Содержание
«Нейронные сети» — Яндекс Кью
Популярное
Сообщества
Нейронные сети
Стать экспертом
- Популярные
- Открытые
- Все вопросы
- Посты и опросы132
- Новые ответы
alexandr azevich
Data science
1г
1,9 K
Учитель — увлекаюсь нейронными сетями, создаю курс занятий по нейронным сетям не для самых маленьких учащихся.
Анонимный вопрос · 12 ответов
Если принять во внимание что —
язык программирования — это формальная знаковая система, предназначенная для записи компьютерных программ, а
фреймворк — программное обеспечение… Читать далее
Анатолий Кубышев6мес
111
Последние 20 лет занимаюсь исследованием разума. Автор информационно-энергетической гипотезы формирования Вселенной.
Автор информационно-энергетической гипотезы формирования Вселенной.
1. В соответствии с теорией Пуанкаре-Перельмана наш 3-х мерный мир может быть представлен… Развернуть
спрашиваетВиталий Латунов · 4 ответа
Нейронная сеть человека служит механизмом преобразования программы физического тела (информационная энергия управления) в более высокочастотную энергию сознания (информационную энергию… Читать далее
Николай Гладков2г
331
Управляющий
Анонимный вопрос · 9 ответов
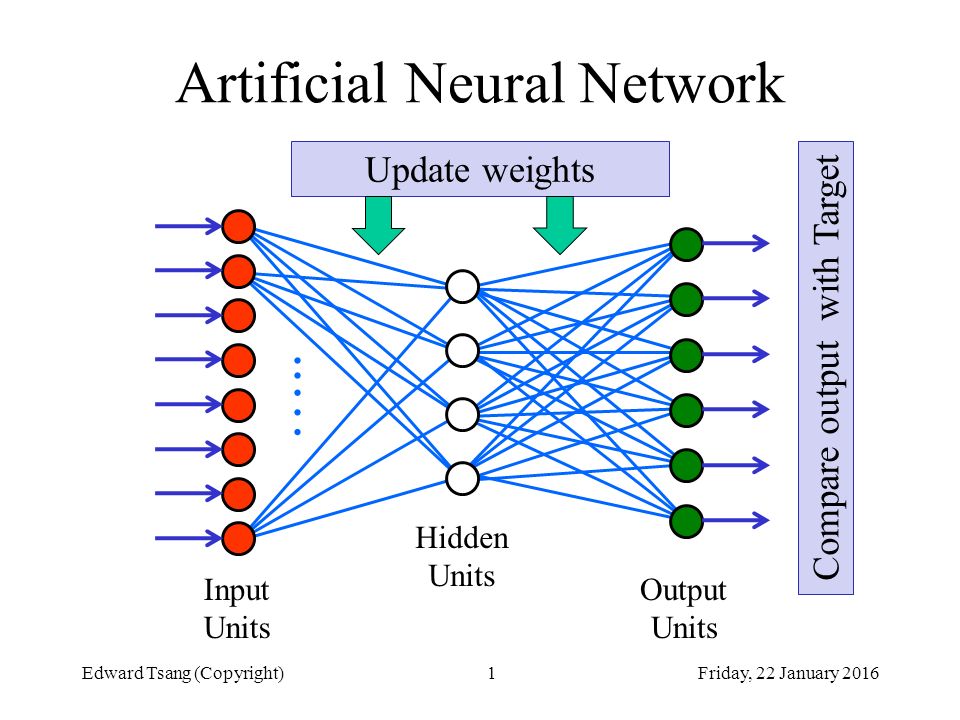
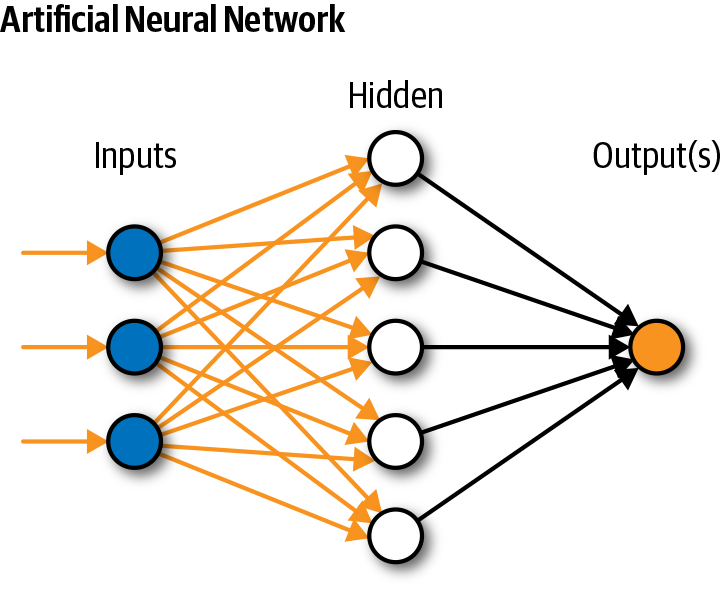
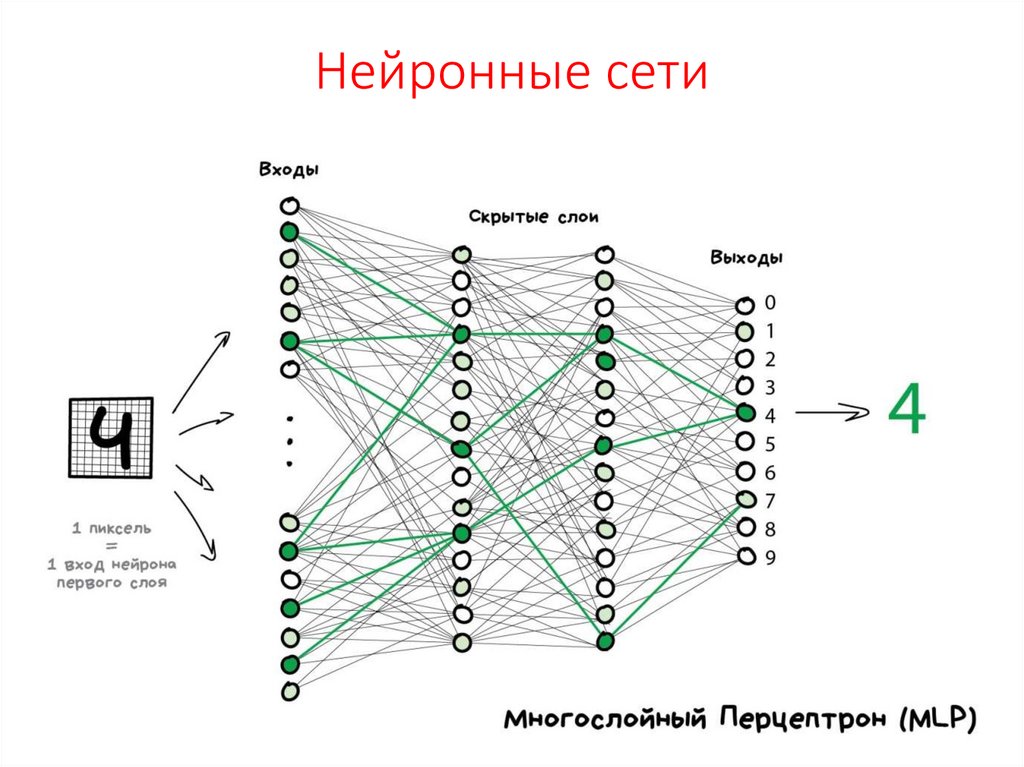
Нейросеть состоит из нейронов, а каждый нейрон — это ячейка, которая хранит в себе какой-то ограниченный диапазон значений. В нашем случае это будут значения от 0 до 1. На вход каждого… Читать далее
Евгений Миронов
Data science
5мес
83
Увлекаюсь физикой, астрономией и финансами.
Анонимный вопрос · 12 ответов
Нейросети, в основном, показали очень хорошие результаты при решении следующих задач:
