Содержание
Алгоритм персонализации выдачи в Google, патент Google индивидуальный Граф знаний — Пиксель Тулс
Продолжаем разбирать важные патенты Google, чтобы лучше понимать работу поисковой системы и учитывать особенности алгоритмов при разработке собственных SEO-стратегий.
Спасибо Биллу Славски, который регулярно отслеживает ключевые патенты Google.
Что такое Google Knowledge Graph?
Knowledge Graph (Граф знаний) — база знаний на основе семантических связей, которая оперирует понятиями / сущностями / терминами / имена. Цель заключается в повышении качества ответов на вопросы пользователей. База основана на данных различных источников, главные из них:
-
Wikipedia.
-
CIA World Factbook (Всемирная книга фактов ЦРУ).
-
Freebase (коллекция данных, собранных интернет-сообществом).
-
Сервисы Google (Maps, Play, YouTube и другие).
Самый простой пример логики использования Графа знаний в SERP:
То есть, для запроса [кто придумал телескоп] используются примерно следующие связи:
Но патент, который мы рассмотрим ниже, затрагивает индивидуальный, то есть персонализированный под пользователя Граф знаний. Это не значит, что если мы уверены — телескоп изобрел Галилей, то Google подтасует результаты согласно нашим убеждениям, но при поиске развлечений на выходные в ход пойдёт всё, что о поисковику о вас известно 🙂
Это не значит, что если мы уверены — телескоп изобрел Галилей, то Google подтасует результаты согласно нашим убеждениям, но при поиске развлечений на выходные в ход пойдёт всё, что о поисковику о вас известно 🙂
User-Specific Knowledge Graph
Глобально, суть патента в следующем — Google использует индивидуальный Граф знаний для ответа на запрос или несколько запросов и прогнозирования подходящих конкретному пользователю результатов. Граф знаний нужно понимать не как единую базу знаний, но как подвижную и гибкую систему на основе всех имеющихся у Google данных о пользователе.
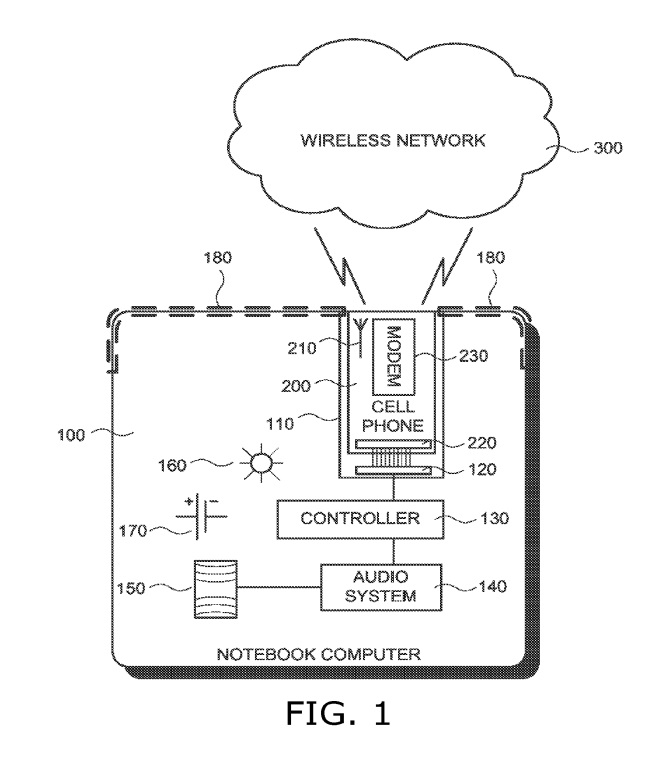
Место индивидуального Графа знаний на схеме формирования ответов на запрос (в нижнем правом углу).
Оригинал патента лежит здесь:
Structured user graph to support querying and predictions
Inventors: Pranav Khaitan and Shobha Diwakar
Assignee: Google LLC
US Patent: 10,482,139
Granted: November 19, 2019
Filed: November 5, 2013
Аннотация
Методы, система и инструменты для получение индивидуального контента, который может быть связан с пользователем одной или нескольких компьютерных услуг (вероятно, имеется в виду различные сервисы Google или устройства, что станет понятно дальше). Обработка индивидуального контента с помощью нескольких анализаторов с целью выявления одной или нескольких сущностей и связей между сущностями. Формирование одного или нескольких индивидуальных Графов знаний, включающих в себя «узлы» и «ребра» (то есть объекты и связи с определенным весом) между ними для определения отношений между сущностями. В результате — сохранение одного или нескольких индивидуальный Графов знаний.
Обработка индивидуального контента с помощью нескольких анализаторов с целью выявления одной или нескольких сущностей и связей между сущностями. Формирование одного или нескольких индивидуальных Графов знаний, включающих в себя «узлы» и «ребра» (то есть объекты и связи с определенным весом) между ними для определения отношений между сущностями. В результате — сохранение одного или нескольких индивидуальный Графов знаний.
Основные цели и преимущества технологии
-
Получение данных о конкретных пользователях в структурированном виде.
-
Предоставление ответов на сложные вопросы или серию запросов пользователя.
-
Индивидуальный Граф знаний позволяет получить единое каноническое представление о пользователе на основе его активности, полученной из одного или нескольких сервисов.
-
Создание универсальных Графов знаний, не привязанных к конкретному пользователю.

