Содержание
Нюансы распознавания речи. Восстанавливаем пунктуацию, числа и заглавные буквы / Хабр
⭐ градиент обреченный
В задачах распознаваниях речи при переводе аудио в текст есть дополнительные этапы, делающие этот текст более человекочитаемым. Например, предложение «привет хабр сегодня мы сделаем двадцать шесть моделей по распознаванию голоса» будет выглядеть лучше в таком виде: «Привет, хабр. Сегодня мы сделаем 26 моделей по распознаванию голоса«. Другими словами, сегодня мы поговорим про то, как автоматически восстановить пунктуацию и капитализацию (сделать нужные буквы заглавными). Также упомянем денормализацию текста (при этом числа обретут свою цифровую форму обратно, эту задачу еще называют inverse text normalization).
Пунктуация и капитализация
После непродолжительного поиска выяснится, что пара решений для русского языка в этом направлении уже есть (например, модели от vosk и silero). Мы же копнем чуть глубже и разберемся как самому натренировать такую модель. Это даст нам возможность выбора знаков препинания, нужного языка (например, башкирского или чувашского) и подбора соответствующего нашему домену корпуса текстов.
Мы же копнем чуть глубже и разберемся как самому натренировать такую модель. Это даст нам возможность выбора знаков препинания, нужного языка (например, башкирского или чувашского) и подбора соответствующего нашему домену корпуса текстов.
Важно понимать, что так как мы работаем исключительно с текстами, то предложения типа «казнить нельзя помиловать» модель будет разрешать на основании данных, на которых она обучалась. Эти данные никак не связаны с аудио (я встречал идеи о том, как можно использовать паузы из аудио в виде признаков, но это не очень надежно, особенно в разговорной речи) и неточности обязательно будут. Нашей задачей здесь является лишь сделать текст более легким для восприятия.
Данные
Первым делом нам нужно раздобыть тренировочный корпус. Это должен быть текстовый документ с одним предложением на строку. В предложениях должны быть знаки препинания, которые мы хотим восстанавливать. Подготовить такой файл, имея на руках обычные тексты, довольно просто.
Если вы делаете модель для малоресурсного языка, то можно воспользоваться проектом Lingtrain, который я делаю для создания параллельных книг (проект открытый и идеи приветствуются). На первом этапе в нем идет разбитие всего текстового документа на предложения, после чего такой файл можно скачать.
Если же вы делаете модель для какого-то популярного языка, то можно воспользоваться готовыми датасетами типа Tatoeba. Для удобства я оформил скрипты для подготовки и обучения в репозиторий multipunct, поэтому дальше я буду обращаться к нему. Качаем его и начинаем подготовку данных.
Чтобы скачать датасет (около 500Mb) и извлечь из него предложения на русском языке нужно выполнить следующую команду:
python ./get_tatoeba.py --data_dir ./dataset --lang rus
Предложения сохранятся в файл sentences.txt. Этот файл — часть большого скачанного датасета sentences.csv, в котором находятся предложения на многочисленных языках. Параметр lang задает русский язык. Теперь нам нужно каким-то образом разметить данные, чтобы модель могла на них обучаться. Про модель мы пока не говорили, поэтому следующим шагом перейдем к ней.
Теперь нам нужно каким-то образом разметить данные, чтобы модель могла на них обучаться. Про модель мы пока не говорили, поэтому следующим шагом перейдем к ней.
Модель
Есть очень популярный фреймворк для задач ASR (automatic speech recognition или же распознавание речи) от Nvidia, который называется NeMo. В нем можно найти много полезного, нас же сейчас интересует Punctuation and Capitalization Model. Эта модель на основе BERT’а будет определять для каждого кусочка предложения (токена) и его класс — заглавная у него буква или нет и какой знак препинания после него ставить, если это нужно. Затем токены собираются воедино с учетом классов и мы получим наше готовое предложение.
Для тех, кто только интересуется машинным обучением и NLP в частности, рекомендую ознакомиться с замечательными статьями Джея Аламмара, переводы которых есть на хабре (один, два).
Важным для нас тут является то, данные мы размечаем сами (тем самым контролируя набор знаков препинания), а при обучении можно передать предтренированную модель с huggingface, что очень сильно упрощает задачу.
Разметим данные. При помощи второго скрипта из multipunct разметим наш корпус, а также разобьем его на тренировочные и валидационные части.
python ./prepare_data.py --data_dir ./dataset --num_samples 50000 --percent_dev 0.2
По умолчанию, размечаться будут знаки «.,!?», остальная пунктуация будет удалена. Изменить этот набор можно в скрипте prepare_data.py. Также в этом скрипте пунктуация немного стандартизируется, обрабатываются случаи с unicode’ными тире и т.д.
Важный момент — в скрипте есть параметр lines_to_combine. Если установить его равным двум, то на одну строку будет по два предложения. Эффектом от этого станет то, что модель будет учиться разбивать текст на несколько предложений. Выбирайте параметр в зависимости от ваших потребностей.
Разметка будет представлять из себя что-то типа такого: «OU OO ?O». Здесь символ «O» говорит, что ничего делать не нужно, «U» — первая буква должна быть заглавной, а знак препинания говорит сам за себя.
Обучение
Обучать будем в Colab’e. Так мы используем предтренированную модель (в ноутбуке это DeepPavlov/distilrubert-tiny-cased-conversational-v1), то бесплатной версии будет вполне достаточно. Не забываем выбрать GPU в меню среды выполнения. Константа PRETRAINED_BERT_MODEL задает путь к модели на huggingface, здесь можно попробовать другую модель. Перед началом тренировки загрузите размеченные выше данные в папку /data.
Далее запускаем обучение и ждём. Состояние модели будет сохраняться в checkpoint’ах, которые можно будет загружать позже. Весь дополнительный код по токенизации и постобработке выхода модели заключен внутри самой модели. Поэтому при простом ее использовании потребуется только вызвать метод add_punctuation_capitalization().
Если понадобится экспортировать модель для инференса, например, в TorchScript, то для этого есть метод export(). Обратите внимание, что экспортируется при этом только модель, выдающая логиты (числа, по которым определяются вероятности принадлежности к классам). Весь инфраструктурный код придется вытащить дополнительно.
Весь инфраструктурный код придется вытащить дополнительно.
Итак, модель натренирована, можно передавать в нее тексты в нижнем регистре без пунктуации.
queries = [
'меня зовут сергей а как тебя',
'закрой за мной дверь я ухожу'
]
results = model.add_punctuation_capitalization(queries)
for query, result in zip(queries, results):
print(f'TEXT : {query}')
print(f'RESULT: {result.strip()}\n')TEXT : привет меня зовут сергей а как тебя RESULT: Привет, меня зовут Сергей. А как тебя? TEXT : закрой за мной дверь я ухожу RESULT: Закрой за мной дверь. Я ухожу.
Для улучшения качества попробуйте поиграться с разными моделями и сбалансируйте датасет в соответствии с вашими знаками препинания.
Текст стал выглядеть лучше, давайте теперь попробуем разобраться с переводом чисел из текстового вида в исходный.
Денормализация
Опять же, есть статьи на тему нейронных сетей и денормализации. Мы же для этой задачи воспользуемся неплохой библиотекой Word-to-Number-Russian от Kouki_RUS. Она основана на другой известной библиотеке natasha от alexanderkuk, — обязательно посмотрите, если интересуетесь обработкой текстов.
Она основана на другой известной библиотеке natasha от alexanderkuk, — обязательно посмотрите, если интересуетесь обработкой текстов.
Однако сразу использовать эти скрипты для задач ASR (где текст без пунктуации) будет не очень удобно, — случаи типа «шестьсот одиннадцать два два три» будут схлапываться в «618» (парсинг работает жадно). Но так как у нас на руках есть код парсинга, а не нейронная сеть, то можно поправить логику, проделав некоторые алгоритмические упражнения. Я добавил пару проверок на разрядность чисел, чтобы понимать нужно ли прибавлять следующее число к предыдущему, а также обработку нулей. После этого имеем такой результат:
>> мой телефон девятьсот десять ноль девяносто пять пятьдесят шесть десять >> мой телефон 910 0 95 56 10
О временных метках
Еще один важный момент — если после транскрибирования аудио у нас есть временные метки на уровне слов (по таким меткам можно извлечь отдельное слово из аудио), то после денормализации они станут неактуальными (количество слов поменяется). Нам необходимо понять, какие слова были схлопнуты в одно. Для случая, когда в тексте только одно составное число, это сделать довольно тривиально, но как быть с таким:
Нам необходимо понять, какие слова были схлопнуты в одно. Для случая, когда в тексте только одно составное число, это сделать довольно тривиально, но как быть с таким:
>> в этом предложении есть числа тридцать три двадцать пять и семь >> в этом предложении есть числа 33 25 и 7
В исходном предложении 11 слов и 11 пар меток, в денормализованном — по 9, и граница между 33 и 25 неясна. Нужен некоторый маппинг, например, массив индексов, который бы показывал сколько слов из исходного предложения соответствуют каждому выходному. Давайте еще немного доработаем логику в этом направлении.
