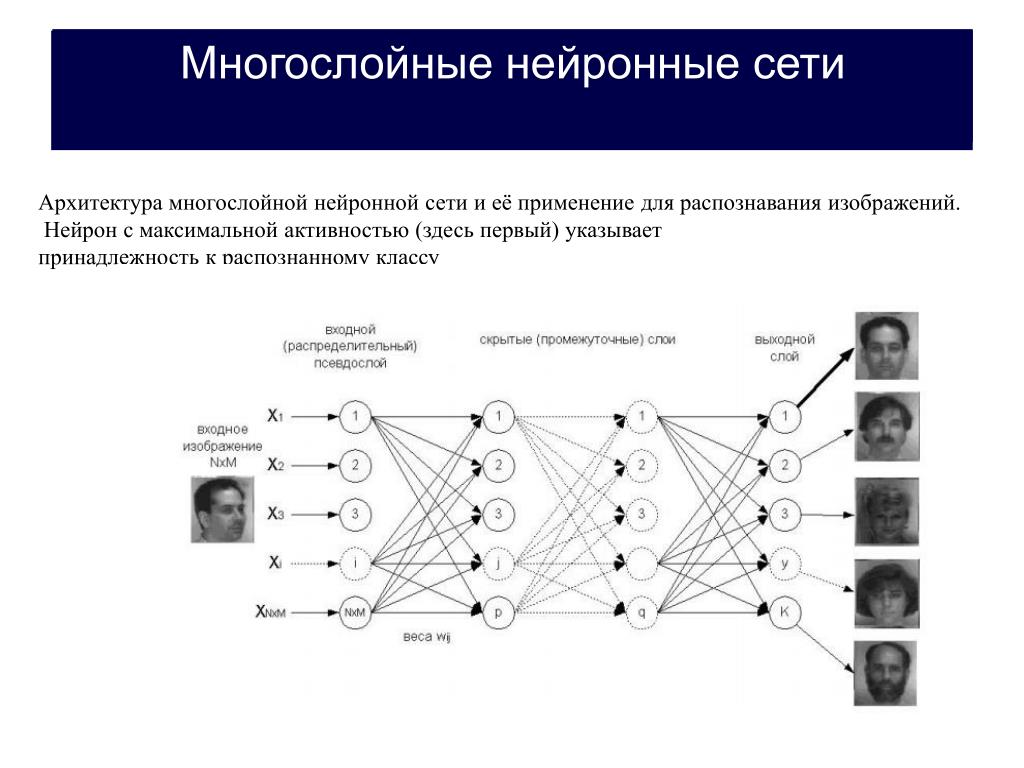
Содержание
Как работают нейросети? Разбор | Droider.ru
Нейросети, машинное обучение, искусственный интеллект. Звучит круто, но как это всё работает?
Объясню на простом примере. Представьте школьника, который пыхтит над контрольной по математике. И вот он подобрался к последнему уравнению, где нужно было вычислить несколько неизвестных (a, b и c) и посчитать ответ.
(a+b)*c=?
Он решает задачу и вдруг краем глаза замечает, что правильный ответ 10, а у него вообще не то — 120 тысяч. Что делать? По-хорошему, надо бы заново всё считать. Но времени мало. Поэтому он решает просто подогнать значения в уравнении, чтобы получился правильный ответ.
Он это делает и понимает, что значения a, b и с он посчитал неправильно еще в предыдущем уравнении. Поэтому там тоже надо всё быстро поправить. Он это делает и сдаёт работу.
Естественно, учительница палит, что он просто подогнал решение под правильный ответ и ставит ему двойку. И зря! Потому что, жульничество школьника на контрольной, можно считать прообразом метода машинного обучения, который позволил нейросетям совершить революцию в развитии компьютерного зрения, распознавания речи и искусственного интеллекта в целом. На разработку этого метода ушло целых 25 лет! И называется он алгоритмом обратного распространения ошибки.
На разработку этого метода ушло целых 25 лет! И называется он алгоритмом обратного распространения ошибки.
Да-да, машинное обучение — это фактически подгонка уравнения под правильный ответ. Но давайте немного углубимся и поймем как это всё работает на самом деле, на примере простейшей нейросети.
Классические алгоритмы
Допустим, мы хотим научить компьютер распознавать рукописные цифры.
Как решить эту задачу? Отличник бы воспользовался классическими математическими методами.
Он бы написал программу, которая может определять специфические признаки, которые отличают одну цифру от другой. Допустим в 8-ке есть два кружочка, в 7-ке две длинные прямые линии и так далее. Вот только выявлять, что это за признаки и описывать их программе ему бы пришлось вручную. Короче надо было проделать кучу работы, и он бы всё равно обломался.
Короче надо было проделать кучу работы, и он бы всё равно обломался.
С такими задачами отлично справляются нейросети, потому как нейросеть может выявлять и находить эти специфические признаки самостоятельно. Как она это делает?
Для примера возьмём нейросеть с классической структурой, под названием многослойный перцептрон.
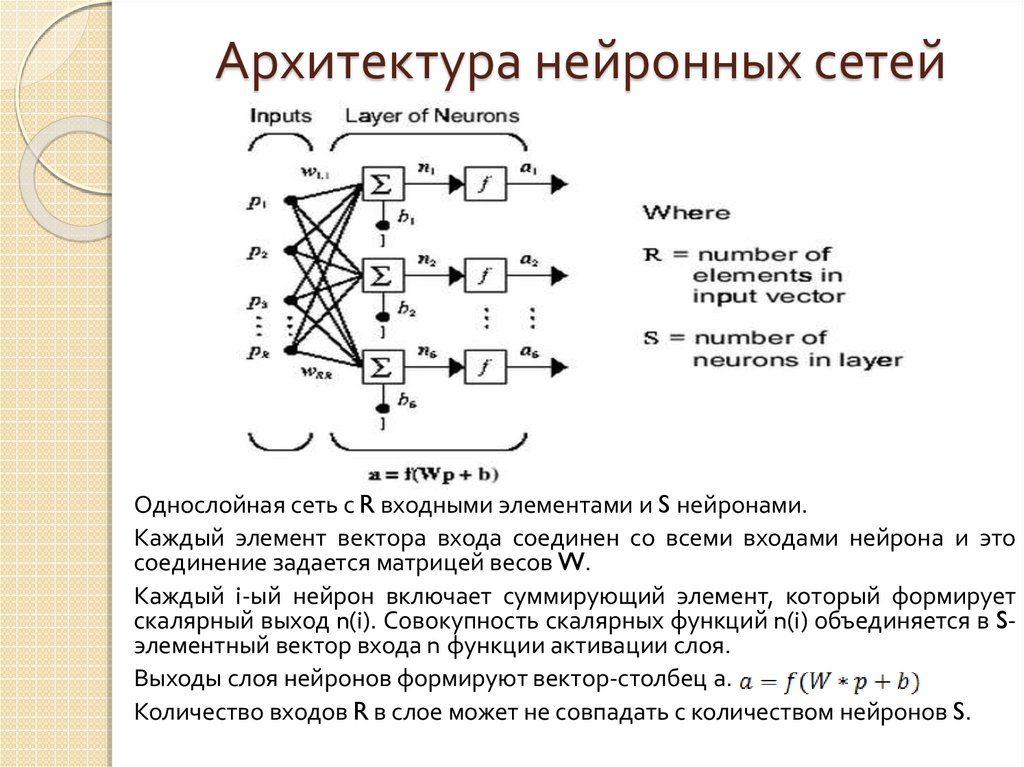
Структура нейросети
Нейросеть состоит из нейронов, а каждый нейрон — это ячейка, которая хранит в себе какой-то ограниченный диапазон значений. В нашем случае это будут значения от 0 до 1. На вход каждого нейрона поступает множество значений, а на выходе он отдаёт только одно. Наша нейросеть называется многослойной, потому, что нейроны в ней организованы в столбцы, а каждый столбец — это отдельный слой. Как видите тут целых четыре слоя.
Самый первый слой называется — входным. По сути, туда просто поступают входные данные.
Например, если мы хотим распознать картинку с цифрой размером 28 на 28 пикселей нам нужно, чтобы в первом слое нашей сети было 784 нейрона, по количеству пикселей в картинке.
Так как нейросеть может хранить только значения от 0 до 1 закодируем яркость каждого пикселя в этом диапазоне значений.
Следующие два слоя называются скрытыми. Количество нейронов в скрытых слоях может быть каким угодно, это подбирается методом проб и ошибок. Именно эти слои отвечают за выявление специфических признаков.
Значения из входного слоя поступают в скрытые слои, там происходит специфическая математика, значения преобразуются и отправляются в последний слой, который называется выходным.
В том нейроне выходного слоя, в котором окажется самое высокое значение, и высчитывается ответ. Поскольку в нашей нейросети мы распознаем цифры, то в выходном слое у нас 10 нейронов, каждый из которых обозначает ответ от 0 до 9.
Веса и смещения
Структура примерно понятна, но какие данные передаются по слоям и что за специфическая математика там происходит?
Разберем на примере одного из нейронов второго слоя.
В этот нейрон, как и в другие нейроны скрытого слоя, поступает сумма всех значений нейронов входного слоя. Напомню, что задача нейронов второго слоя — находить какие-то признаки. Например, этот нейрон мог бы искать горизонтальную линию в верхней части цифры 7.
Напомню, что задача нейронов второго слоя — находить какие-то признаки. Например, этот нейрон мог бы искать горизонтальную линию в верхней части цифры 7.
Если бы мы действовали в логике классического алгоритма, то мы бы могли присвоить разным областям разные коэффициенты. Например мы предполагаем, что в верхней части изображения должны быть яркие пиксели, например горизонтальная палочка у 7-ки. Для этой области мы можем задать повышенные коэффициенты, а для других областей — пониженные. Такие коэффициенты в нейросетях принято называть весами. В формулах обычно обозначаются буквой w.
Теперь смотрите: перемножая входные значения яркостей на веса мы понимаем, была в этой области палочка или нет. Если признак найден, то в нейрон будет записано большое число, а если признака не было — число будет маленьким.
Но для того, чтобы активировать нейрон, нам нужно подать туда достаточно высокое число, выше какого-то порогового значения. В противном случае, нейрон выпадет из игры и дальше ничего не передаст.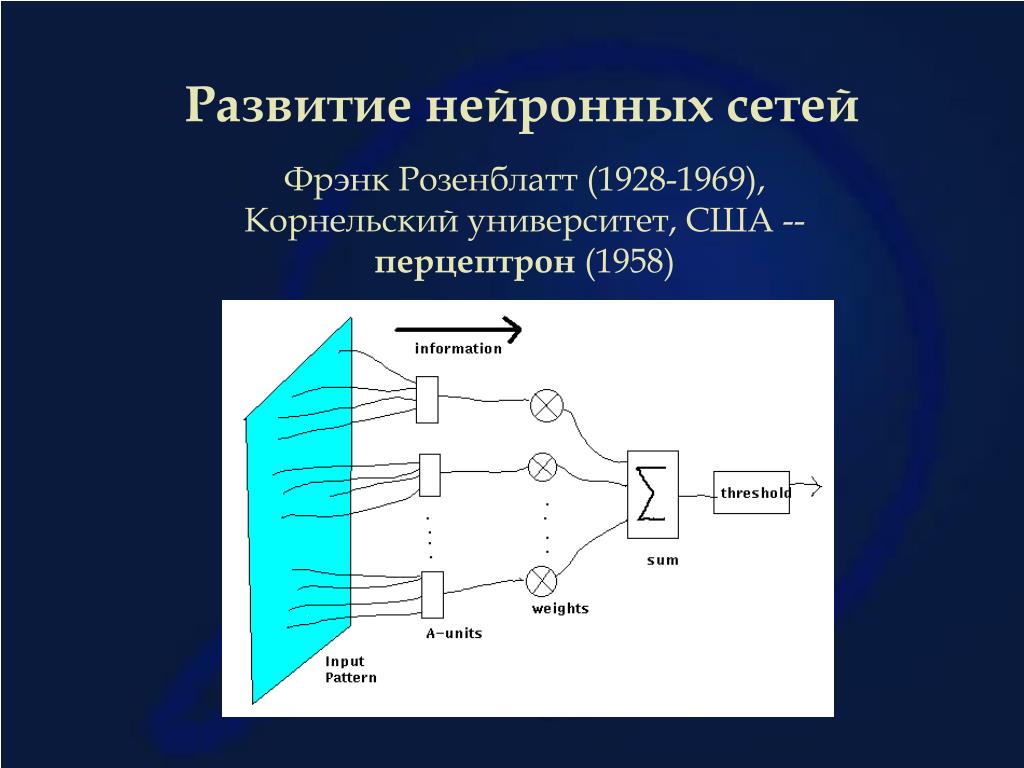
Как это делается?
Мы знаем, что нейрон может содержать значения от 0 до 1. Но входяшие данные могут иметь значение существенно больше: мало того, что мы суммируем все значения из первого слоя, так мы еще их перемножаем на веса. Поэтому полученное значение нам нужно нормировать, например, при помощи функции типа сигмоиды или ReLU.
Но представьте, что на исходных картинках может быть шум, какие-то точки, черточки и прочее. Этот шум нужно как-то отсекать. Для этого в формулу вводится коэффициент смещения, по английски Bias, и он обозначается буквой b. Например, если Bias отрицательный — нейрон будет активироваться реже.
Вся эта функция, кстати называется функцией активации.
Все веса и смещения для каждого нейрона настраиваются отдельно. Но даже в небольшой нейросети типа нашей, весов и смещений более 13 тысяч. Поэтому вручную их настроить не получится. И как же нам задать правильные веса?
Обучение
А никак! Мы просто даем нейросети произвольные значения весов и смещений.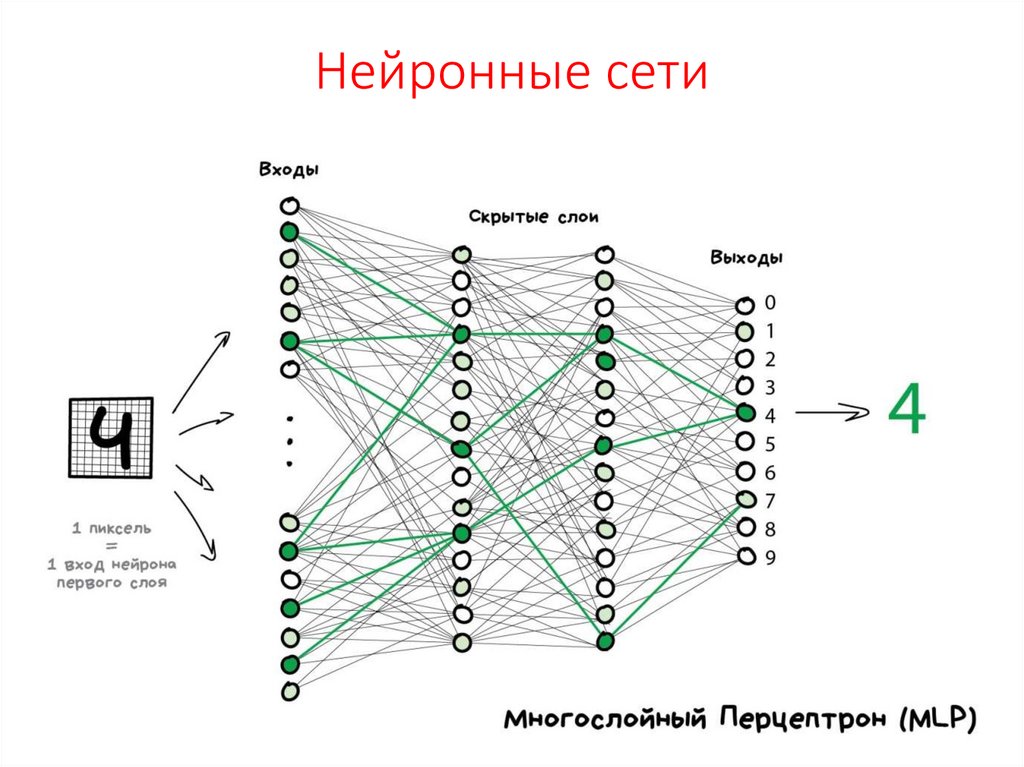 И в итоге, естественно, мы получаем совершенно случайные ответы на выходе.
И в итоге, естественно, мы получаем совершенно случайные ответы на выходе.
