Содержание
Что такое ДНК, полезная информация
Главная
Генетические исследования
ДНК
ДНК (сокращение от дезоксирибонуклеиновая кислота) – это одна из важнейших для живых существ молекула, в которой содержится вся генетическая информация о них. Если представить, что живое существо – это какой-нибудь сложный прибор, например, магнитофон, то понять, что такое ДНК, можно сравнив его с пленкой, на которой записаны инструкции по созданию магнитофона и его функционированию.
Молекулы ДНК есть в каждой клетке нашего организма, и они хранятся в ядре (существует еще одна внеядерная разновидность ДНК –митохондриальная, она кратко описана в словаре). Если достать ДНК всего лишь из одной клетки и вытянуть, то длина полученной нити составит около двух метров. При этом размеры клеточного ядра не превышают шести микрометров (микрометр – это одна миллионная часть метра). ДНК помещается в ядро за счет того, что она многократно свернута и уложена в компактные тельца – хромосомы. У человека в ядре каждой клетки хранятся 23 пары хромосом – один набор приходит от отца, второй – от матери. Исключением являются половые клетки – яйцеклетка и сперматозоид, которые несут только половину всех хромосом. Такое «сокращение» необходимо, чтобы при слиянии сперматозоида и яйцеклетки образовался бы организм с нормальным набором хромосом.
У человека в ядре каждой клетки хранятся 23 пары хромосом – один набор приходит от отца, второй – от матери. Исключением являются половые клетки – яйцеклетка и сперматозоид, которые несут только половину всех хромосом. Такое «сокращение» необходимо, чтобы при слиянии сперматозоида и яйцеклетки образовался бы организм с нормальным набором хромосом.
В каждой клетке есть специальные системы, которые считывают заложенную в ДНК информацию и на ее основе создают новые белки (белки выполняют в клетке огромное число функций – от строительства до регуляции прочтения заложенных в ДНК инструкций). Хранящиеся в ДНК «послания» особым образом закодированы. Код ДНК состоит из четырех «символов», или нуклеотидов. Эти четыре разновидности нуклеотидов обозначаются буквами А (аденин), Т (тимин), Г (гуанин) и Ц (цитозин).
В нитях ДНК нуклеотиды соединены один за другим в длинные цепочки. В итоге закодированная информация выглядит примерно так: ААТГЦГТААГЦЦ… и так далее. Для непосвященного человека подобный набор букв кажется бессмысленным, однако клеточные «шифровальщики» точно знают, как на основе заложенной в ДНК информации синтезировать нужные клетке белки. «Шифровальщики» узнают определенные последовательности нуклеотидов, называемые генами. Каждый ген кодирует один белок. Именно поэтому гены называют элементарными единицами наследственности.
«Шифровальщики» узнают определенные последовательности нуклеотидов, называемые генами. Каждый ген кодирует один белок. Именно поэтому гены называют элементарными единицами наследственности.
Если спросить человека на улице, что приходит ему в голову, когда он слышит слово «ДНК», то, скорее всего, ответом будет «двойная спираль». У нас пока о двойной спирали не было ни слова. Что же это такое, и почему за ее открытие американские ученые Джеймс Уотсон и Френсис Крик получили Нобелевскую премию по физиологии и медицине?
Двойная спираль – это пространственная структура, в форме которой существует ДНК. Дело в том, что нити ДНК «не любят» быть поодиночке. У каждой нити есть напарница, с которой они переплетаются на всем своем протяжении. В итоге как раз и образуется двойная спираль. Нити ДНК объединяются в пары не просто так. Во-первых, двойная спираль значительно более стабильна, чем одиночная нить. Во-вторых, сдвоенные цепочки ДНК не путаются, поэтому считывание информации проходит без проблем.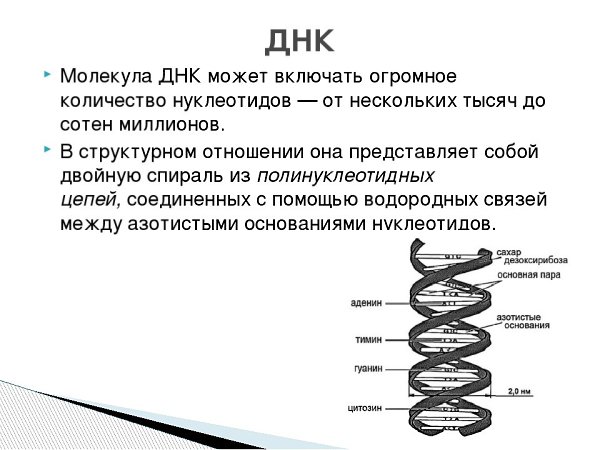 В-третьих, вторая цепь необходима в качестве гарантии сохранности информации. Нити ДНК соединяются в пары случайным образом, а, как говорят ученые, по принципу комплементарности. Это означает, что напротив каждого нуклеотида в одной нити всегда находится строго определенный нуклеотид из второй нити. Парой для А всегда выступает Т, а напарником Г является Ц.