В результате получаем что-то типа такого:
>> в этом предложении есть числа тридцать три двадцать пять и семь >> в этом предложении есть числа 33 25 и 7 >> [1, 1, 1, 1, 1, 2, 2, 1, 1]
>> одна тысяча восемьсот тридцать первый и тысяча девятьсот пятьдесят четвертый >> 1831 и 1954 >> [5, 1, 4]
Чтобы попробовать самостоятельно и внести свои коррективы, предлагаю воспользоваться этим репозиторием, коммиты и баги приветствуются.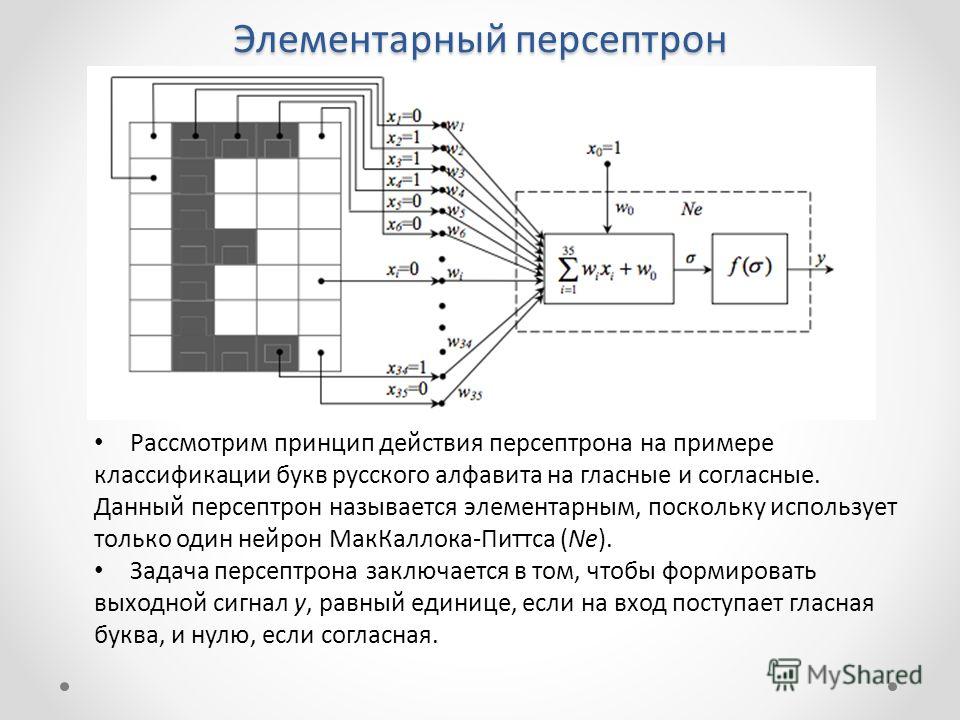
Заключение
Мы посмотрели на то как можно улучшать читаемость текста в задачах распознавания речи, но можно найти этим решениям и другие применения, — например, расстановка знаков препинания для сообщений из чатов. Подходы же в дообучении нейросетевых моделей (transfer learning) вообще являются очень общими и используются повсеместно (от генерации контента до классификации чего-бы то ни было).
P.S. Как многие увлекающиеся машинным обучением люди я тоже завел свой телеграм канал для заметок и новостей из мира ML, куда вас и приглашаю.
Ссылки
- градиент обреченный
- github с пунктуацией
- github с денормализацией
прототип игры Wordle в ProtoPie — Разработка на vc.ru
Наш арт-директор Женя Гребенщиков решил попробовать сделать прототип игры Wordle в ProtoPie. Рассказываем, что получилось.
472
просмотров
ProtoPie — это инструмент, который позволяет дизайнерам создавать интерактивные прототипы, практически неотличимые от настоящих приложений.
Главным преимуществом ProtoPie является возможность использования функционала устройств (камера, акселерометр, вибрация, звук, распознавание голоса и т.д.), а также возможность тестирования прототипа на любом устройстве.
 Главным преимуществом ProtoPie является возможность использования функционала устройств (камера, акселерометр, вибрация, звук, распознавание голоса и т.д.), а также возможность тестирования прототипа на любом устройстве.
Главным преимуществом ProtoPie является возможность использования функционала устройств (камера, акселерометр, вибрация, звук, распознавание голоса и т.д.), а также возможность тестирования прототипа на любом устройстве.Wordle — браузерная игра в слова, в которой игроки должны угадать загаданное слово методом подбора букв. Каждый день программа загадывает слово из пяти букв, и игроки подбирают верный вариант. После каждого предположения буквы выделяются зеленым, желтым или серым цветом: зеленый означает, что буква находится на верной позиции, желтый — что буква есть в слове, но на другом месте, и серый — что буквы в слове нет. Так, методом подбора, разгадывается полное слово.
Когда начал создавать прототип, понял, что раньше никто не использовал в ProtoPie что-то похожее на базы данных. Самое важное, когда пришла какая-то идея, — подумать о концепции и возможностях. Точно ли получится сделать такую игру в ProtoPie? Обычно я мысленно перебираю весь функционал и абстрактно придумываю те или иные решения, которые буду использовать.
Итак, программа загадывает слово, значит, должна быть база данных этих слов. Как сделать базу данных слов в ProtoPie? Я уже делал много таких штук, и обычно довольно сложно объяснить на пальцах, как оно работает. Постараюсь как можно подробнее все описать.
В начале придумал, что будет под капотом игры
За основу взял простую базу данных со списком слов. Но чтобы выбрать случайное слово, надо каждому слову присвоить айдишник. Поэтому формат базы сделал idWord и выглядеть она будет примерно так:
Начинаем тестировать: берем рандомное число, например 12. Ищем через indexof(text,” 12”), на какой позиции оно находится. Например, это 67-й символ. Смотрим в базу и видим там «12БАРЖА». Переносим слово из базы в переменную.
Для начала функцией right стираем все, что было до нужного слова. Наша «база данных» — это, по сути, очень длинная строка, которая начинается с символа «1» и заканчивается последней буквой последнего слова. Поэтому мы можем использовать функции работы со строками. С помощью функции right мы сможем «обрезать» строку до нужного слова, а функцией left — после этого слова. Тем самым мы достанем из базы нужное нам слово.
Поэтому мы можем использовать функции работы со строками. С помощью функции right мы сможем «обрезать» строку до нужного слова, а функцией left — после этого слова. Тем самым мы достанем из базы нужное нам слово.
Теперь нам надо понять, сколько символов надо оставить «справа» функцией right. Предыдущая функция indexOf дала нам информацию, что номер нужного слова находится с 67-го символа. Чтобы достать слово, надо убрать эти 67 символов и еще 2 символа номера 12 («12БАРЖА»). Так как номер у нас может быть и однозначный, и двух-трех-четырехзначный, то используем функцию length для определения количества символов в этом числе. В текущем виде нам надо убрать 69 символов. Следовательно, чтобы понять, сколько оставить, надо от значения длины всей базы данных отнять 69.
Для решения задачи можно использовать код:
right(`riddle_bd`.text,(length(`riddle_bd`.text) — (length(rnd_num)) — (indexOf(`riddle_bd`.text,rnd_num))))
Затем от всего этого нужно отрезать функцией left пять символов, так как слова у нас состоят из пяти букв. Таким образом мы получили рандомное слово из базы.
Таким образом мы получили рандомное слово из базы.
Кстати, выбранное слово из базы надо будет потом удалить, чтобы оно не повторялось в следующих играх. Делаем это функцией replace. Плюс делаем проверку: если рандом выдаст число, которого в базе нет, повторяем рандом.
