Содержание
«Мы уже можем с точностью более 90% определить по фото сексуальную ориентацию человека»
«Мы уже можем с точностью более 90% определить по фото сексуальную ориентацию человека» | Colta.ru
6 апреля 2017ОбществоВнутри цифры
165502
Юк Хуэй: «Технологии должны стать частью нас, функцией разума»Лев Манович: «Инстаграм занят тем же, чем раньше музыка: созданием субкультур»Герт Ловинк: «Платформы типа Facebook — это трагический момент»Самосуд 2.0Битва за приватность в сети проиграна. Что дальше?Фейсбук-войны: WTF?
Михал Косински — гуру цифровой психометрии, анализирующей людей по их дигитальным следам. Что будет с нашей приватностью, с тревогой выясняла у него Ника Дубровская
текст: Ника Дубровская
Михал Косински — психолог, специалист по big data, бывший заместитель директора Центра психометрии Кембриджского университета, сейчас доцент Стэнфордского университета, один из ведущих спецов в мире по психометрии нового образца, которую бизнес, политика, спецслужбы, здравоохранение или просто другие люди могут использовать в своих целях.
— Расскажи о том, что такое психометрия, как давно она существует и как развивалась.
— Психометрия — это наука, изучающая теорию и методику психологических измерений. Ей занимаются психологи, которые анализируют личностные черты человека с помощью различных анкет и тестов. Существует она очень давно: более тысячи лет назад китайских чиновников нанимали на работу на основе стандартизированных тестов, подобных современным GMAT и SAT, которые мы используем в Америке сегодня.
Самое большое изменение в психометрии заключается в том, что вместо опроса людей с помощью анкет теперь мы можем наблюдать за их поведением. Психологи давно знают, что лучший способ оценить человека — пронаблюдать за ним. Вместо того чтобы спрашивать, как часто вы ходите на вечеринки, лучше это самим увидеть. В реальной жизни это очень трудно, потребовалось бы невероятное количество времени и ресурсов, чтобы следить за людьми и записывать, чем они занимаются, не говоря уже о том, что это довольно жутко.
Но в мире новых технологий мы сами, не задумываясь, оставляем множество цифровых отпечатков — каждый раз, когда пользуемся Facebook, браузером, Google, смартфоном. Сегодня нетрудно использовать эти данные, чтобы составить портрет человека. И у этого метода много преимуществ. Например, людям сложнее исказить информацию о себе. В прошлом если ты солгал в психологическом тесте, то легко мог получить преимущество перед тем, кто был честен. Сегодня тебе пришлось бы полностью изменить свое поведение и придерживаться его много лет подряд, чтобы обмануть систему. Так что если ты действительно в состоянии в течение пяти лет вести себя как хорошо организованный человек, то, вероятно, ты им и являешься.
— Мне бы тоже хотелось узнать свой психологический профиль. Но ведь это интересует не только меня, но и тех, кто не прочь продать мне что-нибудь или как-то на меня повлиять.
— Безусловно, есть люди, которые этого хотят, и в некотором смысле это даже хорошо. Министр здравоохранения хочет, чтобы ты не курила, питалась здоровой пищей и жила дольше. И у него больше шансов помочь тебе, если он будет знать, как тебе это правильно подать. Твой школьный учитель помогает тебе стать хорошим, честным человеком. Есть множество примеров, когда на наше поведение влияют нам же во благо.
Министр здравоохранения хочет, чтобы ты не курила, питалась здоровой пищей и жила дольше. И у него больше шансов помочь тебе, если он будет знать, как тебе это правильно подать. Твой школьный учитель помогает тебе стать хорошим, честным человеком. Есть множество примеров, когда на наше поведение влияют нам же во благо.
Я не сторонник того, чтобы вся персональная информация была в открытом доступе и чтобы любой желающий мог получить ее без нашего ведома. Но если человек согласен, мы могли бы, например, помочь ему найти работу, на которой он может реализовать себя, ради которой ему хотелось бы вставать по утрам. Или проследить симптомы психических заболеваний и даже предвидеть высокий риск самоубийства, анализируя фотографии лиц или цифровые следы. Болезнь влияет на твое поведение, но это влияние может быть настолько малым, что обычный человек, в отличие от компьютеров, его не заметит. В прошлом только люди c деньгами могли позволить себе визиты к психологу. Сегодня благодаря алгоритмам мы можем дать все это простым людям, не предлагая им тратить сотни долларов в кабинетах врачей.
Или подумай, например, об образовании. Предположим, учитель что-то рассказывает аудитории — но к кому он в действительности обращается? Он говорит со средним студентом, которого на самом деле не существует. В результате много студентов скучает: для кого-то он говорит слишком быстро, для кого-то — слишком медленно. И мы разрабатываем алгоритмы, которые могут определять, насколько быстро студент справляется с заданиями, и подстраивать под него программу. Быстрый студент будет в состоянии прогрессировать быстро, медлительный не будет брошен в отстающих, потому что компьютер терпеливо подождет и объяснит ему все более четко.
— И как же именно, основываясь на наблюдении за поведением пользователей онлайн, можно узнать о них что-то личное?
— Пока ты пользуешься Facebook, он изучает твое поведение и на основе этой информации создает твой психологический профиль. Впоследствии он используется другими алгоритмами, чтобы в ленте отображались только интересующие тебя новости и истории. И это классно, потому что иначе тебе бы очень быстро надоело сталкиваться с ненужной информацией. Те же механизмы Facebook использует, чтобы показывать тебе рекламу. Это тоже отлично — зачем тебе видеть объявления, которые тебя вообще не интересуют? Facebook должен показывать рекламу, чтобы зарабатывать, — для нас это своего рода плата за пользование. Но лучше, чтобы эти объявления, по крайней мере, были полезными. Так что в целевом маркетинге часто нет ничего плохого, если никто не вторгается в твою жизнь без твоего ведома и согласия. Конечно, у всех должна быть возможность отказаться, запретить алгоритму создавать профиль. Но всем остальным это заметно облегчает жизнь.
