Содержание
Топ-17 нейросетей по обработке изображений, фото, картинок
Искусственные нейронные сети, придуманные 50 лет назад, стали широко использовать только с 2015 года. Сегодня AI успешно заменяют собой устаревшие технологии. Например, нейросети существенно облегчают работу с изображениями — реставрируют фото лиц, делают черно-белые картинки цветными, увеличивают иллюстрации без потери качества, накладывают силуэты и многое другое.
Что не могут сделать нейросети с изображением
Главное преимущество ИНС — это способность распознавать более глубокие, иногда неожиданные закономерности в данных. Например, в интернете они могут ассоциативно искать информацию — то есть как человек!
Хотя они и умеют делать кучу вещей, при работе с ними нередко сталкиваешься со сложностями. К сожалению, нейросеть не умеет думать, а просто преобразует информацию. Такие сети непрозрачны, не умеют аккуратно хранить все изученное в своей памяти. Информация размазывается, поэтому ее становится трудно расшифровать.
По этой же причине нейросети медленные — по крайней мере они уступают возможностям человеческого мозга в десять раз. Вместо того, чтобы находить логическую последовательность в потоке, они лишь «запоминают» ответы. Кроме того, ученые пока не разобрались досконально, в какую сторону надо развивать ИНС.
Нейросети — всего лишь комплексный инструмент, активно помогающий овладевать новыми технологиями и совершенствовать их. Это не «волшебная палочка», способная решать задачи самостоятельно. ИНС хотя и могут улучшать качество изображений, но отстают в создании картинок высокого разрешения. Они не умеют творить — стилизуют, но не рисуют. По сути, нейронки используют плагиат, когда одна часть данных “впихивается” в другую программу.
Нейросети, улучшающие качество фото/изображения/картинки
Без картинок не обходится практически ни одна деятельность в Интернете. Они нужны для иллюстрирования статей, рекламных креативов, регистраций с фото и т. д. Чем качественнее будет картинка, тем она привлечет больше внимания.
- Topaz Gigapixel AI. Для нормальной работы этой программы потребуется мощное железо. Topaz Gigapixel Al можно использовать 30 дней бесплатно и без ограничений, скачав на свой компьютер. Справляется инструмент со своей задачей превосходно — улучшает фото на 600% за счет детализации.
- Remini. Условно бесплатное приложение для смартфонов — использовать можно не более 5 раз за сутки. Если нужно чаще, тогда придется платить. Прога способна реально улучшать снимки — удалять царапины, вмятины и точки на старых фото. Работает на устройствах с Android 5.0 и выше, скачать можно с Гугл Плэй.
Стоит также упомянуть On1 NoNoise AI, которое выйдет в июне этого года. Способно удалять шумы и восстанавливать качество изображений, используя машинное обучение. Будет доступно как отдельное приложение и плагин для продуктов Adobe. Ключевыми особенностями новой программы станет подавление шума на основе искусственного интеллекта, быстрые и простые в использовании элементы управления, демозаизация на основе AI, сохранение необработанных файлов DNG, возможность комбинирования фото в несколько слоев и многое другое.


Нейросети для обработки фото/изображения/картинки
Даже профессиональные дизайнеры отдают самую рутинную часть работы — обработку картинок, нейросетям. Таким образом, экономится время, а процесс заметно упрощается и ускоряется. Ниже подобраны популярные сервисы, работающие по технологии ИНС.
- Nvidia InPainting. Это инструмент для ретушевки снимков. Загружается любая картинка, после чего на ней «умной» кистью исправляются любые детали.
- Remove.bg. Чтобы убрать задний фон с картинки, можно использовать Photoshop. Но в этой программе такая работа займет много времени, да и навыки специальные нужны. А на removebg удалить фон получится всего за пару минут — достаточно загрузить нужное изображение. Сервис условно бесплатный, каждому пользователю дается возможность использовать программу для одной картинки, затем надо подписаться на один из тарифных планов (0,20 или 0,90 долларов за picture). Одновременно через API удастся обработать до 500 иллюстраций.

- Deepart. Сервис, где обычные фото можно превратить в произведения искусства совершенно бесплатно. Как все происходит: загружаете изображение, выбираете стиль (футуризм, абстракция, поп-арт) и нажимаете кнопку вперед. Примерно через 10 минут картинка будет готова.
- Autodraw. Графический редактор от Google для подготовки различных иконок, логотипов, элементов дизайна. Вы просто рисуете каракули, а нейросеть предлагает свой вариант фигуры. Например, вы пытаетесь нарисовать кошачью морду — сервис быстро подбирает аккуратную гравюру в 2D.
- StyleGAN. Принцип функционирования сервиса на основе AI. Лица генерируются на основе множества разных фото. Просто перейдите на https://thispersondoesnotexist.com/ и перед вами откроется новый облик. Все изображения созданы как раз для тех, кто регистрируется на нескольких площадках и кому нужны фейковые фото.
- Imaginary Soundscape. Нейросети от японской компании Qosmo автоматически накладывают аудио на картинки и фото. Выглядит очень оригинально и интересно, ведь звук или музыка соответствует тому или иному изображению.
 Нейросети от японской компании Qosmo автоматически накладывают аудио на картинки и фото. Выглядит очень оригинально и интересно, ведь звук или музыка соответствует тому или иному изображению.
Нейросети от японской компании Qosmo автоматически накладывают аудио на картинки и фото. Выглядит очень оригинально и интересно, ведь звук или музыка соответствует тому или иному изображению. - Reflect. В этом сервисе можно быстро и качественно заменить лица на фотографиях — делать swap. Например, вставить свое лицо на фигуру культуриста или героя какой-нибудь сказки. Одним словом, раздолье для творчества.
Всего пара кликов и из Арнольда Шварценеггера получился Илья Муромец
Нейросети, увеличивающие качество фото/изображения/картинки
Основной принцип этой функции — разумно уменьшить шум и зазубренность, чтобы сделать изображение больше и качественнее. В сети имеются сервисы, обеспечивающие это с помощью нейросетей.
- Let’s Enhance. Способен увеличить картинку без потери качества. Сервис очень быстрый, с мощным искусственным интеллектом. 5 картинок можно обработать бесплатно, затем 9 долларов в месяц. Загружаете фото, нажимаете обработать — через несколько секунд вариант для скачивания готов.
 Загружаете фото, нажимаете обработать — через несколько секунд вариант для скачивания готов.
Загружаете фото, нажимаете обработать — через несколько секунд вариант для скачивания готов.Let’s Enhance увеличил иллюстрацию в два раза, качество не ухудшилось, а стало даже лучше
- Alien Skin Blow Up. Аналог Let’s Enhance, но представляющий собой плагин для Фотошопа. Способен значительно расширить размеры изображения, сохранив при этом его качество. Программа платная, но есть возможность скачать ее и использовать 30 дней в тестовом режиме.
- Vision. Увеличивает фотографии, но есть требование — минимальный размер для каждой стороны 300 пикселей, а максимальный — 5МБ.
Картинку Илью Муромца сервис быстро увеличил в 4 раза
- Bigjpg. С виду простой редактор, позволяющий увеличивать размер картинки без потери качества. Здесь можно выбрать определенную настройку — тип изображения, размер увеличения, степень устранения шума.
Нейросети для реставрации фото/изображения/картинки
Их также называют реставраторами. Рассмотрим самые известные программы, представленные в Интернете.
Рассмотрим самые известные программы, представленные в Интернете.
- Реставратор от Mail.ru. Разработан в рамках проекта «Лица победы». С его помощью были восстановлены многие черно-белые фото — устранены дефекты, улучшено качество, добавлен цвет. Vision — это технология распознавания лиц и объектов, работающая на базе нейросетей.
- DFDNet.Программа способна отреставрировать даже самые низкокачественные изображения и видеоролики — восстановление фотографий происходит за счет глубоких многомасштабных словарей. Работает преимущественно с лицами. Является бесплатным аналогом Remini.
- Colorize. В этой программе, созданной российской компанией, удастся быстро раскрасить черно-белое изображение. Просто загружаешь, ждешь несколько секунд, и система выдает готовый вариант с оригинальной подвижной планкой: тянешь ее влево, картинка цветная, вправо — черно-белая. Кроме этого, в сервисе есть другие функции, но они платные.

- Movavi. Программа для Виндовс, работающая как обычный редактор. Хорошо восстанавливает старые фотографии — скрывает царапины, устраняет шумы, добавляет цвет.
Ну и конечно, на основе нейросетей функционирует многим известный редактор селфи и макияжа Face App, делающий лица молодыми или старыми.
