Содержание
Как была расшифрована ДНК | Forbes.ru
Создатель метода чтения ДНК стал единственным ученым, дважды получившим Нобелевскую премию по химии
В первые два десятилетия после того, как Уотсон и Крик открыли двойную спираль ДНК, человечеству удалось очень многое понять о молекулярной природе жизни. Была сформулирована знаменитая «центральная догма», согласно которой генетическая информация в клетке передается только в одном направлении: от ДНК к белку. Был полностью расшифрован генетический код, который позволяет клетке переводить тексты нуклеиновых кислот в тексты белков, то есть последовательность нуклеотидов в ДНК и РНК — в последовательность аминокислотных остатков в белках. Все это были огромные достижения.
Проблема, однако, состояла в том, что, хотя молекулярные биологи все время рассуждали про эти тексты, самих текстов никто не знал. Не было способа расшифровать гены. Или, иными словами, не было метода определения последовательности нуклеотидов в ДНК.
Или, иными словами, не было метода определения последовательности нуклеотидов в ДНК.
К тому времени это уже умели делать для белков — метод чтения их последовательности был разработан в начале 1950-х годов, еще до открытия двойной спирали. Кроме того, ученые уже немного умели читать короткие последовательности РНК. А вот последовательности ДНК не умели читать вообще. Это создавало колоссальную брешь в реальном понимании молекулярных основ жизни и сдерживало как развитие биотехнологий, которых, собственно говоря, еще не было, так и медицинского применения этих знаний.
Стало даже казаться, что это слишком сложная задача и ее не удастся решить — все попытки оказывались безуспешными.
Но вот в середине 70-х годов XX века произошел прорыв. Метод определения последовательности ДНК был разработан британским ученым-химиком Фредериком Сенгером.
Сенгер — великий человек. Он единственный в истории науки, кто получил две Нобелевские премии по химии.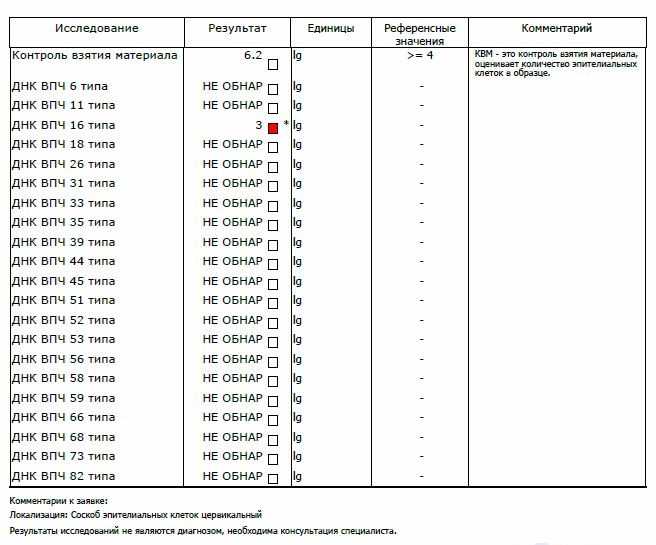 Нобель запретил давать два раза одному и тому же человеку премию в одной и той же области. А Сенгер к тому времени уже получил премию как раз за разработку метода чтения аминокислотных последовательностей в белках. И когда он разработал метод чтения последовательности ДНК, Нобелевский комитет оказался в очень трудном положении: он должен был либо не дать человеку премию за выдающееся открытие, либо нарушить завещание Нобеля. Решили все-таки нарушить завещание. И это единственный случай в области химии.
Нобель запретил давать два раза одному и тому же человеку премию в одной и той же области. А Сенгер к тому времени уже получил премию как раз за разработку метода чтения аминокислотных последовательностей в белках. И когда он разработал метод чтения последовательности ДНК, Нобелевский комитет оказался в очень трудном положении: он должен был либо не дать человеку премию за выдающееся открытие, либо нарушить завещание Нобеля. Решили все-таки нарушить завещание. И это единственный случай в области химии.
Как теперь читают последовательности ДНК? С тех пор в этом направлении был сделан огромный прогресс, и он основан на прорыве Сенгера. Последовательность ДНК — это колоссальной длины текст, написанный с помощью всего четырех «букв» — четырех химических соединений: аденина (А), тимина (Т), гуанина (G) и цитозина (С). У нас в каждой клетке имеется геном, который состоит из трех миллиардов нуклеотидов, трех миллиардов таких «букв».
Как этот текст прочитать?
Прежде всего, ДНК разрезают на фрагменты с помощью специальных ферментов, которые называются рестриктазы. Рестриктазы узнают короткие последовательности ДНК, содержащие приблизительно от 6 до 8 нуклеотидов, и только в этом месте определенным образом разрезают двойную спираль ДНК. Открытие таких «ножниц» стало еще одним прорывом начала 1970-х годов.
Рестриктазы узнают короткие последовательности ДНК, содержащие приблизительно от 6 до 8 нуклеотидов, и только в этом месте определенным образом разрезают двойную спираль ДНК. Открытие таких «ножниц» стало еще одним прорывом начала 1970-х годов.
