Новая AlphaGo сама научилась играть еще лучше. И обыграла все предыдущие версии. Что такое alphago
Пошаговая инструкция по удалению рекламного вируса “ALPHAGO” из браузеров Chrome, Firefox, IE, Edge.
ALPHAGO — это рекламный вирус, при заражении которым браузер вашего компьютера начинает перенаправлять вас на сайты с рекламой вне зависимости от используемого вами браузера.Вирусы, подобные ALPHAGO, как правило занимаются подменой домашних страниц вашего браузера, меняют поисковый сайт, создают собственные задания в расписании, видоизменяют свойства ярлыков ваших браузеров.
Как происходит заражение вирусом ALPHAGO?
Я очень часто пишу в рекомендациях о вреде установки программ по-умолчанию. Ведь в результате такого необдуманного поступка вы рискуете установить себе кучу нежелательного софта.
А вот сегодня я сам облажался подобным же образом. В результате этого браузер принялся постоянно демонстрировать мне тонны рекламы с сайта ALPHAGO. Я слегка попенял на себя, и приступил к лечению.

Как избавиться от рекламы ALPHAGO?
Конечно для меня это было уже рутинной операцией. Но прежде, чем поделиться инструкцией по удалению вируса ALPHAGO, опишем, что он из себя представляет.
На самом деле это типичный перенаправитель на сайт с рекламой. После доменного имени могут идти разнообразные оконцовки, но домен ALPHAGO присутствует всегда. Во всех этих вариантах ваш браузер переходит на те же рекламные страницы. Также зловред поражает ярлыки ваших браузеров и настройки домашней страницы.
Кроме того рекламный вирус ALPHAGO создает задания для исполнения, для поддержания своего присутствия на вашей машине. Подвергаются атаке все браузеры, которые он сможет найти в вашей системе. Поэтому в результате такой массовой рекламной атаки не мудрено подцепить и что-нибудь более серьезное.
Именно поэтому данный вирус следует уничтожить сразу по обнаружению. Ниже я приведу несложные инструкции, которые помогут вам в лечении. Но как всегда я рекомендую использовать автоматизированный метод как наиболее эффективный и простой.
Инструкция по ручному удалению рекламного вируса ALPHAGO
Для того, чтобы самостоятельно избавиться от рекламы ALPHAGO, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «ALPHAGO» в списке установленных программ и удалить ее.
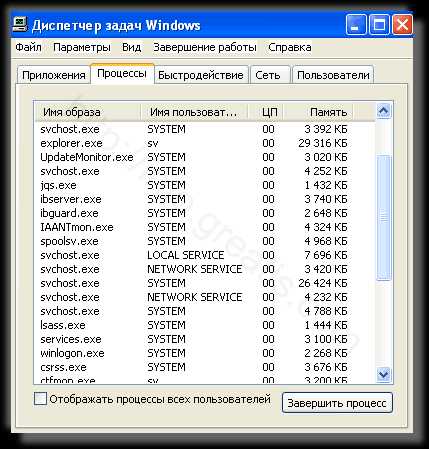
- Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «ALPHAGO». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
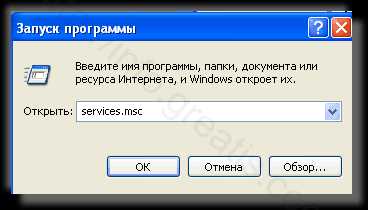
- Запретить вредные службы с помощью консоли services.msc.
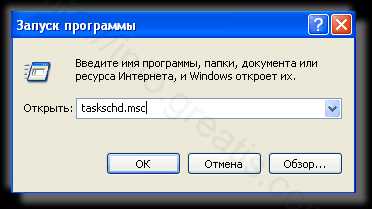
- Удалить “Назначенные задания”, относящиеся к ALPHAGO, с помощью консоли taskschd.msc.
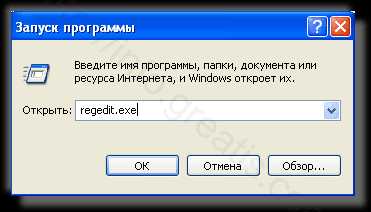
- С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «ALPHAGO» в реестре.
- Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
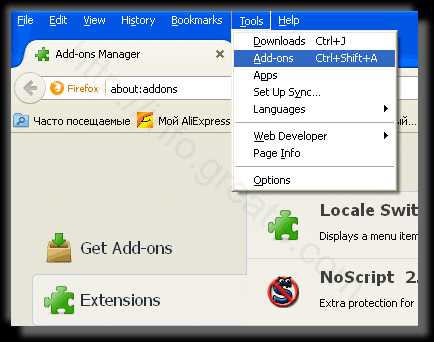
- Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
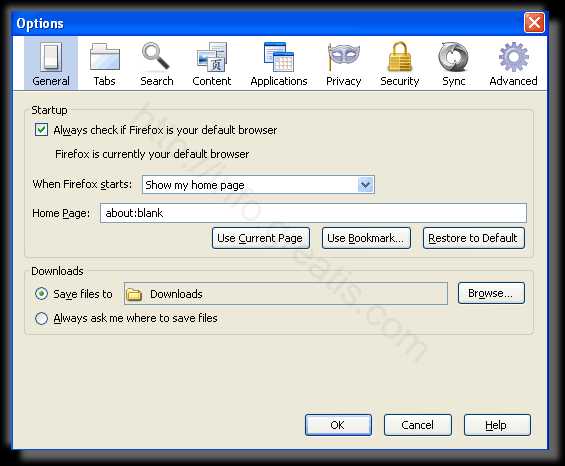
- Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
- Очистить корзину, временные файлы, кэш браузеров.
И все же автоматика лучше!
Если ручной метод — не для вас, и хочется более легкий путь, существует множество специализированного ПО, которое сделает всю работу за вас. Я рекомендую воспользоваться UnHackMe от Greatis Software, выполнив все по пошаговой инструкции.Шаг 1. Установите UnHackMe. (1 минута)Шаг 2. Запустите поиск вредоносных программ в UnHackMe. (1 минута)Шаг 3. Удалите вредоносные программы. (3 минуты)
UnHackMe выполнит все указанные шаги, проверяя по своей базе, всего за одну минуту.
При этом UnHackMe скорее всего найдет и другие вредоносные программы, а не только редиректор на ALPHAGO.
При ручном удалении могут возникнуть проблемы с удалением открытых файлов. Закрываемые процессы могут немедленно запускаться вновь, либо могут сделать это после перезагрузки. Часто возникают ситуации, когда недостаточно прав для удалении ключа реестра или файла.
UnHackMe легко со всем справится и выполнит всю трудную работу во время перезагрузки.
И это еще не все. Если после удаления редиректа на ALPHAGO какие то проблемы остались, то в UnHackMe есть ручной режим, в котором можно самостоятельно определять вредоносные программы в списке всех программ.
Итак, приступим:
Шаг 1. Установите UnHackMe (1 минута).
- Скачали софт, желательно последней версии. И не надо искать на всяких развалах, вполне возможно там вы нарветесь на пиратскую версию с вшитым очередным мусором. Оно вам надо? Идите на сайт производителя, тем более там есть бесплатный триал. Запустите установку программы.
- Затем следует принять лицензионное соглашение.
- И наконец указать папку для установки. На этом процесс инсталляции можно считать завершенным.
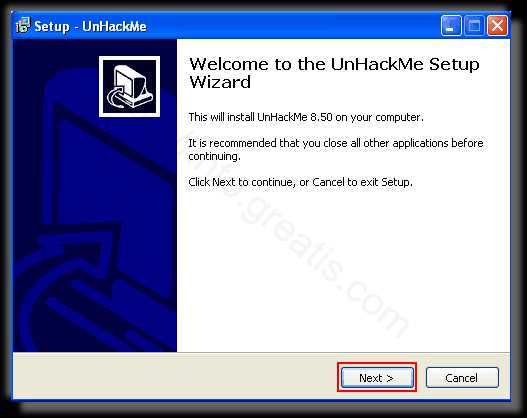
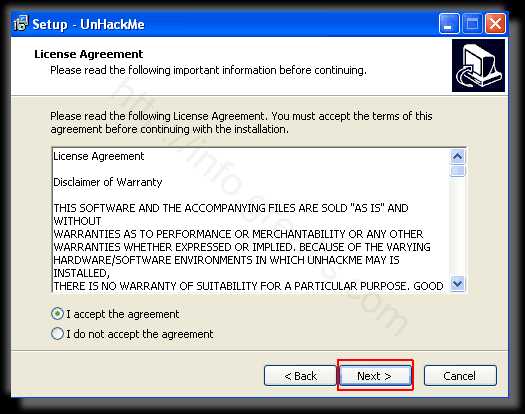
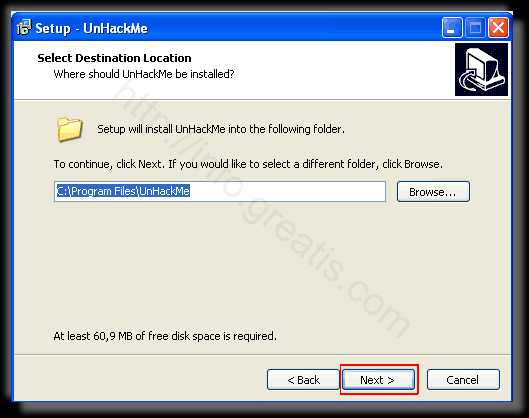
Шаг 2. Запустите поиск вредоносных программ в UnHackMe (1 минута).
- Итак, запускаем UnHackMe, и сразу стартуем тестирование, можно использовать быстрое, за 1 минуту. Но если время есть — рекомендую расширенное онлайн тестирование с использованием VirusTotal — это повысит вероятность обнаружения не только перенаправления на ALPHAGO, но и остальной нечисти.
- Мы увидим как начался процесс сканирования.
