Содержание
Искусственный перевод / Аналитика
Perhaps the
history of the errors of mankind, all things considered, is more
valuable and
interesting than that of their discoveries. Truth is uniform and
narrow; it constantly exists,
and does not seem to require so much an active energy, as a passive
aptitude of the soul in
order to encounter it. But error is endlessly diversified; it has no
reality, but is the pure and
simple creation of the mind that invents it. In this field the soul has
room enough to expand herself,
to display all her boundless faculties, and all her beautiful and
interesting extravagancies and absurdities.
(с) Benjamin Franklin
Взгляд на системы машинного перевода изнутри
Знание иностранных языков — это не только полезный навык в повседневной
жизни, но также одно из основных требований при приеме на работу.
Однако сегодня одного только знания иностранных языков бывает
недостаточно, поскольку объем информации, которую необходимо ежедневно
переводить, существенно возрос. Вместе с тем, эта задача успешно
решается, и ни для кого не составляет труда всего за несколько секунд
перевести контракт или контент иностранного сайта. А все потому, что
переводом в этом случае занимается программа-переводчик: человек не
успевает и глазом моргнуть, а перевод уже готов.
Машинный (или автоматизированный) перевод – именно так
называется технология, с помощью которой компьютерная программа
осуществляет связный перевод текста с одного языка на другой.
Технология машинного перевода (МП) как научное направление имеет уже
почти вековую историю, а первые идеи автоматизации переводческого
процесса появились еще в XVII столетии. В 1954 году в США состоялся так
называемый Джорджтаунский эксперимент, на котором была представлена
первая версия электронного переводчика: программа имела словарный запас
всего в 250 слов и действовала на основе шести правил.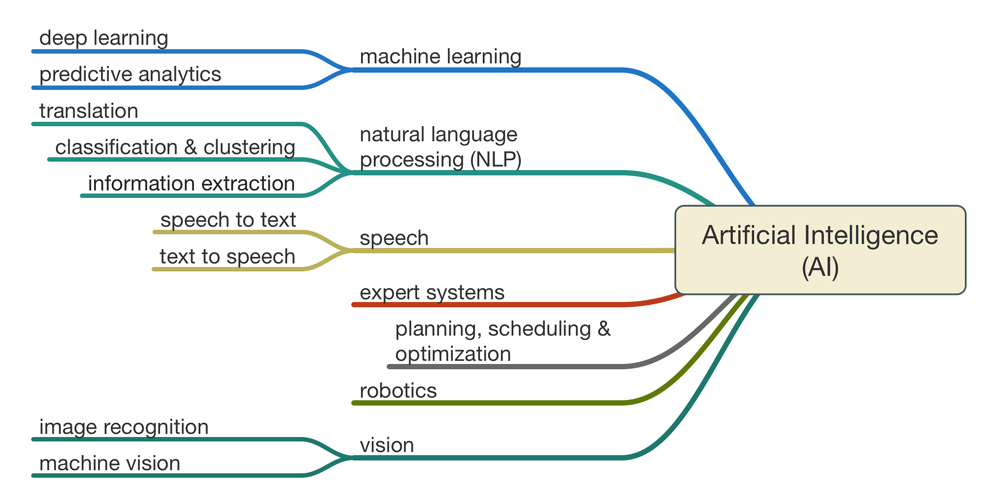
Сегодняшние программы-переводчики имеют гораздо более широкий
«кругозор» и действуют на основе более совершенных
переводческих технологий. Системы перевода активно используются во всем
мире в случаях, когда требуется быстро понять смысл текста или часто
переводить большие объемы информации. Некоторым разработчикам на
сегодняшний день удалось достичь весьма приемлемого качества перевода
по отдельным языковым направлениям. В этом материале мы предлагаем
посмотреть, как выглядит процесс перевода изнутри, каким образом
программе удается «понять» иностранный текст и
перевести его на другой язык.
