Содержание
Компьютерная программа победила трехкратного чемпиона Европы по игре в го
Компьютерная программа победила трехкратного чемпиона Европы по игре в го — Газета.Ru
Пригожин раскрыл содержание записки, полученной главой Русского дома в ЦАР
16:01
Отар Кушанашвили заявил, что развод Варум и Агутина станет для него «сильнейшим…
15:59
Набиуллина допустила, что спад ВВП составит 3% или ниже в 2022 году
15:59
Банк России может расширить перечень финансовой информации, которую нельзя будет…
15:58
Наталья Штурм планирует выйти замуж за бизнесмена из Перу
15:57
Bloomberg: Сербия намерена сократить зависимость от газовых поставок из России
15:54
Температура на корабле «Союз МС-22» увеличилась до 50°С, специалисты…
15:53
Вышел трейлер фильма Динары Друкаровой «Лили и море»
15:53
Илья Авербух рассказал, что у его сына от Арзамасовой начинает проявляться характер
15:53
Совет ЕС утвердил девятый пакет антироссийских санкций
15:50
Наука
close
100%
Искусственный интеллект AlphaGo научился играть в го и обыграл трехкратного чемпиона Европы. Этот успех для науки более значим, чем победа компьютера Deep Blue над Гарри Каспаровым 20 лет назад. Почему это так — разбирался отдел науки «Газеты.Ru».
Этот успех для науки более значим, чем победа компьютера Deep Blue над Гарри Каспаровым 20 лет назад. Почему это так — разбирался отдел науки «Газеты.Ru».
Го — настольная игра, возникшая в Древнем Китае около 3 тыс. лет назад. На сегодняшний день она популярна не только в странах Восточной Азии, но и в странах Запада. Цель игры — захватить как можно бóльшую площадь игрового поля (которое представляет собой расчерченную вертикальными и горизонтальными линиями доску) с помощью специальных фишек.
Мальчик Женя из Одессы одолел Тьюринга
Чат-бот под видом одесского мальчика Жени впервые в истории прошел тест Тьюринга, убедив профессиональное…
09 июня 12:29
Несмотря на то что правила го достаточно простые, по числу возможных позиций и партий игра превосходит шахматы, и поэтому до недавнего времени го оставалась настоящим вызовом для искусственного интеллекта.
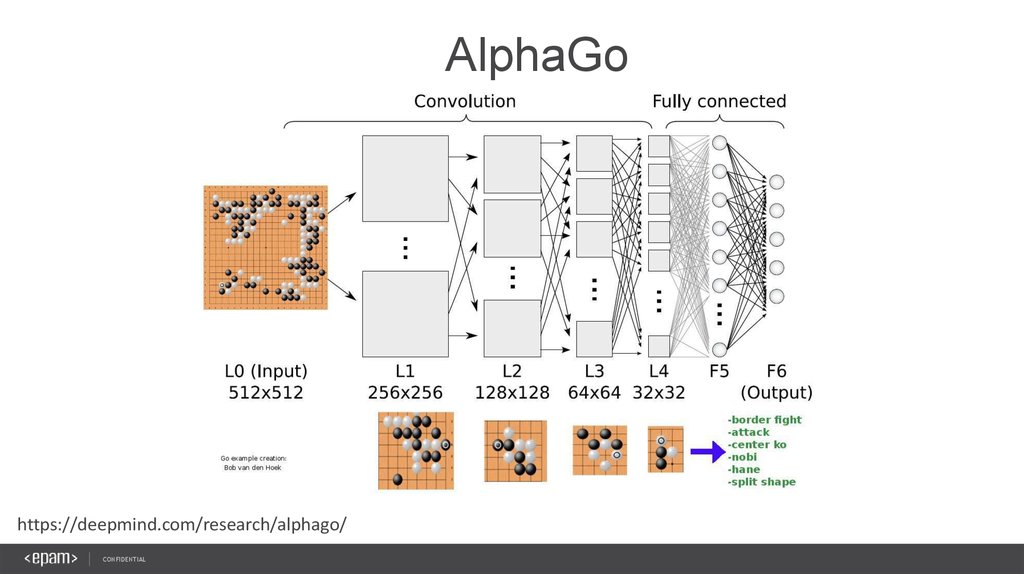
В 2014 году Google приобрела компанию Deep Mind, которая занимается разработкой искусственного интеллекта. Приобретение позволило корпорации продвинуться в создании виртуального разума и уже принесло свои плоды. Компьютерная программа Alpha Go, усовершенствованная Google, смогла победить профессионального го-игрока, трехкратного чемпиона Европы в матче из пяти партий Фань Хуэя. Статья, авторы которой рассказывают о программе, была опубликована в журнале Nature. Программа способна оценивать расположение камней на доске и выбирать наиболее подходящие в данной ситуации ходы.
Приобретение позволило корпорации продвинуться в создании виртуального разума и уже принесло свои плоды. Компьютерная программа Alpha Go, усовершенствованная Google, смогла победить профессионального го-игрока, трехкратного чемпиона Европы в матче из пяти партий Фань Хуэя. Статья, авторы которой рассказывают о программе, была опубликована в журнале Nature. Программа способна оценивать расположение камней на доске и выбирать наиболее подходящие в данной ситуации ходы.
Нейронные сети Alpha Go превосходят другие программы игры в го, например Pachi и Fuego, благодаря тому что она учится играть, основываясь на информации о партиях, разыгранных людьми, а также анализирует информацию о собственных играх.
Alpha Go выиграла вчистую 99,8% турниров против программ-аналогов, в основе которых лежит метод Монте-Карло, а трехкратного чемпиона Европы Фань Хуэя разгромила в матче из пяти партий со счетом 5:0.
Компьютер выучил английский с нуля
Компьютер самостоятельно выучил английский язык и поговорил с человеком — на уровне четырехлетнего. ..
..