После разрезания ДНК задача сводится к тому, чтобы определить последовательность короткого куска — он может содержать сотню или несколько сотен звеньев. И здесь используется метод Сенгера.
К полученному фрагменту молекулы добавляются с обоих концов специальные адаптеры, потому что рестриктаза оставляет неровные концы. Адаптер имеет определенную последовательность, которую выбираем мы сами, так как он синтетический. После добавления адаптера каждый фрагмент получит определенные — известные нам — последовательности на концах. Эти последовательности мы сможем использовать для того, чтобы добавить к фрагменту молекулы синтетические праймеры (фрагменты нуклеиновой кислоты), начиная с которых по имеющейся последовательности ДНК будет синтезироваться комплементарная цепочка.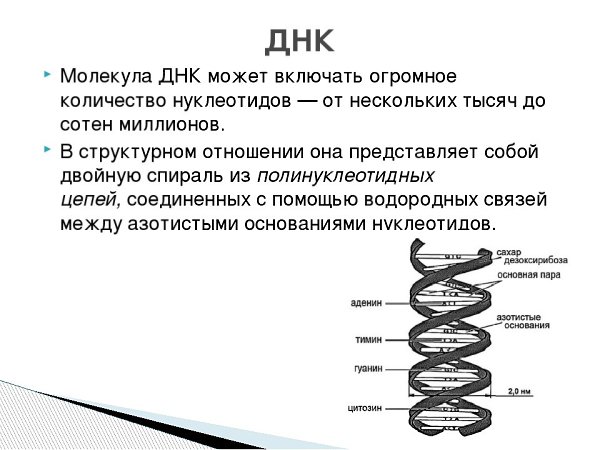
Идея Сенгера состояла в том, что в процессе такого синтеза нужно добавить к смеси нормальных предшественников нуклеотидов, называющихся нуклеозидтрифосфатами, специально модифицированные нуклеозидтрифосфаты, которые не смогут удлиняться.
В результате синтез останавливается на месте той или иной «буквы». Тем самым мы получаем молекулы с набором длин, который точно говорит нам, в каком месте встроена та или иная «буква». И тогда остается только разделить эти молекулы по длине, что делается при помощи гель-электрофореза.
Готовится специальный гель, то есть полимерная сетка, к которому прикладывается постоянное электрическое поле. Под действием электрического поля отрицательно заряженные молекулы ДНК ползут через полимерную сетку. И чем длиннее молекула, тем медленнее она движется в геле. Это позволяет разделять смесь молекул согласно их длинам, и там, где стоит тот нуклеотид, который мы в данный момент изучаем, мы будем видеть остановку синтеза, то есть длины фрагментов, когда мы будем разделять их по длине, соответствующие номеру этих нуклеотидов.
