Содержание
как именно работает нейросеть NVIDIA GauGAN / Хабр
В прошлом месяце на NVIDIA GTC 2019 компания NVIDIA представила новое приложение, которое превращает нарисованные пользователем простые цветные шарики в великолепные фотореалистичные изображения.
Приложение построено на технологии генеративно-состязательных сетей (GAN), в основе которой лежит глубинное обучение. Сама NVIDIA называет его GauGAN — это каламбур-отсылка к художнику Полу Гогену. В основе функциональности GauGAN лежит новый алгоритм SPADE.
В этой статье я объясню, как работает этот инженерный шедевр. И чтобы привлечь как можно больше заинтересованных читателей, я постараюсь дать детализированное описание того, как работают свёрточные нейронные сети. Поскольку SPADE — это генеративно-состязательная сеть, я расскажу подробнее и о них. Но если вы уже знакомы с эти термином, вы можете сразу перейти к разделу «Image-to-image трансляция».
Генерация изображений
Давайте начнем разбираться: в большинстве современных приложений глубинного обучения используется нейронный дискриминантный тип (дискриминатор), а SPADE — это генеративная нейронная сеть (генератор).
Дискриминаторы
Дискриминатор занимается классификацией вводимых данных. Например, классификатор изображения — это дискриминатор, который берет изображение и выбирает одну подходящую метку класса, например, определяет изображение как «собаку», «автомобиль» или «светофор», то есть выбирает метку, которая целиком описывает изображение. Полученный классификатором вывод обычно представлен в виде вектора чисел , где — это число от 0 до 1, выражающее уверенность сети в принадлежности изображения к выбранному -классу.
Дискриминатор также может составить целый список классификаций. Он может классифицировать каждый пиксель изображения как принадлежащий классу «людей» или «машин» (так называемая «семантическая сегментация»).
Классификатор берет изображение с 3 каналами (красный, зеленый и синий) и сопоставляет его с вектором уверенности в каждом возможном классе, который может представлять изображение.
Поскольку связь между изображением и его классом очень сложна, нейронные сети пропускают его через стек из множества слоев, каждый из которых «немного» обрабатывает его и передает свой вывод на следующий уровень интерпретации.
Генераторы
Генеративная сеть наподобие SPADE получает набор данных и стремится создавать новые оригинальные данные, которые выглядят так, как будто они принадлежат этому классу данных. При этом данные могут быть любыми: звуками, языком или чем-то еще, но мы сосредоточимся на изображениях. В общем случае ввод данных в такую сеть представляет собой просто вектор случайных чисел, причем каждый из возможных наборов вводимых данных создает свое изображение.
Генератор на основе случайного входного вектора работает фактически противоположно классификатору изображения. В генераторах «условных классов» входной вектор — это, фактически, вектор целого класса данных.
Как мы уже видели, SPADE использует намного больше, чем просто «случайный вектор». Система руководствуется своеобразным чертежом, который называется «картой сегментации». Последняя указывает, что и где размещать. SPADE проводит процесс, обратный семантической сегментации, упомянутой нами выше. В целом, дискриминационная задача, переводящая один тип данных в другой, имеет аналогичную задачу, но идет другим, непривычным путем.
В целом, дискриминационная задача, переводящая один тип данных в другой, имеет аналогичную задачу, но идет другим, непривычным путем.
Современные генераторы и дискриминаторы обычно используют сверточные сети для обработки своих данных. Для более полного ознакомления со сверточным нейронным сетям (CNNs), см. пост Ужвал Карна или работу Андрея Карпати.
Между классификатором и генератором изображения есть одно важное различие, и заключается оно в том, как именно они изменяют размер изображения в ходе его обработки. Классификатор изображения должен уменьшать его до тех пор, пока изображение не потеряет всю пространственную информацию и не останутся только классы. Это может быть достигнуто объединением слоев, либо через использование сверточных сетей, через которые пропускают отдельные пиксели. Генератор же создает изображение с помощью процесса, обратного «свертке», который называется сверточным транспонированием. Его еще часто путают с «деконволюцией» или «обратной сверткой».
Обычная свертка 2×2 с шагом «2» превращает каждый блок 2×2 в одну точку, уменьшая выходные размеры на 1/2.
Транспонированная свертка 2×2 с шагом «2» генерирует блок 2×2 из каждой точки, увеличивая выходные размеры в 2 раза.
Тренировка генератора
Теоретически, сверточная нейронная сеть cможет генерировать изображения описанным выше образом. Но как мы мы ее натренируем? То есть, если учитывать набор входных данных-изображений, как мы можем настроить параметры генератора (в нашем случае SPADE), чтобы он создавал новые изображения, которые выглядят так, как будто они соответствуют предложенному набору данных?
Для этого нужно проводить сравнение с классификаторами изображений, где каждое из них имеет правильную метку класса. Зная вектор предсказания сети и правильный класс, мы можем использовать алгоритм обратного распространения (backpropagation algorithm), чтобы определить параметры обновления сети. Это нужно, чтобы повысить ее точность в определении нужного класса и уменьшить влияние остальных классов.
Точность классификатора изображения можно оценить, поэлементно сравнив его вывод с правильным вектором класса. Но для генераторов не существует «правильного» выходного изображения.
Но для генераторов не существует «правильного» выходного изображения.
Проблема в том, что когда генератор создает изображение, для каждого пикселя нет «правильных» значений (мы не можем сравнить результат, как в случае классификатора по заранее подготовленной базе, — прим. пер.). Теоретически, любое изображение, которое выглядит правдоподобно и похоже на целевые данные, является действительным, даже если его значения пикселей сильно отличаются от реальных изображений.
Итак, как мы можем сообщить генератору, в каких пикселях он должен изменять свой вывод и каким образом он может создавать более реалистичные изображения (т.е. как подавать «сигнал об ошибке»)? Исследователи много размышляли над этим вопросом, и на самом деле это довольно сложно. Большинство идей, таких как вычисление некоторого среднего «расстояния» до реальных изображений, дают размытые картинки низкого качества.
В идеале мы могли бы «измерить», насколько реалистично выглядят сгенерированные изображения через использование концепции «высокого уровня», такой как «Насколько сложно это изображение отличить от реального?»…
Генеративные состязательные сети
Именно это реализовали в рамках работы Goodfellow et al. , 2014. Идея состоит в том, чтобы генерировать изображения, используя две нейронные сети вместо одной: одна сеть —
, 2014. Идея состоит в том, чтобы генерировать изображения, используя две нейронные сети вместо одной: одна сеть —
генератор, вторая — классификатор изображений (дискриминатор). Задача дискриминатора состоит в том, чтобы отличать выходные изображения генератора от реальных изображений из первичного набора данных (классы этих изображений обозначены как «поддельные» и «реальные»). Работа же генератора заключается в том, чтобы обмануть дискриминатор, создавая изображения, максимально похожие на изображения в наборе данных. Можно сказать, что генератор и дискриминатор являются противниками в этом процессе. Отсюда и название: генеративно-состязательная сеть.
Your browser does not support HTML5 video.
Генеративно-состязательная сеть, работающая на базе случайного векторного ввода. В этом примере один из выходов генератора пытается обмануть дискриминатор при выборе «реального» изображения.
Как это нам помогает? Теперь мы можем использовать сообщение об ошибке, основанное исключительно на предсказании дискриминатора: значение от 0 («фальшивый») до 1 («реальный»). Поскольку дискриминатор является нейронной сетью, мы можем делиться его выводами об ошибках и с генератором изображений. То есть, дискриминатор может сообщать генератору, где и как тот должен корректировать свои изображения, чтобы лучше «обмануть» дискриминатор (т.е. — как повысить реалистичность своих изображений).
Поскольку дискриминатор является нейронной сетью, мы можем делиться его выводами об ошибках и с генератором изображений. То есть, дискриминатор может сообщать генератору, где и как тот должен корректировать свои изображения, чтобы лучше «обмануть» дискриминатор (т.е. — как повысить реалистичность своих изображений).
В процессе обучения по нахождению поддельных изображений дискриминатор дает генератору все лучшую и лучшую обратную связь о том, как последний может улучшить свою работу. Таким образом, дискриминатор выполняет «learn a loss»-функцию для генератора.
«Славный малый» GAN
Рассматриваемый нами GAN в своей работе следует описанной выше логике. Его дискриминатор анализирует изображение и получает значение от 0 до 1, которое отражает его степень уверенности в том, реальное это изображение, или же подделанное генератором. Его генератор получает случайный вектор нормально распределенных чисел и выводит изображение , которое может обмануть дискриминатор (по факту, это изображение )
Один из вопросов, который мы не обсуждали, — это как обучают GAN и какую функцию потерь используют разработчики для измерения производительности сети. В общем случае функция потерь должна возрастать по мере обучения дискриминатора и понижаться по мере обучения генератора. Функция потерь исходного GAN использовала два следующих параметра. Первый —
В общем случае функция потерь должна возрастать по мере обучения дискриминатора и понижаться по мере обучения генератора. Функция потерь исходного GAN использовала два следующих параметра. Первый —
представляет степень того, как часто дискриминатор правильно классифицирует реальные изображения как реальные. Второй — насколько хорошо дискриминатор обнаруживает поддельные изображения:
Дискриминатор выводит свое утверждение о том, что изображение реально. Это имеет смысл, так как возрастает, когда дискриминатор считает x реальным. Когда же дискриминатор лучше выявляет поддельные изображения, увеличивается и значение выражения (начинает стремиться к 1), так как будет стремиться к 0.
На практике мы оцениваем точность, используя целые партии изображений. Мы берем много (но далеко не все) реальных изображений и много случайных векторов , чтобы получить усредненные числа по формуле выше. Затем мы выбираем распространенные ошибки и набор данных.