В-третьих, вторая цепь необходима в качестве гарантии сохранности информации. Нити ДНК соединяются в пары случайным образом, а, как говорят ученые, по принципу комплементарности. Это означает, что напротив каждого нуклеотида в одной нити всегда находится строго определенный нуклеотид из второй нити. Парой для А всегда выступает Т, а напарником Г является Ц.
Эта особенность ДНК позволяет однозначно восстановить последовательность нити, имея на руках ее комплементарную копию. Если ДНК каким-либо образом повреждается и теряются кусочки одной из нитей, специальные белки заполняют возникшие бреши, используя в качестве матрицы для синтеза новой нити ее напарницу.
Существует еще один критически важный для клетки процесс, который требует существования двойной спирали. Это деление клеток. Перед тем как удвоиться, клетка синтезирует вторую копию всей своей ДНК. Это происходит так: двойные спирали расплетаются, и специальные белки создают новые комплементарные копии к каждой из оставшихся поодиночке нитей. В итоге снова образуются двойные спирали, но их уже вдвое больше, чем было исходно. Когда клетка разделяется надвое, каждая половинка получает по одному полному комплекту ДНК.
В итоге снова образуются двойные спирали, но их уже вдвое больше, чем было исходно. Когда клетка разделяется надвое, каждая половинка получает по одному полному комплекту ДНК.
Механизмы синтеза новых цепей работают очень точно, однако иногда происходят сбои, и на месте, скажем, нуклеотида А появляется нуклеотид Г. Причем ошибка может произойти не только в одном нуклеотиде: из цепи ДНК могут выпасть (или появиться) сразу несколько «букв». Ошибки размером в один нуклеотид получили название однонуклеотидных полиморфизмов, ошибки большего размера специального названия не имеют и объединяются под термином «мутации» (сюда входят и однонуклеотидные полиморфизмы).
Мутации могут никак не сказываться на работе клетки (например, если они произошли между генами), могут улучшить ее работу, а могут вызвать серьезный сбой. Последнее часто происходит в том случае, если из-за мутаций нарушается синтез того или иного белка. Именно мутации являются причиной многих наследственных заболеваний.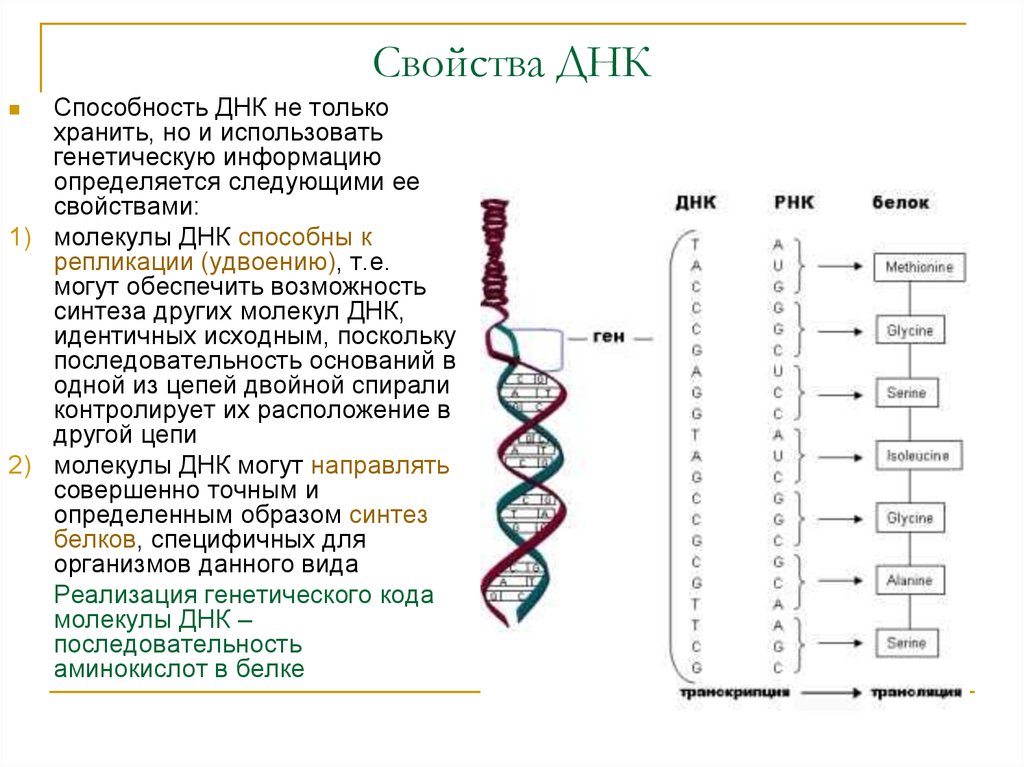
что это такое, строение, влияние на многообразие белков
Оглавление
- Как устроена ДНК?
- Как синтезируются белки?
