Два сервиса распознавания речи и перевода в текст онлайн. С распознавание речи
Речевые технологии. Распознавание слитной речи для чайников на примере IVR систем / Блог компании Центр речевых технологий (ЦРТ) / Хабр
— Синтез речи (перевод текста в речь). С этой технологией мы пока мало сталкиваемся в реальной жизни. Или просто не замечаем ее. Есть специальные «читалки» для iOS и Android, способные читать вслух книги, которые вы загружаете в устройство. Читают вполне сносно, через день-два уже не замечаешь, что текст читает робот. Во многих колл-центрах динамическую информацию абонентам озвучивает синтезированный голос, т.к. записать заранее все звуковые ролики, озвученные человеком, достаточно сложно, особенно если информация меняется каждые 3 секунды Например, в Метрополитене Санкт-Петербурга многие информационные сообщения на станциях читает именно синтез, но почти никто этого не замечает, т.к. текст звучит довольно-таки неплохо.
— Голосовая биометрия (поиск и подтверждение личности по голосу). Да, да — голос человека также уникален, как отпечаток пальцев или сетчатка глаза. Надежность верификации (сличения двух отпечатков голоса) достигает 98%. Для этого анализируется 74 параметра голоса. В повседневной жизни технология пока встречается очень редко. Но тенденции говорят о том, что скоро это будет распространено повсеместно, особенно в колл-центрах финансовых компаний. Интерес с их стороны к этой технологии очень большой. У голосовой биометрии есть 2 уникальные особенности: — это единственная технология, которая позволяет подтверждать личность удаленно, например, по телефону. И для этого не нужны специальные сканирующие устройства. — это единственная технология, которая подтверждает активность человека, т.е. то, что по телефону разговаривает живой человек. Сразу скажу, что записанный на качественный диктофон голос не сработает – доказано. Если где-то такая запись «пройдет», значит в систему заложен изначально низкий порог «доверия».
— Анализ речи. Мало кто знает, что по голосу можно определить настроение человека, его эмоциональное состояние, пол, примерный вес, национальную принадлежность и т.д. Конечно, никакая машина не сможет сразу сказать, грустит человек или радуется (вполне возможно, что у него всегда по жизни такое состояние: например, среднестатистическая речь итальянца и финна очень отличаются по темпераменту), но по изменению голоса в процессе разговора, определить это уже вполне реально.
— Распознавание речи (перевод речи в текст). Это самая распространенная речевая технология в нашей жизни, и в первую очередь — благодаря мобильным устройствам, т.к. многие производители и разработчики считают, что сказать что -то в смартфон человеку гораздо удобнее, чем набрать этот же текст на маленькой клавиатуре экрана. Предлагаю вначале поговорить вот о чем: где мы встречаемся с технологией распознавания речи в жизни и откуда вообще мы о ней знаем?
Большинство из нас сразу вспомнят Siri (iPhone), Голосовой поиск Google, иногда — IVR системы с голосовым управлением в некоторых колл-центрах, например РЖД, Аэрофлот и т.д. Это то, что лежит на поверхности, и то, что вы легко можете попробовать сами.
Существует распознавание речи, встроенное в систему автомобиля (набор телефонного номера, управление магнитолой), в телевизоры, инфоматы (штуки, похожие на те, которые принимают деньги за мобильных операторов). Но это мало распространено и практикуется больше как «фишка» определенных производителей. Дело даже не в технических ограничениях и качестве работы, а в удобстве пользования и привычках людей. Я плохо представляю себе человека, который голосом листает программы на телевизоре, когда под рукой есть пульт ДУ.
Итак. Технология распознавания речи. Какие они бывают? Сразу хочу сказать, что почти вся моя работа связана с телефонией, поэтому многие примеры по тексту ниже будут взяты именно оттуда – из практики работы колл-центров.
Распознавание по закрытым грамматикам. Распознавание одного слова (голосовой команды) из списка слов (базы). Понятие «закрытые грамматики» означает, что в систему заложена определенная конечная база слов, в которой система будет искать произнесенное абонентом слово или выражение. В этом случае система должна поставить вопрос абоненту так, что бы получить однозначный ответ, состоящий из одного слова.
Пример: Вопрос системы: «Какой день недели вас интересует?» Ответ абонента: «Вторник»
В этом примере вопрос поставлен так, что система ожидает совершенно определенный ответ от абонента. База слов в приведенном примере может состоять из следующих вариантов ответа: «понедельник, вторник, среда, четверг, пятница, суббота, воскресенье». Также следует предусмотреть и заложить в базу следующие варианты ответов: «не знаю», «все равно», «любой» и т.д. — эти ответы абонента должны также предусматриваться и обрабатываться системой отдельно, согласно заранее заложенным сценарием диалога.
Встроенные грамматики. Это разновидность закрытых грамматик. Распознавание часто запрашиваемых стандартных выражений и понятий. Понятие «встроенные грамматики» означает, что в систему уже заложены грамматики (т.е. ее не нужно отдельно «обучать»), которые способны распознавать конкретные тематические фразы абонента. При составлении сценария диалога, необходимо просто сослаться на определенную встроенную грамматику.
Пример: Вопрос системы: «В какое время фильм Вас интересует?» Ответ абонента: «В 15.30»
В приведенном примере распознается значения времени. Вся необходимая грамматика по распознаванию времени уже заложена в систему. Встроенные грамматики служат для упрощения разработки голосовых меню, когда можно использовать стандартные универсальные блоки.
Распознавание по открытым грамматикам. Распознавание всей произнесенной абонентом фразы целиком. Это позволяет системе задать абоненту открытый вопрос и получить ответ, сформулированный в свободной форме. Понятие «открытые грамматики» означает, что система ожидает услышать от абонента не конкретное слово/команду, а все смысловое предложение целиком, в котором систему будет интересовать каждое слово.
Пример: Вопрос системы: «Что вас интересует?» Ответ абонента: «Какие документы нужны для кредита?»
В этом примере распознается каждое слово в ответе абонента и выявляется общий смысл сказанного. На основании распознанных ключевых слов и понятий в предложении формируется запрос в базу данных и «собирается» ответ абоненту – предоставляется справочная информация.
Распознавание слитной речи дает системе много больше возможностей для автоматизации процесса диалога с абонентом. Плюс к этому возрастает скорость и удобство пользования системой со стороны абонента. Но такие системы сложнее в реализации. Если решение задачи может подразумевать односложные ответы абонента, то лучше применять закрытые грамматики. Они надежнее работают, такие системы просты в реализации и более привычны для абонентов, которые привыкли пользоваться DTMF набором (навигация с помощью донабора номера в тоновом режиме). Но будущее, конечно, за слитным распознаванием речи. Постепенно и пользователи к этому привыкнут и не будут «подвисать» на 5-10 секунд, когда система предлагает им вступить в открытый диалог с ней.
Как работает IVR система с распознаванием слитной речи? На примере ПО VoiceNavigator — синтез и распознавание русской речи для IVR системы.
! Осторожно. Дальше будет более сложный текст для понимания.
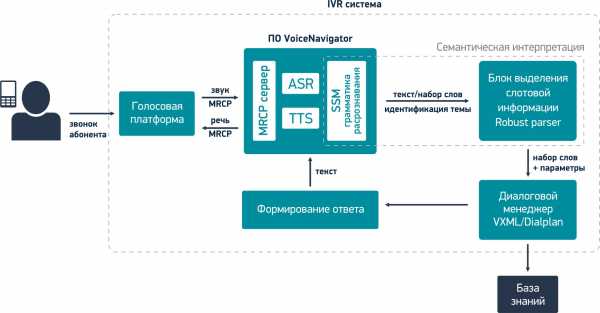
1.Сразу остановимся на том, что вызов абонента пришел в колл-центр и был переведен на голосовую платформу. Голосовая платформа – это ПО, которое занимается отработкой всей логики диалога абонента с системой, т.е. на голосовой платформе работает IVR меню. Наиболее популярные голосовые платформы: Avaya, Genesys, Cisco и Asterisk. Итак, голосовая платформа передает в VoiceNavigator звук с микрофона телефона абонента.
2.Звук попадает в модуль распознавания речи (ASR), который преобразует речь человека в текст в виде последовательности отдельно составленных слов. Полученные слова не имеют для системы пока никакого смысла.
Пример голосовой фразы абонента по теме расписания поездов:
3.Далее текст попадает в модуль SSM грамматики распознавания (на том, что это такое, здесь останавливаться не буду, кто захочет углубиться в тематику, сможет найти сам. Это будет касаться и остальных терминов ниже по тексту), где полученные слова анализируются на предмет тематики высказывания (к какой теме относится распознанная фраза). В нашем примере распознанная фраза относится к теме: «Поезда дальнего следования» и имеет свой уникальный идентификатор.
4.Затем текст вместе с идентификатором темы передается в модуль выделения слотовой информации (robust parser), в котором выделяются определенные понятия и выражения, важные для данной предметной области (смысл высказывания пользователя). В этом модуле система «понимает», что сказал абонент и анализирует, достаточно ли данной информации для формирования запроса в базу знаний или требуются уточняющие вопросы.
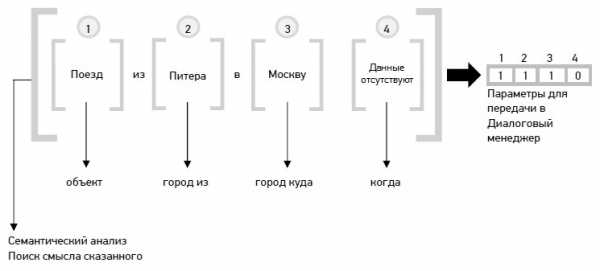
Модуль выделения слотовой информации формирует определенные параметры, которые передаются далее в диалоговый менеджер вместе с распознанными словами.
5.Диалоговый менеджер занимается обработкой всей логики (алгоритма) ведения диалога IVR системы с абонентом. На основании переданных параметров, диалоговый менеджер может отправить запрос в базу знаний (в речи абонента содержится вся информация) для формирования ответа абоненту или запросить у абонента дополнительную информацию, уточнить запрос (в речи абонента содержится не вся информация).
6.Для формирования ответа абоненту диалоговый менеджер обращается в базу знаний. Она содержит всю информацию по предметной области.
7.Далее система формирует ответ абоненту на основании информации из базы знаний и согласно сценарию диалога из диалогового менеджера.
8.После предоставления ответа абоненту, IVR система готова к продолжению работы.
С чего следует начать при создании IVR системы на основе распознавания речи?
Обучение системы распознавания слитной речи. 1.Основой распознавания слитной речи является статистика. Поэтому любой проект по внедрению IVR системы с применением распознавания слитной речи начинается со сбора статистики. Необходимо знать, что интересует абонентов, как они формулируют вопросы, какой информацией изначально обладают, что ожидают услышать в ответ и т.д.
Сбор информации начинается с прослушивания и анализа реальных записей разговоров абонентов с операторами КЦ. На основе этой информации строятся статистические таблицы, из которых становится понятным, какие голосовые запросы абонентов необходимо автоматизировать, и как это можно сделать.
2.Этой информации становится достаточно для создания упрощенного прототипа будущего IVR меню. Такой прототип необходим для сбора и анализа более релевантных ответов абонентов на вопросы IVR меню, т.к. манера общения абонентов с операторами КЦ и с речевыми IVR меню сильно отличается.
Созданный прототип IVR меню размещается на входящем номере телефона в компанию. Он может быть максимально упрощен или вообще не отрабатывать заложенный функционал, т.к. его основная задача заключается в накоплении статистического материала (всевозможных ответов абонентов), который будет являться основой для формирования статистической языковой модели (SLM) направленной на определенную тематику. Гибкость языковой модели для конкретной предметной области позволяет улучшить качество распознавания.
