Содержание
Нейронная сеть Google: что нового и какие возможности у сети Гугла?
Нейронная сеть в компании Google используется во многих сервисах. Вообще, нейронная сеть и искусственный интеллект все чаще встречаются в различных приложениях и устройствах. Их частое использование касается не только компании Google, но и других крупных и мелких IT-разработчиков. Нейронная сеть может быть использована практически любым разработчиком. Да, в большинстве случаев это будет не написанная с нуля нейронная сеть, а использование какой-нибудь доступной библиотеки, но все же доступность нейросетей и искусственного интеллекта нельзя отрицать.
Но если присмотреться, то такая доступность ИИ не была бы возможной без крупных IT-игроков, таких как Google, Microsoft, Amazon и др. Ведь именно они вкладывают свои усилия и финансы в развитие библиотек для нейронных сетей, а потом открывают им доступ для всех разработчиков.
Сегодня в статье мы рассмотрим, какими программными продуктами представлена нейронная сеть в Google.
Разбирать все продукты мы не будем, потому что их сотни, но наиболее интересные и значимые — обязательно.
Чем представлена нейронная сеть в Google
Нейронная сеть в Google представлена множеством различных продуктов, но самая главная из всех — это нейронная сеть Bert. Главная, потому что она затрагивает большое количество людей. Ведь именно благодаря этой нейронной сети в 2019 году произошло большое обновление поисковых алгоритмов в Google-поиске. Это обновление так или иначе затронуло всех владельцев собственных сайтов, а около 10% владельцев ресурсов заявили о проблемах после внедрения Bert:
Нейронная сеть Bert от компании Google
Bert — это новейшая нейронная сеть от Google, которая была разработана в 2018 году. Ее основное поле деятельности — это научить компьютеры понимать текст так, как его понимает человек. А это очень сложная задача, ведь в тексте есть много нюансов, которые пока понимает только человек, например: сарказм, подтекст, двусмысленность, недоговоренность, исключение слов из предложений и др.
Поисковая выдача — это лишь одно направление, где работает Bert, но именно здесь она лежит в основе поискового алгоритма. Почему не все веб-мастеры заметили внедрение Берт, а только около 10%? Потому что эта нейронная сеть от Google сфокусирована на анализе длинных поисковых запросов, чтобы выдавать максимально релевантный материал. А основная масса веб-мастеров развивают свои ресурсы с фокусировкой на короткие запросы в 1-3 слова. Такие мастеры не заметили обновление поисковых алгоритмов.
Но нужно понимать, что Bert внедрена в поисковую систему только для более качественной обработки текста, а не для того, чтобы влиять на ранжирование. Именно поэтому специалисты Google после внедрения Bert рекомендовали веб-мастерам ориентироваться на размещение качественного контента на своих ресурсах, а не на внедрении определенного количества ключевых слов.
На сегодняшний день мы имеем следующее: Bert показалась во всей красе в работе с англоязычным контентом. В работе с другими языками, в том числе и с русским, она испытывает небольшие трудности, однако она постоянно обучается. А это означает, что изменения в поисковой выдаче в русскоязычном сегменте можно ожидать в любое время.
Нейронная сеть в других программных продуктах Google
Нейронная сеть в Google представлена не только Bert, но и многими другими продуктами, которые также имеют должную популярность в кругах, где они применяются.
Среди таких продуктов можно выделить:
TensorFlow. Когда-то этот инструмент был просто библиотекой, чуть позже он перерос в целый набор библиотек, но уже сейчас ему придают статус полноценного фреймворка, который можно использовать для обучения собственной нейронной сети.
ML Kit. Это набор библиотек, который необходим для внедрения собственной нейронной сети в мобильный телефон. Например, при помощи этого инструмента можно организовать в своем приложении распознавание языка пользователя и внедрять языковое управление, также можно организовать распознавание объектов, в том числе и QR-код.
AutoFlip. Это система для обработки видео на основе искусственного интеллекта. При помощи этого инструмента можно качественно обрабатывать видео без потери качества, например, можно из альбомной ориентации получить вертикальное видео и наоборот.
Colab. Это инструмент для разработчиков, который сочетает в себе онлайн-редактор кода и компилятор Python.
Cloud AI. Это набор из нескольких инструментов на основе искусственного интеллекта, которые можно внедрять в собственный бизнес для улучшения его показателей.
Cloud AutoML. Это платформа для бизнеса, где можно проводить машинное обучение своих собственных продуктов.
Teachable Machine 2.0. Это платформа для обучения собственных нейронных сетей. Причем это может делать каждый пользователь сети и даже школьники, которые никак не связаны с программированием. Ведь обучать свою нейросеть можно при помощи микрофона и видеокамеры, а потому уже обученную нейросеть можно экспортировать в свои приложения и сайты.
И др.
Заключение
Нейронная сеть и искусственный интеллект понемногу проникают в жизнедеятельность человека благодаря таким компаниям, как Google. Встретить их можно везде: в телефоне, телевизоре, «умном доме», беспилотном автомобиле, в играх, на сайтах, в «умных часах», производственных станках, приложениях и т. д.
Самое важное, что практически любой человек, если ему нужно, может создать и обучить собственную нейросеть, используя наработки и инструменты крупных компаний, опять же, таких как Google.
 Эта нейросеть обучена на нескольких миллиардах слов и продолжает постоянно обучаться до сих пор. Основная сфера ее деятельности — это обработка текста в разных ситуациях: начиная от голосовых помощников в пользовательских устройствах и заканчивая внедрением в различные приложения.
Эта нейросеть обучена на нескольких миллиардах слов и продолжает постоянно обучаться до сих пор. Основная сфера ее деятельности — это обработка текста в разных ситуациях: начиная от голосовых помощников в пользовательских устройствах и заканчивая внедрением в различные приложения. Джон Мюллер на одной пресс-конференции заявил, что умышленная оптимизация контента под Bert невозможна, так как эта нейросеть проверяет текст на естественность, а не на количество вхождений ключевых слов.
Джон Мюллер на одной пресс-конференции заявил, что умышленная оптимизация контента под Bert невозможна, так как эта нейросеть проверяет текст на естественность, а не на количество вхождений ключевых слов.

Google использует нейронные сети для поиска красивых фотографий
Главная
Рынок
Технологии
25.12.2017Автор
Ольга Блинкова
Специалисты использовали в своей работе «свёрточную нейронную сеть», архитектуру нейронных сетей, предложенную еще в 1988 году, имитирующую некоторые особенности зрительной коры головного мозга человека и нацеленную на распознавание изображений…
Компания Google создала алгоритм, который определяет качество фотографий. Об этом сообщает блог об исследованиях и разработках предприятия Google Research Blog,.
Специалисты предприятия использовали в своей работе так называемую «свёрточную нейронную сеть» (convolutional neural network, CNN), архитектуру нейронных сетей, предложенную еще в 1988 году, имитирующую некоторые особенности зрительной коры головного мозга человека и нацеленную на распознавание изображений.
