Десять алгоритмов машинного обучения, которые вам нужно знать. Машинного обучения
Машинное обучение - это... Что такое Машинное обучение?
Машинное обучение (англ. Machine Learning) — обширный подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться. Различают два типа обучения. Обучение по прецедентам, или индуктивное обучение, основано на выявлении закономерностей в эмпирических данных. Дедуктивное обучение предполагает формализацию знаний экспертов и их перенос в компьютер в виде базы знаний. Дедуктивное обучение принято относить к области экспертных систем, поэтому термины машинное обучение и обучение по прецедентам можно считать синонимами.
Машинное обучение находится на стыке математической статистики, методов оптимизации и дискретной математики, но имеет также и собственную специфику, связанную с проблемами вычислительной эффективности и переобучения. Многие методы индуктивного обучения разрабатывались как альтернатива классическим статистическим подходам. Многие методы тесно связаны с извлечением информации, интеллектуальным анализом данных (Data Mining).
Общая постановка задачи обучения по прецедентам
Имеется множество объектов (ситуаций) и множество возможных ответов (откликов, реакций).
Существует некоторая зависимость между ответами и объектами, но она неизвестна. Известна только конечная совокупность прецедентов — пар «объект, ответ», называемая обучающей выборкой. На основе этих данных требуется восстановить зависимость, то есть построить алгоритм, способный для любого объекта выдать достаточно точный ответ. Для измерения точности ответов определённым образом вводится функционал качества.Данная постановка является обобщением классических задач аппроксимации функций. В классических задачах аппроксимации объектами являются действительные числа или векторы. В реальных прикладных задачах входные данные об объектах могут быть неполными, неточными, нечисловыми, разнородными. Эти особенности приводят к большому разнообразию методов машинного обучения.
Способы машинного обучения
Так как раздел машинного обучения, с одной стороны, образовался в результате разделения науки о нейросетях на методы обучения сетей и виды топологий архитектуры сетей, а с другой, вобрал в себя методы математической статистики, то указанные ниже способы машинного обучения исходят из нейросетей. То есть базовые виды нейросетей, такие как перцептрон и многослойный перцептрон (а также их модификации) могут обучаться как с учителем, без учителя, с подкреплением, и активно. Но некоторые нейросети и большинство статистических методов можно отнести только к одному из способов обучения. Поэтому если нужно классифицировать методы машинного обучения в зависимости от способа обучения, то, касательно нейросетей, некорректно их относить к определенному виду, а правильнее классифицировать алгоритмы обучения нейронных сетей.
- Метод коррекции ошибки
- Метод обратного распространения ошибки
- Обучение без учителя — для каждого прецедента задаётся только «ситуация», требуется сгруппировать объекты в кластеры, используя данные о попарном сходстве объектов, и/или понизить размерность данных:
- Альфа-система подкрепления
- Гамма-система подкрепления
- Метод ближайших соседей
- Генетический алгоритм.
- Активное обучение — отличается тем, что обучаемый алгоритм имеет возможность самостоятельно назначать следующую исследуемую ситуацию, на которой станет известен верный ответ:
- Обучение с частичным привлечением учителя (semi-supervised learning) — для части прецедентов задается пара «ситуация, требуемое решение», а для части — только «ситуация»
- Трансдуктивное обучение (transduction) — обучение с частичным привлечением учителя, когда прогноз предполагается делать только для прецедентов из тестовой выборки
- Многозадачное обучение (multi-task learning) — одновременное обучение группе взаимосвязанных задач, для каждой из которых задаются свои пары «ситуация, требуемое решение»
- Многовариантное обучение (multiple-instance learning) — обучение, когда прецеденты могут быть объединены в группы, в каждой из которых для всех прецедентов имеется «ситуация», но только для одного из них (причем, неизвестно какого) имеется пара «ситуация, требуемое решение»
Классические задачи, решаемые с помощью машинного обучения
Типы входных данных при обучении
- Признаковое описание объектов — наиболее распространённый случай.
- Описание взаимоотношений между объектами, чаще всего отношения попарного сходства, выражаемые при помощи матрицы расстояний, ядер либо графа данных
- Временной ряд или сигнал.
- Изображение или видеоряд.
Типы функционалов качества
- При обучении с учителем — функционал качества может определяться как средняя ошибка ответов. Предполагается, что искомый алгоритм должен его минимизировать. Для предотвращения переобучения в минимизируемый функционал качества часто в явном или неявном виде добавляют регуляризатор.
- При обучении без учителя — функционалы качества могут определяться по-разному, например, как отношение средних межкластерных и внутрикластерных расстояний.
- При обучении с подкреплением — функционалы качества определяются физической средой, показывающей качество приспособления агента.
Практические сферы применения
Целью машинного обучения является частичная или полная автоматизация решения сложных профессиональных задач в самых разных областях человеческой деятельности.
Машинное обучение имеет широкий спектр приложений:
Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объёмов данных в науке, производстве, бизнесе, транспорте, здравоохранении. Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
Литература
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: основы моделирования и первичная обработка данных. — М.: Финансы и статистика, 1983.
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: исследование зависимостей. — М.: Финансы и статистика, 1985.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
- Вапник В. Н. Восстановление зависимостей по эмпирическим данным. — М.: Наука, 1979.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8.
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2.
- Hastie, T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. — 2nd ed. — Springer-Verlag, 2009. — 746 p. — ISBN 978-0-387-84857-0.
- Mitchell T. Machine Learning. — McGraw-Hill Science/Engineering/Math, 1997. ISBN 0-07-042807-7.
- Ryszard S. Michalski, Jaime G. Carbonell, Tom M. Mitchell (1983), Machine Learning: An Artificial Intelligence Approach, Tioga Publishing Company, ISBN 0-935382-05-4[1].
- Vapnik V.N. Statistical learning theory. — N.Y.: John Wiley & Sons, Inc., 1998. [1]
- Bernhard Schölkopf, Alexander J. Smola Learning with Kernels. Support Vector Machines, Regularization, Optimization, and Beyond. — MIT Press, Cambridge, MA, 2002 ISBN 978-0-262-19475-4 [2]
- I.H. Witten, E. Frank Data Mining: Practical Machine Learning Tools and Techniques (Second Edition). — Morgan Kaufmann, 2005 ISBN 0-12-088407-0 [3]
Ссылки
Ресурсы
Журналы
- Pattern Recognition and Image Analysis
Конференции
Курсы лекций
Российские исследовательские группы и коммерческие фирмы
- Лаборатория распознавания образов (московский Центр непрерывного математического образования).
- ABBYY — один из ведущих мировых разработчиков ПО в области распознавания документов (OCR), ввода форм (ICR) и прикладной лингвистики.
- BaseGroup — добыча данных, анализ и прогнозирование, создание прикладных аналитических систем (Рязань).
- Forecsys — интеллектуальный анализ данных, прогнозирование продаж, кредитный скоринг, распознавание образов.
- Megaputer — разработка и производство аналитических систем для углубленного анализа числовых и текстовых баз данных.
- NeurOK — анализ данных и управление знаниями.
- SnowCactus — Аналитические технологии для бизнеса.
- Solutions — Центр технологий анализа данных и прогнозирования (Долгопрудный).
- ZSoft — Проектирование, разработка и внедрение информационно-аналитических систем (Санкт-Петербург).
Примечания
dic.academic.ru
10 крутых примеров использования машинного обучения
Искусственный интеллект и машинное обучение – одни из самых значимых технологических разработок последнего времени. Однако они до сих пор остаются недооцененными.
10 примеров использования машинного обучения
Хотите увидеть, как применяется машинное обучение в реальной жизни?
Ниже мы расскажем вам о 10 компаниях, которые эффективно используют новые технологии в своей стратегии.
1. Yelp – Курирование изображений
Хоть Yelp, популярный сайт с отзывами, и не кажется высокотехнологическим брендом, он активно использует машинное обучение для улучшения опыта пользователей.
Классификация изображений по категориям фасад/интерьер кажется легкой задачей для человека, но компьютеру с ней справится совсем непросто.
Фото важны для Yelp не меньше отзывов пользователей, вот почему компания прикладывает не мало усилий для повышения эффективности работы с изображениями.
Несколько лет назад бренд решил обратиться к машинному обучению и впервые применил технологию классификации фото. Алгоритмы помогают сотрудникам компании выбирать категории для изображений и проставлять метки. Вклад машинного обучения сложно переоценить, ведь бренду приходится анализировать десятки миллионов фото.
Основная функция соцсети Pinterest – курирование контента. И компания делает все возможное, чтобы повысить эффективность этого процесса, в том числе применяя машинное обучение.
В 2015 Pinterest приобрел Kosei – компанию, специализирующуюся на коммерческом применении машинного обучения (в частности, на поиске контента и алгоритмах рекомендаций).
Сегодня машинное обучение участвует в каждом аспекте бизнес-операций Pinterest, от модерации спама и поиска контента до монетизации рекламы и снижения числа отписок от рассылки. Очень неплохо.
3. Facebook – Армия чатботов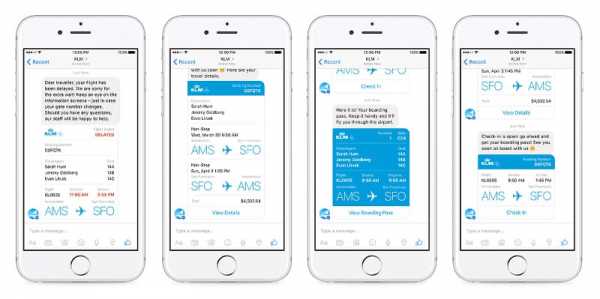
Facebook Messenger – один из самых интересных продуктов крупнейшей социальной платформы в мире. Все потому, что мессенджер стал своеобразной лабораторией чатботов. При общении с некоторыми из них сложно понять, что ты разговариваешь не с человеком.
Любой разработчик может и запустить его на базе Facebook Messenger. Благодаря этому даже небольшие компании имеют возможность предлагать клиентам отличный сервис.
Конечно, это не единственная сфера применения машинного обучения в Facebook. AI приложения используются для фильтрации спама и контента низкого качества, также компания разрабатывает алгоритмы компьютерного зрения, которые позволяют компьютерам “читать” изображения.
4. Twitter – Новостная лентаОдно из самых значимых изменений в Twitter за последнее время – переход к новостной ленте на базе алгоритмов.
Теперь пользователи соцсети могут сортировать отображаемый контент по популярности или по времени публикации.
В основе этих изменений лежит применение машинного обучения. Искусственный интеллект анализирует каждый твит в реальном времени и оценивает его по нескольким показателям.
