Содержание
Как Найти Человека по Фото
Как найти человека по фото
Одной из наиболее востребованных функций всемирной паутины, безусловно, является поисковая система.
Но далеко не всем известно, что разыскать в сети можно не только через текст, но также и по фотографии.
Как это сделать?
От вас требуется загрузить фотографию, если она находится на переносном носителе, или просто «показать» имеющееся на компьютере изображение программе поиска.
В свою очередь, она определит в сети копии этой картинки, предложит похожие фотографии, а также выдаст ссылки на страницы, где имеется информация о том, чье изображение стало объектом поиска.
Для каких целей появляется необходимость найти человека по фото?
Причин может быть много:
- Информация о новых популярных личностях, чьи имена пока не очень известны;
- Разоблачение мошенников, которые присваивают себе чужую личность;
- Необходимость получения имеющейся фотокарточки в других замерах и более точном разрешении;
- Желание отыскать понравившихся девушку или парня, повстречавшихся в метро или на улицах города;
- Поиск родственников по сохранившимся старым фотографиям.


Подготовка картинки под запрос
Как найти человека по фото
Процесс поиска по фотографии в сети аналогичен текстовому – идет разбивка полотна на мелкие фрагменты, которые воспринимаются системой как виртуальные слова, по которым и происходит подбор ответов.
Чтобы получить четкие и быстрые результаты по своему запросу, необходимо привести графический файл в правильный вид, убрав лишние элементы и других людей (в случаях группового снимка).
Дополнительные вещи и лица на картинке расширяют границы диагностики и теряется полная концентрация на отдельном человеке, а учитываются все детали.
Самый простой способ детализировать фото, воспользоваться стандартной программой-редактором Paint.
1На рабочем столе компьютера в левом нижнем углу выбираем клавишу «Пуск», отправляемся во вкладку «Все программы» — «Стандартные» и выбираем искомый редактор.
2В открывшемся окне с помощью функции «Вставить» добавляем фотографию.
3Выделяем нужный для поиска участок картинки и кликаем на опцию «Обрезать».
4Сохраняем готовый вариант.
Когда иллюстрация включает в себя только объект нашего поиска, самое время выбрать помощника, который сможет грамотно прочитать запрос и предоставить удовлетворительный результат.
к оглавлению ↑
Окей, Google
Классическим и самым простым способом поиска выступает знакомый всем Гугл.
Однако, для розыска по фотографии стандартная страница не годится, требуется переход на ссылку https://images.google.com/.
Нажимаем на фотоаппарат в поисковой строке и прикрепляем изображение либо через загрузку с лэптопа, либо указываем его адрес нахождения в сети.
Выбираем значок фотоаппарата
Приведенный ниже пример показывает принцип действия программы:
1Заходим на сайт, жмем на фотоаппарат и вставляем URL-адрес на фотографию, которую хотим просканировать.
Указываем ссылку
2Получаем результаты, они могут состоять из следующей информации:
- Указание человека, который изображен на фото;
- Подача искомого изображения, но в других размерах;
- Ссылки с подробными данными об объекте на фотографии;
- Выдача фотографий похожих людей (в случаях, если личность не известная).

Поисковик предложит свои варианты
Полученные страницы можно отсортировать, исключив, к примеру, те, в которых указаны какие-то ненужные или неактуальные слова.
Обратным принципом станет сортировка с добавлением слов, помогающих найти желаемые данные.
Есть еще третий вариант, как найти человека по фото через браузер Chrome.
1На странице, где находится графический файл, кликнуть по нему правой кнопкой мыши и выбрать опцию «Найти картинку Google».
2
Сервер переадресует вас на страницу с найденной информацией.
Выбираем Найти картинку
к оглавлению ↑
Главный поисковик рунета
С недавнего времени Яндекс также обзавелся функцией, позволяющей найти человека по фото.
Новый инструмент получил название «Компьютерного зрения» и специализируется на дроблении картинки для извлечения визуальных слов.
Чем более подробной будет разбивка на границы, области смены контраста, тем легче сервису будет найти в своей базе искомые данные.
Алгоритм работы с поисковиком практически идентичен Гуглу:
- Перейти по ссылке https://yandex.ru/images/;
- Кликнуть на иконку фотоаппарата или прописать адрес изображения в поисковой строке и нажать «Найти»;
- Получить конечный результат.
Многие сталкиваются с проблемой нахождения URL-адреса фотографии, которую хотят загрузить в программу поиска.
Чтобы получить необходимую ссылку, достаточно кликнуть по картинке правой кнопкой мыши и выбрать «Копировать URL картинки».
Копируем ссылку на картинку
к оглавлению ↑
Варианты расширенного поиска
Если отбор с применением классических программ не дал ожидаемого результата, тогда стоит подключать тяжелую артиллерию.
TinEye
Среди сервисов «ищеек» можно выделить достаточно известный сайт TinEye.
Интерфейс программы схож с предыдущими и также предлагает найти человека по фото двумя способами – через загрузку или прописыванием адреса в специальном поле.
Нажимаем на значок
Весомым минусом программы является нечастое обновление имеющейся базы, поэтому новые изображения, по которым разыскивается человек, могут остаться вовсе неопознанными.
Еще один нюанс ТинАй – это осуществление поиска исключительно по точным совпадениям, поэтому в отличие от двух предыдущих сайтов, вам не предоставят варианты со схожими графическими файлами.
к оглавлению ↑
Социальные сети в помощь
Отдельной функции «Поиск по фото» на платформах популярных социальных сетей нет, однако благодаря своей распространенности, они позволяют находить людей по дополнительным характеристикам:
- Персональная информация (если известна) – Ф.И.О., возраст, место проживания;
- Через общих знакомых;
- По геолокации и тегам.
Задавая новые параметры, вы уменьшаете количество подходящих вариантов, а значит, сокращаете список потенциальных «потеряшек».
Каждая социальная сеть имеет своих помощников в поиске людей.
Так во ВКонтакте это стартовая страница «Вход», которая позволяет разыскивать людей, отслеживать друзей в онлайне и совершать другие полезные действия.