И это классно, потому что иначе тебе бы очень быстро надоело сталкиваться с ненужной информацией. Те же механизмы Facebook использует, чтобы показывать тебе рекламу. Это тоже отлично — зачем тебе видеть объявления, которые тебя вообще не интересуют? Facebook должен показывать рекламу, чтобы зарабатывать, — для нас это своего рода плата за пользование. Но лучше, чтобы эти объявления, по крайней мере, были полезными. Так что в целевом маркетинге часто нет ничего плохого, если никто не вторгается в твою жизнь без твоего ведома и согласия. Конечно, у всех должна быть возможность отказаться, запретить алгоритму создавать профиль. Но всем остальным это заметно облегчает жизнь.
© Lauren Bamford
— Очень странно, что ты так оптимистично настроен. В других интервью, после победы Трампа, ты был куда менее жизнерадостен.
— Это журналисты выбирают только негативное. Плохие новости продаются, никто не хочет слушать ничего оптимистического.
— И тем не менее. Например, я — американский гражданин, и на последних выборах я не голосовала, потому что не хотела отдавать голос за Хиллари, но была абсолютно уверена, что она в любом случае победит. Но теперь я думаю, что это решение навязал мне Facebook, фильтруя информацию в ленте. Мой профиль говорит о том, что я не буду голосовать за Трампа, но могу, если что, не проголосовать и за Хиллари тоже. Вот за это «если что» система и могла ухватиться.
— Да, люди говорят об информационном пузыре, даже Обама упоминал его в прощальной речи. Это модный тренд, основанный на ложном представлении. Есть даже институты, которые по сути являются научно-исследовательскими центрами по изучению феномена информационного пузыря. Очевидно, что если ты — научно-исследовательский центр по изучению какой-то проблемы, ты ее найдешь, поскольку получаешь на это гранты. Но на самом деле нет никакого научного обоснования информационных пузырей. Как раз наоборот.
В прошлом такой феномен действительно был, и он был связан с тем, что из информационного пузыря невозможно было выбраться. Если ты жил в России, то слышал только российскую пропаганду. Если родился в богатой английской семье, то получал информацию только от зажиточных друзей. Если в деревне, то только от своих священника и библиотекаря.
Если ты жил в России, то слышал только российскую пропаганду. Если родился в богатой английской семье, то получал информацию только от зажиточных друзей. Если в деревне, то только от своих священника и библиотекаря.
Теперь у нас есть интернет. Но у людей сохранилась тенденция воспринимать только информацию, подтверждающую их взгляды. Эта склонность к подтверждению своей точки зрения — одно из наиболее исследованных когнитивных искажений в психологии. Оно подразумевает, что если ты либерал, то ты предпочитаешь либеральную информацию, если консерватор — консервативную. Раньше ты ничего не мог с этим поделать, даже не понимал этого. Но сегодня на Facebook ты время от времени сталкиваешься с совершенно сумасшедшей информацией от людей, которые находятся за пределами твоего пузыря. Это дает тебе возможность узнать что-то, абсолютно противоположное тому, что ты знал до этого.
Сегодня люди потребляют беспрецедентное разнообразие информации, причем не только в политической сфере. Недавно я разговаривал с главным инженером Spotify, и он сказал мне, что только за 2016 год вариативность музыкальных коллективов, которые слушают люди, увеличилась в среднем на 20%. Так что, даже несмотря на нашу предрасположенность, мы все равно получаем более широкую информацию. Очевидно, что часть ее будет низкого качества, а часть — просто фальшивкой. Это новые медиа, и мы должны научиться пользоваться ими, фильтровать — этот навык сегодня становится важнее, чем когда-либо.
Недавно я разговаривал с главным инженером Spotify, и он сказал мне, что только за 2016 год вариативность музыкальных коллективов, которые слушают люди, увеличилась в среднем на 20%. Так что, даже несмотря на нашу предрасположенность, мы все равно получаем более широкую информацию. Очевидно, что часть ее будет низкого качества, а часть — просто фальшивкой. Это новые медиа, и мы должны научиться пользоваться ими, фильтровать — этот навык сегодня становится важнее, чем когда-либо.
И целевой политический маркетинг — тоже вещь хорошая. Если ты живешь в большом городе, проблемы, связанные с сельским хозяйством, тебя не интересуют. И если ты увидишь на ТВ политика, который говорит об этом, ты, вероятно, переключишь канал, а это неправильно, потому что ты исключаешь себя из политического процесса. Но новый алгоритм дает политикам возможность общаться с избирателями один на один о проблемах, которые их интересуют. Программы партий — это длинные документы, сотни, если не тысячи, страниц. Простой человек не сможет в них разобраться. Алгоритмы позволяют выбрать часть программы, которая относится к тебе, и показать ее так, что ты можешь с ней ознакомиться.
Простой человек не сможет в них разобраться. Алгоритмы позволяют выбрать часть программы, которая относится к тебе, и показать ее так, что ты можешь с ней ознакомиться.
Это раньше политики просто посылали одно сообщение всем сразу о проблеме, до которой многим не было дела. Теперь они могут говорить о том, что актуально для тебя. И очевидно, что некоторые начнут делать это раньше, некоторые позже. Те, кто раньше, получат преимущество просто потому, что они уже сейчас слышат тебя лучше. Другие политики вскоре подключатся, и равновесие сил будет восстановлено, мы все извлечем из этого выгоду.