Источники данных
Вот какие сервисы Google и другие источники могут учитываться при составлении User-Specific Knowledge Graph:
-
Поисковая система.
-
Электронная почта.
-
Чаты.
-
Сервис обмена документами.
-
Календарь.
-
Сервис обмена фото.
-
Сервис обмена видео.
-
Блоггинг и микроблоггинг.
-
Службы регистрации.
-
Рейтинги и отзывы.
Как же информационная безопасность? В патенте есть небольшая ремарка: «пользовательские данные обрабатывается таким образом, чтобы личную информация было невозможно определить». А также «геолокация обобщается, чтобы конкретное местоположение не было определено». Не очень надёжно, но тем не менее.
Ниже пример получения структурированных данных о пользователе и различных источников:
Обратите внимание, на иллюстрации есть связи, определяющие социальный Граф знаний, то есть родственные или другие взаимоотношения, которые также могут учитываться при обработке запросов.
Какие ещё данные Google получает о пользователях?
-
Активность в социальных сетях.
-
Профессия.
-
Предпочтения пользователя.
-
Текущее местоположение.
-
Посещаемые мероприятия.
-
Просмотренные фильмы.
-
Социальные связи в сетях и офлайн.
-
Лайки и дизлайки.
Как это работает?
Итак, для ответов на запросы Google оперирует сущностями, узлами и связями между ними. Важно здесь — связи имеют коэффициенты, то есть вес и он может меняться.
Пример запроса из патента [playing tennis with my kids in mountain view], в переводе «играю в теннис со своими детьми в Маунтин-Вью». Ниже представлена схема, которая демонстрирует сущности и связи, используемые для формирования выдачи:
Мы видим узлы-сущности: «семья», «отдых», «теннис», «ребенок», «Маунтин-Вью» (город), «Waikiki» (отель) и связи-рёбра: «локация / где играют», «семья / член семьи», «спорт / играть с чем» и так далее.
Откуда они берутся? Например, пользователь выложил пост в социальной сети: «Мы отлично провели время сегодня, играя в теннис с детьми», а геолокация указывала на Маунтин-Вью, штат Калифорния.
И/или пользователю на почту пришло письмо из отеля: «Подтверждаем бронирование отеля в Waikiki. Желаем приятного отдыха вашей семье». В итоге к изначальным узлам из запроса добавляются дополнительные — название отеля, отпуск, дата и так далее.
Чем больше повторяющихся данных, тем сильнее вес сущностей и связей. Например, пользователь также запланировал тренировку на корте в календаре Google, искал спортивные клубы в поиске ранее, смотрел видеообзоры теннисных ракеток. В зависимости от наших активностей и информации со всех источников, к которым имеет доступ Google, узлы могут меняться местами, добавляться и исключаться.
В зависимости от наших активностей и информации со всех источников, к которым имеет доступ Google, узлы могут меняться местами, добавляться и исключаться.
Что делать?
Во-первых, понять отличие от простого персонализированного поиска — учитываются не только предыдущие поисковые сессии, но и другие источники и сервисы (судя по всему, от писем до лайков на YouTube).
Во-вторых, обратить внимание, что один и тот же запрос для различных пользователей может давать разный результат, но в то же время Граф знаний может из индивидуального превратиться в универсальный.
В-третьих, стараться проработать целевые страницы таким образом, чтобы охватить максимальное количество релевантных для конкретного пользователя фактов. Если мы не можем повлиять на выбор SERP Google в отношении конкретного пользователя, то способны:
-
Определить интент и проработать тексты словами задающими тематику, думая не только о вхождениях ключевых фраз, но о сущностях, логике, стуктуре и связности контента.
-
Определить геозависимость и локализацию и использовать топонимы не только для городов, но и улиц или станций метро.
-
Собрать подсказки Google и расширить СЯ (чем больше семантики вы охватите, тем выше шансы удовлетворить самые вариативные варианты запросов и интента).
-
Представлять бизнес в социальных сетях, Google Maps и Google My Business.

Комментарий Дмитрия Севальнева
Google и вообще поисковые системы продолжают развивать персонализацию выдачи под конкретного пользователя. Стоит вспомнить, что активно этот подход ранее развивался и в Яндексе, хотя последние несколько лет тут нет публичных новостей и прорывов и вот Google нарушил молчание. Стоит отметить, что ранее Google не всегда лестно отзывался о персонализации.
1. Первое, что начал учитывать Яндекс — умение пользователя читать на иностранном языке и повышать или наоборот понижать в результатах документы на, скажем, английском языке.
2. Далее были добавлены факторы, учитывающие:
-
Какие сайты посещал пользователь.
-
Какие запросы были заданы в Яндекс за последние несколько минут, неделю и два месяца.
-
Введенный поисковый запрос, если он уже был задан.
Последний фактор, а именно, подстройка поисковых подсказок под текущий запрос пользователя, довольно активно применяется в Яндексе и сейчас, хотя Google «фишку» так и не скопировал.
автоматически собирать данные и взаимодействовать с другими от вашего имени — Сетевое администрирование
by adminОпубликовано
Социальные сети в последнее время значительно выросли, и приложения всегда доступны для информирования пользователей о новых сообщениях, фотографиях и другой информации.
Многое из того, что происходит на таких сайтах, как Facebook, Twitter или Google+, основано на реакции пользователей. Пользователи посещают сайт в Интернете, используют один из клиентов или стороннее приложение или сервис, который предлагает интеграцию в той или иной форме.
