снижения пространства признаков без существенной потери информации. В задаче распознавания лиц его применяют главным образом для представления изображения лица вектором малой размерности (главных компонент), который сравнивается затем с эталонными векторами, заложенными в базу данных. Главной целью метода главных компонент является значительное уменьшение размерности пространства признаков таким образом, чтобы оно как можно лучше описывало «типичные» образы, принадлежащие множеству лиц. Используя этот метод можно выявить различные изменчивости в обучающей выборке изображений лиц и описать эту изменчивость в базисе нескольких ортогональных векторов, которые называются собственными (eigenface).
Полученный один раз на обучающей выборке изображений лиц набор собственных векторов используется для кодирования всех остальных изображений лиц, которые представляются взвешенной комбинацией этих собственных векторов. Используя ограниченное количество собственных векторов можно получить сжатую аппроксимацию входному изображению лица, которую затем можно хранить в базе данных в виде вектора коэффициентов, служащего одновременно ключом поиска в базе данных лиц.
Суть метода главных компонент сводится к следующему. Вначале весь обучающий набор лиц преобразуется в одну общую матрицу данных, где каждая строка представляет собой один экземпляр изображения лица, разложенного в строку. Все лица обучающего набора должны быть приведены к одному размеру и с нормированными гистограммами.
Преобразования обучающего набора лиц в одну общую матрицу X
Затем производится нормировка данных и приведение строк к 0-му среднему и 1-й дисперсии, вычисляется матрица ковариации. Для полученной матрицы ковариации решается задача определения собственных значений и соответствующих им собственных векторов (собственные лица). Далее производится сортировка собственных векторов в порядке убывания собственных значений и оставляют только первые k векторов по правилу:
Алгоритм РСА
Пример первых десяти собственных векторов (собственных лиц), полученных на обучаемом наборе лиц
= 0.956*-1.842*+0.046 …
Пример построения (синтеза) человеческого лица с помощью комбинации собственных лиц и главных компонент
Принцип выбора базиса из первых лучших собственных векторов
Пример отображения лица в трехмерное метрическое пространство, полученном по трем собственным лицам и дальнейшее распознавание
Метод главных компонент хорошо зарекомендовал себя в практических приложениях. Однако, в тех случаях, когда на изображении лица присутствуют значительные изменения в освещенности или выражении лица, эффективность метода значительно падает. Все дело в том, что PCA выбирает подпространство с такой целью, чтобы максимально аппроксимировать входной набор данных, а не выполнить дискриминацию между классами лиц.
В [22] было предложено решение этой проблемы с использование линейного дискриминанта Фишера (в литературе встречается название “Eigen-Fisher”, “Fisherface”, LDA). LDA выбирает линейное подпространство, которое максимизирует отношение:
где
матрица межклассового разброса, и
Матрица внутриклассового разброса; m – число классов в базе данных.
LDA ищет проекцию данных, при которой классы являются максимально линейно сепарабельны (см. рисунок ниже). Для сравнения PCA ищет такую проекцию данных, при которой будет максимизирован разброс по всей базе данных лиц (без учета классов). По результатам экспериментов [22] в условиях сильного бакового и нижнего затенения изображений лиц Fisherface показал 95% эффективность по сравнению с 53% Eigenface.
Принципиальное отличие формирования проекций PCA и LDA
Отличие PCA от LDA
5. Active Appearance Models (AAM) и Active Shape Models (ASM) (Хабраисточник)
Active Appearance Models (AAM)Активные модели внешнего вида (Active Appearance Models, AAM) — это статистические модели изображений, которые путем разного рода деформаций могут быть подогнаны под реальное изображение. Данный тип моделей в двумерном варианте был предложен Тимом Кутсом и Крисом Тейлором в 1998 году [17,18]. Первоначально активные модели внешнего вида применялись для оценки параметров изображений лиц.Активная модель внешнего вида содержит два типа параметров: параметры, связанные с формой (параметры формы), и параметры, связанные со статистической моделью пикселей изображения или текстурой (параметры внешнего вида). Перед использованием модель должна быть обучена на множестве заранее размеченных изображений. Разметка изображений производится вручную. Каждая метка имеет свой номер и определяет характерную точку, которую должна будет находить модель во время адаптации к новому изображению.Пример разметки изображения лица из 68 точек, образующих форму AAM.
Процедура обучения AAM начинается с нормализации форм на размеченных изображениях с целью компенсации различий в масштабе, наклоне и смещении. Для этого используется так называемый обобщенный Прокрустов анализ.
Координаты точек формы лица до и после нормализации
Из всего множества нормированных точек затем выделяются главные компоненты с использованием метода PCA.
Модель формы AAM состоит из триангуляционной решетки s0 и линейной комбинации смещений si относительно s0
Далее из пикселей внутри треугольников, образуемых точками формы, формируется матрица, такая что, каждый ее столбец содержит значения пикселей соответствующей текстуры. Стоит отметить, что используемые для обучения текстуры могут быть как одноканальными (градации серого), так и многоканальными (например, пространство цветов RGB или другое). В случае многоканальных текстур векторы пикселов формируются отдельно по каждому из каналов, а потом выполняется их конкатенация. После нахождения главных компонент матрицы текстур модель AAM считается обученной.