— Но пока в авангарде Трамп…
— Да, Трамп — это история успеха парня без поддержки крупных лоббистов. Это ведь было просто смешно: у него не было внятной идеи, он говорил глупости. У Клинтон был в разы больший бюджет. Но Трамп обратился к людям напрямую. Берни Сандерс тоже сегодня может зайти на выборах далеко просто потому, что ему есть что сказать в Твиттере, — это настоящая революция в политике. Еще 10 или 20 лет назад никто бы о нем не услышал.
Еще 10 или 20 лет назад никто бы о нем не услышал.
— Вопрос в том, есть ли у меня или у любого пользователя реальная возможность остановить постоянную слежку и выбраться из паутины, собирающей персональную информацию.
— Остановить это невозможно. Хотя можно просто прекратить пользоваться Facebook и Твиттером. Кстати, эти две компании собирают данные наименее агрессивно. Подумай о кредитной карте или веб-браузере — это очень личные данные, цифровые следы, которые действительно могут сказать о тебе многое. Так что пришлось бы выключить свет, переехать в пещеру посреди леса и избавиться от всех цифровых устройств. И даже в этом случае тебя нашел бы какой-нибудь турист и сделал бы твой снимок, потому что ты чудак. И вот снова ты оставляешь цифровые следы. Готовых решений тут нет, нужно быть осторожным, анализировать, создавать новую политику конфиденциальности, разрабатывать необходимые технологии для ее реализации. Можно голосовать за политиков, которые относятся серьезно к вопросам приватности.
— Менять законы?
— Я думаю, это просто замедляет процесс. Если ты примешь закон, запрещающий любое профилирование пользователей, это приведет к коллапсу, вся рекомендательная система прекратит работать. Твой Spotify, Last.fm, Netflix, Facebook — всё. Результаты поисковой выдачи, которые ты видишь, — тоже часть рекомендательного механизма, и Google прекратил бы работать тоже. В целом я считаю, что, поскольку мы все сильнее погружаемся в цифровую среду и оставляем все больше дигитальных отпечатков, а алгоритмы становятся все умнее, сохранить приватность в будущем у нас не получится.
— И что будет означать эта потеря приватности?
— Возможно, в будущем ты не сможешь скрыть даже свои самые личные черты. Сегодня ты можешь сказать мне, какие у тебя политические взгляды, сексуальная ориентация, религиозная принадлежность, а можешь и не говорить. Но в будущем у тебя может не быть такого выбора. Алгоритмы видят тебя насквозь. Уже сегодня мы в состоянии взять фотографию любого человека и с точностью более 90% определить, какая у него сексуальная ориентация, не прибегая к анализу дополнительных данных. Не говоря уже о том, сколько о тебе можно узнать, когда есть лайки и твиты. Это будут в состоянии сделать правительства, компании и даже обычные люди. То, что Штази делала в Восточной Германии, используя сотни тысяч людей на зарплате, сегодня может сделать за своим ноутбуком ученик средней школы.
Алгоритмы видят тебя насквозь. Уже сегодня мы в состоянии взять фотографию любого человека и с точностью более 90% определить, какая у него сексуальная ориентация, не прибегая к анализу дополнительных данных. Не говоря уже о том, сколько о тебе можно узнать, когда есть лайки и твиты. Это будут в состоянии сделать правительства, компании и даже обычные люди. То, что Штази делала в Восточной Германии, используя сотни тысяч людей на зарплате, сегодня может сделать за своим ноутбуком ученик средней школы.
При этом та же самая технология представляет гораздо большую опасность для людей, живущих в таких странах, как Саудовская Аравия или, возможно, Россия. Если ты живешь в Саудовской Аравии и алгоритм может сообщить правительству, какие у тебя политические взгляды и сексуальная ориентация, — тебя могут просто убить.
— При этом тот же Фейсбук — это еще и частная компания, бизнес.
— Кто контролирует медиа — это важно. Очевидно, что Марк Цукерберг сегодня единолично управляет средой, которую множество людей использует для потребления информации. Ларри Пейдж и Сергей Брин управляют еще одной средой, которая потенциально имеет огромное влияние на результаты выборов. И это действительно опасно на многих уровнях. Возможно, все они — хорошие парни, но кто знает наверняка? Предположим, Цукерберг в порядке, но что, если следующий Цукерберг — монстр? Для демократии всегда плохо, когда один человек имеет слишком много власти, но это — то, с чем мы уже имеем дело сейчас.
Ларри Пейдж и Сергей Брин управляют еще одной средой, которая потенциально имеет огромное влияние на результаты выборов. И это действительно опасно на многих уровнях. Возможно, все они — хорошие парни, но кто знает наверняка? Предположим, Цукерберг в порядке, но что, если следующий Цукерберг — монстр? Для демократии всегда плохо, когда один человек имеет слишком много власти, но это — то, с чем мы уже имеем дело сейчас.
Прежде всего, Цукерберг может изменить свой алгоритм. Но Марк, по крайней мере, — ответственное лицо, и люди знают: если что, его можно обвинять. А у простого разработчика, анонимного парня, который сидит в серверной, такой ответственности нет. Завтра он может изменить пару строк кода в алгоритме работы Facebook и повлиять на работу этой огромной машины, и этого никто не заметит, более того, людям будет сложно вычислить, что это сделал именно он.
Вторая проблема состоит в том, что алгоритм может начать делать вещи, которых никто не ожидает, даже сам Цукерберг и его разработчики. В прошлом, если у тебя была газета и ты хотел завести политическую колонку, ты организовывал встречу с редакторами и говорил им, как это должно выглядеть. Это было легко контролировать, и как владелец ты сразу видел, если твоя газета печатала что-то не то.