Выводы
Чтобы проверить, как работают AI для обработки изображений, не нужно становиться сотрудником Гугл или Фейсбук. Как видим, в открытом доступе, часто просто бесплатно, можно воспользоваться возможностями современных искусственных нейросетей.
Дата:15.05.2021
Автор:CPAMonstro
создаем оригинальные изображения с помощью нейронных сетей (удивляем девушку!)
Автор: Alexandr, 17.09.2022
Рубрики: Android (смартфоны, планшеты), Картинки, скрины и фото
Доброго времени!
Бесспорно, что яркие и броские фотографии всегда привлекали и будут привлекать внимание! Ну а вовремя сделанная такая необычная фотография способна не только поднять настроение, но и стать неплохим подарком по любому поводу 😉. Например, можно неплохо так удивить девушку!
Например, можно неплохо так удивить девушку!
Собственно, как вы догадались из названия статьи и предисловия — речь сегодня пойдет о нескольких сервисах, способных в авто режиме превратить вашу фотографию в яркую и интригующую картину (причем, не в простой рисунок, а во что-то более утонченное…).
Кстати, наверное, стоит отметить одну деталь: большинство нижеприведенных сервисов работают на основе нейросетей (т.е. одного из способа воплощения «искусственного интеллекта»). Так что есть (👇) неплохой способ проверить, что «думает» о вашем фото интеллект машины…
Приступим?!
*
📌 Близко к теме!
Как создать красивую открытку (картинку) для поздравления с Днем Рождения, Юбилеем, 8 марта и др. праздниками
*
Содержание статьи
- 1 Подборка интересных сервисов и приложений по обработке фото
- 1.1 Ostagram
- 1.2 DeepArt.io
- 1.3 Для Android
- 1.3. 1 Приложение Prisma
- 1.3.2 Приложение Vinci
- 1.3.3 Приложение GoArt
- 1.3.4 Приложение Toolwiz Photos
- 1.3.
 1 Приложение Prisma
1 Приложение Prisma→ Задать вопрос | дополнить
Ostagram
Сайт: https://www.ostagram.me/
Было — стало (Ostagram)
Очень интересный сервис, позволяющий вам получить оригинальную и красивую картину из фотографий (причем, вам совсем не нужно уметь рисовать — все сделает нейросеть).
Как это работает: вы загружаете на сервис парочку нужных вам фотографий (для обработки), одна из которых выступает в роли «базового» изображения, а вторая в роли «стиля». И из двух картинок автоматически получается одна, но зато какая!
Нейросеть иногда творит чудеса и сможет хорошо так удивить вас! Кстати, на главной страничке сайта вы можете просмотреть все самые интересные и популярные картины (весьма занимательно!).
1+1 равно…
Примечание: для использования сервиса — потребуется регистрация. В бесплатной версии время на обработку одной фотографии может варьироваться (в зависимости от нагрузки) — в среднем 3-7 мин.
*
DeepArt.io
Сайт: https://deepart.io/
Примечание: в августе 2022г. сайт периодически стал недоступен. Надеюсь, владельцы доведут его до ума…
DeepArt — главная страничка сервиса (скриншот с офиц. сайта)
Этот сервис во многом похож на первый… Однако, в качестве изображения под «стилевую основу» здесь есть свой набор и из него вам и придется выбирать.
Полученные картины смотрятся весьма необычно и даже местами экстравагантно. Точно можно удивить собеседника!
Также отметил бы, что на подготовку одной картины здесь уйдет чуть больше времени — около 10 минут. За ускоренную обработку — предусмотрен тариф ~2 евро…
Примеры работ с DeepArt
*
Для Android
Приложение Prisma
Play Market: https://play.google.com/
Prisma — главное окно приложения
Весьма популярное приложение для обработки фотографий. Позволяет в мгновение ока стать художником! См. примеры ниже (👇).
примеры ниже (👇).
В чем суть: разработчики «оцифровали» и смоделировали стили популярных художников (Ван Гога, Пикассо, Левитана). Искусственный интеллект при помощи этих моделей может «изменить» любую картинку или фотографию — и это можете сделать вы с любым изображением прямо на своем телефоне!
По-моему, звучит весьма заманчиво?! Благо, что в отличие от вышеприведенных сервисов фотографии обрабатываются моментально!
Фото превратилось в картину… / Prisma
Примечание: в приложении десятки различных арт-стилей (на любой вкус!). Часть из этих стилей — бесплатны, другие — платны. Из минусов: настойчиво предлагается купить годовую подписку.
*
Приложение Vinci
Play Market: https://play.google.com/
Vinci – Обработка фото нейросетями
Добротное приложение для ретуширования и мгновенной обработки картинок и фото. В арсенале приложения несколько десятков арт-стилей и моделей, благодаря которым можно изменить изображение до неузнаваемости! 👆
Например, можно превратить фото в мозаику (кистью), рисунок карандашом, мультипликационный кадр и т. д. Даже бесплатных фильтров хватит, чтобы вдоволь «поколдовать» над снимками.
д. Даже бесплатных фильтров хватит, чтобы вдоволь «поколдовать» над снимками.
Кстати, приложение позволяет отправить созданное изображение своим друзьям и знакомым.
*
Приложение GoArt
Play Market: https://play.google.com/
GoArt — пример изменения фото
Это приложение также, как и предыдущие, позволяет применять различные эффекты к фото, за исключением одного момента: можно обрабатывать изображения вплоть до 10M Pixel!
Благодаря новейшим технологиям нейросетей — можно практически мгновенно имитировать живопись от Ван Гога до Моне к выбранной вами фотографии. (ряд эффектов, кстати, платные, но и открытых — хватает с лихвой!)
Стоит отметить, что приложение активно развивается и разработчики почти каждую неделю добавляют новые эффекты и стили (вы всегда сможете удивлять своих друзей, коллег, близких!).
Рекомендую к ознакомлению!
*
Приложение Toolwiz Photos
Play Market: https://play.google.com/
Toolwiz Photos — раздел фильтры
Toolwiz Photos — это полноценный редактор фотографий, позволяющий не только применять какие-то креативные эффекты, но и, например, изменить размер изображения, что-то подрезать, замазать и т. д. ✌
д. ✌
Что касается темы нашей статьи: обратите внимание на вкладку «Фильтры» (см. скрин ниже). В ней вы сможете найти несколько десятков фильтров и эффектов, которые смогут изменить ваше фото до неузнаваемости! Парочка примеров у меня приведена ниже. 👇
Пример наложения эффектов
Кстати, что радует — в процессе работы не выскакивает никаких рекламных окон с предложением что-то приобрести.
В целом, весьма удобное приложение для повседневных нужд. Также рекомендуется к знакомству! 👌
*
Дополнения по теме — точно не будут лишними (благодарю заранее за комментарии).
Всего наилучшего!
👋
Первая публикация: 22.10.2020
Корректировка: 17.09.2022
RSS (как читать Rss)
Полезный софт:
- Видео-Монтаж
Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
- Ускоритель компьютера
Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
Другие записи:
Нейронные сети на службе фотографии. Ретушь портрета в два клика, натуральная подстановка неба и другие современные возможности обработки
Порой совсем не обязательно добиваться идеальной картинки вручную: нужно обработать фото быстро, эффектно, пускай и не контролируя весь процесс. Последние версии редактора Adobe Photoshop как раз получили новые функции, базирующиеся на искусственном интеллекте (ИИ). До этого они были реализованы, например, в виде контентно-зависимого кадрирования, которое может дорисовать края изображения, инструмента Spot Healing Brush. Но технологии продвинулись настолько, что теперь нам доступны быстрая ретушь портрета, замена неба на фотографиях и не только. Искусственный интеллект берёт на себя всё больше.
Давайте посмотрим, какие инструменты будут полезны фотографу? Наша цель — не рассказать обо всех кнопках и регуляторах, а вдохновить читателя на новые подходы к обработке и познакомить с интересными программами.
Для подготовки обзора мы использовали рабочую станцию ConceptD СT-500 (ConceptD СT-500-51AD). Дело в том, что процессы, связанные с искусственным интеллектом, требовательны к ресурсам компьютера, в частности к видеокарте. В нашей конфигурации — мощнейшая видеокарта NVIDIA Quadro RTX4000. Линейка Quadro рассчитана не столько на геймеров, сколько на тех, кто работает с графикой: дизайнеров, архитекторов, видеомонтажёров и, конечно, фотографов. Зачем такая мощь для обработки картинок? Этим вопросом задаются до тех пор, пока фотограф не начал снимать профессионально, пока не появились задачи быстро и качественно обработать гигабайты снимков, пока он снимает в JPEG с низким разрешением… Да и упомянутые программы с ИИ на мощной видеокарте работают гораздо быстрее, что повышает и продуктивность, и комфорт.
