Содержание
Информатика 7 класс урок 5
Алфавитный подход к измерению информации
Алфавитный подход —
это единственный способ измерения информации, который может применяться по отношению к информации, циркулирующей в информационной технике,
в компьютерах.
Алфавит —
это вся совокупность символов, используемых в некотором языке для представления информации.
Мощность алфавита — это число символов в алфавите ( N ).
Например, алфавит десятичной системы счисления – множество цифр- 0,1,2,3,4,5,6,7,8,9.
Мощность этого алфавита – 10.
Компьютерный алфавит , используемый для представления текстов в компьютере, использует 256 символов .
Алфавит двоичной системы кодирования информации имеет всего два символа- 0 и 1.
Алфавиты русского и английского языков имеют различное число букв, их мощности – различны.
Информационный вес символа
При алфавитном подходе считается, что каждый символ текста имеет определенный информационный вес. Информационный вес символа зависит от мощности алфавита.
А каким может быть наименьшее число символов в алфавите?
Двоичным называется алфавит, мощность которого равна 2 .
Информационный вес
1 символа двоичного алфавита принят за единицу информации и
называется 1 бит .
Один символ из четырехсимвольного
алфавита ( N = 4) «весит» 2 бита.
Порядковый номер символа
1
Двузначный двоичный код
2
00
3
01
4
10
11
Комбинацию из нескольких
(двух, трех и т. д.) знаков двоичного алфавита назовем двоичным кодом.
Используя три двоичные цифры, можно составить 8 различных комбинаций.
Порядковый номер символа
1
Трехзначный двоичный код
2
000
3
001
4
010
5
011
6
100
7
101
8
110
111
Найдем зависимость между мощностью алфавита N и
количеством знаков в коде i .
N
2
i
4
1 бит
8
2 бита
16
3 бита
4 бита
Заметим, что 2 = 2 1 , 4 = 2 2 , 8 = 2 3 , 16 = 2 4 .
В общем виде это записывается
следующим образом:
N = 2 i
Информационный вес каждого символа, выраженный в битах ( i ) и мощность алфавита ( N ) связаны между собой формулой:
N = 2 i .
N = 2 i
8=2 i
2 3 =2 i 3= i
N=8
i — ?
Какой объем информации несет
слово «информация»?
32=2 i
2 5 =2 i i = 5 бит – 1 буква
N= 32
K= 10
I- ?
I = K· i I = 1 0 · 5 = 5 0
Ответ: 50 бит
15
ЕДИНИЦЫ ИНФОРМАЦИИ
СИМВОЛЬНЫЙ АЛФАВИТ КОМПЬЮТЕРА
- русские (РУССКИЕ) буквы
- латинские ( LAT ) буквы
- цифры
- математические знаки
- прочие символы
i = 8 бит = 1 байт
N = 256 = 2 8
N = 2 i
1 байт — это информационный вес одного символа компьютерного алфавита
1024 байта
1 килобайт
=
=
1 Кб
=
2 10 байт
2 10 Кб
1024 Кб
1 мегабайт
1 Мб
=
=
=
2 10 Мб
1024 Мб
1 Гб
1 гигабайт
=
=
=
I = K · i ,
I — количество информации в тексте
K – количество символов в тексте
i — информационный вес 1 символа
Найти информационный объем текста, записанного с помощью двоичного алфавита:
1101001011000101110010101101000111010010
содержит 40 символов,
Так как мощность алфавита N=2
2 =2 i 2 1 =2 i 1= i
I = K· i I = 40 · 1= 40 .
Ответ: информационный объем равен 40 битам.
2 i = N
I = K · i
Выполнить в тетради:
- Один символ алфавита «весит» 8 бит, сколько символов в алфавите? И какой объем будет занимать сообщение, состоящее из 7 символов?
- Подсчитать информационный объем слова «компьютер»
- Информационное сообщение объёмом
1,5 Кбайта содержит 3072 символа.
Сколько символов содержит алфавит,
при помощи которого было записано это сообщение?
2. Сообщение занимает 2 страницы и содержит 1/16 Кбайта информации. На каждой странице записано 256 символов. Какова мощность используемого алфавита?
3. Сколько килобайтов составляет сообщение, содержащее 12288 битов?
РЕШЕНИЕ задачи1
- Надо найти мощность алфавита N.


По условию задачи
I=1,5 Кб=1.5*1024*8=12 288 бит
I=i*k Значит, i=I/k=12 288/ 3072 = 4 бита
Так как N=2 i , то N=2 4 = 16 символов.
ОТВЕТ: 16 символов
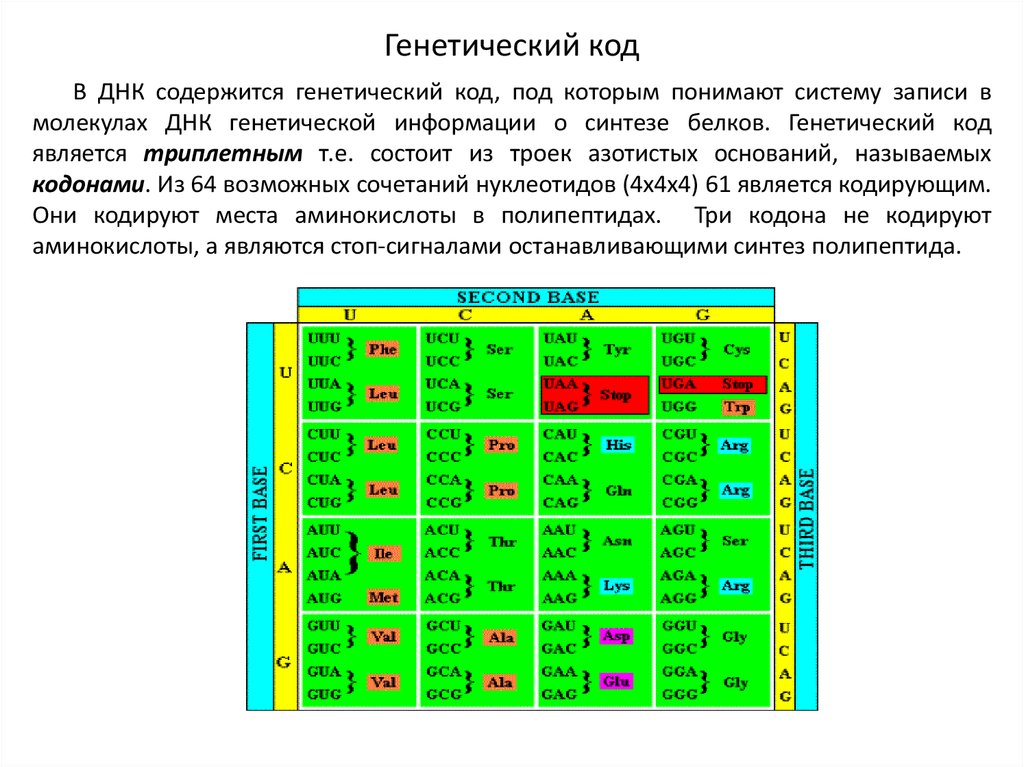
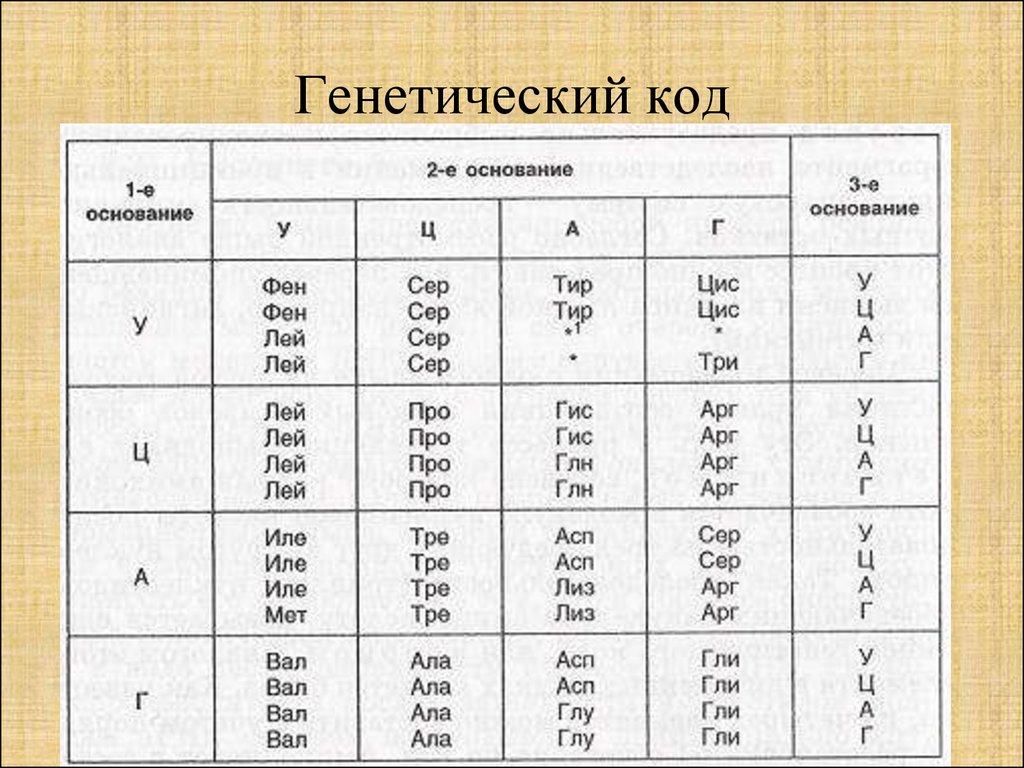
- ДНК человека (генетический код) можно представить себе как некоторое слово в четырёхбуквенном алфавите, где каждой буквой помечается звено цепи ДНК, или нуклеотид.