При этом новый алгоритм оценивает фотографии как с точки зрения качества, так и с эстетической стороны. Новый алгоритм протестирован на наборе фотографий, который также оценивали люди-эксперты. Сообщается, что мнение ИИ в большинстве случаев совпадало с мнением людей.
Отмечается, что алгоритм может применяться не только для субъективной оценки изображений, но и для решения разнообразных трудоемких задач, таких как интеллектуальное редактирование фотографий и оптимизация качества изображения для увеличения пользовательского взаимодействия. В настоящее время алгоритм в продуктах Google еще не применяется.
Журнал IT News
ГуглНейронные сети
Предыдущая
Инновационная компания: создавая воображаемое будущее
Следующая
Microsoft получила патент на шарнир для складного смартфона
Хотите узнавать о новых материалах первыми?
Подписывайтесь на рассылку
Еженедельник
Лента материалов
Нажимая на кнопку, я принимаю условия соглашения.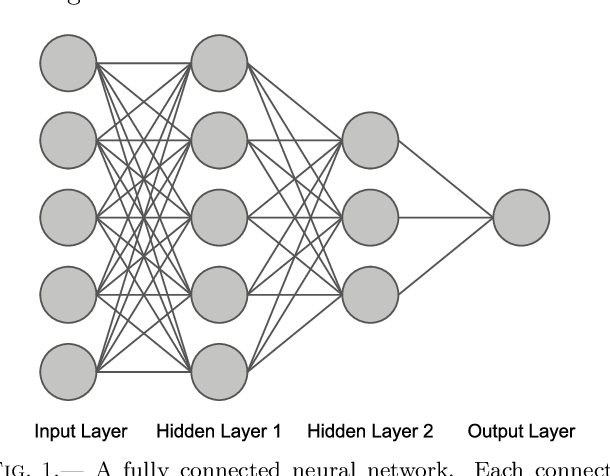
Похожие статьи
Ученые запустили нейросеть для оценки состояния Байкала
Команда ученых и разработчиков запустила нейросеть для экомониторинга Байкала на облачной платформе Yandex Cloud. Алгоритм машинного обучения анализир…
ЯндексТехнологии, 23.09.22
Альтернативное медицинское ПО
Медицинские технологии движутся вперед с небывалой скоростью. Если еще недавно программное обеспечение для врачей-диагностов могли выпустить только им…
Марк МишинТехнологии, 25.03.22
Нейронную сеть научили определять риск развития осложнений у пациентов с болезнями сердца
Выявляя ишемию миокарда, искусственный интеллект добился точности в 93%, в то время как суточный мониторинг ЭКГ — только 87%.
Технологии, 02.02.22
Мультимодальная нейросеть ruDALL-E генерирует картинки по описанию
Сбер создал первую в мире нейронную сеть ruDALL-E, которая способна создавать изображения на основе текстового описания на русском языке.
СберТехнологии, 02. 11.21
11.21
Загрузить ещё1
2
3
4
5
»»
Следующая →
10:36
Вакансий в сфере телекома по РФ за год стало больше на 52%
20:52
Apple вынуждена согласится с повышением цен на чипы TSMC
20:35
ITentika: создаем решения, позволяющие клиентам увеличивать прибыль
20:03
Дроны Mavic 3 Enterprise и Mavic 3 Thermal в России
16:49
Датчики температуры и влажности воздуха GoodWAN доступны в OCS
16:13
«Деснол Софт» представила новую редакцию «1С:ТОИР»
15:57
Справки и свидетельства из ЗАГСа можно заказать на Госуслугах
15:48
Как обучать сотрудников: мотивация, персональный подход и дискуссионные сообщества
15:42
«Инфаприм» повышает эффективность с помощью «Оптимакроса»
14:09
Google работает над искусственным интеллектом – создателем видео
Перейти в раздел
Road Show SearchInform 2022: Безопасность в новых реалиях
Оффлайн
Дата: 20.09.22 — 22. 11.22
11.22
Global Information Security Days
Онлайн
Дата: 05.10.22 — 07.10.22
GLOBAL INFORMATION SECURITY DAYS 2022
Гибридный формат
Дата: 05.10.22 — 07.10.22
Все мероприятия
Журнал IT-News № 09/2022
Сделано в России
Технологическая импортонезависимость бизнеса: опыт и решения
Политика
Мобилизация. Как это отразится на рынке ИТ?
Опыт
Работа в условиях санкций. Как бизнес справляется с вызовами и ограничениями
Видеожурнал
ИТ Среда
ИТ и Бизнес.
Что сегодня важно?
Идеи и мнения из первых рук
Валерий Баулин, Group-IB: «Работы сильно прибавилось»
Параллельный импорт ИТ-оборудования: турбулентность сменится адаптацией
ИБ в условиях повышенной облачности. Киберпротивостояние
The Merge: конец эпохи майнинговых ферм
Многофакторная аутентификация с MULTIFACTOR: удалёнка без опасности
Двухконтурная валютно-финансовая система РФ: конец гегемонии доллара или возврат к плановой экономике?
ИБ в условиях повышенной облачности. «Железные» поставки
«Железные» поставки
BI-аналитика без аналитического хранилища: лайфхак или ошибка?
Российский рынок программных роботов
Видеоконференцсвязь по-русски
Тренируйте нейронные сети быстрее с помощью TPU Google с вашего ноутбука.
Автор оригинала: Mauhcs.
Вы знаете, как это делается, у вас есть такая милая архитектура глубоких нейронных сетей, но для обучения требуется целая вечность. В этот момент вы начинаете просматривать Amazon в поисках самого дешевого графического процессора, который вы можете найти для обучения своих моделей, хотя вы даже не знаете, как подключить его к своей машине, но все лучше, чем те часы, которые ваша модель тратит на обучение одного набора гиперпараметров. Ну, прежде чем вы начнете тратить сотни долларов на аппаратное обеспечение, вам следует рассмотреть тензорные процессоры (Cpu) от Google. TPU-это аппаратный компонент, предназначенный для ускорения обучения и прогнозирования моделей машинного обучения, чтобы исследователи и инженеры могли сосредоточиться на своих решениях для своих любимых людей, а не сходить с ума в течение всей жизни.
Если вы хотите поиграть с Push, прежде чем стать серьезным, взгляните на этот учебник от Google (https://www.tensorflow.org/guide/tpu). Он научит вас, как работать в TPUS из Collapse (ноутбуки Jupyter в облаке Google). Это аккуратная функция, и ее довольно легко запустить, так что это хорошее начало. Но что, если вы хотите разработать свою модель локально, даже выполнить небольшую выборку на своем компьютере и только затем отправить данные в облачные ТПУ для обучения? Оказывается, для этого тебе нужно немного попрыгать. Но я могу показать вам прямую линию через дикую землю документации Google Cloud, чтобы достичь именно этого.
Возьмите свою любимую машину и пристегнитесь. Вот краткое изложение того, что происходит:
- Узнайте, как создать собственный облачный ТПУ в Google.
- Создайте свой собственный облачный сервер и хранилище Google для хранения обучающих данных.
