Содержание
как они работают и зачем нужны
Если с картинкой все плохо, она замылена, перегружена деталями, или размыта, пикселит и ее сложно рассмотреть — нет смысла хвататься за голову. Хватайтесь за возможности, которые дают вам нейросети, мы собрали для вас целую подборку сервисов в помощь. Читайте, переходите, изучайте, пробуйте и применяйте!
Зачем нужна обработка картинок с помощью нейросетей
Нейросети научились отлично работать, помогая дизайнерам, а в некоторых случаях даже заменяя их. А это значит, что с помощью отличных современных сервисов вы сможете:
Повысить посещаемость блога, делая узнаваемые шапки и иллюстрации для статей.
Улучшить активность и вовлечение в ваших группах в социальных сетях — известно, что на визуал люди реагируют сначала, а текст читают уже потом.
Запустить таргетированную или контекстную рекламу, которая привлечет внимание — и получить больше продаж.
Улучшить изображения в товарных карточках, получить еще больше продаж на маркетплейсах и в собственном интернет-магазине.

Предоставить достойные фото для полиграфии — например, для буклетов — и улучшить имидж компании.
Получить фотографии для отзывов в случаях, когда реальные фотографии поставить невозможно.
Получить логотип для стартапа или малого бизнеса, когда средств заказывать лого у дорогого дизайнера пока нет.

Все цели понятны, достижимы, измеримы, значит, пора знакомиться с сервисами, которые вам помогут круто поработать с картинками. Все они доступны в России сегодня, во втором полугодии 2022 года, и все с функционалом, достаточным чтобы приносить пользу. Или, как минимум, развлекать, что тоже бывает нелишним.
Читайте также:
Как продвигаться на маркетплейсах?
Сервис Vance Al Image Enlarger называет себя № 1 в мире нейросетей для обработки изображений. Основное позиционирование — «умный увеличитель» изображений до 800 %, есть возможность фиксированного увеличения в 2, 4, 6 раз; функции произвольного выбора размера изображения я не нашла.
Картинки становятся по-настоящему живыми, это точно
Что еще можно сделать:
обрезать изображение;
повернуть изображение, отразить зеркально, перевернуть;
отредактировать — улучшить яркость, контрастность, наложить текст;
удалить фон полностью или отдельные элементы;
удалить водяные знаки.
Сервис дает возможность восстановить и раскрасить фотографии, а еще здесь есть целая библиотека фильтров — настоящее раздолье для фотографа, дизайнера и любого, кому нужно из посредственной картинки сделать ослепительную.
Сервис заботится о конфиденциальности информации пользователей — он сообщает, что все загруженные для обработки фото удаляются бесследно через 24 часа.
Стоимость:
100 картинок в месяц — $ 9,90.
200 картинок в месяц — $ 12,90.
400 картинок в месяц — $ 19,90.
1 200 картинок в месяц — $ 49,90.

AI Image Enlarger — многофункциональный инструмент с функцией увеличения изображения. Что он может:
повысить резкость и контрастность;
удалить с фото шумы;
улучшить цветопередачу;
отретушировать лица;
удалить фон;
добавить на фото маркер, текст, линию, стрелку, прямоугольник или эллипс;
восстановить старые фотографии и раскрасить черно-белые.
Разработчики заявляют, что их сервис улучшает качество фотографии в 6-8 раз.
Вы сами можете оценить результат
Функция ретуширования близка к фотошопу — можно увеличить глаза или губы, поправить форму носа или овал лица.
Масштабировать можно даже размытые изображения, они станут не только больше, но и четче, чем оригинал. При увеличении размера увеличивается и разрешение.
Можно из обычного фото, например, портрета, сделать картинку в стиле анимэ.
Пример: было фото, стала картинка в стиле анимэ
Стоимость:
Обработка до 8 картинок в месяц — бесплатно.
От 9 до 100 картинок в месяц — $ 9.
До 500 картинок в месяц — $ 19.
Функцию улучшения цветопередачи можно использовать отдельно и совершенно бесплатно.
Читайте также:
76 ссылок, которые помогут сделать концепцию дизайна эффектнее и быстрее
Этот функциональный сервис-редактор позволяет загружать картинки пакетно, ограничивая только вес такого пакета — не больше 5 МБ. Изображение любого размера он обещает увеличить без потери, даже с улучшением качества максимум до размера 7 680×7 680 пикселей.
Особенно показательно, как сервис работает с лицами, это его фишка
Что еще можно сделать:
повысить резкость;
подавить шумы;
навести фокус на лицо;
восстановить фотографии, отсканированные с бумажных носителей, в 1 клик;
обработать детские рисунки, скриншоты, логотипы.

И даже записи в школьных тетрадях
А еще можно получить доступ к API сервиса и интегрировать его функции в свои ресурсы, получая таким образом встроенный редактор для автоматической обработки изображений, которые загружаются на сайт.
Стоимость:
Пробная версия и обработка до 50 картинок — бесплатно.
1000 картинок в месяц — $ 250.
10 000 картинок в месяц — $ 400.
Сервис заявляет о возможности увеличить любое изображение в 16 раз — каждый пиксель увеличивается в 4 раза по горизонтали и в 4 раза по вертикали. Создатели сервиса считают его идеальным инструментом для получения картинок с высоким разрешением из исходников с низким разрешением.
На обработку любого изображения сервис тратит ровно 10 секунд
Максимальное разрешение — 10 000 пикселей.
Глядя на примеры, в это с легкостью верится
Что еще можно сделать:
отретушировать и откорректировать лица;
создать гифку;
разложить фото на слои и поработать с каждым отдельно;
вырезать элемент по контуру;
сделать из монохромного цветное фото.

Стоимость:
Обработать одно фото можно бесплатно.
До 200 картинок — $ 48.
До 500 картинок — $ 98.
Восстанавливать цветные картинки из монохрома можно и бесплатно, но в этом случае они будут с водяными знаками сервиса.
Midjourney.com — это генератор креативов, появился в 2022 году, сейчас находится в стадии бета-тестирования. Функционал — пока только генерация, только на основе искусственного интеллекта, то есть результат красив, но непредсказуем.
Так выглядят результаты работы генератора
Сервис работает через Discord, чтобы попасть в него сначала нужно авторизоваться в «Дискорде», а затем вновь перейти по ссылке, которую мы дали.
Тогда вы увидите такое приглашение
Переходите по нему, а дальше действовать нужно так:
Зайдите в один из каналов #newbies — их там несколько.
Введите запрос на креатив, обязательно на английском языке.
Запрос должен выглядеть так: /imagine prompt: ваш запрос, например, cats.
 Запрос должен выглядеть так: /imagine prompt: ваш запрос, например, cats.
Запрос должен выглядеть так: /imagine prompt: ваш запрос, например, cats.
После этого сервис сгенерирует и загрузит вам картинку прямо в чат. Фактически он действует как чат-бот. Вот здесь размещена более подробная инструкция для новых пользователей.
Стоимость:
Любопытно, что она определяется минутами, а не картинками.
25 минут — бесплатно.
200 минут — $ 10.
15 часов — $ 30.
Этот умный сервис уже не про увеличение или генерацию, а про возможность почувствовать себя художником, даже если вы совсем не умеете рисовать. Фишка сервиса в том, что вы можете начать рисовать — форму, линию, любой элемент — а смарт-алгоритмы сами дорисуют вашу картинку. Так из кривоватого знака бесконечность легким движением руки.
Может получиться вот такой велосипед
Что еще можно сделать:
Вот так нарисовала кита я:
Получился какой-то мутант
А вот такое изображение сотворил на основе моего «эскиза» искусственный интеллект:
Очень милый кит без признаков мутации
Отличный вариант для любителей стиля примитивизма и простых иллюстраций.