Инстаграм определяет местонахождение разыскиваемого человека при переходе на ссылку https://www.instagram.com/explore/locations/.
Все эти приложения помогут в тех случаях, когда помимо главного объекта, фотография несет в себе дополнительную информацию, к примеру, случайно попавший в кадр магазин или отличительное здание.
Как найти человека по фото в ВК
Есть ответ 100% результат!
к оглавлению ↑
Нейронные сети
Если ничего из вышеперечисленного не дало результат, остается обратиться к экспериментальным системам. Анализ изображений с помощью нейросети работает по принципиально иному алгоритму распознавания образов. Упрощенно он напоминает работу головного мозга. Такие системы обрабатывают и сохраняют в своей базе не фотографии целиком, а уникальные черты лица человека, выдавая результат в порядке убывания схожести.
До недавнего времени широкой популярностью пользовался коммерческий сервис FindFace.ru, но, к сожалению, летом 2018 года он был закрыт для публичного доступа по решению разработчиков.
Существует его бесплатный аналог — сайт http://searchface.ru/. Стоит отметить, что у нового сервиса пока не столь обширная база данных профилей из социальных сетей, поэтому результаты могут выдавать просто двойников или людей с довольно похожей внешностью (но не родственников). Зато если человек в базе уже есть, скорее всего сработает даже школьная фотография.
Сервис Searchface
Важно добавить, что в настоящее время из-за поступившей претензии одной из соцсетей результаты выдаются только в виде фотографий, без ссылки на конкретный профиль. Поэтому если посчастливилось найти человека или нужно убедиться, что человек тот самый, вы можете сохранить полученную таким образом фотографию и уже по ней осуществить поиск с помощью ранее описанных методов. Вероятность успеха велика, если эта обнаруженная фотография проиндексирована поисковыми системами и находится в открытом доступе.
к оглавлению ↑
Почему поиск не дает результатов
Даже при наличии в интернете фотографий определенного человека поисковые системы могут дать отрицательный исход поиска. Причин такого явления несколько.
1Настройки приватности аккаунта скрывают информацию о владельце от широкой публики. В таких случаях, программы не могут добраться до тех данных, которые люди не желают выставлять. Повторите поиск через несколько месяцев — искомый человек однажды может открыть свой профиль или зарегистрировать новый.
2Сервисы поиска еще не работали со страницами, на которых размещены фото разыскиваемого человека, и просто не знают об этой информации. Попробуйте поискать позднее, со временем сервисы доберутся до каждой страницы.
3Неудачно выбрана сама фотография: плохое качество, неподходящий ракурс или слишком большое изменение в возрасте. Используйте несколько разных фотографий для поиска поочередно и удача не с первого раза, но все же может улыбнуться.
к оглавлению ↑
Вывод
На сегодняшний день найти человека по фото достаточно простая задача, с которой легко справляются поисковые системы Яндекса и Гугла, а также нейронные сети, ведь к общению в соцсетях стремится все больше людей, и просторы сети Интернет перенасыщены информацией о том или ином пользователе.
Грамотный подход, несколько минут времени и ваш поисковый запрос будет удовлетворен, а также расширен дополнительными сведениями.
9.5 Total Score
Оценки покупателей: 2.44 (18 Голосов)
Найти человека по фото — сервисы поиска людей
В этом уроке я покажу, как найти человека по фото в ВК и других социальных сетях. Для этого мы будем использовать бесплатные онлайн сервисы поиска людей по лицу.
ТОП-6 сервисов поиска людей по лицу
- Search5faces – бесплатный сервис поиска в социальных сетях Вконтакте и Одноклассники. Работает без регистрации.
- Findclone – ищет по ВК, требуется регистрация по номеру телефона. Бесплатно доступно 25 запросов.
- Google Images – поисковик Гугл Картинки.
- Yandex Images – поисковик Яндекс Картинки.
- TinEye – сервис поиска по изображениям Тинай.
- PimEyes – англоязычный сайт поиска людей по фото (платный).

Как найти человека по фото – инструкция
Шаг 1: подготовка фотографии
Сначала нужно обрезать снимок. Таким образом, мы уменьшим его размер (обычно он большой), и уберем лишнее.
1. Открываем программу для редактирования изображений: Пуск → Стандартные — Windows → Paint.
2. Добавляем фото в окно. Для этого перетягиваем его в программу или выбираем вручную из папки компьютера (Файл – Открыть).
3. Нажимаем на инструмент «Выделить» в верхнем меню, и обводим человека.
4. Нажимаем кнопку «Обрезать».
5. Сохраняем: – Сохранить как…
Шаг 2: поиск в соцсетях
Далее нужно загрузить снимок в систему поиска человека по фото. И если будут совпадения, сайт покажет страницы найденных людей. Два наиболее популярных сервиса:
- Search5faces.com – бесплатный, без регистрации. Ищет людей по социальным сетям Вконтакте и Одноклассники. Большая база профилей.
- Findclone.ru – требуется регистрация по номеру телефона. Умеет весьма точно находить человека по фото, но только в соцсети ВК. Бесплатно можно выполнить 25 поисков.
 Умеет весьма точно находить человека по фото, но только в соцсети ВК. Бесплатно можно выполнить 25 поисков.
Умеет весьма точно находить человека по фото, но только в соцсети ВК. Бесплатно можно выполнить 25 поисков.Был еще один хороший сервис Findface с очень точным распознаванием лиц, но, к сожалению, он закрылся.
Пример
Покажу, как найти человека через сервис Search5faces. Открываем сайт search5faces.com и выбираем режим поиска: «Аватарки Вконтакте и Одноклассников» или «Фотографии профиля Вконтакте». Нажимаем «Загрузить».
Затем добавляем фото человека (можно просто перетащить внутрь окошка) и нажимаем «Загрузить».
Обратите внимание: можно не только выбрать файл с ПК, но и загрузить фотографию по ссылке, в том числе из Инстаграма.
В следующем окне можно задать настройки: пол, страна, город, возраст. Но лучше их не указывать, а сразу нажать «Найти».
Появится список найденных профилей.