- Получите ключи учетной записи службы, чтобы программно подключить сценарий обучения к Google.
- Туннелирование по SSH. Подключите локальную машину к облачному ТПУ в одну линию.
- Погрузитесь в простой пример репо git для обучения вашей первой модели в TPUS

Откройте окно терминала и создайте рабочий каталог для этого руководства. Кроме того, оставьте терминал открытым, так как мы будем настраивать среду по мере прохождения урока.
# Make a folder for this tutorial mkdir -p ~/tpu-tutorial
Чтобы получить свой собственный, вы заходите в консоль Google Cloud Platform (GCP): https://console.cloud.google.com/compute/tpus и нажмите “Создать узел TPU” в верхней части страницы (или в середине страницы, если это ваш первый узел TPU).
Затем выберите имя для своего узла, это не важно, поэтому любое имя подходит, или просто оставьте как узел-1, и все будет в порядке.
Ниже приведены важные шаги:
- Выберите us-central-1-c в качестве зоны для вашего узла TPU. На момент написания статьи только несколько центров обработки данных имели, таким образом, это Айова (США-central1-{a,b,c}), Нидерланды (Европа-запад 4a) и Тайвань (азия-восток 1-c). TPU Айовы являются самыми дешевыми (1,35 доллара США), поэтому для этого урока давайте придерживаться их, выберите us-central1-c.
- Нажмите кнопку “Вытеснение”. Это позволяет Google отключить ваш процессор, если это необходимо их системе. Это звучит плохо, и это в производственной среде, но этот вариант делает узел TPU намного дешевле, и дополнительный риск на самом деле не имеет значения для этого урока. Я был просто в порядке с проверкой этой опции.
Наконец, выберите тип ТПУ. Тип v2–8 отлично подходит для нас здесь. Нажмите кнопку “Создать.”
См. Рисунок ниже, как выглядит настройка:
Рисунок ниже, как выглядит настройка:
Настройка узла ТПУ. Получите свои в США-central1, так как они дешевле.
ВАЖНО: ВЫКЛЮЧАЙТЕ СВОЙ ТПУ, когда вы им не пользуетесь, чтобы не тратить деньги без необходимости. Google очень легко запускает и запускает новый ТПУ, поэтому не стесняйтесь уничтожить его, если вы сделаете перерыв в этом уроке. Ваш карман благодарит вас
После нажатия кнопки создать вы будете перенаправлены на панель мониторинга с вашими узлами TPU. После инициализации узла слева от имени узла появится зеленая галочка, а под столбцом “Внутренний IP” появится IP-адрес (если столбец “Внутренний IP” не отображается, нажмите “столбцы” и выберите “Внутренний IP”). Скопируйте IP-адрес и выполните следующую команду в терминале:
# Change TPU.
 INTERNAL.IP with TPU node's IP
export TPU="TPU.INTENAL.IP"
INTERNAL.IP with TPU node's IP
export TPU="TPU.INTENAL.IP"
Обратите внимание, что IP-адрес TPU является только внутренним (как следует из названия), это означает, что вы не можете подключиться к нему напрямую с вашего компьютера. Для этого нам нужен сервер перехода между вашим компьютером и ТПУ, но это очень просто.
Перейдите к экземплярам GCP и создайте экземпляр. Есть три важных шага, чтобы правильно подключить локальную машину к ТПУ.
- Создайте экземпляр в том же регионе, что и на предыдущем шаге (us-central1-c, если вы следуете умолчанию в этом руководстве).
- В конфигурации машины вы можете выбрать самый дешевый сервер (f1-micro). Это идеально подходит для этого урока.
См. Изображение для справки:
Выберите свой регион, как в предыдущем разделе. Здесь достаточно самой низкой конфигурации сервера. В моем случае я смог получить экземпляр бесплатно от GCP.
- Добавьте свой открытый ключ ssh на сервер, чтобы подключиться к нему с локальной машины. Для этого в нижней части страницы нажмите там, где написано “Управление, безопасность, диски, сеть, единоличное владение”, чтобы развернуть форму. Выберите “Безопасность” и введите свой открытый ключ SSH в текстовое поле “Введите открытый ключ SSH”.
 Для этого в нижней части страницы нажмите там, где написано “Управление, безопасность, диски, сеть, единоличное владение”, чтобы развернуть форму. Выберите “Безопасность” и введите свой открытый ключ SSH в текстовое поле “Введите открытый ключ SSH”.
Для этого в нижней части страницы нажмите там, где написано “Управление, безопасность, диски, сеть, единоличное владение”, чтобы развернуть форму. Выберите “Безопасность” и введите свой открытый ключ SSH в текстовое поле “Введите открытый ключ SSH”.Чтобы просмотреть открытый ключ ssh, выполните следующую команду:
# Display ssh public-key cat ~/.ssh/id_rsa.pub
Результат должен выглядеть примерно так:
# ssh public-key example ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSU GPl+nafzlHDTYW7hdI4yZ5ew18Jh5JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3 Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XA t3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/En mZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbx NrRFi9wrf+M7Q== USERNAME@email.
Запомните свое имя пользователя, так как будет важно подключить локальную машину к экземпляру.
Если у вас нет открытого ключа ssh, предыдущая команда должна была выдать ошибку, в этом случае выполните следующую команду, чтобы создать свой собственный ключ ssh:
# Generate a ssh public-key ssh-keygen -t rsa -b 4096 -C "USERNAME@email.com"
Затем скопируйте и вставьте свой открытый ключ ssh в форму и нажмите “Создать.” См.Изображение ниже для справки.
Вставьте свой открытый ключ ssh в поле “Введите открытый ключ SSH”, затем нажмите “Создать”
После нажатия кнопки “Создать” вы будете перенаправлены на панель мониторинга с вашими экземплярами. Когда ваш новый экземпляр будет запущен, вы увидите зеленую галочку слева от имени. Пришло время получить его IP. См. Изображение для справки:
Когда ваш новый экземпляр будет запущен, вы увидите зеленую галочку слева от имени. Пришло время получить его IP. См. Изображение для справки:
Получите “Внешний IP-адрес вашего экземпляра”
Как и в случае с турами, вам понадобится IP-адрес экземпляра, но на этот раз “Внешний IP”. Кроме того, запомните свой открытый ключ SSH и выполните следующую команду в ранее открытом терминале:
# Save the jump server's IP and your username in it: export JUMP="INSTANCE.EXTERNAL.IP"; export USER=USERNAME
С инициализацией TPU и созданием экземпляра облачного сервера мы ПОЧТИ готовы начать обучение наших моделей. Недостающая часть-это данные, и они ДОЛЖНЫ храниться в облачном хранилище Google. Итак, давайте создадим наше собственное ведро в следующем разделе.
Перейдите в Google Storage (gs) и нажмите “Создать ведро”.” Выполните следующие действия, чтобы убедиться, что ваш ТПУ может видеть ваше ведро.
- Назовите его “dnn-bucket”.
- Выберите Регион в качестве типа местоположения корзины.