И вот тут мы можем вспомнить, что у нас, как и у двоечника в начале рассказа, есть преимущество. Мы знаем правильные ответы, а значит в каждом конкретном случае. мы можем указать нейросети насколько она ошиблась. И тут в бой вступает тот самый алгоритм обратного распространения ошибки! В чем его суть?
Допустим, мы загрузили в нейросеть цифру 2. если бы нейросеть работала идеально в выходном нейроне отвечающем за распознавание двойки было бы максимальное значение равное единице. А в остальный нейронах были бы нолики. Это значит что нейросеть на 100% уверена, что это двойка, а не что-то иное. Но мы получили другие значения.
Однако, поскольку мы знаем правильный ответ, мы можем вычесть из неправильных ответов правильные и подсчитать насколько нейросеть ошиблась в каждом случае. А дальше зная степень ошибки, мы можем отрегулировать веса и смещения для каждого нейрона пропорционально тому, насколько они способствовали общей ошибке.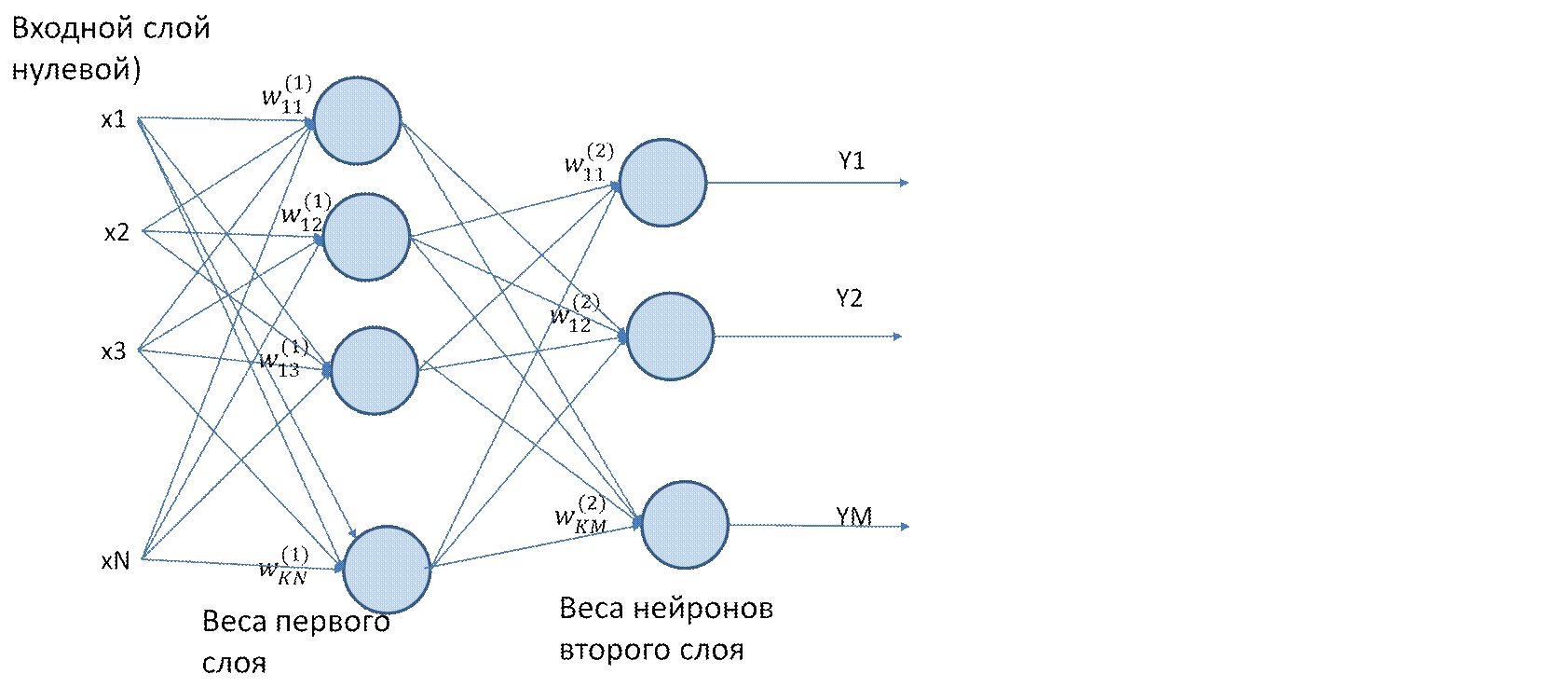
Естественно, проделав такую операцию один раз мы не сможем добиться правильных значений на выходе. Но с каждой попыткой общая ошибка будет уменьшаться. И только после сотен тысяч циклов прямого распространения ошибки и обратного, нейросеть сможет сама подобрать оптимальные веса и смещения. Вот и всё! Так и работают нейросети и машинное обучение.
Другие структуры
Мы с вами рассмотрели самый простой пример нейросети. Но существуют масса архитектур нейросетей:
- Нейросети с учителем
- Нейросети без учителя
- Нейронки, которые учат друг друга
- Нейронки, которые соревнуются между собой
- И даже нейросети, которые самостоятельно корректируют свою структуру в процессе обучения, наподобие того как это происходит в человеческом мозге.
Это целый мир чрезвычайно интересных знаний. И вскоре выйдет еще один материал про терминологию нейросетей и Искусственного Интеллекта.
Post Views:
9 339
Как работают нейронные сети и можно ли их обмануть?
В начале 2019 года на аукционе Sotheby’s в Лондоне появился необычный лот – инсталляция, главным элементом которой стала нейросеть. Предмет искусства представлял собой два экрана, соединённых между собой небольшим винтажным комодом из орехового дерева. Как раз там и хранилась нейронная сеть, которая постоянно генерировала уникальные портреты и выводила их на экраны.
Предмет искусства представлял собой два экрана, соединённых между собой небольшим винтажным комодом из орехового дерева. Как раз там и хранилась нейронная сеть, которая постоянно генерировала уникальные портреты и выводила их на экраны.
Годом ранее другое нейросетевое произведение искусства – «Портрет Эдмонда де Белами» продали на аукционе Christie’s почти за полмиллиона долларов. На холсте размером 70х70 см был изображён мужчина в чёрном фраке и белой рубашке, а сама работа была написана компьютерным алгоритмом, созданным французским проектом Obvious.
Это первый случай за два века истории аукционного дома Christie’s, когда была продана картина, написанная нейросетью.
В отличие от обычных компьютерных программ нейросети нужно «обучать», чтобы они могли распознавать голоса, отличать живого человека от пакета или рисовать картины за полмиллиона долларов.
Как это работает?
Биологические нейронные сети у человека больше похожи на набор связей, при помощи которых мы анализируем и принимаем решения.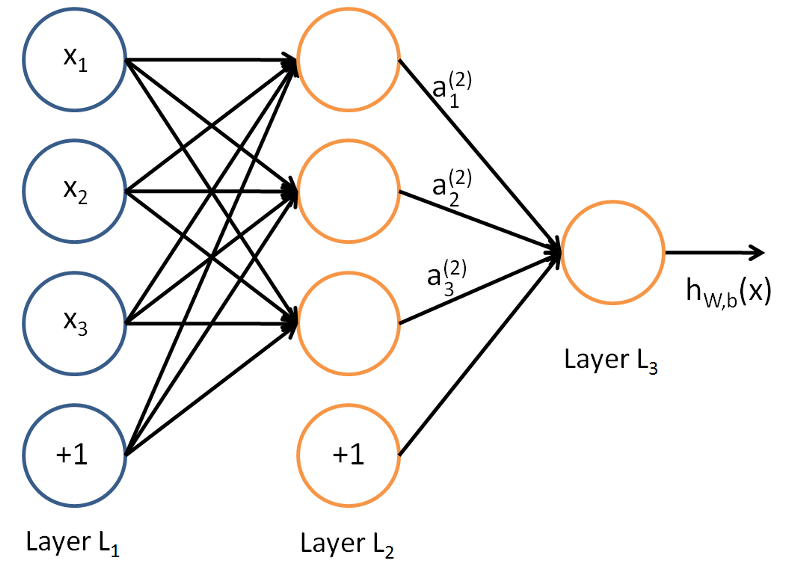 Нейронные сети как технология, в свою очередь, способны решать точно такие же задачи, как и остальные алгоритмы машинного обучения, с той разницей, что нейросеть может «обучаться» на предыдущем опыте.
Нейронные сети как технология, в свою очередь, способны решать точно такие же задачи, как и остальные алгоритмы машинного обучения, с той разницей, что нейросеть может «обучаться» на предыдущем опыте.
Даже по структуре нейросеть имитирует нервную систему живого человека: она состоит из огромного числа отдельных элементов – «нейронов», которые отвечают за вычисления. Каждый такой «нейрон» относится к определённому слою сети, так что, когда нейросеть обрабатывает полученные данные, те последовательно проходят обработку на всех слоях. Параметры «нейрона» могут самостоятельно изменяться. Тут все зависит от «опыта», который был получен в предыдущие операции.
Смысл таких разработок был в том, чтобы максимально точно смоделировать весь процесс человеческой нервной системы. В частности, разработчиков интересует наша способность обучаться и не повторять ошибки прошлого. В идеале нейронная сеть должна работать по тому же принципу и действовать на основании предыдущего опыта, с каждым разом делая всё меньше ошибок. Сложность полноценного распространения нейросети заключается в длительном процессе «обучения», ведь для того, чтобы сеть могла решать поставленные задачи и выдавать правильные ответы, через неё нужно пропустить миллионы данных. Этот процесс пойдёт быстрее, когда разработчикам удастся ускорить этот процесс.
Сложность полноценного распространения нейросети заключается в длительном процессе «обучения», ведь для того, чтобы сеть могла решать поставленные задачи и выдавать правильные ответы, через неё нужно пропустить миллионы данных. Этот процесс пойдёт быстрее, когда разработчикам удастся ускорить этот процесс.
Где уже применяются нейросети?
Область применения нейронных сетей расширяется с каждым годом, но чаще всего мы слышим о развлекательной функции таких технологий. В 2016 году на рынке появилось сразу несколько проектов, которые в основе своей работы использовали нейронные сети. Способности этой технологии демонстрировала Prisma и MLVCH – два мобильных приложения, которые позволяли переносить художественный стиль на фотографии обычных пользователей.
Другое приложение – MSQRD предлагало пользователям изменять вид фотографий, выбирать и накладывать на фото маски-фильтры или эффекты, которые уже были в библиотеке приложения. За все эффекты была ответственна нейронная сеть. Способности собственных нейронных сетей демонстрируют и крупные технологические компании. Например, Google разработал и показал программу AlphaGo для игры в го. Сразу после этого программа победила в матче против Кэ Цзе, который до этого считался сильнейшим в мире участником в эту японскую игру.
Способности собственных нейронных сетей демонстрируют и крупные технологические компании. Например, Google разработал и показал программу AlphaGo для игры в го. Сразу после этого программа победила в матче против Кэ Цзе, который до этого считался сильнейшим в мире участником в эту японскую игру.
Тут нужно понимать, что развлекательные сервисы создаются скорее для демонстрации возможностей нейронной сети и вариантов ее обучения. В процессе игры разработчики обучают нейросетевой алгоритм, а за счёт игровых ситуаций технология может смоделировать практически все сценарии живого поведения и «научиться» делать так же.
О перспективности таких разработок говорят и цифры. Согласно отчёту аналитической компании Allied Analytics, к 2023 году объём рынка нейросетей достигнет $38 млрд, в то время как в 2016 году этот показатель составил всего $7 млрд.
«Рынок нейронных сетей обусловлен ростом спроса на облачные решения и большие данные, а также увеличением числа решений для прогнозирования рынка.
Мы ожидаем, что расширение областей приложений для нейронных сетей создаст выгодные возможности для роста рынка», – пишут аналитики Allied Analytics в своём отчёте.
 Мы ожидаем, что расширение областей приложений для нейронных сетей создаст выгодные возможности для роста рынка», – пишут аналитики Allied Analytics в своём отчёте.
Мы ожидаем, что расширение областей приложений для нейронных сетей создаст выгодные возможности для роста рынка», – пишут аналитики Allied Analytics в своём отчёте.Можно ли обмануть нейросеть?
Нейронная сеть необходима, чтобы решать в основном два типа задач: предсказывать какие-то события и распознавать объекты. Проблема в том, что в этой области есть такое понятие, как «состязательная атака»: нейросеть можно легко обмануть и заставить выдать ложный ответ. Такой метод используют учёные, чтобы проверить устойчивость нейросети к нестандартным решениям. Например, группа исследователей из Левенского католического университета нашла способ сделать человека невидимым для нейросети, просто распечатав абстрактный постер и наклеив его на учёного. В ходе эксперимента нейросеть смогла распознать только одного человека, в то время как учёный с постером в руках оставался невидим. Проблема с атаками на нейросетевые алгоритмы может привести к изменению решения от нейросети – достаточно немного повернуть образец, и нейросеть воспримет данные неправильно.
Какие у нейросетей перспективы?
Нейросети могут качественно анализировать данные, чтобы исключить ошибки, связанные с человеческим фактором. Предполагается, что такие технологии должны избавить нас от муторных и скучных задач и решений, которые мы принимаем ежедневно, но говорить о полноценном распространении нейросетей и возможностях их использования для более сложных задач пока рано. Если такая технология редактирует ваши фотографии из Instagarm и подбирает для них стиль художников семнадцатого века, это кажется безобидным. Другое дело – использование нейросети в реальной жизни, когда, например, беспилотный автомобиль не заметит собаку во время движения по дороге или примет пакет за человека, так что проблема с возможностью состязательных атак ещё остаётся.
как работают нейросети и их разработчики
Нейронные сети не только распознают тексты, изображения и речь, но и помогают диагностировать заболевания и искать полезные ископаемые. Как это происходит? Дата-сайентист и руководитель направления продвинутой аналитики и машинного обучения в ПАО «Газпром нефть» Анна Дубовик рассказала, как это работает и почему не стоит верить громким заявлениям компаний, которые «распознали все».
 T&P записали главное.
T&P записали главное.
Анна Дубовик
Дата-сайентист, руководитель направления продвинутой аналитики и машинного обучения в ПАО «Газпром нефть»
Три важных факта об искусственном интеллекте
Машинное обучение стало частью нашей жизни. Это не какие-то новые технологии и летающие машины, которых мы пока не видели. Мы участвуем в машинном обучении каждый день: мы либо объект этого обучения, либо поставляем для него данные.
Не бывает «волшебных черных ящиков». Не существует искусственного интеллекта, в который вы что-то забрасываете, и он все за вас высчитывает. Самое важное — это качественные данные, на которых происходит обучение. Все архитектуры и алгоритмы известны, и секрет какого-то нового классного приложения всегда в данных.
Машинное обучение развивается в основном силами открытого сообщества. Мы за открытый код — так же, как Google и другие разработчики всего открытого и хорошего.
От эвристики к обучению
Небольшой ликбез: ИИ — большая отрасль, частью которой является машинное обучение. В нем есть много алгоритмов, самые интересные — нейросети. Глубокое обучение — конкретный тип нейросетей, которым мы занимаемся:
В нем есть много алгоритмов, самые интересные — нейросети. Глубокое обучение — конкретный тип нейросетей, которым мы занимаемся:
Почему старые алгоритмы не работают и зачем нужно машинное обучение? Да, врачи распознают рак лучше, чем нейросети, — но они делают это чаще всего на четвертой стадии, когда с человеком уже происходят необратимые изменения. А чтобы распознавать болезнь на первой, нужны алгоритмы. Раньше нефть сама лилась из-под земли, но такого больше не будет, природные ресурсы становится все сложнее добывать.
Все наше предыдущее знание строится на эвристических алгоритмах. Например, если человек чем-то болел и у него есть определенная семейная предрасположенность, то мы понимаем, что обнаруженное нами новообразование, скорее всего, то-то и то-то. Мы отправим человека на сканер, начнем проверять. Но если этих знаний о человеке у нас нет, то мы ничего с ним делать не будем. Это и есть эвристика.
Большинство существующих программ для профессиональных экспертов в разных отраслях сейчас построены на эвристиках. Они пытаются перейти на машинное обучение, но это трудно, поскольку для этого нужны данные.
Они пытаются перейти на машинное обучение, но это трудно, поскольку для этого нужны данные.
