Содержание
Из чего собрана наша ДНК
Научная догма
В 1953 году Джеймс Уотсон и Фрэнсис Крик опубликовали в журнале Nature двухстраничную статью с заголовком «Молекулярная структура дезоксирибонуклеиновых кислот». В статье коротенечко сообщалось, что ДНК — это двойная спираль, нити которой состоят из нуклеотидов, букв «генетического текста», и удерживаются вместе эфемерными водородными связями. Примерно тогда же стало понятно, как ДНК воспроизводит свои копии, и был сформулирован ключевой для всей биологии принцип — центральная догма* молекулярной биологии.
*Ее автор, один из первооткрывателей молекулярной структуры ДНК Фрэнсис Крик, объяснял выбор этого слова желанием подобрать звучное название.
Эта догма гласит: ДНК является средоточием генетической (наследственной) информации и может служить инструкцией — матрицей для синтеза своей ближайшей родственницы РНК, рибонуклеиновой кислоты. Последняя содержит информацию, которая используется для синтеза белков, а уже те самостоятельно принимаются за дело, выполняя огромное разнообразие работ в клетке. Вольный пересказ центральной догмы молекулярной биологии на сем окончен.
Вольный пересказ центральной догмы молекулярной биологии на сем окончен.
Появление этой догмы ознаменовало наступление «нового времени» в науке о живом. Но заметьте: что догма, что открытия 1950-х выхватили, словно лучом прожектора, только самый центральный, основополагающий сюжет с участием ДНК — кодирующие последовательности в генах. Все остальное первооткрыватели структуры чудо-молекулы пренебрежительно назвали «мусорной ДНК» (англ. Junk DNA), оставив без внимания.
16 000 томов Толстого
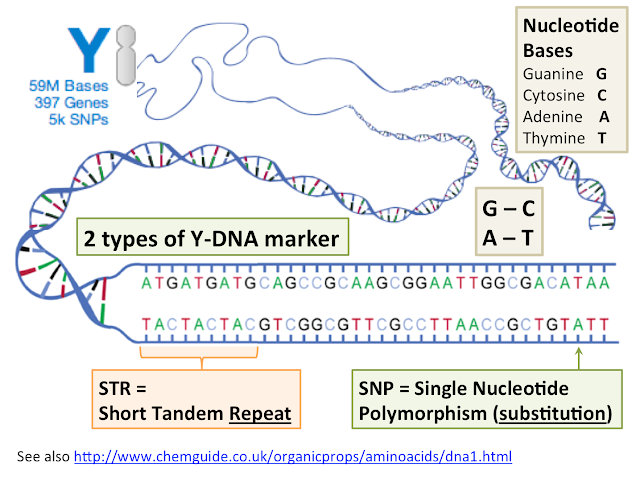
В последующие десятилетия некодирующей «темной материи» не придавали особого значения. Но время шло, не стоял на месте и научный прогресс — ученые понемногу узнавали о разнообразии процессов, происходящих внутри ДНК и с ее участием. Немало удивительного удалось узнать и о геноме в целом. Например, что весь генетический код представляет собой длинный текст, который записан 4-буквенным алфавитом. Это так называемые нуклеотиды: аденин — A, тимин — T, гуанин — G и цитозин — C.
Не так давно, на рубеже тысячелетий, чтобы получить полную версию этого сакраментального «текста», был создан огромный международный консорциум «Геном человека». На протяжении более чем 10 лет исследователи из 20 научных центров США, Великобритании, Японии, Франции, Германии, Испании и Китая и нескольких частных компаний сплоченно работали и ежедневно докладывали о своих успехах.
На протяжении более чем 10 лет исследователи из 20 научных центров США, Великобритании, Японии, Франции, Германии, Испании и Китая и нескольких частных компаний сплоченно работали и ежедневно докладывали о своих успехах.
В результате огромной работы к 2003 году этот написанный природой и прочитанный человеком опус был наконец опубликован. В последовательности из 3 миллиардов букв* было найдено около 20-25 тысяч фрагментов — генов, — в которых непосредственно закодирована наследственная информация.
*Для сравнения: в 4-томном романе «Война и мир» всего-навсего около 750 тысяч знаков, включая знаки препинания и пробелы. Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.
Средняя длина гена — около 25-27 тысяч пар нуклеотидов. Если посчитать долю знаков всех генов от объема общего текста, получится около 2%. Если вычесть некодирующие элементы внутри генов, и того меньше. Но если в категорию «мусора» попало 98% генома, значит, этот мусор для чего-то да нужен?
Для сравнения: в 4-томном романе «Война и мир» всего-навсего около 750 тысяч знаков, включая знаки препинания и пробелы. Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.Проект «Геном человека» подарил много новых инструментов для работы с ДНК. Историки науки даже называют 2003 год началом новой эры в биологии — постгеномной. Менее чем за два десятилетия в арсенале учёных появились методы, позволяющие распознавать отдельный нуклеотиды при протягивании молекулы ДНК через нанопору, — в ХХ веке о таком не помышляли даже фантасты. И потихоньку наука начала разбираться с завалами «мусора».
Если разбить ДНК на отрезки, равные по числу знаков томам «Войны и мира», получится, что геном человека — это 16 000 таких томов.Проект «Геном человека» подарил много новых инструментов для работы с ДНК. Историки науки даже называют 2003 год началом новой эры в биологии — постгеномной. Менее чем за два десятилетия в арсенале учёных появились методы, позволяющие распознавать отдельный нуклеотиды при протягивании молекулы ДНК через нанопору, — в ХХ веке о таком не помышляли даже фантасты. И потихоньку наука начала разбираться с завалами «мусора».
Так из какого сора?
Что же представляет собой это «молчаливое большинство» нашего генома?
Безусловно, нельзя говорить о ненужности и бессмысленности 98% генетического материала. Эту хаотичную и слабо понятную сейчас массу можно назвать не мусором, а скорее свалкой сокровищ.
Некодирующие области могут выполнять разные функции или не выполнять никаких. Чтобы попасть в эту огромную категорию, участкам ДНК достаточно не хранить в себе информацию о структуре РНК или белка.
Компоненты человеческого генома
Кодирующие области 2%
Интроны 26%
ДНК-транспозоны 3%
LTR-ретротранспозоны 8%
LINEs 20%
SINEs 10%
Микросателлиты 3%
Другие типы 28%
Непосредственно внутри кодирующих областей встречаются интроны. Это такие участки ДНК, которые сидят внутри генов, но при этом ничего не кодируют. В дальнейшем интроны безжалостно вырезаются и выбрасываются из уже из РНК (этот процесс называется сплайсингом). Обилие подобных побочных продуктов производства РНК характерно для эукариот: у них для генома есть специальный контейнер, способный вместить сколь угодно много сора, — ядро. В человеческой ДНК на интроны приходится аж четверть текста. У бактерий такого контейнера нет, их геномы более компактные и рационализированные.
За границами кодирующих областей встречаются два типа крайне важных последовательностей: промоторы и терминаторы. Первые обозначают место, откуда надо начать считывание гена, вторые — конец.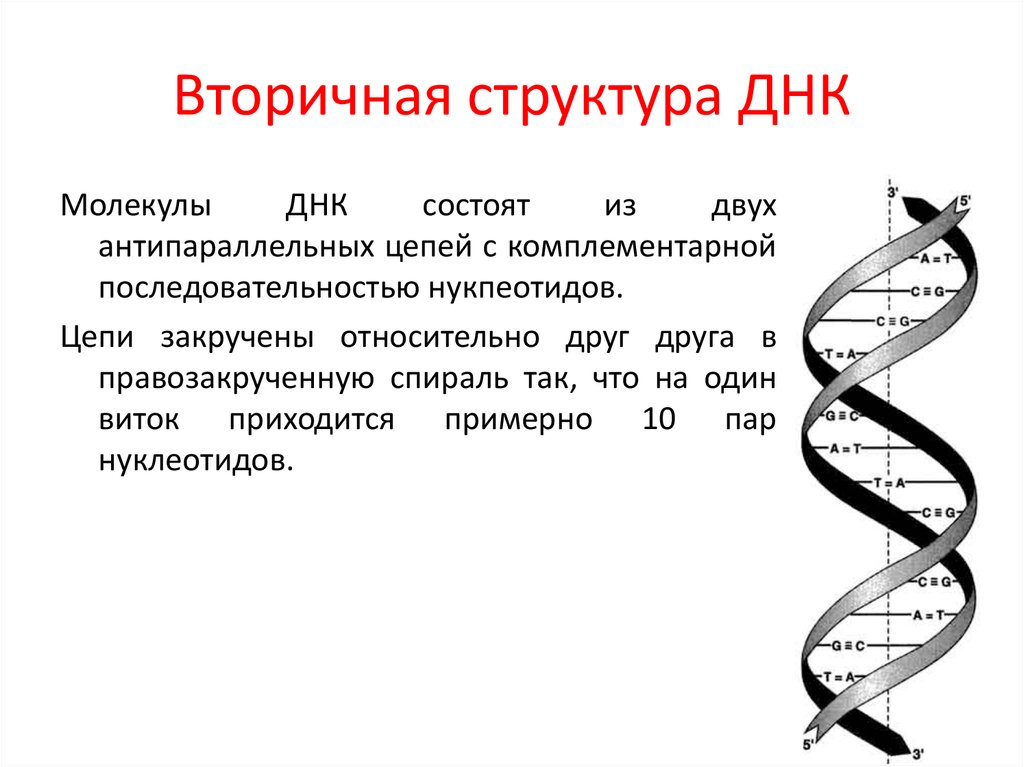 Рядом могут находиться энхансеры и сайленсеры — своеобразные тумблеры, позволяющие настроить активность считывания гена. Регуляторные участки ДНК — важный тип некодирующих последовательностей, ведь такая сложная машина, как организм, должна, во-первых, правильно собирать себя в процессе развития и, во-вторых, оперативно реагировать на изменения состояния — своего собственного и окружающей среды.
Рядом могут находиться энхансеры и сайленсеры — своеобразные тумблеры, позволяющие настроить активность считывания гена. Регуляторные участки ДНК — важный тип некодирующих последовательностей, ведь такая сложная машина, как организм, должна, во-первых, правильно собирать себя в процессе развития и, во-вторых, оперативно реагировать на изменения состояния — своего собственного и окружающей среды.
Плодятся буквы, как лопухи и лебеда, как буквы в ворде
«Ааааааааааааааааааааааааааааааааааааааааааааааааааа», — повторяет Владимир Сорокин несколько страниц в своем дебютном романе «Норма», используя бессмысленный повтор как средство художественной выразительности. TTTTTTTTTTTTTTTTTTTTT или GCAGCAGCAGCAGCAGCAGCAGCA, — вторит ему ДНК. На такие последовательности приходится около 1,5 миллиарда знаков из 3-миллиардного текста нашего генома. Почему бессмысленные повторы занимают столько места? Или, раз это место им отведено, они что-то да значат? Учёные считают, что повторяющиеся последовательности — это горячие точки эволюции: с ними связаны быстрые и неожиданные изменения генома. Исследования показали, что не все повторы одинаковы, их можно разделить на два больших типа: прямые и диспергированные, причём в каждом по несколько разновидностей.
Исследования показали, что не все повторы одинаковы, их можно разделить на два больших типа: прямые и диспергированные, причём в каждом по несколько разновидностей.
Диспергированные повторы, в отличие от прямых, не идут впритык друг за другом, а перемежаются с другими участками ДНК. По большей части диспергированные повторы — это транспозоны, последовательности-анархисты, способные скакать с места на место, то есть перемещаться по геному. Свободолюбивое поведение делает транспозоны важной движущей силой эволюции: они перемешивают и прочее население генома, вмешиваясь в работу генов.
Некоторые транспозоны — ретротранспозоны — могут не только скакать по геному, но и плодиться в нём. Их название отражает не художественные пристрастия, а механизм, который эти мобильные генетические элементы используют для передвижения по ДНК. Корень «ретро-» по аналогии с ретровирусами намекает на переход в форму РНК. То есть такие последовательности сначала считываются, а потом из РНК-матрицы переходят снова в ДНК, встраиваясь в новое место генома. Принцип «копировать — вставить». Оставшиеся малочисленные ДНК-транспозоны переходить в РНК не умеют, им остается вариант «вырезать — вставить».