В прошлом, если у тебя была газета и ты хотел завести политическую колонку, ты организовывал встречу с редакторами и говорил им, как это должно выглядеть. Это было легко контролировать, и как владелец ты сразу видел, если твоя газета печатала что-то не то.
Алгоритмы Facebook контролировать гораздо сложнее, они показывают всем разные вещи. Ни Цукерберг, ни его инженеры не в силах понять, что этот алгоритм фактически делает, что происходит у него внутри. То есть мы, конечно, можем понять, как это работает, ведь даже нейронные сети довольно просты — но они огромны. Там такое количество слоев этих простых вещей, что система становится совершенно непонятной. Это делает возможной парадоксальную ситуацию, когда алгоритм Цукерберга начнет делать вещи, о которых мы не догадываемся и которые, соответственно, не можем проконтролировать.
— Ничего себе. И каким видишь ты решение этой проблемы?
— Традиционные СМИ находятся под контролем общественных организаций и правительственных медиаагентств, следящих за тем, чтобы журналисты не публиковали ложную информацию. Я думаю, что те же самые стандарты должны применяться и к таким компаниям, как Facebook или Google. Очевидно, что это намного сложнее осуществить, поскольку у каждого пользователя Facebook свой персонализированный опыт. Это не похоже на отношения с традиционными СМИ, когда ты можешь подсчитать, кто сколько раз солгал, и оштрафовать их. Но я думаю, что мы можем анализировать опыт случайных десяти или ста тысяч пользователей и на основе этого делать выводы о поведении алгоритма в целом.
Я думаю, что те же самые стандарты должны применяться и к таким компаниям, как Facebook или Google. Очевидно, что это намного сложнее осуществить, поскольку у каждого пользователя Facebook свой персонализированный опыт. Это не похоже на отношения с традиционными СМИ, когда ты можешь подсчитать, кто сколько раз солгал, и оштрафовать их. Но я думаю, что мы можем анализировать опыт случайных десяти или ста тысяч пользователей и на основе этого делать выводы о поведении алгоритма в целом.
— Ты предлагаешь контролировать алгоритм, а не пользователя, верно?
— Я предлагаю использовать один алгоритм, чтобы контролировать другие алгоритмы. Если бы за работой алгоритмов Марка Цукерберга следили другие алгоритмы, не только он полнее осознавал бы свою ответственность, но и люди больше доверяли бы ему. Общество, политики, Цукерберг — мы все должны принять эту новую политику, способную застраховать нас от вмешательства программиста в серверной. Все только выиграют от этого дополнительного контроля, публичного и открытого. За этим могут следить университет, несколько университетов, общественные организации или каждый пользователь.
Все только выиграют от этого дополнительного контроля, публичного и открытого. За этим могут следить университет, несколько университетов, общественные организации или каждый пользователь.
Сейчас, когда в Facebook замечают за своим алгоритмом странности, они пытаются разобраться с этим. Возьмем, к примеру, fake news. Это проблема, с которой они давно столкнулись и над решением которой упорно работают. И можно сказать, что им удалось настроить алгоритм таким образом, чтобы он прекратил показывать fake news. Но все это говорит о том, что никто не понимает, как работает алгоритм, — мы можем только смотреть на результат и исправлять ошибки. Это касается и других областей — очень скоро ты придешь к доктору, а он скажет тебе: «Выпей это лекарство, оно поможет тебе. Но я не знаю почему — так сказал компьютер. Должно быть, это правда, потому что он практически не ошибается и знает все лучше меня».
— Я бы, наверное, не стала пить эти таблетки.
— Думаю, стоило бы — компьютеры тут точнее.
— И все-таки, как ты думаешь, будем ли мы в состоянии защитить себя в будущем?
— Мы можем изменить законы и создать компании, которые в состоянии лучше защитить наши технологии; мы можем обсуждать децентрализованные технологии шифрования. Но вместо того, чтобы продолжать участвовать в битве за приватность, которую мы уже проиграли, мы должны подумать, как вести себя дальше. Давайте попытаемся сделать общество более открытым и терпимым. Образованными избирателями манипулировать сложнее, толерантное общество не будет угрожать людям с иными взглядами, сексуальной ориентацией или вероисповеданием. И мы не сможем защитить себя, если не объединимся. Эта проблема слишком серьезна — нельзя в одиночку защитить себя от ядерной бомбы. Хотя этот пример как раз обнадеживает. У нас есть много других потенциально опасных технологий, которые разработало человечество, и нам удалось с ними разобраться. Подумай о ядерной энергии, динамите или кухонных ножах. Очевидно, есть примеры использования этих технологий против нашего благополучия, но в целом нам удается их контролировать. Мы справляемся с ядерной энергией — справимся и с алгоритмами.
Мы справляемся с ядерной энергией — справимся и с алгоритмами.
В работе над текстом принимал участие Арнольд Хачатуров.
Понравился материал? Помоги сайту!
Тест
Разбираетесь в искусстве XX века?
Давайте проверим вас на птицах и арт-шарадах художника Егора Кошелева
новости
11 марта 2022
14:52COLTA.RU заблокирована в России
3 марта 2022
17:48«Дождь» временно прекращает вещание
17:18Союз журналистов Карелии пожаловался на Роскомнадзор в Генпрокуратуру
16:32Сергей Абашин вышел из Ассоциации этнологов и антропологов России
15:36Генпрокуратура назвала экстремизмом участие в антивоенных митингах
Все новости
Новое в разделе «Общество»Самое читаемое
Почему вина обездвиживает, и что должно прийти ей на смену?