И таким образом мы можем прочитать всю последовательность.
Этот замечательный, гениальный метод, благодаря которому мы смогли секвенировать человеческий геном, и был придуман Сенгером. Первый геном человека был прочитан в самом начале нашего века. Тогда это обошлось в сумму порядка трех миллиардов долларов. Затем метод был модифицирован, роботизирован и сегодня процедура определения последовательности стоит несравненно меньше. Цена приближается к $1000 за расшифровку ДНК конкретного человека.
Совершенно фантастическое развитие методов секвенирования ДНК создало неимоверный прогресс и в области понимания молекулярной природы жизни, и в области биотехнологического и медицинского применения.
Из чего собрана наша ДНК
Научная догма
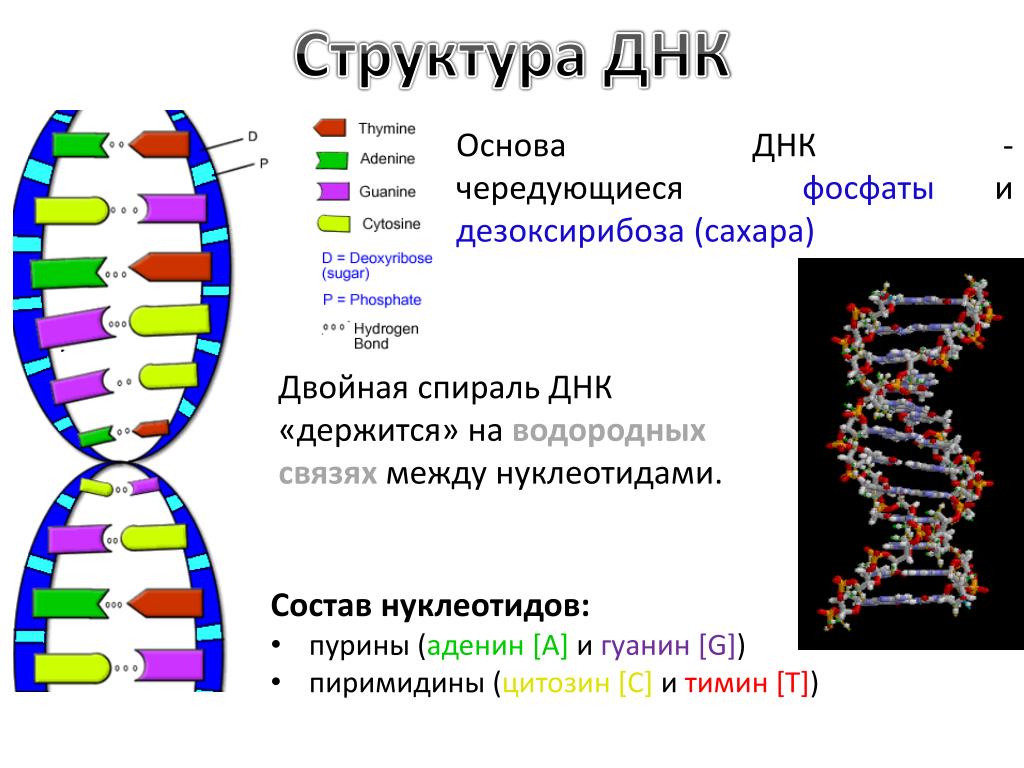
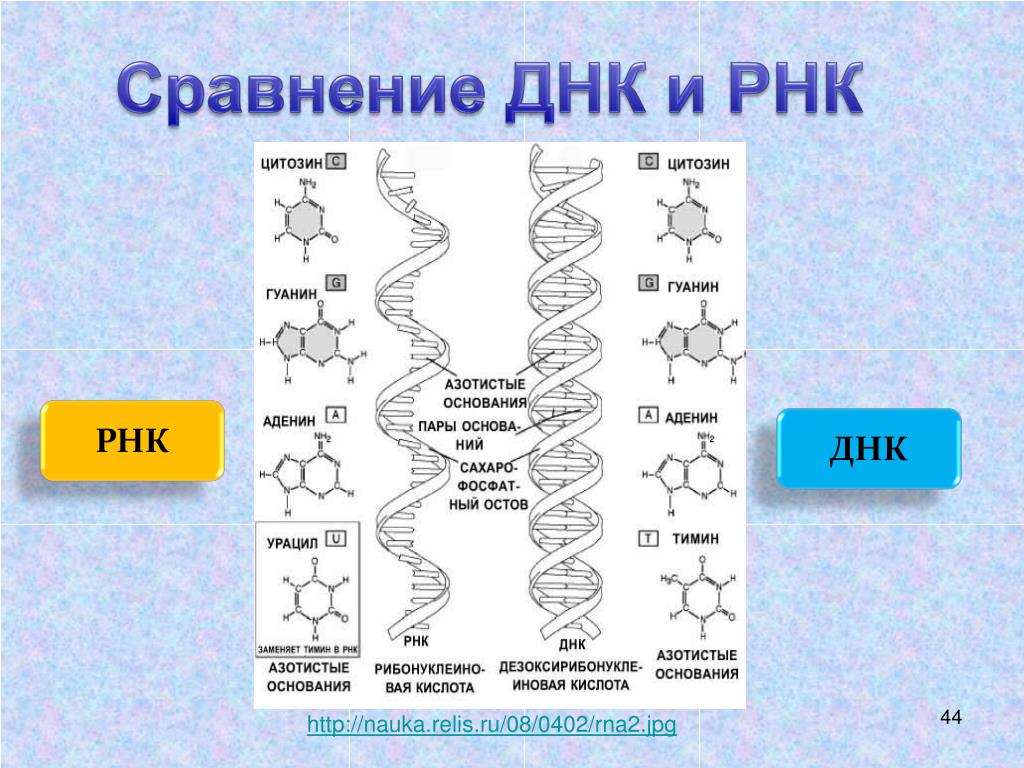
В 1953 году Джеймс Уотсон и Фрэнсис Крик опубликовали в журнале Nature двухстраничную статью с заголовком «Молекулярная структура дезоксирибонуклеиновых кислот». В статье коротенечко сообщалось, что ДНК — это двойная спираль, нити которой состоят из нуклеотидов, букв «генетического текста», и удерживаются вместе эфемерными водородными связями. Примерно тогда же стало понятно, как ДНК воспроизводит свои копии, и был сформулирован ключевой для всей биологии принцип — центральная догма* молекулярной биологии.
В статье коротенечко сообщалось, что ДНК — это двойная спираль, нити которой состоят из нуклеотидов, букв «генетического текста», и удерживаются вместе эфемерными водородными связями. Примерно тогда же стало понятно, как ДНК воспроизводит свои копии, и был сформулирован ключевой для всей биологии принцип — центральная догма* молекулярной биологии.
*Ее автор, один из первооткрывателей молекулярной структуры ДНК Фрэнсис Крик, объяснял выбор этого слова желанием подобрать звучное название.