- Выберите его местоположение как us-central1 (Айова) — или убедитесь, что это тот же регион, что и ваш ТПУ
- Выберите размер хранилища, равный 1 ГБ.
- Оставьте все остальные параметры и поля как есть.
- Нажмите кнопку Создать
Следующий шаг-создать ключи учетной записи службы, чтобы ваш скрипт мог подключиться к ведру. Для этого нажмите на ссылку ниже и следуйте инструкциям: Создание ключа учетной записи службы Google: https://cloud.google.com/iam/docs/creating-managing-service-account-keys#creating_service_account_keys
После создания ключей сохраните файл как “~/tpu-tutorial/tensorflow-tutorial-crud.json.”
Теперь, когда создан экземпляр TPU и сервера Jump, создано хранилище Google и ваша локальная машина имеет доступ к нему, единственная недостающая часть-это подключение всего. Мы сделаем это с помощью туннелирования SSH в следующем разделе.
Мы сделаем это с помощью туннелирования SSH в следующем разделе.
Туннелирование SSH позволяет серверу jump, созданному в облаке, подключить вашу локальную машину к облачному ТПУ таким образом, чтобы нашей глубокой нейронной сети не нужно было беспокоиться о сетевом подключении. С точки зрения обучающего сценария соединение происходит с локальной машиной.
Чтобы создать туннель, выполните следующие команды в новом терминале:
# Export TPU's Internal IP if you did not do that yet export TPU="TPU.INTERNAL.IP" # Export Jump Server's IP and username if you did not do that yet export JUMP="JUMP.EXTERNAL.IP"; export USER=JUMP_USERNAME # Make the SSH Tunnel between your local port 2000 and the TPU: ssh $USER@$JUMP -L 2000:$TPU:8470
Эта команда зарегистрирует ваш терминал на сервере перехода, и туннель будет подключен до тех пор, пока вы подключены к серверу. Чтобы отключить, отключив туннель, нажмите ctrl-d с подключенным терминалом.
Чтобы отключить, отключив туннель, нажмите ctrl-d с подключенным терминалом.
Теперь мы готовы к последнему шагу-обучению нашей глубокой нейронной сети в облачном ТПУ Google. Насколько это будет быстрее, чем работать на вашем локальном компьютере?
В качестве первой попытки обучения с использованием облачного ТПУ я сделал пример репо git. Чтобы установить его, на вашем компьютере должен быть установлен python 3. Затем клонируйте репо git следующим образом:
# Create working directory if not create already and navigate to it: mkdir -p ~/tpu-tutorial cd ~/tpu-tutorial git clone https://github.com/mauhcs/tpu-from-home.git cd tpu-from-home
Затем создайте среду, обновите pip и установите требования python с помощью:
python -m venv tpu-env source tpu-env/bin/activate pip install --upgrade pip pip install -r requirements.
 txt
txt
Вот и все, вы готовы обучить свою собственную модель. Если вы хотите, вы можете использовать удобные сценарии, которые я написал. Например, вот как тренироваться локально:
# Train locally: time bash local_run.sh
Вот как тренироваться в вашем ВЫ (помните, что мы получили файл tensorflow-tutorial-crud.json с предыдущего шага):
# Train in the TPU # The file tensorflow-tutorial-cred.
 json is from a previous step
time bach tpu_run.sh ~/tpu-tutorial/tensorflow-tutorial-cred.json
json is from a previous step
time bach tpu_run.sh ~/tpu-tutorial/tensorflow-tutorial-cred.json
Если вы хотите погрузиться в детали того, как работает модель, взгляните на main.py. Дайте мне знать, если вам нужна статья о глубоком погружении в распределенном обучении, ориентированном на ТПУ.
Это мои результаты, запущенные с моего MacBook pro в качестве локальной машины и запущенные в ТПУ в Айове (из Токио). Модель представляет собой многослойную сверточную сеть для визуального распознавания MNIST с 50 эпохами обучения. Смотрите модель здесь.
# Local run
{'accuracy_top_1': 0.9893662929534912,
'eval_loss': 0.032137673969070114,
'loss': 0. 033212198394125904,
'training_accuracy_top_1': 0.989628255367279}
real 34m12.642s
user 101m32.471s
sys 11m41.765s
# TPU training
{'accuracy_top_1': 0.9892578125,
'eval_loss': 0.031606151825851865,
'loss': 0.032124145309729825,
'training_accuracy_top_1': 0.989863932132721}
real 16m54.201s
user 0m20.993s
sys 0m4.911s
 033212198394125904,
'training_accuracy_top_1': 0.989628255367279}
real 34m12.642s
user 101m32.471s
sys 11m41.765s
# TPU training
{'accuracy_top_1': 0.9892578125,
'eval_loss': 0.031606151825851865,
'loss': 0.032124145309729825,
'training_accuracy_top_1': 0.989863932132721}
real 16m54.201s
user 0m20.993s
sys 0m4.911s
033212198394125904,
'training_accuracy_top_1': 0.989628255367279}
real 34m12.642s
user 101m32.471s
sys 11m41.765s
# TPU training
{'accuracy_top_1': 0.9892578125,
'eval_loss': 0.031606151825851865,
'loss': 0.032124145309729825,
'training_accuracy_top_1': 0.989863932132721}
real 16m54.201s
user 0m20.993s
sys 0m4.911s
Обучение простой сверточной нейронной сети на наборе данных MNIST в облачном ТПУ было в два раза быстрее, чем обучение локально (MacBook Pro 3,5 ГГц Intel Core i7). Это может быть хорошим способом помочь вашим моделям выполнять поиск гиперпараметров или просто обучать более сложные модели. Я ожидал бы лучшей производительности от Pub, поэтому я ожидаю, что больше настроек в модели и конвейере данных должно улучшить производительность TPU.
Облачные ТПУ также недешевы, поэтому, если вы не уверены, что сможете воспользоваться его скоростью обучения, вам, возможно, будет лучше тренироваться на своих локальных компьютерах. TPU требуют большой интеграции с Google cloud (ведра хранения, экземпляры облачных серверов и т. Д.), но с задержкой, которая была бы добавлена, если бы какой-либо компонент находился на вашем локальном компьютере, было бы трудно оправдать использование TPU, так как сетевые запросы замедлили бы обучение. Чтобы убедиться в этом, удалите опцию –no_callback из файла tpc_run.sh и посмотрите всю задержку, которую он добавляет.
Д.), но с задержкой, которая была бы добавлена, если бы какой-либо компонент находился на вашем локальном компьютере, было бы трудно оправдать использование TPU, так как сетевые запросы замедлили бы обучение. Чтобы убедиться в этом, удалите опцию –no_callback из файла tpc_run.sh и посмотрите всю задержку, которую он добавляет.
В конечном счете, из-за задержки в сети запуск cloud Push с локального компьютера следует рассматривать как тестовый запуск перед развертыванием обучающих сценариев на облачном сервере.
Собираетесь ли вы начать использовать TPUS? Вам нужен учебник о том, как писать свои собственные модели для обучения? Дайте мне знать в комментариях ниже, что вы думаете.