Две стороны МП
В рамках технологии машинного перевода существует два подхода:
традиционный (основанный на правилах, rule-based machine translation) и
статистический (основанный на статистической обработке словарных баз,
statistical based machine translation). Традиционный метод МП
используется большинством разработчиков систем перевода. Работа такой
Работа такой
программы включает в себя несколько этапов и, по сути, заключается в
использовании лингвистических правил (алгоритмов). Соответственно,
создание такого электронного переводчика включает в себя разработку
правил и пополнение словарных баз системы. От разработки необходимых
алгоритмов зависит качество перевода на выходе. Богатый словарь системы
также позволяет справиться с переводом самых разнообразных по тематике
текстов.
Статистический метод МП действует совсем по иному принципу. В его
основе лежат математические методы для получения перевода. Точнее
сказать, весь принцип работы подобной системы основан на статистическом
вычислении вероятности совпадений фраз из исходного текста с фразами,
которые хранятся в базе системы перевода.
Правила перевода изнутри
Как уже было сказано выше, метод машинного перевода, основанный на
правилах, называется традиционным, поскольку на его основе работает
большинство систем автоматизированного перевода. В России с помощью
В России с помощью
традиционного способа МП разрабатываются программные продукты компании
ПРОМТ — единственного в нашей стране производителя
программ-переводчиков. Самое время рассказать об этом методе МП
поподробнее.
Работа системы машинного перевода, основанной на правилах, состоит из
нескольких этапов. Сначала система осуществляет морфологический анализ
слов (указывает род, число, лицо и другие морфологические
характеристики для каждого слова). Кроме того, программа фиксирует
полную информацию по многозначным словам (тем словам, которые могут
относиться к разным частям речи или иметь разные значения).
Затем происходит объединение отдельных слов в группы: именные (где
главным словом является существительное, а зависимые от него слова
определяются по идентичным морфологическим характеристикам), глагольные
(главное слово – глагол) и др. Кроме того, в этот момент
система может решить вопрос многозначности для некоторых слов в
зависимости от их контекста.
На следующем этапе программа приступает к определению членов
предложения и их роли в предложении, границ и типа связи между простыми
предложениями. Сначала она ищет границы простых предложений, которые
определены знаками препинания. Затем определяет главные члены, причем
сначала система ищет сказуемое и только потом подлежащее перед ним
(если перед сказуемым подлежащего нет, программа ищет его за сказуемым
или делает вывод, что подлежащее отсутствует (например, в безличных
предложениях)). Завершив поиск главных членов предложения, система
определяет сферы их влияния (слова и группы слов, зависимые от
подлежащего и от сказуемого). Все группы, которые система не смогла
отнести ни к сфере влияния подлежащего, ни к группе сказуемого,
считаются обстоятельствами.
И, наконец, на заключительной стадии работы происходит окончательное
согласование всех членов предложения и построение предложений с учетом
требований грамматики выходного языка. Элементы согласуются внутри
Элементы согласуются внутри
групп, а также уточняется их зависимость от подлежащего или сказуемого
и подтверждается порядок слов в предложении.
Таким образом, процесс перевода системы логически понятен: происходит
поиск языковых эквивалентов, их объединение по морфологическим
признакам, синтаксический анализ членов предложения и окончательный
синтез предложения на выходном языке.
Статистический метод МП работает совсем иначе. Здесь главным является
наличие как можно большего количества парных фрагментов текста и
вычисление наибольшей вероятности их употребления. Программа вычисляет
наиболее вероятную последовательность слов выходного языка, которую она
считает наиболее соответствующей переводу исходного текста.
На данный момент очевидным является то, что системы традиционного
метода МП справляются с переводом текстов лучше, чем статистические
системы. Примеры сравнения качества перевода двух методов МП
представлены в Таблице 1.
