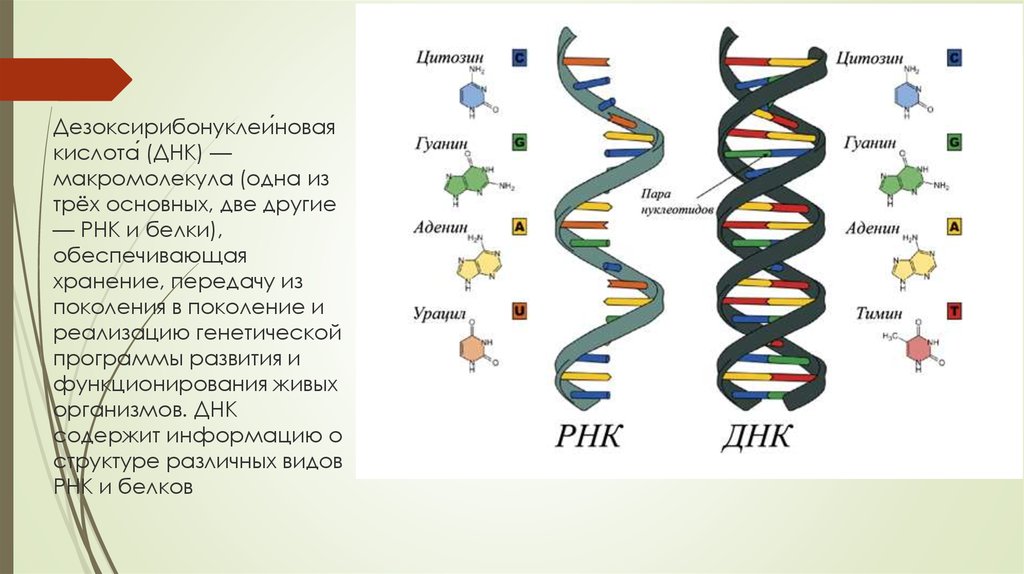
Содержание
Геном человека: двадцать лет спустя
Что на самом деле произошло, когда «расшифровали геном человека» — и происходит сейчас
20 лет назад президент США Билл Клинтон и премьер-министр Великобритании Тони Блэр объявили, что проект «Геном человека» и корпорация Celera Genomics завершили «первоначальное секвенирование генома человека». Говорят, что с этого момента биология вступила в «постгеномную эру». Назвать эту дату «днем расшифровки человеческого генома» можно, правда, только условно — на той конференции ученые лишь рассказали о первом «черновике» последовательности ДНК всех хромосом человека со множеством пробелов, некоторые из которых не заполнены до сих пор. Обе публикации, описывающие «черновик» человеческого генома, вышли в 2001 году, а «чистовая» версия появилась еще через три года. После этого проект «Геном человека» завершился — а вот расшифровка генома человека нет. Осмысление и дополнение полученных тогда данных продолжается до сих пор. N + 1 рассказывает о судьбе, пожалуй, важнейшего для науки XXI века проекта и том, что он сделал — и продолжает делать — с миром.
N + 1 рассказывает о судьбе, пожалуй, важнейшего для науки XXI века проекта и том, что он сделал — и продолжает делать — с миром.
Генетический телескоп
Проект «Геном человека» иногда называют самой успешной международной научной коллаборацией в истории. Однако на старте единодушного оптимизма научное сообщество не испытывало: подготовку сопровождали публичные дискуссии и разгромные статьи, авторы которых утверждали, что прочитать последовательность человеческой ДНК невозможно, и деньги налогоплательщиков стоит потратить на что-то более полезное.
Хотя чисто техническая возможность секвенировать геном была показана еще в 70-х годах, когда был расшифрован первый геном вируса, о человеке задумались не сразу. По легенде, эта идея оформилась благодаря биологу Роберту Синшеймеру из Калифорнийского университета в Санта-Крус. Его коллеги-астрономы работали над созданием самого большого (на тот момент) наземного телескопа, и Синшеймер раздумывал над проектом подобного масштаба в биологии.
В 1985 году он собрал несколько ведущих генетиков для обсуждения проекта по секвенированию генома человека. Коллектив пришел к заключению, что идея заманчива, но не реализуема. К тому моменту не был расшифрован даже геном кишечной палочки размером «всего» в пять миллионов пар нуклеотидов, а максимальная продолжительность нуклеотидной последовательности, которую можно было прочитать за раз методом Сэнгера, составляла несколько сот нуклеотидов.
В обсуждении участвовал Уолтер Гилберт, который за 10 лет до того предложил свой метод секвенирования ДНК (известный как метод Максама-Гилберта или метод химической деградации ДНК), практически одновременно с Фредериком Сэнгером. Он загорелся идеей создания геномного института и увлек ей первооткрывателя структуры ДНК Джеймса Уотсона и Чарльза Делиси, который возглавлял подразделение здоровья и окружающей среды в Министерстве энергетики США. Последнему геномный проект виделся логичным продолжением исследований влияния радиации на человека.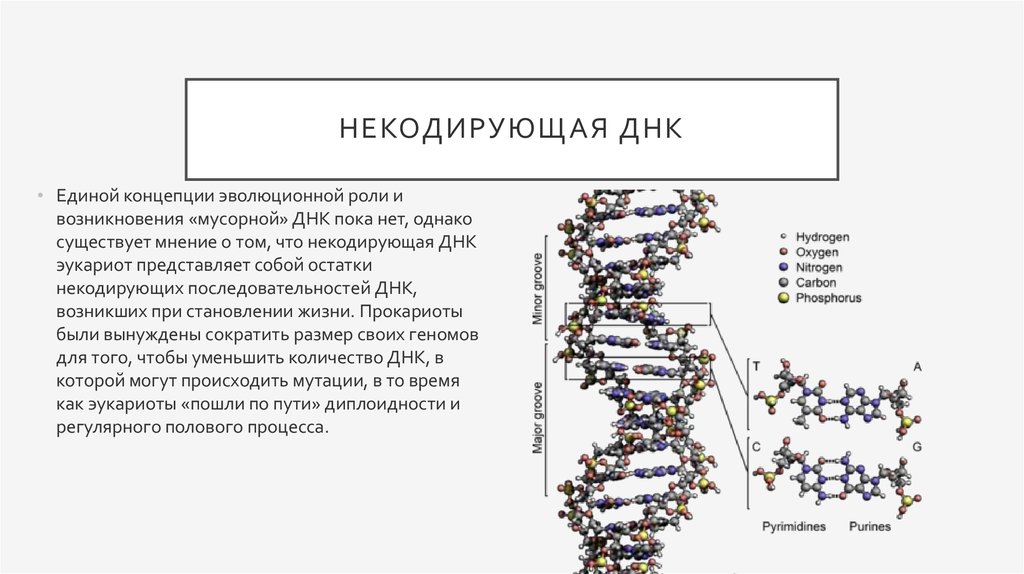 В 1986 году они уже подсчитывали затраты на расшифровку последовательности генома человека.
В 1986 году они уже подсчитывали затраты на расшифровку последовательности генома человека.
Настроенные скептически коллеги оценивали продолжительность проекта в десятки лет рутинной работы, если «читать» ДНК небольшими научными коллективами — а ведь только в этом случае, по их мнению, работу можно сделать хорошо. Объем предстоящей работы казался невероятно огромным: один из столпов молекулярной биологии Сидни Бреннер шутил, что секвенировать ДНК будут заставлять преступников, причем размер хромосомы будет прямо пропорционален тяжести преступления. Однако Уотсон и Делиси решили сделать ставку на крупные автоматизированные центры и международное сотрудничество. Финальный план американской части проекта был рассчитан на 15 лет и три миллиарда долларов.
Эта цифра кажется большой — но, к примеру, космический проект «Аполлон», реализованный двадцатью годами ранее, стоил американцам в 10 раз дороже (без учета инфляции). При этом в результате выполнения проекта «Геном человека» ученые обещали что-то не менее значимое, чем полет в космос — как минимум, разобраться в природе 4000 наследственных заболеваний и продвинуть вперед медицинскую генетику и сопутствующие технологии.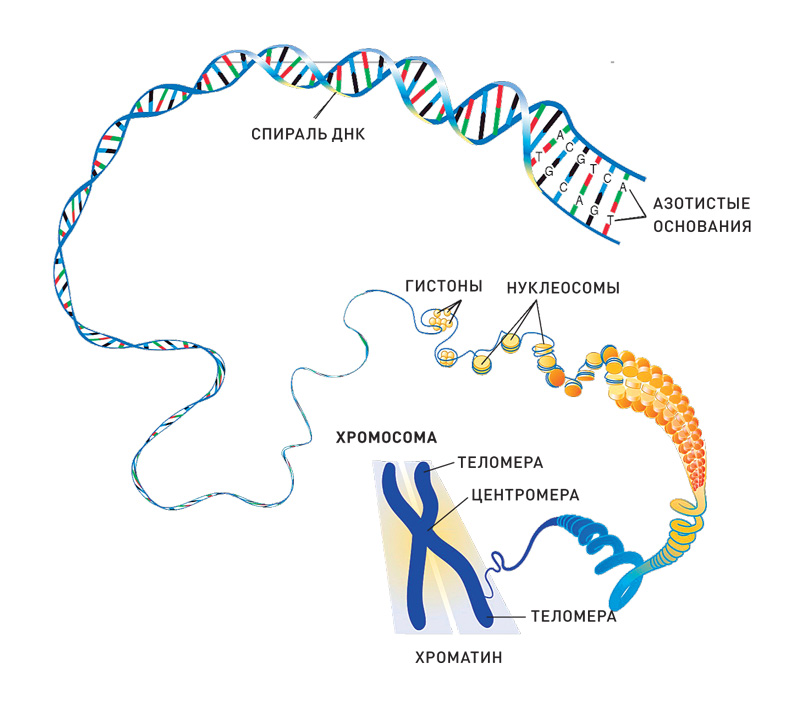
Несмотря на критику и ценник, им удалось продавить как Министерство энергетики, так и Национальные институты здоровья США (NIH). В 1990 году проект стартовал. Панель экспертов настоятельно порекомендовала кроме генома человека заняться также исследованием геномов модельных организмов: кишечной палочки, дрожжей, круглых червей и мыши — чтобы в случае успеха гены человека было с чем сравнивать.
