Содержание
Расшифровка ДНК — Нож
Как только выяснилось, что в ДНК содержится код жизни — набор инструкций, используемых клеткой для производства белков, которые в действительности и обеспечивают жизнедеятельность организма, а также формируют его части, ученые начали прилагать массу усилий, чтобы «взломать» этот код и выяснить, как работают эти механизмы. На решение этой задачи ушло много лет; над ней трудилось множество групп исследователей, которые проводили сложные биохимические эксперименты, хотя описать их подробно не позволяет формат этой книги. Но мы по крайней мере расскажем о принципах, лежавших в основе этих исследований, и о результатах всей этой работы.
Рассказ о расшифровке ДНК начинается с книги физика, а не биолога. Один из пионеров квантовой теории Эрвин Шредингер (1887–1961) был заинтригован идеей, что квантовые процессы могут играть важную роль при внесении изменений в молекулы, несущие код жизни, — то есть при мутациях. В то время, в 1940-е гг., носителями генетической информации все еще считались белки, но гипотезы Шредингера, опубликованные в 1944 г. , не зависели от того, что конкретно это были за молекулы. Он проводил различие между кристаллом такого вещества, как поваренная соль, который состоит из бесконечного повторения одинаковых мотивов из атомов натрия и хлора, и кристаллом, который он назвал апериодическим, чье строение можно сравнить с «рафаэлевским гобеленом, который дает не скучное повторение, но сложный, последовательный и полный значения рисунок» *, хотя этот рисунок и соткан из нитей ограниченного количества цветов. Информацию, переносимую молекулами жизни, Шредингер называл «шифровальным кодом» и указывал, как с помощью даже ограниченного числа символов (например, отдельных молекулярных групп) информацию можно передавать так же эффективно, как с помощью букв алфавита. Он отмечал, что «не нужно особенно большого количества атомов в такой структуре, чтобы обеспечить почти безграничное число возможных комбинаций» и что в азбуке Морзе два знака (точка и тире), объединенные в группы не более чем по четыре, дают тридцать различных кодирующих групп — достаточно, чтобы охватить весь английский алфавит и некоторые знаки препинания.
, не зависели от того, что конкретно это были за молекулы. Он проводил различие между кристаллом такого вещества, как поваренная соль, который состоит из бесконечного повторения одинаковых мотивов из атомов натрия и хлора, и кристаллом, который он назвал апериодическим, чье строение можно сравнить с «рафаэлевским гобеленом, который дает не скучное повторение, но сложный, последовательный и полный значения рисунок» *, хотя этот рисунок и соткан из нитей ограниченного количества цветов. Информацию, переносимую молекулами жизни, Шредингер называл «шифровальным кодом» и указывал, как с помощью даже ограниченного числа символов (например, отдельных молекулярных групп) информацию можно передавать так же эффективно, как с помощью букв алфавита. Он отмечал, что «не нужно особенно большого количества атомов в такой структуре, чтобы обеспечить почти безграничное число возможных комбинаций» и что в азбуке Морзе два знака (точка и тире), объединенные в группы не более чем по четыре, дают тридцать различных кодирующих групп — достаточно, чтобы охватить весь английский алфавит и некоторые знаки препинания. Немного забегая вперед, скажем, что число перестановок четырех разных знаков равно 24 (4 × 3 × 2 × 1), а 20 разных знаков — приблизительно 24 × 10 (24 с 17 нулями). Четырехбуквенного кода достаточно, чтобы описать все двадцать аминокислот в составе белков; разных аминокислот вполне достаточно, чтобы описать все разнообразие белков в живых организмах.
Немного забегая вперед, скажем, что число перестановок четырех разных знаков равно 24 (4 × 3 × 2 × 1), а 20 разных знаков — приблизительно 24 × 10 (24 с 17 нулями). Четырехбуквенного кода достаточно, чтобы описать все двадцать аминокислот в составе белков; разных аминокислот вполне достаточно, чтобы описать все разнообразие белков в живых организмах.
Книга Шредингера «Что такое жизнь?» (What is Life?) оказала огромное влияние как на биологов, так и на физиков, которые во время Второй мировой войны насмотрелись на смерть и хотели исследовать жизнь. Среди тех, кто позже особо отмечал влияние идей Шредингера, были Морис Уилкинс, Эрвин Чаргафф, Фрэнсис Крик и Джеймс Уотсон. А сразу после публикации первых статей Уотсона и Крика о ДНК этой темой заинтересовался еще один физик, Георгий Гамов (1904–1968).
Его внимание привлекла скорее вторая статья кембриджской группы о ДНК, опубликованная в журнале Nature 30 мая 1953 г. В то время он находился с визитом в Калифорнийском университете в Беркли, куда приехал из Вашингтона, где тогда работал. Позже он вспоминал:
Позже он вспоминал:
Я шел по коридору радиационной лаборатории и наткнулся на Луиса Альвареса с журналом Nature в руках… Он сказал: «Взгляните, какую чудесную статью написали Уотсон и Крик». Так я ее впервые и увидел. А затем я вернулся в Вашингтон и начал размышлять о ней.
Плоды этих размышлений были опубликованы в журнале Nature в феврале 1954 г. Гамов ухватился за открытие, что ДНК состоит из четырех типов оснований, апериодически распределенных по ее нити, и подчеркнул, что молекулы белка могут строиться из цепочек аминокислот, удерживаемых рядом с ДНК так, что каждая аминокислота расположена напротив определенной кодирующей группы оснований ДНК. Детали предложенного им механизма были ошибочны, однако он объяснял:
Наследственные свойства любого конкретного организма можно выразить в виде длинного числа, записанного с использованием четырехзначной системы. С другой стороны, ферменты, чей состав должен полностью определяться молекулой дезоксирибонуклеиновой кислоты, являются длинными пептидными цепочками, образованными примерно двадцатью различными аминокислотами, и их можно считать длинными «словами», записанными 20-буквенным алфавитом.

В результате кропотливой работы, последовавшей за этим предположением, были установлены два ключевых факта. Во-первых, цепочки аминокислот не строятся непосредственно на ДНК. Когда клетке нужен конкретный белок (а как она «узнает», когда он ей нужен, до сих пор во многом остается загадкой), необходимый фрагмент ДНК высвобождается из двойной спирали одной из хромосом, используется как шаблон при синтезе цепочки РНК, а затем снова скручивается в спираль и упаковывается обратно в хромосому. Получившаяся цепочка РНК используется как шаблон для синтеза белка, после чего расщепляется для повторного использования ее компонентов. Во-вторых, хотя генетический код содержит четыре буквы, эти буквы используются для образования трехбуквенных слов (кодонов), каждое из которых обозначает конкретную аминокислоту или, в некоторых случаях, команды «старт» или «стоп» для строительства новой пептидной цепочки. Поскольку именно РНК, а не ДНК непосредственно участвует в синтезе белков, эти четыре буквы — A, У, Г и Ц. Например, тройка АГУ является кодоном аминокислоты серин, ГГУ — это валин, ЦЦА — пролин, а УАГ означает «стоп». Таким образом, последовательность оснований в молекуле РНК, например УЦЦAГУAГЦГГAЦAГ, следует читать как УЦЦ AГУ AГЦ ГГA ЦAГ.
Например, тройка АГУ является кодоном аминокислоты серин, ГГУ — это валин, ЦЦА — пролин, а УАГ означает «стоп». Таким образом, последовательность оснований в молекуле РНК, например УЦЦAГУAГЦГГAЦAГ, следует читать как УЦЦ AГУ AГЦ ГГA ЦAГ.
Чтобы продемонстрировать, как это влияет на эволюцию, мы приведем пример из нашего алфавита. Вот предложение из трехбуквенных слов: КОТ БЫЛ СЫТ ПЕС БЫЛ ЗОЛ. За счет простой мутации, изменившей всего одну букву, в цепочке может появиться бессмысленное слово: КУТ БЫЛ СЫТ ПЕС БЫЛ ЗОЛ, и это может быть, а может и не быть важным для процессов, протекающих в клетке. Или может появиться новое правильное слово («правильное» в том смысле, что оно кодирует другую аминокислоту ): КИТ БЫЛ СЫТ ПЕС БЫЛ ЗОЛ. В результате изменения одной аминокислоты в клетке может начаться синтез бесполезного белка. Или иногда может получиться белок даже более эффективный, чем исходный. Более резкие мутации могут менять целые слова — например, слово КОТ может превратиться в ЛЕВ — или вообще удалять слова: КОТ БЫЛ СЫТ БЫЛ ЗОЛ. А пропуск (или добавление) одной буквы может полностью изменить весь текст. Например, если убрать из исходного сообщения первую букву К, то мы получим ОТБ ЫЛС ЫТП ЕСБ ЫЛЗ ОЛ.
А пропуск (или добавление) одной буквы может полностью изменить весь текст. Например, если убрать из исходного сообщения первую букву К, то мы получим ОТБ ЫЛС ЫТП ЕСБ ЫЛЗ ОЛ.