Отказ от ответсвенности
Обращаем ваше внимание, что вся информация, размещённая на сайте
Prowellness предоставлена исключительно в ознакомительных целях и не является персональной программой, прямой рекомендацией к действию или врачебными советами. Не используйте данные материалы для диагностики, лечения или проведения любых медицинских манипуляций. Перед применением любой методики или употреблением любого продукта проконсультируйтесь с врачом. Данный сайт не является специализированным медицинским порталом и не заменяет профессиональной консультации специалиста. Владелец Сайта не несет никакой ответственности ни перед какой стороной, понесший косвенный или прямой ущерб в результате неправильного использования материалов, размещенных на данном ресурсе.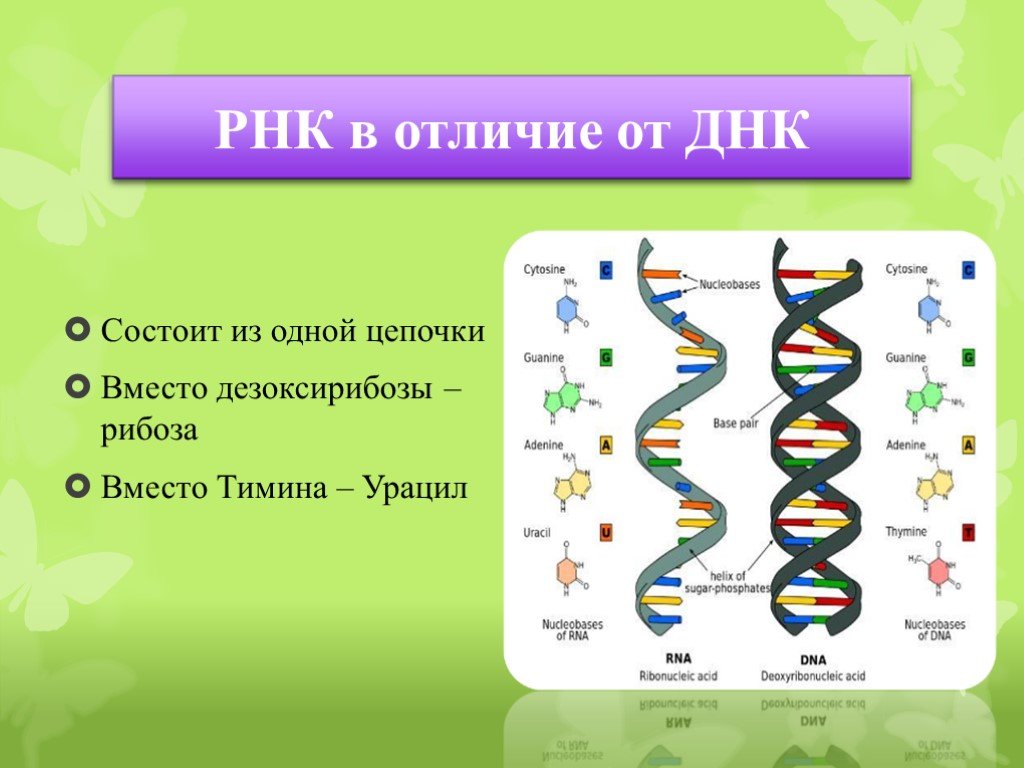
Простыми словами и сложном ДНК: что это такое, строение, влияние на многообразие белков.
ДНК – это сложный код, хранящий данные о наследственной информации. Это сложная макромолекула, которая способна поколениями хранить и передавать генетические данные, определяя наследственность и изменчивость всех существ. В ней закодирована полная программа развития любого из нас.
Как устроена ДНК?
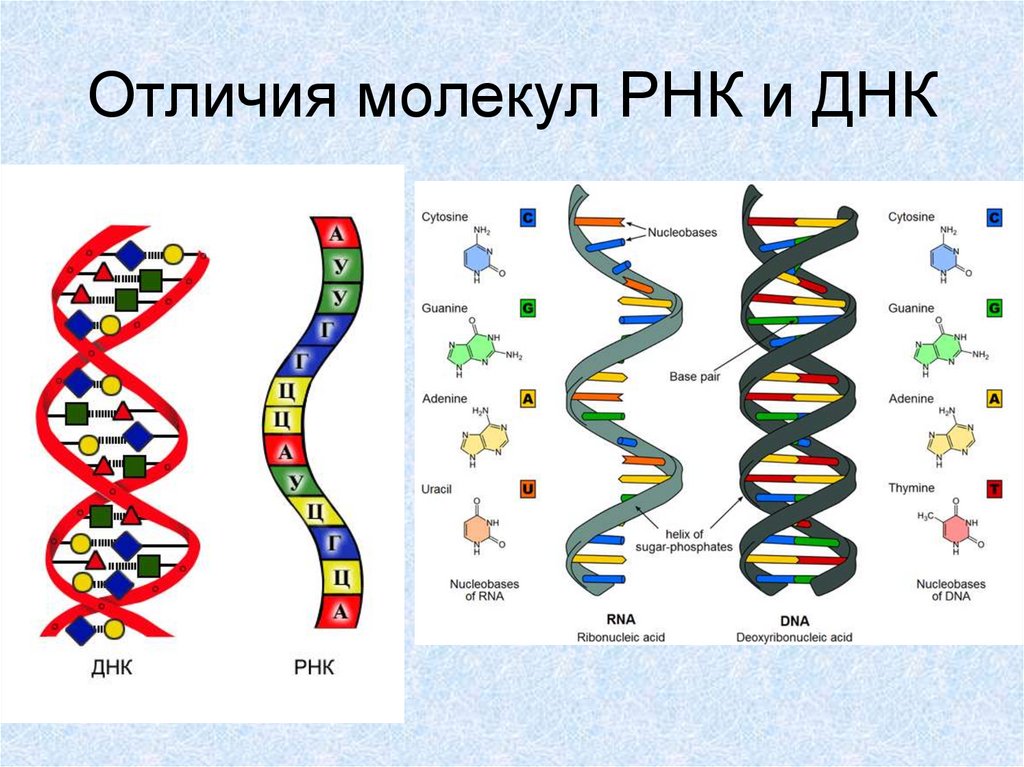
ДНК – длинная полимерная молекула. Она имеет структуру из двух цепочек, представляющих собой строго определенные нуклеотидные последовательности.