Также в ConceptD СT-500 установлен процессор Core i9 девятого поколения (5 Ггц, 8 ядер) и целых 64 ГБ оперативной памяти — спасение для тех, кто работает с фото, ведь те же Adobe Lightroom и Photoshop требовательны к этому параметру.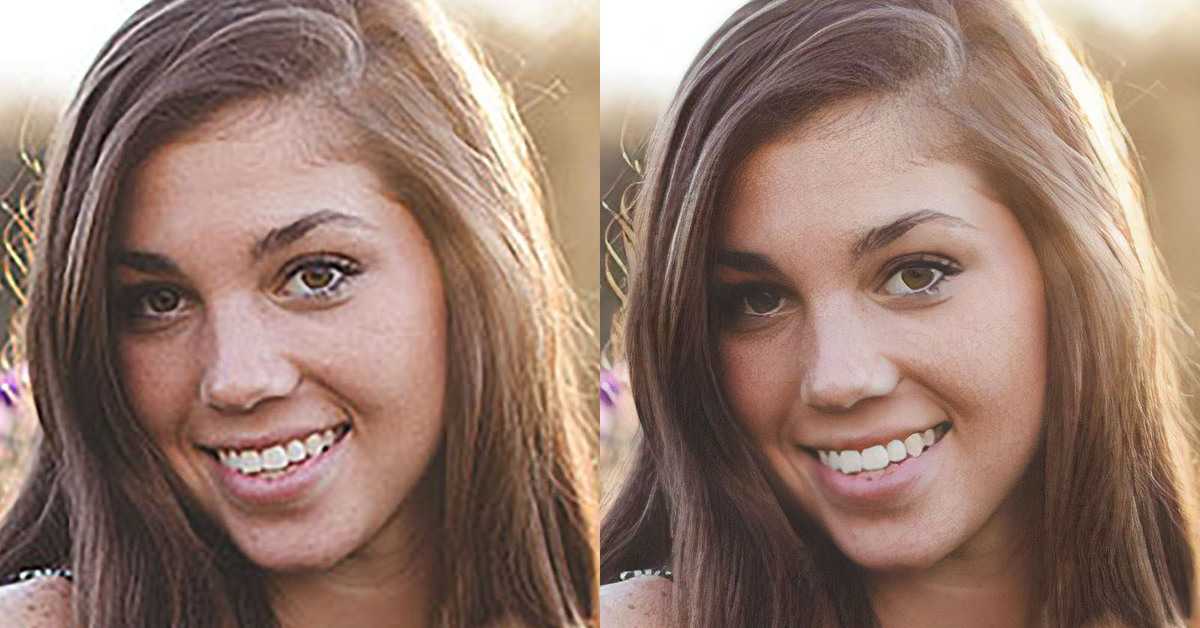
Формат стационарного ПК хорош тем, что в него можно установить мощные десктопные комплектующие, сохранив низкий уровень шума при работе, ведь охлаждение в крупном корпусе реализовать проще, чем в тонком ноутбуке.
Корпус ConceptD СT-500 стильный: верх отделан под дерево, оранжевая подсветка. Здесь есть всё для удобной работы. К примеру, встроенный ридер для карт SD. Мечта фотографа и видеографа — больше не нужно подключать устройства для чтения карт памяти! Рядом есть встроенная беспроводная зарядка: кладём на неё смартфон, поддерживающий эту функцию, и он заряжается. Ещё один плюс — выдвигающаяся подставка для наушников. Её оценят и видеомонтажёры, и те, кто любит слушать музыку за работой.
Кстати, можно установить другой процессор, память, дополнительные жёсткие диски… Последнее актуально для тех, у кого объёмный фото- или видеоархив.
Что ж, приступим к изучению возможностей искусственного интеллекта.
Инструмент Neural Filters в Adobe Photoshop: быстрая ретушь портрета
Одна из сложностей портретной съёмки в том, что на ретушь порой уходит много времени, ведь нужно привести в порядок кожу модели. И если отдельные точки убрать легко, то с мелкими многочисленными недостатками справиться непросто. Здесь поможет новая функция — Neural Filters. Заявленный список возможностей Neural Filters гораздо шире, чем обработка портрета (к примеру, можно менять выражение лица модели). Но пока они находятся на уровне карикатурных скетчей и не способны выдать рабочий результат, так что сосредоточимся на сглаживании кожи в портрете.
И если отдельные точки убрать легко, то с мелкими многочисленными недостатками справиться непросто. Здесь поможет новая функция — Neural Filters. Заявленный список возможностей Neural Filters гораздо шире, чем обработка портрета (к примеру, можно менять выражение лица модели). Но пока они находятся на уровне карикатурных скетчей и не способны выдать рабочий результат, так что сосредоточимся на сглаживании кожи в портрете.
Откроем портретный снимок и с помощью Spot Removal Tool уберём все крупные изъяны кожи. Теперь запустим Neural Filters.
Я специально взял кадр со сложным боковым светом, который подчеркнул все неровности кожи. Попробуем их исправить.
В открывшемся окне активируем пункт Skin Smoothing. Цвет и свет выровнены, убраны мелкие морщины. На этом можно было бы закончить, но обычно фильтр размывает кожу, отчего кадр выглядит «мыльным». Исправим это, подвинув регулятор Blur влево. Теперь всё отлично! Нажимаем «Ок». Окно Neural Filter закроется, а обработанное лицо появится в новом слое. Очень удобно!
Очень удобно!
Раз уж мы говорим о программах для обработки портрета, упомянем и Anhtropics PortraitPro, более мощный инструмент для бьюти-ретуши. Его отличают большие возможности настройки процесса, а также функция коррекции светотени на лице — эдакий Dodge and Burn за секунды. Если вы часто проводите портретные фотосессии, вам наверняка будет интересна эта программа. Однако такой эффект пригоден не для всех кадров, применять его нужно аккуратно.
С этими возможностями обработки главное — не перестараться. Чтобы эффективно ими пользоваться, нужно иметь чувство вкуса и меры, уметь вручную править результат средствами Adobe Photoshop: работать с масками, цветокоррекцией и прочим.
Luminar AI — редактор, базирующийся на функциях искусственного интеллекта
Luminar AI — графический редактор и RAW-конвертер, отличающийся от остальных решений на рынке. Если Capture One Pro нацелен на ручное управление процессом обработки (и от этого выглядит как пульт управления самолётом), то в Luminar AI тончайшие настройки подкрутить вручную нельзя, зато можно сказать программе «сделай красиво», и она сделает. Благодаря ИИ Luminar AI выполняет задачи, которые другим программам просто недоступны. Но обо всём по порядку.
Благодаря ИИ Luminar AI выполняет задачи, которые другим программам просто недоступны. Но обо всём по порядку.
Luminar AI умеет работать как самостоятельная программа, но можно запускать её и в среде Adobe Photoshop в качестве плагина.
Конечно, в Luminar AI есть привычные для любого RAW-конвертера функции регулировки яркости, контраста, цветов, работы с масками. Но в рамках этого обзора мы разберём интересные функции, связанные с ИИ.
Готовые решения обработки и простая ретушь портрета
Программа предлагает готовые решения обработки с учётом контента. Функция отлично подходит начинающим: подсказки программы сэкономят много времени.
Если открыть фото в Luminar AI, вы попадёте в раздел «Шаблоны» (зелёная стрелка). Здесь программа предложит варианты обработки (жёлтая стрелка). Ниже доступны и остальные шаблоны.
Готовые пресеты обработки были и раньше, в других программах. Отличие Luminar AI в том, что эти пресеты контентно-зависимые. Кстати, в них заложены не только параметры цветокоррекции, но и портретная ретушь.
Переходим в раздел «Редактирование», вкладка «Портрет AI». Здесь можно поработать над каждой частью лица отдельно, с помощью одного ползунка откорректировать форму лица. В Photoshop есть функция Liquify, и там пропорции можно настроить более детально. Но в этом и заключается философия Luminar — делать сразу всё с помощью одного регулятора. Кроме того, в Luminar AI можно быстро скорректировать фигуру: например, сделать модель стройнее или, наоборот, плечистее.
Доступные коррекции лица
Ретушь кожи — два ползунка и одна галочка. И при этом минимуме регулировок можно добиться хороших результатов!
Сглаживание неровностей кожи работает отлично. Полезная функция — устранение свечения. С её помощью можно убрать неестественный эффект размытия. А вот функция «Устранение дефектов кожи», призванная убирать значительные недостатки, не всегда работает корректно. Для этого по-прежнему удобнее использовать стандартные инструменты Adobe Photoshop (Spot Healing Brush).