Принцип «копировать — вставить». Оставшиеся малочисленные ДНК-транспозоны переходить в РНК не умеют, им остается вариант «вырезать — вставить».
Ретротранспозоны нашего генома можно разделить на несколько групп. Во-первых, это LTR-ретротранспозоны. На концах таких последовательностей присутствуют особые повторяющиеся участки. Подобные концевые повторы есть у ретровирусов и используются ими для встраивания генетического материала в геном хозяина. Это сходство названий и последовательностей не случайно: LTR-ретротранспозоны происходят от ретровирусов. Очередной вирусный след в человеческом геноме, притом увесистый: на LTR-повторы приходится порядка 8% генома Homo sapiens.
Ретротранспозоны LINEs и SINEs таких концевых повторов лишены. Главное различие между ними в размере: от менее 500 нуклеотидов у SINEs до в среднем 7000 у LINEs. Самые любопытные из них Alu-повторы. Подавляющее большинство SINEs генома Homo sapiens — это именно они. Предполагают, что Alu-элементы возникли около 100 млн лет назад и с тех пор изменялись вместе с расходящимися по собственной эволюционной ветке обезьянами. Изучение Alu-повторов помогает лучше понять родословную наших родичей.
Изучение Alu-повторов помогает лучше понять родословную наших родичей.
Ну сколько можно повторять!
Тандемные повторы ДНК вплотную примыкают друг к другу, почти как ездоки велосипеда-тандема. Отсюда их правильная структура с регулярным чередованием. Ну а свойства определяются размером повторов, по этому признаку тандемные повторы делят на три типа: сателлиты, минисателлиты и микросателлиты.
Самые длинные — сателлиты, или сателлитная ДНК, — могут тянуться миллионы и миллионы нуклеотидов подряд. Космическое название (англ. Satellite — спутник) связано с тем, что при ультрацентрифугировании (метод разделения веществ в результате очень быстрого раскручивания на ультрацентрифуге) эта часть ДНК легко отделялась от прочего генома. Сателлиты не кодируют РНК и белки и вообще складированы в «технических» областях хромосом: центромерах и теломерах. Центромеры и сателлитные повторы важны при делении клетки. Когда дело доходит до разделения удвоенных хромосом, микротрубочки подходят именно к центромерам и тянут за них хромосомы в противоположном направлении.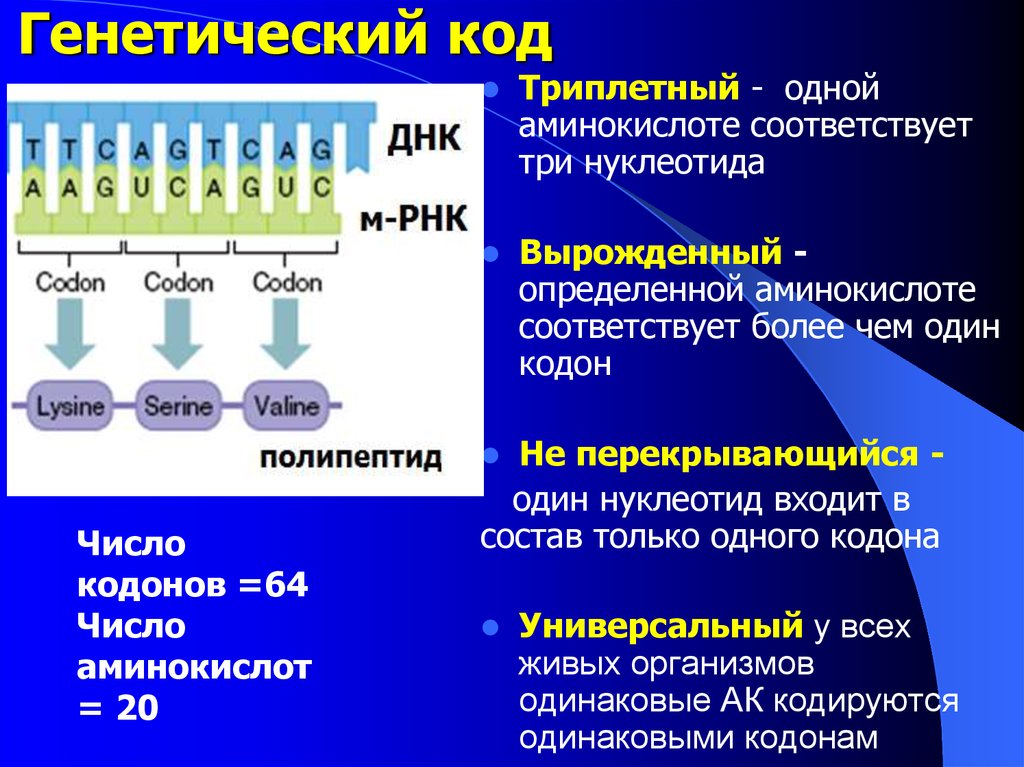 А сателлиты в теломерах не позволяют концам хромосом слипаться (и самой хромосоме — разрушиться). Еще они защищают нас от старения, препятствуя укорачиванию хромосом.
А сателлиты в теломерах не позволяют концам хромосом слипаться (и самой хромосоме — разрушиться). Еще они защищают нас от старения, препятствуя укорачиванию хромосом.
Фото: Журнал «Кот Шрёдингера»
Средненькие в семье тандемных — минисателлиты, — как заведено и у людей, следуют за старшенькими. Они обнаружены не в самих центромерах и теломерах, а по соседству. Именно по последовательностям минисателлитов в детективных сериалах определяют сходство ДНК с места преступления с ДНК подозреваемого, а в романтических — устанавливают родительство. Длина каждого отдельного минисателлита довольно специфична у каждого из нас, однако у близких родственников они схожи.
Самые маленькие из тандемных повторов длиной всего 6-10 нуклеотидов — микросателлиты. Как и средненькие (и по тому же принципу), самые короткие в семействе нашли применение в криминалистике, но на этом их сходство со старшими братьями заканчивается. В отличие от них, микросателлиты находятся не в определённых участках хромосом, а распределены по всей ДНК почти равномерно. И не криминалистическое применение в них самое интересное. Микросателлиты, несмотря на малый размер, — кипучие котлы эволюции. Мутации в них происходят в тысячу раз чаще, чем в каких-либо других нуклеотидах. Характер этих мутаций заключается в потере или дублировании единиц-повторов целиком. Притом не одной — иногда «проскальзывание» копирующего ДНК белка затрагивает большие участки ДНК со следующими один за другим микросателлитами.
И не криминалистическое применение в них самое интересное. Микросателлиты, несмотря на малый размер, — кипучие котлы эволюции. Мутации в них происходят в тысячу раз чаще, чем в каких-либо других нуклеотидах. Характер этих мутаций заключается в потере или дублировании единиц-повторов целиком. Притом не одной — иногда «проскальзывание» копирующего ДНК белка затрагивает большие участки ДНК со следующими один за другим микросателлитами.
Если такое нарастание происходит в некоторых пределах, то в целом ситуация остается под контролем. Если же они превышены (к этому располагает наследственность), никто и ничто уже не сможет удержать микросателлиты. Происходит так называемая экспансия: единицы микросателлитов повторяются сотни и тысячи раз подряд, а обладатель соответствующего генома приобретает серьезное, обычно неизлечимое и быстро прогрессирующее заболевание. Это может быть и болезнь Хантингтона — неуклонно прогрессирующее заболевание мозга, прославившееся вместе с Тринадцатой из сериала «Доктор Хаус», и синдром хрупкой Х-хромосомы.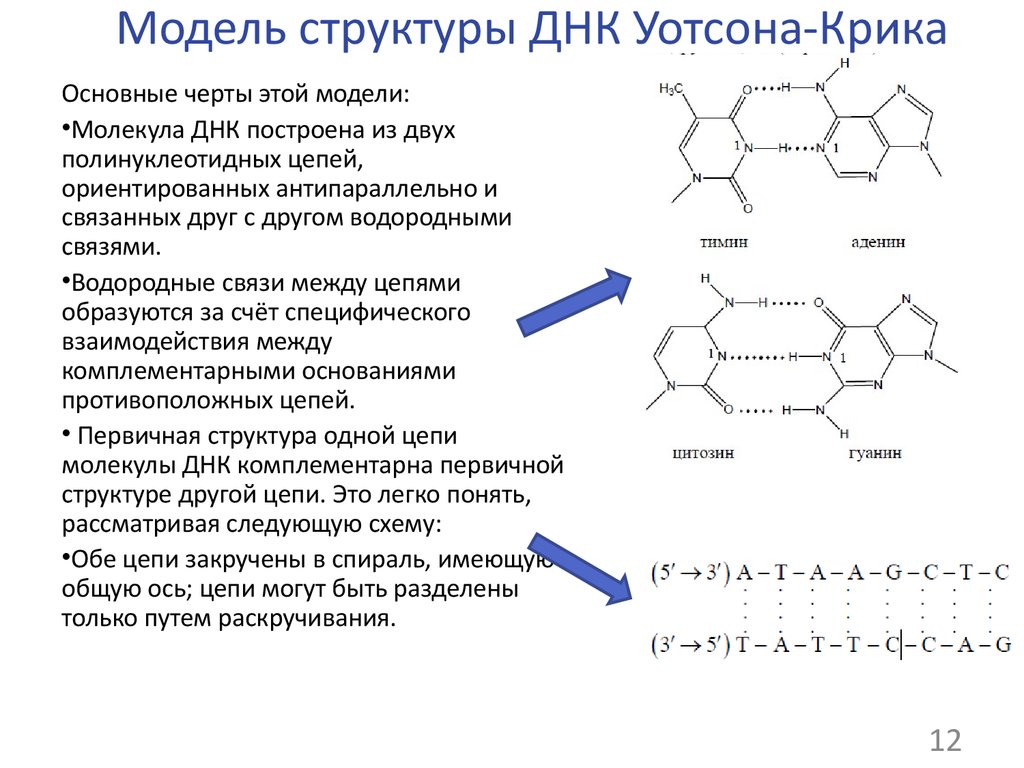 Хрупкой оказывается как раз область микросателлитов, причем хрупкой настолько, что часть этой хромосомы может просто… отвалиться.
Хрупкой оказывается как раз область микросателлитов, причем хрупкой настолько, что часть этой хромосомы может просто… отвалиться.
Геном Homo sapiens — это текст из 3 миллиардов букв, который очень далек от порядка и предсказуемости. Наш геном — это разнообразие, хаос, повторы и… своеобразная эволюционная разумность. И неожиданные сюжетные повороты. Почти как в стихотворении Хармса об устройстве человека:
А, впрочем, не рук пятнадцать штук,
пятнадцать штук,
пятнадцать штук.
Хэу-ля-ля,
дрюм-дрюм-ту-ту!
Пятнадцать штук, да не рук.