1. Распознавание объектов на картинках (в том числе и на видео, так как видео, это серия… Читать далее
Мазуренко Олег Михайлович
Финансы
1г
268
Квал. инвестор (реестр Сбера). МВА «Стратегия». Дрессировщик ИИ. К.х.н. «Коллоидная химия». С.н.с. «Вооруж. и воен. техника».
спрашиваетСергей Нестеров · 9 ответов
У меня то же такая мысль появилась в конце прошлого года. Начал с посещений разных бесплатных вебинаров и интенсивов.
Послушал, порешал задачки.
Потом выбрал Университет Искусственного… Читать далее
1 эксперт согласен
Дима Коршакевич4г
133
Дата сайентист, мамин игродел, игратель душевных песен на гитаре, любитель Queen и белорусской поэзии, в душе филолог, в молодости неудавшийся каратист и золотой призёр олимпиады по информатике.
спрашиваетИлья Пономарев · 3 ответа
Мысль, что достаточно скачать готовую нейронную сеть и просто скормить ей данные, кажется не совсем правдивой, поскольку нейронка — это конкретная математическая модель, заточенная… Читать далее
игорь козлов8мес
65
Оптимизация бизнес процессов. Оптимизация производства. Оптимизации рекламы. Бережливое производство. Консультирование.
Анонимный вопрос · 6 ответов
Если они «говорят о примитивных программах так, словно это ИИ. Будто они не знают что такое ИИ.»- это значит, что они ПОХОЖЕ действительно не знают что такое ИИ.
Сергей Акимов3г
969
Анонимный вопрос · 6 ответов
Поддержу ответ про Яндекс практикум. Также Франсуа Шолле написал неплохую книгу про нецросети на керас. Минимум математики, максимум программирования. 3Blue1Brown канал тоже очень. .. Читать далее
.. Читать далее
Дмитрий Моисеев
Психология
2г
864
Исследую человеческую психику, учусь помогать себе и другим людям.