84741
Родина как утрата
60490
Письмо из России
72148
Архитектурная история американской полиции
44769
Виктор Вахштайн: «Кто не хотел быть клоуном у урбанистов, становился урбанистом при клоунах»
54862
Кто и почему сражается за Сретенку, 13?
36679
Темная сторона экрана
14859
«Добрые души» Никиты Ефимова. Онлайн-премьера
Онлайн-премьера
13102
Антифа: что это было? И будет ли вновь?
52612
Бабушка
13991
Разумные дебаты в эпоху соцсетей и cancel culture
15922
Петр Павленский. Большой разговор
29211
Сегодня на сайте
Colta Specials
От редакции COLTA.RU
Обращение к читателям
5 марта 2022109492
Colta Specials
Культура во время «военных операций»
Нужны ли сейчас стихи, выставки и концерты? Блиц-опрос COLTA.RU
3 марта 202299976
Общество
Почему вина обездвиживает, и что должно прийти ей на смену?
Философ Мария Бикбулатова о том, что делать с чувствами, охватившими многих на фоне военных событий, — и как перейти от эмоций к рациональному действию
1 марта 202284741
Общество
Родина как утрата
Глеб Напреенко о том, на какой внутренней территории он может обнаружить себя в эти дни — по отношению к чувству Родины
1 марта 202260490
Литература
Often you write das Leid but read das Lied
Англо-немецкий и русско-украинский поэтический диалог Евгения Осташевского и Евгении Белорусец
1 марта 202260182
Общество
Письмо из России
Надя Плунгян пишет из России в Россию
1 марта 202272148
Colta Specials
Полифонические свидетели конца и начала. Эссе Ганны Комар
Эссе Ганны Комар
В эти дни Кольта продолжает проект, посвященный будущему Беларуси
1 марта 202254681
Театр
Случайность и неотвратимость
Зара Абдуллаева о «Русской смерти» Дмитрия Волкострелова в ЦИМе
22 февраля 202245524
Литература
«Меня интересуют второстепенные женские персонажи в прозе, написанной мужчиной»
Милена Славицка: большое интервью
22 февраля 202245374
Общество
Архитектурная история американской полиции
Глава из новой книги Виктора Вахштайна «Воображая город. Введение в теорию концептуализации»
22 февраля 202244769
Общество
Виктор Вахштайн: «Кто не хотел быть клоуном у урбанистов, становился урбанистом при клоунах»
Разговор Дениса Куренова о новой книге «Воображая город», о блеске и нищете урбанистики, о том, что смогла (или не смогла) изменить в идеях о городе пандемия, — и о том, почему Юго-Запад Москвы выигрывает по очкам у Юго-Востока
22 февраля 202254862
Искусство
Два мела на голубой бумаге
Что и как смотреть на выставке французского рисунка в фонде In Artibus
21 февраля 202248564
Программа для определения сексуальной ориентации вызвала споры
Автор фото, STANFORD UNIVERSITY
Специалисты из Стэнфордского университета создали компьютерную программу, позволяющую, как они уверяют, определить сексуальную ориентацию человека по чертам лица.
Приложение уже вызвало горячие споры между разработчиками программы и ведущими правозащитными ЛГБТ-группами.
Ученых обвинили в том, что изложенные факты — опасны и недостаточно обоснованы научно.
- Гетеросексуальные женщины испытывают оргазм реже всех остальных
Однако исследователи называют подобные обвинения импульсивной реакцией.
Подробности проекта вскоре должны быть опубликованы в журнале психологии личности и социальной психологии, издаваемом Американской психологической ассоциацией.
«Узкие челюсти»
По словам ученых, точность установления ориентации человека даже по одному фото равна 81% для мужчин и 71% для женщин. Исследование было проведено по фотографиям более 75 тысяч мужчин и женщин разной ориентации, взятым с сайтов знакомств.
При использовании алгоритмом пяти фото одного человека точность определения возрастала до 91% для мужчин и 83% для женщин.
Нейросеть сравнивала фотографии двух случайно отобранных людей, один из которых гетеросексуален, а другой нет.
Автор фото, Getty Images
Підпис до фото,
Защитники прав ЛГБТ указывают на недостатки исследования
Согласно результатам исследования, у гомосексуальных мужчин могут быть в среднем более узкие нижние челюсти, более длинные носы и высокие лбы, чем у гетеросексуалов; у лесбиянок, напротив, более широкие челюсти и более низкие лбы.
Этот эксперимент, как считают его авторы, подтверждает теорию о том, что сексуальная ориентация — врожденный, а не приобретенный признак.
«Безрассудные выводы»
Пропустити подкаст і продовжити
подкаст
Що це було
Головна історія тижня, яку пояснюють наші журналісти
Випуски
Кінець подкаст
В прошлую пятницу две американские правозащитные группы, специализирующиеся на защите ЛГБТ, обнародовали заявление с критикой результатов исследования.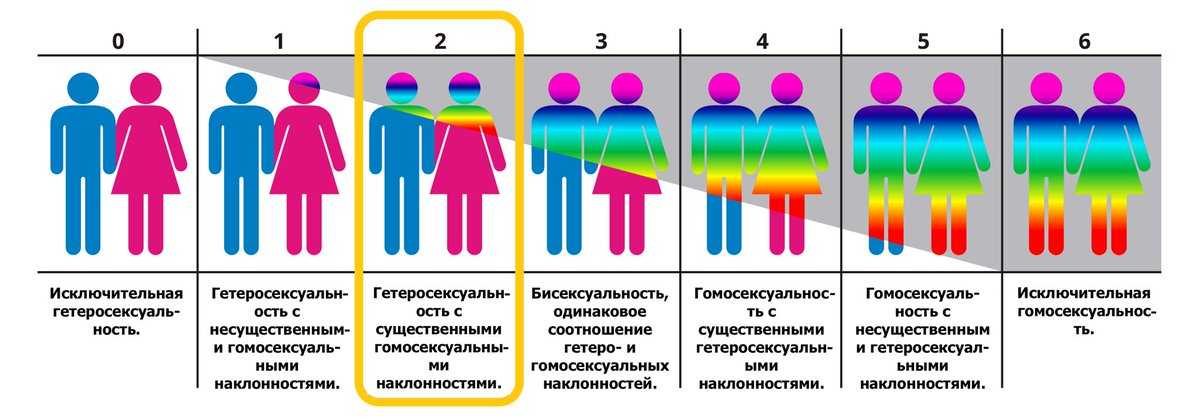
«Это исследование не является научным. Это просто описание стандартов красоты на сайтах знакомств. Для исследования были отобраны снимки только белых людей, поскольку достаточного количества гомосексуалов с другим цветом кожи на сайте не нашлось», — заявил Джим Галлорат, руководитель службы мониторинга медиа ЛГБТ-группы GLAAD.
