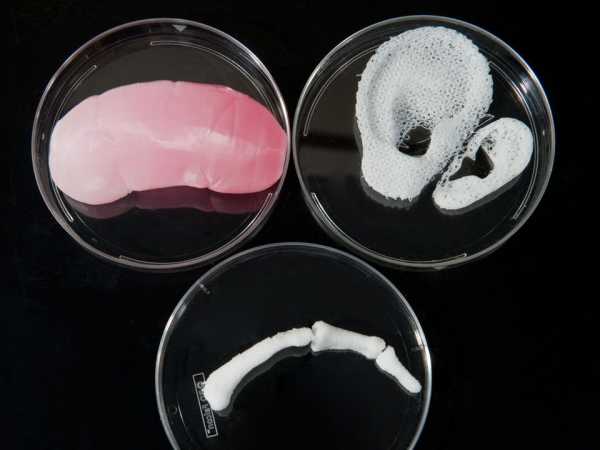
Искусственный интеллект как совокупность вопросов. Хабрахабр искусственный интеллект
что о нем думают ученые / Блог компании 1cloud.ru / Хабр
Сегодня об искусственном интеллекте не пишет только ленивый. Например, в Autodesk считают, что искусственный интеллект может учитывать гораздо больше факторов, чем человек, и, таким образом, давать более точные, логичные и даже более креативные решения сложных проблем. В Оксфордском университете вообще высказывают предположения о том, что искусственный интеллект в недалеком будущем может заменить штатных журналистов и писать за них обзоры и статьи (и того и гляди выиграет Пулитцеровскую премию).
Общее увлечение темой искусственного интеллекта давно вышло за рамки научных конференций и будоражит умы писателей, кинематографистов и широкой общественности. Кажется, что от будущего, в котором роботы (или Скайнет) правят миром или, как минимум, решают большую часть повседневных задач, рукой подать. Но что по этому поводу думают сами ученые?
Для начала стоит разобраться с термином «искусственный интеллект»: слишком много существует на эту тему домыслов и художественных преувеличений. В этом вопросе лучше всего обратиться к автору этого термина (и по совместительству создателю языка Лисп и лауреату множества премий) – Джону Маккарти. В статье с одноименным названием («Что такое искусственный интеллект?») Маккарти приводил следующее определение:
Это наука и технология создания интеллектуальных машин, в особенности – интеллектуальных компьютерных программ. Искусственный интеллект связан с задачей использования компьютеров для понимания работы человеческого интеллекта, но не ограничивается использованием методов, наблюдаемых в биологии. Получается, что искусственный интеллект и интеллект «человеческий» тесно связаны? Не совсем так – сам Маккарти подчеркивал: если интеллект «вообще» – это «вычислительная» составляющая того, что помогает субъекту достигать заданных целей, тогда интеллект человека, животных и машин будет работать по-разному.Выходит, что искусственный интеллект – это не подобие человеческого, хотя многим футуристам, писателям и даже ученым хочется верить в то, что это не так. Об этом часто повторяет Майкл Джордан, почетный профессор Калифорнийского Университета в Беркли. Он считает, что недостаточное понимание того, что же представляет из себя искусственный интеллект, приводит не просто к созданию «красивых образов», не связанных с реальной наукой, а к самой настоящей дезинформации и разного рода мифам, процветающим в этой области.
Миф первый: для создания или усовершенствования искусственного интеллекта надо разобраться с тем, как работает человеческий мозг
Джордан утверждает, что это вовсе не так. Работа искусственного интеллекта, как правило, не имеет ничего общего с тем, как устроен интеллект человека. Этот «миф» глубоко укоренился из-за пристрастия общественности к «красивым идеям»: авторам научно-популярных статей об искусственном интеллекте пришлись очень по душе метафоры, взятые из нейробиологии.
На самом деле нейробиология имеет очень опосредованное отношение (или вообще не имеет никакого отношения) к работе искусственного интеллекта. Для Майкла Джордана идея о том, что «для глубинного обучения нужно понимание того, как обрабатывает информацию и учится человеческий мозг», звучит как откровенная ложь.
«Нейроны», задействованные в глубинном обучении – это метафора (или, выражаясь языком Джордана, вообще «карикатура» на работу мозга), которая применяется только для краткости и удобства. В действительности же работа механизмов того же глубинного обучения гораздо ближе к процедуре построения статистической модели логистической регрессии, чем к работе настоящих нейронов. При этом, никому не приходит в голову для «краткости и удобства» использовать метафору «нейрона» в статистике и эконометрике.
Миф второй: искусственный интеллект и глубинное обучение – последние достижения современной науки
Мнение о том, что «думающие как человек» компьютеры будут сопровождать нас в недалеком будущем, напрямую связано с идеей, согласно которой искусственный интеллект, нейронные сети, глубинное обучение являются достоянием исключительно современной науки. Ведь если допустить мысль о том, что все это было придумано десятилетия назад (а роботы к сегодняшнему дню так и не захватили мир), «порог ожиданий» от научных достижений вообще и скорости их развития в частности придется серьезно снизить.
К сожалению, СМИ стараются сделать все возможное, чтобы подогреть интерес к своим материалам, и очень избирательно относятся к выбору тематик, которые, по мнению редакторов, вызовут интерес у читателей. В итоге описываемые ими достижения и их перспективы оказываются гораздо более внушительными, чем реальные открытия, а часть информации просто «аккуратно опускается», чтобы не снижать накала страстей.
Многое из того, что сейчас преподносят «под соусом» искусственного интеллекта, является просто переработанной информацией о нейронных сетях, которые известны человечеству с 80-х годов.
А в восьмидесятые все повторяли то, что было известно в 1960е годы. Такое чувство, что каждые 20 лет проходит волна интереса к одним и тем же темам. В нынешней волне главной идеей является сверточная нейронная сеть, о которой уже говорили лет двадцать назад – Майкл ДжорданМиф третий: искусственная нейронная сеть состоит из тех же элементов, что и «реальная»На самом деле специалисты, занятые вопросами разработки вычислительных систем, оперируют нейробиологическими терминами и формулировками гораздо смелее, чем многие нейробиологи. Интерес к работе мозга и устройству интеллекта человека стал питательной средой для развития такой теории как «невральный реализм».
В системах искусственного интеллекта нет ни спайков, ни дендритов, более того, принципы их работы далеки не только от работы головного мозга, но и от пресловутого «неврального реализма». Фактически, в нейронных сетях ничего «нейронного» нет.
Более того, идея «неврального реализма», основанная на уподоблении работы систем искусственного интеллекта работе мозга, по мнению Джордана, не выдерживает критики. По его словам, к прогрессу в сфере искусственного интеллекта привел не «невральный реализм», а использование принципов, совершенно не согласующихся с тем, как работает мозг человека.
В качестве примера Джордан приводит популярный алгоритм глубинного обучения, основанный на «обратной передаче ошибки обучения». Его принцип работы (а именно передача сигнала в обратном направлении) явно противоречит тому, как работает человеческий мозг.
Миф четвертый: ученые хорошо понимают, как работает «человеческий» интеллект
И это снова далеко от истины. Как утверждает все тот же Майкл Джордан, глубинные принципы работы мозга не просто остаются нерешенной проблемой нейробиологии – в этой области ученых отделяют от решения вопроса десятки лет. А попытки создать работающую имитацию мозга так же не приближают исследователей к пониманию того, как устроен человеческий интеллект.
На этот вопрос ученые пытаются ответить по-разному. В своей книге «Нейронные сети и глубинное обучение» Майкл Нилсен приводит несколько точек зрения. Например, с позиции коннектомики наш интеллект и его работа объясняются тем, сколько нейронов и глиальных клеток содержит наш мозг, и сколько соединений наблюдается между ними.
Учитывая, что в нашем мозге насчитывается порядка 100 млрд нейронов, 100 млрд глиальных клеток и 100 трлн соединений между нейронами, говорить о том, что мы можем «в точности воссоздать» эту архитектуру и заставить ее работать, в ближайшем будущем крайне маловероятно.
А вот молекулярные биологи, изучающие геном человека и его отличия от близких родственников людей по эволюционной цепочке, дают более обнадеживающие прогнозы: оказывается, геном человека отличается от генома шимпанзе на 125 миллионов пар оснований. Цифра большая, но не бесконечно огромная, что дает Нилсену повод надеяться, что на основании этих данных группа ученых сможет составить если не «работающий прототип», то как минимум сколь бы то ни было адекватное «генетическое описание» человеческого мозга или скорее базовые принципы, лежащие в основе его работы.
Стоит сказать, что Нилсен придерживается «общепринятого человеческого шовинизма» и полагает, что значимые принципы, определяющие работу человеческого интеллекта, лежат в тех самых 125 миллионах пар оснований, а не в остальных 96% генома, которые у человека и шимпанзе совпадают.
Так сможем ли мы создать искусственный интеллект, равный по возможностям человеческому? Получится ли у нас в обозримом будущем понять, как именно работает наш собственный мозг? Майкл Нилсен, считает, что это вполне возможно – если вооружиться верой в светлое будущее и в то, что многие вещи в природе работают по более простым законам, чем это кажется на первый взгляд.
А вот Майкл Джордан дает более близкий к практической работе исследователей совет: не поддаваться на провокации журналистов и не искать «революционные» решения. По его мнению, привязываясь к человеческому интеллекту как отправной точке и конечной цели своих исследований, ученые, работающие над проблемой искусственного интеллекта, излишне ограничивают себя: интересные решения в этой области могут лежать в направлениях, никак не связанных с тем, как устроен наш мозг (и как нам представляется его устройство).