Эта догма гласит: ДНК является средоточием генетической (наследственной) информации и может служить инструкцией — матрицей для синтеза своей ближайшей родственницы РНК, рибонуклеиновой кислоты. Последняя содержит информацию, которая используется для синтеза белков, а уже те самостоятельно принимаются за дело, выполняя огромное разнообразие работ в клетке. Вольный пересказ центральной догмы молекулярной биологии на сем окончен.
Появление этой догмы ознаменовало наступление «нового времени» в науке о живом. Но заметьте: что догма, что открытия 1950-х выхватили, словно лучом прожектора, только самый центральный, основополагающий сюжет с участием ДНК — кодирующие последовательности в генах. Все остальное первооткрыватели структуры чудо-молекулы пренебрежительно назвали «мусорной ДНК» (англ. Junk DNA), оставив без внимания.
Но заметьте: что догма, что открытия 1950-х выхватили, словно лучом прожектора, только самый центральный, основополагающий сюжет с участием ДНК — кодирующие последовательности в генах. Все остальное первооткрыватели структуры чудо-молекулы пренебрежительно назвали «мусорной ДНК» (англ. Junk DNA), оставив без внимания.
16 000 томов Толстого
В последующие десятилетия некодирующей «темной материи» не придавали особого значения. Но время шло, не стоял на месте и научный прогресс — ученые понемногу узнавали о разнообразии процессов, происходящих внутри ДНК и с ее участием. Немало удивительного удалось узнать и о геноме в целом. Например, что весь генетический код представляет собой длинный текст, который записан 4-буквенным алфавитом. Это так называемые нуклеотиды: аденин — A, тимин — T, гуанин — G и цитозин — C.
Не так давно, на рубеже тысячелетий, чтобы получить полную версию этого сакраментального «текста», был создан огромный международный консорциум «Геном человека». На протяжении более чем 10 лет исследователи из 20 научных центров США, Великобритании, Японии, Франции, Германии, Испании и Китая и нескольких частных компаний сплоченно работали и ежедневно докладывали о своих успехах.
На протяжении более чем 10 лет исследователи из 20 научных центров США, Великобритании, Японии, Франции, Германии, Испании и Китая и нескольких частных компаний сплоченно работали и ежедневно докладывали о своих успехах.
В результате огромной работы к 2003 году этот написанный природой и прочитанный человеком опус был наконец опубликован. В последовательности из 3 миллиардов букв* было найдено около 20-25 тысяч фрагментов — генов, — в которых непосредственно закодирована наследственная информация.
*Для сравнения: в 4-томном романе «Война и мир» всего-навсего около 750 тысяч знаков, включая знаки препинания и пробелы. Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.
Средняя длина гена — около 25-27 тысяч пар нуклеотидов. Если посчитать долю знаков всех генов от объема общего текста, получится около 2%. Если вычесть некодирующие элементы внутри генов, и того меньше. Но если в категорию «мусора» попало 98% генома, значит, этот мусор для чего-то да нужен?
Для сравнения: в 4-томном романе «Война и мир» всего-навсего около 750 тысяч знаков, включая знаки препинания и пробелы. Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.Проект «Геном человека» подарил много новых инструментов для работы с ДНК. Историки науки даже называют 2003 год началом новой эры в биологии — постгеномной. Менее чем за два десятилетия в арсенале учёных появились методы, позволяющие распознавать отдельный нуклеотиды при протягивании молекулы ДНК через нанопору, — в ХХ веке о таком не помышляли даже фантасты. И потихоньку наука начала разбираться с завалами «мусора».
Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.Проект «Геном человека» подарил много новых инструментов для работы с ДНК. Историки науки даже называют 2003 год началом новой эры в биологии — постгеномной. Менее чем за два десятилетия в арсенале учёных появились методы, позволяющие распознавать отдельный нуклеотиды при протягивании молекулы ДНК через нанопору, — в ХХ веке о таком не помышляли даже фантасты. И потихоньку наука начала разбираться с завалами «мусора».
Так из какого сора?
Что же представляет собой это «молчаливое большинство» нашего генома?
Безусловно, нельзя говорить о ненужности и бессмысленности 98% генетического материала. Эту хаотичную и слабо понятную сейчас массу можно назвать не мусором, а скорее свалкой сокровищ.
