Содержание
Алгоритм распознавания лиц NtechLab признан лучшим в мире
Фото: Виктор Молодцов
Компания NtechLab, один из мировых лидеров в области биометрических технологий и технологический партнер Госкорпорации Ростех, победила в конкурсе алгоритмов распознавания лиц Face Recognition Vendor Test (FRVT) Национального института стандартов и технологий Министерства торговли США (NIST). Алгоритм NtechLab признан американским институтом лучшим в мире по результатам проведения семи независимых тестов, а по трем из них поставлен рекорд за всю историю проведения испытаний.
Тестирование FRVT от NIST является единственным общепризнанным мировым соревнованием алгоритмов распознавания лиц, в том числе призванным помочь Министерству торговли США выявить лучших мировых поставщиков подобных программных решений. Оно соответствует сценарию подтверждения личности человека по фотографии. Данный сценарий используется в широком спектре гражданских, правоохранительных и национальных программ безопасности, включая проверку фото на визовых документах и при выдаче паспортов, а также в системах оплаты с помощью биометрических данных («по лицу»).
Данный сценарий используется в широком спектре гражданских, правоохранительных и национальных программ безопасности, включая проверку фото на визовых документах и при выдаче паспортов, а также в системах оплаты с помощью биометрических данных («по лицу»).
«За шесть лет NtechLab из перспективного стартапа выросла в компанию с более чем сотней сотрудников, сохранив при этом гибкость управления и нестандартность инженерных решений, благодаря которым и обратила на себя внимание Ростеха еще на ранних этапах своего развития. Миллиардные инвестиции, крупные заказы, технологическое лидерство – все это делает NtechLab одной из ведущих компаний российского IT-рынка. Сейчас одним из главных направлений работы компании является международное развитие – открываются зарубежные офисы, растет сеть партнеров по всему миру. Признание превосходства российских технологий на престижном международном конкурсе позволит кратно увеличить темпы роста зарубежной выручки компании», – рассказал председатель совета директоров NtechLab, директор по особым поручениям Госкорпорации Ростех Василий Бровко.
В рамках FRVT оценивалось более 100 алгоритмов от разработчиков из большого количества стран, включая Китай, США и Израиль. Тестирование FRVT проводилось по нескольким базам фото. При подведении итогов учитывались точность и скорость поиска, а также адаптируемость алгоритма к последующим изменениям. Алгоритм NtechLab стал номером один в работе с базами VISA, VISABORDER и BORDER, в которых содержатся изображения, идентичные по качеству фотографиям, снятым при пересечении границы и из визовых разрешений. По результатам работы с этими базами NtechLab показала лучшие результаты за всю историю конкурса NIST. Кроме того, NtechLab вошла в тройку по результативности распознавания лиц в медицинских масках.
«Так как все эти годы конкуренция росла, а точность и скорость работы алгоритмов конкурентов увеличивались, сегодня мы можем с уверенностью сказать, что алгоритм интеллектуальной видеоаналитики NtechLab является лучшим в мире по целом ряду параметров. Для получения этого выдающегося результата инженеры NtechLab использовали инновационные подходы к обучению нейронных сетей, а также новые алгоритмы обработки и подготовки данных для машинного обучения. Результаты этих наработок уже используются в продуктах NtechLab и послужат повышению комфорта и безопасности жителей «умных городов» по всему миру», – отметил основатель NtechLab, глава лаборатории нейронных сетей компании Артем Кухаренко.
Для получения этого выдающегося результата инженеры NtechLab использовали инновационные подходы к обучению нейронных сетей, а также новые алгоритмы обработки и подготовки данных для машинного обучения. Результаты этих наработок уже используются в продуктах NtechLab и послужат повышению комфорта и безопасности жителей «умных городов» по всему миру», – отметил основатель NtechLab, глава лаборатории нейронных сетей компании Артем Кухаренко.
Алгоритмы NtechLab неоднократно доказывали свое техническое превосходство в рамках репрезентативных международных конкурсов. В 2017 году разработка NtechLab уже признавалась лучшей Национальным институтом стандартов и технологий Министерства торговли США, а также заняла первое место по итогам соревнования американского Агентства передовых исследований в сфере разведки в категориях самый точный и самый быстрый алгоритм. В 2018 году NtechLab вошла в тройку победителей конкурса WIDER Pedestrian Challenge по детектированию пешеходов на основе их силуэтов, в 2019 году – заняла второе место на международном конкурсе ActEV-PC по распознаванию действий человека на видео.
Алгоритм распознавания лиц [Название_Компании] признан лучшим в мире / Хабр
Возможно, время от времени вам попадались новости с заголовком, похожим на этот. (Если нет, то вот несколько примеров: первый, второй.)
«Первое место в мире» — звучит круто! Но одновременно с этим возникает много вопросов. Кто участвует? Как участники соревнуются? А кто распределяет места?
Мы хотим познакомить вас с самым авторитетным на сегодняшний день «чемпионатом мира» по распознаванию лиц, NIST Face Recognition Vendor Test (FRVT) — что он из себя представляет, для чего создан, как проходит соревнование и главное, насколько он действительно важен для разработчиков и бизнеса.
Что такое NIST?
Национальный институт стандартов и технологий (National Institute of Standards and Technology, NIST) был основан Конгрессом в 1901 году для обеспечения промышленной конкурентоспособности страны по сравнению с ведущими в те годы экономиками — в первую очередь, Германией и Великобританией; и с тех самых пор он является главным государственным органом США по метрологии и стандартизации. Такой, проще говоря, американский аналог нашего Росстандарта, который издаёт американские «госты».
Такой, проще говоря, американский аналог нашего Росстандарта, который издаёт американские «госты».
Здесь иной читатель скажет: при чём тут распознавание лиц? где, простите, «госты» и где инновации, какая вообще связь? А связь самая прямая. Когда в нашу жизнь врывается какая-то новая технология, первое, что должны понять её разработчики и пользователи — как эту технологий «померить». Какие исчисляемые показатели можно предложить, чтобы, анализируя их и сопоставляя с какими-то целевыми значениями, делать вывод о состоятельности технологии и целесообразности её применения? И органу по стандартизации здесь самое место — и в части выбора таких показателей, и в части разработки и утверждения безусловно приемлемой для всех заинтересованных сторон методики их измерения.
Измерениями и стандартизацией в области биометрии — технологий распознавания человека по его физическим или поведенческих характеристикам — NIST занимается очень давно. Сфера его интересов охватывает все практически применимые модальности: отпечатки пальцев и радужную оболочку глаза, анализ речи и идентификацию человека по голосу. Первые серьёзные исследования в области распознавания лица человека начались в 2003 году (стимулом к их проведению послужили трагические события 11 сентября), а с 17 февраля 2017 года институт запустил FRVT в качестве регулярно возобновляемого соревнования среди разработчиков технологии. С тех пор в общей сложности протестировали 662 алгоритма, представленные 248 компаниями.
Первые серьёзные исследования в области распознавания лица человека начались в 2003 году (стимулом к их проведению послужили трагические события 11 сентября), а с 17 февраля 2017 года институт запустил FRVT в качестве регулярно возобновляемого соревнования среди разработчиков технологии. С тех пор в общей сложности протестировали 662 алгоритма, представленные 248 компаниями.
Как организовано тестирование
Соревнование состоит из нескольких треков (позже мы обсудим их подробнее), каждый из которых представляет свой сценарий тестирования. Чтобы принять участие, любой желающий разработчик может отправить свой алгоритм организаторам, и через какое-то время его результаты появятся на сайте. Тест — по крайней мере, на сегодняшний день — проводится регулярно и бессрочно, но обновить алгоритм можно не чаще чем раз в четыре месяца. Участие бесплатное.