Алгоритм Twitte в первую очередь показывает те записи, которые с большей вероятностью понравятся пользователю. При этом выбор основывается на его личных предпочтениях.
5. Google – Нейронные сети
У Google впечатляющие технологические амбиции. Сложно представить себе сферу научных исследований, в которую бы не внесла вклад эта корпорация (или ее головная компания Alphabet).
Например, за последние годы Google занимались разработкой технологий, замедляющих старение, медицинских устройств и нейронных сетей.
Самое значимое достижение компании – создание в DeepMind машин, которые могут мечтать и создавать необычные изображения.
Google стремится изучить все аспекты машинного обучения, что помогает компании совершенствовать классические алгоритмы, а также эффективнее обрабатывать и переводить естественную речь, улучшать ранжирование и предсказательные системы.
6. Edgecase – Показатели конверсии
Уже давно ритейлеры пытаются объединить шопинг в онлайн и оффлайн-магазинах. Но только немногим это действительно удается.
Edgecase использует машинное обучение для улучшения опыта своих клиентов. При этом бренд стремится не только повысить показатели конверсии, но хочет помочь тем покупателям, которые имеют смутное представление о том, чего они хотят.
Анализируя поведение и действия пользователей, которые свидетельствуют о намерении совершить покупку, бренд делает онлайн-поиск более полезным и приближает его к опыту шопинга в традиционном магазине.
7. Baidu – Будущее голосового поискаОдна из самых интересных разработок компании – Deep Voice, нейронная сеть, способная генерировать синтетические человеческие голоса, которые практически невозможно отличить от настоящих. Система может имитировать особенности интонации, произношения, ударения и высоты тона.
Последнее изобретение Baidu Deep Voice 2 значительно повлияет на эффективность обработки естественного языка, голосового поиска и систем распознавания речи. Применять новую технологию можно будет в других сферах, например, устных переводах и системах биометрической безопасности.
8. HubSpot – Умные продажи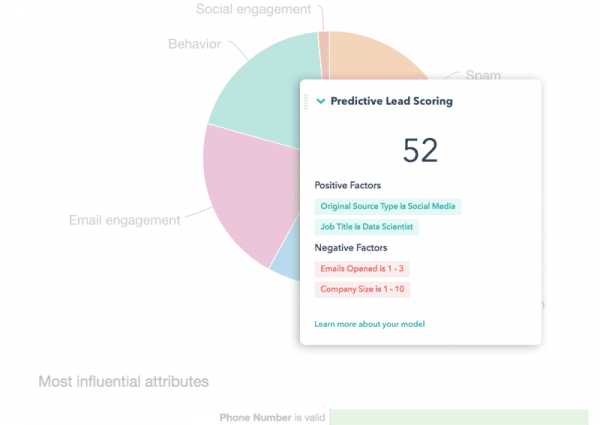
HubSpot уже давно известен своим интересом к технологиям. Компания недавно приобрела Kemvi – бренд, специализирующийся на машинном обучении.
HubSpot планирует использовать технологию Kemvi для нескольких целей: самая значимая – интеграция машинного обучения и обработки естественного языка DeepGraph с внутренней системой управления контентом.
Это позволит компании эффективнее определять “триггеры” – изменения в структуре и управлении компании, которые влияют на повседневные операции. Благодаря этому нововведению HubSpot сможет эффективнее привлекать клиентов и обеспечивать высокий уровень обслуживания.
Крупнейшая технологическая корпорация IBM отказывается от устаревшей бизнес-модели и активно осваивает новые направления. Самый известный сегодня продукт бренда – искусственный интеллект Watson.
За последние несколько лет Watson использовался в госпиталях и медицинских центрах, где диагностировал определенные виды рака намного эффективнее, чем онкологи.
У Watson также есть огромный потенциал в сфере ритейла, где он может выполнять роль консультанта. IBM предлагает свой продукт на основе лицензии, что делает его уникальным в своем роде и более доступным.
10. Salesforce – Умные CRM системы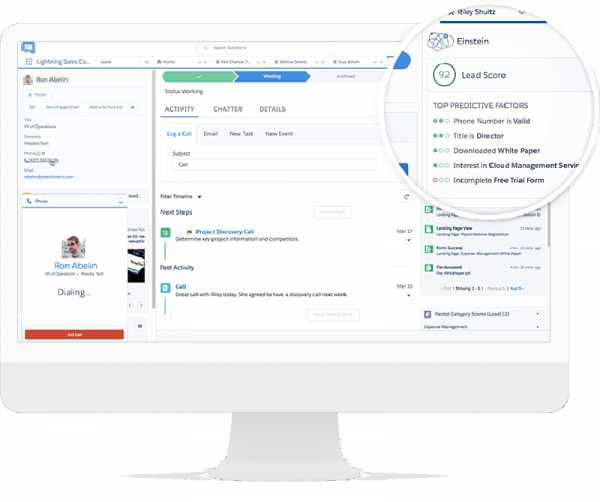
Salesforce – титан мира технологий со значительной долей рынка в сфере управления отношениями с клиентам (CRM).
Предсказательная аналитика и оценка лидов – основные вызовы современных интернет-маркетологов, вот почему Salesforce делает высокие ставки на свою технологию машинного обучения Einstein.
Einstein позволяет компаниям, которые используют CRM от Salesforce, анализировать каждый аспект отношений с клиентами – от первого контакта до последующих точек соприкосновения. Благодаря этому они могут создавать более детальные профили и определять важнейшие моменты в процессе продаж. Все это ведет к более эффективной оценке лидов, повышению качества клиентского опыта и расширению возможностей.
Будущее машинного обучения
Некоторые формы применения машинного обучения, перечисленные выше, казались фантастикой еще десять лет назад. При этом каждое новое открытие не перестает удивлять и сегодня.
Какие тренды машинного обучения ждут нас в ближайшем будущем?
1. Машины, которые учатся еще эффективнееСовсем скоро искусственный интеллект сможет обучаться намного эффективнее: машины будут совершенствоваться при минимальном участии человека.
2. Автоматизация борьбы с кибератакамиРост киберпреступности заставляет компании задумываться о методах защиты. Вскоре AI будет играть все более важную роль в мониторинге, предотвращении и реакции на кибератаки.
3. Убедительные генеративные моделиГенеративные модели такие, как используются в Baidu из примера выше, и сегодня довольно убедительны. Но скоро мы вообще не сможем отличить машин от людей. В будущем алгоритмы смогут создавать картины, имитировать человеческую речь и даже целые личности.
4. Быстрое обучениеДаже самому сложному искусственному интеллекту необходим огромный объем данных для обучения. Вскоре системам машинного обучения для этого будет требоваться все меньше информации и времени.
5. Самостоятельный искусственный интеллектУже давно люди задаются вопросом, может ли искусственный интеллект представлять опасность для человека.
В июне этого года специалисты отдела Facebook по исследованию возможностей искусственного интеллекта (FAIR) решили отключить одну из созданных ими систем, так как боты начали общаться на собственном, непонятном для человека, языке. Эксперты призывают ввести регулирование этой области технологий, чтобы избежать угрозы выхода искусственного интеллекта из под контроля.
В будущем это может привести к введению ограничений и даже замедлению темпов развития этого направления. В любом случае, важно использовать новые технологии во благо человечества, а не во вред. А для этого необходимо жесткое регулирование отрасли.
rusability.ru
Вопросы и ответы / Блог компании Университет ИТМО / Хабр

Как вы уже успели заметить, мы достаточно часто обращаем внимание на тему машинного обучения. Так, мы рассказывали о глубоком обучении, писали о работе с данными и адаптировали различные подборки источников по теме: 1, 2, 3.
Сегодня мы решили посмотреть на наиболее интересные вопросы и ответы по теме машинного обучения на ресурсе Quora.
Какой язык программирования лучше всего подходит для машинного обучения?
Йошуа Бенгио (глава Института Алгоритмов Машинного Обучения, Монреаль) говорит, что многие годы они программируют на Python, наряду с другими языками. Но ему бы хотелось использовать что-нибудь наподобие Python, что при этом обладало бы более мощным компилятором, способным выдавать эффективный и распределенный (по кластерам) код, который будет легко портировать.
Именно по этой причине они начали разрабатывать библиотеку Theano (нельзя сказать, что это полноценный язык – скорее набор функций для создания выражений и компилятор).
Сколько алгоритмов используется в рекомендательной системе Netflix? Существует мнение, что более 800. Так ли это?
Ксавье Аматриан (технический директор Netflix с 2011 по 2014) говорит, что все зависит от того, что подразумевается под системой рекомендаций. Если речь идет о предпочтениях на основе рейтинга, то для них используются два алгоритма.
Если же вопрос подразумевает в целом рекомендательную экосистему Netflix, то конечно же, используется куда больше алгоритмов, но никак не 800. Здесь он описывает, как работает алгоритм рекомендации фильмов.
Действительно ли необходимо получать докторскую степень, чтобы иметь хорошую работу в сфере машинного обучения? Правда ли, что в таких компаниях как Google докторская степень – это базовое требование [к кандидатам]?
Бэн Чжао (профессор информатики Калифорнийского университета) знаком со многими студентами, которые после окончания обучения получили должность в Google, Microsoft, Twitter, Linkedin и Zynga. Большинство из них получили эти должности не благодаря степени, а потому, что в свое время они вместе с Чжао проводили исследования по аналитике социальных сетей или попали в толковые руки отдела кадров.
Получение докторской степени, безусловно, дает свои преимущества. Это – возможность изучать ныне существующие проблемы и постоянно возникающие технологии работы с ними ещё несколько лет. Поэтому докторская степень точно не помешает в получении должности (если кандидат действительно хочет заниматься исключительно вопросами машинного обучения).
Что вы думаете о недавно выпущенном Yahoo своде данных по машинному обучению?
Джеймс Бейкер (занимался машинным обучением еще до того, как его стали так называть) надеется, что это подвигнет и другие компании выпустить аналогичные наборы. Он прекрасно понимает, какого объема должен быть этот набор, поэтому не собирается самостоятельно изучать его – он заинтересован в помощниках или коллаборации с кем-нибудь.
Сложность одиночной работы с подобными наборами данных, как отмечает Джеймс, состоит в том, что у исследователя может не оказаться достаточно мощностей для его обработки.
У самого Джеймса есть есть теоретическая модель глубокого обучения, которую он хотел бы применить к этому набору от Yahoo, но проблема заключается в том, что его «железо» это не потянет, кроме того, ему не хватает помощников в обслуживании его модели.
Поэтому он ищет заинтересованных лиц, а исследователям, которые находятся в подобном положении, Джеймс настоятельно рекомендует дождаться формирования команд энтузиастов – так шанс на практике воспользоваться данными от Yahoo может серьезно вырасти.