Шаг 3: поиск по всему интернету
Если не получилось найти человека по фото через сервис Search5faces и Findclone, попробуйте поискать в Гугле и Яндексе.
Сделать это можно через функцию поиска по изображениям:
- Google Images (images.google.com)
- Google Images (images.yandex.ru)
Пользоваться ими очень легко: нужно просто перетянуть фото в строку.
Google Images
Google Images
Результат появится сразу же. Сначала будет показана эта же картинка, но в других размерах (если таковые в сети имеются), чуть ниже — похожие фотографии. Еще ниже – страницы в интернете, на которых они размещены.
Рекомендую искать в обоих поисковиках. Частенько они выдают разные результаты.
TinEye (tineye.com). Популярный иностранный сайт поиска изображений.
Здесь все точно так же: перетаскиваем снимок со своего компьютера в поисковую строку, и сразу же получаем результат.
Подробнее об этих сервисах читайте в уроке Поиск по фото.
Расширения для браузера
Расширения или дополнения – это такие маленькие примочки, которые добавляются в программу для интернета и выполняют в ней определенные задачи. Например, переводят тексты, делают скриншоты. Такие программки есть и для поиска по фотографиям.
Например, переводят тексты, делают скриншоты. Такие программки есть и для поиска по фотографиям.
Практически у каждого браузера имеется своя коллекция разнообразных дополнений, но больше всего их в Google Chrome.
Для установки перейдите в магазин расширений:
- Google Chrome
- Яндекс и Opera
- Mozilla Firefox
В строке поиска напечатайте ключевые слова и нажмите Enter. Появятся найденные дополнения и приложения. Установите нужное — его потом в любой момент можно будет удалить.
Плагин добавится сразу после адресной строки.
На телефоне
С телефона можно также искать людей по фото через сервисы Search5faces.com и Findclone.ru. Или через поисковики Гугл (images.google.com) и Яндекс (images.yandex.ru). Кроме того, есть отдельные приложения для поиска по фото: работают они на основе всё тех же Яндекс, Гугл, TinEye. Это такие программы, как:
- Google Объектив (Play Market, App Store)
- Photo Sherlock (Play Market, App Store)
Но есть еще один хитрый, но точный способ поиска человека по фото в Одноклассниках. Для этого нужно установить официальное приложение ОК. Загрузить его можно по ссылке:
Для этого нужно установить официальное приложение ОК. Загрузить его можно по ссылке:
- Для Android
- Для iPhone
1. Зарегистрируйтесь или войдите в свой профиль, если он есть на сайте. Нажмите на иконку с изображением трех горизонтальных линий (вверху или внизу программы).
2. Выберите пункт «Друзья».
3. Перейдите в раздел «Дружба по фото» или «Найти по фото».
4. Разрешите доступ к камере.
5. Сделайте снимок человека или его фотографии (например, открыв ее на ПК или другом телефоне).
6. Если программа найдет страницу пользователя, он получит приглашение в «Друзья».
Автор: Илья Кривошеев
Создание обратного поиска изображений с помощью сверточных нейронных сетей
Свяжитесь с нами
Владислав Исаев
17.04.2018
• 12 минут чтения
Мистер и миссис Смит — обычная пара из среднего класса, занимающаяся реконструкцией и ремонтом своего дома. После долгих и неустанных поисков на Pinterest и других сайтах, посвященных образу жизни, они наконец нашли концепцию для своих новых планов оформления интерьера. Единственная проблема заключалась в том, что на самом деле найти и купить эти продукты в Интернете было чрезвычайно сложно из-за ограничений, связанных с обнаружением продуктов электронной коммерции.
После долгих и неустанных поисков на Pinterest и других сайтах, посвященных образу жизни, они наконец нашли концепцию для своих новых планов оформления интерьера. Единственная проблема заключалась в том, что на самом деле найти и купить эти продукты в Интернете было чрезвычайно сложно из-за ограничений, связанных с обнаружением продуктов электронной коммерции.
Используя систему текстового поиска, Смиты пытались описать товары для образа жизни, в которые они влюбились, но так и не смогли найти нужные элементы в результатах поиска. Фильтрация каталога по категориям товаров и поиск вручную были крайне трудоемкими и не приводили к успеху. После нескольких подобных опытов на нескольких других сайтах электронной коммерции Смиты сдались и должны были рассмотреть вопрос о том, чтобы просмотреть кучу обычных магазинов или вообще отказаться от своей концепции.
Розничные продавцы все больше осознают, как негативный опыт клиентов снижает их доход от продаж и отталкивает людей от их сайтов. В частности, ритейлеры обращают внимание на ограничения текстового поиска. Даже если у вас есть очень четкое представление о том, что вы ищете, может быть сложно точно описать некоторые типы продуктов. Это особенно актуально для товаров для декора и образа жизни, поскольку некоторые характеристики или элементы этих товаров уникальны, и их сложно осмысленно описать в строке поиска.
В частности, ритейлеры обращают внимание на ограничения текстового поиска. Даже если у вас есть очень четкое представление о том, что вы ищете, может быть сложно точно описать некоторые типы продуктов. Это особенно актуально для товаров для декора и образа жизни, поскольку некоторые характеристики или элементы этих товаров уникальны, и их сложно осмысленно описать в строке поиска.
Один из наших клиентов, который предлагает товары для декора и стиля жизни, столкнулся именно с этой проблемой. Они сообщали, что многие из их товаров на складе не были найдены с помощью текстового поиска. Из-за этого у них были очень низкие коэффициенты конверсии в их интернет-магазине. Желая увеличить продажи, наш клиент хотел, чтобы его клиенты могли искать товары с помощью изображений, а не только текста.
Эта идея предполагает, что люди, которые хотят украсить свой дом, ищут концепции дизайна в Интернете на таких сайтах, как Pinterest, а затем используют найденные фотографии для автоматического сопоставления элементов из каталога. Наш клиент также хотел иметь возможность рекомендовать продукты клиентам, которые имеют схожие характеристики, такие как цвет, форма или рисунок, с их образцами изображений. Это обеспечило бы хороший метод дополнительных продаж и, кроме того, позволило бы поисковой системе быть более полезной, фактически находя продукты, которые искали клиенты.