Со временем это приводит к интересным результатам:
Goodfellow GAN, имитирующий наборы данных MNIST, TFD и CIFAR-10. Контурные изображения являются самыми близкими в наборе данных к смежным подделкам.
Контурные изображения являются самыми близкими в наборе данных к смежным подделкам.
Все это было фантастикой всего 4,5 года назад. К счастью, как показывает SPADE и другие сети, машинное обучение продолжает быстро прогрессировать.
Проблемы тренировки
Генеративно-соревновательные сети печально известны своей сложностью в подготовке и нестабильностью работы. Одна из проблем заключается в том, что если генератор слишком сильно опережает дискриминатор в темпах обучения, то его выборка изображений сужается до конкретно тех, которые помогают ему обмануть дискриминатор. Фактически, в итоге обучение генератора сводится к созданию одного-единственного универсального изображения для обмана дискриминатора. Эта проблема называется «режимом коллапса».
Режим коллапса GAN похож на Goodfellow’s. Обратите внимание, многие из этих изображений спальни выглядят очень похожими друг на друга. Источник
Другая проблема заключается в том, что, когда генератор эффективно обманывает дискриминатор , он оперирует очень маленьким градиентом, поэтому не может получить достаточно данных для нахождения истинного ответа, при которых это изображение выглядело бы более реалистичным.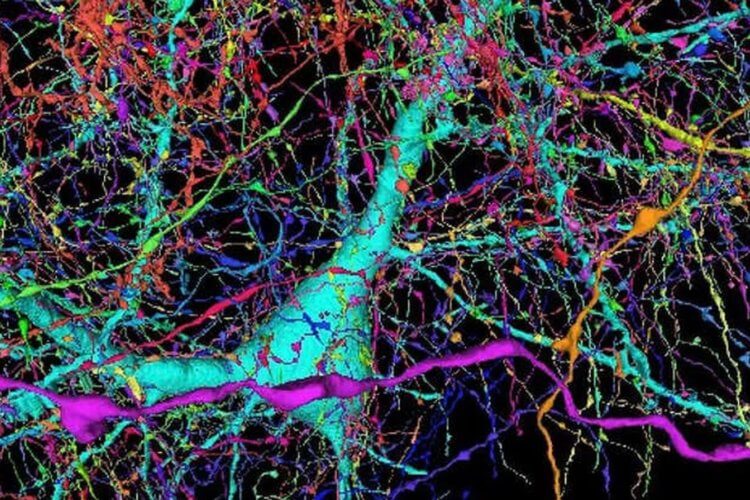
Усилия исследователей по решению этих проблем в основном были направлены на изменение структуры функции потерь. Одним из простых изменений, предложенных Xudong Mao et al., 2016, является замена функции потерь на пару простых функций , в основе которых лежат квадраты меньшей площади. Это приводит к стабилизации процесса тренировки, получению более качественных изображений и меньшему шансу коллапса с использованием незатухающих градиентов.
Другая проблема, с которой столкнулись исследователи, — это сложность получения изображений с высоким разрешением, отчасти из-за того, что более детальное изображение дает дискриминатору больше информации для обнаружения поддельных изображений. Современные GAN начинают обучать сеть с картинок в низком разрешении и постепенно добавляют все больше и больше слоев, пока не будет достигнут желаемый размер изображения.
Постепенное добавление слоев с более высоким разрешением во время обучения GAN существенно повышает стабильность всего процесса, а также скорость и качество получаемого изображения.
Image-to-image трансляция
До сих пор мы говорили о том, как генерировать изображения из случайных наборов вводных данных. Но SPADE не просто использует случайные данные. Эта сеть использует изображение, которое называется картой сегментации: она назначает каждому пикселю класс материала (например, трава, дерево, вода, камень, небо). Из этого изображения-карты SPADE и генерирует то, что выглядит как фотография. Это и называется «Image-to-image трансляция».
Шесть различных видов Image-to-image трансляции, продемонстрированные сетью pix2pix. Pix2pix является предшественником двух сетей, которые мы рассмотрим далее: pix2pixHD и SPADE.
Для того чтобы генератор выучил этот подход, ему нужен набор карт сегментации и соответствующие фотографии. Мы модифицируем архитектуру GAN, чтобы и генератор, и дискриминатор получили карту сегментации. Генератору, конечно, нужна карта, чтобы знать, «в какую сторону рисовать». Дискриминатору она также необходима, чтобы убедиться, что генератор размещает правильные вещи в правильных местах.
В ходе обучения генератор учится не ставить траву там, где на карте сегментации указано «небо», поскольку в противном случае дискриминатор легко определит поддельное изображение, и так далее.
Для image-to-image трансляции входное изображение принимается как генератором, так и дискриминатором. Дискриминатор дополнительно получает либо выходные данные генератора, либо истинный вывод из набора обучающих данных. Пример
Разработка image-to-image транслятора
Давайте посмотрим на реальный image-to-image транслятор: pix2pixHD. Кстати, SPADE спроектирован большей частью по образу и подобию pix2pixHD.
Для image-to-image транслятора наш генератор создает изображение и принимает его в качестве входного. Мы могли бы просто использовать карту сверточных слоев, но поскольку сверточные слои объединяют значения только в небольших участках, нам нужно слишком много слоев для передачи информации об изображении в высоком разрешении.
pix2pixHD решает эту проблему более эффективно при помощи «Кодировщика», который уменьшает масштаб входного изображения, за которым следует «Декодер», увеличивающий масштаб для получения выходного изображения. Как мы скоро увидим, у SPADE более элегантное решение, не требующее кодировщика.
Схема сети pix2pixHD на «высоком» уровне. «Остаточные» блоки и «+операция» относятся к технологии «skip connections» из Residual neural network. В сети есть скипаемые блоки, которые соотносятся между собой в кодировщике и декодере.
Пакетная нормализация — это проблема
Почти все современные свёрточные нейронные сети используют пакетную нормализацию или один из ее аналогов, чтобы ускорить и стабилизировать процесс тренировки. Активация каждого канала сдвигает среднее к 0 и стандартное отклонение к 1 до того, как пара параметров каналов и позволяют им снова денормализоваться.
К сожалению, пакетная нормализация вредит генераторам, затрудняя для сети реализацию некоторых типов обработки изображений. Вместо того чтобы нормализовать партию изображений, pix2pixHD использует эталон нормализации, который нормализует каждое изображение по отдельности.
Вместо того чтобы нормализовать партию изображений, pix2pixHD использует эталон нормализации, который нормализует каждое изображение по отдельности.
Обучение pix2pixHD
Современные GAN, такие как pix2pixHD и SPADE, измеряют реалистичность своих выходных изображений немного иначе, чем это было описано для оригинального дизайна генеративно-состязательных сетей.
Для решения проблемы генерации изображений в высоком разрешении pix2pixHD использует три дискриминатора одинаковой структуры, каждый из которых получает выходное изображение в разном масштабе (обычный размер, уменьшенный в 2 раза и уменьшенный в 4 раза).
Для определения своей функции потерь pix2pixHD использует , а также включает в себя другой элемент, предназначенный для того чтобы сделать выводы генератора более реалистичными (независимо от того, помогает ли это обмануть дискриминатор). Этот элемент называется «сопоставление признаков» — он побуждает генератор сделать распределение слоев при симуляции дискриминации одинаковым между реальными данными и выходами генератора, сводя к минимуму между ними.
Так, оптимизация сводится к следующему:
где потери суммируются по трем дискриминационным факторам и коэффициенту , который контролирует приоритет обоих элементов.
pix2pixHD использует карту сегментации, составленную из реальной спальни (слева в каждом примере), чтобы создать поддельную спальню (справа).
Хотя дискриминаторы уменьшают масштаб изображения до тех пор, пока не разберут изображение целиком, они останавливаются на «пятнах» размером 70×70 (в соответствующих масштабах). Затем они просто суммируют все значения этих «пятен» для всего изображения.
И такой подход отлично работает, поскольку функция заботится о том, чтобы изображение реалистично смотрелось в большом разрешении, и требуется только для проверки мелких деталей. Такой подход также имеет дополнительные преимущества в виде ускорения работы сети, уменьшения количества используемых параметров и в возможности ее использования для генерации изображений любого размера.
pix2pixHD генерирует из простых набросков лиц фотореалистичные изображения с соответствующими гримасами. Каждый пример показывает реальное изображение из набора данных CelebA слева, эскиз выражения лица этой знаменитости в виде скетча и созданное из этих данных изображение справа.
Каждый пример показывает реальное изображение из набора данных CelebA слева, эскиз выражения лица этой знаменитости в виде скетча и созданное из этих данных изображение справа.
Что не так с pix2pixHD?
Эти результаты невероятны, но мы можем добиться большего. Оказывается, pix2pixHD очень сильно проигрывает в одном важном аспекте.
Рассмотрим, что делает pix2pixHD с одноклассным вводом, скажем, с картой, на которой повсюду трава. Поскольку вход является пространственно однородным, выходы первого сверточного слоя также являются одинаковыми. Затем нормализация экземпляров «нормализует» все (идентичные) значения для каждого канала в изображении и возвращает как вывод для всех них. β-параметр может сдвинуть это значение от нуля, но факт остается фактом: выход больше не будет зависеть от того, была на входе «трава», «небо», «вода» или что-то еще.
В pix2pixHD нормализация экземпляров имеет тенденцию игнорировать информацию из карты сегментации. Для изображений, состоящих из одного класса, сеть генерирует одно и то же изображение независимо от этого самого класса.
Для изображений, состоящих из одного класса, сеть генерирует одно и то же изображение независимо от этого самого класса.
И решение этой проблемы — главная особенность дизайна SPADE.
Решение: SPADE
Наконец-то мы достигли принципиально нового уровня в создании изображений из карт сегментации: пространственно-адаптивная (де)нормализация (SPADE).