Стоимость:
Читайте также:
Как оптимизировать картинки для SEO-продвижения и привлечь дополнительный трафик: чек-лист
Сервис Looka — это нейросеть для автоматического создания логотипов. Логотипы создаются на основе данных о сфере деятельности компании и предпочтений пользователя. Чтобы эти предпочтения выявить, сервис предложит:
выбрать наиболее приятные логотипы из большой линейки предложенных;
ввести слоган компании или ее уникальное торговое предложение;
отметить символы, которые ассоциируется с компанией.
После этого искусственный интеллект сгенерирует до 10-12 вариантов логотипа.
Вот что предложил сервис лично мне
Варианты, которые предлагает сервис — не предел мечтаний, но точно помогут пользователю лучше понять, каким он хочет видеть логотип своей компании. Или личного бренда.
Стоимость:
Если ваш бизнес уже перерос бесплатные креативы от нейросетей, то найти веб-дизайнеров, которые нарисуют вам уникальный трендовый логотип, можно в базе специалистов Workspace, где зарегистрированы почти 9 000 диджитал-специалистов.
Минималистичный сервис с одной функцией, о которой все сказано в названии — сервис генерирует очень реалистичные и живые фото людей, которых не существует.
Сложно поверить, но этой женщины не существует
Работать с сервисом предельно просто — обновляйте страницу, вы каждый раз будете получать новое портретное изображение.
Отличный вариант, когда нужно проиллюстрировать тексты фотографиями, но поставить фото реальных людей по каким-то причинам невозможно. Например, из опасений нарушить авторское право.
Стоимость:
Бесплатно.
Когда вы уже хорошо поработали, и очень хочется отвлечься на что-то за пределами бизнеса, можно воспользоваться нейросетью Pornpen. ai. Этот сервис создает фотографии женщин, потренировавшись на базе эротических фото, в том числе известных актрис, которые снимаются в фильмах для взрослых.
ai. Этот сервис создает фотографии женщин, потренировавшись на базе эротических фото, в том числе известных актрис, которые снимаются в фильмах для взрослых.
А для начала нужно подтвердить, что вам исполнилось 18 лет
Можно выбирать запросы из заданного списка, получать сгенерированную картинку, соответствующую этим запросам. Вводить запросы вручную возможности нет — разработчик предлагает выбирать из заранее введенных тегов, которые насчитывается несколько десятков.
Тегов предусмотрено немало, но…
Сервис пользуется большой популярностью, часто из-за перегрузки отключается возможность генерации новых фото. Зато остается возможность просматривать все, что было создано до вас.
Вот самые скромные примеры «горячей» генерации артов
Стоимость:
Бесплатно.
Подводим итоги
Нейросети сегодня способны работать с картинками изощренно и разнообразно, начиная от бесплатных развлечений до платной и очень качественной работы с изображениями для бизнеса. Пользуйтесь возможностями искусственного интеллекта — это тренд, от которого уже никуда не деться.
Пользуйтесь возможностями искусственного интеллекта — это тренд, от которого уже никуда не деться.
Workspace.LIVE — мы в Телеграме
Новости в мире диджитал, ответы экспертов на злободневные темы, опросы, статьи и многое другое.
Подписывайтесь:
https://t.me/workspace
Обработка изображений — Работаем с фото и видео / Хабр
Работаем с фото и видео
Статьи
Авторы
Компании
Сначала показывать
Порог рейтинга
ru_vds
Блог компании RUVDS.com Обработка изображений *Машинное обучение *Искусственный интеллект
Перевод
Изображение, сгенерированное AI по промпту «photograph of a robot drawing in the wild, nature, jungle» («фотография робота, рисующего в природе, джунглях»)
22 августа 2022 года Stability. AI объявила о публичном релизе Stable Diffusion — мощной диффузионной модели text-to-image. Модель способна генерировать различные варианты изображений на основании текстового или графического ввода.
AI объявила о публичном релизе Stable Diffusion — мощной диффузионной модели text-to-image. Модель способна генерировать различные варианты изображений на основании текстового или графического ввода.
Стоит заметить, что «модель выпущена под лицензией Creative ML OpenRAIL-M. Лицензия допускает коммерческое и некоммерческое использование. Ответственность за этическое использование модели лежит на разработчиках. Это относится и к производным от неё моделям».
В этой статье я расскажу, как точно настраивать эмбеддинги для создания персонализированных изображений на основании произвольных стилей или объектов. Вместо переучивания модели мы можем представить собственный стиль в виде новых слов в пространстве эмбеддингов модели. В результате этого новое слово будет руководить созданием новых изображений интуитивно понятным образом.
Читать дальше →
Всего голосов 17: ↑16 и ↓1 +15
Просмотры
797
Комментарии
0
artkulakov
 000Z» title=»2022-12-18, 09:20″>18 декабря в 09:20
000Z» title=»2022-12-18, 09:20″>18 декабря в 09:20
Python *Обработка изображений *Big Data *Машинное обучение *Научно-популярное
Перевод
Tutorial
Многие уже слышали, а может и пробовали модель Stable Diffusion для генерации картинок из текста. Но знаете ли вы, как с помощью той же модели можно генерировать аудио?
Читать далее
Всего голосов 13: ↑13 и ↓0 +13
Просмотры
3.4K
Комментарии
13
alexey_rybakov
Глобальные системы позиционирования *Обработка изображений *Unity *Разработка под AR и VR *AR и VR
В этом году появилось сразу несколько сервисов, позволяющих найти новые применения дополненной реальности в мобильных приложениях и сделать отображения AR графики более реалистичной. Эти сервисы определяют куда смотрит пользователь и помогут разместить AR контент на фасаде здания, отобразить AR навигацию по помещению или превратить пространство вокруг в игровой уровень. Я изучил большинство этих сервисов, чтобы определить кому и для каких целей они подходят.
Я изучил большинство этих сервисов, чтобы определить кому и для каких целей они подходят.
Читать далее
Всего голосов 5: ↑5 и ↓0 +5
Просмотры
997
Комментарии
2
andreybondar
Блог компании Datanomica Python *Обработка изображений *Машинное обучение *Искусственный интеллект
Tutorial
Сегодня мы расскажем вам, как дообучить новую state-of-the-art модель SVTR-Tiny для распознавания текста сцены (текста в реальных уличных условиях) на собственноручно сгенерированных изображениях с помощью API библиотеки PaddleOCR.
Читать далее
Всего голосов 6: ↑6 и ↓0 +6
Просмотры
666
Комментарии
2
Laggg
 000Z» title=»2022-12-15, 14:00″>15 декабря в 14:00
000Z» title=»2022-12-15, 14:00″>15 декабря в 14:00
Блог компании Open Data Science Обработка изображений *Машинное обучение *Научно-популярное Искусственный интеллект
Привет, Хабр! Меня зовут Клоков Алексей, сегодня поговорим об алгоритмах компьютерного зрения, обработке видеопотока и методах трекинга множества объектов без разметки (unsupervised multiple object tracking) на примере пузырьков. Методичка будет полезна как опытным специалистам, перед которыми стоит похожая задача, так и начинающим энтузиастам.
В этой статье вы найдете:
— описание домена данных и технологического процесса флотации;
— подход к cегментации множества подобных объектов;
— существующие методы трекинга без разметки;
— подход к одновременному сопровождению множества подобных объектов;
— сравнение качества работы алгоритмов, полезный python-код и демонстрации!
Читать дальше →
Всего голосов 36: ↑36 и ↓0 +36
Просмотры
2. 8K
8K
Комментарии
4
Data_center_MIRAN
Блог компании Дата-центр «Миран» Обработка изображений *Сжатие данных *История IT Старое железо
Перевод
Формат JPEG представили в 1993 году, а GIF — в 1987-м. Но тогда непонятно, как смотрели фотографии девушек на этой прекрасной машине образца 1983 года?