Пример реализации прототипа IVR меню: Вопрос системы: «Какая услуга Вас интересует?» Ответ абонента: «Я хотел бы взять кредит» Ответ системы: «Вызов будет переведен на оператора контактного центра» Действия системы: Перевод на оператора КЦ при любом ответе абонента.
С помощью прототипа IVR меню, разработчик создает эмуляцию работы системы и собирает реальные записи ответов абонентов (сбор фонограмм), по которым впоследствии будет обучаться система. Не имеет значение, что произнесет абонент на вопрос системы, вызов в любом случае будет переведен на оператора контактного центра. Таким образом, абонент будет обслужен без причинения ему неудобств, а разработчики IVR меню получать базу всех возможных вариантов ответов по данной тематике на примере реального диалога. Необходимое количество фонограмм для реализации проекта может достигать нескольких тысяч, а время для сбора фонограмм может занять несколько месяцев. Все зависит от сложности проекта.
3.Затем собранные записи разговоров транскрибируются. Каждая запись прослушивается специалистом и переводится в текст. Транскрибированные фразы не должны содержать пунктуационные знаки и специальные символы. Также все слова и аббревиатуры должны быть прописаны полностью, как их произносит клиент. Данная работа занимает достаточно много времени, но не требует специфических знаний, поэтому к работе обычно одновременно привлекается сразу много сотрудников.
4.Транскрибированные файлы служат для построения тренировочного файла (словарь слов и выражений, конфигурационные параметры), который представляет собой XML документ. Чем объемней будет тренировочный файл по предметной области, тем более качественным будет распознавание. Тренировочный файл позволяет сформировать языковую модель (SLM), которая является основой распознавания слитной речи.
Для этого тренировочный файл загружается в специальную утилиту, разработанную компанией ЦРТ (именно она является автором ПО VoiceNavigator) – ASR Конструктор, который строит языковую модель. Затем языковая модель загружается в программное обеспечение VoiceNavigator.
На данном этапе работы по построению речевого IVR меню, система способна распознавать речь абонента в виде отдельно составленных слов, не связанных друг с другом.
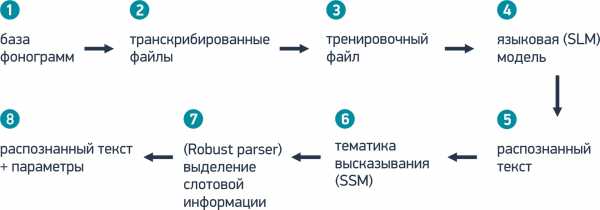
5.Затем в распознанном списке слов необходимо выявить тему обращения абонента (SSM грамматика распознавания) и выделить слотовую информацию (Robust parser). Для этого требуется дополнительное обучение системы с помощью соответствующих тренировочных файлов. Тренировочные файлы могут быть созданы на основе уже полученных ранее транскрибированных файлов. Но в отличие от задачи по получению языковой модели, транскрибированные файлы должны быть соответствующим образом доработаны под их пригодность для SSM грамматики и Robust parser.
Что же, начало статьи получилось достаточно простым для понимания тех, кто вообще не знаком с речевыми технологиями. А потом я с головой окунулся в тонкости создания реальных систем голосового самообслуживания. Прошу прощения за такие метаморфозы.
Кого заинтересовала данная тема, и он хочет больше узнать про создание IVR систем с голосовым управлением, хочу порекомендовать посетить специальный wiki сайт – www.vxml.ru Он посвящен разработке IVR систем на диалоговом языке VoiceXML, который является основным в данной работе.
Спасибо.
habr.com
Лучшая программа распознания русской речи
Обновлено: Понедельник, Июль 31, 2017
 Какое отношение имеет полу фантастическая идея разговора с компьютером к профессиональной фотографии? Почти никакого, если вы не поклонник идеи бесконечного развития всего технического окружения человека. Представьте на минуту, что вы отдаете голосом приказы своему фотоаппарату изменить фокусное расстояние и сделать коррекцию экспозиции на пол ступени в плюс. Дистанционное управление камерой уже реализовано, но там нужно молча нажимать на кнопки, а тут слышащий фотик!
Какое отношение имеет полу фантастическая идея разговора с компьютером к профессиональной фотографии? Почти никакого, если вы не поклонник идеи бесконечного развития всего технического окружения человека. Представьте на минуту, что вы отдаете голосом приказы своему фотоаппарату изменить фокусное расстояние и сделать коррекцию экспозиции на пол ступени в плюс. Дистанционное управление камерой уже реализовано, но там нужно молча нажимать на кнопки, а тут слышащий фотик!
Стало традицией приводить в пример голосового общения человека с ЭВМ какой- либо фантастический фильм, ну хоть бы «Космическая одиссея 2001» режиссера Стэнли Кубрика. Там бортовой компьютер не только ведет осмысленный диалог с астронавтами, но умеет читать по губам как глухой. Другими словами, машина научилась распознавать человеческую речь без ошибок. Возможно, кому-то дистанционное голосовое управление фотокамерой покажется лишним, но многим бы понравилось такая фраза «Сними нас, крошка» и снимок всей семьи на фоне пальмы готов.
Ну, вот и я отдал дань традиции, слегка пофантазировал. Но, говоря от души, эта статья писалась трудно, а началось все с подарка в виде смартфона с ОС «Андроид 4». Эта модель HUAWEI U8815 имеет небольшой сенсорный экран в четыре дюйма и экранную клавиатуру. Набирать на ней несколько непривычно, но оказалось это и не особенно нужно. (image01)
1. Распознание голоса в смартфоне на ОС «Андроид»
Осваивая новую игрушку, я заметил графическое изображение микрофона в строке поиска Google и на клавиатуре в «Заметках». Ранее мне было не интересно, что этот символ обозначает. Разговоры я вел в Skype, а письма набирал на клавиатуре. Так поступает большинство пользователей Интернета. Но как потом мне объяснили, в поисковик Google был добавлен голосовой поиск на русском языке и появились программы, позволяющие диктовать короткие сообщения при использовании браузера «Chrome».
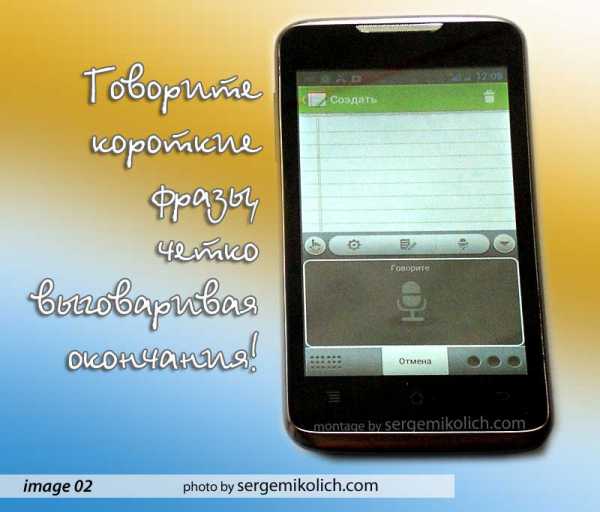 Я произнес фразу из трех слов, программа их определила и показала в ячейке с синим фоном. Тут было чему удивиться, потому что все слова были написаны правильно. Если нажать на эту ячейку, то фраза появляется в текстовом поле андроид-блокнота. Так еще пару фраз наговорил и отправил сообщение помощнику по SMS.
Я произнес фразу из трех слов, программа их определила и показала в ячейке с синим фоном. Тут было чему удивиться, потому что все слова были написаны правильно. Если нажать на эту ячейку, то фраза появляется в текстовом поле андроид-блокнота. Так еще пару фраз наговорил и отправил сообщение помощнику по SMS.
 2. Краткая история программ распознания голоса.
2. Краткая история программ распознания голоса.
Для меня не было открытием, что современные достижения в области управления голосом позволяют отдавать команды бытовой технике, автомобилю, роботу. Командный режим был представлен в прошлых версиях Windows, OS/2 и Mac OS. Мне встречались программы-говорилки, но что с них пользы? Возможно, это моя особенность, что говорить мне проще, чем печатать на клавиатуре, а на сотовом телефоне я вообще не могу ничего набрать. Приходится записывать контакты на ноутбуке с нормальной клавиатурой и передавать по USB кабелю. Но чтобы просто говорить в микрофон и компьютер сам набирал текст без ошибок – это для меня было мечтой. Атмосферу безнадежности поддерживали дискуссии на форумах. В них везде была такая печальная мысль:
«Однако на деле до настоящего времени программ для реального распознавания речи (да еще и на русском языке) практически не существует, и созданы они будут, очевидно, не скоро. Более того, даже обратная распознаванию задача — синтез речи, что, казалось бы, значительно проще распознавания, до конца так и не решена». (КомпьютерПресс №12, 2004г.)
«Нормальных программ распознавания речи (не только русской) по сию пору нет, поскольку задача изрядно трудна для компьютера. А хуже всего то, что механизм распознавания слов человеком так и не осознан, поэтому не от чего отталкиваться при создании программ-распознавалок». (Еще одно обсуждение на форуме).
При этом обзоры англоязычных программ ввода текста голосом указывали на явные успехи. Например, IBM ViaVoice 98 Executive Edition имела базовый словарь в 64000 слов и возможность добавления такого же количества своих слов. Процент распознания слов без тренировки программы был около 80% и при последующей работе с конкретным пользователем доходил до 95%.
Из программ распознания русского языка стоит отметить «Горыныч» – дополнение к англоязычной Dragon Dictate 2.5. Про поиски, а потом «битву с пятью Горынычами» я расскажу во второй части обзора. Первым я нашел «английского Дракона».
3. Программа распознания слитной речи «Dragon Naturally Speaking»
Современная версия программы фирмы «Nuance» оказалась у моей давнишней знакомой по Минскому институту иностранных языков. Она ее привезла из заграничной поездки, а купила, думая, что та сможет быть «компьютерным секретарем». Но что-то не пошло, и программа осталась на ноутбуке почти забытая. По причине отсутствия сколь-нибудь внятного опыта мне пришлось ехать к своей знакомой самому. Все это длительное вступление необходимо для правильного понимания выводов, которые я сделал.
Полное название первого моего дракона звучало так: «Dragon Naturally Speaking Premium Edition». Программа на английском и все в ней понятно даже без руководства. Первым шагом необходимо создать профиль конкретного пользователя для определения особенностей звучания слов в его исполнении. Что я и сделал – важен возраст говорящего, страна, особенности произношения. Мой выбор таков: возраст 22–54 года, английский UK, произношение стандартное. Далее идет несколько окон, в которых вы настраиваете свой микрофон. (image04)
 Следующий этап у серьезных программ распознания речи – тренировка под особенности произношения конкретного человека. Вам предлагается выбрать характер текста: мой выбор – краткая инструкция по диктовке, но можно «заказать» и юмористический рассказ.
Следующий этап у серьезных программ распознания речи – тренировка под особенности произношения конкретного человека. Вам предлагается выбрать характер текста: мой выбор – краткая инструкция по диктовке, но можно «заказать» и юмористический рассказ.