Вы можете сами поразвлечься с другими примерами. Для эволюции важно то, что такие ошибки могут возникать в результате сбоев копирования, когда хромосомы перетасовываются, перед тем как попасть в половые клетки, которые передают гены следующему поколению. Могут происходить и более серьезные изменения, например, когда целые участки ДНК неправильно соединяются после кроссинговера или вообще удаляются. В детали этого процесса мы вдаваться не будем.
Что здесь действительно важно, так это то, что был открыт источник неидеально точного копирования генетического материала, который является одной из основ эволюции. Учитывая все вышеизложенное, давайте снова вернемся к эволюции на уровне целых организмов и рассмотрим открытия, которые были сделаны во второй половине XX в.
Основы для этих открытий были заложены еще в 1930-е гг.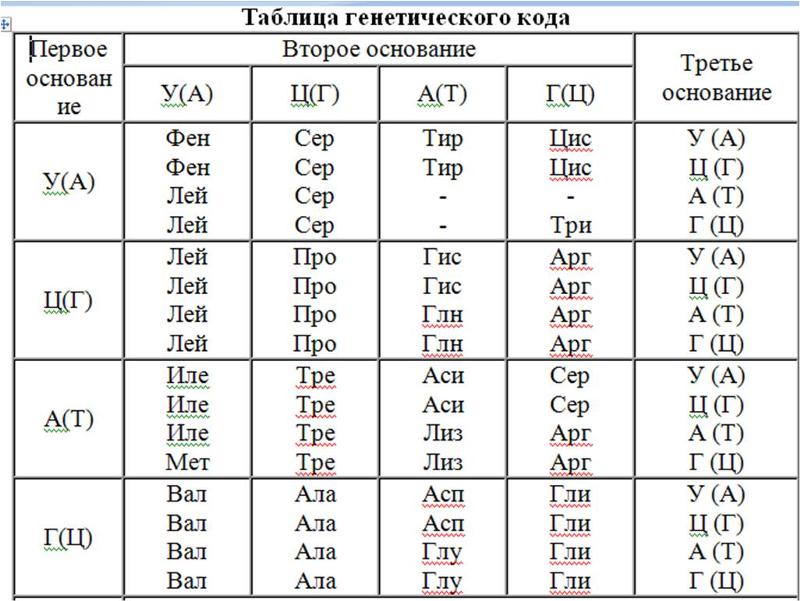 , но тогда эти исследования не получили широкого признания. Хотя к тому времени ученые уже в основном изучали все более мелкие формы жизни, одна исследовательница продолжала заниматься крупными организмами, как Грегор Мендель. Ее имя — Барбара Макклинток (1902–1992). Организмом, который она изучала, была кукуруза, которая, как и менделевский горох, давала всего одно поколение в год. Макклинток сближало с Менделем еще и то, что результаты ее работы были оценены в полной мере только через 40 лет, но она, в отличие от Менделя, дожила до этого момента.
, но тогда эти исследования не получили широкого признания. Хотя к тому времени ученые уже в основном изучали все более мелкие формы жизни, одна исследовательница продолжала заниматься крупными организмами, как Грегор Мендель. Ее имя — Барбара Макклинток (1902–1992). Организмом, который она изучала, была кукуруза, которая, как и менделевский горох, давала всего одно поколение в год. Макклинток сближало с Менделем еще и то, что результаты ее работы были оценены в полной мере только через 40 лет, но она, в отличие от Менделя, дожила до этого момента.
Макклинток родилась спустя два года после повторного открытия законов Менделя и училась в Колледже сельского хозяйства и естественных наук при Корнеллском университете в Итаке, штат НьюЙорк, который окончила в 1923 г. В своей нобелевской лекции, произнесенной в 1983 г., она вспоминала: «Я начала активно заниматься генетикой через 21 год после повторного открытия принципов наследственности Менделя в 1900 г., когда эти принципы еще не были приняты большинством биологов». Она отучилась в аспирантуре Корнеллского университета, в 1927 г. защитила диссертацию, разработав методы анализа хромосом кукурузы, и продолжила работать в этом направлении после получения докторской степени. Для ее исследований не имело значения, из чего состоят хромосомы, поскольку Макклинток и созданную ею группу ученых интересовали хромосомы в целом и гены как участки хромосом, а также их влияние на организм. Кукуруза (маис), которую она изучала, — гораздо более интересный объект для исследований, чем однообразная желтая кукуруза из супермаркета. У дикой кукурузы разноцветные зерна, и они расположены в початке рядами, так что их очень удобно учитывать. Вместо того чтобы рассматривать глаза крошечных мушек или изучать под микроскопом бактерии, все, что вам нужно сделать для выявления изменений (мутаций), это вскрыть початок и изучить узоры из разноцветных зерен, представленные во всей своей красе.
Она отучилась в аспирантуре Корнеллского университета, в 1927 г. защитила диссертацию, разработав методы анализа хромосом кукурузы, и продолжила работать в этом направлении после получения докторской степени. Для ее исследований не имело значения, из чего состоят хромосомы, поскольку Макклинток и созданную ею группу ученых интересовали хромосомы в целом и гены как участки хромосом, а также их влияние на организм. Кукуруза (маис), которую она изучала, — гораздо более интересный объект для исследований, чем однообразная желтая кукуруза из супермаркета. У дикой кукурузы разноцветные зерна, и они расположены в початке рядами, так что их очень удобно учитывать. Вместо того чтобы рассматривать глаза крошечных мушек или изучать под микроскопом бактерии, все, что вам нужно сделать для выявления изменений (мутаций), это вскрыть початок и изучить узоры из разноцветных зерен, представленные во всей своей красе.
Читайте также
Парадокс добродетели: как в ходе эволюции развились наши представления о добре и зле
Но для изучения генов все равно нужен был микроскоп. Чтобы сделать их видимыми, Макклинток разработала усовершенствованные методы окрашивания хромосом, благодаря чему первой описала морфологию десяти хромосом кукурузы. Самое значимое открытие на раннем этапе исследований Макклинток сделала в 1929 г. с помощью студентки Гарриет Крейтон (1909–2004). У одной линии кукурузы зерна были либо темные, либо светлые, что свидетельствовало о присутствии хромосомы с двумя разными аллелями (такую пару называют «гетерозиготной»). Нечто подобное предполагалось и раньше, в частности во время экспериментов Томаса Моргана с плодовыми мушками. Но тогда существование разных аллелей так и осталось лишь предположением. Макклинток и Крейтон пошли гораздо дальше: окрашивая хромосомы и изучая их под микроскопом, они обнаружили, что эти два типа кукурузы отличаются друг от друга за счет видимого различия между аллелями. У хромосомы растений с темными зернами имелся «бугорок», который отсутствовал в хромосоме растений со светлыми зернами. Это стало первым прямым эмпирическим доказательством того, что физические различия в хромосомах влияют на весь организм — на его фенотип.
Чтобы сделать их видимыми, Макклинток разработала усовершенствованные методы окрашивания хромосом, благодаря чему первой описала морфологию десяти хромосом кукурузы. Самое значимое открытие на раннем этапе исследований Макклинток сделала в 1929 г. с помощью студентки Гарриет Крейтон (1909–2004). У одной линии кукурузы зерна были либо темные, либо светлые, что свидетельствовало о присутствии хромосомы с двумя разными аллелями (такую пару называют «гетерозиготной»). Нечто подобное предполагалось и раньше, в частности во время экспериментов Томаса Моргана с плодовыми мушками. Но тогда существование разных аллелей так и осталось лишь предположением. Макклинток и Крейтон пошли гораздо дальше: окрашивая хромосомы и изучая их под микроскопом, они обнаружили, что эти два типа кукурузы отличаются друг от друга за счет видимого различия между аллелями. У хромосомы растений с темными зернами имелся «бугорок», который отсутствовал в хромосоме растений со светлыми зернами. Это стало первым прямым эмпирическим доказательством того, что физические различия в хромосомах влияют на весь организм — на его фенотип. Когда Морган посетил Корнеллский университет и узнал об этой работе, которая легла в основу диссертации Крейтон, он настоятельно рекомендовал опубликовать ее как можно скорее, и в 1931 г. она вышла в журнале Proceedings of the National Academy of Sciences. Всего через два года Морган получил Нобелевскую премию «за открытия, связанные с ролью хромосом в наследственности».
Когда Морган посетил Корнеллский университет и узнал об этой работе, которая легла в основу диссертации Крейтон, он настоятельно рекомендовал опубликовать ее как можно скорее, и в 1931 г. она вышла в журнале Proceedings of the National Academy of Sciences. Всего через два года Морган получил Нобелевскую премию «за открытия, связанные с ролью хромосом в наследственности».
Как понять результаты анализа ДНК: расшифровать экспертизу
Главная
Список статей
Как понять результаты анализа ДНК
Генетическая экспертиза все чаще используется для решения различных задач, в том числе медицинской и юридической направленности. Применение высокотехнологичного оборудования позволяет получить максимальную вероятность результата, которая достигает 99,999999%. Как правило, этот относительный показатель указывается в официальном заключении после расшифровки полученного результата. А как понять анализ ДНК, как можно интерпретировать процентный показатель? В данном случае имеет значение цель, с которой проводился ДНК тест, поскольку с помощью анализа абсолютно точно определяют:
- отца, мать, брата и других биологических родственников до 5-6 поколения;
- расовую и этническую принадлежность;
- пол ребенка и резус фактор;
- риск развития генетических мутаций и других заболеваний;
- наличие способностей к разным видам деятельности;
- личность погибшего человека.