Кроме того, ВЫКЛЮЧИТЕ СВОЙ TPU , когда вы его не используете. Добро пожаловать
Google AI представляет два новых семейства нейронных сетей под названием «EfficientNetV2» и «CoAtNet» для распознавания изображений
- О нас
Войти
Добро пожаловать! Войдите в свою учетную запись
ваше имя пользователя
ваш пароль
Забыли свой пароль?
Конфиденциальность и ТК
Восстановление пароля
Восстановить пароль
ваш адрес электронной почты
Поиск
Главная Технические новости Резюме доклада об искусственном интеллекте Google AI представляет два новых семейства нейронных сетей под названием «EfficientNetV2» и…
Эффективность обучения стала важным фактором для глубокого обучения по мере роста моделей нейронных сетей и увеличения объема обучающих данных. GPT-3 — отличный пример, показывающий, насколько критическим может быть фактор эффективности обучения, поскольку требуются недели обучения с тысячами графических процессоров, чтобы продемонстрировать замечательные возможности в обучении за несколько шагов.
GPT-3 — отличный пример, показывающий, насколько критическим может быть фактор эффективности обучения, поскольку требуются недели обучения с тысячами графических процессоров, чтобы продемонстрировать замечательные возможности в обучении за несколько шагов.
Чтобы решить эту проблему, команда искусственного интеллекта Google представляет два семейства нейронных сетей для распознавания изображений. Во-первых, EfficientNetV2, состоящий из CNN (сверточных нейронных сетей) с небольшим набором данных для повышения эффективности обучения, например, ImageNet1k (с 1,28 миллиона изображений). Во-вторых, это гибридная модель под названием CoAtNet, которая сочетает в себе свертки и самостоятельное внимание для достижения более высокой точности крупномасштабных наборов данных, таких как ImageNet21 (с 13 миллионами изображений) и JFT (с миллиардами изображений). Согласно исследовательскому отчету Google, EfficientNetV2 и CoAtNet работают в 4–10 раз быстрее, обеспечивая при этом самые современные и 90,88 % – точность первого уровня в хорошо зарекомендовавшем себя наборе данных ImageNet .
EfficientNetV2 : Модели для более быстрого обучения и меньшего размера
EfficientNetV2 основан на предыдущей архитектуре EfficientNet. Команда Google AI изучила узкие места в скорости обучения на современных TPU/GPU, чтобы улучшить исходную модель. Они обнаружили следующее:
- Обучение с большими размерами изображений приводит к более высокому использованию памяти, что приводит к снижению скорости на TPU/GPU.
- Глубинные свертки неэффективны для TPU/GPU, поскольку они имеют низкую загрузку оборудования.
- Общепринятый подход к единообразному составному масштабированию, который одинаково масштабирует каждую стадию сверточных сетей, является неоптимальным.
Исследовательская группа Google предлагает поиск нейронной архитектуры с учетом обучения (NAS), где скорость обучения включена в цель оптимизации, и метод масштабирования, который неравномерно масштабирует различные этапы для решения этих проблем, как описано выше.
Исследовательская группа Google оценивает модели EfficientNetV2 в ImageNet и нескольких других наборах данных трансферного обучения. В ImageNet модели EfficientNetV2 превосходят предыдущие модели: скорость обучения примерно в 5–11 раз выше, а размер модели меньше в 6,8 раза.
https://ai.googleblog.com/2021/09/toward-fast-and-accurate-neural.html
CoAtNet : Модели с более высокой скоростью и большей точностью для крупномасштабного распознавания изображений
В CoAtNet ( CoAtNet: Объединение свертки и внимания для всех размеров данных) исследовательская группа изучила способы сочетания свертки и внутреннего внимания для разработки быстрых и точных нейронных сетей для крупномасштабного распознавания изображений. Комбинируя свертку и самостоятельный анализ, предлагаемые гибридные модели могут обеспечить как большую пропускную способность, так и лучшее обобщение.
Исследовательская группа обнаружила два важных открытия, связанных с обнаружением COAtNet:
- Глубинная свертка и самовнимание могут быть естественным образом объединены с помощью простого относительного внимания.
- Вертикальное размещение слоев свертки и слоев внимания таким образом, чтобы учитывать их пропускную способность и вычисления, необходимые на каждом этапе (разрешение), удивительно эффективно для улучшения обобщения, пропускной способности и эффективности.

Основываясь на вышеизложенном, исследовательская группа Google создала семейство гибридных моделей, состоящих как из свертки, так и из внимания, под названием CoAtNets.
Согласно данным исследовательской статьи Google, модель CoAtNet превосходит модели ViT и ее варианты в ряде наборов данных, таких как ImageNet1K, ImageNet21K и JFT. По сравнению со свёрточными сетями CoAtNet демонстрирует аналогичное поведение производительности на небольшом наборе данных, таком как ImageNet1K.
https://ai.googleblog.com/2021/09/toward-fast-and-accurate-neural.html
Paper (CoAtNet): https://arxiv.org/abs/2106.04803
Paper (EfficientNetV2): https://arxiv.org/abs/2104.00298
Источник: https://ai. googleblog.com/2021/09/toward-fast-and-accurate-neural.html
googleblog.com/2021/09/toward-fast-and-accurate-neural.html
Код: https://github.com/google/automl/tree/master/ эффективныйнетв2
Асиф Раззак
Веб-сайт
|
+ posts
Асиф Раззак — журналист в области искусственного интеллекта и соучредитель Marktechpost, LLC. Он провидец, предприниматель и инженер, который стремится использовать силу искусственного интеллекта во благо.
Последним предприятием Асифа является разработка Медиа-платформы искусственного интеллекта (Marktechpost), которая изменит способы поиска релевантных новостей, связанных с искусственным интеллектом, наукой о данных и машинным обучением.
Асиф был представлен Onalytica в своей книге «Кто есть кто в ИИ?». (Влиятельные голоса и бренды)» как одного из «Влиятельных журналистов в области ИИ» (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). Его интервью также было опубликовано Onalytica (https://onalytica. com/blog/posts/interview-with-asif-razzaq/).
com/blog/posts/interview-with-asif-razzaq/).
Предыдущая статьяПоследние исследования Еврейского университета объясняют сходство между нейронами и искусственными нейронными сетями
Следующая статьяИсследователи представляют OncoPetNet: систему искусственного интеллекта на основе глубокого обучения для подсчета митотических фигур в ветеринарной диагностической лаборатории
Резюме статьи AI: неконтролируемое изучение вероятно симметричных деформируемых 3D-объектов из изображений в дикой природе
Изучите лучшие практики ИИ от более чем 120 экспертов на конференции TransformX
Зарегистрируйтесь бесплатно
X
Deep Neural Networks — Introduction to Google AI Platform Course
- Home
 org/ListItem»> Учебная библиотека
org/ListItem»> Учебная библиотека- Google Cloud Platform
- Курсы
- Introduction to Google AI Platform
Введение 19039 keyboard_tab0130 Обучение вашей первой нейронной сети
Повышение точности
Масштабирование с помощью платформы ИИ
Резюме
Курс является частью этих направлений обучения
Подготовка к экзамену на инженера по машинному обучению Google
Машинное обучение на Google Cloud Platform
9 Подготовка к экзамену Professional Data Engineer
Начальный курс
Обзор
Сложность
Средний уровень
Продолжительность
1h 3m
Студенты
3179
Рейтинги
4. 7/5
7/5
starstarstarstarstarstar-half
Описание
Машинное обучение — горячая тема в наши дни, и Google является одним из крупнейших новостных агентств. Машинное обучение Google ежедневно используется миллионами людей за кулисами. Когда вы ищете изображение в Интернете или используете Google Translate для текста на иностранном языке или используете голосовую диктовку на своем телефоне Android, вы используете машинное обучение. Теперь Google запустил платформу AI, чтобы дать своим клиентам возможность обучать свои собственные нейронные сети.
