Содержание
AlphaGo: что это за программа и как она навсегда перевернула мир ИИ?
Кинематограф постоянно твердит нам, что в скором времени искусственный интеллект захватит Землю и поработит всех людей, а предвестниками такого расклада являются программы типа «АльфаГо».
АльфаГо — это несколько версий программ на основе искусственного интеллекта, которые играют в игру Го. Из всех версий этой программы настоящий фурор навела версия AlphaGo Zero, которая обыграла в Го все предыдущие версии этой программы и чемпиона мира по этой игре. Но самое важное, что AlphaGo Zero тренировалась самостоятельно и без вмешательства людей. А как мы знаем, любой искусственный интеллект обучается и тренируется только при помощи человека.
Что это за игра такая — «Го»
Го — это очень старая настольная игра, по разным данным, ей около 5000 лет. Суть ее в том, что:
есть игровое поле, которое расчертили перпендикулярными линиями на множество «квадратиков»;
в нее играют 2 игрока с черными и белыми камнями;
в порядке очереди игроки расставляют камни в местах пересечения линий;
когда камни одного цвета окружают со всех сторон камни другого цвета, то те камни, что внутри, снимаются с игрового поля;
победу одерживает тот, кто к концу игры «окружил» максимальную площадь территории.
Там есть и другие правила, но для понимания того, что такое «АльфаГо», этого будет достаточно.
Сложная ли игра Го?
Не все понимают, что такое игра Го и насколько она сложная. Но многие знают такие игры, как шашки и шахматы, поэтому давайте сравним игру Го с ними.
Когда игрок играет в шашки, у него есть примерно 10 вариантов, как осуществить ход, поэтому шашки считаются не очень сложной игрой. Однако в 1994-м году была написана программа, которая в том же году обыграла чемпиона мира по шашкам.
Когда игрок играет в шахматы, то у него в течение игры в среднем появляется около 25 вариантов, как осуществить ход. И таких ходов у него может быть около 45 за игру. Однако в 1997 году была создана программа, которая выиграла партию у тогдашнего чемпиона по шахматам Гарри Каспарова.
Когда игрок играет в Го, то перед ним поле с 361-м вариантом, куда можно выставить камень.
Количество вариантов со временем уменьшается, однако если учесть, что за партию игрок делает около 45-75 ходов, то видно, что ему нужно проводить просто огромный анализ игрового поля. Ведь ему нужно выстраивать фигуры, чтобы окружить камни соперника. Поэтому поставленный камень на 5-м ходу может принести пользу только на 45-м ходу. А может и не принести пользу вообще. Все эти комбинации нужно уметь просчитывать, поэтому профессиональная игра в Го считается довольно сложной. Однако в 2016 году была разработана программа АльфаГо и проведена игра в Го с тогдашним чемпионом Ли Седолем. Человек проиграл со счетом 4:1, сумев выиграть один раз у программы.
Как видно, временной промежуток между разработкой программ для шахмат и игры Го очень большой. Это обусловлено по большей степени сложностью игры в Го. Алгоритм программы для шашек, шахмат и Го одинаков: выстраивается дерево возможных вариантов игры, и программа просто идет по ветке, которая приводит ее к обязательной победе.
Программа АльфаГо
Продолжая отвечать на вопрос: «AlphaGo — что это за программа?», хочется остановиться немного на том, как она обучалась. При построении алгоритма AlphaGo одновременно тренировались две нейронные сети, которые старались предугадывать ход, который сделал бы человек:
медленная — показывала хороший процент предсказаний, 57% верных, но делала все это по-настоящему медленно;
быстрая — показывала процент предсказаний намного хуже, однако работала очень быстро.
Обе эти нейронные сети тренировались на реальных человеческих ходах и играх. Данные о человеческих играх игроков высокого уровня собирались с различных серверов игры Го и «скармливались» обеим нейронным сетям.
Чуть позже к этим натренированным сетям подключили третью сеть, в чью задачу входила оценка конкретной ситуации всего на два значения: «выиграешь» или «проиграешь». Вот и получается, что AlphaGo состоит из трех разных функций, каждая из которых осуществляет собственную задачу.