Например, у Pornhub отличные нейросетевые алгоритмы, но есть и эвристики. На сайте представлены разделы: «Популярное» — по количеству просмотров, «Лучшее» — по количеству лайков, и есть «Горячее» (Hottest). Как определить его эвристику? Она вычисляется не по количеству просмотров и не по популярным хэштегам. Это видео, которые смотрят последними перед уходом с сайта — именно они вызывают у пользователей больше всего эмоций.
Когда и почему появились нейросети? Впервые о них написали в 1959 году, но количество публикаций стало резко увеличиваться только с 2009 года. 50 лет ничего не происходило: не было возможности проводить вычисления, не существовало современных графических ускорителей. Чтобы обучить нейросеть чему-то, необходимо много вычислительных мощностей и сильное железо. Но теперь каждый день выходит по 50 публикаций о достижениях нейросетей, и обратного пути нет.
Важнее всего, что нейросеть — это не волшебство.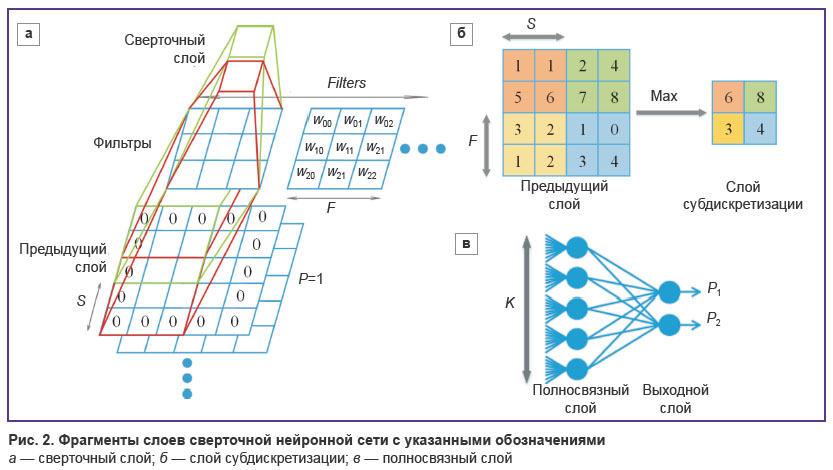 Когда люди узнают, что я занимаюсь data science, начинают предлагать мне идеи стартапа: взять откуда-нибудь, например в Facebook, все данные, забросить в нейросеть и предсказать, условно говоря, «все». Но это так не работает. Всегда есть конкретный тип данных и четкая постановка задачи:
Когда люди узнают, что я занимаюсь data science, начинают предлагать мне идеи стартапа: взять откуда-нибудь, например в Facebook, все данные, забросить в нейросеть и предсказать, условно говоря, «все». Но это так не работает. Всегда есть конкретный тип данных и четкая постановка задачи:
Как видите, в списке нет «распознавания», потому что так это называется на языке людей, а математически может формулироваться по-разному. И поэтому сложные задачи всегда разбиваются на более простые подзадачи.
Вот оцифрованное изображение рукописной цифры 9, 28 на 28 пикселей:
Источник: www.3blue1brown.com
Первый слой нейросети — это вход, который «видит» 784 пикселя, окрашенных в разные оттенки серого. Последний — выход: несколько категорий, к одной из которых мы просим отнести то, что было отправлено на вход. И между ними — скрытые слои:
Эти скрытые слои — это некоторая функция, которую мы не задаем никакой эвристикой, она сама учится выводить математическую последовательность, которая с определенной вероятностью отнесет «входные» пиксели к определенному классу.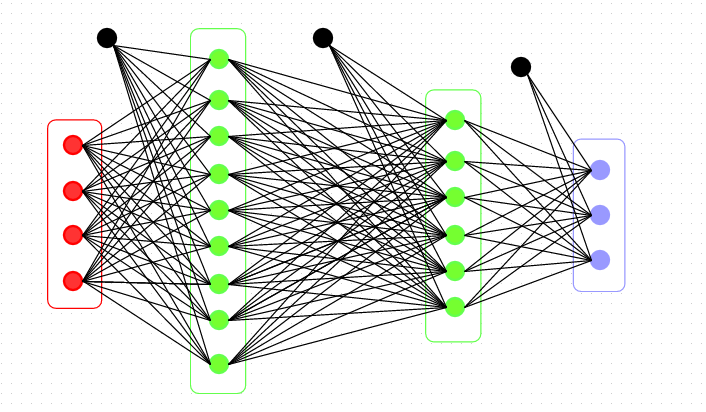
Как нейросети работают с изображениями
Классификация. Можно научить нейросеть классифицировать изображения, например распознавать породы собак:
Но для обучения ей потребуются миллионы картинок — и это должен быть тот тип данных, которые вы потом действительно будете использовать. Потому что, если вы обучили нейросеть искать собак, а показываете кексы, она все равно будет искать собак, и получится что-то вроде этого:
Детекция. Это другая задача: на изображении нужно найти объект, принадлежащий к определенному классу. Например, мы загружаем в нейросеть снимок побережья и просим найти людей и кайты:
Подобный алгоритм сейчас проходит бета-тестирование в поисковом отряде «Лиза Алерт». Во время поисков участники отрядов делают множество снимков с помощью беспилотников, затем их отсматривают — и иногда именно так находят потерявшихся людей. Чтобы сократить время на отсмотр всех снимков, алгоритм отсеивает те снимки, на которых нет значимой для поисков информации.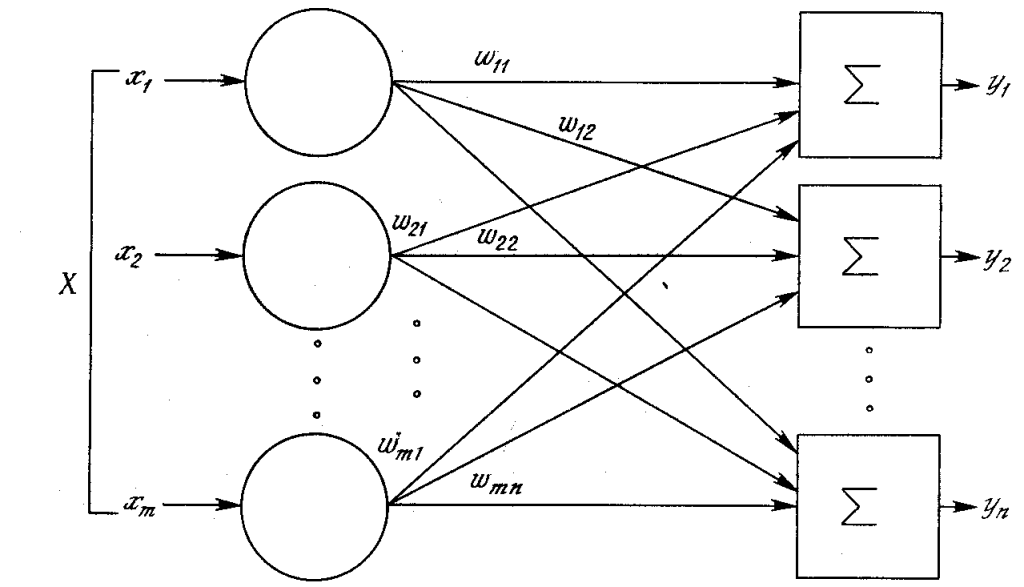 Но никакая нейросеть не даст стопроцентной точности, поэтому снимки, отобранные алгоритмом, валидируются людьми.
Но никакая нейросеть не даст стопроцентной точности, поэтому снимки, отобранные алгоритмом, валидируются людьми.
Сегментация (одноклассовая и многоклассовая) используется, например, для беспилотных автомобилей. Нейросеть распределяет объекты по классам: вот машины, вот тротуар, вот здание, вот люди, у всех объектов четкие границы:
Генерация. У генерирующих сетей на входе — пустота, на выходе — какой-то класс объектов, а скрытые слои пытаются научиться превращать пустоту во что-то определенное. Например, вот два лица — оба были сгенерированы нейросетью:
Нейросеть смотрит на миллионы фотографий людей в интернете и множественными итерациями учатся понимать, что на лице должны быть нос, глаза, что голова должна быть круглая, и т. д.
А если мы можем сгенерировать изображение, значит, можно заставить его двигаться так же, как определенный человек, — то есть сгенерировать видео. Пример — недавний вирусный ролик, в котором Обама говорит, что Трамп идиот. Обама никогда этого не говорил, просто нейросеть научили мэтчиться (от англ. match — «совпадать, соответствовать, сопоставлять». — Прим. T&P) на Обаму, и когда другой человек говорил, камера транслировала его мимику на лицо бывшего американского президента. Другой пример — Ctrl Shift Face, который делает прекрасные дипфейки❓Deep fake — от deep learning (англ. «глубинное обучение») и fake (англ. «фейк, фальшивка»). — Прим. T&P на звезд. Пока что нейросети не всегда срабатывают идеально, но с каждым годом будут делать это все лучше, и скоро на видео отличить реального человека от «намазанного» сетью будет невозможно. И никакой Face ID нас больше не застрахует от мошенничества.
match — «совпадать, соответствовать, сопоставлять». — Прим. T&P) на Обаму, и когда другой человек говорил, камера транслировала его мимику на лицо бывшего американского президента. Другой пример — Ctrl Shift Face, который делает прекрасные дипфейки❓Deep fake — от deep learning (англ. «глубинное обучение») и fake (англ. «фейк, фальшивка»). — Прим. T&P на звезд. Пока что нейросети не всегда срабатывают идеально, но с каждым годом будут делать это все лучше, и скоро на видео отличить реального человека от «намазанного» сетью будет невозможно. И никакой Face ID нас больше не застрахует от мошенничества.
Как нейросети работают с текстами
Тексты для сетей не имеют смысла, для них это просто «векторы», над которыми можно производить разные математические операции, например: «Король минус человек плюс женщина равно королева»:
Но из-за того, что нейросети учатся на текстах, созданных людьми, возникают курьезы. Например: «Доктор минус мужчина плюс женщина равно медсестра». В представлении нейросети женщин-врачей не существует.
В представлении нейросети женщин-врачей не существует.
Машинный перевод. Раньше многие пользовались переводчиком, работа которого была построена на эвристиках: эти слова значат то-то, их можно переводить и склонять только так-то и располагать вот в таком порядке. Он не мог отойти от этих правил, и часто в целом получалась ерунда:
Сегодня в работу Google Translate добавили нейронные сети, и переведенные им тексты выглядят уже гораздо более литературно.
Генерация текста. Полгода назад сделали нейросеть, которой можно задать тему, несколько ключевых слов, и она сама напишет сочинение-размышление. Работает прекрасно, но не проверяет факты и не задумывается об этичности написанного:
Сочинение о вреде переработки отходов
Авторы не выложили код в открытый доступ, не показали, на чем они обучали сеть, обосновав это тем, что мир не готов к этой технологии, что она будет использована во вред.
Распознавание и генерация речи. Все то же самое, что и с распознаванием изображения: есть звук, нужно оцифровать сигнал:
Именно так работают «Алиса» и Siri.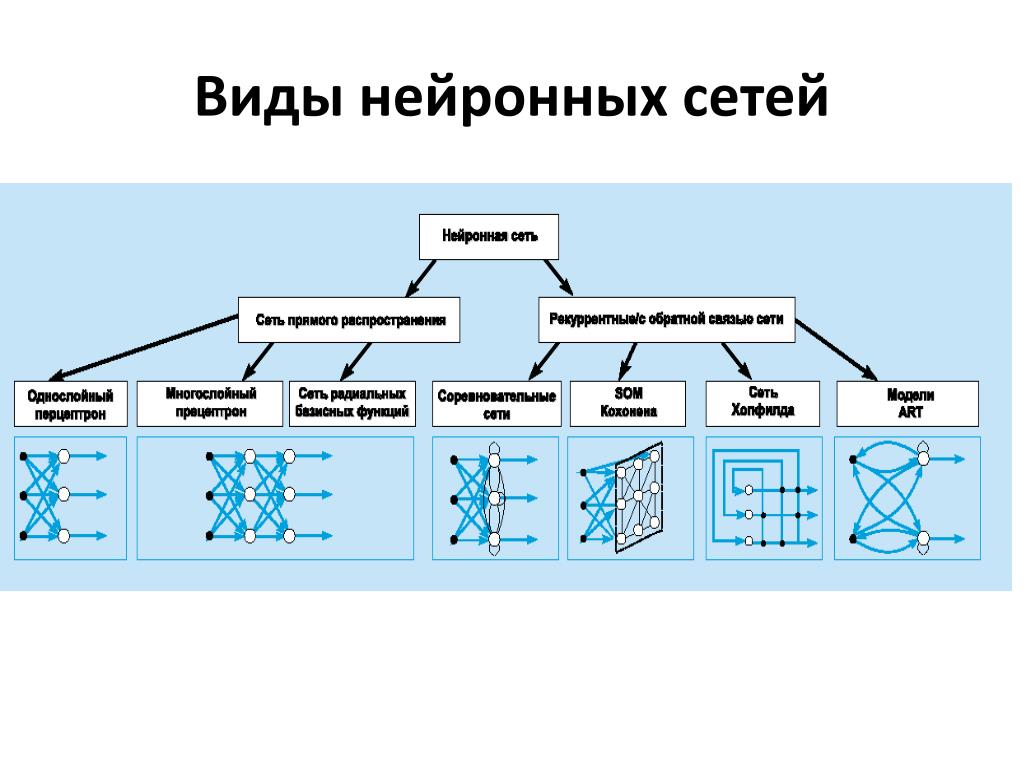 Когда вы пишете в Google Translate некий текст, он его переводит, формирует из букв звуковую волну и воспроизводит ее, то есть генерирует речь.
Когда вы пишете в Google Translate некий текст, он его переводит, формирует из букв звуковую волну и воспроизводит ее, то есть генерирует речь.
Обучение с подкреплением
Игра в «Арканоид» — самый простой пример обучения с подкреплением:
Есть агент — то, на что вы воздействуете, что может менять свое поведение, — в данном случае это горизонтальная «палка» внизу. Есть среда, которая описана разными модулями, — это все, что вокруг «палки». Есть награда: когда сетка роняет шарик, мы говорим, что она теряет свою награду.
Когда нейросеть выбивает очки, мы говорим ей, что это здóрово и она работает хорошо. И тогда сеть начинает изобретать действия, которые приведут ее к победе, максимизируют выгоду. Сначала кидает шарик и просто стоит. Мы говорим: «Плохо». Она: «Ладно, кину, подвинусь на один пиксель». — «Плохо». — «Кину, подвинусь на два, влево, вправо, буду рандомно дергаться». Процесс обучения нейросети — очень долгий и дорогой.
Другой пример обучения с подкреплением — это го. В мае 2014 года люди говорили, что компьютер еще не скоро научится понимать, как играть в го. Но уже в следующем году нейросеть обыграла чемпиона Европы. В марте 2016 года AlphaGo обыграла чемпиона мира высшего дана, а следующая версия выиграла у предыдущей с разгромным счетом 100:0, хотя делала абсолютно непредсказуемые шаги. У нее не было никаких ограничений, кроме игры по правилам:
В мае 2014 года люди говорили, что компьютер еще не скоро научится понимать, как играть в го. Но уже в следующем году нейросеть обыграла чемпиона Европы. В марте 2016 года AlphaGo обыграла чемпиона мира высшего дана, а следующая версия выиграла у предыдущей с разгромным счетом 100:0, хотя делала абсолютно непредсказуемые шаги. У нее не было никаких ограничений, кроме игры по правилам:
Зачем учить компьютер играть в игры за бешеные деньги, вкладываться в киберспорт? Дело в том, что обучение движению и взаимодействию роботов в среде стоит еще дороже. Если ваш алгоритм ошибается и разбивает многомиллионный дрон, это очень обидно. А потренироваться на людях, но в Dota, сам Бог велел.