Как была расшифрована ДНК | Forbes.ru
Создатель метода чтения ДНК стал единственным ученым, дважды получившим Нобелевскую премию по химии
В первые два десятилетия после того, как Уотсон и Крик открыли двойную спираль ДНК, человечеству удалось очень многое понять о молекулярной природе жизни. Была сформулирована знаменитая «центральная догма», согласно которой генетическая информация в клетке передается только в одном направлении: от ДНК к белку.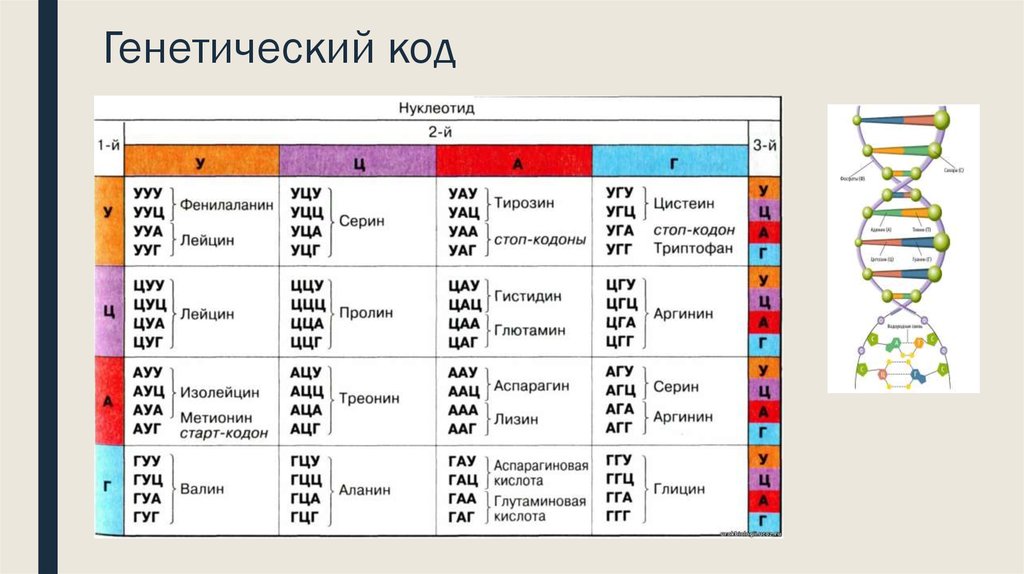 Был полностью расшифрован генетический код, который позволяет клетке переводить тексты нуклеиновых кислот в тексты белков, то есть последовательность нуклеотидов в ДНК и РНК — в последовательность аминокислотных остатков в белках. Все это были огромные достижения.
Был полностью расшифрован генетический код, который позволяет клетке переводить тексты нуклеиновых кислот в тексты белков, то есть последовательность нуклеотидов в ДНК и РНК — в последовательность аминокислотных остатков в белках. Все это были огромные достижения.
Проблема, однако, состояла в том, что, хотя молекулярные биологи все время рассуждали про эти тексты, самих текстов никто не знал. Не было способа расшифровать гены. Или, иными словами, не было метода определения последовательности нуклеотидов в ДНК.
К тому времени это уже умели делать для белков — метод чтения их последовательности был разработан в начале 1950-х годов, еще до открытия двойной спирали. Кроме того, ученые уже немного умели читать короткие последовательности РНК. А вот последовательности ДНК не умели читать вообще. Это создавало колоссальную брешь в реальном понимании молекулярных основ жизни и сдерживало как развитие биотехнологий, которых, собственно говоря, еще не было, так и медицинского применения этих знаний.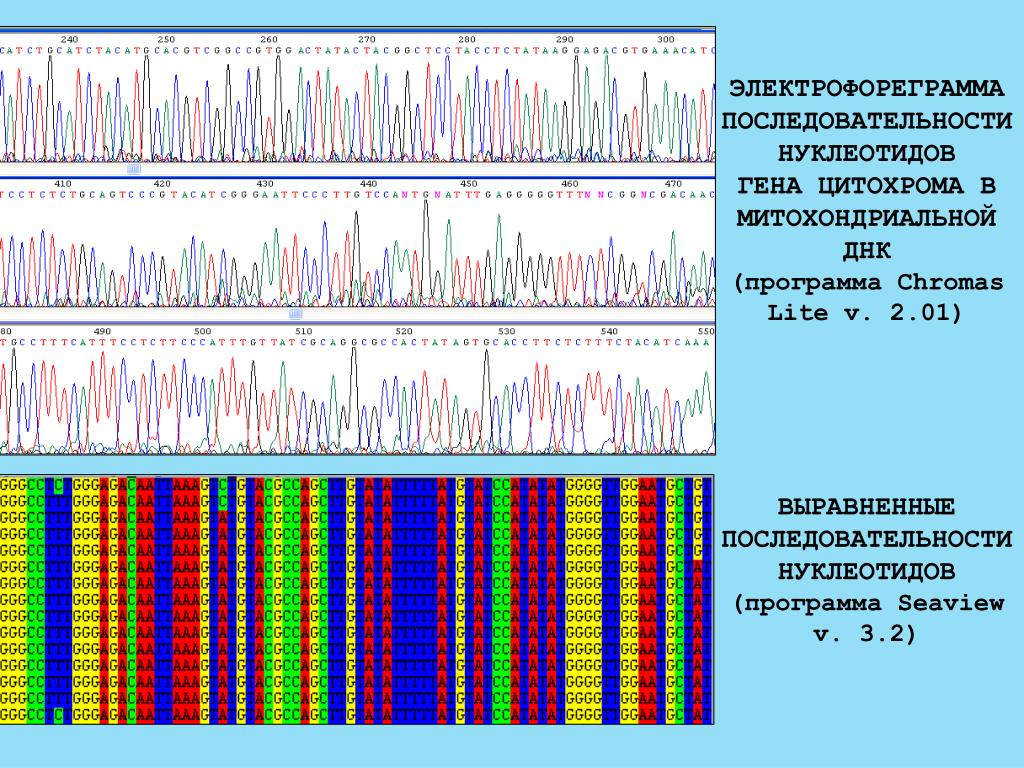
Стало даже казаться, что это слишком сложная задача и ее не удастся решить — все попытки оказывались безуспешными.
Но вот в середине 70-х годов XX века произошел прорыв. Метод определения последовательности ДНК был разработан британским ученым-химиком Фредериком Сенгером.
Сенгер — великий человек. Он единственный в истории науки, кто получил две Нобелевские премии по химии. Нобель запретил давать два раза одному и тому же человеку премию в одной и той же области. А Сенгер к тому времени уже получил премию как раз за разработку метода чтения аминокислотных последовательностей в белках. И когда он разработал метод чтения последовательности ДНК, Нобелевский комитет оказался в очень трудном положении: он должен был либо не дать человеку премию за выдающееся открытие, либо нарушить завещание Нобеля. Решили все-таки нарушить завещание. И это единственный случай в области химии.
Как теперь читают последовательности ДНК? С тех пор в этом направлении был сделан огромный прогресс, и он основан на прорыве Сенгера. Последовательность ДНК — это колоссальной длины текст, написанный с помощью всего четырех «букв» — четырех химических соединений: аденина (А), тимина (Т), гуанина (G) и цитозина (С). У нас в каждой клетке имеется геном, который состоит из трех миллиардов нуклеотидов, трех миллиардов таких «букв».
Последовательность ДНК — это колоссальной длины текст, написанный с помощью всего четырех «букв» — четырех химических соединений: аденина (А), тимина (Т), гуанина (G) и цитозина (С). У нас в каждой клетке имеется геном, который состоит из трех миллиардов нуклеотидов, трех миллиардов таких «букв».
Как этот текст прочитать?
Прежде всего, ДНК разрезают на фрагменты с помощью специальных ферментов, которые называются рестриктазы. Рестриктазы узнают короткие последовательности ДНК, содержащие приблизительно от 6 до 8 нуклеотидов, и только в этом месте определенным образом разрезают двойную спираль ДНК. Открытие таких «ножниц» стало еще одним прорывом начала 1970-х годов.
После разрезания ДНК задача сводится к тому, чтобы определить последовательность короткого куска — он может содержать сотню или несколько сотен звеньев. И здесь используется метод Сенгера.
К полученному фрагменту молекулы добавляются с обоих концов специальные адаптеры, потому что рестриктаза оставляет неровные концы. Адаптер имеет определенную последовательность, которую выбираем мы сами, так как он синтетический. После добавления адаптера каждый фрагмент получит определенные — известные нам — последовательности на концах. Эти последовательности мы сможем использовать для того, чтобы добавить к фрагменту молекулы синтетические праймеры (фрагменты нуклеиновой кислоты), начиная с которых по имеющейся последовательности ДНК будет синтезироваться комплементарная цепочка.
Адаптер имеет определенную последовательность, которую выбираем мы сами, так как он синтетический. После добавления адаптера каждый фрагмент получит определенные — известные нам — последовательности на концах. Эти последовательности мы сможем использовать для того, чтобы добавить к фрагменту молекулы синтетические праймеры (фрагменты нуклеиновой кислоты), начиная с которых по имеющейся последовательности ДНК будет синтезироваться комплементарная цепочка.
Идея Сенгера состояла в том, что в процессе такого синтеза нужно добавить к смеси нормальных предшественников нуклеотидов, называющихся нуклеозидтрифосфатами, специально модифицированные нуклеозидтрифосфаты, которые не смогут удлиняться.
В результате синтез останавливается на месте той или иной «буквы». Тем самым мы получаем молекулы с набором длин, который точно говорит нам, в каком месте встроена та или иная «буква». И тогда остается только разделить эти молекулы по длине, что делается при помощи гель-электрофореза.
Готовится специальный гель, то есть полимерная сетка, к которому прикладывается постоянное электрическое поле. Под действием электрического поля отрицательно заряженные молекулы ДНК ползут через полимерную сетку. И чем длиннее молекула, тем медленнее она движется в геле. Это позволяет разделять смесь молекул согласно их длинам, и там, где стоит тот нуклеотид, который мы в данный момент изучаем, мы будем видеть остановку синтеза, то есть длины фрагментов, когда мы будем разделять их по длине, соответствующие номеру этих нуклеотидов.
И таким образом мы можем прочитать всю последовательность.
Этот замечательный, гениальный метод, благодаря которому мы смогли секвенировать человеческий геном, и был придуман Сенгером. Первый геном человека был прочитан в самом начале нашего века. Тогда это обошлось в сумму порядка трех миллиардов долларов. Затем метод был модифицирован, роботизирован и сегодня процедура определения последовательности стоит несравненно меньше.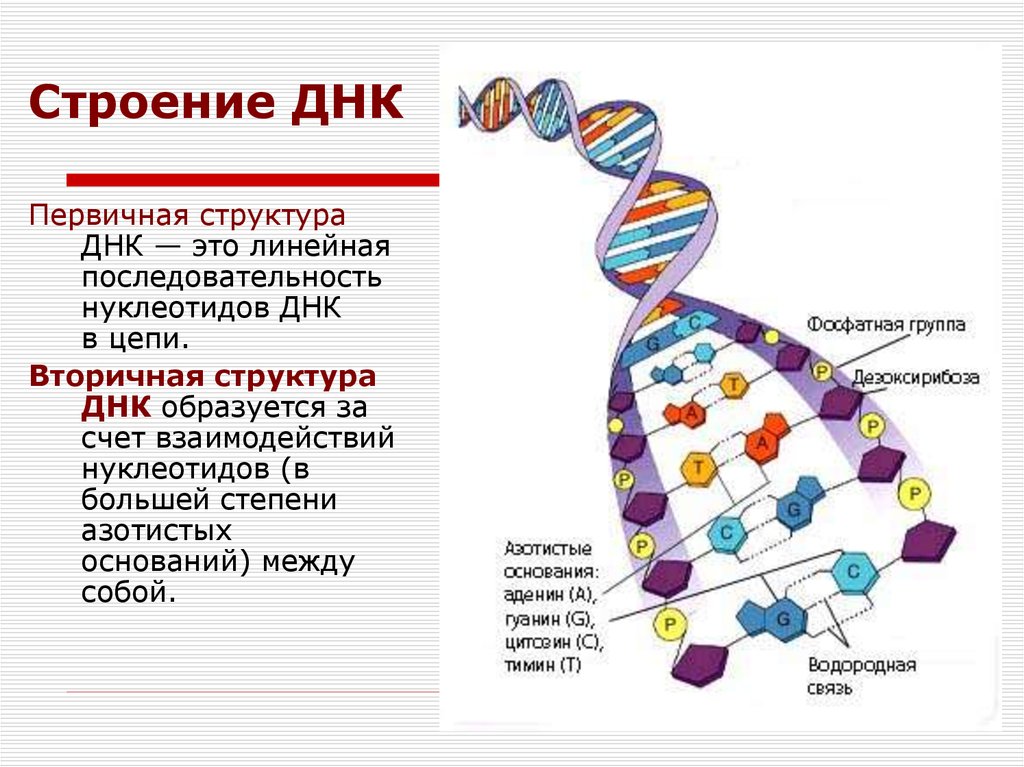 Цена приближается к $1000 за расшифровку ДНК конкретного человека.
Цена приближается к $1000 за расшифровку ДНК конкретного человека.
Совершенно фантастическое развитие методов секвенирования ДНК создало неимоверный прогресс и в области понимания молекулярной природы жизни, и в области биотехнологического и медицинского применения.