Это – только часть задач, которые можно решить путем анализа ДНК в Москве, на самом деле возможности этой технологии являются безграничными.
Как расшифровать ДНК анализ
Как происходит расшифровка анализа ДНК и что показывает ее результат? Для этого в лаборатории проводят секвенирование, то есть определяют, в каком порядке выстраиваются микроскопические структуры, представляющие множество значений, состоящих из буквенных символов. В процессе исследования молекулярных частиц их предварительно извлекают из образца биологического материала, копируют и делят на части для подробного анализа. Соединения азота, которые являются основой генетического кода, окрашивают специальным составом. При воздействии лазерного луча такие фрагменты будут заметно выделяться. Сейчас на практике применяются менее затратные и более ускоренные методы секвенирования, в том числе:
- терминация цепи;
- лигирование;
- анализ одиночных молекул.
В результате любого генетического исследования выдается заключение, в котором результат указан в процентах. Например, при определении этноса указывается доля каждой из четырех этнических групп, которая присуща конкретному человеку. При определении родства по ДНК максимальный показатель составляет 99,9999%, при отрицательном ответе — 100,0%. Теоретически у каждого мужчины Москвы может быть брат-близнец с точно таким же набором хромосом, на что и остается 0,01%.
Например, при определении этноса указывается доля каждой из четырех этнических групп, которая присуща конкретному человеку. При определении родства по ДНК максимальный показатель составляет 99,9999%, при отрицательном ответе — 100,0%. Теоретически у каждого мужчины Москвы может быть брат-близнец с точно таким же набором хромосом, на что и остается 0,01%.
Анализ ДНК: как расшифровать и понять
Наша лаборатория предлагает современные решения в области генетических исследований и обеспечивает максимально возможную точность результата. Наших клиентов ждут самые лучшие условия:
- персональное обслуживание и полная конфиденциальность;
- оперативные сроки проведения анализа;
- бесплатные наборы для забора образцов дома;
- ценовая привлекательность и выгодные скидки.
Если Вы не можете самостоятельно понять анализ ДНК, обращайтесь к нашим консультантам за бесплатной профессиональной помощью. Мы всегда готовы ответить на все вопросы и предоставить подробную консультацию!
Голосов: 1
Наноструктуры бинарной ДНК для шифрования данных
- Список журналов
- PLoS Один
- PMC3439488
PLoS Один. 2012 г.; 7(9): e44212.
2012 г.; 7(9): e44212.
Опубликовано в Интернете 11 сентября 2012 г. doi: 10.1371/journal.pone.0044212
1
,
2
и
1
,
2
,
*
Мени Вануну, редактор
Информация об авторе Примечания к статье Информация об авторских правах и лицензиях Отказ от ответственности
Мы представляем простую и безопасную систему для шифрования и дешифрования информации с использованием самосборки ДНК. Двоичные данные закодированы в геометрии наноструктур ДНК с двумя различными конформациями. Удаление или исключение одного компонента сводит эти структуры к зашифрованному раствору одноцепочечной ДНК, тогда как добавление этого отсутствующего «ключа дешифрования» вызывает спонтанное формирование сообщения посредством самосборки, что позволяет быстро считывать его с помощью гель-электрофореза. Приложения включают аутентификацию, безопасный обмен сообщениями и штрих-кодирование.
Являясь основой для всех живых существ, ДНК обладает замечательной способностью надежно хранить и передавать информацию.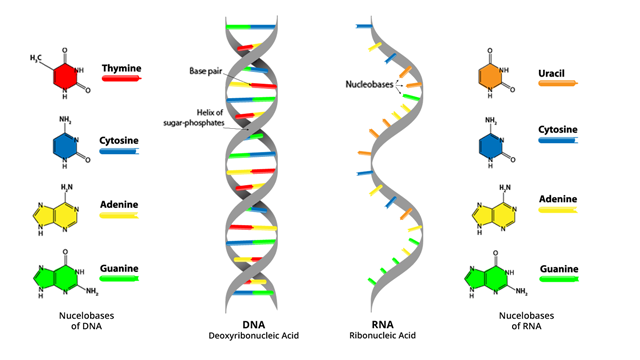 Это возможно благодаря двум характерным особенностям ДНК: ее модульной конструкции из четырех различных оснований (A, C, G, T), последовательность которых определяет генетический код, и специфическому спариванию между комплементарными основаниями, которое обеспечивает гибридизацию в двухцепочечный комплекс. Эти особенности ДНК использовались для выполнения вычислений и обработки информации [1]–[6], включая сокрытие и шифрование секретных сообщений [7]–[10]. Мало того, что ДНК сформировала основу для области биомолекулярных вычислений, надежность спаривания ДНК и оснований также привела к ее использованию в качестве программируемый конструкционный материал для создания объектов с наноразмерными характеристиками [11]. В последнее время доступность и универсальность ДНК-нанотехнологии значительно увеличились благодаря подходу, известному как ДНК-оригами [12]. С тщательно разработанной коллекцией олигонуклеотидов ДНК может самособираться в двухмерные и трехмерные формы невероятной сложности [12]–[14], некоторые из которых включают в себя восприятие и активацию [15], [16].
Это возможно благодаря двум характерным особенностям ДНК: ее модульной конструкции из четырех различных оснований (A, C, G, T), последовательность которых определяет генетический код, и специфическому спариванию между комплементарными основаниями, которое обеспечивает гибридизацию в двухцепочечный комплекс. Эти особенности ДНК использовались для выполнения вычислений и обработки информации [1]–[6], включая сокрытие и шифрование секретных сообщений [7]–[10]. Мало того, что ДНК сформировала основу для области биомолекулярных вычислений, надежность спаривания ДНК и оснований также привела к ее использованию в качестве программируемый конструкционный материал для создания объектов с наноразмерными характеристиками [11]. В последнее время доступность и универсальность ДНК-нанотехнологии значительно увеличились благодаря подходу, известному как ДНК-оригами [12]. С тщательно разработанной коллекцией олигонуклеотидов ДНК может самособираться в двухмерные и трехмерные формы невероятной сложности [12]–[14], некоторые из которых включают в себя восприятие и активацию [15], [16]. Объединив концепции ДНК как молекулы, обрабатывающей информацию, и структурного материала, мы разработали простой и мощный подход к кодированию и шифрованию информации.
Объединив концепции ДНК как молекулы, обрабатывающей информацию, и структурного материала, мы разработали простой и мощный подход к кодированию и шифрованию информации.
В предыдущей работе мы использовали методы ДНК-оригами для создания наноразмерного механического переключателя [17], который мы использовали для изучения силовой зависимости молекулярных взаимодействий на уровне одной молекулы. Этот переключатель мог находиться в одном из двух состояний, с петлей или без петли, и мы заметили, что эти конформационные различия были четко разрешены в агарозном геле (10). Таким образом, в то время как были представлены другие схемы представления бинарных данных с использованием ДНК [8], [18], [19], здесь мы сосредоточимся на использовании геометрической конформации наноструктур ДНК для кодирования бинарных значений из-за простоты как кодирования, так и декодирование информации с использованием этого подхода. Мы сделали три различные реализации этой концепции, как показано в . Эти наноструктуры могут переключаться между двумя различными состояниями, действуя как «механический бит», позволяющий хранить и обрабатывать информацию (по аналогии с механическими реле в первых цифровых компьютерах). Эти механические биты можно приготовить в любом состоянии (0 или 1), а переходы между этими состояниями можно контролировать с помощью химических или физических средств (например, путем изменения наличия или отсутствия критического молекулярного компонента, изменения температуры, взаимодействия с светом [20] или с применением механической силы [17], [21]). Важно отметить, что состояние этих битов может быть считано за считанные минуты с помощью гель-электрофореза или быстрее с использованием методов визуализации и манипулирования одной молекулой, а несколько битов могут быть представлены ДНК разной длины для облегчения мультиплексной обработки и считывания информации.
Эти механические биты можно приготовить в любом состоянии (0 или 1), а переходы между этими состояниями можно контролировать с помощью химических или физических средств (например, путем изменения наличия или отсутствия критического молекулярного компонента, изменения температуры, взаимодействия с светом [20] или с применением механической силы [17], [21]). Важно отметить, что состояние этих битов может быть считано за считанные минуты с помощью гель-электрофореза или быстрее с использованием методов визуализации и манипулирования одной молекулой, а несколько битов могут быть представлены ДНК разной длины для облегчения мультиплексной обработки и считывания информации.
Открыть в отдельном окне
ДНК как бинарный переключатель.