Пользователи посещают сайт в Интернете, используют один из клиентов или стороннее приложение или сервис, который предлагает интеграцию в той или иной форме.
Существуют варианты публикации автоматических сообщений, и многие веб-мастера используют их для продвижения своих последних статей без необходимости делать это вручную.
Такие компании, как Google, в последнее время начали экспериментировать с автоматизацией. Например, браузер Chrome компании пытается предсказать следующие сетевые действия, предварительно загружая содержимое, к которому пользователи могут получить доступ, в то время как Google Now, программное обеспечение личного помощника Google, доставляет информацию пользователю, предсказывая, чего он хочет.
Недавний Патент Google идет еще дальше. Он описывает систему, которая будет генерировать индивидуальную реакцию от имени пользователя. Первоначально только в виде предложений, которые отображаются в интерфейсе, но в конечном итоге автоматически от имени пользователя.
Система будет собирать и анализировать как можно больше данных о пользователе и его взаимодействии на сайтах социальных сетей. Эта информация берется не только с таких сайтов, как Google+, но также из электронных писем, посещенных веб-сайтов, SMS и других источников, доступных для различных модулей сбора, которые подробно описаны в патенте.
Цель здесь — понять, как пользователь взаимодействует на сайтах социальных сетей и в других формах общения, что осуществляется путем анализа предшествующих реакций на контент.
Способ создания индивидуальной реакции, включающий:
сбор , используя одно или несколько вычислительных устройств, элементы взаимодействия, связанные с первым пользователем и доступные первому пользователю из одного или нескольких источников данных, один или несколько источников данных, включая социальную сеть, элементы взаимодействия, включая онлайн-сообщение пользователя и пользователя реакция;
обработка с использованием одного или нескольких вычислительных устройств собранные элементы взаимодействия для создания одной или нескольких меток для собранных элементов взаимодействия;
рейтинг с использованием одного или нескольких вычислительных устройств, каждый собираемый элемент взаимодействия на основе меток и на основе предшествующих реакций первого пользователя на другие элементы взаимодействия и соответствующих меток предыдущих реакций первого пользователя;
определение что публикация онлайн-пользователя удовлетворяет пороговому значению вероятности быть важной или интересной для первого пользователя;
а также автоматически генерирует с использованием одного или нескольких вычислительных устройств, предлагаемую персонализированную реакцию на публикацию онлайн-пользователя от имени первого пользователя, предлагаемую персонализированную реакцию на основе одной или нескольких меток, связанных с онлайн-публикацией пользователя.
Хотя это, безусловно, впечатляет с чисто технологической точки зрения, это может вызвать тревогу у некоторых пользователей Интернета.
Система не только собирает информацию о пользователе, она также анализирует их на предмет поведенческих подсказок, создает профиль пользователя в процессе и может в конечном итоге публиковать сообщения для пользователя.
Google, похоже, предопределен для этого, поскольку он может собирать информацию из своей социальной сети Google Plus, из своего почтового сервиса Gmail, из своего веб-браузера Google Chrome, Google Search и всех других продуктов, к которым у него есть доступ.
Для некоторых это пугает, в то время как другие могут принять новую технологию с распростертыми объятиями. А что насчет тебя?
Posted in Интересное
Патент Google направлен на удовлетворение потребности пользователей в соответствующем медиа-контенте
Недавно выданный Google патент включает методы, системы и медиа для представления контента, организованного по категориям.
Этот патент привлек мое внимание тем, что в нем говорится о связанных объектах и описывается, как они сочетаются друг с другом в мире медиа.
Это продвигает идею выполнения поиска без запросов, отличительной черты Google Discover, для мультимедийного контента, такого как телешоу, фильмы и многое другое.
Что это может означать для поисковиков — и для специалистов по поисковой оптимизации? Давайте взглянем.
Трудности, связанные с поиском встреч Интерес к связанным медиа
Поисковики часто хотят найти и просмотреть медиаконтент, связанный с определенной темой.
Например, если человека интересует определенное телешоу, его могут заинтересовать:
- Просмотр нескольких или разных эпизодов телешоу.
- Видеоинтервью с актерами телешоу.
- Эпизоды других телешоу с участием тех же актеров.
- Фото актеров и др.
Этот патент говорит нам о том, что может быть сложно идентифицировать, систематизировать и представить связанный контент пользователю, выполняющему поиск.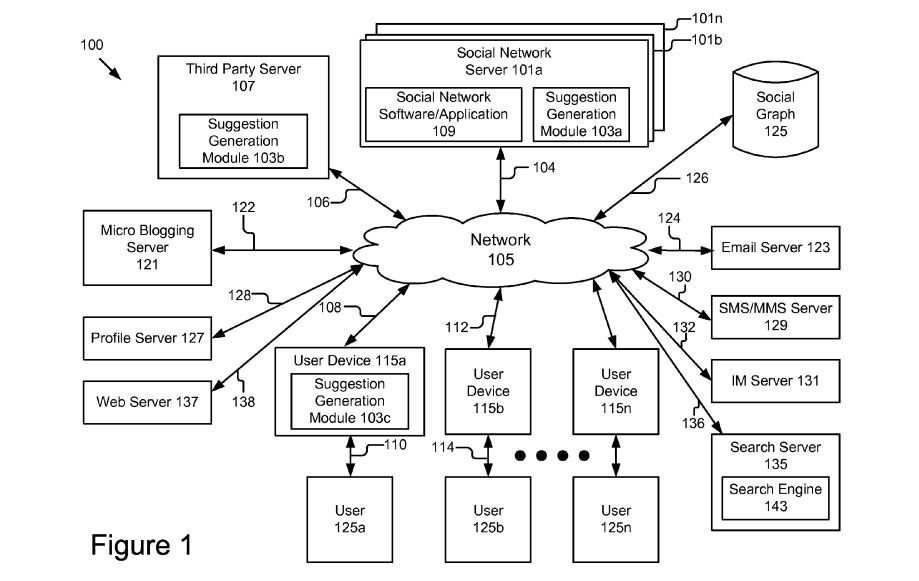 Трудность может заключаться в том, чтобы заставить компьютер подключить эту информацию.
