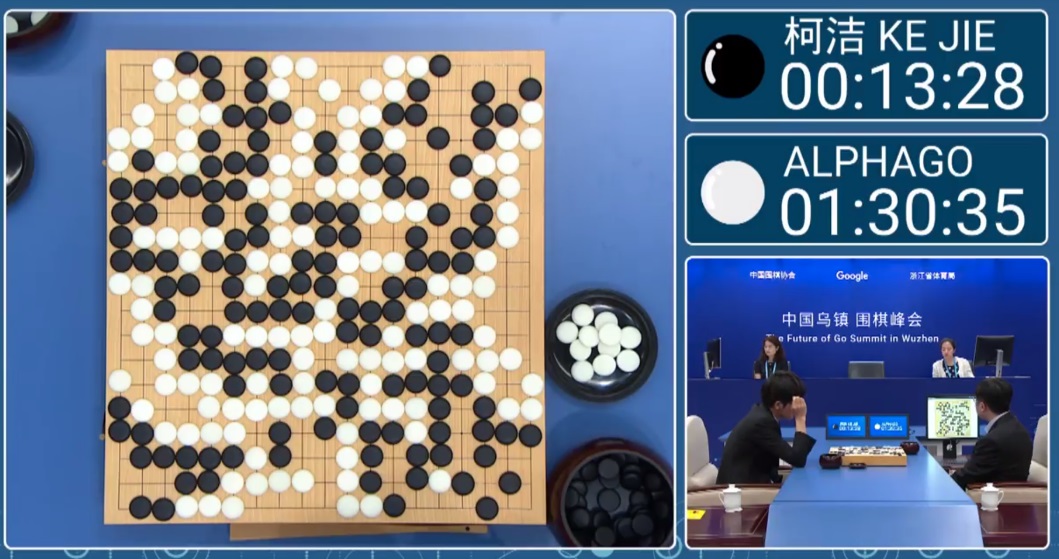
Содержание
AlphaGo на пальцах / Хабр
Итак, пока наши новые повелители отдыхают, давайте я попробую рассказать как работает AlphaGo. Пост подразумевает некоторое знакомство читателя с предметом — нужно знать, чем отличается Fan Hui от Lee Sedol, и поверхностно представлять, как работают нейросети.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа «количество степеней свободы камня», или «количество камней, которые будут взяты этим ходом»
Есть и формально неважные фичи типа «как давно было сделан ход»
И даже специальная фича для частого явления «ladder capture/ladder escape» — потенциально долгой последовательности вынужденных ходов.
а что за «всегда 1» и «всегда 0»?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)
Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич
То есть, ей дают фичи в виде заранее заготовленных паттернов
Она гораздо хуже, чем модель с глубокой сетью, но зато сверх-быстрая. Как она используется — будет понятно дальше
Шаг 2: тренируем policy еще лучше через игру с собой (reinforcement learning) — RL-policy network
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.
Единственный reward — это собственно результат игры, выиграл или проиграл.
После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага.
Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука?
С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Шаг 3: натренируем сеть, которая «с одного взгляда» на расстановку говорит нам, какие у нас шансы выиграть! — Value network
Т. е. предсказывает всего одно значение от -1 до 1.
е. предсказывает всего одно значение от -1 до 1.
У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.
То есть у нее те же фичи?
value network дают еще одну фичу — играет игрок черными или нет (policy network передают «свой-чужой» камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию.
Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
TL;DR: Policy network предсказывает вероятные ходы чтобы уменьшить ширину перебора (меньше возможных ходов в ноде), value network предсказывает насколько выигрышна позиция, чтобы уменьшить необходимую глубину перебора
Внимание, картинко!
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили
(это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет…
То новый созданный нод дерева оценивается двумя способами
- во-первых, через описанный выше value network
- во-вторых, играется до конца с помощью супер-быстрой модели из Шага 1 (это и называется rollout)
Результаты этих двух оценок смешиваются с неким весом (в релизе он натурально 0.5), и получившийся score записывается всем нодам дерева, через которые прошла симуляция, а Q в каждом ноде апдейтится как среднее от всех score для проходов через эту ноду.
(там совсем чуть-чуть сложнее, но можно пренебречь)
Т.е. каждая симуляция бежит по дереву в наиболее перспективную область (с учетом exploration), находит новую позицию, оценивает ее, записывает результат вверх по всем ходам, которые к ней привели. А потом Q в каждом ноде вычисляется как усреднение по всем симуляциям, которые через него бежали.
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy.
Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
- Кластер мог стать больше.
 Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs. - Похоже, стала больше тратить времени на ход (в статье все эстимейты даны для 2 секунд на ход) + добавился некий ML на тему менеджмента времени
- Было больше времени на тренировку сетей до матча. Мое личное подозрение — принципиально то, что больше времени на reinforcement learning. 1 день в изначальной статье это как-то даже не смешно.
 Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
Пожалуй, все. Ждем 5:0!
Бонус: Попытка опенсурсной реализации. Там, конечно, еще пилить и пилить.
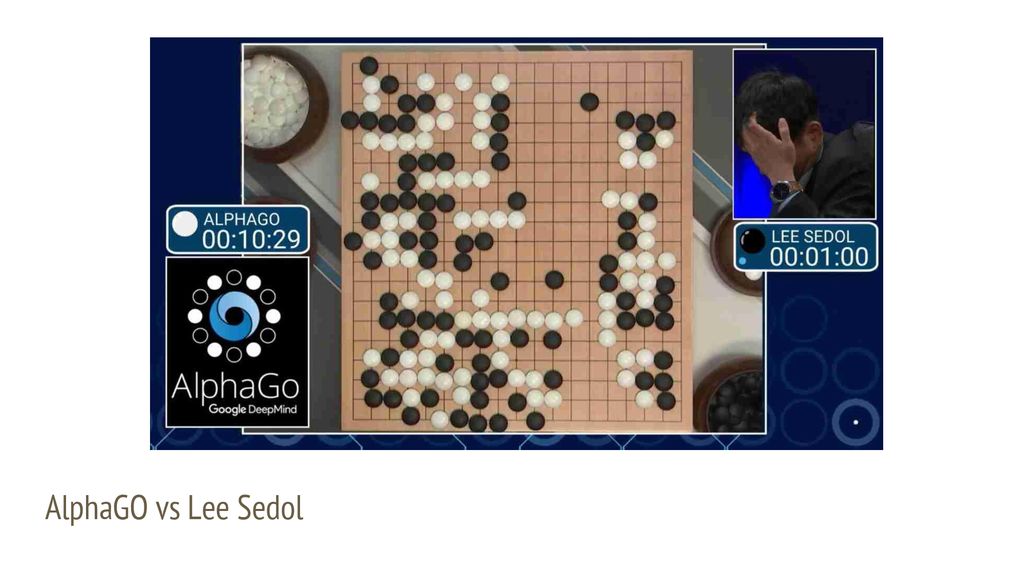
Ли Седоль уходит из большого го из-за AlphaGo. Как это понимать?
В понедельник 25 ноября южнокорейский мастер игры го 9 дана Ли Седоль рассказал в интервью, что он больше не будет участвовать в профессиональных соревнованиях. В качестве главной причины для завершения своей спортивной карьеры Седоль называет появление систем компьютерного го, которые играют лучше любого из людей. Даже если стать лучшим, всё равно будет нечто, что никогда не превзойти, говорит Седоль.
Даже если стать лучшим, всё равно будет нечто, что никогда не превзойти, говорит Седоль.
За пределами кругов поклонников го Ли Седоль получил известность благодаря играм против системы AlphaGo, разработанной компанией Google DeepMind. Го из-за своих особенностей долгое время не удавалось оптимизировать так, чтобы компьютеры могли обыгрывать людей. В 2016 году британская DeepMind провела матч из пяти партий, в котором один из лучших из людей — Седоль — проиграл до этого малоизвестной программе.
С той игры прошли три года. За это время улучшенная версия AlphaGo обыграла другого человека-чемпиона, DeepMind выпустила несколько научных работ по нейросети и рассказала о системе AlphaZero, а потом, кажется, потеряла любой интерес к проекту. Лишь сейчас Седоль решил оставить го. Есть ли для его решения другие причины?
О развитии систем компьютерного го и причинах поступка Ли Седоля мы поговорили с 7-кратным чемпионом Европы по го, действующим чемпионом России и членом президиума Российской федерации го Александром Динерштейном.
В январе 2016 года обычно немногословная DeepMind разразилась научной работой, пресс-релизом и видеороликом. Впервые в мире был создан искусственный интеллект, который способен обыграть человека-чемпиона в азиатскую игру го.