Идея SPADE состоит в том, чтобы предотвратить потерю семантической информации в сети, позволяя карте сегментации управлять параметрами нормализации γ, а также β, локально, на уровне каждого отдельного слоя. Вместо того чтобы использовать только одну пару параметров для каждого канала, они вычисляются для каждой пространственной точки путем подачи карты сегментации с пониженной дискретизацией через 2 сверточных слоя.
Вместо того чтобы раскатывать карту сегментации на первый слой, SPADE использует ее версии с пониженной дискретизацией для модуляции нормализованных выходных данных для каждого слоя.
Генератор SPADE объединяет всю эту конструкцию в небольшие «остаточные блоки», которые помещаются между слоями повышающей дискретизации (транспонированная свертка):
Высокоуровневая схема генератора SPADE в сравнении с генератором pix2pixHD
Теперь, когда карта сегментации подается «изнутри» сети, нет необходимости использовать ее в качестве входных данных для первого слоя. Вместо этого мы можем вернуться к исходной схеме GAN, в которой в качестве входных данных использовался случайный вектор. Это дает нам дополнительную возможность генерировать различные изображения из одной карты сегментации («мультимодальный синтез»). Это также делает ненужным весь «кодировщик» pix2pixHD, а это серьезное упрощение.
SPADE использует ту же функцию потерь, что и pix2pixHD, но с одним изменением: вместо возведения в квадрат значений в ней используется hinge loss.
С этими изменениями мы получаем прекрасные результаты:
Здесь результаты SPADE сравниваются с результатами pix2pixHD
Интуиция
Давайте подумаем о том, как SPADE может показывать такие результаты. В приведенном ниже примере у нас есть дерево. GauGAN использует один «древовидный» класс для представления как ствола, так и листьев дерева. Тем не менее, каким-то образом SPADE узнает, что узкая часть в нижней части «дерева» является стволом и должна быть коричневой, в то время как большая капля сверху должна быть листвой.
В приведенном ниже примере у нас есть дерево. GauGAN использует один «древовидный» класс для представления как ствола, так и листьев дерева. Тем не менее, каким-то образом SPADE узнает, что узкая часть в нижней части «дерева» является стволом и должна быть коричневой, в то время как большая капля сверху должна быть листвой.
Сегментация с пониженной дискретизацией, которую использует SPADE для модуляции каждого слоя, и обеспечивает подобное «интуитивное» распознавание.
Your browser does not support HTML5 video.
Вы можете заметить, что ствол дерева продолжается и в части кроны, которая относится к «листве». Так как же SPADE понимает, где разместить там часть ствола, а где листву? Ведь судя по карте 5х5, там должно быть просто «дерево».
Ответ заключается в том, что показанный участок может получать информацию от слоев с более низким разрешением, где блок 5×5 содержит все дерево целиком. Каждый последующий сверточный слой также обеспечивает некоторое перемещение информации по изображению, что дает более полную картину.
SPADE позволяет карте сегментации напрямую модулировать каждый слой, но это не препятствует процессу связного распространения информации между слоями, как это происходит, например, в pix2pixHD. Это предотвращает потерю семантической информации, поскольку она обновляется в каждом последующем слое за счет предыдущего.
Стиль передачи
В SPADE есть еще одно волшебное решение — способность генерировать изображение в заданном стиле (например, освещение, погодные условия, время года).
SPADE может генерировать несколько разных изображений на базе одной карты сегментации, мимикрируя под заданный стиль.
Это работает следующим образом: мы пропускаем изображения через кодировщик и обучаем его, чтобы задать векторы генератора , который в свою очередь сгенерирует похожие изображения. После того как кодировщик обучен, мы заменяем соответствующие карты сегментации на произвольные, и генератор SPADE создает изображения, соответствующие новым картам, но в стиле предоставленных изображений на базе ранее полученного обучения.
Поскольку генератор обычно ожидает получить выборку на базе многомерного нормального распределения, то для получения реалистичных изображений мы должны обучить кодировщик выводить значения с аналогичным распределением. Фактически, это идея вариационных автокодировщиков, которую объясняет Йоэль Зельдес.
Вот так функционирует SPADE / GaiGAN. Я надеюсь, эта статья удовлетворила ваше любопытство на тему того, как работает новая система NVIDIA. Связаться со мной вы можете через Twitter @AdamDanielKin или по электронной почте [email protected].
генерируем изображения по текстовому описанию, или Самый большой вычислительный проект в России / Хабр
2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети CogView позволяет решать ту же задачу — получать изображения из текстов. Но что в России? Разобрать, понять, обучить — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды Sber AI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов — Василия Кандинского и Казимира Малевича:
ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
ruDALL-E Malevich (XL) c 1.3 миллиардами параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
ruDALL-E Malevich (XL) [GitHub, HuggingFace, Kaggle]
Sber VQ-GAN [GitHub, HuggingFace]
ruCLIP Small [GitHub, HuggingFace]
Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Потестировать ruDALL-E Malevich (XL) или посмотреть на результаты генерации можно здесь:
Demo и галерея лучших изображений
Telegram bot
Instagram
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small уже доступны в DataHub. Модели ruCLIP Large и Super Resolution (Real ESRGAN) скоро будут доступны там же.
Обучение нейросети ruDALL-E на кластере Christofari стало самой большой вычислительной задачей в России:
Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 — всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло 24 256 GPU-дней.
Разберём возможности наших генеративных моделей.
«Озеро в горах, а рядом красивый олень пьёт воду» — генерация ruDALL-E Malevich (XL)
Почему Big Tech изучает генерацию изображений
Долгосрочная цель нового направления — создание «мультимодальных» нейронных сетей, которые выучивают концепции в нескольких модальностях, в первую очередь в текстовой и визуальной областях, чтобы «лучше понимать мир».
Генерация изображений может показаться достаточно избыточной задачей в век больших данных и доступа к поисковикам. Однако, она решает две важных потребности, которые пока не может решить информационный поиск:
Возможность точно описать желаемое — и получить персонализированное изображение, которое раньше не существовало.
В любой момент создавать необходимое количество licence-free иллюстраций в неограниченном объеме.
Первые очевидные применения генерации изображений:
Фото-иллюстрации для статей, копирайтинга, рекламы. Можно автоматически (а значит — быстрее и дешевле) создавать иллюстрации к статьям, генерировать концепты для рекламы по описанию:
«Лиса в лесу»«Орел сидит на дереве, вид сбоку»«Автомобиль на дороге среди красивых гор»
Визуализации дизайна интерьеров — можно проверять свои идеи для ремонта, играть с цветовыми решениями, формами и светом:
«Шикарная гостиная с зелеными креслами»«Современное кресло фиолетового цвета»
Visual Art — источник визуальных концепций, соединений различных признаков и абстракций:
«Темная энергия»
«Кот на Луне»«Кошка, которая сделана из белого облака»«Енот с пушкой»«Красивое озеро на закате»«Радужная сова»«Ждун с авокадо»
Более подробно о самой модели и процессе обучения
В основе архитектуры DALL-E — так называемый трансформер, он состоит из энкодера и декодера. Общая идея состоит в том, чтобы вычислить embedding по входным данным с помощью энкодера, а затем с учетом известного выхода правильным образом декодировать этот embedding.
Общая идея состоит в том, чтобы вычислить embedding по входным данным с помощью энкодера, а затем с учетом известного выхода правильным образом декодировать этот embedding.
Совсем верхнеуровневая схема «ванильного» трансформера
В трансформере энкодер и декодер состоят из ряда идентичных блоков.
Чуть более подробная схема «ванильного» трансформера
Основу архитектуры трансформера составляет механизм Self-attention. Он позволяет модели понять, какие фрагменты входных данных важны и насколько важен каждый фрагмент входных данных для других фрагментов. Как и LSTM-модели, трансформер позволяет естественным образом моделировать связи «вдолгую». Однако, в отличие от LSTM-моделей, он подходит для распараллеливания и, следовательно, эффективных реализаций.
Первым шагом при вычислении Self-attention является создание трёх векторов для каждого входного вектора энкодера (для каждого элемента входной последовательности). То есть для каждого элемента создаются векторы Query, Key и Value. Эти векторы получаются путем перемножения embedding’а и трех матриц, которые мы получаем в процессе обучения. Далее мы используем полученные векторы для формирования Self-attention-представления каждого embedding’а, что дает возможность оценить возможные связи в элементах входных данных, а также определить степень «полезности» каждого элемента.
Эти векторы получаются путем перемножения embedding’а и трех матриц, которые мы получаем в процессе обучения. Далее мы используем полученные векторы для формирования Self-attention-представления каждого embedding’а, что дает возможность оценить возможные связи в элементах входных данных, а также определить степень «полезности» каждого элемента.
Трансформер также характеризует наличие словаря. Каждый элемент словаря — это токен. В зависимости от модели размер словаря может меняться. Таким образом, входные данные сначала превращаются в последовательность токенов, которая далее конвертируется в embedding с помощью энкодера. Для текста используется свой токенизатор, для изображения сначала вычисляются low-level-фичи, а затем в скользящем окне вычисляются визуальные токены. Применение механизма Self-attention позволяет извлечь контекст из входной последовательности токенов в ходе обучения. Следует отметить, что для обучения трансформера требуются большие объёмы (желательно «чистых») данных, о которых мы расскажем ниже.
Как устроен ruDALL-E
Глобальная идея состоит в том, чтобы обучить трансформер авторегрессивно моделировать токены текста и изображения как единый поток данных. Однако использование пикселей непосредственно в качестве признаков изображений потребует чрезмерного количества памяти, особенно для изображений с высоким разрешением. Чтобы не учить только краткосрочные зависимости между пикселями и текстами, а делать это более высокоуровнево, обучение модели проходит в 2 этапа:
Предварительно сжатые изображения с разрешением 256х256 поступают на вход автоэнкодера (мы обучили свой SBER VQ-GAN, улучшив метрики для генерации по некоторым доменам, и об этом как раз рассказывали тут, причем также поделились кодом), который учится сжимать изображение в матрицу токенов 32х32. Фактор сжатия 8 позволяет восстанавливать изображение с небольшой потерей качества: см. котика ниже.