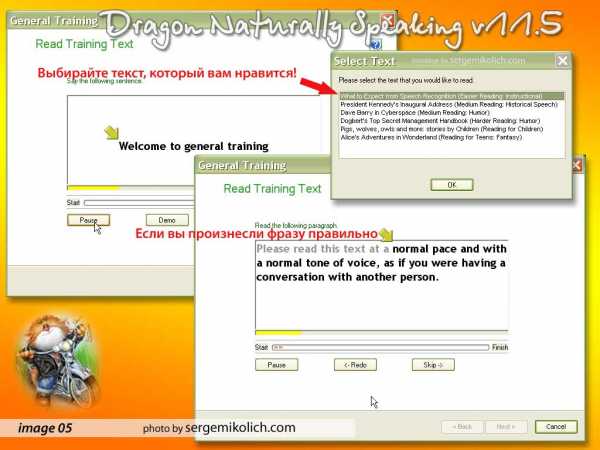
Суть этого этапа работы с программой предельно проста – в окошке выводится текст, над ним желтая стрелочка. При правильном произнесении стрелочка перемещается по фразам, а внизу идет полоса прогресса тренировки. Английский разговорный был мной изрядно позабыт, так что продвигался я с трудом. Время также было ограничено – компьютер ведь не мой и пришлось тренировку прервать. Но подруга сказала, что проходила тест менее чем за полчаса. (image05)
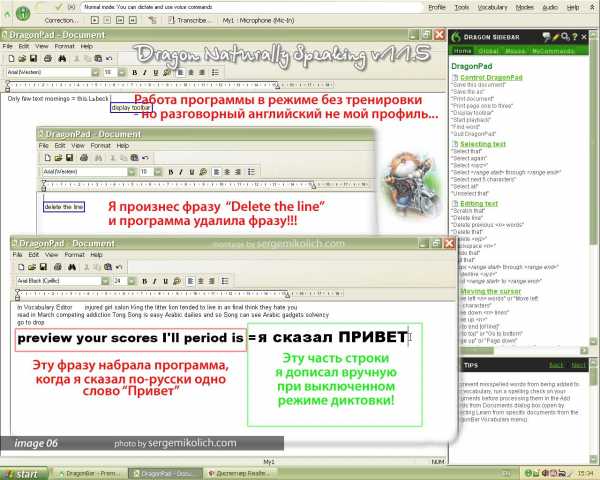
 Отказавшись от адаптации программой моего произношения, я перешел в основное окно и запустил встроенный текстовой редактор. Говорил отдельные слова из каких-то текстов, что нашел на компьютере. Те слова, что произнес правильно, программа напечатала, те, что плохо сказал, заменила чем-то «английским». Произнеся команду «стереть строку» по-английски четко – программа ее выполнила. Значит, команды я читаю правильно, и программа распознает их без предварительной тренировки.
Отказавшись от адаптации программой моего произношения, я перешел в основное окно и запустил встроенный текстовой редактор. Говорил отдельные слова из каких-то текстов, что нашел на компьютере. Те слова, что произнес правильно, программа напечатала, те, что плохо сказал, заменила чем-то «английским». Произнеся команду «стереть строку» по-английски четко – программа ее выполнила. Значит, команды я читаю правильно, и программа распознает их без предварительной тренировки.
Но мне было важно, как этот «дракон» пишет по-русски. Как вы поняли из предыдущего описания, при тренировке программы можно выбрать только английский текст, русского там попросту нет. Понятно, что и натренировать распознание русской речи не получится. На следующем фото можно увидеть, какую фразу набрала прога при произнесении русского слова «Привет». (image06)
 Итог общения с первым драконом получился слегка комичным. Если внимательно почитать текст на официальном сайте, то можно увидеть английскую «специализацию» этого программного продукта. Кроме того, при загрузке мы читаем в окне программы «English». Так зачем это все было нужно. Понятно, что виноваты форумы и слухи…
Итог общения с первым драконом получился слегка комичным. Если внимательно почитать текст на официальном сайте, то можно увидеть английскую «специализацию» этого программного продукта. Кроме того, при загрузке мы читаем в окне программы «English». Так зачем это все было нужно. Понятно, что виноваты форумы и слухи…
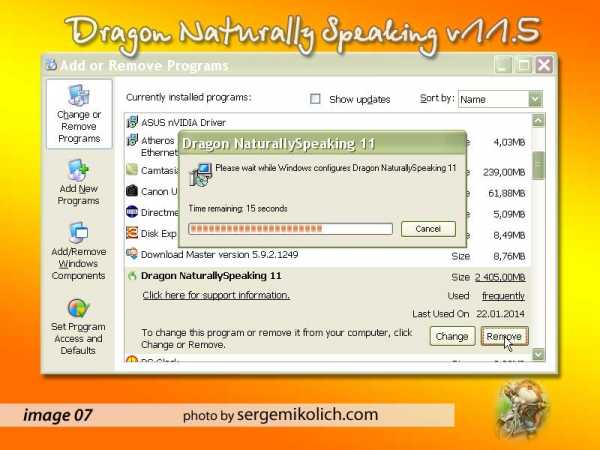
Но есть и полезный опыт. Моя знакомая попросила посмотреть состояние ее ноутбука. Как-то медленно он стал работать. Это не удивительно – системный раздел имел только 5% свободного места. Удаляя ненужные программы я увидел, что официальная версия занимала более 2,3 Гб. Эта цифра нам пригодится позже. (image. 07)
 4. Программа распознавания русской речи «Горыныч»
4. Программа распознавания русской речи «Горыныч»
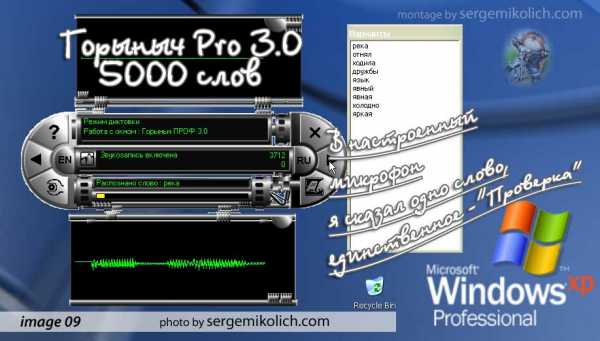
Распознание русской речи, как оказалось, было задачей нетривиальной. В Минске мне удалось найти у знакомого «Горыныча». Диск он долго искал в своих старых завалах и, по его словам, это официальное издание. Установилась прога мгновенно, и я узнал, что в ее словаре есть 5000 русских слов плюс 100 команд и 600 английских слов плюс 31 команда.
Вначале нужно настроить микрофон, что я сделал. Потом открыл словарь и добавил слово «проверка» ибо его не оказалось в словаре программы. Старался говорить четко, монотонно. Наконец, открыл программу «Горыныч Про 3,0», включил режим диктовки и получил вот такой список «близких по звучанию слов». (image. 09)
 Полученный результат меня озадачил, ведь он явно отличался в худшую сторону от работы андроид-смартфона, и я решил попробовать другие программы из «интернет-магазина Google Chrome». А разбираться со «змеями-горынычами» отложил на потом. Мне показалось это откладывание действием в исконно русском духе
Полученный результат меня озадачил, ведь он явно отличался в худшую сторону от работы андроид-смартфона, и я решил попробовать другие программы из «интернет-магазина Google Chrome». А разбираться со «змеями-горынычами» отложил на потом. Мне показалось это откладывание действием в исконно русском духе
5. Возможности компании Google по работе с голосом
Для работы с голосом на обычном компьютере с OS Windows вам понадобится установить браузер Google Chrome. Если вы в нем работаете в Интернете, то внизу справа можно нажать на ссылку магазина программного обеспечения. Там совершенно бесплатно я нашел две программы и два расширения для голосового ввода текста. Программы называются «Голосовой блокнот» и «Войснот – голос в текст». После установки их можно найти на закладке «Приложения» вашего браузера «Хром». (image. 10)
 Расширения называются «Google Voice Search Hotword (Beta) 0.1.0.5» и «Голосовой ввод текста — Speechpad.ru 5.4». После установки их можно будет выключить или удалить на вкладке «Расширения». (image. 11)
Расширения называются «Google Voice Search Hotword (Beta) 0.1.0.5» и «Голосовой ввод текста — Speechpad.ru 5.4». После установки их можно будет выключить или удалить на вкладке «Расширения». (image. 11)
 VoiceNote. На вкладке приложения в браузере «Хром» дважды щелкните иконку программы. Откроется диалоговое окно как на картинке ниже. Нажав на значке микрофона, вы говорите в микрофон короткие фразы. Программа передает ваши слова на сервер по распознанию речи и набирает текст в окне. Все слова и фразы, показанные на иллюстрации, были набраны с первого раза. Очевидно, что этот способ работает только при активном подключении к Интернету. (image. 12)
VoiceNote. На вкладке приложения в браузере «Хром» дважды щелкните иконку программы. Откроется диалоговое окно как на картинке ниже. Нажав на значке микрофона, вы говорите в микрофон короткие фразы. Программа передает ваши слова на сервер по распознанию речи и набирает текст в окне. Все слова и фразы, показанные на иллюстрации, были набраны с первого раза. Очевидно, что этот способ работает только при активном подключении к Интернету. (image. 12)
 Голосовой блокнот. Если запустить программу на вкладке приложений, то откроется новая вкладка Интернет страницы Speechpad.ru. Там есть подробная инструкция, как пользоваться этой службой и компактная форма. Последняя показана на иллюстрации ниже. (image. 13)
Голосовой блокнот. Если запустить программу на вкладке приложений, то откроется новая вкладка Интернет страницы Speechpad.ru. Там есть подробная инструкция, как пользоваться этой службой и компактная форма. Последняя показана на иллюстрации ниже. (image. 13)
 Голосовой ввод текста позволяет заполнять текстовые поля Интернет страниц голосом. Для примера я вышел на свою страницу «Google+». В поле ввода нового сообщения щелкнул правой кнопкой мыши и выбрал пункт «SpeechPad». Окрашенное в розовый цвет окно ввода говорит, что можно диктовать ваш текст. (image. 14)
Голосовой ввод текста позволяет заполнять текстовые поля Интернет страниц голосом. Для примера я вышел на свою страницу «Google+». В поле ввода нового сообщения щелкнул правой кнопкой мыши и выбрал пункт «SpeechPad». Окрашенное в розовый цвет окно ввода говорит, что можно диктовать ваш текст. (image. 14)
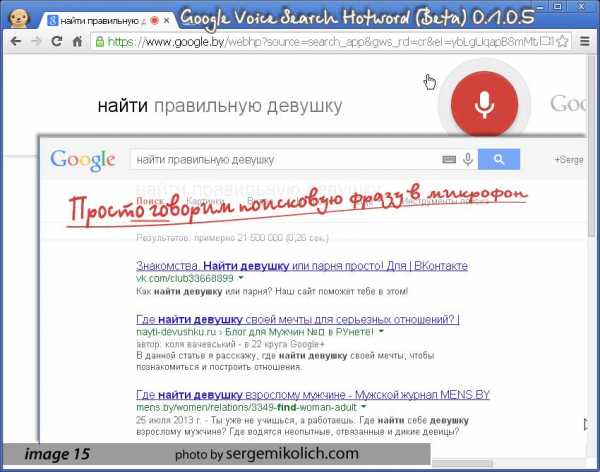
 Google Voice Search позволяет производить поиск голосом. При установке и активации этого расширения в строке поиска появляется символ микрофона. Когда вы его нажмете, появится символ в большом красном круге. Просто скажите поисковую фразу и она появится в результатах поиска. (image. 15)
Google Voice Search позволяет производить поиск голосом. При установке и активации этого расширения в строке поиска появляется символ микрофона. Когда вы его нажмете, появится символ в большом красном круге. Просто скажите поисковую фразу и она появится в результатах поиска. (image. 15)
 Важное замечание: для работы микрофона с расширениями «Хром» вам нужно разрешить доступ к микрофону в настройках браузера. По умолчанию в целях безопасности он запрещен. Пройдите в Настройки→Личные данные→Настройки контента. (Для доступа ко всем настройкам в конце списка щелкните Показать дополнительные настройки). Откроется диалоговое окно Настройки содержания страницы. Выберите вниз по списку пункт Мультимедиа→микрофон.
Важное замечание: для работы микрофона с расширениями «Хром» вам нужно разрешить доступ к микрофону в настройках браузера. По умолчанию в целях безопасности он запрещен. Пройдите в Настройки→Личные данные→Настройки контента. (Для доступа ко всем настройкам в конце списка щелкните Показать дополнительные настройки). Откроется диалоговое окно Настройки содержания страницы. Выберите вниз по списку пункт Мультимедиа→микрофон.