На тот момент го считалась одной из последних настольных логических игр, в которую люди могли играть лучше любого компьютерного алгоритма. Как и шахматы, го — игра с совершенной информацией, то есть игроки знают обо всех ходах, которые ранее совершили другие игроки. Но если ни один гроссмейстер уже с 2005 года не может обыграть лучшие из шахматных программ, то компьютерные алгоритмы в го на тот момент играли на уровне любителей.
Два игрока расставляют на доске определённого размера камни чёрного или белого цвета. Цель игры — отгородить на доске камнями своего цвета территорию большего, чем оппонент, размера. Многие из ходов го основаны на интуиции, которую сложно описать алгоритмом.
Вычислительная сложность го связана с большим числом возможных позиций и корректных ходов из них. Задача поиска исхода игры связана с вычислениями функции оптимального значения в дереве поиска, в котором находятся bd ходов. В го количество корректных ходов b ≈ 250, длина игры d ≈ 150. На стандартной доске 19×19 линий возможных позиций в гугол (10100) раз больше, чем атомов во Вселенной.
Задача поиска исхода игры связана с вычислениями функции оптимального значения в дереве поиска, в котором находятся bd ходов. В го количество корректных ходов b ≈ 250, длина игры d ≈ 150. На стандартной доске 19×19 линий возможных позиций в гугол (10100) раз больше, чем атомов во Вселенной.
Программы до AlphaGo полагались на поиск по дереву Монте-Карло для оценки ценности каждого состояния в дереве поиска. При создании AlphaGo к этому алгоритму добавили глубинные свёрточные нейросети. Нейросети обучили с помощью 160 тысяч матчей с сервера игры го через Интернет KGS с 29,4 млн позиций. Дополнительно AlphaGo играла пять тысяч партий против самой себя.
Полученная программа в лабораторных условиях превзошла любые коммерчески доступные продукты и открытые проекты компьютерного го. AlphaGo выиграла 499 матчей из 500 против игроков-программ. Алгоритм нужно было опробовать на человеке, поэтому против программы пригласили играть трёхкратного чемпиона Европы Фань Хуэя. В октябре 2015 года в лондонском офисе Google Хуэй проиграл алгоритму пять из пяти игр.
В октябре 2015 года в лондонском офисе Google Хуэй проиграл алгоритму пять из пяти игр.
На тот момент это не было окончательным поражением. Конечно, Хуэй — хороший игрок, но для чемпионатов Европы. Наивысшим уровнем обладают мастера го из основного очага распространения игры — Азии. Поэтому для закрепления результата Google объявила о намерении провести в марте 2016 года в Сеуле матч AlphaGo против Ли Седоля, который на тот момент считался лучшим игроком десятилетия.
Из пяти партий серии Седоль выиграл одну. Лишь в четвёртой игре — когда три победы AlphaGo уже определили исход матча — ИИ признал поражение.
Программисты DeepMind почему-то не предусмотрели драматичного сообщения на случай поражения программы.
DeepMind могла бы удовлетвориться счётом 4:1. Но внутри компании продолжали работать. К июню 2016 года сформировались планы дать AlphaGo поиграть против другого чемпиона го — китайца Кэ Цзе. Матч назначили на май 2017.
С 29 декабря 2016 года на корейском сервере Tygem и китайском Fox начал регулярно играть необычно сильный игрок под именем Magister или Master. Игрок выиграл 60 партий у профессионалов высокого уровня. За победу против незнакомца даже назначали награду. 4 января глава DeepMind Демис Хассабис признался, что этот игрок — новая версия AlphaGo.
Игрок выиграл 60 партий у профессионалов высокого уровня. За победу против незнакомца даже назначали награду. 4 января глава DeepMind Демис Хассабис признался, что этот игрок — новая версия AlphaGo.
AlphaGo Fan играл против Фань Хуэя, игравший против Седоля вариант назвали AlphaGo Lee, в Интернете и против Кэ Цзе играл AlphaGo Master. Каждая из версий требовала для запуска всё меньше и меньше оборудования, но играла сильнее предшественника. В DeepMind оценили, что для игры Fan c Lee на равных первому пришлось бы дать три камня форы, Master оказался сильнее Lee ещё на три камня. Неудивительно, что на Future of Go Summit весной 2017 года Кэ Цзе проиграл новой версии AlphaGo все три игры.
Google не выпустила исходные коды AlphaGo и не продаёт программу. Вероятно, эти игры — лишь демонстрация технологического могущества компании. AlphaGo обязана своим успехом аппаратному вычислительному ускорителю TPU собственной разработки Google. По уменьшению количества необходимых модулей легко отследить увеличение эффективности. Партии игры Фань Хуэя обсчитывали 176 видеоускорителей, против Седоля играли 50 плат TPU, против Цзэ выставили всего одну.
Партии игры Фань Хуэя обсчитывали 176 видеоускорителей, против Седоля играли 50 плат TPU, против Цзэ выставили всего одну.
Вычислительный кластер, который обыграл Ли Седоля.
DeepMind демонстрировала успехи программной разработки. Для обучения трёх первых версий AlphaGo правилам игры требовались сотни тысяч партий людей, в алгоритм заложены некоторые вручную заданные функции. Версия AlphaGo Zero училась играть полностью самостоятельно, а нейросети политики и ценности в ней объединены в одну. За 3 дня самообучения Zero превзошла Lee, за 40 дней — Master. Менее чем за полтора месяца алгоритм с нуля научился играть лучше людей в игру, история которой насчитывает тысячелетия человеческого опыта.
DeepMind так никогда и не выпустила исходные коды AlphaGo. Программу невозможно нигде приобрести или сыграть против неё, с весны 2017 она не играет против людей. Для желающих перенять мудрость AlphaGo есть лишь обнародованные партии продукта. Возможно, Google не хочет ассоциировать свою деятельность с системами компьютерного го.
Зато другие быстро переняли знания из опубликованных данных. Похожая масштабом и охватом деятельности на Google китайская Tencent начала создавать собственный алгоритм почти сразу после самой первой публикации научной работы по матчу Фань Хуэя. За год продукт под названием Fine Art сильно прокачали. Уже в 2017 году на сервере FGS алгоритм впервые набрал 10 дан. На чемпионате компьютерного го Computer Go UEC Cup в марте 2017 года программа Fine Art превзошла 29 алгоритмов и получила право сыграть против чемпиона-человека и одержала победу. За схожесть с программой DeepMind алгоритм Fine Art прозвали «китайский AlphaGo».
AlphaGo Zero и AlphaZero учатся не на основе партий игроков-людей, а в играх против самих себя. Сторонние разработчики пытались повторить и эти программы. Проект с открытым исходным кодом Leela Zero откровенно говорит, что пытается воссоздать описанное в научной работе DeepMind.
Собственную реализацию компьютерного го создал и Facebook. В мае 2018 компания открыла исходные коды проекта ELF OpenGo. Натренированный на 2000 видеоускорителях алгоритм запускается на одной видеокарте. Он играет сильнее четырёх из тридцати лучших игроков го в мире.
Натренированный на 2000 видеоускорителях алгоритм запускается на одной видеокарте. Он играет сильнее четырёх из тридцати лучших игроков го в мире.
Facebook также не скрывала, что работает на основе исследований DeepMind. Об этом говорит не только текст, но и даже названия научных работ: «ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero». На основании ELF OpenGo Facebook создала инструмент для анализа партий игроков-людей. На сегодняшний день эта программа остаётся одной из сильнейших среди общедоступных, её анализируют собственные партии многие профессиональные игроки.
Южнокорейская компания NHN Entertainment также переняла опыт DeepMind. Разработка программы HanDol начались в 2016 году в период общей заинтересованности в AlphaGo. Версия 1.0 вышла в декабре 2017 года, её уровень игры был сравним с уровнем игрока 9 дана. HanDol 1.0 требовала обучения на записях игр людей, HanDol 2.0 переняла идею тренировок только на играх против самой себя. NHN Entertainment утверждает, что HanDol Lee играет не хуже AlphaGo Lee, игроки говорят, что алгоритм чуть хуже AlphaGo Master.
HanDol также зарекомендовала себя как система компьютерного го сильнее людей. К концу января 2019 года программа одержала победу над пятью лучшими в Южной Корее мастерами 9 дана. NHN Entertainment предлагает HanDol как услугу тренировок игроков и анализа партий.
Через три года после публикации первой научной работы DeepMind об AlphaGo от превосходства людей в го не осталось и следа. Сила компьютерных систем в го не вызывает вопросов, к ним уже обращаются за советами, у них учатся. Несколько научных работ и десятки партий без какого-либо доступа к программе — но по ней снят даже документальный фильм AlphaGo (доступен в пиратском переводе на русский язык).
Тем не менее с матча Ли Седоль — AlphaGo прошло уже больше трёх лет. Почему Седоль решил уйти из го только сейчас?
На наши вопросы ответил 7-кратный чемпион Европы и действующий чемпион России по го Александр Динерштейн.