Таблица
1. Сравнение
традиционного и статистического методов МП.
| Пример | Традиционный метод МП | Статистический метод
МП |
| Your iDisk Public
folder makes exchanging files with friends a no-brainer. | Ваша iDisk
Общественная папка делает файлы обмена с друзьями легкой задачей. | Ваш iDisk
общественной папке позволяет обмениваться файлами с друзьями один не элементарно. |
Статистика на подходе
Однако, несмотря на явное, на сегодняшний день, преимущество
традиционного метода, статистический машинный перевод в последнее время
более явно заявляет о себе. Самыми продуктивными разработками в этой
области занимается компания Google, которая предлагает онлайновый
сервис перевода на своем портале. Google заявляет о преимуществе именно
Google заявляет о преимуществе именно
статистического метода перевода и видит причину успеха в максимально
обширных словарных базах, имеющих необходимое количество сегментов
текста для их правильного перевода. Однако пока успехи в этой области
незначительные. Перевод, выполняемый сервисом, постоянно меняется, но
далеко не всегда в лучшую сторону (см. примеры в Таблице 2). Как видно
из примера, одно и то же выражение (attorney’s fees) было переведено
совершенно по-разному (и спустя месяц перевод не выглядит корректным).
Кроме того, система часто неправильно распознает артикли и не всегда
согласует слова между собой по морфологическим признакам.
Таблица
2. Перевод статистическим методом МП.
| Пример | Первый перевод Google
(декабрь 2007 г.) | Перевод Google
(январь 2008 г.  ) )
|
| Attorney’s
Fees A clause for attorney’s fees is normally included in the note in the event the borrower defaults in repayment of the loan. | Прокурора
Тарифы Положение на адвоката гонорар, как правило, включены в записку в случае невыполнения заемщиком в погашение кредита. | Прокурора
сборы А положение на гонорар адвоката, как правило, включена в записку, в случае, если заемщик по умолчанию в качестве погашения кредита. |
Возможность быстрого пополнения словарных баз, безусловно, является
преимуществом статистического метода МП. Однако у этого обстоятельства
есть и обратная сторона: большое количество информации требует немалого
объема памяти для хранения. Возможно, в будущем, эту проблему удастся
Возможно, в будущем, эту проблему удастся
успешно решить, но на данный момент она существует.
Нюансы технологии машинного перевода, основанной на правилах
(традиционного метода МП), не позволяют разработчикам так же быстро
публиковать изменения, как это делает Google. Работа в рамках
традиционного метода МП заключается, главным образом, в
совершенствовании самого механизма перевода, разработке новых
алгоритмов. Однако эти усилия, пусть и не столь быстрые, оправдывают
себя. Например, последняя версия уже упоминавшейся системы PROMT
представляет качество перевода на порядок выше, чем ее предшественница.
Повод улыбнуться
Однако пока качество перевода, предлагаемое традиционной системой МП и
статистической системой, нельзя назвать идеальным. Особенно сложным для
программы-переводчика является перевод художественных текстов, где
велика вероятность нестандартного порядка слов в предложении, и от
переводчика требуется понимание иносказательного смысла выражения.
Поскольку программа-переводчик пока не обладает образным мышлением,
перевод таких предложений выглядит забавно. Некоторые примеры забавных
переводов системами МП приведены в Таблице 3.
Таблица
3. Примеры забавных переводов пословиц.
| Пример (пословицы) | Правильный перевод | Перевод, сделанный системой
перевода |
| Even a wise man stumbles. | На всякого мудреца довольно простоты. | Даже мудрый человек натыкается. |
| Sure as eggs are eggs. | Ясно, как божий день. | Уверенный, поскольку яйца — яйца. |
| No news is good news. | Отсутствие новостей — уже хорошая новость. | Никакие новости не хорошие новости. |
Однако существует немало примеров электронных переводов, которые
невозможно отличить от работы, выполненной человеком-переводчиком.
Например:
Таблица
4. Примеры удачных переводов, сделанных системой МП.
| Пример | Перевод системой МП |
|
Fair words butter no parsnips. |
Соловья баснями не кормят. |
|
One will reap what he’ll sow. |
Каждый будет пожинать то, что он посеет. |
|
Information that defines a GPRS connection between a mobile phone and the network. PDP context activation also means that other subscriber-related parameters are activated.  |
Информация, которая определяет связь GPRS между мобильным телефоном и сетью. Активация контекста PDP также означает, что активизированы другие связанные с подписчиком параметры. |
Что дальше?