Почему существует так мало стартапов в области машинного обучения и в области обработки естественного языка?
Джозеф Туриан (консультант по вопросам Data Mining и обработки естественного языка) отмечает: дело в повышенных рисках. Большинство технологических стартапов сталкивается с относительно высокими маркетинговыми рисками, которые уравновешиваются сравнительно низкими рисками, касающимися технологической составляющей.
В сфере машинного обучения и обработки естественного языка высоки как маркетинговые, так и технологические риски – все это не позволяет основателям таких стартапов привлекать стороннее финансирование. Не в пользу основателей говорит в данном случае и тот факт, что у них далеко не всегда есть адекватное представление о бизнесе и рыночных отношениях в целом – большую часть времени специалисты по машинному обучению проводят в таких спокойных и мало подверженных влиянию «большого мира» местах, как университеты и крупные корпорации.
Джеймс Бейкер дополняет ответ Джозефа. Он подчеркивает, что [несмотря на общий пессимизм] в этих областях работает больше стартапов, чем мы привыкли думать. Он отмечает, что стартапы, использующие в работе технологии машинного обучения или обработки естественного языка, должны использовать большие объемы данных.
В этой среде их конкурентами становятся такие гиганты, как Google, Microsoft и др., поэтому, стремясь избежать конкуренции, маленькие компании просто не афишируют эту составляющую своей работы.
Какие замечательные идеи наиболее популярны в сфере машинного обучения?
Чарльз Мартин считает, что одна из них это – нейронная сеть Хопфилда, ее связь с моделью Изинга и ее применение в современной реализации глубокого обучения. Такие простые модели находят свое применение не только в статистической физике, но и в развитии современных алгоритмов глубокого обучения.
Он также отмечает важность ограниченной машины Больцмана в машинном обучении несмотря на то, что с момента появления этой архитектуры и до момента ее активного применения в моделях глубокого обучения прошло почти 20 лет.
Абинав Маурья добавляет к этому списку kernel trick (ядерный метод) для метода опорных векторов (список наиболее часто используемых функций для этого метода можно найти здесь). Другие исследователи отмечают метод максимального правдоподобия (за его понятность и простоту) и теорию приближенно правильного обучения Лесли Гэбриела Вэлианта – за то, что она широко используется в современных алгоритмах машинного обучения.
Какие алгоритмы должен использовать каждый, кто исследует данные?
У Уильяма Чена (исследователя данных в Quora) есть 3 любимых алгоритма:
По его мнению модели регрессии крайне эффективны, а знание статистики поможет раскрыть их скрытый потенциал. Random Forests ему нравится за хорошую способность прогнозирования, а с TF-IDF удобно конвертировать текстовую информацию в числовые вектора. Другие исследователи отмечают также перцептрон, метод k-средних и рекуррентные нейронные сети.Какое будущее ждет науку о данных?
Брайан Ланж (исследователь данных в Datascope) считает, что появятся новые источники данных: данные, которые будут генерировать сенсоры на производстве, в транспорте, даже в офисах, станут источником новой информации для исследователей.
Появятся новые инструменты, значительно упрощающие работу с данными. В первую очередь это связано с появлением открытых библиотек и активным обменом информацией между исследователями. Брайан подчеркивает: алгоритмы, которые 10 лет назад приходилось писать вручную, сейчас находятся в прямом доступе и их легко инкорпорировать в работу.
Профессия исследователя данных пополнится рядом разновидностей. По мнению Брайана, с ростом количества информации и задач, которые выполняет исследователь данных, все больше сотрудников из разных подразделений компаний начнут в той или иной мере работать в области data science – работа исследователей не будет ограничиваться одним отделом.
Дима Королев (специалист по работе с Большими данными), напротив, считает, что в будущем появится full-stack инженер по работе с данными (по аналогии с full-stack разработчиками). Он рассказывает, что, к примеру, на обработке чисел в Excel, применении различных моделей в Python или R и трансляции результатов в режиме реального/близкого к реальному времени, сейчас обычно заняты три человека. В будущем же потребуется один, который будет выполнять множество процессов от начала и до конца.
Существуют ли простые проекты по применению машинного обучения на финансовых рынках?
Владимир Новаковский (заведующий машинным обучением в Quora) считает, что любой проект, хорошо предсказывающий результаты торгов однозначно не будет простым. Он предлагает задуматься о двух областях, в которых машинное обучение может быть успешно применено в сфере трейдинга.
Первая область: прогнозирование показателей, которые опосредованно влияют на торги. Одними из таких показателей может быть волатильность (машинное обучение можно использовать для улучшения GARCH-модели волатильности), уровень безработицы или показатель инфляции.
Суть другого направления для работы заключается в анализе поведения рыночных цен.
По словам Владимира, для создания неплохого проекта, позволяющего разобраться в теме трейдинга, достаточно применить машинное обучение для анализа цен, не «перегружая» модель информацией о транзакционных издержках: конечно, с такой моделью нельзя торговать на бирже, но она может отлично подойти для того, чтобы «вкатиться» в профессию.
В чем разница между «большими данными» и «машинным обучением»?
Владимир Новаковский объясняет, что «большие данные» напрямую не связаны с какими-либо конкретными вычислениями. Например, создание технологии для агрегирования данных о миллиардах транзакций по кредиткам и формирование SQL-запросов к полученному массиву, чтобы понять, сколько операций было совершено на сумму свыше $10 – задача, относящаяся к сфере больших данных, но не имеющая отношения к машинному обучению.
Владимир отмечает, что большой объем данных для проведения вычислений не является обязательной составляющей машинного обучения – алгоритмы можно запускать и на сравнительно небольших массивах (на больших они, тем не менее, как правило, более эффективны, поэтому так часто эти два понятия между собой перекликаются).
P.S. В нашем блоге мы пишем о разработке систем связи и о первых шагах на пути к продвинутому программированию. Постараемся радовать вас регулярными публикациями, друзья.
habr.com
Как выбирать алгоритмы для машинного обучения Microsoft Azure / Блог компании Microsoft / Хабр
Ответ на вопрос «Какой алгоритм машинного обучения использовать?» всегда звучит так: «Смотря по обстоятельствам». Выбор алгоритма зависит от объема, качества и природы данных. Он зависит от того, как вы распорядитесь результатом. Он зависит от того, как из алгоритма были созданы инструкции для реализующего его компьютера, а еще от того, сколько у вас времени. Даже самые опытные специалисты по анализу данных не скажут вам, какой алгоритм лучше, пока сами не попробуют.
Шпаргалка по алгоритмам машинного обучения Microsoft Azure
Скачать шпаргалку по алгоритмам машинного обучения Microsoft Azure можно здесь.Она создана для начинающих специалистов по анализу данных с достаточным опытом в сфере машинного обучения, которые хотят выбрать алгоритм для использования в Студии машинного обучения Azure. Это означает, что информация в шпаргалке обобщена и упрощена, но она покажет вам нужное направление дальнейших действий. Также в ней представлены далеко не все алгоритмы. По мере того как машинное обучение Azure будет развиваться и предлагать больше методов, алгоритмы будут дополняться.
Эти рекомендации созданы на основе отзывов и советов множества специалистов по анализу данных и экспертов по машинному обучению. Мы не во всем согласны друг с другом, но постарались обобщить наши мнения и достичь консенсуса. Большинство спорных моментов начинаются со слов «Смотря по обстоятельствам...» :)
Как использовать шпаргалку
Читать метки пути и алгоритма на схеме нужно так: «Для метка пути> использовать лгоритм>». Например, «Для speed использовать two class logistic regression». Иногда можно использовать несколько ветвей. Иногда ни одна из них не будет идеальным выбором. Это всего лишь рекомендации, поэтому не беспокойтесь о неточностях. Некоторые специалисты по анализу данных, с которыми мне удалось пообщаться, говорят, что единственный верный способ найти лучший алгоритм — попробовать их все.Вот пример эксперимента из Cortana Intelligence Gallery, в котором пробуются несколько алгоритмов с одними и теми же данными и сравниваются результаты.
Скачать и распечатать диаграмму с обзором возможностей Студии машинного обучения можно в этой статье.
Разновидности машинного обучения
Обучение с учителем
Алгоритмы обучения с учителем делают прогнозы на основе набора примеров. Так, чтобы предсказать цены в будущем, можно использовать курс акций в прошлом. Каждый пример, используемый для обучения, получает свою отличительную метку значения, в данном случае это курс акций. Алгоритм обучения с учителем ищет закономерности в этих метках значений. Алгоритм может использовать любую важную информацию — день недели, время года, финансовые данные компании, вид отрасли, наличие серьезных геополитических событий, и каждый алгоритм ищет разные виды закономерностей. После того как алгоритм находит подходящую закономерность, с ее помощью он делает прогнозы по неразмеченным тестовым данным, чтобы предугадать цены в будущем.Это популярный и полезный тип машинного обучения. За одним исключением все модули машинного обучения Azure являются алгоритмами обучения с учителем. В службах машинного обучения Azure представлено несколько конкретных видов машинного обучения с учителем: классификация, регрессия и выявление аномалий.
- Классификация. Когда данные используются для прогнозирования категории, обучение с учителем называется классификацией. В этом случае происходит назначение изображения, например «кот» или «собака». Когда есть только два варианта выбора, это называется двухклассовой классификацией. Когда категорий больше, например, при прогнозировании победителя турнира NCAA March Madness, это называется многоклассовой классификацией.
- Регрессия. Когда прогнозируется значение, например, в случае с курсом акций, обучение с учителем называется регрессией.
- Фильтрация выбросов. Иногда нужно определить необычные точки данных. Например, при обнаружении мошенничества под подозрение попадают любые странные закономерности трат средств с кредитной карты. Возможных вариантов так много, а примеров для обучения так мало, что практически невозможно узнать, как будет выглядеть мошенническая деятельность. При фильтрации выбросов просто изучается нормальная активность (с помощью архива допустимых транзакций) и находятся все операции с заметными отличиями.