«Заслуга запуска проекта, конечно, принадлежит Уотсону. И он изначально задумывался как международный. Во многих странах выделялось на это финансирование в рамках национальных проектов, — рассказывает Юрий Лебедев, заведующий лабораторией сравнительной и функциональной геномики ИБХ РАН и член Международной организации по изучению генома человека (HUGO), который в рамках проекта участвовал в создании карты 19-й хромосомы. — Люди из институтов США, Англии, Франции, Германии, Швеции, России — даже тех стран, которые не вошли в соавторы статьи в итоге — ездили друг к другу и работали над задачей сообща.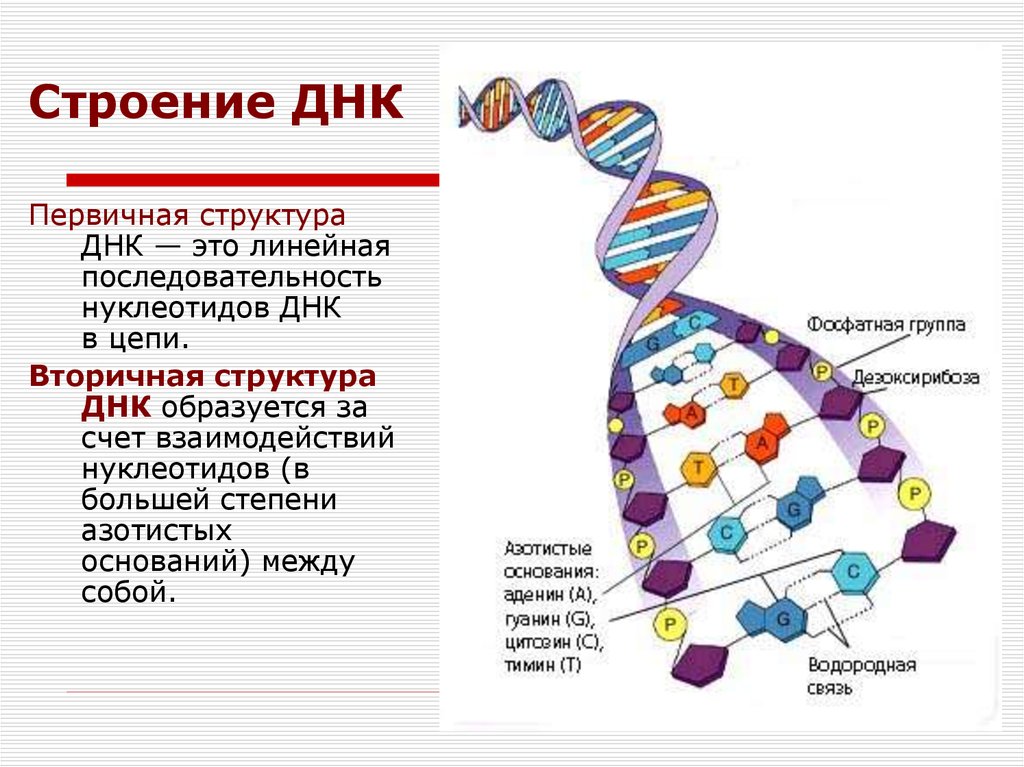 В одиночку Америка бы конечно ничего не сделала».
В одиночку Америка бы конечно ничего не сделала».
В авторах статьи 2001 года были члены International Human Genome Sequencing Consortium из 20 научных групп США, Великобритании, Германии, Франции, Японии и Китая.
Почти одновременно со стартом проекта в США, советский академик Александр Баев смог убедить Горбачева выделить значительное финансирование на оборудование лабораторий и создание научных групп, которые могли бы участвовать в международном консорциуме по расшифровке генома человека. По воспоминаниям академика Льва Киселева, который в то время был председателем научного совета российской части программы, отечественный проект начинался очень активно — на его развитие было выделено около 20 миллионов долларов. Однако в 90-х годах государство уже не могло финансировать столь дорогостоящие фундаментальные исследования, и участие в консорциуме, хотя и не закрылось окончательно, было сокращено до минимума.
«У нас работой по проекту занимались несколько десятков групп.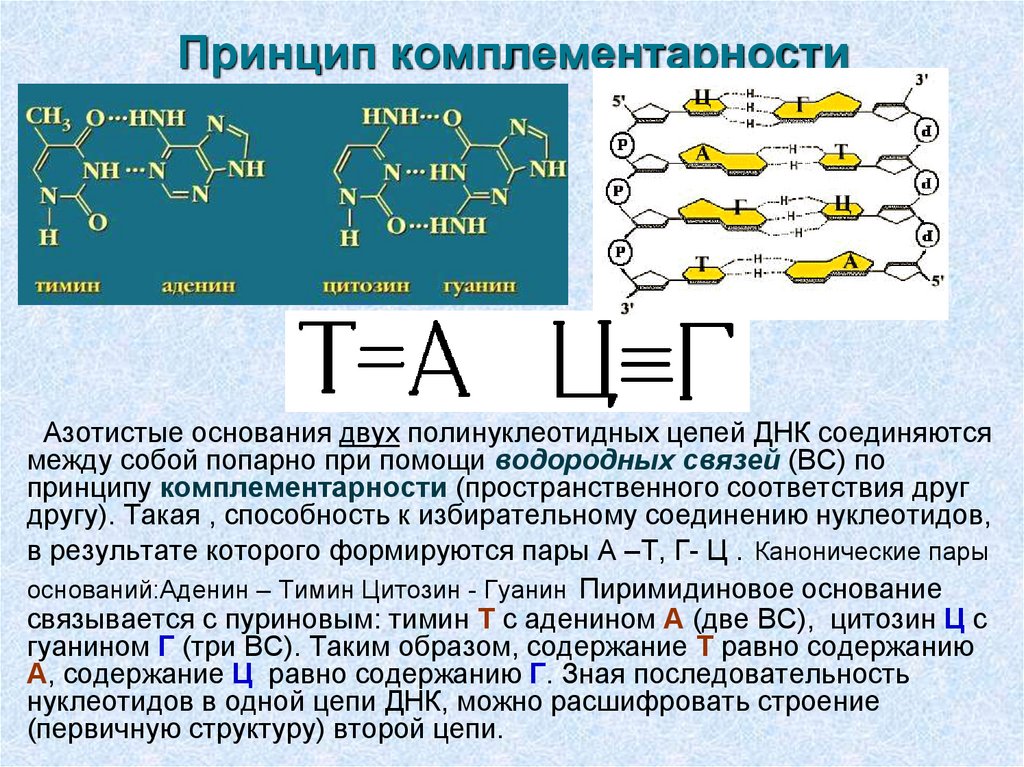 Многие из людей, которые работали тогда в проекте, сейчас возглавляют институты и лаборатории у нас и за рубежом», — вспоминает Лебедев.
Многие из людей, которые работали тогда в проекте, сейчас возглавляют институты и лаборатории у нас и за рубежом», — вспоминает Лебедев.
Через несколько лет после старта одинокий марафон международного консорциума стал гонкой. Крейг Вентер, который изначально возглавлял одну из лабораторий в составе NIH, разработал новый способ исследования геномов под названием «expressed sequence tags», значительно ускоривший процесс поиска генов по их транскриптам. Вооружившись этой технологией и поддержкой венчурных инвесторов, он ушел из NIH и основал Институт геномных исследований.
В 1998 году Вентер объединился с производителем автоматических секвенаторов под вывеской Celera Genomics и объявил, что тоже займется расшифровкой генома человека. Начав на восемь лет позже, чем «Геном человека», Вентер собирался справиться с задачей всего за три года — в то время как международный консорциум не собирался финишировать раньше, чем через семь лет. Его компания планировала извлечь из этого немалую выгоду, запатентовав гены, связанные с наследственными заболеваниями (впрочем, в 2000 году Клинтон заявил, что последовательность генома является достоянием общественности, и патентовать ее нельзя, так что усилия бизнесмена в каком-то смысле оказались напрасными).
Появление конкурента подстегнуло «Геном человека», и цель в итоге была достигнута на два года раньше. Федеральный проект договорился с Celera, и результаты обоих проектов были одновременно объявлены на той самой пресс-конференции 26 июня 2001 года. В зале присутствовали и основатель «Генома человека» Джим Уотсон, и Джон Уайт, директор PE Corporations, спонсировавшей Вентера — лица обоих явно давали понять, что войну удалось закончить дурным миром. Статья группы Вентера вышла в Science, через день после публикации статьи «Генома человека» в Nature.