В процессе тестирования систем МП стало ясно, что возможность быстрого
пополнения словарных хранилищ статистической системы на данный момент
не дает нужного результата. Однако, вполне возможно, это вопрос
времени. В то же время разработчики традиционных систем МП сегодня
могут гарантировать перевод высокого, но не идеального качества.
В настоящее время существует идея объединить оба метода машинного
перевода, в результате чего, возможно, удастся создать систему нового
поколения, которая совместит преимущества каждого метода и сможет
выполнять перевод, максимально близкий к идеальному. Некоторые
производители уже приступили к разработкам в этой области. А нам
А нам
остается ждать от них качественно новых результатов.
Автор выражает благодарность компании ПРОМТ
за консультации при создании материала.
— Обсудить материал в конференции
Искусственный интеллект научился переводить на иностранные языки без помощи человека
Фото: iStock
Ученый из испанского Университета Страны Басков (UPV) и программист из Facebook в двух разных исследованиях доказали, что нейросети способны самостоятельно обучаться переводу на иностранные языки, пишет журнал Science. Теперь, если компьютеру дать много книг на китайском и арабском языках, которые не будут дублироваться, то алгоритм сможет сам научиться переводу.
В двух работах использовался метод машиного обучения без учителя, в котором алгоритмам предлагалось создать двуязычные словари без помощи человека. Это решение основано на том, что языки сильно похожи по тому, как слова группируются друг с другом. Так, слова, обозначающие «стол» и «стул» во всех языках часто используются вместе. Поэтому, если компьютер распределяет эти совместные появления слов в форме большого дорожного атласа со словами вместо городов, то «карты» для разных языков будут напоминать друг друга, однако в них будут разные «названия». Затем машина определит, как лучше всего наложить один «атлас» с другим, и создаст двуязычный словарь.
Поэтому, если компьютер распределяет эти совместные появления слов в форме большого дорожного атласа со словами вместо городов, то «карты» для разных языков будут напоминать друг друга, однако в них будут разные «названия». Затем машина определит, как лучше всего наложить один «атлас» с другим, и создаст двуязычный словарь.
Алгоритмы, предложенные в исследованиях, также могут переводить тексты на уровне предложений. Для этого используются методы обратного перевода и шумоподавления. В рамках обратного перевода предложение грубо переводится с одного языка на другой, а затем — на язык оригинала. Если итоговое предложение не идентично оригинальному, то нейросети настраивают перевод таким образом, чтобы в следующий раз перевод был точнее. Метод шумоподавления добавляет в предложение «шум» (изменяет порядок слов или удаляет некоторые из них) и пытается перевести предложение на язык оригинала. Вместе эти методы обучают нейросети структуре языка.
Однако предложенные методы несколько различаются. Так, система из UPV, предложенная программистом Микелем Артексте, чаще пользуется методом обратного перевода во время обучения. А вторая система, которую описал программист из Facebook Гийом Лампль, добавляет еще один шаг к переводу. Обе системы, перед переводом предложения кодируют его в более абстрактное представление, а лишь затем переводят. Однако система, предложенная в Facebook проверяет, чтобы «промежуточный язык» стал полностью абстрактным. По словам авторов двух исследований, объединив усилия, они смогут улучшить результаты своих работ.
Так, система из UPV, предложенная программистом Микелем Артексте, чаще пользуется методом обратного перевода во время обучения. А вторая система, которую описал программист из Facebook Гийом Лампль, добавляет еще один шаг к переводу. Обе системы, перед переводом предложения кодируют его в более абстрактное представление, а лишь затем переводят. Однако система, предложенная в Facebook проверяет, чтобы «промежуточный язык» стал полностью абстрактным. По словам авторов двух исследований, объединив усилия, они смогут улучшить результаты своих работ.
В переводе текста с английского на французский, который был составлен из набора в почти 30 млн предложений, оба алгоритма набрали по 15 баллов во время автоматической оценки качества машинного перевода (BLEU) при переводе в обоих направлениях. У Google Translate 40 баллов за тест, но технология переводчика обучается под контролем. Специалисты по переводу набирают в таком тесте более 50 баллов. Авторы утверждают, что результаты систем можно улучшить, добавив при обучении несколько тысяч параллельных предложений.