Обучение без учителя
В рамках обучения без учителя у объектов данных нет меток. Вместо этого алгоритм обучения без учителя должен организовать данные или описать их структуру. Для этого их можно сгруппировать в кластеры, чтобы они стали более структурированными, или найти другие способы упростить сложные данные.Обучение с подкреплением
В рамках обучения с подкреплением алгоритм выбирает действие в ответ на каждый входящий объект данных. Через некоторое время алгоритм обучения получает сигнал вознаграждения, который указывает, насколько правильным было решение. На этом основании алгоритм меняет свою стратегию, чтобы получить наивысшую награду. В настоящее время в машинном обучении Azure нет модулей обучения с подкреплением. Обучение с подкреплением распространено в роботехнике, где набор показаний датчика в определенный момент времени является объектом, и алгоритм должен выбрать следующее действие робота. Кроме того, этот алгоритм подходит для приложений в Интернете вещей.Советы по выбору алгоритма
Точность
Не всегда нужен самый точный ответ. В зависимости от цели иногда достаточно получить примерный ответ. Если так, то вы можете значительно сократить время отработки, выбирая приближенные методы. Еще одно преимущество приближенных методов заключается в том, что они исключают переобучение.Время обучения
Количество минут или часов, необходимых для обучения модели, сильно зависит от алгоритмов. Зачастую время обучения тесно связано с точностью — они определяют друг друга. Кроме того, некоторые алгоритмы более чувствительны к объему обучающей выборки, чем другие. Ограничение по времени помогает выбрать алгоритм, особенно если используется обучающая выборка большого объема.Линейность
Во многих алгоритмах машинного обучения используется линейность. Алгоритмы линейной классификации предполагают, что классы можно разделить прямой линией (или ее более многомерным аналогом). Здесь речь идет о логистической регрессии и метод опорных векторов (в машинном обучении Azure). Алгоритмы линейной регрессии предполагают, что распределение данных описывается прямой линией*. Эти предположения подходят для решения ряда задач, но в некоторых случаях снижают точность.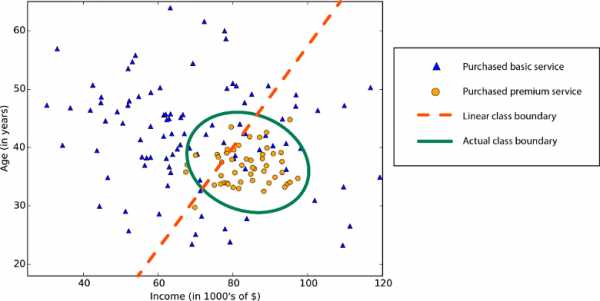 Ограничение нелинейных классов — использование алгоритма линейной классификации снижает точность
Ограничение нелинейных классов — использование алгоритма линейной классификации снижает точность
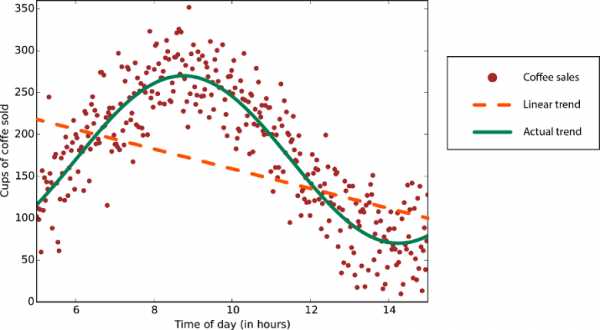 Данные с нелинейной закономерностью — при использовании метода линейной регрессии возникают более серьезные ошибки, чем это допустимо
Данные с нелинейной закономерностью — при использовании метода линейной регрессии возникают более серьезные ошибки, чем это допустимо
Несмотря на недостатки, к линейным алгоритмам обычно обращаются в первую очередь. Они просты с алгоритмической точкой зрения, а обучение проходит быстро.
Количество параметров
Параметры — это рычаги, с помощью которых специалисты по данным настраивают алгоритм. Это числа, которые влияют на поведение алгоритма, например устойчивость к ошибкам или количество итераций, либо различия в вариантах поведения алгоритма. Иногда время обучения и точность алгоритма могут меняться в зависимости от тех или иных параметров. Как правило, найти хорошую комбинацию параметров для алгоритмов можно путем проб и ошибок.Также в машинном обучении Azure есть модульный блок подбора параметров, который автоматически пробует все комбинации параметров с указанной вами степенью детализации. Хоть этот способ и позволяет опробовать множество вариантов, однако чем больше параметров, тем больше времени уходит на обучение модели.
К счастью, если параметров много, это означает, что алгоритм отличается высокой гибкостью. И при таком способе можно добиться отличной точности. Но при условии, что вам удастся найти подходящую комбинацию параметров.
Количество признаков
В некоторых типах данных признаков может быть гораздо больше, чем объектов. Это обычно происходит с данными из области генетики или с текстовыми данными. Большое количество признаков препятствует работе некоторых алгоритмов обучения, из-за чего время обучения невероятно растягивается. Для подобных случаев хорошо подходит метод опорных векторов (см. ниже).Особые случаи
Некоторые алгоритмы обучения делают допущения о структуре данных или желаемых результатах. Если вам удастся найти подходящий вариант для своих целей, он принесет вам отличные результаты, более точные прогнозы или сократит время обучения.Свойства алгоритма:
• — демонстрирует отличную точность, короткое время обучения и использование линейности. ○ — демонстрирует отличную точность и среднее время обучения.
Примечания к алгоритму
Линейная регрессия
Как мы уже говорили, линейная регрессия рассматривает данные линейно (или в плоскости, или в гиперплоскости). Это удобная и быстрая «рабочая лошадка», но для некоторых проблем она может быть чересчур простой. Здесь вы найдете руководство по линейной регрессии.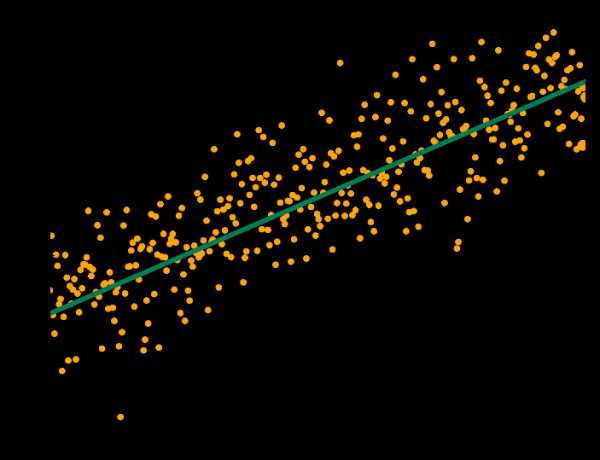 Данные с линейным трендом
Данные с линейным трендом
Логистическая регрессия
Пусть слово «регрессия» в названии не вводит вас в заблуждение. Логистическая регрессия — это очень мощный инструмент для двухклассовой и многоклассовой классификации. Это быстро и просто. Поскольку вместо прямой линии здесь используется кривая в форме буквы S, этот алгоритм прекрасно подходит для разделения данных на группы. Логистическая регрессия ограничивает линейный класс, поэтому вам придется смириться с линейной аппроксимацией.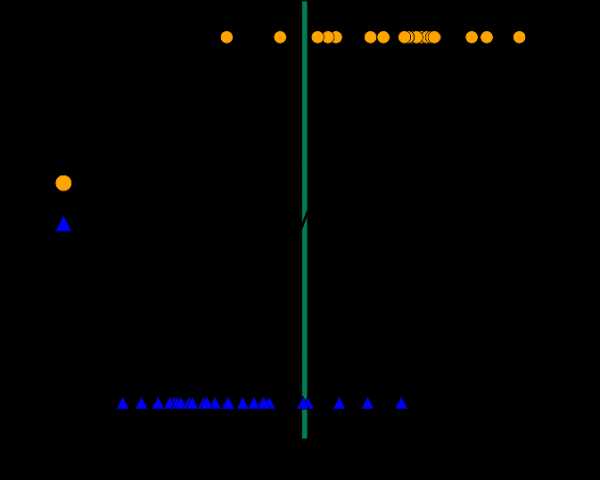 Логистическая регрессия для двухклассовых данных всего с одним признаком — граница класса находится в точке, где логистическая кривая близка к обоим классам
Логистическая регрессия для двухклассовых данных всего с одним признаком — граница класса находится в точке, где логистическая кривая близка к обоим классам
Деревья, леса и джунгли
Леса решающих деревьев (регрессия, двухклассовые и многоклассовые), джунгли решающих деревьев (двухклассовые и многоклассовые) и улучшенные деревья принятия решений (регрессия и двухклассовые) основаны на деревьях принятия решений, базовой концепции машинного обучения. Существует много вариантов деревьев принятия решений, но все они выполняют одну функцию — подразделяют пространство признаков на области с одной и той же меткой. Это могут быть области одной категории или постоянного значения, в зависимости от того, используете ли вы классификацию или регрессию.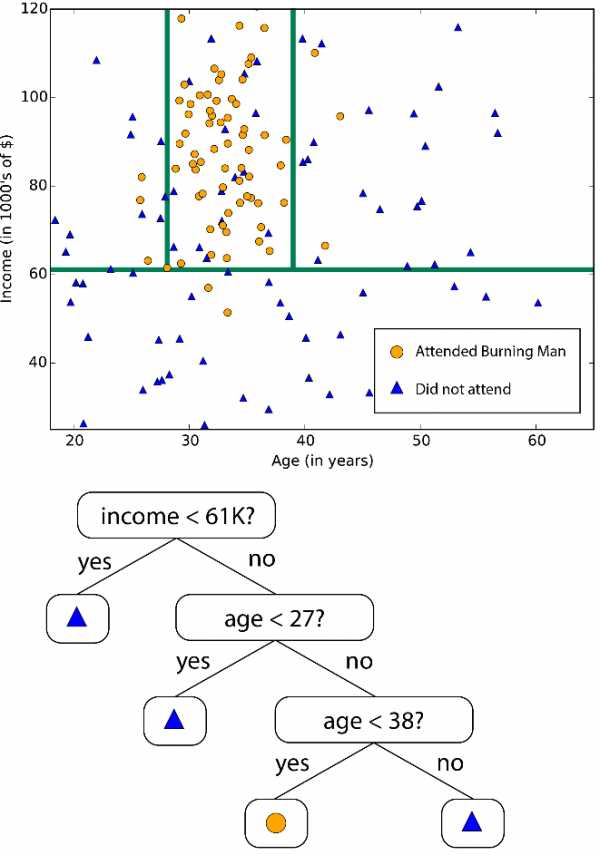 Дерево принятия решений подразделяет пространство признаков на области с примерно одинаковыми значениями
Дерево принятия решений подразделяет пространство признаков на области с примерно одинаковыми значениями
Поскольку пространство признаков можно разделить на небольшие области, это можно сделать так, чтобы в одной области был один объект — это грубый пример ложной связи. Чтобы избежать этого, крупные наборы деревьев создаются таким образом, чтобы деревья не были связаны друг с другом. Таким образом, «дерево принятия решений» не должно выдавать ложных связей. Деревья принятия решений могут потреблять большие объемы памяти. Джунгли решающих деревьев потребляют меньше памяти, но при этом обучение займет немного больше времени.