Сколько аминокислот в ДНК? Нисколько. В ней есть четыре нуклеотида. Это гуанин, аденин, цитозин, тимин.
Они действуют как маленькие магниты, удерживая обе цепочки вместе посредством водородных связей. Аденин сцепляется исключительно с тимином. Цитозин же исключительно с гуанином. В человеческой ДНК около трех миллиардов таких пар нуклеотидов.
Как синтезируются белки?
ДНК имеет форму двойной спирали. Примагниченные друг к другу цепочки из двух нуклеотидов можно сравнить с винтовой лестницей. Все ступени в ней прочно связаны. Но сами по себе довольно хрупкие и легко ломаются пополам. С одной стороны молекулы сохраняется аденин, с другой – тимин. Так задумано природой, чтобыобеспечить расплетание особыми белками молекулы ДНК и плетение ими же идентичныхДНК новых цепей РНК.
РНК – это последовательность из одной цепочки, наделенная многочисленными биологическими функциями. Она зеркальна ДНК. То есть в РНК напротив аденина в ДНК будет стоять тимин и наоборот. Так же зеркальнов ней хранятся данные, имеющиеся в ДНК.
ДНК хранятся в хромосомных клеточных ядрах. А белки синтезируются в цитоплазме, где их штампует рибосомный «станок», «сотрудничающий» с РНК. Процесс осуществляется следующим образом:
- Белок распрямляет ДНК изеркально копирует данные на РНК.

- РНК поставляет данные рибосоме.По пути она подвергается многочисленным преобразованиям. Включая вырезание данных, которые рибосоме не требуются.
- Рибосома движется по РНК и выстраивает комплементарную цепочку, вновь зеркально отражая данные, возвращая им первичную ДНК-последовательность.
- Уже на новой комплементарной цепочке рибосома расшифровывает код и выстраивает из нужных аминокислот требуемые белки.

Рибосома собирает белки из 20 аминокислот. В ДНК же всего 4 нуклеотида. Ими нельзя закодировать столько аминокислот – мало вариантов. Что делать? На помощь спешат гены.
Аминокислота кодируется последовательностью из трех нуклеотидов в гене – отрезке ДНК. Это дает возможность закодировать 64 аминокислоты. Хотя требовалось всего 20. Происходит это так:
- Рибосома двигает по РНК считывающую антенну.
- Когда антенна обнаруживает старт-кодон, стартует считывание данных для синтеза.
- Антеннапостепенно продвигается по отрезку из трех нуклеотидов, и рибосома создает требуемую аминокислоту.
- Когда антенна находит на стоп-кодон, синтез заканчивается.
Таким образом уникальная последовательность аминокислот образует уникальный белок. Это одно из самых древних изобретений эволюции.