P.S. Мы в 1cloud рассматриваем самые разные темы в нашем блоге на Хабре – пара примеров:
И рассказываем о собственном облачном сервисе:habr.com
Искусственный интеллект как совокупность вопросов / Хабр
 Когда мы рассуждаем о сильном искусственном интеллекте, то мы понимаем, что это не изолированный вопрос, не вещь в себе, а вопрос ответ на который подразумевает объяснение всех явлений, которые связаны с мышлением человека. То есть, ответив на вопрос о природе интеллекта, мы неизбежно должны будем ответить на такие вопросы как:
Когда мы рассуждаем о сильном искусственном интеллекте, то мы понимаем, что это не изолированный вопрос, не вещь в себе, а вопрос ответ на который подразумевает объяснение всех явлений, которые связаны с мышлением человека. То есть, ответив на вопрос о природе интеллекта, мы неизбежно должны будем ответить на такие вопросы как: - Что есть информация?
- Как мозг представляет знания?
- Что такое язык?
- Какова роль языка в мышлении?
- Как совершаются поступки?
- Как осуществляется планирование?
- Какова природа фантазий и воспоминаний?
- Что такое мотивация?
- Какова природа эмоций?
- Откуда берется многообразие эмоциональных оценок?
- Что есть смысл?
- Как рождается мысль и какова ее природа?
- Что такое внимание?
- Что есть любовь?
- Что есть гармония и красота?
Основное мнение относительно современного состояния поисков природы мышления, которое, кстати, сформировано не столько учеными, а в основном популяризаторами, желающими разобраться в проблеме, — это, что: «Мы многое знаем о физиологии мозга, существует огромная теория нейронных сетей и нейросетевого управления, есть множество психологических теорий, опирающихся на абстрактное представление о мозге, но при этом пока не существует объяснения тайны мышления, объяснения механизма того как именно мозг оперирует информацией и какие именно процессы ответственны за способность мыслить». К этому иногда добавляется утверждение — вариация парадокса «китайской комнаты», что: «создание сильного ИИ принципиально невозможно без моделирования биологического сознания». А это приводит к рассуждениям, что ко всем «рациональным» моделям надо относиться только, как к попыткам смоделировать некую «техническую» часть мозга, и не стоит ожидать от них полной разгадки главной тайны. Но так ли это?
Огромное количество очень неглупых людей пытались дать ответы на поставленные выше вопросы. Существует множество неплохих теорий. Правда, сложность в том, что многие из этих теории существуют изолированно, не пытаясь состыковаться с ответами на другие вопросы. Причина сложности понятна: вопросы относятся к разным научным дисциплинам, а играть на чужом поле тяжело, как минимум в силу различия терминологии. То есть для каждого вопроса есть множество вариантов ответов, среди которых возможно есть и правильные, но нужна концепция, вписывающаяся в известные данные о строении реального мозга, которая позволит в каждой области выбрать «стыкующиеся» с остальными теории.
Так вот самое интересное, что и такая концепция, и ответы на все приведенные вопросы все это уже есть и, как это не странно звучит, но вопрос о создании сильного ИИ во многом идеологически уже понятен. Оставшиеся вопросы носят скорее технический характер и относятся больше к алгоритмам реализации.
Я подготовил несколько лекций, которые позволяют проникнуться пониманием основных принципов и перейти, как я надеюсь, на новый уровень понимания вопросов ИИ. К сожалению, получилось долго, очень долго, но множество великих умов успело поработать над вопросом и если короче, то выходит или совсем непонятно, или слишком сильно рвется логика рассуждений. Обязательное условие — если слушать, то последовательно. Бесполезно начинать с середины, ища ответ на интересующий вопрос, поймете слова и интонацию, но гарантировано упустите или поймете превратно главные мысли. Даже если вам кажется, что какая-то тема вам знакома, не перематывайте, — моя задача была не объяснить еще раз общеизвестные принципы, а заострить внимание на тех глобальных идеях, что стоят за ними.
Общее название цикла: «Логика мышления». Часть 1. Вступление о сильном ИИ. Бихевиоризм. Персептрон Розенблатта и его связь с идеями бихевиоризма. Обучение с подкреплением. Оценка качества ситуации как сигнал подкрепления. Адаптивные критики. Q и V критики. Мотивация. Модели явной и неявной мотивации. Строение мозга. Кора. Работа коры на примере первичной зрительной коры. Неокогнитрон Фукушимы, как модель зрительной коры. Обобщение. Аналогия с факторным анализом. Суть обобщения.
Плейлист
habr.com
Еще раз про искусственный интеллект / Хабр

Источник
У порога встали горы громадно, Я к подножию щекой припадаю. И не выросла еще та ромашка, На которой я себе погадаю.
Роберт Рождественский
Искусственный интеллект (ИИ) или же Artificial Intelligence (AI) — быстроразвивающаяся технология, о которой стоит говорить даже чаще, чем это делают сегодня. Она стремительно развивается вместе с такими дополняющими друг друга технологиями, как нейронные сети и машинное обучение (к которым в последнее время подключился Интернет вещей – IoT), и, по слухам, даже собирается захватить весь мир. Причем с нашей непосредственной помощью. О ней непрерывно говорят и пишут, пишут и говорят. ИИ уже применяется в сложном моделировании, в играх, в медицинской диагностике, в поисковых движках, в логистике, в военных системах и много где еще, обещая в обозримом будущем охватить и, возможно, основательно «перелопатить» весь постиндустриальный ландшафт. И он даже начал писать литературные произведения вроде вот таких: «Давным-давно жила-была золотая лошадь с золотым седлом и красивым фиолетовым цветком в волосах. Лошадь принесла цветок в деревню, где принцесса пустилась в пляс от мысли о том, как красиво и хорошо выглядит лошадь».
Что можно сказать? — Лошади, они такие. Да и принцессы обретаются, как известно, больше по деревням… Однако ИИ имеет способность обучаться в отличие от пришедшего на ум от приведенных выше строк незабвенного Ляписа Трубецкого из Ильфа и Петрова. «Первый блин комом» бывает не только в литературе, поэтому и всем остальным почитателям ИИ стоит к нему также приготовиться.
И еще ИИ – это мантра, которую раз от раза повторяют технологи, академики, журналисты и венчурные капиталисты для привлечения внимания как к проблемам человечества, так и к себе, любимым. Одни специалисты в лице известных представителей науки и бизнеса, как Стивен Хокинг, Билл Гейтс и Элон Маск не так давно беспокоились по части будущего ИИ, поскольку дальнейшее развитие ИИ-технологий может приоткрыть «ящик Пандоры», когда ИИ станет доминирующей формой «жизни» на нашей планете. Другие специалисты озабочены разработкой этических норм, дабы обуздать разрушительную силу ИИ (впрочем, ИИ пока еще ничего не разрушил), направив ее на служение общему благу цивилизации.
А вот Пентагон, к примеру, уже решил, что ИИ – это ключевое направление, в которое необходимо вложить максимум усилий, чтобы не дать Китаю и России вырваться вперед. В связи с этим в США под руководством министра обороны создается соответствующий центр ИИ.
В настоящее время значительная часть того, что в публичной сфере называется ИИ, является лишь так называемым «машинным обучением» (МL – Machine Learning). В частности, с помощью технологии Big Data ML позволяет компьютерной программе обучаться на всех собранных данных и выдавать предсказания/прогнозы с растущей по мере обучения точностью для использования при автоматическом (или под контролем человека) принятии решений. В целом ML – это алгоритмическое поле, объединяющее идеи из статистики, информатики и многих других дисциплин для разработки алгоритмов, которые позволяют делать указанное выше.
Кстати, ML родилось не сегодня. Его роль в промышленности была в целом понятна еще в начале 1990-х годов, и к концу ХХ века такие перспективные компании, как Amazon, уже использовали ML во всем своем бизнесе, решая критически важные проблемы с обнаружением мошенничества, прогнозированием логистических цепочек или созданием рекомендаций потребителям. По мере того, как объемы данных и вычислительные ресурсы компьютеров быстро возрастали в течение последующих двух десятилетий, стало ясно, что вскоре ML будет управлять не только Amazon, но и практически любой компанией, в которой решения могут быть привязаны к крупномасштабным данным. По мере того, как специалисты в области алгоритмов ML сотрудничали со специалистами в области баз данных и распределенных систем для создания масштабируемых и надежных систем ML, раздвигались шире социальные и экологические границы полученных систем. Сегодня именно это слияние идей и технологических тенденций и называется ИИ.
С другой стороны, исторически сложилось так, что термин AI появился еще в конце 1950-х годов, чтобы на взлете появившихся идей по части развития кибернетики (по большей части там, где она не считалась «лженаукой») окунуться в столь пьянящее душу ученого стремление реализовать в программном и аппаратном обеспечении сущность с интеллектом, приближенном к интеллекту человека. Революция представлялась такой близкой, и искусственная разумная сущность должна была казаться одной из нас, если не физически, по крайней мере, мысленно. Новый термин сразу же подхватили писатели-фантасты, но в реальной жизни у творцов «новых сущностей» успехи не особо приближались к успехам Господа или же просто Природы (как принято говорить у атеистов).
В те далекие времена термин ИИ использовался на «высоком уровне», приближающемся к способности людей «рассуждать» и «думать». Как отмечают специалисты, несмотря на то, что с тех пор прошло почти 70 лет, все те былые высокоуровневые рассуждения и идеи по-прежнему остаются неуловимыми и не получили какого-либо программно-аппаратного воплощения. В отличие от восторженных прошлых ожиданий весь сегодняшний «реальный» ИИ в основном сформировался в областях техники, связанных с низкоуровневым распознаванием образов и управлением движением. И частично в области статистики в отношении дисциплин, ориентированных на поиск шаблонов данных и на создание логически связанных с ними прогнозов. То есть столь давно ожидаемой революции в области ИИ пока еще не случилось.