Что такое ДНК человека | Как расшифровывают результаты ДНК-анализа
ДНК – что это такое простыми словами и как она устроена? Физически это макромолекула, которая не только хранит в себе наследственную информацию, но и является подробной инструкцией по развитию всего организма условно из одной универсальной клетки.
Если сравнить человека с компьютером, а все многообразие биологической жизни – с различными формами роботизированных компьютеров, ДНК в этом сравнении будет биологическим языком программирования. С той лишь разницей, что биологические виды устроены намного сложнее и совершеннее самых передовых компьютеров.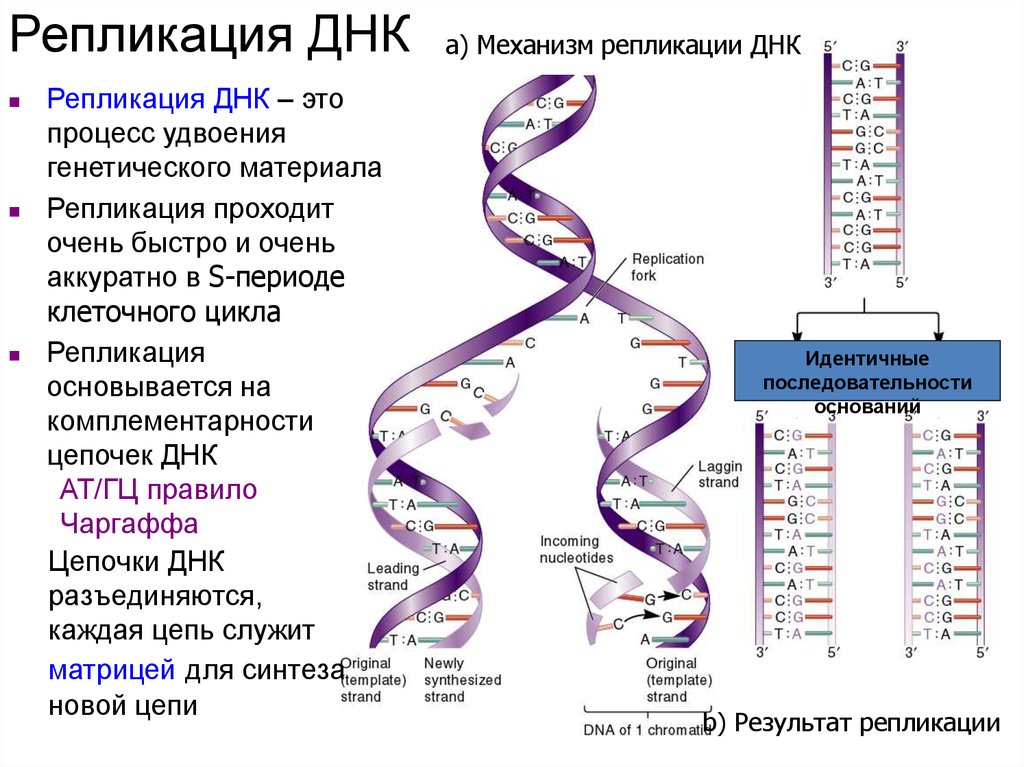
К примеру, все биологические виды обладают уникальной способностью деления и преобразования клетки. Фактически в ходе самовоспроизводства клетки биомасса не только материализуется сама из себя, но и физически преобразовывается под решение множества узкоспециализированных задач. А все многообразие живых видов, их форм, уникальных способностей исходит из деления одной универсальной клетки. Одно это уже уходит далеко за грань всех современных генетических достижений.
История открытия
Фактически открытие дезоксирибонуклеиновой кислоты произошло дважды. Первым открытие молекулы совершил Иоганн Фридрих Мишер в 1869 году. Будучи швейцарским биологом и физиологом, он из клеток, содержащихся в гное, смог выделить большую молекулу с высоким содержанием азота и фосфора. Свое открытие он назвал нуклеин, а позже – нуклеиновой кислотой, когда были открыты ее кислотные свойства.
Свое открытие он назвал нуклеин, а позже – нуклеиновой кислотой, когда были открыты ее кислотные свойства.
Первоначально ученые считали, что основная функция нуклеиновой кислоты состоит в хранении фосфора. А предположения, что она может содержать в себе наследственную информацию, вызывали насмешки, поскольку структура молекулы казалась им слишком простой и однообразной для таких функций. Также считалось, что наличие дезоксирибонуклеиновой кислоты свойственно только животным клеткам, а в растениях содержится только РНК. Но в 1934–1935 годах советские ученые-биологи А. Н. Белозерский и А. Р. Кизель это наглядно опровергли и опубликовали результаты своих работ в советских и мировых научных журналах.
Повторное открытие ДНК уже в качестве носителя наследственной информации и не только было совершено в 1944 году. Группа исследователей, состоящая из Освальда Эвери, Колина Маклауда и Маклина Маккарти, проводила эксперименты с трансформацией бактерий и доказала, что основную роль в этом процессе играет дезоксирибонуклеиновая кислота.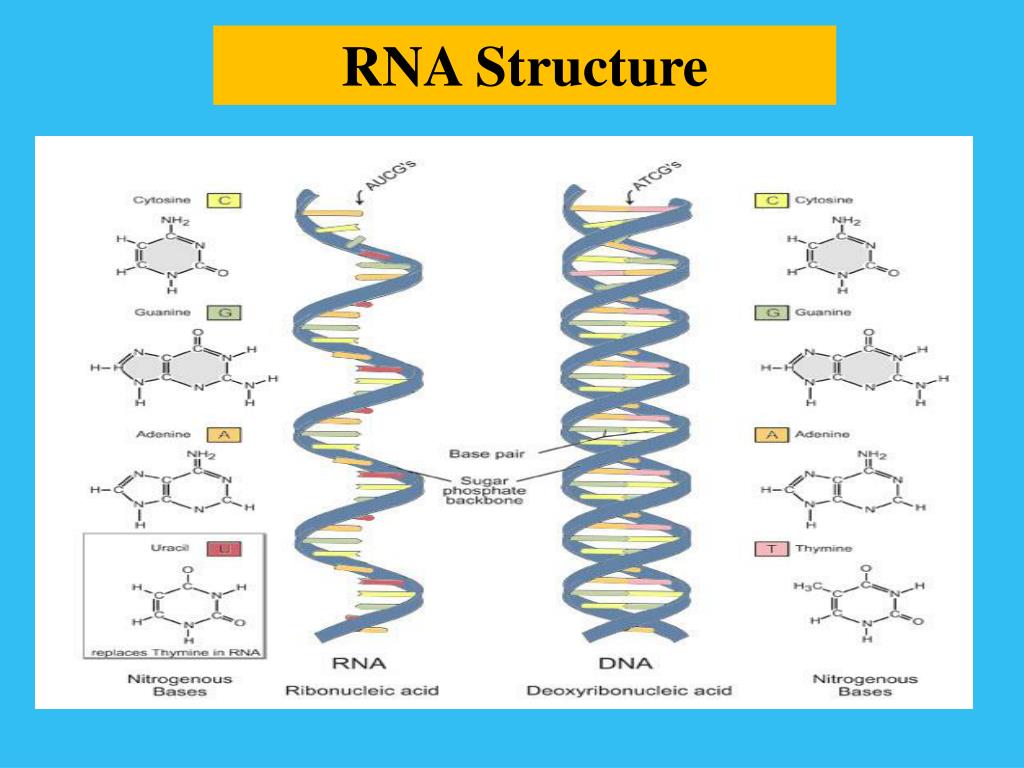
Значение ДНК в медицине
Открытие ДНК в медицине, расшифровка этой кислоты – это события, значение которых трудно преувеличить. Большая часть современных прорывных технологий и исследований прямо или косвенно базируется на этом фундаментальном для науки открытии. Не знай мы про гены, не было бы многих современных методов лечения и диагностики, многих технических изобретений. По сути, не было бы и генетики как полноценной самостоятельной науки. Застопорилось бы изучение клетки и того, как она функционирует. А без этих знаний и множество открытий в этой области было бы невозможно.
На сегодняшний день знания о генах помогают многим людям:
- Узнать о заболевании намного раньше наступления первых симптомов. Лечение на сверхранней стадии всегда более успешно.
- Узнать свою генетику просто – для этого достаточно сделать ДНК-анализ. С помощью него вы можете понять, к каким заболеваниям у вас есть предрасположенность, или, например, как вам стоит питаться, какие витамины просто необходимо включить в рацион, а какие вещества, наоборот, нужно ограничить, и даже определить, каким видом спорта вам стоит заниматься
- Найти своих близких и родных.
 Узнать много подробностей о своем роде
Узнать много подробностей о своем роде - Благодаря открытию носителя наследственной информации у медицины появился шанс побороть наследственные заболевания, которые ранее казались неизлечимыми
- Вполне возможно, что именно благодаря этому открытию человечество решит задачу многих тысячелетий и найдет эликсир бессмертия или таблетку от всех болезней.
 Узнать много подробностей о своем роде
Узнать много подробностей о своем роде
Молекула ДНК
ДНК-определение, поиск ее места в уже систематизированном знании не так прост. По существу, к молекулам ДНК отнесли условно, для удобства. Молекула ДНК – это структура, превосходящая размером обычные молекулы. И она имеет уникальную спиральную структуру. В то время как физики и химики считают молекулами электрически нейтральные частицы, состоящие из одного и более атомов, связанных ковалентными связями. Либо же, по результатам международного съезда химиков 1860 года, молекулой считается наименьшая частица вещества, обладающая всеми его химическими свойствами.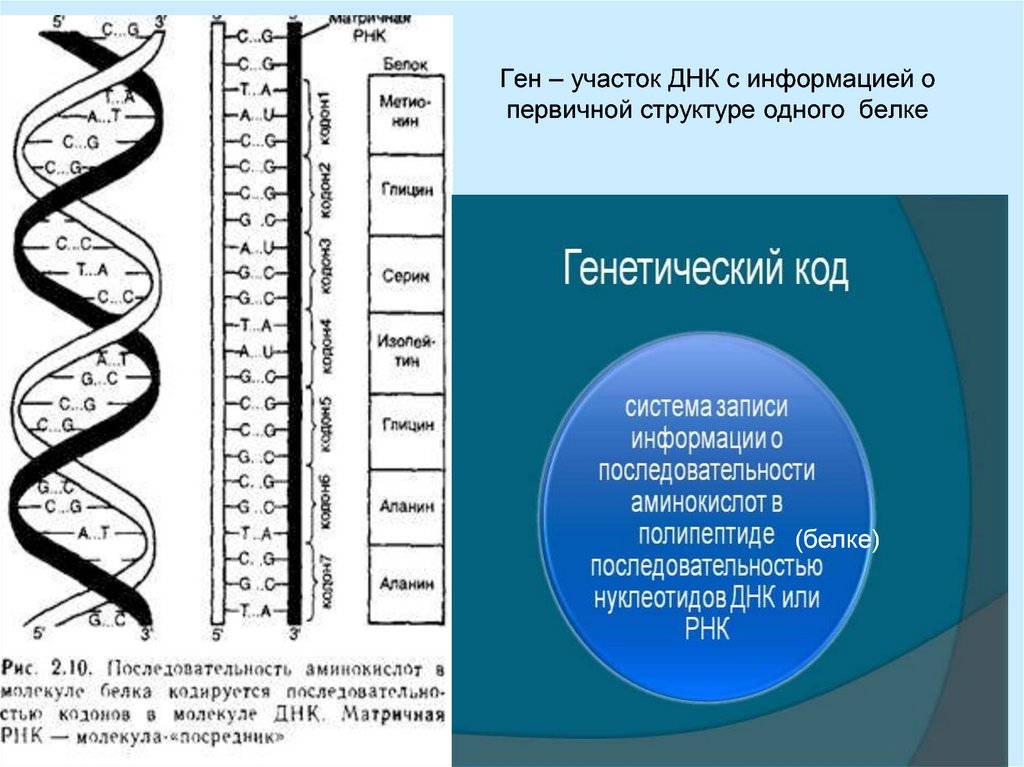
Структура ДНК
У всех на слуху, что дезоксирибонуклеиновая кислота имеет двуспиральную структуру. В интернете, в фильмах, в рекламе – всюду можно встретить ее многократно увеличенное изображение. Но что ответить, если попросят объяснить подробнее. Это уже более сложный вопрос. Давайте разберемся лучше, из чего эта структура состоит:
- Нуклеотиды – базовые структурные элементы.