Алгоритм должен реализовывать программный интерфейс (API) испытательного стенда, его спецификация описана в документации для каждого конкретного трека. Для удобства организаторы уже реализовали соответствующий шаблон в своем репозитории — участникам нужно только заменить модели на свои собственные, собрать посылку (бинарный файл динамической библиотеки) зашифровать её и отправить. Исходный код алгоритма, вопреки расхожему заблуждению, передавать не нужно. Тестирование проводится на CPU — графические ускорители NIST не поддерживает.
Для удобства организаторы уже реализовали соответствующий шаблон в своем репозитории — участникам нужно только заменить модели на свои собственные, собрать посылку (бинарный файл динамической библиотеки) зашифровать её и отправить. Исходный код алгоритма, вопреки расхожему заблуждению, передавать не нужно. Тестирование проводится на CPU — графические ускорители NIST не поддерживает.
В ходе испытаний замеряют операционные характеристики, иллюстрирующие точность и скорость работы алгоритмов, а также некоторые дополнительные метрики (например, размер вектора признаков в байтах). Все эти сведения для всех протестированных алгоритмов включаются в очередной отчёт, который публикуется на сайте NIST примерно раз в месяц.
Кто участвует в тесте
Количество участников FRVT растет год от года. Если подсчитать всех, кто хоть раз отправлял свой алгоритм в трек FRVT 1:1 Verification с 2020 года, получится такое распределение (в скобках — число участников):
Более половины участников представляют пять стран: Китай, США, Южную Корею, Тайвань и Россию. Если же обратиться к таблице с результатами, то верхние позиции преимущественно занимают организации из России, Китая, США, Южной Кореи и Японии.
Если же обратиться к таблице с результатами, то верхние позиции преимущественно занимают организации из России, Китая, США, Южной Кореи и Японии.
Среди участников есть как крупные корпорации, такие как Intel, Samsung или Tencent, так и учебные заведения: МГУ и ИТМО. Здесь есть как компании, специализирующиеся на видеоаналитике, так и те, для которых это направление не является основным — например, банки.
Датасеты и домены
Важным фактором, влияющим на качество работы алгоритма распознавания — это условия, в которых он применяется. Для тестирования алгоритмов NIST использует собственные массивы данных, доступа к которым у участников нет. О датасетах известно немного: описание доменов и пара примеров на каждый из них.
Одна большая часть изображений связана с иммиграционным контролем — как правило, это достаточно качественные фронтальные портретные изображения, которые делятся на следующие домены в зависимости от способа получения изображений:
Visa (Application) — фронтальные портретные снимки, собранные в иммиграционных офисах, на белом фоне, с использованием специального оборудования для захвата и освещения.
 Размер фотографий примерно 300×300 пикселей. Всего таких изображений 1,6 миллиона, по одному на человека.
Размер фотографий примерно 300×300 пикселей. Всего таких изображений 1,6 миллиона, по одному на человека.Border (Immigration Lane) — фотографии, сделанные сотрудниками миграционной службы в кооперативном режиме (при взаимодействии с объектом съёмки). Возможны небольшие повороты головы, иногда встречается фоновая засветка и искажение перспективы из-за съемки с близкого расстояния. Количество таких изображений — порядка миллиона.
Kiosk — фотографии, собранные при взаимодействии мигранта с автоматическим киоском. Камера расположена над дисплеем киоска, поэтому для этих изображений характерен наклон головы вперёд, иногда значительный (45° и более).
 Размер фотографий примерно 300×300 пикселей. Всего таких изображений 1,6 миллиона, по одному на человека.
Размер фотографий примерно 300×300 пикселей. Всего таких изображений 1,6 миллиона, по одному на человека.Вторая — самая значительная по объёму — часть изображений связана с деятельностью правоохранительных органов. В ней представлены три подмножества:
Webcam — изображения, собранные с помощью недорогой веб-камеры, имеют размер 240×240 пикселей.
Как видно на иллюстрации, встречаются отклонения от фронтального ракурса, низкая контрастность и плохое пространственное разрешение.
 Как видно на иллюстрации, встречаются отклонения от фронтального ракурса, низкая контрастность и плохое пространственное разрешение.
Как видно на иллюстрации, встречаются отклонения от фронтального ракурса, низкая контрастность и плохое пространственное разрешение.Последний, самый сложный домен, представленный в FRVT — Wild. Он включает множество изображений, полученных при репортажной съёмке (в некооперативном режиме). Разрешение варьируется в очень широких пределах, изображения очень непринужденные, с широкими вариациями положения головы, лица могут быть частично перекрыты, например волосами или руками.
Треки
Мы уже упоминали, что NIST FRVT состоит из нескольких треков. Нас интересуют два из них, FRVT 1:1 Verification и FRVT 1:N Identification, непосредственно связанные с распознаванием лиц.
Здесь мы хотим отослать читателя к одной из наших предыдущих статей, где мы рассказывали об основах распознавания лиц:
верификация (она же сопоставление 1:1) представляет собой сравнение двух образцов для исследования их принадлежности одному и тому же человеку.
Верификация, в частности, выполняется, когда вы пытаетесь разблокировать смартфон при помощи изображения лица — здесь биометрическая система отвечает на вопрос, достаточна ли высока её уверенность в том, что предъявленное изображение принадлежит владельцу устройства;идентификация (она же поиск, она же сопоставление 1:N) подразумевает отбор из некоторого множества образцов-кандидатов тех, что предположительно принадлежат тому же человеку, что и представленный системе искомый образец. В качестве примера можно предложить систему контроля доступа, которая отпирает магнитный замок, когда «видит» на камере знакомое лицо.
 Верификация, в частности, выполняется, когда вы пытаетесь разблокировать смартфон при помощи изображения лица — здесь биометрическая система отвечает на вопрос, достаточна ли высока её уверенность в том, что предъявленное изображение принадлежит владельцу устройства;
Верификация, в частности, выполняется, когда вы пытаетесь разблокировать смартфон при помощи изображения лица — здесь биометрическая система отвечает на вопрос, достаточна ли высока её уверенность в том, что предъявленное изображение принадлежит владельцу устройства;Оба трека исчисляют для каждого алгоритма одну и ту же метрику качества, FNMR@FMR= (она же FNIR@FPIR=, она же 1 — TMR@FMR=).
Верификация
Сценарий тестирования верификации выглядит следующим образом: из тестового датасета составляется большое количество пар картинок. Какие-то пары будут «позитивными» (включают два изображения одного и того же человека), какие-то — «негативными» (изображения принадлежат разным людям), причем программа испытательного стенда точно знает, где какая пара. Все эти пары сопоставляются тестируемым алгоритмом, который возвращает соответствующие степени схожести.
Все эти пары сопоставляются тестируемым алгоритмом, который возвращает соответствующие степени схожести.
Полученные результат можно проиллюстрировать примерно следующим образом (зелёные галочки отмечают позитивные пары, а красные крестики — негативные, сами алгоритмы при этом ничего не знают о позитивности или негативности):
Одна и та же картинка может участвовать в нескольких парах. Если тестовый датасет невелик, можно сформировать вообще все возможные пары, а на больших датасетах стандарты предписывают, чтобы на каждую позитивную пару предлагалось не менее 30 негативных пар.
На полученном примере посчитаем FNMR@FMR=0,1. Сначала выберем значение степени схожести, при котором FMR=0,1, то есть такое значение, при котором 10% всех негативных пар алгоритм ошибочно принимает за позитивные. Отсортируем по возрастанию степени схожести, исчисленные для негативных пар:
0,24 0,32 0,33 0,42 0,48 0,49 0,51 0,57 0,61 0,69
Так как в этом примере мы сопоставляли всего 10 негативных пар, порог должен быть таким, чтобы алгоритм счёл позитивной только одну из них — он должен быть меньше 0,69, но больше 0,61.