Трансформер учится сопоставлять токены текста (у ruDALL-E их 128) и 32×32=1024 токена изображения (токены конкатенируются построчно в последовательность).
 Для токенизации текстов использовался токенизатор YTTM.
Для токенизации текстов использовался токенизатор YTTM.Исходный и восстановленный котик
 Для токенизации текстов использовался токенизатор YTTM.
Для токенизации текстов использовался токенизатор YTTM.Важные аспекты обучения
На данный момент в открытом доступе нет кода модели DALL-E от OpenAI. Публикация описывает её общими словами, но обходит вниманием некоторые важные нюансы реализации. Мы взяли наш собственный код для обучения ruGPT-моделей и, опираясь на оригинальную статью, а также попытки воспроизведения кода DALL-E мировым ds-сообществом, написали свой код DALL-E-модели. Он включает такие детали, как позиционное кодирование блоков картинки, свёрточные и координатные маски Attention-слоёв, общее представление эмбеддингов текста и картинок, взвешенные лоссы для текстов и изображений, dropout-токенизатор.
Из-за огромных вычислительных требований эффективно обучать модель можно только в режиме точности fp16. Это в 5-7 раз быстрее, чем обучение в классическом fp32. Кроме того, модель с таким подходом занимает меньше места. Но ограничение точности представления чисел повлекло за собой множество сложностей для такой глубокой архитектуры:
a) иногда встречающиеся очень большие значения внутри сети приводят к вырождению лосса в Nan и прекращению обучения;
b) при малых значениях learning rate, помогающих избежать проблемы а), сеть перестает улучшаться и расходится из-за большого числа нулей в градиентах.
Для решения этих проблем мы имплементировали несколько идей из работы китайского университета Цинхуа CogView, а также провели свои исследования стабильности, с помощью которых нашли ещё несколько архитектурных идей, помогающих стабилизировать обучение. Так как делать это приходилось прямо в процессе обучения модели, путь тренировки вышел долгим и тернистым.
Для распределенного обучения на нескольких DGX мы используем DeepSpeed, как и в случае с ruGPT-3.
Сбор данных и их фильтрация: безусловно, когда мы говорим об архитектуре, нововведениях и других технических тонкостях, нельзя не упомянуть такой важный аспект как данные. Как известно, для обучения трансформеров их должно быть много, причем «чистых». Под «чистотой» мы понимали в первую очередь хорошие описания, которые потом нам придётся переводить на русский язык, и изображения с отношением сторон не хуже 1:2 или 2:1, чтобы при кропах не потерять содержательный контент изображений.
Первым делом мы взялись за те данные, которые использовали OpenAI (в статье указаны 250 млн.
пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.После сбора и фильтрации данных от слишком коротких описаний, маленьких изображений и изображений с непригодным отношением сторон, а также изображений, слабо соответствующих описаниям (мы использовали для этого англоязычную модель CLIP), перевода всех английских описаний на русский язык, был сформирован широкий спектр данных для обучения — около 120 млн. пар изображение-описание.
Кривая обучения ruDALL-E Kandinsky (XXL): как видно, обучение несколько раз приходилось возобновлять после ошибок и уходов в Nan.
Обучение модели ruDALL-E Kandinsky (XXL) происходило в 2 фазы: 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100.
Подробная информация об обучении ruDALL-E Malevich (XL):
Динамика loss на train-выборкеДинамика loss на valid-выборкеДинамика learning rate
Обучение модели ruDALL-E Malevich (XL) происходило в 3 фазы: 8 дней на 128 GPU TESLA V100, а затем еще 6.5 и 8.5 дней на 192 GPU TESLA V100, но с немного отличающимися обучающими выборками.
Хочется отдельно упомянуть сложность выбора оптимальных режимов генерации для разных объектов и доменов. В ходе исследования генерации объектов мы начали с доказавших свою полезность в NLP-задачах подходов Nucleus Sampling и Top-K sampling, которые ограничивают пространство токенов, доступных для генерации. Эта тема хорошо исследована в применении к задачам создания текстов, но для изображений общепринятые настройки генерации оказались не самыми удачными. Серия экспериментов помогла нам определить приемлемые диапазоны параметров, но также указала на то, что для разных типов желаемых объектов эти диапазоны могут очень существенно отличаться.
И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.

 пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.
пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.
 И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.
И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.Вот не совсем удачные генерации объектов на примере котиков, сгенерированные по запросу «Котик с красной лентой»:
Картинка 1 — у кота 3 уха; второй не вышел формой; третий немного не в фокусе.
А вот «Автомобиль на дороге среди красивых гор». Автомобиль слева въехал в какую-то трубу, а справа — странноватой формы.
«Автомобиль на дороге среди красивых гор»
Пайплайн генерации изображений
Сейчас генерация изображений представляет из себя пайплайн из 3 частей: генерация при помощи ruDALL-E — ранжирование результатов с помощью ruCLIP — и увеличение качества и разрешения картинок с помощью SuperResolution.
При этом на этапе генерации и ранжирования можно менять различные параметры, влияющие на количество генерируемых примеров, их отбор и абстрактность.
Пайплайн генерации изображений по тексту
В Colab можно запускать инференс модели ruDALL-E Malevich (XL) с полным пайплайном: генерацией изображений, их автоматическим ранжированием и увеличением.
Рассмотрим его на примере с оленями выше.
Шаг 1. Сначала делаем импорт необходимых библиотек
git clone https://github.com/sberbank-ai/ru-dalle
pip install -r ru-dalle/requirements.txt > /dev/null
from rudalle import get_rudalle_model, get_tokenizer, get_vae, get_realesrgan, get_ruclip
from rudalle.pipelines import generate_images, show, super_resolution, cherry_pick_by_clip
from rudalle.utils import seed_everything
seed_everything(42)
device = ‘cuda’
Шаг 2. Теперь генерируем необходимое количество изображений по тексту
text = 'озеро в горах, а рядом красивый олень пьет воду'
tokenizer = get_tokenizer()
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
vae = get_vae(). to(device)
to(device)
pil_images, _ = generate_images(text, tokenizer, dalle, vae, top_k=1024, top_p=0.99, images_num=24)
show(pil_images, 24)
Результат:
Генерация изображений по тексту
Шаг 3. Далее производим автоматическое ранжирование изображений и выбор лучших изображений
ruclip, ruclip_processor = get_ruclip('ruclip-vit-base-patch42-v5')
ruclip = ruclip.to(device)
top_images, _ = cherry_pick_by_clip(pil_images, text, ruclip, ruclip_processor, device=device, count=24)
show(top_images, 6)
Результат ранжирование ruCLIP-ом (топ6)
Можно заметить, что один из оленей получился достаточно «улиточным». На этапе генерации можно делать перебор гиперпараметров для получения наиболее удачного результата именно под ваш домен. Опытным путем мы установили, что параметры top_p и top_k контролируют степень абстрактности изображения. Их общие рекомендуемые значения:
top_k=2048, top_p=0.995
top_k=1536, top_p=0.
99top_k=1024, top_p=0.99
 99
99Шаг 4. Делаем Super Resolution
realesrgan = get_realesrgan('x4', device=device)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 6)
Super Resolution версии генерации
Для запуска пайплайна с моделью ruDALL-E Kandinsky (XXL) или Malevich (XL) можно также использовать каталог моделей DataHub (ML Space Christofari).
Будущее мультимодальных моделей
Мультимодальные исследования становятся всё более популярны для самых разных задач: прежде всего, это задачи на стыке CV и NLP (о первой такой модели для русского языка, ruCLIP, мы рассказали ранее), а также на стыке NLP и Code. Хотя последнее время становятся популярными архитектуры, которые умеют обрабатывать много модальностей одновременно, например, AudioCLIP. Представляет отдельный интерес Foundation Model, которая совсем недавно была анонсирована исследователями из Стэнфордского университета.
И Сбер не остается в стороне — так в соревновании Fusion Brain Challenge конференции AI Journey предлагается создать единую архитектуру, с помощью которой можно решить 4 задачи:
С2С — перевод с Java на Python;
HTR — распознавание рукописного текста на фотографиях;
Zero-shot Object Detection — детекция на изображениях объектов, заданных на естественном языке;
VQA — ответы на вопросы по картинкам.
По условиям соревнования (которое продлится до 5 ноября) на общие веса нейросети должно приходиться как минимум 25% параметров! Совместное использование весов для разных задач делает модели более экономичными в сравнении с их мономодальными аналогами. Организаторами также был предоставлен бейзлайн решения, который можно найти на официальном GitHub соревнования.
И пока команды соревнуются за первые места, а компании наращивают вычислительные мощности для обучения закрытых моделей, нашим интересом остается open source и расширение сообщества. Будем рады вашим прототипам, неожиданным находкам, тестам и предложениям по улучшению моделей!
Самые важные ссылки:
Demo и галерея лучших изображений
Github
Telegram bot
Instagram
Коллектив авторов: @rybolos, @shonenkov, @ollmer, @kuznetsoff87, @alexander-shustanov, @oulenspeigel, @mboyarkin, @achertok, @da0c, @boomb0om
Как обучить нейронные сети классификации изображений — Часть 1 | Сэнди Ли
Классификация изображений — горячая тема в науке о данных, и за последние несколько лет во многих областях произошли огромные улучшения. Везде куча приложений, но как это делается?.