Впрочем, в отличие от человеческого мозга, поверх которого существует и наш интеллект, ИИ не зависит от атомов углерода, белковой жизни и всяческих эволюционных ограничений. Благодаря этому он способен непрерывно обучаться и совершенствоваться, и, в конце концов, он позволит человечеству решить массу насущных проблем — от климатических изменений до онкологических заболеваний. Такого мнения придерживается, в частности, Макс Тегмарк, физик из MTI и сооснователь так называемого «Института будущего человечества». В интервью изданию The Verge Тегмарк представил свое видение трех эволюционных форматов жизни (на нашей планете).
Жизнь 1.0 характерна для бактерий, которых Тегмарк называет «небольшими атомами, соединенными вместе в простейший алгоритм саморегулирования». Бактерии не способны освоить ничего нового в течение своей жизни, а механизмы их работы крайне примитивны – они могут только поворачиваться в ту сторону, где больше еды. В свою очередь, развитие их «программного обеспечения» (современные ученые теперь легко разделяют все сущее на ПО и «железо») возможно только в рамках эволюционных изменений.
Жизнь 2.0 воплощается в людях. И, несмотря на то, что человек также обладает жестко заданным и ограниченным эволюцией телом — «железом», он также обладает серьезным преимуществом в виде более совершенного разума – «программного обеспечения», которое позволяет ему учиться самостоятельно. Благодаря способности совершенствовать свое программное обеспечение по собственному усмотрению, приобретая знания и не дожидаясь эволюционного развития, люди начали доминировать на этой планете, создали современную цивилизацию и культуру. Тем не менее, несмотря на все преимущества, у нашего совершенствования есть предел. Именно поэтому со временем жизнь 2.0 будет вытеснена менее ограниченной жизнью 3.0 (учитывая сказанное немного выше, делать подобные заявления было бы несколько опрометчивым).
Жизнь 3.0 характеризуется тем, что в ней не существует не только эволюционных, но и биологических ограничений. ИИ, в отличие от предыдущих форматов, будет способен развивать как свое ПО, так и «железо». Например, установить в себя больше памяти, чтобы запоминать в миллион раз больше информации или получить большую вычислительную мощь (кстати, было бы интересно посмотреть – нет ли у Тегмарка где-нибудь за ухом USB-разъема). В отличие от жизни 3.0, мы, довольствующиеся жизнью 2.0, – хотя и можем поддерживать собственное сердцебиение при помощи кардиостимуляторов или облегчить пищеварение таблеткой – не в состоянии внести в свои тела кардинальные изменения. Ну, разве что небольшую коррекцию с помощью пластических хирургов или вживления чипов. Нам не дано серьезно увеличить свой рост или в тысячу раз ускорить мышление в собственном мозге. Человеческий интеллект работает на биологических нейронных связях, причем объем нашего мозга ограничен таким образом, чтобы при рождении голова могла пройти через родовое отверстие матери. ИИ же ничем не ограничен и может совершенствоваться бесконечно – поясняет ученый.
Впрочем, похоже, что Тегмарк как-то не учитывает прогресс в генетическом проектировании – неровен час, люди таки научатся корректировать свои тела, чтобы отрастить длинные ноги, цепкие щупальца, увеличить родовое отверстие или добавлять ума тем, кому его катастрофически не хватает.
Тегмарк отмечает, что многие люди сегодня воспринимают разум как загадочное свойство биологических организмов. Однако, по его словам, эти представления ошибочны. «С точки зрения физика, разум — это всего лишь обработка информации, которую выполняют элементарные частицы, движущиеся по определенным физическим законам», – говорит он. Законы физики никак не препятствуют созданию машин, намного превосходящих человека по интеллекту (хорошо бы при этом поточнее знать – что же такое интеллект). Помимо этого, подчеркивает Тегмарк, нет никаких свидетельств в пользу того, что разум зависит от наличия органической материи:
«Я не думаю, что есть какой-то секретный соус, в котором обязательно должны присутствовать атомы углерода и кровь. Я много раз задумывался, каким может быть предел интеллекта с точки зрения физики, и каждый раз приходил к выводу, что если такой предел и существует, то мы от него находимся очень и очень далеко. Мы даже не можем его вообразить. Тем не менее, я уверен, что именно человечество вдохнет во Вселенную то, что впоследствии станет жизнью 3.0 – и это, с моей точки зрения, звучит очень романтично».
В ответ хочется не менее романтично добавить – а нас туда с нашим ИИ со всеми так сказать нашими «трещинками» звали? Что касается «трещинок». Если жизнь 3.0 не будет знать ограничений, то неплохо бы узнать, в каких именно: в обмане, в безразличии, в подлости? А, быть может, в возможности убивать? Точно такие же проблемы регулярно встают перед отдельными представителями рода человеческого, которые раз за разом поддаются искушению.
«Мы сталкиваемся с ограничениями нашего разума каждый раз, когда проводим то или иное исследование. Именно поэтому я полагаю, что как только нам удастся объединить наш собственный ум с ИИ, перед нами откроются огромные возможности по решению практически всех проблем», – утверждает Тегмарк, а проблем, как мы знаем, у людей бывает много. Ну что же. Для этого не нужно, как говорится, далеко ходить. За последние 20 лет как в промышленности, так и в научных кругах наблюдался значительный прогресс в создании так называемого «усиления интеллекта» или IA (Intelligence Amplification). В этом случае вычисления и данные используются для создания служб, которые дополняют человеческий интеллект и творчество. Поисковая система тоже может рассматриваться как пример IA (она увеличивает человеческую память и фактические знания), а также естественный перевод языка (он увеличивает способность человека общаться). Генерация звуков и изображений служит палитрой и усилителем творчества для художников. В то время как услуги такого рода могут, вероятно, включать в себя высокоуровневые рассуждения и идеи, в настоящее время этого не происходит. В основном все сводится к выполнению различных сопоставлений наборов данных с шаблонами или числовых операций. Возможно, мы еще увидим какие-нибудь облачные сервисы типа InaaS (Intellect-as-a-Service), помогающие пользователю поумнеть в разных областях знаний, но это будет лишь развитием поисковых систем, но ни в коем случае не заменой человеческого интеллекта.
Существует также такая «умная» вещь, как «интеллектуальная инфраструктура» (II – Intelligent Infrastructure), в которой сосуществуют сети вычислений, данных и физических объектов и которая начинает появляться в таких областях, как транспорт, медицина, торговля и финансы. Все это имеет огромное значение для отдельных людей и сообществ. Иногда понятие II возникает в разговорах об интернет-вещах, но обычно это относится к простой проблеме получения «вещей» в Интернете, а не к решению значительного набора проблем, связанных с этими «вещами», чтобы анализировать потоки данных, обнаружить их связи с внешним миром и взаимодействовать с людьми и другими «вещами» на гораздо более высоком уровне абстракции, чем просто биты. В общем, IA и II – это еще не «настоящий» ИИ.
А что есть «настоящий» интеллект? Надо ли именно его имитировать в рамках создания ИИ? Конечно, человеческий интеллект – это единственный вид интеллекта, который нам известен. Но мы знаем и то, что на самом деле люди не очень хорошо разбираются в некоторых суждениях: у нас есть свои упущения, предвзятости и ограничения. Бывает, люди ошибаются. Более того, критически мы не эволюционировали для того, чтобы выполнять виды широкомасштабного принятия решений, с которыми сталкиваются современные системы, уготованные на роль ИИ. Разумеется, можно сколько угодно рассуждать о том, что система ИИ не только подражает человеческому интеллекту, но и дополняет, исправляет его, а потом будет еще и масштабироваться до решения сколь угодно больших проблем, стоящих перед человечеством. Но, извините, это уже из области научной фантастики. И подобные умозрительные аргументы, вот уже 70 лет питающие художественную литературу, не должны становиться основной стратегией формирования ИИ. Очевидно, ИА и II будут и дальше развиваться, решая свои частные задачи, но без претензии на то, чтобы стать «настоящим» ИИ. Пока еще мы очень далеки хотя бы от реализации «человекоподражательного» ИИ.
К тому же успех в ИА и II не является ни достаточным, ни необходимым для решения важных проблем ИИ. Если обратиться к беспилотным автомобилям, то для реализации подобной технологии необходимо будет решить ряд технических проблем, которые могут иметь совсем мало отношения к компетенциям человека. Интеллектуальная транспортная система (а это система II), скорее всего, будет в большей степени напоминать существующую систему управления воздушным движением, чем популяция слабо связанных, ориентированных на собственные цели и в целом невнимательных людей-водителей. Точнее, она будет намного сложнее, чем нынешняя система управления воздушным движением хотя бы в части использования огромных объемов данных и адаптивного статистического моделирования для информирования о частных решениях по каждому маневру каждого автомобиля.
Вместе с тем, несмотря на в целом оптимистичный настрой по части будущего ИИ, специалисты признают, что ИИ несет серьезные риски. Помнится, Стивен Хокинг и др. полагали, что ИИ станет или самым худшим, или самым лучшим явлением в истории человечества. К тому же, когда люди говорят о нынешней тотальной автоматизации рабочих мест, они часто забывают, что намного важнее заглянуть вперед, чтобы понять, что будет дальше.