Сколько информации (в битах) содержит ДНК человека, содержащий примерно 1,5*10 23 нуклеотидов?
Ответ:3*10 23 бит
АЛФАВИТНЫЙ ПОДХОД К ИЗМЕРЕНИЮ ИНФОРМАЦИИ
2 i = N
МОЩНОСТЬ АЛФАВИТА
число символов в алфавите (его размер)
N
ИНФОРМАЦИОННЫЙ ВЕС СИМВОЛА
количество информации в одном символе (в битах)
i
ЧИСЛО СИМВОЛОВ В СООБЩЕНИИ
I = K · i
K
КОЛИЧЕСТВО ИНФОРМАЦИИ В СООБЩЕНИИ
I
Урок информатики по теме Кодирование информации доклад, проект
Кодирование информации с помощью знаковых систем
Знаки: форма и значение
Знаковые системы
активизировать знания по теме «Информация. Информационные процессы»;
Информационные процессы»;
познакомиться с кодированием информации с помощью знаковых систем;
познакомиться со знаками, их формами и значениями.
Цели урока
Кодирование информации — это специально выработанная система приемов (правил) фиксирования информации.
Основные атрибуты кодирования — код, знак, язык, с помощью которых информация фиксируется и передается в пространстве и времени.
С древних времен знаки используются человеком для долговременного хранения информации и ее передачи на большие расстояния.
Образец письменности майя
Знак — это метка, предмет, которым обозначается что-нибудь (буква, цифра, отверстие).
Знак вместе с его значением называют символом.
Форма знаков
В соответствии со способом восприятия знаки можно разделить на зрительные, слуховые, осязательные, обонятельные и вкусовые, причем в человеческом общении используются знаки первых трех типов.
Классификация знаков –
это их группировка по определенным признакам.
Классификация знаков
К зрительным знакам, воспринимаемым с помощью зрения, относятся буквы и цифры, которые используются в письменной речи, знаки химических элементов, музыкальные ноты, дорожные знаки и т. д.
1, 2, 3, 4, 5
I, II, III, IV, V
А, Б, В, Г, Д
A, B, C, D, E
К слуховым знакам, воспринимаемым с помощью слуха, относятся звуки, которые используются в устной речи, а также звуковые сигналы, которые производятся с помощью звонка, колокола, свистка, гудка, сирены и т. д.
Для слепых разработана азбука Брайля, которая использует осязательный способ восприятия текстовой информации.
Азбука Брайля
В коммуникации многих видов животных особую роль играют обонятельные знаки. Например, медведи и другие дикие животные помечают место обитания клочьями шерсти, сохраняющей запах, чтобы отпугнуть чужака и показать, что данная территория уже занята.
Для долговременного хранения знаки записываются на носители информации
Первые носители информации:
Камень, глина, дерево
Неудобные в применении
За 3000 лет до нашей эры в Египте разработали технологию изготовления тонкого листа – папируса из стебля тростника.
Папирус
Пергамент
Пергамент делали из кожи животных.
Кожу выделывали и вытягивали, чтобы получить тонкие листы.
Бумага
Во II веке в Китае изобрели технологию изготовления бумаги.
Секрет её изготовления тщательно скрывали.
Поэтому бумага появилась в Европе в XI веке, а на Руси в XVI веке.
Для передачи информации на большие расстояния используются знаки в форме сигналов. Например: световые сигналы светофора, звуковые сигналы школьного звонка оповещают о начале или конце урока, электрические сигналы передают информацию по телефонным и компьютерным сетям, электромагнитные волны передают сигналы радио и телевидения.
Значение знаков
Знаки отображают объекты окружающего мира или понятия, т. е. имеют определенное значение (смысл).
Знаки различаются по способу связи между их формой и значением.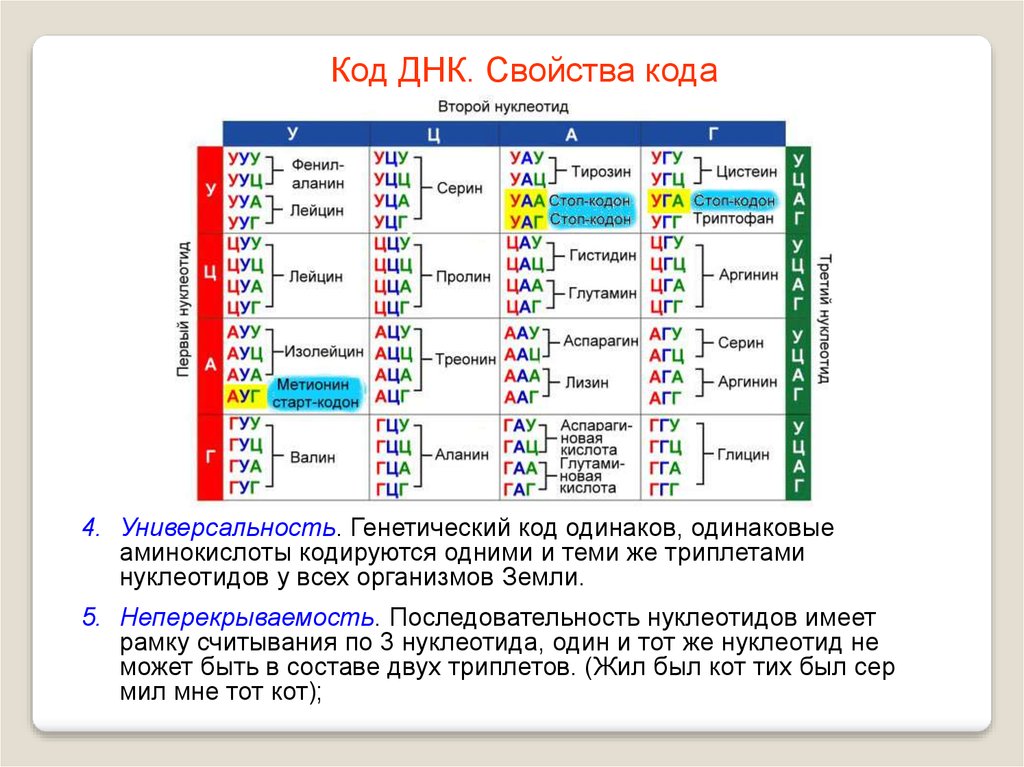
Иконические знаки позволяют догадаться об их смысле, так как они имеют форму, похожую на отображаемый объект.
Символами называются знаки, для которых связь между формой и значением устанавливается по общепринятому соглашению. Это символы химических элементов, отображающие атомы химических веществ, ноты, любые современные буквы или цифры и пр.
Если неизвестно соглашение о связи формы и значения символов, то ничего нельзя сказать о смысле информации, записанной такими знаками.
Существуют найденные археологами и до сих пор нерасшифрованные тексты на древних языках, так как неизвестно значение знаков, которыми они записаны.
В современном мире широко используется шифрование, которое использует секретный ключ в качестве соглашения о связи формы символов с их значениями. Если секретный ключ неизвестен, то содержание передаваемого текста понять невозможно.