Оценим, каково будет отношение FNMR — то есть, какую долю позитивных пар алгоритм ошибочно признает негативными — при значении порога 0,61. Отсортируем по возрастанию значения степени схожести, исчисленные для позитивных пар:
0,59 0,72 0,84 0,86
Видно, что установив порог в 0,61, из четырёх сопоставленных позитивных пар алгоритм пропустит одну — ту, для которой получена степени схожести 0,59. Значит, FNMR@FMR=0,1 = 0,25.
(Более подробно об оценке алгоритмов распознавания мы рассказывали в этой статье.)
При тестировании верификации NIST составляет пары из изображений одного датасета или смешивает картинки разных датасетов — например, в тесте VISABORDER изображения датасета Visa сопоставляются датасетом Border. Есть и дополнительный трек, FRVT Face Mask Effects, в котором изучается, насколько хорошо алгоритмы справляются с медицинскими масками. Чтобы избежать дорогостоящего сбора дополнительных данных, однотонную маску искусственно подрисовывают:
Идентификация
Сценарий тестирования второго трека, FRVT 1:N, подразумевает, что накоплена база с изображениями лиц (может быть, достаточно большая) и есть некоторый набор фотографий. Про каждую из них нужно выяснить, есть ли в базе изображение этого человека или нет. Как и в случае с верификацией, какие-то поиски будут позитивными, когда априори известно, что фото этого человека есть в базе, какие-то — негативными.
Про каждую из них нужно выяснить, есть ли в базе изображение этого человека или нет. Как и в случае с верификацией, какие-то поиски будут позитивными, когда априори известно, что фото этого человека есть в базе, какие-то — негативными.
Проиллюстрируем поиск такой схемой и попробуем по ней вычислить метрику FNIR@FPIR=0,5 (false negative identification rate, при условии что false positive identification rate равен 0,5):
Как и ранее, сначала необходимо найти порог схожести, при котором FPIR = 0,5. Негативных поисков здесь всего два, чтобы один из них мы ошибочно сочли позитивным, порог схожести должен быть равен 0,45. Организаторы FRVT предлагают два варианта подсчета метрики: Identification (T>0) и Investigation (R=1, T=0).
При Identification (T>0) важно, чтобы у положительных поисков схожесть с правильной картинкой была выше порога, и не важно, если в базе найдется какая-то другая картинка с ещё большей схожестью. В этом случае, оба положительных поиска будут успешными, так как 0,65 > 0,45 и 0,8 > 0,45. Следовательно, FNIR@FPIR=0,5 = 0.
Следовательно, FNIR@FPIR=0,5 = 0.
При Investigation (R=1, T=0) порог для положительных поисков не важен, но правильная картинка из базы должна давать самую высокую схожесть. Здесь самый нижний поиск на картинке будет неудачным, так как 0,65 < 0,75. Следовательно, FNIR@FPIR=0,5 = 0,5.
Ещё один интересный трек — FRVT Paperless Travel. Его идея заключается в том, чтобы протестировать возможность пересадки при транзитном авиарейсе без использования бумажных документов, только по биометрическим данным.
В этом сценарии составляется 567 групп, по 420 человек в каждой (примерное число пассажиров рейса). Чтобы симулировать реальный перелет, группы формируются с учетом географии, то есть в одну группу попадают люди из одного региона. При прилете в страну транзита делается входное фото пассажира, которое сразу же попадает в базу пассажиров, вылетающих транзитным рейсом из страны. При посадке на вылетающий рейс делается еще одно, выходное фото пассажира, которое сверяется с базой входных лиц, и если путешественник найден в базе, он допускается на борт.
Дополнительные показатели
Метрики производительности
Помимо метрик качества NIST также предоставляет некоторую информацию о параметрах модели. Для этого нужно перейти во вкладку “Resources” на странице трека:
Например, в треке FRVT 1:1 могут быть интересны следующие показатели:
А. Размер вектора признаков модели в байтах — позволяет грубо оценить вычислительные ресурсы, требуемые для обработки поискового массива.
В. Время построения вектора признаков из картинки в миллисекундах. В это время входит весь пайплайн, от детектора лиц до отработки модели. Замеры, напомним, выполняются на CPU. Следует отметить, что в данном треке есть ограничение на этот показатель — он не должен превышать 1500 миллисекунд.
С. Время подсчета схожести между двумя векторами признаков в наносекундах.
Похожие показатели можно найти и для трека FRVT 1:N:
D. Время построения вектора признаков из картинки в миллисекундах.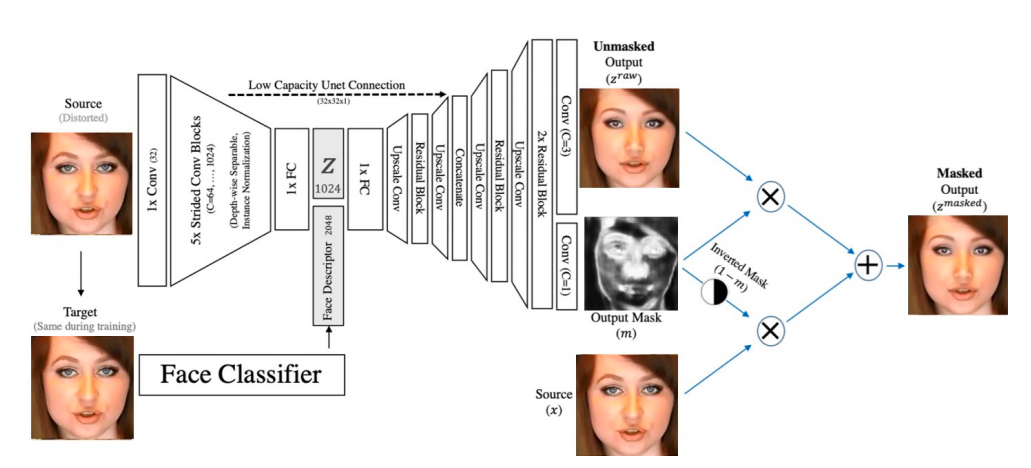 В этом треке более жёсткие ограничения: не выше 1000 миллисекунд.
В этом треке более жёсткие ограничения: не выше 1000 миллисекунд.
Е. Время поиска по базе в миллисекундах. Здесь N означает размер базы, а L — ранг идентификации (какое количество кандидатов следует вернуть).
Сами по себе приведенные в этих таблицах цифры, возможно, представляют не самый большой интерес для конечного пользователя, так как условия реального применения алгоритма могут довольно сильно отличаться от тестовых.
Графики и диаграммы
По итогам каждой очередной итерации тестирования NIST публикует объёмный отчёт — несколько сотен страниц с графиками, иллюстрациями и подробными разъяснениями. Среди прочего, он позволяет выяснить, как разные алгоритмы ведут себя при сопоставлении лиц разного пола, возраста, этнической принадлежности. Мы изучим соответствующие графики на примере трёх алгоритмов: ntechlab_011 (один из лидеров NIST), canon_003 (алгоритм из top25) и cyberlink_006 (алгоритм из top50) — при этом мы не ставим себе задачу сравнивать эти алгоритмы между собой.
Вот, например, как разные алгоритмы ведут себя при работе с лицами, отнесёнными к разным когортам: белые мужчины, белые женщины, темнокожие мужчины и темнокожие женщины. Для каждой когорты показана зависимость ошибки второго рода (когда алгоритм ошибочно принимает двух разных людей за одного человека) от порога схожести, на основе которого принято решение (если исчисленная при сопоставлении схожесть выше порога, это один и тот же человек, если ниже — разные):
Поведение моделей может также значительно варьироваться в зависимости от других критериев. На следующих диаграммах зеленая и красная точки показывают пороги для FMR=0,001 и FMR=0,0001 соответственно при работе с лицами разной этнической принадлежности:
…разного возраста (обратите внимание, то самую большую сложность представляют маленькие дети):
Наконец, интересно также изучить, насколько хорошо алгоритмы справляются с возрастными изменениями — когда сопоставляются снимки, сделанные с определённой разницей во времени (дополнительно можно посмотреть результаты в разрезе пола и цвета кожи). На следующей диаграмме порог для каждого алгоритма зафиксирован для FMR=0,0001 на общей совокупности негативных пар:
На следующей диаграмме порог для каждого алгоритма зафиксирован для FMR=0,0001 на общей совокупности негативных пар:
В чём практическая польза
Давайте поразмышляем, какую практическую пользу можно извлечь из наблюдения за соревнованием NIST FRVT.