Большинство систем на основе машинного обучения тренируются под наблюдением человека: компьютер делает предположение, узнает правильный ответ, а затем корректирует процесс. Эта система хорошо работает, когда компьютер нужно обучить переводу между, например, французским и английским языками, поскольку на них языках написано множество документов. Однако такая модель работает хуже для менее популярных языков, а также для пар, в которых мало одинаковых текстов.
Подписывайтесь на наш канал в Telegram!
Краткое руководство по переводу с использованием искусственного интеллекта
Искусственный интеллект (ИИ) обеспечил некоторые из наиболее значительных достижений в области технологий перевода за последнее десятилетие. Благодаря прорывам в технологиях машинного обучения, таких как нейронные сети, обработка естественного языка и глубокое обучение, ИИ-переводчик может многое порадовать.
Благодаря прорывам в технологиях машинного обучения, таких как нейронные сети, обработка естественного языка и глубокое обучение, ИИ-переводчик может многое порадовать.
Однако вокруг этой технологии ходит много слухов и спекуляций.
В этом кратком руководстве мы рассмотрим основы перевода с использованием искусственного интеллекта, развеем несколько распространенных мифов, а также объясним, как лингвисты используют эту технологию для более быстрого получения результатов без потери качества перевода.
Что такое перевод ИИ и как он работает?
ИИ-перевод — это самый передовой подход к машинному переводу, использующий ряд технологий машинного обучения для более глубокого понимания языка. Искусственный интеллект значительно продвинулся за последние пару десятилетий, в основном благодаря достижениям в двух ключевых областях: вычислительной мощности компьютера и технологии машинного обучения.
Машинное обучение использует интеллектуальные алгоритмы для анализа огромных объемов данных и выявления закономерностей, что позволяет «обучаться» и воспроизводить автоматизированные задачи, включая перевод.
В рамках машинного обучения развитие технологии, называемой нейронными сетями, и методологий, называемых глубоким обучением, привело к созданию самой передовой на сегодняшний день итерации перевода ИИ: нейронного машинного перевода (NMT).
Для более подробного ознакомления с нейронным машинным переводом ознакомьтесь со следующей статьей в нашем блоге: Что такое нейронный машинный перевод?
В этой статье мы цитируем следующее определение с DeepAI.org:
«Нейронный машинный перевод — это подход к машинному переводу, который применяет большую искусственную нейронную сеть для прогнозирования вероятности последовательности слов, часто в форме целых предложений. Системы [нейронного машинного перевода] быстро выходят на передний план машинного перевода, недавно вытеснив традиционные формы систем перевода».
Нейронный машинный перевод — это технология, на которой в настоящее время работают самые передовые в отрасли инструменты перевода с искусственным интеллектом, включая Google Translate, Microsoft Translator, Unbabel и наши собственные решения для машинного перевода.
По сути, нейронная сеть — это особый тип алгоритма машинного обучения, который воспроизводит нейронное поведение человеческого мозга. В частности, он имитирует человеческое обучение, повторяя одну и ту же задачу и изучая последовательности событий, которые наиболее эффективно достигают желаемого результата.
В больших масштабах эти алгоритмы обучаются переводу между языками, учатся на собственных ошибках (и успехах) и продолжают совершенствоваться, анализируя огромные объемы данных. Google Translate, например, анализирует миллиарды переводов на тысячи языков, чтобы улучшить качество своего вывода.
Насколько хорош последний перевод искусственного интеллекта?
Технологии, лежащие в основе современных систем перевода с искусственным интеллектом, впечатляют, но задача, которую они решают, огромна. Та же технология предназначена для выявления заболеваний еще до того, как появятся симптомы; управлять беспилотными транспортными средствами и «видеть» содержимое изображений.
Тем временем результаты лучших доступных инструментов перевода ИИ остаются относительно неутешительными. Это не делает технологию менее впечатляющей; это просто подтверждает реальность того, как много делает человеческий мозг, когда он слушает или читает и понимает язык со всем контекстом и нюансами, которые мы используем ежедневно.