Наш клиент также хотел иметь возможность рекомендовать продукты клиентам, которые имеют схожие характеристики, такие как цвет, форма или рисунок, с их образцами изображений. Это обеспечило бы хороший метод дополнительных продаж и, кроме того, позволило бы поисковой системе быть более полезной, фактически находя продукты, которые искали клиенты.
Обеспечение решения с помощью сверточных нейронных сетей
Наше решение состояло в том, чтобы создать механизм обратного поиска, работающий на основе сверточной нейронной сети. В последние годы глубокое обучение значительно улучшило способность распознавать различные типы объектов с помощью сверточных нейронных сетей. Это распространяется на способность распознавать объекты независимо от их положения, точки зрения или фона.
Стандартный подход предполагает использование предварительно обученной модели, которая может находить похожие объекты с использованием таких показателей, как евклидово расстояние. Однако этот метод не будет эффективен для такого типа проектов, потому что один и тот же объект, повернутый под другим углом или на другом фоне, даст разные результаты. Нам нужно было разработать решение, которое будет способно распознавать похожие объекты, а также иметь возможность давать визуальные рекомендации.
Нам нужно было разработать решение, которое будет способно распознавать похожие объекты, а также иметь возможность давать визуальные рекомендации.
На рисунке ниже показано, как работает наша система обратного поиска. На левой панели показан ввод фотографий, из которого необходимо извлечь объекты для идентификации. Это достигается за счет использования вектора признаков из ImSeNet, что позволяет проводить поиск похожих продуктов из соответствующей категории.
Система рекомендаций по визуальному поиску должна иметь возможность извлекать похожее изображение из каталога (обычно объект на белом фоне) на основе изображений объектов в различных средах (например, фотографий образа жизни), загруженных пользователем. Эта задача очень сложна, потому что объект изображения запроса может быть разного размера, ориентации или снят на разных типах фона или в разных условиях освещения. Это можно увидеть на трех разных изображениях стульев на рисунке 2 ниже.
Все решение состоит из следующих связанных частей:
- Показатель схожести обучения
- Сетевая архитектура
- Набор данных для обучения
- Показатели оценки
- Результаты
Установление показателя сходства обучения
Существует множество подходов, которые можно использовать для выполнения поиска визуального сходства. Некоторые строят представление объектов на основе различных типов дескрипторов изображений и используют методы сжатой гистограммы градиентов (CHoG) или вектора локально агрегированных дескрипторов (VLAD) или сложные комбинации шаблонов и цветов. Другие типы решений полагаются на возможность автоматического обучения, чтобы создавать функции непосредственно из входного изображения.
Некоторые строят представление объектов на основе различных типов дескрипторов изображений и используют методы сжатой гистограммы градиентов (CHoG) или вектора локально агрегированных дескрипторов (VLAD) или сложные комбинации шаблонов и цветов. Другие типы решений полагаются на возможность автоматического обучения, чтобы создавать функции непосредственно из входного изображения.
Метрика подобия обучения необходима для создания встраивания, чтобы метрика расстояния между изображением запроса и его исходным изображением объекта была меньше, чем то же изображение запроса и любое другое исходное изображение объекта в пространстве признаков.
Для обучения нейронной сети используется триплет из трех изображений: запрос, положительное и отрицательное изображения (q, p, n). Это достигается следующим образом:
L = ΣLp (q, p) + ΣLn(q,n)
Функция потери тройки состоит из двух штрафов: Lp наказывает положительную пару, если метрика расстояния слишком велика, а Ln наказывает отрицательная пара, если метрика расстояния меньше поля.
Существует несколько вариантов окончательной функции потерь триплетов, которые подробно описаны в нескольких недавних статьях:
- Изучение визуального подобия для дизайна продукта с помощью сверточных нейронных сетей
- Крупномасштабные визуальные рекомендации и поиск на основе глубокого обучения для электронной коммерции
- Улучшенное глубокое метрическое обучение с многоклассовой целью потери N-пар
В нашей работе мы используем вариант:
L = 1/n Σ max(0, m + Dp — Dn)
Где Dp — евклидово расстояние между q и p, а Dn — евклидово расстояние между q и n .
Эта формула работает, когда Dp слишком мало, а Dn больше, чем m, и в этом случае Dp — Dn < 0 является отрицательным, и окончательная потеря будет равна 0. Это приводит к полезному процессу обучения для сети. В других случаях, если потеря не равна 0, нам нужно ее минимизировать. Это включает в себя минимизацию Dp и максимизацию Dn, что заставляет нашу сеть изучать сходство между изображениями. Параметр поля (m) для тонкой настройки обучения может принимать разные значения, но при этом учитывается нормализация вектора, которая влияет на этот гиперпараметр.
Параметр поля (m) для тонкой настройки обучения может принимать разные значения, но при этом учитывается нормализация вектора, которая влияет на этот гиперпараметр.
Создание маржи может вызвать проблемы нестабильности или дивергенции. Если маржа слишком мала, это может сделать обучение слишком медленным или рухнуть для всех продуктов. Мы выбрали m = 1, потому что это делает пространство признаков более стабильным. Одним из вариантов является использование функции потерь, которая также называется контрастной или шарнирной потерей, поскольку у нее другая роль, как подробно описано здесь:
Архитектура нейронной сети
использовать сиамскую нейронную сеть. Архитектура сиамской нейронной сети содержит две или более идентичных сетей с общими параметрами и весами. Подсети используются для обработки нескольких входов, затем их выход объединяется с помощью другого модуля. Эта сеть используется для непосредственного обучения задачи, которую мы пытаемся решить, но ее нельзя использовать для решения всех задач, поскольку мы можем обучить ее только для определения сходства трех изображений.
Под капотом наша сиамская нейронная сеть использует нейронную сеть свертки (CNN). Если вы не знакомы с CNN, вы можете обратиться к этой ссылке. CNN используются для обработки изображений и состоят из трех слоев: свертки, объединения и исправления. CNN в последние годы очень хорошо справляются с такими задачами, как классификация и обнаружение объектов.