Некодирующие области могут выполнять разные функции или не выполнять никаких. Чтобы попасть в эту огромную категорию, участкам ДНК достаточно не хранить в себе информацию о структуре РНК или белка.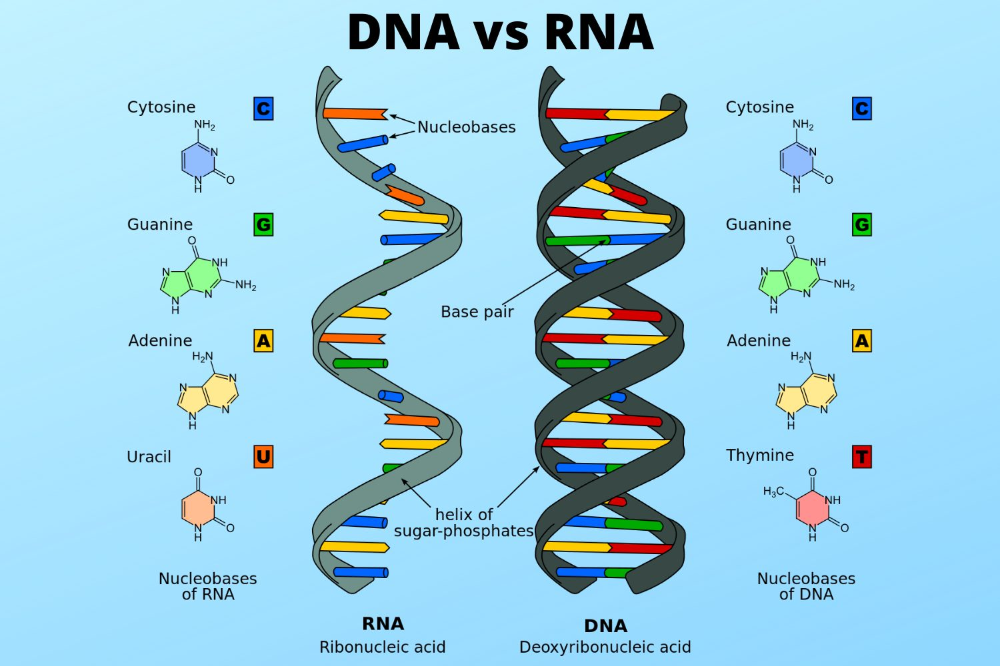
Компоненты человеческого генома
Кодирующие области 2%
Интроны 26%
ДНК-транспозоны 3%
LTR-ретротранспозоны 8%
LINEs 20%
SINEs 10%
Микросателлиты 3%
Другие типы 28%
Непосредственно внутри кодирующих областей встречаются интроны. Это такие участки ДНК, которые сидят внутри генов, но при этом ничего не кодируют. В дальнейшем интроны безжалостно вырезаются и выбрасываются из уже из РНК (этот процесс называется сплайсингом). Обилие подобных побочных продуктов производства РНК характерно для эукариот: у них для генома есть специальный контейнер, способный вместить сколь угодно много сора, — ядро. В человеческой ДНК на интроны приходится аж четверть текста. У бактерий такого контейнера нет, их геномы более компактные и рационализированные.
За границами кодирующих областей встречаются два типа крайне важных последовательностей: промоторы и терминаторы. Первые обозначают место, откуда надо начать считывание гена, вторые — конец. Рядом могут находиться энхансеры и сайленсеры — своеобразные тумблеры, позволяющие настроить активность считывания гена. Регуляторные участки ДНК — важный тип некодирующих последовательностей, ведь такая сложная машина, как организм, должна, во-первых, правильно собирать себя в процессе развития и, во-вторых, оперативно реагировать на изменения состояния — своего собственного и окружающей среды.
Рядом могут находиться энхансеры и сайленсеры — своеобразные тумблеры, позволяющие настроить активность считывания гена. Регуляторные участки ДНК — важный тип некодирующих последовательностей, ведь такая сложная машина, как организм, должна, во-первых, правильно собирать себя в процессе развития и, во-вторых, оперативно реагировать на изменения состояния — своего собственного и окружающей среды.
Плодятся буквы, как лопухи и лебеда, как буквы в ворде
«Ааааааааааааааааааааааааааааааааааааааааааааааааааа», — повторяет Владимир Сорокин несколько страниц в своем дебютном романе «Норма», используя бессмысленный повтор как средство художественной выразительности. TTTTTTTTTTTTTTTTTTTTT или GCAGCAGCAGCAGCAGCAGCAGCA, — вторит ему ДНК. На такие последовательности приходится около 1,5 миллиарда знаков из 3-миллиардного текста нашего генома. Почему бессмысленные повторы занимают столько места? Или, раз это место им отведено, они что-то да значат? Учёные считают, что повторяющиеся последовательности — это горячие точки эволюции: с ними связаны быстрые и неожиданные изменения генома. Исследования показали, что не все повторы одинаковы, их можно разделить на два больших типа: прямые и диспергированные, причём в каждом по несколько разновидностей.
Исследования показали, что не все повторы одинаковы, их можно разделить на два больших типа: прямые и диспергированные, причём в каждом по несколько разновидностей.
Диспергированные повторы, в отличие от прямых, не идут впритык друг за другом, а перемежаются с другими участками ДНК. По большей части диспергированные повторы — это транспозоны, последовательности-анархисты, способные скакать с места на место, то есть перемещаться по геному. Свободолюбивое поведение делает транспозоны важной движущей силой эволюции: они перемешивают и прочее население генома, вмешиваясь в работу генов.