«Эти безрассудные выводы исследования могут послужить в качестве оружия как против гетеросексуалов, так и против гомосексуалов и лесбиянок, для которых публичность может быть опасной», — отмечают представители ЛГБТ-сообщества.
Правозащитники добавили, что отправили в университет свои замечания еще месяц назад.
Они считают, что Стэнфордский университет должен дистанцироваться от таких псевдонаучных вещей, а не прикрывать своим именем и авторитетом исследование, которое может сделать жизнь миллионов людей опасной.
Ученые, в свою очередь, просят не делать преждевременных выводов.
«Результаты исследования могут быть ошибочными, но они могут быть опровергнуты только с помощью научных данных, а не умелыми адвокатами и специалистами по связям с общественностью, которым не хватает научных знаний», — сказано в ответном письме исследователей.
Автор фото, Getty Images
Підпис до фото,
Для исследования были отобраны снимки только белых людей
изображений — Алгоритм определения ориентации фотографий
спросил
Изменено
11 лет, 1 месяц назад
Просмотрено
14 тысяч раз
Я хочу автоматически поворачивать фотографии, даже если метаданные EXIF об ориентации изображения недоступны.
Есть ли хорошие алгоритмы для определения ориентации фотографии? Изображения являются фотографиями с цифровой камеры. Алгоритм не обязательно должен работать идеально, но любое сокращение человеческого взаимодействия, необходимого для правильного поворота фотографий, было бы преимуществом.
Я нашел эти две статьи по теме:
- Предварительная классификация для автоматической ориентации изображения (2006)
- Вероятностный подход к обнаружению ориентации изображения посредством основанной на достоверности интеграции низкоуровневых и семантических сигналов (2004)
Приветствуются ссылки на другие исследования и особенно на реализации.
- изображение
- обработка изображений
- ориентация
- эвристика
6
На многих фотографиях с бытовых цифровых камер изображены люди, которые можно использовать для ориентации. Распознавание лиц — хорошо изученная область исследований. Базовое обнаружение лица даст вам прямоугольник, длинная сторона которого должна быть вертикальным размером. Кроме того, если вы можете обнаружить глаза/рот, вы сможете выбрать правильную ориентацию прямоугольника.
Многие другие фотографии сделаны туристами, на них небо голубое, а земля зеленая.
4
Я смог найти только http://sourceforge.net/projects/rotator/.
Я использовал тестовый набор праздничных фотографий, состоящий из 70 снимков, примерно 18 из которых требовали поворота.
После обработки с настройками по умолчанию было 20, которые были повернуты или не повернуты по ошибке.
Не очень хороший результат.
1
Если изображения не квадратные, вы можете сделать предположение, что изображения по умолчанию шире, чем в высоту.
Если это так, определение того, нужно ли вам поворачивать, — это просто вопрос сравнения соотношения сторон и поворота, чтобы изменить ориентацию по умолчанию. Хотя вы можете получить перевернутые изображения.
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как определить ориентацию объекта с помощью OpenCV — автоматический Addison
В этом руководстве мы создадим программу, которая может определять ориентацию объекта (то есть угол поворота в градусах), используя популярную библиотеку компьютерного зрения OpenCV.
Содержание
Одним из наиболее распространенных реальных случаев использования программы, которую мы разработаем в этом руководстве, является разработка системы захвата и размещения для манипуляторов роботов. Определение ориентации объекта на конвейерной ленте является ключом к определению подходящего способа схватить объект, поднять его и поместить в другое место.
Начнем!
- Python 3.7 или выше
Прежде чем мы начнем, убедитесь, что у нас установлены все программные пакеты. Проверьте, установлен ли на вашем компьютере OpenCV . Если вы используете Anaconda, вы можете ввести:
conda install -c conda-forge opencv
Кроме того, вы можете ввести:
pip install opencv-python
Установите Numpy, библиотеку научных вычислений.
pip установить numpy
Найдите изображение. Мое входное изображение имеет ширину 1200 пикселей и высоту 900 пикселей. Имя файла моего входного изображения input_img. jpg .
jpg .
Вот код. Он принимает изображение с именем input_img.jpg и выводит аннотированное изображение с именем output_img.jpg . Фрагменты кода взяты из официальной реализации OpenCV.