- Две цепочки генов, закрученные в спираль.
- Каждая цепочка состоит из нуклеотидов, которые кодируют определенный ген.
- Связывают две цепочки воедино водородные связи.
В цепочках нуклеотидов присутствуют и совсем не изученные структуры, которые, на первый взгляд, никак не участвуют в физиологических процессах. Эти довольно обширные участки называют мусорными.
Состав ДНК
Если говорить о составе ДНК более подробно, то нуклеотиды – это базовый структурный элемент, кирпичики, из которых состоят обе цепи спирали.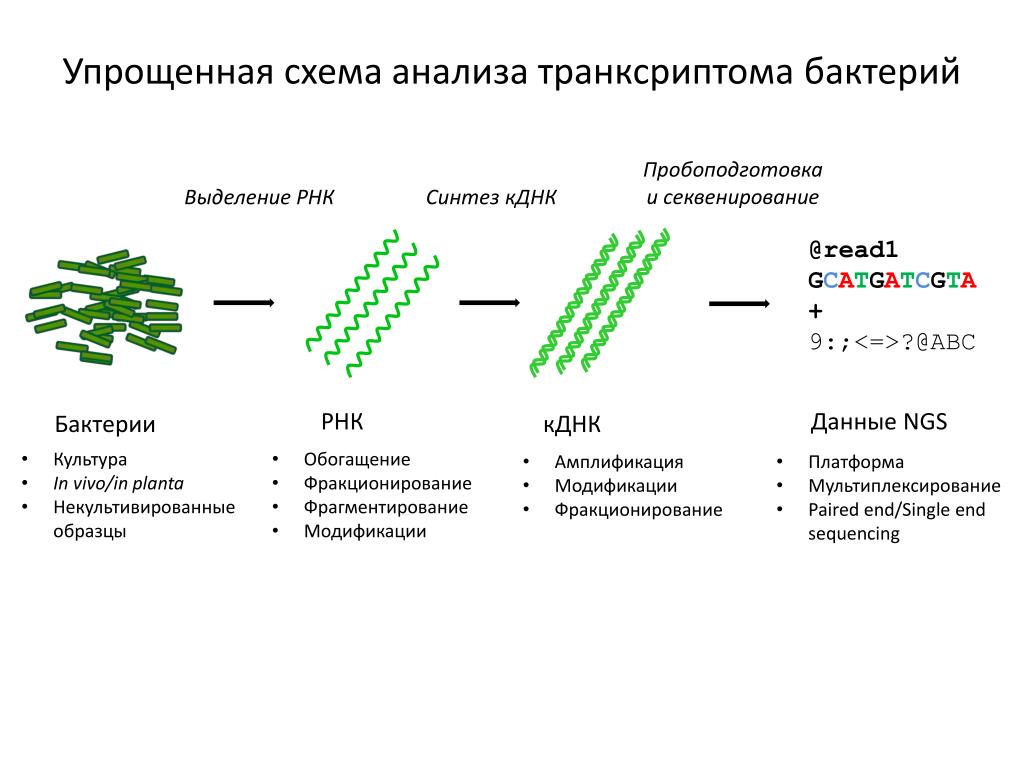 Нуклеотиды подразделяются на 4 разновидности: аденин, тимин, гуанин и цитозин. И всего четыре этих нуклеотида осуществляют запись всей наследственной информации и составляют все известные гены.
Нуклеотиды подразделяются на 4 разновидности: аденин, тимин, гуанин и цитозин. И всего четыре этих нуклеотида осуществляют запись всей наследственной информации и составляют все известные гены.
Закручиваются в спираль обе цепочки генов тоже не просто так. Из всех четырех различных нуклеотидов находиться напротив друг друга в разных цепочках они могут только двумя парами: аденин-тимин и гуанин-цитозин. В науке эти пары называются комплементарными.
Между парными нуклеотидами возникает крепкая водородная связь. При этом связь аденином и тимином немного слабее, чем между гуанином и цитозином. Но закручиваются цепочки в спираль по иным причинам:
-
Исследования показали, что скручивание помогает сократить длину цепочки генов в 5-6 раз. А во время суперспирализации (такое тоже бывает) длина цепочки может сократиться в целых 30 раз! -
Помимо того, что пара цепочек генов закручена в спираль, существует и суперспирализация. За это явление отвечают гистоновые белки, которые имеют форму катушек для ниток. Уже закрученная двойная спираль наматывается на эти белки, как нитка. Что не оставляет сомнений в том, что спиральность как таковая специально служит тому, чтобы более компактно упаковать наследственную информацию в клетку.
 За это явление отвечают гистоновые белки, которые имеют форму катушек для ниток. Уже закрученная двойная спираль наматывается на эти белки, как нитка. Что не оставляет сомнений в том, что спиральность как таковая специально служит тому, чтобы более компактно упаковать наследственную информацию в клетку.
За это явление отвечают гистоновые белки, которые имеют форму катушек для ниток. Уже закрученная двойная спираль наматывается на эти белки, как нитка. Что не оставляет сомнений в том, что спиральность как таковая специально служит тому, чтобы более компактно упаковать наследственную информацию в клетку.
Роль в клетке
Конечно, одна, даже большая двойная спираль не способна вместить в себя весь объем информации, необходимый для такого сложного проекта, как человеческое тело. Возможно, поэтому эти цепочки объединены в пары, что делает их похожими на букву «Х». Хромосомы, в свою очередь, тоже парные, и их у человека 46 пар.
Помимо того, что хромосома содержит в себе подробную инструкцию по функционированию клетки, она же путем активации актуальных моменту генов провоцирует клетку вырабатывать определенные белки с самыми различными свойствами. Например, в борьбе с опухолями активно участвует ген старости, который старит ее недоброкачественные клетки и не дает им бесконечно делиться.
Что такое нуклеотиды
Нуклеотиды – это четыре элемента, которые являются основой биоязыка программирования цепи ДНК, так же, как ноль и единица являются основой ассемблера (первого из языков программирования). Уникальная последовательность нуклеотидов в одной из двух цепочек ДНК является геном. Если хотя бы немного изменить эту последовательность, то ген уже будет поврежден или разрушен.
Синтез белка
Синтез белков – это ключевое таинство всей физиологии человека. Именно белки запускают и контролируют все процессы в организме на клеточном уровне. Если полностью изучить, какие гены и группы генов в каких случаях запускают синтез белков и сами эти белки, то наука научится полностью настраивать и перенастраивать весь человеческий организм.
На сегодняшний день нам известно, что, реагируя на различные раздражители, в двойной спирали дезоксирибонуклеиновой кислоты активируются гены или участки с генами. Информация с этих участков копируется на РНК (рибонуклеиновая кислота), и уже РНК переносит информацию из ядра клетки, в котором находятся хромосомы, в саму клетку. РНК выступает своего рода глашатаем, который читает указ всем работникам. Так РНК заставляет клетку вести себя тем либо иным образом и вырабатывать различные белки.
Информация с этих участков копируется на РНК (рибонуклеиновая кислота), и уже РНК переносит информацию из ядра клетки, в котором находятся хромосомы, в саму клетку. РНК выступает своего рода глашатаем, который читает указ всем работникам. Так РНК заставляет клетку вести себя тем либо иным образом и вырабатывать различные белки.
Что такое РНК
Если ДНК – это кабинет министров, которые всем управляют и принимают все решения, то РНК – это пресс-атташе. Она извещает всех о новых распоряжениях и указах и раздает инструкции на местах.
РНК – это рибонуклеиновая кислота, которая может копировать формы различных участков дезоксирибонуклеиновой кислоты и транспортировать их из ядра клетки в ее внутриклеточное пространство.
Расшифровка ДНК
ДНК-расшифровка стала возможна только благодаря открытию полимеразной цепной реакции, и происходит она следующим образом:
Проба, содержащая образцы дезоксирибонуклеиновой кислоты, быстро нагревается. Это необходимо, чтобы двойная спираль раскрутилась и распалась на две самостоятельные нити.
Это необходимо, чтобы двойная спираль раскрутилась и распалась на две самостоятельные нити.
-
К интересующему исследователей участку цепи генов прилепляется полимераза. Эта процедура происходит при немного более низких температурах. -
Полимераза активирует деление пойманного участка – так происходит синтез необходимых для изучения участков генов. -
Участки пропитываются специальной краской, которая светится при воздействии направленного пучка лазера. Так получают картину гена, которую можно изучать и расшифровывать.
Таким образом, изучение ДНК стало доступным инструментом, который позволяет людям узнать о себе много нового и может помочь сохранить здоровье, избавиться от уже имеющихся заболеваний, похудеть, сохранить молодость и улучшить качество своей жизни!
Как ученые расшифровывают геномы и зачем это нужно? Отвечаем в 9 карточках
Как ученые расшифровывают геномы и зачем это нужно? Отвечаем в 9 карточках | SCAMT
В последние годы ученые постоянно объявляют о расшифровке геномов тех или иных видов. ITMO.NEWS и ученый Международного научного центра SCAMT Алексей Комиссаров в карточках объясняют: что такое ДНК, как с ее помощью изучают историю животных и в чем отличие ДНК-теста от геномного исследования.
ITMO.NEWS и ученый Международного научного центра SCAMT Алексей Комиссаров в карточках объясняют: что такое ДНК, как с ее помощью изучают историю животных и в чем отличие ДНК-теста от геномного исследования.
Иллюстрации: Дмитрий Лисовский, ITMO.NEWS
Каждый более или менее знает, что есть белки, жиры и углеводы. Но еще у нас в каждой клетке есть ДНК, дезоксирибонуклеиновые кислоты, которые отвечают за хранение информации. Для геномного биоинформатика ДНК ― это прежде всего один из главных языков биологии, который состоит всего лишь из четырех букв: A, T, G и C. Эти буквы являются сокращениями имен четырех азотистых оснований, из которых состоит ДНК: аденин (А), цитозин (C), гуанин (G) и тимин (Т). ДНК можно сравнить с компьютерной программой, очень сложной, запутанной, со множеством ошибок и костылей, но, тем не менее, она работает.
ДНК содержится почти во всех клетках организма, исключение — эритроциты, которые в зрелом состоянии теряют ядро, чтобы было легче переносить кислород.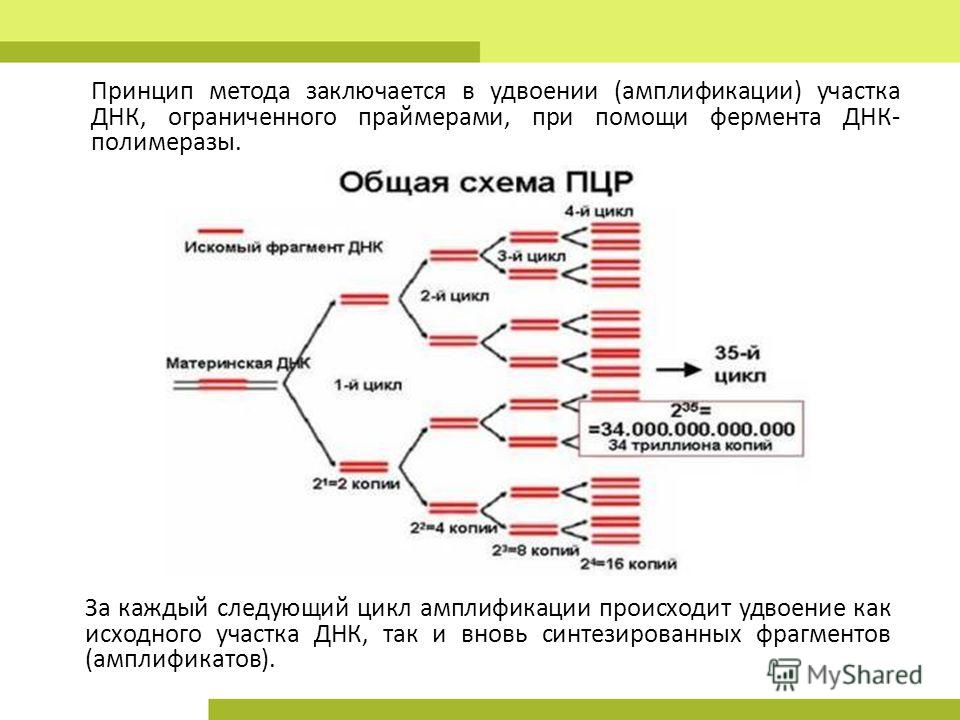 Поэтому биологический материал для выделения ДНК может быть разнообразен. Процесс выделения ДНК состоит из четырех этапов: разрушение мембраны клеток для высвобождения ДНК; очистка от связанных с ДНК белков; очистка от разного рода примесей; растворение ДНК для хранения. ДНК можно выделить и в домашних условиях, но тогда ДНК будет не очень чистой и ее будет сложно использовать для каких-либо научных исследований. От качества этих процедур будет зависеть и полученная из нее информация. Поэтому необходима лабораторная точность работы специалистов, молекулярных биологов. Проще всего ДНК выделять из крови, потому что это легкий для получения биоматериал. Хотя в эритроцитах ДНК нет, в крови плавает огромное количество других клеток — белых кровяных телец, так что и ДНК из них получается много. Из слюны или кусочков эпителия во рту ― уже меньше, из волос ― еще меньше. Например, чтобы прочитать весь геном достаточно точно, необходима кровь, а не слюна.