Предпосылки и последствия
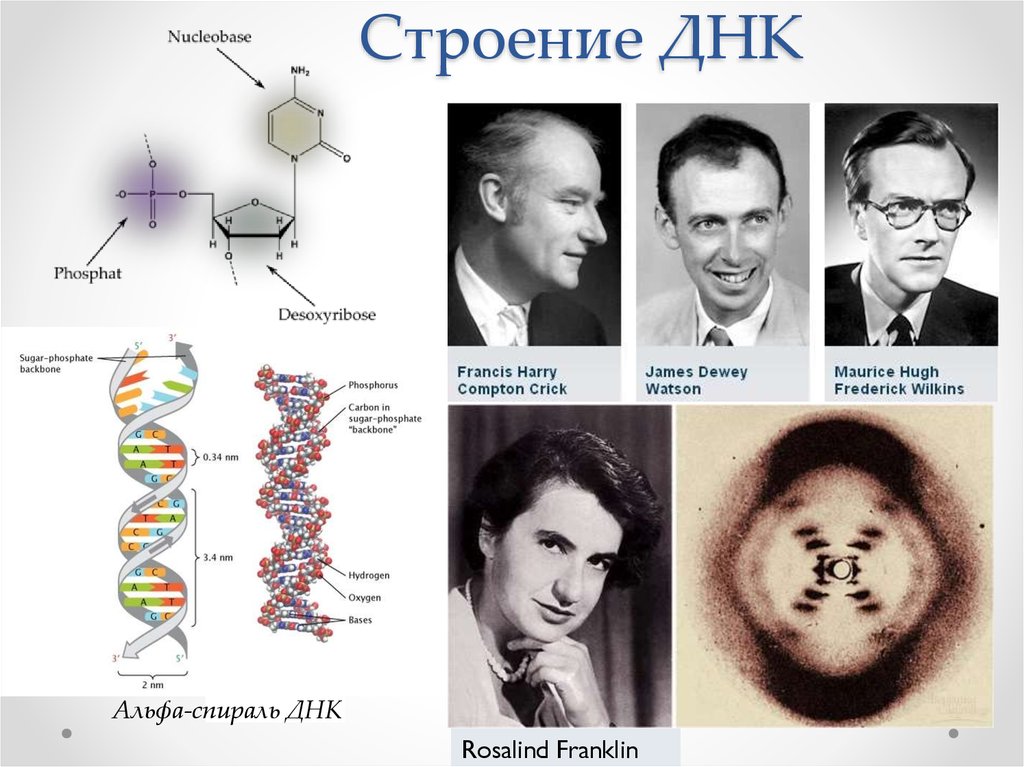
В 80-е годы у генетиков уже были инструменты, позволяющие исследовать размер хромосом и расположение на них генов — в основном, при помощи ферментативного расщепления ДНК рестриктазами, разделения фрагментов в геле и гибридизации с радиоактивно меченой последовательностью. Взглянуть на ДНК более пристально удалось благодаря изобретению производительного метода секвенирования англичанином Фредериком Сэнгером, который до того уже придумал способ чтения аминокислотной последовательности белковых молекул.
Определение последовательности ДНК по Сэнгеру, в свою очередь, стало возможным благодаря открытию ДНК-полимеразы — фермента, который в клетке обеспечивает удвоение молекул ДНК за счет комплементарного достраивания цепи на одноцепочечной матрице.
Этот метод, в отличие от чисто химического метода Максама-Гилберта (деградация ДНК по участкам модификации определенных нуклеотидов), основан на ферментативной достройке второй цепи на матрице цепочки, которую необходимо прочитать, и поэтому более производителен. Синтез комплементарной цепи происходит с использованием стандартных нуклеотидов (A, T, G, C), но в определенный момент в пробирку добавляют радиоактивно меченый дидезоксинуклеотид, после встройки которых синтез цепи обрывается (сейчас для рутинного секвенирования используют тот же способ, но вместо радиометок используют флуоресцентные). Анализ в геле получившихся фрагментов разных размеров, оканчивающихся на одну и ту же «букву», позволяет восстановить всю нуклеотидную последовательность.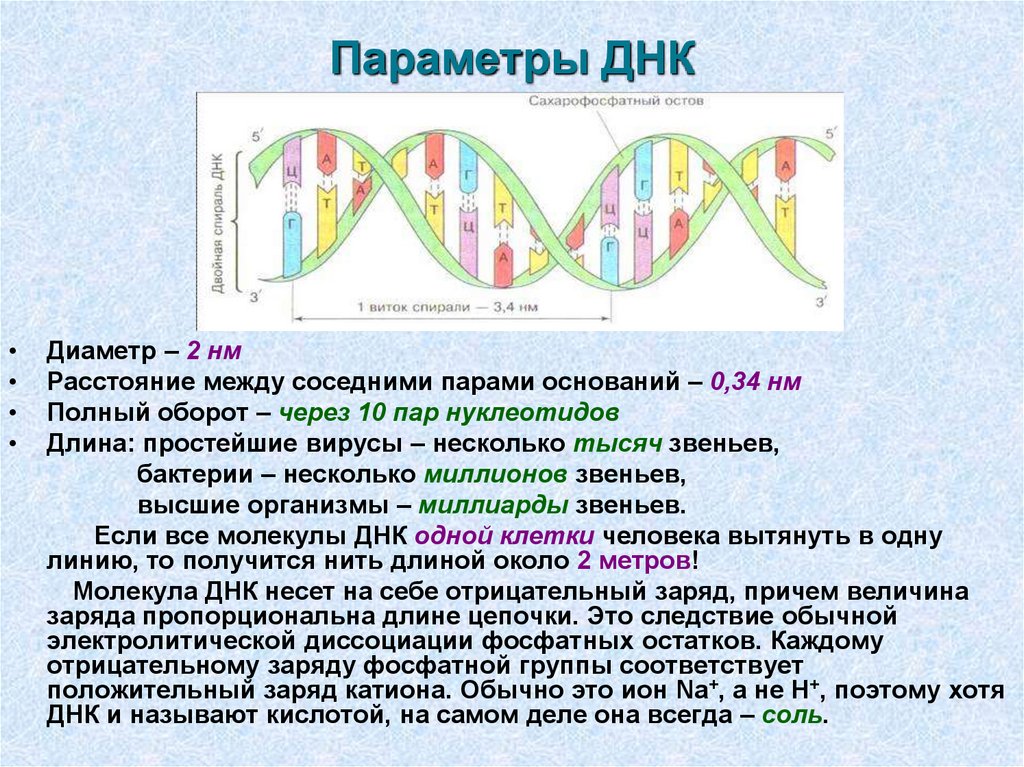
«Для того, чтобы получить представление о последовательности генома, важно было не только секвенирование, — уточняет Юрий Лебедев. — Нужно было составить физические карты хромосом с последовательностью генов, структурных и регуляторных участков. Это делалось путем клонирования в генетические вектора, дрожжевые, бактериальные и фаговые, перекрывающихся кусков генома размером десятки и сотни тысяч пар, и расставления на них известных генетических маркеров, по которым эти куски можно было сопоставлять. Нужно понимать, что к тому моменту ряд генов человека уже был клонирован с кДНК (ДНК, соответствующая матричной РНК после вырезания некодирующих участков — прим. N + 1) и отсеквенирован, так что мы могли использовать определенные последовательности для расставления „столбиков“, и параллельно искали новые маркеры. На это ушла значительная часть времени. Вентер поступил хитро — он использовал уже готовые физические карты, и только наложил на них сиквенсы, и ему, конечно, понадобилось гораздо меньше времени».
Надо пояснить, что все полученные данные по ходу дела выкладывались в открытый доступ, в том числе и карты хромосом с расположением на них генов. Это значительно упростило задачу Крейгу Вентеру, который использовал их для картирования последовательностей, полученных модифицированным «методом дробовика».
«Для секвенирования дробили каждый из больших фрагментов на смесь перекрывающихся фрагментов меньшей длины, переклонировали мелкие фрагменты в фаговый вектор (М13) и секвенировали по Сэнгеру на автоматических секвенаторах всю смесь мелких фрагментов», — поясняет Лебедев.
Собственно, метод разбивки на короткие фрагменты и называется «методом дробовика». Первая длинная последовательность ДНК, прочитанная таким образом в 1981 году — геном вируса мозаики цветной капусты. Вентер понял, что короткие кусочки генома необязательно клонировать в вектора, а можно читать с двух сторон прямо так (для этого к ним нужно пришить с краев известные последовательности). Благодаря этому усовершенствованию его команда быстро прочитала последовательность 70 миллионов кусочков, и собрала их воедино при помощи уже готовых физических карт за три года. Стоило это им всего 200 тысяч долларов — несравнимо меньше, чем «Геному человека».
Стоило это им всего 200 тысяч долларов — несравнимо меньше, чем «Геному человека».
К моменту запуска проекта в 1990 году было расшифровано несколько коротких вирусных геномов и плазмид (вспомогательных кольцевых молекул ДНК из бактерий), размер которых ограничивался десятками тысяч пар нуклеотидов. «Геном человека» же собирался прочитать геном размером на несколько порядков больше: три миллиарда пар — именно столько «букв» содержит одинарный набор хромосом человека (23 хромосомы). По мнению большинства, число генов, содержащихся в этой «летописи», должно было составить около 100 тысяч.