Это практический курс, в котором вы можете пройти демонстрацию, используя свою собственную учетную запись Google Cloud или пробную учетную запись.
Цели обучения
- Описать, как функционирует искусственная нейронная сеть
- Запустить простую программу TensorFlow
- Обучение модели с помощью распределенного кластера на платформе ИИ
- Повышение точности прогнозирования с помощью разработки функций и настройки гиперпараметров
- Разверните обученную модель на платформе ИИ, чтобы делать прогнозы на основе новых данных
Ресурсы
- Репозиторий GitHub для этого курса находится по адресу https://github. com/cloudacademy/aiplatform-intro.
 com/cloudacademy/aiplatform-intro.
com/cloudacademy/aiplatform-intro.Обновления
- 20 декабря 2020 г. Курс полностью обновлен в связи с тем, что Google AI Platform заменяет Cloud ML Engine и выпуск TensorFlow 2.
- 16 ноября 2018 г.: обновлено 90 % уроков в связи с серьезными изменениями в TensorFlow и Google Cloud ML Engine. Все демонстрации и пошаговые руководства по коду были полностью переделаны.
Стенограмма
На прошлом уроке мы создали глубокую нейронную сеть. Итак, чем глубокая нейронная сеть отличается от обычной и зачем вам ее использовать? Хотя «глубокое обучение» звучит так, как будто это сложная, почти мистическая концепция, на самом деле это просто означает, что нейронная сеть имеет более трех слоев, как здесь.
Слои между внешними слоями называются скрытыми, потому что их входы и выходы не видны. Скрытые слои полезны, потому что они позволяют сети комбинировать функции для распознавания шаблонов более высокого уровня.
Возвращаясь к нашему оценщику стоимости жилья, предположим, что в некоторых районах старые дома ценятся выше, чем новые дома, но в других районах новые дома ценятся выше, чем старые дома. В двухслойной нейронной сети все функции независимы друг от друга, поэтому невозможно объединить возраст дома и его окрестности, чтобы определить, насколько значение должно увеличиваться или уменьшаться.
На самом деле способ есть, но он требует большого понимания со стороны человека, строящего сеть. Вы можете создавать новые объекты, которые являются комбинациями исходных объектов, и включать их во входной слой. Мы рассмотрим этот подход в другом уроке.
Самое замечательное в глубинных сетях то, что они часто могут обнаруживать эти отношения для вас. Это связано с тем, что каждый узел скрытого слоя по-разному объединяет выходные данные всех узлов предыдущего слоя.
В результате узел в скрытом слое потенциально может стать «детектором признаков». В этой исследовательской статье есть хорошая иллюстрация. Это показывает нейронную сеть, которая пытается обнаружить лицо на изображении. В первом слое он обнаруживает края. На втором уровне он объединяет эти ребра для обнаружения простых форм. На третьем уровне он объединяет простые формы для определения форм лица. Если бы у вас была сеть без скрытых слоев, то ей пришлось бы пытаться обнаружить лицо, основываясь только на отдельных пикселях изображения, что было бы намного сложнее.
Это показывает нейронную сеть, которая пытается обнаружить лицо на изображении. В первом слое он обнаруживает края. На втором уровне он объединяет эти ребра для обнаружения простых форм. На третьем уровне он объединяет простые формы для определения форм лица. Если бы у вас была сеть без скрытых слоев, то ей пришлось бы пытаться обнаружить лицо, основываясь только на отдельных пикселях изображения, что было бы намного сложнее.
Прелесть этого в том, что он сам обнаруживает эти особенности без какого-либо руководства со стороны человека, создающего нейронную сеть. Это то, что может сделать глубокое обучение почти волшебным.
Теперь, возвращаясь к классификатору радужной оболочки, давайте посмотрим на его скрытые слои. В каждом из двух слоев по 10 узлов.
Итак, насколько важны скрытые слои? Что ж, самый простой способ узнать это — удалить скрытые слои и посмотреть, насколько точность ниже. Я просто прокомментирую строки. Теперь снова запустим.
Точность намного ниже. Так что похоже, что скрытые слои действительно имели большое значение.
Так что похоже, что скрытые слои действительно имели большое значение.
Прежде чем двигаться дальше, вы должны отменить изменения, внесенные в сценарий, и снова сохранить его.
На этом урок закончен.
Об авторе
Студенты
164329
Курсы
94
Пути обучения
147
С тех пор как Гай1 запустил свой первый обучающий веб-сайт по информационным технологиям, он помогает изучать 95 человек. Он был системным администратором, инструктором, инженером по продажам, ИТ-менеджером и предпринимателем. В своем последнем предприятии он основал и возглавил компанию, занимающуюся облачной инфраструктурой обучения, которая предоставила виртуальные лаборатории некоторым из крупнейших поставщиков программного обеспечения в мире. Страсть Гая — сделать сложные технологии простыми для понимания. Его деятельность вне работы включала катание на слоне и прыжки с парашютом (хотя и не одновременно).
Страсть Гая — сделать сложные технологии простыми для понимания. Его деятельность вне работы включала катание на слоне и прыжки с парашютом (хотя и не одновременно).
Машинное обучениеИскусственный интеллектОблачная платформа GoogleИскусственный интеллект для GoogleПлатформа искусственного интеллекта Google
Google Just Open Sourced TensorFlow, его механизм искусственного интеллекта
Кейд Мец
Бизнес
900 Google — это программное обеспечение с открытым исходным кодом, которое лежит в основе его онлайн-империи.
Технический эксперт Тим О’Рейли только что попробовал новое приложение Google Photos и был поражен глубиной его искусственного интеллекта.
В мае прошлого года О’Рейли стояла в нескольких футах от генерального директора и соучредителя Google Ларри Пейджа на небольшом коктейльном приеме для прессы в рамках ежегодной конференции Google I/O — главного события года компании. Ранее в тот же день Google представила свое приложение для личных фотографий, и О’Рейли был поражен тем, что если он введет что-то вроде «надгробие» в поле поиска, приложение сможет найти фотографию могилы его дяди, сделанную так давно.
Ранее в тот же день Google представила свое приложение для личных фотографий, и О’Рейли был поражен тем, что если он введет что-то вроде «надгробие» в поле поиска, приложение сможет найти фотографию могилы его дяди, сделанную так давно.