Отказ от ответсвенности
Обращаем ваше внимание, что вся информация, размещённая на сайте
Prowellness предоставлена исключительно в ознакомительных целях и не является персональной программой, прямой рекомендацией к действию или врачебными советами. Не используйте данные материалы для диагностики, лечения или проведения любых медицинских манипуляций. Перед применением любой методики или употреблением любого продукта проконсультируйтесь с врачом. Данный сайт не является специализированным медицинским порталом и не заменяет профессиональной консультации специалиста.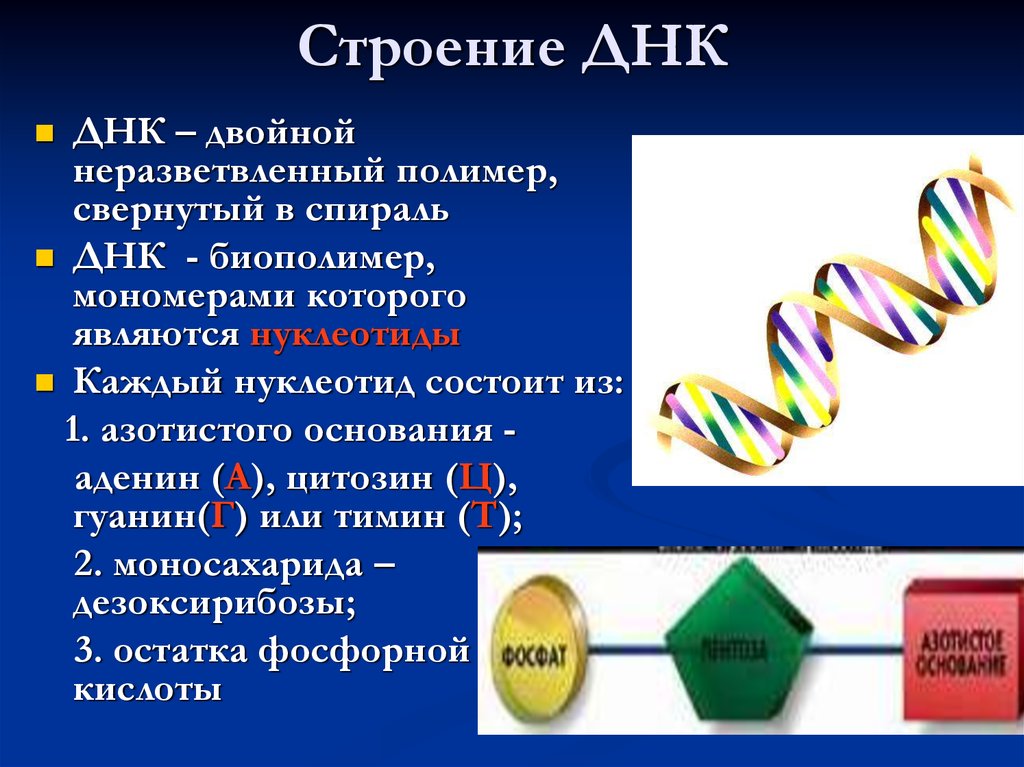 Владелец Сайта не несет никакой ответственности ни перед какой стороной, понесший косвенный или прямой ущерб в результате неправильного использования материалов, размещенных на данном ресурсе.
Владелец Сайта не несет никакой ответственности ни перед какой стороной, понесший косвенный или прямой ущерб в результате неправильного использования материалов, размещенных на данном ресурсе.
Эксперт: Марина Розова специалист по подбору БАД, ведёт Инстаграм блог «Про витамины», где простым языком рассказывает как поддерживать свой ресурс, иммунитет и красоту изнутри при помощи БАД и ЗОЖ
самая длинная в мире последовательность ДНК декодирована
Опубликовано
Источник изображений, научная библиотека
от Ангуса Дэвисона
Университет Ноттингема
за расшифровку самой длинной в мире последовательности ДНК.
Ученые произвели считывание ДНК, которое примерно в 10 000 раз длиннее обычного и вдвое больше, чем у предыдущего рекордсмена из Австралии.
Это исследование положило начало соревнованию в стиле Эша на секвенирование всей хромосомы за одно чтение.
Новым обладателем трофея за самое длинное чтение ДНК в мире стала команда под руководством Мэтта Луза из Ноттингемского университета.
Прогресс носит технологический характер — речь идет о чтении ДНК, а не об открытии особенно большого генома. ДНК, использованная для длинного считывания, была взята у человека.
Но ученые надеются, что работа ускорит и упростит секвенирование генетической информации, потому что в настоящее время ДНК приходится разбивать на более мелкие фрагменты, а затем собирать заново в процессе секвенирования.
Группа доктора Луза также недавно произвела наиболее полную последовательность человеческого генома, используя секвенатор размером с ладонь. Они потенциально предлагают более низкую стоимость и более быструю обработку для секвенирования ДНК.
Он сказал мне: «Был конкурс, чтобы увидеть, кто может получить самую длинную последовательность.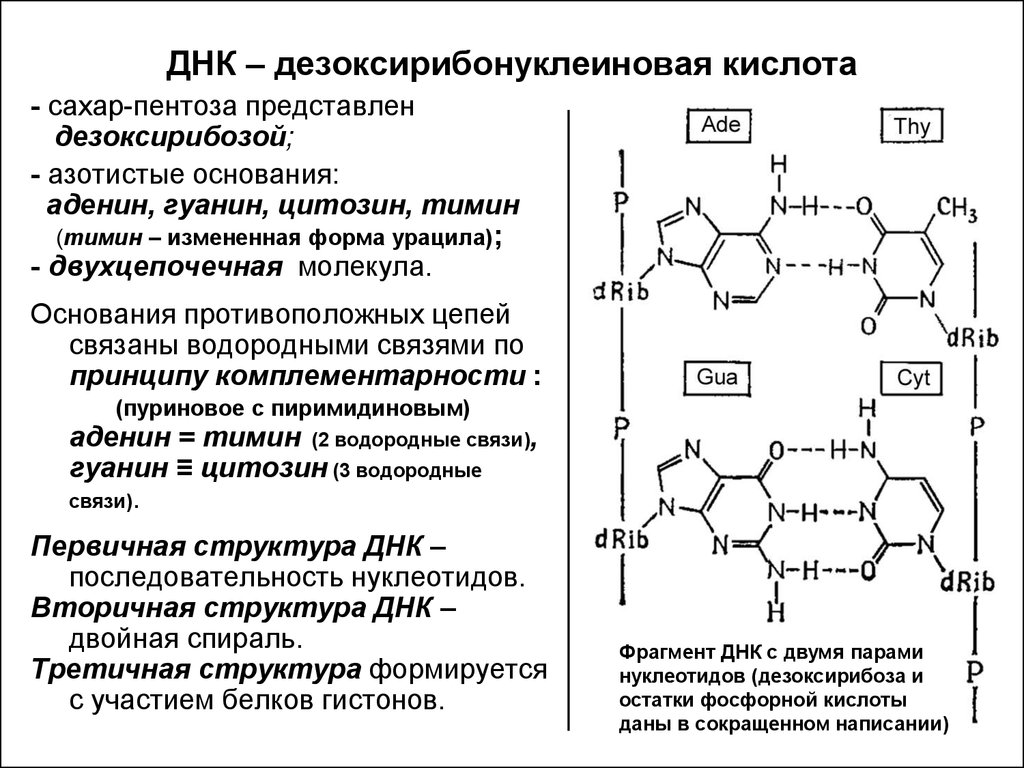 Я думаю, что это все еще дружеские отношения».