Один и тот же символ может иметь различное значение в разных знаковых системах. Например, знак «О» используется в качестве:
• буквы «О» в русском алфавите;
• буквы «О» [оu] в английском алфавите;
• цифры 0 в системах счисления;
• символа химического элемента «О» (кислорода) в таблице Д. И. Менделеева.
Некоторые жесты, имеющие знаковую природу
а – затруднение, растерянность:
«Вот те раз! Что же делать?»;
б – превосходство: «У меня на это своя точка зрения»;
в – скука: «Все это мне совершенно неинтересно»
а
б
в
Язык веера: некоторые знаки
Знаковые системы
являются наборами знаков определенного типа. С некоторыми знаковыми системами вы знакомы и постоянно ими пользуетесь (языки и системы счисления), с другими ещё познакомитесь.
С некоторыми знаковыми системами вы знакомы и постоянно ими пользуетесь (языки и системы счисления), с другими ещё познакомитесь.
Каждая знаковая система строится на основе определенного алфавита (набора знаков) и правил выполнения операций над знаками.
Язык — это сложная система символов, каждый из которых имеет определенное значение.
Естественные языки
Естественные языки начали формироваться еще в древнейшие времена в целях обеспечения обмена информацией между людьми.
В настоящее время существуют сотни естественных языков (русский, английский, китайский, немецкий, польский и др.).
В основе письменной речи лежит алфавит, т. е. набор знаков (букв), которые человек различает по их начертанию. В большинстве современных языков буквы соответствуют определенным звукам устной речи. Алфавит русского языка называется кириллицей и содержит 33 знака, английский язык использует латиницу и содержит 26 знаков.
В устной речи, которая используется как средство коммуникации при непосредственном общении людей, в качестве знаков языка используются различные звуки (фонемы).
На основе алфавита по правилам грамматики образуются основные объекты языка — слова. Синтаксис — правила, согласно которым из слов данного языка строятся предложения. В естественных языках грамматика и синтаксис языка формулируются с помощью большого количества правил, из которых существуют исключения, так как такие правила складывались исторически.
Формальные языки
В процессе развития науки были разработаны формальные языки (системы счисления, алгебра, языки программирования и др.), основное отличие которых от естественных языков состоит в существовании строгих правил грамматики и синтаксиса.
Языки, придуманные и разработанные человеком для определенных целей, называются формальными.
Формальный язык — это язык знаков, формул, схем.
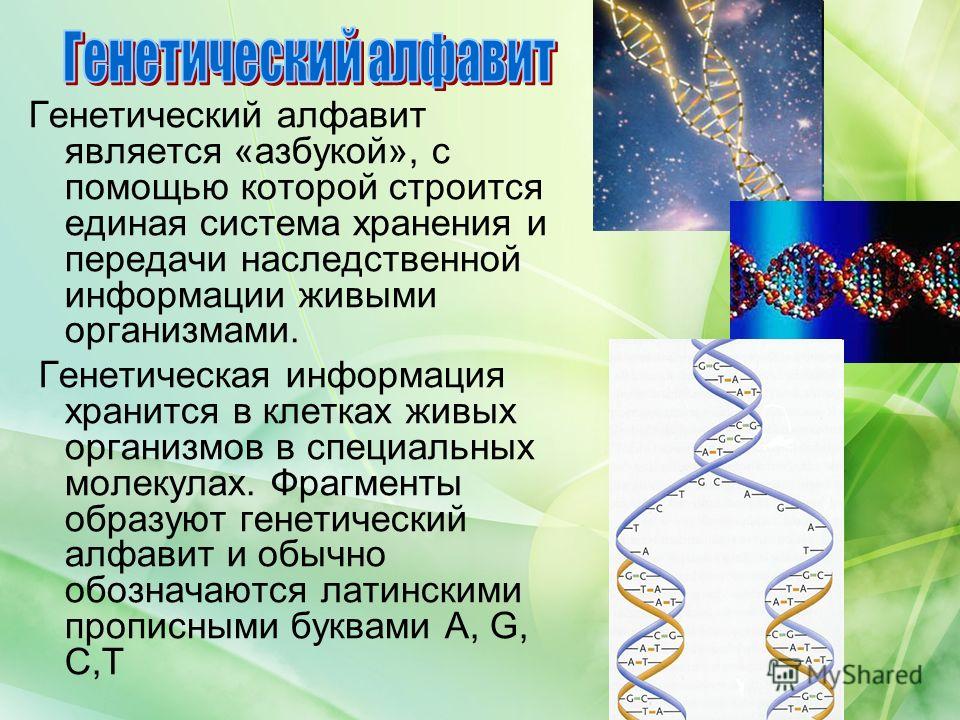
Генетический алфавит
является «азбукой», на которой строится единая система хранения и передачи наследственной информации живыми организмами.
Как слова в языках образуются из букв, так и гены состоят из знаков генетического алфавита. В процессе эволюции от простейших организмов до человека количество генов постоянно возрастало, так как было необходимо закодировать все более сложное строение и функциональные возможности живых организмов.
Генетическая информация
хранится в клетках живых организмов в специальных молекулах. Эти молекулы состоят из двух длинных скрученных друг с другом в спираль цепей, построенных из четырех различных молекулярных фрагментов. Фрагменты образуют генетический алфавит и обычно обозначаются латинскими прописными буквами {A, G, С, Т}.
Двоичная знаковая система
В процессах хранения, обработки и передачи информации в компьютере используется двоичная знаковая система, алфавит которой состоит всего из двух знаков {0, 1}.
1000 0001
0101 1010
0010 0100
0101 1010
0101 1010
0010 0100
0101 1010
1000 0001
1100 0000
1100 0001
1100 0010
1111 1110
1 0 1 1
Физически знаки реализуются в форме электрических импульсов (нет импульса — 0, есть импульс — 1), состояний ячеек оперативной памяти и участков поверхностей носителей информации (одно состояние — 0, другое состояние — 1).
Именно двоичная знаковая система используется в компьютере, так как существующие технические устройства могут надежно сохранять и распознавать только два различных состояния (знака).
Кодовая таблица в системе Windows
Домашнее задание
§1. 2 (1,2)
2 (1,2)
Придумать свой знаковый алфавит и зашифровать любой текст
Мощность (размер) алфавита — полное количество символов в алфавите — Студопедия
Поделись
Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54.
Представьте себе, что текст к вам поступает последовательно, по одному знаку, словно бумажная ленточка, выползающая из телеграфного аппарата. Предположим, что каждый появляющийся на ленте символ с одинаковой вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение. В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле N = 2I (см. содержательный подход) каждый такой символ несет I бит информации, которое можно определить из решения уравнения: 2I = 54. Получаем: I = 5.755 бит — такое количество информации несет один символ в русском тексте.
Чтобы найти количество информации во всем тексте, нужно посчитать число символов в нем и умножить на I.
Посчитаем количество информации на одной странице книги. Пусть страница содержит 50 строк. В каждой строке — 60 символов. Значит, на странице умещается 50×60=3000 знаков. Тогда объем информации будет равен: 5,755 х 3000 = 17265 бит.
При алфавитном подходе к измерению информации количество информации зависит не от содержания, а от размера текста и мощности алфавита.
Таким образом, алфавитный подход к измерению информации можно изобразить в виде схемы:
При использовании двоичной системы (алфавит состоит из двух знаков: 0 и 1) каждый двоичный знак несет 1 бит информации.
Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода.
Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 24 = 16. А если N =32, то один символ «весит» 5 бит.
А если N =32, то один символ «весит» 5 бит.
Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания….
Поскольку 256 = 28, то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название — байт.
1 байт = 8 бит.
Для измерения больших объемов информации используются следующие единицы:
1 Кб (один килобайт)= 1024 байт=210байт
1 Мб (один мегабайт)= 1024 Кб=210Кбайт=220байт
1 Гб (один гигабайт)= 1024 Мб=210Mбайт=230байт
1Тбайт (один терабайт)= 1024Гбайт =210Гбайт=240байт
1Пбайт(один петабайт)= 1024Тбайт= 210Тбайт=250байт
1Эбайт(один эксабайт)= 1024Пбайт =210Пбайт=260байт
1Збайт(один зеттабайт)= 1024Эбайт = 210Эбайт=270байт
1Йбайт(один йоттабайт)= 1024Збайт=210Збайт=280байт.