По этому поводу Тегмарк сказал: «Дело в том, что сегодня перед нами стоят вопросы, на которые мы должны дать ответ прежде, чем на свет появится первый суперинтеллект. Причем эти вопросы довольно сложны, возможно, ответить на них мы сможем не ранее, чем через 30 лет. Но как только мы их разрешим, то сможем обезопасить себя от угроз». «Как мы сможем обеспечить надежность будущих систем ИИ, когда сегодня наши компьютеры очень легко взламываются? Как сделать так, чтобы ИИ понимал наши цели, если он станет умнее нас? Какими должны быть цели у самого ИИ? Сможет ли искусственный разум выработать перед собой высокие задачи, на которые сегодня уповают многие американские программисты, или ИИ вдруг станет мыслить, как сторонник запрещенного в РФ ИГ или человек из Средних веков? Как изменится наше общество после изобретения ИИ? – Когда ваш компьютер зависает, вы начинаете нервничать, потому что потеряли час работы. Но представьте, что речь идет о бортовом компьютере самолета, на котором вы летите, или о системе, отвечающий за ядерный арсенал в США – вот это уже в разы страшнее».
А вот кто, к примеру, должен отвечать, если ИИ или вооруженным им робот совершат действие, причинившие людям вред? Это действие может быть случайным, но это один из многих встающих перед обществом вопросов об автономии и ответственности ИИ, когда его наиболее продвинутые формы, скажем, самоуправляемые автомобили (возможно, первые роботы, которым мы учимся доверять), дроны или даже средства ведения войны, получают все более широкое распространение. Специалисты по ИИ и праву пытаются это понять, однако не видят простого ответа. В любом случае вопрос остается юридически трудным. Как, например, разделить зоны ответственности программиста и владельца, учитывая, что роботы и ИИ обучаются из окружающей их среды?
По словам Тегмарка, чтобы нивелировать исходящие от ИИ риски, надо чаще устраивать дискуссии. Причем в дискуссиях должны принимать участие все слои общества, а не только «повернутые» на ИИ ученые. Ведь ИИ обещает изменить саму сущность нашей цивилизации и затронет жизни буквального каждого человека. Пусть каждый человек и участвует. И что интересно – сегодня в исследования ИИ вкладывают миллиарды, при этом изучения его безопасности практически не финансируются. Кто стал бы строить ядерный реактор, не спроектировав предварительно его защиту? Очевидно, что все бы выиграли, если бы государства и корпорации стали больше вкладывать денег в исследования на тему безопасности ИИ. И тогда у нас что-нибудь получится.
А теперь рассмотрим идеальное информационное общество, в котором окружающая среда увешана датчиками, которые исправно передают адекватную информацию и их никто не «хакает» (в смысле, этому никто не мешает). И вот этот огромный окружающий мир поставляет в нашу высокотехнологичную компанию огромный поток данных, который в реальном времени обрабатывается в ЦОДах, преобразуется, визуализируется и пр., чтобы предстать в «человекочитаемом» виде. И потом человек, которому предназначена эта информация, напрягая мозги, смотрит на все это и принимает операционное решение, которое он транслирует другому человеку, воплощающему это решение в некий в код. Далее этот оптимизированный код управляет производством, компанией или даже государством, и далее производство и пр. начинает улучшать что-то в окружающем мире и так далее.
А вам не кажется, что в истории про ИИ появилось слабое звено, и человек становится просто лишним? Специалисты отмечают, что хорошо «обученный» алгоритм уже сегодня в состоянии сам принимать операционные решения, особенно в более или менее повторяющемся производственном процессе. Причем может делать это гораздо лучше любого самого опытного технолога (не говоря уже о начальнике транспортного цеха), который, к примеру, «жизнь и здоровье положил» на то, чтобы хорошо управлять тем самым производственным процессом. И получается, что наличие человека в цепи принятия решений попросту непрактично. То есть, еще не построив «настоящий» ИИ, человечество уже начинает осознавать собственную ненужность в ряде известных процессов. То ли еще будет, когда появится «настоящий» или «классический» ИИ… Посчитает ли этот ИИ нужным кормить миллионы и даже миллиарды ненужных бездельников на «белковой тяге»? Ведь питающиеся электричеством роботы не нуждаются в сельском хозяйстве, жилье, переработке бытового мусора, отоплении, водоснабжении и пр. и пр. Тут и без ИИ легко сообразить, на чем целесообразно сэкономить. Кто-нибудь кроме писателей-фантастов просчитал такие риски?
Возможно, когда-нибудь какие-нибудь беспроводные технологии и облачные сервисы позволят наделить интеллектом кого угодно. И тогда все вокруг станут умные и образованные. Только это будет уже никому не нужно. ИИ вам заявит, что, мол, ваш поезд, товарищи люди, уже ушел. Что же останется нам? – Ну, хотя бы песня:
Я мечтала о морях и кораллах. Я поесть мечтала суп черепаший. Я шагнула на корабль, а корабликОказался из газеты вчерашней…
По материалам: radio.ru, The Verge, hightech.fm, vz.ru, anews.com, pcweek.ru, medium.com, Defense News
Александр Голышко, к.т.н., системный аналитикhabr.com
Вас атакует искусственный интеллект / Блог компании Positive Technologies / Хабр

В конце прошлого года “искусственный интеллект” многократно упоминали в итогах и прогнозах IT-индустрии. И в нашу компанию, которая занимается информационной безопасностью, всё чаще стали присылать из различных изданий вопросы про перспективы AI. Но эксперты по безопасности не любят комментировать эту тему: возможно, их отталкивает именно эффект “жёлтой прессы”. Легко заметить, как возникают такие вопросы: после очередной новости типа “Искусственный интеллект научился рисовать как Ван Гог” журналисты хватаются за горячую технологию и идут опрашивать по ней всех подряд – а чего может достичь AI в животноводстве? А в сфере образования? Где-то в этом списке автоматически оказывается и безопасность, без особого понимания её специфики.
Кроме того, журналистика, щедро подкормленная IT-индустрией, обожает рассказывать о достижениях этой индустрии в рекламно-восхищенных тонах. Именно поэтому СМИ прожужжали вам все уши о победе машинного интеллекта в игре Го (хотя от этого нет никакой пользы в реальной жизни), но не особенно жужжали о том, что в прошлом году погибло уже как минимум два человека, которые доверили свою жизнь автопилоту автомобиля Tesla.
В этой статье я собрал некоторые наблюдения об искусственном интеллекте с эволюционной точки зрения. Это необычный подход, но как мне кажется, именно он лучше всего позволяет оценить роль AI-агентов в безопасности, а также безопасность AI в других сферах.
Среда и адаптация
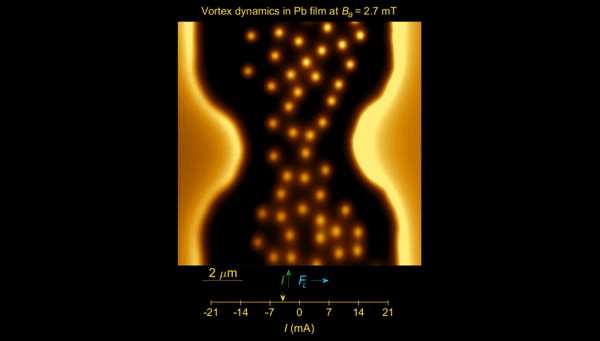
Практически любая новость об искусственном интеллекте рассказывает про повышение уровня самостоятельности машин: “компьютер обыграл...”, “нейронная сеть научилась...”. Это напоминает описания лабораторных опытов с животными. Однако в изучении поведения животных учёные давно пришли к необходимости исследований в естественной среде, поскольку именно среда и адаптация к ней формируют многие свойства организмов, неочевидные и невостребованные в лабораториях.Точно так же перспективы AI станут понятней, если вместо “идеального коня в вакууме” повнимательнее изучить среды, где AI обитает. И заметить, насколько различаются его успехи в зависимости от среды. Попытки создания машинных переводчиков длятся более полувека, на них потрачены миллиарды долларов – но всё равно для перевода с китайского вы скорее наймёте переводчика-человека, чем будете доверять программе. С другой стороны, боты для высокочастотного трейдинга, которые появились где-то в 2006 году, всего через пару лет стали играть серьёзную роль в экономических кризисах. Эти роботы просто оккупировали ту цифровую среду, в которой они чувствуют себя как рыбы в воде – то есть гораздо лучше, чем люди.
Не менее удобная цифровая среда создана для автоматизации хакерских атак: множество устройств с множеством стандартных уязвимостей внезапно объединились в общедоступный океан благодаря Интернету. Как показал опыт прошлого года, чтобы захватить миллион камер безопасности и построить из них ботнет, программе достаточно обладать минимальным интеллектом. Но только… если она одна. Следующая версия ботнета Mirai, захватившая ресурсы предыдущей, оказалась уже посложней. Так включается ещё один движок эволюции – конкуренция.

Гонка вооружений и “смешанная техника”
Удивительно, но большинство академических исследований в области AI игнорировали тот факт, что интеллект вообще – это результат жестокой битвы за выживание. Целые десятилетия теоретические “когнитивные науки” без особого успеха пытались моделировать то, что активно росло где-то рядом, в противостоянии вредоносных программ и систем безопасности.Если вы почитаете в “Википедии” определение дисциплины Artificial Life, то не найдёте там ни слова про компьютерные вирусы – хотя они демонстрируют всё то, что эта дисциплина пытается моделировать аж с семидесятых годов. У вирусов есть адаптивное поведение (разные действия в разных условиях, умение обманывать “песочницы” и отключать антивирусы), есть самовоспроизведение с мутациями (так что сигнатуры родителей становятся бесполезны для ловли отпрысков), есть мимикрия (маскировка под легальные программы) и много ещё чего. Если уж где искать искусственную жизнь – то она именно здесь.