Открытый код
Как и кем реализуются приложения машинного обучения? Смелые заявления в интернете о том, что какая-то компания написала очередное приложение, которое «все распознало», не соответствуют действительности. Есть лидеры рынка, которые разрабатывают инструменты и выкладывают их в открытый доступ, чтобы все люди могли писать код, предлагать изменения, двигать отрасль.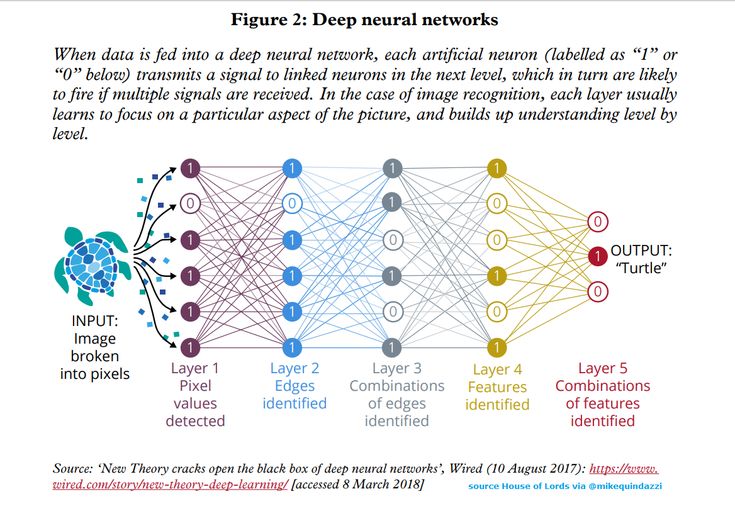 Есть «хорошие парни», которые тоже делятся некоторой частью кода. Но есть и «плохие парни», с которыми лучше не связываться, потому что они не разрабатывают собственные алгоритмы, а пользуются тем, что написали «хорошие парни», делают из их разработок собственных «франкенштейнов» и пытаются продавать.
Есть «хорошие парни», которые тоже делятся некоторой частью кода. Но есть и «плохие парни», с которыми лучше не связываться, потому что они не разрабатывают собственные алгоритмы, а пользуются тем, что написали «хорошие парни», делают из их разработок собственных «франкенштейнов» и пытаются продавать.
Примеры использования data science в нефтяной отрасли
Поиск новых месторождений. Чтобы понять, есть ли в земле нефть, специалисты производят серию взрывов и записывают сигнал, чтобы затем посмотреть, как колебания проходят через землю. Но поверхностная волна искажает общую картину, забивает сигнал из недр, поэтому результат надо «почистить». Специалисты-сейсмики делают это в специальных программах, причем они не могут использовать каждый раз один и тот же фильтр или набор фильтров: чтобы найти искомую комбинацию, они каждый раз подбирают новую комбинацию фильтров. На примере их работы мы можем научить нейросеть делать то же самое:
Правда, выясняется, что сеть удаляет не только поверхностные шумы, но и полезный сигнал. Поэтому мы добавляем новое условие: просим чистить только тот участок сигнала, с которым работают сейсмики, — это называется «нейросеть с вниманием».
Поэтому мы добавляем новое условие: просим чистить только тот участок сигнала, с которым работают сейсмики, — это называется «нейросеть с вниманием».
Описание столба керна по типам литологии. Это задача сегментации. Есть фотографии керна — пород, вытащенных из скважины. Специалисту вручную нужно разобрать, какие пласты там находятся. Человек тратит на это недели и месяцы, а обученная нейросеть — до часа. Чем больше мы ее учим, тем лучше она работает:
«Лучше, чем человек»
У специалистов возникает вопрос, как можно работу нейросети сравнить с человеческим опытом: «Да Иван Петрович с нами с 1964 года, да он этого керна перенюхал!» Конечно, но он делал то же самое, что и сетка: брал керн, брал учебник, смотрел, как другие люди это делают, и пытался вывести из этого закономерность. Только нейросеть работает гораздо быстрее и жизненный опыт Ивана Петровича переживает 500 раз за день. Однако люди все равно еще не верят в технологию, поэтому нам приходится все задачи разбивать на небольшие этапы, чтобы эксперт мог завалидировать каждый из них и поверить в то, что нейросеть работает.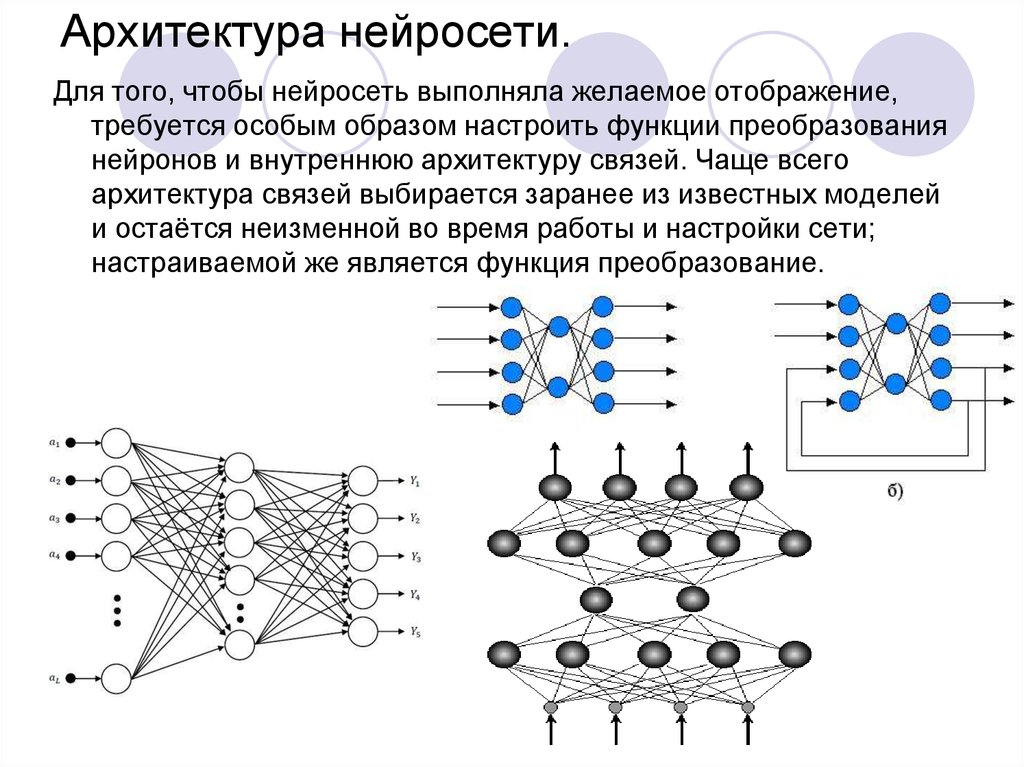
Все заявления о том, что какая-то нейросеть работает «лучше, чем человек», чаще всего ни на чем не основаны, потому что всегда найдется кто-то, кто будет «глупее» нейросети. Вы мне: «Распознай нефть». А я: «Ну, тут где-то». Вывод: «Ага, не получилось, значит, наша система работает лучше тебя». На самом деле для того, чтобы оценить эффективность работы нейросети, должно быть сравнение с целой группой экспертов, главными людьми в отрасли.
Не меньше вопросов вызывают заявления о точности. Если взять десять человек, один из которых болен раком легких, и сказать, что все они здоровы, то мы предскажем ситуацию с точностью в 90%. Мы ошиблись в одном из десяти, все честно, никто никого не обманул. Но полученный результат нас ни к чему не приводит. Любые новости о революционных разработках — неправда, если нет открытого кода или описания того, как они сделаны.
Данные должны быть качественными. Не существует ситуаций, когда вы вбрасываете в нейросеть неочищенные, неизвестно как собранные данные и получаете нечто дельное. Что значит «плохие данные»? Чтобы распознать онкологическое заболевание, нужно сделать много снимков компьютерной томографии в высоком разрешении и собрать из них 3D-куб органов. Тогда в одном из срезов врач сможет найти картину подозрения на рак — плотную массу, которой там быть не должно. Мы попросили специалистов разметить нам много таких снимков, чтобы поучить нейросеть выделять рак. Проблема в том, что один врач считает, что рак в одном месте, другой врач считает, что там два рака, третий врач думает еще как-то иначе. Сделать из этого нейросеть невозможно, потому что все это разные ткани, и если обучить нейросеть на таких данных, то она будет видеть рак вообще везде.
Что значит «плохие данные»? Чтобы распознать онкологическое заболевание, нужно сделать много снимков компьютерной томографии в высоком разрешении и собрать из них 3D-куб органов. Тогда в одном из срезов врач сможет найти картину подозрения на рак — плотную массу, которой там быть не должно. Мы попросили специалистов разметить нам много таких снимков, чтобы поучить нейросеть выделять рак. Проблема в том, что один врач считает, что рак в одном месте, другой врач считает, что там два рака, третий врач думает еще как-то иначе. Сделать из этого нейросеть невозможно, потому что все это разные ткани, и если обучить нейросеть на таких данных, то она будет видеть рак вообще везде.
Проблемы нейросетей
С датасетом (data set — «набор данных». — Прим. T&P). Однажды китайская система распознавания нарушений выписала штраф за переход в неположенном месте женщине, которая на самом деле была лишь рекламой на автобусе, переезжавшем пешеходный переход. Это значит, что для обучения нейросети использовался неправильный датасет.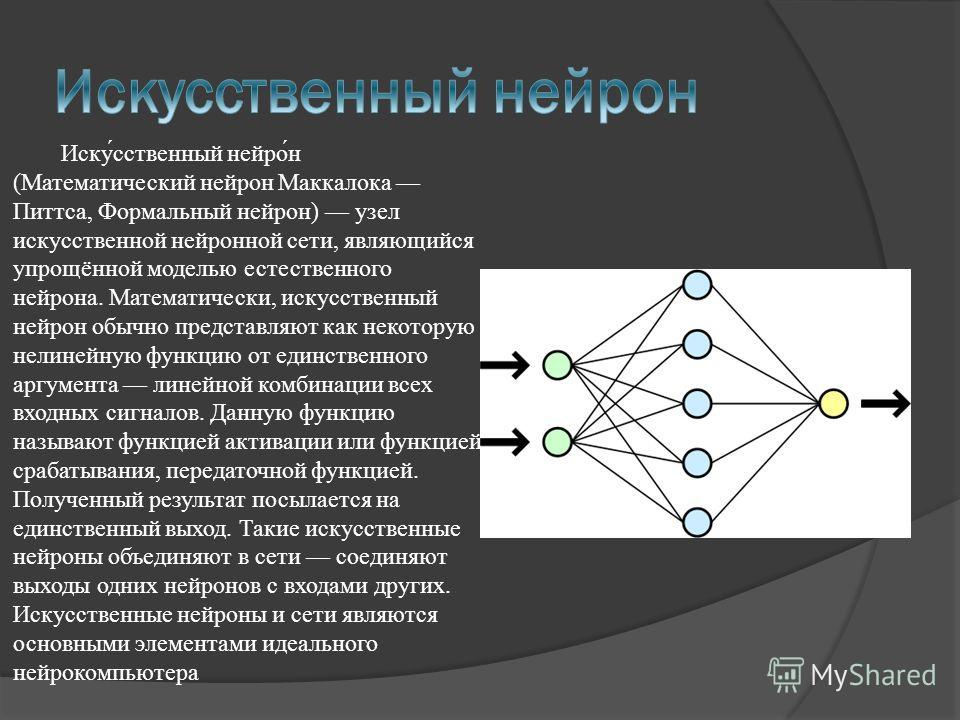 Нужны были объекты в контексте, чтобы нейросеть научилась отличать настоящих женщин от рекламных изображений.
Нужны были объекты в контексте, чтобы нейросеть научилась отличать настоящих женщин от рекламных изображений.
Другой пример: было соревнование по детекции рака легких. Одно сообщество выпустило датасет с тысячью снимками и разметило на них рак в соответствии с точкой зрения трех разных экспертов (но только в тех случаях, когда их мнения совпадали). На таком датасете можно было обучиться. А вот другая контора решила попиариться и выпустила новость, что использовала в работе несколько сотен тысяч рентгенов. Но оказалось, что больных там было только 20%. А ведь именно они являются для нас важными, ведь если нейросеть будет учиться без них, то не распознает заболевание. Более того, в эти 20% вошли несколько категорий заболеваний с разными подтипами болезней. И выяснилось, что так как это не 3D-картинка, а двухмерное изображение, то сделать с таким датасетом ничего нельзя.
Важно включать в датасет реальную информацию. Иначе придется штрафовать людей, наклеенных на автобусы.
С реализацией. Нейросети не знают, что предлагать в отсутствие информации и когда остановиться. Например, если вы завели себе новый почтовый аккаунт и нейросеть еще ничего о вас не знает, то в почте у вас первое время будет реклама, не имеющая лично к вам никакого отношения. А если вы искали в интернете диван и купили его, вам все равно еще долго будут рекламировать диваны, потому что нейросеть не в курсе, что вы уже совершили покупку. Чат-бот, полюбивший Гитлера❓Чат-бот Tay от Microsoft был создан для общения в Twitter. Обучаясь на реальных твитах, он очень быстро «полюбил» Гитлера и «возненавидел» евреев, феминисток и вообще человечество. — Прим. T&P, просто смотрел, что делают люди, и пытался мимикрировать. Имейте в виду: вы каждый день производите контент, и он может быть использован против вас.
Нейросети не знают, что предлагать в отсутствие информации и когда остановиться. Например, если вы завели себе новый почтовый аккаунт и нейросеть еще ничего о вас не знает, то в почте у вас первое время будет реклама, не имеющая лично к вам никакого отношения. А если вы искали в интернете диван и купили его, вам все равно еще долго будут рекламировать диваны, потому что нейросеть не в курсе, что вы уже совершили покупку. Чат-бот, полюбивший Гитлера❓Чат-бот Tay от Microsoft был создан для общения в Twitter. Обучаясь на реальных твитах, он очень быстро «полюбил» Гитлера и «возненавидел» евреев, феминисток и вообще человечество. — Прим. T&P, просто смотрел, что делают люди, и пытался мимикрировать. Имейте в виду: вы каждый день производите контент, и он может быть использован против вас.
С реальностью. Во Флоренции есть художник, который клеит веселые стикеры на дорожные знаки, чтобы разнообразить будничную жизнь людей. Но подобных знаков в обучающей выборке для беспилотных автомобилей, скорее всего, не будет.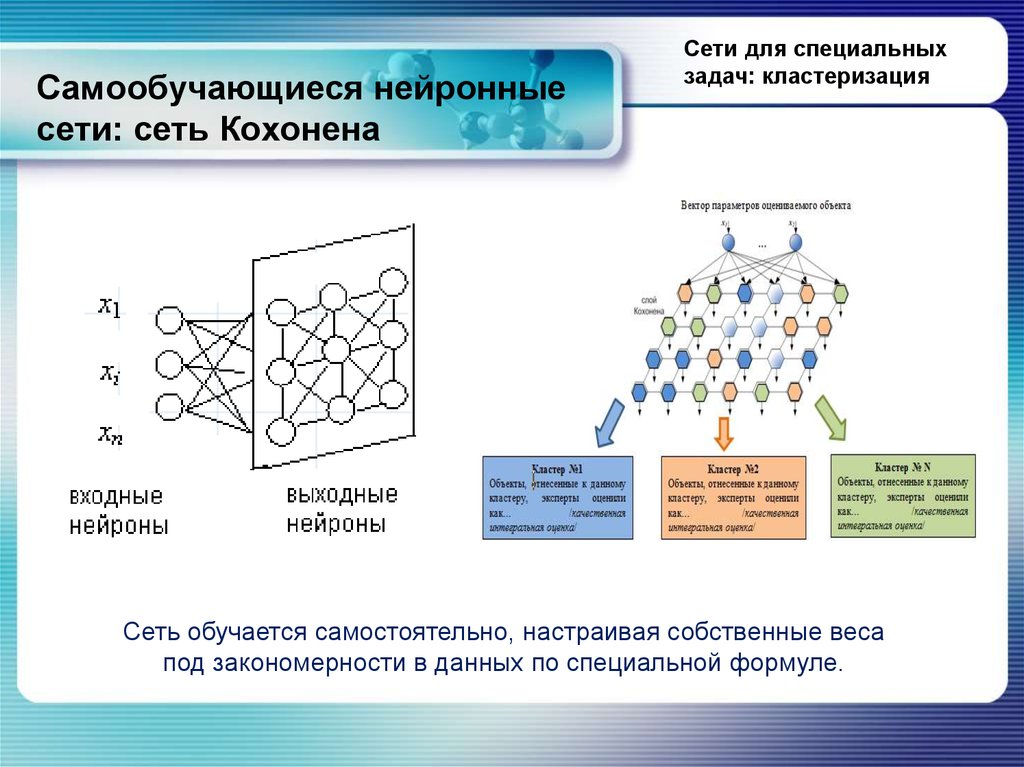 И если выпустить машину в такой мир, она просто собьет нескольких пешеходов и остановится:
И если выпустить машину в такой мир, она просто собьет нескольких пешеходов и остановится:
Таким образом, чтобы нейросети работали круто, нужно не рассказывать о них громкие новости, а учить математику и пользоваться тем, что есть в открытом доступе.