Неудивительно, что многим ведущим генетикам эта задача казалась нерешаемой. Однако по ходу выполнения проекта развитие технологий облегчило ученым работу. Среди технических достижений можно отметить появление автоматического капиллярного секвенатора, где фрагменты разделялись в тонких трубочках, а не в геле. Такие приборы, помимо того, что позволяли увеличить количество образцов, после появления флуоресцентно меченых нуклеотидов, перешли на автоматическую детекцию сигнала.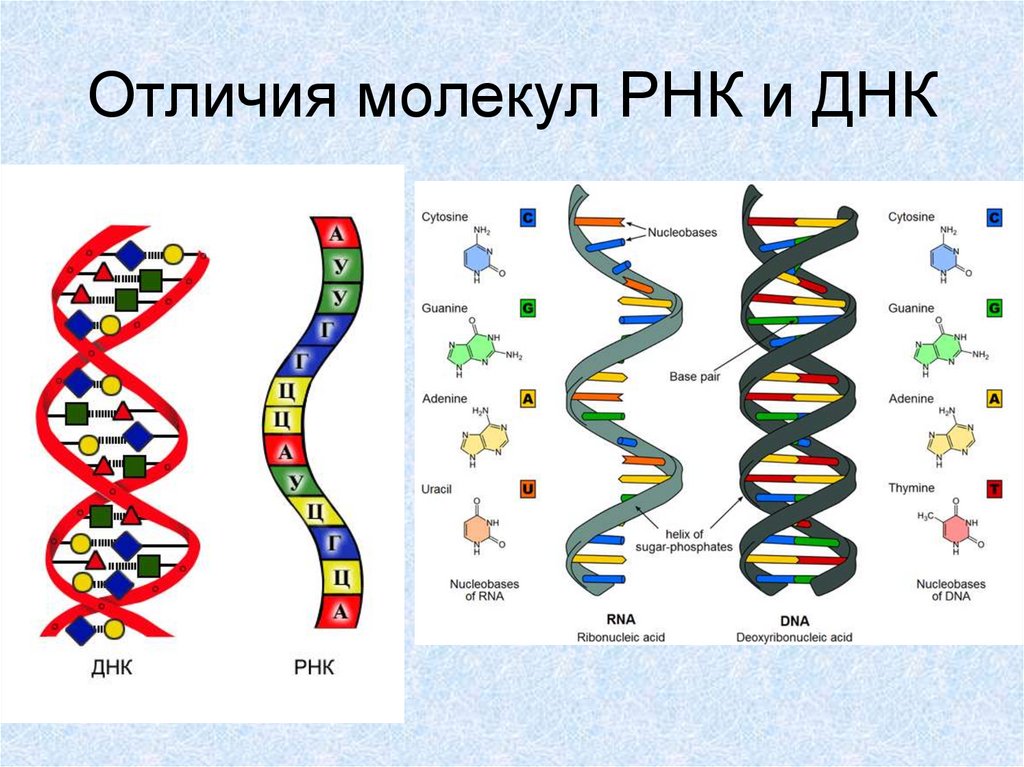 Кроме того, развитие компьютерных технологий: от сетей, которые позволили ученым получать доступ к данным из любой точки, до программ для сравнения и обработки последовательностей.
Кроме того, развитие компьютерных технологий: от сетей, которые позволили ученым получать доступ к данным из любой точки, до программ для сравнения и обработки последовательностей.
Накопление последовательностей послужило толчком для развития целой науки — биоинформатики, которая занимается сборкой, обработкой и анализом геномов с использованием математических методов.
«Высокопроизводительное секвенирование (NGS) появилось именно по итогам секвенирования генома человека — до этого просто не было необходимости читать столько последовательностей. Более того, я уверен, что этот проект подстегнул развитие и компьютерных технологий, и big data analysis — были огромные объемы данных, которые надо было как-то анализировать», комментирует результаты проекта Лебедев. В том же духе высказывается и биоинформатик, заместитель директора Института проблем передачи информации РАН Михаил Гельфанд: «Сейчас уже производительность секвенаторов растет быстрее, чем производительность процессоров и памяти. Данные растут быстрее, чем возможности по их обработке».
Данные растут быстрее, чем возможности по их обработке».
Первые итоги и дальнейшее развитие
Так к 2000 году удалось получить представление о последовательности ДНК человека в составе эухроматина — участков, с которых активно идет транскрипция, то есть считывание данных РНК-полимеразой.
По оценкам ученых, эухроматин составляет около 95 процентов всего генома. Остальная ДНК спрятана в плотно упакованных белковых комплексах и основную часть времени «молчит». Помимо человека, как и рекомендовали в 90-м году эксперты, к 2001 году были отсеквенированы геномы «599 вирусов и вироидов, 205 существующих в природе плазмид, 185 органелл, 31 эубактерии, семи архей, одного гриба, двух животных и одного растения», а к официальному финалу проекта список пополнился геномами мыши и крысы — модельных животных, без которых немыслимо ни одно крупное медицинское исследование.
Одной только сырой последовательностью букв результат проекта, конечно не ограничивается. После расшифровки число генов в геноме человека пришлось сократить со 100 тысяч до 30 тысяч — это число всего в два раза больше, чем у мухи или червя, написали авторы исторической публикации в Nature.
После расшифровки число генов в геноме человека пришлось сократить со 100 тысяч до 30 тысяч — это число всего в два раза больше, чем у мухи или червя, написали авторы исторической публикации в Nature.
Также ученые узнали, что геном человека содержит очень много повторов и мобильных элементов, подавляющее большинство из которых уже не работает. Кроме того, геном человека очень разнообразен — генетики оценили, что количество однонуклеотидных полиморфизмов в нем (участков, в которых у разных людей может стоять тот или иной нуклеотид) достигает 1,5 миллионов. Это стало ясно в том числе благодаря тому, что в проекте была использована ДНК от большого количества добровольцев, а не от одного человека.
«Есть масса вещей, про которые не подозревали, что они в принципе бывают. Вот вы жили где-то на берегу и думали, что живете на маленьком острове. Потом как-то забрались на гору, туман рассеялся, и вы увидели, что на самом деле это целый континент», — описывает научные итоги проекта Михаил Гельфанд, лаборатория которого участвовала в сборке и анализе генома человека.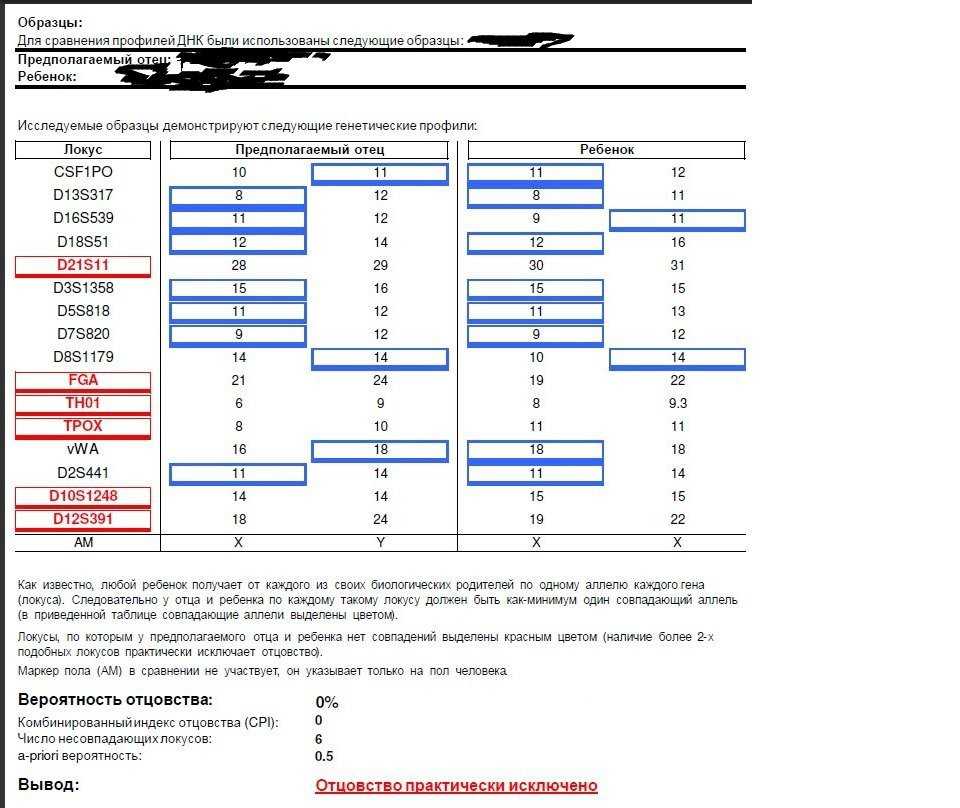
Однако геномные исследования с выходом первой геномной статьи только начались. Гельфанд приводит примеры: «Вслед за проектом „Геном человека“ был, например, проект ENCODE, в которым люди уже целенаправленно изучали именно функциональные вещи. Не просто выписать последовательность букв, а понять: почему ткани разные, почему гены работают по-разному в разных тканях. Опять-таки, как устроено раковое перерождение, как гены начинают по-другому работать, как устроена, как меняется работа гена в ходе раннего развития, когда из одного типа клеток возникает много разных тканей. Как ДНК упакована в клетки и на что это влияет. Есть масса технологий, которые сообщают нам именно функциональные вещи, но они в очень значительной степени привязаны к секвенированию генома. Вы что-то секвенируете, потом картируете геном, а потом из этого делаете какие-то функциональные выводы. Фактически с этого началась наука, которая называется системная биология, когда вы пытаетесь понять не по одному как гены работают, а как работает клетка в целом, но при этом с очень большой детальностью. И это вещь, которая без генома была бы в принципе невозможна. Опять-таки наш уровень понимания того, как клетка устроена, он принципиально изменился. Мы не просто как слепые слона с разных сторон щупаем, а мы теперь смотрим на целого слона, причем насквозь».
И это вещь, которая без генома была бы в принципе невозможна. Опять-таки наш уровень понимания того, как клетка устроена, он принципиально изменился. Мы не просто как слепые слона с разных сторон щупаем, а мы теперь смотрим на целого слона, причем насквозь».
«Стандартный», или референсный геном человека дорабатывается до сих пор. «Финальная точка была очень условная. Договорились, что этот момент считать точкой, когда [Клинтон с Блэром] сделали [свое заявление]. В этот момент геном не был сделан до конца, люди потом много лет дочищали это дело, — рассказывает Гельфанд. — Сейчас выходят чудесные работы, из которых следует, что если взять много-много геномов разных людей, то там будут целые куски, которых в классическом геноме нет, то есть мы отличаемся не только точечными мутациями и заменами, но и целыми большими кусками генома, которые у кого-то есть, а у кого-то нету. В прошлом году вышла статья, они несколько процентов добавили к универсальному геному человека, просто секвенировав много африканцев».
Геном для медицины
За двадцать лет с момента завершения сборки черновой версии генома технологии секвенирования и анализа последовательностей развились настолько, что сегодня узнать последовательность кодирующих участков генома (экзома) обойдется вам уже не в три миллиарда долларов, а лишь несколько сотен.