Еще до того, как мы подумаем о переводе, перспектива алгоритмов, соответствующих способности людей выполнять и понимать один язык, все еще остается научной фантастикой.
Как предприятия используют ИИ-перевод?
Чтобы лучше понять роль ИИ-перевода в языковой индустрии, полезно посмотреть, как компании в настоящее время используют эту технологию. Вот несколько полезных примеров:
Машинный перевод плюс постредактирование (MTPE):
Профессиональные переводчики просматривают и редактируют контент, созданный с помощью ИИ-перевода, чтобы довести его до требуемого качества.
Мгновенный перевод:
Для сценариев, в которых нет времени на полный процесс перевода, и ИИ предпочтительнее, чем отсутствие решения вообще.
Анализ:
Международным компаниям может потребоваться доступ к информации на иностранных языках, а технология ИИ может обеспечить мгновенный перевод (проверьте точность, прежде чем делать какие-либо выводы или принимать решения).
Внутреннее использование:
Для контента, который не просматривается публично, например исследований, цитат, статистики, новостей и т. д. для внутреннего использования.
Стратегическое планирование:
Мгновенные переводы могут помочь командам разрабатывать стратегические планы и быстрее реагировать на возможности — опять же, точность перевода требует проверки, прежде чем предпринимать какие-либо действия.
Чат-боты:
Многоязычные компании используют технологию искусственного интеллекта для обеспечения автоматизированного (хотя и менее совершенного и более механического) взаимодействия с пользователями.
Пользовательский контент:
Такие компании, как Twitter и Airbnb, используют эту технологию для автоматического перевода пользовательского контента, такого как обзоры, сообщения и посты.
Служба поддержки:
Международные компании могут мгновенно реагировать на проблемы клиентов до тех пор, пока сотрудники службы поддержки не будут готовы вмешаться.
По сути, перевод с использованием искусственного интеллекта вступает в действие, когда времени мало и вам нужен мгновенный ответ, то есть когда скорость важнее точности.
Одним из лучших примеров может быть многоязычный чат-бот, встроенный в веб-сайт, обеспечивающий мгновенные ответы на вопросы пользователей. Производительность бота имеет ограничения, и переводы не всегда могут быть точными на 100%, но, по сути, он выполняет роль, которую не могут выполнять люди.
То же самое верно и для профессиональных переводчиков, которые используют решения ИИ для создания мгновенных черновиков, которые они могут просматривать, редактировать и улучшать для достижения требуемого качества. Если инструмент перевода с искусственным интеллектом может достичь даже 20-процентной точности на протяжении всего проекта, это по-прежнему означает значительную экономию времени и средств, что имеет большое значение для клиентов и компаний, использующих эти решения.
Чтобы узнать больше о том, как перевод с использованием искусственного интеллекта может помочь вам сэкономить время и деньги на переводческих проектах независимо от их масштаба, свяжитесь с нами — заполните форму на нашей контактной странице.
Перевод сложнее для бизнеса, и искусственный интеллект может помочь
Искусственный интеллект
Сергей Тарасов — stock.adobe.com
Искусственный интеллект (ИИ) для перевода — это то, что Google и другие компании предоставили частным лицам. Доступ к нему можно получить с вашего телефона. Тем не менее, перевод по-прежнему является гораздо большей и сложной проблемой, чем многие думают. У делового сообщества есть много сложных и уникальных потребностей, которые усложняют задачу точного и надежного перевода, и ИИ демонстрирует все более широкие возможности.
Одним из ключей к деловому переводу является тот простой факт, что в каждой сфере бизнеса есть свои термины, фразы и даже идиомы. Обычная система перевода в облаке, широко обученная с помощью краудсорсинга или других общедоступных методов, не будет обладать точностью, необходимой для делового перевода. Кроме того, само облако по-прежнему является проблемой. Многие цели бизнеса связаны с защитой интеллектуальной собственности (ИС). Для этого они хотят, чтобы их информация оставалась локально, за их брандмауэрами.