Первой проверкой программы АльфаГо стала игра в 2015 году с тогдашним чемпионом Европы по Го, которую программа выиграла со счетом 5:0. Это первая проба программы AlphaGo, однако она не получила широкой огласки из-за того, что «чемпион Европы» по меркам игры Го — это не очень значимый титул.
Но вот игра 2016 года запомнилась навсегда. Во-первых, это была уже вторая версия программы AlphaGo.
После этого были еще игры в 2017-м между программой AlphaGo и топовыми игроками в Го, но все они проигрывали программе. Противостояние между игроками и AlphaGo пока окончено с убедительной победой программы над человеком.
Заключение
АльфаГо — это не конец противостояния между компьютером и человеком. На сегодняшний день ведутся активные разработки по нескольким играм. Го относится к тем играм, где все данные открыты и можно просчитать все возможные ходы наперед, если правильно выстроить систему. Человек научился строить такие системы, именно поэтому он не способен обыграть компьютер в подобных играх. Но что будет, когда в играх и системах не будет рамок, когда придется анализировать и думать, как поступить? Подобные противостояния нам еще предстоит посмотреть.

 Количество вариантов со временем уменьшается, однако если учесть, что за партию игрок делает около 45-75 ходов, то видно, что ему нужно проводить просто огромный анализ игрового поля. Ведь ему нужно выстраивать фигуры, чтобы окружить камни соперника. Поэтому поставленный камень на 5-м ходу может принести пользу только на 45-м ходу. А может и не принести пользу вообще. Все эти комбинации нужно уметь просчитывать, поэтому профессиональная игра в Го считается довольно сложной. Однако в 2016 году была разработана программа АльфаГо и проведена игра в Го с тогдашним чемпионом Ли Седолем. Человек проиграл со счетом 4:1, сумев выиграть один раз у программы.
Количество вариантов со временем уменьшается, однако если учесть, что за партию игрок делает около 45-75 ходов, то видно, что ему нужно проводить просто огромный анализ игрового поля. Ведь ему нужно выстраивать фигуры, чтобы окружить камни соперника. Поэтому поставленный камень на 5-м ходу может принести пользу только на 45-м ходу. А может и не принести пользу вообще. Все эти комбинации нужно уметь просчитывать, поэтому профессиональная игра в Го считается довольно сложной. Однако в 2016 году была разработана программа АльфаГо и проведена игра в Го с тогдашним чемпионом Ли Седолем. Человек проиграл со счетом 4:1, сумев выиграть один раз у программы. А так как в игре Го игровых вариаций очень и очень много, то и дерево получилось очень разветвленным и глубоким, и только на его разработку потребовалась масса времени.
А так как в игре Го игровых вариаций очень и очень много, то и дерево получилось очень разветвленным и глубоким, и только на его разработку потребовалась масса времени. Данные нейронные сети самостоятельно «дописывали» собственные деревья, если вдруг, двигаясь по какой-либо ветке, они достигали ее конца. Потом эти две сети сталкивали между собой и давали им возможность играть друг с другом, тем самым они еще больше «прокачивались».