Конформации наноструктур ДНК с двумя состояниями могут представлять биты через открытые или закрытые состояния, представляющие 0 и 1 соответственно. Мы демонстрируем эту концепцию с тремя различными реализациями: а) самособирающаяся конструкция с замыканием адресного цикла, как описано ранее [17], б) переключаемая круговая/линейная конструкция и в) двухцепочечный/одноцепочечный сегмент.
Каждый механический бит образуется в результате самосборки ДНК и может быть зашифрован путем исключения критического компонента его структуры (например, ключевой одноцепочечной молекулы ДНК), который сводит его к неструктурированной смеси олигонуклеотидов. Сообщения, зашифрованные как набор таких битов, трудно расшифровать, поскольку биты 0 и биты 1 представляют собой почти неразличимые смеси олигонуклеотидов, которые идентичны во всем, кроме последовательности. С другой стороны, расшифровка с помощью ключа очень проста — простое добавление недостающего компонента запускает самосборку этих наноразмерных механических битов в их незашифрованные формы. Разделение каждого механического бита на две части или два «ключа» образует асимметричную систему шифрования. Эта система обладает свойством «открытого ключа», если ключ распространяется физически, поскольку один ключ нельзя легко отличить от другого без знания последовательности. Кроме того, подходящие контрмеры, такие как добавление «отвлекающих» олигонуклеотидов к физическому ключу шифрования для сокрытия информации, могут затруднить получение последовательности дешифрования.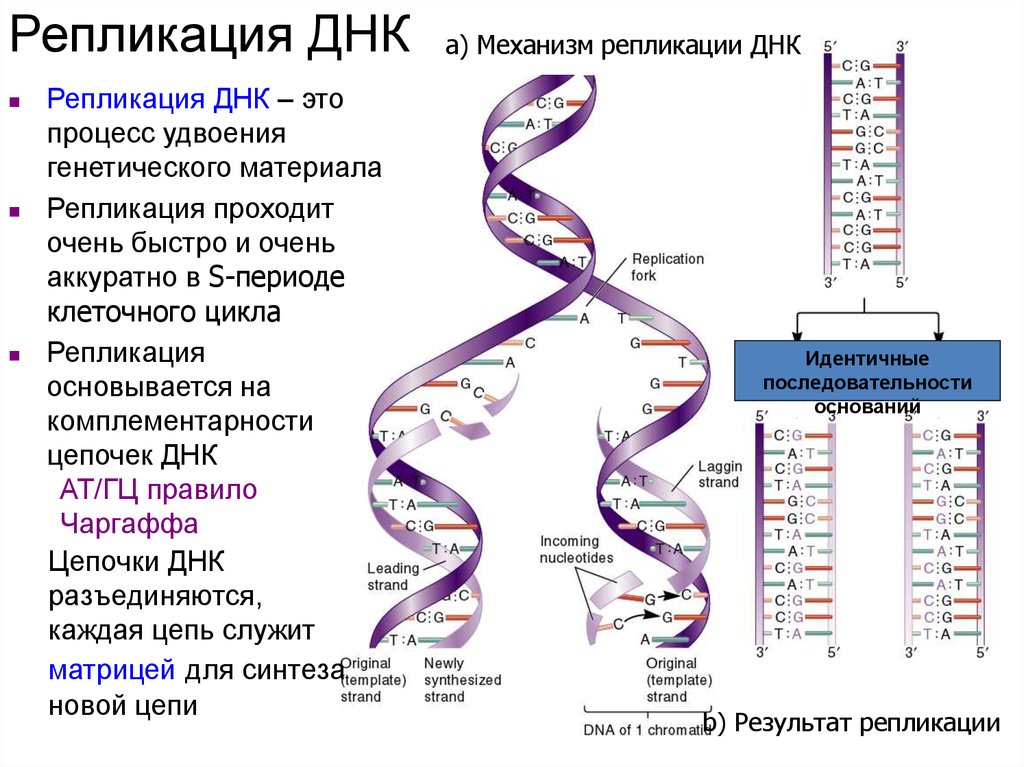
В качестве примера рассмотрим, как Алиса может отправить зашифрованное сообщение Бобу (), используя линейный двоичный переключатель, показанный на рис. Предположим, она хочет послать трехбитное сообщение, например «101». Во-первых, Боб должен сгенерировать соответствующие ключи шифрования и дешифрования ДНК для каждого бита. Чтобы различать биты, он выбирает ДНК разной длины (например, 20 оснований, 30 оснований и 40 оснований), а затем создает 3 олигонуклеотида одинаковой длины для каждого бита (A, A’ и B), два из которых дополняют друг друга и гибридизуются вместе (A и A’), и один из них является инертным (B) (подробности о дизайне олигонуклеотидов см. в разделе «Материалы и методы»). Затем Боб делает флаконы с A и B для каждого доступного бита, которые представляют значения 1 и 0 соответственно, сохраняя при этом флаконы с олиго A’ закрытыми. Вместе флаконы олигонуклеотидов А и В образуют 9Ключ шифрования 0034 , который может использоваться кем угодно для шифрования сообщения. Чтобы послать сообщение Бобу, Алиса смешивала либо A (для 1), либо B (для 0) для каждого бита в одном флаконе и отправляла эту смесь Бобу по общедоступному каналу. На данный момент только Боб может расшифровать сообщение, смешав закрытый ключ дешифрования (набор олигонуклеотидов A) и запустив гель — даже Алиса не имеет возможности расшифровать свое собственное сообщение после его создания.
Чтобы послать сообщение Бобу, Алиса смешивала либо A (для 1), либо B (для 0) для каждого бита в одном флаконе и отправляла эту смесь Бобу по общедоступному каналу. На данный момент только Боб может расшифровать сообщение, смешав закрытый ключ дешифрования (набор олигонуклеотидов A) и запустив гель — даже Алиса не имеет возможности расшифровать свое собственное сообщение после его создания.
Открыть в отдельном окне
Концептуализация шифрования и дешифрования ДНК.
Алиса подготавливает свое сообщение, смешивая вместе олигонуклеотиды, соответствующие либо двоичному 0, либо 1 для каждого бита. Эта смесь отправляется Бобу по общедоступному каналу, который расшифровывает сообщение, добавляя ключ расшифровки ДНК. Это приводит к самосборке сообщения, что позволяет быстро считывать его с помощью гель-электрофореза.
Мы экспериментально продемонстрировали эту схему шифрования для 8-битного кодирования, используя 8 нитей ДНК разной длины для представления отдельных битов.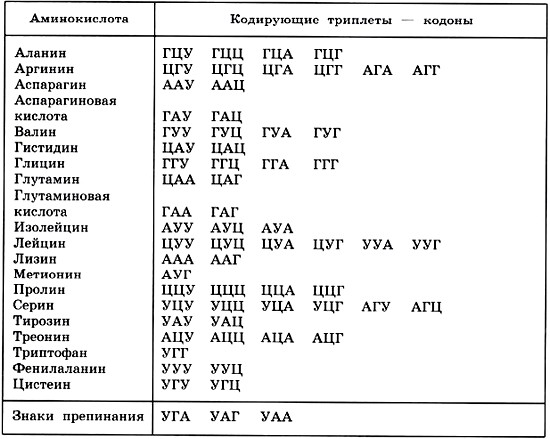 Мы закодировали открытое текстовое сообщение, используя 8-битную двоичную кодировку ASCII с 8-м битом в качестве четного бита четности, и зашифровали сообщение в упорядоченную последовательность смесей ДНК, по одной на каждую букву. Затем эти смеси расшифровывали, смешивая их с олигонуклеотидами секретного ключа, и считывали, немедленно запуская агарозный гель. Читая каждую дорожку геля сверху вниз, расшифрованное сообщение «Hello world» становится однозначно понятным ().
Мы закодировали открытое текстовое сообщение, используя 8-битную двоичную кодировку ASCII с 8-м битом в качестве четного бита четности, и зашифровали сообщение в упорядоченную последовательность смесей ДНК, по одной на каждую букву. Затем эти смеси расшифровывали, смешивая их с олигонуклеотидами секретного ключа, и считывали, немедленно запуская агарозный гель. Читая каждую дорожку геля сверху вниз, расшифрованное сообщение «Hello world» становится однозначно понятным ().
Открыть в отдельном окне
Расшифровка бинарного сообщения на геле.