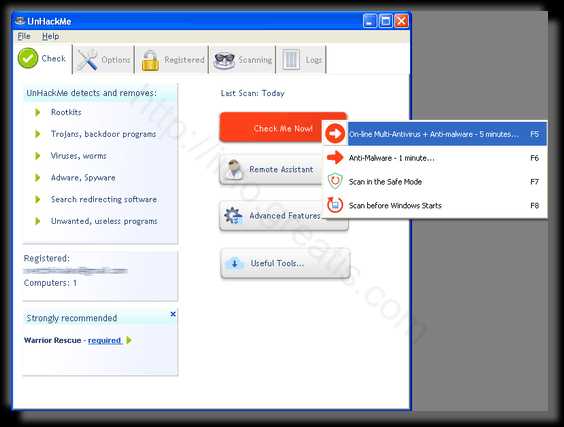
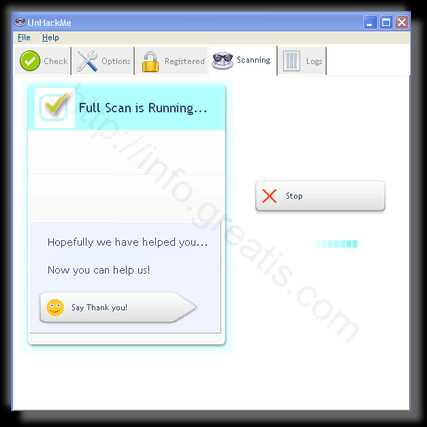
Шаг 3. Удалите вредоносные программы (3 минуты).
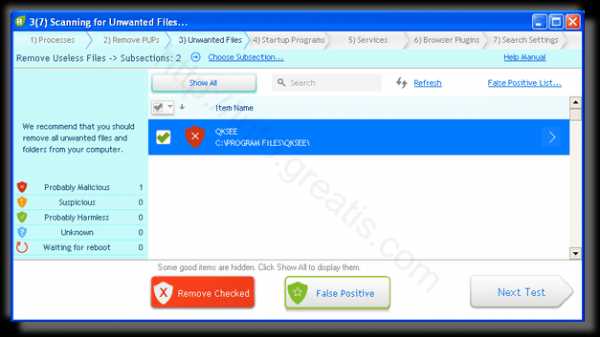
- Обнаруживаем что-то на очередном этапе. UnHackMe отличается тем, что показывает вообще все, и очень плохое, и подозрительное, и даже хорошее. Не будьте обезьяной с гранатой! Не уверены в объектах из разряда “подозрительный” или “нейтральный” — не трогайте их. А вот в опасное лучше поверить. Итак, нашли опасный элемент, он будет подсвечен красным. Что делаем, как думаете? Правильно — убить! Ну или в английской версии — Remove Checked. В общем, жмем красную кнопку.
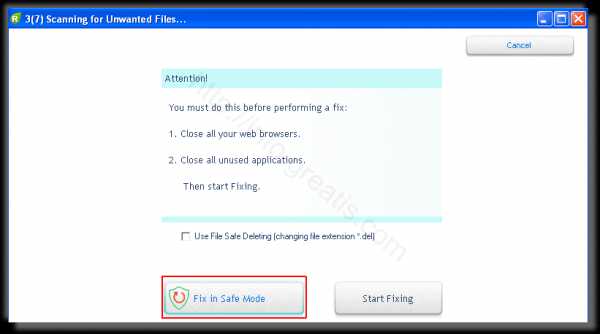
- После этого вам возможно будет предложено подтверждение. И приглашение закрыть все браузеры. Стоит прислушаться, это поможет.
- В случае, если понадобится удалить файл, или каталог, пожалуй лучше использовать опцию удаления в безопасном режиме. Да, понадобится перезагрузка, но это быстрее, чем начинать все сначала, поверьте.
- Ну и в конце вы увидите результаты сканирования и лечения.
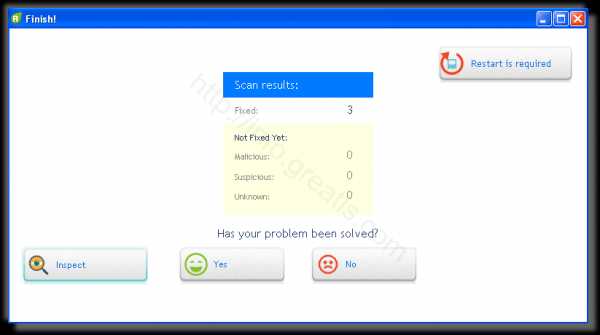
Итак, как вы наверное заметили, автоматизированное лечение значительно быстрее и проще! Лично у меня избавление от перенаправителя на ALPHAGO заняло 5 минут! Поэтому я настоятельно рекомендую использовать UnHackMe для лечения вашего компьютера от любых нежелательных программ!
info.greatis.com
AlphaGo на пальцах / Хабр
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало. Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека. Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела) Важный момент — что нейросети дается на вход: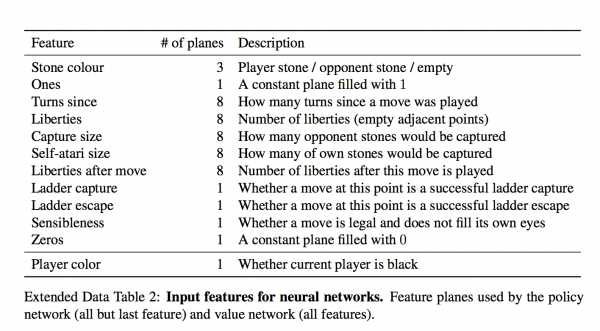
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича) Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там! Есть и тривиально вычисляющиеся фичи типа "количество степеней свободы камня", или "количество камней, которые будут взяты этим ходом" Есть и формально неважные фичи типа "как давно было сделан ход" И даже специальная фича для частого явления "ladder capture/ladder escape" — потенциально долгой последовательности вынужденных ходов.
а что за "всегда 1" и "всегда 0"? Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен. Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)
Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич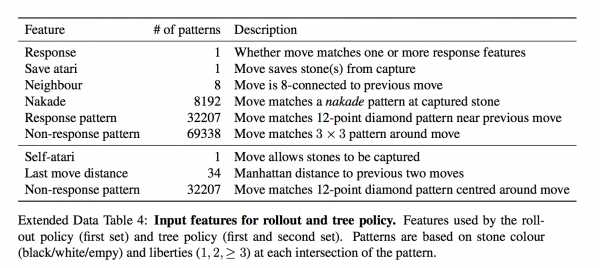
Шаг 2: тренируем policy еще лучше через игру с собой (reinforcement learning) — RL-policy network
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.Единственный reward — это собственно результат игры, выиграл или проиграл. После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага. Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука? С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Шаг 3: натренируем сеть, которая "с одного взгляда" на расстановку говорит нам, какие у нас шансы выиграть! — Value network
Т.е. предсказывает всего одно значение от -1 до 1. У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.То есть у нее те же фичи? value network дают еще одну фичу — играет игрок черными или нет (policy network передают "свой-чужой" камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию. Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
Внимание, картинко!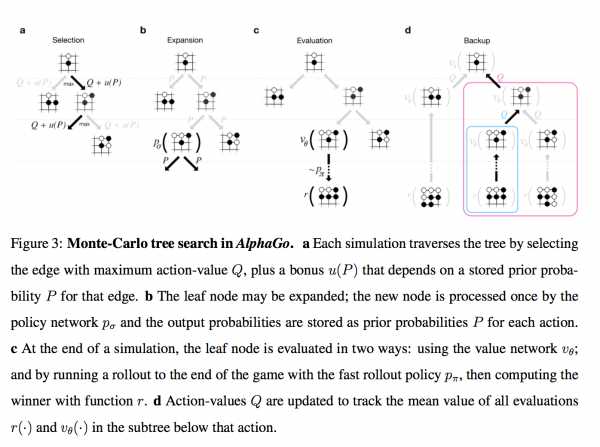
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе. Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили (это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет… То новый созданный нод дерева оценивается двумя способами
- во-первых, через описанный выше value network
- во-вторых, играется до конца с помощью супер-быстрой модели из Шага 1 (это и называется rollout)
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy. Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
- Кластер мог стать больше. Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
- Похоже, стала больше тратить времени на ход (в статье все эстимейты даны для 2 секунд на ход) + добавился некий ML на тему менеджмента времени
- Было больше времени на тренировку сетей до матча. Мое личное подозрение — принципиально то, что больше времени на reinforcement learning. 1 день в изначальной статье это как-то даже не смешно.
Бонус: Попытка опенсурсной реализации. Там, конечно, еще пилить и пилить.
habr.com
Что строит AlphaGo? | Школа Го и стратегии
В нашей школе есть формула «ставь, правь, строй». Она объясняет порядок стратегии в игре. Хорошая формула носит универсальный характер. И я полагаю, что наша формула действительно хороша. Сейчас становится ясной стратегия DeepMind. Мы видим, на что они сделали ставку, Но что намерены изменить и исправить, и что они строят? И это интересный вопрос!
Сейчас, после двух поражений Ли Седоля, мы еще не можем делать окончательный вывод о победе искусственного интеллекта над чемпионом мира. Бог любит троицу, даже если это Го-бог. Кстати, мастер Го Сэйгэн говорил как-то, что сыграл бы с таким сверхразумом на двух или трех камнях форы. Плюс ситуации еще и в том, что в Го нет одного чемпиона мира. AlphaGo придется еще сразиться с чемпионом Китая и чемпионом Японии, чтобы закрепить успех. Но всё это не важно. Наше внимание приковано к матчу, мы следим за камнями, переживаем за Ли Седоля, потому что он не заслужил такого бремени. Но он мастер и возможно, что этот матч изменит его, открыв ему то, что раньше было недоступно. Главное как всегда происходит на периферии внимания: не там где камни, а там, что эти камни окружают. И в эту terra incognita любопытно заглянуть.
Небольшой исторический экскурс поможет нам это сделать. Ведь искусственный интеллект создается не впервые. Более того, мы окружены его формами, некоторые из которых очень стары.

Гадательные кости с предсказаниями, эпоха Шан
Возникновение Го в Древнем Китае окутано мраком. Историки связывают его с возвышением династии Чжоу. Есть даже имя потенциального создателя игры: мифический мудрец-сановник Цзы Ци. Его персона интересна тем, что он был первым министром у последнего императора династии Шан. Но тот, не внял его советам. И тогда по легенде Цзы Ци предложил свои услуги клану Чжоу, возвысив новую династию. Этому мудрецу приписывают изобретение триграмм и Го, которые стали новым методом описания реальности: в первую очередь гадания и предсказания будущего. Чтобы было понятно, о чем идет речь, процитирую Демиса Хассабиса:
«Рак, изменение климата, энергетика, геномика, макроэкономика, финансовые системы, физика. Многие из систем, которые мы хотели бы освоить, становятся слишком сложными. Информационная перегрузка в них такова, что даже для самых умных людей очень трудно справиться с этими проблемами в течение своей жизни. Как пройти через эту лавину данных, чтобы найти правильные идеи? Один из способов мышления AGI это процесс, который будет автоматически конвертировать неструктурированные данные в полезные знания. То, что мы создаем – это алгоритм мета-решения любой проблемы».