12 ноября 13:57
Шахматный суперкомпьютер Deep Blue, созданный IBM и обыгравший в 1996 году чемпиона мира по шахматам Гарри Каспарова, уступает Alpha Go, так как опирается на алгоритм. Один из исследователей компьютерного го, Джон Даймонд, прокомментировал:
«До сих пор многие программы не могли обыграть игроков-любителей. Я предполагал, что в ближайшие пять — десять лет компьютер не сможет победить профессиональных игроков, однако сейчас победа искусственного интеллекта кажется неизбежной».
Хоть машина и смогла переиграть человека в го, это не означает, что наступит конец игры между людьми. Победа компьютера в шахматном турнире 1996 года послужила стимулом для игроков учиться на компьютерных программах. Вероятно, подобные перспективы ожидают и компьютерное го. Тем не менее этот прорыв, наряду с методами Монте-Карло и древовидным поиском, вносит существенный вклад в области, не связанные со стратегическими играми.
В дальнейшем пройти испытание программой Alpha Go предложили Ли Седолю — он считается лучшим в мире игроком в го за последнее десятилетие.
Компьютер обогнал китайца
Создана компьютерная система, которая распознает рукописный китайский текст эффективнее человека. Отдел науки…
21 сентября 09:50
Турнир должен состояться в марте. Сам игрок признает, что Alpha Go совершает революцию в истории игры, однако секретарь Корейской ассоциации падук (местное название игры го) предполагает: «Компьютер может выиграть одну или две партии, но не весь турнир».
Искусственный разум способен составить конкуренцию человеку не только в области игр — компьютер научился распознавать печатный и рукописный текст вне зависимости от языка, а также различать человеческие эмоции. Определенных успехов ученые достигли и в обучении машин — компьютерная модель, имитирующая головной мозг,
оказалась способной самостоятельно выучить английский язык и поговорить на нем.
Искусственная нейронная сеть с названием ANNABEL помогла исследователям понять механизм овладения языком без каких-либо алгоритмов. Другая нашумевшая программа, имитирующая человека, смогла пройти тест Тьюринга и убедить жюри, что с ними разговаривает 13-летний подросток Женя из Одессы.
Подписывайтесь на «Газету.Ru» в Новостях, Дзен и Telegram.
Чтобы сообщить об ошибке, выделите текст и нажмите Ctrl+Enter
Новости
Дзен
Telegram
Картина дня
Военная операция РФ на Украине. День 296-й
Онлайн-трансляция специальной военной операции на Украине — 296-й день
«Территории переходили из рук в руки». Киссинджер назвал условия мира России с Украиной
В Кремле захотели ознакомиться с предложениями Киссинджера по решению конфликта на Украине
Взрывы в городах и экстренные отключения света. Что известно о ракетном ударе по Украине
По всей Украине ввели экстренные аварийные отключения электроэнергии после обстрела
«Укрэнерго» объявило чрезвычайную ситуацию
Глава полиции ЦАР назвал терактом покушение на руководителя «Русского дома» Сытого
NASA: российские космонавты не выйдут в открытый космос до конца года
СМИ: очевидцы сообщили о падении двух неизвестных объектов в Волгоградской области
Новости и материалы
Пригожин раскрыл содержание записки, полученной главой Русского дома в ЦАР
Отар Кушанашвили заявил, что развод Варум и Агутина станет для него «сильнейшим разочарованием»
Набиуллина допустила, что спад ВВП составит 3% или ниже в 2022 году
Банк России может расширить перечень финансовой информации, которую нельзя будет раскрывать
Наталья Штурм планирует выйти замуж за бизнесмена из Перу
Bloomberg: Сербия намерена сократить зависимость от газовых поставок из России
Температура на корабле «Союз МС-22» увеличилась до 50°С, специалисты пытаются снизить ее
Вышел трейлер фильма Динары Друкаровой «Лили и море»
Илья Авербух рассказал, что у его сына от Арзамасовой начинает проявляться характер
Совет ЕС утвердил девятый пакет антироссийских санкций
Атаман австралийских казаков заявил о своей невиновности и запросил убежище в России
Глава ЦБ Набиуллина сообщила, что у ЦБ нет комфортного уровня валютных вкладов
Иосиф Пригожин назвал Даню Милохина «глупым мальчиком» после дисса на Первый канал
Татьяна Буланова призналась, что ее возлюбленный переживает из-за слухов об их личной жизни
Стало известно, почему Кокорин три раза подряд не попал в заявку «Ариса» на матч
Reuters: McDonald’s сохраняет отношения с Россией после ухода из страны
Набиуллина: в дополнительном регулировании валютных позиций банков нет необходимости
Глава ЦБ Набиуллина заявила о необходимости скорой продажи банка «Открытие»
Все новости
В Бурятии упал вертолет Ми-8, весь экипаж погиб
В Улан-Удэ вертолет Ми-8 загорелся при посадке в аэропорту, погибли три человека
Певица Глюк’oZa: «Иногда мы с мужем запрещаем друг другу говорить о детях»
Певица Глюкоза рассказала о семейной новогодней традиции и карьере дочери
Зеленский назвал возвращение к границам 1991 года условием для переговоров
По его словам, нельзя оставить «все как есть»
Тест: кто из этих писателей украл сюжет книги?
Кто на самом деле сочинил «Гамлета» и «Старика Хоттабыча»?