Такой вопрос пришёл мне от читателя обзора портативного компьютера Compaq Portable. Ответ оказался сложнее, чем мы думали. Давайте разберёмся.
Читать дальше →
Всего голосов 87: ↑85 и ↓2 +83
Просмотры
30K
Комментарии
78
honyaki
Блог компании SkillFactory Обработка изображений *Сжатие данных *Машинное обучение *Читальный зал
Перевод
]
Одна из самых приятных вещей в жизни разработчика архитектуры ПО и технологического эксперта Intel — возможность наблюдать за фантастическими достижениями Центров передового опыта (CoE) OneAPI по всему миру.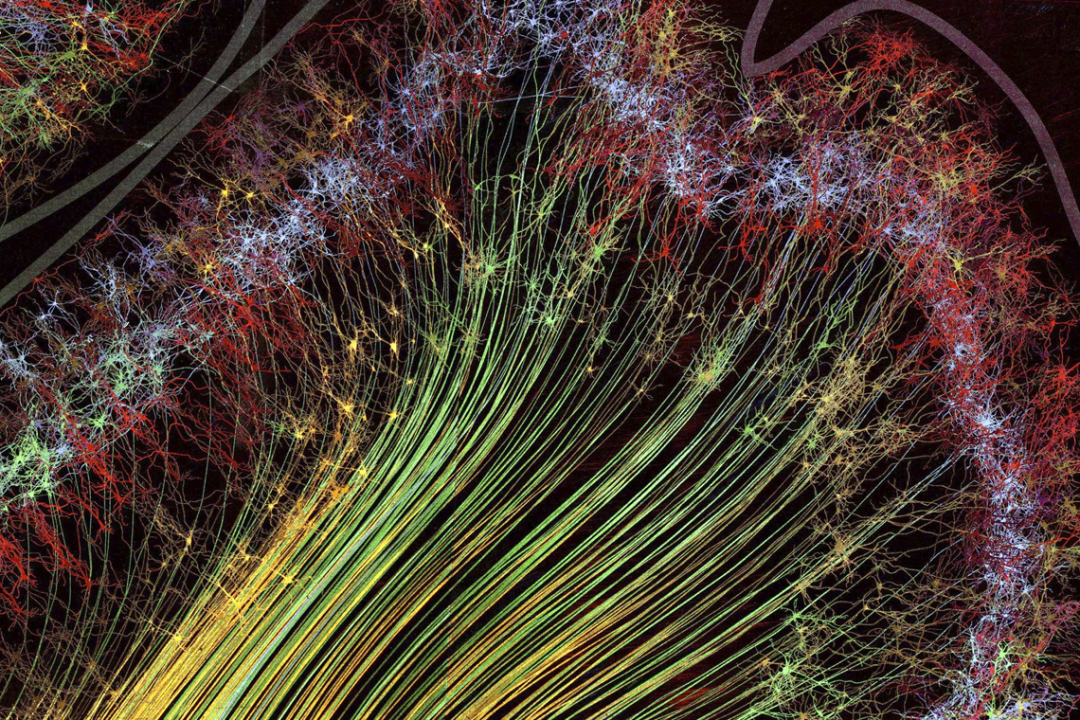 Недавно лаборатория UC Davis Visualization & Interface Design Innovation (VIDI) Lab поделилась опытом применения глубокого обучения в создании интерактивной визуализации для науки. Подробности — к старту флагмансокго курса по Data Science.
Недавно лаборатория UC Davis Visualization & Interface Design Innovation (VIDI) Lab поделилась опытом применения глубокого обучения в создании интерактивной визуализации для науки. Подробности — к старту флагмансокго курса по Data Science.
Читать дальше →
Всего голосов 4: ↑4 и ↓0 +4
Просмотры
1.5K
Комментарии
1
Fil
Программирование *Алгоритмы *Обработка изображений *Математика *
Вы можете сказать, что один факт выбивается из этого ряда в заголовке, потому что он не так очевиден, как остальные. Еще лет 10-15 назад я бы никогда не подумал, что тут могут быть возражения, а сейчас уже и не удивляюсь, что приходится объяснять простые истины: дело в том, что планеты обладают очень большой массой, поэтому гравитация стремится придать им форму шара. Вот и все! Хотел бы на этом закончить статью и поблагодарить за внимание.
Вот и все! Хотел бы на этом закончить статью и поблагодарить за внимание.
Читать далее
Всего голосов 134: ↑134 и ↓0 +134
Просмотры
13K
Комментарии
45
Arseny_Rylov
Блог компании Финолаб Data Mining *Обработка изображений *Искусственный интеллект
Tutorial
Добрый день, Хабр! Меня зовут Арсений Рылов. Я работаю ведущим специалистом по анализу и обработке данных в компании “Финолаб” и сегодня снова речь пойдет об автомобилях, нейросетях и инновационных решениях.
В нашем блоге мы уже рассказывали о сервисе дистанционной оценки технического состояния автомобилей на основе технологий искусственного интеллекта, который который к настоящему времени прошел новый этап развития: дополнен новым функционалом, более совершенными алгоритмами обработки данных и количество скачиваний приложения растет ежемесячно на 40%. Уже сейчас, получая фото- и видеоматериалы со смартфона пользователя, мы научились выполнять качественную оценку в различных условиях: снег, грязь, яркое солнце с бликами и неравномерная освещенность. В целом, мы обеспечиваем обнаружение 92% 11-ти видов повреждений стекол и кузова автомобиля и продолжаем улучшать наши метрики.
Уже сейчас, получая фото- и видеоматериалы со смартфона пользователя, мы научились выполнять качественную оценку в различных условиях: снег, грязь, яркое солнце с бликами и неравномерная освещенность. В целом, мы обеспечиваем обнаружение 92% 11-ти видов повреждений стекол и кузова автомобиля и продолжаем улучшать наши метрики.
В проекте я решаю задачу сегментации деталей корпуса автомобиля. Она многогранна и сложна из-за того, что существует много вариаций марок и моделей машин, у каждой из которых своя форма деталей, а иногда и их набор. Сегодня мне хотелось бы поделиться с вами некоторыми решениями, которые я использовал в своей работе, и отдельно выделить задачу спрямления контуров сегментируемых деталей.
Читать далее
Всего голосов 8: ↑8 и ↓0 +8
Просмотры
970
Комментарии
3
alinyao
Data Mining *Обработка изображений *Big Data *Машинное обучение *Искусственный интеллект
Привет, дорогие читатели! Меня зовут Алина, я работаю операционным менеджером в компании Training Data, которая занимается сбором и разметкой данных. Я веду проекты по разметке, а еще благодаря знанию python пишу скрипты для автоматизации работы своей команды. У меня накопилось много интересного опыта, которым я хочу с вами поделиться.
Я веду проекты по разметке, а еще благодаря знанию python пишу скрипты для автоматизации работы своей команды. У меня накопилось много интересного опыта, которым я хочу с вами поделиться.
Своей первой статьей я открываю рубрику разбора любопытных кейсов, с которыми столкнулись я и мои коллеги во время организации разметки данных в CVAT.
“Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. “ — цитата из статьи создателей.
Все мы с вами прекрасно знаем детскую игру на развитие внимательности и наблюдательности — поиск отличий на картинках. Она встречалась нам в журналах, на календарях, а позже — на сайтах и мемах в VK. Но кто бы мог подумать, что подобная забава дойдет и до разметки данных для обучения нейронных сетей?