В 36 лет Ли Седоль прерывает свою легендарную 24-летнюю карьеру. Случается ли в го такое, что многие профессионалы уходят из игры на рубеже 35—40 лет? Каков типичный путь в жизни мастера го 9 дана?
Случается ли в го такое, что многие профессионалы уходят из игры на рубеже 35—40 лет? Каков типичный путь в жизни мастера го 9 дана?
Этот путь во многом зависит от страны, в которой живёт мастер. В Японии профессионалы частенько играют в турнирах до последнего дня своей жизни. К примеру, один из лидеров японского го середины прошлого века Сугиути Масао (9 дан, 1920—2017) играл турнирные партии даже в возрасте 97 лет, правда, уже без особого успеха. В Китае профессионалы частенько завершают карьеру и переходят на тренерскую работу в 35—40 лет. В Корее регулярно проводятся турниры для ветеранов с хорошими призовыми, поэтому здесь не принято выходить в отставку раньше времени.
Но полагаю, что для Ли Седоля, который за свою карьеру заработал десятки миллионов долларов, призовые не играют существенной роли.
Чем в дальнейшем будет жить Седоль? Вероятно, финансовый вопрос он решил себе до конца своих дней, но чем обычно занимаются бывшие чемпионы после ухода из игры?
Открывают свои школы, тренируют детей.
Я слышал, что он поступил в университет и решил получить высшее образование, но я надеюсь, что он не выберет для себя путь, который совсем не связан с Го. Ведь это тот мастер, который может многое передать будущим поколениям.
 Но Ли Седоль за этим замечен не был. Да, его школа го уже давно существует в Корее и в Китае, но здесь просто используется его раскрученное имя. Сам Ли Седоль никого не обучает.
Но Ли Седоль за этим замечен не был. Да, его школа го уже давно существует в Корее и в Китае, но здесь просто используется его раскрученное имя. Сам Ли Седоль никого не обучает.Чтобы отметить уход из го Ли Седоль в следующем месяце сыграет против системы компьютерного го HanDol. Но чемпион говорит, что проиграет первую игру даже с планируемыми двумя камнями форы. Каковы шансы Седоля в игре против HanDol? В какой форме человек-игрок находится сейчас?
Матч из 3 партий будет проходить на плавающей форе. Если Ли Седоль проиграет на двух камнях, то придется играть на трёх, а потом, возможно, и на четырёх камнях. Но я уверен, что до четырёх камней дело не дойдет. Ли Седоль сейчас занимает 14 строчку в корейском рейтинге го и 54 место в неофициальном мировом рейтинге, но многие по-прежнему считают его одним из сильнейших мастеров в мире.
Победа Ли Седоля над AlphaGo в четвёртой партии матча во многом была случайной — Ли Седоль сильно отставал по очкам, но смог обмануть программу, применив некорректный (но с очень непростым опровержением) ход.
Но я напомню, что все партии того матча игрались на равных. Если посмотреть на современное положение дел, то на равных никто сильнейшие программы обыграть уже не может. Профессионалы берут 2 камня форы у китайской программы FineArt (а она после ухода с арены AlphaGo считается сильнейшей в мире), но на двух камнях программа выигрывает около 95% всех партий.
Думаю, что и Ли Седолю на двух камнях будет непросто, но на трёх он должен справиться. А 4 камня — это уже фора из разряда ладьи в шахматах. Мастера на такой форе проигрывать не должны. Насколько мне известно, шахматисты пока успешно обыгрывают программу с форой в коня, думаю, что и у нас 3 камня — это потолок. И как бы сильно программы не прогрессировали, на 4 камнях обыграть человека они не смогут никогда.
Южнокорейская система компьютерного го HanDol к концу января 2019 года одержала победу над пятью мастерами 9 дана. Где находится HanDol: на уровне AlphaGo Lee (версии для игры с Седолем) или AlphaGo Master (версии для игры против Кэ Цзе)? Есть ли у HanDol потенциал против более поздних и более сильных AlphaGo Zero или AlphaZero?
Где находится HanDol: на уровне AlphaGo Lee (версии для игры с Седолем) или AlphaGo Master (версии для игры против Кэ Цзе)? Есть ли у HanDol потенциал против более поздних и более сильных AlphaGo Zero или AlphaZero?
Те пять партий игрались на равных. Я их смотрел, помню, что шансов у профессионалов не было. Думаю, что сейчас в мире существует несколько программ, которые вполне могли бы составить конкуренцию сильнейшим версиям AlphaGo. Этот вывод можно сделать по анализу партий AlphaGo современными программами. Они находят до 95% ходов, которые играла AlphaGo, и предлагают сыграть именно в эти точки.
Думаю, что Ли Седоль не в состоянии почувствовать разницу между AlphaGo, с которой он сражался в 2016 году, и современными программами. Но у Ли Седоля есть важное преимущество. Тогда он не знал, с кем предстоит иметь дело, и был уверен, что выиграет матч с сухим счётом. Заранее протестировать AlphaGo ему не дали.
Корейские профессионалы вообще не использовали раньше компьютер для изучения го.
А сейчас программы есть в открытом доступе. Ли Седоль сможет потренироваться, поиграть с ними на разной форе. Да и стратегия го с тех пор сильно продвинулась вперед — люди изучили компьютерные идеи, стараются подражать машинам. Теперь, когда ты смотришь современные партии, не сразу становится понятно, кто их играл — человек или программа — настолько всё стало похоже по дебютам.
 Помню, как показывал Ли Сангхуну (старшему брату Ли Седоля, у которого тоже 9 профессиональный дан) украинскую разработку начала 2000-х годов — базу партий профессионалов с возможностью поиска по позициям. Он смотрел на неё с большим удивлением, отмечая, что корейцы таким не пользуются и держат знания в голове.
Помню, как показывал Ли Сангхуну (старшему брату Ли Седоля, у которого тоже 9 профессиональный дан) украинскую разработку начала 2000-х годов — базу партий профессионалов с возможностью поиска по позициям. Он смотрел на неё с большим удивлением, отмечая, что корейцы таким не пользуются и держат знания в голове.Поражение 2016 года не заставило Седоля немедленно отказаться от го. Заметные победы HanDol против корейских чемпионов относятся к началу этого года. В конце 2019 без какого-либо заметного повода он объявил об уходе.
Кроме возросшей силы слабой формы ИИ от DeepMind для ухода Ли Седоля из спорта есть причины в виде судебного конфликта с Корейской ассоциацией падук по поводу финансового вопроса членских взносов. Седоль мог бы играть в составе профессиональной лиги в Китае или Японии, но вопросы национальности от этого заставили отказаться.
Седоль мог бы играть в составе профессиональной лиги в Китае или Японии, но вопросы национальности от этого заставили отказаться.
Возможно ли, что называть причиной ухода систему компьютерного го — это в большей степени комплимент её разработчикам, а реальная причина более приземлённа? Кривит ли душой Седоль?
Ли Седоль всегда был резок в высказываниях и поступках. Его недовольство политикой Корейской федерации падук (го), которая забирала себе 10% призовых, в том числе в турнирах, сыгранных в других странах, известно давно. Но это не те деньги, ради которых стоит бросать го.
Думаю, что у Ли Седоля перед глазами стоит картина другого легендарного корейского мастера — Ли Чангхо. Человека, который считался сильнейшим в мире до появления на арене Ли Седоля в середине 2000-х годов. Ли Чангхо го не бросил. Он активно играет в турнирах, но откатился аж на 40-е место в корейском рейтинге.
Что любопытно — 44-летний Ли Чангхо не признаёт компьютерные схемы.
Ли Седоль, видимо, решил, что здесь ему за молодежью не угнаться. Хотя можно было не бросать Го, а собрать себе штаб, пригласить профессионалов, которые любят эту кропотливую работу. С таких подходом Ли Седоль ещё мог бы держаться на плаву.
 Он играет так, как играл всю свою жизнь. Утверждает, что не пользуется компьютером и даже телефон имеет с кнопками. Похоже, что и Ли Седоль с компьютерами не особо дружит. А современное профессиональное го (как и современные шахматы) — это теперь многочасовые тренировки с машиной, шлифовка вариантов, поиск новинок.
Он играет так, как играл всю свою жизнь. Утверждает, что не пользуется компьютером и даже телефон имеет с кнопками. Похоже, что и Ли Седоль с компьютерами не особо дружит. А современное профессиональное го (как и современные шахматы) — это теперь многочасовые тренировки с машиной, шлифовка вариантов, поиск новинок.У игрока в шахматы поступок Седоля может вызвать улыбку: в шахматах компьютер уже два десятилетия обыгрывает лучших из людей. Шахматисты с этим свыклись.