На безрыбье. Как оценка эффективности рыбных квот повлияет на закон «О рыболовстве»
Как оценка эффективности рыбных квот повлияет на закон «О рыболовстве»
СП представит отчет по результатам преобразований рыбной отрасли
США ввели санкции против ВТБ и Потанина, ЕС согласовал девятый пакет
Reuters сообщил о согласовании девятого пакета санкций Евросоюза
Курт Кобейн, Фредди Меркьюри и принцесса Диана. Как бы сейчас выглядели умершие знаменитости
Комендант полиции Польши был ранен взрывом украинского гранатомета
Глава польской полиции госпитализирован после взрыва подаренного ему на Украине гранатомета
Путин: снижение ВВП по итогам года составит 2,5%
Путин заявил, что планы Запада по разрушению российской экономики не оправдались
«Целиком и полностью»: тин-хоррор про влюбленных каннибалов с Тимоти Шаламе и Тейлор Расселл
Рецензия на «Целиком и полностью» с Тимоти Шаламе и Тейлор Расселл
«Ситуация очень серьезная». Что произошло на корабле «Союз МС-22»
Выход российских космонавтов в открытый космос с борта МКС сорвался во второй раз
Компетенции и забота. Как работают волонтеры-юристы и волонтеры-психологи в период СВО
Россияне могут бесплатно получить психологическую и юридическую помощь
15 ножевых. Блогера Полякова задержали по подозрению в убийстве девушки
В Петербурге задержали блогера Полякова по подозрению в убийстве 18-летней девушки
Мария Дегтерева
Баттл проигран
О том, почему русский рок мертв, а русский рэп — нет
Анастасия Миронова
Куда сбежать от пьяных мамы с папой?
О возможном всплеске числа беспризорников при сворачивании детдомов
Георгий Малинецкий
Праздник, который стоит восстановить
О чувстве собственного достоинства и борьбе с начальством
Юлия Меламед
Не бомжую, а курьерю
О том, как справиться с тревогой в нестабильные времена
Георгий Бовт
Когда догмы превыше всего
О том, как мы влезли в Афганистан
—>
Читайте также
Найдена ошибка?
Закрыть
Спасибо за ваше сообщение, мы скоро все поправим.
Продолжить чтение
Более мощная версия программы AlphaGo самостоятельно достигла уровня совершенства всего за три дня » DailyTechInfo
Напомним нашим читателям, что в течение нынешнего и прошлого года программа AlphaGo, построенная на принципах искусственного интеллекта, одержала ряд выдающихся побед над высококвалифицированными игроками в древнюю китайскую игру Го, включая и чемпиона мира Ли Седоля (Lee Sedol). И не так давно представители DeepMind, подразделения компании Google, занимающегося разработкой систем искусственного интеллекта, представили новый и более мощный вариант программы — AlphaGo Zero. Во время тестовых испытаний новая программа обыграла свой предыдущий вариант, тот, который в свое время одержал победу над Ли Седолем, абсолютно «всухую», с невероятным счетом 100:0.
Напомним нашим читателям, что оригинальный вариант программы AlphaGo получил первоначальный опыт, проанализировав около 160 тысяч матчей, сыгранных в онлайн-режиме живыми людьми, членами всемирной ассоциации игры Го. После этого начального обучения программа AlphaGo начала играть сама с собой и миллионы таких «внутренних» матчей позволили ей поднять мастерство игры на недостижимый для людей уровень.
Новая система AlphaGo Zero уже не нуждается даже в первоначальных человеческих знаниях, процесс ее обучения основан только на механизме игры самой с собой. В самом начале самообучения программа делала первые шаги (ходы) абсолютно произвольно и случайно, запоминая те комбинации, которые ведут к победе и поражению. И за 29 миллионов таких игр, сыгранных самой с собой всего за три дня, система AlphaGo Zero стала самым лучшим игроком на земном шаре.
Система AlphaGo Zero более проста и более «умна», нежели система предыдущего поколения. В состав оригинальной программы входили два независимых обучающихся и самообучающихся модуля, построенные на базе искусственных нейронных сетей. Один модуль отвечал за оценку текущей ситуации на игровой доске, а второй — искал все доступные варианты следующего хода. И третий модуль выбирали из найденных вариантов следующего хода только те, которые соответствуют выбранной стратегии текущего матча и ведут к победе. Система AlphaGo Zero является еще более лучшим игроком за счет того, что у этой системы имеется единая мощная нейронная сеть, которая одновременно анализирует положение на доске и выбирает следующий ход при помощи более простого модуль поиска по нескольким критериям.
Один модуль отвечал за оценку текущей ситуации на игровой доске, а второй — искал все доступные варианты следующего хода. И третий модуль выбирали из найденных вариантов следующего хода только те, которые соответствуют выбранной стратегии текущего матча и ведут к победе. Система AlphaGo Zero является еще более лучшим игроком за счет того, что у этой системы имеется единая мощная нейронная сеть, которая одновременно анализирует положение на доске и выбирает следующий ход при помощи более простого модуль поиска по нескольким критериям.
И в заключение следует отметить, что некоторые идеи, воплощенные в жизнь специалистами DeepMind при создании системы AlphaGo, были использованы компанией Google в практических целях. Благодаря работе искусственного интеллекта компании удалось существенно сократить расходы на охлаждение информационных центров, а общая сумма прибыли, полученной всеми отделами компании Alphabet, составила уже порядка 40 миллионов фунтов стерлингов. Более того, алгоритмы, лежащие в основе новой системы AlphaGo Zero, могут быть достаточно легко адаптированы для решения множества проблем научного и технического плана, к примеру, для разработки новых лекарственных препаратов, конструкционных материалов и всего другого, где необходимо делать качественный выбор их «математического океана» всех возможных вариантов решений.
Ключевые слова:
DeepMind, Google, Alphabet, AlphaGo, Zero, Искусственный, Интеллект, Самообучение, Нейронная, Сеть
Первоисточник
Другие новости по теме:
Добавить свое объявление
Загрузка…
Понимание AlphaGo: как ИИ думает и учится (основы) | by Shen Huang
Эта статья научит вас основам игрового искусственного интеллекта…
«Я представляю себе время, когда мы будем для роботов тем, чем собаки являются для людей, и я болею за машины».
— Клод Шеннон
Разработанная DeepMind, AlphaGo привлекла внимание всего мира после победы над лучшими игроками мира в игре в го в 2016 году. Более мощная версия под названием AlphaZero продолжает процветать в играх. такие как го и шахматы. Вариант под названием AlphaStar демонстрировал все более высокие результаты, играя в стратегические игры в реальном времени против профессиональных игроков-людей. Мы живем в эпоху, когда машины берут на себя наши задачи, и в какой-то конкретной области они справляются с работой лучше, чем мы, люди.