Поэтому биологический материал для выделения ДНК может быть разнообразен. Процесс выделения ДНК состоит из четырех этапов: разрушение мембраны клеток для высвобождения ДНК; очистка от связанных с ДНК белков; очистка от разного рода примесей; растворение ДНК для хранения. ДНК можно выделить и в домашних условиях, но тогда ДНК будет не очень чистой и ее будет сложно использовать для каких-либо научных исследований. От качества этих процедур будет зависеть и полученная из нее информация. Поэтому необходима лабораторная точность работы специалистов, молекулярных биологов. Проще всего ДНК выделять из крови, потому что это легкий для получения биоматериал. Хотя в эритроцитах ДНК нет, в крови плавает огромное количество других клеток — белых кровяных телец, так что и ДНК из них получается много. Из слюны или кусочков эпителия во рту ― уже меньше, из волос ― еще меньше. Например, чтобы прочитать весь геном достаточно точно, необходима кровь, а не слюна. А для того, чтобы сделать какой-нибудь ДНК-тест, где точность не очень важна ― достаточно и слюны.
А для того, чтобы сделать какой-нибудь ДНК-тест, где точность не очень важна ― достаточно и слюны.
ДНК — это название молекулы, которая хранит наследственную информацию. Геном ― это совокупность всей ДНК организма со всеми записанными в ней особенностями конкретного вида или даже индивида. Поэтому можно говорить о геноме человека вообще, а можно — о геноме конкретных Васи или Кати. На физическом уровне геном разделен на хромосомы, в случае человека — 23 пары хромосом, 23 от мамы, и 23 от папы, всего 46. Когда организм начинает расти после оплодотворения, в каждой клетке копируется этот набор, но иногда это происходит с небольшими ошибками. Это называется соматическими мутациями. Иногда эти ошибки могут быть весьма критическими и приводить к разным заболеваниям.
Его никто не зашифровывал, но это слово хорошо передает ощущения от работы с геномными данными. Если продолжать аналогию с геномом как с очень сложной программой, можно сказать, что она не только очень сложная, но и очень плохо написана. И кроме собственно четырех букв A, C, G и Т, он содержит много дополнительных уровней кодирования информации, которые не обязательно будут наследоваться и могут меняться в процессе жизни организма. Это часто называют эпигеномом, который изучает эпигенетика. Вся эта неимоверная сложность и создает ощущение расшифровки. Помимо этого, злую шутку здесь сыграл не очень корректный перевод с английского, где использовали слово decoding и encoding, декодировали и закодировали. Код — это просто система условных обозначений, не предполагающая никакого секрета, никакой защиты от взлома. Любой человеческий язык — это код, система дорожных знаков — это код. Шифр — это код, намеренно защищенный от взлома. Но, конечно, в английских терминах меньше романтики, чем в слове расшифровали.
И кроме собственно четырех букв A, C, G и Т, он содержит много дополнительных уровней кодирования информации, которые не обязательно будут наследоваться и могут меняться в процессе жизни организма. Это часто называют эпигеномом, который изучает эпигенетика. Вся эта неимоверная сложность и создает ощущение расшифровки. Помимо этого, злую шутку здесь сыграл не очень корректный перевод с английского, где использовали слово decoding и encoding, декодировали и закодировали. Код — это просто система условных обозначений, не предполагающая никакого секрета, никакой защиты от взлома. Любой человеческий язык — это код, система дорожных знаков — это код. Шифр — это код, намеренно защищенный от взлома. Но, конечно, в английских терминах меньше романтики, чем в слове расшифровали.
Под ДНК-тестом часто имеют в виду анализ только некоторых небольших участков генома, вариации в которых имеют какой-то известный эффект. В геномных исследованиях ученые работают с гораздо большим количеством ДНК, в идеале со всей доступной информацией.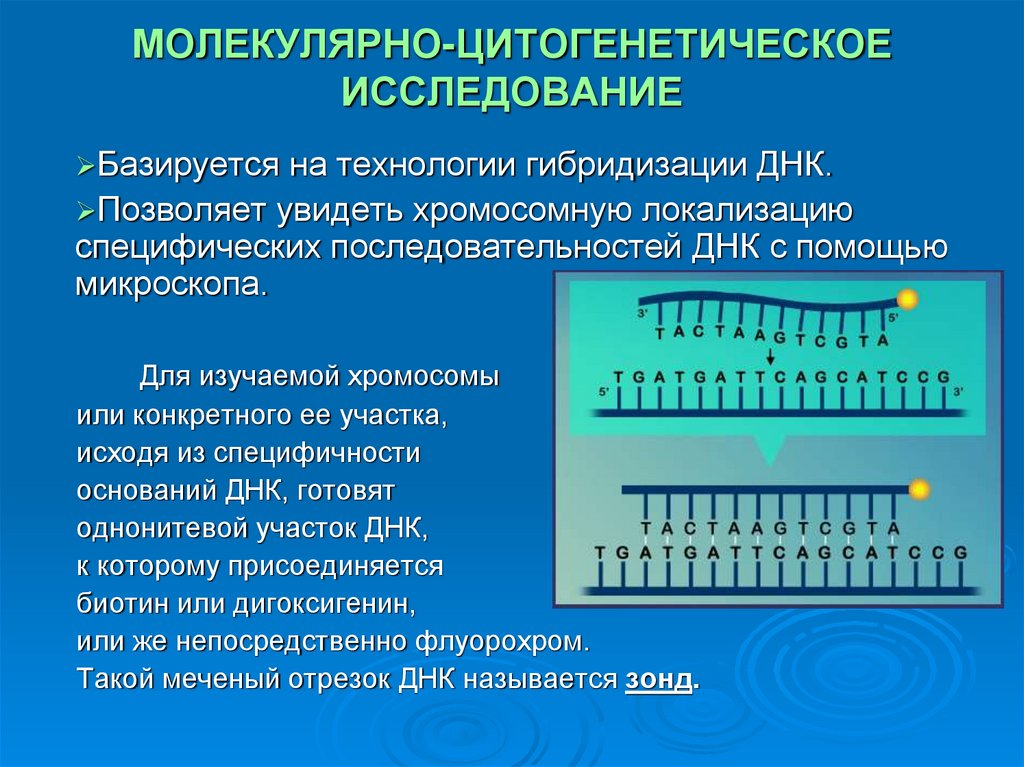 Это называется полногеномными исследованиями. Но даже генетических тестов, направленных на выяснения значения только некоторых фрагментов генома, часто достаточно для того, чтобы проследить генетическую историю или оценить степень родства между двумя людьми. Это возможно, во-первых, благодаря тому, что у нас в геноме есть фрагменты, которые очень вариабельны и отличаются у разных людей, и, во-вторых, благодаря математике.
Это называется полногеномными исследованиями. Но даже генетических тестов, направленных на выяснения значения только некоторых фрагментов генома, часто достаточно для того, чтобы проследить генетическую историю или оценить степень родства между двумя людьми. Это возможно, во-первых, благодаря тому, что у нас в геноме есть фрагменты, которые очень вариабельны и отличаются у разных людей, и, во-вторых, благодаря математике.
Есть очень сложные математические алгоритмы, которые позволяют по генетическим данным найти наиболее вероятный сценария развития событий: когда происходили мутации отдельных фрагментов, которые привели к образованию того генома, который мы видим сейчас. Своего рода, математическая машина времени. Ученые ИТМО недавно опубликовали программу, направленную как раз на решение проблемы — как наиболее точно заглянуть в прошлое генома. Одним из самых захватывающих расширений этого подхода является добавление еще и географических точек.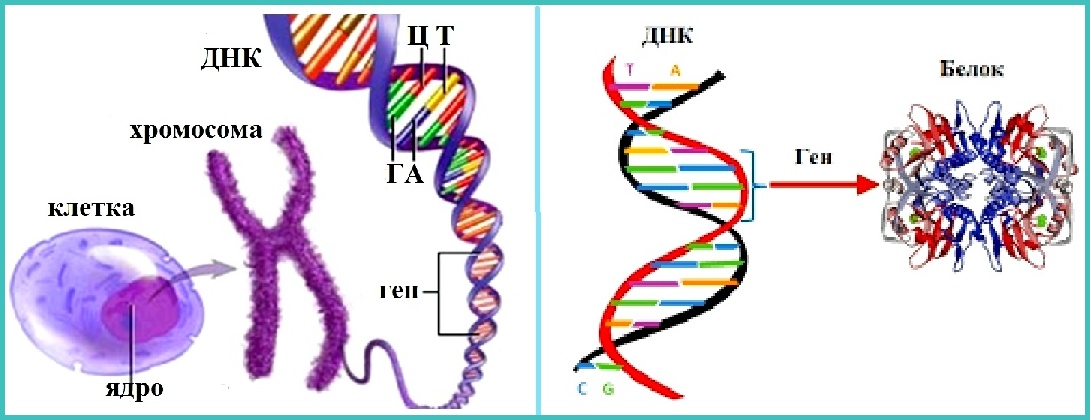 Тогда мы можем не только смоделировать, как происходили изменения в геноме, ни и посмотреть, как отдельные популяции с этими геномными вариациями перемещались из одной точки в другую.
Тогда мы можем не только смоделировать, как происходили изменения в геноме, ни и посмотреть, как отдельные популяции с этими геномными вариациями перемещались из одной точки в другую.
Мы стараемся получить модель, которая наиболее правдоподобно описывает сценарий развития событий в прошлом. Чтобы сделать модель более точной, одного образца часто недостаточно, и чем больше образцов у нас есть, тем более точной становится наша модель. У каждого из нас очень много редких генетических вариантов, бывают и варианты, которые присущи только нам. И если у нас есть уже несколько образов, то такие индивидуальные варианты ученые отфильтровывают именно затем, чтобы они не мешали анализу. Так как единицей эволюции является популяция, а не отдельный индивид.