Исследовательские базы данных продолжают пополняться — этим занимается, например, проект «Тысяча геномов», который призван оценить генетическое разнообразие жителей планеты. Создаются национальные банки ДНК. К примеру, исландская компания deCODE genetics владеет генетической информацией двух третей населения Исландии. Эти данные в том числе используются для развития персонализированной медицины — индивидуального назначения терапии на основании генетических данных пациента.
Генотипирование, то есть определение однонуклеотидных полиморфизмов конкретного человека, уже во многом стало рутиной — в базе данных UK Biobank хранятся данные полногеномного типирования 500 тысяч человек. Кроме генетических данных, записи участников содержат информацию о показателях здоровья, привычках, семейных историях болезни и т.п. Такие наборы данных позволяют исследователям проводить так называемые полногеномные анализы ассоциаций (GWAS — Genome-Wide Association Study), которые позволяют выявить, например, генетическую предрасположенность к определенному заболеванию.
Кроме генетических данных, записи участников содержат информацию о показателях здоровья, привычках, семейных историях болезни и т.п. Такие наборы данных позволяют исследователям проводить так называемые полногеномные анализы ассоциаций (GWAS — Genome-Wide Association Study), которые позволяют выявить, например, генетическую предрасположенность к определенному заболеванию.
«Геномные исследования могут показать, что у носителей такого варианта гена заболевание встречается, к примеру, в пять раз чаще, чем у носителей другого варианта. Это знание может помочь скорректировать образ жизни так, чтобы минимизировать вероятность. Но вычисление рисков развития заболевания полностью опирается на статистику, здесь еще есть куда развивать математический аппарат, — говорит Лебедев. — Что касается предсказания способностей к спорту и музыке по геному ребенка, это, конечно, вещь из области фантастики. Однако, секвенирование генома или экзома может помочь родить здоровых детей в том случае, если родители являются носителями каких-то вредных мутаций».
В последние годы секвенирование и генотипирование ДНК активно применяется в онкологии (об этом мы уже подробно рассказывали в материале «С индивидуальным наведением»). Помимо назначения терапии в зависимости от наличия тех или иных мутаций в опухоли, онкогеномика помогает понять природу возникновения опухолей и их метастазирования. «Очень много вещей в медицинской генетике, в онкологии, иммунологии тоже завязано на геномы. Сейчас люди начали смотреть уже геномы индивидуальных клеток, это позволяет, например, засечь развитие рака. Раковая опухоль неоднородна, в ней много разных клонов, и это очень важно для лечения. В ней есть клоны устойчивые и неустойчивые к какому-либо лечению. Которые могут дать метастаз, и те, кто недостаточно злокачественные, чтобы метастазировать. И теперь первые работы такого сорта появляются, когда люди просто делают генеалогию индивидуальных клеток в раковой опухоли», — поясняет Гельфанд.
«При помощи современных постгеномных технологий можно посмотреть, сколько клеток в организме человека заражено SARS-CoV-2, — приводит злободневный пример Лебедев, лаборатория которого в настоящее время занимается изучением субпопуляций иммунных клеток человека.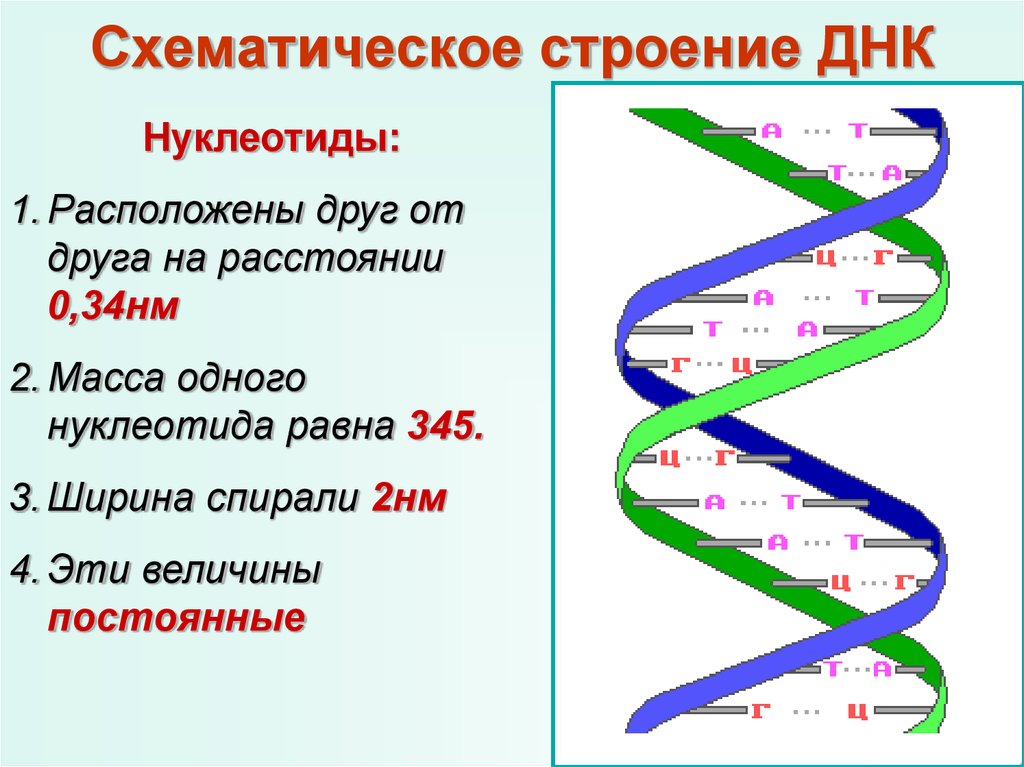 — И можно понять, это клетки убитые, погибающие или борющиеся, как развивается иммунный ответ. С использованием как секвенирования, так и других методов, например, многопараметрической флуоресцентной гибридизации (FISH) можно посчитать в образце крови больного, сколько там цитотоксических лимфоцитов, сколько хэлперных, сколько антител-продуцирующих, сколько из них уже перешли в клетки памяти».
— И можно понять, это клетки убитые, погибающие или борющиеся, как развивается иммунный ответ. С использованием как секвенирования, так и других методов, например, многопараметрической флуоресцентной гибридизации (FISH) можно посчитать в образце крови больного, сколько там цитотоксических лимфоцитов, сколько хэлперных, сколько антител-продуцирующих, сколько из них уже перешли в клетки памяти».
20 лет спустя
Когда Френсиса Коллинза, который в 1993-м сменил Уотсона на посту руководителя американской программы «Геном человека», в 2000 году спросили о перспективах геномных исследований, он предположил, что к 2020 году будет повсеместно распространено генетическое тестирование, появится генная терапия для наследственных заболеваний, а генотерапия на уровне зародышевых клеток докажет свою безопасность. Как показало время, он почти оказался прав — и генотерапия, и редактирование эмбрионов уже существуют, но их повсеместному применению препятствуют совсем другие вещи — вопросы безопасности, эффективности, этики, да и вопросы целесообразности (зачем редактировать эмбрион, если можно отобрать здоровый на стадии ЭКО?).
«В Америке все боятся, что геномная информация приведет к дискриминации отдельных работников страховыми компаниями. То есть, если у тебя склонность к развитию болезни в пять раз выше, то и плати в пять раз больше. Но это же проблема страховых, а не генетики, — указывает Лебедев. — Я не думаю, что законодательное регулирование сейчас как-то ограничивает развитие генетических технологий в отношении человека. Вот где дело касается генно-модифицированных растений, там да, законы мешают развитию отрасли».
«Да, счастье пока не наступило. Но если бы счастье не обещали, то денег бы никто не дал, — делится соображениями по поводу перспектив геномики Михаил Гельфанд. Это окупается, просто медленнее и не так ощутимо. В биологических вещах дольше путь от понимания к использованию. На самом деле очень сильно продвинулась медицина, мы просто этого не замечаем».
У Юрия Лебедева несколько иная точка зрения: «Уже сегодня в соседнем институте подбирают терапию детских лейкозов, основываясь на генетической информации пациентов. А режим лечения для больных болезнью Бехтерева (аутоиммунное заболевание) регулируют исходя из данных UK Biobank. Это и есть персонализированная терапия — я не ожидал, что это будет доступно так скоро».
А режим лечения для больных болезнью Бехтерева (аутоиммунное заболевание) регулируют исходя из данных UK Biobank. Это и есть персонализированная терапия — я не ожидал, что это будет доступно так скоро».
Дарья Спасская
Как ученые расшифровывают геномы и зачем это нужно? Отвечаем в 9 карточках
Как ученые расшифровывают геномы и зачем это нужно? Отвечаем в 9 карточках | SCAMT
В последние годы ученые постоянно объявляют о расшифровке геномов тех или иных видов. ITMO.NEWS и ученый Международного научного центра SCAMT Алексей Комиссаров в карточках объясняют: что такое ДНК, как с ее помощью изучают историю животных и в чем отличие ДНК-теста от геномного исследования.
Иллюстрации: Дмитрий Лисовский, ITMO.NEWS
Каждый более или менее знает, что есть белки, жиры и углеводы. Но еще у нас в каждой клетке есть ДНК, дезоксирибонуклеиновые кислоты, которые отвечают за хранение информации. Для геномного биоинформатика ДНК ― это прежде всего один из главных языков биологии, который состоит всего лишь из четырех букв: A, T, G и C. Эти буквы являются сокращениями имен четырех азотистых оснований, из которых состоит ДНК: аденин (А), цитозин (C), гуанин (G) и тимин (Т). ДНК можно сравнить с компьютерной программой, очень сложной, запутанной, со множеством ошибок и костылей, но, тем не менее, она работает.
Эти буквы являются сокращениями имен четырех азотистых оснований, из которых состоит ДНК: аденин (А), цитозин (C), гуанин (G) и тимин (Т). ДНК можно сравнить с компьютерной программой, очень сложной, запутанной, со множеством ошибок и костылей, но, тем не менее, она работает.