Трудность может заключаться в том, чтобы заставить компьютер подключить эту информацию.
Патент пытается решить эту проблему, предоставляя новые способы и средства для представления контента, организованного по категориям.
«Методы, системы и носители для представления контента, организованного по категориям» начинается с демонстрации потребности многих людей в информации, а затем описывает решение этой проблемы в патенте, выданном 15 июня 2021 г.
Представление контента для связанных сущностей, организованного по категориям
Патент показывает способы представления контента, организованного по категориям.
Вот как это работает:
- Поисковая система получает запрос на страницу с контентом о первом объекте.
- Первая группа связанных сущностей идентифицируется на основе информации о взаимодействии искателя.
- Идентифицирован ряд свойств, относящихся к первому объекту.
- Для каждого из этих свойств определяется вторая группа объектов.
- Каждое из этих свойств получает оценку, частично основанную на первой группе сущностей (идентифицированных на основе информации о взаимодействии с поисковиком) и второй группе связанных сущностей для свойства.
- Оценка указывает на вероятность того, что пользователь поискового устройства будет заинтересован в содержимом свойства.
- Поисковая система определяет подмножество свойств в группе свойств на основе оценки каждого из них.
- Идентифицирует группу элементов контента для каждого из свойств.
- Определено подмножество элементов содержимого из группы элементов содержимого.
- Элементы контента отображаются на вычислительном устройстве.

Вот как это могло бы выглядеть на практике, исходя из вышеизложенного:
В этом патенте Google предлагается диаграмма знаний о медиа
В какой-то степени этот патент описывает диаграмму знаний о связанных сущностях и атрибутах, не упоминая фразу «график знаний».
Но именно это меня и интересовало в нем — наблюдение за тем, как он ищет связанные объекты, свойства и атрибуты, элементы контента и то, как все может быть связано, лежит в основе этого подхода.
Несколько замечаний технического характера:
- Расчет оценки свойств может означать расчет доли объектов, включенных во вторую группу объектов, включенных в первую группу объектов.
- Подмножество элементов содержимого может быть определено на основе популярности каждого элемента содержимого в группе элементов содержимого.
- Система может также означать выбор для каждого свойства в подмножестве свойств типа контента на основе популярности элементов контента, связанных с этим свойством, и типа контента, где указания подмножества элементов контента представлены в соответствии с контентом. тип и свойство, соответствующее каждому элементу содержимого.
- По крайней мере один элемент контента, включенный в подмножество элементов контента, может включать в себя объединение нескольких видео.
- Первым объектом может быть имя персонажа в элементе медиаконтента.
- Группа свойств может включать свойство, соответствующее другому медиаконтенту, в котором появлялся персонаж.

Для каждого свойства в группе свойств идентификация второй группы объектов, соответствующих свойству, включает средства для доступа к базе данных, которые указывают на взаимосвязь каждого объекта во второй группе объектов с первым объектом через свойство.
Это средство категоризации медиаконтента по связанным объектам.
Этот патент можно найти по адресу:
Методы, системы и средства представления контента, организованные по категориям
Изобретатели: Александр Пак, Феликс Раймундо, Сертан Гиргин, Рафаэль Маринье и Винсент Симоне
Патент США: 11 036 743
Правопреемник: Google LLC
Выдано: 15 июня 2021 г.
Подано: 23 мая 2016 г.
Резюме:
Предоставляются методы, системы и носители для представления контента, организованного по категориям.
 В некоторых вариантах осуществления способ включает: получение запроса на представление страницы, указывающей контент, относящийся к первому объекту; идентификацию первой группы объектов, связанных с первым объектом, по меньшей мере частично на основании информации о взаимодействии с искателем; идентификацию группы свойств, соответствующих первому объекту; идентификацию для каждого свойства второй группы объектов, соответствующих этому свойству; вычисление для каждого свойства оценки свойства; определение подмножества свойств в группе свойств на основе оценки каждого свойства; идентификацию для каждого свойства в подмножестве свойств группы элементов контента, соответствующих свойству; определение подмножества элементов контента из группы элементов контента; и вызывает интерфейс средства поиска, указывающий подмножество элементов контента, которое должно быть представлено.