Фото Алины Грубняк на Unsplash
Глубокая нейронная сеть — это сеть искусственных нейронов, организованных в слои (с помощью программного обеспечения). Каждый слой соединен со следующим, и каждое соединение имеет вес, который помогает определить, насколько активен искусственный нейрон. Это срабатывание помогает определить, насколько сильны связи между слоями, и в целом нейроны, которые активируются вместе, имеют более сильные связи. Как и в случае с биологическими нейронами.
Насколько сильны эти соединения, определяется тем, как сеть обучается на данных, которые вы в нее вкладываете. Эти сети обучаются с помощью процесса, называемого обратным распространением, который работает для передачи данных в сеть, а затем измеряет производительность сети. Эта ошибка измеряется с помощью функции потерь.
Обратное распространение работает с использованием градиентного спуска для измерения скорости изменения функции потерь по отношению к весу каждого соединения, а шаг градиентного спуска используется, чтобы убедиться, что частота ошибок для каждого соединения снижается как можно ближе к ноль по возможности. В конечном итоге сеть должна прийти к решению, при котором общая ошибка минимизируется.
Скорость обучения сети называется скоростью обучения, и это еще один гиперпараметр, который можно настраивать при обучении нейронных сетей. Если скорость обучения слишком мала, сети может потребоваться слишком много времени, чтобы прийти к решению, и наоборот, если скорость обучения слишком велика, сеть будет «прыгать» и никогда не сойдется к оптимальному решению.
В нейронных сетях есть разные типы слоев, и каждый из них по-своему преобразует данные. Самый простой тип — это плотный слой, в котором соединены все нейроны. Другие типы включают сверточные слои, которые в основном используются для задач обработки изображений, и рекуррентные слои, которые используются для обработки данных временных рядов. Есть и другие, но это самые распространенные типы.
В этой статье я сосредоточусь на том, как реализовать простой классификатор изображений, используя серию плотных слоев в Python, используя Keras как часть Tensorflow. Как упоминалось выше, сверточные нейронные сети обычно лучше подходят для задач классификации изображений, и я расскажу о них во второй части этой серии. Поскольку моя основная область интересов — поисковая оптимизация, я свяжу все это воедино в части 3 о том, как нейронные сети используются в поиске.
Нейронные сети — это увлекательно, и если вам интересна эта тема, я бы посоветовал вам посмотреть этот отличный плейлист на YouTube на канале Deep Lizard. У них отличный и доступный контент по нейронным сетям и глубокому обучению.
Если вас больше интересует реализация с использованием Python с Keras, я бы посоветовал вам взглянуть на Практическое машинное обучение с помощью Scikit-Learn, Keras и Tensorflow от Аурелиона Герона. Это отличная книга, написанная бывшим сотрудником Google и рецензированная автором Keras. Я очень рекомендую это.
Начало работы с Keras и TensorFlow
Keras — это высокоуровневый API глубокого обучения на Python, который позволяет легко создавать и обучать модели глубокого обучения. Он был запущен в 2016 году и завоевал популярность в сообществе специалистов по данным благодаря простоте использования, поскольку его синтаксис очень похож на Scikit-Learn.
TensorFlow — это библиотека, созданная командой Google Brain для задач машинного обучения, которая часто конкурировала с PyTorch (созданной Facebook) за долю рынка, но не смогла этого сделать, поскольку ее документация была не так доступна. Чтобы исправить это, Google выпустил TensorFlow 2, который содержал множество улучшений, особенно в отношении кросс-совместимости с моделями, поддержки графического процессора и графических утилит.
С выпуском TensorFlow 2 Keras теперь объединен с Tensorflow, а отдельная версия больше не поддерживается. Если вы хотите установить Keras и TensorFlow, то это просто. Просто зайдите в свою среду Python (я рекомендую использовать виртуальную среду/менеджер пакетов, например pipenv) и используйте любой менеджер пакетов Python, который вам нравится:
python -m pip install TensorFlow
Обязательно используйте 64-битную версию Python, чтобы это работало. Получить поддержку графического процессора в Windows немного сложно, но это видео на YouTube покажет вам, как это сделать. Тем не менее, вам, вероятно, не понадобится это для этого урока. Вы можете взглянуть на Google Colab, поскольку у него есть графические процессоры, доступные без настройки.
Вы можете проверить установку в ноутбуке Jupyter следующим образом:
импортировать TensorFlow как tf
из tensorflow import keras
print(tf.
print(keras.__version__)
Если все это заработало, то на момент написания вы должны увидеть что-то вроде:
2.3.0
2.4.0
Когда вы получили Keras и TensorFlow работают, вы должны быть готовы к созданию классификатора изображений с помощью нейронной сети.
Импорт набора данных
Для большинства простых задач классификации изображений популярно использовать набор данных MNIST, который состоит из 60 000 фотографий рукописных чисел. Однако для этой задачи мы собираемся использовать набор данных MNIST Fashion, который состоит из 60 000 изображений в градациях серого 28 x 28 изображений модных статей Zalando, классифицированных по 10 различным классам. Причина этого в том, что классификаторы изображений, как правило, находят это более сложным.
У Keras есть служебные функции, помогающие импортировать этот набор данных, поэтому его довольно просто использовать (аналогично Sklearn). Работайте в блокноте Jupyter и начните с того, что убедитесь, что у нас есть все необходимые импорты: будет работать с массивами NumPy и отображать их с помощью Matplotlib, поэтому вам необходимо убедиться, что они доступны в вашей среде. Как только это будет сделано, вы можете импортировать набор данных:
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
тест). Данные по оси X — это изображения, а данные по оси Y — это метки. Чтобы сделать это более полезным для работы, рекомендуется также создать набор проверочных данных, чтобы мы могли убедиться, что модель не переоснащена:
X_valid, X_train = X_train_full[:5000] X_train_full[5000:]
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
Данные по оси Y представляют собой просто ряд чисел, связанных с каждой меткой класса, поэтому нам нужно определить метки классов вручную:
class_names = [ «Футболка/топ», «Брюки», «Пуловер», «Платье», «Пальто», «Сандалии», «Рубашка», «Кроссовки», «Сумка», «Ботильоны»]
Получить представление о том, что на самом деле представляет собой набор данных, мы можем использовать простой цикл и Matplotlib:
plt.
для i в диапазоне (25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow( X_train_full[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train_full[i]])
plt.show()
Отсюда вы увидите примерно следующее:
Первые 25 записей из Набор данных Fashion MNIST
Как видите, несмотря на то, что классов всего 10 (аналогично набору данных MNIST), изображения различаются для каждого класса, поэтому работать с этим набором данных сложнее.
Нормализация набора данных
Первым шагом в работе с нейронными сетями является нормализация набора данных, в противном случае сети может потребоваться намного больше времени, чтобы прийти к решению.
Обычным способом нормализации набора данных является масштабирование признаков, и это делается путем вычитания среднего из каждого признака и деления на стандартное отклонение. Это поместит функции в одинаковую шкалу где-то между 0 — 1.
Поскольку мы работаем с массивами NumPy 28 x 28, представляющими каждое изображение, и каждый пиксель в массиве имеет интенсивность где-то между 1 — 255, более простой способ получить всех этих изображений по шкале от 0 до 1 — разделить каждый массив на 255.
X_valid, X_train = X_valid / 255., X_train / 255.
X_test = X_test / 255.
Оттуда мы готовы построить нейронную сеть с плотным слоем и обучить ее на нашем наборе данных.
Построение нейросетевого классификатора изображений
Чтобы построить модель, мы должны указать ее структуру, используя синтаксис Keras. Как упоминалось выше, он очень похож на Scikit-Learn, поэтому он должен быть узнаваем, если вы знакомы с этим пакетом. Код для построения модели следующий:
model = keras.models.Sequential([keras.layers.Flatten(input_shape = [28, 28]),
keras.layers.Dense(300, активация = «relu»),
keras.layers.Dense(100 , активация = «relu»),
keras.layers.Dense(100, активация = «relu»),
keras.
keras.layers.Dense(10, активация = «softmax» )])
Чтобы объяснить этот код:
- Первая строка создает модель Sequential , и это самый простой тип структуры данных в Keras, который в основном представляет собой последовательность связанных слоев в сети
- Первый слой в модели — это плоский слой , он предназначен для предварительной обработки данных и сам по себе не поддается обучению. Это берет каждый массив NumPy 28 x 28 для каждого изображения и сглаживает его в массив 1 x 784, с которым сеть может работать
- . Затем мы добавляем скрытый слой Dense с 300 нейронами. Он будет использовать функцию активации ReLU. Каждый слой Dense управляет собственной матрицей весов, содержащей все веса соединений между нейронами и их входами
- Далее мы добавляем еще 3 слоя Dense по 100 нейронов в каждом. Отдача от добавления новых слоев уменьшается, и это то, что нам нужно проверить при построении и оптимизации сети. , мы используем функцию активации softmax
Чтобы получить полное представление о структуре модели, мы можем использовать:
model.summary()
И это даст нам вывод полной структуры сети:
Модель: «sequential_2» _________________________________________________________________ Слой (тип) Параметр формы вывода # ================= =============================================== flatten_2 ( Flatten) (Нет, 784) 0 ________________________________________________________________ плотности_10 (Плотность) (Нет, 300) 235500 _________________________________________________________________ плотности_11 (Плотность) (Нет, 100) 30100 _________________________________________________________________ плотности_12 (Плотность) (Нет, 100) 10100 _________________________________________________________________ плотности_13 (Плотность) (Нет, 100 ) 10100 ________________________________________________________________ плотно_14 (Плотное) (Нет, 10) 1010 =================================== ============================ Всего параметров: 286 810 Обучаемых параметров: 286 810 Необучаемых параметров: 0 ________________________________________________ _____________________________
Как видно, эта сеть имеет в общей сложности 286 810 обучаемых параметров (состоящих из весов между нейронами и смещений), и это дает сети большую гибкость, но это также означает, что ей будет очень легко переобучиться, поэтому нам нужно быть осторожными.