Мой Дзен-канал: https://zen.yandex.ru/id/5b35108a867e2700a832bff9
Анонимный вопрос · 5 ответов
Давайте сначала определимся, о чём именно речь, поскольку термины в вопросе далеко не однозначны.
1. IQ, коэффициент интеллекта — количественная оценка уровня интеллекта человека на… Читать далее
В этой теме к непроверенным ответам нужно относиться с осторожностью
Позвать экспертов
Достоверно
Машинное обучение и Нейронные сети
1г
1,0 K
Даниил АраповЭкс-преподаватель msu.ai, специалист образовательного центра Института ИИ при Университете Иннополис, программист.
спрашиваетАлена Каменецких · 3 ответа
Я лично не рекомендовал бы новичкам сразу переходить к глубокому обучению.
Для затравки, приведу простую и понятную очень многим аналогию извне мира науки о данных. Какой из этих языков… Читать далее
2 эксперта согласны
«Машинное обучение и Нейронные сети » — сообщество Яндекс Кью
Популярное
Сообщества
Машинное обучение и Нейронные сети
Сообщество, в котором практикующие специалисты и ученые в области Машинного обучения и Искусственного интеллекта делятся опытом и помогают начинающим.
Машинное обучение и Нейронные сети Куок Энджоер14ч
Ответить
Пока нет ответов
Вопросы сообществу
Все
Алексей Юрьевич Соколов
Интересно, куда по взрослению пропадают вундеркинды?
Ответить
annа atоm
Почему интернет называют «мусоркой»? Как правильно искать. ..
..
Ответить
annа atоm
Возможно ли прогнозирование в условиях управляемого хаоса?
Ответить
Эмир Зейлан
Где можно применить систему распознавания объектов с…
Ответить
annа atоm
Приверженцам «матричного» мировоззрения: если мир не…
Ответить
annа atоm
В тик-токе воздействие специально рассчитанного алгоритма…
Ответить
annа atоm
Если чистый спрос и предложение хорошо работают в маленьких…
Ответить
uwagauwagauwaga
С# Visual Studio Создание базы данных
Ответить
Аскар Кобыланов
Обясни виды нейронных сетей и приведи примеры к каждому:
Ответить
annа atоm
Эвристический способ поиска решения — это и есть метод…
Ответить
Машинное обучение и Нейронные сети
23д
269
Евгений МироновУвлекаюсь физикой, астрономией и финансами.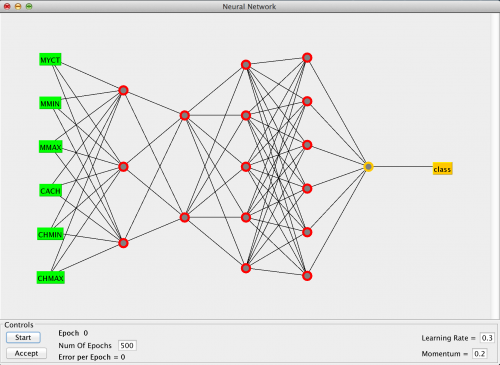
В конце концов мы отправляем вопрос и получаем ответ которого за ранее не знаем. Мы именно… Развернуть
спрашиваетИлья · 4 ответа
В узком понимании слово общение понимается, как некоторое взаимодействие между людьми. В этом смысле, взаимодействие человека с нейросетью не является общением.
Но в широком понимании… Читать далее
Машинное обучение и Нейронные сети
1мес
302
Евгений МироновУвлекаюсь физикой, астрономией и финансами.
В процессе получения ответа люди поначалу довольно хаотично пишут свои ответы, но потом с… Развернуть
спрашиваетИлья · 1 ответ
В каком-то смысле да. Но это это очень ПЕРЕОБУЧЕННАЯ нейросеть (overfitting).
Если ориентироваться только на какой-то один из таких сайтов, то вы рискуете оказаться в «информационном… Читать далее
Машинное обучение и Нейронные сети
2мес
409
Теплухин АркадийПишу книги о бизнесе и не только.
Провожу семинары, тренинги.
Эксперт в области открытия стартапов.
Моя Программа.
Блок 1. · Что такое цифровая трансформация организации? · Цифровизация и IT-архитектура организации. · Организации будущего сегодня. · Цифровые угрозы. · Диагностика… Читать далее
Машинное обучение и Нейронные сети
2мес
486
Евгений ПугачевАвтор книги «Как остаться инженером в век искусственного интеллекта»
Задача — парсинг научных статей (математика, физика) на определенную тему, определение… Развернуть
спрашиваетРоман Рютин · 1 ответ
Судя по тому, что российский тренер Дмитрий Хохлов отсудил у фейсбука 65 млн.р. за то что сеть не отличает его фамилию от оскорбления по национальному признаку, таких решений нет.