ДНК содержится почти во всех клетках организма, исключение — эритроциты, которые в зрелом состоянии теряют ядро, чтобы было легче переносить кислород. Поэтому биологический материал для выделения ДНК может быть разнообразен. Процесс выделения ДНК состоит из четырех этапов: разрушение мембраны клеток для высвобождения ДНК; очистка от связанных с ДНК белков; очистка от разного рода примесей; растворение ДНК для хранения. ДНК можно выделить и в домашних условиях, но тогда ДНК будет не очень чистой и ее будет сложно использовать для каких-либо научных исследований. От качества этих процедур будет зависеть и полученная из нее информация.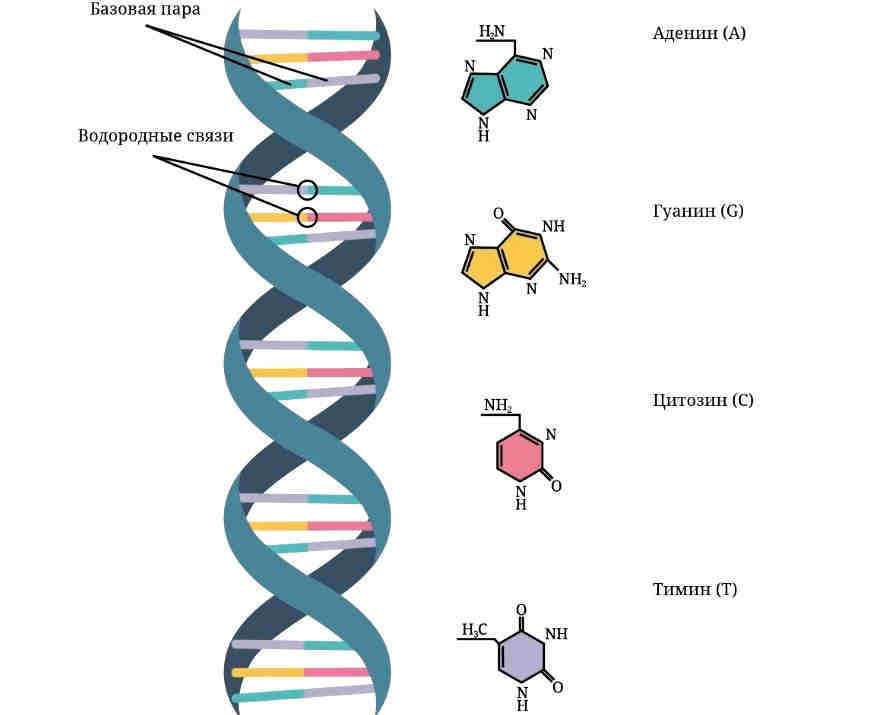 Поэтому необходима лабораторная точность работы специалистов, молекулярных биологов. Проще всего ДНК выделять из крови, потому что это легкий для получения биоматериал. Хотя в эритроцитах ДНК нет, в крови плавает огромное количество других клеток — белых кровяных телец, так что и ДНК из них получается много. Из слюны или кусочков эпителия во рту ― уже меньше, из волос ― еще меньше. Например, чтобы прочитать весь геном достаточно точно, необходима кровь, а не слюна. А для того, чтобы сделать какой-нибудь ДНК-тест, где точность не очень важна ― достаточно и слюны.
Поэтому необходима лабораторная точность работы специалистов, молекулярных биологов. Проще всего ДНК выделять из крови, потому что это легкий для получения биоматериал. Хотя в эритроцитах ДНК нет, в крови плавает огромное количество других клеток — белых кровяных телец, так что и ДНК из них получается много. Из слюны или кусочков эпителия во рту ― уже меньше, из волос ― еще меньше. Например, чтобы прочитать весь геном достаточно точно, необходима кровь, а не слюна. А для того, чтобы сделать какой-нибудь ДНК-тест, где точность не очень важна ― достаточно и слюны.
ДНК — это название молекулы, которая хранит наследственную информацию. Геном ― это совокупность всей ДНК организма со всеми записанными в ней особенностями конкретного вида или даже индивида. Поэтому можно говорить о геноме человека вообще, а можно — о геноме конкретных Васи или Кати. На физическом уровне геном разделен на хромосомы, в случае человека — 23 пары хромосом, 23 от мамы, и 23 от папы, всего 46. Когда организм начинает расти после оплодотворения, в каждой клетке копируется этот набор, но иногда это происходит с небольшими ошибками. Это называется соматическими мутациями. Иногда эти ошибки могут быть весьма критическими и приводить к разным заболеваниям.
Когда организм начинает расти после оплодотворения, в каждой клетке копируется этот набор, но иногда это происходит с небольшими ошибками. Это называется соматическими мутациями. Иногда эти ошибки могут быть весьма критическими и приводить к разным заболеваниям.
Его никто не зашифровывал, но это слово хорошо передает ощущения от работы с геномными данными. Если продолжать аналогию с геномом как с очень сложной программой, можно сказать, что она не только очень сложная, но и очень плохо написана. И кроме собственно четырех букв A, C, G и Т, он содержит много дополнительных уровней кодирования информации, которые не обязательно будут наследоваться и могут меняться в процессе жизни организма. Это часто называют эпигеномом, который изучает эпигенетика. Вся эта неимоверная сложность и создает ощущение расшифровки. Помимо этого, злую шутку здесь сыграл не очень корректный перевод с английского, где использовали слово decoding и encoding, декодировали и закодировали. Код — это просто система условных обозначений, не предполагающая никакого секрета, никакой защиты от взлома. Любой человеческий язык — это код, система дорожных знаков — это код. Шифр — это код, намеренно защищенный от взлома. Но, конечно, в английских терминах меньше романтики, чем в слове расшифровали.
Код — это просто система условных обозначений, не предполагающая никакого секрета, никакой защиты от взлома. Любой человеческий язык — это код, система дорожных знаков — это код. Шифр — это код, намеренно защищенный от взлома. Но, конечно, в английских терминах меньше романтики, чем в слове расшифровали.
Под ДНК-тестом часто имеют в виду анализ только некоторых небольших участков генома, вариации в которых имеют какой-то известный эффект. В геномных исследованиях ученые работают с гораздо большим количеством ДНК, в идеале со всей доступной информацией. Это называется полногеномными исследованиями. Но даже генетических тестов, направленных на выяснения значения только некоторых фрагментов генома, часто достаточно для того, чтобы проследить генетическую историю или оценить степень родства между двумя людьми. Это возможно, во-первых, благодаря тому, что у нас в геноме есть фрагменты, которые очень вариабельны и отличаются у разных людей, и, во-вторых, благодаря математике.
Есть очень сложные математические алгоритмы, которые позволяют по генетическим данным найти наиболее вероятный сценария развития событий: когда происходили мутации отдельных фрагментов, которые привели к образованию того генома, который мы видим сейчас. Своего рода, математическая машина времени. Ученые ИТМО недавно опубликовали программу, направленную как раз на решение проблемы — как наиболее точно заглянуть в прошлое генома. Одним из самых захватывающих расширений этого подхода является добавление еще и географических точек. Тогда мы можем не только смоделировать, как происходили изменения в геноме, ни и посмотреть, как отдельные популяции с этими геномными вариациями перемещались из одной точки в другую.
Мы стараемся получить модель, которая наиболее правдоподобно описывает сценарий развития событий в прошлом. Чтобы сделать модель более точной, одного образца часто недостаточно, и чем больше образцов у нас есть, тем более точной становится наша модель. У каждого из нас очень много редких генетических вариантов, бывают и варианты, которые присущи только нам. И если у нас есть уже несколько образов, то такие индивидуальные варианты ученые отфильтровывают именно затем, чтобы они не мешали анализу. Так как единицей эволюции является популяция, а не отдельный индивид.
У каждого из нас очень много редких генетических вариантов, бывают и варианты, которые присущи только нам. И если у нас есть уже несколько образов, то такие индивидуальные варианты ученые отфильтровывают именно затем, чтобы они не мешали анализу. Так как единицей эволюции является популяция, а не отдельный индивид.
Хорошие модели обладают предсказательной способностью. Проверить проще всего новыми данными, которые не должны противоречить модели, но случается, что они противоречат, и тогда модель приходится пересчитывать. Сейчас мы наблюдаем очень красивую иллюстрацию мутаций, эволюции и вот этого всего на примере геномов коронавируса SARS-CoV-2. Настолько подробных данных об эволюции отдельного вида в реальном времени у человечества еще никогда не было. И появляется все больше данных и для остальных геномов. Со временем модели будут все лучше и лучше, а чем больше данных ― тем лучше модели.