Некоторые транспозоны — ретротранспозоны — могут не только скакать по геному, но и плодиться в нём. Их название отражает не художественные пристрастия, а механизм, который эти мобильные генетические элементы используют для передвижения по ДНК. Корень «ретро-» по аналогии с ретровирусами намекает на переход в форму РНК. То есть такие последовательности сначала считываются, а потом из РНК-матрицы переходят снова в ДНК, встраиваясь в новое место генома.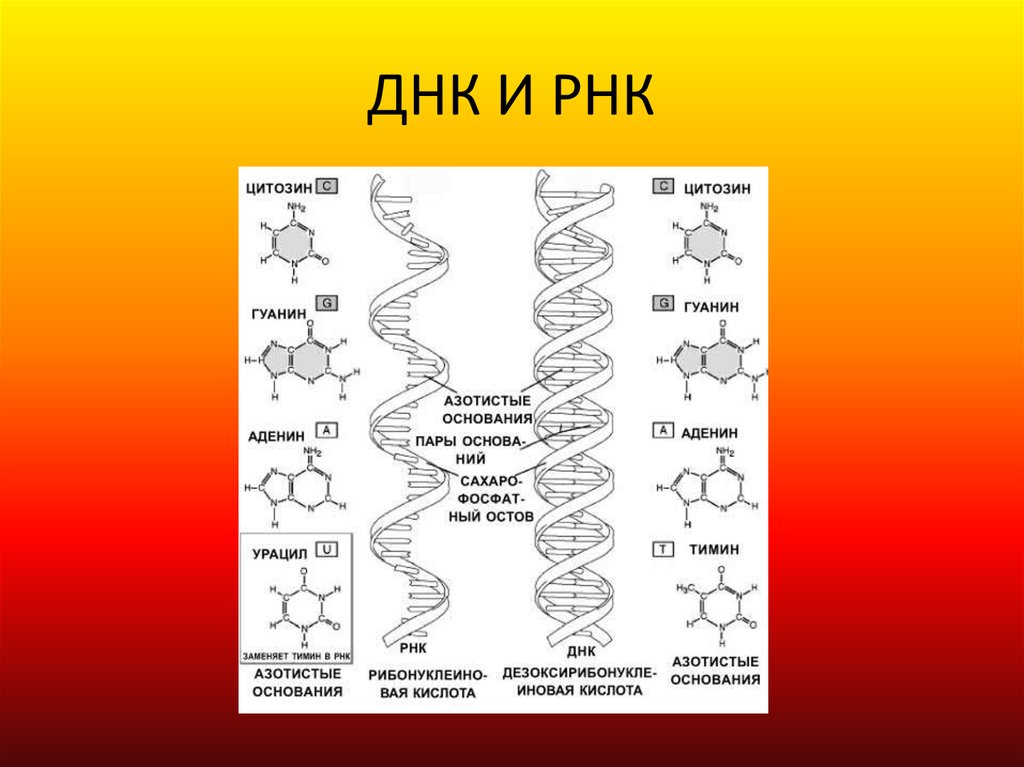 Принцип «копировать — вставить». Оставшиеся малочисленные ДНК-транспозоны переходить в РНК не умеют, им остается вариант «вырезать — вставить».
Принцип «копировать — вставить». Оставшиеся малочисленные ДНК-транспозоны переходить в РНК не умеют, им остается вариант «вырезать — вставить».
Ретротранспозоны нашего генома можно разделить на несколько групп. Во-первых, это LTR-ретротранспозоны. На концах таких последовательностей присутствуют особые повторяющиеся участки. Подобные концевые повторы есть у ретровирусов и используются ими для встраивания генетического материала в геном хозяина. Это сходство названий и последовательностей не случайно: LTR-ретротранспозоны происходят от ретровирусов. Очередной вирусный след в человеческом геноме, притом увесистый: на LTR-повторы приходится порядка 8% генома Homo sapiens.
Ретротранспозоны LINEs и SINEs таких концевых повторов лишены. Главное различие между ними в размере: от менее 500 нуклеотидов у SINEs до в среднем 7000 у LINEs. Самые любопытные из них Alu-повторы. Подавляющее большинство SINEs генома Homo sapiens — это именно они. Предполагают, что Alu-элементы возникли около 100 млн лет назад и с тех пор изменялись вместе с расходящимися по собственной эволюционной ветке обезьянами. Изучение Alu-повторов помогает лучше понять родословную наших родичей.
Изучение Alu-повторов помогает лучше понять родословную наших родичей.
Ну сколько можно повторять!
Тандемные повторы ДНК вплотную примыкают друг к другу, почти как ездоки велосипеда-тандема. Отсюда их правильная структура с регулярным чередованием. Ну а свойства определяются размером повторов, по этому признаку тандемные повторы делят на три типа: сателлиты, минисателлиты и микросателлиты.
Самые длинные — сателлиты, или сателлитная ДНК, — могут тянуться миллионы и миллионы нуклеотидов подряд. Космическое название (англ. Satellite — спутник) связано с тем, что при ультрацентрифугировании (метод разделения веществ в результате очень быстрого раскручивания на ультрацентрифуге) эта часть ДНК легко отделялась от прочего генома. Сателлиты не кодируют РНК и белки и вообще складированы в «технических» областях хромосом: центромерах и теломерах. Центромеры и сателлитные повторы важны при делении клетки. Когда дело доходит до разделения удвоенных хромосом, микротрубочки подходят именно к центромерам и тянут за них хромосомы в противоположном направлении. А сателлиты в теломерах не позволяют концам хромосом слипаться (и самой хромосоме — разрушиться). Еще они защищают нас от старения, препятствуя укорачиванию хромосом.