Придумал концепцию игрового процесса
С базой разобрались — теперь у нас есть первое рандомное слово для игры. Например, «ВИРУС». В игре пользователь вводит свое слово, и нужно показать, какие буквы совпали и какие — не на том месте. Также нужно добавить проверку, есть ли слово в базе.
Пользователь вводит слово «РЕБУС». Буква «Р» есть, но в другом месте. Буква «У» и буква «С» на своих местах.
Как сделать такую проверку? Нужно провести пять проверок для каждой буквы введенного слова. Самый простой способ — помещать каждую букву в отдельное поле ввода, чтобы было проще производить с ней какие-либо манипуляции. Однако надо это сделать так, чтобы игрок не заметил, что это пять полей ввода, и ему казалось, что поле ввода одно. Делитесь идеями, как это можно реализовать, в комментариях.
Делитесь идеями, как это можно реализовать, в комментариях.
Алгоритм поиска совпадений должен работать так:
- Берем первую букву — «Р», производим поиск в слове «ВИРУС». Буква найдена, ее позиция — 3, а в введенном слове «РЕБУС» она первая, значит, красим букву «Р» в желтый цвет.
- Берем вторую букву — «Е», ищем в слове «ВИРУС». Буква не найдена — красим в серый.
- То же самое с третьей буквой — «Б».
- Берем четвертую букву — «У». Буква найдена, и ее позиция — 4. Красим в зеленый цвет, потому что позиции буквы совпадают в обоих словах.
- Последняя буква — «С» — тоже совпадает по позициям — красим зеленым.
Теперь просим игрока ввести второе слово. Он вводит «ПАРУС» — показываем, что буквы «РУС» на своих местах.
Игрок вводит слово «ВИРУС» — все буквы на своих местах. Ура!
Перешел к созданию игры
Концептуально проблем не обнаружилось — переходим к созданию игры. Процесс я разбил на шаги для наглядности.
Процесс я разбил на шаги для наглядности.
Шаг 1. Создал базу данных. Для того чтобы подготовить базу данных, я взял гугл-табличку. Это довольно простой и удобный инструмент для работы с небольшими базами данных. Надеюсь, когда-нибудь ProtoPie добавит нативную синхронизацию с такими таблицами.
Во второй столбик перенес список слов из интернета. Первый оставил пустым, чтобы позже написать там айдишники слов. Получилось 6266 слов — для тестов слов оказалось слишком много. Поэтому сделал копию страницы и оставил примерно по 20 слов на каждую букву. Получилось 279 слов — теперь сойдет.
Потом, используя функционал гугл-таблиц, сначала все слова сделал большими буквами =UPPER() (потому что поиск букв регистрозависимый). Далее я перемешал слова в рандомном порядке таким образом: добавил в третью колонку случайное число =RAND() и отсортировал табличку по возрастанию этих случайных чисел.
Затем в первую колонку записал номера по порядку от 1 до 279. Чтобы перенести базу в ProtoPie, я скопировал первые два столбика в «Блокнот» и функцией «Заменить» заменил табуляцию между числом и словом на пустоту. В итоге получил нужный мне формат базы данных — idWord:
Чтобы перенести базу в ProtoPie, я скопировал первые два столбика в «Блокнот» и функцией «Заменить» заменил табуляцию между числом и словом на пустоту. В итоге получил нужный мне формат базы данных — idWord:
Шаг 2. В ProtoPie создал текстовый слой bd, куда вставил нашу базу данных. Также создал числовую переменную для случайного числа rnd_num, текстовую переменную для случайного слова rnd_word и переменную lang, чтобы в будущем сделать игру на разных языках.
Шаг 3. Создал промежуточную версию прототипа. Для начала решил сделать простой прототип, который по нажатию кнопки выдает случайное слово из базы данных. Процесс занимает пять шагов:
1. Добавляем на слой текст-кнопку, вешаем триггер Tap и присваиваем переменной rnd_num случайное целое число от 1 до 279, так как моя тестовая база данных содержит 279 слов: Assign rnd_num randomInt(1,279).
2. Детектим изменение переменной rnd_num и сразу вешаем проверку на будущее: если число не найдено: Condition indexOf(`bd`. text, rnd_num) =-1, тогда повторяем предыдущее действие: Assign rnd_num randomInt(1,279).
text, rnd_num) =-1, тогда повторяем предыдущее действие: Assign rnd_num randomInt(1,279).
3. Функция indexOf(`bd`. text, rnd_num) показывает номер символа, после которого идет искомое число.
4. Если же число найдено в базе данных: Condition indexOf(`bd`. text, rnd_num) ≥ 0, то записываем в переменную rnd_word случайное слово тем способом, концепцию которого я описывал в начале статьи:
- Берем все символы базы данных, кроме тех, которые находятся до искомого числа. То есть, используя функцию right, обрезаем начало базы данных: right(`bd`. text, (length(`bd`. text) -(indexOf(`bd`. text, rnd_num))).
- Однако надо не забыть вычесть еще длину самого рандомного числа, чтобы у нас было слово «РЕБУС», а не «123РЕБУС», поэтому добавляем в формулу еще (length(rnd_num)). Получается: right(`bd`. text, (length(`bd`. text) -(length(rnd_num)) -(indexOf(`bd`. text, rnd_num)))).
- Эта функция отрезает только левую часть базы данных. Остается от нее отрезать пять символов нашего слова, и оно будет у нас: left((right(`bd`. text, (length(`bd`. text) -(length(rnd_num)) -(indexOf(`bd`. text, rnd_num))))), 5).
 text, rnd_num)))).
text, rnd_num)))).Все эти формулы выглядят довольно сложно, поэтому постарался все подробно изложить. Однако если у вас остались вопросы — с радостью отвечу на них в комментариях.
5. Присваиваем переменной rnd_word конструкцию, выведенную выше. Вот что получилось:
Промежуточная версия прототипа
Шаг 4. Сделал игровое поле. Слово загадывать мы умеем, теперь надо сделать игровое поле:
1. Клавиатура будет всегда открыта, поэтому сразу отделяю часть экрана под нее — это 294 px для iPhone X.
2. По правилам оригинальной игры у игрока есть шесть попыток угадать слово, поэтому нужно сделать шесть текстовых полей для предыдущих попыток и одно активное для текущей попытки. Эти поля должны выглядеть одинаково, примерно вот так:
Эти поля должны выглядеть одинаково, примерно вот так:
3. Следующая проблема — разбить слово на буквы. Это нужно, чтобы потом подсветить правильные буквы зеленым и те, которые на других местах, — желтым.
Сначала я решил разбить слово по буквам, используя функции left и right:
- Для первой буквы — просто left(word, 1).
- Для второй буквы берем ту же одну букву слева, но уже от четырех букв: left((right(word, 4)), 1).
- Для третьей, четвертой буквы можно сделать соответственно left((right(word, 3)), 1) и left((right(word, 2)), 1).
- Для пятой буквы достаточно right(word, 1).
Но тут сталкиваемся с проблемой, что введенное слово не всегда состоит из пяти букв. Вот что я имею в виду: пользователь вводит слово «ВИРУС» по буквам. Ввел «ВИ» — получилось слово из двух букв, следовательно, используя функции выше, первая буква («В») найдется верно, вторая («И») тоже, но так как в слове нет третьей, четвертой и пятой букв, то все функции будут выводить вторую букву вместо третьей, четвертой и пятой. Вот как эта проблема выглядит в прототипе.
Вот как эта проблема выглядит в прототипе.
Существует множество способов решить эту проблему. Да и в целом эту задачу можно сделать по-другому… Я решил сделать из пяти полей компонент, в который буду слать вводимое слово. В компоненте получаю вводимый текст и разбиваю его на буквы, проверяя длину текста. Получается шесть проверок: когда нет символов и когда один, два, три, четыре или пять символов.
Добавляю красивые анимации для ввода букв и подсветку текущей буквы. Пока проверку на совпадения делать не буду: для начала надо проверить, как работает ввод слов.
4. На главной сцене дублирую пять раз компонент и строю «игровое поле»:
- Нужно добавить переменную try, которая будет отслеживать количество попыток пользователя. В начале игры она равна 1. Когда игрок ввел первое слово, равна 2 и так далее.