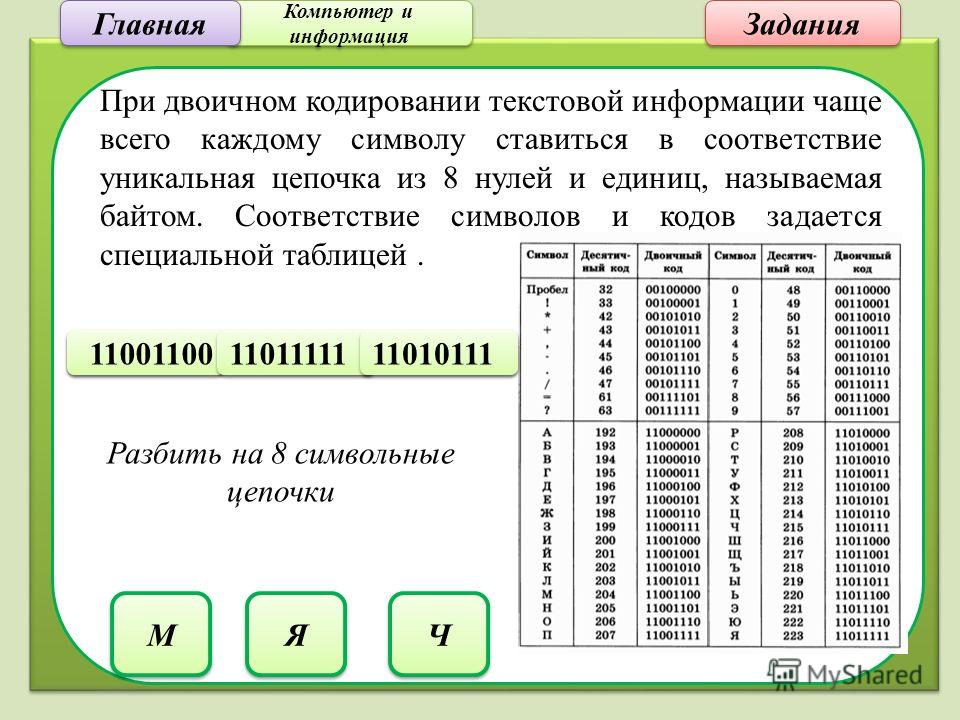
Кодирование текстовой информации
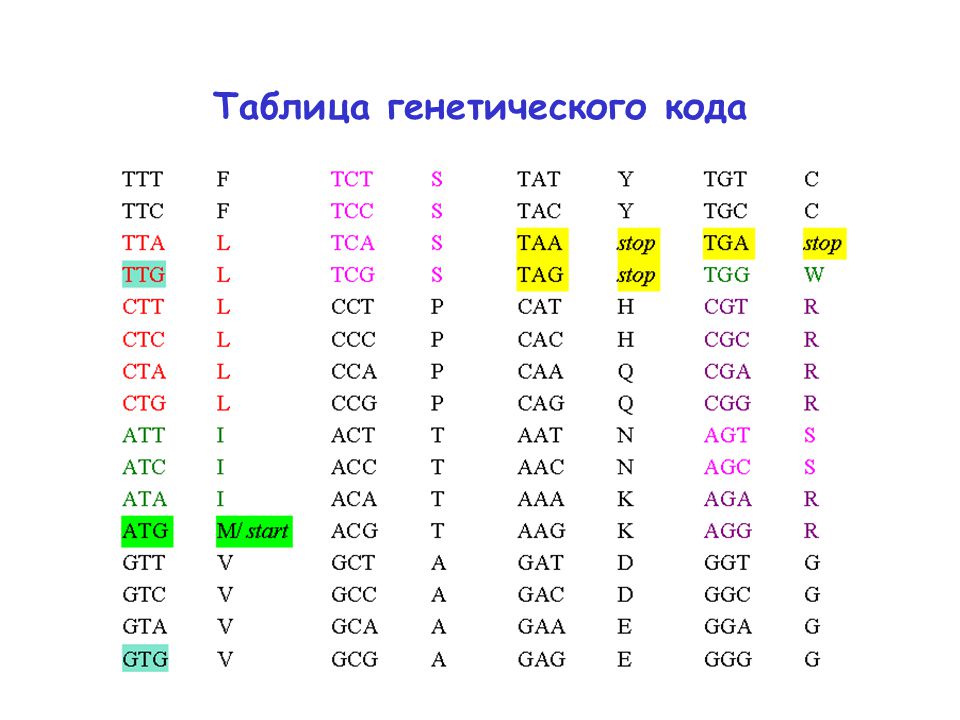
Текстовая информация в компьютере, как и все другие виды информации, кодируется двоичными кодами. Каждому символу алфавита ставится в соответствие целое число, которое принято считать кодом этого символа.
В традиционных кодировках для кодирования одного символа используется последовательность из 8 нулей и единиц 8 бит = 1 байт.
Различных последовательностей из 8 нулей и единиц существует 256 (28=256). Поэтому такой 8-ми разрядный код позволяет закодировать 256 различных символов.
Присвоение символу определенного числового кода — это вопрос соглашения. В качестве международного стандарта принята таблица ASCII(American Standard Code for Information Interchange — Американский стандартный код для обмена информацией), кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII
Для кодирования символов национальных алфавитов используется расширение кодовой таблицы ASCII, то есть 8-ми разрядные коды от 128 до 255.
Национальные стандарты кодировочных таблиц включают международную часть кодовой таблицы без изменений, а во второй содержат коды национальных алфавитов, символы псевдографики и некоторые математические знаки. В настоящее время существует 5 различных кодировок кириллицы (КОИ8, Windows. MSDOS, Macintosh, ISO), что вызывает определенные трудности при работе с русскоязычными документами.
В конце 90-х годов появился новый международный стандарт Unicode, который отводит под 1 символ не один байт, а два, поэтому с его помощью можно закодировать 65536 различных символов. Он включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
вычислений ДНК | информатика
- Похожие темы:
- компьютер
Просмотреть весь связанный контент →
Резюме
Прочтите краткий обзор этой темы
ДНК-вычисления , выполнение вычислений с использованием биологических молекул, а не традиционных кремниевых чипов. Идея о том, что отдельные молекулы (или даже атомы) можно использовать для вычислений, восходит к 1959 году, когда американский физик Ричард Фейнман представил свои идеи о нанотехнологиях. Однако вычисления ДНК не были физически реализованы до 19 века.94, когда американский ученый-компьютерщик Леонард Адлеман показал, как можно использовать молекулы для решения вычислительной задачи.
Идея о том, что отдельные молекулы (или даже атомы) можно использовать для вычислений, восходит к 1959 году, когда американский физик Ричард Фейнман представил свои идеи о нанотехнологиях. Однако вычисления ДНК не были физически реализованы до 19 века.94, когда американский ученый-компьютерщик Леонард Адлеман показал, как можно использовать молекулы для решения вычислительной задачи.
Решение задач с молекулами ДНК
Вычисление можно рассматривать как выполнение алгоритма, который сам по себе может быть определен как пошаговый список четко определенных инструкций, которые принимают некоторые входные данные, обрабатывают их и выдают результат. В вычислениях ДНК информация представляется с использованием четырехсимвольного генетического алфавита (A [аденин], G [гуанин], C [цитозин] и T [тимин]), а не двоичного алфавита (1 и 0), используемого традиционными методами. компьютеры. Это достижимо, потому что короткие молекулы ДНК любой произвольной последовательности могут быть синтезированы на заказ. Таким образом, ввод алгоритма представлен (в простейшем случае) молекулами ДНК с определенными последовательностями, инструкции выполняются лабораторными операциями над молекулами (такими как их сортировка по длине или отсечение нитей, содержащих определенную подпоследовательность), а результат определяется как некоторое свойство конечного набора молекул (например, наличие или отсутствие определенной последовательности).
Таким образом, ввод алгоритма представлен (в простейшем случае) молекулами ДНК с определенными последовательностями, инструкции выполняются лабораторными операциями над молекулами (такими как их сортировка по длине или отсечение нитей, содержащих определенную подпоследовательность), а результат определяется как некоторое свойство конечного набора молекул (например, наличие или отсутствие определенной последовательности).
Викторина «Британника»
Викторина «Компьютеры и технологии»
Компьютеры размещают веб-сайты, состоящие из HTML, и отправляют текстовые сообщения, такие простые, как… LOL. Взломайте эту викторину, и пусть какая-то технология подсчитает ваш результат и раскроет вам ее содержание.