Читать дальше
Всего голосов 5: ↑5 и ↓0 +5
Просмотры
746
Комментарии
11
Gorislav
 000Z» title=»2022-12-07, 12:45″>7 декабря в 12:45
000Z» title=»2022-12-07, 12:45″>7 декабря в 12:45
Разработка игр *Обработка изображений *Машинное обучение *Искусственный интеллект
Tutorial
В свободное время я генерирую тысячи красивых (и не очень) картинок. Иногда я пробую сделать что-то, что будет иметь практическую ценность. Основным преимуществом рисующих нейросетей сейчас я вижу время. Можно сделать портрет почти готового качества за несколько минут; стилизовать любое изображение или набросать композицию. Как же это использовать?
Читать далее
Всего голосов 24: ↑22 и ↓2 +20
Просмотры
8.7K
Комментарии
33
NewTechAudit
Python *Программирование *Обработка изображений *Машинное обучение *
Tutorial
Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA.
Играл ли ты в детстве в игру, в которой необходимо было найти отличия на изображениях? Сегодня рассмотрю похожую задачу, называемую поиском изображений, в которой нужно будет найти все похожие изображения из датасета на загруженную фотографию из того же датасета.
Читать далее
Всего голосов 9: ↑8 и ↓1 +7
Просмотры
1.5K
Комментарии
10
kucev
Data Mining *Обработка изображений *Big Data *Машинное обучение *Искусственный интеллект
Перевод
Наша компания знает важность подбора качественных инструментов разметки и аннотирования изображений для создания точных и полезных массивов данных. В нашем блоге можно найти серию статей Tools we love, в которой мы подробно рассматриваем некоторые из наших любимых инструментов аннотирования, а также выбранные нами лучшие инструменты аннотирования за 2019, 2020 и 2021 годы.
В процесса роста сферы аннотирования изображений мы наблюдаем увеличение количества опенсорсных инструментов, позволяющих любому размечать изображения бесплатно и пользоваться широким набором функций. В этой статье мы расскажем о десяти лучших опенсорсных инструментах аннотирования для машинного зрения!
Читать дальше →
Всего голосов 5: ↑5 и ↓0 +5
Просмотры
2.6K
Комментарии
1
victor30608
Open source *Обработка изображений *Хакатоны Машинное обучение *Искусственный интеллект
Tutorial
Привет, Хабр!
Это статья является продолжением цикла материалов по разбору задач Всероссийского чемпионата «Цифровой Прорыв», связанных с Computer Vision. Решение, предлагаемое в статье, позволяет получить место в топ-10 лидерборда, при это реализация самого подхода у автора статьи заняла ~ 3-4 часа. В конце даются советы по улучшению решения, а также идеи, которые могут привести к победе.
В конце даются советы по улучшению решения, а также идеи, которые могут привести к победе.
Под катом вас ждут: Focal Loss, RetinaNet и причём тут YOLOv5.
Читать далее
Всего голосов 18: ↑17 и ↓1 +16
Просмотры
3K
Комментарии
39
netsvetaev
Python *Обработка изображений *Машинное обучение *Графический дизайн *Искусственный интеллект
Привет! InvokeAI 2.2 теперь доступен для всех. В этом обновлении добавлены UI Outpainting, Embedding Management и другие функции. Ознакомьтесь с выделенными обновлениями ниже, а также с полным описанием всех функций, включенных в релиз.
Что нового?
Всего голосов 23: ↑23 и ↓0 +23
Просмотры
4.3K
Комментарии
25
NapoleonIT
 000Z» title=»2022-12-01, 10:33″>1 декабря в 10:33
000Z» title=»2022-12-01, 10:33″>1 декабря в 10:33
Python *Обработка изображений *Хакатоны Машинное обучение *
Привет, Хабр! Я Вова, Lead Data Scientist. Заметил, что вам очень нравится вместе с нами разбирать решения задач с хакатонов. Сегодня расскажу, как я занял 4 место в соревновании по выявлению незаконных построек по спутниковым снимкам и что мне не хватило, чтобы попасть в топ-3 на Цифровом прорыве.
Читать далее
Всего голосов 9: ↑8 и ↓1 +7
Просмотры
3.8K
Комментарии
20
omyhosts
Блог компании ISPsystem Обработка изображений *Машинное обучение *Искусственный интеллект
Перевод
В 1992 году поэтесса Энн Карсон опубликовала небольшую книжку под названием «Короткие беседы». Это серия микроэссе, каждое длиной от предложения до абзаца, на, казалось бы, несвязанные темы: орхидеи, дождь, мифическая андская викунья. Например, в ней есть «Краткое измышление об ощущениях при взлёте самолёта». И, вы удивитесь, повествует оно ровно о том, что написано в заголовке. А «Короткая беседа о форели» рассказывает нам главным образом о разновидностях форели, которые встречаются в японских хайку. В предисловии к книге Карсон пишет с присущей всем канадцам суховатой непосредственностью: «Я пойду на все, чтобы не поддаваться скуке. Это цель всей моей жизни».
Это серия микроэссе, каждое длиной от предложения до абзаца, на, казалось бы, несвязанные темы: орхидеи, дождь, мифическая андская викунья. Например, в ней есть «Краткое измышление об ощущениях при взлёте самолёта». И, вы удивитесь, повествует оно ровно о том, что написано в заголовке. А «Короткая беседа о форели» рассказывает нам главным образом о разновидностях форели, которые встречаются в японских хайку. В предисловии к книге Карсон пишет с присущей всем канадцам суховатой непосредственностью: «Я пойду на все, чтобы не поддаваться скуке. Это цель всей моей жизни».
С тех пор минуло уже 30 лет. Я тоже сознательно борюсь со скукой и праздностью. Вот, например, один из моих способов скрасить досуг: мне нравится засиживаться допоздна и возиться с генерацией изображений при помощи искусственного интеллекта. Таким инструментам, как DALL-E 2, Midjourney и Stable Diffusion, можно дать короткую текстовую инструкцию, а они в свою очередь изучат ее и произведут на свет безвкусную картину маслом в стиле Тициана, изображающую собак в милых шляпках.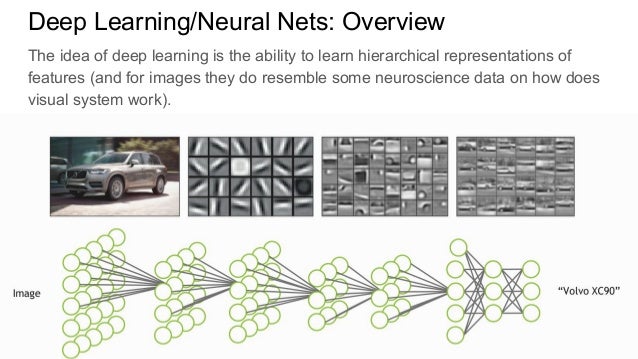
Позволю себе еще одну небольшую ремарку: книга Карсон вышла в то время, когда Интернет только-только начал набирать обороты.
Читать далее
Всего голосов 16: ↑15 и ↓1 +14
Просмотры
3.5K
Комментарии
20
ternaus
Обработка изображений *Расширения для браузеров Машинное обучение *Искусственный интеллект
Я добавил Chrome extension, которое позволяет по тексту и по картинкам в интернете искать похожие в базе данных на Ternaus.com.
* ссылка на Extension
* ссылка на GitHub
Читать далее
Всего голосов 6: ↑6 и ↓0 +6
Просмотры
1K
Комментарии
1
Gorislav
 000Z» title=»2022-11-24, 15:42″>24 ноября в 15:42
000Z» title=»2022-11-24, 15:42″>24 ноября в 15:42
Обработка изображений *Машинное обучение *Искусственный интеллект
Тема нейронных сетей волнует сейчас почти всех, кто рисует. За последние пол года прогресс выглядит для кого-то головокружительным, а для кого-то пугающим. В этой статье я хочу рассмотреть основные страхи, претензии и впечатления в целом по отношению к нейронным сетям среди творческих людей, профессия или хобби которых создание визуальной эстетики.