Прежде чем мы сможем обучить сеть, нам необходимо ее скомпилировать, и это делается с помощью следующего кода: )
В этой строке мы указываем 3 вещи:
i) Используемая функция потерь. В этом случае мы используем разреженную категориальную перекрестную энтропию — это потому, что у нас есть индекс исключительных (разреженных) меток, которые мы пытаемся предсказать по сравнению с
ii) Оптимизатор , который мы собираемся использовать для оптимизации модель против функции потерь стохастический градиентный спуск и это обеспечит сходимость модели к оптимальному решению, т.е. Keras будет использовать метод обратного распространения, описанный выше
iii) Наконец, мы указываем показатель, который будем использовать в дополнение к потерям, чтобы дать нам представление о том, насколько хорошо работает наша модель. В этом случае мы используем точность , которая дает представление о том, насколько хорошо работает наша модель, давая процент того, сколько прогнозов соответствует фактическому классу для модели, которую мы обучаем
Обучение сети
Обучение сети сеть проста после того, как она была скомпилирована. Все, что вам нужно сделать, это вызвать метод подгонки модели (например, Sklearn) следующим образом:0003
history = model.fit(X_train,
y_train,
epochs = 10,
validation_data = (X_valid, y_valid))
Сначала мы передаем данные, на которых мы хотим обучить сеть, в данном случае X_train — это изображения, а y_train — это массив, содержащий метки. Мы также указываем количество эпох, с которыми мы хотим обучать модель (эпоха определяется тем, сколько раз мы хотим передавать данные обучения через сеть в целях обучения).
Keras также позволяет указать необязательный аргумент validation_data , в который мы передаем набор данных проверки. Если мы это сделаем, то в конце каждой эпохи Keras будет проверять производительность сети на проверочном наборе данных. Это хороший способ убедиться, что модель не переобучен, однако он не влияет на само обучение.
По ходу обучения вы увидите примерно следующее:
Эпоха 1/10 1719/1719 [========================== ===] — 5 с 3 мс/шаг — потеря: 0,7698 — точность: 0.
Эпоха 2/10 1719/1719 [============================ ==] — 5 с 3 мс/шаг — потери: 0,4830 — точность: 0,8283 — val_loss: 0,4570 — val_accuracy: 0,8404
Эпоха 3/10 1719/1719 [================= =============] — 5 с 3 мс/шаг — потери: 0,4261 — точность: 0,8480 — val_loss: 0,4121 — val_accuracy: 0,8522
Эпоха 4/10 1719/1719 [====== =======================] — 5s 3ms/шаг — потери: 0,3932 — точность: 0,8582 — val_loss: 0,3951 — val_accuracy: 0,8566
Эпоха 5/10 1719/1719 [==============================] — 5 с 3 мс/шаг — потери: 0,3708 — точность: 0,8660 — val_loss: 0,3597 — val_accuracy: 0,8682
Эпоха 6/10 1719/1719 [============================== ] — 5 с 3 мс/шаг — потери: 0,3518 — точность: 0,8728 — val_loss: 0,3397 — val_accuracy: 0,8756
Эпоха 7/10 1719/1719 [=================== ===========] — 5 с 3 мс/шаг — потери: 0,3369 — точность: 0,8779 — val_loss: 0,3506 — val_accuracy: 0,8738
Эпоха 8/10 1719/1719 [======== ======================] — 5 с 3 мс/шаг — потери: 0,3243 — точность: 0,8814 — val_loss: 0,3343 — val_accuracy: 0,8774
Эпоха 9/10 1719/1719 [==============================] — 4 с 3 мс/шаг — потери: 0,3128 — точность: 0,8861 — val_loss: 0,3415 — val_accuracy: 0,8794
Эпоха 10/10 1719/1719 [============================== ] — 4 с 2 мс/шаг — потеря: 0,3019 — точность: 0,8888 — val_loss: 0,3265 — val_accuracy: 0,8822
Это будет продолжаться до тех пор, пока происходит обучение, есть метрики точности и потери для обучения и наборы данных проверки. Значение точность — это простая процентная мера того, сколько элементов сеть обработала правильно. Значение loss представляет собой перекрестную энтропийную потерю.
После того, как модель обучена, можно вызвать ее метод history , чтобы получить словарь потерь и любых других показателей, необходимых на каждом этапе обучения. Мы можем поместить их в Pandas DataFrame и построить их следующим образом: (0, 1)
plt.show() Потери и точность для нашей модели
Как видно выше, чем меньше потерь, тем выше точность. На этом графике выделяются еще две вещи:
- Мы, вероятно, могли бы обучать эту модель дольше, так как не похоже, что потери достигли минимума
- Точность набора данных для обучения выше, чем для проверочного набора (что нормально), но не сильно отличается от набора данных проверки. Это означает отсутствие переоснащения
Оценка производительности нейронной сети
Оценка производительности сети проста и соответствует передовым принципам обработки данных. Мы вызываем метод модели evalute на тестовом наборе данных, чтобы увидеть, как он работает. Помните, что тестовый набор данных не использовался в обучении, и сеть не видела эти данные раньше. Мы должны выполнить этот шаг только один раз , чтобы мы могли получить точное представление о производительности модели.
model.evalute(X_test, y_test)
Это запустит модель на тестовом наборе данных, и результат должен выглядеть примерно так:
313/313 [======================= =======] — 0 с 2 мс/шаг — потери: 0,3802 — точность: 0,8858
Вы получите вывод потерь и любых других показателей, указанных при компиляции модели. Здесь мы видим, что эта модель верна в 88% случаев, что неплохо для простой сети с таким сложным набором данных.
Следующие шаги
В следующей части этой серии я расскажу о том, как реализовать описанное выше с помощью сверточной нейронной сети, и покажу, как и почему они работают лучше для задач классификации изображений.
Вы можете получить код, который я использовал для этой работы, на моем Github здесь. Спасибо за чтение.
DALL·E: Создание изображений из текста
Прочитать документПросмотреть код
DALL·E — это версия GPT-3 с 12 миллиардами параметров, обученная генерировать изображения из текстовых описаний с использованием набора данных пар текст-изображение. Мы обнаружили, что он обладает разнообразным набором возможностей, включая создание антропоморфных версий животных и объектов, правдоподобное объединение несвязанных концепций, рендеринг текста и применение преобразований к существующим изображениям.
См. также: DALL·E 2, который создает более реалистичные и точные изображения с 4-кратным увеличением разрешения.
Текстовая подсказка
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку . . . .
Сгенерировано ИИ
изображений
Подсказка редактирования или просмотра дополнительных изображений
Текстовая подсказка
витрина магазина, на которой написано слово «openai». . . .
Создано AI
изображений
Подсказка редактирования или просмотра других изображений больше изображений
GPT-3 показал, что язык можно использовать для указания большой нейронной сети выполнять различные задачи по генерации текста. Image GPT показал, что тот же тип нейронной сети можно использовать для создания изображений с высокой точностью. Мы расширили эти результаты, чтобы показать, что манипулирование визуальными понятиями с помощью языка теперь доступно.
Обзор
Как и GPT-3, DALL·E представляет собой языковую модель преобразователя. Он получает и текст, и изображение как единый поток данных, содержащий до 1280 токенов, и обучается с использованием максимальной вероятности для генерации всех токенов один за другим. [1] Эта обучающая процедура позволяет DALL·E не только генерировать изображение с нуля, но и регенерировать любую прямоугольную область существующего изображения, простирающуюся до нижнего правого угла, таким образом, чтобы это соответствовало тексту. быстрый.
Мы понимаем, что работа с генеративными моделями может иметь значительные, широкие социальные последствия. В будущем мы планируем проанализировать, как такие модели, как DALL·E, связаны с социальными проблемами, такими как экономическое влияние на определенные рабочие процессы и профессии, потенциальная систематическая ошибка в результатах модели и долгосрочные этические проблемы, связанные с этой технологией.
Возможности
Мы обнаружили, что DALL·E может создавать правдоподобные образы для самых разных предложений, исследующих композиционную структуру языка. Мы проиллюстрируем это с помощью серии интерактивных изображений в следующем разделе. Образцы, показанные для каждой подписи в визуальных элементах, получены путем выбора 32 лучших из 512 после повторного ранжирования с помощью CLIP, но мы не используем никакого ручного выбора, кроме миниатюр и отдельных изображений, которые появляются снаружи. [2]
Управление атрибутами
Мы проверяем способность DALL·E изменять несколько атрибутов объекта, а также количество его появления.
Нажмите, чтобы отредактировать текстовую подсказку или просмотреть больше изображений, созданных искусственным интеллектом
зеленые пятиугольные часы. зеленые часы в форме пятиугольника.
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображения
Мы обнаружили, что DALL·E может отображать знакомые объекты в многоугольных формах, которые иногда вряд ли встречаются в реальном мире. Для некоторых объектов, таких как «рамка для картины» и «тарелка», DALL·E может надежно нарисовать объект любой из многоугольных форм, кроме семиугольника. Для других объектов, таких как «крышка люка» и «знак остановки», вероятность успеха DALL·E для более необычных форм, таких как «пятиугольник», значительно ниже.
Мы обнаружили, что для некоторых изображений в этом посте повтор подписи, иногда с альтернативными формулировками, улучшает согласованность результатов.
navigationupwide
куб из дикобраза. куб с текстурой дикобраза.