импортировать cv2 как cv из математики импортировать atan2, cos, sin, sqrt, pi импортировать numpy как np def drawAxis(img, p_, q_, цвет, масштаб): р = список (р_) д = список (д_) ## [визуализация1] angle = atan2(p[1] - q[1], p[0] - q[0]) # угол в радианах гипотенуза = sqrt((p[1] - q[1]) * (p[1] - q[1]) + (p[0] - q[0]) * (p[0] - q[0] )) # Здесь мы удлиняем стрелку в масштабе q[0] = p[0] - масштаб * гипотенуза * cos(угол) q[1] = p[1] - масштаб * гипотенуза * sin(угол) cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA) # создаем хуки со стрелками р[0] = д[0] + 9* cos(угол + пи/4) p[1] = q[1] + 9 * sin(угол + пи / 4) cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA) p[0] = q[0] + 9 * cos(угол - пи / 4) p[1] = q[1] + 9 * sin(угол - пи / 4) cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA) ## [визуализация1] def getOrientation (pts, img): ## [пка] # Создать буфер, используемый для анализа PCA sz = длина (pts) data_pts = np.empty((sz, 2), dtype=np.float64) для i в диапазоне (data_pts.shape[0]): data_pts[i,0] = очки[i,0,0] data_pts[i,1] = очки[i,0,1] # Выполнить анализ PCA среднее значение = np.пусто((0)) среднее значение, собственные векторы, собственные значения = cv.PCACompute2 (data_pts, среднее значение) # Сохраняем центр объекта cntr = (int (среднее [0,0]), int (среднее [0,1])) ## [пка] ## [визуализация] # Нарисуйте главные компоненты cv.circle(img, cntr, 3, (255, 0, 255), 2) p1 = (cntr[0] + 0,02 * собственные векторы [0,0] * собственные значения [0,0], cntr[1] + 0,02 * собственные векторы [0,1] * собственные значения [0,0]) p2 = (cntr[0] - 0,02 * собственные векторы [1,0] * собственные значения [1,0], cntr[1] - 0,02 * собственные векторы [1,1] * собственные значения [1,0]) drawAxis(img, центр, p1, (255, 255, 0), 1) drawAxis(img, центр, p2, (0, 0, 255), 5) angle = atan2(eigenvectors[0,1],eigenvectors[0,0]) # ориентация в радианах ## [визуализация] # Метка с углом поворота label = "Угол вращения:" + str(-int(np.
 LINE_AA)
p[0] = q[0] + 9 * cos(угол - пи / 4)
p[1] = q[1] + 9 * sin(угол - пи / 4)
cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA)
## [визуализация1]
def getOrientation (pts, img):
## [пка]
# Создать буфер, используемый для анализа PCA
sz = длина (pts)
data_pts = np.empty((sz, 2), dtype=np.float64)
для i в диапазоне (data_pts.shape[0]):
data_pts[i,0] = очки[i,0,0]
data_pts[i,1] = очки[i,0,1]
# Выполнить анализ PCA
среднее значение = np.пусто((0))
среднее значение, собственные векторы, собственные значения = cv.PCACompute2 (data_pts, среднее значение)
# Сохраняем центр объекта
cntr = (int (среднее [0,0]), int (среднее [0,1]))
## [пка]
## [визуализация]
# Нарисуйте главные компоненты
cv.circle(img, cntr, 3, (255, 0, 255), 2)
p1 = (cntr[0] + 0,02 * собственные векторы [0,0] * собственные значения [0,0], cntr[1] + 0,02 * собственные векторы [0,1] * собственные значения [0,0])
p2 = (cntr[0] - 0,02 * собственные векторы [1,0] * собственные значения [1,0], cntr[1] - 0,02 * собственные векторы [1,1] * собственные значения [1,0])
drawAxis(img, центр, p1, (255, 255, 0), 1)
drawAxis(img, центр, p2, (0, 0, 255), 5)
angle = atan2(eigenvectors[0,1],eigenvectors[0,0]) # ориентация в радианах
## [визуализация]
# Метка с углом поворота
label = "Угол вращения:" + str(-int(np.
LINE_AA)
p[0] = q[0] + 9 * cos(угол - пи / 4)
p[1] = q[1] + 9 * sin(угол - пи / 4)
cv.line(img, (int(p[0]), int(p[1])), (int(q[0]), int(q[1])), color, 3, cv.LINE_AA)
## [визуализация1]
def getOrientation (pts, img):
## [пка]
# Создать буфер, используемый для анализа PCA
sz = длина (pts)
data_pts = np.empty((sz, 2), dtype=np.float64)
для i в диапазоне (data_pts.shape[0]):
data_pts[i,0] = очки[i,0,0]
data_pts[i,1] = очки[i,0,1]
# Выполнить анализ PCA
среднее значение = np.пусто((0))
среднее значение, собственные векторы, собственные значения = cv.PCACompute2 (data_pts, среднее значение)
# Сохраняем центр объекта
cntr = (int (среднее [0,0]), int (среднее [0,1]))
## [пка]
## [визуализация]
# Нарисуйте главные компоненты
cv.circle(img, cntr, 3, (255, 0, 255), 2)
p1 = (cntr[0] + 0,02 * собственные векторы [0,0] * собственные значения [0,0], cntr[1] + 0,02 * собственные векторы [0,1] * собственные значения [0,0])
p2 = (cntr[0] - 0,02 * собственные векторы [1,0] * собственные значения [1,0], cntr[1] - 0,02 * собственные векторы [1,1] * собственные значения [1,0])
drawAxis(img, центр, p1, (255, 255, 0), 1)
drawAxis(img, центр, p2, (0, 0, 255), 5)
angle = atan2(eigenvectors[0,1],eigenvectors[0,0]) # ориентация в радианах
## [визуализация]
# Метка с углом поворота
label = "Угол вращения:" + str(-int(np. rad2deg(угол)) - 90) + "градусы"
textbox = cv.rectangle(img, (cntr[0], cntr[1]-25), (cntr[0] + 250, cntr[1] + 10), (255 255 255), -1)
cv.putText(img, label, (cntr[0], cntr[1]), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1, cv.LINE_AA)
угол возврата
# Загрузить изображение
img = cv.imread("input_img.jpg")