Кроме того, что это захватывающе любопытно, это имеет множество практических применений во всех сферах деятельности человека.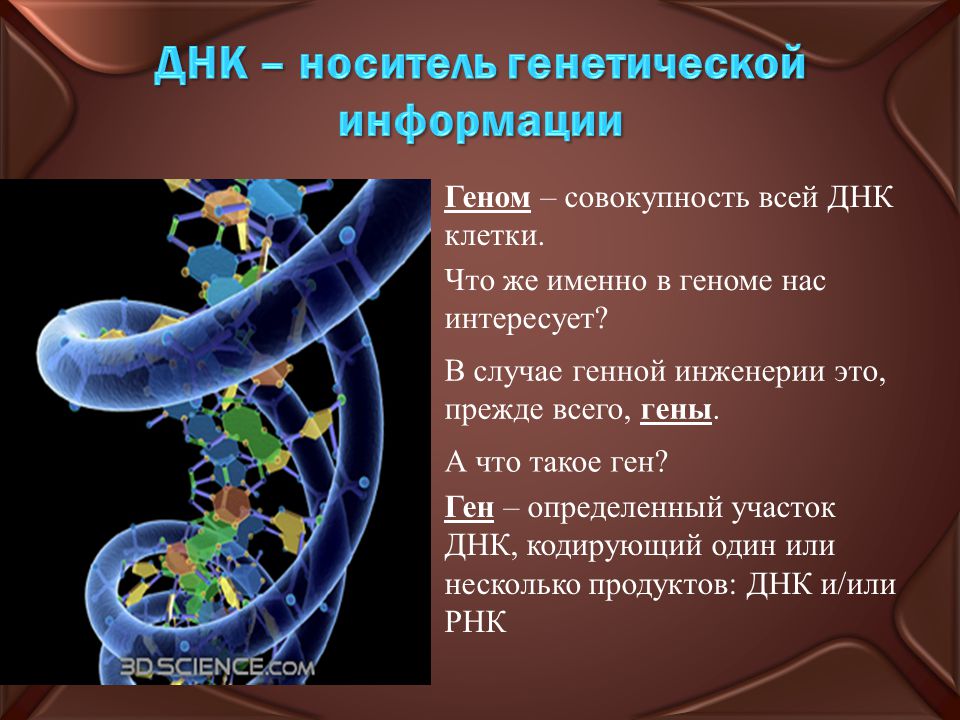 Если продолжать рассуждать об исследовании истории предков, то есть математический аппарат для поиска так называемых событий бутылочного горлышка, когда размер популяции по каким-то причинам резко сократился. Поиск таких событий, своего рода, геномная археология, может дать нам подсказки, как таких событий избежать. Это важно особенно сейчас, когда многие виды животных бесследно исчезают с лица земли.
Если продолжать рассуждать об исследовании истории предков, то есть математический аппарат для поиска так называемых событий бутылочного горлышка, когда размер популяции по каким-то причинам резко сократился. Поиск таких событий, своего рода, геномная археология, может дать нам подсказки, как таких событий избежать. Это важно особенно сейчас, когда многие виды животных бесследно исчезают с лица земли.
(источник https://news.itmo.ru/ru/science/life_science/news/9915/ )
Наконец-то полностью расшифрован геном человека
Фотоохотник | Getty Images
Миссия выполнена — или, по крайней мере, достаточно близко.
Это было послание ученых миру в 2003 году, когда они объявили, что геном человека секвенирован, собран и практически завершен — с несколькими, казалось бы, незначительными пробелами.
На самом деле усилия по количественной оценке и идентификации генетического кода, который делает всех нас людьми, которые обошлись правительству США в миллиарды долларов, так и остались черновиками и по крайней мере на 8 процентов не были завершены.
Некоторые из самых больших, наиболее повторяющихся и сложных фрагментов головоломки ДНК оставались в неведении — до сих пор.
Опираясь на новую мощную технологию секвенирования, группа из примерно 100 ученых объявила в четверг, что они заполнили пробелы, завершили единый геном человека от одного конца до другого и открыли новые, многообещающие направления исследований в областях, в которых ученые бродил в темноте.
Секвенирование генома впервые было опубликовано более года назад, но результаты полного учета, проверенного и используемого исследователями по всему миру, впервые были опубликованы в четверг в рецензируемом журнале. Шесть новых статей описывают все усилия по секвенированию и дополнительный анализ их результатов в журнале Science 9.0015 .
«Это сделано, и это правильно, и это прошло через все эти уровни проверки», — сказал Адам Филлиппи, вычислительный биолог из Национального института исследования генома человека и руководитель недавних усилий. «Мы оптимистичны в том, что могут быть ключи к эволюции человека и к тому, что делает нас уникальными людьми».
«Мы оптимистичны в том, что могут быть ключи к эволюции человека и к тому, что делает нас уникальными людьми».
Эта беготня однажды может помочь исследователям в выявлении генетических причин расстройств, распутывании тайн того, что заставляет некоторые клетки становиться раковыми, и помочь объяснить, как разные группы людей со временем развили разные черты, такие как способность процветать при высоких температурах. высота.
«Это знаковое событие», — сказал Стив Хеникофф, молекулярный биолог и профессор Центра исследования рака Фреда Хатчинсона и Вашингтонского университета, не участвовавший в проекте.
От строк к страницам
Сборка генома сродни «взять книгу, разорвать ее на мелкие кусочки и снова сопоставить», — говорит Меган Деннис, доцент, изучающая генетику и геномику человека в Калифорнийском университете в Дэвисе. кто внес свой вклад в секвенирование.
Во-первых, исследователи должны разрезать ДНК на короткие фрагменты. Затем он обрабатывается и считывается по крупицам.
Разрезанная на части, трудно понять, откуда взялась каждая нить, поэтому ученые должны «сшить эту ДНК вместе вычислительным способом», сказал Деннис.
В 2000-х технология секвенирования ДНК позволяла производить только короткие фрагменты генетического кода — около 500 пар оснований или букв за раз.
Но некоторые области человеческого генома чрезвычайно повторяющиеся, почти как книжная страница со словами, повторяющимися много раз.
Узнайте больше из новостей NBC:
Мерцание, мерцание: астрономы обнаружили самую далекую звезду
Возвышающиеся ледяные вулканы обнаружены на удивительно ярком Плутоне во многих разных местах. Трудно понять, где они принадлежат», — сказал Деннис. В течение многих лет ученым просто приходилось оставлять эти страницы — и их понимание генома — пустыми.
В последние годы новая технология, позволяющая создавать более длинные считывания ДНК, полностью изменила правила игры. Новые машины могут производить сотни тысяч пар оснований в одном фрагменте.
Достижения позволили исследователям восполнить недостающие фрагменты генома.
«20 лет назад было бы немыслимо иметь такую технологию, — сказал Филлиппи. Внезапно исследователи смогли упорядочить и поместить в контекст эти повторяющиеся части генома.
«У этих последовательностей есть гены… в этих участках заключены очень важные функции.»
Пандемический проект
Идея закончить геном выросла органично.
Будучи перфекционисткой в душе, Филлипи всегда раздражало то, что человеческий геном оставался неполным.
Около пяти лет назад он объединился с Карен Мига, доцентом кафедры биомолекулярной инженерии Калифорнийского университета в Санта-Круз, чтобы закончить работу.
Когда они застряли, они обратились за помощью. Проект начал развиваться как снежный ком, собрав около нескольких сотен научных участников и перерос в то, что сейчас называется проектом «теломер-к-теломерам» с использованием термина, описывающего концевые заглушки хромосом.
Когда разразилась пандемия, темпы исследований только ускорились: исследователи общались из грязных подвалов через коммуникационную платформу Slack и по звонкам Zoom.
«2020 год был сумасшедшим по многим причинам. Это дало нам возможность сосредоточиться», — сказал Филлиппи.
В конце концов, исследователи собрали воедино весь генетический код для одной версии генома. Этот геном, который был получен несколько десятилетий назад из клеточной ткани, содержащей генетическую информацию одного сперматозоида, не представляет ни одного человека, который когда-либо жил, потому что он содержит только один набор отцовских хромосом.
Завершенный код станет основой новых геномных исследований и станет новым, законченным эталоном для сравнения.
Теория и практика
Завершенный геном открывает новые возможности для исследований.
На протяжении десятилетий ученые изучали 92 процента доступного генома, исследуя его, чтобы найти генетические вариации, которые могут вызывать заболевания.
«Мы хорошо понимаем, как выглядят вариации в этих регионах, но у нас нет представления об остальных 8 процентах», — сказал Филлиппи.
Теперь исследователи повторно анализируют свои старые данные по сравнению с новым эталонным геномом, пытаясь найти новые подсказки из того, что было утеряно.
«Мы идентифицировали гораздо больше, десятки тысяч, если не сотни тысяч, новых вариантов», — сказал Деннис. «Некоторые из них относятся к генам, кодирующим белки, а некоторые из этих генов важны с медицинской точки зрения, клинически важны и способствуют возникновению заболеваний».
Новая ссылка на геном также позволяет продолжить изучение того, как работают центромеры.
Центромеры представляют собой структуры в середине хромосом, заполненные повторяющимися последовательностями кода и являющиеся неотъемлемой частью процесса клеточного деления. Исторически они относятся к наименее изученным частям генома, потому что содержат очень много утомительного и сложного кода.
«Мы не понимаем основной механизм эволюции центромер», — сказал Хеникофф. «Внезапно за последний год, когда появились данные, мы узнали намного больше о центромерах».
Используя новый геном, исследователи могут лучше изучить, как собираются белки центромер и что происходит, когда они изменяют или теряют функцию.
«Дисфункция центромер может быть серьезной причиной рака», — сказал Хеникофф. До сих пор «нам мешало то, что у нас не было эталонной последовательности».
Дальнейшее изучение недавно секвенированных частей генома также может помочь ученым лучше понять, как люди развили определенные черты, такие как более крупный мозг, который привел их к генетически отличному пути от их великих предков-обезьян.
«Вещи, которые делают нашу лобную кору больше, происходят от генов, которые картируются в этих повторяющихся областях», — сказал Эван Эйхлер, профессор кафедры геномных наук в Медицинской школе Вашингтонского университета, а также участник совместной исследовательской группы. .
.
Достижения в технологии геномного секвенирования могут привести к возрождению медицинских открытий, говорят исследователи.
«Меня больше волнует то, чего мы не знаем, и возможности для открытий», — сказал Мига.
Филиппи сказал, что его следующая цель — упростить процесс секвенирования, чтобы сделать его более дешевым, эффективным и широкодоступным. Он также планирует секвенировать генетический код как с отцовскими, так и с материнскими хромосомами. По его словам, широкое секвенирование среди людей из разных слоев общества поможет описать генетическое разнообразие мира и выявить важные генетические вариации.
Он представляет себе мир, в котором каждый имеет доступ к своим генетическим данным, что может помочь в предоставлении индивидуальной информации о том, какие заболевания врачи должны отслеживать или какие лекарства прописывать.