Каждая дорожка геля содержит смесь олигонуклеотидов, которые вместе образуют 11-байтовое двоичное сообщение ASCII, которое гласит «Hello world». Битовые строки читаются сверху вниз, причем старший бит является самым большим сегментом ДНК. Наличие полосы указывает на двоичную 1, а отсутствие полосы указывает на двоичный 0. Все дорожки имеют одинаковое количество присутствующей ДНК, но окрашиваются только двухцепочечные фрагменты.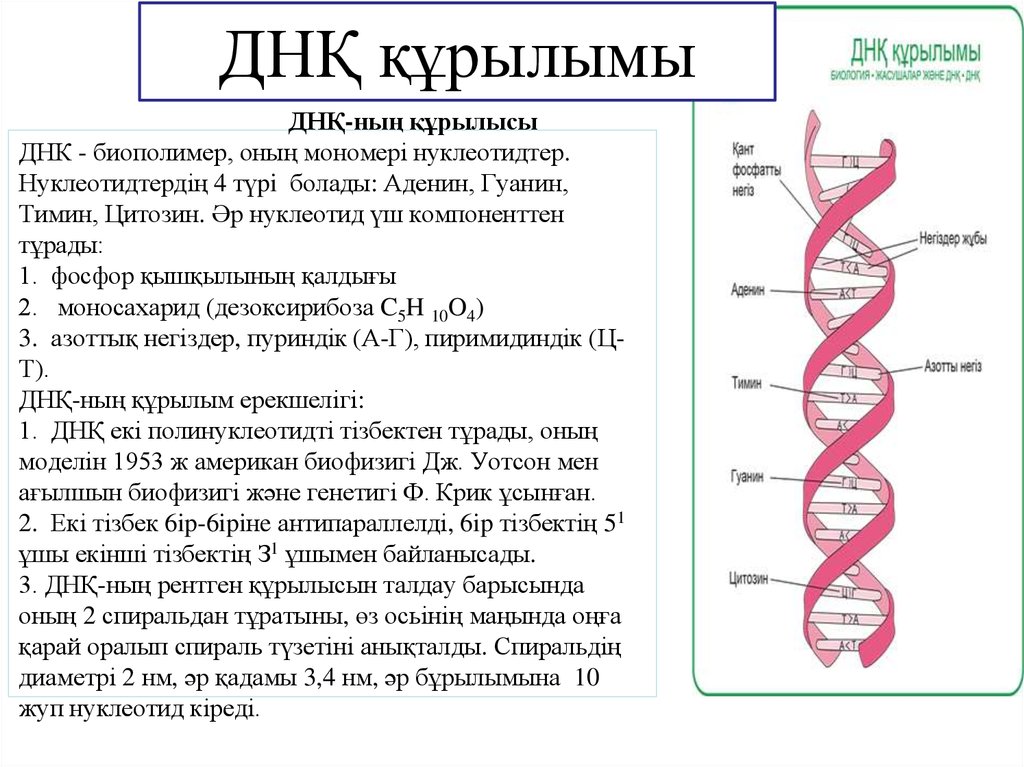
Одним из наиболее интригующих аспектов шифрования сообщений с помощью ДНК, как описано, является сложность расшифровки перехватчиком или злоумышленником. Как минимум, попытки расшифровки требуют владения физическим сообщением, а также технических навыков, лабораторного оборудования и времени. Поскольку сообщение физически зашифровано, передачу данных можно хорошо контролировать, и даже копирование зашифрованного сообщения представляет собой серьезную техническую проблему. В отличие от схем шифрования, основанных на математических алгоритмах, наше шифрование, основанное на биохимии, напрямую не уязвимо для увеличения вычислительной мощности. При физическом дешифровании количество попыток дешифрования ограничено доступностью физического материала, содержащего сообщение, которое истощается с каждой попыткой. На самом деле сообщение теоретически может быть уменьшено до возможности только одной попытки расшифровки.
Попытки взломать сообщение без ключа дешифрования будут затруднены, особенно для злоумышленника, ограниченного теми же ресурсами, что и предполагаемый получатель (например, электрофорезом и оборудованием для смешивания).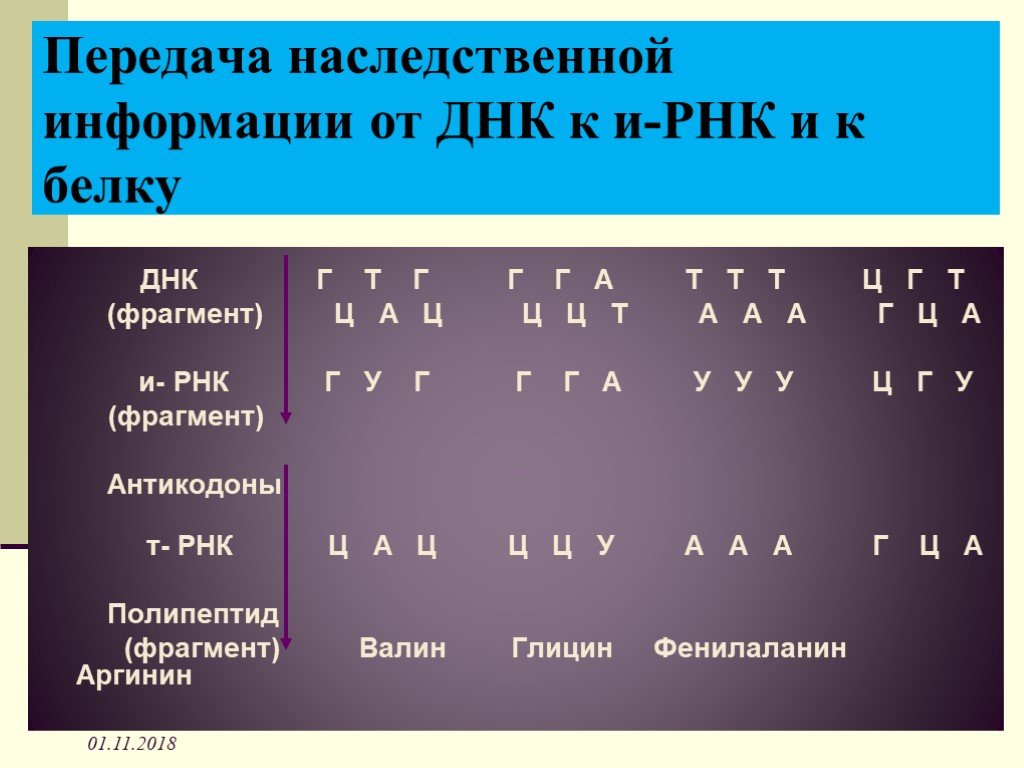 Например, наивная атака грубой силы для поиска ключа дешифрования потребует физической генерации и тестирования астрономического числа возможных ключей, с различными вариантами 4 N или 10 155 для нашей простой 8-битной кодировки. схеме (и примерно 1 из 10 63 шанс угадать ключ дешифрования, если мы допускаем 25% несовпадающих оснований [8], [22]). Однако, кроме правильного ключа дешифрования, также может существовать псевдоключ или набор псевдоключей, которые могут позволить злоумышленнику различать отдельные смеси, предоставляя точку опоры для несанкционированного дешифрования с использованием языковой статистики для большого набора сообщений. Кроме того, если у злоумышленника есть доступ к более сложным подходам, включая методы секвенирования, профилирование ДНК с помощью микрочипов или возможность создавать библиотеки олигонуклеотидов для одновременного тестирования нескольких ключей, то безопасность будет снижена. К счастью, многим из этих подходов можно помешать, приняв соответствующие меры противодействия, как описано ниже.
Например, наивная атака грубой силы для поиска ключа дешифрования потребует физической генерации и тестирования астрономического числа возможных ключей, с различными вариантами 4 N или 10 155 для нашей простой 8-битной кодировки. схеме (и примерно 1 из 10 63 шанс угадать ключ дешифрования, если мы допускаем 25% несовпадающих оснований [8], [22]). Однако, кроме правильного ключа дешифрования, также может существовать псевдоключ или набор псевдоключей, которые могут позволить злоумышленнику различать отдельные смеси, предоставляя точку опоры для несанкционированного дешифрования с использованием языковой статистики для большого набора сообщений. Кроме того, если у злоумышленника есть доступ к более сложным подходам, включая методы секвенирования, профилирование ДНК с помощью микрочипов или возможность создавать библиотеки олигонуклеотидов для одновременного тестирования нескольких ключей, то безопасность будет снижена. К счастью, многим из этих подходов можно помешать, приняв соответствующие меры противодействия, как описано ниже. Кроме того, интересно отметить, что многие из потенциальных способов взлома кода могут потребовать значительных технических знаний, дорогостоящего лабораторного оборудования или трудоемких процессов, что приводит к значительной асимметрии усилий по сравнению с шифрованием и дешифрованием сообщения с помощью правильные ключи.
Кроме того, интересно отметить, что многие из потенциальных способов взлома кода могут потребовать значительных технических знаний, дорогостоящего лабораторного оборудования или трудоемких процессов, что приводит к значительной асимметрии усилий по сравнению с шифрованием и дешифрованием сообщения с помощью правильные ключи.