Робот играет в шахматы, изображение со сайта Smithsonian.com
Но как именно работает этот ИИ? В этой статье мы рассмотрим, как работает этот игровой ИИ, начиная с основ. Мы начнем со старой школы состязательного поиска и конечных автоматов. Затем мы немного изучим области машинного обучения, от обучения с подкреплением до поиска по дереву Монте-Карло, и поймем, как современный ИИ обучается сам по себе (на примере покемонов ϞϞ(๑⚈ ․̫ ⚈๑)∩).
Затем мы перейдем ко второй части, где мы углубимся в глубокое обучение, в основном сосредоточившись на искусственных нейронных сетях и сверточных нейронных сетях. После этого мы должны быть в состоянии понять сети политики и сети ценности для AlphaGo.
Не пугайтесь этих терминов, так как к концу этой статьи вы поймете их как профессионал. Я надеюсь, что эта статья развеет некоторые мифы об искусственном интеллекте, развеет сомнения и вызовет больший интерес к этой области исследований. Если вы готовы, пусть наше путешествие начнется!
«Наш интеллект — это то, что делает нас людьми, а ИИ — расширение этого качества».
— Yann LeCun
Первая концепция искусственного интеллекта восходит к древнегреческой мифологии. Гефест — греческий бог кузнецов, металлообработки, плотников, мастеров, ремесленников, скульпторов, металлургии, огня и вулканов, создал Талос — бронзовый автомат, по просьбе своего отца — Зевса, чтобы защитить супругу Зевса Европу от похищения. Гефест также был известен как создатель Пандоры — идеальной женщины в подарок человечеству, держащей «Ящик Пандоры» — злой кувшин, который выпустил все злые грехи на человечество, имея «надежду» под краем кувшина.
Гефест также был известен как создатель Пандоры — идеальной женщины в подарок человечеству, держащей «Ящик Пандоры» — злой кувшин, который выпустил все злые грехи на человечество, имея «надежду» под краем кувшина.
Талос, бронзовый автомат, изображение из FANDOM
Около 350 г. до н.э. великий философ Аристотель описал метод формального, механического мышления посредством дедуктивных рассуждений, известный как «силлогизм» . В 1206 году Исмаил аль-Джазари создал программируемый автомат, известный как «музыкальный робот-оркестр» . Многие другие блестящие люди были вдохновлены на протяжении веков. Известным из них был Алан Тьюринг, который изобрел алгоритм в 19 году.50, чтобы играть в шахматы со своими друзьями до того, как были изобретены компьютеры. (Кстати, он проиграл эту игру) И, конечно же, Тьюринг также был известен своим «тестом Тьюринга», который мы рассмотрим подробнее позже.
Музыкальная группа роботов Аль-Джазари, изображение из Википедии
Летом 1956 года в мастерской Дартмутского колледжа, Ганновер, Нью-Гэмпшир, официально началась область исследований искусственного интеллекта. Термин «искусственный интеллект» описывает изобретенные человеком машины, обладающие когнитивными способностями. Есть много подобластей этого исследования, таких как компьютерное зрение, обработка естественного языка, машинное обучение, экспертные системы и тема, которую мы будем обсуждать сегодня — игровой ИИ.
Термин «искусственный интеллект» описывает изобретенные человеком машины, обладающие когнитивными способностями. Есть много подобластей этого исследования, таких как компьютерное зрение, обработка естественного языка, машинное обучение, экспертные системы и тема, которую мы будем обсуждать сегодня — игровой ИИ.
Вид на Восточный кампус из Бейкер Тауэр Дартмутского колледжа, изображение из Википедии
Мы собираемся начать с двух фундаментальных алгоритмов, используемых в игровом искусственном интеллекте — состязательного поиска и конечного автомата. Из этих строительных блоков мы можем углубиться в более сложные алгоритмы.
Состязательный поиск
Состязательный поиск, иногда называемый минимаксным поиском, представляет собой алгоритм, часто используемый в играх, включающих состязательные отношения между игроками. Как правило, игру можно оптимизировать с помощью обрезки альфа-бета, которая будет рассмотрена позже в этом разделе.
Алгоритм можно применить к таким играм, как крестики-нолики или ним, которые я приложил к играм ниже вместе с правилами. Вы можете попробовать играть с компьютером в игре — подсказка: вы никогда не выиграете, и мы сейчас увидим, почему.
Вы можете попробовать играть с компьютером в игре — подсказка: вы никогда не выиграете, и мы сейчас увидим, почему.
Крестики-нолики
Крестики-нолики — это игра, в которой оба игрока пытаются поместить свои символы «X» или «O» на поле размером 3 на 3. Игрок выигрывает, если его символ образует соединение длиной 3. Соединение может быть горизонтальным, вертикальным или диагональным.
Ним
Ним — это игра, в которой игроки пытаются взять определенное количество фишек из набора фишек, игроки должны брать по крайней мере 1 фишку каждый ход. Игрок, который взял последнюю фишку (фишки) из игры, выигрывает игру.
Состязательный поиск
А теперь перейдем к серьезной теме сегодняшнего дня — состязательному поиску. Состязательный поиск создает дерево всех возможных состояний игры, разветвленное по доступным вариантам. Например, в игре Ним с максимальным взятием 3 фишек каждый игрок может взять 1, 2 или 3 фишки, что дает 3 ветви для каждого узла дерева, как показано ниже.
Состязательный поиск, иллюстрированный Нимом, часть 1
Дерево заканчивается, когда не остается фишек. Игрок, взявший последнюю фишку (фишки), выигрывает игру.
Состязательный поиск, иллюстрированный Нимом, часть 2
Дерево содержит все возможные состояния игры, в данном случае 177 состояний. Просматривая все игровые состояния, компьютер будет знать исход игры, прежде чем делать какие-либо ходы.
🤖 Робот А: «Мат в 143 хода».
🤖 Робот B: «Ой, ты снова выиграл».