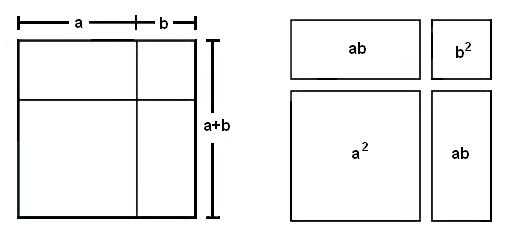
Примерно таким содержанием были наполнены речи министра, обращенные к представителю старого мира шаманов, род которых и был династией правителей Шан. Объявление войны и мира, время начала посевной и сбора урожая, погода на зиму и возможные наводнения весной — ответы на эти вопросы находили с помощью гадания по трещинам обожженных костей. Цзы Ци предложил заменить шаманскую архаику инновационным изобретением. Он придумал новый язык и даже сделал свой «гаджет», с помощью которого можно было бы искать ответы, не рассматривая кости, а на «экране» его устройства под названием zhangfang. Суть заложенных в него алгоритмов иллюстрируют следующие рисунки:
Вы понимаете, что здесь изображено? Если нет, то войдете в положение последнего императора Шан, который отправил своего первого министра отдохнуть в отдаленную провинцию на десять лет. Слева на рисунке показан символ «ци». Это краеугольное понятие древнекитайской философии, согласно которой «единица рождает двойку, двойка рождает тройку, тройка рождает 10 000 вещей». «Ци» может быть раскрыто в динамическом виде как диаграмма инь-ян. Справа показано, как с помощью бинарного кода прямой и прерывистой черт образуются восемь триграмм. Они соотносятся с восемью сторонами света и, условно говоря, моделируют любые явления, которые могут произойти. Далее из них образуется круг из 64 гексаграмм, составляющих Книгу перемен. Для сравнения посмотрите на схему из доклада DeepMind об обучении с подкреплением для нейросетей.
Эта схема также непонятна неискушенному читателю, как и предыдущие рисунки. Но главное, что она работает, что и демонстрирует сейчас AlphaGo в Сеуле. Древнекитайский мудрец построил первый в истории Китая (не берусь говорить о мировой истории) алгоритм искусственного интеллекта, предложив заменить шаманство технологией, если уместно так называть его изобретение. Но заметим вот что. Разработчики AlphaGo не могут нам объяснить, как сеть принимает решения и делает свой выбор. Они не управляют ее выбором, дав ей лишь алгоритмы самообучения. Также мы не можем понять, как работают восемь триграмм и Книга перемен. Мы можем лишь проверять эту интеллектуальную систему на практике. А она интеллектуальна, так как содержит в себе лишь бинарные знаки и отношения между ними.
Считается что игра Го выросла из «гаджета», работающего на древнем аналоге AGI, который играл роль виртуального советника для правителя. DeepMind сейчас разрабатывает на базе AlphaGo своего виртуального помощника для смартфонов. Нейросеть ляжет в основу искусственного интеллекта и для системы здравоохранения Великобритании. Получив такой «гаджет» древнему правителю не надо было жечь кости и рассматривать трещины. Он мог легким движением руки получить комбинацию символов, интерпретация которых давала ответы на поставленные вопросы. До наших дней не сохранилось ни одного zhangfang’a. Можете набить в поиске «китайский компас» — это поздний упрощенный прототип этой древней штуки.
Доска для Го использовалась и как календарь с 24 сезонами, и для гадательных предсказаний, и как зеркало психического состояния вопрошающего, и как агрегатор стратегических паттернов и логических отношений. Китайцы на доске Го объясняли даже бином Ньютона.
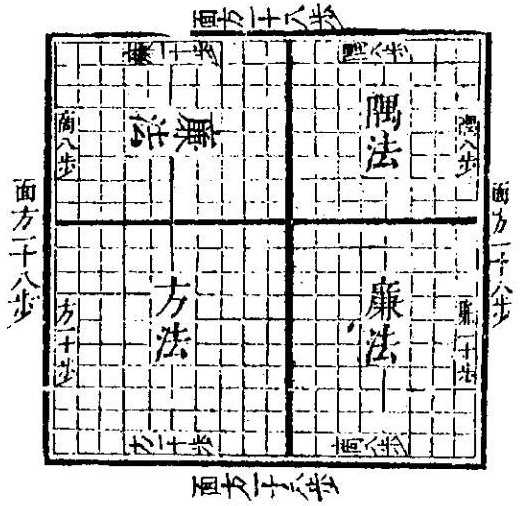
Бином Ньютона объяснен на доске Го с помощью отношения площадей. Источник: «Полная коллекция вычислительных методов» или Suanfa tangzong (1592). Автор Чэн Давэй.
Эта «закрывающая технология» попала в руки к вождю племени Чжоу, знаменитому У Вану, который свергнул династию Шан и установил свою, правившую почти 1000 лет. Цзы Ци стал его первым министром и советником.
Для любителей Го это будет звучать странно, но в те далекие времена в Го вряд ли играли так, как это делаем мы. Скорее, исследовали насущные проблемы, выуживали заложенные в модель знания. Да, гадали о будущем, также как ученые XXI века будут запрашивать у AlphaGo прогнозы катастроф или рассчитывать с ее помощью вероятность обитаемости той или иной планеты. Сам дизайн игры был футуристичен. Для правителей древности было немыслимо разбираться со стратегией войны и мира на доске с помощью камней, а не вопрошать у богов на ритуальных костях. Также как сейчас для нас немыслимо поручать искусственному интеллекту воспитание детей или разрабатывать политику государства.
Мы пока не готовы признать способность системы из 280 GPU и 1920 CPU имитировать интуицию и мышление, побеждая мастеров высшего класса. Ведь Го игра для человека, а какая может быть интуиция у машины? Правда в том, что само Го — это машина. Это модель ratio в чистом виде, которая вытравляла шаманское сознание из голов правителей и окружавших их людей, демонстрируя невероятную в те время идею: надо думать, рассчитывать и моделировать, а не получать готовый ответ от шамана, который в трансе общается с богами. Похоже, что мы сейчас переживаем столкновение нашего шаманского сознания с новым типом машины искусственного интеллекта.
Миссия DeepMind звучит амбициозно и характеризует планы компании: 1. Solve intelligence. 2. Use it to solve everything else (Создать разум. Использовать его для решения любых проблем). AlphaGo — это первый шаг на пути создания такого сверхразума. Сейчас нейросеть состоит из двух сетей: политики, отвечающей за планирование и стратегию, и ценности, которая позволяет оценивать эффективность. Следующий шаг — это подключение функции памяти. У DeepMind есть дорожная карта шагов, которые следует пройти по этому пути. Я не могу себе представить, как сеть будет играть, когда она начнет накапливать опыт не только в сетях политики и ценности, но и в виде прямого запоминания, если и сейчас она действует практически безупречно.
Демис Хассабис относит AlphaGo к классу AGI, то есть неспециализированному искусственному интеллекту. По его определению general — «same system can operate across a wide range of tasks» (одна и даже система может оперировать с широким классом задач). В этом отличие AlphaGo от суперкомпьютеров, победивших человека в шахматах и других играх. AlphaGo запрограммирована только на то, чтобы очень хорошо учиться. Обучение с подкреплением (reinforcement learning) построено по простой схеме. Но за ней стоят «удивительно интересные алгоритмы». Что это за алгоритмы, мы скоро узнаем, так как DeepMind обещает открыть доступ к своим разработкам.
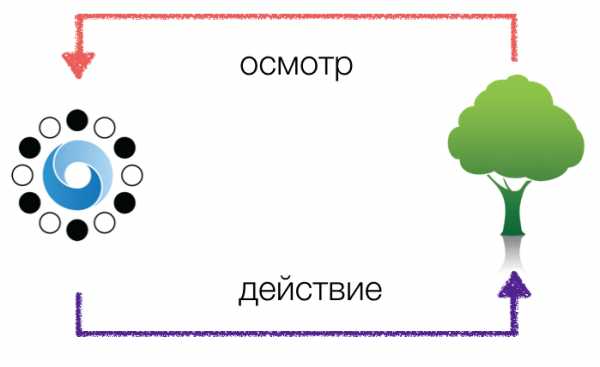
Рисунок на основе схемы из лекции Демиса Хассабиса
Я строю обучение Го по похожей схеме, только из трех элементов: осмотр, понимание, действие. Особенность нейросети, которая позволяет ей побеждать азиатских профессионалов с неожиданной легкостью в том, что она действительно повторяет в той или иной мере мыслительный процесс. Но я не уверен, что этот процесс лежит во главе угла у восточных профессионалов. Одна китайская профессионалка так описала свой способ игры: я выбираю стандартный паттерн из набора вариантов и следую ему, ничего не выдумывая (попробую найти точную цитату). Смысл цитаты заключался в том, что для нее главным является не творчество, а удачно подобранные друг к другу игровые шаблоны. Как становится ясно из объяснений разработчиков, AlphaGo действует принципиально иначе. У нее нет базы стандартных схем. Сеть опирается на натренированные оценки эффективных решений и каждый раз ищет решение с помощью заложенных алгоритмов Монте-Карло. Иногда ошибается, как в самом конце второй игры с Ли Седолем (постановка 167). Другое дело, что чемпион не решился воспользоваться этой ошибкой. Человек, в отличие от программы, физически устает и нервничает.