Если вы просто интересуетесь распознаванием лиц
Даже у простого обывателя, который никак не связан с разработкой алгоритмов и не собирается внедрять решения на основе лицевой биометрии, так или иначе могут возникать вопросы: насколько хорошо сегодня работает распознавание лиц? насколько ему можно доверять? — ведь технология уже прочно вошла в нашу повседневную жизнь. Возможно, уже завтра мы будем проходить контроль в аэропорту, не предъявляя никаких документов, а покупки будем оплачивать не карточкой и не смартфоном, а просто посмотрев в камеру кассового терминала.
Или всё-таки не завтра? Достаточно ли точны алгоритмы? Не окажусь ли я в ситуации, когда из-за ошибки системы деньги за покупку, которую я не совершал, будут списаны с моего счёта? Экстраполируя результаты теста NIST FRVT, можно даже попытаться оценить размер потенциальных потерь от таких ошибок.
Если вы разработчик
Для разработчиков ответ очевиден: NIST FRVT — пожалуй, самый авторитетный на сегодняшний день бенчмарк, и, если вам интересно, где находится разработанная вами технология по сравнению со всем остальным миром (а как это может не быть интересно?!), вам просто необходимо в нём участвовать.
Но не только это — участие в соревновании поможет вам оценить состоятельность принятых вами решений: улучшилась ли точность системы после реализации новой функции потерь? как повлияло на качество работы изменение параметров обучения? NIST FRVT покрывает огромное количество различных сценариев и аспектов тестирования — и дело не только в том, что реализовать их все при собственном «ин-хаус» тестировании было бы очень трудоёмко и затратно, о некоторых из них многие (особенно, начинающие) разработчики даже и не задумываются.
А если ваш алгоритм будет действительно хорош, то… в общем, см. фразу, вынесенную в заголовок этой статьи!
Если вы планируете внедрение технологии
На что стоит смотреть в NIST FRVT и как выбрать вендора под свою задачу, если ваша компания планирует внедрить технологию распознавания лиц?
Во-первых, нужно понять, какой из сценариев тестирования, представленных в NIST FRVT, больше всего похож на ваш. Если планируете сравнивать между собой пары лиц, стоит обратить внимание на FRVT 1:1 Verification (примером может быть подтверждение подлинности документов, когда фото на документе сравнивается с лицом предъявителя, или авторизация по лицу при входе в информационную систему).
Если планируете сравнивать между собой пары лиц, стоит обратить внимание на FRVT 1:1 Verification (примером может быть подтверждение подлинности документов, когда фото на документе сравнивается с лицом предъявителя, или авторизация по лицу при входе в информационную систему).
Если вам нужен поиск по лицу в базе, стоит рассмотреть результаты FRVT 1:N Identification и FRVT Paperless Travel. Вообще, системы типа «один ко многим» можно условно разделить на две группы в зависимости от их толерантности к ложноотрицательным и ложноположительным срабатываниям.
В одном случае ожидается, что человек есть в базе, и наша основная проблема — ложноположительные срабатывания. Такую ситуацию описывает FRVT Paperless Travel, где ожидается, что человек, прилетевший транзитным рейсом, успешно пройдет регистрацию на свой вылетающий рейс. Ложноотрицательное срабатывание системы в данном случае не станет большой трагедией — сотрудник авиакомпании проверит документы пассажира, а вот ложноположительное срабатывание действительно может дорого стоить.
Во втором случае ожидается, что человека в базе нет, и главной проблемой будут ложноотрицательные срабатывания. В таком случае стоит обратиться к FRVT 1:N Identification. Примером может служить проверка посетителя казино по базе шулеров, мошенников и других нежелательных личностей. Здесь ложноположительное срабатывание не страшно — «ручная» проверка позволит устранить возможные недоразумения, а ложноотрицательное срабатывание может повлечь серьезные проблемы. Другим примером может быть поиск пропавшего человека.
Сегодня неотъемлемым атрибутом человеческого лица стала медицинская маска, так что достойны изучения результаты FRVT Face Mask Effects.
Важно также понимать, какой домен наилучшим образом отражает нужные вам результаты. Если условия эксплуатацию проектируемой вами системы предполагают работу в основном с качественными фронтальными изображениями, смотрите на домены Visa и Mugshot. Если возможны произвольные поворотов головы и недостатки освещения, ваш выбор — Border и Kiosk.
Время построения шаблона (читай: скорость работы алгоритма) — важно ли оно? И да, и нет. С одной стороны, можно предположить, если один алгоритм показывает ту же точность, что и другой, но при этом работает быстрее, очевидно, что первый алгоритм окажется эффективнее. С другой стороны, реальная скорость работы будет сильно зависеть от аппаратной платформы. Во-вторых, если вам нужна действительно большая скорость, то, скорей всего, большинство разработчиков сможет предложить вам более быструю (но, вероятно, чуть менее точную) модель, о которой из отчёта NIST FRVT вы бы никогда не узнали.
Здесь также стоит отметить, что набор решений, который предлагает видеоаналитика, не ограничивается одним лишь распознаванием лиц. Разработчики могут дополнительно предлагать решения по определению пола, возраста, атрибутов лица, правильности ношения маски. Можно еще добавить подсчет людей, определения их взаимодействий, кластеризацию и многое другое — обо всем этом не узнать из отчёта NIST FRVT, не говоря уже об удобстве работы с пользовательским интерфейсом системы, качестве технической поддержки и цене.
Иными словами, для выбора решения нельзя целиком и полностью полагаться исключительно на отчёт NIST FRVT. Однако он будет самым правильным местом, чтобы начать — помимо возможности исследовать операционные характеристики алгоритма той или иной компании, сама динамика участия её алгоритма в соревновании может говорить о том, что компания, как говорится, «здесь всерьёз и надолго».
Другие соревнования
NIST FRVT является самым большим и разнообразным бенчмарком для распознавания лиц на данный момент. Можно даже сказать, что на сегодняшний день у него просто нет конкурентов, сопоставимых по масштабу и авторитету.
Стоит отметить, что за последний год сразу два вендора из Китая, Insightface и XForwardAI, попробовали создать собственные бенчмарки, их платформы использовались для проведения соревнования по распознаванию лиц в рамках ICCV 2021 Workshop. Пока оба проекта находятся в зачаточном состоянии и даже рядом не стоят с NIST FRVT.
Есть и другие способы сравнить вендоров, которыми нередко пользуются на практике. Вы можете сами построить бенчмарк на основе своих собственных данных, выбрать небольшой пул интересующих вас разработчиков и попросить их прогнать свои решения на вашем тесте. Очевидный плюс — тестирование будет проходить ровно в том сценарии, который вам нужен, и ровно на том домене данных, с которым в дальнейшем будет работать выбранный алгоритм. Если ваш домен очень специфичен, такой подход может оказаться более чем оправданным. Очевидный минус — высокая стоимость с точки зрения времени, усилий и, как следствие, денег.
Вы можете сами построить бенчмарк на основе своих собственных данных, выбрать небольшой пул интересующих вас разработчиков и попросить их прогнать свои решения на вашем тесте. Очевидный плюс — тестирование будет проходить ровно в том сценарии, который вам нужен, и ровно на том домене данных, с которым в дальнейшем будет работать выбранный алгоритм. Если ваш домен очень специфичен, такой подход может оказаться более чем оправданным. Очевидный минус — высокая стоимость с точки зрения времени, усилий и, как следствие, денег.