На обработку этого снимка ушло немного времени. Luminar AI сам предложил такой стиль, и он действительно подходит сюжету.
Luminar AI сам предложил такой стиль, и он действительно подходит сюжету.
Тревел-фотографы и пейзажисты также найдут здесь массу полезных функций. К примеру, можно подставить солнечные лучи, если того требует сюжет, или поработать с эффектом свечения, который часто используется в пейзажной фотографии.
Обработка пейзажной фотографии
Давайте рассмотрим на примере, какие уникальные возможности даст фотографу-пейзажисту софт с функциями ИИ.
Я немного опоздал на место съёмки: закатное солнце только что спряталось за гору, и эффектное освещение запечатлеть не получилось. Базовых коррекций в Lightroom оказалось недостаточно. Попробуем исправить ситуацию средствами Luminar AI.
Откорректируем базовые параметры яркости, контраста и цвета.
Регулировки «Акцент AI» и «Коррекция Неба AI» — это в прямом смысле ползунки «сделать красиво».
Добавляем солнце в нужном фрагменте кадра и настраиваем регулировки.
Добавим эффект «Мистика» (по сути это тоже эффект свечения).
И дополнительно настроим опции, которые есть в пункте «Свечение».
С помощью локальной маски я затемнил отвлекающее светлое пятно на земле. Но это можно сделать и стандартными инструментами Photoshop — кривыми и масками.
К минусам Luminar стоит отнести требовательность к ресурсам ПК, не очень стабильную работу. Однако эти проблемы решаются с помощью мощного компьютера с хорошей видеокартой. Последнюю программа нагружает очень активно!
Обработка изображений с использованием CNN | Руководство для начинающих по обработке изображений
Расширенный
Алгоритм
Глубокое обучение
Изображение
Анализ изображения
Проект
питон
Структурированные данные
Эта статья была опубликована в рамках блога Data Science Blogathon
Введение
Различные методы глубокого обучения используют данные для обучения алгоритмов нейронных сетей выполнению различных задач машинного обучения, таких как классификация различных классов объектов. Сверточные нейронные сети — это алгоритмы глубокого обучения, которые очень эффективны для анализа изображений. Эта статья объяснит вам, как создавать, обучать и оценивать сверточные нейронные сети.
Эта статья объяснит вам, как создавать, обучать и оценивать сверточные нейронные сети.
Вы также узнаете, как улучшить свою способность учиться на данных и как интерпретировать результаты обучения. Глубокое обучение имеет различные приложения, такие как обработка изображений, обработка естественного языка и т. д. Оно также используется в медицине, медиа и развлечениях, автономных автомобилях и т. д.
Источник: Google Картинки.
Что такое CNN?
CNN — это мощный алгоритм обработки изображений. Эти алгоритмы в настоящее время являются лучшими алгоритмами для автоматической обработки изображений. Многие компании используют эти алгоритмы, например, для идентификации объектов на изображении.
Изображения содержат данные комбинации RGB. Matplotlib можно использовать для импорта изображения в память из файла. Компьютер не видит изображения, он видит только массив чисел. Цветные изображения хранятся в трехмерных массивах. Первые два измерения соответствуют высоте и ширине изображения (количеству пикселей).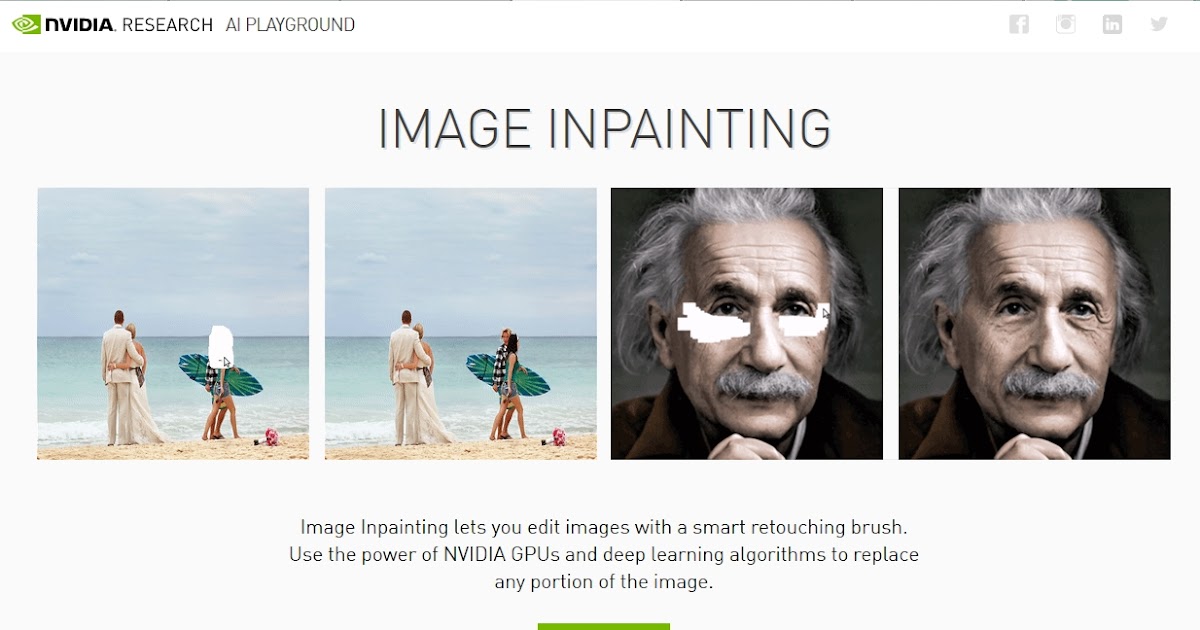 Последнее измерение соответствует красному, зеленому и синему цветам, присутствующим в каждом пикселе.
Последнее измерение соответствует красному, зеленому и синему цветам, присутствующим в каждом пикселе.
Три слоя CNN
Сверточные нейронные сети, специализирующиеся на приложениях для распознавания изображений и видео. CNN в основном используется в задачах анализа изображений, таких как распознавание изображений, обнаружение объектов и сегментация.
В сверточных нейронных сетях есть три типа слоев:
1) Сверточный слой: в типичной нейронной сети каждый входной нейрон соединен со следующим скрытым слоем. В CNN только небольшая область нейронов входного слоя соединяется со скрытым слоем нейронов.
2) Слой объединения: Слой объединения используется для уменьшения размерности карты объектов. Внутри скрытого слоя CNN будет несколько уровней активации и объединения.
3) Уровень с полным подключением: Уровни с полным подключением образуют несколько последних уровней в сети. Входные данные для полносвязного слоя — это выходные данные из окончательного Пулирующего или Сверточного слоя, которые сглаживаются и затем передаются в полносвязный слой.
Источник: Google Images
Набор данных MNIST
Набор данных MNIST состоит из изображений цифр из различных отсканированных документов. Каждое изображение представляет собой квадрат размером 28×28 пикселей. В этом наборе данных 60 000 изображений используются для обучения модели и 10 000 изображений используются для тестирования модели. Всего 10 цифр (от 0 до 9).) или 10 классов для прогнозирования.
Источник: Google Images
Загрузка набора данных MNIST.
Постройте образец вывода изображения
!pip install tensorflow
из keras.datasets импортировать mnist
импортировать matplotlib.pyplot как plt
(X_train, y_train), (X_test, y_test) = mnist.load_data()
plt.subplot()
plt.imshow (X_train [9], cmap=plt.get_cmap('gray')) Вывод:
Модель глубокого обучения с многослойными персептронами с использованием MNIST
В этой модели мы построим простую модель нейронной сети с одним скрытый слой для набора данных MNIST для распознавания рукописных цифр.
Персептрон — это модель одного нейрона, которая является основным строительным блоком для более крупных нейронных сетей. Многослойный персептрон состоит из трех слоев: входного слоя, скрытого слоя и выходного слоя. Скрытый слой не виден внешнему миру. Видны только входной слой и выходной слой. Для всех моделей DL данные должны быть числовыми по своей природе.
Шаг 1: импортировать библиотеки ключей
импортировать numpy как np из keras.models импорт последовательный из keras.layers импорт плотный from keras.utils import np_utils
Шаг 2: Измените форму данных
Каждое изображение имеет размер 28X28, то есть 784 пикселя. Итак, выходной слой имеет 10 выходов, скрытый слой имеет 784 нейрона, а входной слой имеет 784 входа. Затем набор данных преобразуется в тип данных с плавающей запятой.
number_pix=X_train.shape[1]*X_train.shape[2]
X_train=X_train.reshape(X_train.shape[0], number_pix).astype('float32')
X_test=X_test.reshape(X_test. shape[0], number_pix).astype('float32')  shape[0], number_pix).astype('float32')
shape[0], number_pix).astype('float32') Шаг 3. Нормализация данных
Для моделей NN обычно требуются масштабированные данные. В этом фрагменте кода данные нормализуются от (0-255) до (0-1), а целевая переменная подвергается прямому кодированию для дальнейшего анализа. Целевая переменная имеет всего 10 классов (0-9)
X_train=X_train/255 Х_тест=Х_тест/255 y_train = np_utils.to_categorical (y_train) y_test = np_utils.to_categorical (y_test) num_classes=y_train.shape[1] print(num_classes)
Вывод:
10
Теперь мы создадим функцию NN_model и скомпилируем ее.