Систему HanDol предоставляют в качестве сервиса для тренировок. Она может обыграть почти любого человека, поэтому у неё есть чему поучиться.
Бессмысленно ходить в тени гигантов-машин или достаточно отбирать смартфоны на чемпионатах? Мы теперь будем учиться у программ, а не мудрых мастеров-людей? Как вы оцениваете будущее профессионального го в эпоху, когда коммерчески доступны компьютерные системы сильнее человека?
Главный минус — го потеряла статус единственной в мире игры, с которой не может справиться машина.
Но главный плюс в том, что теперь необязательно учиться в Китае, Корее, или Японии. Для того, чтобы обыгрывать азиатских профессионалов, теперь достаточно установить себе программу и пытаться играть так, как она это делает.
Но пока, правда, у нас не особо это получается. Турниры с призами в сотни тысяч долларов по-прежнему выигрывают азиаты. А европейцы и американцы, даже те, которые «спят в обнимку с компьютером», по-прежнему им проигрывают. Но, надеюсь, ситуация изменится в будущем, и мы им ещё покажем!
 А мы использовали этот лозунг, даже на буклектах для начинающих радостно о нём сообщали. Таинственность пропала. Профессионалы потеряли статус богов, превратившись в простых смертных. Книги по го потеряли свой смысл — если верить программам, они учат нас неправильным вещам. Минусов, конечно, много.
А мы использовали этот лозунг, даже на буклектах для начинающих радостно о нём сообщали. Таинственность пропала. Профессионалы потеряли статус богов, превратившись в простых смертных. Книги по го потеряли свой смысл — если верить программам, они учат нас неправильным вещам. Минусов, конечно, много.AlphaGo: Как это работает технически? | Джонатан Хуэй
«Лего-штурмовик на песке» Дэниел Чунг
Как обучение с подкреплением сочетается с глубоким обучением, чтобы победить мастера го? Поскольку это звучит неправдоподобно, технология, стоящая за этим, должна быть непонятна. На самом деле это не так. Если вы знаете, как обучить классификатор CNN, у вас будет достаточно знаний, чтобы понять большую часть материала здесь. В этой статье мы расскажем, как обучается AlphaGo и как он делает движения, чтобы победить человека.
На самом деле это не так. Если вы знаете, как обучить классификатор CNN, у вас будет достаточно знаний, чтобы понять большую часть материала здесь. В этой статье мы расскажем, как обучается AlphaGo и как он делает движения, чтобы победить человека.
Представьте, что у вас есть мастер го по имени Йода, который выступает вашим советником на турнире. Всякий раз, когда наступает ваша очередь, вы просите Йоду сделать следующий ход. Через некоторое время вы решаете собрать все его предыдущие игры и подражать тому, что делает Йода. Однако комбинаций ходов слишком много ( состояний ). Итак, мы моделируем функцию f , которая берет доску го и выводит распределение вероятностей для всех возможных ходов. Чтобы сделать ход, мы можем выбрать ход с наибольшей вероятностью или выбрать ход из распределения вероятностей.
Звучит странно, но это работает, и основная концепция аналогична глубокому классификатору сети.
Фактически, мы перепрофилируем классификатор глубокого обучения для модели f . Классификатор состоит из 13 слоев, содержащих альтернативные сверточные фильтры и выпрямители, за которыми следует классификатор softmax. Поскольку эта сеть создана с помощью контролируемого обучения, она называется SL сеть политик .
Классификатор состоит из 13 слоев, содержащих альтернативные сверточные фильтры и выпрямители, за которыми следует классификатор softmax. Поскольку эта сеть создана с помощью контролируемого обучения, она называется SL сеть политик .
Доска для го имеет сетку 19 × 19. Ниже приведены 2 разные доски позиций (состояний).
2 разные доски позиций
Однако классификатор не берет необработанное изображение. Для представления доски требуется входная функция 19 × 19 × 48. Но эти функции довольно просты и их легко получить. (Никаких сложных функций ручной работы)
Входные функции для сетей политик SL
Давайте введем несколько терминов RL, чтобы уравнения были менее пугающими. действие a наш ход, состояние с — это наша позиция в совете директоров, а политика p — это распределение вероятностей предпринятых действий a .
Обучение
Для обучения сети политик SL AlphaGo собирает ходы для 30 миллионов позиций на доске. Затем он применяет обратное распространение в глубоком обучении для обучения параметров модели σ. (Это то же самое, как вы обучаете глубокий сетевой классификатор.)
AlphaGo использует 50 графических процессоров для обучения сети, и это занимает 3 недели. Сеть политик SL достигает точности 57%. Звучит не слишком точно, но эта политическая сеть уже может победить продвинутого любителя.
Политика развертывания
Во время моделирования игры (обсуждается позже) нам нужно что-то более быстрое, чтобы сузить поиск ходов. Мы создаем еще одну политику под названием rollout policy π , которая использует более простой линейный классификатор softmax. Для вычисления каждого перемещения требуется 2 мкс вместо 3 мс в сети политик SL. Эта политика развертывания имеет более низкую точность 24,2% (по сравнению с 55,7%), но она в 1500 раз быстрее.
Обучение с подкреплением (RL) сетей политик
Теперь у нас есть политика сети, приближенная к мастеру перемещений. Но это еще не достаточно точно, чтобы победить мастера. На втором этапе обучения AlphaGo начинает играть в игры с самой собой, чтобы сформулировать лучшую политику.
Сначала мы дублируем сеть политик SL и называем ее Сеть политик RL ρ . Мы используем обучение с подкреплением градиента политики для итеративного улучшения сети политик RL. Мы начинаем играть в игры, используя новую сеть политик RL. Для нашего противника мы случайным образом повторно используем одну из старых сетей политик RL. Мы не играем друг с другом с одной и той же сетью политик, потому что она будет превосходить текущую политику. (т.е. он будет запоминать ходы, а не обобщать их для разных противников.) Мы играем, пока игра не закончится. Для временного шага t , результат игры z t равен 1, если мы выиграем в конце, или -1, если проиграем. Мы модифицируем параметр модели ρ , чтобы упростить политику RL. Фактически, это почти то же самое, что и обратное распространение глубокого обучения (DL), за исключением того, что мы используем результат игры z , чтобы определить, в каком направлении двигаться.
Мы модифицируем параметр модели ρ , чтобы упростить политику RL. Фактически, это почти то же самое, что и обратное распространение глубокого обучения (DL), за исключением того, что мы используем результат игры z , чтобы определить, в каком направлении двигаться.
Для обучения сети политик RL требуется около одного дня с использованием 50 графических процессоров.
Обучение с подкреплением (RL) сетей создания ценности
Мастера Йоду трудно понять, и, что еще хуже, он непредсказуем. Сеть политик RL страдает от той же проблемы. Результат игры в го может варьироваться с небольшим изменением. Небольшая «неточность» в сети политик RL может превратить выигрыш в проигрыш. Человек расставляет приоритеты в поиске ходов и соответственно оценивает позицию на доске. На последнем этапе обучения AlphaGo мы хотим воспроизвести способность человека оценивать позицию на доске. Мы обучаем глубокую сеть оценивать значение наших позиций. В Go значение равно 1, если мы выиграем, или -1, если проиграем. Позже мы дополняем нашу политическую сеть и сеть ценностей друг другом, чтобы искать и делать лучшие шаги.
В Go значение равно 1, если мы выиграем, или -1, если проиграем. Позже мы дополняем нашу политическую сеть и сеть ценностей друг другом, чтобы искать и делать лучшие шаги.
В обучении RL значение измеряет, насколько хорошо находиться в состоянии s. Мы часто называем значение функцией значения .
Чтобы обучить сеть ценности, мы играем друг с другом в игры, используя одну и ту же сеть политик RL. Структура сети ценности аналогична сети политик, за исключением того, что она выводит скалярное значение вместо распределения вероятностей. Мы вычисляем среднеквадратичную ошибку MSE нашей функции ценности v(s) с результатом игры z. Так же, как и обучение с учителем, мы используем обратное распространение для изменения параметров нашей модели θ .
От начала до конца игры мы можем собрать множество позиций на доске из последовательности ходов и добавить их в обучающий набор данных. Однако мы не собираем более одной позиции на доске за игру. Все позиции на доске в игре приводят к одному и тому же результату (победе или поражению), они тесно связаны. Чтобы эффективно обучать модель, мы хотим, чтобы выборки в обучающем наборе данных были независимыми. Поэтому мы используем сеть политик RL, чтобы сыграть более 30 миллионов игр и собрать только одну позицию из каждой игры в набор обучающих данных. Сеть ценности AlphaGo обучается на 50 графических процессорах в течение одной недели.