Модель внешнего вида AAM состоит из базового вида A0, определенного пикселями внутри базовой решетки s0 и линейной комбинации смещений Ai относительно A0
Пример конкретизации AAM. Вектор параметров формыp=(p_1,p_2,〖…,p〗_m )^T=(-54,10,-9.1,…)^T используется для синтеза модели формы s, а вектор параметров λ=(λ_1,λ_2,〖…,λ〗_m )^T=(3559,351,-256,…)^Tдля синтеза внешнего вида модели. Итоговая модель лица 〖M(W(x;p))〗^ получается как комбинация двух моделей – формы и внешнего вида.
Подгонка модели под конкретное изображение лица выполняется в процессе решения оптимизационной задачи, суть которой сводится к минимизации функционала
методом градиентного спуска. Найденные при этом параметры модели и будут отражать положение модели на конкретном изображении.
Пример подгонки модели на конкретное изображение за 20 итераций процедуры градиентного спуска.
С помощью AAM можно моделировать изображения объектов, подверженных как жесткой, так и нежесткой деформации. ААМ состоит из набора параметров, часть которых представляют форму лица, остальные задают его текстуру. Под деформации обычно понимают геометрическое преобразование в виде композиции переноса, поворота и масштабирования. При решении задачи локализации лица на изображении выполняется поиск параметров (расположение, форма, текстура) ААМ, которые представляют синтезируемое изображение, наиболее близкое к наблюдаемому. По степени близости AAM подгоняемому изображению принимается решение – есть лицо или нет.
Active Shape Models (ASM)
Суть метода ASM [16,19,20] заключается в учете статистических связей между расположением антропометрических точек. На имеющейся выборке изображений лиц, снятых в анфас. На изображении эксперт размечает расположение антропометрических точек. На каждом изображении точки пронумерованы в одинаковом порядке.
Пример представления формы лица с использованием 68 точек
Для того чтобы привести координаты на всех изображениях к единой системе обычно выполняется т.н. обобщенный прокрустов анализ, в результате которого все точки приводятся к одному масштабу и центрируются. Далее для всего набора образов вычисляется средняя форма и матрица ковариации. На основе матрицы ковариации вычисляются собственные вектора, которые затем сортируются в порядке убывания соответствующих им собственных значений. Модель ASM определяется матрицей Φ и вектором средней формы s ̅. Тогда любая форма может быть описана с помощью модели и параметров:
Локализации ASM модели на новом, не входящем в обучающую выборку изображении осуществляется в процессе решения оптимизационной задачи.
а) б) в) г)Иллюстрация процесса локализации модели ASM на конкретном изображении: а) начальное положение б) после 5 итераций в) после 10 итераций г) модель сошлась
Однако все же главной целью AAM и ASM является не распознавание лиц, а точная локализация лица и антропометрических точек на изображении для дальнейшей обработки.
Практически во всех алгоритмах обязательным этапом, предваряющим классификацию, является выравнивание, под которым понимается выравнивание изображения лица во фронтальное положение относительно камеры или приведение совокупности лиц (например, в обучающей выборке для обучения классификатора) к единой системе координат. Для реализации этого этапа необходима локализация на изображении характерных для всех лиц антропометрических точек – чаще всего это центры зрачков или уголки глаз. Разные исследователи выделяют разные группы таких точек. В целях сокращения вычислительных затрат для систем реального времени разработчики выделяют не более 10 таких точек [1].
Модели AAM и ASM как раз и предназначены для того чтобы точно локализовать эти антропометрические точки на изображении лица.
6. Основные проблемы, связанные с разработкой систем распознавания лиц
Проблема освещенности
Проблема положения головы (лицо – это, все же, 3D объект).
С целью оценки эффективности предложенных алгоритмов распознавания лиц агентство DARPA и исследовательская лаборатория армии США разработали программу FERET (face recognition technology).
В масштабных тестах программы FERET принимали участие алгоритмы, основанные на гибком сравнении на графах и всевозможные модификации метода главных компонент (PCA). Эффективность всех алгоритмов была примерно одинаковой. В этой связи трудно или даже невозможно провести четкие различия между ними (особенно если согласовать даты тестирования). Для фронтальных изображений, сделанных в один и тот же день, приемлемая точность распознавания, как правило, составляет 95%. Для изображений, сделанных разными аппаратами и при разном освещении, точность, как правило, падает до 80%. Для изображений, сделанных с разницей в год, точность распознавания составило примерно 50%. При этом стоит заметить, что даже 50 процентов — это более чем приемлемая точность работы системы подобного рода.
Ежегодно FERET публикует отчет о сравнительном испытании современных систем распознавания лиц [55] на базе лиц более одного миллиона. К большому сожалению в последних отчетах не раскрываются принципы построения систем распознавания, а публикуются только результаты работы коммерческих систем. На сегодняшний день лидирующей является система NeoFace разработанная компанией NEC.