Шаг 4: Определим функцию модели
def nn_model():
модель = Последовательный ()
model.add (плотный (number_pix, input_dim = number_pix, активация = 'relu'))
mode.add (плотный (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'Адам', метрики = ['точность'])
return model Есть два слоя: один — скрытый слой с функцией активации ReLu, а другой — выходной слой, использующий функцию softmax.
Шаг 5: Запустите модель
model=nn_model()
model.fit (X_train, y_train, validation_data = (X_test, y_test), эпохи = 10, batch_size = 200, подробный = 2)
оценка = model.evaluate (X_test, y_test, подробный = 0)
print('Ошибка: %.2f%%'%(100-score[1]*100)) Вывод:
Эпоха 1/10 300/300 — 11 с — потеря: 0,2778 — точность: 0,9216 — val_loss: 0,1397 — val_accuracy: 0,9604 Эпоха 2/10 300/300 — 2 с — потеря: 0,1121 — точность: 0,9675 — val_loss: 0,0977 — val_accuracy: 0,9692 Эпоха 3/10 300/300 - 2 с - потеря: 0,0726 - точность: 0,9790 - val_loss: 0,0750 - val_accuracy: 0,9778 Эпоха 4/10 300/300 — 2 с — потеря: 0,0513 — точность: 0,9851 — val_loss: 0,0656 — val_accuracy: 0,9796 Эпоха 5/10 300/300 - 2 с - потеря: 0,0376 - точность: 0,9892 - val_loss: 0,0717 - val_accuracy: 0,9773 Эпоха 6/10 300/300 - 2 с - потеря: 0,0269 - точность: 0,9928 - val_loss: 0,0637 - val_accuracy: 0,9797 Эпоха 7/10 300/300 - 2 с - потери: 0,0208 - точность: 0,9948 - val_loss: 0,0600 - val_accuracy: 0,9824 Эпоха 8/10 300/300 - 2 с - потеря: 0,0153 - точность: 0,9962 - val_loss: 0,0581 - val_accuracy: 0,9815 Эпоха 9/10 300/300 - 2 с - потеря: 0,0111 - точность: 0,9976 - val_loss: 0,0631 - val_accuracy: 0,9807 Эпоха 10/10 300/300 — 2 с — потеря: 0,0082 — точность: 0,9985 — val_loss: 0,0609 — val_accuracy: 0,9828 Ошибка составляет: 1,72%
В результатах модели видно, что по мере увеличения количества эпох точность улучшается. Ошибка составляет 1,72%, чем меньше ошибка, тем выше точность модели.
Ошибка составляет 1,72%, чем меньше ошибка, тем выше точность модели.
Модель сверточной нейронной сети с использованием MNIST
В этом разделе мы создадим простые модели CNN для MNIST, которые демонстрируют сверточные слои, объединяющие слои и выпадающие слои.
Шаг 1: импортируйте все необходимые библиотеки
импортируйте numpy как np из keras.models импорт последовательный из keras.layers импорт плотный из keras.utils импортировать np_utils из keras.layers импортировать Dropout из keras.layers импортировать Flatten из keras.layers.convolutional импорт Conv2D из keras.layers.convolutional импортировать MaxPooling2D
Шаг 2: Установите начальное значение для воспроизводимости и загрузите данные Данные MNIST
начальное значение = 10 np.random.seed (семя) (X_train,y_train), (X_test, y_test)= mnist.load_data()
Шаг 3: преобразование данных в значения с плавающей запятой
X_train=X_train.reshape(X_train.
 shape[0], 1,28,28) .astype('поплавок32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).astype('float32')
shape[0], 1,28,28) .astype('поплавок32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).astype('float32') Шаг 4. Нормализация данных
X_train=X_train/255 Х_тест=Х_тест/255 y_train = np_utils.to_categorical (y_train) y_test = np_utils.to_categorical (y_test) num_classes=y_train.shape[1] печать (число_классов)
Классическая архитектура CNN выглядит так, как показано ниже:
Источник: Google Images
| Выходной уровень (10 выходов) |
| Скрытый слой (128 нейронов) |
| Выровнять слой |
| Выпадающий слой 20% |
Макс.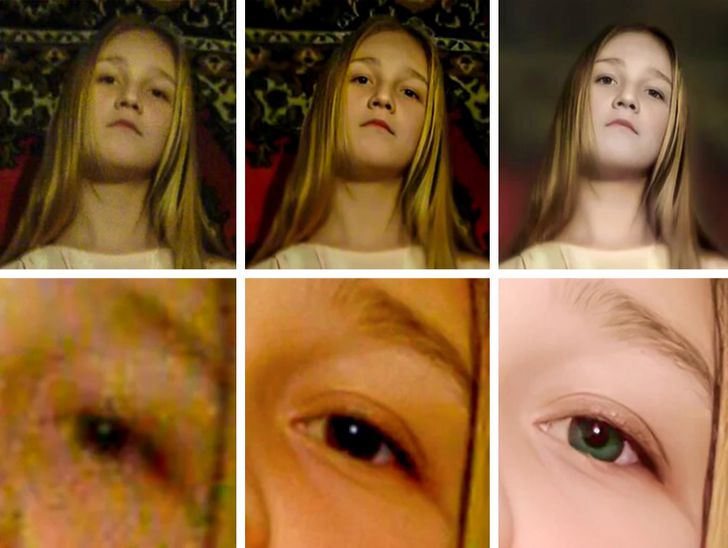 уровень объединения уровень объединения 2×2 |
| Сверточный слой 32 карты, 5×5 |
| Видимый слой 1x28x28 |
Первый скрытый слой — это сверточный слой, называемый Convolution2D. Он имеет 32 карты признаков размером 5×5 и с функцией выпрямления. Это входной слой. Далее идет слой пула, который принимает максимальное значение, называемое MaxPooling2D. В этой модели он настроен как размер пула 2×2.
В выпадающем слое происходит регуляризация. Он настроен на случайное исключение 20% нейронов в слое, чтобы избежать переобучения. Пятый слой — это сглаженный слой, который преобразует данные 2D-матрицы в вектор, называемый Flatten. Это позволяет полностью обрабатывать выходные данные стандартным полносвязным слоем.
Далее используется полносвязный слой со 128 нейронами и функцией активации выпрямителя. Наконец, выходной слой имеет 10 нейронов для 10 классов и функцию активации softmax для вывода вероятностных прогнозов для каждого класса.
Наконец, выходной слой имеет 10 нейронов для 10 классов и функцию активации softmax для вывода вероятностных прогнозов для каждого класса.
Шаг 5: Запустите модель
определение cnn_model():
модель = Последовательный ()
model.add(Conv2D(32,5,5, padding='same',input_shape=(1,28,28), активация='relu'))
model.add(MaxPooling2D(pool_size=(2,2), padding='same'))
model.add (Выпадение (0,2))
model.add(Свести())
model.add (плотный (128, активация = 'relu'))
model.add (Dense (num_classes, активация = 'softmax'))
model.compile (потеря = 'categorical_crossentropy', оптимизатор = 'адам', метрики = ['точность'])
вернуть модель модель=cnn_model()
model.fit (X_train, y_train, validation_data = (X_test, y_test), эпохи = 10, batch_size = 200, подробный = 2)
оценка = model.evaluate (X_test, y_test, подробный = 0)
print('Ошибка: %.2f%%'%(100-score[1]*100)) Выход:
Эпоха 1/10 300/300 - 2 с - потеря: 0,7825 - точность: 0,7637 - val_loss: 0,3071 - val_accuracy: 0,9069 Эпоха 2/10 300/300 - 1 с - потеря: 0,3505 - точность: 0,8908 - val_loss: 0,2192 - val_accuracy: 0,9336 Эпоха 3/10 300/300 - 1с - потери: 0,2768 - точность: 0,9126 - val_loss: 0,1771 - val_accuracy: 0,9426 Эпоха 4/10 300/300 - 1 с - потеря: 0,2392 - точность: 0,9251 - val_loss: 0,1508 - val_accuracy: 0,9537 Эпоха 5/10 300/300 - 1 с - потеря: 0,2164 - точность: 0,9325 - val_loss: 0,1423 - val_accuracy: 0,9546 Эпоха 6/10 300/300 - 1 с - потеря: 0,1997 - точность: 0,9380 - val_loss: 0,1279 - val_accuracy: 0,9607 Эпоха 7/10 300/300 - 1 с - потеря: 0,1856 - точность: 0,9415 - val_loss: 0,1179 - val_accuracy: 0,9632 Эпоха 8/10 300/300 - 1с - потери: 0,1777 - точность: 0,9433 - val_loss: 0,1119 - val_accuracy: 0,9642 Эпоха 9/10 300/300 - 1 с - потеря: 0,1689 - точность: 0,9469 - val_loss: 0,1093 - val_accuracy: 0,9667 Эпоха 10/10 300/300 - 1 с - потеря: 0,1605 - точность: 0,9493 - val_loss: 0,1053 - val_accuracy: 0,9659 Ошибка: 3,41%
В результатах модели видно, что по мере увеличения количества эпох повышается точность. Ошибка составляет 3,41%, чем меньше ошибка, тем выше точность модели.