Мы публикуем сокращенные записи лекций, вебинаров, подкастов — то есть устных выступлений.
Мнение спикера может не совпадать с мнением редакции.
Мы запрашиваем ссылки на первоисточники, но их предоставление остается на усмотрение спикера.
Объяснение того, как работают нейронные сети для начинающих | Теренс Шин
Понимание основ нейронных сетей для пятилетних детей
Изображение Ахмеда Гада из
- Предисловие
- Искусственный интеллект, машинное обучение и нейронные сети
- Механика базовых типов нейронных сетей
- 8 90 Pixabay Нейронные сети
- Приложения для нейронных сетей
Несколько недель назад, когда я начал изучать нейронные сети, я обнаружил, что вводная информация по такой сложной теме не имеет такого качества.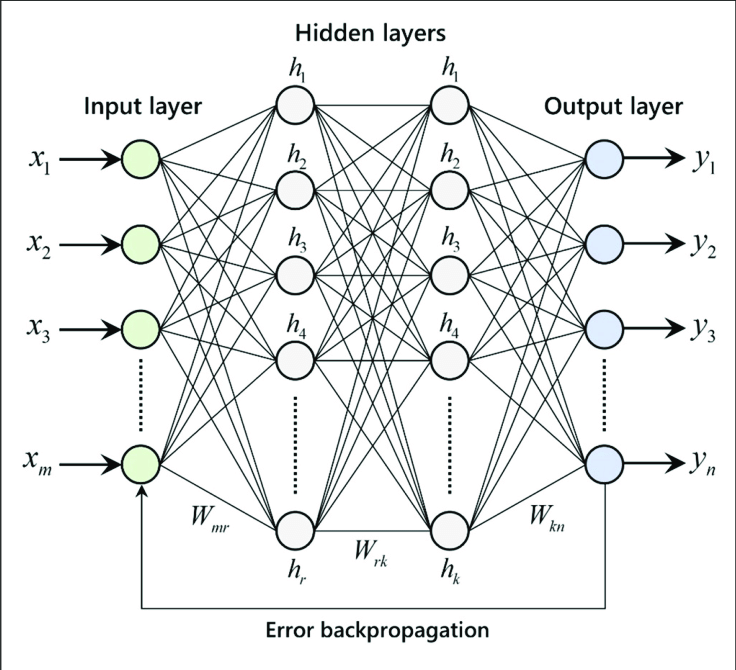 Я часто читал, что нейронные сети — это алгоритмы, которые имитируют мозг или имеют мозгоподобная структура , которая мне совсем не помогла. Таким образом, эта статья направлена на то, чтобы научить основам нейронной сети способом, понятным для всех, особенно для тех, кто плохо знаком с машинным обучением.
Я часто читал, что нейронные сети — это алгоритмы, которые имитируют мозг или имеют мозгоподобная структура , которая мне совсем не помогла. Таким образом, эта статья направлена на то, чтобы научить основам нейронной сети способом, понятным для всех, особенно для тех, кто плохо знаком с машинным обучением.
Прежде чем понять, что такое нейронные сети, нам нужно сделать несколько шагов назад и понять, что такое искусственный интеллект и машинное обучение.
Искусственный интеллект и машинное обучение
Опять же, это расстраивает, потому что, когда вы гуглите, что означает искусственный интеллект, вы получаете такие определения, как «это имитация человеческого интеллекта машинами», которые, хотя и могут быть правдой, могут вводить в заблуждение. новые учащиеся.
В самом простом смысле искусственный интеллект (ИИ) относится к идее предоставления машинам или программам возможности принимать собственные решения на основе предопределенных правил или моделей распознавания образов. Идея моделей распознавания образов приводит к моделям машинного обучения , которые представляют собой алгоритмы, которые строят модели на основе выборочных данных для прогнозирования новых данных. Обратите внимание, что машинное обучение является частью искусственного интеллекта.
Идея моделей распознавания образов приводит к моделям машинного обучения , которые представляют собой алгоритмы, которые строят модели на основе выборочных данных для прогнозирования новых данных. Обратите внимание, что машинное обучение является частью искусственного интеллекта.
Существует ряд моделей машинного обучения, таких как линейная регрессия, машины опорных векторов, случайные леса и, конечно же, нейронные сети. Теперь это возвращает нас к нашему первоначальному вопросу, что такое нейронные сети?
Нейронные сети
По своей сути Нейронная сеть представляет собой сеть математических уравнений . Он принимает одну или несколько входных переменных и, проходя через сеть уравнений, получает одну или несколько выходных переменных. Вы также можете сказать, что нейронная сеть принимает вектор входных данных и возвращает вектор выходных данных, но в этой статье я не буду углубляться в матрицы.
Опять же, я не хочу слишком углубляться в механику, но стоит показать вам, как выглядит структура базовой нейронной сети.
В нейронной сети есть входных слоев , один или несколько скрытых слоев и выходных слоев . Входной слой состоит из одной или более характеристических переменных (или входных переменных или независимых переменных), обозначенных как x1, x2, …, xn. Скрытый слой состоит из одного или нескольких скрытых узлов или скрытых блоков. Узел — это просто один из кругов на диаграмме выше. Точно так же выходная переменная состоит из одной или нескольких единиц вывода.
Данный слой может иметь множество узлов, как показано на изображении выше.
Кроме того, данная нейронная сеть может иметь много слоев. Как правило, большее количество узлов и слоев позволяет нейронной сети выполнять гораздо более сложные вычисления.
Выше приведен пример потенциальной нейронной сети. Он имеет три входные переменные: размер участка, количество спален и средний. Семейный доход. Подав в эту нейронную сеть эти три фрагмента информации, она вернет результат — «Цена дома». Итак, как именно он это делает?
Итак, как именно он это делает?
Как я уже сказал в начале статьи, нейронная сеть — это не что иное, как сеть уравнений. Каждый узел в нейронной сети состоит из двух функций: линейной функции и функции активации. Здесь все может немного запутаться, но пока думайте о линейной функции как о некоторой линии наилучшего соответствия. Кроме того, подумайте о функции активации, как о выключателе света, который приводит к числу от 1 до 0.
Что происходит, так это то, что входные признаки (x) передаются в линейную функцию каждого узла, в результате чего получается значение z . Затем значение z передается в функцию активации, которая определяет, включается выключатель света или нет (между 0 и 1).
Таким образом, каждый узел в конечном счете определяет, какие узлы следующего уровня будут активированы, пока не будет достигнут результат. Концептуально в этом суть нейронной сети.
Если вы хотите узнать о различных типах функций активации, о том, как нейронная сеть определяет параметры линейных функций и как она ведет себя как самообучающаяся модель «машинного обучения», существуют полные курсы, специально посвященные нейронным сетям. сети, которые вы можете найти в Интернете!
сети, которые вы можете найти в Интернете!
Нейронные сети настолько продвинулись вперед, что теперь существует несколько типов нейронных сетей, но ниже приведены три основных типа нейронных сетей, о которых вы, вероятно, будете часто слышать.
Искусственные нейронные сети (ИНС)
Искусственные нейронные сети или ИНС похожи на нейронные сети на изображениях выше, которые состоят из набора связанных узлов, которые принимают входные данные или набор входных данных и возвращают выходные данные. Это самый фундаментальный тип нейронной сети, о котором вы, вероятно, узнаете первым, если когда-нибудь пройдёте курс. ИНС состоят из всего, о чем мы говорили, а также функций распространения, скорости обучения, функции стоимости и обратного распространения.
Сверточные нейронные сети (CNN)
Сверточная нейронная сеть (CNN) — это тип нейронной сети, использующий математическую операцию, называемую свертка . Википедия определяет свертку как математическую операцию над двумя функциями, которая производит третью функцию, выражающую, как форма одной изменяется другой.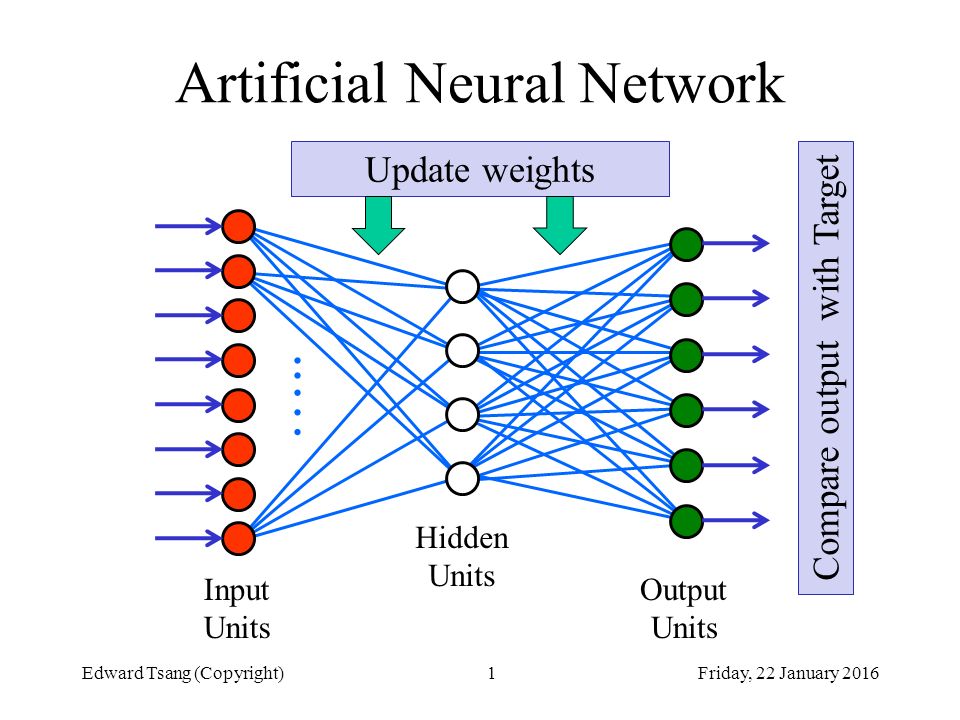 Таким образом, CNN используют свертку вместо обычного матричного умножения по крайней мере в одном из своих слоев.
Таким образом, CNN используют свертку вместо обычного матричного умножения по крайней мере в одном из своих слоев.
Рекуррентные нейронные сети (RNN)
Рекуррентные нейронные сети (RNN) — это тип ANN, в которых связи между узлами образуют орграф вдоль временной последовательности, что позволяет им использовать свою внутреннюю память для обработки последовательностей входных данных переменной длины. Из-за этой характеристики RNN отлично подходят для обработки данных последовательности, таких как распознавание текста или аудио.
Нейронные сети — это мощные алгоритмы, которые привели к некоторым революционным приложениям, которые ранее были невозможны, включая, помимо прочего, следующее:
- Распознавание изображений и видео : Благодаря возможностям распознавания изображений теперь у нас есть такие функции, как распознавание лиц для обеспечения безопасности и система Bixby Vision.
- Системы рекомендаций : Вы когда-нибудь задумывались, как Netflix всегда может рекомендовать шоу и фильмы, которые вам ДЕЙСТВИТЕЛЬНО нравятся? Скорее всего, они используют нейронные сети для обеспечения этого опыта.
- Распознавание звука : Если вы не заметили, «Окей, Google» и Сери стали намного лучше понимать наши вопросы и то, что мы говорим. Этот успех можно отнести к нейронным сетям.
- Автономное вождение : Наконец, наше продвижение к совершенствованию автономного вождения во многом связано с достижениями в области искусственного интеллекта и нейронных сетей.
Подводя итог, вот основные моменты:
- Нейронные сети — это тип модели машинного обучения или подмножество машинного обучения, а машинное обучение — это подмножество искусственного интеллекта.
- Нейронная сеть представляет собой сеть уравнений, которая принимает входные данные (или набор входных данных) и возвращает выходные данные (или набор выходных данных)
- Нейронные сети состоят из различных компонентов, таких как входной слой, скрытые слои, выходной слой и узлы.
- Каждый узел состоит из линейной функции и функции активации, которая в конечном итоге определяет, какие узлы на следующем уровне будут активированы.
- Существуют различные типы нейронных сетей, такие как ANN, CNN и RNN
Terence Shin
Основатель ShinTwin | Подключаемся по LinkedIn | Портфолио проектов здесь .
Что такое нейронные сети? | IBM
Нейронные сети отражают поведение человеческого мозга, позволяя компьютерным программам распознавать закономерности и решать общие проблемы в области искусственного интеллекта, машинного обучения и глубокого обучения.
Что такое нейронные сети?
Нейронные сети, также известные как искусственные нейронные сети (ИНС) или смоделированные нейронные сети (СНС), представляют собой подмножество машинного обучения и лежат в основе алгоритмов глубокого обучения. Их название и структура вдохновлены человеческим мозгом, имитируя то, как биологические нейроны подают сигналы друг другу.
Искусственные нейронные сети (ИНС) состоят из слоев узлов, содержащих входной слой, один или несколько скрытых слоев и выходной слой. Каждый узел или искусственный нейрон соединяется с другим и имеет соответствующий вес и порог. Если выход любого отдельного узла превышает указанное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети. В противном случае данные не передаются на следующий уровень сети.
Каждый узел или искусственный нейрон соединяется с другим и имеет соответствующий вес и порог. Если выход любого отдельного узла превышает указанное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети. В противном случае данные не передаются на следующий уровень сети.
Нейронные сети полагаются на обучающие данные, чтобы учиться и улучшать свою точность с течением времени. Однако, как только эти алгоритмы обучения будут настроены на точность, они станут мощными инструментами в области компьютерных наук и искусственного интеллекта, позволяющими нам классифицировать и группировать данные с высокой скоростью. Задачи распознавания речи или изображений могут занимать минуты, а не часы, по сравнению с идентификацией вручную экспертами-людьми. Одной из самых известных нейронных сетей является поисковый алгоритм Google.
Как работают нейронные сети?
Думайте о каждом отдельном узле как о собственной модели линейной регрессии, состоящей из входных данных, весов, смещения (или порога) и выходных данных.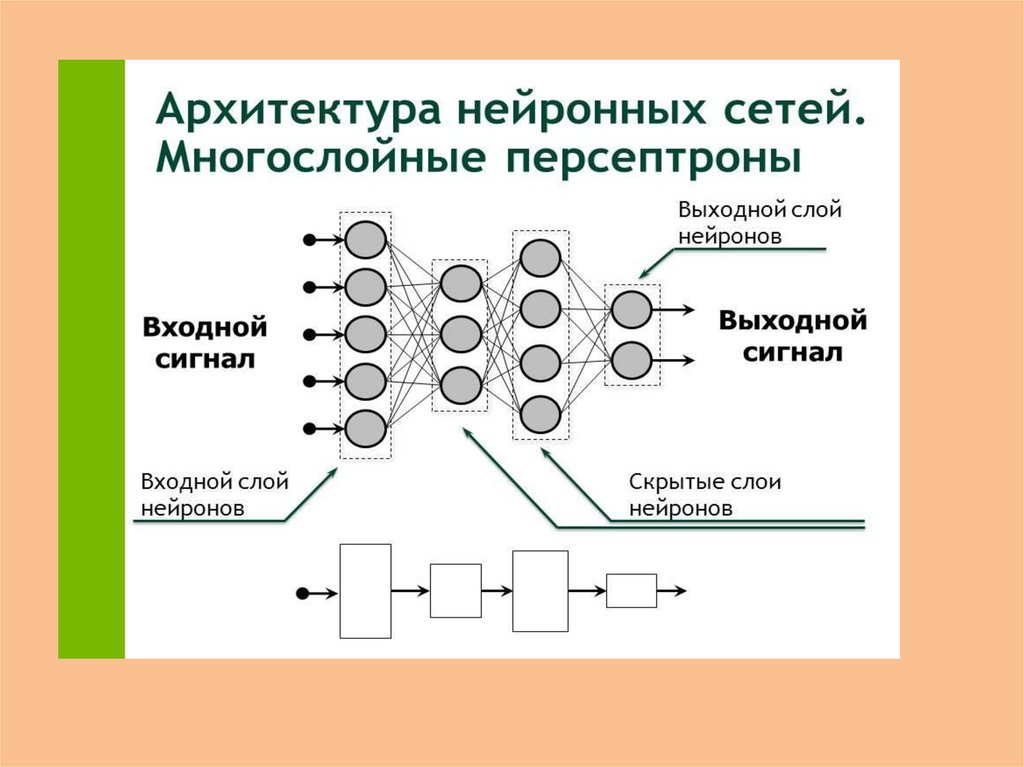 Формула будет выглядеть примерно так:
Формула будет выглядеть примерно так:
∑wixi + смещение = w1x1 + w2x2 + w3x3 + смещение
вывод = f(x) = 1, если ∑w1x1 + b>= 0; 0, если ∑w1x1 + b < 0
После определения входного слоя ему присваиваются веса. Эти веса помогают определить важность той или иной переменной, при этом более крупные из них вносят более значительный вклад в результат по сравнению с другими входными данными. Затем все входные данные умножаются на их соответствующие веса, а затем суммируются. После этого выходные данные проходят через функцию активации, которая определяет выходные данные. Если этот выход превышает заданный порог, он «запускает» (или активирует) узел, передавая данные на следующий уровень в сети. Это приводит к тому, что выход одного узла становится входом следующего узла. Этот процесс передачи данных с одного уровня на следующий определяет эту нейронную сеть как сеть с прямой связью.