Эксперимент Адлемана заключался в поиске маршрута через сеть «городов» (обозначенных от «1» до «7»), соединенных «дорогами» с односторонним движением. В задаче указано, что маршрут должен начинаться и заканчиваться в определенных городах и посещать каждый город только один раз. (Математикам она известна как проблема гамильтоновой траектории, двоюродная сестра более известной задачи коммивояжера.) Адлеман воспользовался свойством комплементарности ДНК по Уотсону-Крику: А и Т слипаются попарно, как и G и C (так что последовательность AGCT идеально подходит для TCGA). Он разработал короткие нити ДНК для представления городов и дорог таким образом, чтобы нити дорог скрепляли нити городов вместе, образуя последовательности городов, которые представляли маршруты (например, фактическое решение, которое оказалось «1234567»). Большинство таких последовательностей представляли собой неверные ответы на задачу («12324» посещает город более одного раза, а «1234» не посещает каждый город), но Адлеман использовал достаточное количество ДНК, чтобы быть достаточно уверенным, что правильный ответ будет представлен в его исходном коде. горшок из прядей. Проблема заключалась в том, чтобы извлечь это уникальное решение. Он добился этого, сначала сильно амплифицируя (используя метод, известный как полимеразная цепная реакция [ПЦР]) только те последовательности, которые начинались и заканчивались в нужных городах.
(Математикам она известна как проблема гамильтоновой траектории, двоюродная сестра более известной задачи коммивояжера.) Адлеман воспользовался свойством комплементарности ДНК по Уотсону-Крику: А и Т слипаются попарно, как и G и C (так что последовательность AGCT идеально подходит для TCGA). Он разработал короткие нити ДНК для представления городов и дорог таким образом, чтобы нити дорог скрепляли нити городов вместе, образуя последовательности городов, которые представляли маршруты (например, фактическое решение, которое оказалось «1234567»). Большинство таких последовательностей представляли собой неверные ответы на задачу («12324» посещает город более одного раза, а «1234» не посещает каждый город), но Адлеман использовал достаточное количество ДНК, чтобы быть достаточно уверенным, что правильный ответ будет представлен в его исходном коде. горшок из прядей. Проблема заключалась в том, чтобы извлечь это уникальное решение. Он добился этого, сначала сильно амплифицируя (используя метод, известный как полимеразная цепная реакция [ПЦР]) только те последовательности, которые начинались и заканчивались в нужных городах. Затем он отсортировал набор нитей по длине (используя технику, называемую гель-электрофорезом), чтобы убедиться, что он сохранил только нити правильной длины. Наконец, он неоднократно использовал молекулярную «удочку» (аффинную очистку), чтобы убедиться, что каждый город по очереди представлен в последовательностях-кандидатах. Затем нити, которые остались у Адлемана, были секвенированы, чтобы выявить решение проблемы.
Затем он отсортировал набор нитей по длине (используя технику, называемую гель-электрофорезом), чтобы убедиться, что он сохранил только нити правильной длины. Наконец, он неоднократно использовал молекулярную «удочку» (аффинную очистку), чтобы убедиться, что каждый город по очереди представлен в последовательностях-кандидатах. Затем нити, которые остались у Адлемана, были секвенированы, чтобы выявить решение проблемы.
Хотя Адлеман стремился только установить возможность вычислений с помощью молекул, вскоре после его публикации некоторые представили его эксперимент как начало соревнования между компьютерами на основе ДНК и их кремниевыми аналогами. Некоторые люди верили, что молекулярные компьютеры однажды смогут решить проблемы, которые заставят существующие машины бороться из-за присущего биологии массивного параллелизма. Поскольку маленькая капля воды может содержать триллионы нитей ДНК и поскольку биологические операции воздействуют на все из них — эффективно — параллельно (а не по одной за раз), утверждалось, что однажды ДНК-компьютеры смогут представлять (и решать) сложные задачи, выходящие за рамки «обычных» компьютеров.
Однако в большинстве сложных задач количество возможных решений растет экспоненциально с размером задачи (например, количество решений может удваиваться для каждого добавленного города). Это означает, что даже относительно небольшие проблемы потребуют неуправляемых объемов ДНК (порядка больших ванн), чтобы представить все возможные ответы. Эксперимент Адлемана имел большое значение, поскольку в нем проводились мелкомасштабные вычисления с биологическими молекулами. Однако, что еще более важно, это открыло возможность непосредственно запрограммированных биохимических реакций.
Информационные технологии на основе биохимии
Программируемая информационная химия позволит создавать новые типы биохимических систем, которые могут ощущать собственное окружение, действовать в соответствии с решениями и, возможно, даже общаться с другими подобными формами. Хотя химические реакции происходят в наномасштабе, так называемые информационные технологии, основанные на биохимии (био/химические ИТ), отличаются от нанотехнологий из-за зависимости первых от относительно крупномасштабных молекулярных систем.
Оформите подписку Britannica Premium и получите доступ к эксклюзивному контенту.
Подпишитесь сейчас
Хотя современные био/химические информационные технологии используют множество различных типов (био) химических систем, ранние работы по программируемым молекулярным системам в основном основывались на ДНК. Американский биохимик Надриан Симан был одним из первых пионеров нанотехнологии на основе ДНК, которая изначально использовала эту конкретную молекулу исключительно как наноразмерный «каркас» для манипулирования и контроля над другими молекулами. Американский ученый-компьютерщик Эрик Уинфри работал с Симаном, чтобы показать, как двумерные «листы» из «плиток» на основе ДНК (фактически прямоугольники, состоящие из переплетенных нитей ДНК) могут самостоятельно собираться в более крупные структуры. Затем Уинфри вместе со своим учеником Полом Ротемундом показал, как можно спроектировать эти плитки таким образом, чтобы процесс самосборки мог выполнять определенные вычисления. Позже Ротемунд расширил эту работу своим исследованием «ДНК-оригами», в котором одна нить ДНК многократно складывается в двухмерную форму, чему помогают более короткие нити, которые действуют как «скобы».
Позже Ротемунд расширил эту работу своим исследованием «ДНК-оригами», в котором одна нить ДНК многократно складывается в двухмерную форму, чему помогают более короткие нити, которые действуют как «скобы».
Другие эксперименты показали, что базовые вычисления могут быть выполнены с использованием ряда различных строительных блоков (например, простых молекулярных «машин», которые используют комбинацию ферментов на основе ДНК и белка). Используя силу молекул, возможны новые формы технологий обработки информации, которые могут развиваться, самовоспроизводиться, самовосстанавливаться и реагировать. Возможное применение этой новой технологии окажет влияние на многие области, включая интеллектуальную медицинскую диагностику и доставку лекарств, тканевую инженерию, энергетику и окружающую среду.
Мартин Амос
Математические основы помехоустойчивости генетического кода
Сохранить цитату в файл
Формат:
Резюме (текст)PubMedPMIDAbstract (текст)CSV
Добавить в коллекции
- Создать новую коллекцию
- Добавить в существующую коллекцию
Назовите свою коллекцию:
Имя должно содержать менее 100 символов
Выберите коллекцию:
Не удалось загрузить вашу коллекцию из-за ошибки
Повторите попытку
Добавить в мою библиографию
- Моя библиография
Не удалось загрузить делегатов из-за ошибки
Повторите попытку
Ваш сохраненный поиск
Название сохраненного поиска:
Условия поиска:
Тестовые условия поиска
Эл. адрес:
адрес:
(изменить)
Который день?
Первое воскресеньеПервый понедельникПервый вторникПервая средаПервый четвергПервая пятницаПервая субботаПервый деньПервый рабочий день
Который день?
ВоскресеньеПонедельникВторникСредаЧетвергПятницаСуббота
Формат отчета:
SummarySummary (text)AbstractAbstract (text)PubMed
Отправить максимум:
1 шт. 5 шт. 10 шт. 20 шт. 50 шт. 100 шт. 200 шт.
Отправить, даже если нет новых результатов
Необязательный текст в электронном письме:
Создайте файл для внешнего программного обеспечения для управления цитированием
Полнотекстовые ссылки
Эльзевир Наука
Полнотекстовые ссылки
Обзор
. 2018 Февраль; 164: 186-198.
2018 Февраль; 164: 186-198.
doi: 10.1016/j.biosystems.2017.09.007.
Epub 2017 14 сентября.
Елена Фиммел
1
, Лутц Струнгманн
2
Принадлежности
Принадлежности
- 1 Институт математической биологии, факультет компьютерных наук, Мангеймский университет прикладных наук, 68163 Мангейм, Германия. Электронный адрес: [email protected].