Улучшенные деревья принятия решений ограничивают количество разделений и распределение точек данных в каждой области, чтобы избежать ложных связей. Алгоритм создает последовательность деревьев, каждое из которых исправляет допущенные ранее ошибки. В результате мы получаем высокую степень точности без больших затрат памяти. Полное техническое описание смотрите в научной работе Фридмана.
Быстрые квантильные регрессионные леса — это вариант деревьев принятия решений для тех случаев, когда вы хотите знать не только типичное (среднее) значение данных в области, но и их распределение в форме квантилей.
Нейронные сети и восприятие
Нейронные сети — это алгоритмы обучения, которые созданы на основе модели человеческого мозга и направлены на решение многоклассовой, двухклассовой и регрессионной задач. Их существует огромное множество, но в машинном обучении Azure нейронные сети принимают форму направленного ациклического графика. Это означает, что входные признаки передаются вперед через последовательность уровней и превращаются в выходные данные. На каждом уровне входные данные измеряются в различных комбинациях, суммируются и передаются на следующий уровень. Эта комбинация простых расчетов позволяет изучать сложные границы классов и тенденции данных будто по волшебству. Подобные многоуровневые сети выполняют «глубокое обучение», которое служит источником вдохновения для технических отчетов и научной фантастики.Но такая производительность обходится не бесплатно. Обучение нейронных сетей занимает много времени, особенно для крупных наборов данных с множеством признаков. В них больше параметров, чем в большинстве алгоритмов, и поэтому подбор параметров значительно увеличивает время обучения. А для перфекционистов, которые хотят указать собственную структуру сети, возможности практически не ограничены.
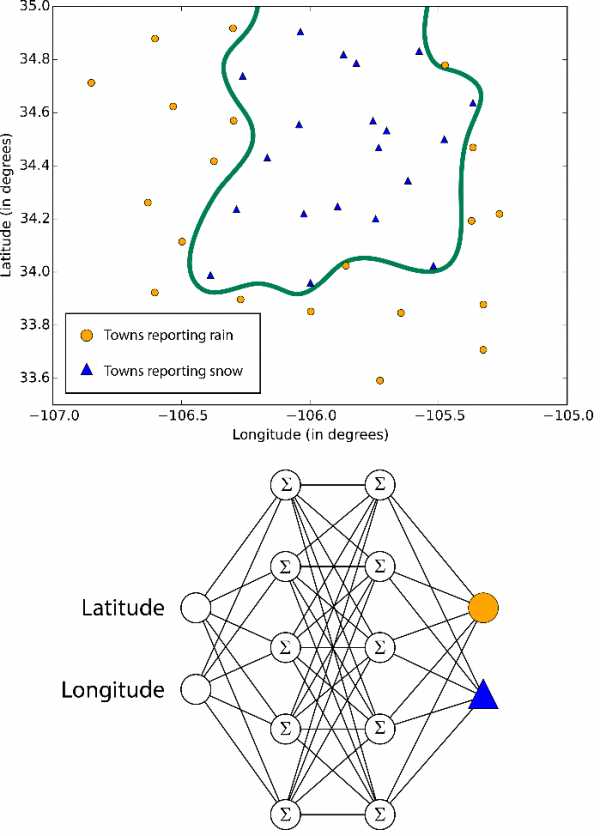 Границы, изучаемые нейронными сетями, бывают сложными и хаотичными
Границы, изучаемые нейронными сетями, бывают сложными и хаотичными
Однослойный перцептрон — это ответ нейронных сетей на увеличение времени обучения. В нем используется сетевая структура, которая создает линейные классовые границы. По современным стандартам звучит примитивно, но этот алгоритм давно проверен на деле и быстро обучается.
Методы опорных векторов
Методы опорных векторов находят границу, которая разделяет классы настолько широко, насколько это возможно. Когда невозможно четко разделить два класса, алгоритмы находят наилучшую границу. Согласно машинному обучению Azure, двухклассовый метод опорных векторов делает это с помощью прямой линии (говоря на языке методов опорных векторов, использует линейное ядро). Благодаря линейной аппроксимации обучение выполняется достаточно быстро. Особенно интересна функция работы с объектами с множеством признаков, например, текстом или геномом. В таких случаях опорные векторные машины могут быстрее разделить классы и отличаются минимальной вероятностью создания ложной связи, а также не требуют больших объемов памяти.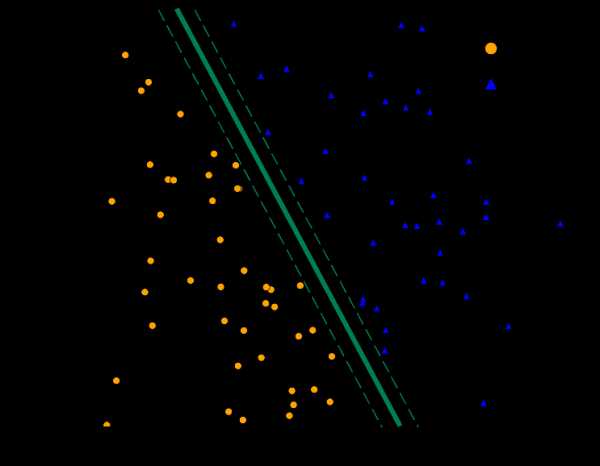 Стандартная граница класса опорной векторной машины увеличивает поле между двумя классами
Стандартная граница класса опорной векторной машины увеличивает поле между двумя классами
Еще один продукт от Microsoft Research — двухклассовые локальные глубинные методы опорных векторов. Это нелинейный вариант методов опорных векторов, который отличается скоростью и эффективностью памяти, присущей линейной версии. Он идеально подходит для случаев, когда линейный подход не дает достаточно точных ответов. Чтобы обеспечить высокую скорость, разработчики разбивают проблему на несколько небольших задач линейного метода опорных векторов. Подробнее об этом читайте в полном описании.
С помощью расширения нелинейных методов опорных векторов одноклассовая машина опорных векторов создает границу для всего набора данных. Это особенно полезно для фильтрации выбросов. Все новые объекты, которые не входят в пределы границы, считаются необычными и поэтому внимательно изучаются.
Байесовские методы
Байесовские методы отличаются очень нужным качеством: они избегают ложных связей. Для этого они заранее делают предположения о возможном распределении ответа. Также для них не нужно настраивать много параметров. Машинное обучение Azure предлагает Байесовские методы как для классификации (двухклассовая классификация Байеса), так и для регрессии (Байесова линейная регрессия). При этом предполагается, что данные можно разделить или расположить вдоль прямой линии.Кстати, точечные машины Байеса были разработаны в Microsoft Research. В их фундаменте лежит великолепная теоретическая работа. Если вас заинтересует эта тема, читайте статью в MLR и блог Криса Бишопа (Chris Bishop).
Особые алгоритмы
Если вы преследуете конкретную цель, вам повезло. В коллекции машинного обучения Azure есть алгоритмы, которые специализируются в прогнозировании рейтингов (порядковая регрессия), прогнозирование количества (регрессия Пуассона) и выявлении аномалий (один из них основан на анализе главных компонентов, а другой — на методах опорных векторов). А еще есть алгоритм кластеризации (метод k-средних).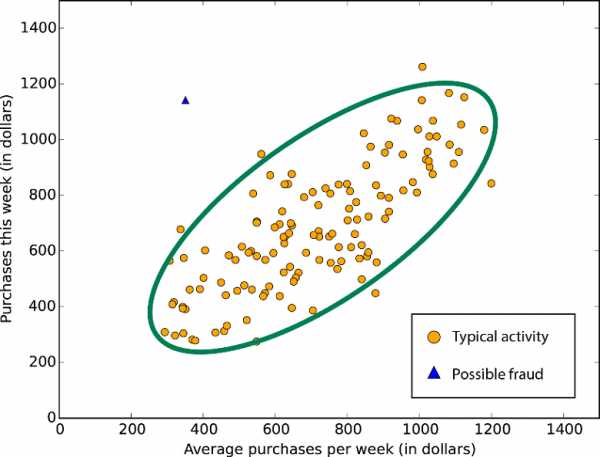 Выявление аномалий на основе PCA — огромное множество данных попадает под стереотипное распределение; под подозрение попадают точки, которые сильно отклоняются от этого распределения
Выявление аномалий на основе PCA — огромное множество данных попадает под стереотипное распределение; под подозрение попадают точки, которые сильно отклоняются от этого распределения
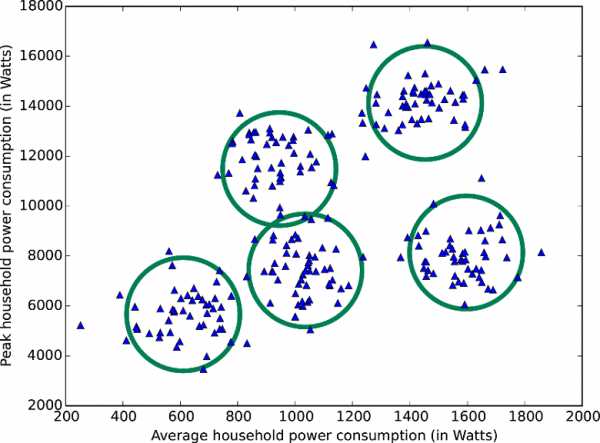 Набор данных разделяется на пять кластеров по методу k-средних
Набор данных разделяется на пять кластеров по методу k-средних
Также есть многоклассовый классификатор «один против всех», который разбивает проблему классификации N-класса на двухклассовые проблемы класса N-1. Точность, время обучения и свойства линейности зависят от используемых двухклассовых классификаторов.
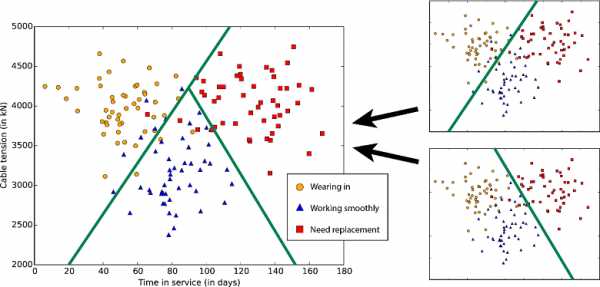 Два двухклассовых классификатора формируют трехклассовый классификатор
Два двухклассовых классификатора формируют трехклассовый классификатор
Кроме того, Azure предлагает доступ к мощной платформе машинного обучения под названием Vowpal Wabbit. VW отказывается от категоризации, поскольку может изучить проблемы классификации и регрессии и даже обучаться от частично помеченных данных. Вы можете выбрать любой из алгоритмов обучения, функций потерь и алгоритмов оптимизации. Эта платформа отличается эффективностью, возможностью параллельного выполнения и непревзойденной скоростью. Она без труда справляется с большими наборами данных. VW была запущена Джоном Лэнгфордом (John Langford), специалистом из Microsoft Research, и является болидом «Формулы-1» в океане серийных автомобилей. Не каждая проблема подходит для VW, но если вы считаете, что это верный для вас вариант, то затраченные усилия обязательно окупятся. Также платформа доступна в виде автономного открытого исходного кода на нескольких языках.