Хорошие модели обладают предсказательной способностью. Проверить проще всего новыми данными, которые не должны противоречить модели, но случается, что они противоречат, и тогда модель приходится пересчитывать.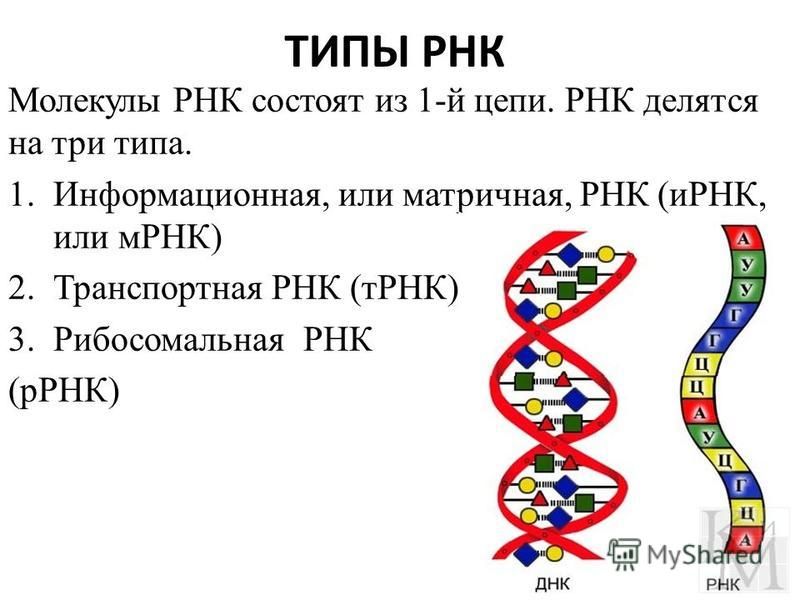 Сейчас мы наблюдаем очень красивую иллюстрацию мутаций, эволюции и вот этого всего на примере геномов коронавируса SARS-CoV-2. Настолько подробных данных об эволюции отдельного вида в реальном времени у человечества еще никогда не было. И появляется все больше данных и для остальных геномов. Со временем модели будут все лучше и лучше, а чем больше данных ― тем лучше модели.
Сейчас мы наблюдаем очень красивую иллюстрацию мутаций, эволюции и вот этого всего на примере геномов коронавируса SARS-CoV-2. Настолько подробных данных об эволюции отдельного вида в реальном времени у человечества еще никогда не было. И появляется все больше данных и для остальных геномов. Со временем модели будут все лучше и лучше, а чем больше данных ― тем лучше модели.
Кроме того, что это захватывающе любопытно, это имеет множество практических применений во всех сферах деятельности человека. Если продолжать рассуждать об исследовании истории предков, то есть математический аппарат для поиска так называемых событий бутылочного горлышка, когда размер популяции по каким-то причинам резко сократился. Поиск таких событий, своего рода, геномная археология, может дать нам подсказки, как таких событий избежать. Это важно особенно сейчас, когда многие виды животных бесследно исчезают с лица земли.
(источник https://news. itmo.ru/ru/science/life_science/news/9915/ )
itmo.ru/ru/science/life_science/news/9915/ )
Антропологи впервые смогли извлечь и расшифровать ядерную ДНК неандертальцев со дна пещеры
16 апреля, 2021 12:10
Источник:
Пресс-служба РНФ
Российские и зарубежные ученые впервые извлекли и расшифровали ядерную ДНК неандертальцев не из костей и зубов, а из грунта пещер, где древние люди обитали. То, что результаты такого подхода сопоставимы с получаемыми традиционным методом – крайне важный шаг для генетических исследований наших предков. Также коллективу, вероятно, удалось отследить момент, когда неандертальцы «классического» вида сменили своих предшественников 100 тысяч лет назад. Результаты работы, поддержанной грантом Российского научного фонда (РНФ), опубликованы в журнале Science.
Поделиться
Фотография с раскопок. Источник: Ксения Колобова
Источник: Ксения Колобова
Чагырская пещера. Источник: Ксения Колобова
Процесс отбора образцов для седиментационной ДНК. Источник: Ксения Колобова
Процесс раскопок. Источник: Ксения Колобова
Процесс отбора образцов для седиментационной ДНК. Источник: Ксения Колобова
3 / 4
Фотография с раскопок. Источник: Ксения Колобова
Чагырская пещера. Источник: Ксения Колобова
Процесс отбора образцов для седиментационной ДНК. Источник: Ксения Колобова
Процесс раскопок. Источник: Ксения Колобова
Процесс отбора образцов для седиментационной ДНК. Источник: Ксения Колобова
Исследование ДНК активно используется в изучении останков древних людей: именно расшифровка и анализ последовательности нуклеиновых кислот помогает специалистам понять, чей именно биологический материал они нашли, откуда человек, какими болезнями страдал и многое другое. Этим всем занимается довольно молодая и активно развивающаяся наука — палеогенетика.
Этим всем занимается довольно молодая и активно развивающаяся наука — палеогенетика.
В основном ДНК получают из костей и зубов, но такие находки — большая редкость. Это связано с тем, что в палеолите не было устоявшихся погребальных обычаев и захоронения делали за пределами стоянок и, кроме того, многие древние люди просто не возвращались с охоты. В случае костей и зубов чаще приходится работать с генетическим материалом митохондрий — энергетических станций клеток. Хотя в них копий ДНК намного больше, чем в ядре, и меньше «бессмысленных» фрагментов, получаемая информация очень ограничена: митохондрии наследуются от матери, и в них зашифровано не так много генов.
«Ядерная ДНК гораздо ценнее, но ее количество очень ограничено: даже имея фрагмент кости, не всегда удается извлечь достаточно материала. Однако мы с коллегами нашли решение этой проблемы. Во-первых, в качестве источника ядерной ДНК мы использовали артефакты с раскопок — камни, орудия труда — словом, все, что могло сохранить биологические следы древнего человека.
 Во-вторых, мы применили совершенно новый подход к обработке метагеномного материала, то есть всей ДНК с наших образцов. Поэтапно сравнивая расшифрованные последовательности нуклеиновых кислот с имеющимися в базе и концентрируясь на фрагментах, характерных только для человека, мы отделили материал неандертальцев от материала животных, таких как медведи, с которыми у нас очень много схожих генов. Важно знать, что ты изучаешь именно ДНК человека, а не какого-то неизвестного вида гиены», — рассказывает один из авторов работы Андрей Кривошапкин, руководитель проекта по гранту РНФ, доктор исторических наук, директор Института археологии и этнографии Сибирского отделения Российской академии наук.
Во-вторых, мы применили совершенно новый подход к обработке метагеномного материала, то есть всей ДНК с наших образцов. Поэтапно сравнивая расшифрованные последовательности нуклеиновых кислот с имеющимися в базе и концентрируясь на фрагментах, характерных только для человека, мы отделили материал неандертальцев от материала животных, таких как медведи, с которыми у нас очень много схожих генов. Важно знать, что ты изучаешь именно ДНК человека, а не какого-то неизвестного вида гиены», — рассказывает один из авторов работы Андрей Кривошапкин, руководитель проекта по гранту РНФ, доктор исторических наук, директор Института археологии и этнографии Сибирского отделения Российской академии наук.
Свой подход ученые применили к артефактам неандертальцев из трех пещер: Чагырской и Денисовской в Горном Алтае на юге Сибири и испанского грота в месте, называемом Атапуэрка. Сибирские стоянки оказались относительно богаты на кости древних людей, потому удалось сравнить результаты для ядерной ДНК из них и из отложений пещер.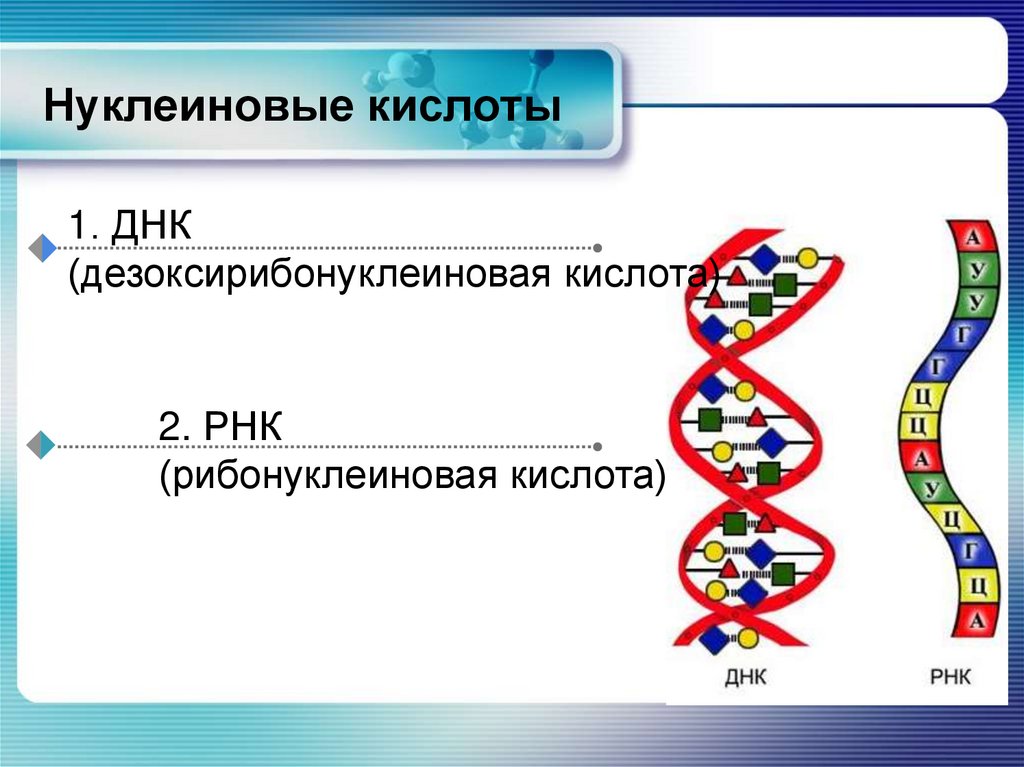 Как показал анализ, данные из двух этих источников согласуются между собой, а значит, даже не имея фрагментов скелета, действительно можно получать надежные результаты из осадков.
Как показал анализ, данные из двух этих источников согласуются между собой, а значит, даже не имея фрагментов скелета, действительно можно получать надежные результаты из осадков.
Еще одна интересная особенность обнаружилась при построении своего рода генетических «генеалогий» на основании расшифрованных последовательной ДНК митохондрий (также выделенных с поверхности артефактов). Оказалось, что в испанской пещере жили две линии неандертальцев, разделившиеся примерно 100 тысяч лет назад. Одна популяция сменила другую, но непонятно, что послужило причиной — климат или некие морфологические изменения. Известно, что примерно 100 тысяч лет назад неандертальцы пришли к своему «классическому» внешнему виду с коренастым телосложением и очень выступающим вперед широким лицом. Переход происходил в несколько стадий, и, возможно, авторам удалось засечь последний этап.
«Пока мы не можем делать конкретных выводов об эволюционных взаимоотношениях обитателей этих пещер — на это будут направлены новые работы.
 Чрезвычайно важно то, что мы доказали надежность нашего подхода. Изучение генетики и эволюции древних людей всегда осложнялось тем, что не хватало материала, откуда можно было бы извлечь ДНК. Найти артефакты гораздо проще, чем кости и зубы, а наша методика позволит сконцентрироваться на последовательностях нуклеиновых кислот именно человека, а не его животных соседей. Результаты этой работы знаменуют рассвет анализа ядерной ДНК из отложений стоянок. Несомненно, это поможет пролить свет на многие спорные и сложные вопросы эволюции человека», — подводит итог Андрей Кривошапкин.
Чрезвычайно важно то, что мы доказали надежность нашего подхода. Изучение генетики и эволюции древних людей всегда осложнялось тем, что не хватало материала, откуда можно было бы извлечь ДНК. Найти артефакты гораздо проще, чем кости и зубы, а наша методика позволит сконцентрироваться на последовательностях нуклеиновых кислот именно человека, а не его животных соседей. Результаты этой работы знаменуют рассвет анализа ядерной ДНК из отложений стоянок. Несомненно, это поможет пролить свет на многие спорные и сложные вопросы эволюции человека», — подводит итог Андрей Кривошапкин.
Теги
Пресс-релизы
ВПЕРВЫЕ ОГРОМНЫЙ ГЕНЕТИЧЕСКИЙ «ЧЕРТЕЖ» МНОГОКЛЕТОЧНОГО СУЩЕСТВА ПРОЧИТАН ПОЛНОСТЬЮ. НА ОЧЕРЕДИ — РАСШИФРОВКА ГЕНОМА ЧЕЛОВЕКА
Достижение века: после восьми лет работы многих
исследовательских групп удалось точно
определить 97 миллионов пар нуклеотидов и их
местонахождение в спирали ДНК, хранящей полную
наследственную информацию микроскопического
червячка Сaenorhabditis elegans.