Однако мы не собираем более одной позиции на доске за игру. Все позиции на доске в игре приводят к одному и тому же результату (победе или поражению), они тесно связаны. Чтобы эффективно обучать модель, мы хотим, чтобы выборки в обучающем наборе данных были независимыми. Поэтому мы используем сеть политик RL, чтобы сыграть более 30 миллионов игр и собрать только одну позицию из каждой игры в набор обучающих данных. Сеть ценности AlphaGo обучается на 50 графических процессорах в течение одной недели.
Вот визуализация прогноза из сети политик и сети ценности для соответствующей позиции на доске. Подобно человеку, AlphaGo начинает игру за углом.
Итак, чего мы достигли на данный момент? Наше обучение завершено, и мы используем глубокое обучение и обучение с подкреплением, чтобы построить
- сеть политики, которая сообщает нам, какие шаги являются многообещающими, и
- сеть ценностей, которая сообщает нам, насколько хороша позиция совета директоров.
Мы знаем, что обе сети несовершенны, и крошечные ошибки могут повлиять на результат игры. Наша последняя задача — дополнить обе сети друг другом, чтобы лучше искать наш последний ход.
Наша последняя задача — дополнить обе сети друг другом, чтобы лучше искать наш последний ход.
Интуиция
Имитация ходов, предложенных политикой и сетью ценности, — лучший способ найти следующий ход. Мы моделируем игры, начиная с текущей позиции на доске. Мы ищем ходы и играем в условные игры до конца. Если мы сыграем достаточно игр, мы получим представление о том, какой ход, скорее всего, принесет больше всего выигрышей. В процессе мы строим дерево поиска, записывая последовательности смоделированных нами ходов и количество выигрышей для каждого хода. Но пространство поиска для го слишком велико, нам нужно расставить приоритеты, чтобы мы могли найти лучшие ходы в меньшем количестве игр. К счастью, мы получаем отличные советы от политики и сети создания ценности. Мы используем обе информации для определения приоритетов наших поисков.
Но этого недостаточно. Мы должны исследовать ходы, о которых пока мало знаем в нашей симуляции ( исследование ). Возможно, совет не работает, поэтому это помогает нам лучше проверять ходы. С другой стороны, если мы выиграем симулированную игру, мы хотим чаще пробовать соответствующие ходы ( эксплуатация ).
Возможно, совет не работает, поэтому это помогает нам лучше проверять ходы. С другой стороны, если мы выиграем симулированную игру, мы хотим чаще пробовать соответствующие ходы ( эксплуатация ).
Следовательно, наш приоритет поиска зависит от:
- прогнозов из сети политик,
- прогнозов из сети ценности,
- от того, сколько раз мы выбираем ход, и
- смоделированные результаты игры с выигрышами.
Поиск по дереву Монте-Карло (MCTS) — это алгоритм, который мы используем для определения приоритетов и построения этого дерева поиска. Он состоит из 4 шагов ниже.
Выбор
MCTS моделирует множество игр, чтобы выяснить, насколько хороши ходы. Цель шага выбора состоит в том, чтобы расставить приоритеты для дальнейших симуляций. Если наш приоритет правильный, мы можем сыграть меньше игр, чтобы выбрать лучший ход.
Для каждой симуляции мы сначала выбираем путь в нашем дереве поиска. (Позже мы обсудим, как построить и расширить это дерево поиска). Предположим, что наше дерево поиска выглядит так, как показано слева ниже. Вершина дерева — это наша текущая позиция на доске, а в дереве есть еще 3 позиции на доске. Каждое ребро — это ход, необходимый для перехода из одной позиции в другую. то есть каждое ребро ( s, a ) представляет действие a для перехода из состояния s в состояние 9. 80 С правой стороны мы вычисляем Q + u для всех узлов и выбираем потомков с наибольшим значением для каждого родителя. Это многообещающий путь (красные стрелки), который нам нужен для дальнейшей симуляции.
Предположим, что наше дерево поиска выглядит так, как показано слева ниже. Вершина дерева — это наша текущая позиция на доске, а в дереве есть еще 3 позиции на доске. Каждое ребро — это ход, необходимый для перехода из одной позиции в другую. то есть каждое ребро ( s, a ) представляет действие a для перехода из состояния s в состояние 9. 80 С правой стороны мы вычисляем Q + u для всех узлов и выбираем потомков с наибольшим значением для каждого родителя. Это многообещающий путь (красные стрелки), который нам нужен для дальнейшей симуляции.
Q и u — функции, определенные ниже. Q для эксплуатации и u для разведки.
Не бойся! Первое уравнение означает выбор действия a (ход), которые имеют наибольшее значение Q + u . Если мы развернули Q и u , наш выбранный ход зависит от:
Если мы развернули Q и u , наш выбранный ход зависит от:
Для каждого движения (ребра), которое мы выбрали на пути, мы увеличиваем количество посещений N(s, a) на 1. Уравнение 1(s, a, i) ниже равно 1, если ход (s, a) выбрано (в противном случае 0). ( i представляет смоделированную игру i .)
Остальные уравнения будут обсуждаться позже.
Расширение
Наше дерево поиска начинается с текущей позиции.
Затем мы добавляем в дерево дополнительные позиции, отражающие то, какие движения (ребра) мы пробовали.
Всякий раз, когда мы расширяем дерево, мы инициализируем новые ребра (s, a) с помощью:
P(s, a) — это вероятность, указывающая, насколько хорош ход a . Он инициализируется сетью политик SL и больше не будет обновляться. Он используется в разведке в вычислениях u . Вы можете спросить, почему это не инициируется сетью политик RL. Получается, мы хотим исследовать еще разнообразных ходов. Верхние шаги в сети политик RL хороши, но менее диверсифицированы. Сеть политик SL изучается на основе человеческого опыта. Оказывается человек пробует более разнообразные варианты в изучении ходов.
Вы можете спросить, почему это не инициируется сетью политик RL. Получается, мы хотим исследовать еще разнообразных ходов. Верхние шаги в сети политик RL хороши, но менее диверсифицированы. Сеть политик SL изучается на основе человеческого опыта. Оказывается человек пробует более разнообразные варианты в изучении ходов.
В следующем примере выбранный нами путь выделен красным цветом.
Мы добавляем новый конечный узел (S L ), чтобы расширить дерево. Мы вычислим его функцию ценности из сети ценности.
И мы инициализируем все ребра из конечного узла и вычисляем P (он же P(s, a)) , используя сеть политик SL σ .
Так что же такое Q ? Мы используем его, чтобы указать путь в выборе. Почему мы используем Q вместо P , чтобы оценить, насколько хорош ход?
Оба P и Q(s, a) оба называются функцией действия-значения . Он измеряет, насколько хорошо сделать ход. Однако P вычисляется только из сети политик SL. Q запускает взвешенную сумму для функций значений конечных узлов
Он измеряет, насколько хорошо сделать ход. Однако P вычисляется только из сети политик SL. Q запускает взвешенную сумму для функций значений конечных узлов
и результатов игры z .
Итак, Q объединяет дополнительную информацию. Кроме того, функция стоимости вычисляется из сети значений θ. Он обучается сетью политик RL, которая считается лучшей, чем сеть политик SL. Таким образом, Q является более точным, и мы используем его для эксплуатации. P более разнообразен и мы используем его для исследования при расчете u .
Оценка
На этапе оценки мы моделируем оставшуюся часть игры, используя Развертывание Монте-Карло , начиная с конечного узла. Это означает, что вы закончите игру, используя политику, и узнаете, выигрываете вы или проигрываете.
В этом случае мы используем политику развертывания вместо политики SL или политики RL. Даже он ниже по точности, но в 1500 раз быстрее. Нам нужна скорость для имитации множества развертываний. Чтобы сыграть в оставшуюся часть игры, мы пробуем ходы, используя политику развертывания.
Резервный
После оценки мы знаем, выигрывают или проигрывают наши ходы в игре. Теперь мы вычисляем Q , чтобы помнить, насколько хорошо делать ход, исходя из результатов игры и функции значения конечного узла.
Мы обновляем Q с помощью:
т. е. Q является средневзвешенным результатом z симуляции игр и значением функции node8 v 0 900.
После многих игровых симуляций у нас должна быть разумная оценка того, насколько удачен ход, основанный на Q . Тем не менее, AlphaGo не использует Q для определения следующего хода для текущей позиции на доске. Он использует ход со старшим N (как часто мы делаем этот ход в игровых симуляциях) . По мере развития моделирования разведка уменьшается, а эксплуатация преобладает. Самый посещаемый ход является и самым перспективным. Но N менее склонен к аутсайдеру, чем Q .
Он использует ход со старшим N (как часто мы делаем этот ход в игровых симуляциях) . По мере развития моделирования разведка уменьшается, а эксплуатация преобладает. Самый посещаемый ход является и самым перспективным. Но N менее склонен к аутсайдеру, чем Q .
После стольких шагов мы, наконец, выбираем ход, чтобы победить мастера!