Последние материалы из нашего блога по данной теме
1. Azure понятным языком (шпаргалка). 2. Грузовики и рефрижераторы в облаке (кейс).Напоминаем, что попробовать Microsoft Azure можно здесь.
Если вы увидели неточность перевода, сообщите, пожалуйста, об этом в личные сообщения.
*UPD
Так как в тексте автора присутствует неточность, дополняем материал (спасибо @fchugunov)Линейная регрессия применяется не только для определения зависимости, которая описывается прямой линией (или плоскостью), как указано в статье. Зависимость может описываться и более сложными функциями. Например, для функции на втором графике может быть применен метод полиномиальной регрессии (разновидность линейной регрессии). Для этого входные данные (например значение x) преобразуются в набор факторов [x, x², x³,..], а метод линейной регрессии уже подбирает коэффициенты к ним.
habr.com
Десять алгоритмов машинного обучения, которые вам нужно знать
Мы живем в начале революционной эры аналитики данных, больших вычислительных мощностей и облачных вычислений. Машинное обучение играет в этом большую роль, а оно основано на алгоритмах. В этой статье собраны десять самых популярных алгоритмов машинного обучения.
Эти алгоритмы можно разделить на три основные категории.
- Контролируемые алгоритмы: набор обучающих данных имеет входные данные, а также желаемый результат. Во время обучения модель будет корректировать свои переменные для сопоставления входных данных с соответствующим выходом.
- Неконтролируемые алгоритмы: в этой категории нет желаемого результата. Алгоритмы будут группировать набор данных на разные группы.
- Алгоритмы с подкреплением: эти алгоритмы обучаются на готовых решениях. На основе этих решений алгоритм будет обучаться на основе успеха/ошибки результата. В конечном счете алгоритм сможет давать хорошие прогнозы.
Следующие алгоритмы будут описываться в этой статье.
- Линейная регрессия
- SVM (метод опорных векторов)
- KNN (метод k-ближайших соседей)
- Логистическая регрессия
- Дерево решений
- Метод k-средних
- Random Forest
- Наивный байесовский классификатор
- Алгоритмы сокращения размеров
- Алгоритмы усиления градиента
1. Линейная регрессия (linear regression)
Алгоритм линейной регрессии будет использовать точки данных для поиска оптимальной линии для создания модели. Линию можно представить уравнением y = m*x + c, где y – зависимая переменная, а x – независимая переменная. Базовые теории исчисления применяются для определения значений для m и c с использованием заданного набора данных.
Существует два типа линейной регрессии: простая линейная регрессия с одной независимой переменной и множественная линейная регрессия, где используется несколько независимых переменных.
scikit-learn — это простой и эффективный инструмент для машинного обучения на Python. Ниже представлена реализация линейной регрессии при помощи scikit-learn.
2. Метод опорных векторов (SVM — Support Vector Machine)
Он принадлежит к алгоритму классификационного типа. Алгоритм будет разделять точки данных, используя линию. Эта линия должна быть максимально удаленной от ближайших точек данных в каждой из двух категорий.
На диаграмме выше красная линия подходит лучше всего, так как она больше всего удалена от всех точек. На основе этой линии данные делятся на две группы.
3. Метод k-ближайших соседей (KNN — K-nearest neighbors)
Это простой алгоритм, который предсказывает неизвестную точку данных на основе её k ближайших соседей. Значение k здесь критически важный фактор, который определяет точность предсказания. Ближайшая точка определяется исходя из базовых функций расстояния, вроде Евклидовой.
Однако этот алгоритм требует высокой вычислительной мощности, и нам необходимо сначала нормализовать данные, чтобы каждая точка данных была в том же диапазоне.
4. Логистическая регрессия (logistic regression)
Логистическая регрессия используется, когда ожидается дискретный результат, например, возникновение какого-либо события (пойдет дождь или нет). Обычно логистическая регрессия использует функцию, чтобы поместить значения в определенный диапазон.
“Сигмоид” — это одна из таких функций в форме буквы S, которая используется для бинарной классификации. Она конвертирует значения в диапазон от 0 до 1, что является вероятностью возникновения события.
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Выше находится простое уравнение логистической регрессии, где b0 и b1 — это постоянные.Во время обучения значения для них будут вычисляться таким образом, чтобы ошибка между предсказанием и фактическим значением становилась минимальной.
5. Дерево решений (decision tree)
Этот алгоритм распределяет данные на несколько наборов на основе каких-либо свойств (независимых переменных). Обычно этот алгоритм используется для решения проблем классификации. Категоризация используется на основе методов вроде Джини, Хи-квадрат, энтропия и так далее.
Возьмем группу людей и используем алгоритм дерева решений, чтобы понять, кто из них имеет кредитную карту. Например, возьмем возраст и семейное положение в качестве свойств. Если человеку больше 30 лет и он/она замужем или женат, то вероятность того, что у них есть кредитная карта, выше.
Дерево решений можно расширить и добавить подходящие свойства и категории. Например, если человек женат и ему больше 30 лет, то он, вероятно, имеет кредитную карту. Данные тестирования будут использоваться для создания этого дерева решений.
6. Метод k-средних (k-means)
Это алгоритм, работающий без присмотра, который предоставляет решение проблемы группировки. Алгоритм формирует кластеры, которые содержат гомогенные точки данных.
Входные данные алгоритма — это значение k. На основе этого алгоритм выбирает k центроидов. Затем центроид и его соседние точки данных формируют кластер, а внутри каждого кластера создается новый центроид. Потом точки данных, близкие к новому центроиду снова комбинируются для расширения кластера. Процесс продолжается до тех пор, пока центроиды не перестанут изменяться.
7. Случайный лес (Random Forest)
Random Forest — это коллекция деревьев решений. Каждое дерево пытается оценить данные, и это называется голосом. В идеале мы рассматриваем каждый голос от каждого дерева и выбираем классификацию с большим количеством голосов.
8. Наивный байесовский классификатор (Naive Bayes)
Этот алгоритм основан на теореме Байеса. Благодаря этому наивный байесовский классификатор можно применить, только если функции независимы друг от друга. Если мы попытаемся предсказать вид цветка на основе длины и ширины его лепестка, мы сможем использовать этот алгоритм, так как функции не зависят друг от друга.
Уравнение Байеса
Наивный байесовский алгоритм также является классификационным. Он используется, когда проблема содержит несколько классов.
9. Алгоритмы сокращения размеров (dimensional reduction algorithms)
Некоторые наборы данных содержат много переменных, которыми сложно управлять. Особенно сейчас, когда системы собирают большое количество детализированных данных из разных источников. В таких случаях данные могут содержать тысячи переменных, многие из которых будут не нужны.
В таком случае почти невозможно определить переменные, которые будут иметь наибольшее влияние на наше предсказание. в таких ситуациях используются алгоритмы сокращения размеров. Они применяют алгоритмы вроде случайного леса или дерева решений, чтобы определить самые важные переменные.
10. Алгоритмы усиления градиента (gradient boosting algorithms)
Алгоритм усиления градиента использует множество слабых алгоритмов, чтобы создать более точный, стабильный и надежный алгоритм.
Существует несколько алгоритмов усиления градиента:
- XGBoost — использует линейные алгоритмы и дерево решений
- LightGBM — использует только алгоритмы, основанные на деревьях
Особенность алгоритмов усиления градиента — это их высокая точность. Более того, алгоритмы вроде LightGBM имеют и высокую производительность.
Если вы нашли опечатку - выделите ее и нажмите Ctrl + Enter! Для связи с нами вы можете использовать [email protected].
apptractor.ru
Вероятностная интерпретация классических моделей машинного обучения / Хабр
Этой статьей я начинаю серию, посвященную генеративным моделям в машинном обучении. Мы посмотрим на классические задачи машинного обучения, определим, что такое генеративное моделирование, посмотрим на его отличия от классических задач машинного обучения, взглянем на существующие подходы к решению этой задачи и погрузимся в детали тех из них, что основаны на обучении глубоких нейронных сетей. Но прежде, в качестве введения, мы посмотрим на классические задачи машинного обучения в их вероятностной постановке.
Классические задачи машинного обучения
Две классические задачи машинного обучения — это классификация и регрессия. Давайте посмотрим ближе на каждую из них. Рассмотрим постановку обеих задач и простейшие примеры их решения.
Классификация
Задача классификации — это задача присвоения меток объектам. Например, если объекты — это фотографии, то метками может быть содержание фотографий: содержит ли изображение пешехода или нет, изображен ли мужчина или женщина, какой породы собака изображена на фотографии. Обычно есть набор взаимоисключающих меток и сборник объектов, для которых эти метки известны. Имея такую коллекцию данных необходимо автоматически расставлять метки на произвольных объектах того же типа, что были в изначальной коллекции. Давайте формализуем это определение. Допустим, есть множество объектов . Это могут быть точки на плоскости, рукописные цифры, фотографии или музыкальные произведения. Допустим также, что есть конечное множество меток . Эти метки могут быть пронумерованы. Мы будем отождествлять метки и их номера. Таким образом в нашей нотации будет обозначаться как . Если , то задача называется задачей бинарной классификации, если меток больше двух, то обычно говорят, что это просто задача классификации. Дополнительно, у нас есть входная выборка . Это те самые размеченные примеры, на которых мы и будем обучаться проставлять метки автоматически. Так как мы не знаем классов всех объектов точно, мы считаем, что класс объекта — это случайная величина, которую мы для простоты тоже будем обозначать . Например, фотография собаки может классифицироваться как собака с вероятностью 0.99 и как кошка с вероятностью 0.01. Таким образом, чтобы классифицировать объект, нам нужно знать условное распределение этой случайной величины на этом объекте .
Задача нахождения при данном множестве меток и данном наборе размеченных примеров называется задачей классификации.
Вероятностная постановка задачи классификации
Чтобы решить эту задачу, удобно переформулировать ее на вероятностном языке. Итак, есть множество объектов и множество меток . — случайная величина, представляющая собой случайный объект из . — случайная величина, представляющая собой случайную метку из . Рассмотрим случайную величину с распределением , которое является совместным распределением объектов и их классов. Тогда, размеченная выборка — это сэмплы из этого распределения . Мы будем предполагать, что все сэмплы независимо и одинаково распределены (i.i.d в англоязычной литературе).