В некоторых вариантах осуществления способ включает: получение запроса на представление страницы, указывающей контент, относящийся к первому объекту; идентификацию первой группы объектов, связанных с первым объектом, по меньшей мере частично на основании информации о взаимодействии с искателем; идентификацию группы свойств, соответствующих первому объекту; идентификацию для каждого свойства второй группы объектов, соответствующих этому свойству; вычисление для каждого свойства оценки свойства; определение подмножества свойств в группе свойств на основе оценки каждого свойства; идентификацию для каждого свойства в подмножестве свойств группы элементов контента, соответствующих свойству; определение подмножества элементов контента из группы элементов контента; и вызывает интерфейс средства поиска, указывающий подмножество элементов контента, которое должно быть представлено.Предусмотрены механизмы представления медиаконтента, организованного по категориям
Объекты, описанные в патенте, могут идентифицировать контент, относящийся к конкретной теме, и определить, может ли идентифицированный контент быть интересным для искателя, используя комбинацию нескольких источников Информация.
Например, в источниках информации могут быть указаны темы, связанные с первой темой, где связь двух тем выводится на основе поведения искателя:
- Поисковые запросы поисковика.
- Контент, который пользователи обычно просматривают в рамках одного и того же сеанса просмотра.
- Любой другой подходящий тип поведения искателя.
Источники информации могут включать структурированную информацию, указывающую свойства, относящиеся к темам.
В этом примере структурированная информация может указывать на то, что два фильма связаны друг с другом, поскольку в них участвует определенный актер (которого Google распознает как сущность в обоих фильмах).
Затем мы можем увидеть информацию, указывающую, что два элемента контента связаны между собой, выведенную на основе действий искателя, со структурированной информацией, указывающей способ, которым два элемента контента связаны.
Механизмы могут затем обеспечить представление идентифицированного содержимого, относящегося к определенной теме, в интерфейсе поисковика, который может группировать идентифицированное содержимое на основе свойства, связывающего идентифицированное содержимое с конкретной темой.
Группа свойств может быть связана с первой темой или сущностью, а группа тем или сущностей связана с каждым свойством.
Свойство может указывать любое подходящее поле или категорию, связанную с определенной темой или сущностью, посредством которых эта конкретная тема или сущность связана с другими темами, сущностями или другой информацией.
Дополнительные примеры мультимедиа
Например, если первым объектом является вымышленный персонаж, группа свойств может включать:
- Фильмы, в которых был изображен вымышленный персонаж.
- Актеры, сыгравшие вымышленного персонажа.
- Другие подходящие свойства.
Продолжая этот пример, группа связанных сущностей, соответствующих свойствам фильмов, в которых был изображен вымышленный персонаж, может включать имена каждого фильма.
Затем механизмы могут идентифицировать элементы контента, связанные с объектами в группе связанных объектов. Это также может привести к тому, что указания этих элементов контента будут представлены в интерфейсе средства поиска, организованном по свойству.
Например, в случаях, когда объекты в группе общеизвестных объектов включают названия фильмов, в которых был изображен вымышленный персонаж, элементы контента могут включать:
- Кадры из фильмов.
- Саундтреки из фильмов.
- Другие подходящие элементы контента.
Поисковая система может идентифицировать свойства, связанные с первым объектом, используя любой подходящий метод или комбинацию методов.
Например, можно определить группу свойств-кандидатов. Подмножество свойств-кандидатов может быть идентифицировано на основе того, насколько релевантно каждое свойство для первого объекта, что основано на том, насколько интересно каждое свойство может быть для искателя.
В другом примере, где первый объект является вымышленным персонажем, группа свойств-кандидатов может включать:
- Фильмы, в которых персонаж был изображен.
- Актеры, сыгравшие персонажа.
- Вымышленный день рождения персонажа. Продолжая этот пример, в некоторых вариантах осуществления описанные здесь механизмы могут определять, что свойства фильмов, в которых персонаж был изображен, и актеров, которые изобразили персонажа, вероятно, будут наиболее интересными для искателя 9. 0018
 0018
0018Следуя тому же примеру, контент, соответствующий каждому свойству, может быть идентифицирован с использованием любой подходящей информации и методов.
Механизмы могут идентифицировать элементы контента на основе популярности нескольких элементов контента, относящихся к каждому выбранному свойству.
Этот патент указывает на широкий спектр типов контента
Элементы контента могут быть любыми подходящими типами контента, включая:
- Видеоконтент.
- Аудиоконтент.
- Телевизионные программы.
- фильмов.
- Прямая трансляция контента.
- Аудиокниги.
- Документы.
- веб-страниц.
- Другие подходящие типы контента.
Элементы контента могут также включать компиляции и/или агрегации нескольких элементов контента.
Элемент контента может быть списком воспроизведения элементов контента, представленных в определенном порядке. Они также могут быть каналом контента, связанным с определенной темой и/или создателем контента.
Интерфейс поиска для представления контента, упорядоченного по категориям
Это то, что делает этот мультимедийный граф знаний доступным для просмотра для изучения отношений и связей между персонажами и историями.
Интерфейс поисковика может включать:
- Заголовок.
- Категории.
- Рекомендации по содержанию в категории.
Название может быть любым подходящим названием и может указывать:
- Сущность или тему, например персонаж (вымышленный или не вымышленный).
- Событие.
- Телепрограмма.
- Книга.
- Интерес или хобби.
- Любая другая подходящая тема.
Заголовок может включать любой подходящий текст, изображения, графику, анимацию, гиперссылки или другой подходящий контент.
В патенте указано, что расположение заголовка в интерфейсе поисковика будет показано в качестве примера и что заголовок может быть представлен в любом подходящем месте. Название можно даже не указывать.
Название можно даже не указывать.
Интерфейс поисковика может включать в себя подходящие категории, связанные с сущностью или темой, соответствующей интерфейсу поисковика.