Данные нейронные сети самостоятельно «дописывали» собственные деревья, если вдруг, двигаясь по какой-либо ветке, они достигали ее конца. Потом эти две сети сталкивали между собой и давали им возможность играть друг с другом, тем самым они еще больше «прокачивались».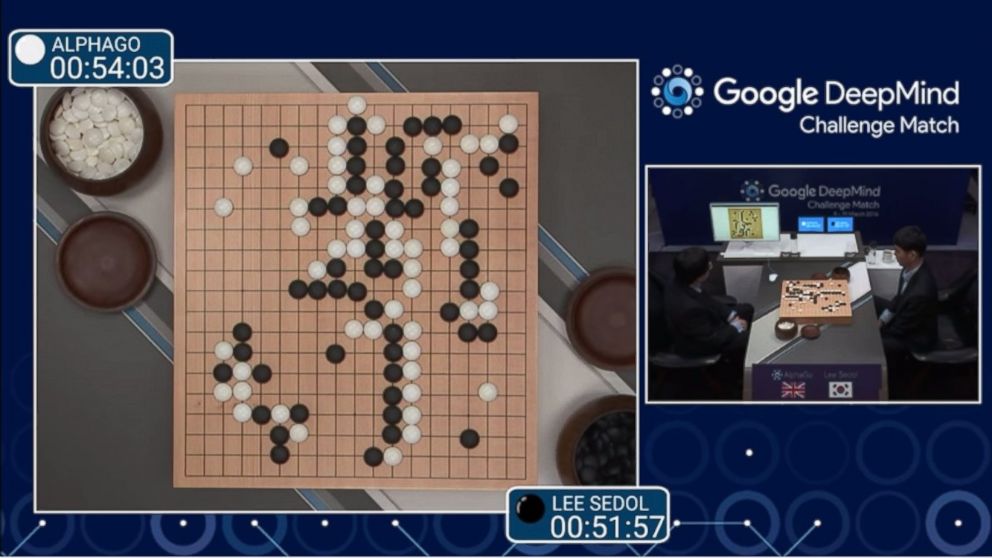 Во-вторых, в соперниках был один из самых титулованных и лучших игроков по Го Ли Седол. А в-третьих, это единственный игрок, который обыграл компьютер, хоть и проиграл по партиям. В честь этого та версия программы стала называться AlphaGo Lee.
Во-вторых, в соперниках был один из самых титулованных и лучших игроков по Го Ли Седол. А в-третьих, это единственный игрок, который обыграл компьютер, хоть и проиграл по партиям. В честь этого та версия программы стала называться AlphaGo Lee.
AlphaGo Zero самостоятельно научилась играть в шахматы и сёги. И снова всех победила
AlphaGo Zero, самообучающаяся программа для игры в го, разработанная программистами из DeepMind, экспериментального подразделения Google, научилась играть и в другие настольные игры. Алгоритму, обновление которого описано в препринте на сайте arXiv, теперь доступны японские шахматы сёги, а также обычные шахматы.
Обновлено: в декабре 2018 года статья опубликована в Science.
Первая версия программы AlphaGo была представлена в 2015 году. Тогда она работала с использованием двух нейросетей: одна вычисляла вероятность ходов, а вторая — оценивала позицию камня на доске. Оригинальная AlphaGo практически полностью полагалась на обучение с учителем и использовала в качестве обучающей выборки данные об успешных ходах игроков-людей, а также поиск по дереву методом Монте Карло, который часто применяется в создании компьютерных игроков. Задача такого поиска — выбрать наиболее выигрышный вариант, анализируя сыгранные и удачные ходы в игре. Алгоритм показал свою эффективность практически сразу же, обыграв профессионального игрока Фаня Хуэя.
Алгоритм показал свою эффективность практически сразу же, обыграв профессионального игрока Фаня Хуэя.
Разработчики DeepMind вскоре улучшили алгоритм, расширив использование в системе обучения с подкреплением (англ. reinforcement learning) — вида машинного обучения, при котором алгоритм обучается, не имея при этом обучающую выборку в виде пары «входные данные — ответ». Тогда AlphaGo смогла обыграть другого игрока в го — Ли Седоля, которого уже относят к сильнейшим игрокам в мире. После этого разработчики модернизировали алгоритм еще раз: последняя версия AlphaGo обыграла третьего сильнейшего игрока в го, Кэ Цзэ, и ушла из спорта.
Недавно авторы программы представили AlphaGo Zero — модернизированную версию, которая была разработана с помощью исключительно обучения с подкреплением, и смогла обыграть все предыдущие версии программы со счетом 100:0. Теперь разработчики DeepMind обучили алгоритм другим настольным играм: классическим шахматам и японским шахматам сёги.
В отличие от го, правила игры как в шахматы, так и в сёги, включают в себя определение позиций фигур на доске: так, например, ферзь может ходить на любое количество клеток в любом направлении, а слон ходит только по диагонали. Поэтому к оригинальному алгоритму AlphaGo Zero добавили правила о ходе фигур в каждой из двух игр — в остальном программа также училась самостоятельно, начиная со случайной игры.