В своей работе мы экспериментировали с множеством различных типов архитектуры. Эти типы архитектуры можно разделить двумя способами. Один из них — это исходный существующий тип архитектуры CNN (назовем его предварительно обученным CNN), который использует предварительно обученные веса в Imagenet, а второй представляет собой сборку небольших предварительно обученных CNN.
В настоящее время существует множество различных архитектур CNN. У нас были некоторые ограничения на то, какие из них были жизнеспособными, поскольку мы хотели использовать предварительно обученную модель. В конечном итоге мы решили использовать Keras, так как он имеет несколько предварительно обученных архитектур CNN, совместимых с Tensorflow.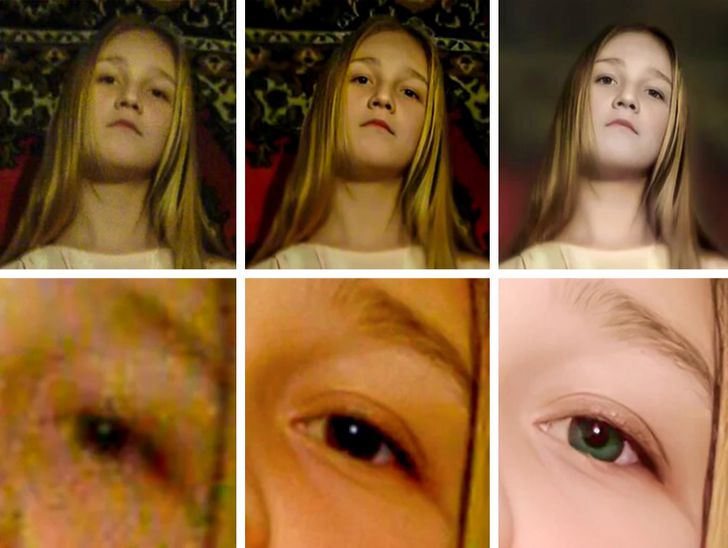
| Модель | размер | Топ-1 точности | Топ-5 точности | параметры | глубина |
| Сецепция | 88 МБ | 0,79 | 0,945 | 22910480 | 126 |
| ВГГ16 | 528 МБ | 0,715 | 0,901 | 138357544 | 23 |
| ВГГ19 | 549 МБ | 0,727 | 0,91 | 143667240 | 26 |
| Реснет50 | 99МБ | 0,759 | 0,929 | 25636712 | 168 |
| Начало V3 | 92 МБ | 0,788 | 0,944 | 23851784 | 159 |
| ИнсепшенРеснетв2 | 215 МБ | 0,804 | 0,953 | 55873736 | 572 |
Для сравнения мы выбрали Xception, InceptionV3 и InceptionResNetV2 и использовали их без верхнего слоя, т. е. последний слой будет плотным. Затем мы ввели поверхностный слой, чтобы иметь возможность извлекать из изображения низкоуровневые детали.
е. последний слой будет плотным. Затем мы ввели поверхностный слой, чтобы иметь возможность извлекать из изображения низкоуровневые детали.
CNN можно рассматривать как идентификатор функций, при этом каждый новый уровень обучается определять более высокоуровневые функции. Используя изображение корабля в качестве примера, первый слой может обнаруживать только кривые или некоторые линии, а следующий слой может обнаруживать комбинацию кривых. По мере того, как вы идете глубже, CNN может распознать мачту, паруса корабля и, наконец, весь корабль.
Мы предполагали, что такое параллельное сочетание функций низкого и высокого уровня даст превосходные результаты. Мы также экспериментировали с большим количеством различных параметров, таких как регуляризация, функции активации, пакетная нормализация и т. д. Позже мы опишем, как можно оценить точность сети.
Последний важный вопрос: нужно ли нам замораживать предварительно обученную CNN и повторно обучать только последний слой, последние N слоев или всю сеть? Чтобы ответить на этот вопрос, нам нужно было выбрать правильное размерное пространство. Мы попробовали несколько измерений — {256, 512, 1536, 2048}. Нам также нужно было избежать классической проблемы «Проклятие размерности», чтобы не потерять какие-либо уникальные особенности продукта, необходимые для его отличия.
Мы попробовали несколько измерений — {256, 512, 1536, 2048}. Нам также нужно было избежать классической проблемы «Проклятие размерности», чтобы не потерять какие-либо уникальные особенности продукта, необходимые для его отличия.
Создание обучающего набора данных
Для обучения сети требуется запрос, положительные и отрицательные изображения. Изображение запроса — это изображение продукта в случайной сцене, которую мы называем изображением образа жизни. Изображение продукта — это изображение этого продукта на белом фоне без других объектов в сцене. Негативное изображение — это изображение любого другого продукта в той же категории продуктов.
Существует несколько различных типов негативов. Это включает в себя негативные изображения в классе, которые учат сеть обращать внимание на нюансы низкого уровня, такие как материал или текстура. Другой тип — внеклассовые негативные изображения, которые обучают сеть обращать внимание на формы и цвета.
При работе с существующим розничным клиентом у вас уже есть доступ к структурированным данным, которые могут помочь вам собрать набор данных для обучения. В противном случае может быть сложно собрать положительные пары и жесткие отрицательные примеры.
В противном случае может быть сложно собрать положительные пары и жесткие отрицательные примеры.
В некоторых случаях у нас есть доступ к нескольким изображениям одного продукта. Если нам повезет, хотя бы одно из изображений будет изображением образа жизни с небелым фоном. В этом случае можно использовать его как положительную пару и собрать тройку таким образом: .