# Было ли там изображение?
если img - None:
print("Ошибка: файл не найден")
выход(0)
cv.imshow('Входное изображение', img)
# Преобразование изображения в оттенки серого
серый = cv.cvtColor (изображение, cv.COLOR_BGR2GRAY)
# Преобразование изображения в двоичное
_, bw = cv.threshold (серый, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# Найти все контуры в пороговом изображении
контуры, _ = cv.findContours (bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)
для i, c в перечислении (контуры):
# Рассчитать площадь каждого контура
площадь = cv.contourArea (с)
# Игнорировать контуры, которые слишком малы или слишком велики
если площадь < 3700 или 100000 < площади:
Продолжать
# Нарисуйте каждый контур только в целях визуализации
cv.
rad2deg(угол)) - 90) + "градусы"
textbox = cv.rectangle(img, (cntr[0], cntr[1]-25), (cntr[0] + 250, cntr[1] + 10), (255 255 255), -1)
cv.putText(img, label, (cntr[0], cntr[1]), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1, cv.LINE_AA)
угол возврата
# Загрузить изображение
img = cv.imread("input_img.jpg")
# Было ли там изображение?
если img - None:
print("Ошибка: файл не найден")
выход(0)
cv.imshow('Входное изображение', img)
# Преобразование изображения в оттенки серого
серый = cv.cvtColor (изображение, cv.COLOR_BGR2GRAY)
# Преобразование изображения в двоичное
_, bw = cv.threshold (серый, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# Найти все контуры в пороговом изображении
контуры, _ = cv.findContours (bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)
для i, c в перечислении (контуры):
# Рассчитать площадь каждого контура
площадь = cv.contourArea (с)
# Игнорировать контуры, которые слишком малы или слишком велики
если площадь < 3700 или 100000 < площади:
Продолжать
# Нарисуйте каждый контур только в целях визуализации
cv. drawContours (изображение, контуры, я, (0, 0, 255), 2)
# Найти ориентацию каждой фигуры
получить ориентацию (с, изображение)
cv.imshow('Выходное изображение', img)
cv.waitKey (0)
cv.destroyAllWindows()
# Сохраняем полученное изображение в текущий каталог
cv.imwrite ("output_img.jpg", изображение)
drawContours (изображение, контуры, я, (0, 0, 255), 2)
# Найти ориентацию каждой фигуры
получить ориентацию (с, изображение)
cv.imshow('Выходное изображение', img)
cv.waitKey (0)
cv.destroyAllWindows()
# Сохраняем полученное изображение в текущий каталог
cv.imwrite ("output_img.jpg", изображение)
Вот результат:
Положительная ось x каждого объекта — красная линия. Положительная ось Y каждого объекта представляет собой синюю линию .
Глобальная положительная ось x проходит слева направо по горизонтали по изображению. Глобальная положительная ось z указывает на эту страницу . Глобальная положительная ось y указывает от нижней части изображения к верхней части изображения по вертикали.
Используя правило правой руки для измерения вращения, вы вытягиваете четыре пальца прямо (указательный палец к мизинцу) в направлении глобальной положительной оси x.
Затем поверните четыре пальца на 90 градусов против часовой стрелки. Кончики ваших пальцев указывают на положительную ось Y, а большой палец указывает за пределы этой страницы на положительную ось Z.
Кончики ваших пальцев указывают на положительную ось Y, а большой палец указывает за пределы этой страницы на положительную ось Z.
Если мы хотим рассчитать ориентацию объекта и убедиться, что результат всегда находится в диапазоне от 0 до 180 градусов, мы можем использовать этот код:
# Эта программа вычисляет ориентацию объекта.
# На входе изображение, а на выходе аннотированное изображение
# с углом ориентации для каждого объекта (от 0 до 180 градусов)
импортировать cv2 как cv
из математики импортировать atan2, cos, sin, sqrt, pi
импортировать numpy как np
# Загрузить изображение
img = cv.imread("input_img.jpg")
# Было ли там изображение?
если img - None:
print("Ошибка: файл не найден")
выход(0)
cv.imshow('Входное изображение', img)
# Преобразование изображения в оттенки серого
серый = cv.cvtColor (изображение, cv.COLOR_BGR2GRAY)
# Преобразование изображения в двоичное
_, bw = cv.threshold (серый, 50, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# Найти все контуры в пороговом изображении
контуры, _ = cv.
для i, c в перечислении (контуры):
# Рассчитать площадь каждого контура
площадь = cv.contourArea (с)
# Игнорировать контуры, которые слишком малы или слишком велики
если площадь < 3700 или 100000 < площади: Продолжать # cv.minAreaRect возвращает: # (center(x, y), (ширина, высота), угол поворота) = cv2.minAreaRect(c) прямоугольник = cv.minAreaRect (с) коробка = cv.boxPoints (прямая) коробка = np.int0 (коробка) # Получить ключевые параметры повернутой ограничивающей рамки центр = (целое (прямая [0] [0]), целое (прямая [0] [1])) ширина = интервал (прямой [1] [0]) высота = интервал (прямой [1] [1]) угол = интервал (прямоугольник [2]) если ширина < высота: угол = 90 - угол еще: угол = -угол label = «Угол поворота:» + str(угол) + «градусы» текстовое поле = cv.rectangle(img, (центр[0]-35, центр[1]-25), (центр [0] + 295, центр [1] + 10), (255 255 255), -1) cv.putText (img, метка, (центр [0] -50, центр [1]), cv.
 findContours (bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)
findContours (bw, cv.RETR_LIST, cv.CHAIN_APPROX_NONE)