DeepFace — самое популярное глубокое распознавание лиц в 2022 году (Руководство)
Распознавание лиц было горячей темой на протяжении нескольких десятилетий. И хотя доступны различные библиотеки распознавания лиц, DeepFace стал широко популярным и используется во многих приложениях для распознавания лиц.
В этой статье мы обсудим, что отличает DeepFace от его альтернатив и почему вам следует его использовать. В частности, в статье будет рассмотрено следующее:
- Что такое DeepFace? Руководство по ключевым функциям.
- Краткие пошаговые руководства по использованию библиотеки DeepFace.
- Как собрать детектор лиц с Deep Face.
- Как пользоваться самыми популярными моделями распознавания лиц.
- Учебное пособие по использованию распознавания лиц на основе глубокого обучения с помощью веб-камеры в режиме реального времени.
- Как установить репозиторий GitHub для распознавания лиц, содержащий библиотеку DeepFace.

Прежде чем мы углубимся: Если вы ищете решение корпоративного уровня для доставки приложений распознавания лиц, вы можете использовать DeepFace с платформой без кода Viso Suite. Viso Suite, используемый ведущими организациями по всему миру, предоставляет DeepFace, полностью интегрированный со всем, что вам нужно для запуска и масштабирования ИИ, включая безопасность с нулевым доверием и конфиденциальность данных для ИИ.
Что такое Deepface?
DeepFace — самая легкая библиотека распознавания лиц и анализа атрибутов лица для Python. Библиотека DeepFace с открытым исходным кодом включает в себя все передовые модели искусственного интеллекта для распознавания лиц и автоматически обрабатывает все процедуры распознавания лиц в фоновом режиме.
Хотя вы можете запустить DeepFace, написав всего несколько строк кода, вам не нужно приобретать глубокие знания обо всех процессах, стоящих за ним. Фактически вы просто импортируете библиотеку и передаете точный путь к изображению в качестве входных данных; это все!
Если вы запускаете распознавание лиц с помощью DeepFace, вы получаете доступ к набору функций:
- Проверка лица : Задача проверки лица относится к сравнению лица с другим, чтобы проверить, совпадает оно или нет. Следовательно, проверка лица обычно используется для сравнения лица кандидата с другим. Это можно использовать для подтверждения того, что физическое лицо совпадает с лицом в документе, удостоверяющем личность.
- Распознавание лиц : Задача относится к поиску лица в базе данных изображений. Выполнение распознавания лиц требует многократного запуска проверки лиц.
- Анализ атрибутов лица: Задача анализа атрибутов лица относится к описанию визуальных свойств изображений лица. Соответственно, анализ атрибутов лица используется для извлечения таких атрибутов, как возраст, гендерная классификация, анализ эмоций или предсказание расы/этнической принадлежности.
- Анализ лиц в реальном времени: Эта функция включает проверку распознавания лиц и анализ атрибутов лица с помощью видеопотока с веб-камеры в реальном времени.
Далее я объясню, как выполнять эти задачи глубокого распознавания лиц с помощью DeepFace.
Как использовать DeepFace?
Deepface — это проект с открытым исходным кодом, написанный на Python и распространяемый по лицензии MIT. Разработчикам разрешено использовать, модифицировать и распространять библиотеку как в частном, так и в коммерческом контексте.
Библиотека Deepface также опубликована в Индексе пакетов Python (PyPI), репозитории программного обеспечения для языка программирования Python. Далее я проведу вас через краткое руководство по использованию DeepFace.
1. Установите пакет DeepFace
Самый простой и быстрый способ установить пакет DeepFace — вызвать следующую команду, которая установит саму библиотеку и все необходимые компоненты с GitHub.
"оболочка" #Репо: https://github.com/serengil/deepface пип установить дипфейс ```
2. Импортируйте библиотеку
Затем вы сможете импортировать библиотеку и использовать ее функции с помощью следующей команды.
```питон из импорта Deepface DeepFace ```
Как выполнить распознавание и анализ лиц
Запустить проверку лица с помощью Deep Learning на DeepFace
Следующий пример проверки лица показывает, насколько просто запустить ее. На самом деле, мы передаем только пару изображений в качестве входных данных, и все!
```питон проверка = DeepFace.verify(img1_path = "img1.jpg", img2_path = "img2.jpg") ```
Несмотря на то, что внешний вид Эмилии Кларк в ее повседневной жизни по сравнению с ее ролью Дейенерис Таргариен в «Игре престолов» сильно отличается, DeepFace может проверить эту пару изображений, и механизм DeepFace возвращает ключ «проверено»: True . Это означает, что человек на каждом изображении фактически распознается как один и тот же человек.
Пример проверки лица с помощью библиотеки DeepFace
Как применить технологию распознавания лиц DeepLearn с помощью DeepFace
В повседневной речи мы понимаем распознавание лиц как задачу поиска лица в списке изображений. Однако в литературе под распознаванием лиц понимается задача определения пары лиц как одного и того же или разных лиц. Реальный функционал распознавания лиц отсутствует в большинстве альтернативных библиотек.
Сказав это, DeepFace также покрывает распознавание лиц своим реальным значением. Для этого вы должны хранить изображения из базы данных лиц в папке. Затем DeepFace будет искать идентификатор переданного изображения в папке вашей базы данных лиц.
```питон распознавание = DeepFace.find(img_path = "img.jpg", db_path = "C:/facial_db") ```
DeepFace сравнивает распознанную личность с результатами в базе данных лиц.
Как выполнять анализ атрибутов лица с помощью DeepFace
Кроме того, DeepFace поставляется с мощным модулем анализа атрибутов лица для прогнозирования возраста, пола, эмоций и расы/этнической принадлежности. В то время как модуль распознавания лиц DeepFace объединяет существующие современные модели, его анализ атрибутов лица имеет свои собственные модели. В настоящее время модель прогнозирования возраста достигает средней абсолютной ошибки +/- 4,6 года; а модель предсказания пола достигает точности 97%.
Вы можете использовать следующую команду, чтобы выполнить анализ атрибутов лица и протестировать его самостоятельно:
```python анализ = DeepFace.analyze(img_path = "img.jpg", действия = ["возраст", "пол", "эмоции", "раса"]) печать (анализ) ```
Согласно результатам анализа черт лица, приведенным ниже, возраст Эмилии Кларк был определен как «31 год», пол «женщина», эмоция «счастливая» на основе этого изображения.
Анализ атрибутов лица с помощью глубокого обучения с использованием библиотеки DeepFace
Используйте распознавание лиц и анализ атрибутов в видео в реальном времени
Кроме того, вы можете тестировать модули распознавания лиц и анализа атрибутов лица в режиме реального времени. Функция потока получит доступ к вашей веб-камере и запустит эти модули. Это весело, не так ли?
```питон DeepFace.stream(db_path = «C:/facial_db») ```
Комбинация распознавания лиц и анализа атрибутов лица, применяемая в режиме реального времени на видео с веб-камеры
Самые популярные модели распознавания лиц
В то время как большинство альтернативных библиотек распознавания лиц обслуживают одну модель ИИ, библиотека DeepFace объединяет множество передовых моделей распознавания лиц. Следовательно, это самый простой способ использовать алгоритм Facebook DeepFace и все остальные алгоритмы распознавания лиц, представленные ниже.
Следующие алгоритмы глубокого обучения распознавания лиц можно использовать с библиотекой DeepFace. Большинство из них основаны на современных сверточных нейронных сетях (CNN) и обеспечивают лучшие в своем классе результаты.
1. VGG-Face
VGG означает Visual Geometry Group. Нейронная сеть VGG (VGGNet) — один из наиболее часто используемых типов моделей распознавания изображений, основанный на глубоких сверточных нейронных сетях. Архитектура VGG прославилась тем, что добилась высочайших результатов в конкурсе ImageNet. Модель разработана исследователями из Оксфордского университета.