Приложение использует все более мощную форму искусственного интеллекта, называемую глубоким обучением. Анализируя тысячи фотографий надгробий, эта технология искусственного интеллекта может научиться идентифицировать надгробие, которое она никогда раньше не видела. То же самое касается кошек и собак, деревьев и облаков, цветов и еды.
Поисковая система Google Фото не идеальна. Но его точность чрезвычайно впечатляет — настолько впечатляет, что О’Рейли не мог понять, почему Google не продает доступ к своему движку ИИ через Интернет, в стиле облачных вычислений, позволяя другим управлять своими приложениями с помощью того же машинного обучения. По его словам, это может быть реальным источником дохода для Google. В конце концов, Google также использует этот механизм искусственного интеллекта для распознавания произносимых слов, перевода с одного языка на другой, улучшения результатов поиска в Интернете и многого другого. Остальной мир может использовать эту технологию для решения многих других задач, от таргетинга рекламы до компьютерной безопасности.
Остальной мир может использовать эту технологию для решения многих других задач, от таргетинга рекламы до компьютерной безопасности.
Сегодня утром Google развил идею О’Рейли дальше, чем он ожидал. Он не продает доступ к своему механизму глубокого обучения. Это открытый исходный код этого движка, свободно распространяющий базовый код со всем миром. Это программное обеспечение называется TensorFlow, и, буквально раздавая технологию, Google полагает, что оно может ускорить эволюцию ИИ. Благодаря открытому исходному коду посторонние могут помочь улучшить технологию Google и, да, вернуть эти улучшения обратно в Google.
«Мы надеемся, что сообщество примет это как хороший способ выражения алгоритмов машинного обучения множества различных типов, а также внесет свой вклад в создание и улучшение [TensorFlow] множеством различных и интересных способов», — говорит Джефф Дин. , один из самых важных инженеров Google и ключевой игрок в развитии технологий глубокого обучения.
В последние годы другие компании и исследователи также добились огромных успехов в этой области искусственного интеллекта, включая Facebook, Microsoft и Twitter. А у некоторых уже есть программное обеспечение с открытым исходным кодом, похожее на TensorFlow. Сюда входит Torch — система, изначально созданная швейцарскими исследователями, — а также такие системы, как Caffe и Theano. Но шаг Google значителен. Это потому, что ИИ-движок Google некоторые считают самым передовым в мире, и потому что это Google.
А у некоторых уже есть программное обеспечение с открытым исходным кодом, похожее на TensorFlow. Сюда входит Torch — система, изначально созданная швейцарскими исследователями, — а также такие системы, как Caffe и Theano. Но шаг Google значителен. Это потому, что ИИ-движок Google некоторые считают самым передовым в мире, и потому что это Google.
«Это действительно интересно», — говорит Крис Николсон, руководитель стартапа Skymind в области глубокого обучения. «Google на пять-семь лет опережает остальной мир. Если они откроют исходный код своих инструментов, это может сделать всех остальных лучше в машинном обучении».
Безусловно, Google не раскрывает всех своих секретов. На данный момент компания является только открытой частью этого ИИ-движка. Он разделяет только некоторые из алгоритмов, которые работают поверх движка. И это не доступ к удивительно продвинутой аппаратной инфраструктуре, на которой работает этот движок (за это, безусловно, придется заплатить). Но Google раздает по крайней мере часть своего наиболее важного программного обеспечения для центров обработки данных, и это не то, что она обычно делала в прошлом.
Google стал самой доминирующей силой в Интернете в значительной степени благодаря уникальному мощному программному и аппаратному обеспечению, которое она встроила в свои компьютерные центры обработки данных — программному и аппаратному обеспечению, которое могло помочь запустить все его онлайн-сервисы, которые могли управлять трафиком и данными из беспрецедентного количества. людей по всему миру. И, как правило, он не делился своими проектами с остальным миром, пока не перешел к другим проектам. Даже тогда он просто делился исследовательскими документами, описывающими его технологию. Компания не открывала исходный код. Так он сохранил преимущество.
Самые популярные
Однако с TensorFlow компания изменила курс, свободно делясь некоторыми из своих новейших и, действительно, наиболее важных программ. Да, Google открывает исходные коды частей своей мобильной операционной системы Android и многих других небольших программных проектов. Но это другое. Выпуская TensorFlow, Google представляет программное обеспечение с открытым исходным кодом, которое лежит в основе его империи. «Это довольно серьезное изменение», — говорит Дин, который участвовал в создании многих революционных программ компании для центров обработки данных, включая файловую систему Google, MapReduce и BigTable.
Но это другое. Выпуская TensorFlow, Google представляет программное обеспечение с открытым исходным кодом, которое лежит в основе его империи. «Это довольно серьезное изменение», — говорит Дин, который участвовал в создании многих революционных программ компании для центров обработки данных, включая файловую систему Google, MapReduce и BigTable.
Открытые алгоритмы
Глубокое обучение основано на нейронных сетях — системах, которые напоминают паутину нейронов в человеческом мозгу. По сути, вы передаете этим сетям огромные объемы данных, и они учатся выполнять задачу. Предложите им множество фотографий завтрака, обеда и ужина, и они научатся распознавать еду. Кормите их произнесенными словами, и они научатся распознавать то, что вы говорите. Накормите их диалогами из старых фильмов, и они научатся поддерживать разговор — не идеальный разговор, но довольно хороший разговор.
Как правило, Google обучает эти нейронные сети, используя огромное количество машин, оснащенных чипами GPU — компьютерными процессорами, которые изначально были созданы для рендеринга графики для игр и других визуальных приложений, но также хорошо зарекомендовали себя в глубоком обучении. Графические процессоры хороши для параллельной обработки большого количества небольших битов данных, и именно этого требует глубокое обучение.
Графические процессоры хороши для параллельной обработки большого количества небольших битов данных, и именно этого требует глубокое обучение.
Но после того, как их обучили — когда пришло время ввести их в действие — эти нейронные сети работают по-разному. Они часто работают на традиционных компьютерных процессорах внутри центра обработки данных, а в некоторых случаях могут работать и на мобильных телефонах. Приложение Google Translate является одним из мобильных примеров. Он может полностью работать на телефоне — без подключения к центру обработки данных через сеть — позволяя вам переводить иностранный текст на ваш родной язык, даже если у вас нет хорошего беспроводного сигнала. Вы можете, например, навести приложение на немецкий уличный знак, и оно мгновенно переведется на английский язык.
TensorFlow — это способ построения и запуска этих нейронных сетей — как на этапе обучения, так и на этапе выполнения. Это набор программных библиотек — набор кода, который вы можете вставить в любое приложение, чтобы оно тоже могло изучать такие задачи, как распознавание изображений, распознавание речи и языковой перевод.