Кроме того, само облако по-прежнему является проблемой. Многие цели бизнеса связаны с защитой интеллектуальной собственности (ИС). Для этого они хотят, чтобы их информация оставалась локально, за их брандмауэрами.
Теперь добавим сложность требований к конфиденциальности, таких как GDPR Европейского Союза и CCPA Калифорнии. Все чаще правительства устанавливают правила в отношении того, где должны храниться данные граждан и чем можно делиться. Местоположение и анонимность информации также усложняют понимание компанией многоязычного бизнеса.
Тогда есть сотрудничество. Почти каждый в бизнесе использует электронные средства связи, будь то электронная почта и обмен текстовыми сообщениями или более формальные системы чата. Дополнение этих приложений точным и мгновенным переводом может улучшить внутреннюю коммуникацию глобальной компании и способствовать успеху.
«В то время как электронное открытие было очевидной точкой входа в бизнес-перевод с помощью ИИ», — начал JP Barazza, директор по информационным технологиям, SYSTRAN. «Представьте глобальные группы разработчиков в таких отраслях, как высокие технологии и биотехнологии. Они могут стать более эффективными с помощью строгого перевода». Поддержка клиентов — еще одна горизонталь, где перевод может быть очень полезен.
«Представьте глобальные группы разработчиков в таких отраслях, как высокие технологии и биотехнологии. Они могут стать более эффективными с помощью строгого перевода». Поддержка клиентов — еще одна горизонталь, где перевод может быть очень полезен.
БОЛЬШЕ ДЛЯ ВАС
Искусственный интеллект — только часть решения
Как и в облачных моделях, система SYSTRAN использует обучение без учителя. Тем не менее, он использует гораздо более тщательный набор данных для обучения систем для каждой отрасли. Нейронная сеть является лишь компонентом логики системы. Из-за специфической терминологии во многих языках процедурная логика используется в предварительной и последующей обработке по сети, чтобы помочь с четкими правилами и терминологией бизнес-секторов. В конце концов, ими легче управлять для четко определенных лингвистических соглашений, в то время как нейронная сеть может справиться с гибкостью общего языка.
Одним из примеров необходимости правил является использование имен в американском английском и французском французском языках (да, мне пришлось это сделать…).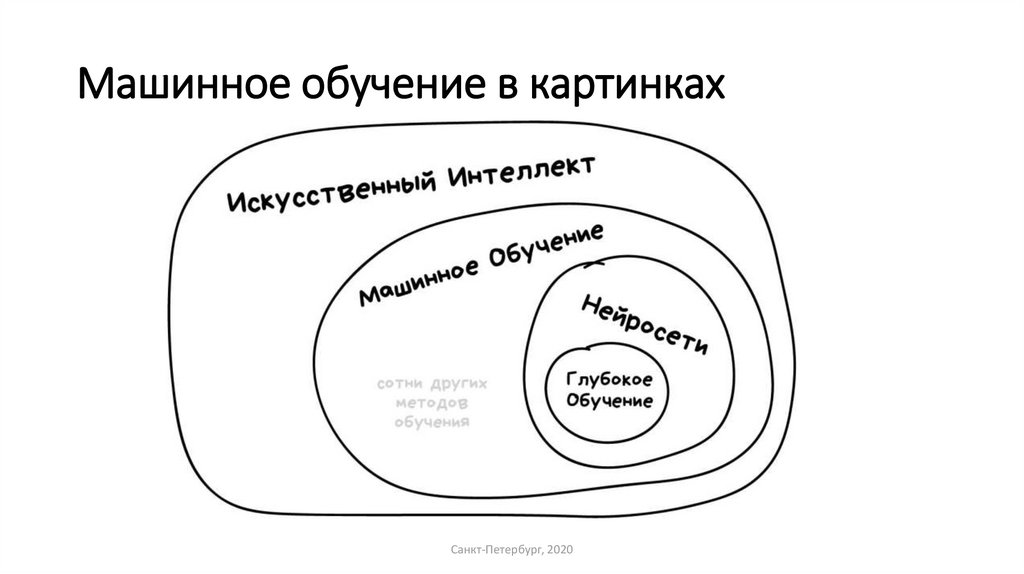 В США мы регулярно используем имя лидера, например «президент Байден». Во Франции в новостях обычно не используются имена, а упоминаются титулы, например «Президент Соединенных Штатов». Подумайте о двухстороннем переводе. «Хотя это просто перевести с английского, опустив название и расширив заголовок», — сказал Жан Сенелларт, генеральный директор. «Если мы добавим имя при переходе с французского на английский, что произойдет при смене президента? Система будет продолжать добавлять имя предыдущего президента до тех пор, пока не будет достаточно данных для переобучения системы. Мы приняли решение сохранить французский справочный стиль при переводе на английский язык, чтобы оставаться точными». Использование явных правил — чистый способ решения этой проблемы.