Читать далее
Всего голосов 39: ↑34 и ↓5 +29
Просмотры
9.5K
Комментарии
102
Razant
Блог компании Сбер Обработка изображений *Машинное обучение *Научно-популярное Искусственный интеллект
Диффузия всё увереннее вытесняет GANы и авторегрессионные модели в ряде задач цифровой обработки изображений. Это не удивительно, ведь диффузия обучается проще, не требует сложного подбора гиперпараметров, min-max оптимизации и не страдает нестабильностью обучения. А главное, диффузионные модели демонстрируют state-of-the-art результаты почти на всех генеративных задачах — генерации картинок по тексту, генерация звуков, видео и даже 3D!
Это не удивительно, ведь диффузия обучается проще, не требует сложного подбора гиперпараметров, min-max оптимизации и не страдает нестабильностью обучения. А главное, диффузионные модели демонстрируют state-of-the-art результаты почти на всех генеративных задачах — генерации картинок по тексту, генерация звуков, видео и даже 3D!
К сожалению, большинство работ в области text-to-something сосредоточены только на английском и китайском языках. Чтобы исправить эту несправедливость, мы решили создать мультиязычную text-to-image диффузионную модель Kandinsky 2.0, которая понимает запросы более чем на 100 языках! И главное, на русском 😉 Подробности — под катом.
Читать далее
Всего голосов 39: ↑36 и ↓3 +33
Просмотры
11K
Комментарии
18
Обработка изображений с использованием CNN | Руководство для начинающих по обработке изображений
Расширенный
Алгоритм
Глубокое обучение
Изображение
Анализ изображения
Проект
питон
Структурированные данные
Эта статья была опубликована в рамках блога Data Science Blogathon
Введение
Различные методы глубокого обучения используют данные для обучения алгоритмов нейронных сетей выполнению различных задач машинного обучения, таких как классификация различных классов объектов. Сверточные нейронные сети — это алгоритмы глубокого обучения, которые очень эффективны для анализа изображений. Эта статья объяснит вам, как создавать, обучать и оценивать сверточные нейронные сети.
Сверточные нейронные сети — это алгоритмы глубокого обучения, которые очень эффективны для анализа изображений. Эта статья объяснит вам, как создавать, обучать и оценивать сверточные нейронные сети.
Вы также узнаете, как улучшить свою способность учиться на данных и как интерпретировать результаты обучения. Глубокое обучение имеет различные приложения, такие как обработка изображений, обработка естественного языка и т. д. Оно также используется в медицине, медиа и развлечениях, автономных автомобилях и т. д.
Источник: Google Картинки.
Что такое CNN?
CNN — это мощный алгоритм обработки изображений. Эти алгоритмы в настоящее время являются лучшими алгоритмами для автоматической обработки изображений. Многие компании используют эти алгоритмы, например, для идентификации объектов на изображении.
Изображения содержат данные комбинации RGB. Matplotlib можно использовать для импорта изображения в память из файла. Компьютер не видит изображения, он видит только массив чисел. Цветные изображения хранятся в трехмерных массивах. Первые два измерения соответствуют высоте и ширине изображения (количеству пикселей). Последнее измерение соответствует красному, зеленому и синему цветам, присутствующим в каждом пикселе.
Цветные изображения хранятся в трехмерных массивах. Первые два измерения соответствуют высоте и ширине изображения (количеству пикселей). Последнее измерение соответствует красному, зеленому и синему цветам, присутствующим в каждом пикселе.
Три слоя CNN
Сверточные нейронные сети, специализирующиеся на приложениях для распознавания изображений и видео. CNN в основном используется в задачах анализа изображений, таких как распознавание изображений, обнаружение объектов и сегментация.
В сверточных нейронных сетях есть три типа слоев:
1) Сверточный слой: в типичной нейронной сети каждый входной нейрон соединен со следующим скрытым слоем. В CNN только небольшая область нейронов входного слоя соединяется со скрытым слоем нейронов.
2) Слой объединения: Слой объединения используется для уменьшения размерности карты объектов. Внутри скрытого слоя CNN будет несколько уровней активации и объединения.
3) Уровень с полным подключением: Уровни с полным подключением образуют несколько последних уровней в сети. Входные данные для полносвязного слоя — это выходные данные из окончательного Пулирующего или Сверточного слоя, которые сглаживаются и затем передаются в полносвязный слой.
Входные данные для полносвязного слоя — это выходные данные из окончательного Пулирующего или Сверточного слоя, которые сглаживаются и затем передаются в полносвязный слой.
Источник: Google Images
Набор данных MNIST
Набор данных MNIST состоит из изображений цифр из различных отсканированных документов. Каждое изображение представляет собой квадрат размером 28×28 пикселей. В этом наборе данных 60 000 изображений используются для обучения модели и 10 000 изображений используются для тестирования модели. Всего 10 цифр (от 0 до 9).) или 10 классов для прогнозирования.
Источник: Google Images
Загрузка набора данных MNIST.
Постройте образец вывода изображения
!pip install tensorflow из keras.datasets импортировать mnist импортировать matplotlib.pyplot как plt (X_train, y_train), (X_test, y_test) = mnist.load_data() plt.subplot() plt.
 imshow (X_train [9], cmap=plt.get_cmap('gray'))
imshow (X_train [9], cmap=plt.get_cmap('gray')) Вывод:
Модель глубокого обучения с многослойными персептронами с использованием MNIST
В этой модели мы построим простую модель нейронной сети с одним скрытый слой для набора данных MNIST для распознавания рукописных цифр.
Персептрон — это модель одного нейрона, которая является основным строительным блоком для более крупных нейронных сетей. Многослойный персептрон состоит из трех слоев: входного слоя, скрытого слоя и выходного слоя. Скрытый слой не виден внешнему миру. Видны только входной слой и выходной слой. Для всех моделей DL данные должны быть числовыми по своей природе.
Шаг 1: импортировать библиотеки ключей
импортировать numpy как np из keras.models импорт последовательный из keras.layers импорт плотный from keras.utils import np_utils
Шаг 2: Измените форму данных
Каждое изображение имеет размер 28X28, то есть 784 пикселя. Итак, выходной слой имеет 10 выходов, скрытый слой имеет 784 нейрона, а входной слой имеет 784 входа. Затем набор данных преобразуется в тип данных с плавающей запятой.
Затем набор данных преобразуется в тип данных с плавающей запятой.
number_pix=X_train.shape[1]*X_train.shape[2]
X_train=X_train.reshape(X_train.shape[0], number_pix).astype('float32')
X_test=X_test.reshape(X_test.shape[0], number_pix).astype('float32') Шаг 3. Нормализация данных
Для моделей NN обычно требуются масштабированные данные. В этом фрагменте кода данные нормализуются от (0-255) до (0-1), а целевая переменная подвергается прямому кодированию для дальнейшего анализа. Целевая переменная имеет всего 10 классов (0-9)
X_train=X_train/255 Х_тест=Х_тест/255 y_train = np_utils.to_categorical (y_train) y_test = np_utils.to_categorical (y_test) num_classes=y_train.shape[1] print(num_classes)
Вывод:
10
Теперь мы создадим функцию NN_model и скомпилируем ее.
Шаг 4: Определим функцию модели
def nn_model():
модель = Последовательный ()
model.add (плотный (number_pix, input_dim = number_pix, активация = 'relu'))
mode. add (плотный (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'Адам', метрики = ['точность'])
return model  add (плотный (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'Адам', метрики = ['точность'])
return model
add (плотный (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'Адам', метрики = ['точность'])
return model Есть два слоя: один — скрытый слой с функцией активации ReLu, а другой — выходной слой, использующий функцию softmax.