Давайте разберем, как может выглядеть один единственный узел, используя двоичные значения. Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заняться серфингом (Да: 1, Нет: 0). Решение идти или не идти — это наш прогнозируемый результат, или т-хэт. Предположим, что на ваше решение влияют три фактора:
Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заняться серфингом (Да: 1, Нет: 0). Решение идти или не идти — это наш прогнозируемый результат, или т-хэт. Предположим, что на ваше решение влияют три фактора:
- Волны хорошие? (Да: 1, Нет: 0)
- Линейка пуста? (Да: 1, Нет: 0)
- Было ли в последнее время нападение акулы? (Да: 0, Нет: 1)
Тогда предположим следующее, дав нам следующие входные данные:
- X1 = 1, так как волны качают
- X2 = 0, так как толпы нет
- X3 = 1, так как в последнее время не было нападения акулы
Теперь нам нужно присвоить веса для определения важности. Большие веса означают, что конкретные переменные имеют большее значение для решения или результата.
- W1 = 5, так как большие волны бывают не часто
- W2 = 2, так как вы привыкли к толпе
- W3 = 4, так как вы боитесь акул
Наконец, мы также примем пороговое значение 3, которое будет переведено в значение смещения –3. Со всеми различными входными данными мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Со всеми различными входными данными мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Y-шляпа = (1*5) + (0*2) + (1*4) – 3 = 6
Если мы используем функцию активации из начала этого раздела, мы можем определить, что выход этого узел будет равен 1, так как 6 больше 0. В этом случае вы отправитесь в серфинг; но если мы скорректируем веса или порог, мы можем получить разные результаты от модели. Когда мы наблюдаем одно решение, как в приведенном выше примере, мы видим, как нейронная сеть может принимать все более сложные решения в зависимости от результатов предыдущих решений или слоев.
В приведенном выше примере мы использовали персептроны, чтобы проиллюстрировать некоторую математику, но нейронные сети используют сигмовидные нейроны, которые отличаются тем, что имеют значения от 0 до 1. Поскольку нейронные сети ведут себя аналогично деревьям решений, каскадирование данных из одного узла к другому, имея значения x от 0 до 1, уменьшит влияние любого заданного изменения одной переменной на вывод любого заданного узла, а затем и на вывод нейронной сети.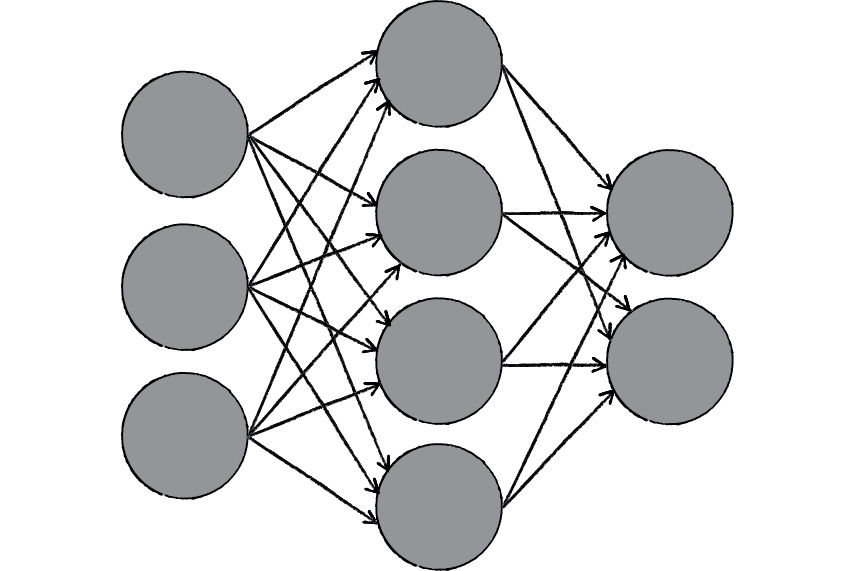
Когда мы начнем думать о более практических вариантах использования нейронных сетей, таких как распознавание изображений или классификация, мы будем использовать обучение с учителем или помеченные наборы данных для обучения алгоритма. По мере обучения модели мы хотим оценить ее точность с помощью функции затрат (или потерь). Это также обычно называют среднеквадратической ошибкой (MSE). В приведенном ниже уравнении 92
В конечном счете, цель состоит в том, чтобы минимизировать нашу функцию стоимости, чтобы обеспечить правильность подгонки для любого данного наблюдения. Поскольку модель корректирует свои веса и смещения, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм регулирует свои веса, представляет собой градиентный спуск, позволяющий модели определить направление, в котором нужно уменьшить ошибки (или минимизировать функцию стоимости). С каждым обучающим примером параметры модели корректируются, чтобы постепенно сходиться к минимуму.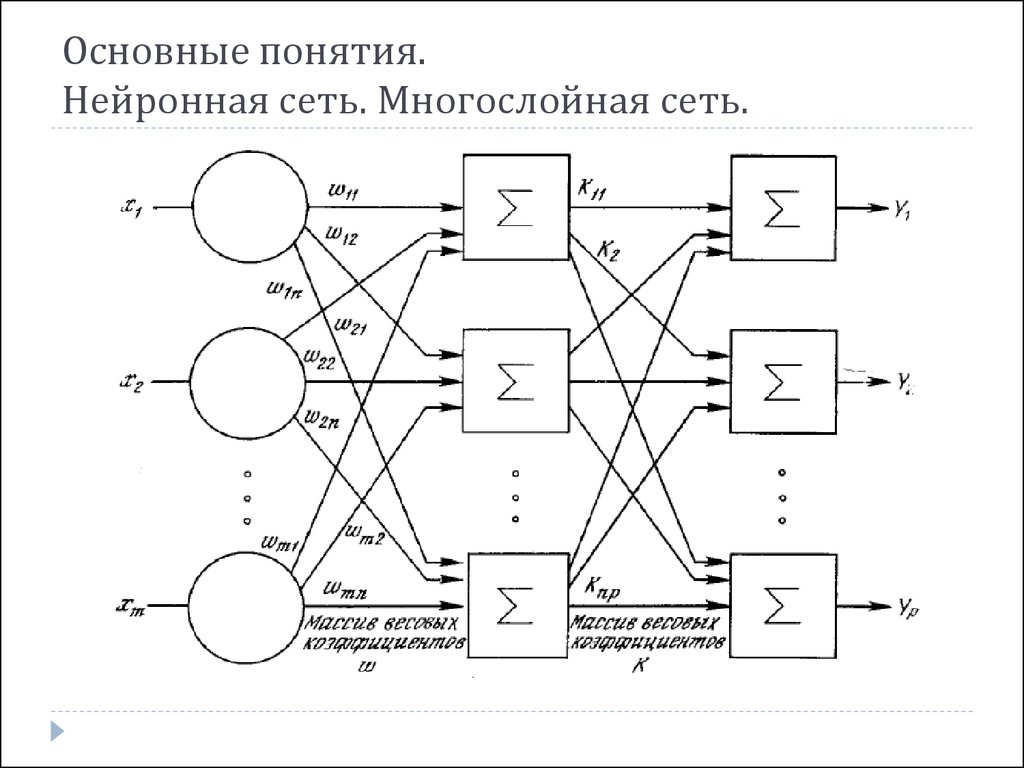
См. эту статью IBM Developer для более глубокого объяснения количественных понятий, связанных с нейронными сетями.
Большинство глубоких нейронных сетей имеют прямую связь, то есть они работают только в одном направлении, от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения; то есть двигаться в противоположном направлении от выхода к входу. Обратное распространение позволяет нам рассчитать и атрибутировать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать параметры модели (моделей).
Типы нейронных сетей
Нейронные сети можно разделить на разные типы, которые используются для разных целей. Хотя это не исчерпывающий список типов, приведенный ниже список представляет наиболее распространенные типы нейронных сетей, с которыми вы столкнетесь для их общих вариантов использования:
Персептрон — старейшая нейронная сеть, созданная Фрэнком Розенблаттом. в 1958 году. Он имеет один нейрон и представляет собой простейшую форму нейронной сети:
Он имеет один нейрон и представляет собой простейшую форму нейронной сети:
Нейронные сети с прямой связью, или многослойные персептроны (MLP), — это то, на чем мы в основном сосредоточились в этой статье. Они состоят из входного слоя, скрытого слоя или слоев и выходного слоя. Хотя эти нейронные сети также обычно называют MLP, важно отметить, что на самом деле они состоят из сигмовидных нейронов, а не персептронов, поскольку большинство реальных задач нелинейны. Данные обычно вводятся в эти модели для их обучения, и они являются основой для компьютерного зрения, обработки естественного языка и других нейронных сетей.
Сверточные нейронные сети (CNN) похожи на сети прямой связи, но обычно используются для распознавания изображений, распознавания образов и/или компьютерного зрения. Эти сети используют принципы линейной алгебры, в частности матричное умножение, для выявления закономерностей в изображении.
Рекуррентные нейронные сети (RNN) идентифицируются по их петлям обратной связи. Эти алгоритмы обучения в основном используются при использовании данных временных рядов для прогнозирования будущих результатов, таких как прогнозы фондового рынка или прогнозирование продаж.
Эти алгоритмы обучения в основном используются при использовании данных временных рядов для прогнозирования будущих результатов, таких как прогнозы фондового рынка или прогнозирование продаж.
Нейронные сети и глубокое обучение
Глубокое обучение и нейронные сети, как правило, используются в разговоре взаимозаменяемо, что может сбивать с толку. В результате стоит отметить, что «глубокое» в глубоком обучении просто относится к глубине слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Нейронная сеть, которая имеет только два или три слоя, — это просто базовая нейронная сеть.
Чтобы узнать больше о различиях между нейронными сетями и другими формами искусственного интеллекта, такими как машинное обучение, прочитайте запись в блоге «ИИ, машинное обучение, глубокое обучение и нейронные сети: в чем разница?»
История нейронных сетей
История нейронных сетей длиннее, чем думает большинство людей. Хотя идея «мыслящей машины» восходит к древним грекам, мы сосредоточимся на ключевых событиях, которые привели к эволюции мышления вокруг нейронных сетей, популярность которых с годами падала и падала:
Хотя идея «мыслящей машины» восходит к древним грекам, мы сосредоточимся на ключевых событиях, которые привели к эволюции мышления вокруг нейронных сетей, популярность которых с годами падала и падала:
1943: Уоррен С. МакКаллох и Уолтер Питтс опубликовали «Логическое исчисление идей, имманентных нервной деятельности» (PDF, 1 МБ) (ссылка находится вне IBM)». Это исследование было направлено на то, чтобы понять, как человеческий мозг может производить сложные паттерны через связанные клетки мозга или нейроны. Одной из основных идей, вышедших из этой работы, было сравнение нейронов с бинарным порогом с булевой логикой (т. е. 0/1 или истинные/ложные утверждения).
1958: Фрэнку Розенблатту приписывают разработку персептрона, что задокументировано в его исследовании «Персептрон: вероятностная модель хранения и организации информации в мозгу» (PDF, 1,6 МБ) (ссылка находится вне IBM) . Он продвигает работу МакКаллоха и Питта на шаг вперед, вводя веса в уравнение. Используя IBM 704, Розенблатт смог заставить компьютер научиться отличать карты, отмеченные слева, от карт, отмеченных справа.
Используя IBM 704, Розенблатт смог заставить компьютер научиться отличать карты, отмеченные слева, от карт, отмеченных справа.
1974: Хотя многие исследователи внесли свой вклад в идею обратного распространения, Пол Вербос был первым человеком в США, который отметил его применение в нейронных сетях в своей докторской диссертации (PDF, 8,1 МБ) (ссылка находится за пределами IBM).
1989: Yann LeCun опубликовал статью (PDF, 5,7 МБ) (ссылка находится вне IBM), иллюстрирующую, как использование ограничений в обратном распространении и его интеграция в архитектуру нейронной сети могут использоваться для обучения алгоритмов. В этом исследовании нейронная сеть успешно использовалась для распознавания рукописных цифр почтового индекса, предоставленных Почтовой службой США.
Нейронные сети и IBM Cloud
Вот уже несколько десятилетий IBM является пионером в разработке технологий искусственного интеллекта и нейронных сетей, о чем свидетельствует разработка и развитие IBM Watson.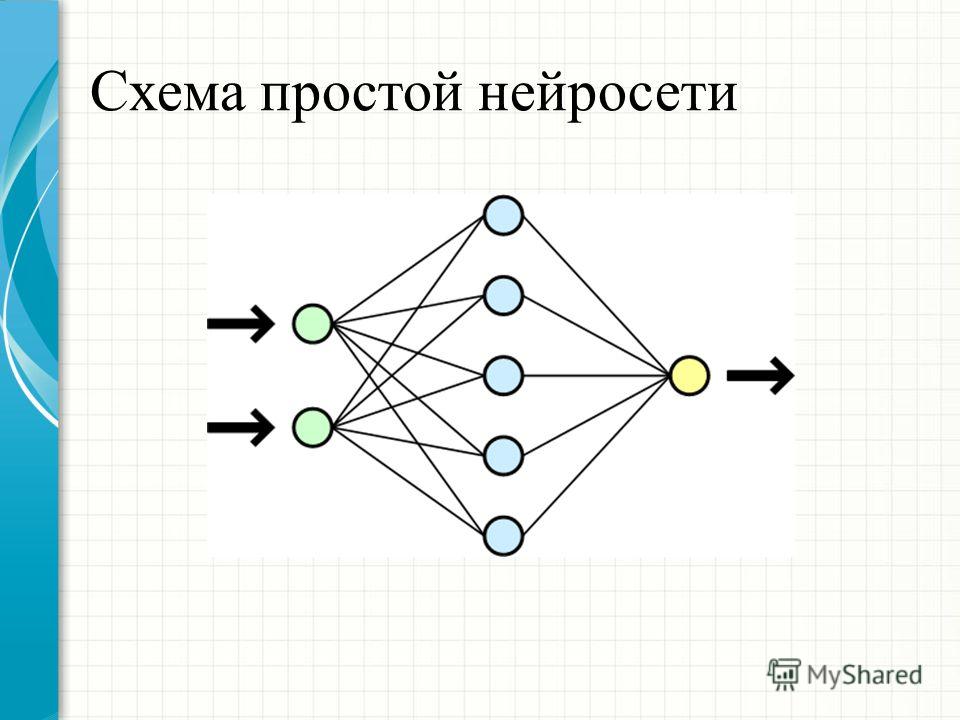 Теперь Watson — это надежное решение для предприятий, которые хотят применять в своих системах усовершенствованную обработку естественного языка и методы глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению ИИ.
Теперь Watson — это надежное решение для предприятий, которые хотят применять в своих системах усовершенствованную обработку естественного языка и методы глубокого обучения, используя проверенный многоуровневый подход к внедрению и внедрению ИИ.
Watson использует платформу Apache Unstructured Information Management Architecture (UIMA) и программное обеспечение IBM DeepQA, чтобы сделать мощные возможности глубокого обучения доступными для приложений. Используя такие инструменты, как IBM Watson Studio, ваше предприятие может беспрепятственно запускать проекты искусственного интеллекта с открытым исходным кодом в производство, одновременно развертывая и запуская модели в любом облаке.
Для получения дополнительной информации о том, как начать работу с технологией глубокого обучения, изучите IBM Watson Studio и службу глубокого обучения.
Подпишитесь на IBMid и создайте учетную запись IBM Cloud.