Помогает ли это встречному развитию интеллекта защитных систем? Конечно. Особенно если учесть, что с ними воюют не только вирусы, но и коллеги-безопасники. Например, компания Google последние два года регулярно ломает антивирусы (чужие, конечно же). Уязвимости в системах защиты находили и раньше, но благодаря Google антивирусные продукты уже начинают восприниматься как угроза. Можно предположить, что глобальный поисковик зачищает поляну, чтобы выкатить собственные продукты в области безопасности. А может уже и выкатил, но не для всех.
Здесь самое время произнести волшебные слова “машинное обучение” и “поведенческий анализ” — ведь именно такими технологиями может отличиться Google, который контролирует огромные потоки данных (индексация сайтов, почта, браузер и т.д.). Однако и эти технологии в безопасности развиваются несколько иначе, чем в академических игрушках AI.
Посмотрим для начала на когнитивные науки, которые я обвинил в тормозах. Более полувека в исследованиях поведения животных и людей шёл спор “бихевиористов” и “этологов”. Первые, преимущественно американские учёные, утверждали, что поведение – лишь набор рефлексов, реакций на окружающую среду; наиболее радикальные из них исповедовали принцип tabula rasa в отношении обучения, заявляя, что могут превратить любого новорожденного в представителя любой заданной профессии, поскольку его сознание – чистый лист, куда надо просто записать правильные инструкции. Второе направление, этология, возникло среди европейских зоологов, которые настаивали на том, что многие сложные паттерны поведения являются врожденными, и для их понимания нужно изучать устройство и эволюцию организма – то, чем вначале занималась сравнительная анатомия, а затем нейробиология и генетика.
Именно эти две группы спорящих определили академические направления развития искусственного интеллекта. Сторонники нисходящего AI пытались описать весь мир “сверху вниз”, в виде символьных правил реагирования на внешние запросы – так появились экспертные системы, диалоговые боты, поисковики. Сторонники восходящего подхода строили низкоуровневые “анатомические” модели – перцептроны, нейронные сети, клеточные автоматы. Какой подход мог победить в США в эпоху процветания бихевиоризма и идеи сознания как “чистого листа”? Конечно, нисходящий. Лишь ближе к концу XX века восходящие реабилитировались.
Однако на протяжении десятилетий в теориях AI почти не развивалась идея о том, что лучшая модель интеллекта должна быть “смешанной”, способной применять разные методы. Такие модели стали появляться только в конце XX века, причём опять-таки не самостоятельно, а вслед за достижениями естественных наук. Свёрточные нейронные сети возникли после того, как выяснилось, что клетки зрительной коры кошки обрабатывают изображения в две стадии: сначала простые клетки выявляют простые элементы образа (линии под разными углами), а затем на других клетках происходит распознавание изображения как набора из этих простых элементов. Без кошки, конечно, нельзя было догадаться.
Ещё один яркий пример – метания Марвина Мински, который в 50-е годы стал создателем теории нейронных сетей, в 70-е разочаровался в них и подался к “нисходящим”, а в 2006 году покаялся и выпустил книгу The Emotion Machine, где разругал рациональную логику. Неужели до этого люди не догадывались, что эмоции – это другой, не менее важный вид интеллекта? Конечно, догадывались. Но чтобы сделать из этого уважаемую науку, им понадобилось дождаться появления MRT-сканнеров с красивыми картинками. Без картинок в науке – никак.
А вот эволюция через гонку вооружений в дикой среде Интернета идёт значительно быстрее. Межсетевые экраны уровня приложений (WAF) появились совсем недавно: гартнеровский рейтинг Magic Quadrant для WAF выпускается только с 2014 года. Тем не менее, уже на момент этих первых сравнительных исследований оказалось, что некоторые WAF используют сразу несколько “разных интеллектов”. Это и сигнатуры атак (нисходящий символьный интеллект), и поведенческий анализ на основе машинного обучения (строится статистическая модель нормального функционирования системы, а затем выявляются аномалии), и сканнеры уязвимостей для проактивного патчинга (этот вид интеллекта у людей называется “самокопание”), и корреляция событий для выявления цепочек атак во времени (кто-нибудь в академических разработках AI строил интеллект, способный работать с концепцией времени?). Осталось добавить сверху ещё какой-нибудь “женский интеллект”, который будет сообщать об атаках приятным голосом – и вот вам вполне реалистичная модель человеческого разума, как минимум в плане разнообразия способов мышления.

Имитация и ко-эволюция
Выше было сказано, что теоретики AI сильно зависели от веяний когнитивных наук. Ну ладно, они не интересовались компьютерными вирусами – но может быть, вместо этого они научились хорошо имитировать человека, по заветам великого Тьюринга?Едва ли. Уже много лет различные визионеры обещают, что рекламные системы, собрав наши персональные данные, вкусы и интересы, начнут довольно точно предсказывать наше поведение – и получать всякие выгоды от такой прозорливости. Но на практике мы видим, что контекстная реклама целый месяц показывает нам вещь, которую мы уже давно купили, а Facebook скрывает письма, которые на самом деле являются важными.
Означает ли это, что человек очень сложен для имитации? Но с другой стороны, один из главных трендов года – множество серьёзных атак на основе банального фишинга. Многомиллионные потери банков, утечка переписки крупных политиков, заблокированные компьютеры метро Сан-Франциско – всё начинается с того, что один человек открывает одно электронное письмо. Там нет никакой имитации голоса или логичного диалога, никакой нейронной сети. Просто одно письмо с правильным заголовком.
Так может, для более реалистичной картины мира стоит переписать тьюринговское определение с точки зрения безопасности? — давайте считать машину “мыслящей”, если она может обокрасть человека. Да-да, это нарушает красивые философские представления об интеллекте. Зато становится понятно, что имитация человека на основе его прошлого опыта (поисковые запросы, история переписки) упускает из виду множество других вариантов. Человек может заинтересоваться вещами, которые задевают самые базовые всеобщие ценности (эротика) — или наоборот, включают любопытство в отношении редких явлений, вообще не встречавшихся в прошлом опыте этого человека (победа в лотерее).
Кстати, многие фантасты чувствовали, что из всех вариантов “игры в имитацию” наибольшего внимания стоит именно та, которая связана с безопасностью. Не так уж важно, что у Филипа Дика андроидов вычисляли по неправильной эмоциональной реакции (это можно подделать), а у Мерси Шелли – по неумению написать хайку (этого и большинство людей не умеют). Важно, что это была игра на выживание, а не просто подражание. Сравните это с расплывчатыми целями контекстной рекламы – включая такую великую цель, как “освоить заданный бюджет, но при этом дать понять, что этого мало”. И вы поймёте, почему искусственный интеллект рекламных систем не торопится развиваться, в отличие от систем безопасности.
И ещё один вывод, который можно сделать из успешности фишинговых атак — совместная эволюция машин и людей влияет на обе стороны этого симбиоза. Боты пока с трудом говорят по-человечески, зато у нас уже есть сотни тысяч людей, которые всю жизнь говорят и думают на машинных языках; раньше этих бедняг честно называли “программистами”, теперь их политкорректно маскируют под словом “разработчики”. Да и остальные миллионы граждан, подсев на машинные форматы мышления (лайки, смайлы, теги), становятся более механистичны и предсказуемы — а это упрощает техники влияния.
Более того, замена разнообразного сенсорного опыта на один шаблонный канал коммуникации (окно смартфона с френдлентой Фейсбука) ведёт к тому, что внушить человеку чужой выбор становится проще, чем вычислять его собственные вкусы. В начале прошлого века Ленину приходилось часами вживую выступать с броневика для убеждения народных масс, которые считались “неграмотными” — но сегодня такой же эффект на грамотных людей оказывают банальные спам-боты в социальных сетях. Они не только разводят граждан на миллионы долларов, но и участвуют в государственных переворотах – так что агентство стратегических исследований DARPA уже воспринимает их как оружие и проводит конкурс по борьбе с ними.
И вот что забавно: в конкурсе DARPA методы защиты предполагают гонку вооружений в той же электронной среде социальных сетей, словно такая среда является неизменной данностью. Хотя это как раз тот случай, который отличает нас от животных: люди сами создали цифровую среду, в которой даже простые боты легко дурят человека. А значит, мы можем проделать и обратный трюк в целях безопасности. Высуши болото, вымрут и малярийные комары.
Возможно, такой подход покажется кому-то архаичным – дескать, автор предлагает отказаться от прогресса. Поэтому приведу более практичный пример. В прошлом году появилось несколько исследований, авторы которых используют машинное обучение для подслушивания паролей через «сопутствующие» электронные среды – например, через флуктуации сигнала Wi-Fi при нажатии клавиш, или через включенный рядом Skype, позволяющий записать звук этих самых клавиш. Ну и что, будем изобретать в ответ новые системы зашумления эфира? Едва ли. Во многих случаях эффективнее будет вырубить лишний «эфир» на момент идентификации, да и самую идентификацию по паролю (простой машинный язык!) заменить на нечто менее примитивное.