Шаг 5: Запустите модель
model=nn_model()
model.fit (X_train, y_train, validation_data = (X_test, y_test), эпохи = 10, batch_size = 200, подробный = 2)
оценка = model.evaluate (X_test, y_test, подробный = 0)
print('Ошибка: %.2f%%'%(100-score[1]*100)) Вывод:
Эпоха 1/10 300/300 — 11 с — потеря: 0,2778 — точность: 0,9216 — val_loss: 0,1397 — val_accuracy: 0,9604 Эпоха 2/10 300/300 — 2 с — потеря: 0,1121 — точность: 0,9675 — val_loss: 0,0977 — val_accuracy: 0,9692 Эпоха 3/10 300/300 - 2 с - потеря: 0,0726 - точность: 0,9790 - val_loss: 0,0750 - val_accuracy: 0,9778 Эпоха 4/10 300/300 — 2 с — потеря: 0,0513 — точность: 0,9851 — val_loss: 0,0656 — val_accuracy: 0,9796 Эпоха 5/10 300/300 - 2 с - потеря: 0,0376 - точность: 0,9892 - val_loss: 0,0717 - val_accuracy: 0,9773 Эпоха 6/10 300/300 - 2 с - потеря: 0,0269 - точность: 0,9928 - val_loss: 0,0637 - val_accuracy: 0,9797 Эпоха 7/10 300/300 - 2 с - потери: 0,0208 - точность: 0,9948 - val_loss: 0,0600 - val_accuracy: 0,9824 Эпоха 8/10 300/300 - 2 с - потеря: 0,0153 - точность: 0,9962 - val_loss: 0,0581 - val_accuracy: 0,9815 Эпоха 9/10 300/300 - 2 с - потеря: 0,0111 - точность: 0,9976 - val_loss: 0,0631 - val_accuracy: 0,9807 Эпоха 10/10 300/300 — 2 с — потеря: 0,0082 — точность: 0,9985 — val_loss: 0,0609 — val_accuracy: 0,9828 Ошибка составляет: 1,72%
В результатах модели видно, что по мере увеличения количества эпох точность улучшается. Ошибка составляет 1,72%, чем меньше ошибка, тем выше точность модели.
Ошибка составляет 1,72%, чем меньше ошибка, тем выше точность модели.
Модель сверточной нейронной сети с использованием MNIST
В этом разделе мы создадим простые модели CNN для MNIST, которые демонстрируют сверточные слои, объединяющие слои и выпадающие слои.
Шаг 1: импортируйте все необходимые библиотеки
импортируйте numpy как np из keras.models импорт последовательный из keras.layers импорт плотный из keras.utils импортировать np_utils из keras.layers импортировать Dropout из keras.layers импортировать Flatten из keras.layers.convolutional импорт Conv2D из keras.layers.convolutional импортировать MaxPooling2D
Шаг 2: Установите начальное значение для воспроизводимости и загрузите данные Данные MNIST
начальное значение = 10 np.random.seed (семя) (X_train,y_train), (X_test, y_test)= mnist.load_data()
Шаг 3: преобразование данных в значения с плавающей запятой
X_train=X_train.reshape(X_train.
 shape[0], 1,28,28) .astype('поплавок32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).astype('float32')
shape[0], 1,28,28) .astype('поплавок32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).astype('float32') Шаг 4. Нормализация данных
X_train=X_train/255 Х_тест=Х_тест/255 y_train = np_utils.to_categorical (y_train) y_test = np_utils.to_categorical (y_test) num_classes=y_train.shape[1] печать (число_классов)
Классическая архитектура CNN выглядит так, как показано ниже:
Источник: Google Images
| Выходной уровень (10 выходов) |
| Скрытый слой (128 нейронов) |
| Выровнять слой |
| Выпадающий слой 20% |
Макс. уровень объединения уровень объединения 2×2 |
| Сверточный слой 32 карты, 5×5 |
| Видимый слой 1x28x28 |
Первый скрытый слой — это сверточный слой, называемый Convolution2D. Он имеет 32 карты признаков размером 5×5 и с функцией выпрямления. Это входной слой. Далее идет слой пула, который принимает максимальное значение, называемое MaxPooling2D. В этой модели он настроен как размер пула 2×2.
В выпадающем слое происходит регуляризация. Он настроен на случайное исключение 20% нейронов в слое, чтобы избежать переобучения. Пятый слой — это сглаженный слой, который преобразует данные 2D-матрицы в вектор, называемый Flatten. Это позволяет полностью обрабатывать выходные данные стандартным полносвязным слоем.
Далее используется полносвязный слой со 128 нейронами и функцией активации выпрямителя. Наконец, выходной слой имеет 10 нейронов для 10 классов и функцию активации softmax для вывода вероятностных прогнозов для каждого класса.
Наконец, выходной слой имеет 10 нейронов для 10 классов и функцию активации softmax для вывода вероятностных прогнозов для каждого класса.
Шаг 5: Запустите модель
определение cnn_model():
модель = Последовательный ()
model.add(Conv2D(32,5,5, padding='same',input_shape=(1,28,28), активация='relu'))
model.add(MaxPooling2D(pool_size=(2,2), padding='same'))
model.add (Выпадение (0,2))
model.add(Свести())
model.add (плотный (128, активация = 'relu'))
model.add (Dense (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'адам', метрики = ['точность'])
вернуть модель модель=cnn_model()
model.fit (X_train, y_train, validation_data = (X_test, y_test), эпохи = 10, batch_size = 200, подробный = 2)
оценка = model.evaluate (X_test, y_test, подробный = 0)
print('Ошибка: %.2f%%'%(100-score[1]*100)) Выход:
Эпоха 1/10 300/300 - 2 с - потеря: 0,7825 - точность: 0,7637 - val_loss: 0,3071 - val_accuracy: 0,9069 Эпоха 2/10 300/300 - 1 с - потеря: 0,3505 - точность: 0,8908 - val_loss: 0,2192 - val_accuracy: 0,9336 Эпоха 3/10 300/300 - 1с - потери: 0,2768 - точность: 0,9126 - val_loss: 0,1771 - val_accuracy: 0,9426 Эпоха 4/10 300/300 - 1 с - потеря: 0,2392 - точность: 0,9251 - val_loss: 0,1508 - val_accuracy: 0,9537 Эпоха 5/10 300/300 - 1 с - потеря: 0,2164 - точность: 0,9325 - val_loss: 0,1423 - val_accuracy: 0,9546 Эпоха 6/10 300/300 - 1 с - потеря: 0,1997 - точность: 0,9380 - val_loss: 0,1279 - val_accuracy: 0,9607 Эпоха 7/10 300/300 - 1 с - потеря: 0,1856 - точность: 0,9415 - val_loss: 0,1179 - val_accuracy: 0,9632 Эпоха 8/10 300/300 - 1с - потери: 0,1777 - точность: 0,9433 - val_loss: 0,1119 - val_accuracy: 0,9642 Эпоха 9/10 300/300 - 1 с - потеря: 0,1689 - точность: 0,9469 - val_loss: 0,1093 - val_accuracy: 0,9667 Эпоха 10/10 300/300 - 1 с - потеря: 0,1605 - точность: 0,9493 - val_loss: 0,1053 - val_accuracy: 0,9659 Ошибка: 3,41%
В результатах модели видно, что по мере увеличения количества эпох повышается точность. Ошибка составляет 3,41%, чем меньше ошибка, тем выше точность модели.
Ошибка составляет 3,41%, чем меньше ошибка, тем выше точность модели.
Надеюсь, вам понравилось читать, и вы можете свободно использовать мой код, чтобы попробовать его для своих целей. Кроме того, если у вас есть какие-либо отзывы о коде или просто о сообщении в блоге, не стесняйтесь обращаться ко мне по адресу [email protected]
Медиафайлы, показанные в этой статье об обработке изображений с использованием CNN, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathonCNNОбработка изображенийОбработка изображений с использованием CNN
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политика конфиденциальности и использования файлов cookie
Узнать | Написать | Заработайте
Участвуйте и станьте частью более чем 800 авторов по науке о данных Зарегистрируйтесь сейчас
Машинное обучение обработки изображений
Задумались о проблеме обработки изображений с помощью машинного обучения? Хотите использовать ML и DL для автоматизации обработки изображений?