Я думаю, что это все еще дружеские отношения».
Д-р Луз продолжил: «Некоторое время Австралия лидировала, но потом у нас было число чуть меньше миллиона. -парное чтение
«Дружеское завершение запустило трофей в стиле Ashes, который должен путешествовать по миру, поскольку люди читают его дольше всех.»
Австралийская команда из Центра клинической геномики Кингхорна первой преодолела отметку в миллион оснований.
Создание головоломки
Технология, позволяющая ученым считывать ряды последовательностей ДНК, прошла долгий путь со времен гонки тысячелетий по расшифровке первого человеческого генома.
За последние 10 или около того лет усовершенствования в технологиях секвенирования ДНК привели к тому, что первоначальный человеческий геном стоимостью в миллиард долларов, созданный в 2001 году, теперь можно воспроизвести примерно за 1000 долларов.
Поскольку затраты продолжают падать, есть надежда, что персонализированное секвенирование ДНК не за горами. Вскоре наш геном может быть расшифрован во время поездки к врачу, или, что более спорно, наши родители могут прочитать его для нас еще до нашего рождения.
Вскоре наш геном может быть расшифрован во время поездки к врачу, или, что более спорно, наши родители могут прочитать его для нас еще до нашего рождения.
Но один из оставшихся камней преткновения — собрать фрагменты ДНК в правильном порядке. Точно так же, как теоретически возможно, но весьма маловероятно, что шимпанзе сможет воспроизвести произведение Шекспира, печатая текст одним пальцем, компьютерные программы не способны повторно собрать геном из коротких, перемешанных последовательностей ДНК.
Источник изображения, Uni Nottingham
Подпись к изображению,
Д-р Луз говорит, что новая работа может найти дополнительное применение, в том числе в медицине
Д-р Луз сказал мне: проблема в том, что генетический код, или геном, часто состоит из многих миллиардов оснований, и поэтому прочитать их все очень сложно
«В прошлом люди использовали много разных способов, но, по сути, то, что они делали, это нарезало ДНК. на маленькие кусочки, а затем снова собрать их вместе, немного похоже на то, что вы делаете с головоломкой.
«Вы пытаетесь получить перекрывающиеся изображения, чтобы найти, где небо, а где деревья, и построить свою картину.»
Он объяснил: «Секвенирование с помощью нанопор обещает более низкую стоимость и большую длину считывания, что означает, что мы можем наблюдать за интересными организмами, которые еще предстоит секвенировать, потому что их геномы необычайно велики».
Точно так же, как ученые соревнуются в создании самой длинной последовательности ДНК, технологические компании борются за лидерство на рынке в области внедрения новых технологий.
В будущем эти методы обещают произвести революцию в понимании здоровья человека, а также применить те же методы к другим растениям и животным. Длинное секвенирование ДНК можно использовать для идентификации патогенов в пищевых продуктах, для борьбы с болезнями у животных, для диагностики инфекции и найти применение в огромном количестве областей, связанных с пищевыми продуктами.
«Наблюдение за китами»
Я спросил доктора Луза о восторженных ссылках на «наблюдение за китами» в социальных сетях.
«Мы хотели найти способ различать длинные чтения. Что означает «длинное»? Раньше это означало чтение из 300 оснований вместо 150, затем это означало 5000. Так что мы придумали китовую шкалу — чтение в миллион пар оснований был бы эквивалентен киту весом около тонны, как нарвал.
«Самое длинное чтение, которое у нас есть на данный момент, это белуха».
Я спросил его, сколько времени пройдет, прежде чем мы получим » синий кит», считанный с целой хромосомы.
Мэтт сказал мне: «Было бы фантастически секвенировать всю хромосому, если это возможно. Если масштабировать нанопору до размера человеческого кулака, то мегабаза ДНК — это веревка длиной 3,2 км, которую нужно продеть сквозь пальцы, чтобы она не запуталась и не порвалась.