Несмотря на то, что VGG-Face имеет ту же структуру, что и обычная модель VGG, она настроена на изображения лиц. Модель распознавания лиц VGG достигает 9 баллов.Точность 7,78% в популярном наборе данных Labeled Faces in the Wild (LFW).
Как использовать VGG-Face: Библиотека DeepFace использует VGG-Face в качестве модели по умолчанию.
2. Google FaceNet
Данная модель разработана исследователями Google. FaceNet считается современной моделью для обнаружения и распознавания лиц с помощью глубокого обучения. FaceNet можно использовать для распознавания лиц, проверки и кластеризации (кластеризация лиц используется для кластеризации фотографий людей с одинаковой идентичностью).
Основным преимуществом FaceNet является его высокая эффективность и производительность. Сообщается, что он достигает точности 99,63% в наборе данных LFW и 95,12% в базе данных Youtube Faces, используя при этом всего 128 байт на лицо.
Как использовать FaceNet: Вероятно, самый простой способ использования Google FaceNet — это библиотека DeepFace, которую вы можете установить и указать в качестве аргумента в функциях DeepFace (см. главу ниже).
3. OpenFace
Эта модель распознавания лиц создана исследователями из Университета Карнеги-Меллона. Следовательно, OpenFace во многом вдохновлен проектом FaceNet, но он более легкий, а его тип лицензии более гибкий. OpenFace получает 9 балловТочность 3,80% в наборе данных LFW.
Как использовать OpenFace: Как и в предыдущих моделях, вы можете использовать модель ИИ OpenFace с помощью библиотеки DeepFace.
4. Facebook DeepFace
Эта модель распознавания лиц была разработана исследователями Facebook. Алгоритм Facebook DeepFace был обучен на размеченном наборе данных из четырех миллионов лиц, принадлежащих более чем 4000 человек, который на момент выпуска был самым большим набором данных о лицах. Подход основан на глубокой нейронной сети с девятью слоями.
Точность модели Facebook составляет 97,35 % (+/- 0,25 %) на эталонном наборе данных LFW. Исследователи утверждают, что алгоритм DeepFace Facebook сократит отставание от производительности на уровне человека (97,53%) на том же наборе данных. Это указывает на то, что DeepFace иногда более успешен, чем люди, при выполнении задач по распознаванию лиц.
Как использовать Facebook DeepFace: Простым способом использования алгоритма распознавания лиц Facebook является использование одноименной библиотеки DeepFace, которая содержит модель Facebook. Читайте ниже, как
5. DeepID
Алгоритм проверки лица DeepID выполняет распознавание лиц на основе глубокого обучения. Это была одна из первых моделей, использующих сверточные нейронные сети и обеспечивающих лучшую, чем у человека, производительность в задачах распознавания лиц. Deep-ID был представлен исследователями Китайского университета Гонконга.
Системы, основанные на распознавании лиц DeepID, были одними из первых, кто превзошел человека в выполнении этой задачи. Например, DeepID2 достиг 99,15% в наборе данных Labeled Faces in the Wild (LFW).
Как использовать модель DeepID: DeepID — одна из внешних моделей распознавания лиц, встроенная в библиотеку DeepFace.
6. Dlib
Модель распознавания лиц Dlib называет себя «самым простым в мире API распознавания лиц для Python». Модель машинного обучения используется для распознавания лиц и управления ими из Python или из командной строки. Хотя библиотека dlib изначально написана на C++, она имеет простые в использовании привязки к Python.
Интересно, что модель Dlib не была разработана исследовательской группой. Он представлен Дэвисом Э. Кингом, главным разработчиком библиотеки обработки изображений Dlib.
Инструмент распознавания лиц Dlib отображает изображение человеческого лица в 128-мерном векторном пространстве, где изображения одного и того же человека находятся рядом друг с другом, а изображения разных людей находятся далеко друг от друга. Поэтому dlib выполняет распознавание лиц, сопоставляя лица с пространством 128d, а затем проверяя, достаточно ли мало их евклидово расстояние.
При пороге расстояния 0,6 модель dlib достигла точности 99,38 % в стандартном тесте распознавания лиц LFW, что ставит ее в один ряд с лучшими алгоритмами распознавания лиц.
Как использовать Dlib для распознавания лиц: Модель также завернута в библиотеку DeepFace и может быть задана в качестве аргумента в функциях Deep Face (подробнее об этом ниже).
7. ArcFace
Это новейшая модель в линейке моделей. Его совместными разработчиками являются исследователи Имперского колледжа Лондона и InsightFace. Точность модели ArcFace для набора данных LFW составляет 99,40 %.
Как использовать модели распознавания лиц
Как упоминалось выше, эксперименты показывают, что люди достигают 97,53% баллов за распознавание лиц в наборе данных Labeled Faces in the Wild. Интересно, что VGG-Face, FaceNet, Dlib и ArcFace уже преодолели этот балл (алгоритмы ИИ, работающие лучше, чем человек). С другой стороны, OpenFace, DeepFace и DeepID показывают очень близкие результаты по производительности человека.
Чтобы использовать эти модели, их можно задать в качестве аргумента в функциях deepface:
```python
модели = ["VGG-Face", "Facenet", "OpenFace", "DeepFace", "DeepID", "Dlib", "ArcFace"]
#проверка лица
проверка = DeepFace.verify("img1.jpg", "img2.jpg", имя_модели = модели[1])
#распознавание лица
распознавание = DeepFace.find(img_path = "img.jpg", db_path = "C:/facial_db", model_name = models[1])
```
Библиотека DeepFace поддерживает 7 современных моделей распознавания лиц.
DeepFace расширяет свой портфель моделей с момента своего первого коммита. Его первоначальная версия охватывает только VGG-Face и Facenet. Он поддерживает семь передовых моделей распознавания лиц. Но и в будущем вы сможете легко использовать новейшие модели распознавания лиц с DeepFace, потому что имя модели является аргументом ее функций, а интерфейс всегда остается прежним.
Самые популярные детекторы лиц
Обнаружение и выравнивание лиц — очень важные этапы конвейера распознавания лиц. Google заявил, что только выравнивание лица увеличивает показатель точности распознавания лиц на 0,76%.
В общем, DeepFace — это простой способ использовать самые популярные современные детекторы лиц. В настоящее время в DeepFace встроено несколько передовых детекторов лиц:
OpenCV
По сравнению с другими, OpenCV является самым легким детектором лиц. Популярный инструмент обработки изображений использует каскадный алгоритм Хаара, который не основан на методах глубокого обучения. Вот почему он быстрый, но его производительность относительно низкая. Для правильной работы OpenCV требуются фронтальные изображения. Кроме того, его производительность обнаружения глаз средняя. Это вызывает проблемы с выравниванием. Обратите внимание, что детектором по умолчанию в DeepFace является OpenCV.
Обнаружение лиц с помощью OpenCV
Dlib
Этот детектор использует алгоритм борова в фоновом режиме. Следовательно, как и OpenCV, он не основан на глубоком обучении. Тем не менее, он имеет относительно высокие показатели обнаружения и выравнивания.
SSD
SSD означает однократный детектор; это популярный детектор на основе глубокого обучения. Производительность SSD сравнима с OpenCV. Однако SSD не поддерживает лицевые ориентиры и зависит от модуля обнаружения глаз OpenCV для выравнивания. Несмотря на то, что его эффективность обнаружения высока, оценка выравнивания только средняя.
MTCNN
Это детектор лиц, основанный на глубоком обучении, и он поставляется с ориентирами лица. Вот почему у MTCNN высокие показатели обнаружения и выравнивания. Однако он медленнее, чем OpenCV, SSD и Dlib.