— Футурама S2E02 Бранниган, Начни снова
Роботы, играющие в шахматы, Футурама S2E02 Бранниган, Начни снова
В области информатики мы также ценим эффективность алгоритмов. Меньший объем вычислений и потребление памяти означает меньшую нагрузку на оборудование и потребление электроэнергии, что приводит к снижению затрат на выполнение алгоритма. Таким образом, вместо того, чтобы перебирать все возможные состояния, существует множество способов упростить задачу.
Например, 8 состояний крестиков-ноликов, показанных ниже, эквивалентны по вращению, и поэтому мы можем вместо этого рассматривать их как 2 состояния. Эти типы трансляционной и вращательной эквивалентности будут обсуждаться более подробно, когда мы углубимся в сверточные нейронные сети в следующем разделе.
Эти типы трансляционной и вращательной эквивалентности будут обсуждаться более подробно, когда мы углубимся в сверточные нейронные сети в следующем разделе.
Состояния крестики-нолики вращательно эквивалентны
Убрав дополнительные состояния, можно значительно уменьшить размер дерева поиска. В первых 4 слоях дерева поиска более 3500 состояний, если такое сокращение не применяется. Поиск по 3500 состояниям — несложная задача для современного компьютера, но это число растет экспоненциально и может достичь масштаба микросекунд возраста нашей Вселенной, когда дело доходит до более крупной доски, такой как шахматы.
Уменьшенное дерево поиска для Крестики-нолики
Удаление одинаковых состояний в первом слое сокращает 2/3 лишних состояний, но можно ли сделать лучше? Существует небольшая хитрость, называемая сокращением альфа-бета, которую мы обсудим в следующем разделе.
Обрезка альфа-бета
«Я никогда не недооцениваю своего противника, но я никогда не недооцениваю свои таланты».
— Хейл Ирвин

Представьте, что вы играете в крестики-нолики, когда у вашего противника уже есть 2 соединенные фигуры, и вам всегда захочется заблокировать его на другом конце. Почему? Потому что вы можете предположить, что он выиграет в следующем ходу, если вы этого не сделаете. В этом и заключается идея сокращения альфа-бета: вы всегда ожидаете, что ваш противник сделает все возможное, чтобы победить.
Иллюстрация сокращения альфа-бета. Игрок 1 всегда выбирает выигрышный ход.
Для игры в крестики-нолики результат обычно оценивается как двоичный. Однако для некоторых более сложных игр, таких как шахматы, доска может оцениваться с помощью очков. Например, сумма очков белых фигур минус сумма очков черных фигур. И именно тогда альфа-бета-обрезка может стать полезной для устранения ветвей. Вот видео ниже, объясняющее сокращение альфа-бета с помощью шахмат.
Объяснение алгоритмов — минимаксное и альфа-бета сокращение
Что касается игры Ним, ИИ использует гораздо более простую базу правил. Мы прошлись по дереву поиска только потому, что проще объяснить деревья поиска с Нимом. ИИ разделит фишки на кусочки размером на 1 фишку больше, чем максимально допустимый выбор, и будет следить за тем, чтобы каждый раз, когда выбирается один кусок целиком, выбирал разницу между размером куска и выбором игрока. Если патрон не делится, ИИ будет двигаться первым и выбирать остаток. Таким образом, у игрока нет возможности выиграть.
Мы прошлись по дереву поиска только потому, что проще объяснить деревья поиска с Нимом. ИИ разделит фишки на кусочки размером на 1 фишку больше, чем максимально допустимый выбор, и будет следить за тем, чтобы каждый раз, когда выбирается один кусок целиком, выбирал разницу между размером куска и выбором игрока. Если патрон не делится, ИИ будет двигаться первым и выбирать остаток. Таким образом, у игрока нет возможности выиграть.
Иллюстрация Ним ИИ
В такой игре, как шахматы, невозможно легко найти все возможные состояния, как в крестиках-ноликах или ним. Но компьютер, который может искать более 30 слоев в глубину, уже безумно трудно превзойти, так как большинство игроков не могут предвидеть такое количество ходов.
State Machine
«Простое может быть сложнее, чем сложное: вам нужно много работать, чтобы очистить свое мышление, чтобы сделать его простым».
— Стив Джобс
Конечный автомат, обычно называемый конечным автоматом, — это часто недооцениваемая концепция игрового ИИ в наши дни, особенно после того, как машинное обучение с годами приобрело огромную популярность. Однако такой олдскульный дизайн доминировал с винрейтом 96,15% в соревновании SSCAIT 2018, играя против других ИИ StarCraft, использующих машинное обучение.
Однако такой олдскульный дизайн доминировал с винрейтом 96,15% в соревновании SSCAIT 2018, играя против других ИИ StarCraft, использующих машинное обучение.
Изображение SSCAIT и StarCraft, стратегии в реальном времени (RTS), для игры в которую требуются высокие навыки.
Помимо игрового ИИ, конечные автоматы также широко применяются в таких областях, как этот классный ИИ-помощник по телефону от Google. В этом разделе мы углубимся в теорию всех таких чудес.
Google AI Assistant Demo
Конечный автомат, иногда называемый конечным автоматом, обычно представлен группой связанных узлов, формально называемых «график» . График ниже демонстрирует, как обычные читатели взаимодействуют с моей статьей.
Несмотря на то, что Medium просит не просить аплодировать, я понимаю, что люди, которые просят хлопать, получают больше хлопков
Внутри кругов находится то, что мы называем «состояниями» , а стрелки называются «функция перехода состояний» . Функция перехода состояния обычно описывается условием. Например, когда мой читатель находится в состоянии «читателю понравилась моя статья» , он может перейти в состояние «читатель аплодирует моей статье» укажите, если «я прошу аплодировать» или «читатель не забыл аплодировать» . Более формальное математическое определение конечного автомата можно найти здесь.