Они предоставляют пример: если интерфейс поисковика связан с конкретным вымышленным персонажем (например, «Супергерой X»). Категории могут включать фильмы, в которых был изображен вымышленный персонаж (например, «Фильм 1»), актер, сыгравший вымышленного персонажа (например, «Актер 1»), или любые другие подходящие категории.
Обратите внимание, что патент говорит нам, что может быть включено любое подходящее количество категорий.
Каждая категория, представленная в интерфейсе средства поиска, может включать указания элементов медиаконтента, соответствующих этой категории.
Например, если категория относится к определенному фильму, то рекомендацией по содержанию может быть список воспроизведения песен и/или музыкальных клипов, включенных в саундтрек к фильму.
Элементами контента могут быть:
- Видео (например, сцены из фильма, интервью с актерами из фильма, трейлер и/или любые другие подходящие видео).
- Набор медиаконтента, относящегося к категории (например, список воспроизведения песен, список воспроизведения видео, относящихся к категории, канал, связанный с категорией, или любой другой подходящий медиаконтент).
- Ссылки на веб-сайты, связанные с категорией.
- изображений.
- Или любые другие подходящие типы контента.

В патенте также содержится просьба отметить, что каждая категория может включать любое подходящее количество элементов контента.
Категории в интерфейсе поисковика и элементы контента в каждой категории могут быть идентифицированы с использованием любого подходящего метода или комбинации методов. Эти категории могут быть основаны на темах или объектах, имеющих отношение к теме.
Или элементы контента, представленные в каждой категории, могут быть основаны на популярности элементов контента.
Представление контента, организованного по категориям Обзор
Я подумал, что это интересно, потому что он объединяет связанные объекты и темы, чтобы позволить искателям исследовать эти отношения и связи.
До того, как Google представил граф знаний, они работали над репозиторием фактов с возможностью просмотра. Мы возвращаемся к тому моменту, когда нам хотят показать связи в такой области, как медиа (что может привлечь много внимания).
Он охватывает широкий спектр средств массовой информации и развлечений, на которые в прошлом распространялась серия патентов Google. Тем не менее, у них есть несколько историй потребления медиа, где они собирают информацию о медиа, которые люди потребляют как часть нашей повседневной жизни.
Компания Google приложила много усилий для уточнения графа знаний о медиа и элементов контента для различных связанных объектов, чтобы найти новые эпизоды, персонажей, которые действуют вместе, серии шоу, награды, призы, продюсеров, каталоги и другие, которые работают на СМИ.
Возможные категории, которые может охватывать этот патент, могут охватывать широкий диапазон. Кроме того, примеры мультимедиа, которые он предоставляет, могут показать, как он может связать множество связанных объектов.
Дополнительные ресурсы:
- Рейтинг объектов в результатах поиска Google
- Как поисковые запросы вызывают структурированные информационные карты (панели знаний)
- Core Web Vitals: полное руководство
Категория
SEO
Объявление о наборе данных сходства патентных фраз — блог Google AI
Опубликовано Григор Асланян, инженер-программист, Google
Патентные документы обычно используют юридический и высокотехнологичный язык с контекстно-зависимыми терминами, которые могут иметь значение, совершенно отличное от разговорного употребления, и даже между разными документами. Процесс использования традиционных методов патентного поиска (например, поиска по ключевым словам) для поиска в корпусе из более чем ста миллионов патентных документов может быть утомительным и приводить к большому количеству пропущенных результатов из-за используемого широкого и нестандартного языка. Например, «футбольный мяч» может быть описан как «сферическое приспособление для отдыха», «надувной спортивный мяч» или «мяч для игры в мяч». Кроме того, язык, используемый в некоторых патентных документах, может запутывать термины в своих интересах, поэтому более мощная обработка естественного языка (NLP) и понимание семантического сходства могут предоставить каждому доступ к тщательному поиску.
Например, «футбольный мяч» может быть описан как «сферическое приспособление для отдыха», «надувной спортивный мяч» или «мяч для игры в мяч». Кроме того, язык, используемый в некоторых патентных документах, может запутывать термины в своих интересах, поэтому более мощная обработка естественного языка (NLP) и понимание семантического сходства могут предоставить каждому доступ к тщательному поиску.
Патентная область (и более общая техническая литература, такая как научные публикации) создает уникальные проблемы для моделирования НЛП из-за использования юридических и технических терминов. Хотя существует несколько широко используемых эталонных наборов данных семантического текстового сходства (STS) общего назначения (например, STS-B, SICK, MRPC, PIT), насколько нам известно, в настоящее время нет наборов данных, ориентированных на технические концепции, найденные в патентах. и научные публикации (отчасти связанная задача BioASQ содержит задание на ответ на биомедицинский вопрос). Более того, с постоянным ростом размера патентного корпуса (ежегодно во всем мире выдаются миллионы новых патентов) возникает необходимость в разработке более полезных моделей НЛП для этой области.
Более того, с постоянным ростом размера патентного корпуса (ежегодно во всем мире выдаются миллионы новых патентов) возникает необходимость в разработке более полезных моделей НЛП для этой области.