Делаю проект «Справочник базовых навыков». Предлагаю заполнить форму по ссылке:
Перейти на forms.gle/AUgJWTBEpNUbZPuN6
Машинное обучение и Нейронные сети
2мес
125
Евгений МироновУвлекаюсь физикой, астрономией и финансами.
Какие базовые вещи нужны для всех?
Пример ответа:
* математика (статистика (чем… Развернуть
спрашиваетРоман Рютин · 1 ответ
Сейчас практически уже нет таких людей, которые в одиночку занимаются разработкой любых приложений на основе нейросетей. В этой области идет очень сильная специализация и разделение труда… Читать далее
Мазуренко Олег МихайловичвМашинное обучение и Нейронные сети
Инвестиции, трейдинг и ИИ
2мес
1,3 K
Мазуренко Олег МихайловичКвал. инвестор (реестр Сбера). МВА «Стратегия». Дрессировщик ИИ. К.х.н. «Коллоидная химия». С.н.с. «Вооруж. и воен. техника».
Приближается к завершению коммерческая реализация программного комплекса предсказания направления тренда цены на основе нейронной сети NeuroTrend Crypto (НейроТренд Крипто).
В данный… Читать далее
Мазуренко Олег МихайловичвМашинное обучение и Нейронные сети
Мазуренко Олег Михайлович
Data science
2мес
355
Квал. инвестор (реестр Сбера). МВА «Стратегия». Дрессировщик ИИ. К.х.н. «Коллоидная химия». С.н.с. «Вооруж. и воен. техника».
инвестор (реестр Сбера). МВА «Стратегия». Дрессировщик ИИ. К.х.н. «Коллоидная химия». С.н.с. «Вооруж. и воен. техника».
Мне это не актуально, но может кто-то поучаствует.
Добрый день,Олег !
Меня зовут Евгения.
Я — HR-консультант «Центра Карьеры» от федерального проекта «Содействие занятости». Вы у нас… Читать далее
Машинное обучение и Нейронные сети
2мес
395
Борис ДержавецOpenstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of analytic functions in several complex variables ).
Анонимный вопрос · 2 ответа
Формулa алгоритма классификации в методе окна Парзена. Классификатор Парзена оценивает плотность вероятности для каждого класса, используя непараметрический подход на основе сохраненных… Читать далее
Мазуренко Олег МихайловичвМашинное обучение и Нейронные сети
Data ScienceМазуренко Олег Михайлович2мес
Есть нейронка, которая была обучена на временном ряду цены закрытия (1М 1,4 млн. строк)… Развернуть
строк)… Развернуть
Ответить
4 ответа
О сообществе
Это открытое сообщество
Все участники могут задавать вопросы и писать ответы в этом сообществе — тут все равны в своих правах
Образование, Машинное обучение, Исследования, Deep learning, Нейронные сети
Темы сообщества
Анонсы мероприятий
https://yandex.ru/q/article/anonsy_meropriiatii_6f56b6ac/
Конкурсы, гранты
https://yandex.ru/q/article/konkursy_granty_kollaboratsiia_14764d36/
Гайды от участников курса
https://yandex.ru/q/article/super_poleznye_ssylki_e0a357e1/?utm_medium=share&utm_campaign=article
43068 участников
ВСЕ
Павел Кикин
Основатель
Иришка Беккер
Администратор
Алена Каменецких
Куратор
Ульяна Власенко
Куратор
Правила
Будьте вежливы
Будьте вежливы и терпимы в отношении других участников беседы, даже если вы не согласны с другой точкой зрения. Все мы можем ошибаться.
Все мы можем ошибаться.
Пишите подробнее
Четко формулируйте свои вопросы. Указывайте версии ПО, полный стэк ошибки или предысторию вашего вопроса.
Критика
Любая критика должна опираться на факты, а не быть оценочным суждением. Не забывайте при этом о первом пункте.
Оформляйте код
Для вставки кода используйте специальный инструмент в панели оформления: «<>»
Машинное обучение и Нейронные сети
О машинном переводе. Руководство разработчика
Яндекс.Переводчик использует гибридную модель машинного перевода, включающую как нейросетевой (глубокое обучение), так и статистический подходы.
- Статистический машинный перевод
- Нейронный машинный перевод
- Выбор варианта перевода и оценка качества
Статистический подход основан на модели языка и перевода: тысячи параллельных текстов, имеющих одинаковое значение, но написанных на разных языках. Слова, которые являются вероятными совпадениями, извлекаются во время сравнения и сохраняются в матрице. Например, система решает, что «собака» и «собака» являются вероятными переводами друг друга, и сохраняет эту информацию. Полученная матрица помогает определить, какие пары фраз в паре предложений могут служить переводами друг для друга.
Например, система решает, что «собака» и «собака» являются вероятными переводами друг друга, и сохраняет эту информацию. Полученная матрица помогает определить, какие пары фраз в паре предложений могут служить переводами друг для друга.