Это дерево поиска будет повторно использовано для следующего хода. Выбранный ход становится корнем. Мы храним все узлы и их статистику под текущим корнем и отбрасываем остальные.
Для чего нужна сеть политик RL?
Если вы посмотрите на уравнения в MCTS, сеть политик RL не используется для выбора каких-либо ходов. Мы используем сеть политик SL для исследования. Сеть ценности и результаты игры для эксплуатации. Мы тратим так много усилий на обучение сети политики RL. Почему мы его не используем? На самом деле, мы делаем. Мы используем сеть политик RL для обучения сети ценности, которая активно используется при эксплуатации.
Мы используем сеть политик RL для обучения сети ценности, которая активно используется при эксплуатации.
Как запустить MCTS?
Для эффективной работы MCTS поиск (моделирование) выполняется на 48 ЦП в 40 потоках. Оценка политик и значений выполняется на 8 графических процессорах.
Слишком большое пространство для поиска Go. Чтобы победить, игрокам в го нужно расставлять приоритеты в поиске и очень хорошо оценивать позиции. Используя обучение с учителем, мы создаем сеть политик для имитации действий эксперта. С этой политикой мы можем играть в Го на продвинутом любительском уровне. Затем мы позволяем сети политик играть в игры с самой собой. Используя обучение с подкреплением, мы применяем результаты игры для дальнейшего уточнения сети политик. Мы также обучаем сеть ценности для оценки позиций. Наше обучение завершено. Но мы пока не можем победить мастеров. Чтобы определить следующий ход, мы моделируем игры, чтобы найти лучший ход. Но это не так просто. Мы используем сеть политик и сеть создания стоимости, чтобы сузить область поиска. Чтобы смягчить ошибки в нашей оценке, мы вычисляем средневзвешенное значение на основе результатов нашей игры и оценки нашей доски. Даже мы можем смоделировать только ограниченное количество игр, мы надеемся, что этого достаточно, и средневзвешенное значение будет более точным. AlphaGo прав. Эта стратегия превосходит мастеров Го. В приведенной ниже таблице мы видим, как AlphaGo улучшает свой рейтинг Эло (рейтинг игрока в го) за счет применения различных комбинаций сети политик, сети ценности и внедрения Монте-Карло.
Мы используем сеть политик и сеть создания стоимости, чтобы сузить область поиска. Чтобы смягчить ошибки в нашей оценке, мы вычисляем средневзвешенное значение на основе результатов нашей игры и оценки нашей доски. Даже мы можем смоделировать только ограниченное количество игр, мы надеемся, что этого достаточно, и средневзвешенное значение будет более точным. AlphaGo прав. Эта стратегия превосходит мастеров Го. В приведенной ниже таблице мы видим, как AlphaGo улучшает свой рейтинг Эло (рейтинг игрока в го) за счет применения различных комбинаций сети политик, сети ценности и внедрения Монте-Карло.
Я не эксперт в Go, чтобы дать правильный ответ. Но если вы посмотрите интервью Ке Цзе (чемпиона по го) о его матче с AlphaGo, вы можете найти некоторые подсказки. Небольшая часть может быть вызвана беспокойством игрока. Но по большому счету способ обыграть соперника больше не работает для AlphaGo. Человек развивает понимание для решения проблем. Мы распознаем шаблоны и применяем усвоенные решения (часто подсознательно) или избегаем их. Предварительно обученная политика и сети создания ценности — это идеи AlphaGo. AlphaGo обладает большей вычислительной мощностью и может разрабатывать модели, которые могут быть более тонкими, чем мы. Со стороны человека наши умственные способности ограничены, мы разбиваем план игры на промежуточные цели и определяем стратегии и тактики для их достижения. В AlphaGo «выигрыш» или «проигрыш» — единственная целевая функция в расчетах, и в ней используются длинные последовательности прогнозов, извлеченные из смоделированных игр. Цель AlphaGo очень прямолинейна. Если это удастся, решение будет более оптимальным, чем наши цели. Неудивительно, что Цзе считает движения AlphaGo всесторонними. AlphaGo использует другую методологию для создания ходов. Он может смотреть дальше вперед. Половина ходов — не то, что догадался Цзе. Человеческое понимание все еще полезно, но оно не в полной мере. Фактически, мы можем учиться у AlphaGo, чтобы разрабатывать новые идеи и новые шаги. Кроме того, если мы хотим победить, нам нужно исследовать слабости соперника.
Предварительно обученная политика и сети создания ценности — это идеи AlphaGo. AlphaGo обладает большей вычислительной мощностью и может разрабатывать модели, которые могут быть более тонкими, чем мы. Со стороны человека наши умственные способности ограничены, мы разбиваем план игры на промежуточные цели и определяем стратегии и тактики для их достижения. В AlphaGo «выигрыш» или «проигрыш» — единственная целевая функция в расчетах, и в ней используются длинные последовательности прогнозов, извлеченные из смоделированных игр. Цель AlphaGo очень прямолинейна. Если это удастся, решение будет более оптимальным, чем наши цели. Неудивительно, что Цзе считает движения AlphaGo всесторонними. AlphaGo использует другую методологию для создания ходов. Он может смотреть дальше вперед. Половина ходов — не то, что догадался Цзе. Человеческое понимание все еще полезно, но оно не в полной мере. Фактически, мы можем учиться у AlphaGo, чтобы разрабатывать новые идеи и новые шаги. Кроме того, если мы хотим победить, нам нужно исследовать слабости соперника. Без ошибок глубокое обучение может совершать гораздо более глупые ошибки, чем человек. Но поскольку мы обучаем глубокую сеть стохастическим методом, она более случайна и ее гораздо сложнее использовать без доступа к этим миллионам параметров в модели глубокой сети.
Без ошибок глубокое обучение может совершать гораздо более глупые ошибки, чем человек. Но поскольку мы обучаем глубокую сеть стохастическим методом, она более случайна и ее гораздо сложнее использовать без доступа к этим миллионам параметров в модели глубокой сети.
Человеческие потери в игре Го для ИИ. Но это некорректное сравнение, потому что у нас разные подходы. У человека нет скорости вычислений компьютеров, и поэтому мы полагаемся на абстрактное мышление и анализ для решения проблем. AlphaGo может использовать преимущества вычислительной мощности и немного меньше абстрактного мышления. Исследователи находят способы поиска в пространстве Go гораздо более эффективными. Технология на самом деле не слишком сложна для понимания, но есть много деталей, чтобы заставить ее работать. AlphaGo доказывает, что, сочетая грубую скорость, глубокое обучение и обучение с подкреплением, он может победить нас.
Можно сказать, мы делаем компьютер умнее. Но я предпочитаю говорить, что интеллект проще, чем мы думали.

В конце 2017 года DeepMind выпустила AlphaGo Zero. Это необходимо прочитать тем, кто интересуется AlphaGo. AlphaGo Zero не только легко побеждает AlphaGo, но и не требует никаких реальных игр или человеческих знаний для обучения глубокой сети.
В моей предыдущей статье мы рассмотрели технические детали того, как AlphaGo побеждает чемпиона по го. Даже AlphaGo…
medium.com
Дизайн сети
Сеть политик состоит из 12 скрытых слоев сверточных фильтров с нулевым заполнением и шагом 1 для сохранения пространственного измерения. Сеть использует входные функции 19×19×48 для представления доски 19×19. Первый слой использует фильтры 5×5×49×192, а остальные используют фильтры 3×3×192×192. Для каждого слоя мы добавляем выпрямители, чтобы ввести нелинейность. Последний слой представляет собой фильтр 1×1×192×1 с разными смещениями для каждого местоположения, за которым следует функция softmax. Сеть создания стоимости выглядит аналогично. Но скрытый слой 12 — это дополнительный слой свертки, слой 13 — это слой 1×1×19.Фильтр 2×1 и слой 14 представляют собой полносвязный слой с 256 выпрямителями. Выходной слой — это полностью связанный слой с одним выходом tanh . AlphaGo использует 192 фильтра с высочайшей точностью и приемлемым временем обработки:
Но скрытый слой 12 — это дополнительный слой свертки, слой 13 — это слой 1×1×19.Фильтр 2×1 и слой 14 представляют собой полносвязный слой с 256 выпрямителями. Выходной слой — это полностью связанный слой с одним выходом tanh . AlphaGo использует 192 фильтра с высочайшей точностью и приемлемым временем обработки:
Бумага и кредиты
Большинство таблиц и рисунков изменены из оригинальной статьи:
Освоение игры Го с глубокими нейронными сетями и поиском по дереву
Ке Цзе и Фан Хуэй на AlphaGo
Алгоритм поиска
В реализации AlphaGo используется 2 счетчика для подсчета посещений. Поскольку симуляция выполняется в нескольких потоках, дополнительный счетчик временно искусственно завышается, поэтому другим потокам не рекомендуется выбирать те же ходы, пока этот поток все еще работает. Это побуждает параллельные потоки одновременно исследовать разные ходы.