Чтобы максимально повысить безопасность шифрования, можно использовать различные контрмеры, которые включают два подхода: 1) ограничение доступа к физической информации о сообщении (например, олигопоследовательности) и 2) затруднение расшифровки этой физической информации. Одной из простых мер противодействия является ограничение физического количества материала, содержащего сообщение, как упоминалось выше. Кроме того, мы можем препятствовать химическому анализу, модифицируя концы олигонуклеотидов, чтобы предотвратить химическое сопряжение, необходимое для некоторых методов секвенирования и профилирования. Одной из важных контрмер против несанкционированного дешифрования, подпадающего под обе категории, является добавление шума путем подмешивания «отвлекающих цепочек» к физическому сообщению (подробно описано в других источниках [8], [23]).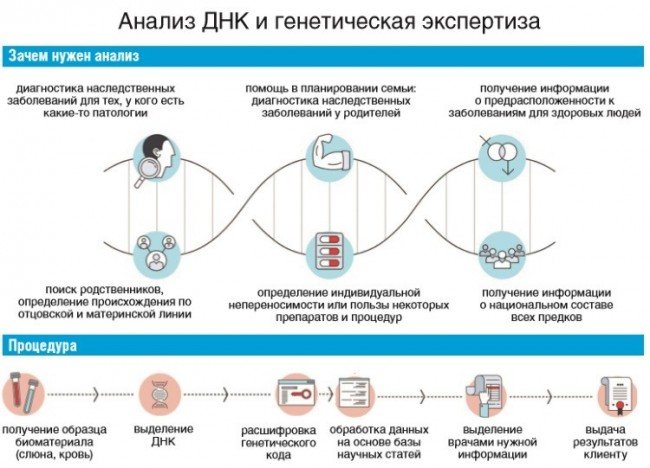 Добавление олигонуклеотидов с такой же длиной и составом, что и сигнальные цепи, но с другими последовательностями, увеличивает время и усилия, необходимые для получения последовательностей олигонуклеотидов в зашифрованной смеси, что уже является проблемой из-за их короткой длины [24]–[26]. ]. Кроме того, дистракторные нити усложняют расшифровку сообщения, поскольку истинное сообщение может быть затемнено шумом, призванным понравиться сигналу, или наоборот [23]. Для системы с открытым ключом следует уделить особое внимание разработке цепочек дистрактора, чтобы гарантировать, что два значения для каждого бита трудно различить с помощью псевдоключа или других биохимических методов (например, масс-спектрометрии). Для системы с закрытым ключом цепи-дистракторы могут быть очень эффективным средством сдерживания статистического анализа, поскольку каждое вхождение данной буквы может быть смешано с другим набором цепочек-дистракторов. На самом деле ложные сообщения могут быть закодированы в смеси с отвлекающими цепями, которые представляют собой «ложные ключи шифрования», и у злоумышленника будет мало возможностей идентифицировать истинное сообщение, не зная конкретной последовательности ключей дешифрования.
Добавление олигонуклеотидов с такой же длиной и составом, что и сигнальные цепи, но с другими последовательностями, увеличивает время и усилия, необходимые для получения последовательностей олигонуклеотидов в зашифрованной смеси, что уже является проблемой из-за их короткой длины [24]–[26]. ]. Кроме того, дистракторные нити усложняют расшифровку сообщения, поскольку истинное сообщение может быть затемнено шумом, призванным понравиться сигналу, или наоборот [23]. Для системы с открытым ключом следует уделить особое внимание разработке цепочек дистрактора, чтобы гарантировать, что два значения для каждого бита трудно различить с помощью псевдоключа или других биохимических методов (например, масс-спектрометрии). Для системы с закрытым ключом цепи-дистракторы могут быть очень эффективным средством сдерживания статистического анализа, поскольку каждое вхождение данной буквы может быть смешано с другим набором цепочек-дистракторов. На самом деле ложные сообщения могут быть закодированы в смеси с отвлекающими цепями, которые представляют собой «ложные ключи шифрования», и у злоумышленника будет мало возможностей идентифицировать истинное сообщение, не зная конкретной последовательности ключей дешифрования. В качестве альтернативы, чтобы сигнал больше походил на шум, структуры ДНК могут быть предварительно зашифрованы стандартными алгоритмами компьютерного шифрования. Кроме того, взлом кода становится все более сложной задачей, чем больше добавляется отвлекающих цепочек и чем больше битов закодировано в сообщении.
В качестве альтернативы, чтобы сигнал больше походил на шум, структуры ДНК могут быть предварительно зашифрованы стандартными алгоритмами компьютерного шифрования. Кроме того, взлом кода становится все более сложной задачей, чем больше добавляется отвлекающих цепочек и чем больше битов закодировано в сообщении.
Хотя наша демонстрация показала 1 байт (8 бит) для хранения данных на смесь (и на дорожку геля), объем сохраняемых и считываемых данных можно легко увеличить. Если бы длины ДНК были оптимизированы для равномерного распределения в геле, разрешение 1 мм дало бы 10 бит/см длины геля, что соответствует примерно 8 байтам данных для одной короткой дорожки геля, 10–20 байтам для более длинных гелей. и до 125 байт (~1000 бит) для более сложных гелей для секвенирования с разрешением пар оснований [27]. Расширение до нескольких байтов может позволить передавать целые слова или короткие сообщения в одной смеси, особенно если используется более эффективная схема кодирования символов (например, 5-битный код Бодо) или схема кодирования на основе слов (например, 10 байтов). может закодировать восемь слов из словарного запаса в 1000 слов). Кроме того, плотность данных может быть значительно увеличена за счет объединения нескольких сообщений в одну смесь, при этом каждое сообщение будет связано с другим ключом дешифрования. Мы отмечаем, что эти подходы повысят безопасность, затруднив статистический анализ сообщения.
может закодировать восемь слов из словарного запаса в 1000 слов). Кроме того, плотность данных может быть значительно увеличена за счет объединения нескольких сообщений в одну смесь, при этом каждое сообщение будет связано с другим ключом дешифрования. Мы отмечаем, что эти подходы повысят безопасность, затруднив статистический анализ сообщения.
Таким образом, мы разработали новый метод кодирования двоичной информации в наноструктурах ДНК с двумя состояниями, для шифрования и дешифрования этой информации с помощью самосборки и для быстрого считывания этой информации с помощью гель-электрофореза. Поскольку состояние таких наноструктур может использоваться для сообщения о молекулярных событиях (таких как разрыв межмолекулярных связей [17]), дополнительные приложения этой работы помимо информационной безопасности включают характеристику молекулярных взаимодействий с мультиплексным считыванием геля. Более конкретно, этот подход обеспечивает относительно простой и недорогой способ отправки безопасных и потенциально скрытых сообщений по общедоступному каналу.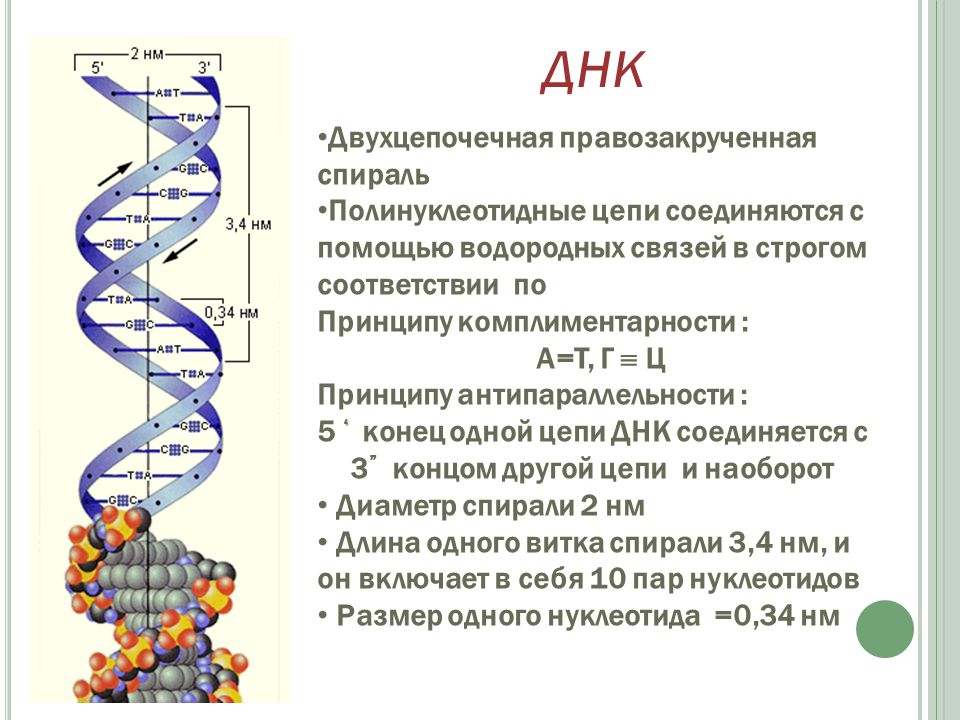 В отличие от аналогичных методов шифрования ДНК, которые требуют специальной лабораторной работы (например, ПЦР, секвенирования, клонирования), которая может занимать от нескольких часов до нескольких дней [7]–[10], наш метод позволяет шифровать и расшифровывать сообщения всего за несколько минут, требуя всего лишь одноразовых пипеток и безбуферная (даже портативная) гелевая система без подготовки (например, системы Invitrogen E-gel). Это удобство и простота также открывают технологию для других приложений, таких как аутентификация и штрих-кодирование. Например, увеличение емкости памяти до 40 бит позволит хранить вездесущий 12-значный универсальный код продукта (UPC). Было продемонстрировано несколько методов хранения печатной ДНК на бумаге [28], [29].], что в сочетании с нашим методом быстрого считывания может обеспечить новый уровень безопасности при идентификации продукта. На самом деле, маркировка ДНК-чернилами недавно нашла коммерческое применение (DNA Technologies, Галифакс, Канада) в усилиях по борьбе с контрафактной продукцией, включая спортивные памятные вещи, произведения искусства, фармацевтические препараты и предметы роскоши.