Паразиты сложности и AI-психиатры
Поскольку в предыдущих строках я принизил AI до простых социоботов, теперь поговорим об обратной проблеме — о сложности. Любую новость об умных нейронных сетях можно продолжить шуткой о том, что их достижения никак не относятся к людям. Например, читаем заголовок “Нейронная сеть научилась отличать преступников” — и продолжаем “… а её создатели не научились”. Ну в самом деле, как вы можете интерпретировать или перенести куда-то знания, которые представляют собой абстрактные весовые коэффициенты, размазанные по тысячам узлов и связей нейросети? Любая система на основе такого машинного обучения – это “чёрный ящик”.Другой парадокс сложных систем состоит в том, что они ломаются простыми способами. В природе это с успехом демонстрируют различные паразиты: даже одноклеточное существо вроде токсоплазмы умудряется управлять сложнейшими организмами млекопитающих.
Вместе эти два свойства интеллектуальных систем дают отличную цель для хакеров: взломать — легко, зато отличить взломанную систему от нормальной – тяжело.
Первыми с этим столкнулись поисковики: на них пышным цветом расцвёл паразитный бизнес поисковой оптимизации (SEO). Достаточно было скормить поисковику определённую “наживку”, и заданный сайт попадал в первые строки выдачи по заданным запросам. А поскольку алгоритмы поисковика для обычного пользователя непонятны, то он зачастую и не подозревает о такой манипуляции.
Конечно, можно выявлять косяки “чёрного ящика” с помощью внешней оценки экспертами-людьми. Сервис Google Flu Trends вообще перестал публиковать свои предсказания после публикации исследования, которое выявило, что этот сервис сильно преувеличивал все эпидемии гриппа с 2011 по 2014-й, что могло быть связано с банальной накруткой поисковых запросов. Но это тихое закрытие – скорее исключение: обычно сервисы с подобными косяками продолжают жить, не зря же на них деньги тратили! Сейчас, когда я пишу эти строки, Яндекс.Переводчик говорит мне, что “bulk” переводится как “Навальный”. Но у этого глючного интеллекта есть трогательная кнопка “Сообщить об ошибке” — и возможно, если ею воспользуются ещё пятьсот вменяемых людей, накрученный Навальный тоже сгинет.
Постоянными человеческими поправками кормятся теперь и сами поисковики, хотя они не любят это признавать, и даже название для этой профессии придумали максимально загадочное (“асессор”). Но по факту – на галерах машинного обучения Гугла и Яндекса вкалывают тысячи людей-тестировщиков, которые целыми днями занимаются унылой работой по оценке результатов работы поисковиков, для последующей корректировки алгоритмов. О тяжкой доле этих бурлаков не знал президент Обама, когда в своей прощальной речи обещал, что искусственный интеллект освободит людей от низкоквалифицированной работы.
Но поможет ли такой саппорт, когда уровень сложности повысится до персонального искусственного интеллекта, с которым все несчастные будут несчастливы по-своему? Скажем, ваша персональная Siri или Alexa выдала вам странный ответ. Что это, недостатки стороннего поисковика? Или косяк самообучения по вашей прошлой истории покупок? Или разработчики просто добавили боту немного спонтанности и юмора в синтезатор речи, чтобы он звучал более естественно? Или ваш AI-агент взломан хакерами? Очень непросто будет выяснить.
Добавим сюда, что влияние интеллектуальных агентов уже не ограничивается “ответами на вопросы”. Взломанный бот из игры дополненной реальности, типа Pokemon Go, может подвергнуть опасности целую толпу людей, заводя их в места, более удобные для грабежа. А если уже упомянутая “Тесла” на автопилоте врезается в мирно стоящий грузовик, как это случалось не раз в прошлом году – у вас просто нет времени позвонить в саппорт.
Может, нас спасут более умные системы безопасности? Но вот беда: становясь более сложными и вооружаясь машинным обучением, они тоже превращаются в “чёрные ящики”. Уже сейчас системы мониторинга событий безопасности (SIEM) собирают столько данных, что их анализ напоминает то ли гадание шамана на внутренностях животных, то ли общение дрессировщика со львом. По сути, это новый рынок профессий будущего, среди которых AI-психиатр – даже не самая шизовая.

Моральный Бендер
Вы наверняка заметили, что описанные в этой статье отношения людей и машин – конкуренция, симбиоз, паразитизм – не включают более привычную картинку, где умные машины являются послушными слугами людей и заботятся только о человеческом благе. Да-да, все мы читали Азимова с его принципами робототехники. Но в реальности ничего подобного в системах искусственного интеллекта до сих пор нет. И неудивительно: люди сами пока не понимают, как можно жить, не причиняя вреда никакому другому человеку. Более популярная мораль состоит в том, чтобы заботится о благе для определенной группы людей – но другим группам при этом можно и навредить. Все равны, но некоторые равнее.В сентябре 2016-го британский Институт стандартов выпустил “Руководство по этическому дизайну роботов”. А в октябре исследователи из Google представили свой “тест на дискриминацию” для AI-алгоритмов. Примеры в этих документах очень схожи. Британцы переживают, что полицию захватят роботы-расисты: на основе данных о более частых преступлениях среди чернокожих система начинает считать более подозрительными именно чернокожих. А американцы жалуются на слишком разборчивый банковский AI: если мужчины вдвое чаще оказываются неспособны выплатить кредит, чем женщины, машинный алгоритм на основе таких данных может предложить банку выигрышную стратегию, которая заключается в выдаче кредитов преимущественно женщинам. Это будет “недопустимая дискриминация”.
Вроде всё логично – но ведь устраивая равноправие в этих случаях, можно запросто увеличить риски для других людей. Да и как вообще машина будет применять абстрактную этику вместо голой статистики?
Вероятно, это и есть главный нынешний тренд в теме “безопасность AI” — попытки ограничить искусственный интеллект с помощью принципов, которые сами по себе сомнительны. В октябре прошлого года администрация президента США выпустила документ под названием "Подготовка к будущему искусственного интеллекта”. В документе упомянуты многие из тех рисков, которые я описал выше. Однако ответом на все проблемы являются размытые рекомендации о том, что “надо тестировать, надо убеждаться в безопасности”. Из содержательных законов, касающихся AI, названы только новые правила министерства транспорта США по поводу коммерческого использования беспилотников – им, например, запрещено летать над людьми. С другой стороны, главка про летальное автономное оружие (LAWS) скромно сообщает, что “будущее LAWS сложно предсказать”, хотя оно уже давно используется.
Ту же тему развил Европарламент, который в начале 2017 года опубликовал свой набор расплывчатых рекомендаций о том, как внедрять этику в роботов. Здесь даже сделана попытка определить их юридический статус, не такой уж далёкий от человеческого — “электронная личность со специальными правами и обязанностями”. Ещё немного, и нам запретят стирать глючные программы, чтобы не нарушить их права. Впрочем, у российских собственная гордость: представители Госдумы РФ сравнивают искусственный интеллект с собакой, на которую нужно надеть намордник. На этом месте появляется прекрасная тема для протестных выступлений – за свободу роботов в отдельнно взятой стране.
Шутки шутками, но не исключено, что именно в этих туманных принципах кроется лучшее решение проблемы безопасности AI. Нам-то кажется, что эволюционная гонка вооружений может развить искусственные интеллекты до опасного превосходства над Homo sapiens. Но когда умным машинам придётся столкнуться с человеческой бюрократией, этикой и политкорректностью, это может значительно притупить весь их интеллект.
=============================== Автор: Алексей Андреев, Positive Technologies
habr.com
Сумасшедший искусственный интеллект / Хабр
Почему все хотят создать здравомыслящий искусственный интеллект? Что если пойти другим путём, и попробовать создать сумасшедший искусственный интеллект? Случалось ли у вас такое такое, когда какая нибудь навязчивая мысль не давала вам покоя весь день, то и дело всплывая в сознании? Или что вы не могли вспомнить слово, хотя оно крутилось у вас на языке? Или вы пытались что-то вспомнить, но у вас ничего не выходило? А спустя несколько дней, а то и недель, эта информация вдруг всплывала в сознании...
В связи с этим сделаем предположение, что на самом деле мы не управляем мысленным процессом на прямую, а лишь отправляем задания на обработку. Есть задания, ответы на которые находятся на поверхности в быстром доступе. И есть задания, ответы на которые мозг отложил куда-то по дальше.
Тогда ситуацию, в которой мы ни как не можем что-то вспомнить, можно объяснить тем, что мозг взял задание в обработку, не нашел ответа в быстром доступе, и положил это задание в очередь заданий с низким приоритетом. Обработка очереди заданий с низким приоритетом происходит в фоновом режиме, и не гарантирует выполнение задания. Или ситуацию, когда у нас то и дело в сознании всплывает какая-то мысль можно объяснить тем, что мозг и не переставал эту мысль крутить в цикле. И иногда эта мысль попадала в наш фокус.
За дело!
Словарь терминов
- Словарь — набор уникальных слов, полученных путём анализа какого-либо текста;
- Мыслеслово — слово из словаря;
- Мыслеобраз — образ возникший в воображении;
- Мыслечувство — реакции на внешние раздражители: свет, тепло, звук, и т.д.
- Мысль — набор из мыслеслова, мыслеобраза и мыслечувства.
- Мыслеассоциация — связь между мыслесловами, мыслеобразами и мыслечувствами, обладающая весом;
- Мыслефункция — принимает на вход мыслеслово, мыслеобраз и мыслечувство, и вызывает мыслефункцию;
- Мыслепредложение — цепочка из мыслеслов;
- Эфир — непрерывный поток из мыслепредложений;
Обучение ИИ
Наполнение словаря мыслесловами происходит путём анализа какого-либо текста (чем больше текста проанализировано, тем лучше). При анализе производятся следующие операции:
- берём первое слово из текста и добавляем его в словарь;
- связываем это слово с последующими двумя (возможны другие варианты) словами, проставляя вес для каждой новой связи (чем дальше от текущего слова находится последующее слово, тем меньше вес), тем самым мы получили мыслеассоциации;
- вес мыслеассоциации увеличивается каждый раз, когда в тексте повторно встречается сочетание слов;
Давайте пока разберем только мыслеслово, мыслепредложение, эфир и мыслефункцию, которая на вход получает одно мыслеслово. Суть работы мыслефункции в следующем: если мы подадим на вход мыслефункции мыслеслово "лук", то в процессе обработки мыслеслова мыслефункция отберёт из словаря все мыслеслова, которые имеют мыслеассоциации со словом "лук", например "зеленый", "репчатый", "оружие", "овощ", "тетива", "стрела" и т.д. Затем она вызывает саму себя, отправляя на вход мыслеслово вес мыслеассоциации которого наибольший.