Машинное обучение (ML) стало одним из наиболее широко используемых методов искусственного интеллекта для нескольких компаний, учреждений и частных лиц, занимающихся автоматизацией. Это связано со значительным улучшением доступа к данным и увеличением вычислительной мощности, что позволяет специалистам-практикам достигать значимых результатов в нескольких областях.
Это связано со значительным улучшением доступа к данным и увеличением вычислительной мощности, что позволяет специалистам-практикам достигать значимых результатов в нескольких областях.
Сегодня, когда дело доходит до данных изображений, алгоритмы машинного обучения могут интерпретировать изображения так же, как это делает наш мозг. Они используются почти везде, начиная от распознавания лиц и захвата изображений на наши смартфоны, автоматизации утомительной ручной работы, беспилотных автомобилей и всего, что между ними.
В этом блоге мы углубимся в основы машинного обучения обработки изображений и обсудим различные технологии, которые мы могли бы использовать для создания современных алгоритмов обработки данных изображений.
- Что такое обработка изображений и почему это важно
- Работа обработки изображений с помощью машинного обучения
- Библиотеки и платформы для машинного обучения обработки изображений
- Глубокие нейронные сети на изображениях
- Заключение
Что такое обработка изображений и почему это важно
Обработка изображений (IP) — это компьютерная технология, применяемая к изображениям, которая помогает нам обрабатывать, анализировать и извлекать из них полезную информацию.

Обработка цветных изображений (источник)
Это одна из быстрорастущих технологий, которая с годами претерпела значительные изменения. Сегодня несколько компаний и организаций из разных секторов используют обработку изображений для нескольких приложений, таких как визуализация, извлечение информации об изображении, распознавание образов, классификация, сегментация и многое другое!
Существует два основных метода обработки изображений: аналоговая и цифровая обработка изображений. Аналоговый метод IP применяется к печатным копиям, таким как отсканированные фотографии и распечатки, и выходными данными здесь обычно являются изображения. Для сравнения, Digital IP используется для управления цифровыми изображениями с помощью компьютеров; выходные данные здесь обычно представляют собой информацию, связанную с этим изображением, такую как данные об объектах, характеристиках, ограничивающих прямоугольниках или масках.
Как уже говорилось, методы машинного обучения и глубокого обучения могут стать более мощными.
Беспилотные автомобили, стимуляция изображения (источник)
Вот несколько знакомых вариантов использования, в которых используются методы обработки изображений машинного обучения:
- Медицинская визуализация/визуализация : Помогите медицинским работникам быстрее интерпретировать медицинские изображения и диагностировать аномалии.
- Правоохранительные органы и безопасность : помощь в наблюдении и биометрической аутентификации.
- Технология автономного вождения : помогает обнаруживать объекты и имитировать визуальные сигналы и действия человека.
- Игры : Улучшение игровых возможностей дополненной и виртуальной реальности.
- Восстановление изображения и повышение резкости : улучшение качества изображений или добавление популярных фильтров и т. д.
- Распознавание образов: Классифицируйте и распознавайте объекты/узоры на изображениях и анализируйте контекстную информацию. Поиск изображений : Распознавание изображений для более быстрого извлечения из больших наборов данных.
 Поиск изображений : Распознавание изображений для более быстрого извлечения из больших наборов данных.
Поиск изображений : Распознавание изображений для более быстрого извлечения из больших наборов данных.В следующем разделе мы изучим некоторые основы работы с машинным обучением обработки изображений.
Работа машинного обучения по обработке изображений
Как правило, алгоритмы машинного обучения имеют определенный конвейер или шаги для обучения на основе данных. Давайте возьмем тот же общий пример и смоделируем рабочий алгоритм для варианта использования обработки изображений.
Во-первых, алгоритмам машинного обучения требуется значительный объем высококачественных данных для обучения и прогнозирования высокоточных результатов. Следовательно, нам нужно убедиться, что изображения хорошо обработаны, аннотированы и универсальны для обработки изображений ML. Именно здесь на сцену выходит компьютерное зрение (CV); это поле, касающееся машин, способных понимать данные изображения. Используя CV, мы можем обрабатывать, загружать, преобразовывать и манипулировать изображениями для создания идеального набора данных для алгоритма машинного обучения.![]()
Например, мы хотим построить алгоритм, который будет предсказывать, есть ли на данном изображении собака или кошка. Для этого нам нужно собрать изображения собак и кошек и предварительно обработать их с помощью CV. Этапы предварительной обработки включают:
- Преобразование всех изображений в один формат.
- Обрезка ненужных областей на изображениях.
- Преобразование их в числа для обучения алгоритмов (массив чисел).
Компьютеры видят входное изображение как массив пикселей, и это зависит от разрешения изображения. Исходя из разрешения изображения, он увидит высота * ширина * размер . Например, изображение массива 6 x 6 x 3 матрицы RGB (3 относится к значениям RGB) и изображение массива 4 x 4 x 1 матрицы изображения в градациях серого.
Эти признаки (обработанные данные) затем используются на следующем этапе: для выбора и построения алгоритма машинного обучения для классификации неизвестных векторов признаков с учетом обширной базы данных векторов признаков, классификации которых известны. Для этого нам нужно выбрать идеальный алгоритм; некоторые из самых популярных включают байесовские сети, деревья решений, генетические алгоритмы, ближайшие соседи и нейронные сети и т. д.
Для этого нам нужно выбрать идеальный алгоритм; некоторые из самых популярных включают байесовские сети, деревья решений, генетические алгоритмы, ближайшие соседи и нейронные сети и т. д.
Ниже приведен скриншот классического рабочего процесса машинного обучения обработки изображений для данных изображения:
Источник: Сеть разработчиков Qualcomm
Алгоритмы обучаются на шаблонах, основанных на обучающих данных с определенными параметрами. Однако мы всегда можем точно настроить обученную модель на основе показателей производительности. Наконец, мы можем использовать обученную модель, чтобы делать новые прогнозы на невидимых данных.
В следующем разделе мы рассмотрим некоторые технологии и платформы, которые мы можем использовать для построения модели обработки изображений с помощью машинного обучения.
Библиотеки и платформы для машинного обучения обработки изображений
Согласно указателю TIOBE, в настоящее время существует более 250 языков программирования. Из них Python является одним из самых популярных языков программирования, который активно используется разработчиками/практиками для машинного обучения. Однако мы всегда можем переключиться на язык, который подходит для случая использования. Теперь мы рассмотрим некоторые из фреймворков, которые мы используем для различных приложений.
Из них Python является одним из самых популярных языков программирования, который активно используется разработчиками/практиками для машинного обучения. Однако мы всегда можем переключиться на язык, который подходит для случая использования. Теперь мы рассмотрим некоторые из фреймворков, которые мы используем для различных приложений.
OpenCV : OpenCV-Python — это библиотека привязок Python, предназначенная для решения задач компьютерного зрения. Он прост и очень удобен в использовании.
Highlights:
- Huge library of image processing algorithms
- Open Source + Great Community
- Works on both images and videos
- Java API Extension
- Works with GPUs
- Cross-Platform
Tensorflow : Tensorflow, разработанный Google, является одной из самых популярных сквозных сред разработки машинного обучения.
Основные моменты:
- Широкий диапазон ML, Algorithms NN
- Открытый исходный код + Великий сообщество
- Работа на нескольких параллельных процессорах
- Crose-Platform
- GPU. от Facebook) — один из самых любимых среди исследователей нейросетевых фреймворков. Это более pythonic по сравнению с другими библиотеками ML.