Другая проблема заключается в том, как можно отфильтровать неподходящие изображения, например, когда на изображении видна только небольшая часть товара, например, одна ножка стула. Чтобы решить эту проблему, мы использовали обнаружение объектов. Это потому, что когда вы обрабатываете изображения продукта, вы знаете его категорию или этикетку. Если обнаружение объекта находит объект с соответствующей меткой, это означает, что изображение содержит нужный продукт. Обнаружение объектов помогает поиску распознавать целевой объект только на изображении, которое может содержать несколько разных объектов, как показано на рисунке 1.9.0003
Обнаружение объектов помогает поиску распознавать целевой объект только на изображении, которое может содержать несколько разных объектов, как показано на рисунке 1.9.0003
Изображения без белого фона помечаются как изображения образа жизни и используются в качестве запроса в триплете. Для этого мы строим гистограмму цвета пикселя для каждого изображения. Для каждой положительной пары мы используем от 10 до 15 негативных изображений в классе и от 1 до 3 негативных изображений вне класса. Некоторые негативные изображения не являются действительно жесткими негативными примерами, поскольку мы можем выбирать случайные продукты из одной и той же категории.
Процесс может быть дополнительно улучшен после первоначального обучения сети путем повторного использования изображений для построения жестких отрицательных примеров. Для каждой положительной пары с помощью обученной сети можно выбрать от 100 до 1000 похожих товаров. Затем можно использовать случайное дополнение запроса для расширения набора обучающих данных путем выполнения таких действий, как переворачивание изображения, вращение, размытие, обрезка, добавление шума или рандомизация пикселей.
Показатели оценки
Мы также разработали ряд показателей, помогающих оценить результаты и точность процесса обучения сети. Первую мы назвали absolute_accuracy. Эта метрика показывает, сколько Dp < Dn мы пытаемся минимизировать. Однако эта метрика может рассчитать только точность каждого триплета, тогда как мы хотим иметь возможность найти именно нужный продукт среди тысяч других.
Следующими разработанными показателями были Distance_Accuracy и Distance_Accuracy_top_3 (рис. 7). Здесь мы берем N товаров одной категории и строим матрицу расстояний q × p. Диагональный элемент — это q- и p-образ произведения. Модель обрабатывает каждое изображение и векторизирует его. Из этой векторизации создаются два значения, P и Q, поэтому изображения с одинаковыми значениями P и Q также будут выглядеть одинаково. Метрики, указывающие на хорошие результаты, показывают, что изображения, которые были определены как похожие, будут иметь численно небольшие различия между значениями P и Q.
Этот тип метрики дает более реалистичный результат для фактической точности нашей модели, потому что реальная проблема состоит в том, чтобы найти точный или очень похожий продукт на изображение запроса среди многих других продуктов из той же категории. Каждая строка матрицы расстояний состоит из расстояний между изображением запроса и другими проверочными изображениями из той же категории, где диагональный элемент является точным продуктом для этого изображения запроса. Затем мы вычисляем его для n объектов, чтобы определить уровень точности.
Наконец, мы выбрали двух исходных кандидатов: InceptionResNetV2 и ImSeNet (рис. 5). Мы не могли полагаться только на оценочные метрики, поэтому также использовали изображения не из каталога заказчика и проверяли результаты вручную для дальнейшей оценки качества моделей.
Results
Наше окончательное решение состояло в том, чтобы использовать только тройную сеть с чистым InceptionResNetV2. Мы обнаружили, что нейронная сеть эффективно научилась преодолевать проблемы, связанные с разным фоном и уровнем освещения. И даже для повернутых или частично скрытых объектов сеть работала хорошо. Мы добились отличного результата, используя самые современные алгоритмы.
И даже для повернутых или частично скрытых объектов сеть работала хорошо. Мы добились отличного результата, используя самые современные алгоритмы.
Одной из нерешенных проблем была возможность однозначно сказать, что если расстояние между значениями P и Q превышает заданное значение, то два продукта не считаются похожими. Это сложная проблема, потому что иногда нам нужно использовать изображение, содержащее объекты, для которых у нас нет сходства, но мы все же хотим попытаться найти наиболее близкое соответствие.
Будущие улучшения
Для дальнейшего повышения точности результатов поиска можно провести следующие исследования:
- Используйте модели 3D-объектов для создания гораздо большего набора обучающих данных.
- Нейронная сеть может быть обучена игнорировать разные фоны для одного и того же продукта. Способ добиться этого — использовать сегментацию объектов, при которой применяется маска и объект извлекается из фона. Однако риск использования сегментации объектов заключается в том, что при ее использовании существует высокий риск повреждения самого изображения продукта, например, отсечения некоторых частей объекта.

Заключение
Как и наш клиент, многие другие розничные продавцы также обнаруживают, что их текстовые поисковые системы недостаточны для точного поиска продуктов, и обращаются к поиску изображений и более функциональным системам рекомендаций для улучшения обнаружения продуктов. Кроме того, развитие мобильных технологий привело к появлению новых вариантов использования, например, клиенты могут фотографировать продукты, которые они хотят купить, с помощью своих смартфонов и выполнять поиск по изображению. Это событие, на которое ритейлеры стремятся извлечь выгоду.
Перед компаниями стоит задача найти подходящую модель поиска изображений, обучить ее, а затем применить к другим мобильным приложениям или интегрировать со сторонними сервисами. Эти услуги включают в себя возможность поиска продуктов в категории, поиск по различным категориям, поиск дальнейшего использования продукта и поиск похожих продуктов у других розничных продавцов.
Наше решение, основанное на использовании данных каталога, специальном конвейере обучения и обучении сиамской CNN внедрению изображений продуктов для различных категорий, также может быть эффективно применено для других компаний. Это особенно верно для случаев использования, когда было бы полезно иметь модель, которую можно использовать для категорий или продуктов, которые не были частью обучения модели.
Это особенно верно для случаев использования, когда было бы полезно иметь модель, которую можно использовать для категорий или продуктов, которые не были частью обучения модели.
В этом проекте мы экспериментировали с большим количеством различных архитектур и параметров. Мы не утверждаем, что нашли абсолютно самую оптимизированную систему, потому что эта задача потребовала бы огромного количества вычислительных ресурсов. Систему можно было бы дополнительно улучшить, используя более крупный обучающий набор, что позволило бы продолжить оптимизацию. В целом, поскольку поиск по изображениям становится все более и более распространенным явлением, компаниям придется внедрять системы обратного поиска, подобные той, которую мы разработали, иначе они рискуют остаться позади.