6. Итоги работы с программами распознания русской речи
Небольшой опыт использования программ ввода текста голосом показал отличную реализацию этой возможности на серверах интернет-компании Google. Без всякой предварительной тренировки слова распознаются правильно. Это свидетельствует о том, что проблема распознания русской речи решена.
Теперь можно говорить, что результат разработок Google будет новым критерием для оценки продуктов других производителей. Хотелось бы, чтобы система распознания работала в автономном режиме без обращения к серверам компании –так удобнее и быстрее. Но когда будет выпущена самостоятельная программа по работе с непрерывным потоком русской речи неизвестно. Стоит, однако, предположить, что при возможности тренировки это «творение» станет настоящим прорывом.
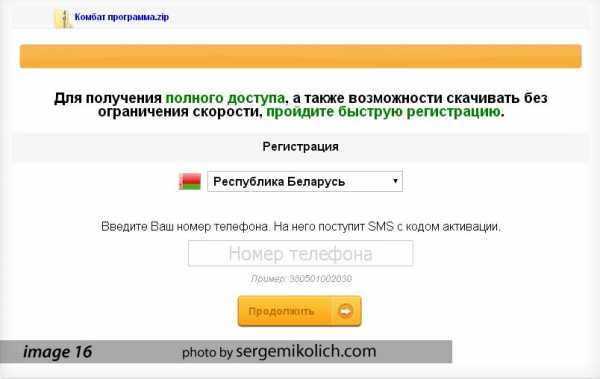
Программы российских разработчиков «Горыныч», «Диктограф» и «Комбат» я подробно рассмотрю во второй части данного обзора. Эта статья писалась очень медленно по той причине, что сам поиск оригинальных дисков сейчас затруднен. На данный момент у меня уже есть все версии российских «распознавалок» голоса в текст кроме «Комбат 2.52». Ни у кого из моих знакомых или коллег нет этой программы, а я сам имею только несколько хвалебных отзывов на форумах. Правда нашелся такой странный вариант – скачать «Комбат» через SMS, но мне он не нравится. (image16)
 Короткий видео ролик покажет вам, как идет распознание речи в смартфоне с ОС Андроид. Особенность голосового набора — это необходимость подключения к серверам Гугла. Таким образом у вас должен работать Интернет
Короткий видео ролик покажет вам, как идет распознание речи в смартфоне с ОС Андроид. Особенность голосового набора — это необходимость подключения к серверам Гугла. Таким образом у вас должен работать Интернет
sergemikolich.com
Задача распознавания речи пока не решена / Хабр
Говорить о том, что мы достигли уровня человека в распознавании речи в разговорах, основываясь лишь на наборе разговоров с телефонного коммутатора, это всё равно, что утверждать, что робомобиль водит не хуже человека, протестировав его в единственном городе в солнечный день без всякого уличного движения. Произошедшие в деле распознавания речи в последнее время сдвиги удивительны. Но заявления по поводу распознавания речи на уровне человека слишком смелы. Вот несколько областей, в которых всё ещё необходимо добиваться улучшений.
Акценты и шум
Один из очевидных недостатков распознавания речи – обработка акцентов и фонового шума. Основная причина этого в том, что большая часть тренировочных данных состоит из американского говора с высоким отношением сигнала к шуму. К примеру, в наборе разговоров с телефонного коммутатора есть только беседы людей, чей родной язык – английский (по большей части, это американцы) с небольшим фоновым шумом.Но увеличение тренировочных данных само по себе, скорее всего, не решит эту проблему. Существует множество языков, содержащих много диалектов и акцентов. Нереально собрать размеченные данные для всех случаев. Создание высококачественного распознавателя речи только для американского английского требует до 5 тысяч часов аудиозаписей, переведённых в текст.
Сравнение людей, занимающихся преобразованием речи в текст, с Baidu’s Deep Speech 2 на разных типах речи. Люди хуже справляются с распознаванием неамериканских акцентов – возможно, из-за обилия американцев среди них. Думаю, что люди, выросшие в определённом регионе, с гораздо меньшим количеством ошибок справились бы с распознаванием акцента этого региона.При наличии фонового шума в движущейся машине отношение сигнал/шум может достигать величин в -5 дБ. Люди легко справляются с распознаванием речи другого человека в таких условиях. Автоматические распознаватели гораздо быстрее ухудшают показатели с увеличением шума. На графике видно, как сильно увеличивается отрыв людей при увеличении шума (при низких значениях SNR, signal-to-noise ratio)
Семантические ошибки
Часто количество ошибочно распознанных слов не является самоцелью системы распознавания речи. Мы нацеливаемся на количество семантических ошибок. Это та доля выражений, у которых мы неправильно распознаём смысл.Пример семантической ошибки – когда кто-то предлагает «let’s meet up Tuesday» [давайте встретимся во вторник] а распознаватель выдаёт «let’s meet up today» [давайте встретимся сегодня]. Бывают и ошибки в словах без семантических ошибок. Если распознаватель не распознал «up» и выдал “let’s meet Tuesday”, семантика предложения не изменилась.
Нам нужно аккуратно использовать количество ошибочно распознанных слов в качестве критерия. Для иллюстрации этого я дам вам пример с наихудшим из возможных случаев. 5% ошибок в словах соответствует одному пропущенному слову из 20. Если в каждом предложении 20 слов (что для английского языка вполне в рамках среднего), то количество неправильно распознанных предложений приближается к 100%. Можно надеяться на то, что неправильно распознанные слова не меняют семантический смысл предложений. А иначе распознаватель может неправильно расшифровать каждое предложение даже с 5% количеством ошибочно распознанных слов.
Сравнивая модели с людьми важно проверять суть ошибок и следить не только за количеством неправильно распознанных слов. По моему опыту, люди, транслирующие речь в текст, делают меньше ошибок и они не такие серьёзные, как у компьютеров.
Исследователи из Microsoft недавно сравнили ошибки людей и компьютерных распознавателей схожего уровня. Одно из найденных различий – модель путает “uh” [э-э-э…] с “uh huh” [ага] гораздо чаще людей. У двух этих терминов очень разная семантика: “uh” заполняет паузы, а “uh huh” обозначает подтверждение со стороны слушателя. Также у моделей и людей обнаружили много ошибок совпадающих типов.
Много голосов в одном канале
Распознавать записанные телефонные разговоры проще ещё и потому, что каждого говорящего записывали на отдельный микрофон. Там не происходит наложения нескольких голосов в одном аудиоканале. Люди же могут понимать нескольких ораторов, иногда говорящих одновременно.Хороший распознаватель речи должен уметь разделять аудиопоток на сегменты в зависимости от говорящего (подвергать его диаризации). Также он должен извлечь смысл из аудиозаписи с двумя накладывающимися друг на друга голосами (разделение источников). Это необходимо делать без микрофона, расположенного прямо у рта каждого из спикеров, то есть так, чтобы распознаватель работал хорошо, будучи размещённым в произвольном месте.
Качество записи
Акценты и фоновый шум – всего два фактора, к которым распознаватель речи должен быть устойчив. Вот ещё несколько:• Реверберация в разных акустических условиях. • Артефакты, связанные с оборудованием. • Артефакты кодека, используемого для записи и сжатия сигнала. • Частота дискретизации. • Возраст говорящего.
Большинство людей не отличат на слух записей из mp3 и wav-файлов. Прежде чем заявлять о показателях, сравнимых с человеческими, распознаватели должны стать устойчивыми и к перечисленным источникам вариаций.
Контекст
Можно заметить, что количество ошибок, которые люди делают на тестах в записях с телефонной станции, довольно высоко. Если бы вы беседовали с другом, который не понимал бы 1 слово из 20, вам бы было очень сложно общаться.Одна из причин этого – распознавание без учёта контекста. В реальной жизни мы используем множество разных дополнительных признаков, помогающих нам понимать, что говорит другой человек. Некоторые примеры контекста, используемые людьми, и игнорируемые распознавателями речи:
• История беседы и обсуждаемая тема. • Визуальные подсказки о говорящем – выражения лица, движение губ. • Совокупность знаний о человеке, с которым мы говорим.
Сейчас у распознавателя речи в Android есть список ваших контактов, поэтому он умеет распознавать имена ваших друзей. Голосовой поиск на картах использует геолокацию, чтобы сузить количество возможных вариантов, до которых вы хотите построить маршрут.
Точность систем распознавания увеличивается с включением в данные подобных сигналов. Но мы только начинаем углубляться в тип контекста, который мы могли бы включить в обработку и в методы его использования.
Развёртывание
Последние достижения в распознавании разговорной речи невозможно развернуть. Представляя себе развёртывание алгоритма распознавания речи, нужно помнить о задержках и вычислительных мощностях. Эти параметры связаны, поскольку алгоритмы, увеличивающие требования к мощности, увеличивают и задержку. Но для простоты обсудим их по отдельности.Задержка: время от окончания речи пользователя и до окончания получения транскрипции. Небольшая задержка – типичное требование для распознавания. Она сильно влияет на ощущения пользователя от работы с продуктом. Часто встречается ограничение в десятки миллисекунд. Это может показаться слишком строгим, но вспомните, что выдача расшифровки — это обычно первый шаг в серии сложных вычислений. К примеру, в случае голосового интернет-поиска после распознавания речи нужно ещё успеть выполнить поиск.
Двунаправленные рекуррентные слои – типичный пример улучшения, ухудшающего ситуацию с задержкой. Все последние результаты расшифровки высокого качества получаются с их помощью. Проблема только в том, что мы не можем ничего подсчитывать после прохода первого двунаправленного слоя до тех пор, пока человек не закончил говорить. Поэтому задержка увеличивается с длиной предложения.
Слева: прямая рекуррентность позволяет начинать расшифровку сразу. Справа: двунаправленная рекуррентность требует подождать окончания речи перед тем, как начинать расшифровку.Хороший способ эффективно включать будущую информацию в распознавание речи пока ещё ищут.
Вычислительная мощность: на этот параметр влияют экономические ограничения. Необходимо учитывать стоимость банкета для каждого улучшения точности распознавателя. Если улучшение не достигает экономического порога, развернуть его не получится.
Классический пример постоянного улучшения, которое никогда не развёртывают – совместное глубинное обучение [ensemble]. Уменьшение количества ошибок на 1-2% редко оправдывает увеличение вычислительных мощностей в 2-8 раз. Современные модели рекуррентных сетей тоже попадают в эту категорию, поскольку их очень невыгодно использовать в поиску по пучку траекторий, хотя, думаю, в будущем ситуация поменяется.
Хочу уточнить – я не говорю, что улучшение точности распознавания с серьёзным увеличением вычислительных затрат бесполезно. Мы уже видели, как в прошлом работает принцип «сначала медленно, но точно, а затем быстро». Смысл в том, что до тех пор, пока улучшение не станет достаточно быстрым, использовать его нельзя.
В следующие пять лет
В области распознавания речи остаётся ещё немало нерешённых и сложных проблем. Среди них:• Расширение возможностей новых систем хранения данных, распознавания акцентов, речи на фоне сильного шума. • Включение контекста в процесс распознавания. • Диаризация и разделение источников. • Количество семантических ошибок и инновационные методы оценки распознавателей. • Очень малая задержка.
С нетерпением жду прогресса, который будет достигнут в следующие пять лет по этим и другим фронтам.
habr.com
Как перевести речь в текст? Выбираем лучший сервис распознавания речи
Для того, чтобы распознать речь и перевести её из аудио или видео в текст, существуют программы и расширения (плагины) для браузеров. Однако зачем всё это, если есть онлайн сервисы? Программы надо устанавливать на компьютер, более того, большинство программ распознавания речи далеко не бесплатны.