Задача классификации теперь может быть переформулирована как задача нахождения при данном сэмпле .
Классификация двух нормальных распределений
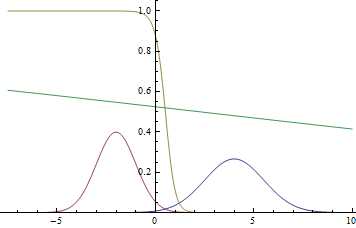
Давайте посмотрим, как это работает на простом примере. Положим , , , , . То есть, у нас есть две гауссианы, из которых мы равновероятно сэмплируем данные и нам нужно, имея точку из , предсказать, из какой гауссианы она была получена.
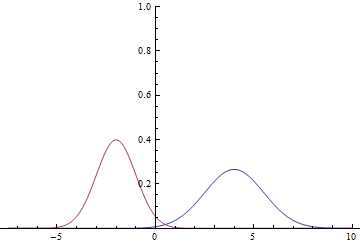
Рис. 1. Плотности распределения и .
Так как область определения гауссианы — вся числовая прямая, очевидно, что эти графики пересекаются, а значит, есть такие точки, в которых плотности вероятности и равны.
Найдем условную вероятность классов:
Т.е.
Вот так будут выглядеть график плотности вероятностей :
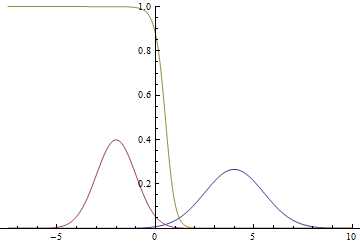
Рис. 2. Плотности распределения , и . там, где две гауссианы пересекаются.
Видно, что близко к модам гауссиан уверенность модели в принадлежности точки конкретному классу очень высока (вероятность близка к нулю или единице), а там, где графики пересекаются модель может только случайно угадывать и выдает .
Метод максимизации правдоподобия
Большая часть практических задач не может быть решена вышеописанным способом, так как обычно не задано явно. Вместо этого обычно имеется набор данных с некоторой неизвестной совместной плотностью распределения . В таком случае для решения задачи используется метод максимального правдоподобия. Формальное определение и обоснование метода можно найти в вашей любимой книге по статистике или по ссылке выше, а в данной статье я опишу его интуитивный смысл.
Принцип максимизации правдоподобия говорит, что если есть некоторое неизвестное распределение , из которого есть набор сэмплов , и некоторое известное параметрическое семейство распределений , то для того, чтобы максимально приблизило , нужно найти такой вектор параметров , который максимизирует совместную вероятность данных (правдоподобие) , которое еще называют правдоподобием данных. Доказано, что при разумных условиях эта оценка является состоятельной и несмещенной оценкой истинного вектора параметров. Если сэмплы выбраны из , то есть данные i.i.d., то совместное распределение распадается на произведение распределений:
Логарифм и умножение на константу — монотонно возрастающие функции и не меняют положений максимумов, потому совместную плотность можно внести под логарифм и умножить на :
Последнее выражение, в свою очередь, является несмещенной и состоятельной оценкой ожидаемого логарифма правдоподобия:
Задачу максимизации можно переписать как задачу минимизации:
Последняя величина называется кросс-энтропией распределений и . Именно ее и принято оптимизировать для решения задач обучения с подкреплением (supervised learning).
Минимизацию на протяжении этого цикла статей мы будем проводить с помощью Stochastic Gradient Descent (SGD), а точнее, его расширения на основе адаптивных моментов, пользуясь тем, что сумма градиентов по подвыборке (так называемому “минибатчу”) является несмещенной оценкой градиента минимизируемой функции.
Классификация двух нормальных распределений логистической регрессией
Давайте попробуем решить ту же задачу, что была описана выше, методом максимального правдоподобия, взяв в качестве параметрического семейства простейшую нейронную сеть. Получившаяся модель называется логистической регрессией. Полный код модели можно найти тут, в статье же освещены только ключевые моменты.
Для начала нужно сгенерировать данные для обучения. Нужно сгенерировать минибатч меток классов и для каждой метки сгенерировать точку из соответствующей гауссианы:
def input_batch(dataset_params, batch_size): input_mean = tf.constant(dataset_params.input_mean, dtype=tf.float32) input_stddev = tf.constant(dataset_params.input_stddev,dtype=tf.float32) count = len(dataset_params.input_mean) labels = tf.contrib.distributions.Categorical(probs=[1./count] * count) .sample(sample_shape=[batch_size]) components = [] for i in range(batch_size): components .append(tf.contrib.distributions.Normal( loc=input_mean[labels[i]], scale=input_stddev[labels[i]]) .sample(sample_shape=[1])) samples = tf.concat(components, 0) return labels, samplesОпределим наш классификатор. Он будет простейшей нейронной сетью без скрытых слоев:
def discriminator(input): output_size = 1 param1 = tf.get_variable( "weights", initializer=tf.truncated_normal([output_size], stddev=0.1) ) param2 = tf.get_variable( "biases", initializer=tf.constant(0.1, shape=[output_size]) ) return input * param1 + param2И запишем функцию потерь — кросс-энтропию между распределениями реальных и предсказанных меток:
labels, samples = input_batch(dataset_params, training_params.batch_size) predicted_labels = discriminator(samples) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits( labels=tf.cast(labels, tf.float32), logits=predicted_labels) )Ниже приведены графики обучения двух моделей: базовой и с L2-регуляризацией:
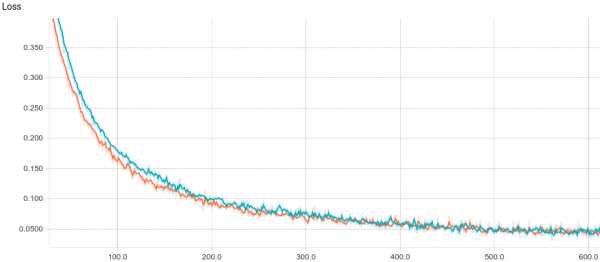
Рис. 3. Кривая обучения логистической регрессии.
Видно, что обе модели быстро сходятся к хорошему результату. Модель без регуляризации показывает себя лучше потому, что в этой задаче не нужна регуляризация, а она слегка замедляет скорость обучения. Давайте взглянем поближе на процесс обучения:
Рис. 4. Процесс обучения логистический регрессии.
Видно, что обучаемая разделяющая поверхность постепенно сходится к аналитически вычисленной, при чем, чем она ближе, тем медленнее сходится из-за все более слабого градиента функции потерь.
Регрессия
Задача регрессии — это задача предсказания одной непрерывной случайной величины на основе значений других случайных величин . Например, предсказание роста человека по его полу (дискретная случайная величина) и возрасту (непрерывная случайная величина). Точно так же, как и в задаче классификации, нам дана размеченная выборка . Предсказать значение случайной величины напрямую невозможно, ведь она случайная и, по сути, является функцией, поэтому формально задача записывается как предсказание ее условного ожидаемого значения:
Регрессия линейно зависимых величин с нормальным шумом
Давайте посмотрим, как решается задача регрессии на простом примере. Пусть есть две независимые случайные величины . Например, это высота дерева и нормальный случайный шум. Тогда мы можем предположить, что возраст дерева является случайной величиной . В таком случае по линейности математического ожидания и независимости и :
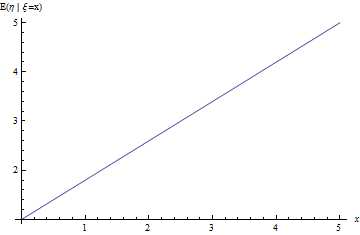
Рис. 5. Линия регрессии задачи про линейно зависимые величины с шумом.
Решение задачи регрессии методом максимального правдоподобия
Давайте сформулируем задачу регрессии через метод максимального правдоподобия. Положим ). Где — новый вектор параметров. Видно, что мы ищем — математическое ожидание , т.е. это корректно поставленная задача регрессии. Тогда
Состоятельной и несмещенной оценкой этого матожидания будет среднее по выборке
Таким образом, для решения задачи регрессии удобно минимизировать среднеквадратичную ошибку на обучающей выборке.
Регрессия величины линейной регрессией
Давайте попробуем решить ту же задачу, что была выше, методом из предыдущего раздела, взяв в качестве параметрического семейства простейшую возможную нейронную сеть. Получившаяся модель называется линейной регрессией. Полный код модели можно найти тут, в статье же освещены только ключевые моменты.
Для начала нужно сгенерировать данные для обучения. Сначала мы генерируем минибатч входных переменных , после чего получаем сэмпл исходной переменной :
def input_batch(dataset_params, batch_size): samples = tf.random_uniform([batch_size], 0., 10.) noise = tf.random_normal([batch_size], mean=0., stddev=1.) labels = (dataset_params.input_param1 * samples + dataset_params.input_param2 + noise) return labels, samplesОпределим нашу модель. Она будет простейшей нейронной сетью без скрытых слоев:
def predicted_labels(input): output_size = 1 param1 = tf.get_variable( "weights", initializer=tf.truncated_normal([output_size], stddev=0.1) ) param2 = tf.get_variable( "biases", initializer=tf.constant(0.1, shape=[output_size]) ) return input * param1 + param2И запишем функцию потерь — L2-расстояние между распределениями реальных и предсказанных значений:
labels, samples = input_batch(dataset_params, training_params.batch_size) predicted_labels = discriminator(samples) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits( labels=tf.cast(labels, tf.float32), logits=predicted_labels) )Ниже приведены графики обучения двух моделей: базовой и с L2-регуляризацией:
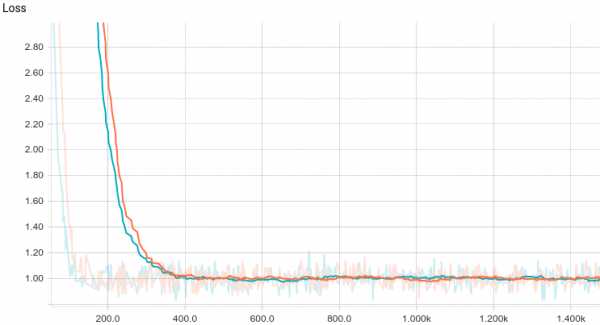
Рис. 6. Кривая обучения линейной регрессии.