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, сгенерированных искусственным интеллектом
Мы обнаружили, что DALL·E может отображать текстуры различных растений, животных и других объектов на трехмерных телах. Как и в предыдущем изображении, мы обнаружили, что повторение подписи с альтернативной формулировкой улучшает согласованность результатов.
navigationupwide
коллекция очков лежит на столе
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные AI
изображения
Мы обнаружили, что DALL·E может рисовать несколько копий объекта сделать это, но не может надежно сосчитать до трех. Когда предлагается нарисовать существительные, для которых есть несколько значений, таких как «стаканы», «чипсы» и «чашки», он иногда рисует обе интерпретации, в зависимости от используемой формы множественного числа.
navigationupwide
Рисование нескольких объектов
Одновременное управление несколькими объектами, их атрибутами и их пространственными отношениями представляет собой новую задачу. Например, рассмотрим фразу «ежик в красной шапке, желтых перчатках, синей рубашке и зеленых штанах». Чтобы правильно интерпретировать это предложение, DALL·E должен не только правильно скомпоновать каждый предмет одежды с животным, но и сформировать ассоциации (шапка, красный), (перчатки, желтый), (рубашка, синий) и (штаны, зеленый). ), не смешивая их. [3] Мы проверяем способность DALL·E делать это для относительного позиционирования, укладки объектов и управления несколькими атрибутами.
маленький красный блок, расположенный на большом зеленом блоке
navigationdownwide
navigationupwide
Текстовая подсказка
AI-сгенерированные
изображений
Мы обнаружили, что DALL·E правильно реагирует на некоторые типы относительных положений, но не на другие. Варианты «сидеть на» и «стоять впереди» иногда работают, а «сидеть внизу», «стоять позади», «стоять слева» и «стоять справа» — нет. DALL·E также имеет более низкий уровень успеха, когда его просят нарисовать большой объект, расположенный поверх меньшего, по сравнению с наоборот.
navigationupwide
стек из 3 кубов. красный куб находится сверху, сидя на зеленом кубе. зеленый куб находится посередине, сидя на синем кубе. синий куб находится внизу.
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные ИИ
изображений
Мы обнаружили, что DALL·E обычно создает изображение с одним или двумя объектами, имеющими правильные цвета. Однако только в нескольких образцах для каждой настройки обычно имеется ровно три объекта, окрашенных точно так, как указано.
navigationupwide
эмодзи пингвиненка в синей шапке, красных перчатках, зеленой рубашке и желтых штанах обычно создает изображение с двумя или тремя предметами одежды, имеющими правильные цвета. Однако лишь немногие из образцов для каждого окружения, как правило, имеют все четыре предмета одежды указанных цветов.
navigationupwide
Хотя DALL·E предлагает некоторый уровень контроля над атрибутами и позициями небольшого числа объектов, вероятность успеха может зависеть от того, как сформулирован заголовок. По мере того, как вводится больше объектов, DALL·E склонен путать ассоциации между объектами и их цветами, и вероятность успеха резко снижается. Мы также отмечаем, что DALL·E хрупок в отношении перефразирования подписи в этих сценариях: альтернативные, семантически эквивалентные подписи часто не дают правильной интерпретации.
Визуализация перспективы и трехмерности
Мы обнаружили, что DALL·E также позволяет управлять точкой обзора сцены и трехмерным стилем, в котором визуализируется сцена.
очень крупный план водосвинки, сидящей в поле
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображений разные взгляды. Некоторые из этих видов, такие как «вид сверху» и «вид сзади», требуют знания внешнего вида животного с необычных ракурсов. Другие, такие как «крайний план», требуют знания мелких деталей кожи или меха животного.
navigationupwide
капибара из вокселей, сидящая в поле
navigationdownwide
navigationupwide
Текстовая подсказка животных в соответствии с выбранным 3D-стилем, таким как «глиняный» и «сделанный из вокселей», и визуализировать сцену с правдоподобным затенением в зависимости от положения солнца. «Рентгеновский» стиль не всегда работает надежно, но он показывает, что DALL·E иногда может ориентировать кости внутри животного в правдоподобных (хотя и не анатомически правильных) конфигурациях.
navigationupwide
Чтобы продвинуться дальше, мы проверяем способность DALL·E многократно рисовать голову известной фигуры под каждым углом из последовательности равноотстоящих углов и обнаруживаем, что можем восстановить плавную анимацию вращения глава.
фотография бюста Гомера
navigationdownwide
navigationupwide
текстовая подсказка
графическая подсказка
сгенерированные AI
изображений область изображения, показывающая шляпу, нарисованную под определенным углом. Затем мы просим DALL·E завершить оставшуюся часть изображения с учетом этой контекстной информации. Мы делаем это неоднократно, каждый раз поворачивая шляпу еще на несколько градусов, и обнаруживаем, что можем восстановить плавную анимацию нескольких хорошо известных фигур, при этом каждый кадр соответствует точным спецификациям угла и окружающего освещения.
navigationupwide
DALL·E может применять некоторые типы оптических искажений к сценам, как мы видим с опциями «вид объектива «рыбий глаз»» и «сферическая панорама». Это побудило нас исследовать его способность генерировать отражения.
простой белый куб, смотрящий на свое отражение в зеркале. простой белый куб, смотрящий на себя в зеркало.
navigationdownwide
navigationupwide
Текстовое приглашение
Графическое приглашение
изображений, созданных искусственным интеллектом
Подобно тому, что было сделано ранее, мы предлагаем DALL·E заполнить нижние правые углы последовательности кадров, каждый из которых содержит зеркало и отражающий пол. Хотя отражение в зеркале обычно напоминает объект за его пределами, оно часто не передает отражение физически правильным образом. Напротив, отражение объекта, нарисованного на отражающем полу, обычно более правдоподобно.
navigationupwide
Визуализация внутренней и внешней структуры
Образцы из стилей «крайний крупный план» и «рентген» позволили нам дополнительно изучить способность DALL·E визуализировать внутреннюю структуру с помощью поперечных сечений и внешнюю структуру с помощью макрофотографий.
вид грецкого ореха в разрезе
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, созданных искусственным интеллектом
Мы обнаружили, что DALL·E может рисовать внутренности нескольких различных видов объектов.
navigationupwide
макрофотография мозгового коралла
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, сгенерированных искусственным интеллектом объекты. Эти детали видны только при близком рассмотрении объекта.
navigationupwide
Определение контекстных деталей
Задача преобразования текста в изображения недостаточно конкретизирована: одна подпись обычно соответствует бесконечному количеству правдоподобных изображений, поэтому изображение не определяется однозначно. Например, рассмотрим подпись «картина с изображением капибары, сидящей в поле на восходе солнца». В зависимости от ориентации водосвинки может возникнуть необходимость нарисовать тень, хотя эта деталь никогда не упоминается явно. Мы изучаем способность DALL·E устранять недочеты в трех случаях: изменение стиля, обстановки и времени; рисование одного и того же объекта в различных ситуациях; и создание изображения объекта с написанным на нем определенным текстом.
рисунок водосвинки, сидящей в поле на восходе солнца
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, созданных искусственным интеллектом стилей и может адаптировать освещение, тени и окружающую среду в зависимости от времени суток или времени года.
navigationupwide
витраж с изображением синей клубники
navigationdownwide
navigationupwide
Текстовое приглашение
Сгенерированные ИИ
изображений
Мы обнаружили, что DALL·E может гибко адаптировать представление объекта в зависимости от среды, на которой он рисуется. Для «фрески», «банки с газировкой» и «чашки» DALL·E должен изменить способ рисования объекта в зависимости от угла и кривизны поверхности рисования. Для «витража» и «неоновой вывески» он должен изменить внешний вид объекта по сравнению с тем, каким он обычно выглядит.
navigationupwide
витрина магазина, на которой написано слово «openai». фасад магазина, на котором написано слово «openai». фасад магазина, на котором написано слово «openai». Фасад магазина «Опенай».
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображения
Мы обнаружили, что DALL·E иногда может отображать текст и адаптировать стиль письма к контексту, в котором он появляется. Например, «пакет чипсов» и «номерной знак» требуют разных типов шрифтов, а «неоновая вывеска» и «надпись в небе» требуют изменения внешнего вида букв.
Как правило, чем длиннее строка, которую DALL·E предлагается записать, тем ниже вероятность успеха. Мы обнаружили, что вероятность успеха повышается, когда части подписи повторяются. Кроме того, вероятность успеха иногда повышается по мере снижения температуры выборки изображения, хотя образцы становятся более простыми и менее реалистичными.
navigationupwide
С различной степенью надежности DALL·E обеспечивает доступ к подмножеству возможностей механизма 3D-рендеринга с помощью естественного языка. Он может независимо контролировать атрибуты небольшого числа объектов и в ограниченной степени, сколько их и как они расположены по отношению друг к другу. Он также может управлять местоположением и углом, с которого визуализируется сцена, и может генерировать известные объекты в соответствии с точными спецификациями угла и условий освещения.
В отличие от механизма 3D-рендеринга, входные данные которого должны быть указаны однозначно и во всех подробностях, DALL·E часто может «заполнить пробелы», когда заголовок подразумевает, что изображение должно содержать определенную деталь, которая явно не указана.
Применение предыдущих возможностей
Далее мы рассмотрим использование предыдущих возможностей для моды и дизайна интерьера.
Композиционная природа языка позволяет нам объединять концепции для описания как реальных, так и воображаемых вещей. Мы обнаружили, что DALL·E также может комбинировать разрозненные идеи для синтеза объектов, некоторые из которых вряд ли существуют в реальном мире. Мы исследуем эту способность в двух случаях: перенос качеств различных концепций на животных и создание продуктов, черпая вдохновение из несвязанных концепций.
улитка из арфы. улитка с текстурой арфы.
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображения
Мы обнаружили, что DALL·E может генерировать животных, синтезированных из различных понятий, включая музыкальные инструменты, продукты питания и предметы домашнего обихода. Хотя это и не всегда удается, мы обнаруживаем, что DALL·E иногда принимает во внимание формы двух объектов, решая, как их объединить. Например, когда ему предлагается нарисовать «улитку, сделанную из арфы», он иногда связывает столб арфы со спиралью раковины улитки.