Получается, что мыслефункция порождает целый ряд вызовов мыслефункций, отправляя на вход очередное мыслеслово, тем самым мы получили цепочку из мыслеслов, т.е. мыслепредложение. Весь этот процесс идёт непрерывно, тем самым создавая эфир.
Построим цепочку из трёх мыслефункций: На вход первой мы подаем мыслеслово "лук". Она, в свою очередь, вызывает вторую мыслефункцию подавая ей на вход мыслеслово "репчатый". Вторая мыслефункция вызывает третью, отправляя ей на вход мыслеслово "овощ" и т.д. Таким образом мы получаем цепочку из мыслефункций, и если взять все мыслеслова этой цепочки, то получим мыслепредложение: "лук репчатый овощ".
С учётом того, что в фокусе сознания человек может держать, по моим наблюдениям, только одну мысль (для этого был придуман простой эксперимент, в ходе которого необходимо перечислить алфавит, произнося после каждой буквы цифру, т.е.: А1 Б2 В3 и т.д.), а все остальные мысли представим как непрерывный поток(эфир), из которого мы иногда ловим в фокусе одну из цепочек мыслей (мыслепредложение).
Изменяя веса мыслеассоциаций мы можем влиять на ход мыслеслов в мыслепредложениях. Это можно сравнить с тем, когда вы читаете статью, и после прочтения ещё долго обдумываете мысль, которой автор с вами поделился. Или же вы посмотрели фильм, и затем рассказываете о нём друзьям. Другой пример когда изменяются веса у мыслеассоциаций, это момент встречи с знакомым человеком, который вам что-то обещал, но вы про это забыли, а теперь увидев его снова вспомнили.
Подытожим
Если у нас получится создать подобный эфир, то поток мыслепредложений в этом эфире будет похож на мысли сумасшедшего человека, который повторяет одно и тоже. Одной из основных задач, решение которой необходимо будет добиться, это создание наибольшей длинны мыслепредложений. Тогда "спрашивая" систему о чём либо, она нам будет отвечать этими мыслепредложениями.
habr.com
Топ-10 трендов технологий искусственного интеллекта (ИИ) в 2018 году / Блог компании Отус / Хабр
Слушатели первого курса «Разработчик BigData» вышли на финишную прямую — сегодня начался последний месяц, где выжившие займутся боевым выпускным проектом. Соответственно, открыли и набор на этот достаточно непростой курс. Поэтому давайте рассмотрим одну интересную статью-заметку по современным трендам в ИИ, которые тесно связаны с BD, ML и прочим.
Поехали.
Искусственный интеллект находится под пристальным вниманием глав правительств и бизнес-лидеров в качестве основного средства оценки верности решений. Но что происходит в лабораториях, где открытия академических и корпоративных исследователей будут устанавливать курс развития ИИ на следующие годы? Наша собственная команда исследователей из AI Accelerator от PwC нацелилась на ведущие разработки, за которыми следует внимательно следить как бизнес-лидерам, так и технологам. Вот что они из себя представляют и почему они так важны.

1. Теория глубокого обучения: демистификация работы нейронных сетей
Что это такое: глубокие нейронные сети, которые имитируют человеческий мозг, продемонстрировали свою способность «учиться» по изображениям, аудио и текстовым данным. Тем не менее, даже с учетом того, что они используются уже более десяти лет, мы все ещ` многого не знаем о глубоком обучении, в том числе то, как обучаются нейронные сети или почему они так хорошо работают. Это может измениться благодаря новой теории, которая применяет принцип узкого места информации для глубокого обучения. В сущности, теория предполагает, что после начальной фазы подстройки глубокая нейронная сеть «забудет» и сожмет данные-шум (то есть наборы данных, содержащие много дополнительной бессмысленной информации), при этом сохраняя информацию о том, что представляют эти данные.
Почему это важно: точное понимание того, как работает глубокое обучение способствует его более широкому развитию и использованию. Например, оно может сделать более очевидным оптимальный выбор дизайна и архитектуры сети, обеспечивая при этом большую прозрачность для систем повышенной надежности или управляющих приложений. Ожидайте увидеть больше результатов от исследования этой теории, в применении к другим типам глубоких нейронных сетей и разработке в целом.
2. Капсульные сети: имитация мозговой обработки визуальной информации
Что это такое: капсульные сети, новый тип глубоких нейронных сетей, обрабатывают визуальные информацию практически так же, как мозг, что означает, что они могут поддерживать иерархические отношения. Это резко контрастирует с сверточными нейронными сетями, одной из наиболее широко используемых нейронных сетей, которые не учитывают важные пространственные иерархии между простыми и сложными объектами, что приводит к ошибочной классификации и высокой частоте ошибок.
Почему это важно: для типичных задач идентификации капсульные сети обещают лучшую точность за счет уменьшения ошибок — на целых 50%. А также им не нужно столько данных для обучающих моделей. Ожидайте увидеть широкое распространение использования капсульных сетей во многих проблемных областях и глубоких нейронных сетевых архитектурах.
3. Глубокое обучение с подкреплением: взаимодействие с окружающей средой для решения бизнес-задач
Что это такое: тип обучения нейронной сети, которая учится, взаимодействуя с окружающей средой посредством наблюдений, действий и вознаграждений. Глубокое обучение с подкреплением (Deep reinforcement learning — DRL) использовалось для изучения игровых стратегий, таким как Atari и Go, включая известную программу AlphaGo, которая победила человека.
Почему это важно: DRL является наиболее универсальным из всех методов обучения, поэтому его можно использовать в большинстве бизнес-приложений. Он требует меньше данных, чем другие методы для обучения своих моделей. Еще более примечательным является тот факт, что его можно обучить с помощью моделирования, что полностью исключает необходимость маркировки данных. Учитывая эти преимущества, ожидайте увидеть больше бизнес-приложений, которые объединяют DRL и агентное моделирование в ближайшем году.
4. Генеративно-состязательные сети: комбинирование нейронных сетей для стимулирования обучения и облегчения вычислительной нагрузки
Что это такое: Генеративно-состязательная сеть (generative adversarial network — GAN) — это тип системы глубокого обучения без учителя, которая реализуется как две конкурирующие нейронные сети. Одна сеть, генератор, создает поддельные данные, которые выглядят точно так же, как реальный набор данных. Вторая сеть, дискриминатор, обрабатывает подлинные и сгенерированные данные. Со временем каждая сеть улучшается, позволяя паре изучать весь дистрибутив данного набора данных.
Почему это важно: GAN открывают глубокое обучение большому диапазону задач обучения без учителя, в которых помеченные данные не существуют или слишком дороги для получения. Они также уменьшают нагрузку, необходимую для реализации глубокой нейронной сети, потому что бремя разделяют две сети. Ожидайте увидеть больше бизнес-приложений, таких как обнаружение кибератак с использованием GAN.
5. Обучение на неполных (Lean Data) и дополненных данных: решение задачи с маркированными даннымиЧто это такое: Довольно крупной проблемой в машинном обучении (в частности, в глубоком обучении) является доступность больших объемов маркированных данных для обучения системы. Два общих метода могут помочь решить эту проблему: (1) синтезировать новые данные и (2) перенести модель, подготовленную для одной задачи или области в другую. Методы, такие как перенос обучения (передача знаний, полученных из одной задачи / области в другую) или обучение с первого раза (“экстремальный” перенос обучения, происходящий лишь с одним или без соответствующих примеров) — это техники обучения на “неполных данных”(Lean Data). Аналогично, синтез новых данных посредством моделирования или интерполяции помогает получить больше данных, тем самым дополняя существующие данные для улучшения обучения.
Почему это важно: используя эти методы, мы можем решать самые разнообразные проблемы, особенно те, которые не имеют полноценных входных данных. Ожидайте увидеть больше вариантов неполных и дополненных данных, а также различные типы обучения, применяемые для решения широкого круга бизнес-задач.
6. Вероятностное программирование: языки для облегчения разработки модели
Что это такое: высокоуровневый язык программирования, который облегчает разработку вероятностной модели, а затем автоматически «решает» эту модель. Вероятностные языки программирования позволяют повторно использовать библиотеки моделей, поддерживают интерактивное моделирование и формальную проверку, а также обеспечивают уровень абстракции, необходимый для создания общего и эффективного вывода в универсальных классах моделей.
Почему это важно: вероятностные языки программирования имеют возможность учитывать неопределенную и неполную информацию, которая так распространена в бизнес-области. Мы увидим более широкое внедрение этих языков и ожидаем, что они также будут применяться к глубокому обучению.
7. Модели гибридного обучения: объединение подходов к неопределенности модели
Что это такое: Различные типы глубоких нейронных сетей, таких как GAN или DRL, показали большие перспективы с точки зрения их производительности и широкого применения с различными типами данных. Однако модели глубокого обучения не моделируют неопределенность, как делают байесовские или вероятностные подходы. Модели гибридного обучения сочетают в себе два подхода, чтобы использовать сильные стороны каждого из них. Некоторыми примерами гибридных моделей являются байесовское глубокое обучение, байесовские GAN и байесовские условные GAN.