Во время расширения мы добавляем конечный узел в дерево поиска, когда родительский элемент выбран на нашем пути. В AlphaGo узел добавляется только в том случае, если родитель посещается более 40 раз (контролируется гиперпараметром порога раскрытия). Но этот порог будет автоматически регулироваться во время выполнения. И добавляемый узел будет выбран другой политикой, аналогичной политике развертывания, но использующей больше входных функций.
В AlphaGo узел добавляется только в том случае, если родитель посещается более 40 раз (контролируется гиперпараметром порога раскрытия). Но этот порог будет автоматически регулироваться во время выполнения. И добавляемый узел будет выбран другой политикой, аналогичной политике развертывания, но использующей больше входных функций.
Конфигурация гиперпараметров
Порог расширения и константа исследования выше, чем в примерах на иллюстрациях. Это указывает на важность изучения дерева для победы над мастером.
Функции политики развертывания
Для повышения скорости обработки в 1500 раз AlphaGo использует сеть развертывания вместо сети политик для выборки перемещений в развертывании Монте-Каро. Однако для повышения точности необходимо вручную обрабатывать входные функции.
Визуализация
Давайте посмотрим, какие ходы (красный кружок внизу) рекомендуются разными методами.
На приведенной ниже диаграмме а представлена оценка сети создания стоимости. Мы показываем позиции с самыми высокими значениями из сети ценности. Красный имеет самое высокое значение из сети создания ценности. Диаграмма b представляет собой значение Q , рассчитанное из MCTS, когда мы используем сеть создания стоимости, но игнорируем результат развертывания ( λ = 0) . Диаграмма c использует результат развертывания, но игнорирует сеть значений ( λ = 1). Диаграмма d из нашей сети политик SL. Диаграмма e взята из счета N . Диаграмма e — это путь с максимальным количеством посещений.
Мы показываем позиции с самыми высокими значениями из сети ценности. Красный имеет самое высокое значение из сети создания ценности. Диаграмма b представляет собой значение Q , рассчитанное из MCTS, когда мы используем сеть создания стоимости, но игнорируем результат развертывания ( λ = 0) . Диаграмма c использует результат развертывания, но игнорирует сеть значений ( λ = 1). Диаграмма d из нашей сети политик SL. Диаграмма e взята из счета N . Диаграмма e — это путь с максимальным количеством посещений.
Машинное обучение и нейронные сети — Инженерная школа Университета Южной Калифорнии в Витерби
Ицин Сюй (Yiqing Xu) — старший студент, изучающий информатику, интересующийся различными языками программирования и обладающий солидным математическим образованием.
Abstract
Настольная игра Го считается одной из самых сложных задач для искусственного интеллекта, потому что она «сложна, основана на шаблонах и трудно программируется». Победа компьютерной программы AlphaGo над Ли Седолем стала важным моментом в истории искусственного интеллекта и вычислительной техники. Мы можем наблюдать огромные возможности AlphaGo, но люди мало знают о том, как он «думает». Правила AlphaGo изучаются, а не разрабатываются, реализуя машинное обучение, а также несколько нейронных сетей, чтобы создать обучающий компонент и стать лучше в Go. В партнерстве с Национальной службой здравоохранения Великобритании AlphaGo имеет многообещающие применения и в других сферах.
Победа компьютерной программы AlphaGo над Ли Седолем стала важным моментом в истории искусственного интеллекта и вычислительной техники. Мы можем наблюдать огромные возможности AlphaGo, но люди мало знают о том, как он «думает». Правила AlphaGo изучаются, а не разрабатываются, реализуя машинное обучение, а также несколько нейронных сетей, чтобы создать обучающий компонент и стать лучше в Go. В партнерстве с Национальной службой здравоохранения Великобритании AlphaGo имеет многообещающие применения и в других сферах.
Предыстория
С 9 по 15 марта 2016 года проходило соревнование по игре в го между вторым в мире профессиональным игроком Ли Седолем и AlphaGo, компьютерной программой, созданной компанией Google DeepMind. Победа AlphaGo со счетом 4:1 над Ли Седолем стала знаменательным моментом в истории искусственного интеллекта. Это был первый раз, когда компьютер победил человека-профессионала в Го. Большинство крупных южнокорейских телеканалов транслировали игру.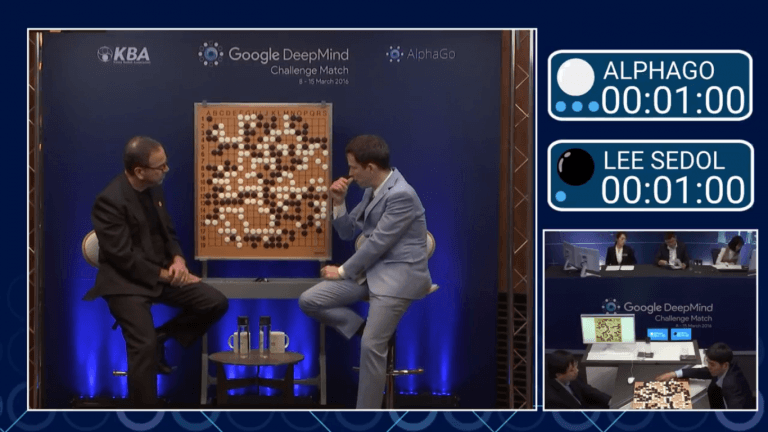 В Китае его посмотрели 60 миллионов человек; Американская ассоциация го и англоязычная прямая трансляция DeepMind на YouTube собрала 100 000 зрителей. Несколько сотен представителей прессы наблюдали за игрой вместе с опытными комментаторами [1]. Что делает эту игру такой важной? Чтобы понять это, мы должны сначала понять корни Go.
В Китае его посмотрели 60 миллионов человек; Американская ассоциация го и англоязычная прямая трансляция DeepMind на YouTube собрала 100 000 зрителей. Несколько сотен представителей прессы наблюдали за игрой вместе с опытными комментаторами [1]. Что делает эту игру такой важной? Чтобы понять это, мы должны сначала понять корни Go.
Игра в го
Го, известная как weiqi в Китае и igo в Японии, представляет собой абстрактную настольную игру для двух игроков, история которой насчитывает 3000 лет. Это настольная игра с абстрактной стратегией, в которую играют на сетке 19*19. Го начинается с пустой доски. Каждый ход игрок кладет на доску черный или белый камень [2]. Общая цель игры состоит в том, чтобы использовать камни, чтобы окружить большую территорию, чем противник. Хотя правило очень простое, оно создает проблему глубины и нюансов. Таким образом, настольная игра Го считается одной из самых сложных задач для искусственного интеллекта из-за ее сложности и состояния, основанного на шаблонах.
В обычных компьютерных играх ИИ обычно использует игровое дерево, чтобы определить лучший следующий ход в игре в зависимости от того, что может сделать противник. Игровое дерево — это ориентированный граф, который представляет игровые состояния (позиции) в виде узлов, а возможные ходы — в виде ребер. Корень дерева представляет состояние в начале игры. Следующий уровень представляет собой возможные состояния после последующих ходов [3]. Возьмем в качестве примера простую игру крестики-нолики, все возможные состояния игры можно изобразить визуально на рисунке 1 [3]. 980 атомов, для справки) [4]. Это объясняет, почему Go так долго считался одной из самых больших проблем для искусственного интеллекта. Большинство ИИ для настольных игр используют созданные вручную правила, созданные инженерами ИИ. Поскольку эти правила могут быть неполными, они обычно ограничивают интеллект ИИ. Например, дизайнеры считают, что для определенного этапа го компьютер должен выбрать один из десяти выбранных шагов, но для профессиональных игроков это может быть глупым ходом. Уровень игры дизайнеров в го будет влиять на уровень интеллекта ИИ.
Уровень игры дизайнеров в го будет влиять на уровень интеллекта ИИ.
Алгоритм AlphaGo
Так как же AlphaGo решила проблему сложности го, а также ограничение, наложенное разработчиками уровнем игры? Все предыдущие методы ИИ для игры в го основывались на каком-то поиске по дереву игры в сочетании с правилами, созданными вручную. AlphaGo, однако, широко использует машинное обучение, чтобы избежать использования правил, созданных вручную, и повысить эффективность. Машинное обучение — это тип искусственного интеллекта, который дает компьютерам возможность учиться без явного программирования. Машинное обучение фокусируется на разработке компьютерных программ, которые могут научить себя расти и изменяться при воздействии новых данных. Системы машинного обучения просматривают данные, чтобы найти закономерности. Но вместо того, чтобы извлекать данные для понимания человеком, как в случае с приложениями для интеллектуального анализа данных, он использует данные для обнаружения шаблонов и соответствующей корректировки действий программы [4]. AlphaGo также использует глубокое обучение и нейронные сети, чтобы научиться играть. Точно так же, как iPhotos может помочь вам разделить фотографии на разные альбомы в соответствии с разными символами, потому что он содержит хранилище бесчисленных изображений персонажей, которые были обработаны до уровня пикселей, интеллект AlphaGo основан на том, что ему были показаны миллионы позиций Go и ходы из человеческих игр.