В предыдущем разделе мы видели, что чем больше объектов вводится в сцену, тем чаще DALL·E путает ассоциации между объектами и их заданными атрибутами. Здесь мы видим иной вид отказа: иногда вместо того, чтобы привязать какой-либо атрибут заданного понятия (скажем, «кран») к животному (скажем, «улитке»), ДАЛЛ·И просто рисует их как отдельные предметы.
navigationupwide
Иллюстрации животных
В предыдущем разделе мы исследовали способность DALL·E комбинировать несвязанные концепции при создании изображений объектов реального мира. Здесь мы исследуем эту способность в контексте искусства для трех видов иллюстраций: антропоморфные версии животных и предметов, химеры животных и смайлики.
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку
Мы обнаружили, что DALL·E иногда может передавать некоторые виды человеческой деятельности и предметы одежды животным и неодушевленным предметам, таким как продукты питания. Мы включили «пикачу» и «владение синим световым мечом», чтобы изучить способность DALL·E использовать популярные медиа.
Нам интересно, как DALL·E адаптирует части человеческого тела к животным. Например, когда его просят нарисовать редис дайкон, сморкающийся, потягивающий латте или катающийся на одноколесном велосипеде, ДАЛЛ·И часто рисует платок, руки и ноги в правдоподобных местах.
navigationupwide
Профессиональная высококачественная иллюстрация химеры черепахи-жирафа. жираф, имитирующий черепаху. жираф из черепахи.
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображения
Мы обнаружили, что DALL·E иногда может комбинировать различных животных правдоподобным образом. Мы включаем «пикачу», чтобы исследовать способность DALL·E использовать знания популярных медиа, и «робот», чтобы исследовать его способность создавать животных-киборгов. Как правило, черты второго животного, упомянутого в подписи, имеют тенденцию быть доминирующими.
Мы также обнаружили, что вставка фразы «профессиональное высокое качество» перед словами «иллюстрация» и «эмодзи» иногда улучшает качество и согласованность результатов.
navigationupwide
профессиональные высококачественные смайлики влюбленной чашки боба
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображений
и неодушевленные предметы, такие как продукты питания. Как и в предыдущем изображении, мы обнаружили, что вставка фразы «профессиональное высокое качество» перед «эмодзи» иногда улучшает качество и согласованность результатов.
navigationupwide
Zero-Shot Visual Reasoning
GPT-3 может быть проинструктирован выполнять многие виды задач исключительно на основе описания и подсказки для получения ответа, предоставленного в его подсказке, без какого-либо дополнительного обучения. Например, на запрос фразы «вот предложение «человек, выгуливающий свою собаку в парке», переведенное на французский язык:», GPT-3 отвечает: «un homme qui promène son chien dans le parc». Эта возможность называется рассуждением с нулевым выстрелом. Мы обнаружили, что DALL·E расширяет эту возможность до визуальной области и может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
точно такой же кот вверху, как и набросок внизу
navigationdownwide
navigationupwide
Текстовое приглашение
Графическое приглашение
Сгенерированное ИИ
изображений
Мы обнаружили, что DALL·E может применять несколько видов преобразования изображений к фотографиям животных с разной степенью надежности. Самые простые из них, такие как «фотография, окрашенная в розовый цвет» и «фотография, отраженная вверх ногами», также, как правило, являются наиболее надежными, хотя фотография часто не копируется или не отражается точно. Преобразование «животное в очень крупном плане» требует, чтобы DALL·E распознал породу животного на фотографии и воспроизвел ее с соответствующими деталями. Это работает менее надежно, и для некоторых фотографий DALL·E генерирует правдоподобные завершения только в одном или двух случаях.
Другие трансформации, такие как «животное в солнечных очках» и «животное в галстуке-бабочке», требуют размещения аксессуара на нужной части тела животного. Те, которые изменяют только цвет животного, такие как «животное окрашено в розовый цвет», менее надежны, но показывают, что DALL·E иногда способен отделить животное от фона. Наконец, трансформации «набросок животного» и «чехол для мобильного телефона с животным» исследуют использование этой возможности для иллюстраций и дизайна продукта.
navigationupwide
точно такой же чайник сверху с надписью «gpt» снизу E может применять несколько различных видов преобразования изображений к фотографиям чайников с разной степенью надежности. Помимо возможности изменять цвет чайника (например, «синий цвет») или его рисунок (например, «с полосами»), DALL·E также может отображать текст (например, «с надписью «gpt» на нем» ) и расположите буквы на изогнутой поверхности чайника правдоподобным образом. С гораздо меньшей надежностью может вытянуть и чайник меньшего размера (для варианта «малюсенький») и в разбитом состоянии (для варианта «разбитый»).
navigationupwide
Мы не ожидали, что эта возможность появится, и не вносили никаких изменений в нейронную сеть или процедуру обучения, чтобы поощрять ее. Вдохновленные этими результатами, мы измеряем способность ДАЛЛ-И решать задачи на рассуждения по аналогии, проверяя ее на прогрессивных матрицах Равена — визуальном тесте IQ, который широко использовался в 20-м веке.
последовательность геометрических фигур.
navigationdownwide
navigationupwide
Текстовое приглашение
Пример подсказки изображения
Сгенерированные ИИ
изображений
Вместо того, чтобы рассматривать IQ-тест как задачу с множественным выбором, как предполагалось изначально, мы просим DALL·E заполнить нижний правый угол каждого изображения, используя выборку argmax, и считаем его завершение правильным, если оно близко визуально соответствует заданному. оригинал.
DALL·E часто может решать матрицы, которые включают в себя непрерывные простые шаблоны или базовые геометрические рассуждения, например, в наборах B и C. Иногда он может решать матрицы, которые включают распознавание перестановок и применение логических операций, таких как те, что в наборах B и C. набор D. Экземпляры в наборе E, как правило, самые сложные, и DALL·E почти ни один из них не дает правильного ответа.
Для каждого из наборов мы измеряем производительность DALL·E как на исходных изображениях, так и на изображениях с инвертированными цветами. Инверсия цветов не должна создавать дополнительных трудностей для человека, но в целом ухудшает работу DALL·E, предполагая, что его возможности могут быть непредсказуемыми.
navigationupwide
Географические знания
Мы обнаружили, что DALL·E узнал о географических фактах, достопримечательностях и районах. Его знание этих понятий удивительно точно в одних отношениях и ошибочно в других.
фото китайской кухни
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, сгенерированных искусственным интеллектом В то время как DALL·E успешно отвечает на многие из этих вопросов, например, о национальных флагах, он часто отражает поверхностные стереотипы выбора, такие как «еда» и «дикая природа», в отличие от представления всего разнообразия, встречающегося в реальном мире.
navigationupwide
фотография площади Аламо, Сан-Франциско, с улицы ночью некоторых мест в Сан-Франциско. Для мест, знакомых авторам, таких как Сан-Франциско, они вызывают чувство дежа вю — жуткие симулякры улиц, тротуаров и кафе, которые напоминают нам об очень конкретных местах, которых не существует.
navigationupwide
фотография моста «Золотые ворота Сан-Франциско»
navigationdownwide
navigationupwide
Текстовая подсказка
Подсказки к изображениям На самом деле, мы даже можем указать, когда была сделана фотография, указав первые несколько рядов неба. Например, когда небо темное, DALL·E распознает ночь и включает свет в зданиях.
navigationupwide
Знания о времени
Помимо изучения знаний DALL·E о концепциях, которые меняются в пространстве, мы также изучаем его знания о концепциях, которые меняются во времени.
фото телефона 20-х годов
navigationdownwide
navigationupwide
текстовая подсказка
графическая подсказка десятилетия. Технологические артефакты, по-видимому, проходят через периоды взрывного изменения, резко меняясь в течение десятилетия или двух, а затем меняясь постепенно, совершенствуясь и совершенствуясь.
navigationupwide
Резюме подхода и предыдущей работы
DALL·E — это простой преобразователь только для декодера, который получает и текст, и изображение как единый поток из 1280 токенов — 256 для текста и 1024 для изображения — и моделирует все из них авторегрессивно. Маска внимания на каждом из 64 слоев внутреннего внимания позволяет каждому маркеру изображения уделять внимание всем текстовым маркерам. DALL·E использует стандартную причинно-следственную маску для текстовых токенов и разреженное внимание для токенов изображения со строкой, столбцом или сверточным шаблоном внимания, в зависимости от слоя. Мы предоставляем более подробную информацию об архитектуре и процедуре обучения в нашей статье.
Синтез текста в изображение был активной областью исследований со времен новаторской работы Reed et. al, чей подход использует GAN, основанный на встраивании текста. Вложения создаются кодировщиком, предварительно обученным с использованием контрастных потерь, мало чем отличающихся от CLIP. StackGAN и StackGAN++ используют многомасштабные GAN для увеличения разрешения изображения и улучшения визуальной точности. AttnGAN объединяет внимание между текстовыми и графическими функциями и предлагает контрастную характеристику текста и изображения, соответствующую потере, в качестве вспомогательной цели. Это интересно сравнить с нашей переоценкой с помощью CLIP, которая выполняется в автономном режиме. Другая работа включает в себя дополнительные источники наблюдения во время обучения для улучшения качества изображения. Наконец, работа Nguyen et. аль и Чо и др. al исследует основанные на выборке стратегии для генерации изображений, в которых используются предварительно обученные мультимодальные дискриминационные модели.
Подобно выборке отклонения, используемой в VQVAE-2, мы используем CLIP для переранжирования 32 лучших выборок из 512 для каждой подписи во всех интерактивных визуальных элементах.