Для создания языковой модели система анализирует тексты на одном языке и составляет списки всех используемых слов и фраз. Каждому слову и фразе присваивается собственный числовой идентификатор, который определяет их статистическую частотность в языке (насколько часто они используются).
При переводе каждое исходное предложение делится на слова и словосочетания, которые переводятся независимо друг от друга. Каждой части предложения соответствует возможный перевод из матрицы. Затем система «собирает» несколько вариантов переведенного предложения и выбирает статистически лучший вариант на основе оптимальных сочетаний слов естественного языка.
Статистический машинный перевод хорошо помогает запоминать и переводить короткие фразы и необычные слова. Однако есть и недостаток — фразы могут быть неуместными или бессвязными, потому что не учитывается контекст.
Однако есть и недостаток — фразы могут быть неуместными или бессвязными, потому что не учитывается контекст.
Аналогично статистическому подходу нейросеть также анализирует массив параллельных текстов, учится находить в них закономерности и составляет списки всех использованных слов и словосочетаний.
Однако вместо использования простых идентификаторов, подобных статистическому подходу, нейромашинный перевод использует так называемое встраивание слов: для каждого слова формируется векторное представление, состоящее из чисел, идентифицирующих его лексические и семантические признаки.
Нейронная сеть переводит каждое исходное предложение целиком, а не разбивает его на слова и фразы для отдельного перевода. Каждое слово в предложении сопоставляется с вектором длиной в несколько сотен чисел. В результате предложение преобразуется в векторное пространство. Это векторное пространство позволяет нейронной сети определять семантику слов и их отношения, даже если слова находятся в разных частях исходного предложения.
Например:
Система может распознать, что «чай» и «кофе» часто используются в одинаковых контекстах.
Оба слова можно найти в контексте нового слова «бутылки».
Однако обучающие данные, содержащие слово «бутылки», содержат только одно из этих слов («чай»). В результате в машинном переводе используется слово «чай».
Преимущество нейронного машинного перевода заключается в том, что он учитывает отношения между словами, что приводит к более плавному переводу. Недостатком нейронного подхода является то, что ему иногда не хватает информации о словах, которые встречаются недостаточно часто, и система не может построить приемлемое векторное представление. К редким словам относятся необычные имена или топонимы.
Как только пользователь вводит текст для перевода, Яндекс.Переводчик отправляет этот текст в обе системы: нейросеть и статистический переводчик.
Результаты, полученные от обеих систем, оцениваются алгоритмом, основанным на методе машинного обучения CatBoost. Алгоритм анализирует десятки факторов, от длины предложения (короткие фразы и редкие слова лучше переводятся статистической моделью) до синтаксиса. Два перевода сравниваются по всем параметрам, и лучший из них показывается пользователю.
Алгоритм анализирует десятки факторов, от длины предложения (короткие фразы и редкие слова лучше переводятся статистической моделью) до синтаксиса. Два перевода сравниваются по всем параметрам, и лучший из них показывается пользователю.
Статья была полезна?
Яндекс Публикует ЯЛМ 100Б. Это крупнейшая нейронная сеть, похожая на GPT, с открытым исходным кодом | Михаил Хрущев | Яндекс
В последние годы крупномасштабные языковые модели на основе трансформеров стали вершиной нейронных сетей, используемых в задачах НЛП. С каждым месяцем они растут в масштабе и сложности, но для обучения таких моделей нужны миллионы долларов, лучшие специалисты и годы разработки. Вот почему только крупные ИТ-компании имеют доступ к этой ультрасовременной технологии. Однако исследователям и разработчикам во всем мире нужен доступ к этим решениям. Без новых исследований их рост может замедлиться. Единственный способ избежать этого — поделиться передовым опытом с сообществом разработчиков.
Мы уже больше года используем языковые модели семейства YaLM в голосовом помощнике Алиса и Поиске Яндекса. Сегодня мы сделали нашу самую большую модель YaLM, которая использует 100 миллиардов параметров, доступной бесплатно. Нам потребовалось 65 дней, чтобы обучить модель на пуле из 800 видеокарт A100 и 1,7 ТБ онлайн-текстов, книг и множества других источников. Мы опубликовали нашу модель и полезные материалы на GitHub под лицензией Apache 2.0, которая разрешает как исследовательское, так и коммерческое использование. В настоящее время это крупнейшая в мире нейронная сеть, подобная GPT, бесплатно доступная для английского языка.
В этой статье мы поделимся не только моделью, но и нашим опытом ее обучения. Вы можете подумать, что с суперкомпьютером обучение крупномасштабных моделей — это проще простого. К сожалению, это не так. Здесь мы расскажем вам, как нам удалось обучить такую огромную языковую модель и как мы вдвое сократили время обучения без ущерба для стабильности. Многие вещи, описанные ниже, можно применять и для обучения небольших моделей.
Многие вещи, описанные ниже, можно применять и для обучения небольших моделей.