Большое число установленных в браузере плагинов сильно тормозит его работу и скорость серфинга в интернет. А сервисы, о которых сегодня пойдет речь, полностью бесплатны и не требуют установки – зашел, попользовался и ушел!В этой статье мы рассмотрим два сервиса перевода речи в текст онлайн. Оба они работают по схожему принципу: Вы запускаете запись (разрешаете браузеру доступ к микрофону на время пользования сервисом), говорите в микрофон (диктуете), а на выходе получаете текст, который можно скопировать в любой документ на компьютере.
Speechpad.ru
Русскоязычный онлайн сервис распознавания речи. Имеет подробную инструкцию по работе на русском языке.
Среди основных функций «Голосового блокнота» (так сам автор называет свой сервис) следует выделить:
- поддержку 7 языков (русский, украинский, английский, немецкий, французский, испанский, итальянский)
- загрузку для транскрибации аудио или видео файла (поддерживаются ролики с YouTube)
- синхронный перевод на другой язык
- поддержку голосового ввода знаков препинания и перевода строки
- панель кнопок (смена регистра, перевод на новую строку, кавычки, скобки и т.п.)
- наличие персонального кабинета с историей записей (опция доступна после регистрации)
- наличие плагина к Google Chrome для ввода текста голосом в текстовом поле сайтов (называется «Голосовой ввод текста — Speechpad.ru»)
Dictation.io
Второй онлайн сервис перевода речи в текст. Иностранный сервис, который между тем, прекрасно работает с русским языком, что крайне удивительно. По качеству распознавания речи не уступает Speechpad, но об этом чуть позже.
Основной функционал сервиса:
- поддержка 30 языков, среди которых присутствуют даже венгерский, турецкий, арабский, китайский, малайский и пр.
- автораспознавание произношения знаков препинания, перевода строки и пр.
- возможность интеграции со страницами любого сайта
- наличие плагина для Google Chrome (называется «VoiceRecognition»)
В деле распознавания речи самое важное значение имеет именно качество перевода речи в текст. Приятные «плюшки» и вохможности – не более чем хороший плюс. Так чем же могут похвастаться в этом плане оба сервиса?
Сравнительный тест сервисов
Для теста выберем два непростых для распознавания фрагмента, которые содержат нечасто употребляемые в нынешней речи слова и речевые обороты. Для начала читаем фрагмент поэмы «Крестьянские дети» Н. Некрасова.
Ниже представлен результат перевода речи в текст каждым сервисом (ошибки обозначены красным цветом):
Как видим, оба сервиса практически с одинаковыми ошибками справились с распознаванием речи. Результат весьма неплохой!
Теперь для теста возьмем отрывок из письма красноармейца Сухова (к/ф «Белое солнце пустыни»):
Отличный результат!
Как видим, оба сервиса весьма достойно справляются с распознаванием речи – выбирайте любой! Похоже что они даже используют один и тот же движок — уж слижком схожие у них оказались допущенные ошибки по результатам тестов ). Но если Вам необходимы дополнительные функции типа подгрузки аудио / видео файла и перевода его в текст (транскрибация) или синхронного перевода озвученного текста на другой язык, то Speechpad будет лучшим выбором!
Кстати вот как он выполнил синхронный перевод фрагмента поэмы Некрасова на английский язык:Ну а это краткая видео инструкция по работе со Speechpad, записанная самим автором проекта:
Друзья, понравился ли Вам данный сервис? Знаете ли Вы более качественные аналоги? Делитесь своими впечатлениями в комментариях.
webtous.ru
Машинное обучение это весело! Часть 6
Часть цикла статей Adam Geitgey – “Машинное обучение это весело!”: ч.1, ч.2, ч.3, ч.4, ч.5, ч.6, ч.7, ч.8.
Распознавание речи с помощью глубокого обучения
Распознавание речи вторгается в нашу жизнь. Оно уже есть в телефонах, игровых консолях и даже в смарт-часах. Даже наши дома автоматизируются с помощью речи. Всего за $50 вы можете купить Amazon Echo Dot – волшебную коробку, которая позволит вам заказать пиццу, получить прогноз погоды или даже купить мешки для мусора – просто произнесите команду:
Echo Dot была настолько популярна в этот праздничный сезон, что Amazon не успевает их поставлять!
Но распознавание речи появилось десятилетия назад – так почему же это только сейчас оно стало мейнстримом? Причина в том, что глубокое обучение наконец-то сделало распознавание речи достаточно точным, чтобы оно стало полезно вне тщательно контролируемой среде.
Эндрю Ын (Andrew Ng) давно предсказал, что, поскольку распознавание речи уже работает с точностью 95-99%, оно скоро станет основным способом нашего взаимодействия с компьютерами. Но дело в том, что именно эти 4% определяют разницу между «раздражающе ненадежным» и «невероятно полезным» алгоритмом. Благодаря глубокому обучению мы, наконец, достигли вершины.
Давайте узнаем, как распознать речь с помощью глубокого обучения!
Машинное обучение – это не всегда «черный ящик»
Если вы знаете, как работает нейросетевой машинный перевод, вы можете догадаться, что можно просто скормить нейросети звуковые записи и обучить ее на них:
Это Святой Грааль распознавания речи с использованием глубокого обучения, но до него пока далеко (по крайней мере, когда я писал это, я думал, что мы придем к этому через пару лет).
Серьезная проблема заключается в том, что речь имеет непостоянную скорость. Один человек может сказать «привет!» очень быстро, а другой скажет «прррриииииввввееееееееет!» очень медленно, создав намного более длинный звуковой файл с гораздо большим объемом данных. А между тем оба звуковых файла должны быть распознаны как одинаковый текст – «привет!». Автоматическое выравнивание аудиофайлов различной длины под фрагмент текста фиксированной длины – задача непростая.
Чтобы обойти эту проблему, нам придется использовать некоторые специальные трюки и дополнительную точность в дополнении к глубокой нейронной сети. Посмотрим, как это работает!
Превращение звуков в биты
Первый шаг в распознавании речи очевиден – нам нужно передать звуки на компьютер.
В третьей части мы узнали, как взять изображение и представить его в виде массива чисел, чтобы напрямую подключиться к нейронной сети для распознавания изображений:
Но звук – это волны. Как превратить звуковые волны в числа? Воспользуемся следующим аудиофайлом с текстом «привет»:
Звуковые волны одномерны. В каждый момент времени у них есть одно значение, зависящее от амплитуды волны. Давайте приблизим некоторую небольшую часть звуковой волны и посмотрим внимательней:
Чтобы превратить эту звуковую волну в числа, мы просто записываем значения амплитуды волны в равноотстоящих точках:
Это называется дискретизацией. Мы считываем данные тысячи раз в секунду и записываем числа, соответствующие амплитуде звуковой волны в этот момент времени. Получаются несжатые .wav аудиофайлы.
Звук, записываемый на CD-диски, дискретизируется с частотой 44,1 кГц (44 100 отсчетов в секунду). Но для распознавания речи достаточно частоты дискретизации 16 кГц (16000 отсчетов в секунду), так как диапазон частот человеческой речи не столь велик.
Давайте оцифруем наш «Привет» 16000 раз в секунду. Вот первые 100 точек:
Простой инструмент цифровой дискретизации
Возможно, вы думаете, что дискретизация создает лишь приближенный вариант исходной звуковой волны, так как мы считываем случайные показания, а в промежутках между отсчетами данные теряются, ведь так?
Но благодаря теореме Котельникова мы знаем, что для идеального воссоздания исходной звуковой волны достаточно использовать частоту дискретизации, вдвое превышающую самую высокую частоту записываемого звука.
Я останавливаюсь на этом только потому, что почти все ошибочно думают, что использование более высоких частот дискретизации всегда приводит к лучшему качеству звука. Это не так.
Предварительная обработка полученных оцифрованных данных
Теперь у нас есть массив чисел, каждое из которых представляет амплитуду звуковой волны через интервалы 1/16000 секунды.
Мы могли бы просто обучить нейросеть на этих числах, но распознание речевых моделей путем обработки этих чисел напрямую затруднительно. Вместо этого мы можем облегчить задачу, проведя некоторую предварительную обработку аудиоданных.
Начнем с того, что сгруппируем наши отсчеты во фрагменты по 20 миллисекунд. Вот первый такой фрагмент (первые 320 отсчетов):
Построение этих чисел в виде простого линейного графика дает приблизительное изображение исходной звуковой волны за выбранный 20 миллисекундный период времени:
Эта запись длится всего 1/50 секунды. Но даже она представляет собой сложную смесь различных частот звука. Есть несколько низких звуков, есть среднечастотные звуки и даже некоторые высокие звуки. Все эти частоты смешиваются вместе – и получается звук человеческой речи.
Чтобы упростить обработку этих данных для нейронной сети, разложим сложную звуковую волну на ее составные части, начиная от самых нижних частот. Затем, суммируя мощности звука в каждой полосе частот, мы создаем частотную картину звука.
Представьте, что у вас была запись того, как кто-то исполняет аккорд До мажор на фортепиано. Этот звук представляет собой комбинацию из трех музыкальных нот – До, Ми и Соль – которые смешивается в один сложный звук. Мы хотим разбить этот сложный звук на отдельные ноты, чтобы обнаружить исходные ноты. Здесь – то же самое.
Это делается с помощью математической операции, называемой преобразованием Фурье. Мы раскладываем сложную звуковую волну на простые звуковые волны, которые ее составляют. Имея отдельные звуковые волны, мы складываем мощности звука в каждой из них.
Конечным результатом является оценка важности каждого частотного диапазона, от низких частот до высоких. Числа ниже показывает мощность звука в каждой полосе по 50 Гц в нашем исходном фрагменте:
Намного проще и наглядней понять это, если нарисовать диаграмму:
Если мы повторим этот процесс на каждом 20-миллисекундном фрагменте аудио, мы получим спектрограмму (каждый столбец слева направо представляет собой один 20-миллисекундный фрагмент):
Спектрограмма – это круто, так как с помощью нее можно выделить музыкальные ноты и другие тона в аудиоданных. Нейронной сети будет проще находить шаблоны в таких данных, чем в сырых записях звука. Теперь мы получили данные, которые передадим нашей нейросети.
Распознавание букв из коротких звуков
Теперь, когда у нас есть аудио в формате, с которым можно работать дальше, мы обучим на этих данных глубокую нейросеть. Нейросеть будет получать аудио-фрагменты длиной 20 мс. Для каждого небольшого фрагмента сеть попробует определить, какая буква была произнесена.
Мы будем использовать рекуррентную нейронную сеть, то есть такую, которая на каждом шаге учитывает результаты предыдущих шагов. Мы делаем так потому, что каждая буква, определенная сетью, должна влиять на вероятную следующую букву. Например, если мы произнесли «ПРИВ», то скорее всего, дальше скажем «ЕТ», чтобы закончить слово «Привет». Гораздо менее вероятно, что мы скажем что-то непроизносимое, например «ШХЩ». Таким образом, запоминая предыдущие результаты, нейросеть сможет делать более точные прогнозы в будущем.
После того как мы пропустим весь наш аудиофайл через нейронную сеть (по одному фрагменту за раз), мы получим разложение каждого фрагмента аудио на буквы, наиболее вероятно произнесенные во время этого фрагмента. Вот как выглядит отображение «Привет»:
Наша нейронная сеть предсказывает что я, вроде бы, сказал «ПРРРИИИ__ВВВ_ВЕЕЕЕЕТ». Но также она может подумать, что я сказал «ПРРРЕЕЕВВВ__ВВ_ЕЕЕДД» или даже «ПРИУУ_УУУЭЭЭЭТ».