Ошибка составляет 3,41%, чем меньше ошибка, тем выше точность модели.
Надеюсь, вам понравилось читать, и вы можете свободно использовать мой код, чтобы попробовать его для своих целей. Кроме того, если у вас есть какие-либо отзывы о коде или просто о сообщении в блоге, не стесняйтесь обращаться ко мне по адресу [email protected]
Медиафайлы, показанные в этой статье об обработке изображений с использованием CNN, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathonCNNОбработка изображенийОбработка изображений с использованием CNN
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политика конфиденциальности и использования файлов cookie
Узнать | Написать | Заработайте
Гарантированное вознаграждение в размере 2000 индийских рупий (26 долларов США) за каждую опубликованную статью! Зарегистрируйтесь сейчас
Понимание обработки изображений с использованием искусственных нейронных сетей
В этой статье рассматриваются основы обработки изображений с использованием ИНС, что очень полезно для начинающих, чтобы лучше понять эту технику.

В настоящее время каждый мобильный телефон и компьютер имеет функцию редактирования и улучшения изображения, потому что современные технологии позволяют манипулировать изображением, на нас нажимают, применяя фильтры, и мы можем сделать его еще красивее.
Основной концепцией этой новой функции применения фильтров или редактирования изображения является обработка изображения. Веками мы наблюдаем, как обработка телевизионных изображений играет заметную роль в то время.
Обработка изображений может быть дополнительно разделена на два разных типа:
- Аналоговая обработка изображений и
- Цифровая обработка изображений.
Аналоговая обработка изображений
Аналоговая обработка изображений выполняется для аналоговых сигналов. Он включает в себя обработку двумерных аналоговых сигналов. В этом типе аналоговой обработки изображения искусно изменяются по цвету с помощью электрических средств путем изменения электрического сигнала.
Типичным примером является телевизионное вещание в прежние времена через параболические антенные системы.
Цифровая обработка изображений
Цифровая обработка изображений — это метод, с помощью которого мы можем манипулировать цифровым изображением с помощью алгоритма, используя цифровой компьютер. Этот алгоритм принимает цифровые изображения в качестве входных данных и выдает характеристики изображений или параметры изображения в качестве выходных данных.
Изображение
Изображение представляет собой двумерный сигнал. Он определяется функцией координат F(a,b), где a и b — две координаты, заданные в горизонтальном и вертикальном направлениях. Значение F(a,b) в любой точке дает значение пикселя в этой точке изображения. Пиксель наиболее широко используется для представления интенсивности цифрового изображения.
Другими словами, изображение может быть определено двумерным массивом, определенным образом упорядоченным по строкам и столбцам.
Это изображение на языке кодирования представлено в виде двумерного массива чисел в диапазоне от 0 до 255. Каждое значение от 0 до 255 представляет интенсивность пикселя.
ПРИМЕНЕНИЕ IP В РЕАЛЬНОЙ ЖИЗНИ
Цифровая обработка изображений имеет широкий выбор приложений в мире. Практически во всех технических аспектах мы используем цифровую обработку изображений.
Цифровая обработка изображений предназначена не только для регулирования пространственного разрешения фотографий, которые мы делаем каждый день камерой. Это не ограничивается только увеличением яркости фотографии, применением фильтров и т. д. Скорее, это намного больше, чем в реальной жизни.
- В медицине обработка изображений имеет очень широкий спектр применений, таких как диагностика заболеваний с помощью рентгена, термография, маммография, определение размера опухоли внутри тела и т. д.
- Удаление шума, фона и восстановление изображения и заточка.
- Обработка видео и прямые телетрансляции.
- Распознавание образов
- Передача и кодирование изображений

ВВЕДЕНИЕ В НЕЙРОННЫЕ СЕТИ
Нейронные сети, называемые просто искусственными нейронными сетями (ИНС), обычно приводятся в движение биологическими нейронными сетями, составляющими головной мозг человека. Искусственная нейронная сеть — это набор узлов, известных как искусственные нейроны, которые больше похожи на нейроны в человеческом разуме. Искусственная нейронная сеть содержит слои взаимосвязанных концентраторов или нейронов. Нейрон в искусственной нейронной сети — это функция, которая накапливает данные и классифицирует данные в соответствии с определенным шаблоном. Искусственный нейрон, который получает сигнал или данные в этой точке, обрабатывает их и может помечать или передавать данные другим связанным с ним нейронам.
Нейронная сеть представляет собой совокупность вычислений, которые пытаются установить фундаментальную связь между набором информации посредством цикла, который в точности аналогичен работе мозга.
Нейронные сети изучают или обучаются на примерах задач, каждая из которых содержит осознанную информацию и результат формирования взвешенной вероятности, характеризующей связь между теми двумя (информация и результат), которые хранятся в структуре данных самой архитектуры .
Искусственная нейронная сеть обучает информацию примера, чтобы различать контраст между ожидаемой доходностью, которую мы получаем, применяя алгоритм, и целевой доходностью. Эта разница известна как ошибка. Затем сеть сама корректирует свою взвешенную вероятность, чтобы минимизировать ошибку. Прогрессивные изменения в сети заставят нейронную сеть давать результат, который будет ближе к целевому результату. После необходимого количества таких изменений тренировку можно закончить в зависимости от определенных правил.
ПРИМЕНЕНИЕ НЕЙРОННЫХ СЕТЕЙ В РЕАЛЬНОЙ ЖИЗНИ
В настоящее время все, от онлайн-покупок до распознавания рукописного текста, стало под рукой, и каждая из этих нейронных сетей играет важную роль. Нейронные сети находят множество применений в тех областях, где традиционные компьютеры работают не очень хорошо.
Нейронные сети находят множество применений в тех областях, где традиционные компьютеры работают не очень хорошо.
- Рекомендуемые системы
- Интернет-магазины
- Поиск напр. Поиск Google выдает наиболее релевантные из-за нейронных сетей
- Обнаружение мошенничества и распознавание лиц
- Распознавание речи и рукописного ввода
- Персональные помощники, такие как Siri, Google, Alexa и т. д.
На изображениях выше показана базовая архитектура ANN.
ОБРАБОТКА ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ
Обработка изображений с использованием искусственных нейронных сетей (ИНС) успешно применяется в различных областях деятельности, таких как прикладная наука, механика, геотехника, промышленный надзор, министерство обороны, автомобили и транспорт, Предварительная обработка изображений, сокращение данных, сегментация и распознавание образов — это процессы, используемые при управлении изображениями с помощью ИНС. Изображение часто представляется в виде матрицы, каждый элемент которой содержит информацию о цвете пикселя. Матрица используется как входной файл в нейронную сеть. Крошечные размеры изображений, просто и быстро помогают узнать, установить размеры вектора и, следовательно, количество входных векторов. Используемая передаточная функция может быть сигмоидальной функцией. Скорость обучения включает значения между [0,1], поэтому рекомендуется, чтобы ошибка была ниже 0,1.
Изображение часто представляется в виде матрицы, каждый элемент которой содержит информацию о цвете пикселя. Матрица используется как входной файл в нейронную сеть. Крошечные размеры изображений, просто и быстро помогают узнать, установить размеры вектора и, следовательно, количество входных векторов. Используемая передаточная функция может быть сигмоидальной функцией. Скорость обучения включает значения между [0,1], поэтому рекомендуется, чтобы ошибка была ниже 0,1.
В матрице изображения каждое значение представляет интенсивность пикселей изображения. Каждое значение пикселя может быть представлено как комбинация основных трех интенсивностей цвета: красный, зеленый, синий (RGB). На рисунке ниже показана пикселизация изображения.