- Добавляем триггер Return (нажатие Enter на клавиатуре, подтверждение ввода) и проверяем введенное слово на наличие в БД с помощью функции indexOf(bd. text, Input 1.text). Если значение формулы =-1, значит такого слова нет в словаре — выводим сообщение об ошибке.
- Если indexOf(bd. text, Input 1.text) больше 0, значит слово есть в словаре и всё в порядке. Заодно проверим, что слово состоит из пяти символов. Изменяем значение переменной try на следующую попытку.
- Добавим переменную success и будем ее проверять. Как только пользователь угадает слово, она станет =1. Но это уже другая история: )
- При try=7 делаем jump на страницу Game Over.
- Для каждого значения переменной try выбираем свой компонент для попытки.
 text, Input 1.text). Если значение формулы =-1, значит такого слова нет в словаре — выводим сообщение об ошибке.
text, Input 1.text). Если значение формулы =-1, значит такого слова нет в словаре — выводим сообщение об ошибке.На этом шаге прототип выглядит так:
Ссылка на прототип
В прототипе можно вводить слова, которые есть в базе данных, попробовать поиграть и потратить все попытки: )
Шаг 5. Добавил две проверки, которые улучшат UX. В первой проверке убрал букву «Ё». В моей базе данных нет слов на букву «Ё», и там, где она должна быть, используется буква «Е». Поэтому просто функцией replace заменим в поле ввода «Ё» на «Е».
Добавил две проверки, которые улучшат UX. В первой проверке убрал букву «Ё». В моей базе данных нет слов на букву «Ё», и там, где она должна быть, используется буква «Е». Поэтому просто функцией replace заменим в поле ввода «Ё» на «Е».
Вторая проверка — для пробела: это большая кнопка, которую случайно можно нажать. Мы просто ее отключим: используем ту же функцию replace и меняем пробел (« ») на ничего («»). Можно еще сделать аналогично с цифрами, но пока влом: )
Шаг 6. Теперь надо сделать так называемый вин кондишен.
1. Для начала сделал примитивную проверку: если введенное слово равно загаданному слову — победа! Для этого просто сравниваем две переменные.
2. Теперь можно добавить проверку букв:
- Сначала происходит проверка на правильность расположения букв, чтобы отметить их зеленым цветом.
- Затем проверка на наличие буквы в слове, чтобы отметить желтым. Для этого берем первую букву загаданного слова с помощью формулы, которой разбивали слово на буквы выше: left(word, 1). Если буква совпадает, красим в зеленый, если нет — переходим к следующей.
- Так делаем с каждой буквой по пять раз: первую букву загаданного слова сверяем с каждой буквой введенного слова.
- Если же обе проверки не принесли результата, оставляем букву серой.
Заметки во время тестирования игры
Заметка 1. Тестируя приложение, я подумал, что базу данных лучше сделать «вверх ногами», чтобы проще было добавлять новые слова, открывая текстовый блок и дописывая значение. Например, «2130ЗЕБРА». Тогда не нужно будет скролить в самый низ. Вот почему:
- У меня рандомится айдишник, и потом берется слово под этим айдишником. База у меня записана «вверх ногами»: последний айдишник в самом верху, так мне было удобнее добавлять слова. Ну и сгенерился айдишник 211, пошел поиск слова, и он нашел после айдишника 2120 айдишник 2119, и взял 211 и дальше слово из пяти букв.
- По факту это слово «2119ТРИБА» (это что-то из биологии), но из-за бага программа загадала слово «9ТРИБ».
- Я вернул базу в прежний вид, и баг исчез.

Заметка 2. Узнал много новых слов. Пришла в голову идея добавить функцию «Посмотреть значение слова».
- Для этого добавил триггер Longtap, в который добавил действие Link.
- В параметр действия написал ссылку на викисловрь с переменной-словом.
- Теперь можно лонгтапнуть на любом слове, и откроется браузер с значением слова.
Заметка 3. Во время тестов словил вот такой баг:
Баг в третьем и пятом слове. Суть в том, что вначале слова проверяется буква «А» и подсвечивается желтым, потому что она не на верном месте. Следом проверяется последняя «А». Она на своем месте, и поэтому она зеленая. Пользователь думает что в слове две буквы «А», но это всего лишь баг.
Исправил я его таким образом: после закрашивания буквы зеленым заменял проверенную букву на цифру 0. Таким образом, при второй проверке, когда происходит закрашивание желтых клеток, система ее уже не проверяет.
Таким образом, при второй проверке, когда происходит закрашивание желтых клеток, система ее уже не проверяет.
Заметка 4. «Причесал» UI, добавил анимацию при неправильном вводе слова в компоненте:
Заметка 5. «Поиграл» с цветами и формами, придав игре более приятный вид.
Сейчас игра выглядит так:
Итоги и планы на будущее
Игра получилась интересная и с большим потенциалом для развития. Кстати, я уже реализовал большую часть задуманных фич. Вот их список:
- Расширил базу слов для игры. Уже нашел базу из 6000 русских слов и базу из 13000 английских слов.
- Добавил свитч языка, чтобы можно было выбрать, какие слова будут загаданы. Кстати, это неплохая тренировка языка.
- Сделал две базы данных для каждого языка. Первая — для слов, которые будет загадывать система, вторая — для слов, которые будет вводить пользователь. В первой базе будут более популярные слова. Нужно это для того, чтобы программа не загадывала редкие, малоиспользуемые, слова. Однако если такие слова введет пользователь, они пройдут проверку. Например, программа загадает слово «МИНАИ» — это слово никто не отгадает (это, кстати, тип художественной керамики). Используя несколько баз данных, можно менять и сложность игры. Чем сложнее игра, тем более редкие слова будет загадывать программа.
- Добавил локальную статистику игр. Показывает, с какого раза игрок угадывает слово.
 Однако если такие слова введет пользователь, они пройдут проверку. Например, программа загадает слово «МИНАИ» — это слово никто не отгадает (это, кстати, тип художественной керамики). Используя несколько баз данных, можно менять и сложность игры. Чем сложнее игра, тем более редкие слова будет загадывать программа.
Однако если такие слова введет пользователь, они пройдут проверку. Например, программа загадает слово «МИНАИ» — это слово никто не отгадает (это, кстати, тип художественной керамики). Используя несколько баз данных, можно менять и сложность игры. Чем сложнее игра, тем более редкие слова будет загадывать программа.Поэтому в следующей статье я расскажу, как изменил базу слов и разбил ее на разные языки и как сделал статистику игр. Сейчас я планирую улучшить игру, добавив в нее темную тему и общий рейтинг. Об этом также напишу в следующей статье. Подписывайте на наш блог, чтобы не пропустить продолжение.
Пишите о ваших идеях, как можно улучшить или дополнить игру! И делитесь своими успехами в игре: будем рады посмотреть скриншоты вашей статистики: )
Преобразование речи в текст в App Store
Описание
Говорите текст вместо того, чтобы печатать. Время диктовки не ограничено. Преобразуйте голосовые заметки в текст и переведите их на любой язык.
Время диктовки не ограничено. Преобразуйте голосовые заметки в текст и переведите их на любой язык.
Диктовка — Преобразование речи в текст позволяет диктовать, записывать, переводить и транскрибировать текст вместо того, чтобы печатать его. Он использует новейшую технологию распознавания речи в текст, и его основной целью является преобразование речи в текст и перевод для обмена текстовыми сообщениями. Никогда не печатайте текст, просто диктуйте и переводите, используя свою речь! Почти каждое приложение, которое может отправлять текстовые сообщения, может быть настроено для работы с «Диктовкой — речь в текст». Диктат использует встроенный механизм распознавания речи в текст.