В контексте крупномасштабных нейронных сетей 10-процентное увеличение скорости обучения может сэкономить вам неделю работы в кластере с высокой ценностью. Здесь мы расскажем вам, как увеличить скорость тренировки более чем в два раза.
Итерации обучения обычно состоят из следующих шагов:
- Подготовка пакета
- Запуск прямого распространения: расчет функций активации и потерь
- Запуск обратного распространения: расчет градиентов
- Запуск этапа шага для обновления весов модели
Давайте посмотрим, как можно ускорить эти этапы.
Поиск узких мест
Чтобы увидеть, как используется время обучения, следует использовать профилировщик. В PyTorch этим занимается модуль torch.autograd.profiler (см. статью). Вот пример трассировки, которую мы получили от профилировщика:
Этот след был создан небольшой 12-слойной нейронной сетью. Вы можете увидеть этапы вперед вверху и этапы назад внизу.
 Что не так с этим следом? Одна операция занимает слишком много времени, около 50% всего времени обучения. Оказалось, что мы забыли изменить размер встраивания токена при копировании обучающей конфигурации для нашей большой модели. Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.
Что не так с этим следом? Одна операция занимает слишком много времени, около 50% всего времени обучения. Оказалось, что мы забыли изменить размер встраивания токена при копировании обучающей конфигурации для нашей большой модели. Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.Профилировщик также помог нам найти более серьезные проблемы, поэтому мы рекомендуем использовать его часто.
Использовать быстрые типы данных
Первое, что влияет на скорость обучения и вывода, — это тип данных, используемый для хранения модели и выполнения вычислений. Мы используем четыре типа данных:
- Формат с одинарной точностью, fp32: обычный формат с плавающей запятой. Это очень точно, но занимает четыре байта, замедляя вычисления. Это тип вашей модели PyTorch по умолчанию.
- Формат половинной точности, fp16: 16-битный тип данных, который намного быстрее, чем fp32, и потребляет вдвое меньше памяти.
- bfloat16, еще один 16-битный тип: по сравнению с fp16 он предоставляет на 3 бита меньше для мантиссы и на 3 бита больше для экспоненты. В результате формат может принимать более широкие диапазоны значений, но страдает от потери точности в числовых операциях.
- Формат TensorFloat, tf32: 19-битный тип данных, который объединяет экспоненту из bf16 и мантиссу из fp16. Он потребляет те же четыре байта, что и fp32, но намного быстрее.
На видеокартах A100 и новее 16-битные типы в 5 раз быстрее, чем fp32, и в 2,5 раза быстрее, чем tf32. Если вы используете карту A100, то вместо fp32 всегда используется tf32, если вы явно не укажете иное.
В старых видеокартах bf16 и tf32 не поддерживаются, а fp16 всего в два раза быстрее, чем fp32. Несмотря на это, это все еще огромный выигрыш в производительности. Всегда имеет смысл выполнять вычисления в формате половинной точности или в формате bf16, хотя у этого подхода есть свои недостатки. Мы обсудим это позже.
Ускорение операций на графическом процессоре
В этой статье дается хорошее объяснение операций на графическом процессоре и способов их ускорения. Здесь мы процитируем пару основных идей оттуда.
Использовать GPU полностью
Для начала разберемся, как выглядит расчет одного CUDA-ядра на GPU. Аналогия с фабрикой из этой статьи помогает проиллюстрировать это:
У вашего графического процессора есть склад (память) и фабрика (вычисления). При выполнении ядра вычисление запрашивает соответствующие данные из памяти, вычисляет результат и записывает его обратно в память.
Что произойдет, если ваш завод работает на половину своей мощности?
Как и на заводе по производству кирпича и минометов, половина ресурсов графического процессора простаивает. Как исправить это во время тренировки? Самый простой способ — увеличить размер партии .
Для небольших моделей увеличение размера партии в N раз может принести многократное увеличение скорости обучения, хотя сама итерация замедлится.
Для крупномасштабных моделей с миллиардами параметров также можно получить небольшой выигрыш от увеличения размера партии.Уменьшить взаимодействие с памятью
Вторая идея из статьи заключается в следующем. Предположим, у нас есть три ядра, которые обрабатывают одни и те же данные в конвейере:
В этом случае время используется не только для вычислений, но и для доступа к памяти: эти операции имеют свою цену. Чтобы уменьшить количество этих операций, вы можете сплавить свои ядра:
Как? Есть несколько способов:
1. Использовать torch.jit.script. Используя этот простой атрибут, вы можете скомпилировать код функции в одно ядро. В приведенном ниже коде мы объединили три операции: добавление тензора, удаление и добавление другого тензора.
Этот подход дал нам увеличение скорости обучения на 5%.
2. Вы можете написать свои собственные ядра CUDA. Таким образом, вы можете не только объединить свои операции, но и оптимизировать использование памяти и избежать ненужных операций.