Мы должны привести результаты в порядок за несколько этапов. Во-первых, мы заменим любые повторяющиеся символы одним символом:
- ПРРРИИИ__ВВВ_ВЕЕЕЕЕТ превратится в ПРИ_В_ЕТ
- ПРРРЕЕЕВВВ__ВВ_ЕЕЕДД превратится в ПРЕ_В_ЕД
- ПРИИИИ_УУ_УУУЭЭЭЭТ превратится в ПРИ_У_ЭТ
Теперь удалим все пропуски:
- ПРИ_В_ЕТ превратится в ПРИВЕТ
- ПРЕ_В_ЕД превратится в ПРЕВЕД
- ПРИ_У_ЭТ превратится в ПРИУЭТ
Итак, мы получили три возможных транскрипции – «Привет», «Превед» и «Приуэт». Если вы произнесете их вслух, все они будут звучать похоже на «Привет». Поскольку все буквы определяются по одной, нейросеть может выдумать совершенно непроизносимые транскрипции. Например, если вы скажете «Он не пойдет», сеть может выдать «Оне пай дёд».
Фокус заключается в том, чтобы уточнять эти предсказания, сравнивая их с большой базой данных письменного текста (книги, новостные статьи и т. д.). Мы отбрасываем транскрипции, которые кажутся наименее вероятными, и выбираем ту, которая кажется наиболее реалистичной.
Из наших вариантов транскрипций «Привет», «Превед» и «Приуэт», очевидно, «Привет» встречается в базе данных текста более часто (не говоря уже о наших исходных аудиофайлах), и поэтому, вероятно, это правильный вариант. Поэтому мы выберем «Привет» в качестве нашей окончательной транскрипции. Готово!
Стоп, секундочку!
Вы можете подумать: «Но что, если кто-то скажет «Превед»? Это будет верное слово, и «Привет» будет неправильной транскрипцией!»
Конечно, возможно, что кто-то на самом деле скажет «Превед» вместо «Привет». Но система распознавания речи, подобная этой (обучаемая на литературном языке), не выберет «Превед» как правильный вариант. Кроме того, когда вы говорите «Превед», вы все равно имеете в виду «Привет», даже если вы подчеркиваете букву Е и Д».
Попробуйте вот что – если ваш телефон настроен на распознавание языка, попробуйте сказать телефону «Превед». Он откажется понимать вас, и неумолимо будет распознавать это как «Привет».
Непризнание «Превед» – это нормально, но может оказаться и так, что ваш телефон просто отказывается понимать что-то действительное правильное и важное. Именно поэтому эти модели распознавания речи всегда обучаются на большом количестве данных, чтобы исправить ошибки.
А смогу ли я создать свою систему распознавания речи?
Одна из самых классных особенностей машинного обучения в том, что оно кажется очень простой штукой. Вы получаете кучу данных, загружаете их в алгоритм машинного обучения, а затем волшебным образом вы получаете систему ИИ мирового уровня, которая работает на вашем ноутбуке … да?
Да, иногда это работает, но не для речи. Распознавание речи – это сложная задача. Вам нужно преодолеть сотню различных трудностей: плохое качество микрофонов, фоновые шумы, реверберация и эхо, вариации произношения и акцента и многое другое. Все эти проблемы должны быть учтены в обучающих данных, чтобы убедиться, что нейронная сеть справляется с ними.
Вот еще один пример. Знаете ли вы, что, когда вы говорите в шумной комнате, вы подсознательно говорите более высоким тоном, чтобы перекрикивать шум? Люди-то понимают вас без проблем, но вот научить этому нейросеть – это целая задача. Таким образом, в ваших обучающих данных должны быть кричащие в шуме люди!
Чтобы создать систему распознавания голоса, которая будет работать на уровне Siri, Google Now или Alexa, вам понадобится много обучающих данных – гораздо больше данных, чем вы, вероятно, сможете получить, не нанимая сотни людей, которые запишут их. А между тем, экономить на этом нельзя – никто не хочет систему распознавания голоса, которая работает лишь в 80% случаев.
Google и Amazon используют сотни тысяч часов разговорной речи, записанной в реальных ситуациях. Это самый большой момент, который отделяет систему распознавания речи мирового класса от вашего хобби. Все дело в том, что Google Now и Siri, работающие бесплатно, или волшебные коробки Alexa за 50$, у которых нет абонентской платы, призваны заставить вас использовать их как можно больше. Все, что вы говорите им, потом записывается навсегда и в дальнейшем будет использовано в качестве обучающих данных для будущих версий алгоритмов распознавания речи. Вот в чем фокус-то!
Не верите? Если у вас есть Android-телефон с Google Now, нажмите здесь, чтобы прослушать все глупые вещи, которые вы когда-либо говорили:
Поэтому, если вы ищете идею для стартапа, я бы не рекомендовал создавать собственную систему распознавания речи и конкурировать с Google. Вместо этого придумайте, как сделать так, чтобы люди передавали вам записи своей речи. Можно же продавать данные, а не системы.
Где узнать больше
- Алгоритм обработки звука с переменной длиной, в общих чертах описанный здесь, называется Connectionist Temporal Classification или CTC. Вы можете прочитать оригинал статьи 2006 года.
- Адам Коутс (Adam Coates) из Baidu сделал отличную презентацию о глубоком обучении распознавания речи в Bay Area Deep Learning School. Вы можете посмотреть видео на YouTube (его выступление начинается в 3:51:00). Настоятельно рекомендую.
algotravelling.com
Распознавание речи на python с помощью pocketsphinx или как я пытался сделать голосового ассистента
Это туториал по использованию библиотеки pocketsphinx на Python. Надеюсь он поможет вам побыстрее разобраться с этой библиотекой и не наступать на мои грабли.
Началось все с того, что захотел я сделать себе голосового ассистента на python. Изначально для распознавания решено было использовать библиотеку speech_recognition. Как оказалось, я не один такой. Для распознавания я использовал Google Speech Recognition, так как он единственный не требовал никаких ключей, паролей и т.д. Для синтеза речи был взят gTTS. В общем получился почти клон этого ассистента, из-за чего я не мог успокоиться.
Правда, успокоиться я не мог не только из-за этого: ответа приходилось ждать долго (запись заканчивалась не сразу, отправка речи на сервер для распознавания и текста для синтеза занимала немало времени), речь не всегда распознавалась правильно, дальше полуметра от микрофона приходилось кричать, говорить нужно было четко, синтезированная гуглом речь звучала ужасно, не было активационной фразы, то есть звуки постоянно записывались и передавались на сервер.
Первым усовершенствованием был синтез речи при помощи yandex speechkit cloud:
URL = 'https://tts.voicetech.yandex.net/generate?text='+text+'&format=wav&lang=ru-RU&speaker=ermil&key='+key+'&speed=1&emotion=good' response=requests.get(URL) if response.status_code==200: with open(speech_file_name,'wb') as file: file.write(response.content)Затем настала очередь распознавания. Меня сразу заинтересовала надпись "CMU Sphinx (works offline)" на странице библиотеки. Я не буду рассказывать об основных понятиях pocketsphinx, т.к. до меня это сделал chubakur(за что ему большое спасибо) в этом посте.
Установка Pocketsphinx
Сразу скажу, так просто pocketsphinx установить не получится(по крайней мере у меня не получилось), поэтому pip install pocketsphinx не сработает, упадет с ошибкой, будет ругаться на wheel. Установка через pip будет работать только если у вас стоит swig. В противном случае чтобы установить pocketsphinx нужно перейти вот сюда и скачать установщик(msi). Обратите внимание: установщик есть только для версии 3.5!
Распознавание речи при помощи pocketsphinx
Pocketsphinx может распознавать речь как с микрофона, так и из файла. Также он может искать горячие фразы(у меня не очень получилось, почему-то код, который должен выполняться когда находится горячее слово выполняется несколько раз, хотя произносил его я только один). От облачных решений pocketsphinx отличается тем, что работает оффлайн и может работать по ограниченному словарю, вследствие чего повышается точность. Если интересно, на странице библиотеки есть примеры. Обратите внимание на пункт "Default config".
Русская языковая и акустическая модель
Изначально pocketsphinx идет с английской языковой и акустической моделями и словарем. Скачать русские можно по этой ссылке. Архив нужно распаковать. Затем надо папку <your_folder>/zero_ru_cont_8k_v3/zero_ru.cd_cont_4000 переместить в папку C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model, где <your_folder> это папка в которую вы распаковали архив. Перемещенная папка — это акустическая модель. Такую же процедуру надо проделать с файлами ru.lm и ru.dic из папки <your_folder>/zero_ru_cont_8k_v3/. Файл ru.lm это языковая модель, а ru.dic это словарь. Если вы все сделали правильно, то следующий код должен работать.
import os from pocketsphinx import LiveSpeech, get_model_path model_path = get_model_path() speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=os.path.join(model_path, 'ru.lm'), dic=os.path.join(model_path, 'ru.dic') ) print("Say something!") for phrase in speech: print(phrase)Предварительно проверьте чтобы микрофон был подключен и работал. Если долго не появляется надпись Say something! — это нормально. Большую часть этого времени занимает создание экземпляра LiveSpeech, который создается так долго потому, что русская языковая модель весит более 500(!) мб. У меня экземпляр LiveSpeech создается около 2 минут.
Этот код должен распознавать почти любые произнесенные вами фразы. Согласитесь, точность отвратительная. Но это можно исправить. И увеличить скорость создания LiveSpeech тоже можно.
JSGF
Вместо языковой модели можно заставить pocketsphinx работать по упрощенной грамматике. Для этого используется jsgf файл. Его использование ускоряет создание экземпляра LiveSpeech. О том как создавать файлы граматики написано здесь. Если языковая модель есть, то jsgf файл будет игнорироваться, поэтому если вы хотите использовать собственный файл грамматики, то нужно писать так:
speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=False, jsgf=os.path.join(model_path, 'grammar.jsgf'), dic=os.path.join(model_path, 'ru.dic') )Естественно файл с грамматикой надо создать в папке C:/Users/tutam/AppData/Local/Programs/Python/Python35-32/Lib/site-packages/pocketsphinx/model. И еще: при использовании jsgf придется четче говорить и разделять слова.
Создаем свой словарь
Словарь — это набор слов и их транскрипций, чем он меньше, тем выше точность распознавания. Для создания словаря с русскими словами нужно воспользоваться проектом ru4sphinx. Качаем, распаковываем. Затем открываем блокнот и пишем слова, которые должны быть в словаре, каждое с новой строки, затем сохраняем файл как my_dictionary.txt в папке text2dict, в кодировке UTF-8. Затем открываем консоль и пишем: C:\Users\tutam\Downloads\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt. Открываем my_dictionary_out.txt, копируем содержимое. Открываем блокнот, вставляем скопированный текст и сохраняем файл как my_dict.dic (вместо "текстовый файл" выберите "все файлы"), в кодировке UTF-8.
speech = LiveSpeech( verbose=False, sampling_rate=16000, buffer_size=2048, no_search=False, full_utt=False, hmm=os.path.join(model_path, 'zero_ru.cd_cont_4000'), lm=os.path.join(model_path, 'ru.lm'), dic=os.path.join(model_path, 'my_dict.dic') )Некоторые транскрипции может быть нужно подправить.
Использование pocketsphinx через speech_recognition
Использовать pocketsphinx через speech_recognition имеет смысл только если вы распознаете английскую речь. В speech_recognition нельзя указать пустую языковую модель и использовать jsgf, а следовательно для распознавания каждого фрагмента придется ждать 2 минуты. Проверенно.
Итог
Угробив несколько вечеров я понял, что потратил время впустую. В словаре из двух слов(да и нет) сфинкс умудряется ошибаться, причем часто. Отъедает 30-40% celeron'а, а с языковой моделью еще и жирный кусок памяти. А Яндекс почти любую речь распознает безошибочно, при том не ест память и процессор. Так что думайте сами, стоит ли за это браться вообще.