Список литературы (гуглится по первой ссылке)
1. Image-based Face Recognition — Issues and Methods 2. Face Detection A Survey.pdf 3. Face Recognition A Literature Survey4. A survey of face recognition techniques5. A survey of face detection, extraction and recognition6. Обзор методов идентификации людей на основе изображений лиц7. Методы распознавания человека по изображению лица 8. Сравнительный анализ алгоритмов распознавания лиц 9. Face Recognition Techniques 10. Об одном подходе к локализации антропометрических точек. 11. Распознавание лиц на групповых фотографиях с использованием алгоритмов сегментации 12. Отчет о НИР 2-й этап по распознаванию лиц 13. Face Recognition by Elastic Bunch Graph Matching 14. Алгоритмы идентификации человека по фотопортрету на основе геометриче-ских преобразований. Диссертация. 15. Distortion Invariant Object Recognition in the Dynamic Link Architecture 16. Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines17. Face Recognition Using Active Appearance Models 18. Active Appearance Models for Face Recognition 19. Face Alignment Using Active Shape Model And Support Vector Machine 20. Active Shape Models — Their Training and Application 21. Fisher Vector Faces in the Wild22. Eigenfaces vs. Fisherfaces Recognition Using Class Specific Linear Projection23. Eigenfaces and fisherfaces24. Dimensionality Reduction 25. ICCV 2011 Tutorial on Parts Based Deformable Registration26. Constrained Local Model for Face Alignment, a Tutorial 27. Who are you – Learning person specific classifiers from video 28. Распознавание человека по изображению лица нейросетевыми методами 29. Face Recognition A Convolutional Neural Network Approach40. Face Recognition using Convolutional Neural Network and Simple Logistic Classifier31. Face Image Analysis With Convolutional Neural Networks32. Методы распознавания лиц на основе скрытых марковских процессов. Авторе-ферат 33. Применение скрытых марковских моделей для распознавания лиц 34. Face Detection and Recognition Using Hidden Markovs Models 35. Face Recognition with GNU Octave-MATLAB36. Face Recognition with Python 37. Anthropometric 3D Face Recognition 38. 3D Face Recognition 39. Face Recognition Based on Fitting a 3D Morphable Model 40. Face Recognition 41. Robust Face Recognition via Sparse Representation 42. The FERET Evaluation Methodology For Face-Recognition Algorithms43. Поиск лиц в электронных коллекциях исторических фотографий 44. Design, Implementation and Evaluation of Hardware Vision Systems dedicated to Real-Time Face Recognition45. An Introduction to the Good, the Bad, & the Ugly Face Recognition Challenge Prob-lem 46. Исследование и разработка методов обнаружения человеческого лица на циф-ровых изображениях. Диплом47. DeepFace Closing the Gap to Human-Level Performance in Face Verification48. Taking the bite out of automated naming of characters in TV video 49. Towards a Practical Face Recognition System Robust Alignment and Illumination by Sparse Representation50. Алгоритмы обнаружения лица человека для решения прикладных задач анализа и обработки изображений 51. Обнаружение и локализация лица на изображении 52. Модифицированный мотод Виолы-Джонса53. Разработка и анализ алгоритмов детектирования и классификации объектов на основе методов машинного обучения 54. Overview of the Face Recognition Grand Challenge 55. Face Recognition Vendor Test (FRVT)56. Об эффективности применения алгоритма SURF в задаче идентификации лицintellect.ml
программа с пошаговой инструкцией и описанием
Система распознавания лиц представляет собой компьютерное приложение, способное идентифицировать или проверять человека из цифрового изображения или видеофрагмента. Один из способов сделать это - сравнить выбранные черты лица с изображением и вариантами из базы данных.

Распознавание лиц (программа) обычно используется в системах безопасности, и может быть сравнена с другими биометрическими системами (например, распознавания отпечатков пальцев или глазной диафрагмы). В последнее время она также стала популярной в качестве инструмента коммерческой идентификации и рекламы.
Некоторые алгоритмы распознавания лиц идентифицируют черты лица, извлекая ориентиры или объекты из изображения лица субъекта. Например, алгоритм может анализировать относительное расположение, размер и/или форму глаз, носа, скул и челюсти. Эти данные затем используются для поиска других изображений с соответствующими параметрами. Другие алгоритмы нормализуют галерею изображений лиц, а затем сжимают сведения о лице, сохраняя только те данные на изображении, которые полезны для распознавания лиц. Затем искомое изображение сравнивается с имеющимися данными. Одна из самых ранних успешных систем основана на методах сопоставления шаблонов, примененных к набору характерных черт лица, предоставляя своего рода сжатое представление о внешности.

Как работает программа распознавания лиц?
Она включает в себя определенные алгоритмы, которые можно разделить на два основных подхода:
- Геометрический, который рассматривает отличительные или фотометрические черты лица.
- Статистический, который переводит изображение в значения и сравнивает их с шаблонами для устранения дисперсий.
Трехмерное распознавание
Новая тенденция, созданная для достижения более высокой точности, представляет собой трехмерное распознавание лиц. Этот метод использует 3D-датчики для сбора информации о форме лица. Эта информация затем используется для идентификации отличительных признаков, таких как контур глазниц, носа и подбородка.