Поэтому к оригинальному алгоритму AlphaGo Zero добавили правила о ходе фигур в каждой из двух игр — в остальном программа также училась самостоятельно, начиная со случайной игры.
После обучения AlphaGo Zero победила Stockfish (шахматную программу, которая несколько лет считалась лучшим компьютерным игроком) со счетом 64:36 (28 побед, 0 поражений, 72 ничьих), а Elmo, программу для игры в сёги, — со счетом 90:8 (2 ничьих). При этом в первом случае алгоритм DeepMind обучался четыре часа, а во втором — всего два.
Один из авторов работы, программист Мэттью Лай (Matthew Lai), ранее уже занимался разработкой алгоритма, который учится шахматам, играя сам с собой: программа, представленная им два года назад, обучалась 72 часа и по окончании тренировки была сравнима по эффективности с лучшими игроками Международной шахматной федерации. Тогда, однако, программа уступила алгоритму Stockfish.
Первая значимая победа компьютера над профессиональными игроками в шахматы произошла еще в 1997 году: тогда программа DeepBlue победила чемпиона по шахматам Гарри Каспарова. Проверить свои знания в вопросах противостояния игроков и машин вы можете с помощью нашего теста.
Проверить свои знания в вопросах противостояния игроков и машин вы можете с помощью нашего теста.
Как правильно заметили наши читатели, AlphaGo Zero не одержала 100 побед из 100 при игре в шахматы против Stockfish, а не проиграла ни одного раза (в действительности побед 28; в ничью игра закончилась в 72 случаях). При игре в сёги побед было 90 (две других игры, помимо 8 поражений, закончились ничьей). Редакция приносит свои извинения за неточности в заметке.
Елизавета Ивтушок
Нашли опечатку? Выделите фрагмент и нажмите Ctrl+Enter.
AlphaGo Zero: все начинается с нуля
Исследования в области искусственного интеллекта добились быстрого прогресса в самых разных областях, от распознавания речи и классификации изображений до геномики и открытия лекарств. Во многих случаях это специализированные системы, использующие огромное количество человеческого опыта и данных.
Однако для некоторых задач эти человеческие знания могут оказаться слишком дорогими, слишком ненадежными или просто недоступными. В результате давняя цель исследований ИИ состоит в том, чтобы обойти этот шаг и создать алгоритмы, которые достигают сверхчеловеческой производительности в самых сложных областях без участия человека. В нашей последней статье, опубликованной в журнале Nature, мы демонстрируем значительный шаг к этой цели.
В результате давняя цель исследований ИИ состоит в том, чтобы обойти этот шаг и создать алгоритмы, которые достигают сверхчеловеческой производительности в самых сложных областях без участия человека. В нашей последней статье, опубликованной в журнале Nature, мы демонстрируем значительный шаг к этой цели.
Статья представляет AlphaGo Zero, последнюю эволюцию AlphaGo, первой компьютерной программы, победившей чемпиона мира в древней китайской игре Го. Зеро еще более силен и, возможно, является самым сильным игроком в го в истории.
Предыдущие версии AlphaGo изначально обучались на тысячах любительских и профессиональных игр, чтобы научиться играть в го. AlphaGo Zero пропускает этот шаг и учится играть, просто играя в игры против себя, начиная с совершенно случайной игры. При этом он быстро превзошел человеческий уровень игры и победил ранее опубликованную версию AlphaGo, победившую чемпионов, со счетом 100 игр до 0,9.0005
Он может сделать это, используя новую форму обучения с подкреплением, в которой AlphaGo Zero становится своим собственным учителем. Система начинается с нейронной сети, которая ничего не знает об игре Го. Затем он играет в игры сам с собой, комбинируя эту нейронную сеть с мощным алгоритмом поиска. Во время игры нейронная сеть настраивается и обновляется, чтобы предсказывать ходы, а также возможного победителя игр.