Какова будет правящая и строящая постановки DeepMind, говоря языком игры Го? Корреспондент The Verge задал такой вопрос главе компании: «AlphaGo обучалась на тысячах игровых паттернов Го. Как она может быть применима, например, к смартфонам, где вариативность входящей информации намного больше?» Демис Хассабис сказал то, что я, как и многие другие, хотели от него услышать:
«Да, есть куча информации об этом, по которой вы и делаете такой вывод. На самом деле AlphaGo — это алгоритм. И мы собираемся попробовать в ближайшие несколько месяцев отказаться от управляемого обучения сети на начальном этапе. Пусть она просто самостоятельно играет, начиная учиться буквально с нуля. Это займет больше времени, поскольку ей придется действовать методом проб и ошибок. А когда играешь на основе случайного выбора, то тренировка занимает больше времени. Нам потребуется, может быть, несколько месяцев. Но мы считаем возможным дойти до чистого обучения. Мы могли бы это сделать и раньше, но такой подход не сделал бы программу сильнее. Хотя в случае с играми Atari у сети не было подсказок от людей. Она начинала играть случайным образом. В Го, в отличие от компьютерных игр Atari, намного сложнее понять, ведут ли твои действия к победе или нет, даже через сто шагов… Цель DeepMind не в том, чтобы побеждать во всех играх ради веселья. Игры полезны для тренировки сети и тестирования алгоритмов, насколько они хороши. Игры позволяют делать это очень эффективно. В конечном счете мы хотим использовать AlphaGo для решения больших мировых проблем».
Машина AlphaGo учится рационально «по-человечески» мыслить на том же инструменте, что и человек древности — с помощью Го и других игр. Facebook создает свой AGI, обучая его читать и понимать тексты. Похоже, что соревнование между буквенной и иероглифической цивилизациями только в самом начале. И нас ждет много сюрпризов.
Есть и другое измерение происходящего. Победа AlphaGo над чемпионом Го Кореи — это удар в сердце культурного кода Азии. Ведь они сознавали превосходство Го над шахматами, свое безусловное превосходство в Го над всем миром и считали, что превосходят запад в разработках искусственного интеллекта. Google бросил вызов Востоку, в первую очередь Китаю, правда, пока не победив китайского чемпиона в Го. Но AlphaGo готовится сделать это, показывая превосходство европейской технологической науки над восточной моделью развития человека. И это тот вызов, на который и надо искать ответ, а не выставлять под каток очередного чемпиона. Что можно противопоставить эволюции машин? Способны ли мы также эффективно развивать человека? DeepMind показывает нам, как надо использовать Го, и у них есть чему поучиться.
автор: Михаил Емельянов.
Метки: AlphaGo, игра Го, искусственный интеллект, человечество
clubgo.ru
Новая AlphaGo сама научилась играть еще лучше. И обыграла все предыдущие версии
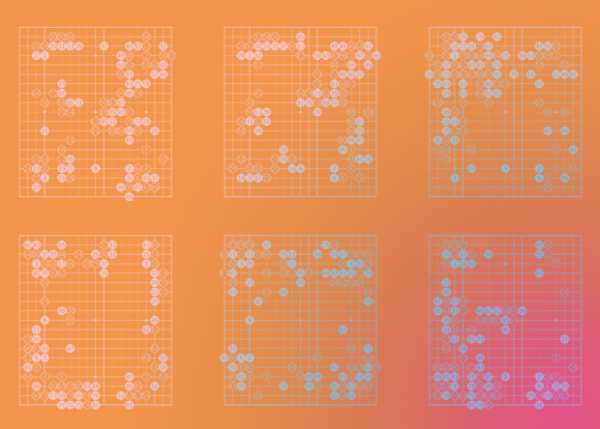
Разработчики DeepMind создали новый алгоритм для программы AlphaGo — искусственного игрока в го. По сравнению с предыдущими моделями новая AlphaGo при обучении была ориентирована строго на обучение с подкреплением (то есть без обучающей выборки). Новая система одержала абсолютную победу над всеми своими предшественниками. Работа опубликована в Nature.
Го — настольная игра, популярная в странах Азии. Сформулировать основные правила игры можно следующим образом. Два игрока получают камни разных цветов (черного и белого), и задача каждого из них — огородить большую территорию своими камнями на гобане — игровой доске. Одна партия может занимать от 10 минут до нескольких часов, а число возможных комбинаций больше числа атомов во Вселенной. Именно из-за огромного количества данных, необходимых для разработки стратегии эффективной игры, разработка компьютерного игрока в го долгое время оставалась недоступной задачей.
Программа AlphaGo была представлена DeepMind, экспериментальным подразделением Google, в 2015 году. Первая версия работала с использованием двух нейросетей: одна вычисляла вероятность ходов, а вторая — оценивала позицию камня на доске. AlphaGo тогда практически полностью полагалась на обучение с учителем, использовала в качестве обучающей выборки данные об успешных ходах игроков-людей, а также поиск по дереву методом Монте Карло, который часто применяется в создании компьютерных игроков. Задача такого поиска — выбрать наиболее выигрышный вариант, анализируя сыгранные и удачные ходы в игре. Алгоритм показал свою эффективность практически сразу же, обыграв профессионального игрока Фаня Хуэя.
Затем разработчики DeepMind улучшили алгоритм, расширив использование в системе обучения с подкреплением — вида машинного обучения, при котором алгоритм обучается, не имея при этом обучающую выборку в виде пары «входные данные — ответ». Тогда AlphaGo смогла обыграть другого игрока в го — Ли Седоля, которого уже относят к сильнейшим игрокам в мире. После этого разработчики модернизировали алгоритм еще раз: последняя версия AlphaGo обыграла третьего сильнейшего игрока в го, Кэ Цзэ, и ушла из спорта. Тем не менее, разработчики DeepMind не прекратили работу над программой и теперь представили новую версию своего игрока.
В отличие от своих предшественников, новая версия AlphaGo (чтобы обозначить, что противником «игрока» является он сам, авторы статьи добавили к его названию индекс Zero) работает строго благодаря обучению с подкреплением, не используя информацию, полученную от игроков-людей. Вместо этого новый алгоритм учится сам: берет в качестве входных данных положения черных и белых камней и начинает со случайной игры, со временем улучшая качество. На каждом шаге алгоритм подключает поиск по дереву методом Монте Карло, высчитывая вероятность следующего шага, а также подбирает следующий за ним наиболее эффективный ход. Таким образом, новый алгоритм обучился игре сам у себя.
Алгоритм обучался около трех дней и успел за это время сыграть около пяти миллионов партий с самим собой. После этого разработчики сравнили работу AlphaGo Zero со всеми предыдущими версиями, обыгравшими ведущих игроков-людей. Все старые версии проиграли AlphaGo Zero со счетом 0:100.
Таким образом, разработчики AlphaGo показали, что сверхчеловеческий (по словам авторов) уровень игры может быть достигнут и без прямого взаимодействия с информацией, полученной от людей. К сожалению, играть против профессионалов-людей новый алгоритм, скорее всего, не будет.
Помимо го разработчики DeepMind также занимаются разработкой и других игровых алгоритмов. Например, здесь вы можете узнать о нейросети, которая играет в StarCraft — и пока что не очень успешно. Дополнительные подробности об истории создания и существования AlphaGo в профессиональном спорте вы можете прочитать в нашем материале.
Елизавета Ивтушок
nplus1.ru
Красивые ходы AlphaGo | Computerworld Россия
Систему для игры в го, разработанную в подразделении Google DeepMind, считают следующим витком развития искусственного интеллекта после компьютера Deep Blue, выигравшего у Гарри Каспарова.
В процессе игры против Ли Седоля, одного из лучших в мире мастеров го, система искусственного интеллекта Google AlphaGo озадачила комментаторов ходами, которые те называли «красивыми», но отмечали, что они не свойственны стилю игры человека.
Эксперты в области искусственного интеллекта считают, что такие ходы стали проявлением главного преимущества AlphaGo — способности учиться на собственном опыте. Подобные ходы нельзя было сгенерировать лишь исходя из накопленных знаний о том, как играют люди, отмечает Доина Прекап, доцент Университета Макгилла.
«AlphaGo не просто мыслит, но и имеет способности к обучению и стратегическому планированию», — соглашается Говард Ю, профессор стратегического управления и инновации бизнес-школы Международного института управленческого развития.
AlphaGo выиграла у Ли Седоля подряд три первых игры, чем заработала себе победу в турнире и призовые миллион долларов, которые в Google собираются пожертвовать на благотворительность. Но четвертую партию система проиграла, допустив ошибку, после чего Ли Седоль отметил, что у AlphaGo есть определенные слабые места.
Работа над программой началась около двух лет тому назад в рамках исследовательского проекта, целью которого было проверить, сможет ли нейронная сеть, работающая по принципу глубинного обучения, освоить игру го, сообщил Дэвид Сильвер, один из ведущих научных сотрудников проекта AlphaGo. Google в 2014 году приобрела DeepMind, британскую компанию, занимающуюся системами искусственного интеллекта.
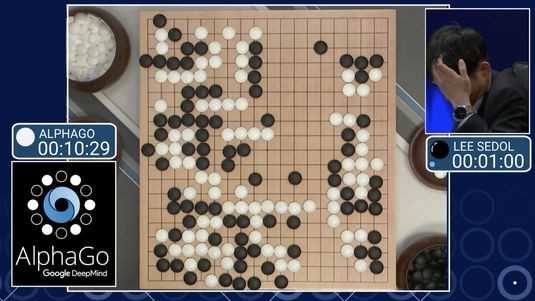 |
| Четвертую партию система проиграла, допустив ошибку, позволившую Ли Седолю утверждать, что у AlphaGo есть слабые места |
Во время игры система руководствуется вероятными ходами людей, генерируемыми «сетью правил» — моделью действий реальных мастеров го в различных ситуациях. Но когда включается «оценочная» нейронная сеть системы, используемая для более глубокого анализа ситуаций, программа может сделать оригинальный ход.
По правилам го, игроки ходят по очереди белыми и черными фишками, которые называются «камнями», ставя их на пересечения линий на доске 19х19 и стараясь захватить как можно большую территорию путем окружения камней противника.
В отличие от людей, AlphaGo старается максимизировать вероятность общей победы, а не захватить наибольшую территорию, чем и объясняются некоторые из ходов системы, сообщил генеральный директор DeepMind Демис Хассабис.
По словам Прекап, специалисты ожидали, что пройдет еще много лет, прежде чем системы искусственного интеллекта смогут победить человека в го, игре, которая считается более сложной, чем другие стратегические игры наподобие шахмат, из-за гораздо большего количества вариантов ветвления и среднего числа возможных действий в расчете на ход.