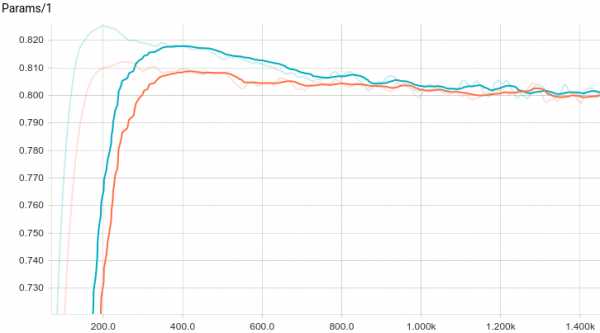
Рис. 7. График изменения первого параметра с шагом обучения.
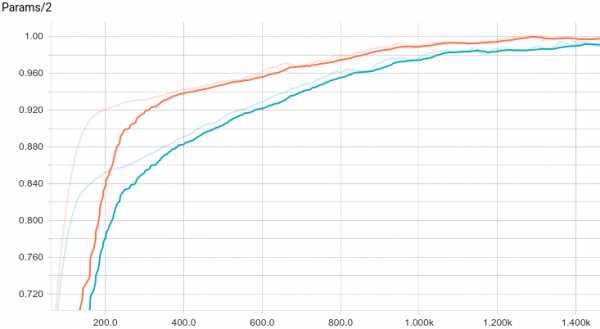
Рис. 8. График изменения второго параметра с шагом обучения.
Видно, что обе модели быстро сходятся к хорошему результату. Модель без регуляризации показывает себя лучше потому, что в этой задаче не нужна регуляризация, а она слегка замедляет скорость обучения. Давайте взглянем поближе на процесс обучения:
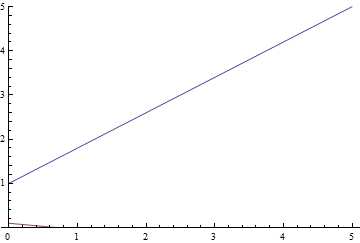
Рис. 9. Процесс обучения линейной регрессии.
Видно, что обучаемое математическое ожидание постепенно сходится к аналитически вычисленному, при чем, чем оно ближе, тем медленнее сходится из-за все более слабого градиента функции потерь.
Другие задачи
В дополнение к изученным выше задачам классификации и регрессии есть и другие задачи так называемого обучения с учителем, в основном сводящиеся к отображению между точками и последовательностями: Object-to-Sequence, Sequence-to-Sequence, Sequence-to-Object. Так же есть и большой спектр классических задач обучения без учителя: кластеризация, заполнение пробелов в данных, и, наконец, явная или неявная аппроксимация распределений, которая и используется для генеративного моделирования. Именно о последнем классе задач будет идти речь в этом цикле статей.
Генеративные модели
В следующей главе мы посмотрим, что такое генеративные модели и чем они принципиально отличаются от рассмотренных в этой главе дискриминативных. Мы посмотрим на простейшие примеры генеративных моделей и попробуем обучить модель, генерирующую сэмплы из простого распределения данных.
Благодарности
Спасибо Olga Talanova за ревью этой статьи. Спасибо Sofya Vorotnikova за комментарии, редактирование и проверку английской версии. Спасибо Andrei Tarashkevich за помощь в верстке.
habr.com
Машинное обучение — Википедия с видео // WIKI 2
Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач. Для построения таких методов используются средства математической статистики, численных методов, методов оптимизации, теории вероятностей, теории графов, различные техники работы с данными в цифровой форме.
Различают два типа обучения:
- Обучение по прецедентам, или индуктивное обучение, основано на выявлении эмпирических закономерностей в данных.
- Дедуктивное обучение предполагает формализацию знаний экспертов и их перенос в компьютер в виде базы знаний.
Дедуктивное обучение принято относить к области экспертных систем, поэтому термины машинное обучение и обучение по прецедентам можно считать синонимами.
Многие методы индуктивного обучения разрабатывались как альтернатива классическим статистическим подходам. Многие методы тесно связаны с извлечением информации (англ. information extraction), интеллектуальным анализом данных (data mining).
Энциклопедичный YouTube
-
1/5
Просмотров:19 804
846
7 023
961
3 024
-
Машинное обучение - Дмитрий Ветров
-
Базовые принципы машинного обучения на примере линейной и логистической регрессии (Павел Нестеров)
-
Байесовские методы машинного обучения — Евгений Бурнаев
-
Машинное обучение и анализ данных. Дмитрий Коробченко (NVIDIA)
-
Задачи в машинном обучении - Александр Дьяконов
Содержание
Общая постановка задачи обучения по прецедентам
Имеется множество объектов (ситуаций) и множество возможных ответов (откликов, реакций). Существует некоторая зависимость между ответами и объектами, но она неизвестна. Известна только конечная совокупность прецедентов — пар «объект, ответ», называемая обучающей выборкой. На основе этих данных требуется восстановить неявную зависимость, то есть построить алгоритм, способный для любого возможного входного объекта выдать достаточно точный классифицирующий ответ. Эта зависимость не обязательно выражается аналитически, и здесь нейросети реализуют принцип эмпирически формируемого решения. Важной особенностью при этом является способность обучаемой системы к обобщению, то есть к адекватному отклику на данные, выходящие за пределы имеющейся обучающей выборки. Для измерения точности ответов вводится оценочный функционал качества.
Данная постановка является обобщением классических задач аппроксимации функций. В классических задачах аппроксимации объектами являются действительные числа или векторы. В реальных прикладных задачах входные данные об объектах могут быть неполными, неточными, нечисловыми, разнородными. Эти особенности приводят к большому разнообразию методов машинного обучения.
Способы машинного обучения
Раздел машинного обучения, с одной стороны, образовался в результате разделения науки о нейросетях на методы обучения сетей и виды топологий их архитектуры, с другой стороны — вобрал в себя методы математической статистики. Указанные ниже способы машинного обучения исходят из случая использования нейросетей, хотя существуют и другие методы, использующие понятие обучающей выборки — например, дискриминантный анализ, оперирующий обобщённой дисперсией и ковариацией наблюдаемой статистики, или байесовские классификаторы. Базовые виды нейросетей, такие как перцептрон и многослойный перцептрон (а также их модификации), могут обучаться как с учителем, так и без учителя, с подкреплением и самоорганизацией. Но некоторые нейросети и большинство статистических методов можно отнести только к одному из способов обучения. Поэтому, если нужно классифицировать методы машинного обучения в зависимости от способа обучения, будет некорректным относить нейросети к определенному виду, правильнее было бы типизировать алгоритмы обучения нейронных сетей.
- Искусственная нейронная сеть
- Глубокое обучение
- Метод коррекции ошибки
- Метод обратного распространения ошибки
- Метод опорных векторов
- Обучение без учителя — для каждого прецедента задаётся только «ситуация», требуется сгруппировать объекты в кластеры, используя данные о попарном сходстве объектов, и/или понизить размерность данных:
- Альфа-система подкрепления
- Гамма-система подкрепления
- Метод ближайших соседей
- Генетический алгоритм.
- Активное обучение — отличается тем, что обучаемый алгоритм имеет возможность самостоятельно назначать следующую исследуемую ситуацию, на которой станет известен верный ответ:
- Обучение с частичным привлечением учителя (англ. semi-supervised learning) — для части прецедентов задается пара «ситуация, требуемое решение», а для части — только «ситуация»
- Трансдуктивное обучение (англ. transduction (machine learning)) — обучение с частичным привлечением учителя, когда прогноз предполагается делать только для прецедентов из тестовой выборки
- Многозадачное обучение (англ. multi-task learning) — одновременное обучение группе взаимосвязанных задач, для каждой из которых задаются свои пары «ситуация, требуемое решение»
- Многовариантное обучение (англ. multiple-instance learning) — обучение, когда прецеденты могут быть объединены в группы, в каждой из которых для всех прецедентов имеется «ситуация», но только для одного из них (причем, неизвестно какого) имеется пара «ситуация, требуемое решение»
- Бустинг (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
- Байесовская сеть
Классические задачи, решаемые с помощью машинного обучения
Типы входных данных при обучении
Типы функционалов качества
- При обучении с учителем — функционал качества может определяться как средняя ошибка ответов. Предполагается, что искомый алгоритм должен его минимизировать. Для предотвращения переобучения в минимизируемый функционал качества часто в явном или неявном виде добавляют регуляризатор.
- При обучении без учителя — функционалы качества могут определяться по-разному, например, как отношение средних межкластерных и внутрикластерных расстояний.
- При обучении с подкреплением — функционалы качества определяются физической средой, показывающей качество приспособления агента.
Практические сферы применения
Целью машинного обучения является частичная или полная автоматизация решения сложных профессиональных задач в самых разных областях человеческой деятельности.
Машинное обучение имеет широкий спектр приложений[источник не указан 1780 дней]:
Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объёмов данных в науке, производстве, бизнесе, транспорте, здравоохранении. Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
См. также
Литература
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: основы моделирования и первичная обработка данных. — М.: Финансы и статистика, 1983.
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: исследование зависимостей. — М.: Финансы и статистика, 1985.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
- Вапник В. Н. Восстановление зависимостей по эмпирическим данным. — М.: Наука, 1979.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8.
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9.
- Флах П. Машинное обучение. — М.: ДМК Пресс, 2015. — 400 с. — ISBN 978-5-97060-273-7.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2.
- Hastie, T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. — 2nd ed. — Springer-Verlag, 2009. — 746 p. — ISBN 978-0-387-84857-0..
- Mitchell T. Machine Learning. — McGraw-Hill Science/Engineering/Math, 1997. ISBN 0-07-042807-7.
- Ryszard S. Michalski, Jaime G. Carbonell, Tom M. Mitchell (1983), Machine Learning: An Artificial Intelligence Approach, Tioga Publishing Company, ISBN 0-935382-05-4 (Machine Learning: An Artificial Intelligence Approach в «Книгах Google»).
- Vapnik V. N. Statistical learning theory. — N.Y.: John Wiley & Sons, Inc., 1998. [1]
- Bernhard Schölkopf, Alexander J. Smola Learning with Kernels. Support Vector Machines, Regularization, Optimization, and Beyond. — MIT Press, Cambridge, MA, 2002 ISBN 978-0-262-19475-4 [2]
- I. H. Witten, E. Frank Data Mining: Practical Machine Learning Tools and Techniques (Second Edition). — Morgan Kaufmann, 2005 ISBN 0-12-088407-0 [3]
- Liang Wang, Li Cheng, Guoying Zhao. Machine Learning for Human Motion Analysis. — IGI Global, 2009. — 318 p. — ISBN 978-1-60566-900-7.
Ссылки
Эта страница в последний раз была отредактирована 9 июля 2018 в 15:05.wiki2.org