Система начинается с нейронной сети, которая ничего не знает об игре Го. Затем он играет в игры сам с собой, комбинируя эту нейронную сеть с мощным алгоритмом поиска. Во время игры нейронная сеть настраивается и обновляется, чтобы предсказывать ходы, а также возможного победителя игр.
Затем эта обновленная нейронная сеть объединяется с алгоритмом поиска для создания новой, более надежной версии AlphaGo Zero, и процесс начинается снова. С каждой итерацией производительность системы немного улучшается, а качество самостоятельных игр повышается, что приводит к появлению все более точных нейронных сетей и все более сильных версий AlphaGo Zero.
Эта техника более мощная, чем предыдущие версии AlphaGo, потому что она больше не ограничена рамками человеческих знаний. Вместо этого он может научиться tabula rasa у самого сильного игрока в мире: самой AlphaGo.
Он также отличается от предыдущих версий другими заметными особенностями.
- AlphaGo Zero использует в качестве входных данных только черные и белые камни с доски го, тогда как предыдущие версии AlphaGo включали небольшое количество функций, разработанных вручную.
- Он использует одну нейронную сеть, а не две. В более ранних версиях AlphaGo использовалась «политическая сеть» для выбора следующего хода и «ценностная сеть» для предсказания победителя игры по каждой позиции. Они объединены в AlphaGo Zero, что позволяет более эффективно обучать и оценивать его.
- AlphaGo Zero не использует «развертки» — быстрые случайные игры, используемые другими программами го для предсказания того, какой игрок выиграет с текущей позиции на доске. Вместо этого он полагается на свои высококачественные нейронные сети для оценки позиций.

Все эти различия помогают повысить производительность системы и сделать ее более универсальной. Но именно алгоритмические изменения делают систему намного более мощной и эффективной.
AlphaGo становится все более эффективной благодаря усовершенствованиям аппаратного обеспечения и недавним усовершенствованиям алгоритмов.
Всего через три дня обучения самостоятельной игре AlphaGo Zero решительно победила ранее опубликованную версию AlphaGo, которая сама победила 18-кратного чемпиона мира Ли Седоля. со 100 игр до 0. После 40 дней самостоятельных тренировок AlphaGo Zero стал еще сильнее, превзойдя версию AlphaGo, известную как «Мастер», которая победила лучших игроков мира и первую ракетку мира Ке Цзе.
со 100 игр до 0. После 40 дней самостоятельных тренировок AlphaGo Zero стал еще сильнее, превзойдя версию AlphaGo, известную как «Мастер», которая победила лучших игроков мира и первую ракетку мира Ке Цзе.
Рейтинги Эло — мера относительного уровня навыков игроков в соревновательных играх, таких как Го, — показывают, как AlphaGo становилась все сильнее в процессе своего развития
В ходе миллионов игр AlphaGo против AlphaGo система постепенно обучалась игре в Го с нуля, аккумулировав тысячи лет человеческих знаний всего за несколько дней. AlphaGo Zero также открыла для себя новые знания, разрабатывая нетрадиционные стратегии и творческие новые ходы, которые повторяли и превосходили новые методы, которые она использовала в играх против Ли Седоля и Ке Цзе.
Эти моменты творчества вселяют в нас уверенность в том, что искусственный интеллект умножит человеческую изобретательность, помогая нам в нашей миссии по решению некоторых из самых важных проблем, с которыми сталкивается человечество.
Хотя AlphaGo Zero еще только начинается, это важный шаг на пути к этой цели. Если аналогичные методы можно будет применить к другим структурным проблемам, таким как свертывание белков, снижение потребления энергии или поиск революционных новых материалов, полученные в результате прорывы могут оказать положительное влияние на общество.
Примечания
Прочитать газету
Прочитать сопроводительную статью Nature News and Views
Скачать игры AlphaGo Zero
Подробнее об AlphaGo
Эта работа выполнена Дэвидом Сильвером, Джулианом Шриттвизером, Карен Симонян, Иоаннисом Антоноглу, Аяннисом Антоноглу Хуан, Артур Гес, Томас Хьюберт, Лукас Бейкер, Мэтью Лай, Адриан Болтон, Ютиан Чен, Тимоти Лилликрап, Фан Хуэй, Лоран Сифре, Джордж ван ден Дрисше, Тор Грепель и Демис Хассабис.