«Уровень развития систем искусственного интеллекта принято оценивать с помощью сложных игр и задач. В данном случае такой задачей стало освоение го, — рассказал Бабак Ходжат, сооснователь, главный научный сотрудник компании Sentient Technologies. — AlphaGo удалось значительно поднять планку уровня сложности задач, которые теперь подвластны системам машинного обучения».
Го требует принятия высокоуровневых стратегических решений, отметила Прекап. На доске несколько боев за разные участки могут вестись параллельно, и нужно выбирать, какой из боев продолжить при очередном ходе, и какую область защищать. «Считалось, что на планирование такого рода способен лишь ум человека», — добавила она. Программы для игры в го раньше уже разрабатывались, но их возможности были очень слабыми по сравнению с людьми .
AlphaGo идет по стопам шахматного компьютера Deep Blue, одержавшего победу над Гарри Каспаровым в 1997 году. Еще один компьютер IBM, Watson, в 2011-м выиграл у людей в телевикторине Jeopardy.
Программа DeepMind сильно отличается от Deep Blue, которая полагалась прежде всего на поиск среди огромного количества позиций, но при этом имела и эвристические механизмы, имитировавшие мышление гроссмейстеров. AlphaGo тоже оснащена мощным поисковым компонентом, но обучается игре самостоятельно, а не просто копирует действия людей.
Весь объем инженерной мысли, вложенный в разработку Deep Blue, служил единственной цели — победить в шахматы, отметил Ю.
В Google собираются попробовать силы своего искусственного интеллекта и в других областях помимо игр, в том числе в здравоохранении и в научных исследованиях. «Глубинное обучение хорошо подходит для любой задачи, связанной с классификацией временных рядов», — говорит Ходжат. В его компании сходную технологию используют в системе Sentient Aware для сайтов электронной коммерции, которая помогает покупателям находить новые товары, отображая те, что внешне похожи на уже просмотренные.
AlphaGo основана на алгоритмах общего назначения, применяемых во многих ситуациях, подчеркивает Прекап. Программа полагается на две методики обучения — обучение с подкреплением и глубокие сети. Обе используются во многих системах, от роботизированных протезов до средств распознавания речи. «Возможно, такие алгоритмы и оптимизируются для конкретных применений, но они рассчитаны не на какую-то одну область задач», — добавила она.
Алгоритм общего назначения, способный к самообучению и имитации обучения с подкреплением, как у людей, открывает «новые возможности, на которые человеческий ум не способен», полагает Ю.
AlphaGo, однако, не способна понимать естественный язык людей, в отличие от системы IBM, которая с этим справляется блистательно, продолжил он. «Обрабатывая миллионы страниц медицинских журналов и информации о пациентах, Watson выдает врачам рекомендации по диагностике и лечению; например, он может посоветовать сделать дополнительный анализ крови или напомнить самые свежие данные по клиническим испытаниям, — говорит Ю. — Если когда-нибудь механизмы самообучения AlphaGo объединят с системой понимания человеческого языка Watson, создав алгоритм общего назначения, превосходству человека над машиной, скорее всего, придет конец».
Беспокойство по поводу утраты преимущества человека перед машиной было фоном состязания между Ли Седолем и AlphaGo. Многие в онлайн-комментариях к игре писали, что южнокорейскому профессионалу выпало «вести грандиозный бой с компьютером от имени всего человечества».
Но эксперты считают, что победа в го — игре на двоих с четко заданными правилами — не означает, что пришло время, когда машины возобладают над людьми. «Сегодня искусственный интеллект неплохо справляется со многими когнитивными задачами, которые раньше были под силу только людям, — указал Ходжат. — Но прежде чем он достигнет человеческой мощи абстрактного мышления, пройдут еще годы».
«У нас еще нет машин с искусственным интеллектом общего назначения, который был бы способен решать многие разные задачи, скажем, играть в го, понимать текст, музицировать на скрипке и т. д., — добавила Прекап. — Это следующий рубеж, но мы еще очень далеко от него».
В Microsoft Research недавно сообщили о работе над проектами в области общего интеллекта. Как отметили в корпорации, исследователи, занимающиеся искусственным интеллектом, создали, к примеру, средства распознавания слов, но пока не научились комбинировать навыки с такой же легкостью, как это удается людям.
www.computerworld.ru
Master AlphaGo против сильнейших игроков Го Азии
В конце 2016 года Google сделал подарок любителям игры Го: выпустив на игровые серверы анонимную версию своего флагмана в области ИИ — AlphaGo. Кто скрывается под никами Master и Magister стало известно лишь после того, как программа обыграла всех оппонентов без исключения. Всего было сыграно 60 игр с малым контролем времени: 60 секунд основного времени плюс три периода по 30 секунд на постановку. Конечно, такого времени недостаточно для того, чтобы человек мог просчитать варианты на достаточную глубину, не говоря о выборе стратегии.
Например, до войны в Японии был принят следующий порядок, согласно которому на ключевых соревнованиях мастерам 5 дана и выше предоставлялось 11 часов времени каждому. Если же один из игроков был профессионал 4 дана, то общим давалось по 9 часов. Когда соперники оба были 4 данами, они получали по 8 часов времени. То есть, чем выше был дан, тем больше давалось времени на размышления (ист: Old Fuseki vs New Fuseki, J. Fairbairn). Ли Седоль в свежем интервью в январе 2017 года отметил: что на его взгляд справедливо дать человеку минимум 2 часа времени, сохранив машине контроль в 30 секунд. Он не видит шансов у человека, если даже уравнять контроль времени, предоставив машине тоже 2 часа.
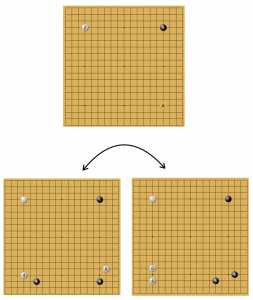
Идеальные фусэки с хоси по версии AlphaGo
AlphaGo удивила новыми идеями в развертывании камней (фусэки). На рисунке показаны два сценария, в котором за оба цвета показаны ходы нейросети. Единого дерева вариантов нет, программа выбирает разные решения в идентичных позициях.
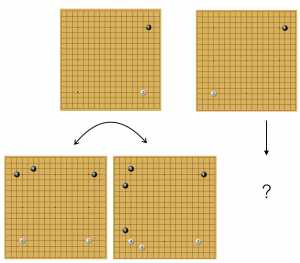
варианты фусэки с комоку по версии Alphago
AlphaGo удивила новыми идеями в развертывании камней (фусэки). На рисунке показаны два сценария, в котором за оба цвета показаны ходы нейросети. Единого дерева вариантов нет, программа выбирает разные решения в идентичных позициях. Также она регулярно использует прессинг и нестандартные решения в углах. Речь идет о самых разных случаях, даже тех, где подобные решения считались уделом новичков. В этой статье собраны варианты первых постановок в начале игры, когда ИИ играл белыми камнями. В большинстве позиций ответы AlphaGo повторяются из игры в игру. Значит за ними стоит высокая оценка шансов на победу. Есть примеры, когда программа выбирала разные решения в аналогичных позициях, но таких случаев немного.
AlphaGo играет белыми камнями
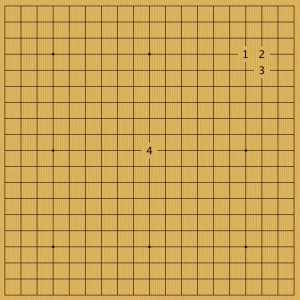
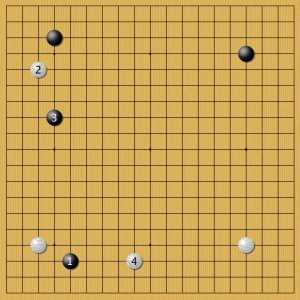
Пример 1
Восточные профессионалы в качестве первой ставки выбирали 4 указанных позиции. 1 — постановка в звезду, согласно теории Новых фусэки, это один из самых сбалансированных камней. 2 — наследние классической японской школы. Комоку (камень 3х4) нацелен на территорию и до эпохи коми считался фундаментом непобедимой стратегии за черный цвет. 3 — гибкая ставка 5х3 (мокухадзуси) нацелена не только на территорию, как комоку, но скорее, на динамичный рост. Одна игра с зеркальным продолжением была сыграна от центра — 4. AlphaGo пока не показала игр, где бы она делала первую ставку в центр.
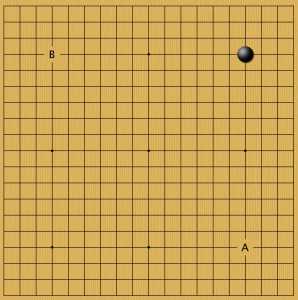
Пример 2
На камень в звезде AlphaGo отвечала также в звезду: причем в соседнем углу. Есть мнение, что с точки зрения равновесия, верно занимать диагональ и избегать параллелизма. Пока мы видим, что AlphaGo не подтверждает эту гипотезу. Хотя, на черный камень 4х3 в этом углу программа уже была готова ставить и по-диагонали. Это случайность, или такая большая разница между хоси и комоку? Пока ответа на этот вопрос нет. Для удобства я свел все позиции из варианта В к А, развернув игры. Это не влияет на расклад, но упрощает сравнение вариантов фусэки.
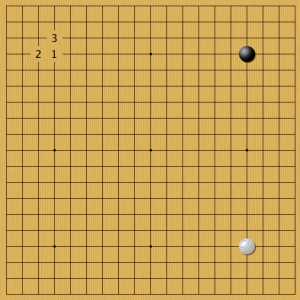
Пример 3
На первый белый камень в звезде игроки отвечали тремя указанными способами. 1 приводит к развертыванию «две звезды» (нирэнсэй). Такой стиль игры пропагандировал Го Сэйгэн. Постановка 2 открывает большое китайское фусэки. Ставка 3 — малое китайское фусэки. Все три стратегии позиционирования популярны и хорошо изучены. Рассмотрим ответы AlphaGo на каждый вариант.
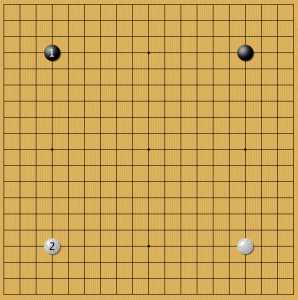
Пример 4
На черный во второй звезде AlphaGo всегда занимает звезду. Можно сделать вывод, что нейросеть считает эту позицию наилучшей для белых. В следующей статье можно посмотреть, как нейросеть предпочитает отвечать за черных в такой позиции. Среди опубликованных игр нет примеров, где бы она сама поставила две звезды за черных.