Фото: Журнал «Кот Шрёдингера»
Средненькие в семье тандемных — минисателлиты, — как заведено и у людей, следуют за старшенькими. Они обнаружены не в самих центромерах и теломерах, а по соседству. Именно по последовательностям минисателлитов в детективных сериалах определяют сходство ДНК с места преступления с ДНК подозреваемого, а в романтических — устанавливают родительство. Длина каждого отдельного минисателлита довольно специфична у каждого из нас, однако у близких родственников они схожи.
Самые маленькие из тандемных повторов длиной всего 6-10 нуклеотидов — микросателлиты. Как и средненькие (и по тому же принципу), самые короткие в семействе нашли применение в криминалистике, но на этом их сходство со старшими братьями заканчивается. В отличие от них, микросателлиты находятся не в определённых участках хромосом, а распределены по всей ДНК почти равномерно. И не криминалистическое применение в них самое интересное. Микросателлиты, несмотря на малый размер, — кипучие котлы эволюции. Мутации в них происходят в тысячу раз чаще, чем в каких-либо других нуклеотидах. Характер этих мутаций заключается в потере или дублировании единиц-повторов целиком. Притом не одной — иногда «проскальзывание» копирующего ДНК белка затрагивает большие участки ДНК со следующими один за другим микросателлитами.
И не криминалистическое применение в них самое интересное. Микросателлиты, несмотря на малый размер, — кипучие котлы эволюции. Мутации в них происходят в тысячу раз чаще, чем в каких-либо других нуклеотидах. Характер этих мутаций заключается в потере или дублировании единиц-повторов целиком. Притом не одной — иногда «проскальзывание» копирующего ДНК белка затрагивает большие участки ДНК со следующими один за другим микросателлитами.
Если такое нарастание происходит в некоторых пределах, то в целом ситуация остается под контролем. Если же они превышены (к этому располагает наследственность), никто и ничто уже не сможет удержать микросателлиты. Происходит так называемая экспансия: единицы микросателлитов повторяются сотни и тысячи раз подряд, а обладатель соответствующего генома приобретает серьезное, обычно неизлечимое и быстро прогрессирующее заболевание. Это может быть и болезнь Хантингтона — неуклонно прогрессирующее заболевание мозга, прославившееся вместе с Тринадцатой из сериала «Доктор Хаус», и синдром хрупкой Х-хромосомы. Хрупкой оказывается как раз область микросателлитов, причем хрупкой настолько, что часть этой хромосомы может просто… отвалиться.
Хрупкой оказывается как раз область микросателлитов, причем хрупкой настолько, что часть этой хромосомы может просто… отвалиться.
Геном Homo sapiens — это текст из 3 миллиардов букв, который очень далек от порядка и предсказуемости. Наш геном — это разнообразие, хаос, повторы и… своеобразная эволюционная разумность. И неожиданные сюжетные повороты. Почти как в стихотворении Хармса об устройстве человека:
А, впрочем, не рук пятнадцать штук,
пятнадцать штук,
пятнадцать штук.
Хэу-ля-ля,
дрюм-дрюм-ту-ту!
Пятнадцать штук, да не рук.
Тестирование и анализ ДНК для здоровья
Начать
Откройте для себя индивидуальные планы питания, пищевых добавок и образа жизни с помощью наших передовых методов тестирования и анализа ДНК здоровья.
Начать
Как показано на
Тест ДНК, который дает
дорожную карту, чтобы чувствовать себя счастливее и здоровее.
Есть файл?
Lifetime Access
Файл загрузки + Premium Insights
*Тестовый комплект ДНК не включен
(см. Приемлемые типы файлов)
Приемлемые типы файлов)
Загрузка + Premium Insights включает в себя
Анализ DNA File
. Персонал. Персонал.
150+ Отчеты о состоянии здоровья
50+ Отчеты о характеристиках
Индивидуальная комплексная формула пищевых добавок
Трекер и рекомендации Лаборатория 9,0040
600+ Персонализированные генетические посты в блоге
SNP & Gene Explorer
Инструмент режима здоровья
Анализатор жизни
Скидки в лабораторном магазине
РАЗВИЧИЕ ИСПОЛЬЗОВАНИЯ К НОВЫМ СМОТРИ .
Мы никогда не продадим ваши данные.0006
Home DNA Test Kit (на основе Saliva)
Персонализированные идеи
150+ Health Report Анализатор, трекер и рекомендации
Более 600 персонализированных сообщений генетического блога
SNP и Gene Explorer
Инструмент режима здоровья
Анализатор образа жизни
Скидка в Лабораторном магазине
Ранний доступ к новым функциям
Мы никогда не продадим ваши данные
SelfDecode
Набор для тестирования ДНК
Наш набор для тестирования ДНК в домашних условиях является единственным в мире набором для тестирования ДНК здоровья, который анализирует 83 миллиона генетических вариантов для получения точных показателей полигенного риска с учетом предков .