«Через 10 лет получение полного, абсолютно точного генома человека станет рутинной частью здравоохранения, и это будет достаточно дешево, чтобы не задумываться — лабораторный тест стоимостью менее 1000 долларов», — сказал Филлиппи.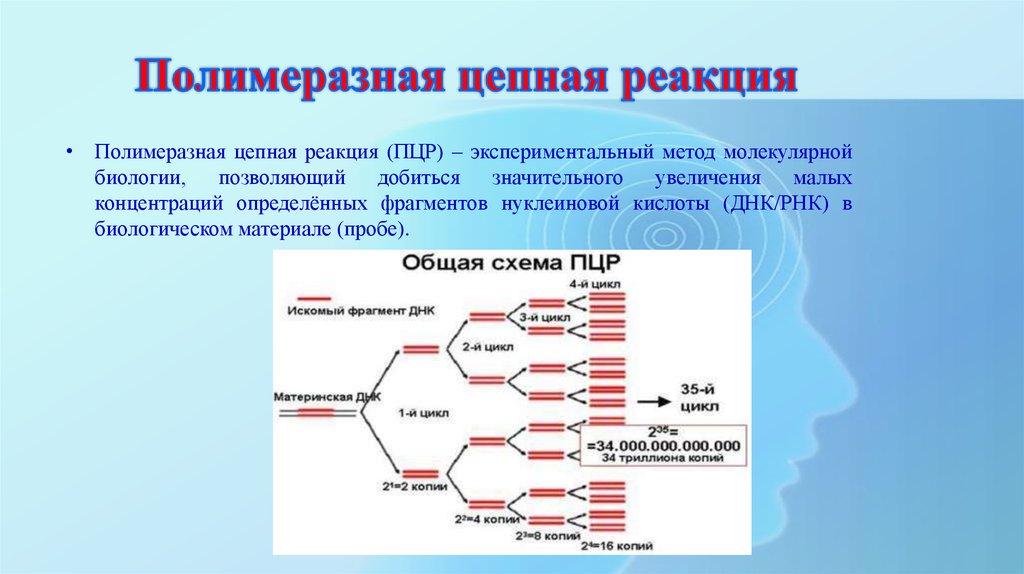 «Полный геном будет у вас в кармане».
«Полный геном будет у вас в кармане».
Расшифровка ДНК | Coursera
Об этом курсе
41 281 недавних просмотров
Вы живое существо? Тогда поздравляем! У вас есть ДНК. Но что вы на самом деле знаете о микроскопических молекулах, которые делают вас уникальными?
 Затем зайдите в нашу виртуальную лабораторию, чтобы провести собственный судебно-медицинский анализ образцов ДНК с места преступления и раскрыть убийство.
Затем зайдите в нашу виртуальную лабораторию, чтобы провести собственный судебно-медицинский анализ образцов ДНК с места преступления и раскрыть убийство.Гибкие сроки
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Совместно используемый сертификат
Совместно используемый сертификат
Получите сертификат по завершении
100% онлайн
100% онлайн
Начните немедленно и учитесь по собственному графику.
Средний уровень
Средний уровень
Часов, чтобы закончить
Прибл. 23 часа
Доступные языки
Английский
Субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, немецкий, русский, английский, испанский
Гибкие сроки
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Совместно используемый сертификат
Совместно используемый сертификат
Получите сертификат по завершении
100% онлайн
100% онлайн
Начните немедленно и учитесь по собственному графику.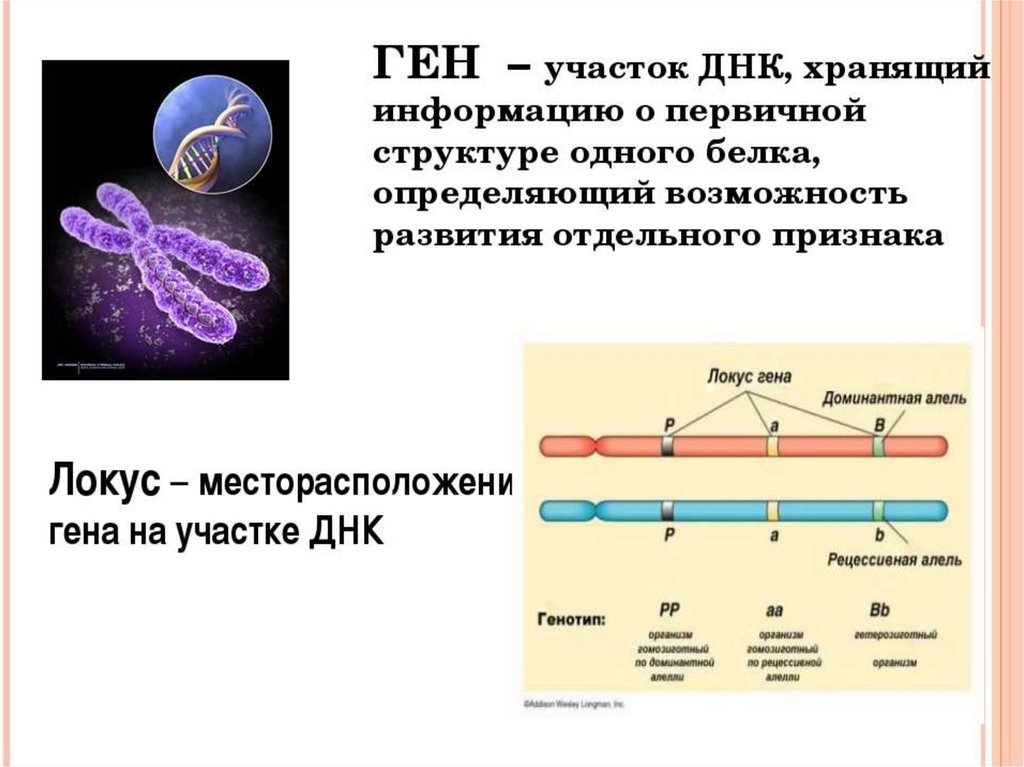
Средний уровень
Средний уровень
Часов, чтобы закончить
Прибл. 23 часа
Доступные языки
Английский
Субтитры: арабский, французский, португальский (европейский), итальянский, вьетнамский, немецкий, русский, английский, испанский
Instructors
Caitlin Mullarkey
Assistant Professor
Health Sciences
32,490 Learners
1 Course
Felicia Vulcu
Assistant Professor
Biochemistry and Biomedical Sciences
32,490 Learners
1 Курс
Предлагается
Университет Макмастера
Университет МакМастер, основанный в 1887 году, стремится к творчеству, инновациям и совершенству, вдохновляя на критическое мышление, личностный рост и страсть к обучению.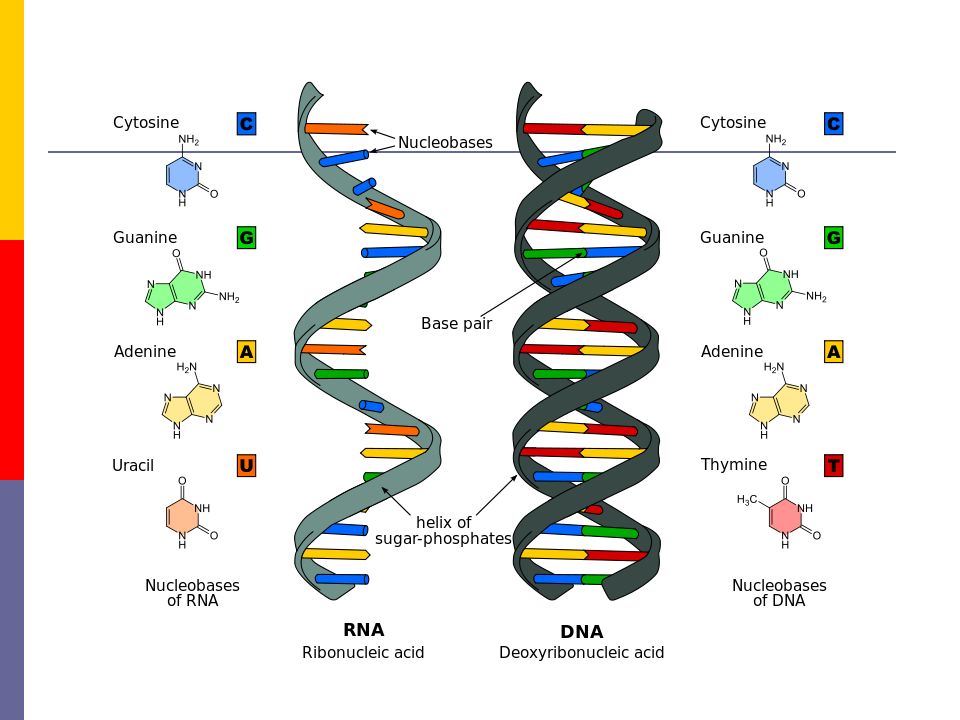 Входящий в число 100 лучших университетов мира, Макмастер стал пионером ориентированного на учащегося проблемного междисциплинарного подхода к обучению, который сейчас известен во всем мире как «Модель Макмастера».
Входящий в число 100 лучших университетов мира, Макмастер стал пионером ориентированного на учащегося проблемного междисциплинарного подхода к обучению, который сейчас известен во всем мире как «Модель Макмастера».
Reviews
4.8
Filled StarFilled StarFilled StarFilled StarFilled Star
315 reviews
5 stars
86.51%
4 stars
11.26%
3 stars
1.66%
2 зв.0002 от BJ 10 февраля 2021 г.
Отличный курс! Преподаватели очень знающие и интересные! Клипы достаточно короткие, чтобы поддерживать интерес. Обязательно пройду еще курсы у этих инструкторов!
Filled StarFilled StarFilled StarFilled StarFilled Star
от AJ 17 января 2020 г.
этот курс был потрясающим. Все в этом курсе было подробно описано. Все мои сомнения развеялись. Теперь я хочу узнать ДНК более подробно. Так что с нетерпением жду некоторых продвинутых курсов отсюда.