В США мы регулярно используем имя лидера, например «президент Байден». Во Франции в новостях обычно не используются имена, а упоминаются титулы, например «Президент Соединенных Штатов». Подумайте о двухстороннем переводе. «Хотя это просто перевести с английского, опустив название и расширив заголовок», — сказал Жан Сенелларт, генеральный директор. «Если мы добавим имя при переходе с французского на английский, что произойдет при смене президента? Система будет продолжать добавлять имя предыдущего президента до тех пор, пока не будет достаточно данных для переобучения системы. Мы приняли решение сохранить французский справочный стиль при переводе на английский язык, чтобы оставаться точными». Использование явных правил — чистый способ решения этой проблемы.
Такое сочетание нейронной сети и процедурных правил также обеспечивает гибкость компании. Базовую систему можно обучать, используя разные плагины для разных компаний. Это обеспечивает как более простой цикл разработки, так и более чистый способ предоставления обновлений. Конкретные корпоративные и отраслевые правила могут быть добавлены без переобучения системы глубокого обучения.
Конкретные корпоративные и отраслевые правила могут быть добавлены без переобучения системы глубокого обучения.
Деловой перевод отличается
Для бизнеса необходима повышенная точность. «Потребители готовы допускать ошибки, если общий смысл передается посредством перевода», — сказал г-н Барацца. «Бизнесу нужна точность. Это касается не только соблюдения нормативных требований и контрактов. Недостаток точности может замедлить разработку продукта, снизить безопасность и вызвать недовольство клиентов».
Из-за этой потребности в точности и из-за состояния отрасли есть еще один компонент решения. Мы еще не достигли того момента, когда автоматизированным системам можно полностью доверять. Люди должны просматривать переводы.
Внутри системы на данный момент перевод сложный и ориентирован на достаточно небольшую группу языков, поэтому они используют попарные механизмы. Например, один движок переводит с английского на французский, а другой — с французского на английский. Обучение систем использует странную форму обратного распространения. В одном движке обратное распространение означает исправление результатов и подачу их обратно в качестве входных данных. В переводе это означает перевод результатов обратно через второй механизм, а затем исправление. Это сложнее (по крайней мере, для меня), но я понимаю основы очень интересного цикла, в котором оба двигателя помогают друг другу тренироваться.
Обучение систем использует странную форму обратного распространения. В одном движке обратное распространение означает исправление результатов и подачу их обратно в качестве входных данных. В переводе это означает перевод результатов обратно через второй механизм, а затем исправление. Это сложнее (по крайней мере, для меня), но я понимаю основы очень интересного цикла, в котором оба двигателя помогают друг другу тренироваться.
Так сейчас делаются переводы, но грядут изменения. Этот стиль означает множество отдельных движков, и чем больше количество языков, тем больше перестановок означает значительное увеличение количества движков. Одно из решений состояло в том, чтобы использовать английский язык в качестве промежуточного языка, переводя все через него, чтобы ограничить различные движки. Это добавляет неэффективности и неточностей. Facebook недавно анонсировал единую модель, которая может переводить во всех направлениях для нескольких языков. В то время как отдельные люди чувствуют себя более комфортно с ошибками, так что это отличное место для проверки такой модели, в конечном итоге технология улучшится, и корпоративный перевод выиграет.