P.S.: это мой первый пост, так что жду советы по оформлению и содержанию статьи.
habr.com
Открытые проблемы в области распознавания речи. Лекция в Яндексе / Блог компании Яндекс / Хабр
Сегодня я поговорю в основном о распознавании речи, хотя есть множество других интересных задач. Рассказ мой будет состоять из трех частей. Для начала напомню в целом, как работает распознавание речи. Дальше расскажу, как люди стараются его улучшить и о том, какие в Яндексе стоят задачи, с которыми обычно не сталкиваются в научных статьях.
Общая схема распознавания речи. Изначально на вход нам поступает звуковая волна. Ее мы дробим на маленькие кусочки, фреймы. Длина фрейма — обычно 25 мс, шаг — 10 мс. Они идут с некоторым захлестом.
Ее мы дробим на маленькие кусочки, фреймы. Длина фрейма — обычно 25 мс, шаг — 10 мс. Они идут с некоторым захлестом.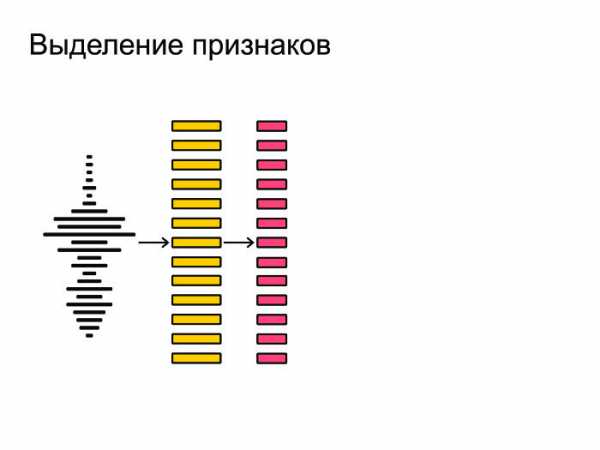 После этого из фреймов мы извлекаем наиболее важные признаки. Допустим, нам не важен тембр голоса или пол человека. Мы хотим распознавать речь вне зависимости от этих факторов, так что мы извлекаем самые важные признаки.
После этого из фреймов мы извлекаем наиболее важные признаки. Допустим, нам не важен тембр голоса или пол человека. Мы хотим распознавать речь вне зависимости от этих факторов, так что мы извлекаем самые важные признаки.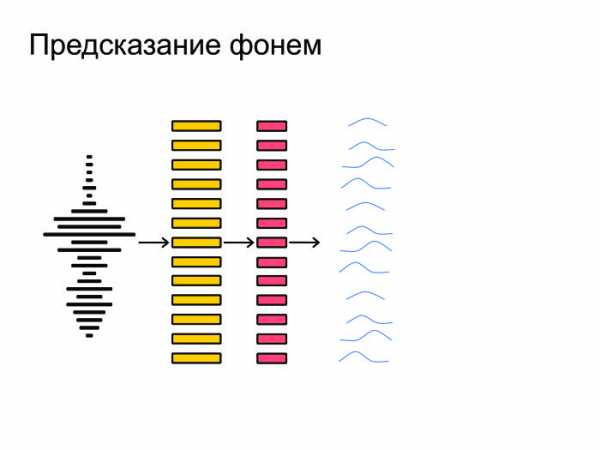 Затем нейронная сеть натравливается на все это и выдает на каждом фрейме предсказание, распределение вероятностей по фонемам. Нейронка старается угадать, какая именно фонема была сказана на том или ином фрейме.
Затем нейронная сеть натравливается на все это и выдает на каждом фрейме предсказание, распределение вероятностей по фонемам. Нейронка старается угадать, какая именно фонема была сказана на том или ином фрейме.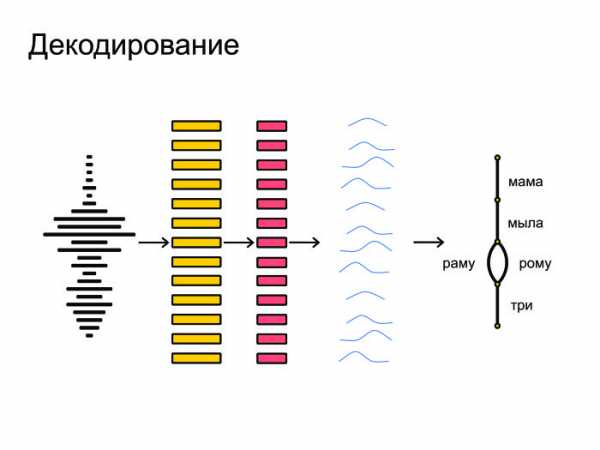 Под конец все это запихивается в граф-декодирование, которое получает распределение вероятностей и учитывает языковую модель. Допустим, «Мама мыла раму» — более популярная фраза в русском языке, чем «Мама мыла Рому». Также учитывается произношение слов и выдаются итоговые гипотезы.
Под конец все это запихивается в граф-декодирование, которое получает распределение вероятностей и учитывает языковую модель. Допустим, «Мама мыла раму» — более популярная фраза в русском языке, чем «Мама мыла Рому». Также учитывается произношение слов и выдаются итоговые гипотезы.
В целом, именно так и происходит распознавание речи. Естественно, о метрике нужно пару слов сказать. Все используют метрику WER в распознавании речи. Она переводится как World Error Rate. Это просто расстояние по Левенштейну от того, что мы распознали, до того, что реально было сказано в фразе, поделить на количество слов, реально сказанных во фразе.
Естественно, о метрике нужно пару слов сказать. Все используют метрику WER в распознавании речи. Она переводится как World Error Rate. Это просто расстояние по Левенштейну от того, что мы распознали, до того, что реально было сказано в фразе, поделить на количество слов, реально сказанных во фразе.
Можно заметить, что если у нас было много вставок, то ошибка WER может получиться больше единицы. Но никто на это не обращает внимания, и все работают с такой метрикой.

Как мы будем это улучшать? Я выделил четыре основных подхода, которые пересекаются друг с другом, но на это не стоит обращать внимания. Основные подходы следующие: улучшим архитектуру нейронных сетей, попробуем изменить Loss-функцию, почему бы не использовать подходы End to end, модные в последнее время. И в заключение расскажу про другие задачи, для которых, допустим, не нужно декодирование.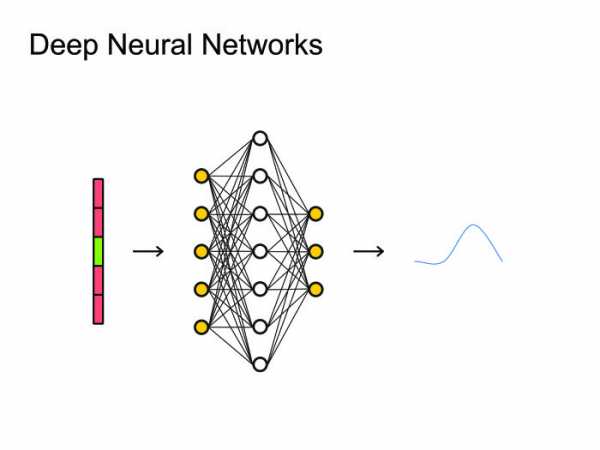 Когда люди придумали использовать нейронные сети, естественным решением было использовать самое простое: нейронные сетки feed forward. Берем фрейм, контекст, сколько-то фреймов слева, сколько-то справа, и предсказываем, какая фонема была сказана на данном фрейме. После чего можно посмотреть на все это как на картинку и применить всю артиллерию, уже использованную для обработки изображений, всевозможные сверточные нейронные сети.
Когда люди придумали использовать нейронные сети, естественным решением было использовать самое простое: нейронные сетки feed forward. Берем фрейм, контекст, сколько-то фреймов слева, сколько-то справа, и предсказываем, какая фонема была сказана на данном фрейме. После чего можно посмотреть на все это как на картинку и применить всю артиллерию, уже использованную для обработки изображений, всевозможные сверточные нейронные сети.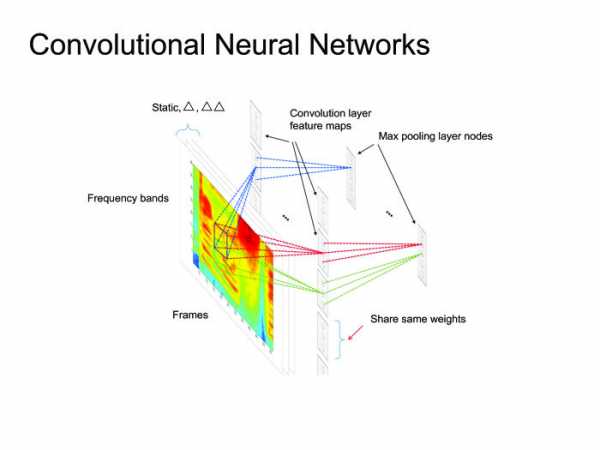 Вообще многие статьи state of the art получены именно с помощью сверточных нейронных сетей, но сегодня я расскажу больше о рекуррентных нейронных сетях.
Вообще многие статьи state of the art получены именно с помощью сверточных нейронных сетей, но сегодня я расскажу больше о рекуррентных нейронных сетях.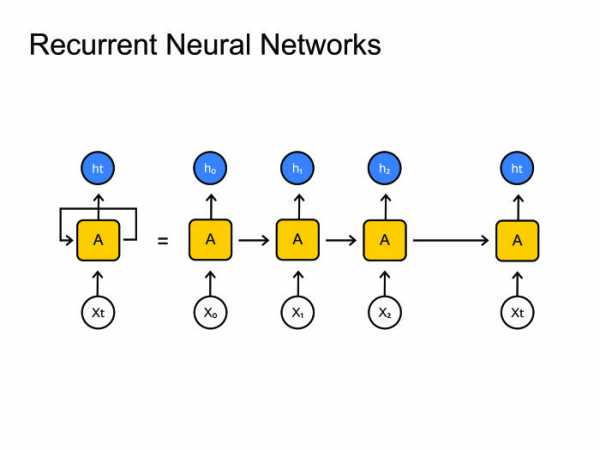 Рекуррентные нейронные сети. Все знают, как они работают. Но возникает большая проблема: обычно фреймов намного больше, чем фонем. На одну фонему приходится 10, а то и 20 фреймов. С этим нужно как-то бороться. Обычно это зашивается в граф-декодирование, где мы остаемся в одном состоянии много шагов. В принципе, с этим можно как-то бороться, есть парадигма encoder-decoder. Давайте сделаем две рекуррентных нейронных сетки: одна будет кодировать всю информацию и выдавать скрытое состояние, а декодер будет брать это состояние и выдавать последовательность фонем, букв или, может быть, слов — это как вы натренируете нейронную сеть.
Рекуррентные нейронные сети. Все знают, как они работают. Но возникает большая проблема: обычно фреймов намного больше, чем фонем. На одну фонему приходится 10, а то и 20 фреймов. С этим нужно как-то бороться. Обычно это зашивается в граф-декодирование, где мы остаемся в одном состоянии много шагов. В принципе, с этим можно как-то бороться, есть парадигма encoder-decoder. Давайте сделаем две рекуррентных нейронных сетки: одна будет кодировать всю информацию и выдавать скрытое состояние, а декодер будет брать это состояние и выдавать последовательность фонем, букв или, может быть, слов — это как вы натренируете нейронную сеть.