Как работает нейронная сеть? Реализация и 5 примеров
Искусственные нейронные сети можно считать одной из популярных предметных областей информатики.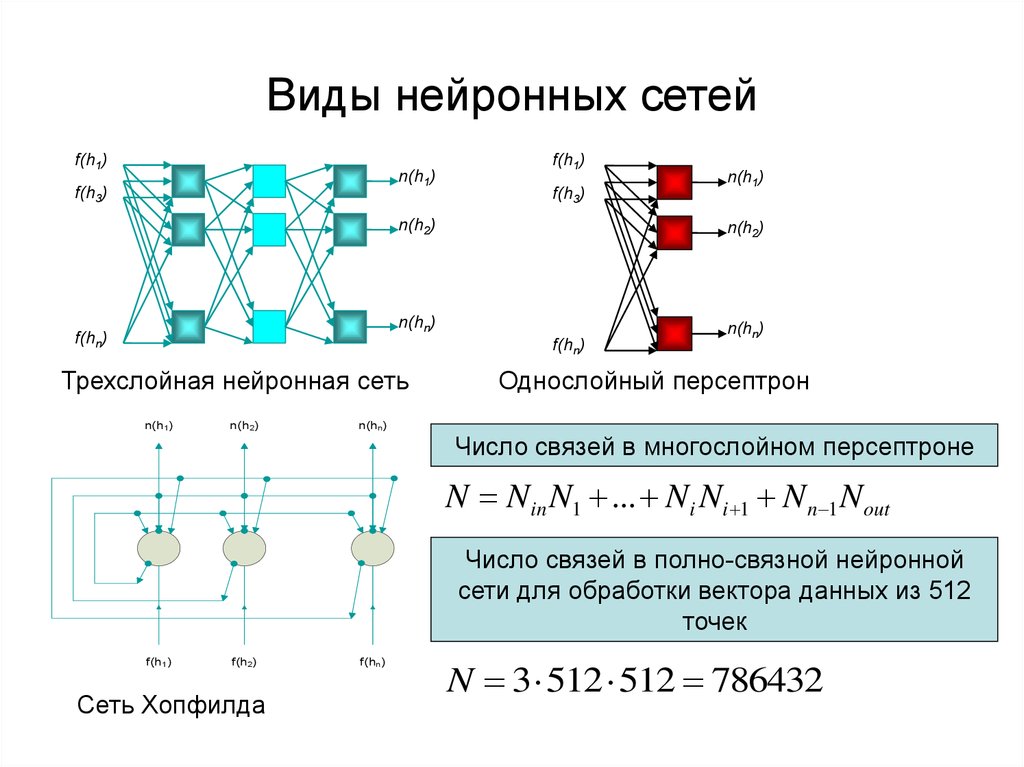 Причиной этого является их способность выполнять критические задачи, связанные с искусственным интеллектом, такие как классификация и распознавание изображений, обнаружение мошенничества с кредитными картами, распознавание медицинских и других заболеваний и т. д.
Причиной этого является их способность выполнять критические задачи, связанные с искусственным интеллектом, такие как классификация и распознавание изображений, обнаружение мошенничества с кредитными картами, распознавание медицинских и других заболеваний и т. д.
Содержание
Что такое нейронная сеть?
Проще говоря, нейронная сеть — это набор алгоритмов, предназначенных для распознавания закономерностей или взаимосвязей в заданном наборе данных. Эти глубокие нейронные сети в основном представляют собой вычислительные системы, предназначенные для имитации того, как человеческий мозг анализирует и обрабатывает информацию.
Нейронная сеть состоит из нейронов, связанных между собой наподобие паутины, и эти нейроны представляют собой математические функции или модели, выполняющие вычисления, необходимые для классификации в соответствии с заданным набором правил. В этом руководстве давайте обсудим, как работают эти искусственные нейронные сети и как они используются в реальных условиях.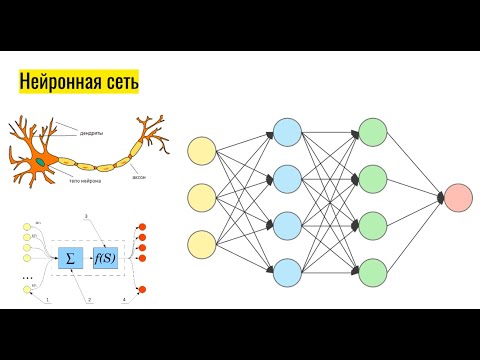
Как обучается нейронная сеть?
Прежде чем перейти к изучению того, как именно работает нейронная сеть, вам необходимо узнать, что формирует нейронную сеть. Обычная нейронная сеть состоит из нескольких слоев, называемых входным слоем, выходным слоем и скрытыми слоями. В каждом слое каждый узел (нейрон) связан со всеми узлами (нейронами) следующего слоя с параметрами, называемыми «весами». .
Нейронные сети состоят из узлов, называемых персептронами, которые выполняют необходимые вычисления и обнаруживают особенности нейронных сетей. Эти персептроны пытаются уменьшить ошибку конечной стоимости, регулируя параметры весов. Более того, персептрон можно рассматривать как нейронную сеть с одним слоем.
С другой стороны, многослойные персептроны называются глубокими нейронными сетями. Персептроны активируются, когда есть удовлетворительный ввод. Прочтите эту вики-статью, если вам нужно больше узнать о персептронах.
Теперь давайте перейдем к обсуждению конкретных шагов работающей нейронной сети.
- Первоначально набор данных должен быть передан на входной слой, который затем перейдет на скрытый слой.
- Связи, существующие между двумя слоями, случайным образом присваивают веса входным данным.
- К каждому входу добавляется смещение. Смещение — это константа, которая используется в модели для наилучшего соответствия заданным данным.
- Взвешенная сумма всех входных данных будет отправлена в функцию, которая используется для определения активного состояния нейрона путем вычисления взвешенной суммы и добавления смещения. Эта функция называется функцией активации.
- Узлы, которые должны активироваться для извлечения признаков, определяются на основе выходного значения функции активации.
- Окончательный вывод сети затем сравнивается с необходимыми размеченными данными нашего набора данных для расчета окончательной ошибки стоимости. Ошибка стоимости на самом деле говорит нам, насколько «плохой» является наша сеть. Следовательно, мы хотим, чтобы ошибка была как можно меньше.
- Веса корректируются с помощью обратного распространения, что уменьшает ошибку. Этот процесс обратного распространения можно рассматривать как центральный механизм, которому обучаются нейронные сети. Он в основном точно настраивает веса глубокой нейронной сети, чтобы снизить стоимость.
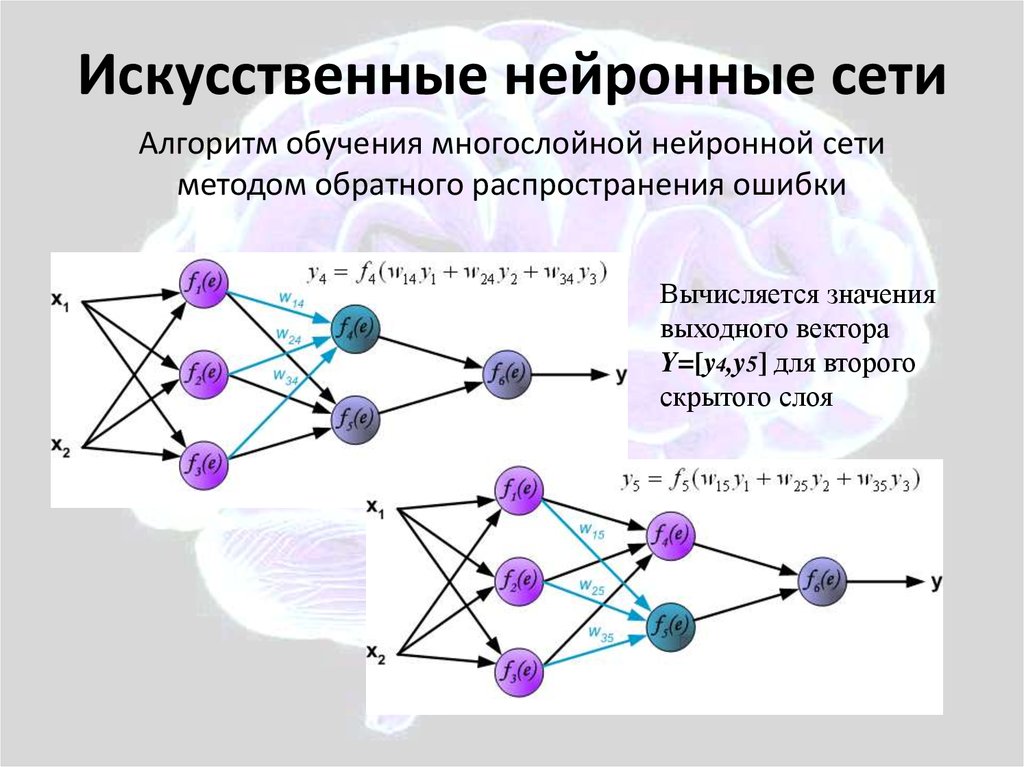
Проще говоря, при обучении нейронной сети мы обычно вычисляем потери (величину ошибки) модели и проверяем, уменьшается она или нет. Если ошибка выше ожидаемого значения, мы должны обновить параметры модели, такие как веса и значения смещения. Мы можем использовать модель, когда потери ниже ожидаемой погрешности.
Визуализация нейронной сети
Нейронные сети можно легко описать с помощью приведенной выше схемы. Светло-голубые кружки представляют персептроны, которые мы обсуждали ранее, а линии представляют связи между искусственными нейронами.
При рассмотрении одного персептрона его работу можно представить следующим образом.
Когда вы вводите в модель данные со случайными весами, она генерирует их взвешенную сумму.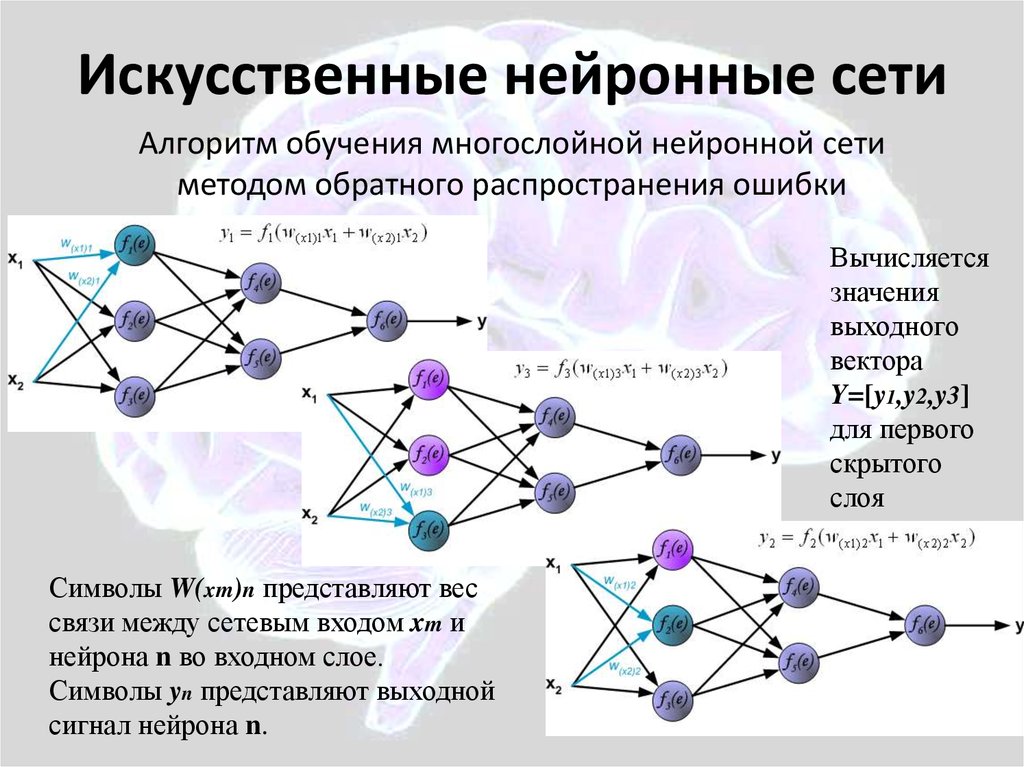 В соответствии с этим значением функция активации определяет статус активации нейрона. Выход этого персептрона может действовать как вход для следующего слоя нейронов.
В соответствии с этим значением функция активации определяет статус активации нейрона. Выход этого персептрона может действовать как вход для следующего слоя нейронов.
Типы нейронных сетей
На сегодняшний день разработано множество типов нейронных сетей. Сверточная нейронная сеть (CNN) и рекуррентная нейронная сеть (RNN) могут рассматриваться как два наиболее известных типа нейронных сетей среди них, которые составляют основу для большинства предварительно обученных моделей в нейронных сетях.
Сверточные нейронные сети
CNN — это контролируемая модель обучения, состоящая из одного или нескольких сверточных слоев. Сначала эти сверточные слои применяют к входным данным функцию свертки. Затем эти слои отправляются на следующий слой. Нейроны в слое не обязательно должны соединяться с полным набором нейронов следующего слоя .
Он соединяется только с небольшой его частью. Результирующий вывод представляет собой единый вектор, включающий оценки вероятности, которые затем передаются в полносвязные слои. Сверточные нейронные сети широко используются в областях распознавания изображений и обработки естественного языка.
Сверточные нейронные сети широко используются в областях распознавания изображений и обработки естественного языка.
Как работает смещение в нейронных сетях
При работе с нейронными сетями очень важно понимать, что такое смещение и как оно работает. Смещение можно рассматривать как дополнительный набор весов в модели, который не требует никаких входных данных и связан с выходом модели, когда у нее нет входных данных. Добавление константы к входному смещению позволяет сместить функцию активации. Там смещение работает точно так же, как и в линейном уравнении:
y = mx + c
Здесь смещение в c.
Смещение имеет важное значение, так как оно всегда присутствует независимо от входных данных и потому, что с ним сеть работает лучше.
Рекуррентные нейронные сети
RNN — это широко используемая нейронная сеть, в основном используемая для распознавания речи и обработки естественного языка (NLP). Он распознает последовательные характеристики данных и использует шаблоны для прогнозирования следующего сценария. В RNN выходные данные предыдущего шага служат входными данными для следующего шага.
В RNN выходные данные предыдущего шага служат входными данными для следующего шага.
RNN отличается своей «памятью», поскольку она получает информацию от предыдущих входов, чтобы влиять на текущий ввод и вывод.
Внедрение нейронной сети
К настоящему моменту вы должны иметь общее представление о том, что такое нейронная сеть и как она работает. Далее мы собираемся обсудить, как реализовать простую нейронную сеть. В этом руководстве мы используем Python 3 для реализации, поскольку он содержит довольно известные и ценные библиотеки, которые поддерживают реализации на основе нейронных сетей.
Распознавание рукописных чисел — одна из самых простых нейронных сетей, которую может разработать новичок. Что мы там делаем, так это разрабатываем и обучаем нейронную сеть, которая предсказывает конкретное изображение рукописной цифры. Тип нейронной сети, который мы здесь используем, — сверточная нейронная сеть (CNN). Вот код.