В отличие от аналогичных методов шифрования ДНК, которые требуют специальной лабораторной работы (например, ПЦР, секвенирования, клонирования), которая может занимать от нескольких часов до нескольких дней [7]–[10], наш метод позволяет шифровать и расшифровывать сообщения всего за несколько минут, требуя всего лишь одноразовых пипеток и безбуферная (даже портативная) гелевая система без подготовки (например, системы Invitrogen E-gel). Это удобство и простота также открывают технологию для других приложений, таких как аутентификация и штрих-кодирование. Например, увеличение емкости памяти до 40 бит позволит хранить вездесущий 12-значный универсальный код продукта (UPC). Было продемонстрировано несколько методов хранения печатной ДНК на бумаге [28], [29].], что в сочетании с нашим методом быстрого считывания может обеспечить новый уровень безопасности при идентификации продукта. На самом деле, маркировка ДНК-чернилами недавно нашла коммерческое применение (DNA Technologies, Галифакс, Канада) в усилиях по борьбе с контрафактной продукцией, включая спортивные памятные вещи, произведения искусства, фармацевтические препараты и предметы роскоши. Как предполагалось ранее, штрих-коды ДНК могут также найти применение для маркировки жидкостей, таких как краска и масло, или, возможно, даже продуктов питания [8]. В качестве другого примера, это может предоставить фармацевтическим компаниям простой и недорогой способ дискретной маркировки лекарств с информацией о производстве или сроке годности, даже на уровне съедобных зашифрованных штрих-кодов на отдельных таблетках. Это особенно своевременно в свете недавно введенных правительственных постановлений (например, Калифорнийского закона об электронной родословной) для сериализации фармацевтических препаратов и, в конечном итоге, для их «отслеживания и отслеживания», поскольку наш метод предлагает способ идентификации и аутентификации лекарств, уменьшая кражу и подделку. Можно также представить, что персональные идентификационные карты (например, водительские права, паспорта) печатаются с маркерами ДНК в качестве дополнительной защиты от мошенничества или кражи личных данных или даже с использованием собственной геномной ДНК в качестве ключа аутентификации.
Как предполагалось ранее, штрих-коды ДНК могут также найти применение для маркировки жидкостей, таких как краска и масло, или, возможно, даже продуктов питания [8]. В качестве другого примера, это может предоставить фармацевтическим компаниям простой и недорогой способ дискретной маркировки лекарств с информацией о производстве или сроке годности, даже на уровне съедобных зашифрованных штрих-кодов на отдельных таблетках. Это особенно своевременно в свете недавно введенных правительственных постановлений (например, Калифорнийского закона об электронной родословной) для сериализации фармацевтических препаратов и, в конечном итоге, для их «отслеживания и отслеживания», поскольку наш метод предлагает способ идентификации и аутентификации лекарств, уменьшая кражу и подделку. Можно также представить, что персональные идентификационные карты (например, водительские права, паспорта) печатаются с маркерами ДНК в качестве дополнительной защиты от мошенничества или кражи личных данных или даже с использованием собственной геномной ДНК в качестве ключа аутентификации.
Мы разработали и приобрели олигонуклеотиды (Bioneer, Inc.) для представления 8 различных битов, которые будут примерно равномерно распределены на 4% агарозном геле. Мы выбрали следующие длины: 20, 22, 25, 28, 32, 37, 43 и 50 нуклеотидов. Для каждой длины было куплено 3 олигонуклеотида: случайно сгенерированная последовательность, ее комплементарная цепь и случайный набор с произвольными основаниями. Мы обозначаем их как множества A, A’ и B соответственно.
Чтобы кодировать сообщения, мы сначала преобразовали наше текстовое сообщение «Hello world» в двоичный код, используя 8-битную кодировку символов ASCII с 8-м битом в качестве бита четности для проверки ошибок. Поскольку у нас всего 8 бит, каждая буква была подготовлена с использованием смеси олигонуклеотидов A и B для представления нулей и единиц. Например, «H» в «Hello world» имеет 8-битное двоичное представление 01001000. Младший значащий бит закодирован в наименьшем (20 nt) олиго, который мы будем обозначать олиго 1. Для кодирования «H» , смешиваем олигонуклеотиды 4 и 7 из набора A с олигонуклеотидами 1, 2, 3, 5, 6 и 8 из набора B.
Для кодирования «H» , смешиваем олигонуклеотиды 4 и 7 из набора A с олигонуклеотидами 1, 2, 3, 5, 6 и 8 из набора B.
Для декодирования смеси закодированных сообщений по отдельности смешивали со всем набором олигонуклеотидов A’ в буферном растворе (1× Buffer 4, New England Biolabs) и загружали в гель (в течение нескольких минут). Мы запустили автоматизированный сборный 4% агарозный гель (E-gel, Invitrogen), содержащий запатентованный краситель (с характеристиками, очень похожими на Sybr gold) на 15 минут, и сразу же сделали снимок. Бинарное представление каждой дорожки геля можно было прочитать непосредственно сверху вниз.
Авторы хотели бы поблагодарить Даниэля Ченга, Теда Фельдмана, Даррена Янга и Мунира Куссу за полезные обсуждения.
Эта работа была поддержана стартовыми фондами IDI. Спонсоры не участвовали в разработке исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи. URL-адрес IDI: http://www.idi.harvard.edu/.
1.
Адлеман Л. (1994) Молекулярное вычисление решений комбинаторных задач. Наука
266: 1021–1024. [PubMed] [Google Scholar]
2.
Липтон Р. (1995) ДНК решение сложных вычислительных задач. Наука
268: 542–545. [PubMed] [Google Scholar]
3.
Гварньери Ф., Флисс М., Бэнкрофт С. (1996) Добавление ДНК. Наука
273: 220–223. [PubMed] [Google Scholar]
4.
Оуян К., Каплан П., Лю С., Либчабер А. (1997) ДНК-решение задачи о максимальной клике. Наука
278: 446–449. [PubMed] [Google Scholar]
5.
Брайх Р., Челяпов Н., Джонсон С., Ротемунд П., Адлеман Л. (2002) Решение задачи с 20 переменными и тремя спутниками на ДНК-компьютере. Наука
296: 499–502. [PubMed] [Google Scholar]
6.
Цянь Л., Уинфри Э. (2011) Расширение вычислений цифровых схем с помощью каскадов смещения цепей ДНК. Наука
332: 1196. [PubMed] [Google Scholar]
7.
Клелланд С., Риска В., Бэнкрофт С. (1999) Сокрытие сообщений в микроточках ДНК. Природа
399: 533–534. [PubMed] [Google Scholar]
8.
Лейер А. , Рихтер С., Банцаф В., Раухе Х. (2000) Криптография с бинарными цепями ДНК. Биосистемы
, Рихтер С., Банцаф В., Раухе Х. (2000) Криптография с бинарными цепями ДНК. Биосистемы
57: 13–22. [PubMed] [Академия Google]
9.
Танака К., Окамото А., Сайто И. (2005) Система с открытым ключом, использующая ДНК в качестве односторонней функции для распределения ключей. Биосистемы
81: 25–29. [PubMed] [Google Scholar]
10.
Cui G, Qin L, Wang Y, Zhang X (2008) Схема шифрования с использованием технологии ДНК. Био-вдохновленные вычисления: теории и приложения
2008 г.
37–42. [Google Академия]
11.
Seeman N (2007) Обзор нанотехнологии структурной ДНК. Молекулярная биотехнология
37: 246–257. [Бесплатная статья PMC] [PubMed] [Google Scholar]
12.
Ротемунд П. (2006) Сворачивание ДНК для создания наноразмерных форм и узоров. Природа
440: 297–302. [PubMed] [Google Scholar]
13.
Инь П., Хариади Р., Саху С., Чой Х., Парк С. и др. (2008) Программирование окружностей трубок ДНК. Наука
321: 824–826. [PubMed] [Google Scholar]
14.
Дуглас С., Дитц Х., Лидл Т. , Хёгберг Б., Граф Ф. и др. (2009) Самосборка ДНК в наноразмерные трехмерные формы. Природа
, Хёгберг Б., Граф Ф. и др. (2009) Самосборка ДНК в наноразмерные трехмерные формы. Природа
459: 414–418. [Бесплатная статья PMC] [PubMed] [Google Scholar]
15.
Андерсен Э., Донг М., Нильсен М., Ян К., Субрамани Р. и др. (2009) Самосборка наноразмерного ящика для ДНК с управляемой крышкой. Природа
459: 73–76. [PubMed] [Google Scholar]
16.
Дуглас С., Бачелет И., Черч Г. (2012) Наноробот с логическим управлением для целенаправленной транспортировки молекулярных полезных нагрузок. Наука
335: 831–834. [PubMed] [Google Scholar]
17.
Халворсен К., Шаак Д., Вонг В. (2011)Наноинженерия одномолекулярного механического переключателя с использованием самосборки ДНК. Нанотехнологии
22:494005. [PubMed] [Google Scholar]
18.