Сегодня мы объявляем о выпуске набора данных сходства патентных фраз, нового набора данных контекстуального семантического сопоставления фраз с фразами, оцениваемого людьми, и сопроводительного документа, представленного на семинаре SIGIR PatentSemTech Workshop, в котором основное внимание уделяется техническим терминам из патентов. Набор данных сходства патентных фраз содержит около 50 000 пар фраз с рейтингом, каждая из которых имеет класс совместной патентной классификации (CPC) в качестве контекста. В дополнение к показателям сходства, которые обычно включаются в другие эталонные наборы данных, мы включаем детальные классы рейтинга, аналогичные WordNet, такие как синоним, антоним, гипероним, гипоним, холоним, мероним и связанные с доменом. Этот набор данных (распространяемый по международной лицензии Creative Commons Attribution 4. 0) использовался Kaggle и USPTO в качестве эталонного набора данных в конкурсе сопоставления патентных фраз с фразами США, чтобы привлечь больше внимания к производительности моделей машинного обучения для технического текста. Первоначальные результаты показывают, что модели, точно настроенные на этом новом наборе данных, работают значительно лучше, чем обычные предварительно обученные модели без тонкой настройки.
0) использовался Kaggle и USPTO в качестве эталонного набора данных в конкурсе сопоставления патентных фраз с фразами США, чтобы привлечь больше внимания к производительности моделей машинного обучения для технического текста. Первоначальные результаты показывают, что модели, точно настроенные на этом новом наборе данных, работают значительно лучше, чем обычные предварительно обученные модели без тонкой настройки.
Набор данных сходства патентных фраз
Чтобы лучше обучать современные модели следующего поколения, мы создали набор данных сходства патентных фраз, который включает множество примеров для решения следующих проблем: (1) устранение неоднозначности фразы, (2) состязательное сопоставление ключевых слов и (3). ) жесткие минус-слова (т. е. ключевые слова, которые не связаны между собой, но получили высокий балл за сходство с другими моделями). Некоторые ключевые слова и фразы могут иметь несколько значений (например, фраза «мышь» может относиться к животному или компьютерному устройству ввода), поэтому мы устраняем неоднозначность фраз, включая классы CPC в каждую пару фраз. Кроме того, многие модели НЛП (например, модели мешка слов) не будут работать с данными с фразами, которые имеют совпадающие ключевые слова, но в остальном не связаны (противоположные ключевые слова, например, «секция контейнера» → «кухонный контейнер», «стол смещения» → «настольный вентилятор»). Набор данных сходства патентных фраз включает в себя множество примеров сопоставления ключевых слов, которые не связаны посредством состязательного сопоставления ключевых слов, что позволяет моделям НЛП повышать свою эффективность.
Кроме того, многие модели НЛП (например, модели мешка слов) не будут работать с данными с фразами, которые имеют совпадающие ключевые слова, но в остальном не связаны (противоположные ключевые слова, например, «секция контейнера» → «кухонный контейнер», «стол смещения» → «настольный вентилятор»). Набор данных сходства патентных фраз включает в себя множество примеров сопоставления ключевых слов, которые не связаны посредством состязательного сопоставления ключевых слов, что позволяет моделям НЛП повышать свою эффективность.
Каждая запись в наборе данных сходства патентных фраз содержит две фразы, якорь и цель, контекстный класс CPC, рейтинговый класс и показатель сходства. Набор данных содержит 48 548 записей с 973 уникальными якорями, разделенными на обучающие (75%), проверочные (5%) и тестовые (20%) наборы. При разделении данных все записи с одним и тем же якорем сохраняются вместе в одном наборе. Существует 106 различных контекстных классов CPC, и все они представлены в обучающем наборе.
| Анкер | Цель | Контекст | Рейтинг | Оценка |
| абсорбция кислоты | поглощение кислоты | Б08 | точный | 1,0 |
| абсорбция кислоты | погружение в кислоту | Б08 | синоним | 0,75 |
| абсорбция кислоты | химически пропитанный | Б08 | связанный с доменом | 0,25 |
| абсорбция кислоты | кислотный рефлюкс | Б08 | не связано | 0,0 |
| бензиновая смесь | С10 | синоним | 0,75 | |
| бензиновая смесь | С10 | гипероним | 0,5 | |
| бензиновая смесь | фруктовая смесь | С10 | не связано | 0,0 |
| кран в сборе | водопроводный кран | А22 | гипоним | 0,5 |
| кран в сборе | водоснабжение | А22 | холоним | 0,25 |
| кран в сборе | школьное собрание | А22 | не связано | 0,0 |
Небольшая выборка датасета с анкорными и целевыми фразами, контекст, класс CPC (B08: Очистка, C10: Нефть, газ, топливо, смазочные материалы, A22: Разделка мяса, переработка мяса/птицы/рыбы), рейтинг класс и показатель сходства. |
Создание набора данных
Чтобы сгенерировать данные о схожести патентных фраз, мы сначала обрабатываем около 140 миллионов патентных документов в базе данных Google Patent и автоматически извлекаем важные английские фразы, которые обычно являются словосочетаниями с существительными (например, «застежка», «подъемная сборка») и функциональными фразами ( например, «пищевая промышленность», «чернильная печать»). Затем мы фильтруем и сохраняем фразы, которые встречаются как минимум в 100 патентах, и случайным образом выбираем около 1000 из этих отфильтрованных фраз, которые мы называем якорными фразами. Для каждой якорной фразы мы находим все соответствующие патенты и все классы CPC для этих патентов. Затем мы случайным образом отбираем до четырех совпадающих классов CPC, которые становятся контекстными классами CPC для конкретной ключевой фразы.