- 2 Институт математической биологии, факультет компьютерных наук, Мангеймский университет прикладных наук, 68163 Мангейм, Германия. Электронный адрес: [email protected].
PMID:
28918301
DOI:
10.
1016/j.biosystems.2017.09.007
 1016/j.biosystems.2017.09.007
1016/j.biosystems.2017.09.007Обзор
Elena Fimmel et al.
Биосистемы.
2018 фев.
. 2018 Февраль; 164: 186-198.
doi: 10.1016/j.biosystems.2017.09.007.
Epub 2017 14 сентября.
Авторы
Елена Фиммель
1
, Лутц Струнгманн
2
Принадлежности
- 1 Институт математической биологии, факультет компьютерных наук, Мангеймский университет прикладных наук, 68163 Мангейм, Германия. Электронный адрес: [email protected].
- 2 Институт математической биологии, факультет компьютерных наук, Мангеймский университет прикладных наук, 68163 Мангейм, Германия. Электронный адрес: [email protected].
 Электронный адрес:
Электронный адрес: PMID:
28918301
DOI:
10.1016/j.biosystems.2017.09.007
Абстрактный
Симметрия — один из основных и наиболее заметных паттернов, которые можно увидеть в природе. Начиная с лево-правой симметрии человеческого тела, все виды симметрии можно найти в кристаллах, растениях, животных и природе в целом. Точно так же принципы симметрии также являются одними из фундаментальных и наиболее полезных инструментов в современном математическом естествознании, которые играют важную роль в теории и приложениях. Как следствие, неудивительно, что стремление понять происхождение жизни на основе генетического кода вынуждает нас привлекать симметрию как математическое понятие. Генетический код можно рассматривать как ключ к биологической самоорганизации. Все живые организмы имеют одинаковые молекулярные основы — алфавит, состоящий из четырех букв (азотистых оснований): аденина, цитозина, гуанина и тимина. Линейно упорядоченные последовательности этих оснований содержат генетическую информацию для синтеза белков у всех форм жизни. Таким образом, одна из самых увлекательных загадок природы состоит в том, чтобы объяснить, почему генетический код такой, какой он есть. Генетическое кодирование обладает помехоустойчивостью, что является фундаментальным свойством, позволяющим передавать генетическую информацию от родителей к потомкам. Следовательно, со времени открытия генетического кода ученые пытались объяснить помехозащищенность генетической информации. В этой главе мы обсудим последние результаты математического моделирования генетического кода с точки зрения помехоустойчивости, в частности обнаружения и исправления ошибок. Мы сосредоточимся на двух центральных свойствах: вырождении и коррекции сдвига рамки отсчета.
Генетический код можно рассматривать как ключ к биологической самоорганизации. Все живые организмы имеют одинаковые молекулярные основы — алфавит, состоящий из четырех букв (азотистых оснований): аденина, цитозина, гуанина и тимина. Линейно упорядоченные последовательности этих оснований содержат генетическую информацию для синтеза белков у всех форм жизни. Таким образом, одна из самых увлекательных загадок природы состоит в том, чтобы объяснить, почему генетический код такой, какой он есть. Генетическое кодирование обладает помехоустойчивостью, что является фундаментальным свойством, позволяющим передавать генетическую информацию от родителей к потомкам. Следовательно, со времени открытия генетического кода ученые пытались объяснить помехозащищенность генетической информации. В этой главе мы обсудим последние результаты математического моделирования генетического кода с точки зрения помехоустойчивости, в частности обнаружения и исправления ошибок. Мы сосредоточимся на двух центральных свойствах: вырождении и коррекции сдвига рамки отсчета.
Вырождение:
Разные аминокислоты кодируются разным количеством кодонов, и связь между этим вырождением и помехозащищенностью генетической информации является давней гипотезой. Биологические последствия вырождения интенсивно изучались, и до сих пор ведутся споры о том, является ли естественный код замороженной случайностью или высоко оптимизированным продуктом эволюции. Симметрии в структуре вырожденности генетического кода существенны и свидетельствуют о существенных преимуществах природного кода перед другими возможными. В настоящей главе мы представим новейший подход к объяснению вырождения генетического кода алгоритмическими методами биоинформатики и обсудим его биологические последствия.
Коррекция сдвига кадра:
Биологи осознали эту проблему сразу же после обнаружения неперекрывающейся структуры генетического кода, т. е. кодирующие последовательности должны считываться уникальным образом, определяемым их рамкой считывания.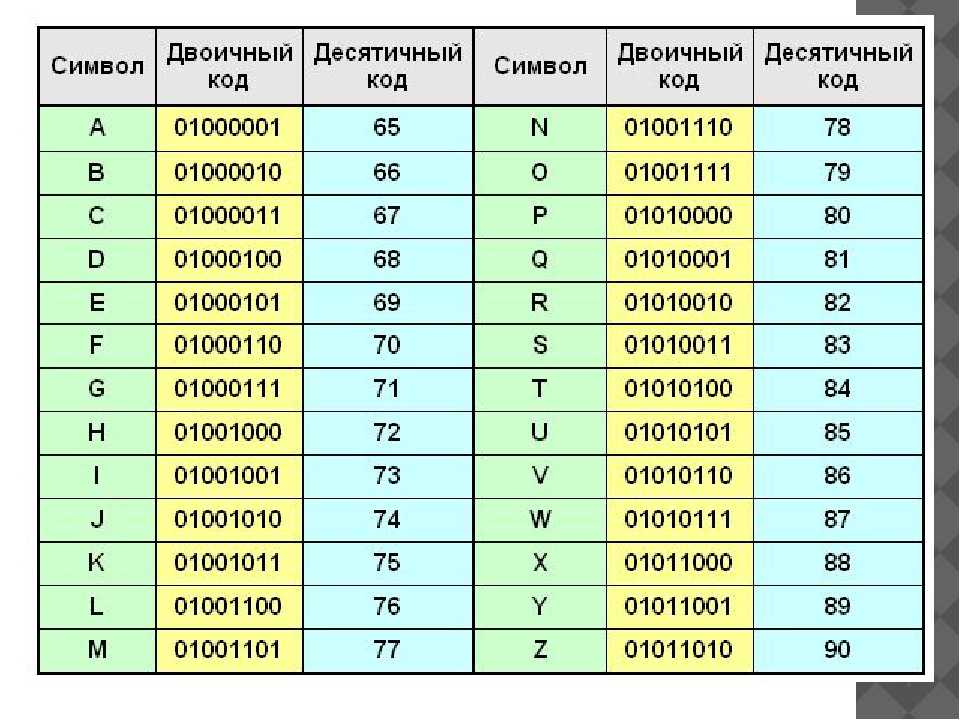 Но как считывающая головка рибосомы распознает ошибку в группировке кодонов, вызванную, например, вставка или делеция основания, которые могут быть фатальными в процессе трансляции и могут привести к нефункциональным белкам? В этой главе мы обсудим возможные решения проблемы сдвига рамки отсчета, сосредоточив внимание на теории так называемых циклических кодов, которые были обнаружены в больших генных популяциях прокариот и эукариот в начале XIX века.0 с. Циклические коды позволяют обнаруживать сдвиг рамки на одну или две позиции, и недавно была разработана красивая теория таких кодов с использованием статистики, теории групп и теории графов.
Но как считывающая головка рибосомы распознает ошибку в группировке кодонов, вызванную, например, вставка или делеция основания, которые могут быть фатальными в процессе трансляции и могут привести к нефункциональным белкам? В этой главе мы обсудим возможные решения проблемы сдвига рамки отсчета, сосредоточив внимание на теории так называемых циклических кодов, которые были обнаружены в больших генных популяциях прокариот и эукариот в начале XIX века.0 с. Циклические коды позволяют обнаруживать сдвиг рамки на одну или две позиции, и недавно была разработана красивая теория таких кодов с использованием статистики, теории групп и теории графов.
Ключевые слова:
Циркулярные коды; Вырожденность генетического кода; Эволюция генетического кода; проблема сдвига кадра; Генетический код; теория графов; Симметричная группа.
Copyright © 2017 Elsevier B.V. Все права защищены.
Похожие статьи
Циркулярные коды Тессеры в эволюции генетического кода.
Фиммель Э., Старман М., Струнгманн Л.
Фиммел Э. и др.
Бык Математика Биол. 2020 4 апр;82(4):48. doi: 10.1007/s11538-020-00724-z.