Google создал базовое программное обеспечение TensorFlow с помощью языка программирования C++. Но при разработке приложений для этого механизма ИИ программисты могут использовать либо C++, либо Python, самый популярный язык среди исследователей глубокого обучения. Однако есть надежда, что аутсайдеры расширят инструмент на другие языки, включая Google Go, Java и, возможно, даже на Javascript, чтобы у программистов было больше способов создавать приложения.
ioulex
По словам Дина, TensorFlow хорошо подходит не только для глубокого обучения, но и для других форм ИИ, включая обучение с подкреплением и логистическую регрессию. Этого не было в предыдущей системе Google, DistBelief. DistBelief был довольно хорош в глубоком обучении — он помог победить в важнейшем конкурсе Large Scale Visual Recognition Challenge в 2014 году — но Дин говорит, что TensorFlow в два раза быстрее.
В открытом исходном коде инструмента Google также предоставит некоторые образцы моделей и алгоритмов нейронных сетей, включая модели для распознавания фотографий, идентификации рукописных чисел и анализа текста. «Мы предоставим вам все алгоритмы, необходимые для обучения этих моделей на общедоступных наборах данных», — говорит Дин.
«Мы предоставим вам все алгоритмы, необходимые для обучения этих моделей на общедоступных наборах данных», — говорит Дин.
Самое популярное
Беда в том, что Google еще не открыл версию TensorFlow, которая позволяет обучать модели на огромном количестве машин. Первоначальная версия с открытым исходным кодом работает только на одном компьютере. Этот компьютер может включать в себя множество графических процессоров, но, тем не менее, это один компьютер. «Google по-прежнему сохраняет преимущество, — говорит Николсон. «Чтобы создавать настоящие корпоративные приложения, вам необходимо анализировать данные в масштабе». Но на этапе исполнения воплощение TensorFlow с открытым исходным кодом будет работать на телефонах, а также на настольных компьютерах и ноутбуках, и Google указывает, что компания может в конечном итоге открыть исходный код версии, которая работает на сотнях машин.
Изменение в философии
Почему это очевидное изменение в философии Google — это решение открыть исходный код TensorFlow после стольких лет хранения важного кода в тайне? Отчасти это связано с тем, что сообщество машинного обучения обычно работает таким образом. Глубокое обучение началось с ученых, которые открыто делились своими идеями, и многие из них сейчас работают в Google, включая профессора Университета Торонто Джеффа Хинтона, крестного отца глубокого обучения.
Глубокое обучение началось с ученых, которые открыто делились своими идеями, и многие из них сейчас работают в Google, включая профессора Университета Торонто Джеффа Хинтона, крестного отца глубокого обучения.
Но Дин также говорит, что TensorFlow был создан в совсем другое время, чем такие инструменты, как MapReduce, GFS, BigTable, Dremel, Spanner и Borg. Движение за открытый исходный код, когда интернет-компании делятся многими своими инструментами, чтобы ускорить темпы разработки, за последнее десятилетие значительно ускорилось. Google теперь создает программное обеспечение с прицелом на открытый исходный код. Дин объясняет, что многие из этих ранних инструментов были слишком тесно связаны с инфраструктурой Google. На самом деле не имело смысла открывать их исходный код.
«Они не разрабатывались с учетом открытого исходного кода. У них было много отростков к существующим системам Google, и было бы трудно отрезать эти отростки», — говорит Дин. «С TensorFlow, когда мы начали его разрабатывать, мы как бы посмотрели на себя и сказали: «Эй, может быть, нам следует открыть исходный код этого». инфраструктуры, по словам инженера Google Раджата Монги. Вот почему Google не открыл исходный код всего TensorFlow, объясняет он. Как указывает Николсон, вы также можете поспорить, что Google сдерживает код, потому что компания хочет сохранить преимущество. Но показательно — и довольно важно — то, что Google открыл исходный код в той же степени, что и раньше.
инфраструктуры, по словам инженера Google Раджата Монги. Вот почему Google не открыл исходный код всего TensorFlow, объясняет он. Как указывает Николсон, вы также можете поспорить, что Google сдерживает код, потому что компания хочет сохранить преимущество. Но показательно — и довольно важно — то, что Google открыл исходный код в той же степени, что и раньше.
Цикл обратной связи
Компания Google не передала проект с открытым исходным кодом независимой третьей стороне, как это сделали многие другие в области разработки программного обеспечения с открытым исходным кодом. Сам Google будет управлять проектом на новом веб-сайте Tensorflow.org. Но он поделился кодом под так называемой лицензией Apache 2, что означает, что любой может использовать код по своему усмотрению. «Наши условия лицензирования должны убедить сообщество в том, что это действительно открытый продукт, — говорит Дин.
Несомненно, этот шаг завоюет расположение Google среди мировых разработчиков программного обеспечения. Но что более важно, это подпитает новые проекты. По словам Дина, вы можете думать о TensorFlow как об объединении лучшего из Torch, Caffe и Theano. По его словам, как Torch и Theano, они хороши для быстрого развертывания исследовательских проектов, и, как и Caffe, хороши для внедрения этих исследовательских проектов в реальный мир.
Но что более важно, это подпитает новые проекты. По словам Дина, вы можете думать о TensorFlow как об объединении лучшего из Torch, Caffe и Theano. По его словам, как Torch и Theano, они хороши для быстрого развертывания исследовательских проектов, и, как и Caffe, хороши для внедрения этих исследовательских проектов в реальный мир.
Самые популярные
Другие могут не согласиться. По мнению многих в сообществе, DeepMind, известный стартап глубокого обучения, который теперь принадлежит Google, продолжает использовать Torch, хотя у него уже давно есть доступ к TensorFlow и DistBelief. Но, по крайней мере, TensorFlow с открытым исходным кодом дает сообществу больше возможностей. И это хорошо.
«Немалая часть прогресса в области глубокого обучения за последние три-четыре года была достигнута за счет такого рода библиотек, которые помогают исследователям сосредоточиться на своих моделях. Им не нужно так сильно беспокоиться о базовой разработке программного обеспечения, — говорит Джимми Ба, аспирант Университета Торонто, специализирующийся на глубоком обучении и обучающийся у Джеффа Хинтона.
Даже имея в руках TensorFlow, создание приложения для глубокого обучения требует серьезного мастерства. Но и это может измениться в ближайшие годы. Как отмечает Дин, проект Google с открытым исходным кодом для глубокого обучения и облачный сервис Google для глубокого обучения не исключают друг друга. Большая идея Тима О’Рейли все еще может осуществиться.
Но в краткосрочной перспективе Google просто заинтересован в обмене кодом. Как говорит Дин, это поможет компании улучшить этот код. Но в то же время, говорит Монга, это также поможет улучшить машинное обучение в целом, порождая всевозможные новые идеи. И, что ж, они тоже вернутся в Google. «Любой прогресс в области машинного обучения, — говорит он, — будет и для нас прогрессом».
Исправление: эта история была обновлена, чтобы правильно показать, что структура Torch была первоначально разработана исследователями в Швейцарии.
Вам также может понравиться:
Кейд Мец — бывший старший штатный сотрудник WIRED, освещающий Google, Facebook, искусственный интеллект, биткойн, центры обработки данных, компьютерные чипы, языки программирования и другие способы изменения мира.