Ровейс С., Уинфри Э., Бургойн Р., Челяпов Н., Гудман М. и др. (1998) Модель на основе наклеек для вычисления ДНК. Журнал вычислительной биологии
5: 615–629. [PubMed] [Google Scholar]
19.
Yan H, LaBean T, Feng L, Reif J (2003)Направленная сборка зародышеобразования комплексов фрагментов ДНК для решеток с рисунком штрих-кода. Труды Национальной академии наук
Труды Национальной академии наук
100: 8103. [Бесплатная статья PMC] [PubMed] [Google Scholar]
20.
Шефер С., Эккель Р., Рос Р., Маттай Дж., Ансельметти Д. (2007) Фотохимический одномолекулярный аффинный переключатель. Журнал Американского химического общества
129: 1488–1489. [PubMed] [Google Scholar]
21.
Quek S, Kamenetska M, Steigerwald M, Choi H, Louie S, et al. (2009) Механически управляемое бинарное переключение проводимости одномолекулярного соединения. Природа Нанотехнологии
4: 230–234. [PubMed] [Google Scholar]
22.
Lee I, Dombkowski A, Athey B (2004) Руководство по включению неидеально согласованных олигонуклеотидов в целевые гибридизационные зонды для ДНК-микрочипов. Исследование нуклеиновых кислот
32: 681–690. [Бесплатная статья PMC] [PubMed] [Google Scholar]
23. Gehani A, LaBean T, Reif J (2004) Криптография на основе ДНК. Аспекты молекулярных вычислений: 34–50.
24.
Oberacher H, Mayr B, Huber C (2004)Автоматизированное секвенирование de novo нуклеиновых кислот с помощью жидкостной хроматографии и тандемной масс-спектрометрии.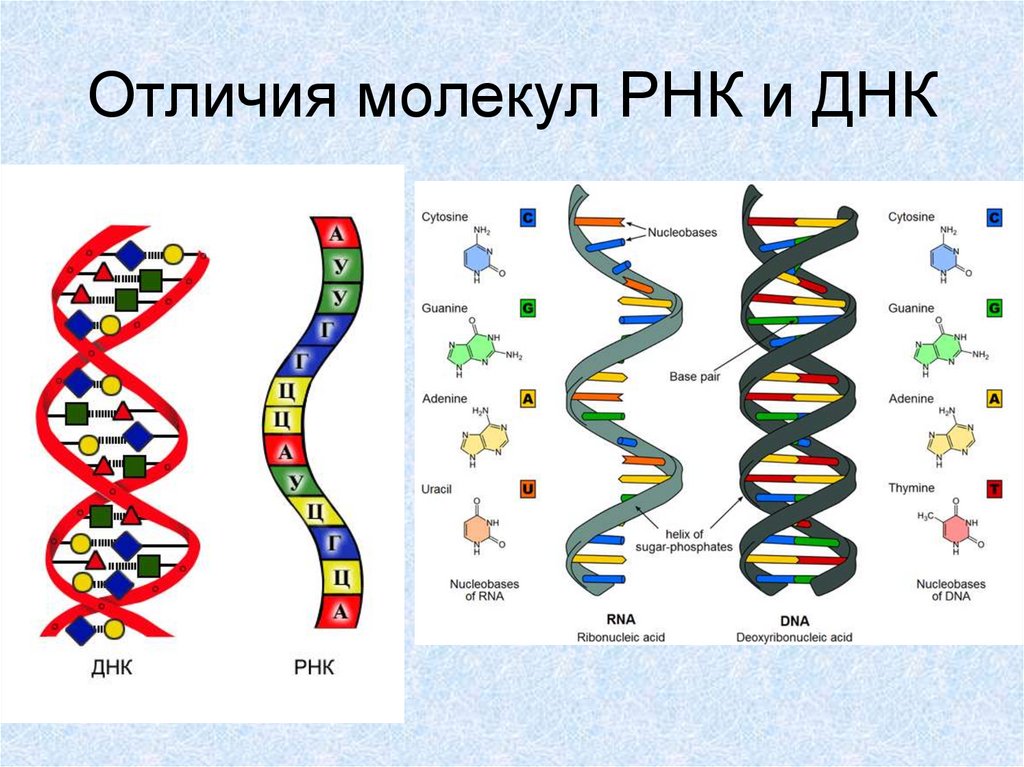 Журнал Американского общества масс-спектрометрии
Журнал Американского общества масс-спектрометрии
15: 32–42. [PubMed] [Google Scholar]
25.
Oberacher H, Pitterl F (2009) Об использовании esi-qqtof-ms/ms для сравнительного секвенирования нуклеиновых кислот. Биополимеры
91: 401–409. [PubMed] [Google Scholar]
26.
Farand J, Gosselin F (2009)Определение последовательности De novo модифицированных олигонуклеотидов. Аналитическая химия
81: 3723–3730. [PubMed] [Google Scholar]
27.
França L, Carrilho E, Kist T (2002) Обзор методов секвенирования ДНК. Ежеквартальные обзоры биофизики
35: 169–200. [PubMed] [Google Scholar]
28.
Каваи Дж., Хаяшизаки Й. (2003) Книга о ДНК. Исследование генома
13: 1488–1495. [Бесплатная статья PMC] [PubMed] [Google Scholar]
29.
Хашияда М. (2004) Разработка биометрических чернил ДНК для обеспечения безопасности аутентификации. Журнал экспериментальной медицины Тохоку
204: 109–117. [PubMed] [Google Scholar]
Статьи из PLOS ONE предоставлены здесь с любезного разрешения PLOS
Научно обосновано — Настоящее шифрование ДНК (или, по крайней мере, затрудняющее декодирование/изменение)
Вам не нужно шифровать последовательность ДНК, чтобы другие люди не смогли ее использовать.
Молекула ДНК не имеет внутреннего значения, а это означает, что, хотя вы можете различать закономерности, вы никогда не получите всю информацию об организме, просто взглянув на его ДНК.
Позвольте мне объяснить это аналогией с языком. Если бы я дал вам книгу на языке, которого вы не читаете, вы бы не смогли ее понять. Вы знаете, что это книга, и вы знаете, что в ней есть смысл, но вы не можете реконструировать ее, не протестировав. Например, взять предложение и повторить его тому, кто говорит на этом языке, или изменить порядок слов и проверить, производят ли они желаемый эффект, когда вы говорите их тому, кто их понимает.
Код, в данном случае генетический код, требует системы декодирования, чтобы содержать значимую информацию. В биологии декодер состоит из многих других частей клетки, включая, помимо прочего, аппарат транскрипции, который транскрибирует ДНК в РНК, аппарат трансляции, который переводит РНК в белки, эпигенетический аппарат, который контролирует, какие области должны быть транскрибированы. , клеточные сигнальные пути, которые модулируют предыдущие системы на основе внешних и внутренних факторов, и так далее.
, клеточные сигнальные пути, которые модулируют предыдущие системы на основе внешних и внутренних факторов, и так далее.
Итак, все возвращается к яйцеклетке. Это не просто молекула ДНК сама по себе. Это молекула ДНК в очень специфическом клеточном контексте, а в случае многоклеточных животных это также клетка в очень специфическом органном контексте. Человеческая яйцеклетка не может развиваться в вашем мочевом пузыре. У него есть определенные требования, которым (обычно) отвечает матка.
Если у ваших существ есть половое размножение, вы можете сконструировать племенную породу существа, которое рождает стерильное потомство. Чтобы избежать возможности экстракорпорального оплодотворения, вы можете создать у них потомство, не имеющее эквивалента матки, или вы можете систематически выполнять гистерэктомию перед их продажей.
Если вы действительно хотите, чтобы он был невероятно непрозрачным, тогда вам нужно изменить способ работы различных механизмов, о которых я упоминал ранее:
Измените стартовый и стоп-кодоны, изменив транскрипционный механизм для распознавания различных паттернов.
Вам также потребуется изменить последовательность сайта начала транскрипции.Расшифруйте генетический код, заставив различные тРНК соответствовать разным аминокислотам, что заставит потенциальных воров проводить эксперименты, чтобы выяснить, чему соответствует ваша запатентованная версия генетического кода.
Если вы используете уже существующие факторы транскрипции, проведите эксперименты по направленному мутагенезу, чтобы заставить их распознавать различные мотивы последовательности.
 Вам также потребуется изменить последовательность сайта начала транскрипции.
Вам также потребуется изменить последовательность сайта начала транскрипции.Что касается сложности чтения и интерпретации ДНК, вот несколько идей:
Вы должны включить в свою ДНК множество очень длинных участков повторяющихся участков, а также транспозонов. Это значительно усложняет сборку полного генома организма. Мы начинаем решать эту проблему с помощью методов секвенирования третьего поколения, которые генерируют длинные чтения, которые могут разрешить эти повторяющиеся последовательности.
Добавьте много псевдогенов, чтобы запутать интерпретацию, это последовательности ДНК, которые выглядят как гены и распознаются автоматическими инструментами, но не функционируют как таковые.