ВВОД В АЛГОРИТМ НЕЙРОННОЙ СЕТИ
Все изображения в наборе данных должны быть масштабированы до одинакового размера, чтобы сделать процедуру простой и удобной. Алгоритм нейронной сети принимает на вход только одномерный массив, поэтому нам нужно преобразовать двумерное матричное представление в одномерный массив. Каждый входной нейрон алгоритма представляет информацию о цвете, а каждый выходной нейрон соответствует изображению.
Каждый входной нейрон алгоритма представляет информацию о цвете, а каждый выходной нейрон соответствует изображению.
Этапы обработки изображений с использованием ANN
- Предварительная обработка изображений : Предварительная обработка включает преобразование в оттенки серого, удаление шума путем применения фильтров, сглаживание изображения, восстановление и улучшение изображений. Результатом предварительной обработки будет изображение с теми же размерами, что и на входе, но в расширенной версии.
- Сокращение данных или извлечение признаков: Каждое изображение имеет множество различных значений пикселей; Из всех этих значений пикселей необходимые извлекаются как признаки, и эти признаки передаются в окно ввода. Извлечение признаков может быть выполнено путем сжатия изображения или путем обнаружения краев.
- Сегментация: Сегментация включает определение области интереса (ROI) путем разделения изображения на сегменты.
- Классификация: Этот шаг включает в себя классификацию объектов или изображений по соответствующим классам.

РЕАЛЬНЫЕ ПРИМЕНЕНИЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ANN
- Обнаружение мошенничества или промышленная инспекция — для обнаружения мошенничества и дефектных продуктов в отрасли.
- Департамент обороны – для идентификации целей на войне
- Область медицины – Обнаружение опухолей и диагностика
- Транспорт
- Автоматизация
На приведенном выше рисунке показано применение обработки изображений с использованием ИНС, то есть распознавания лиц.
Пожалуйста, оставьте это поле пустым
Электронная почта *
Лучшие инструменты обработки изображений, используемые в машинном обучении
Обработка изображений — очень полезная технология, и кажется, что спрос со стороны отрасли растет с каждым годом. Исторически обработка изображений с использованием машинного обучения появилась в 1960-х годов как попытка смоделировать систему человеческого зрения и автоматизировать процесс анализа изображений. По мере развития и совершенствования технологии стали появляться решения для конкретных задач.
По мере развития и совершенствования технологии стали появляться решения для конкретных задач.
Быстрое ускорение компьютерного зрения в 2010 году благодаря глубокому обучению и появлению проектов с открытым исходным кодом и больших баз данных изображений только увеличило потребность в инструментах обработки изображений.
В настоящее время создано множество полезных библиотек и проектов, которые могут помочь вам решить проблемы обработки изображений с помощью машинного обучения или просто улучшить конвейеры обработки в проектах компьютерного зрения, где вы используете машинное обучение.
В этой статье мы даем вам список инструментов, которые улучшат ваши проекты компьютерного зрения, разделенный на:
- фреймворки и библиотеки
- наборы данных
- готовые решения для конкретных задач
Давайте погрузимся!
Фреймворки и библиотеки
Теоретически вы можете создать свое приложение для обработки изображений с нуля, только вы и ваш компьютер. Но на самом деле гораздо лучше стоять на плечах гигантов и использовать то, что создали другие люди, и расширять или корректировать это там, где это необходимо.
Но на самом деле гораздо лучше стоять на плечах гигантов и использовать то, что создали другие люди, и расширять или корректировать это там, где это необходимо.
Именно здесь на помощь приходят библиотеки и фреймворки, а также обработка изображений, где создание эффективных реализаций часто является сложной задачей, и это тем более верно.
Итак, позвольте мне дать вам мой список библиотек и фреймворков, которые вы можете использовать в своих проектах по обработке изображений:
OpenCV
Библиотека компьютерного зрения и алгоритмов обработки изображений с открытым исходным кодом.
Разработан и хорошо оптимизирован для приложений компьютерного зрения в реальном времени.
Предназначен для развития открытой инфраструктуры.
Функциональность:
- Базовые структуры данных
- Алгоритмы обработки изображений
- Базовые алгоритмы компьютерного зрения
- Ввод и вывод изображений и видео
- Распознавание лица человека
- Поиск совпадений стереопотока 20421HD
- Система непрерывной интеграции
- Архитектура, оптимизированная для CUDA
- Версия Android
- Java API
- Встроенная система тестирования производительности
- Кроссплатформенный
TensorFlow
Программная библиотека с открытым исходным кодом для машинного обучения.
Создан для решения задач построения и обучения нейронной сети с целью автоматического поиска и классификации изображений, достижения качества человеческого восприятия.
Функциональность:
- Работа на нескольких параллельных процессорах
- Расчет через многомерные массивы данных – тензоры
- Оптимизация для тензорных процессоров
- Немедленная итерация модели
- Простая отладка
- Собственная система ведения журнала
- Интерактивный визуализатор журнала
PyTorch
Платформа машинного обучения с открытым исходным кодом.
Предназначен для ускорения цикла разработки от создания прототипа до промышленной разработки.
Функциональность:
- Простой переход к производству
- Распределенное обучение и оптимизация производительности
- Богатая экосистема инструментов и библиотек
- Хорошая поддержка основных облачных платформ.
- Модули оптимизации и автоматического дифференцирования.
Caffe
Фреймворк глубокого обучения, ориентированный на решение проблемы классификации и сегментации изображений.
Функциональность:
- Вычисления с использованием больших двоичных объектов – многомерных массивов данных, используемых в параллельных вычислениях
- Определение модели и оптимизация конфигурации, без жесткого кодирования
- Простое переключение между CPU и GPU
- Высокая скорость работы
EmguCV
Кроссплатформенный .Net-аддон для OpenCV для обработки изображений.
Функциональность:
- Работа с .NET-совместимыми языками — C#, VB, VC++, IronPython и др.
- Совместимость с Visual Studio, Xamarin Studio и Unity iOS и Android
VXL
Коллекция библиотек C++ с открытым исходным кодом.
Функциональность:
- Загрузка, сохранение и изменение изображений во многих распространенных форматах файлов, включая очень большие изображения
- Геометрия точек, кривых и других элементарных объектов в 1, 2 или 3 измерениях
- Геометрия камеры
- Восстановление структуры от движения
- Проектирование графического пользовательского интерфейса
- Топология
- Трехмерные изображения
GDAL
Библиотека для чтения и записи растровых и векторных форматов геопространственных данных.
Functionality:
- Getting information about raster data
- Convert to various formats
- Data re-projection
- Creation of mosaics from rasters
- Creation of shapefiles with raster tile index
MIScnn
Framework for 2D/ Сегментация 3D медицинских изображений.
Функциональность:
- Создание конвейеров сегментации
- Предварительная обработка
- Ввод-вывод
- Увеличение данных
- Патч-анализ
- Автоматическая оценка
- Перекрестная проверка
Отслеживание
Библиотека JavaScript для компьютерного зрения.
Функциональность:
- Отслеживание цвета
- Распознавание лиц
- Использование современных спецификаций HTML5
- Облегченное ядро (~7 КБ)
WebGazer
Библиотека для отслеживания глаз.
Использует веб-камеру для определения места взгляда посетителей на странице в режиме реального времени (куда смотрит человек).
Функциональность:
- Самокалибровка модели, которая наблюдает за взаимодействием посетителей Интернета с веб-страницей и обучает отображение между функциями глаз и положением на экране
- Предсказание взгляда в реальном времени в большинстве современных браузеров
- Простая интеграция всего несколькими строками JavaScript
- Возможность предсказывать несколько просмотров
- Работа в браузере на стороне клиента, без передачи данных на сервер
Марвин
Фреймворк для работы с видео и изображениями.
Функциональность:
- Захват видеокадров
- Обработка кадров для фильтрации видео
- Многопоточная обработка изображений
- Поддержка интеграции плагинов через GUI
- Извлечение признаков2 из компонентов изображения0242
- Motion Detection
Kornia
Библиотека для компьютерного зрения в PyTorch.
Functionality:
- Image conversion
- Epipolar geometry
- Depth estimation
- Low-level image processing (such as filtering and edge detection directly on tensors)
- Color correction
- Feature recognition
- Image filtering
- Border распознавание
Наборы данных
Вы не можете создавать модели машинного обучения без данных.
Это особенно важно в приложениях для обработки изображений, где добавление большего количества размеченных данных в ваш набор данных для обучения обычно дает вам большие улучшения, чем современные сетевые архитектуры или методы обучения.Имея это в виду, позвольте мне дать вам список наборов данных изображений, которые вы можете использовать в своих проектах:
Разнообразие лиц
Набор данных, предназначенный для уменьшения предвзятости алгоритмов.