Диктовка — Функции преобразования речи в текст:
► Более 40 языков диктовки
Диктовка — Преобразование речи в текст поддерживает более 40 языков. Диктат предлагает 3 текстовые зоны, отмеченные языковыми флагами, для которых вы можете настроить другой язык в настройках. Таким образом, вы можете переключаться между проектами на разных языках одним щелчком мыши.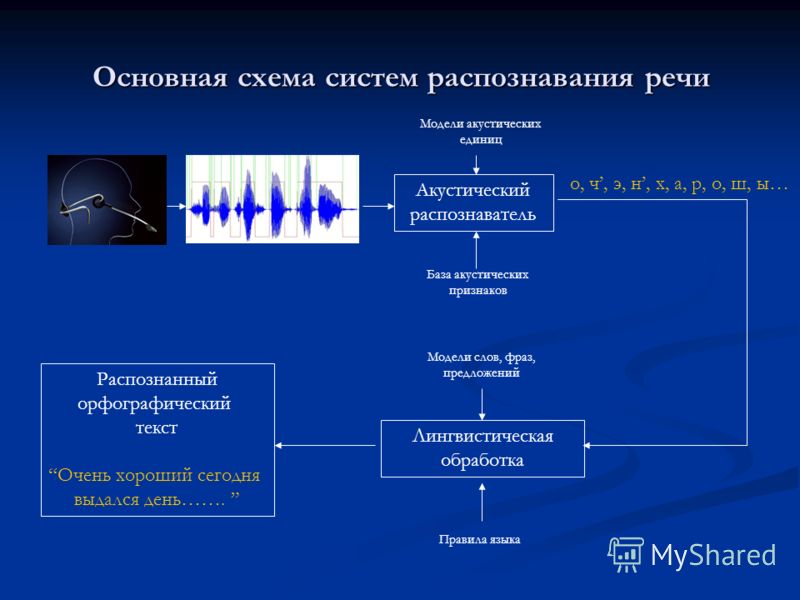
► Более 40 языков перевода
Перевод так же прост, как нажатие кнопки перевода. Вы можете указать целевой язык перевода в настройках приложения. Затем вы нажимаете кнопку перевода, чтобы перевести его.
► Аудиозапись
К вашим аудиозаписям и текстовым файлам можно получить доступ через приложение Apple «Файлы».
► Транскрипция записанных аудиофайлов
Используя транскрипцию аудиофайлов, вы можете транскрибировать записанные аудиофайлы, содержащие речь, в текст одним щелчком мыши. Поддерживаются все основные форматы аудиофайлов.
► Синхронизация с iCloud
После включения iCloud ваш текст автоматически синхронизируется на всех ваших устройствах, на которых работает Dictate, например. iPhone, iPad, macOS и Apple Watch.
► Поддержка людей с нарушениями зрения
Диктат теперь поддерживает настройку размера системного шрифта и предоставляет настраиваемые размеры кнопок для пользователей с нарушениями зрения. Также тщательно настроен VoiceOver.![]()
► Easy Text Sharing
Для быстрой отправки продиктованных текстовых сообщений есть кнопка «Поделиться», которая позволяет запустить целевое приложение, т. е. Twitter, Facebook, WhatsApp, Flickr, электронную почту или любое другое приложение, которое может принимать текст из системы.
► Подписки на версию Pro
Если вы собираетесь чаще использовать Диктовку — Речь в текст, вам необходимо подписаться на версию Pro. Версия Pro свободна от рекламы.
► Важные примечания относительно подписки
Все вышеперечисленное «Диктовка» — подписка на преобразование речи в текст продлевается в течение 24 часов до окончания текущего периода, и с вас будет взиматься плата через вашу учетную запись iTunes. Любая неиспользованная часть бесплатного пробного периода, если она предлагается, будет аннулирована при покупке подписки. Управляйте подпиской или отмените ее в настройках учетной записи iTunes. Ознакомьтесь с нашими Условиями и положениями (https://www.ibn-software. com/app-terms-conditions) и Политикой конфиденциальности (https://www.ibn-software.com/app-privacy-policy).
com/app-terms-conditions) и Политикой конфиденциальности (https://www.ibn-software.com/app-privacy-policy).
Версия 3.32
► Повышение производительности ядра диктовки и расшифровки файлов
► Новый помощник по выбору языка
Рейтинги и обзоры
1,8 тыс. оценок
Помощь глухим!
Недавно я потерял слух и глух на оба уха. Мне нравится ваше приложение для разговоров один на один. Наличие дополнительных людей в комнате усложняет задачу, потому что это приложение улавливает все, включая мой голос. Одновременно может говорить только один человек. Теперь мне нужно найти приложение, которое будет работать с моим iPhone, чтобы я мог совершать телефонные звонки.
Приложение показывает меню поддерживаемых языков речи, но некоторые из желаемых языков не могут быть выбраны
Ранее я написал отрицательный (2 *) предварительный просмотр, потому что после того, как я купил Pro-версию, я пытался настроить приложение для преобразования голоса в текст на выбранном языке, но не видел ни кнопки, ни поля для подтверждения выбранный язык рядом с опцией «Отклонить». Но после нескольких попыток я понял, что после того, как я выбрал «Настройка» для выбора языка распознавания речи, мне просто нужно было выбрать «Отклонить», чтобы вернуться к интерфейсу, где я могу начать процесс преобразования голоса в текст, нажав на красную кнопку в нижней части экрана и просто сказал несколько слов на ранее установленном языке и увидел, что речь транскрибируется на этом установленном языке.
 Я бы хотел, чтобы были какие-то инструкции, помогающие пользователю настроить приложение для выполнения v-to-t на этом языке. Таким образом, 4 звезды вместо 5.
Я бы хотел, чтобы были какие-то инструкции, помогающие пользователю настроить приложение для выполнения v-to-t на этом языке. Таким образом, 4 звезды вместо 5. Лучшее приложение для диктовки, которое я когда-либо использовал
И я использовал все виды приложений для диктовки, начиная с Via Voice (IBM). Помните тот? С тех пор, как IBM убрала VV с рынка, Dragon/Nuance всегда был знаменосцем, и их продукты всегда были хороши (за исключением технической поддержки), но это приложение намного лучше. Отлично работает на iOS/iPADOS/MACOS. Точность замечательная. Исправления делаются очень легко, обычно нужны только очень незначительные. Настраиваемый интерфейс. Лист общего доступа Apple открывает доступ к приложениям «Сообщения», «Почта», «Файлы», «Заметки» и так далее. Невероятно быстро. Огромный прирост моей продуктивности. Попробуйте бесплатно… вы поймете, что я имею в виду.
 Также чрезвычайно доступный с гибкими планами оплаты, если вы решите купить после первоначального бесплатного использования. Я перепробовал все доступные в настоящее время приложения… это на голову выше всех остальных.
Также чрезвычайно доступный с гибкими планами оплаты, если вы решите купить после первоначального бесплатного использования. Я перепробовал все доступные в настоящее время приложения… это на голову выше всех остальных.Подписки
Dictate Pro
Использование в течение 1 года (iOS и macOS)
17,49 долл. США
Dictate Pro
Использование в течение 1 месяца (iOS и macOS)
6,99 долл. США
Разработчик, Кристиан Нойбауэр, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, используемые для отслеживания вас
Следующие данные могут использоваться для отслеживания вас в приложениях и на веб-сайтах, принадлежащих другим компаниям:
Данные, не связанные с вами
Следующие данные могут собираться, но они не связаны с вашей личностью:
Идентификаторы
Данные об использовании
Диагностика
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста. Узнать больше
Узнать больше
Информация
- Продавец
- Кристиан Нойбауэр
- Размер
- 3,6 МБ
- Категория
Производительность
- Возрастной рейтинг
- 4+
- Авторское право
- © 2022 Программное обеспечение IBN
- Цена
- Бесплатно
Сайт разработчика
Тех. поддержка
Политика конфиденциальности
Опоры
Еще от этого разработчика
Вам также может понравиться
Распознавание голоса — обзор
В этом информационном бюллетене представлен обзор того, как вы можете использовать распознавание голоса. Вы можете использовать распознавание голоса для управления умным домом, инструктировать умный динамик и управлять телефонами и планшетами. Кроме того, вы можете устанавливать напоминания и взаимодействовать с персональными технологиями без помощи рук. Наиболее существенное использование для ввода текста без использования экранной или физической клавиатуры.
Вы можете использовать распознавание голоса для управления умным домом, инструктировать умный динамик и управлять телефонами и планшетами. Кроме того, вы можете устанавливать напоминания и взаимодействовать с персональными технологиями без помощи рук. Наиболее существенное использование для ввода текста без использования экранной или физической клавиатуры.
Технологии связи продолжают быстро развиваться. Использование распознавания голоса для ввода текста, проверки правописания слов и диктовки сообщений стало очень простым. На большинстве экранных клавиатур есть значок микрофона, который позволяет пользователям легко переключаться с набора текста на распознавание голоса.