Почему это важно: модели гибридного обучения позволяют расширить разнообразие бизнес-задач, включая глубокое обучение с неопределенностью. Это может помочь нам достичь лучшей производительности и объяснимости моделей, что, в свою очередь, может способствовать более широкому внедрению. Ожидайте, что более глубокие методы обучения получат байесовские эквиваленты, а компоновка вероятностных языков программирования начнет включать глубокое обучение.
8. Автоматическое машинное обучение (AutoML): создание модели без программирования
Что это такое: разработка моделей машинного обучения требует трудоемкого рабочего процесса под наблюдением экспертов, который включает подготовку данных, выбор функций, выбор модели или техники, обучение и настройку. AutoML стремится автоматизировать этот рабочий процесс, используя ряд различных методов статистического и глубокого обучения.
Почему это важно: AutoML является частью того, что рассматривается как демократизация инструментов AI, позволяя бизнес-пользователям разрабатывать модели машинного обучения без глубокого программирования. Это также ускорит время, затрачиваемое учеными-данными для создания моделей. Ожидайте увидеть больше коммерческих пакетов AutoML и интеграцию AutoML на более крупных платформах машинного обучения.
9. Цифровой двойник: виртуальные копии за пределами промышленных приложений
Что это такое: цифровой двойник — это виртуальная модель, используемая для облегчения детального анализа и мониторинга физических или психологических систем. Концепция цифрового двойника возникла в промышленном мире, где она широко использовалась для анализа и мониторинга таких вещей, как ветряные фермы или промышленные системы. Теперь, используя моделирование на основе агентов (вычислительные модели для моделирования действий и взаимодействия автономных агентов) и системной динамики (компьютерный подход к анализу и моделированию линий поведения), цифровые двойники применяются к нефизическим объектам и процессам, включая прогнозирование поведение покупателя.
Почему это важно: цифровые двойники могут способствовать развитию и более широкому внедрению Интернета вещей (IoT), обеспечивая способы предсказательной диагностики и поддерживая системы IoT. В будущем ожидаем большего использования цифровых двойников как в физических системах, так и в моделировании потребительского выбора.
10. Объяснимый ИИ: метод черного ящика
Что это такое: сегодня существует множество алгоритмов машинного обучения, которые осязают, мыслят и действуют в великом множестве самых разных приложений. Тем не менее многие из этих алгоритмов считаются «черными ящиками», проливая очень мало света на то, как они достигли своего результата. Объяснимый ИИ — это движение в сторону разработки методов машинного обучения, которые создают более объяснимые модели, сохраняя при этом точность прогнозирования.
Почему это важно: ИИ, объяснимый, доказуемый и прозрачный, будет иметь решающее значение для установления доверия к этой технологии и будет способствовать более широкому внедрению методов машинного обучения. Предприятия будут применять объясняемый ИИ в качестве требования или передовой практики, прежде чем приступать к широкомасштабному развертыванию ИИ, в то время как правительства могут сделать объяснимый ИИ нормативным стандартом в будущем.
THE END
Как всегда ждём комментарии, обсуждения вопросы тут или, например, это можно обсудить с Ксенией на открытом уроке.
habr.com
Почему искусственный интеллект не решит всех проблем / Хабр

Истерия вокруг будущего искусственного интеллекта (ИИ) захватила мир. Нет недостатка в сенсационных новостях о том, как ИИ сможет лечить болезни, ускорять инновации и улучшать творческий потенциал человека. Если читать заголовки СМИ, вы можете решить, что уже живёте в будущем, в котором ИИ проник во все аспекты общества.
И хотя нельзя отрицать, что ИИ открыл нам богатый набор многообещающих возможностей, он также привёл к появлению мышления, которое можно охарактеризовать, как веру во всемогущество ИИ. По этой философии, при наличии достаточного количества данных, алгоритмы машинного обучения смогут решить все проблемы человечества. Но у этой идеи есть большая проблема. Она не поддерживает прогресс ИИ, а наоборот, ставит под удар ценность машинного интеллекта, пренебрегая важными принципами безопасности и настраивая людей на нереалистичные ожидания по поводу возможностей ИИ.
Вера во всемогущество ИИ
Всего за несколько лет вера во всемогущество ИИ пробралась из разговоров технологических евангелистов Кремниевой долины в умы представителей правительств и законодателей всего мира. Маятник качнулся от антиутопического представления об уничтожающем человечество ИИ к утопической вере в пришествие нашего алгоритмического спасителя.Мы уже видим, как правительства обеспечивают поддержку национальным программам развития ИИ и соревнуются в технологической и риторической гонке вооружений, чтобы получить преимущество в бурно растущем секторе машинного обучения (МО). К примеру, британское правительство пообещало вложить £300 млн в исследования ИИ, чтобы стать лидером этой области. Очарованный преобразовательным потенциалом ИИ, французский президент Эмманюэль Макрон решил превратить Францию в международный центр ИИ. Китайское правительство увеличивает свои возможности в области ИИ с помощью государственного плана по созданию китайской ИИ-индустрии объёмом в $150 млрд к 2030 году. Вера во всемогущество ИИ набирает обороты и не собирается сдаваться.

Нейросети – легче сказать, чем сделать
В то время как многие политические заявления расхваливают преобразующие эффекты надвигающейся "революции ИИ", они обычно недооценивают сложности внедрения передовых систем МО в реальном мире.Одна из наиболее многообещающих разновидностей технологии ИИ – нейросети. Эта форма машинного обучения основывается на примерном подражании нейронной структуры человеческого мозга, но в гораздо меньшем масштабе. Многие продукты на основе ИИ используют нейросети, чтобы извлекать закономерности и правила из больших объёмов данных. Но многие политики не понимают, что просто добавив к проблеме нейросеть, мы не обязательно тут же получим её решение. Так, добавив нейросеть к демократии, мы не сделаем её мгновенно менее дискриминированной, более честной или персонализованной.
Бросая вызов бюрократии данных
Системам ИИ для работы нужно огромное количество данных, но в госсекторе обычно не бывает подходящей инфраструктуры данных для поддержки передовых систем МО. Большая часть данных хранится в офлайн-архивах. Небольшое количество существующих оцифрованных источников данных тонут в бюрократии. Данные чаще всего размазаны по различным правительственным департаментам, каждому из которых для доступа требуется особое разрешение. Кроме всего прочего, госсектору обычно не хватает талантов, оснащённых нужными техническими способностями, чтобы в полной мере пожать плоды преимуществ ИИ.По этим причинам связанный с ИИ сенсационализм получает множество критики. Стюарт Рассел, профессор информатики в Беркли, давно уже проповедует более реалистичный подход, концентрирующийся на простейших, повседневных применениях ИИ, вместо гипотетического захвата мира сверхразумными роботами. Сходным образом профессор робототехники из MIT, Родни Брукс, пишет, что «почти всем инновациям в робототехнике и ИИ требуется гораздо, гораздо больше времени для реального внедрения, чем это представляют себе как специалисты в этой области, так и все остальные».
Одна из множества проблем внедрения систем МО состоит в том, что ИИ чрезвычайно подвержен атакам. Это значит, что злонамеренный ИИ может атаковать другой ИИ, чтобы заставить его выдавать неправильные предсказания или действовать определённым образом. Многие исследователи предупреждали о том, что нельзя так сразу выкатывать ИИ, не подготовив соответствующих стандартов по безопасности и защитных механизмов. Но до сих пор тема безопасности ИИ не получает должного внимания.
Машинное обучение – это не волшебство
Если мы хотим пожать плоды ИИ и минимизировать потенциальные риски, мы должны начать размышлять о том, как мы можем осмысленно применить МО к определённым областям правительства, бизнеса и общества. А это значит, что нам необходимо начать обсуждения этики ИИ и недоверия многих людей к МО.Самое важное, нам нужно понимать ограничения ИИ и те моменты, в которые люди всё ещё должны брать управление в свои руки. Вместо того, чтобы рисовать нереалистичную картину возможностей ИИ, необходимо сделать шаг назад и отделить реальные технологические возможности ИИ от волшебства.
Долгое время Facebook считала, что проблемы типа распространения дезинформации и разжигание ненависти можно алгоритмически распознать и остановить. Но под давлением законодателей компания быстро пообещала заменить свои алгоритмы на армию из 10 000 рецензентов-людей.

В медицине тоже признают, что ИИ нельзя считать решением всех проблем. Программа "IBM Watson for Oncology" была ИИ, который должен был помочь докторам бороться с раком. И хотя она была разработана так, чтобы выдавать наилучшие рекомендации, экспертам оказывается сложно доверять машине. В результате программу закрыли в большинстве госпиталей, где проходили её пробные запуски.
Схожие проблемы возникают в законодательной области, когда алгоритмы использовались в судах США для вынесения приговоров. Алгоритмы подсчитывали значения рисков и давали судьям рекомендации по приговорам. Но обнаружилось, что система усиливает структурную расовую дискриминацию, после чего от неё отказались.
Эти примеры показывают, что решений на основе ИИ для всего не существует. Использование ИИ ради самого ИИ не всегда оказывается продуктивным или полезным. Не каждую проблему лучше всего решать с применением к ней машинного интеллекта. Это важнейший урок для всех, кто намеревается увеличить вложения в государственные программы по развитию ИИ: у всех решений есть своя цена, и не всё, что можно автоматизировать, нужно автоматизировать.
habr.com