Миллион размеченных изображений лиц людей разных национальностей, возрастов и полов, а также других показателей – размера головы, контраста лица, длины носа, высоты лба, пропорций лица и т.д. и их отношения друг к другу.
FaceForencis
Набор данных для распознавания поддельных фото и видео.
Набор изображений (более полумиллиона), созданных методами Face2Face, FaceSwap и DeepFakes.
1000 видео с лицами, сделанными каждым из способов фальсификации.
YouTube-8M Segments
Датасет видео Youtube, с размеченным контентом в динамике.
Около 237 тысяч макетов и 1000 категорий.
SketchTransfer
Набор данных для обучения нейронных сетей обобщению
Данные состоят из реальных изображений с тегами и немаркированных эскизов.
DroneVehicle
Набор данных для подсчета объектов на изображениях дронов.
15 532 RGB-снимка с дрона, для каждого изображения есть инфракрасный снимок.
Маркировка объектов доступна как для RGB, так и для инфракрасных изображений.
Набор данных содержит направленные границы объектов и классы объектов.
Всего в наборе данных для 31 064 изображений было отмечено 441 642 объекта.
Открытый набор данных Waymo
Набор данных для обучения автомобилей с автопилотом.
Включает видео вождения с отмеченными объектами.
3000 видеороликов о вождении общей продолжительностью 16,7 часов, 600 000 кадров, около 25 миллионов границ 3D-объектов и 22 миллиона границ 2D-объектов.
Для устранения проблемы однообразия видео записи производились в различных условиях.
Варианты видео включают погоду, пешеходов, освещение, велосипедистов и строительные площадки.Разнообразие данных увеличивает способность моделей, обученных на них, к обобщению.
ImageNet-A
Набор данных изображений, которые нейронная сеть не может правильно классифицировать.
По результатам тестирования модели предсказали объекты из набора данных с точностью 3%.
Содержит 7,5 тысяч изображений, особенность которых в том, что они содержат естественные оптические иллюзии.
Предназначен для исследования устойчивости нейронных сетей к неоднозначным изображениям объектов, что поможет повысить обобщающую способность моделей.
Готовые решения
Готовые решения — это репозитории с открытым исходным кодом и программные средства, созданные для решения определенных, часто специализированных задач.
Используя эти решения, вы можете передать конвейер построения модели или обработки изображений на аутсорсинг инструменту, который делает это одним щелчком мыши или выполнением одной команды.
Имея это в виду, позвольте мне дать вам мой список.
MobileNet
Набор алгоритмов компьютерного зрения, оптимизированных для мобильных устройств.
Функциональность:
- Анализ лица
- Определение местоположения по среде
- Распознавание прямо на смартфоне
- Низкая задержка и низкое энергопотребление
Fritz
Платформа машинного обучения для разработчиков iOS и Android.
Функциональность:
- Работает напрямую на мобильных устройствах, без передачи данных
- Перенос моделей на другие фреймворки и обновление моделей в приложениях без выпуска новой версии
Инструмент аннотации компьютерного зрения
Интерактивный инструмент для разметки фотографий и видео.
Функциональность:
- Формы для маркировки – прямоугольники, многоугольники, полилинии, точки
- Не требует установки
- Возможность совместной работы
- Автоматизация процесса маркировки
- Поддержка различных скриптов аннотации
52 3 90D-NetBo
Сегментация объектов в 3D изображениях.
Решение проблемы сегментации экземпляра в 10 раз лучше с вычислительной точки зрения, чем другие существующие подходы.
Сквозная нейронная сеть, принимающая на вход 3D-изображение, а на выходе выдающая границы распознанных объектов.
Reasoning-RCNN
Распознавание объектов из тысяч категорий.
Обнаружение трудноразличимых объектов на изображении.
Архитектура, позволяющая работать поверх любого существующего детектора.
STEAL
Обнаружение границ объекта на зашумленных данных.
Увеличить точность маркировки границ объектов.
Дополнительный слой к любому семантическому редактору и функции потери.
VQ-VAE-2
Генерация реалистичных универсальных изображений.
Некоторое исправление недостатков использования GAN для создания изображений.
Система связи энкодера и декодера на двух уровнях.
ЭДВР
Восстановление кадров из видео.
Восстановление резкости при приближении кадра и восстановление содержимого размытых кадров в видеозаписи.
На вход модели модель получает размытые кадры, а на выходе восстановленные кадры без размытия.
CorrFlow
Автоматическая маркировка видео.
Распространение разметки с одного изображения на все видео.
На основе модели с самоконтролем.
FUNIT
Замена объектов другими.
Преобразование изображений объектов из одного класса в другой с минимальным объемом обучающих данных.
Основан на архитектуре GAN.
Максимизация информации Генерация визуальных вопросов
Генерация вопросов для изображений.
На основе изображения и желаемого типа ответа отображается сгенерированный вопрос.
На основе максимизации взаимной информации.
Алгоритм визуального распознавания объекта по частям
Зрительное распознавание объекта по частям.
Идентификация объектов реального мира по частям их изображений.
На основе разделения изображений на части и изучения того, как эти части сочетаются друг с другом.
Уголки для макета
Макет по фотографии.
Восстановление планировки помещения по фотографии 360°.
Сквозная модель.
Speech3Face
Генерация изображения лица человека из аудиозаписи голоса.
Восстановление основных внешних характеристик обладателя голоса.
Принимая на вход спектрограмму, он генерирует лицо человека в анфас и без эмоций.
Близость объекта к камере
Близость объекта к камере.
Определение того, насколько близко объект находится к камере.
На основе сравнения полных карт близости.
Mesh R-CNN
Моделирование трехмерной формы объектов по изображению.
Трехмерное прогнозирование формы объектов на входном изображении.
Сквозная модель.
DeepView
Восстановление 3D вида по паре фото.
Восстановление из пары выходных фотографий, вид с других ракурсов, чтобы изображение можно было просматривать в 3D.
На основе последовательности сверточных нейронных сетей.
Увеличить разрешение изображения до 8 раз
Увеличить разрешение изображения до 8 раз.
Более точные изображения лиц в лучшем качестве без искажений.
На основе ГАН.
DSNet
Прогноз количества людей на изображении.
Определение с сохранением информации с разных частей изображения.
Сквозная модель.
ПИФу
Моделирование 3D фигуры человека.
Восстановление 3D модели одетого человека по одной фотографии.
Сквозная модель.
Заключение
Успех, эффективность выполнения и качество ваших проектов могут зависеть от многих факторов, но выбор правильных инструментов является одним из самых важных — он позволяет значительно сэкономить время и ресурсы и получить наилучшие результаты.
Зная инструменты машинного обучения для обработки изображений, вы сможете решать такие задачи проще, быстрее и эффективнее.
Тем не менее, читать о лучших инструментах недостаточно: вам еще нужно выполнить работу самостоятельно.
Так что выбирайте инструменты, которые лучше всего подходят для вас, и приступайте к работе!Виталий Лялин
Индивидуальный предприниматель
ЧИТАТЬ ДАЛЬШЕ
Отслеживание экспериментов в машинном обучении: что это такое, почему это важно и как это реализовать
10 минут чтения | Автор Якуб Чакон | Обновлено 14 июля 2021 г.
Позвольте мне поделиться историей, которую я слышал слишком много раз.
”… Мы разрабатывали модель машинного обучения с моей командой, мы провели много экспериментов и получили многообещающие результаты…
…к сожалению, мы не могли точно сказать, какая из моделей работала лучше всего, потому что мы забыли сохранить какую-то модель параметры и версии наборов данных…
…через несколько недель мы даже не были уверены, что мы на самом деле пробовали, и нам нужно было перезапустить почти все»
– несчастный исследователь машинного обучения.



 Это особенно важно в приложениях для обработки изображений, где добавление большего количества размеченных данных в ваш набор данных для обучения обычно дает вам большие улучшения, чем современные сетевые архитектуры или методы обучения.
Это особенно важно в приложениях для обработки изображений, где добавление большего количества размеченных данных в ваш набор данных для обучения обычно дает вам большие улучшения, чем современные сетевые архитектуры или методы обучения.
 Варианты видео включают погоду, пешеходов, освещение, велосипедистов и строительные площадки.
Варианты видео включают погоду, пешеходов, освещение, велосипедистов и строительные площадки.



 Так что выбирайте инструменты, которые лучше всего подходят для вас, и приступайте к работе!
Так что выбирайте инструменты, которые лучше всего подходят для вас, и приступайте к работе!