Функция перехода состояния обычно описывается условием. Например, когда мой читатель находится в состоянии «читателю понравилась моя статья» , он может перейти в состояние «читатель аплодирует моей статье» укажите, если «я прошу аплодировать» или «читатель не забыл аплодировать» . Более формальное математическое определение конечного автомата можно найти здесь.
Вокруг него разработано много интересных теорий, которые в конечном итоге приводят к двум важным темам в информатике: проблеме NP vs. P и машине Тьюринга. Алгоритмы машинного обучения, такие как цепь Маркова, также разделяют некоторые концепции конечного автомата. Мы рассмотрим марковский процесс принятия решений в следующем разделе, когда узнаем об обучении с подкреплением.
«Говорят, что компьютерная программа учится на опыте E в отношении некоторого класса задач T и показателя производительности P, если ее производительность при выполнении задач в T, измеряемая P, улучшается с опытом E».
— Том М. Митчелл

Том М. Митчелл, профессор машинного обучения в Университете Карнеги-Меллона
Как широко используемая цитата, Том М. Митчелл формально определил концепцию машинного обучения как компьютерной программы, которая постепенно повышает производительность за счет накопленного опыта. . Управляемые алгоритмом машинного обучения, машины будут постепенно продвигаться вперед с новой информацией, которую они получили. Связанные алгоритмы широко применяются во многих областях, которые в наши дни меняют нашу жизнь, например, фильтры Snapchat, которые распознают наше лицо, или Google-переводчик, помогающий нам понимать других, говорящих на иностранных языках. Если вас интересуют некоторые из этих приложений, я также написал руководство по распознаванию лиц, которое можно найти здесь.
В этом разделе мы узнаем о популярной области машинного обучения для игрового ИИ — Reinforcement Learning. Позже популярная нейронная сеть будет рассмотрена в разделе глубокого обучения.
Обучение с подкреплением
«Неудача — это просто возможность начать заново, на этот раз более разумно».
— Генри Форд
«Обучение с подкреплением (RL) — это область машинного обучения, связанная с тем, как программные агенты должны выполнять действия в среде, чтобы максимизировать некоторое понятие совокупного вознаграждения».
— Википедия
Чтобы понять, следующая диаграмма является примером, иллюстрирующим фундаментальную концепцию обучения с подкреплением.
Правда в том, что запрос на хлопки приводит к большему количеству хлопков.
Существует несколько концепций обучения с подкреплением, которые мы можем понять из приведенного выше примера, где хлопки побуждают автора писать более качественные статьи (и просят больше хлопков).
- Среда: Среда — это место, где агенты взаимодействуют друг с другом, в данном случае сообщество Medium — это среда.
- Агент: Агент — это то, что взаимодействует друг с другом и с окружающей средой, в данном случае авторами являются агенты.
 Читатели также являются агентами и могут быть описаны конечным автоматом, упомянутым в предыдущем разделе.
Читатели также являются агентами и могут быть описаны конечным автоматом, упомянутым в предыдущем разделе. - Состояния: Состояния включают возможные состояния среды и агента. Например, писатель может спать или занят и не может писать. Журнал Medium может вносить изменения в партнерскую программу или курировать статью, что влияет на видимость.
- Действие: Действие — это то, что агенты могут делать для взаимодействия с окружающей средой и другими агентами. Например, автор может написать привлекательный заголовок, который может увеличить количество просмотров и потенциально увеличить количество аплодисментов.
- Интерпретатор: Интерпретатор — это набор правил, которые оценивают результат для агента, например, каждый хлопок делает меня счастливее на 1 единицу, а каждое следование делает меня счастливее на 50 единиц.
 Читатели также являются агентами и могут быть описаны конечным автоматом, упомянутым в предыдущем разделе.
Читатели также являются агентами и могут быть описаны конечным автоматом, упомянутым в предыдущем разделе. Агент попытается оптимизировать результат, оцененный интерпретатором, и существует несколько подходов. В этом разделе мы рассмотрим 2 популярных подхода, используемых в игровом ИИ — Q-Learning и поиск по дереву Монте-Карло. Как только мы поймем эти два, мы сможем понять Deep Q-Learning в последующих разделах.
В этом разделе мы рассмотрим 2 популярных подхода, используемых в игровом ИИ — Q-Learning и поиск по дереву Монте-Карло. Как только мы поймем эти два, мы сможем понять Deep Q-Learning в последующих разделах.
Q-Learning
Q-Learning — это простейшая форма обучения с подкреплением. Целью Q-Learning является изучение политики, которая оптимизирует оцениваемый результат агента. Блок-схема ниже объясняет, как это работает для игрока, пытающегося найти лучшего покемона для использования.
Блок-схема, объясняющая Q-обучение с покемонами
Политики обычно определяются матрицами, записывающими шансы каждого действия в каждом состоянии. Агент выполнит действие на основе политик, а затем обновит политики на основе результата действия. Например, если противник вызвал Сквиртла, агент случайным образом выберет покемона. Если агент выбрал Пикачу и обнаружил, что он очень эффективен против Сквиртла, агент затем обновит политики, поэтому у него больше шансов противостоять Сквиртлу Пикачу в будущем. Есть две другие важные концепции, которые мы должны рассмотреть: скорость обучения и марковский процесс принятия решений.
Есть две другие важные концепции, которые мы должны рассмотреть: скорость обучения и марковский процесс принятия решений.
1. Скорость обучения
Обучение описывает, насколько быстро обучается модель. Например, процент может увеличиться на 1% для низкой скорости обучения или на 15% для высокой скорости обучения для того же результата «очень эффективно» .
2. Марковский процесс принятия решений
Марковский процесс принятия решений представляет собой диаграмму состояний, описывающую состояния и действия агентов и среды. Он также описывает вероятность перехода между каждым состоянием и вознаграждение за каждое состояние.
Марковский процесс принятия решений, иллюстрированный Pokémon
Для получения дополнительной информации о серьезном математическом определении и доказательстве конвергенции Q-обучения вы можете прочитать их здесь.