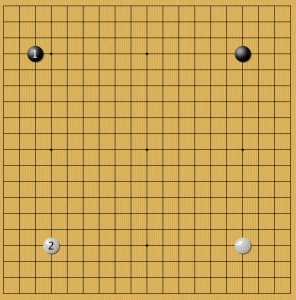
Пример 5
На китайское фусэки программа также всегда выбирала занять вторую звезду. То есть для белых нирэнсэй приемлем и хорош, по крайней мере по отношению к такому положению черных камней, как в примерах 4 и 5.
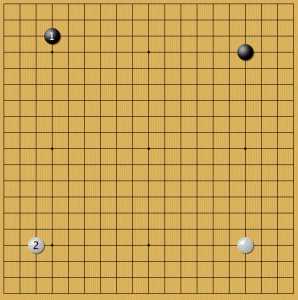
Пример 6
Малый китайский стиль AlphaGo всегда балансировала низким камнем 2.
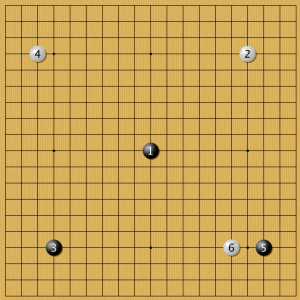
Пример 7
Наиболее интригующий вариант с постановкой в центр. Здесь программа выбрала классическое китайское фусэки (сочетание белого в звезде с низким камнем в соседнем углу), а затем незамедлительно вторглась в сферу влияния черных. Игрок черными выбрал зеркальную стратегию, вынудив программу играть против себя самой почти 100 постановок. Я думаю, что ее анализ с точки зрения эффективности решений, баланса и гармонии был бы интересен.
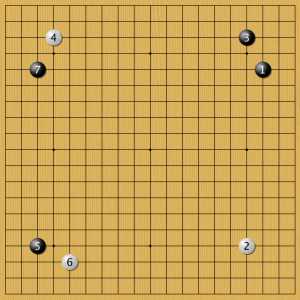
Пример 8
Любопытно, что в необычном сейчас фусэки 1-3 AlphaGo вышла на перекрестную позицию 2-4. Выходит, что черная угловая крепость балансируется такой позицией (если конечно, AlphaGo не ошибается в своих оценках). Дальше мы видим классическое продолжение в духе эпохи Эдо, за исключением высокого камня 2.
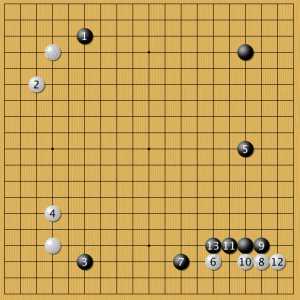
Санрэнсэй
В одной из игр с Гу Ли китайский мастер поставил санрэнсэй за черных. Вы увидите, что программа не жалует высокие прыжки типа 4 и почти всегда на них набрасывается снаружи. Но в этой позиции она выбрала именно такой способ развития белого угла. Трудно сказать, является ли это самым лучшим решением или же здесь мы видим один из вариантов. Ведь нейросеть не может просчитать все варианты, а значит должна угадывать и выбирать. Игра очень интересная, в ней нейросеть провела успешное вторжение в область черных благодаря продаже второстепенного камня на стороне. Он был поставлен казалось бы совсем по иным причинам, но идеально вписался в позицию:
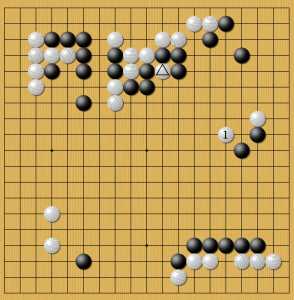
вторжение в санрэнсэй
Постановка 1 — стандартное развитие вторжения. Но здесь этот камень одновременно работает на спасение отмеченного белого наверху. Гу Ли был вынужден добить этот белый камень, за что нейросеть получила еще одну постановку внутри сферы влияния черных. В стратегии случайностей не бывает. Было ли это частью расчета? Люди вряд ли способны так далеко рассчитать сценарии, так как отмеченный камень появился на доске за 20 ходов до постановки 1 и был частью совсем иного сценария.
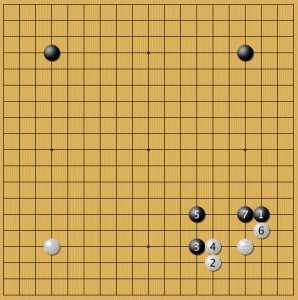
Гу Ли применяет новый ход AlphaGo
В последней опубликованной партии Гу Ли попробовал сыграть против нейросети в ее стиле — постановка 3. Фусэки этой партии получилось необычным, что вообще характерно для игр с нейросетью. Но кажется, что профессионалы пока не понимают, как следует развивать позиции, подобные черному камню 3. Сама нейросеть не всегда поддерживает эти камни. Продолжение фусэки:
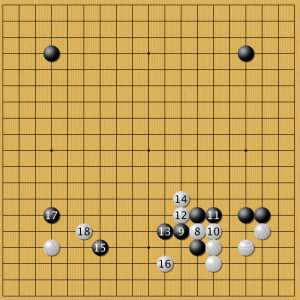
продолжение борьбы
Высокие клещи 15-17 больше характерны для форовой игры, нечасто их встретишь в поединках мастеров. Теперь разберем примеры позиций с китайским стилем.
китайский стиль
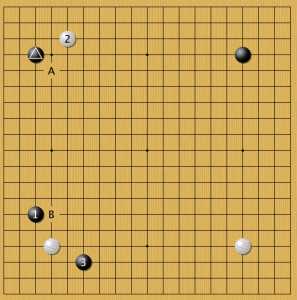
Когда мастера ставили отмеченный черный камень в 4х3 нейросеть занимала вторую звезду. Дальше начинались разные сценарии. Например, здесь AlphaGo пробовала два разных решения А и В. Вопрос эквивалентны ли они или это творческий поиск? Тактика тоже оригинальная: подставить угловой камень под двойные клещи черных 1-3. Примеры таких игр есть, но это считается сложным маршрутом.
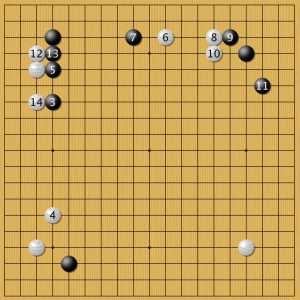
Низкий китай 1
На постановку 1 нейросеть всегда подходила к черному углу справа 2 и вторгалась в угол 4. Затем позиция развивалась согласно планам игроков. Это первый вариант, где нейросеть смело вторгается низким камнем 10 в плотную область черных. Продолжение лучше посмотреть в полной записи игры.
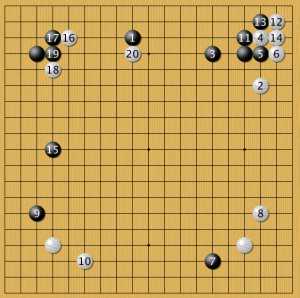
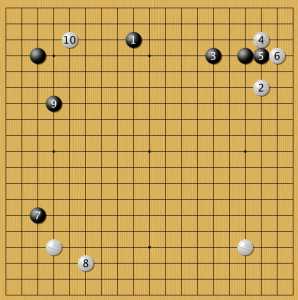
низкий китай 2
Второй сценарий: где черные сначала ставят камень 7, а потом 9. Опять низкий вход в зону черных камнем 16 и гибкая организация белых 18-20. Видимо, скоро такой способ игры станет новым стандартном.
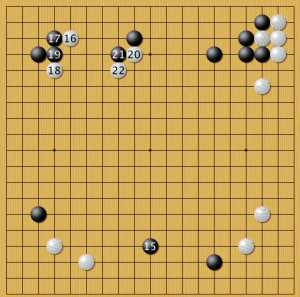
низкий китай 3
Третий сценарий отличается положением камня 15. AlphaGo, несмотря на это, вторгается 16-18-20. Последний набор сценариев этой группы посвящен малому китайскому стилю. Напомню, что здесь его выбирают мастера, хотя и нейросеть любит такое расположение камней за черных.
малый китай 1
Вариантов этого сценария много. Три первых начинаются с обмена какари 1-2.
малый китай 2
Здесь камень 3 поставлен ближе к белому, то есть клещи жестче. В ответ иное положение камня 4, который как бы готовится помогать белым слева. А в предыдущем примере белые активно развиваются внизу, атакуя одинокий черный.
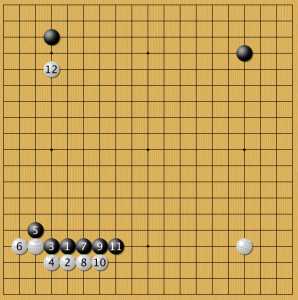
малый китай 3
новое дзёсэки?
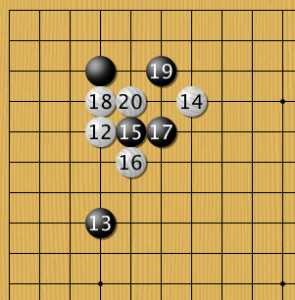
Высокий подход к белому углу 1 привел к такому сценарию. В современном справочнике дзёсэки Такао Синдзи (2011 год) прорезание белых 20 рассматривается как маневр в пользу черных. Похоже, что эту оценку нужно теперь уточнять.
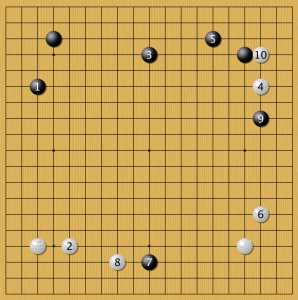
малый китай 4
Широкое развитие угла за черных AlphaGo встречала высоким камнем 2. Дальше снова начинались варианты: в зависимости от действий соперников нейросети. В этом примере черные строят большую сферу влияния.
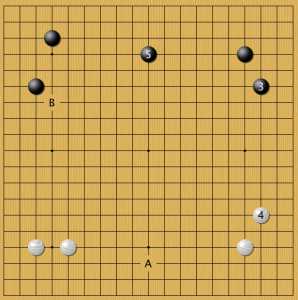
малый китай 5
Этот кейс интересен тем, что у нейросети были разные варианты ответов в такой позиции: А и В. Первый путь укладывается в логику современной теории Го, а вариант В необычен. Это пример прессинга.