Одним из преимуществ трехмерных программ распознавания лиц является то, что на них не влияют изменения в освещении, в отличие от других вариантов. Эта технология также может идентифицировать из разного диапазона углов обзора, включая вид профиля. Трехмерные точки данных значительно улучшают точность распознавания лиц. 3D-исследования усиливаются благодаря разработке сложных датчиков, которые улучшают работу по захвату изображений в виде трехмерных изображений. Датчики работают, проецируя структурированный свет на лицо. До десятка или более из этих датчиков изображения могут быть размещены на одном чипе CMOS - каждый из них захватывает другую часть спектра.
Однако, даже идеальный метод 3D-соответствия может быть чувствительным к выражениям лица. Для этой цели группа исследователей в Technion применила инструменты из метрической геометрии для обработки выражений как изометрии. После этого компания Vision Access создала свое решение для трехмерного распознавания лица. Позднее компания была приобретена Bioscrypt Inc., которая разработала версию программы для распознавания лица человека, известную как 3D FastPass.

Новый метод заключается в том, чтобы ввести способ захвата трехмерного изображения с помощью трех следящих камер, которые указывают на разные углы. Одна из них будет указывать на лицевую сторону объекта, вторую – со стороны, третья - под углом. Все они будут работать вместе, чтобы получить возможность отслеживать лицо объекта в реальном времени и быть в состоянии идентифицировать его. Считается, что на этой технологии вскоре будет базироваться любая программа для распознавания лиц через камеру.
Анализ текстуры кожи
Другая новая тенденция использует визуальные детали кожи, которые фиксируются в стандартных цифровых или отсканированных изображениях. Этот метод, называемый анализом текстуры кожи, превращает уникальные линии, узоры и пятна, видимые в коже человека, в математическое пространство.

Тесты показали, что с добавлением этой технологии эффективность распознавания лиц может увеличиться на 20-25%.
Термокамеры
Другая форма приема входных данных для распознавания лиц заключается в использовании тепловизионных камер. Благодаря этой процедуре камеры будут только определять форму головы, и при этом игнорировать такие предметы, как очки, шляпы или макияж. Проблема использования термических изображений для распознавания лиц заключается в том, что базы данных для этого ограничены.
В настоящее время исследователи изучают использование этой технологии в реальной жизни и эксплуатационных ландшафтов и в то же время создают новую базу данных тепловизионных изображений. В исследовании используются низкочувствительные ферроэлектрические электрические датчики низкого разрешения, которые способны получать длинноволновые тепловые инфракрасные образы (LWIR). Результаты показывают, что слияние LWIR и обычных визуальных камер имеет большие результаты в наружных зондах. На таком сочетании может работать очень мощная программа распознавания лиц для камеры.

Массовое использование
В то время как исследователи работают над новейшими технологиями, доступными только специалистам, разработчики массовых приложений тоже не стоят на месте. После того, как было объявлено о создании Google Glass, возникло много шума вокруг распознавания лиц и программ для этого в интернете. Считается, что это откроет массу возможностей для пользователей не только для взаимодействия друг с другом, но и с различными объектами.
Сегодня доступен большой перечень интерфейсов распознавания лиц, которые вы можете использовать для своих приложений. Наиболее распространенными являются следующие.
Face Recognition Stephen
Разработка от из Lambda Labs, которая обеспечивает распознавание лиц по расположению глаз, форме носа и рта, а также проводит гендерную классификацию. Доступно на официальном сайте разработчика.
Face Detection
Компьютерная программа распознавания лиц в интернете, которая является идеальной заменой Face.com. В настоящее время предоставляется бесплатно.
Animetrics Face Recognition
Приложение Animetrics Face Recognition API может использоваться для обнаружения лиц на фотографиях. Информация о чертах лица или ориентирах возвращается в виде координат на изображении.

Skybiometry
Чтобы воспользоваться им, у вас должно быть приложение, созданное в вашей учетной записи в SkyBiometry. Для ее создания достаточно простой регистрации.
Face ++
Это приложение использует передовую технологию компьютерного зрения и интеллектуального анализа данных для обеспечения 3-х основных служб (обнаружение, распознавание и анализ). Программа обеспечивает обнаружение и анализ Landmark (23 точки), ориентир (81 пункт), атрибуты: возраст, пол, очки, раса и так далее.
FaceMark
Это мощный API-интерфейс для распознавания лиц. Он находит 68 точек ориентира для изображения лица анфас и 35 - для профиля. FaceMark обнаруживает ориентиры для лиц на изображении, указанном по URL-адресу, или на загруженном файле, и выдает результат в виде JSON-файла, содержащего вектор ориентиров лица и точек совпадения для каждого найденного варианта.
EmoVu by Eyeris
Интеллектуальное программное обеспечение для распознавания эмоций, которое позволяет камерам читать человеческие микро-выражения, пол и возрастную группу. Это программа распознавания лиц в реальном времени, которая работает, когда пользователи смотрят видео на своих компьютерах или мобильных устройствах.