Для некоторых людей с ограниченными возможностями, которые могут с трудом или не могут работать с мышью или клавиатурой, распознавание речи открывает мир продуктивных возможностей. Это может освободить людей от набора текста и использования клавиатуры, помогая людям с физическими недостатками и снижая риск повторяющихся травм от перенапряжения из-за чрезмерного набора текста или использования мыши. Например, люди с дислексией могут писать более бегло, точно и быстро, используя распознавание голоса, и могут испытывать меньше стресса, чем обычный почерк или набор текста.
Например, люди с дислексией могут писать более бегло, точно и быстро, используя распознавание голоса, и могут испытывать меньше стресса, чем обычный почерк или набор текста.
Для работодателей включение распознавания голоса в системах и поощрение его использования на рабочем месте может быть «разумной корректировкой»: предотвращение дискриминации и максимальное повышение производительности труда сотрудников с ограниченными возможностями.
Требуется руководство по использованию технологии распознавания голоса? Изучите основы и способы использования программного обеспечения для распознавания голоса для тестирования специальных возможностей с помощью нашего учебного курса.
Включает в себя
- 1.1. Как вы можете управлять устройствами с помощью голоса?
- 2.2. Зачем использовать распознавание голоса?
- 2.1. Обеспечение сотрудников на рабочем месте
- 3.3. Как получить доступ к распознаванию голоса на настольном устройстве
- 3. 1. Распознавание речи Windows
- 3.2. Microsoft Office 19 и Office 365
- 3.3. Диктовка на Mac OS
- 3.4. Распознавание речи Google
- 3.
 1. Распознавание речи Windows
1. Распознавание речи Windows90 Программное обеспечение для распознавания голоса специалиста
- 4.1.Dragon Individual Professional
- 5.1. Голосовое управление для мобильных устройств Android
- 5.2. Голосовое управление для iOS
- 5.3. Интеллектуальные персональные помощники
- 6.1.Запись голоса
- 6.2.Регистрация
- 7.1. Преобразование текста в речь
- 7.2. Насколько важно обучение?
- 8.1. Программное обеспечение для преобразования текста в речь
1.
 Как можно управлять устройствами с помощью голоса?
Как можно управлять устройствами с помощью голоса?
Распознавание голоса встроено в большинство устройств. Например, смартфоны и планшеты оснащены хорошими микрофонами, которые поддерживают голосовой ввод и команды. Точно так же компьютеры часто поставляются со встроенными камерами, микрофонами и динамиками.
p>Распознавание голоса может стать альтернативой набору текста на клавиатуре. В самом простом случае он обеспечивает быстрый способ письма на компьютере, планшете или смартфоне. Вы можете говорить во внешний микрофон, гарнитуру или встроенный микрофон, и ваши слова будут отображаться на экране в виде текста. Это может быть текстовая панель поисковой системы, чат или мессенджер, электронное письмо или документ.
Некоторые системы и программы имеют распознавание голоса, которое можно настроить для управления устройствами и ввода текста. Простые голосовые команды при правильной настройке могут запускать и выключать компьютер, а также открывать и запускать различные программы и приложения. Это очень важно для людей с ограниченными физическими возможностями, которые могут использовать свои устройства самостоятельно, просто используя голосовые команды.
Это очень важно для людей с ограниченными физическими возможностями, которые могут использовать свои устройства самостоятельно, просто используя голосовые команды.
Если распознавание голоса может быть настроено и имеет настройки, вы можете использовать его для выполнения таких команд, как:
- Форматирование и сохранение текста.
- Печать и отправка документов. Но чтобы получить высокий уровень контроля и функциональности, вы можете заплатить за специализированное программное обеспечение.
2. Зачем использовать распознавание голоса?
Распознавание голоса предлагает значительные преимущества широкому кругу потенциальных пользователей. Совершенно очевидно, что это чрезвычайно полезно для людей с ограниченными физическими возможностями, которым трудно, больно или невозможно печатать. Кроме того, это может помочь снизить риск получения повторяющихся травм от перенапряжения (RSI) или более эффективно лечить любое такое заболевание верхних конечностей.
Программы распознавания голоса также могут принести большую пользу людям с дислексией, которые в противном случае столкнулись бы с трудностями при написании и/или правильном построении предложений.
В более общем плане распознавание голоса может помочь упростить работу в мобильном режиме, а также предложить потенциальные преимущества производительности для тех, кто не очень хорошо умеет печатать. На самом деле, большинство людей могут говорить намного быстрее, чем они могут точно печатать, в то время как «свободные руки» также предлагают дополнительные возможности для многозадачности.
Предоставление сотрудникам возможности на рабочем месте
Работодатели используют распознавание голоса по ряду причин. Например, RSI — это распространенная жалоба на рабочем месте, вызванная повторяющимися задачами с клавиатурой и мышью; 19% людей трудоспособного возраста являются инвалидами.
Надлежащее использование программного обеспечения для распознавания голоса может помочь работодателям выполнять свои юридические обязанности заботиться о здоровье, безопасности и благополучии своих сотрудников на работе и вносить разумные коррективы.
Работодатели должны принимать меры для сведения к минимуму риска заболевания или травматизма своих сотрудников. Программное обеспечение для распознавания голоса помогает предотвратить усталость и травмы, предлагая удобную и эргономичную альтернативу клавиатуре и мыши.
Работодатели, которые не выполняют свои установленные законом обязанности по охране труда и технике безопасности, могут быть привлечены к суду по трудовым спорам.
Они также могут быть уязвимы для обвинений в дискриминации в соответствии с Законом о равенстве, если они не внесут «разумных корректировок» для своих сотрудников-инвалидов. Использование распознавания голоса — это очень простая и экономически эффективная регулировка, которую работодатель может сделать, чтобы предоставить сотруднику с ограниченными возможностями равный доступ ко всему, что связано с выполнением и сохранением его работы в качестве работника без инвалидности.
Помимо беспокойства по поводу здоровья и безопасности или дискриминации, работодатели должны учитывать потенциальное повышение эффективности и производительности, которое может быть достигнуто за счет более широкого внедрения распознавания голоса, особенно для сотрудников, работающих «на ходу».
распознавание голоса на настольном устройствеДоступ к распознаванию голоса дома и на работе можно легко получить с помощью многих устройств, в том числе в стандартной комплектации. Мы перечислили подробности ниже, но вы также можете узнать больше в нашем бесплатном инструменте My Computer My Way.
Распознавание речи Windows
Microsoft Windows имеет встроенную программу распознавания речи под названием Распознавание речи, разработанную для помощи людям с ограниченными возможностями, которые не могут пользоваться мышью или клавиатурой.
В Windows 10 это позволяет пользователям управлять компьютером с помощью голосовых команд. Его можно настроить и использовать для таких вещей, как навигация, открытие и закрытие приложений и диктовка текста. Доступ к нему осуществляется через панель управления и «Простота доступа». Корпорация Майкрософт рекомендует использовать микрофоны гарнитуры или массивы микрофонов.
Вам нужно будет «зарегистрироваться», но это может сделать любой.
Узнайте больше о распознавании речи. и устройство с микрофоном. Раньше эта функция была доступна только пользователям Office 365, но теперь она доступна в Office 19. Также есть некоторые поддерживаемые команды форматирования. Дополнительную информацию можно получить в службе поддержки Microsoft (там сказано, что диктат доступен только в Office 365, но это не так).
Функция диктовки имеет некоторые параметры настройки, включая язык, который вы хотите использовать. Он распознает широкий спектр языков, но вам нужно будет загрузить базу данных для них, и он предложит вам это сделать. Функция диктовки также доступна в Powerpoint.
Диктовка на Mac OS
Компьютеры Apple Mac под управлением OS X Mountain Lion, Mavericks или Yosemite имеют бесплатное встроенное программное обеспечение для диктовки. Доступ к этому можно получить через панель «Диктовка и речь» в Системных настройках.
В более поздних версиях ОС, El Capitaine (11) Sierra и High Sierra 12/13) Mojave (14), вы можете настроить диктовку через системные настройки, клавиатуру и параметр для диктовки.
Кроме того, расширенная диктовка позволяет пользователю работать в автономном режиме.В macOS Sierra можно попросить Siri «включить диктовку». Это не то же самое, что встроенная программа для диктовки, но Siri может составлять короткие текстовые сообщения и сообщения электронной почты.