Однако написание этого кода требует очень специфических знаний, а разработка ядра может оказаться слишком дорогой.3. Либо можно использовать готовые ядра CUDA. Давайте быстро взглянем на ядра в библиотеках Megatron-LM и DeepSpeed (мы их часто используем):
- Внимание softmax с треугольной маской обеспечивает ускорение на 20–100%. Прирост скорости также особенно высок в небольших сетях, когда вы используете fp32 в своих вычислениях.
- Внимание софтмакс с произвольной маской обеспечивает ускорение до 90%.
- Fused LayerNorm — это объединенная версия LayerNorm в fp32. Мы его не использовали, но он тоже должен дать выигрыш в скорости.
- Трансформаторы DeepSpeed представляют собой трансформатор с полностью плавкими предохранителями. Он обеспечивает ускорение, но его крайне сложно масштабировать и поддерживать, поэтому мы его не используем.
Используя различные виды слитых ядер, мы ускорили процесс обучения более чем в 1,5 раза.
Dropouts
Если у вас много данных и нет переобучения при dropout == 0, отключите dropouts! Это увеличило скорость наших вычислений на 15%.
Случай с несколькими графическими процессорами
Что изменится, если вы запустите несколько графических процессоров? Теперь наш процесс выглядит следующим образом:
- Подготовка пакета
- Вперед
- Назад
- all_reduce градиенты: усредните градиенты на ваших видеокартах, чтобы объединить их ресурсы
- Шаг: Обновление весов модели
Усреднение всех градиентов требует времени. Каждый графический процессор должен отправлять и получать как минимум столько градиентов, сколько у вас есть параметров в вашей сети. Давайте посмотрим, как мы можем значительно ускорить эту и ступенчатую стадию.
Связь
Как работает оптимальная связь? Используемая нами библиотека NVIDIA NCCL вычисляет обмен данными при инициализации и позволяет графическим процессорам обмениваться данными по сети без каких-либо посредников ЦП.
Это обеспечивает максимальную скорость связи. Вот статья NVIDIA об этой библиотеке.В коде это выглядит так:
Коммуникации NCCL очень быстрые, но даже с ними скорость этапа all_reduce займет много времени. ZeRO помогает нам ускорить его еще больше.
ZeRO
ZeRO означает оптимизатор нулевой избыточности.
В левой части картинки вы видите стандартную тренировку на нескольких GPU. В стандартной схеме мы распределяем все параметры и состояния оптимизации, а также усредненные градиенты между нашими процессами. Это стоит нам много памяти.
Блок-схема высокого уровня ZeRO показана справа. Каждому процессу мы назначаем группу параметров. Для этих параметров процесс всегда сохраняет значения и состояния оптимизатора, и только этот процесс может их обновлять. Таким образом, вы можете сэкономить огромные объемы памяти, которые теперь могут быть выделены для больших пакетов. Однако это добавляет новый этап: all_gather weights. Нам нужно собрать все параметры сети в каждом процессе, чтобы запустить прямой и обратный этапы.
Теперь сложность операций после расчета градиентов будет следующей:- градиенты all_reduce: O(N), где N — количество параметров.
- шаг: O(N/P), где P — количество процессов. Это уже приличный разгон.
- параметры all_gather: O(N).
Как видите, мы ускорили один этап, но за счет добавления новых, тяжелых операций. Так как же нам их ускорить? Просто: запускайте их асинхронно!
Соберите свои слои асинхронно один за другим во время предварительной стадии:
- Собираем первый слой для всех процессов.
- Собирая второй слой, мы запускаем предварительную стадию для первого слоя.
- Собирая третий слой, мы запускаем предварительную стадию для второго слоя.
И так далее, пока не закончим все этапы вперед. Вы можете ускорить обратную стадию почти таким же образом.
Это увеличило скорость наших моделей на 80%! Даже на небольших моделях (100M на 16 GPU) мы увидели ускорение на 40–50%. Для этого подхода требуется довольно быстрая сеть, но если она у вас есть, вы можете значительно ускорить обучение на нескольких GPU.
Результат
Мы применили четыре подхода к нашему тренировочному процессу:
- Мы объединили часть наших операций: +5% скорости
- Мы использовали ядро внимания softmax с треугольной маской: +20–80%
- Мы отключено отсев: +15%
- Мы применили ZeroRO: +80%
Неплохо. Давайте двигаться дальше.
Долгая итерация — не единственное препятствие для обучения действительно большой модели. Может показаться, что если у вас достаточно вычислительной мощности, вы можете просто начать обучение модели, отправиться в отпуск на два месяца, а по возвращении вас будет ждать уже готовая модель. Однако модели такого масштаба достаточно хрупкие и склонны к расхождению. Что такое дивергенция и как ее контролировать?
Что такое дивергенция?
Допустим, вы запустили тренировку, посмотрели на графики и увидели, что убыток уменьшается. Первый день, второй день, третий день, все еще уменьшается. Затем, утром четвертого дня, вы смотрите на график потерь, и он выглядит так:
Сейчас потери выше, чем через несколько часов после начала тренировки.