Владислав Исаев
Подпишитесь на наши последние новости
Под капотом: Поиск фотографий
Сегодня объем фотографий, сделанных людьми с камерами смартфонов, бросает вызов ограничениям структурированной категоризации. Одному человеку сложно классифицировать собственное хранилище фотографий со смартфона, не говоря уже о том, чтобы определить структурированную таксономию для всех фотографий.
Одному человеку сложно классифицировать собственное хранилище фотографий со смартфона, не говоря уже о том, чтобы определить структурированную таксономию для всех фотографий.
На Facebook люди ежедневно обмениваются миллиардами фотографий, что затрудняет прокрутку назад во времени, чтобы найти фотографии, опубликованные несколько дней назад, не говоря уже о месяцах или годах назад. Чтобы помочь людям легче находить фотографии, которые они ищут, команда поиска фотографий Facebook применила методы машинного обучения, чтобы лучше понять, что находится на изображении, а также улучшить процесс поиска и извлечения.
Поиск фотографий был создан с помощью Unicorn, системы индексации в памяти и флэш-памяти, предназначенной для поиска триллионов ребер между десятками миллиардов пользователей и объектов. Созданный несколько лет назад для поддержки поиска Graph с поддержкой социальных графов, Unicorn поддерживает миллиарды запросов в день, поддерживая несколько компонентов в Facebook.
Graph Search был создан для извлечения объектов из социального графа на основе отношений между ними, таких как «Мои друзья, которые живут в Сан-Франциско». Это доказало свою эффективность, но создает инженерные проблемы при ограничении запроса релевантным подмножеством, сортировке и оценке результатов по релевантности, а затем предоставлению наиболее релевантных результатов. В дополнение к этому подходу команда Photo Search применила глубокие нейронные сети для повышения точности поиска изображений на основе визуального содержимого фотографии и текста, доступного для поиска.
Что поиск должен понимать о фотографиях
Понимание фотографий в масштабе Facebook представляет собой другую задачу по сравнению с демонстрацией низкого уровня ошибок распознавания изображений в конкурсе Imagenet Challenge. Прикладные исследования позволили разработать передовые методы глубокого обучения, способные обрабатывать миллиарды фотографий для извлечения доступного для поиска семантического значения в огромных масштабах. Каждая общедоступная фотография, загруженная на Facebook, обрабатывается распределенной системой реального времени, называемой механизмом понимания изображений.
Каждая общедоступная фотография, загруженная на Facebook, обрабатывается распределенной системой реального времени, называемой механизмом понимания изображений.
Механизм понимания изображений представляет собой глубокую нейронную сеть с миллионами обучаемых параметров. Движок построен на основе современной глубокой остаточной сети, обученной с использованием десятков миллионов фотографий с аннотациями. Он может автоматически предсказывать широкий набор понятий, включая сцены, объекты, животных, аттракционы и предметы одежды. Мы можем обучать модели и заранее сохранять полезную информацию, что позволяет реагировать на запросы пользователей с малой задержкой.
Механизм понимания изображений создает высокоразмерные плавающие векторы семантических признаков, которые требуют слишком больших вычислительных ресурсов для индексации и поиска в масштабе Facebook. Используя итеративное квантование и технологию хеширования с учетом местоположения, функции дополнительно сжимаются до небольшого количества битов, которые по-прежнему сохраняют большую часть семантики. Битовое представление используется для компактного встраивания фотографий, которые можно непосредственно использовать при ранжировании, поиске и дедупликации фотографий. Компактные вложения ранжируют результаты в ответ на поисковый запрос. Это аналогичный метод, применяемый для поиска и извлечения документов, для которого изначально был создан Unicorn, с другими алгоритмами, применяемыми к слоям глубокой нейронной сети, специфичным для поиска в крупномасштабной коллекции изображений. Теги объектов и семантические вложения заполняют Unicorn индексом для поисковых запросов. Обновление для использования компактных вложений для поиска с малой задержкой находится в стадии разработки.
Битовое представление используется для компактного встраивания фотографий, которые можно непосредственно использовать при ранжировании, поиске и дедупликации фотографий. Компактные вложения ранжируют результаты в ответ на поисковый запрос. Это аналогичный метод, применяемый для поиска и извлечения документов, для которого изначально был создан Unicorn, с другими алгоритмами, применяемыми к слоям глубокой нейронной сети, специфичным для поиска в крупномасштабной коллекции изображений. Теги объектов и семантические вложения заполняют Unicorn индексом для поисковых запросов. Обновление для использования компактных вложений для поиска с малой задержкой находится в стадии разработки.
Использование тегов и вложений для моделирования
Сложная модель ранжирования, применяемая ко всему магазину фотографий, невозможна, учитывая масштаб Facebook и ожидания людей в отношении быстрого ответа на их запросы. Модель релевантности, применяемая к тегам и встраиваниям, оценивает релевантность и дает результаты запроса с малой задержкой.
Релевантность концепции
Релевантность оценивается с помощью расширенных сигналов запроса и фотографии путем сравнения наборов концепций с помощью функции сходства. Например, концепции запроса напрямую связаны с концепциями фотографии для запроса «Центральный парк», чтобы продвигать фотографии по теме и удалять фотографии не по теме во время ранжирования.
Внедрение релевантности
Непосредственного измерения концептуальной корреляции между запросом и результатом часто недостаточно для точного прогнозирования релевантности. Разработанная модель релевантности использует мультимодальное обучение для изучения совместного встраивания между запросом и изображением.
Входными данными для модели являются векторы встраивания запроса и результат фотографии. Целью обучения является минимизация потери классификации. Каждый вектор обучается вместе и обрабатывается несколькими слоями глубокой нейронной сети для получения бинарного сигнала, где положительный результат означает совпадение, а отрицательный — несовпадение. Входные векторы запроса и фотографии создаются их отдельными сетями, потенциально с разным количеством слоев. Сети можно обучать или настраивать вместе с параметрами слоя внедрения.
Входные векторы запроса и фотографии создаются их отдельными сетями, потенциально с разным количеством слоев. Сети можно обучать или настраивать вместе с параметрами слоя внедрения.