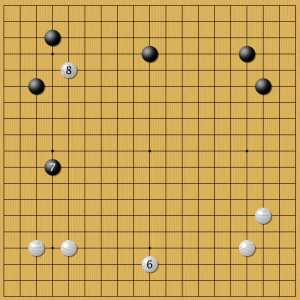
вариант А
Постановка 8 ожидаема, но пожалуй, необычна.
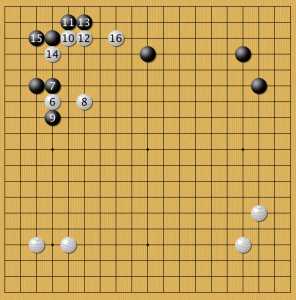
вариант В
В этом варианте показано как нейросеть организует отряд в зоне чужого влияния (по-японски эта техника называется сабаки).
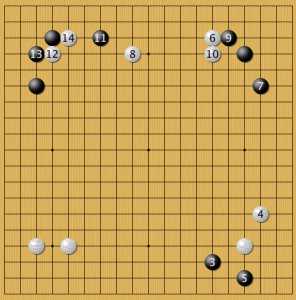
малый китай 6
Эта позиция уже стала предметом дискуссий. Растяжка между белыми камнями 6 и 8 не вписывается в современные стандарты. Считается, что камни хорошо работают на дистанции 2, 3 или 5 шагов. Тут же белые ставят камни через 4. Противник нейросети попытался наказать ее за это сначала придав белому отряду «плохую» форму, так как от двух белых камень 8 стоит через четыре, а не через три шага. Затем мастер поджал белых с фланга 11. Что делает нейросеть? Как всегда поступает нестандартно: вторжение в плотную зону черных камнем 12!
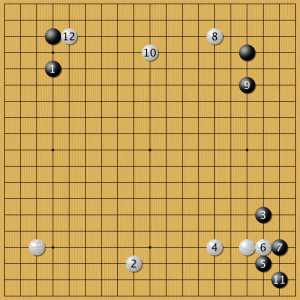
малый китай 7
Еще одно оригинальное начало игры, где черные ставят высокий камень 1. Любопытно, что на низкий черный камень 1 белые меняют позицию камня 2:
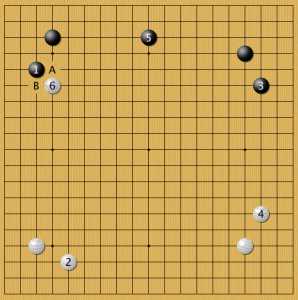
малый китай 8
Снова ставший фирменным стилем прессинг 6: дальше два варианта. Похожую стратегию предлагал Го Сэйгэн в книге о стиле игры Го в 21 веке. Правда, он разбирал примеры иного контекста. В 2010 году я хотел изложить схожие идеи в первом томе Русского Учителя японского Го, но эта часть осталась в черновиках, так как оценить эффективность предлагаемых сценариев было очень нелегко. Так что идея не нова, и сейчас мы видим, как она работает.
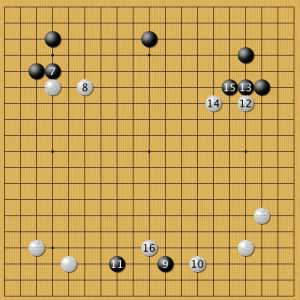
Вариант А
Первый вариант демонстрирует радикальную стратегию белых по выстраиванию господства в центре. Пожалуй, похожих игр среди профессионалов не найти, разве что у Такэмии.
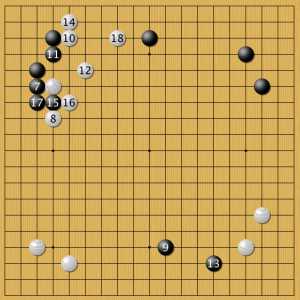
Вариант В начало
Второй вариант не менее интересен и заслуживает двух диаграмм:
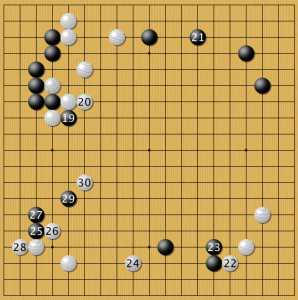
Вариант В продолжение
Постановка 30 на шестую линию — изящный пример комплексной атаки: прямая атака на три черных под номерами 25, 27, 29, затем косвенная атака на три черных справа (где 23) и атака камня 19, прерывая облаву (лестницу). На этом варианты с первым черным камнем в звезду закончились.
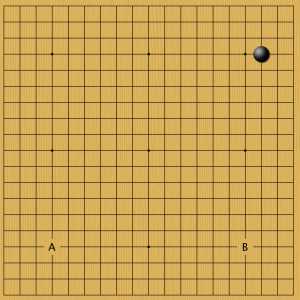
Пример 9
На низкий камень комоку программа давала два ответа, оба в звезды: А и В. Когда она играла уже за черных, то мастера создавали схожие позиции, играя за белый цвет. Их можно сравнить с этими вариантами (см. примеры ниже).
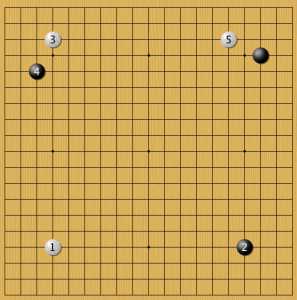
Пример 10
Первое фусэки с диагональным белым камнем 1. Можем отметить, что такой ответ на комоку, видимо, хорошо сбалансирован. Но есть и вариант В! Почему? Это равные варианты, или программа экспериментирует в условиях дефицита информации? Далее белые ставят камень 3 (китайский стиль), и если черные подходят к белому камню № 4, то и белые в ответ подходят к черному углу № 5. Одно из классических начал.
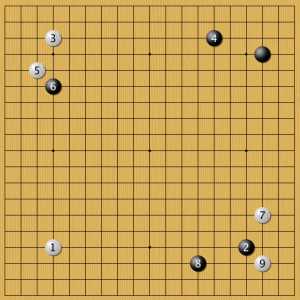
Пример 11
Это второй вариант постановки 4. Здесь игрок черными решил развернуть свой угол. В ответ AlphaGo строит крепость в своем углу. Сравните положение камня 5 с примером «малый китай 4», где нейросеть поставила высокий камень. Можно сказать что постановки 4-5 в этом варианте и в предыдущем примере — миаи. Затем черные пробуют проверить технику AlphaGo на ней самой — камень 6. Обычно мастера отвечали в таких позициях на подобные «наезды». Искусственный интеллект его игнорирует и начинает долгую игру в нижней части доски. Возможно, что так и нужно действовать? Постановки подобные № 6 встречаются в партиях AlphaGo с завидной регулярностью.
Теперь посмотрим, как разворачивается игра, когда белые ставят камень не в диагональный угол, а параллельно черным.
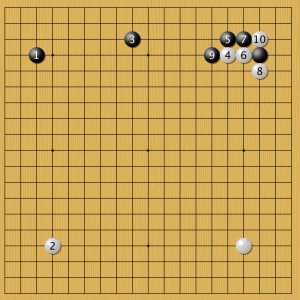
Пример 12
Если черные ставят два смотрящих друг на друга комоку (изящный стиль), то белые занимают вторую звезду, а затем подходят к правому углу, так как там расстояние между черными наибольшее. Затем белые запускают дзёсэки под названием «малая лавина», и начинается сложная позиционная борьба, которую лучше посмотреть в полной записи игры.
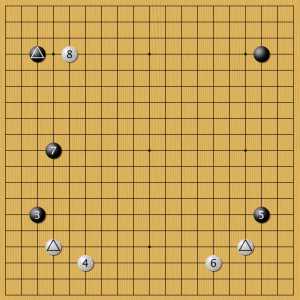
Пример 13
Еще одна ветка. Отмеченные треугольником камни там же, а постановка № 3 иная. Черные быстро развивают позицию, а не выстраивают сторону, как в примере выше. Здесь белые как-то покорно укрепляются камнями 4 и 6, а затем подходят к тому углу, где у черных наибольший территориальный потенциал. Это согласуется со стандартной теорией игры Го. В примере с игрой Гу Ли нейросеть ставила камень 6 выше в схожей позиции. Видимо, здесь мы вновь видим несчетную вариативность игры Го. А это означает, что пока нет единого сценария игры даже для первых постановок.
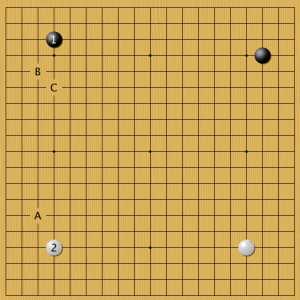
Пример 14
Много вариантов было испробовано в такой конфигурации черных камней (классический территориальный стиль эпохи Сюсаку). Программа как обычно занимает звезды. Есть два примера такого фусэки за черных у ИИ Google. Оно показано ниже для сравнения. Сначала посмотрим, как действовал профессиональный игрок, а потом как AlphaGo.