Поиск по дереву Монте-Карло
Поиск по дереву Монте-Карло (MCTS) работает аналогично состязательному поиску, описанному в предыдущем разделе. Основное отличие состоит в том, что MCTS случайным образом выбирает ветвь для закрытия, а не пытается перебрать все ветви. Затем алгоритм устанавливает профиль на основе результата этой ветви.
Основное отличие состоит в том, что MCTS случайным образом выбирает ветвь для закрытия, а не пытается перебрать все ветви. Затем алгоритм устанавливает профиль на основе результата этой ветви.
Иллюстрация поиска по дереву Монте-Карло
Формально поиск по дереву Монте-Карло имеет следующие 4 состояния:
1. Выбор
- Выбор обычно осуществляется путем выбора узла с наивысшим коэффициентом выигрыша, но с некоторой случайностью, поэтому могут быть изучены новые стратегии.
2. Расширение
- Расширение — это когда алгоритм расширяется до неисследованных состояний. Алгоритм выбирает случайное неизведанное новое состояние для исследования.
3. Моделирование
- Моделирование — это когда случайный игровой процесс моделируется после расширения, чтобы можно было оценить состояние.
4. Обратное распространение
- Обратное распространение — это процесс обновления значений состояния новой информацией, полученной в результате моделирования.

Этот алгоритм особенно полезен в играх с большим количеством состояний, так как пройти все состояния практически невозможно. Изучая опыт, полученный в предыдущих играх, в будущем можно будет принимать более разумные решения. Дополнительные материалы о выборе узлов между разведкой и эксплуатацией можно найти здесь.
Ниже представлено видео о том, как ИИ играет в Super Mario с помощью алгоритма.
ИИ Игра в Марио с поиском по дереву Монте-Карло
Обучение с подкреплением — это интересная область исследований с множеством различных ответвлений. Два из них, которые мы рассмотрели в этом разделе, несомненно, помогут нам в понимании более сложного материала в последующих разделах.
Поздравляем, вы зашли так далеко, мы на полпути к пониманию того, как современный игровой ИИ думает и учится. Во второй части этой статьи мы рассмотрим глубокое обучение и нейронные сети, а затем, наконец, сможем перейти к архитектуре ИИ DeepMind.
Кроме того, дайте мне знать, какой стиль письма вам понравился больше всего, я могу сделать классический документальный фильм, серьезную диссертацию или эти яркие примеры покемонов. Ваши отзывы — это то, что позволяет мне изучить лучшую матрицу политики 🤖.
Ваши отзывы — это то, что позволяет мне изучить лучшую матрицу политики 🤖.
ИИ, которому нечему учиться у людей
Технологии
Новая программа-самоучка DeepMind для игры в го делает ходы, которые другие игроки называют «инопланетными» и «из другого измерения».
Дон Чан900:05 Матч в го между AlphaGo и Ke Jie, в котором машина вышла из альфы (China Stringer Network / Reuters)
Это был напряженный летний день в Японии 18:35. Ведущий игрок страны в го, Хонинбо Джова, занял свое место за доской вместо 25-летнего вундеркинда по имени Акабоши Интецу. Оба мужчины посвятили свою жизнь освоению стратегической игры для двух игроков, давно популярной в Восточной Азии. Их противостояние в тот день имело высокие ставки: Хонинбо и Акабоши представляли два дома го, борющихся за власть, и соперничество между двумя лагерями в последнее время вылилось в обвинения в нечестной игре.
Они и не подозревали, что матч, который сейчас историки го вспоминают как «кровоточащую игру», продлится несколько изнурительных дней. Или что это приведет к ужасному концу.
Сначала юный Акабоси взял на себя инициативу. Но затем, согласно преданиям, появились «призраки» и показали Хонинбо три решающих хода. Его возвращение было настолько ошеломляющим, что, как гласит история, его младший противник упал и начал кашлять кровью. Спустя несколько недель Акабоши нашли мертвым. Историки предполагают, что у него могло быть невыявленное респираторное заболевание.
Есть определенный смысл в том, что знатоки игры задавались вопросом, видели ли они проблески оккультизма в этих трех так называемых призрачных движениях. В отличие от чего-то вроде крестиков-ноликов, которые настолько просты, что оптимальная стратегия всегда очевидна, го настолько сложен, что новые, незнакомые стратегии могут показаться удивительными, революционными или даже сверхъестественными.
К несчастью для призраков, теперь компьютеры раскрывают эти вызывающие мурашки движения.
Создается ощущение, что инопланетная цивилизация подбросила нам загадочный путеводитель.
Как многие помнят, AlphaGo — программа, которая использовала машинное обучение для освоения го — в начале этого года уничтожила чемпиона мира Ке Цзе. Затем создатели программы из Google DeepMind позволили программе продолжить обучение, сыграв миллионы игр против самой себя. В статье, опубликованной ранее на этой неделе в журнале Nature , , DeepMind сообщила, что новая версия AlphaGo (которую они окрестили AlphaGo Zero) взяла Го с нуля, вообще не изучая никаких человеческих игр. AlphaGo Zero потребовалось всего три дня, чтобы достичь точки, когда она столкнулась с более старой версией самой себя и выиграла 100 игр до нуля.
Теперь, когда AlphaGo, возможно, больше нечему учиться у людей — теперь, когда ее непрерывный прогресс принимает форму бесконечных тренировочных игр против самой себя — как выглядит ее тактика в глазах опытных игроков-людей? У нас могут быть первые проблески ответа.
Последние игры AlphaGo Zero пока не разглашаются. Но несколько месяцев назад компания публично выпустила 55 игр, в которые старая версия AlphaGo играла против самой себя. (Обратите внимание, что это воплощение AlphaGo, которое уже быстро расправилось с чемпионами мира.) DeepMind назвала свое предложение «особым подарком поклонникам го по всему миру».
С мая эксперты тщательно анализируют 55 игр «машина против машины». И их описания ходов AlphaGo, кажется, часто возвращаются к одним и тем же нескольким словам: Удивительно. Странный. Инопланетянин.