Обычно в распознавании речи мы работаем с очень большими последовательностями. Там спокойно бывает 1000 фреймов, которые нужно закодировать одним скрытым состоянием. Это нереально, ни одна нейронная сеть с этим не справится. Давайте использовать другие методы.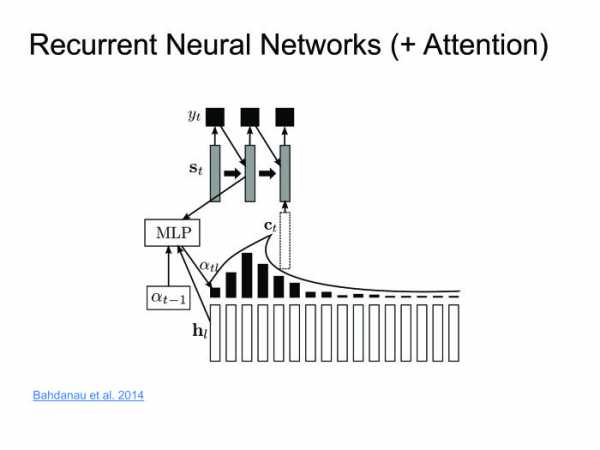 Димой Богдановым, выпускником ШАД, был придуман метод Attention. Давайте encoder будет выдавать скрытые состояния, и мы их не будем выкидывать, а оставим только последнее. Возьмем взвешенную сумму на каждом шаге. Декодер будет брать взвешенную сумму скрытых состояний. Таким образом, мы будем сохранять контекст, то, на что мы в конкретном случае смотрим.
Димой Богдановым, выпускником ШАД, был придуман метод Attention. Давайте encoder будет выдавать скрытые состояния, и мы их не будем выкидывать, а оставим только последнее. Возьмем взвешенную сумму на каждом шаге. Декодер будет брать взвешенную сумму скрытых состояний. Таким образом, мы будем сохранять контекст, то, на что мы в конкретном случае смотрим.
Подход прекрасный, работает хорошо, на некоторых датасетах дает результаты state of the art, но есть один большой минус. Мы хотим распознавать речь в онлайне: человек сказал 10-секундную фразу, и мы сразу ему выдали результат. Но Attention требует знать фразу целиком, в этом его большая проблема. Человек скажет 10-секундную фразу, 10 секунд мы ее будем распознавать. За это время он удалит приложение и никогда больше не установит. Нужно с этим бороться. Совсем недавно с этим поборолись в одной из статей. Я назвал это online attention.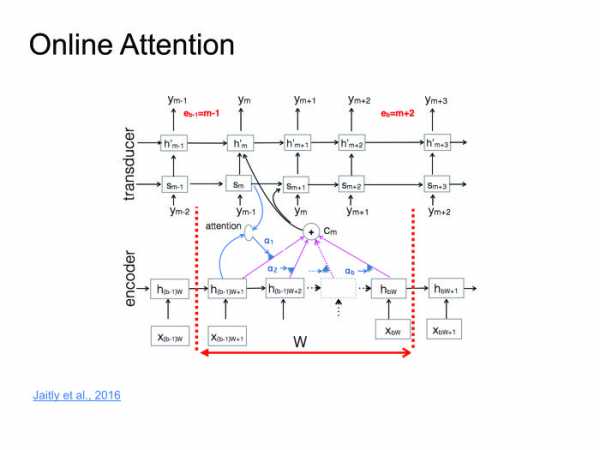 Давайте поделим входную последовательность на блоки какой-то небольшой фиксированной длины, внутри каждого блока устроим Attention, затем будет декодер, который выдает на каждом блоке соответствующие символы, после чего в какой-то момент выдает символ end of block, перемещается к следующему блоку, поскольку мы тут исчерпали всю информацию.
Давайте поделим входную последовательность на блоки какой-то небольшой фиксированной длины, внутри каждого блока устроим Attention, затем будет декодер, который выдает на каждом блоке соответствующие символы, после чего в какой-то момент выдает символ end of block, перемещается к следующему блоку, поскольку мы тут исчерпали всю информацию.
Тут можно серию лекций прочитать, я постараюсь просто сформулировать идею. Когда начали тренировать нейронные сети для распознавания речи, старались угадывать фонему. Для этого использовали обычную кросс-энтропийную функцию потерь. Проблема в том, что даже если мы соптимизируем кросс-энтропию, это еще не будет значить, что мы хорошо соптимизировали WER, потому что у этих метрик корреляция не 100%.
Когда начали тренировать нейронные сети для распознавания речи, старались угадывать фонему. Для этого использовали обычную кросс-энтропийную функцию потерь. Проблема в том, что даже если мы соптимизируем кросс-энтропию, это еще не будет значить, что мы хорошо соптимизировали WER, потому что у этих метрик корреляция не 100%.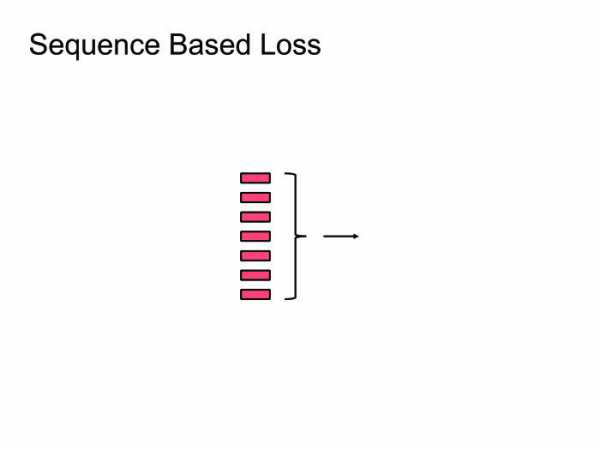 Чтобы с этим побороться, были придуманы функции Sequence Based Loss: давайте саккумулируем всю информацию на всех фреймах, посчитаем один общий Loss и пропустим градиент обратно. Не буду вдаваться в детали, можете прочитать про CTC или SNBR Loss, это очень специфичная тема для распознавания речи.
Чтобы с этим побороться, были придуманы функции Sequence Based Loss: давайте саккумулируем всю информацию на всех фреймах, посчитаем один общий Loss и пропустим градиент обратно. Не буду вдаваться в детали, можете прочитать про CTC или SNBR Loss, это очень специфичная тема для распознавания речи.
В подходах End to end два пути. Первый — делать более «сырые» фичи. У нас был момент, когда мы извлекали из фреймов фичи, и обычно они извлекаются, стараясь эмулировать ухо человека. А зачем эмулировать ухо человека? Пусть нейронка сама научится и поймет, какие фичи ей полезны, а какие бесполезны. Давайте в нейронку подавать все более сырые фичи.
Второй подход. Мы пользователям выдаем слова, буквенное представление. Так зачем нам предсказывать фонемы? Хотя их предсказывать очень естественно, человек говорит в фонемах, а не буквах, — но итоговый результат мы должны выдать именно в буквах. Поэтому давайте предсказывать буквы, слоги или пары символов.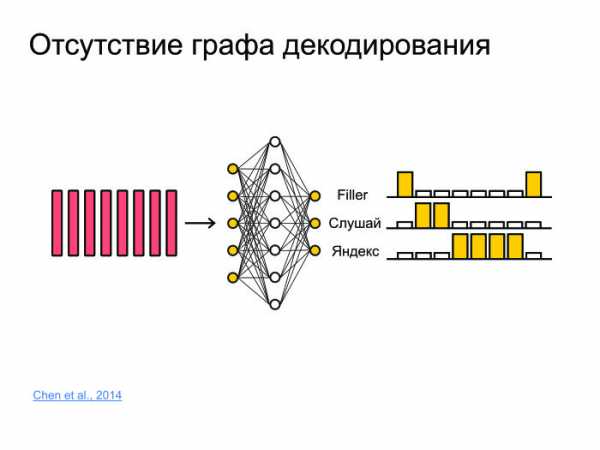 Какие еще есть задачи? Допустим, задача фреймспоттинга. Есть какой-нибудь кусок звука, откуда надо извлечь информацию о том, была ли сказана фраза «Слушай, Яндекс» или не была. Для этого можно фразу распознать и грепнуть «Слушай, Яндекс», но это очень брутфорсный подход, причем распознавание обычно работает на серверах, модели очень большие. Обычно звук отсылается на сервер, распознается, и распознанная форма высылается обратно. Грузить 100 тыс. юзеров каждую секунду, слать звук на сервер — ни одни сервера не выдержат.
Какие еще есть задачи? Допустим, задача фреймспоттинга. Есть какой-нибудь кусок звука, откуда надо извлечь информацию о том, была ли сказана фраза «Слушай, Яндекс» или не была. Для этого можно фразу распознать и грепнуть «Слушай, Яндекс», но это очень брутфорсный подход, причем распознавание обычно работает на серверах, модели очень большие. Обычно звук отсылается на сервер, распознается, и распознанная форма высылается обратно. Грузить 100 тыс. юзеров каждую секунду, слать звук на сервер — ни одни сервера не выдержат.
Надо придумать решение, которое будет маленьким, сможет работать на телефоне и не будет жрать батарейку. И будет обладать хорошим качеством.
Для этого давайте всё запихнем в нейронную сеть. Она просто будет предсказывать, к примеру, не фонемы и не буквы, а целые слова. И сделаем просто три класса. Сеть будет предсказывать слова «слушай» и «Яндекс», а все остальные слова замапим в филлер.
Таким образом, если в какой-то момент сначала шли большие вероятности для «слушай», потом большие вероятности для «Яндекс», то с большой вероятностью тут была ключевая фраза «Слушай, Яндекс». Задача, которая не сильно исследуется в статьях. Обычно, когда пишутся статьи, берется какой-то датасет, на нем получаются хорошие результаты, бьется state of the art — ура, печатаем статью. Проблема этого подхода в том, что многие датасеты не меняются в течение 10, а то и 20 лет. И они не сталкиваются с проблемами, с которыми сталкиваемся мы.
Задача, которая не сильно исследуется в статьях. Обычно, когда пишутся статьи, берется какой-то датасет, на нем получаются хорошие результаты, бьется state of the art — ура, печатаем статью. Проблема этого подхода в том, что многие датасеты не меняются в течение 10, а то и 20 лет. И они не сталкиваются с проблемами, с которыми сталкиваемся мы.
Иногда возникают тренды, хочется распознавать, и если этого слова нет в нашем графе декодирования в стандартном подходе, то мы никогда его не распознаем. Нужно с этим бороться. Мы можем взять и переварить граф декодирования, но это трудозатратный процесс. Может, утром одни трендовые слова, а вечером другие. Держать утренний и вечерний граф? Это очень странно.  Был придуман простой подход: давайте к большому графу декодирования добавим маленький граф декодирования, который будет пересоздаваться каждые пять минут из тысячи самых лучших и трендовых фраз. Мы просто будем параллельно декодировать по этим двум графам и выбирать наилучшую гипотезу.
Был придуман простой подход: давайте к большому графу декодирования добавим маленький граф декодирования, который будет пересоздаваться каждые пять минут из тысячи самых лучших и трендовых фраз. Мы просто будем параллельно декодировать по этим двум графам и выбирать наилучшую гипотезу.
Какие задачи остались? Там state of the art побили, тут задачи решили… Приведу график WER за последние несколько лет. Как видите, Яндекс улучшился за последние несколько лет, и тут приводится график для лучшей тематики — геопоиска. Вы можете понять, что мы стараемся и улучшаемся, но есть тот маленький разрыв, который нужно побить. И даже если мы сделаем распознавание речи — а мы его сделаем, — которое сравнится со способностями человека, то возникнет другая задача: это сделалось на сервере, но давайте перенесем это на устройство. Речь идет об отдельной, сложной и интересной задаче.
Как видите, Яндекс улучшился за последние несколько лет, и тут приводится график для лучшей тематики — геопоиска. Вы можете понять, что мы стараемся и улучшаемся, но есть тот маленький разрыв, который нужно побить. И даже если мы сделаем распознавание речи — а мы его сделаем, — которое сравнится со способностями человека, то возникнет другая задача: это сделалось на сервере, но давайте перенесем это на устройство. Речь идет об отдельной, сложной и интересной задаче.
У нас есть и множество других задач, о которых меня можно спросить. Спасибо за внимание.
habr.com