Встраивание с потерей ранжирования
Описанный выше подход к определению релевантности между запросом и фотографией формулируется как задача классификации. Однако основная цель рейтинга — определить наилучший порядок набора фоторезультатов. Мы вышли за рамки формулировки классификации и использовали обучение с потерей ранжирования, которое одновременно обрабатывает пару релевантных и нерелевантных результатов для одного запроса.
Как показано на этом рисунке, правая часть модели является глубокой копией левой части; то есть он имеет ту же сетевую структуру и параметры. Во время обучения запрос и два его результата подаются в левый и правый компоненты соответственно. Положительное изображение ранжируется выше, чем отрицательное изображение для данного запроса. Эта стратегия обучения показывает значительный прирост показателей качества ранжирования.
Понимание запроса применено к поиску фотографий
Фотокорпус доступен для поиска с помощью Unicorn, а вложения применяются механизмом понимания изображений. Растровое изображение не связано с запросом и поиском, за исключением индекса, используемого для извлечения фотографии, если семантика запроса, примененная к вложениям, дает высокую вероятность релевантности. Некоторые из основных сигналов, которые играют роль в понимании семантики запроса, приведены ниже:
Намерения запроса предлагают, какие типы сцен мы должны получить. Например, запрос с намерением получить животное должен отображать фотографии с животным в качестве центральной темы.
Синтаксический анализ помогает понять грамматические составляющие предложения, части речи, синтаксические отношения и семантику. Поисковые запросы обычно не соблюдают грамматику письменного языка, а существующие синтаксические анализаторы работают плохо. Мы используем самые современные методики обучения нейротегеров части речи по поисковым запросам.
Связывание сущностей помогает нам идентифицировать фотографии о конкретных концепциях, часто представленных страницей; например, места или телешоу.
Переписывание знаний запроса для извлечения понятий обеспечивает семантическую интерпретацию запроса. Понятия не только расширяют значение запроса, но и устраняют разрыв между различными словарями, используемыми запросом и результатом.
Вложение запроса представляет собой представление запроса в непрерывном векторном пространстве. Он изучается с помощью трансферного обучения поверх векторного представления слов word2vec, которое сопоставляет похожие запросы с соседними точками.
Вертикали и переписывание запросов
Когда кто-то вводит запрос и нажимает поиск, запрос генерируется и отправляется на наши серверы. Запрос сначала направляется на веб-уровень, который собирает различную контекстуальную информацию о запросе. Запрос и связанный с ним контекст отправляются на верхний уровень агрегатора, который переписывает запрос в s-выражение, которое затем описывает, как получить набор документов с сервера индексирования.
В зависимости от намерения запроса используется механизм запуска с использованием модели нейронной сети, чтобы решить, какие вертикали — например, новости, фотографии или видео — являются релевантными, чтобы избежать ненужных запросов, обрабатываемых на менее релевантных вертикалях. Например, если человек запрашивает термин «смешные кошки», намерение будет искать и возвращать больше результатов из вертикали фотографий и пропускать результаты запроса из вертикали новостей.
Если запрос о Хэллоуине инициирует намерение по общедоступным фотографиям и фотографиям друзей в хэллоуинских костюмах, поиск будет осуществляться как по общедоступным, так и по социальным фотовертикалям. Фотографии, которыми поделились друзья искателя, и общедоступные фотографии, оцененные как релевантные, будут возвращены. Два независимых запроса сделаны, потому что социальные фотографии очень персонализированы и требуют собственного специализированного поиска и оценки. Конфиденциальность фотографий защищена применением общесистемных средств контроля конфиденциальности Facebook к результатам. На приведенной ниже диаграмме показан модуль, в котором верхний раздел является социальным, а нижний — общедоступным.
На приведенной ниже диаграмме показан модуль, в котором верхний раздел является социальным, а нижний — общедоступным.
Ранжирование на первом этапе
После того, как серверы индексирования извлекают документы в соответствии с s-выражением, к этим документам применяется ранжирование на первом этапе с использованием машинного обучения. Лучшие M документов с наивысшими оценками отправляются обратно на уровень агрегатора стойки, который выполняет сортировку слиянием всех полученных документов, а затем возвращает первые N результатов на верхний уровень агрегатора. Основная цель ранжирования на первом этапе — убедиться, что документы, возвращаемые в агрегатор стеллажей, сохраняют актуальность для запроса. Например, по запросу «собака» фотографии с собаками должны ранжироваться выше, чем без собак. Задержка из-за сложности этапа поиска и ранжирования сбалансирована для обслуживания релевантных фотографий порядка миллисекунд.
Второй этап повторного ранжирования
После того, как ранжированные документы возвращаются в агрегатор верхнего уровня, они проходят еще один раунд расчета сигналов, дедупликации и ранжирования. Рассчитываются сигналы, описывающие распределение всего результата, обнаруживая выбросы результатов. Затем документы дедуплицируются из визуально похожих результатов с использованием отпечатков изображений. Затем глубокая нейронная сеть оценивает и ранжирует окончательный порядок результатов фотографий. Коллекция ранжированных фотографий, называемая модулем, затем передается в пользовательский интерфейс страницы результатов.
Рассчитываются сигналы, описывающие распределение всего результата, обнаруживая выбросы результатов. Затем документы дедуплицируются из визуально похожих результатов с использованием отпечатков изображений. Затем глубокая нейронная сеть оценивает и ранжирует окончательный порядок результатов фотографий. Коллекция ранжированных фотографий, называемая модулем, затем передается в пользовательский интерфейс страницы результатов.
Точная настройка ранжирования релевантности для поиска фотографий
Оценка релевантности запроса фотографии и наоборот является основной проблемой поиска фотографий, которая выходит за рамки перезаписи и сопоставления текстовых запросов. Это требует всестороннего понимания запроса, автора, текста публикации и визуального содержания результата фотографии. Усовершенствованные модели релевантности, включающие самые современные методы ранжирования, обработки естественного языка и компьютерного зрения, были разработаны для точной настройки релевантности этих результатов, что дало нам новую систему таксономии изображений, способную быстро предоставлять релевантные результаты в любом масштабе.