RetinaFace
RetinaFace признана самой современной моделью распознавания лиц, основанной на глубоком обучении. Его производительность в дикой природе является сложной задачей. Однако для этого требуется высокая вычислительная мощность. Вот почему RetinaFace — самый медленный детектор лиц по сравнению с другими.
Как использовать детекторы лиц
Подобно моделям распознавания лиц, детекторы также могут быть установлены в качестве аргумента в функциях DeepFace:
```python
Детекторы = ["opencv", "ssd", "mtcnn", "dlib", "retinaface"]
#проверка лица
верификация = DeepFace.verify("img1.jpg", "img2.jpg",Detector_backend=детекторы[0])
#распознавание лица
распознавание = DeepFace.find(img_path = "img.jpg", db_path = "C:/facial_db",Detector_backend=детекторы[0])
``` Какой детектор лиц следует использовать?
Если ваше приложение требует высокой достоверности, вам следует рассмотреть возможность использования RetinaFace или MTCNN. С другой стороны, если для вашего проекта важнее высокая скорость, то стоит использовать OpenCV или SSD.
Как выполнять задачи по извлечению лиц с помощью DeepFace
Deepface имеет пользовательскую функцию распознавания лиц в своем интерфейсе. Вы также можете использовать библиотеку с широким набором детекторов лиц только для извлечения лиц. В приведенном ниже примере показано, как распознается и выравнивается лицо актрисы Эмилии Кларк. Программное обеспечение добавляет некоторые отступы, чтобы изменить размер извлеченного изображения, чтобы оно соответствовало ожидаемому размеру целевой модели распознавания лиц.
```питон
Детекторы = ["opencv", "ssd", "mtcnn", "dlib", "retinaface"]
img = DeepFace.detectFace("img1.jpg",Detector_backend=детекторы[4])
```
Обнаружение лиц для извлечения лиц с помощью DeepFace
Преимущества библиотеки Deepface
Вы можете спросить себя, почему вы должны использовать библиотеку Deepface по сравнению с альтернативами? Я думаю, что это самые важные причины, по которым люди используют DeepFace для создания приложений для распознавания лиц:
Он легкий
Вы можете использовать любую функциональность с помощью одной строки кода. Вам не нужно приобретать глубокие знания о процессах, стоящих за этим.
Простота установки
Для некоторых популярных библиотек распознавания лиц требуются основные зависимости C и C++. Это затрудняет их установку и инициализацию. У вас могут возникнуть проблемы при компиляции. Однако дипфейс в основном основан на TensorFlow и Keras. Это делает его очень простым в установке.
Несколько моделей и детекторов
В настоящее время библиотека Deepface объединяет семь современных моделей распознавания лиц и пять передовых детекторов лиц. Список поддерживаемых моделей и детекторов расширялся с момента первого коммита и будет продолжать расти в течение следующих нескольких месяцев.
Распознавание лиц с открытым исходным кодом
Deepface находится под лицензией MIT License. Это означает, что вы можете совершенно свободно использовать его как в личных, так и в коммерческих целях. Кроме того, он полностью открыт. Вы можете настроить библиотеку в соответствии с вашими требованиями.
Растущее сообщество Deepface
Более того, библиотека Deepface очень популярна в сообществе. Десятки участников, тысячи звезд на GitHub и сотни тысяч установок на pip. Даже если вы столкнетесь с какой-либо проблемой, вы, скорее всего, найдете решение на дискуссионных форумах.
Пакет, независимый от языка
Deepface — это независимый от языка пакет. Основные функции DeepFace написаны на Python. Его можно развернуть для выполнения выводов ИИ на периферии (распознавание лиц на устройстве). Однако он также обслуживает API (API Deepface), позволяющий запускать распознавание лиц и анализ атрибутов лица с мобильных или веб-клиентов.
Запланированные функции DeepFace
Несмотря на то, что библиотека Deepface уже сегодня поддерживает обширные функции, сообщество получит дополнительные преимущества от новых и будущих функций, таких как: новые модели распознавания лиц, такие как CosFace или SphereFace
Что дальше?
Основная идея DeepFace — объединить лучшие инструменты распознавания изображений для глубокого анализа лица в одной легкой и гибкой библиотеке. Поскольку простота очень важна, мы также называем ее LightFace. Любой может внедрить DeepFace в задачи производственного уровня с высокой оценкой уверенности в использовании самых мощных алгоритмов с открытым исходным кодом.
Если вы хотите использовать DeepFace в приложениях компьютерного зрения корпоративного уровня, рассмотрите возможность использования Viso Suite — комплексной платформы для компьютерного зрения без кода, которая легко интегрируется с DeepFace.
Мы рекомендуем вам ознакомиться с проектом DeepFace на Github. Пожалуйста, помогите и поддержите проект, пометив ⭐️ его репозиторий на GitHub 🙏.
Продолжить чтение по связанным темам:
- Глубокое распознавание лиц: простой для понимания обзор
- Обнаружение лиц в 2022 году: приложения реального времени с глубоким обучением
- +70 Самые популярные приложения компьютерного зрения в 2022 году
- Самое популярное программное обеспечение для глубокого обучения в 2022 году
15 лучших API распознавания лиц в 2021 году
1900 Февраль 2021
Программное обеспечение для распознавания лиц завоевывает мировой рынок цифровых продуктов. API распознавания лиц используются в различных сферах бизнеса и маркетинговых стратегиях. Анализ лица является неотъемлемой частью систем кибербезопасности. Многие API-интерфейсы обнаружения лиц основаны на машинном обучении и используют нейронную сеть для выполнения задач.
Содержание
15 основных API распознавания лиц
1. Microsoft Computer Vision API — точность 96 %
2. API Lambda Labs — точность 99 %
3. Inferdo — точность 100 %++
— 9 Face 4. Точность
5. EyeRecognize — Точность 99%
6. Kairos — Точность 62%
7. Аниметрика — Точность 100%
8. Macgyver — Точность 74%
9. BetaFace — Точность 81%
10. Luxand.62ud EyeFace
12. Обнаружение и распознавание лиц Skybiometry
13. EmoVu
14. FaceMark
15. Deep Face Detect
Резюме
Весь список API распознавания лиц: почетные упоминания от их целей и бюджета. Инструменты идентификации лиц различаются по своей функциональности, точности и цене. Распознавание изображений, распознавание лиц, защита данных или проверка личности — у каждого API распознавания лиц есть свои ключевые функции. Вот обзор лучших API распознавания лиц в 2021 году.
1. Microsoft Computer Vision API — точность 96 %
Подходит для: обработки содержимого изображений
Microsoft Computer Vision API распознавания лиц и изображений предлагает высокоуровневые алгоритмы разработки для обработки изображений и возврата информации. Пользователи могут анализировать изображения и их особенности.
Этот API может маркировать визуальные функции, идентифицировать объекты и бренды, определять лица и типы изображений и даже определять цветовые схемы. Данные ответа OCR включают язык, текст, слова, регионы и другие данные.
В дополнение к бесплатному базовому плану доступно несколько платных планов стоимостью от 19 до 199 долларов.
2. API-интерфейс Lambda Labs — точность 99 %
Лучше всего подходит для: распознавания лиц, пола и идентификации черт лица
API-интерфейс распознавания лиц, разработанный Lambda Labs, позволяет распознавать и классифицировать лица по полу. Он также обеспечивает определенные функции позиционирования глаз, носа и рта.
Пользователи могут создавать фотоальбомы и библиотеки. Приложение для распознавания лиц помогает анализировать и сравнивать новые изображения и их совместимость с существующими изображениями.
Lambda Labs предлагает 1000 бесплатных запросов в месяц с бесплатным планом. Несколько вариантов платного плана варьируются от 149 до 1449 долларов в месяц.
Демо доступно здесь.
3. Inferdo — точность 100 %
Подходит для: распознавания лиц с оценкой возраста
Inferdo Face Detection локализует человеческие лица на изображениях. API хорошо работает для определения лиц и пола, оценки возраста и определения черт лица.