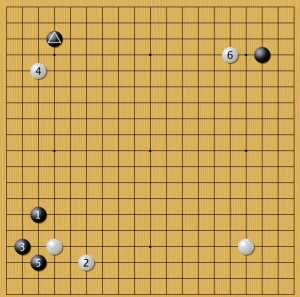
Пример 15
Итак, человек поставил отмеченный треугольником камень, а затем подступил к белому углу по наиболее выгодной стороне для черных. В ответ на проникновение в углу 3 AlphaGo немедленно подступает к одному из углов черных, а затем и ко второму углу, сочетая низкий и высокий подходы. Трудно сказать, почему камень 4 поставлен низко. Камень 6, похоже, поставлен высоко для того, чтобы вся позиция белых не оказалось слишком низкой. Теперь второй пример стратегии черных со стороны человека:
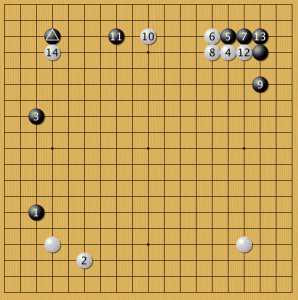
Пример 16
Здесь мастер сразу отступил 3 и пресек подход белых, как в предыдущем примере. Программа подступила к свободному черному камню в правом углу высоким подходом (какари). Дальше обычная позиция развивалась в неожиданном ключе: белые форсировали укрепление черных 13, а затем вторглись 14, что уже стало привычным ходом AlphaGo. Сравним этот пример с тем, как действовала AlphaGo в аналогичном случае:
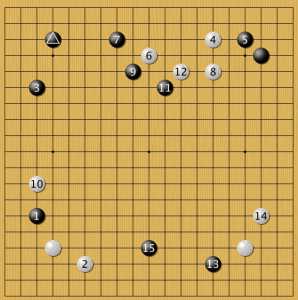
Пример 17
Тут программа уже за черных. ИИ выбирает подход 1, как и мастер, но затем действует иначе: гибче. Камень 3 меньше помогает черному 1, но больше нацелен на развитие зоны наверху, где у черных преимущество. Затем мы видим иной ход человека № 4 и как черные в ответ стремительно развивают свою зону, даже в ущерб камню 1. Стратегия белых в предыдущем примере была нацелена на то, чтобы пресечь такой сценарий в зародыше.
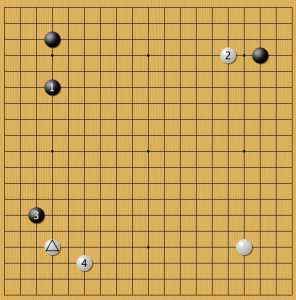
Пример 18
Возвращаемся к вариантам. Напомню, что программа за белый цвет поставила отмеченный треугольником камень. Теперь черные ставят гибкий камень 1 — его применила AlphaGo в похожем фусэки против Кэ Цзэ. Однако в отличие от чемпиона Китая белые ставят камень 2 (он занял точку, в которую здесь поставлен камень 3).
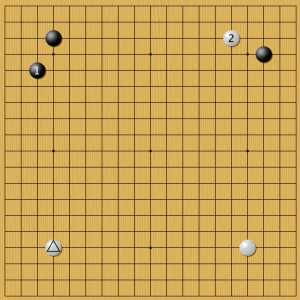
Пример 19
Это последнее фусэки, где AlphaGo играет за белых. Если черные строят крепость в углу, программа препятствует построить вторую крепость. Как по учебнику. Но она ставит низкий камень, хотя японские мастера не советуют так делать. Считается, что низкий камень 2 легко атаковать, у него будет тяжелая позиция. Либо AlphaGo так не считает, либо тут возможны варианты. Все-таки опубликовано всего 60 игр.
Метки: AlphaGo, DeepMind, Google, magister, master, игра Го, искусственный интеллект, искуственный интеллект, компьютерное Го, профессионалы, фусэки, чемпионы
clubgo.ru
Красивые ходы AlphaGo | Журнал Digital World
Систему для игры в го, разработанную в подразделении Google DeepMind, считают следующим витком развития искусственного интеллекта после компьютера Deep Blue, выигравшего у Гарри Каспарова.
В процессе игры против Ли Седоля, одного из лучших в мире мастеров го, система искусственного интеллекта Google AlphaGo озадачила комментаторов ходами, которые те называли «красивыми», но отмечали, что они не свойственны стилю игры человека.
Эксперты в области искусственного интеллекта считают, что такие ходы стали проявлением главного преимущества AlphaGo — способности учиться на собственном опыте. Подобные ходы нельзя было сгенерировать лишь исходя из накопленных знаний о том, как играют люди, отмечает Доина Прекап, доцент Университета Макгилла.
«AlphaGo не просто мыслит, но и имеет способности к обучению и стратегическому планированию», — соглашается Говард Ю, профессор стратегического управления и инновации бизнес-школы Международного института управленческого развития.
AlphaGo выиграла у Ли Седоля подряд три первых игры, чем заработала себе победу в турнире и призовые миллион долларов, которые в Google собираются пожертвовать на благотворительность. Но четвертую партию система проиграла, допустив ошибку, после чего Ли Седоль отметил, что у AlphaGo есть определенные слабые места.
Работа над программой началась около двух лет тому назад в рамках исследовательского проекта, целью которого было проверить, сможет ли нейронная сеть, работающая по принципу глубинного обучения, освоить игру го, сообщил Дэвид Сильвер, один из ведущих научных сотрудников проекта AlphaGo. Google в 2014 году приобрела DeepMind, британскую компанию, занимающуюся системами искусственного интеллекта.
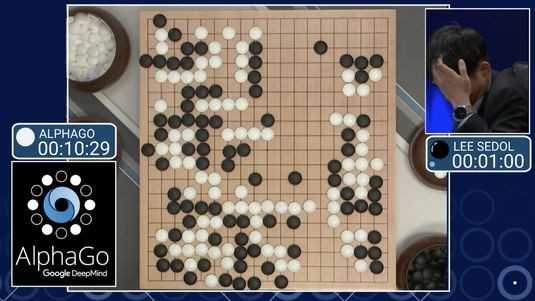 |
| Четвертую партию система проиграла, допустив ошибку, позволившую Ли Седолю утверждать, что у AlphaGo есть слабые места |
Во время игры система руководствуется вероятными ходами людей, генерируемыми «сетью правил» — моделью действий реальных мастеров го в различных ситуациях. Но когда включается «оценочная» нейронная сеть системы, используемая для более глубокого анализа ситуаций, программа может сделать оригинальный ход.
По правилам го, игроки ходят по очереди белыми и черными фишками, которые называются «камнями», ставя их на пересечения линий на доске 19х19 и стараясь захватить как можно большую территорию путем окружения камней противника.
В отличие от людей, AlphaGo старается максимизировать вероятность общей победы, а не захватить наибольшую территорию, чем и объясняются некоторые из ходов системы, сообщил генеральный директор DeepMind Демис Хассабис.
По словам Прекап, специалисты ожидали, что пройдет еще много лет, прежде чем системы искусственного интеллекта смогут победить человека в го, игре, которая считается более сложной, чем другие стратегические игры наподобие шахмат, из-за гораздо большего количества вариантов ветвления и среднего числа возможных действий в расчете на ход.
«Уровень развития систем искусственного интеллекта принято оценивать с помощью сложных игр и задач. В данном случае такой задачей стало освоение го, — рассказал Бабак Ходжат, сооснователь, главный научный сотрудник компании Sentient Technologies. — AlphaGo удалось значительно поднять планку уровня сложности задач, которые теперь подвластны системам машинного обучения».
Го требует принятия высокоуровневых стратегических решений, отметила Прекап. На доске несколько боев за разные участки могут вестись параллельно, и нужно выбирать, какой из боев продолжить при очередном ходе, и какую область защищать. «Считалось, что на планирование такого рода способен лишь ум человека», — добавила она. Программы для игры в го раньше уже разрабатывались, но их возможности были очень слабыми по сравнению с людьми .
AlphaGo идет по стопам шахматного компьютера Deep Blue, одержавшего победу над Гарри Каспаровым в 1997 году. Еще один компьютер IBM, Watson, в 2011-м выиграл у людей в телевикторине Jeopardy.
Программа DeepMind сильно отличается от Deep Blue, которая полагалась прежде всего на поиск среди огромного количества позиций, но при этом имела и эвристические механизмы, имитировавшие мышление гроссмейстеров. AlphaGo тоже оснащена мощным поисковым компонентом, но обучается игре самостоятельно, а не просто копирует действия людей.
Весь объем инженерной мысли, вложенный в разработку Deep Blue, служил единственной цели — победить в шахматы, отметил Ю.
В Google собираются попробовать силы своего искусственного интеллекта и в других областях помимо игр, в том числе в здравоохранении и в научных исследованиях. «Глубинное обучение хорошо подходит для любой задачи, связанной с классификацией временных рядов», — говорит Ходжат. В его компании сходную технологию используют в системе Sentient Aware для сайтов электронной коммерции, которая помогает покупателям находить новые товары, отображая те, что внешне похожи на уже просмотренные.
AlphaGo основана на алгоритмах общего назначения, применяемых во многих ситуациях, подчеркивает Прекап. Программа полагается на две методики обучения — обучение с подкреплением и глубокие сети. Обе используются во многих системах, от роботизированных протезов до средств распознавания речи. «Возможно, такие алгоритмы и оптимизируются для конкретных применений, но они рассчитаны не на какую-то одну область задач», — добавила она.
Алгоритм общего назначения, способный к самообучению и имитации обучения с подкреплением, как у людей, открывает «новые возможности, на которые человеческий ум не способен», полагает Ю.
AlphaGo, однако, не способна понимать естественный язык людей, в отличие от системы IBM, которая с этим справляется блистательно, продолжил он. «Обрабатывая миллионы страниц медицинских журналов и информации о пациентах, Watson выдает врачам рекомендации по диагностике и лечению; например, он может посоветовать сделать дополнительный анализ крови или напомнить самые свежие данные по клиническим испытаниям, — говорит Ю. — Если когда-нибудь механизмы самообучения AlphaGo объединят с системой понимания человеческого языка Watson, создав алгоритм общего назначения, превосходству человека над машиной, скорее всего, придет конец».
Беспокойство по поводу утраты преимущества человека перед машиной было фоном состязания между Ли Седолем и AlphaGo. Многие в онлайн-комментариях к игре писали, что южнокорейскому профессионалу выпало «вести грандиозный бой с компьютером от имени всего человечества».
Но эксперты считают, что победа в го — игре на двоих с четко заданными правилами — не означает, что пришло время, когда машины возобладают над людьми. «Сегодня искусственный интеллект неплохо справляется со многими когнитивными задачами, которые раньше были под силу только людям, — указал Ходжат. — Но прежде чем он достигнет человеческой мощи абстрактного мышления, пройдут еще годы».
«У нас еще нет машин с искусственным интеллектом общего назначения, который был бы способен решать многие разные задачи, скажем, играть в го, понимать текст, музицировать на скрипке и т. д., — добавила Прекап. — Это следующий рубеж, но мы еще очень далеко от него».
В Microsoft Research недавно сообщили о работе над проектами в области общего интеллекта. Как отметили в корпорации, исследователи, занимающиеся искусственным интеллектом, создали, к примеру, средства распознавания слов, но пока не научились комбинировать навыки с такой же легкостью, как это удается людям.
www.dgl.ru