Авторов
David Silver, Demis Hassabis
* External authors
AlphaGo (2017) — IMDb
- Cast & crew
- User reviews
IMDbPro
- 20172017
- 1h 30m
IMDb RATING
7. 8 /10
8 /10
6,2K
Ваш рейтинг
Play Trailer1
:
31
2 Видео
25 Фотографии
DypomarySport
Google DeepMind разработала программу для игры в 3000 -летнюю игру. Тестируют AlphaGo на чемпионе Европы, потом 9 марта-15, 2016, о лучшем игроке, Ли Седоле, в … Читать полностьюDeepMind от Google разработал программу для игры в 3000-летнюю игру Го с использованием ИИ. Они тестируют AlphaGo на чемпионе Европы, а затем 9-15 марта 2016 года на лучшем игроке Ли Седоле в турнире лучших из 5 в Сеуле. Компания DeepMind от Google разработала программу для игры в 3000-летнюю игру Го с использованием ИИ. Они тестируют AlphaGo на чемпионе Европы, а затем 9-15 марта 2016 года на лучшем игроке Ли Седоле в турнире Best of 5 в Сеуле.
IMDb RATING
7.8/10
6.2K
YOUR RATING
- Director
- Greg Kohs
- Stars
- Ioannis Antonoglou
- Lucas Baker
- Nick Bostrom
- Director
- Грег Кохс
- Старз
- Иоаннис Антоноглу
- Лукас Бейкер
- Ник Бостром
- 28User reviews
- 12Critic reviews
- Awards
- 4 wins & 3 nominations
Videos2
Trailer 1:31
Watch Official Trailer
Trailer 1:31
Watch AlphaGo
Фото25
Лучшие актеры
Иоаннис Антоноглу
Лукас Бейкер
Ник Бостром
Ю Чанхьюк
Нам Чи-Хён
Hyeyeon Cho
Joseph Choi
John Daugman
Chris Garlock
Thore Graepel
Arthur Guez
Demis Hassabis
John Holmes
Aja Huang
Fan Hui
Lee Hyunwook
Andrew Jackson
Майк Джонсон
- Режиссер
- Грег Кос
- Весь актерский состав и съемочная группа
- Производство, кассовые сборы и многое другое на IMDbPro
Больше похоже на это
Собственный мальчик Интернета: История Аарона Шварца
TPB AFK: Пиратская бухта Вдали от клавиатуры
Мы — Легион: История хактивистов
Икар
Магнус
0 Коин 9 Great Alone
Мой учитель-осьминог
The Bit Player
Free Solo
Бобби Фишер против всего мира
Социальная дилемма
Сюжетная линия
9015
Отсылки The Terminator (1984)
Отзывы пользователей28
Обзор
Рекомендуемый обзор
8/
10
10
Игра не мешает.
Документальный фильм о битве между Искусственным Интеллектом и Человеком. На этот раз фоном служит игра «Го».
Это захватывающая часть, которая показывает, насколько умными становятся компьютеры в процессе развития. Это отражает наше восприятие иерархии человека и машины. Он ставит под сомнение нашу ценность и роль в будущем и обсуждает страхи. Он глубоко проникает в нашу психику и самоанализ, и в основном это устройство представляет собой противостояние между системой искусственного интеллекта DeepMind и легендарным гроссмейстером Го.
Это ошеломляет, как ваша лояльность и эмоции главных героев колеблются, когда вы имеете дело с непрозрачной, нейтральной компьютерной программой, когда игры разыгрываются на наших глазах. Фильм прекрасно понимает, что ваше понимание игры может быть минимальным. Вы обнаружите, что приклеены к реакции комментаторов на размещение кнопки. Как растет и падает процент выигрышных прогнозов ИИ. Вам нравится 95% из представленных наблюдают за игрой, сыгранной на таком высоком уровне, что это невозможно понять, и вы можете разделить эмоции тех, кто смотрит, поскольку вы равны им.