В macOS после включения «Расширенной диктовки» в Mavericks включается непрерывное распознавание речи и автономная обработка. Yosemite и далее представил много новых команд редактирования и форматирования. и возможность создавать дополнительные команды диктовки. Все команды форматирования присутствуют в Мохаве.
Mac OS Catalina предоставила голосовое управление, которое стало последним шагом и позволило полностью управлять компьютером с помощью голоса. Шаги, необходимые для его включения, можно найти в Интернете.
Подробнее о диктовке в macOS
Распознавание речи Google
Распознавание речи Google использует другую архитектуру нейронной сети. Это бесплатно, и Google продолжает развивать и работать над ним.
Он не требует регистрации и считается «независимым от говорящего». Распознавание речи доступно на устройствах Android, в приложениях Google, таких как Keep, и в документах Google с помощью модуля записи речи надстроек. Это не то же самое, что помощник Google.Есть некоторые ограниченные настройки, а команды форматирования и скорость распознавания сильно зависят от качества оборудования и фонового шума.
Подробнее о распознавании речи Google
Распознавание речи для Документов Google
Ниже мы также включили сведения о специализированном программном обеспечении для распознавания голоса.
4. Программное обеспечение для распознавания голоса Specialist
Dragon Individual Professional
Производитель Nuance, Dragon Professional Individual – это ведущее на рынке программное обеспечение для распознавания голоса для компьютеров Microsoft Windows. Кроме того, Nuance выпускает версию для мобильных устройств под названием Dragon Anywhere, которая доступна по подписке.
Версия программного обеспечения и приложения не совпадают.В 2018 году компания Nuance объявила о прекращении выпуска Dragon и любого программного обеспечения для распознавания голоса для Mac и больше не будет предоставлять обновления для него после этой даты. Пользователи Mac могут использовать программное обеспечение только с помощью bootcamp или виртуальной машины, такой как рабочий стол Parallels, и им требуется лицензия для операционной системы Windows.
Nuance утверждают, что использование их распознавания голоса Dragon работает в три раза быстрее, чем набор текста, и обеспечивает точность 99%.
Dragon в Windows может быть настроен в широких пределах. Его можно использовать в разных языковых версиях и с плагинами для предоставления специальных словарей, таких как медицинский, юридический, географический и инженерный.
С его помощью можно диктовать текст, форматировать и исправлять его, перемещаться по компьютеру, управлять рабочими процессами и выполнять большинство функций.
Есть родные приложения, где можно использовать его полный функционал. Тем не менее, есть несколько сторонних приложений 3 rd , где он не будет работать.Предлагаемые дополнительные функции важны для рабочего места и включают возможность:
- Создание электронных таблиц и презентаций с помощью Excel и PowerPoint
- Предложение расшифровки записей
- Создание собственных команд и сценариев для вставки часто используемого текста и автоматизации повторяющихся задач.
Чтобы получить дополнительную информацию и приобрести программное обеспечение Dragon, посетите сайт www.nuance.co.uk/dragon/index.htm
5. Как получить доступ к распознаванию голоса на мобильном устройстве
Популярность смартфонов и планшетов увеличивает спрос на голосовое управление и диктовку среди инвалидов и здоровых людей. Среди тех, кто использует вспомогательные технологии, предпочтение смартфонов увеличилось с 9% до 35%, по данным CickAway Pound.
Небольшая клавиатура упрощает использование голосового управления.Голосовое управление для мобильных устройств Android
Голосовой ввод доступен на устройствах Android, в приложениях Google, таких как Keep и Google docs, с помощью меню инструментов для выбора голосового ввода. Вам потребуется подключение к Интернету. Это не то же самое, что Google Ассистент. Чтобы использовать голосовой ввод, вам необходимо использовать документы Google в браузере Google Chrome, и вы можете использовать его на разных платформах, в Windows или Mac OS.
Некоторые настройки и команды форматирования ограничены, а скорость распознавания высока и зависит от качества оборудования и фонового шума.
Здесь вы найдете голосовые команды, которые можно использовать.
Чтобы использовать голосовую диктовку на Android, откройте любое приложение и запустите экранную клавиатуру. Затем коснитесь значка микрофона в левом нижнем углу клавиатуры и начните говорить, чтобы начать голосовую диктовку.
Обратите внимание, что вам нужно будет произносить знаки препинания при вводе текста.Приложение Google Voice Access для Android позволяет управлять устройством с помощью голосовых команд, чтобы вы могли открывать приложения, перемещаться и редактировать текст без помощи рук. Конечно, вы также можете использовать Google Assistant. Просто скажите: «Окей, Google, открой настройки Ассистента» и выберите голосовой ввод в качестве предпочтительного варианта ввода.
Распознавание голоса для iOS
Голосовое управление доступно на iPad и iPhone с iOS 13 или более поздней версии. После завершения загрузки файла вам не нужно подключение к Wi-Fi.
Это видео поможет использовать его на Big Sur, последней версии iOS и покажет, как использовать диктовку, а также использовать голосовое управление. После Каталины изменений не так много.
Различные языки также могут быть добавлены после загрузки файлов.
Интеллектуальные персональные помощники
Интеллектуальные персональные помощники — важная функция всех современных планшетов и смартфонов.
Они используют технологию распознавания голоса и пользовательский интерфейс на естественном языке для предоставления ряда услуг. Некоторые из самых популярных личных помощников включают в себя:- Siri — для устройств iOS (iPad и iPhone)
- Google Now — для устройств iOS, интегрированных в браузер для Android и Chromebook.
- Cortana — для устройств Windows.
- Alexa-Amazon Echo
Эти персональные помощники предлагают схожие функции для помощи в выполнении повседневных задач — реагирование на голосовые команды и запросы на предоставление информации и ответы на запросы (через онлайн-источники), отправка сообщений и электронных писем, телефонные звонки, создание заметок , планирование встреч и прослушивание музыки.
6. Как работает программное обеспечение для распознавания голоса?
Программы распознавания голоса анализируют звуки и преобразуют их в текст. Программное обеспечение опирается на обширный словарный запас и знание того, как говорят по-английски, чтобы определить, что, скорее всего, сказал говорящий.
В некоторых программах специальный словарь или часто используемые слова, такие как имена, могут быть добавлены путем предоставления им документов, списков слов или с помощью плагинов 3 rd party.Запись вашего голоса
Программное обеспечение для распознавания голоса
захватывает и преобразует речь через микрофон. Некоторые компьютеры оснащены встроенными микрофонами, но большинство специализированных программ распознавания голоса также включают гарнитуру с микрофоном. Его можно подключить к компьютеру либо через разъем для звуковой карты, либо через USB (или аналогичное) соединение.
Также можно использовать подходящий портативный цифровой диктофон для диктовки записей, что может быть особенно полезно при мобильной работе. Некоторые приложения для распознавания голоса могут расшифровывать записи из различных форматов (включая wav, mp3 и wma).
Регистрация
Голос и фразы у всех звучат немного по-разному, поэтому наиболее эффективная программа использует простой одноразовый процесс, называемый «регистрация».
Это занимает всего минуту и просто включает в себя чтение короткого текста из нескольких строк. Однако не все большинство программ для распознавания используют регистрацию, но могут потребовать от пользователя сказать, есть ли у него акцент, и выбрать, какой именно.7. Как наилучшим образом использовать программное обеспечение для распознавания голоса
Во время разговора люди часто колеблются, бормочут или невнятно произносят слова. Одним из ключевых навыков использования программного обеспечения для распознавания голоса является умение четко говорить, чтобы компьютер или устройство могли распознавать сказанное. Это может помочь спланировать, что сказать, а затем говорить целыми фразами или предложениями.
Программное обеспечение для распознавания голоса может неправильно понимать некоторые слова, которые вы произносите, и может вставлять слова с похожим звучанием, поэтому важно тщательно их вычитывать.
Несмотря на то, что программное обеспечение для распознавания голоса постоянно совершенствуется, количество ошибок все еще может быть довольно высоким.