AlphaGo также использует глубокое обучение и нейронные сети, чтобы научиться играть. Точно так же, как iPhotos может помочь вам разделить фотографии на разные альбомы в соответствии с разными символами, потому что он содержит хранилище бесчисленных изображений персонажей, которые были обработаны до уровня пикселей, интеллект AlphaGo основан на том, что ему были показаны миллионы позиций Go и ходы из человеческих игр.
Интеллект AlphaGo опирается на два разных компонента: процедуру поиска по дереву игры и нейронные сети, упрощающие процедуру поиска по дереву. Процедуру поиска по дереву можно рассматривать как подход грубой силы, тогда как сверточные сети обеспечивают уровень интуиции в игровом процессе [5]. Нейронные сети концептуально аналогичны функции оценки в других ИИ, за исключением того, что AlphaGo обучаются, а не проектируются, что решает проблему уровня игры дизайнеров, влияющего на уровень интеллекта ИИ.
Нейронные сети
Как правило, в AlphaGo обучаются два основных типа нейронных сетей: сеть политик и сеть ценности. Оба типа сетей принимают текущее состояние игры в качестве входных данных, оценивают каждый возможный следующий ход по разным формулам и выводят вероятность выигрыша. С одной стороны, сеть значений дает оценку ценности текущего состояния игры: какова вероятность того, что черный игрок в конечном счете выиграет игру, учитывая текущее состояние? Результатом сети ценности является вероятность выигрыша. С другой стороны, сети политик предоставляют рекомендации относительно того, какое действие выбрать в зависимости от текущего состояния игры. Выход представляет собой значение вероятности для каждого возможного допустимого хода (выход сети равен размеру доски). Действия (ходы) с более высокими значениями вероятности соответствуют действиям, которые имеют более высокий шанс привести к выигрышу. Одним из наиболее важных аспектов AlphaGo является способность к обучению. Глубокое обучение позволяет AlphaGo постоянно улучшать свой интеллект, играя в большое количество игр против самой себя. Это обучает сеть политик, чтобы помочь AlphaGo предсказывать следующие шаги, которые, в свою очередь, обучают сеть создания ценности для определения и оценки этих позиций [5].
Оба типа сетей принимают текущее состояние игры в качестве входных данных, оценивают каждый возможный следующий ход по разным формулам и выводят вероятность выигрыша. С одной стороны, сеть значений дает оценку ценности текущего состояния игры: какова вероятность того, что черный игрок в конечном счете выиграет игру, учитывая текущее состояние? Результатом сети ценности является вероятность выигрыша. С другой стороны, сети политик предоставляют рекомендации относительно того, какое действие выбрать в зависимости от текущего состояния игры. Выход представляет собой значение вероятности для каждого возможного допустимого хода (выход сети равен размеру доски). Действия (ходы) с более высокими значениями вероятности соответствуют действиям, которые имеют более высокий шанс привести к выигрышу. Одним из наиболее важных аспектов AlphaGo является способность к обучению. Глубокое обучение позволяет AlphaGo постоянно улучшать свой интеллект, играя в большое количество игр против самой себя. Это обучает сеть политик, чтобы помочь AlphaGo предсказывать следующие шаги, которые, в свою очередь, обучают сеть создания ценности для определения и оценки этих позиций [5]. AlphaGo просматривает возможные ходы и перестановки, анализируя различные возможности, прежде чем выбрать тот, который, по ее мнению, с наибольшей вероятностью увенчается успехом.
AlphaGo просматривает возможные ходы и перестановки, анализируя различные возможности, прежде чем выбрать тот, который, по ее мнению, с наибольшей вероятностью увенчается успехом.
В общем, объединенные две нейронные сети позволяют AlphaGo избежать лишней работы: сеть политик фокусируется на настоящем и решает следующий шаг, чтобы сэкономить время на поиске по всему игровому дереву, а сеть ценности фокусируется на долгосрочной перспективе, анализируя вся ситуация, чтобы уменьшить возможные ходы в игровом дереве. Затем AlphaGo усредняет предложения двух сетей, чтобы принять окончательное решение. Что делает AlphaGo таким важным, так это то, что он не только следует теории игр, но и включает в себя обучающий компонент. Играя против себя, AlphaGo автоматически становилась все лучше и лучше в го.
Будущее AlphaGo
Игры в го были захватывающими, но более важным является то, что AlphaGo продемонстрировала, как алгоритмы искусственного интеллекта повлияют на нашу жизнь; ИИ сделает людей лучше. На 37-м ходу во второй партии AlphaGo приняла очень неожиданное решение. Чемпион Европы по го сказал: «Это не человеческий ход. Я никогда не видел, чтобы человек играл этот ход. Как прекрасно.» Этот чемпион Европы по го, который помогал обучать AlphaGo, играя против него, сказал, что, хотя он проиграл почти все игры, его понимание го значительно улучшилось благодаря необычному способу игры программы. Это отразилось и на его скачке в мировом рейтинге [6].
На 37-м ходу во второй партии AlphaGo приняла очень неожиданное решение. Чемпион Европы по го сказал: «Это не человеческий ход. Я никогда не видел, чтобы человек играл этот ход. Как прекрасно.» Этот чемпион Европы по го, который помогал обучать AlphaGo, играя против него, сказал, что, хотя он проиграл почти все игры, его понимание го значительно улучшилось благодаря необычному способу игры программы. Это отразилось и на его скачке в мировом рейтинге [6].
Согласно данным, в Соединенных Штатах около 40 500 пациентов умирают от ошибочного диагноза. Объем доступной медицинской информации огромен, поэтому врачам не под силу разобраться в каждой мелочи. ИИ, такие как AlphaGo, могут собирать всю историю медицинской литературы, а также медицинские случаи, медицинские изображения и другие данные в системе и могут выводить лучшее решение, чтобы помочь врачам. Недавно AlphaGo начала партнерство с Национальной службой здравоохранения Великобритании, чтобы улучшить процесс оказания медицинской помощи с помощью цифровых решений. AlphaGo использует свои вычислительные мощности для анализа медицинских данных и записей. [6] Это откроет новые возможности лечения для пациентов и поможет врачам в лечении пациентов. Повышение эффективности также снизит затраты страховых компаний [6].
AlphaGo использует свои вычислительные мощности для анализа медицинских данных и записей. [6] Это откроет новые возможности лечения для пациентов и поможет врачам в лечении пациентов. Повышение эффективности также снизит затраты страховых компаний [6].
Будущее ИИ
Люди уже многому учатся у лучших людей, но теперь благодаря ИИ можно получить еще больше знаний. [6] Искусственный интеллект может превосходить человеческие возможности в определенных ситуациях, и это может вызвать дискомфорт у некоторых людей. Искусственный интеллект использует множество методов в дополнение к искусственному интеллекту настольной игры, представленному AlphaGo, с различными техническими областями, включая визуальное распознавание и распознавание голоса. Тот факт, что ИИ может превзойти людей в специализированной области, неудивителен. Однако по всестороннему интеллекту и способности к обучению люди намного лучше, чем ИИ. Хотя глубокое обучение достигло значительного прогресса, машинное обучение по-прежнему опирается на прогресс ручного проектирования. Более того, для глубокого обучения требуется большой объем данных в качестве основы для обучения и обучения, а процесс обучения недостаточно гибкий.
Более того, для глубокого обучения требуется большой объем данных в качестве основы для обучения и обучения, а процесс обучения недостаточно гибкий.
Идея о том, что всеобъемлющий искусственный интеллект будет управлять людьми и окажет разрушительное воздействие на человеческое общество, является вымышленной. Не исключено, что ИИ выйдет за рамки человеческого, но этот день еще далеко, и «запредельное» все еще будет под контролем человека.
Заключение
Независимо от того, победит ли АльфаГо или Ли Седол, в целом победа принадлежит человечеству. ИИ, стоящий за AlphaGo, использует машинное обучение и нейронные сети, чтобы позволить себе постоянно улучшать свои навыки, играя против самого себя. Этот метод искусственного интеллекта также предлагает потенциал для улучшения нашей жизни.
ИИ выиграл игру в го, но человек выиграл будущее.
Ссылки
[1] «Как Google AlphaGo победил чемпиона мира по го» The Atlantic.