Rekognition.com
Это одна из лучших альтернатив Face.com. Быстрый, надежный и масштабируемый движок rekognition может выполнять обнаружение лица, сканирование, распознавание и поиск. Его можно автоматически обучать с помощью изображений и тегов на Facebook. Поскольку она ориентирована на социальные сети, это лучшая программа распознавания лиц для «Андроид».
FaceRect
Это также мощный и бесплатный интерфейс для обнаружения лиц. Он находит лица (как анфас, так и профиль) на изображении, указанном по URL-адресу или загруженном в виде файла, и может находить несколько лиц на одной фотографии, и выдает ответ в JSON-формате. При этом изображение загружается с ограничивающей рамкой для каждого найденного лица.
fb.ru
Лучший алгоритм распознавания лиц для контроля допуска
—Безопасность
По сравнению с остальными решениями на рынке уникальная нейронная сеть FindFace практически исключает вероятность ошибки. Коэффициент ложной идентификации практически равен 1 на 1 000 000, что обеспечивает максимальную безопасность независимо от того, используется технология отдельно или в совокупности с другими способами аутентификации.
—Легкость использования
Распознавание лиц является наиболее простым способом аутентификации, придуманным на сегодняшний день. Вы только задумайтесь: сколько раз в день ваши сотрудники вводят пароли, пин-коды или проводят карточкой по считывателю? Аутентификация на основе лица отбрасывает необходимость всего этого, а в качестве идентификатора используется лицо человека.
—Независимость
В отличие от других способов аутентификации распознавание лиц не требует каких-либо действий. Достаточно всего лишь пройти мимо камеры. FindFace обладает самым низким в индустрии коэффициентом ошибочного отказа в доступе, а это означает, что люди будут аутентифицированы правильно с первого же раза.
—Универсальность
Помимо применения в целях контроля допуска перед началом работы или на контрольно-пропускных пунктах, алгоритмы FindFace способны обрабатывать изображения низкого качества и с различным освещением, а также те изображения, где перед лицом имеются препятствия. Это обеспечивает незамедлительное распознавание людей из белого или черного списка на основе видеопотока с камеры наблюдения.
—Производительность
Высокоэффективные алгоритмы не требуют высокой производительности от аппаратных средств и, следовательно, больших затрат. Мгновенный индексированный поиск среди миллиардов лиц практически отменяет ограничения на количество зарегистрированных пользователей.
findface.pro
ПРОБЛЕМА РАСПОЗНАВАНИЯ ЛИЦ. ОБЗОР МЕТОДОВ ЕЕ РЕШЕНИЯ
FACE RECOGNITION: A PROBLEM AND A SOLUTION
Alexandr Morgunov
student the department "Information technology" Don State Technical University research fellow in FGANU NII Specvuzavtomatika,
Russia, Rostov-on-Don
Diana Mansurova
research fellow in FGANU NII Specvuzavtomatika,
Russia, Rostov-on-Don
Kay Tyurin
research fellow in FGANU NII Specvuzavtomatika,
Russia, Rostov-on-Don
АННОТАЦИЯ
В статье описаны результаты сравнительного анализа существующих методов и алгоритмов распознавания человеческих лиц.
ABSTRACT
In this paper the problem of the human face recognition was considered. Various face recognition methods and algorithms were described and compared.
Ключевые слова: распознавание лиц, машинное обучение, компьютерное зрение, нейронные сети.
Keywords: face recognition, machine learning, computer vision, neural networks.
Распознавание объектов является легкой задачей для людей, эксперименты, проведенные в работе [1] показали, что даже дети в возрасте от одного до трех дней способны различать запомненные лица. Так как человек видит мир не как набор отдельных частей, наш мозг должен как-то комбинировать различные источники информации в полезные паттерны. Задача автоматического распознавания лиц состоит в выделении этих значащих признаков из изображения, преобразуя их в полезное представление и производя некоторого вида классификации.
Процесс распознавания лиц, основывающийся на геометрических признаках лица, является, вероятно, наиболее интуитивным подходом к задаче распознавания лиц [2, 3]. Эксперименты на большом наборе данных показали, что в одиночку геометрические признаки не могут дать достаточно информации для распознавания лица.
Метод, который носит название Eigenfaces, описанный в работе [4], приводит целостный подход к задаче распознавания лиц. Изображение лица является точкой из многомерного пространства изображений, которому сопоставляется представление из так называемого маломерного пространства, где классификация становится простой задачей. Маломерное подпространство находится с помощью метода анализа принципиальных компонент (PCA), который идентифицирует оси с максимальной дисперсией. В то время, как такой вид трансформации является оптимальным с точки зрения реконструкции, он не учитывает классовые метки. Если дисперсия сгенерирована из внешнего источника (например, освещенности), оси с максимальной дисперсией могут не содержать какой-либо отчетливой информации, следовательно, классификация становится невозможной. Поэтому в работе [5] для задачи распознавания лиц была применена классовая проекция с линейным дискриминантным анализом. Основная идея заключалась в том, чтобы минимизировать дисперсию внутри класса и в то же время максимизировать дисперсию между классами.