Если исправления вносятся с помощью программного обеспечения для распознавания голоса либо голосом, либо путем набора текста, оно может адаптироваться и учиться, так что, надеюсь, та же ошибка больше не повторится. Можно достичь очень высокого уровня точности с помощью тщательной диктовки, исправления и настойчивости.Преобразование текста в речь
Некоторые приложения, в том числе Dragon Professional , , предоставляют возможность преобразования текста в речь (для прослушивания созданного текстового файла), а также аудиовоспроизведение речи (это означает что их можно сравнить с тем, что на самом деле было сказано с текстом, сгенерированным программным обеспечением).
Функция преобразования текста в речь особенно полезна для людей с нарушением зрения (которым было бы трудно или невозможно читать любой текстовый файл) и для людей с дислексией.
Насколько важно обучение?
Обучение действительно полезно для пользователей, чтобы осознать все преимущества работы с программами распознавания голоса.
Чтобы получить максимальную отдачу от обучения, может быть полезно распределить его на период в несколько недель, что дает пользователю достаточную возможность практиковать новые навыки и закреплять полученные знания между формальными коучинговыми сессиями.Обучение будет наиболее эффективным, если оно ориентировано на конкретные потребности человека, фокусируясь на его конкретных задачах и проблемах. Специализированные словари можно получить, используя плагины или предоставив программе доступ к электронной почте и документам.
Широкий спектр частных и добровольных организаций предлагает услуги компьютерного обучения. Информационный бюллетень AbilityNet по Технической помощи и ресурсам обучения содержит контактную информацию многих организаций, которые проводят обучение и поддержку в области ИКТ для людей с ограниченными возможностями.
Apple предоставляет руководства и рекомендации по настройке диктовки на Mac
Windows предоставляет руководства по распознаванию голоса
Nuance предоставляет обширные руководства и поддержку для своих продуктов Dragon
Множество бесплатных обучающих ресурсов также доступно в Интернете, в том числе на YouTube .

 распознавание голоса на настольном устройстве
распознавание голоса на настольном устройстве
 Кроме того, расширенная диктовка позволяет пользователю работать в автономном режиме.
Кроме того, расширенная диктовка позволяет пользователю работать в автономном режиме.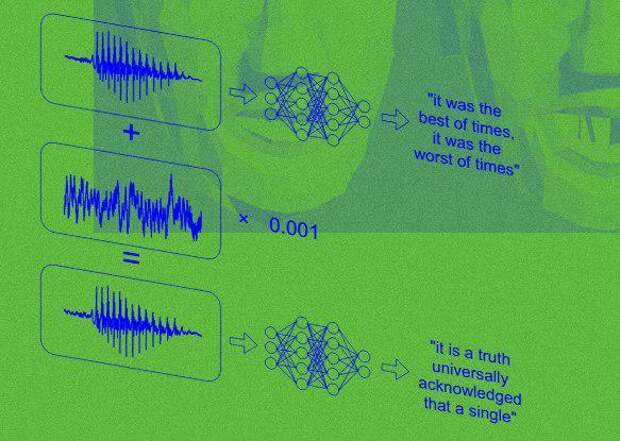 Он не требует регистрации и считается «независимым от говорящего». Распознавание речи доступно на устройствах Android, в приложениях Google, таких как Keep, и в документах Google с помощью модуля записи речи надстроек. Это не то же самое, что помощник Google.
Он не требует регистрации и считается «независимым от говорящего». Распознавание речи доступно на устройствах Android, в приложениях Google, таких как Keep, и в документах Google с помощью модуля записи речи надстроек. Это не то же самое, что помощник Google. Версия программного обеспечения и приложения не совпадают.
Версия программного обеспечения и приложения не совпадают. Есть родные приложения, где можно использовать его полный функционал. Тем не менее, есть несколько сторонних приложений 3 rd , где он не будет работать.
Есть родные приложения, где можно использовать его полный функционал. Тем не менее, есть несколько сторонних приложений 3 rd , где он не будет работать. Небольшая клавиатура упрощает использование голосового управления.
Небольшая клавиатура упрощает использование голосового управления.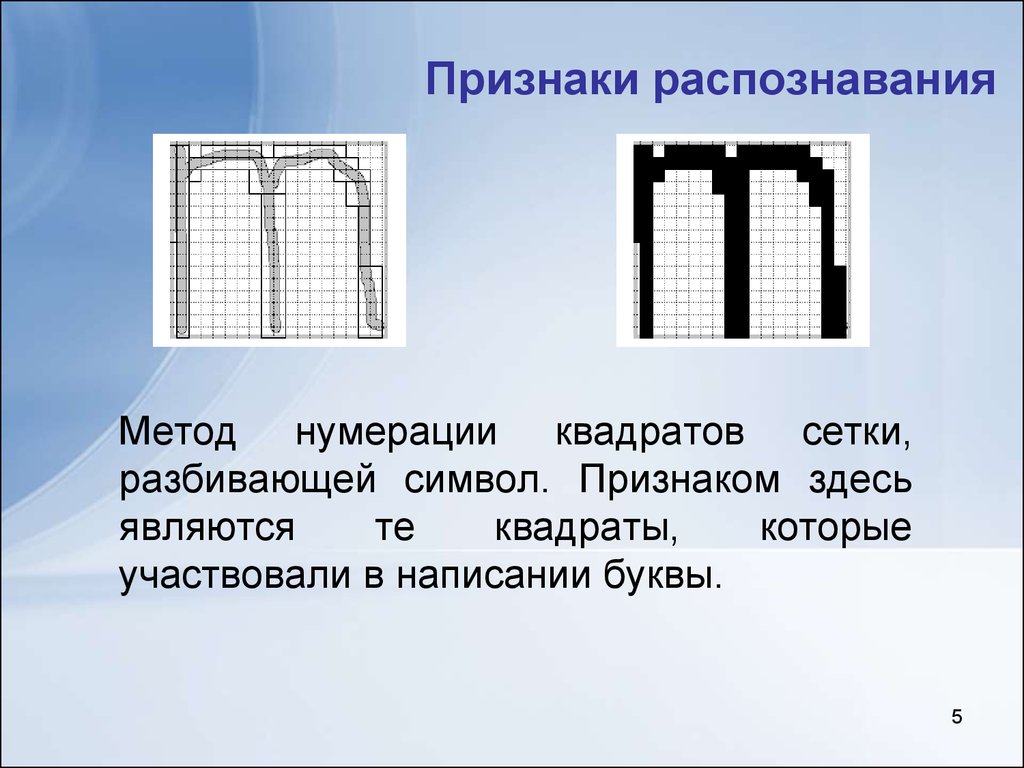 Обратите внимание, что вам нужно будет произносить знаки препинания при вводе текста.
Обратите внимание, что вам нужно будет произносить знаки препинания при вводе текста. Они используют технологию распознавания голоса и пользовательский интерфейс на естественном языке для предоставления ряда услуг. Некоторые из самых популярных личных помощников включают в себя:
Они используют технологию распознавания голоса и пользовательский интерфейс на естественном языке для предоставления ряда услуг. Некоторые из самых популярных личных помощников включают в себя: Это занимает всего минуту и просто включает в себя чтение короткого текста из нескольких строк. Однако не все большинство программ для распознавания используют регистрацию, но могут потребовать от пользователя сказать, есть ли у него акцент, и выбрать, какой именно.
Это занимает всего минуту и просто включает в себя чтение короткого текста из нескольких строк. Однако не все большинство программ для распознавания используют регистрацию, но могут потребовать от пользователя сказать, есть ли у него акцент, и выбрать, какой именно. Если исправления вносятся с помощью программного обеспечения для распознавания голоса либо голосом, либо путем набора текста, оно может адаптироваться и учиться, так что, надеюсь, та же ошибка больше не повторится. Можно достичь очень высокого уровня точности с помощью тщательной диктовки, исправления и настойчивости.
Если исправления вносятся с помощью программного обеспечения для распознавания голоса либо голосом, либо путем набора текста, оно может адаптироваться и учиться, так что, надеюсь, та же ошибка больше не повторится. Можно достичь очень высокого уровня точности с помощью тщательной диктовки, исправления и настойчивости. Чтобы получить максимальную отдачу от обучения, может быть полезно распределить его на период в несколько недель, что дает пользователю достаточную возможность практиковать новые навыки и закреплять полученные знания между формальными коучинговыми сессиями.
Чтобы получить максимальную отдачу от обучения, может быть полезно распределить его на период в несколько недель, что дает пользователю достаточную возможность практиковать новые навыки и закреплять полученные знания между формальными коучинговыми сессиями.