Мы используем два разных метода для предварительного создания целевых фраз: (1) частичное совпадение и (2) модель маскированного языка (MLM). Для частичного сопоставления мы случайным образом выбираем из всего корпуса фразы, частично совпадающие с якорной фразой (например, «снижение уровня шума» → «снижение шума», «материальное образование» → «формовочный материал»). Для MLM мы выбираем предложения из патентов, которые содержат заданную якорную фразу, маскируем их и используем модель Patent-BERT для прогнозирования кандидатов на замаскированную часть текста. Затем все фразы очищаются, включая строчные буквы, удаляются знаки препинания и некоторые стоп-слова (например, «и», «или», «сказал»), и отправляются экспертам для проверки. Каждая пара фраз оценивается независимо двумя экспертами в области технологий. Каждый оценщик также генерирует новые целевые фразы с разными рейтингами. В частности, их просят сгенерировать несколько целей с низким уровнем сходства и несвязанных между собой, которые частично совпадают с исходным якорем и/или с некоторыми целями с высоким уровнем сходства. Наконец, оценщики встречаются, чтобы обсудить свои оценки и выставить окончательные оценки.
Для частичного сопоставления мы случайным образом выбираем из всего корпуса фразы, частично совпадающие с якорной фразой (например, «снижение уровня шума» → «снижение шума», «материальное образование» → «формовочный материал»). Для MLM мы выбираем предложения из патентов, которые содержат заданную якорную фразу, маскируем их и используем модель Patent-BERT для прогнозирования кандидатов на замаскированную часть текста. Затем все фразы очищаются, включая строчные буквы, удаляются знаки препинания и некоторые стоп-слова (например, «и», «или», «сказал»), и отправляются экспертам для проверки. Каждая пара фраз оценивается независимо двумя экспертами в области технологий. Каждый оценщик также генерирует новые целевые фразы с разными рейтингами. В частности, их просят сгенерировать несколько целей с низким уровнем сходства и несвязанных между собой, которые частично совпадают с исходным якорем и/или с некоторыми целями с высоким уровнем сходства. Наконец, оценщики встречаются, чтобы обсудить свои оценки и выставить окончательные оценки.
Оценка набора данных
Чтобы оценить его производительность, набор данных сходства патентных фраз использовался в конкурсе U.S. Patent Phrase Matching Phrase Matching Kaggle. Соревнование было очень популярным, собрав около 2000 участников со всего мира. Команды, набравшие наибольшее количество очков, успешно использовали различные подходы, в том числе ансамблевые модели вариантов BERT и подсказки (см. полное обсуждение для получения более подробной информации). В таблице ниже показаны лучшие результаты конкурса, а также несколько готовых базовых показателей из нашей статьи. Метрика корреляции Пирсона использовалась для измерения линейной корреляции между прогнозируемыми и истинными оценками, которая является полезной метрикой для целевых моделей, чтобы они могли различать разные оценки сходства.
Исходные данные в статье можно считать нулевыми в том смысле, что они используют готовые модели без какой-либо дальнейшей точной настройки нового набора данных (мы используем эти модели, чтобы отдельно встраивать якорные и целевые фразы и вычислять косинус сходство между ними). Результаты конкурса Kaggle демонстрируют, что, используя наши обучающие данные, можно добиться значительных улучшений по сравнению с существующими моделями НЛП. Мы также оценили человеческую производительность при выполнении этой задачи, сравнив баллы одного оценщика с суммарным баллом обоих оценщиков. Результаты показывают, что это не особенно простая задача даже для экспертов-людей.
Результаты конкурса Kaggle демонстрируют, что, используя наши обучающие данные, можно добиться значительных улучшений по сравнению с существующими моделями НЛП. Мы также оценили человеческую производительность при выполнении этой задачи, сравнив баллы одного оценщика с суммарным баллом обоих оценщиков. Результаты показывают, что это не особенно простая задача даже для экспертов-людей.
| Модель | Обучение | Корреляция Пирсона |
| word2vec | Нулевой выстрел | 0,44 |
| Патент-BERT | Нулевой выстрел | 0,53 |
| Приговор-BERT | Нулевой выстрел | 0,60 |
| Kaggle 1-е место в одиночном разряде | Тонкая настройка | 0,87 |
| Kaggle Ансамбль 1-го места | Тонкая настройка | 0,88 |
| Человек | 0,93 |
Производительность популярных моделей без тонкой настройки (zero-shot), модели, настроенные на основе набора данных Patent Phrase Similarity в рамках конкурса Kaggle, и производительность одного человека. |
Заключение и будущая работа
Мы представляем набор данных сходства патентных фраз, который использовался в качестве эталонного набора данных в конкурсе сопоставления патентных фраз с фразами США, и демонстрируем, что, используя наши обучающие данные, можно добиться значительных улучшений по сравнению с существующими моделями НЛП.
Дополнительные сложные контрольные показатели машинного обучения могут быть созданы на основе корпуса патентов, а патентные данные нашли отражение во многих наиболее изученных сегодня моделях. Например, набор текстовых данных C4, используемый для обучения T5, содержит множество патентных документов. Модели BigBird и LongT5 также используют патенты из набора данных BIGPATENT. Доступность, полнота и открытые условия использования полнотекстовых данных (см. Общедоступные наборы данных Google Patents) делают патенты уникальным ресурсом для исследовательского сообщества. Возможности для будущих задач включают массовую классификацию с несколькими метками, обобщение, поиск информации, сходство изображения и текста, предсказание графа цитирования и перевод.