Бык Математика Биол. 2020.PMID: 32248310
Бесплатная статья ЧВК.Преобразование Румера: загадка симметрии, стоящая полвека.
Гонсалес Д.Л., Джаннерини С., Роза Р.
Гонсалес Д.Л. и соавт.
Биосистемы. 2020 янв; 187:104036. doi: 10.1016/j.biosystems.2019.104036. Epub 2019 4 октября.
Биосистемы. 2020.PMID: 31589913
Эволюция генетического кода путем постепенного нарушения симметрии.
Ленстра Р.
Ленстра Р.
Дж Теор Биол. 2014 21 апреля; 347: 95-108. doi: 10.1016/j.jtbi.2014.01.002. Epub 2014 14 января.
Дж Теор Биол. 2014.PMID: 24434741
Стандартный генетический код против суперсимметричного генетического кода — Алфавитная таблица против физико-химической таблицы.
Росандич М., Паар В.
Розандич М. и др.
Биосистемы. 2022 авг; 218:104695. doi: 10.1016/j.biosystems.2022.104695. Epub 2022 14 мая.
Биосистемы. 2022.PMID: 35580818
Красочное происхождение генетического кода: теория информации, статистическая механика и появление молекулярных кодов.
Тласти Т.
Тласти Т.
Phys Life Rev. 2010 Sep; 7 (3): 362-76. doi: 10.1016/j.plrev.2010.06.002. Epub 2010 4 июня.
Phys Life Ред. 2010.PMID: 20558115
Обзор.

Посмотреть все похожие статьи
Цитируется
Классы эквивалентности циклических кодов, индуцированные группами подстановок.
Фаязи Ф., Фиммель Э., Струнгманн Л.
Фаязи Ф. и др.
Теория Биологии. 2021 фев; 140 (1): 107-121. doi: 10.1007/s12064-020-00337-z. Epub 2021 1 февраля.
Теория Биологии. 2021.PMID: 33523355
Бесплатная статья ЧВК.Связь между k-цикличностью и цикличностью кодов.
Фиммель Э., Мишель С.Дж., Пиро Ф., Серени Дж.С., Старман М., Струнгманн Л.
Фиммел Э. и др.
Бык Математика Биол. 2020 4 августа; 82 (8): 105. doi: 10.1007/s11538-020-00770-7.
Бык Математика Биол. 2020.PMID: 32754878
Бесплатная статья ЧВК.Циркулярные коды Тессеры в эволюции генетического кода.
Фиммель Э., Старман М., Струнгманн Л.
Фиммел Э. и др.
Бык Математика Биол. 2020 4 апр;82(4):48. doi: 10.1007/s11538-020-00724-z.
Бык Математика Биол. 2020.PMID: 32248310
Бесплатная статья ЧВК.Выявление периодичности циклического кода в бактериальной рибосоме: происхождение периодичности кодонов в генах?
Мишель Си Джей, Томпсон Джей Ди.
Мишель CJ и др.
РНК биол. 2020 апр; 17 (4): 571-583. дои: 10.1080/15476286.2020.1719311. Epub 2020, 11 февраля.
РНК биол. 2020.PMID: 31960748
Бесплатная статья ЧВК.Пентамеры с неизбыточными каркасами: систематическая ошибка для кодонов с естественным циклическим кодом.
Демонжот Дж., Селигманн Х.
Демонжо Дж. и др.
Дж Мол Эвол. 2020 март;88(2):194-201. doi: 10.1007/s00239-019-09925-0. Epub 2020 7 января.
Дж Мол Эвол. 2020.PMID: 31907555

Просмотреть все статьи «Цитируется по»
Типы публикаций
термины MeSH
вещества
Полнотекстовые ссылки
Эльзевир Наука
Укажите
Формат:
ААД
АПА
МДА
НЛМ
Отправить на
Сколько писем? | Научный проект
Научные проекты
Реферат
Можете ли вы вспомнить всю свою азбуку? Компьютеры тоже должны «запоминать» буквы. Каждый раз, когда мы используем компьютер для написания рассказа, компьютер должен «запомнить» буквы в рассказе, сохранив их в памяти компьютера в виде файла. В этом эксперименте выясните, сколько памяти требуется компьютеру, чтобы «запомнить» серию букв.
Каждый раз, когда мы используем компьютер для написания рассказа, компьютер должен «запомнить» буквы в рассказе, сохранив их в памяти компьютера в виде файла. В этом эксперименте выясните, сколько памяти требуется компьютеру, чтобы «запомнить» серию букв.
Резюме
Компьютерная наука
Очень короткий (≤ 1 день)
Нет
. Легко доступно
Очень низкий (до 20 долларов США)
Sara Agee, Ph.D., Science Buddies
.
Задача
В этом эксперименте вы проверите, как количество букв (или символов) в файле влияет на размер файла.
Введение
Сколько букв вы можете запомнить? На самом деле вы можете запомнить гораздо больше букв, чем вы думаете. Трюк с вашей памятью заключается в том, как буквы соединяются осмысленно: слова, предложения, абзацы и рассказы. Это называется использованием ассоциаций. Если вы выучили алфавит, то вы выучили схему из 26 букв. Если вы выучили песню «Мерцай, мерцай, звездочка» (и можешь произнести все слова по буквам), то ты выучил сложный узор из 129буквы! Это много информации!
Если вы выучили песню «Мерцай, мерцай, звездочка» (и можешь произнести все слова по буквам), то ты выучил сложный узор из 129буквы! Это много информации!
Как компьютер запоминает информацию? Поскольку компьютеры не могут думать так, как мы с вами, они не могут запоминать вещи, формируя ассоциации. Вместо этого они должны кодировать информацию с помощью шаблона. Одним из примеров является двоичный код, представляющий собой набор нулей и единиц, который можно использовать для кодирования информации и сохранения ее на жестком диске в виде файла.
Каждая часть информации, хранящаяся в файле, занимает определенное место в памяти компьютера. Поскольку компьютер имеет ограниченный объем памяти, необходимо измерять размер каждого файла, чтобы компьютер мог отслеживать, сколько памяти было использовано и сколько памяти свободно. Объем пространства, который использует файл, называется размером файла и обычно измеряется в килобайтах (КБ) или мегабайтах (МБ).
В этом эксперименте вы проверите, сколько памяти требуется для хранения простой части информации, буквы А. На самом деле, тысяча букв А! Но не волнуйтесь, у меня есть хитрость, чтобы вы не утомляли свои печатающие пальцы.
На самом деле, тысяча букв А! Но не волнуйтесь, у меня есть хитрость, чтобы вы не утомляли свои печатающие пальцы.
Термины и понятия
Для проведения такого рода экспериментов вы должны знать, что означают следующие термины. Попросите взрослого помочь вам с поиском в Интернете или отведите вас в местную библиотеку, чтобы узнать больше!
- буква (символ)
- текст
- файл
- память
- килобайт (КБ)
- мегабайта (МБ)
Вопросы
- Сколько информации в письме?
- Как изменяется размер файла по мере добавления в файл новых букв (или символов)?
- Как измеряется размер файла?
Библиография
- Каждая буква представляет собой часть информации, которая закодирована и хранится в виде файла на вашем компьютере. Узнайте о том, как информация хранится и измеряется:
T1 Shopper, 2006. Конвертер байтов — Калькулятор размера файла. Проверено 10.03.06. - В вычислительной терминологии буква является одним из примеров символа. Узнайте больше о символах и о том, как они кодируются:
- Участники Википедии, 2006 г. Персонаж (компьютер), Википедия, Бесплатная энциклопедия. Проверено 10.03.06.
 Проверено 10.03.06.
Проверено 10.03.06.Материалы и оборудование
- компьютер
- программное обеспечение для обработки текстов (Text Edit, Microsoft Word, Word Perfect, Claris и т. д.)
- миллиметровая бумага
- цветные карандаши или маркеры
Экспериментальная процедура
- Откройте программу обработки текстов. Я могу быть любой программой для записи и редактирования текстовых файлов или документов. Некоторыми примерами пакетов программного обеспечения для редактирования являются Text Edit, Microsoft Word, Word Perfect или Claris Works.
- Откройте новый документ. Обычно это делается нажатием на «Файл», а затем «Создать. ..» в меню «Файл» в верхней части экрана.
- Ниже находится коробка, заполненная 1000 буквами А:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
ааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааааа0
ааааааааааааааа
- Скопируйте букву А, щелкнув и перетащив, чтобы выделить все буквы, а затем нажав «Редактировать» и «Копировать» в меню «Файл» в верхней части экрана.