«Есть также очень интересный вопрос о том, сколько разрывов имеет каждая хромосома. Я не уверен, что вы когда-нибудь сможете секвенировать хромосому от одного конца до другого. Рекордный результат гласил: «Теоретически секвенирование с помощью нанопор позволяет секвенировать молекулы ДНК любой длины. Это действительно сильно отличается от того, как мы уже много лет секвенируем ДНК. Прорыв в этой статье заключается в том, что мы смогли секвенировать молекулу длиной 2,3 миллиона оснований, чего раньше не удавалось никому.
Это действительно сильно отличается от того, как мы уже много лет секвенируем ДНК. Прорыв в этой статье заключается в том, что мы смогли секвенировать молекулу длиной 2,3 миллиона оснований, чего раньше не удавалось никому.
«Раньше наиболее распространенная длина считывания составляла 150 оснований [основания или пары оснований — это четыре «буквы», составляющие последовательность ДНК].
«Недавно мы учили людей в Сингапуре, как использовать эти секвенсоры одновременно с Гран-при. Если трасса Гран-при Сингапура равна 150 основаниям, то считывание 2,3 миллиона пар оснований составляет два оборота по окружности Земли», — пояснил он.
Источник изображения, доктор Мартин Смит
Подпись к изображению,
Между командами проходит товарищеское соревнование. Это сообщение, созданное с помощью программного обеспечения nanopore, расшифровывается как «Loose Sucks» (зеленые квадраты)
. В ноябре 2017 года доктор Мартин Смит из Центра клинической геномики Кингхорна в Австралии объявил, что они прочитали более миллиона оснований. По словам доктора Луза, трофей Пепла упаковывали, чтобы отправиться в Австралию, как раз в тот момент, когда Ноттингем произвел выигрышное чтение в 1,2 миллиона пар оснований. Теперь его снова превзошло считывание размером 2,3 миллиона пар оснований размером с белугу.
По словам доктора Луза, трофей Пепла упаковывали, чтобы отправиться в Австралию, как раз в тот момент, когда Ноттингем произвел выигрышное чтение в 1,2 миллиона пар оснований. Теперь его снова превзошло считывание размером 2,3 миллиона пар оснований размером с белугу.
Эти достижения не слишком хорошо восприняли в Австралии, где доктор Смит в шутку ответил изображением «Отстой», используя макет программного обеспечения nanopore.
Каковы возможные применения?
Доктор Лус надеется, что мы начнем использовать эти методы для изучения таких вещей, как раковые геномы, где происходит перестройка ДНК. Хромосомы ломаются и неправильно сливаются.
В одном из интервью д-р Смит сказал мне, что первый рекордсмен «кит» из 473 000 оснований был из линии раковых клеток.
Его команда изучает эти раковые клетки, полученные от пациентов, потому что их геномы особенно беспорядочны, очень похожи на головоломку, в которой отсутствуют части и есть части из другой головоломки.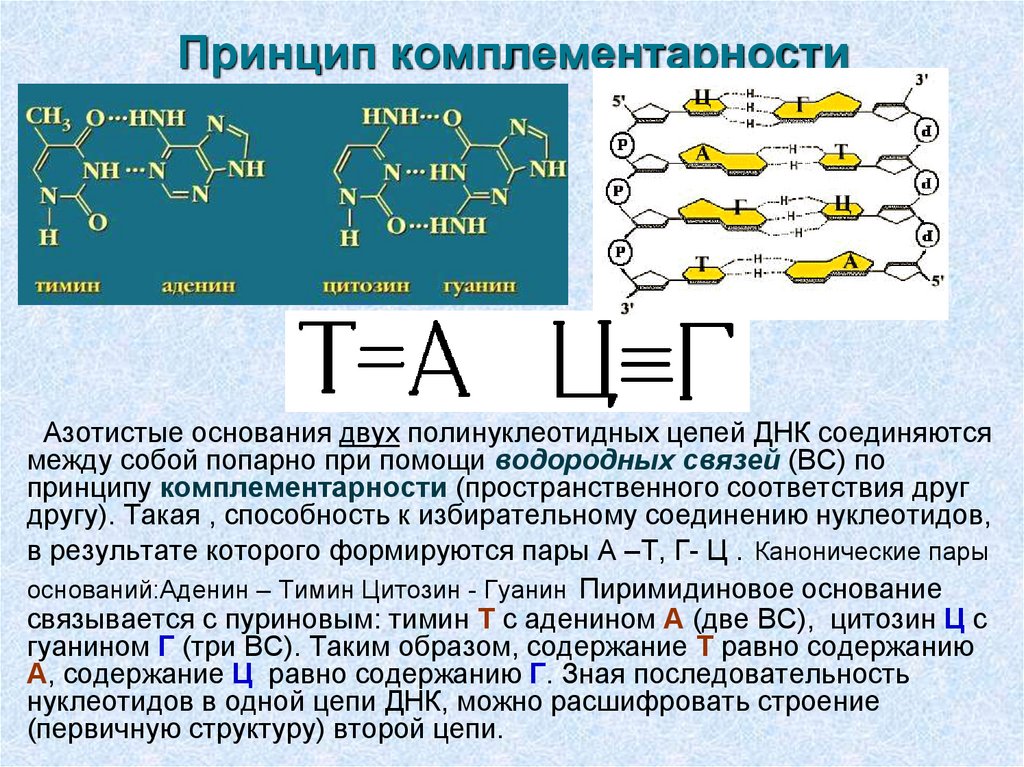 В будущем эти методы также будут более регулярно использоваться в клиниках, при вспышках заболеваний и при перемещении из лабораторий в руки отдельных лиц.