Более того, модель буквально забыла все, что знала. Это непоправимо: дни тренировок насмарку.Что случилось?
Первые наблюдения
Мы заметили три вещи:
1. Оптимизатор LAMB гораздо менее склонен к расхождениям, чем Адам.
2. Снижая скорость обучения, мы можем решить проблему расхождения. Но не все так просто:
- Чтобы правильно подобрать параметр lr, нужно многократно перезапускать процесс обучения.
- Уменьшение lr часто замедляет обучение: например, здесь двукратное уменьшение lr привело к замедлению на 30%:
3. fp16 более подвержен проблемам расхождения, чем fp32. В основном это было связано с переполнением значений fp16 в наших функциях активации и градиентах. Максимальное абсолютное значение fp16 равно 65535. Переполнение привело к NaN в значениях функции потерь.
Термометры
Одной из вещей, которые мы долгое время использовали для продолжения обучения, были термометры. Измерялись максимумы и минимумы функций активации в различных сегментах сети, а также глобальная норма градиентов.
Вот пример значений термометра для дивергентной тренировки:Видно, что начиная примерно с 14000 итераций, максимумы матмуля во внимании стали резко расти. Этот рост является причиной дивергенции. Если вы откатите обучение до 13 000 итераций и пропустите ошибочные пакеты, вызвавшие расхождение, или уменьшите скорость обучения, вы можете значительно снизить вероятность повторного расхождения.
У этого подхода есть два недостатка:
- Он не устраняет 100% расхождения.
- Вы тратите драгоценное время на откат обучения. Это конечно лучше, чем совсем отказаться от дивергентной тренировки, но все же.
Позже мы представили некоторые приемы, которые уменьшили вероятность расхождения до такой степени, что позволили нам обучить множество моделей разных размеров, включая 100B.
Стабилизации. BFloat 16
BFloat 16 не переполняется даже при больших значениях градиентов и активаций. Вот почему этот формат является проверенным вариантом для хранения весов и выполнения вычислений.
К сожалению, он недостаточно точен, поэтому произвольные арифметические операции могут накапливать ошибки, приводящие к замедлению обучения или другому виду расхождений.Чтобы компенсировать расхождение, мы начали просчитывать следующие слои и операции в tf32 (или fp32 на старых видеокартах):
- Softmax во внимание (вот где наши ядра пригодились), softmax на токенах до функции потери .
- Все функции LayerNorm.
- Все операции с Residual: так мы избежали накопления ошибок и перемещения градиентов вглубь сети.
- all_reduce градиентов, о которых мы упоминали ранее.
Все эти стабилизации замедлили обучение всего на 2%.
Стабилизации. LayerNorm
В статьях о BERT и GPT использовался подход, известный сейчас как post-layernorm (слева на картинке). Однако с точки зрения стабильности и скорости сходимости на больших моделях pre-LayerNorm показал себя превосходно (справа на картинке). Итак, для наших моделей мы используем pre-LayerNorm.
BigScience просветила нас о неожиданном варианте стабилизации: вводя layernorm в самом начале сети, после встраивания, можно также существенно снизить вероятность коллапса.
Стабилизация. Curriculum Learning
Мы также использовали подход из статьи Curriculum Learning. Мы хотим обучить нашу нейронную сеть на большом пакете и большой длине строки, но мы начинаем с обучения на небольшом пакете и небольшой длине строки, а затем постепенно увеличиваем их по мере обучения.
Этот подход имеет два преимущества:
- Функция потерь довольно быстро падает в самом начале, независимо от количества токенов, видимых модели на каждой итерации. Поскольку мы уменьшаем количество вычислений в начале обучения, мы намного быстрее проходим этот этап плато потерь.
- Авторы статьи утверждают, что такой подход приводит к стабилизированному обучению.
Стабилизации. Резюме
Мы реализовали следующие подходы:
- Мы приняли bf16 в качестве основного типа для весов
- Мы выполнили критичные к точности вычисления в tf32
- Мы ввели pre-LayerNorm
- Мы поставили LayerNorm сразу после встраивания
6 б/у Curriculum learning
В результате мы уже более 6 месяцев обучаем наши модели без расхождений.
 Что не так с этим следом? Одна операция занимает слишком много времени, около 50% всего времени обучения. Оказалось, что мы забыли изменить размер встраивания токена при копировании обучающей конфигурации для нашей большой модели. Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.
Что не так с этим следом? Одна операция занимает слишком много времени, около 50% всего времени обучения. Оказалось, что мы забыли изменить размер встраивания токена при копировании обучающей конфигурации для нашей большой модели. Это привело к чрезмерному умножению матриц в конце сети. Уменьшив размер встраивания, мы значительно ускорили процесс обучения.
 Для крупномасштабных моделей с миллиардами параметров также можно получить небольшой выигрыш от увеличения размера партии.
Для крупномасштабных моделей с миллиардами параметров также можно получить небольшой выигрыш от увеличения размера партии.