Не так давно несколько методов выделения локальных признаков были объединены. Для того чтобы избежать многомерности входных данных, описываются только локальные области изображения. Выделенные признаки получаются более устойчивыми против частичного перекрытия, освещенности и малого размера входного изображения. Алгоритмами, которые используют выделение локальных признаков, являются: Вейвлеты Габора [6], Дискретное косинусное преобразование [7] и Локальные бинарные шаблоны [8]. Вопрос о том, какой способ сохранить пространственную информацию при применении метода выделения локальных признаков является наилучшим, все еще открыт для исследований, так как пространственная информация является потенциально полезной для решения задачи распознавания лиц.
Метод Eigenfaces выполняет распознавание лица, по следующим шагам:
- проецирование всех обучающих примеров в подпространство анализа принципиальных компонент;
- проецирование запрошенного изображения в подпространство анализа принципиальных компонент;
- поиск ближайших соседей между спроецированными тренировочными изображениями и спроецированным запрошенным изображением.
На рисунке 1 представлен пример того, как представляются лица алгоритмом Eigenfaces. Была использована цветовая схема jet для того, чтобы показать, как значения оттенков серого распределяются в конкретных лицах. Алгоритм кодирует не только признаки лица, но также освещенность изображений.
Рисунок 1. Представление лиц алгоритмом Eigenfaces в цветовой схеме jet
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Данные лица были реконструированы из аппроксимации малой размерности. На рисунке 2 представлены реконструкции с различным числом компонент от 10 до 310.
Рисунок 2. Реконструкции с различным числом компонент алгоритмом Eigenfaces
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Очевидно, что 10 собственных векторов являются незначительным числом для хорошей реконструкции изображения. 50 собственных векторов уже могут способствовать кодированию важных признаков лиц. Можно получить хорошую реконструкцию с аппроксимацией в 300 собственных векторов. Существуют правила по подбору необходимого числа собственных векторов для удачного процесса распознавания лица, однако, они сильно зависит от входных данных [10].
Анализ принципиальных компонент (PCA), который является основой алгоритма Eigenfaces, находит линейные комбинации признаков, которые максимизируют общую дисперсию в данных. В то время, как PCA является хорошим способом представления данных, он не учитывает классы, и много полезной информации может быть потеряно во время преобразований. Если дисперсия данных генерируется внешним источником, таким как свет, компоненты, идентифицируемые PCA, могут не содержать четкой информации. Вследствие чего проецируемые данные смешиваются, и классификация становится невыполнимой задачей.
Линейный дискриминантный анализ, выполняющий классовое понижение размерности входных данных, был предложен статистиком Рональдом Фишером, который успешно использовал его для классификации цветов [11]. Метод находит линейные комбинации признаков, которые лучше всего разделяют несколько классов объектов, а также максимизирует соотношение между разбросом разрозненных и тесно связанных классов, вместо того, чтобы максимизировать общее соотношение. Простая идея заключается в том, что одинаковые классы должны быть тесно связаны, и в то же время различные классы должны находиться максимально далеко друг от друга и представлении данных малой размерности. Подобный подход также был предложен Бельхамером, Хеспаной и Кригманом, которые применили дискриминантный анализ в задаче распознавания лиц в работе [12].
На рисунке 3 представлен пример работы алгоритма Fisherfaces, на котором изображены так называемые лица фишера. Каждое лицо фишера имеет такой же размер, как и оригинальное изображение, поэтому оно может быть отображено как изображение.
Рисунок 3. Пример работы алгоритма Fisherfaces
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Алгоритм Fisherfaces использует трансформирующую матрицу, основанную на классах, поэтому он не учитывает освещение, также как алгоритм Eigenfaces. Вместо этого дискриминантный анализ находит признаки лица для установления различия между персонами. Важно отметить, что производительность алгоритма Fisherfaces также сильно зависит от входных данных. Если обучать алгоритм Fisherfaces на изображениях с сильным освещением, а потом попытаться распознать лица на плохо освещенных изображениях, метод, скорее всего, найдет неверные компоненты потому, что эти признаки могут не быть доминантными на плохо освещенных изображениях. Что является очевидным, так как алгоритм невозможно обучить распознавать освещение.
Алгоритм Fisherfaces позволяет делать реконструкции спроецированных изображений так же, как и Eigenfaces. Но в силу того, что алгоритм идентифицирует только лишь главные признаки, которые позволяют отличить объекты, нельзя ожидать хорошую реконструкцию исходного изображения. Для визуализации алгоритма Fisherfaces исходное изображение спроецировано на каждое из лиц фишера. На рисунке 4 представлена визуализация алгоритма Fisherfaces, где показано, какие признаки описывает каждое из лиц фишера.