Основные моменты:
- Обучение распределению
- Облачная поддержка
- Открытый исходный код + большое сообщество
- Работает с графическими процессорами
- Готовность к производству
Caffe : Caffe — это среда глубокого обучения, созданная с учетом выразительности, скорости и модульности. Он разработан Berkeley AI Research (BAIR) и участниками сообщества.
Особенности:
- Открытый исходный код + отличное сообщество
- На основе C++
- Выразительная архитектура
- Простое и быстрое выполнение
EmguCV : Emgu CV — это кроссплатформенная оболочка .Net для библиотеки обработки изображений OpenCV.
Особенности:
- Открытый исходный код и кроссплатформенность
- Работа с языками, совместимыми с . NET — C#, VB, VC++, IronPython и т. д.
- Совместимость с Visual Studio, Xamarin Studio и Unity
8
MATLAB Image Processing Toolbox : Приложения Image Processing Toolbox позволяют автоматизировать стандартные рабочие процессы обработки изображений. Вы можете в интерактивном режиме сегментировать данные изображений, сравнивать методы совмещения изображений и выполнять пакетную обработку больших наборов данных.
Основные моменты:
- Широкий диапазон методов глубокого обучения обработке изображений
- CUDA включен
- 3D-обработка. местонахождение глаз посетителей веб-страницы на странице в режиме реального времени.
Особенности:
- Множественные модели предсказания взгляда
- Непрерывная поддержка и открытый исходный код более 4 лет
- Без специального оборудования; WebGazer.js использует вашу веб-камеру
Apache Marvin-AI : Marvin-AI — это платформа искусственного интеллекта с открытым исходным кодом, которая помогает предоставлять сложные решения, поддерживаемые масштабируемой, малой задержкой, независимой от языка и стандартизированной архитектурой, одновременно упрощая эксплуатации и моделирования.
Особенности:
- Открытый исходный код и хорошо документированные
- Простой в использовании интерфейс командной строки
- Многопоточная обработка изображений
- Извлечение признаков из компонентов изображения
MIScnn : Платформа глубокого обучения с открытым исходным кодом для сегментации медицинских изображений.
Highlights:
- Open Source and Well Documented
- Creation of segmentation pipelines
- Decently pre-processing and post-processing tools
- CNN Implementation
Kornia : PyTorch based open-source differentiable computer библиотека зрения.
Основные моменты:
- Богатые и низкоуровневые методы обработки изображений
- Открытый исходный код и большое сообщество
- Дифференцируемое программирование для больших приложений
- Готовность к производству, поддержка JIT Libraries) — это набор библиотек C++, предназначенных для исследования и реализации компьютерного зрения.
Особенности:
- Открытый исходный код
- Рабочие процессы обработки 3D-изображений
- Разработка графического пользовательского интерфейса
Глубокая обработка изображений
Сегодня несколько методов машинного обучения для обработки изображений используют сети глубокого обучения. Это особый вид фреймворка, который имитирует человеческий мозг, чтобы учиться на данных и создавать модели. Одной из знакомых архитектур нейронной сети, которая совершила значительный прорыв в данных изображений, являются нейронные сети свертки, также называемые CNN. Теперь давайте посмотрим, как CNN используются на изображениях с различными задачами обработки изображений для создания современных моделей.
Сверточная нейронная сеть построена на трех основных слоях:
- Сверточный слой
- Пулирующий слой
- Полносвязный слой
Сверточный слой: Сверточный слой — это сердцевина СНС.
работы по выявлению признаков на данном изображении. Затем в слое свертки мы рассматриваем квадратные блоки некоторого случайного размера входного изображения и применяем скалярное произведение с фильтром (случайный размер фильтра). Если две матрицы (исправление и фильтр) имеют высокие значения в одних и тех же позициях, выходной сигнал слоя свертки будет высоким (что дает яркую сторону изображения). Если они этого не сделают, это будет низко (темная сторона изображения). Таким образом, одно значение вывода скалярного произведения может сказать нам, соответствует ли шаблон пикселей в базовом изображении шаблону пикселей, выраженному нашим фильтром.Давайте рассмотрим это на примере, где мы хотим применить фильтр для обнаружения вертикальных краев изображения с помощью свертки и посмотреть, как работает математика.
Операция CNN
Слой пула : Когда мы идентифицируем функции с помощью сверточных слоев, у нас есть несколько карт функций. Эти карты объектов получаются, когда операция свертки применяется между входным изображением и фильтром.
Следовательно, нам нужна еще одна операция, которая понижает разрешение изображения. Следовательно, чтобы облегчить процесс обучения сети, значения пикселей в массивах уменьшаются с помощью операции «объединения». Они работают автономно с каждым срезом входных данных по глубине и изменяют его размер в пространстве, используя две разные операции:0003- Максимальный пул — возвращает максимальное значение из массива изображения, покрываемого ядром.
- Среднее пулирование — возвращает среднее значение всех значений из массива изображения, покрываемого ядром.
Ниже приведен пример того, как операция объединения вычисляется для заданного массива пикселей.
Полносвязный слой: Полносвязный слой (FC) работает с плоским входом, где каждый вход связан со всеми нейронами. Обычно они используются в конце сети для подключения скрытых слоев к выходному слою, что помогает оптимизировать оценки класса.
Вот скриншот всей архитектуры CNN всех трех слоев вместе:
Архитектура CNN
Заключение
В этом блоге мы увидели, как методы машинного обучения и глубокого обучения обработки изображений помогают создавать высокопроизводительные модели в масштабе.
 от Facebook) — один из самых любимых среди исследователей нейросетевых фреймворков. Это более pythonic по сравнению с другими библиотеками ML.
от Facebook) — один из самых любимых среди исследователей нейросетевых фреймворков. Это более pythonic по сравнению с другими библиотеками ML. NET — C#, VB, VC++, IronPython и т. д.
NET — C#, VB, VC++, IronPython и т. д.

 работы по выявлению признаков на данном изображении. Затем в слое свертки мы рассматриваем квадратные блоки некоторого случайного размера входного изображения и применяем скалярное произведение с фильтром (случайный размер фильтра). Если две матрицы (исправление и фильтр) имеют высокие значения в одних и тех же позициях, выходной сигнал слоя свертки будет высоким (что дает яркую сторону изображения). Если они этого не сделают, это будет низко (темная сторона изображения). Таким образом, одно значение вывода скалярного произведения может сказать нам, соответствует ли шаблон пикселей в базовом изображении шаблону пикселей, выраженному нашим фильтром.
работы по выявлению признаков на данном изображении. Затем в слое свертки мы рассматриваем квадратные блоки некоторого случайного размера входного изображения и применяем скалярное произведение с фильтром (случайный размер фильтра). Если две матрицы (исправление и фильтр) имеют высокие значения в одних и тех же позициях, выходной сигнал слоя свертки будет высоким (что дает яркую сторону изображения). Если они этого не сделают, это будет низко (темная сторона изображения). Таким образом, одно значение вывода скалярного произведения может сказать нам, соответствует ли шаблон пикселей в базовом изображении шаблону пикселей, выраженному нашим фильтром. Следовательно, нам нужна еще одна операция, которая понижает разрешение изображения. Следовательно, чтобы облегчить процесс обучения сети, значения пикселей в массивах уменьшаются с помощью операции «объединения». Они работают автономно с каждым срезом входных данных по глубине и изменяют его размер в пространстве, используя две разные операции:0003
Следовательно, нам нужна еще одна операция, которая понижает разрешение изображения. Следовательно, чтобы облегчить процесс обучения сети, значения пикселей в массивах уменьшаются с помощью операции «объединения». Они работают автономно с каждым срезом входных данных по глубине и изменяют его размер в пространстве, используя две разные операции:0003