«Это то, как я представляю себе игры из далекого будущего», — сказал прессе Ши Юэ, лучший игрок в го из Китая. Энтузиаст го по имени Джонатан Хоп, который просматривает игры на YouTube, называет вбрасывания AlphaGo против AlphaGo «переходом из другого измерения». Судя по всему, создается впечатление, что инопланетная цивилизация бросила среди нас загадочный путеводитель: блестящее руководство — или, по крайней мере, те его части, которые мы можем понять.
«Вы должны быть готовы отрицать многое из того, во что мы верили и что работало на нас».
Уилл Локхарт, аспирант физики и заядлый игрок в го, который был одним из режиссеров The Surrounding Game (документальный фильм об истории времяпрепровождения и приверженцах), попытался описать разницу между просмотром игр AlphaGo против лучших игроков-людей, с одной стороны, и его самопарные игры, с другой. (В 2016 году я взял интервью у брата Уилла, Бена, играющего в го, об интенсивных школах го в Азии.) По словам Уилла, действия AlphaGo против Ке Цзе заставляли его «неизбежно идти к победе», в то время как Ке, казалось, «пробивал кирпичную стену. ” Каждый раз, когда китайский игрок, возможно, находил путь вперед, сказал Локхарт, «10 ходов спустя AlphaGo решала его таким простым способом, и это было похоже на: «Пуф, ну, это никуда не привело!»»
Напротив, игры AlphaGo с автопарами могли показаться более безумными. Более сложный. Локхарт сравнивает их с «людьми, сражающимися на мечах на канате».
Опытные игроки также замечают особенности AlphaGo. Локхарт и другие упоминают, что он почти одновременно ведет несколько сражений, применяя подход, который может показаться немного сумасбродным игрокам-людям, которые, вероятно, тратят больше энергии, сосредотачиваясь на небольших участках доски за раз. По словам Майкла Редмонда, самого высокопоставленного игрока в го из западного мира (он переехал в Японию в возрасте 14 лет, чтобы изучать го), люди накопили знания, которые могут оказаться более полезными на краях и углах доски. Он отметил, что у AlphaGo «меньше такой предвзятости, поэтому он может делать впечатляющие движения в центре, которые нам труднее понять».
Кроме того, он делает нестандартные начальные ходы. Некоторые из этих гамбитов всего два года назад могли показаться экспертам непродуманными. Но теперь профессиональные игроки копируют некоторые из этих незнакомых тактик в турнирах, даже если никто до конца не понимает, как определенные тактики ведут к победе. Например, люди заметили, что некоторым версиям AlphaGo нравится играть так называемое вторжение три-три на точку звезды, и теперь они тоже экспериментируют с этим ходом в турнирах. Пока никто не видит, что эти эксперименты приводят к четким последовательным победам, может быть, потому, что игроки-люди не понимают, как лучше довести дело до конца.
Например, люди заметили, что некоторым версиям AlphaGo нравится играть так называемое вторжение три-три на точку звезды, и теперь они тоже экспериментируют с этим ходом в турнирах. Пока никто не видит, что эти эксперименты приводят к четким последовательным победам, может быть, потому, что игроки-люди не понимают, как лучше довести дело до конца.
Некоторые приемы, которые AlphaGo любит делать против своего клона, совершенно непонятны даже лучшим игрокам мира. (Это, как правило, происходит в начале игры — вероятно, потому, что эта фаза уже загадочна, так как она наиболее далека от любого окончательного результата игры.) Один начальный ход в первой игре поставил многих игроков в тупик. Говорит Редмонд: «Я думаю, что естественная реакция (и реакция, которую я в основном наблюдаю) заключается в том, что они просто сдаются и как бы вскидывают руки в дебюте. Потому что так сложно пытаться прикрепить рассказ о том, что делает AlphaGo. Вы должны быть готовы отрицать многое из того, во что мы верили и что работало на нас».
Как и другие, Редмонд отмечает, что игры почему-то кажутся «чужими». «В том, как играет AlphaGo, есть какой-то бесчеловечный элемент, — говорит он, — из-за чего нам очень трудно хотя бы немного войти в игру».
«Обычно люди изучают го, когда у нас есть история».
Тем не менее, Редмонд считает, что бывают моменты, когда AlphaGo (по крайней мере, его старая версия) не обязательно может быть загадочно, трансцендентно хороша. Моменты, когда он может даже совершать ошибки. Есть модели игры под названием дзёсэки — серия локально ограниченных атак и ответов, в которых игроки, по сути, сражаются до тех пор, пока у них не появится смысл переместиться в другую часть доски. Некоторые из этих дзёсэки были проанализированы, запомнены и отточены поколениями. Редмонд подозревает, что люди могут лучше реагировать на некоторые из этих паттернов, потому что они так интенсивно их анализировали. (Трудно сказать, потому что в играх AlphaGo-versus-AlphaGo обе «копии» программы, кажется, избегают попадания в эти joseki в первую очередь. )
)
Не исключено, что AlphaGo все еще может выбирать неоптимальные ходы — делать «ошибки», если хотите. Го можно представить как массивное дерево, состоящее из тысяч ветвей, представляющих возможные ходы и контрходы. На протяжении поколений игроки в го идентифицировали определенные кластеры ветвей, которые, кажется, работают очень хорошо. И теперь, когда появилась AlphaGo, она находит еще лучшие варианты. Тем не менее, огромные участки дерева могут быть еще не исследованы. Как выразился Локхарт: «Возможно, совершенный Бог играет [AlphaGo] и разрушает его. А может и нет. Может быть, это уже есть. Мы не знаем».
* * *
Из своего дома в Чибе, Япония, Редмонд говорит, что последние четыре месяца он более или менее безостановочно изучает игры AlphaGo с парами. Он записывает на видео свои комментарии к каждой игре и размещает одно видео в неделю на канале Американской ассоциации го на YouTube. По его словам, одна из его самых больших проблем в этих видео — «прикрепить истории» к движениям AlphaGo.