Рисунок 4. Реконструированные лица фишера
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Алгоритмы Eigenfaces и Fisherfaces предлагают некий целостный подход к решению задачи распознавания лиц. Представить данные в виде вектора где-нибудь в многомерном пространстве изображения. Известно, что многомерность является плохим свойством данных, поэтому определяется подпространство малой размерности, где вероятно сохраняется полезная информация. Алгоритм Eigenfaces максимизирует общий разброс, который может привести к проблеме, когда дисперсия генерируется из внешнего источника, так как компоненты с максимальной из всех классов дисперсией не обязательно являются полезными для классификации объекта. Поэтому для сохранения некоторой отчетливой информации применяется линейный дискриминантный анализ с оптимизацией, описанной в алгоритме Fisherfaces. Алгоритм Fisherfaces работает сравнительно хорошо, по крайней мере, для ограниченного сценария при одинаковом уровне освещенности изображения.
Но в реальности нельзя гарантировать идеальные параметры освещенности на изображениях. К тому же, если имеется только одно изображение на каждую личность, ковариационное счисление для подпространства, следовательно, и распознавание, может быть существенно неверным. Для открытой базы данных лиц AT&T алгоритмы Eigenfaces и Fisherfaces имеют уровень распознавания в 96%, но этот уровень сильно зависит (помимо остального) от числа обучающих изображений. На рисунке 5 представлены уровни распознавания алгоритмов Eigenfaces и Fisherfaces на открытой базе данных лиц AT&T, которая является достаточно легкой для распознавания.
Рисунок 5. Уровень распознавания алгоритмов Eigenfaces и Fisherfaces
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
По рисунку видно, что для получения хорошего показателя распознавания требуется хотя бы 8(+–1) изображений на каждую личность, и алгоритм Fisherfaces не сильно помогает в данном случае.
Поэтому некоторые исследования сконцентрированы на извлечении локальных признаков из изображений. Идея заключается в том, чтобы не представлять все изображение в виде многомерного вектора, а описывать только локальные признаки объекта. Извлекаемые таким образом признаки имеют представление малой размерности. Однако представление входных изображений страдает не только от пока¬зателей освещенности, но и от размера изображения, его смещения или вращения. Поэтому локальное описание должно быть устойчиво к таким видам изменений. Методология локальных бинарных шаблонов имеет корни из двумерного текстурного анализа. Основная идея метода заключается в суммировании локальных структур изображения путем сравнения каждого пикселя с его соседями. В качестве центра берется пиксель и преобразуются значения его соседей. Если интенсивность пикселя-соседа больше или равна интенсивности центрального пикселя, то сосед помечается 1, иначе 0. После преобразования берется получившееся бинарное число (например, как 0010011). В итоге из 8 соседних пикселей получается 28 возможных комбинаций, называемых локальными бинарными шаблонами (LBP коды). Первый LBP-оператор описанный в литературе использовал окно размером 3×3, пример представлен на рисунке 6.
Рисунок 6. LBP-оператор
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Такой подход позволяет захватить мелкие детали изображений. Фактически авторы могли конкурировать с передовыми результатами в классификации текстур. Вскоре было замечено, что фиксированный размер окна не мог закодировать детали различающегося размера. Поэтому оператор был расширен для использования переменного размера окна в работе [8]. Идея заключается в выравнивании произвольного числа соседей в окружности переменного радиуса, которая позволяла бы захватить такие локальные бинарные шаблоны, которые представлены на рисунке 7.
Рисунок 7. Различные локальные бинарные шаблоны
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Такой оператор является расширением оригинальных LBP-кодов, поэтому иногда он называется расширенный LBP. Если координаты точек на окружности не соответствуют координатам изображения, точка интерполируется. По определению LBP оператор устойчив к монотонным трансформациям в оттенках серого. Это можно увидеть на рисунке 8, где представлены LBP-изображения искусственно модифицированных исходных изображений.
Рисунок 8. Устойчивость LBP-оператора к монотонным трансформациям в оттенках серого
Источник: Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
Осталось только объединить пространственную информацию в модели распознавания лиц. Подход, предложенный в работе [8], заключается в разделении LBP-изображения на m локальных областей и извлечь гистограммы из каждого. После чего, получается пространственно-расширенный вектор путем конкатенации гистограмм (не объединения). Такие гистограммы называются гистограммами локальных бинарных шаблонов.
На сегодняшний день дальше всего прошли методы и алгоритмы, основанные на нейронных сетях, такие как DeepFace [13] и FaceNet [14]. Так же большой вклад в решение проблемы распознавания лиц внесли работы Visual Geometry Group [15] и Lightened Convolutional Neural Networks [16]. Нейронные сети состоят из множества композиций функций или слоев, с последующей функцией потерь, которая определяет насколько хорошо нейронная сеть моделирует данные, т. е. насколько точно классифицирует изображение. Для решения проблемы распознавания лиц система, использующая нейронную сеть, должна найти лицо на изображении с помощью одного из многих существующих методов. Далее система из каждого найденного лица формирует нормализованные входные данные для нейронной сети. Такие данные являются слишком многомерными для того, чтобы сразу отдать их классификатору. Нейронная сеть используется для выделения главных характеристик с целью маломерное представление данных, которые описывают лицо. Такое маломерное представление данных уже может быть эффективно использовано в классификаторах.