Доставка по всему миру!
Отчеты о состоянии ДНК
Отчеты о состоянии ДНК
Признаки
Признаки
Лабораторный анализатор
Лабораторный анализатор
Доверяют
103,500+
пользователей и
1,150+
12
2
врачей
Precision Health:
Оценка полигенного риска
Единственная в мире компания, использующая оценку полигенного риска на основе информации о происхождении для анализа 83 миллионов генетических вариантов и получения точных оценок риска.
Более 65 ученых
и инженеров
Квалифицированные специалисты с опытом работы в области геномики, искусственного интеллекта и машинного обучения революционизируют отрасль здравоохранения.
Предсказание генетических вариантов
Усовершенствованные алгоритмы на основе искусственного интеллекта анализируют и прогнозируют 83 миллиона генетических вариантов с точностью 99,7 %.
Конфиденциальность и безопасность
и поэтому мы:
- Предоставляем вам бесплатный доступ к необработанным данным
- Являются единственной генетической платформой, предназначенной для прямого доступа к потребителю, соответствующей требованиям HIPAA и GDPR
- Используют методы шифрования мирового класса
- Анонимизируют генетические данные в наших собственных системах
- Хранят генетическую информацию и информацию об учетной записи отдельно
- Позволяют вам удалять свои данные в любое время
- Не разрешать использование вторичных данных
- Создайте команду, занимающуюся вопросами безопасности и конфиденциальности
С SelfDecode
ВЫ владеете 100% своих данных.
С самодекодированием
Вы владеете 100% ваших данных.
Одна добавка со всеми ингредиентами, подходящими для вашей ДНК
SelfDecode — единственное место, где вы можете получить полностью индивидуальную формулу добавки на основе вашего генетического тестирования.
Начать
Начать
SelfDecode — это служба персонализированных отчетов о состоянии здоровья, которая позволяет пользователям получать подробную информацию и отчеты на основе их генома. SelfDecode не лечит, не диагностирует и не излечивает какие-либо заболевания, а предназначен исключительно для информационных и образовательных целей.
Тестирование недоступно лицам моложе 18 лет, а также жителям штатов Нью-Йорк, Нью-Джерси, Род-Айленд и Аризона.
Политики
Навигация
SelfDecode © 2022. Все права защищены.
Страница обучения — SelfDecode
Страница обучения — SelfDecode
SelfDecode Learn
Помогаем понять науку, лежащую в основе персонализированного здоровья.
Воспроизвести видео
Отличие SelfDecode
В SelfDecode мы используем передовые алгоритмы искусственного интеллекта и машинного обучения, чтобы наука, стоящая за SelfDecode, была более точной и действенной, чем кто-либо другой.

Понимание науки, лежащей в основе SelfDecode
Основы
Что такое ДНК
Воспроизвести видео
Ваше здоровье и окружающая среда
Воспроизвести видео
Что такое генетическое вменение
?
Воспроизвести видео
Понимание оценки воздействия и доказательств
 vimeo.com/video/594932605?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=b69d7da7b8#t=»/>
vimeo.com/video/594932605?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=b69d7da7b8#t=»/>
Воспроизвести видео
Что такое SelfDecode?
SelfDecode — единственное в мире программное обеспечение для геномики ИИ, которое предоставляет персонализированные рекомендации по здоровью. Узнайте, какие добавки, диету и изменения в образе жизни вам следует внести, исходя из вашей ДНК, лабораторных анализов и образа жизни.
Воспроизвести видео
Как пользоваться комплектом
SelfDecode DNA Kit
Воспроизвести видео
Использование функции «Мой режим»
 vimeo.com/video/589310443?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=d5e2bab823#t=»/>
vimeo.com/video/589310443?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=d5e2bab823#t=»/>
2
92
92
Расширенное обучение
Что такое гены?
Воспроизвести видео
Что такое генетические варианты?
Воспроизвести видео
Что такое
генетических мутаций?
Воспроизвести видео
Что такое
фенотипов?
 vimeo.com/video/613908939?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=04baf03f08#t=»/>
vimeo.com/video/613908939?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=04baf03f08#t=»/>
Воспроизвести видео
Понимание показателей полигенного риска
Воспроизвести видео
Знакомьтесь, Декоди!
Ваш новый тренер по здоровью с искусственным интеллектом!
Декоди — это наш продвинутый ИИ, и его работа — узнать вас на личном уровне, чтобы он мог предоставить вам комплексные рекомендации по здоровью, адаптированные к вашей ДНК, образу жизни, окружающей среде и результатам лабораторных исследований!
Получите наш бесплатный путеводитель!
Как использовать ДНК
для оптимизации
вашего здоровья
Посмотрите, как другие люди использовали науку геномики, чтобы стать здоровыми!