Разработчики обещают простую интеграцию своего алгоритма машинного обучения и вашего приложения.
Inferdo предлагает базовый бесплатный план и различные модели с помесячной оплатой от 10 до 1000 долларов в месяц.
4. Face++ — Точность 99 %
Подходит для: извлечения информации о лицах из изображений
Face++ API распознавания лиц от Megvii обнаруживает и анализирует людей с помощью моделей глубокого обучения. Эти модели обучаются на миллионах изображений, чтобы обеспечить максимальную точность распознавания лиц.
Основные функции Face ++ включают распознавание лиц, идентификацию и сравнение лиц, а также модели распознавания тела с высокой точностью. Однако функции распознавания лиц нет. Вы можете определить возраст, расу и пол.
У Face++ есть бесплатная версия. Платные пакеты доступны от 500 до 10 500 долларов, в зависимости от функций.
5. EyeRecognize — точность 99 %
Подходит для: распознавания лиц по биометрическим данным
EyeRecognize API распознавания лиц предоставляет координаты для определенных черт лица: носа, рта и глаз. Также работает с биометрическими характеристиками: расой, полом и возрастом.
EyeRecognize обеспечивает аналитику на основе соотношения лица и изображения, а также цвета кожи, глаз и волос.
API EyeRecognize Face Detection имеет бесплатный базовый и платный планы в диапазоне от 29 до 249 долларов США в месяц.
6. Kairos — Точность 62 %
Подходит для: поиска лиц и определения функций
API распознавания лиц Kairos очень популярен и предлагает широкий спектр решений для распознавания изображений. API определяет пол и возраст и распознает лица на изображениях, видео и в потоковом режиме в реальном времени. Этот API используется для предотвращения мошенничества с идентификацией и обеспечения безопасной связи с клиентами.
Кайрос славится своим этическим подходом к идентичности. Продукция компании отвечает требованиям самых разных сообществ по всему миру.
Доступен в нескольких платных планах, от 19 до 499 долларов в месяц.
7. Animetrics — 100% точность
Подходит для: распознавания лиц на основе глубокого обучения
API распознавания лиц Animetrics обнаруживает человеческие лица и характерные точки, исправляет изображения под углом и выполняет распознавание лиц. Он обрабатывает информацию о чертах лица, включая брови, нос, уши, подбородок и губы, как координаты на изображении. Он также определяет пол и размещает ориентацию лиц по трем осям.
API Animetrics предоставляет некоторые специальные функции, такие как параметр повторной визуализации SetPose.
Пользователям предлагается бесплатный базовый план и платные планы от 49 до 999 долларов в месяц.
8. Macgyver — Точность 74 %
Подходит для: распознавания лиц и сравнения
API распознавания лиц Macgyver предоставляет набор инструментов для распознавания лиц и изображений. Он может сравнивать два лица, определять наличие лиц на изображении и возвращать координаты (X, Y) людей на изображении.
API использует машинное обучение и высокоточные нейронные сети, встроенные в TensorFlow.
Предлагаются как бесплатные, так и гибкие платные планы в зависимости от использования.
9. BetaFace — Точность 81 %
Лучше всего подходит для: распознавания и преобразования лиц
BetaFace Face Recognition API позволяет легко обнаруживать, анализировать, распознавать и сравнивать лица. Инструмент также определяет пол, возраст, выражение лица, этническую принадлежность и контент NSFW с несколькими ссылками на лица и более чем 40 чертами лица.
API сравнивает лица, создает и ищет лица в ваших базах данных. Он определяет возраст, пол, выражение лица и этническую принадлежность. Он также обрабатывает черты лица, геометрические свойства и цвета, включая цвета одежды и прически. Он используется для обнаружения контента для взрослых.
BetaFace доступен бесплатно и имеет платные тарифные планы от 245 до 1595 долларов США в месяц.
10. Luxand.cloud
Подходит для: обнаружения и сравнения человеческих лиц
API распознавания лиц Luxand.cloud обнаруживает и сравнивает человеческие лица. Он распознает возраст, пол и эмоции на фотографии и идентифицирует ранее отмеченных людей на изображениях.
Этот API позволяет легко находить и проверять людей на фотографиях или фотоколлекциях. Пользователи могут создать галерею в облаке и пометить людей их именами и личностями. Luxand.cloud обеспечивает процесс проверки.
API предлагает бесплатный базовый план и платные планы от 19 до 499 долларов в месяц.
11. EyeFace
Подходит для: распознавания лиц и управления изображениями
EyeFace API, разработанный Eyedea Recognition, обеспечивает обнаружение лиц, анализ лиц и уникальный подсчет людей. Он оценивает возраст и определяет пол, анализируя фото и видео даже в низком разрешении.
Разработчики обещают, что их продукт будет быстрым, оптимизированным, точным и гибким.
Eyedea предлагает три основных пакета для своего API: от 299,00 евро, 499,00 евро и 599,00 евро, а также бесплатную демоверсию.
12. Skybiometry Обнаружение и распознавание лиц
Подходит для: облачного распознавания лиц под сложными углами
Skybiometry Обнаружение и распознавание лиц API обеспечивает обнаружение, распознавание и группировку лиц. Он одновременно распознает несколько лиц под разными углами с любым выражением лица, в очках или без них.
Пользователи могут выбирать между бесплатным планом, 50/100 евро в месяц или пользовательской моделью оплаты.
13. EmoVu
Подходит для: интеллектуальных адаптивных интерфейсов и распознавания эмоций
EmoVu, разработанный Eyeris, распознает эмоции из потоков веб-камеры в реальном времени.
Основные функции включают распознавание лиц и эмоций, а также определение пола и возраста. Это помогает компаниям следить за настроением клиентов и вовлеченностью в продукт. Он возвращает до 20 параметров на каждый обнаруженный объект. Его алгоритм, основанный на глубоком обучении, позволяет анализировать микровыражения человеческих лиц.
Eyeris предлагает своим пользователям либо бесплатную версию, либо индивидуальные платные планы в зависимости от требований.
14. FaceMark
Подходит для: распознавания ориентиров лица
FaceMark — это мощный API для распознавания черт лица. Он обнаруживает до 68 точек-ориентиров (фронтально) и до 35 точек (в профиль).
Базовый план предлагается бесплатно. Пользователи могут выбирать между планами за 18, 65 и 250 долларов.
15. Deep Face Detect
Подходит для: архитектуры глубокой нейронной сети
API Deep Face Detect основан на глубокой нейронной сети и имеет множество функций. Он распознает пол, ориентиры лица, очки, растительность на лице, позы, качество изображения и т. д.
Пользователи могут выбирать между бесплатным базовым планом, планом за 29, 99 и 249 долларов.
Summary
| API | Recfaces Score | % Accuracy | Latency | Best for | Price |
|---|---|---|---|---|---|
| Kairos | 8.6 | 62% | 1344 ms | Finding faces and detecting features | Freemium |
| Аниметрика | 9.7 | 100% | 2688 ms | Deep learning-powered face recognition | Freemium |
| Lambda Labs | 9. 5 | 99% | 1045 ms | Face detection, gender, and features identification | Freemium |
| Inferdo | 9,8 | 100% | 906 мс | Распознавание лиц с оценкой возраста | Freemium |
| Luxand.cloud | 8,8 | 94% | 1301 ms | Detection and comparison of human faces | Freemium |
| EyeRecognize | 8.4 | 99% | 4763 ms | Face detection by biometrics | Freemium |
| Face++ | 9,5 | 99% | 147 мс | Извлечение информации о лицах из изображений | Freemium |
| Macgyver | 7.9 | 74% | 7693 ms | Facial recognition and comparison | Free |
| Microsoft Computer Vision | 8.9 | 96% | 889 ms | Processing content from images | Freemium |
| BetaFace | 9.
|