В будущем эти методы также будут более регулярно использоваться в клиниках, при вспышках заболеваний и при перемещении из лабораторий в руки отдельных лиц.
Я также спросил обоих ученых, как долго, по их мнению, будет стоять текущий рекорд и кто получит трофей следующим. Оба согласились с тем, что рекорд может продержаться около года, но разошлись во мнениях относительно того, кто может победить, будь то Великобритания, Австралия или новичок.
С дружеским взглядом доктор Смит сказал мне: «Мэтт должен спать с одним открытым глазом, потому что разговоры об этом длинном чтении снова заставили меня жаждать записи. Следите, мы собираемся получить этот кубок Пепла». снова однажды».
Доктор Ангус Дэвисон () — генетик из Ноттингемского университета и научный сотрудник BSA по связям со СМИ в BBC.
Новый метод помогает исследователям расшифровывать геномы
Shu-Bing Qian
В клетках информационная РНК (фиолетовая) расшифровывается рибосомами (бежевая), которые, в свою очередь, производят нужные цепочки аминокислот, из которых состоят белки, называются полипептидами (розовая спираль). Чтобы понять, где начинается код гена, исследователи использовали два родственных, но разных ингибитора трансляции (красный и зеленый), чтобы заморозить процесс трансляции ДНК.
Чтобы понять, где начинается код гена, исследователи использовали два родственных, но разных ингибитора трансляции (красный и зеленый), чтобы заморозить процесс трансляции ДНК.
Хотя ученые секвенировали весь геном человека более 10 лет назад, предстоит еще много работы, чтобы понять, какие белки кодируют все эти гены.
Теперь исследование, опубликованное в Интернете 27 августа в Proceedings of the National Academy of Sciences, описывает новый подход, который позволяет исследователям расшифровывать геном, понимая, где гены начинают кодировать полипептиды, длинные цепочки аминокислот, из которых состоят белки. .
«Ключом к расшифровке генома является точное знание того, где гены начинают кодировать полипептиды», — сказал Шу-Бин Цянь, старший автор статьи и доцент кафедры диетологии в Корнелле. «Если мы знаем, где они начинаются, то мы можем предсказать, какие белки они производят, основываясь на последовательности гена».
Генные последовательности состоят из четырех нуклеотидов — аденина (А), цитозина (С), гуанина (G) и тимина (Т) — но коды состоят из трех последовательных нуклеотидов. Проблема в том, что в зависимости от того, где вы начинаете читать код, один и тот же сегмент ДНК может генерировать разные генные продукты.
Проблема в том, что в зависимости от того, где вы начинаете читать код, один и тот же сегмент ДНК может генерировать разные генные продукты.
В новом подходе используются рибосомы, механизм трансляции, который расшифровывает информационную РНК (мРНК), которая несет кодирующую информацию из ДНК и переводит эти коды в цепочки аминокислот, строительные блоки белков.
При трансляции мРНК рибосома в начальной позиции имеет внутри пустое пространство. Цянь и его коллеги использовали специальное химическое соединение, которое заполняет это пустое пространство и замораживает эту рибосому. Это позволяет исследователям точно определить, где ген начинает кодировать полипептиды. Затем они используют эту информацию, чтобы предсказать, какие белки будут получены из последовательности.
Используя этот метод, исследователи обнаружили, что одна и та же мРНК может иметь несколько инициирующих сайтов, которые приводят к производству разных белков.
«Около 50 процентов мРНК имеют более одного стартового сайта», — сказал Цянь. Таким образом, ограниченный геном может иметь множество возможностей в зависимости от того, где в гене находится стартовый сайт. Например, если он встречается позже в последовательности гена, он может кодировать более короткий или совершенно другой белок.
Таким образом, ограниченный геном может иметь множество возможностей в зависимости от того, где в гене находится стартовый сайт. Например, если он встречается позже в последовательности гена, он может кодировать более короткий или совершенно другой белок.
Во время транскрипции мРНК заменяет урацил (U) на T, обнаруженный в ДНК. «Традиционно все известные стартовые сайты трансляции были AUG. Но мы обнаружили, что другие кодоны, такие как CUG, также могут служить стартовым сайтом», — сказал Цянь. Он добавил, что это открытие изменит общепринятое представление о генах и о том, где они начинают кодироваться.
Результаты показывают, что весь набор белков, которые могут экспрессироваться одним геном, гораздо более разнообразен, чем считалось ранее. Кроме того, предсказать, какие белки может кодировать ген, может быть гораздо сложнее из-за этого альтернативного процесса декодирования.
Этот метод также можно использовать для исследования генома вирусов, известных тем, что они захватывают механизм трансляции клетки для создания новых вирусов.