Например, алгоритм DeepFace сначала использует трехмерное моделирование лица для нормализации входного изображения с целью получения фронтального отображения лица даже, если лицо на фотографии изначально было под другим углом. Далее алгоритм определяет классификацию как тесно связанный слой нейронной сети с Softmax‑функцией, что позволяет получить на выходе нормализованное вероятностное распределение. Нововведениями алгоритма DeepFace являются: выравнивание по 3D-модели, нейронная сеть с 120 миллионами параметров и обучение на 4,4 миллионах изображений лиц. После завершения обучения нейронной сети на таком большом количестве лиц, финальный классификационные слой удаляется и выходные данные предыдущего слоя используются как маломерное представление лица.
Часто программы по распознаванию лиц ищут маломерное представление, которое хорошо обобщает новые лица, на которых не была обучена нейронная сеть. Подход алгоритма DeepFace справляется с такой проблемой, но представление является следствием обучения сети для высокоточной классификации Недостатком такого подхода является то, что полученное представление трудно использовать, так как лица одного человека не обязательно будут на кластеризованы, следовательно, классификационные алгоритмы не получат преимущества. Триплетная функция потерь (triplet-loss) в алгоритме FaceNet определена непосредственно в представлении. На рисунке 9 представлена процедура triplet-loss обучения.
Рисунок 9. Процедура triplet-loss обучения
Источник: Amos B., Ludwiczuk B., Satyanarayanan M. Openface: A general-purpose face recognition library with mobile applications //CMU School of Computer Science. – 2016. – С. 4.
Единичная гиперсфера является такой многомерной сферой, что каждая ее точка находится на расстоянии 1 от начала координат. Ограничение вложения единичной гиперсферы предоставляет структуру в пространстве, которая в остальном является неограниченной. Нововведениями алгоритма FaceNet являются: триплетная функция потерь (triplet-loss), триплетная процедура отбора, обучение на 200 миллионах изображений лиц и обширные экспериментальные исследования для поиска архитектуры нейронной сети.
Таким образом, на сегодняшний день проблема распознавания человеческих лиц остается не решенной до конца. Наиболее точные результаты удалось получить методам и алгоритмам, основанным на глубоком обучении и нейронных сетях. Так как данная область очень актуальна в наши дни, активно ведутся исследования, формируются новые подходы и совершенствуются уже предложенные.
Список литературы:
- Turati C. et al. Newborns' face recognition: Role of inner and outer facial features //Child development. – 2006. – Т. 77. – №. 2. – С. 297-311.
- Kanade T. Picture processing system by computer complex and recognition of human faces. – 1974.
- Brunelli R., Poggio T. Face recognition through geometrical features //Computer Vision—ECCV'92. – Springer Berlin/Heidelberg, 1992. – С. 792-800.
- Turk M., Pentland A. Eigenfaces for recognition //Journal of cognitive neuroscience. – 1991. – Т. 3. – №. 1. – С. 71-86.
- Belhumeur P. N., Hespanha J. P., Kriegman D. J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection //IEEE Transactions on pattern analysis and machine intelligence. – 1997. – Т. 19. – №. 7. – С. 711-720.
- Wiskott L. et al. Face recognition by elastic bunch graph matching //IEEE Transactions on pattern analysis and machine intelligence. – 1997. – Т. 19. – №. 7. – С. 775-779.
- Messer K. et al. Performance characterization of face recognition algorithms and their sensitivity to severe illumination changes //ICB. – 2006. – С. 1-11.
- Ahonen T., Hadid A., Pietikäinen M. Face recognition with local binary patterns //Computer vision-eccv 2004. – 2004. – С. 469-481.
- Face Recognition with OpenCV // OpenCV 2.4.13.4 documentation. URL: https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial....
- Zhao W. et al. Face recognition: A literature survey //ACM computing surveys (CSUR). – 2003. – Т. 35. – №. 4. – С. 399-458.
- Fisher R. A. The use of multiple measurements in taxonomic problems //Annals of human genetics. – 1936. – Т. 7. – №. 2. – С. 179-188.
- Raudys S. J. et al. Small sample size effects in statistical pattern recognition: Recommendations for practitioners //IEEE Transactions on pattern analysis and machine intelligence. – 1991. – Т. 13. – №. 3. – С. 252-264.
- Taigman Y. et al. Deepface: Closing the gap to human-level performance in face verification //Proceedings of the IEEE conference on computer vision and pattern recognition. – 2014. – С. 1701-1708.
- Schroff F., Kalenichenko D., Philbin J. Facenet: A unified embedding for face recognition and clustering //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. – 2015. – С. 815-823.
- Parkhi O. M. et al. Deep Face Recognition //BMVC. – 2015. – Т. 1. – №. 3. – С. 6.
- Wu X. et al. A light CNN for deep face representation with noisy labels //arXiv preprint arXiv:1511.02683. – 2015.
- Amos B., Ludwiczuk B., Satyanarayanan M. Openface: A general-purpose face recognition library with mobile applications //CMU School of Computer Science. – 2016.
sibac.info