- Вставьте букву А в новый файл, щелкая внутри нового документа, пока не появится мигающий курсор, затем нажмите «Редактировать» и «Вставить» в меню файлов в верхней части экрана.
- Это будет ваш первый файл. Он содержит 1000 букв А. Сохраните файл на свой компьютер, нажав «Файл» и «Сохранить» в меню файлов в верхней части экрана.
- Введите имя файла (например, A1000.txt) и нажмите кнопку «Сохранить».
- Теперь вы хотите создать новый файл с еще 1000 буквами А в нем. Сделайте это, нажав «Файл» и «Сохранить как» в меню «Файл» в верхней части экрана.
- Это будет ваш второй файл. Введите имя нового файла (например, A2000.txt) и нажмите кнопку «Сохранить».
- Теперь вы хотите добавить больше букв А в ваш новый файл. Сейчас в нем 1000 букв А, и вы хотите добавить еще 1000. Скопируйте еще 1000 букв А, щелкнув и перетащив, чтобы выделить все буквы, а затем нажав «Изменить» и «Копировать» в меню файлов в верхней части экрана.
- Вставьте новую букву А в конец вашей старой буквы А, щелкнув в конце последней буквы А (пока вы не увидите мигающий курсор после последней буквы А), затем нажмите «Редактировать» и «Вставить» из меню файлов в верхней части экрана.
- Ваш новый файл содержит 2000 букв А. Сохраните файл на свой компьютер, нажав «Файл» и «Сохранить» в меню файлов в верхней части экрана.
- Повторите шаги 8-12, чтобы создать файлы с буквами A 3000, 4000, 5000 и т. д. Не забудьте сохранить каждый новый файл с новым именем, которое отражает количество букв в файле (например, A3000.txt, A4000.txt, A5000.txt и т. д.).
- После того, как вы создали и сохранили каждый файл, вы можете закрыть приложение для обработки текста.
- Далее вам нужно будет просмотреть файлы, которые вы создали, заглянув в папку документов на вашем компьютере. Используйте средство поиска, если вы используете Mac, или меню «Пуск», если вы используете ПК с Windows.
- Запишите размер каждого файла в таблицу данных:
- Создайте гистограмму ваших данных. В левой части графика сделайте шкалу размера файла от нуля до чуть больше вашего самого большого фрагмента данных с шагом 5000 КБ. Например, если мой самый большой размер файла составляет 67 000 КБ, я бы увеличил масштаб до 70 000 КБ. Нарисуйте полосу для каждого тестового файла до числа, соответствующего размеру файла. Не забудьте пометить каждый столбец количеством букв в файле, пометить каждую ось и дать вашему графику описательное название.
- Что произошло с размером файла при добавлении новых букв? Вы сразу увидели эффект? Сколько букв потребовалось, прежде чем вы увидели заметное изменение размера файла?
 ..» в меню «Файл» в верхней части экрана.
..» в меню «Файл» в верхней части экрана.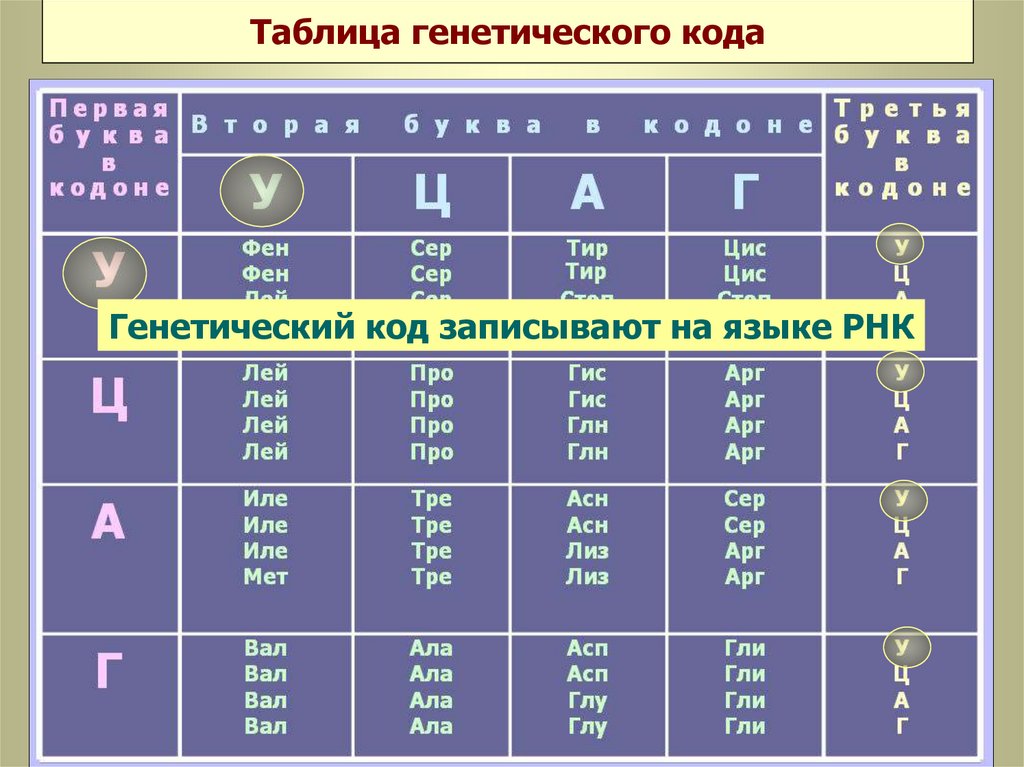

 В левой части графика сделайте шкалу размера файла от нуля до чуть больше вашего самого большого фрагмента данных с шагом 5000 КБ. Например, если мой самый большой размер файла составляет 67 000 КБ, я бы увеличил масштаб до 70 000 КБ. Нарисуйте полосу для каждого тестового файла до числа, соответствующего размеру файла. Не забудьте пометить каждый столбец количеством букв в файле, пометить каждую ось и дать вашему графику описательное название.
В левой части графика сделайте шкалу размера файла от нуля до чуть больше вашего самого большого фрагмента данных с шагом 5000 КБ. Например, если мой самый большой размер файла составляет 67 000 КБ, я бы увеличил масштаб до 70 000 КБ. Нарисуйте полосу для каждого тестового файла до числа, соответствующего размеру файла. Не забудьте пометить каждый столбец количеством букв в файле, пометить каждую ось и дать вашему графику описательное название.Задать вопрос эксперту
У вас есть конкретные вопросы о вашем научном проекте? Наша команда ученых-добровольцев может помочь. Наши эксперты не сделают всю работу за вас, но они сделают предложения, дадут рекомендации и помогут устранить неполадки.
Опубликовать вопрос
Варианты
- Попробуйте использовать буквы, отличные от буквы А, или комбинации букв. Попробуйте скопировать алфавит снова и снова. У вас есть аналогичный результат?
- Попробуйте сравнить разные стили шрифтов или размеры букв. Увеличивает ли размер файла изменение размера шрифта? Занимают ли некоторые стили шрифтов больше памяти, чем другие стили?
- Если у вас более одного текстового редактора или программы обработки текстов, вы можете сравнить размеры файлов одного и того же текста, созданного тремя разными приложениями. Сохраните один и тот же текст в виде файла в каждом приложении и сравните размеры файлов. Файлы одного размера? Какое приложение создает файлы, которые используют больше всего памяти? Какое приложение создает файлы, которые используют меньше всего? Как это может быть связано с количеством функций, предлагаемых каждым приложением?
- Для более сложного проекта вы можете построить линейный график результатов для каждого приложения. Поместите количество букв по оси X и размер файла по оси Y. Является ли связь линейной? Ваша линия проходит через начало координат? Какую информацию может дать Y-перехват о базовом уровне для каждого приложения? Является ли Y-перехват одинаковым для каждого приложения? Является ли наклон одинаковым для каждого приложения?
 Попробуйте скопировать алфавит снова и снова. У вас есть аналогичный результат?
Попробуйте скопировать алфавит снова и снова. У вас есть аналогичный результат?Вакансии
Если вам нравится этот проект, вы можете изучить следующие родственные профессии:
- Руководство по проекту научной ярмарки
- Другие подобные идеи
- Идеи проекта по информатике
- Мои любимые
Лента новостей по этой теме
,
,
Процитировать эту страницу
Общая информация о цитировании представлена здесь.