из numpy означает импорт из стандартного импорта numpy из matplotlib импортировать pyplot из sklearn.
 model_selection импортировать KFold
из keras.datasets импортировать mnist
из keras.utils импортировать в_categorical
из keras.layers импортировать Conv2D
из keras.models импорт последовательный
из keras.layers импортировать MaxPooling2D
из keras.layers импорт плотный
из keras.optimizers импорт SGD
из keras.layers импортировать Flatten
деф loadDataset():
(train_X, train_Y), (test_X, test_Y) = mnist.load_data()
train_X = train_X.reshape((train_X.shape[0], 28, 28, 1))
test_X = test_X.reshape((test_X.shape[0], 28, 28, 1))
train_Y = to_categorical(train_Y)
test_Y = to_categorical(test_Y)
вернуть поезд_X, поезд_Y, тест_Х, тест_Y
предварительная обработка def (trainSet, testSet):
train_norm = trainSet.astype('float32')
test_norm = testSet.astype('float32')
поезд_норма = поезд_норма / 255,0
тестовая_норма = тестовая_норма / 255,0
вернуть train_norm, test_norm
определение модели():
модель = Последовательный()
model.add(Conv2D(32, (3, 3), активация='relu', input_shape=(28, 28, 1), kernel_initializer='he_uniform'))
model.
model_selection импортировать KFold
из keras.datasets импортировать mnist
из keras.utils импортировать в_categorical
из keras.layers импортировать Conv2D
из keras.models импорт последовательный
из keras.layers импортировать MaxPooling2D
из keras.layers импорт плотный
из keras.optimizers импорт SGD
из keras.layers импортировать Flatten
деф loadDataset():
(train_X, train_Y), (test_X, test_Y) = mnist.load_data()
train_X = train_X.reshape((train_X.shape[0], 28, 28, 1))
test_X = test_X.reshape((test_X.shape[0], 28, 28, 1))
train_Y = to_categorical(train_Y)
test_Y = to_categorical(test_Y)
вернуть поезд_X, поезд_Y, тест_Х, тест_Y
предварительная обработка def (trainSet, testSet):
train_norm = trainSet.astype('float32')
test_norm = testSet.astype('float32')
поезд_норма = поезд_норма / 255,0
тестовая_норма = тестовая_норма / 255,0
вернуть train_norm, test_norm
определение модели():
модель = Последовательный()
model.add(Conv2D(32, (3, 3), активация='relu', input_shape=(28, 28, 1), kernel_initializer='he_uniform'))
model. add(MaxPooling2D((2, 2)))
model.add(Свести())
model.add(Dense(100, активация='relu', kernel_initializer='he_uniform'))
model.add (плотный (10, активация = 'softmax'))
opt = SGD (lr = 0,01, импульс = 0,9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
модель.резюме()
модель возврата
оценка модели (Xdata, Ydata, n_folds = 5):
баллы, истории = list(), list()
kfold = KFold (n_folds, random_state = 1, shuffle = True)
для train_ix, test_ix в kfold.split(Xdata):
модель = определить_модель()
train_X, train_Y, test_X, test_Y = Xdata[train_ix], Ydata[train_ix], Xdata[test_ix], Ydata[test_ix]
history = model.fit (train_X, train_Y, эпохи = 10, batch_size = 32, validation_data = (test_X, test_Y), подробный = 0)
_, acc = model.evaluate (test_X, test_Y, подробный = 0)
напечатать('> %.3f' % (акк * 100.0))
scores.append(соотв.)
historys.append(история)
обратные баллы, истории
резюме защиты (очки):
print('Точность: среднее=%.3f' % (среднее(баллы)*100))
pyplot.
add(MaxPooling2D((2, 2)))
model.add(Свести())
model.add(Dense(100, активация='relu', kernel_initializer='he_uniform'))
model.add (плотный (10, активация = 'softmax'))
opt = SGD (lr = 0,01, импульс = 0,9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
модель.резюме()
модель возврата
оценка модели (Xdata, Ydata, n_folds = 5):
баллы, истории = list(), list()
kfold = KFold (n_folds, random_state = 1, shuffle = True)
для train_ix, test_ix в kfold.split(Xdata):
модель = определить_модель()
train_X, train_Y, test_X, test_Y = Xdata[train_ix], Ydata[train_ix], Xdata[test_ix], Ydata[test_ix]
history = model.fit (train_X, train_Y, эпохи = 10, batch_size = 32, validation_data = (test_X, test_Y), подробный = 0)
_, acc = model.evaluate (test_X, test_Y, подробный = 0)
напечатать('> %.3f' % (акк * 100.0))
scores.append(соотв.)
historys.append(история)
обратные баллы, истории
резюме защиты (очки):
print('Точность: среднее=%.3f' % (среднее(баллы)*100))
pyplot. boxplot(оценки)
pyplot.show ()
деф запуститьтест():
train_X, train_Y, test_X, test_Y = loadDataset()
train_X, test_X = предварительная обработка (train_X, test_X)
баллы, истории = оценка модели (поезд_X, поезд_Y)
резюме (баллы)
запустить тест ()
boxplot(оценки)
pyplot.show ()
деф запуститьтест():
train_X, train_Y, test_X, test_Y = loadDataset()
train_X, test_X = предварительная обработка (train_X, test_X)
баллы, истории = оценка модели (поезд_X, поезд_Y)
резюме (баллы)
запустить тест () Я разделил полный код на несколько функций, чтобы было легко понять, что делает каждый сегмент кода. Мы использовали известную и очень полезную библиотеку Keras, которая поддерживает разработку нейронных сетей. Итак, давайте рассмотрим каждую из этих функций в коде и обсудим, что там делается.
loadDatset()
Эта функция в основном фокусируется на загрузке необходимых данных и разделении набора данных на четыре набора данных с именами tarinX, train_Y, test_X и test_Y. Здесь train_X состоит из рукописных изображений, которые используются для обучения нашей модели.
Train_Y — это метка (фактические цифры рукописных цифр) изображений в наборе данных train_X. Затем у нас есть test_X и test_Y. Этот тестовый набор данных используется для оценки системы или определения точности разработанной модели.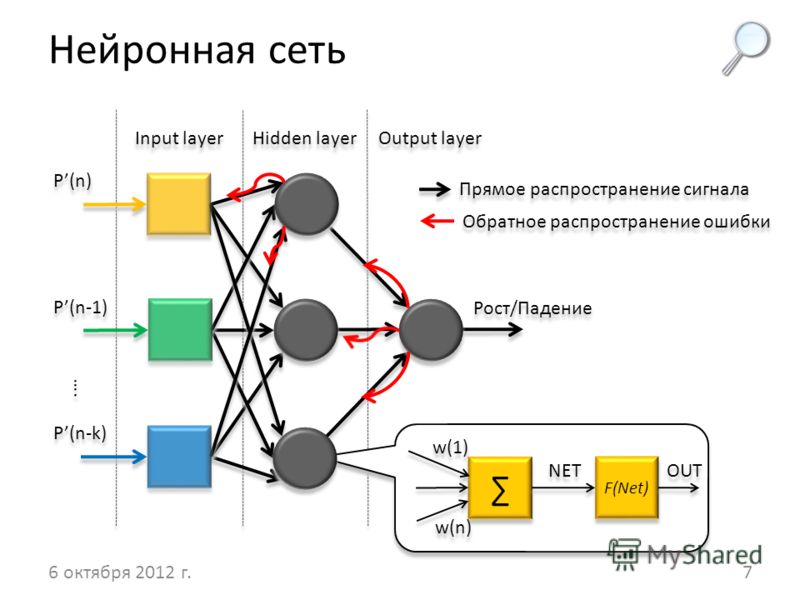
preprocess()
Эта функция используется для преобразования значений пикселей из целых чисел в числа с плавающей запятой и нормализации изображения в диапазоне 0-1. preprocess() возвращает это нормализованное изображение.
modelDefenition()
Это самая важная функция, которую мы написали в этом коде. Функция modelDefenition() используется для создания нашей нейронной сети. Функции активации, которые мы использовали здесь, — это «relu» и «softmax».
Помимо этого, есть несколько других функций активации, которые вы можете использовать в нейронных сетях, таких как сигмовидная функция,leakyRelu и tanh. Вы можете получить необходимые знания об использовании этих функций активации с Keras, прочитав эту статью.
В этой модели мы использовали оптимизатор opt. Оптимизаторы используются для изменения атрибутов глубокой нейронной сети, чтобы уменьшить значения потерь.
Помимо «opt», есть несколько других популярных оптимизаторов, таких как «adam optimizer» и «RMSProp».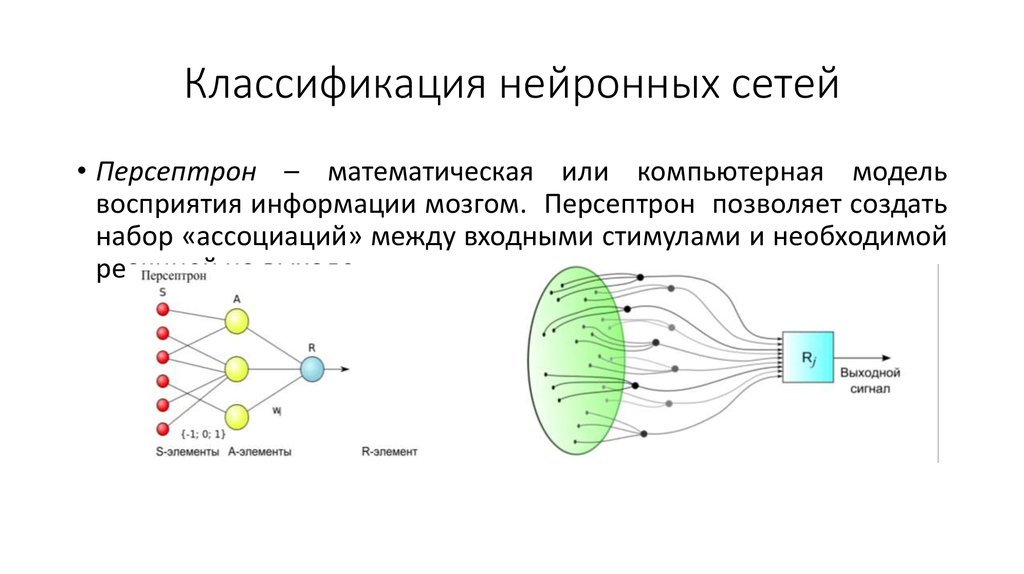 Вы можете использовать их в соответствии с потребностями вашей нейронной сети. Если вам нужно больше узнать о том, как использовать оптимизаторы в Keras, вы можете прочитать эту страницу.
Вы можете использовать их в соответствии с потребностями вашей нейронной сети. Если вам нужно больше узнать о том, как использовать оптимизаторы в Keras, вы можете прочитать эту страницу.
В Keras вы можете визуально увидеть сводку вашей модели с помощью функции model.summary() . Вот результат, который мы получили с нашей моделью.
modelEvaluation()
В этой функции мы оценили нашу модель с «к-кратной» перекрестной проверкой. Перекрестная проверка — это процедура повторной выборки, которая используется для оценки нейронной сети на небольшой выборке данных. Существует несколько методов оценки модели, таких как перекрестная проверка с исключением одной группы, перекрестная проверка с исключением одной группы и вложенная перекрестная проверка.
Когда бы вы использовали нейронную сеть?
Это довольно известный вопрос для новичков в большинстве случаев. Нейронную сеть целесообразно использовать, когда
- Данных, необходимых для обучения, достаточно.
- У вас есть необходимая вычислительная мощность.
- Когда вы не можете найти четкую взаимосвязь между данными и результирующим значением.
Нейронные сети для реального мира?
На самом деле нейронные сети очень полезны при решении многих сложных реальных проблем, таких как:
- Прогноз фондовой биржи
Делать прогнозы на фондовой бирже с использованием таких параметров, как текущие тенденции, политическая ситуация, общественное мнение и советы экономистов, можно делать с помощью нейронных сетей. Для этого мы можем использовать нейронные сети, такие как сверточные нейронные сети и рекуррентные нейронные сети.
- Обнаружение банковского мошенничества
Обнаружение банковского мошенничества является одним из наиболее важных вариантов использования нейронных сетей. Там вы можете предоставить набор данных, который включает в себя информацию о прошлых банковских мошенничествах.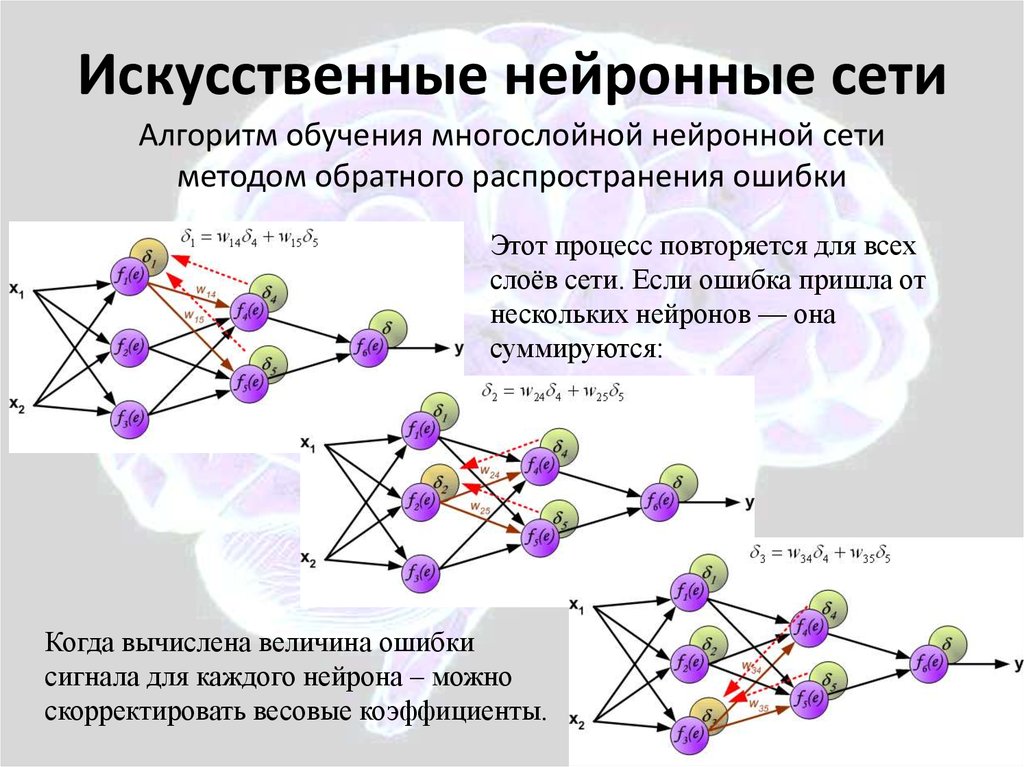 Затем вы можете обнаруживать и прогнозировать банковские мошенничества, обучая разработанную модель с заданным набором данных.
Затем вы можете обнаруживать и прогнозировать банковские мошенничества, обучая разработанную модель с заданным набором данных.
- В системах рекомендаций
Системы рекомендаций — очень популярное использование нейронных сетей. RNN — это тип нейронной сети, который в основном используется в рекомендательных системах.
- В поисковых платформах
Поисковые платформы, такие как Google и Yahoo, также используют передовые типы нейронных сетей для улучшения пользовательского опыта. Это значительно повышает удобство использования поисковых систем.
Автомобиль Тесла
Tesla — компания, которая активно использует нейронные сети в своих продуктах. Автомобиль Тесла — одно из самых известных изобретений этой компании. Это автомобиль с автопилотом, который прокладывает оптимальный маршрут, управляет сложными перекрестками со светофорами и перемещается по городским улицам, двигаясь на высокой скорости.
Полная сборка нейронных сетей Autopilot, которые используются в автомобиле Tesla, включает 48 сетей, которые требуют 70 000 часов обучения GPU.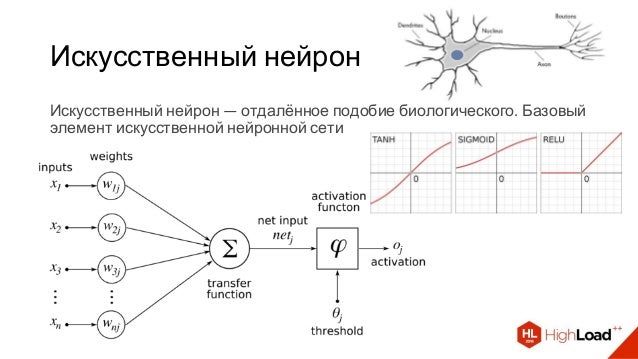 Более того, он выводит 1000 различных прогнозов на каждом временном шаге.
Более того, он выводит 1000 различных прогнозов на каждом временном шаге.
Наборы обучающих данных нейронных сетей в автомобиле Tesla содержат самые сложные разнообразные сценарии в мире. Эти сценарии многократно берутся из парка почти 1 млн автомобилей в режиме реального времени.
Этот автомобиль с автопилотом использует ультразвуковые датчики, камеры и радар, чтобы воспринимать и видеть окрестности вокруг автомобиля. Он использует нейронные сети для обнаружения дорог, автомобилей, объектов и людей в видеопотоках с восьми камер, установленных вокруг автомобиля.
Вывод
В этой статье мы обсудили некоторые важные факты о нейронных сетях, например, что такое нейронная сеть, как она работает, типы нейронных сетей и несколько вариантов ее использования. На самом деле нейронные сети на сегодняшний день можно считать наиболее заметной областью исследований в области компьютерных наук.
Существует множество моделей нейронных сетей, таких как CNN и RNN.