Так выглядит при сильном увеличении героиня грандиозного эксперимента — нематода С. elegans. Ее истинная величина — 1мм.
Просматриваются фрагменты расшифровки строения генома.
Сотрудники Сенгеровского центра в Кембридже, принимавшие участие в расшифровке генома C. elegans.
На рисунке показано строение C. elegans: 1 — так называемый желудочек, 2 — тонкий отдел кишечника, 3 — яичник, 4 — яйца.
Машины, применявшиеся для секвенирования генома С. elegans.
‹
›
Открыть в полном размере
С самых древних времен люди задумывались над
вопросом о том, как особенности живых организмов
передаются их потомкам. Разрабатывались самые
разные теории, иногда очень остроумные и не
противоречащие многим фактам, но по-настоящему
материальные основы наследственности начали
проясняться лишь 45 лет назад, когда Дж. Уотсон и Ф.
Крик расшифровали строение ДНК. Оказалось, что в
этой скрученной двойным жгутом гигантской
молекуле записаны все признаки организма.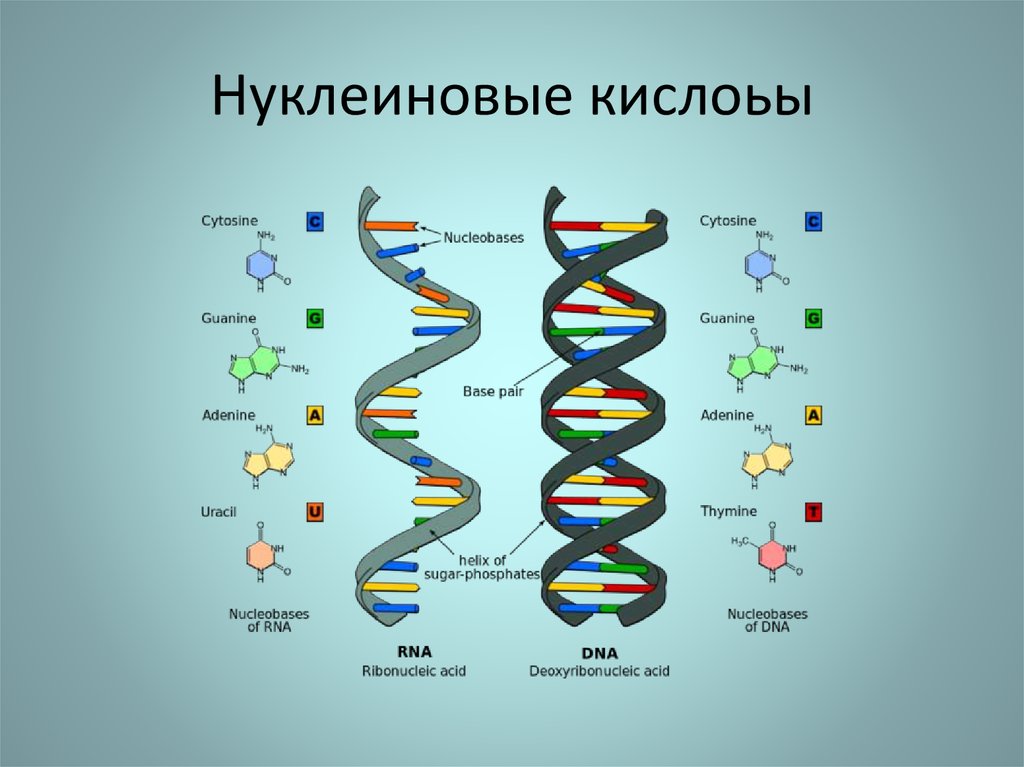
Каждая прядь молекулы ДНК представляет собой
цепочку из четырех типов звеньев — нуклеотидов,
повторяющихся в разном порядке. Нуклеотиды
обычно считают парами, как сапоги или перчатки,
потому что в молекуле ДНК две цепочки и их
нуклеотиды соединены поперечными связями
попарно. Четыре сорта нуклеотидов, четыре
«буквы» позволяют записать генетический
«текст», который прочитывается механизмом
синтеза белка в живой клетке. Группа из трех
стоящих подряд нуклеотидов, действуя через
довольно сложный передаточный механизм,
заставляет рибосому — внутриклеточную частичку,
занимающуюся синтезом белков, — подхватывать из
цитоплазмы определенную аминокислоту, следующие
три нуклеотида через посредников «диктуют»
рибосоме, какую аминокислоту ставить в цепочку
белка на следующее место, и так постепенно
получается молекула белка. А белки — не только
основной строительный материал живого
организма: многие из них — ферменты — управляют
процессами в клетке.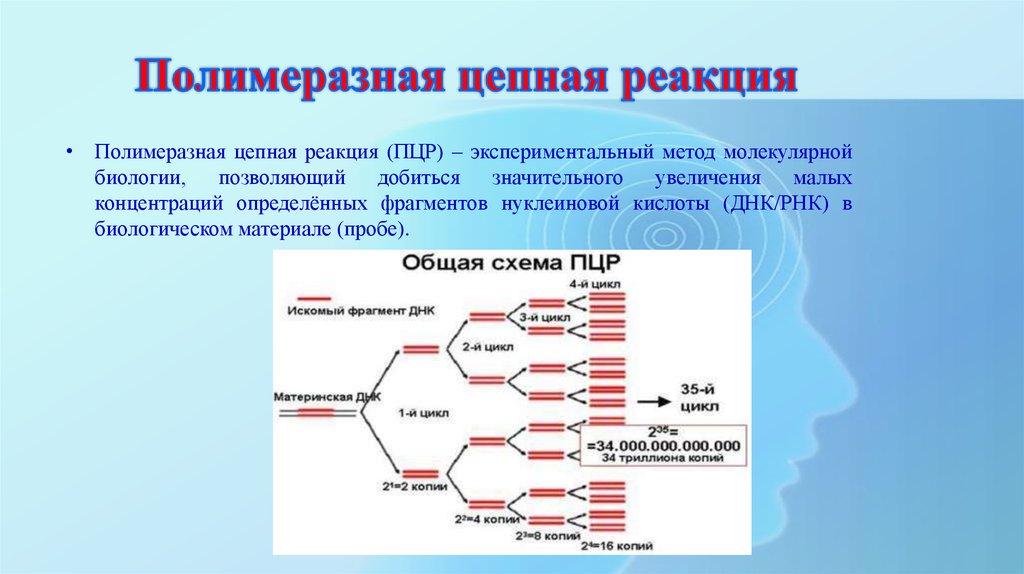 Так что информации,
Так что информации,
записанной в ДНК тройками пар нуклеотидов,
достаточно для построения нового организма со
всеми его особенностями.
Еще задолго до открытия всех этих (и многих
других) молекулярных тонкостей, изучая передачу
наследственных признаков при скрещивании,
биологи поняли, что каждый признак определяется
отдельной частицей, которую назвали геном.
Удалось понять, что гены лежат в ядре клетки, в
хромосомах. А после открытия роли ДНК и механизма
синтеза белков стало ясно, что ген — это участок
цепочки ДНК, на котором записано строение
молекулы определенного белка. В некоторых генах
всего 800 пар нуклеотидов, в
других — около миллиона. У человека около 80-90
тысяч генов. Набор генов, присущий организму,
называется его геномом.
В последние годы зародилась новая отрасль
генетики — геномика, изучающая не отдельные гены,
а целые геномы. Достижения молекулярной биологии
и генной инженерии дали человеку возможность
читать генетические тексты — сначала вирусов,
бактерий, дрожжевых грибков. А сейчас впервые
А сейчас впервые
удалось полностью прочитать геном
многоклеточного животного — обитающего в почве
микроскопического червячка длиной около
миллиметра. В лабораториях мира полным ходом
идет расшифровка генома человека. Эта
международная программа была начата в 1989 году,
тогда же благодаря инициативе и энергии
выдающегося биолога, ныне покойного академика А.
А. Баева, к программе подключилась и Россия. В
феврале этого года в Черноголовке под Москвой
прошла конференция «Геном человека-99»,
посвященная десятилетию начала этих работ и
памяти их инициатора, руководившего российской
частью программы первые пять лет. Сейчас в разных
странах мира, в лабораториях,
разделивших между собой «фронт работ» (всего
надо прочитать около трех миллиардов пар
нуклеотидов), ежедневно расшифровывается более
миллиона нуклеотидных пар, причем темп работ все
ускоряется.
Об успехах и перспективах геномики
рассказывает публикуемая статья.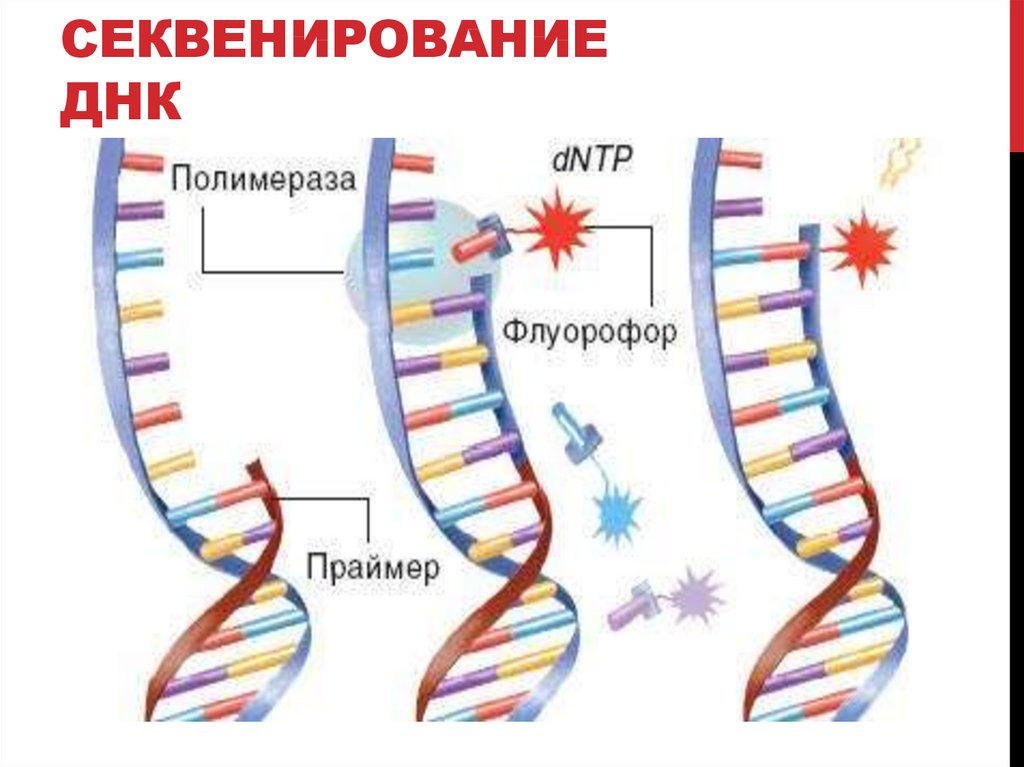
Как это было
Биология, по всеобщему признанию, заняла
доминирующее положение среди естественных наук
во второй половине уходящего века. В конце 1998
года эта точка зрения получила новое мощное
подтверждение: завершена восьмилет няя работа по
расшифровке строения генома (совокупности генов
и межгенных участков) многоклеточного животного,
круглого червя, нематоды, имеющего латинское
название Caenorhabditis elegans.
Хотя это очень маленький червь, скорее
червячок, с него без всякого преувеличения
начинается новая эра в биологии. Геном этой
нематоды состоит из 97 миллионов пар нуклеотидов
ДНК, округленно 0,1 миллиарда пар. Геном человека,
согласно большинству оценок, — 3 миллиарда
нуклеотидных пар. Разница в 30 раз. Однако именно
эта работа, о которой идет речь, окончательно
убедила даже самых закоренелых скептиков, что
расшифровка строения всего генома человека не
только возможна, но и достижима в ближайшие годы.
Расшифровка, или, как говорят биологи,
секвенирование, генома C. elegans была осуществлена
по совместному проекту двумя исследовательскими
группами: из Центра геномного секвенирования
Вашингтонского университета (США) и
Сенгеровского центра (Кембридж, Англия). В
журнале «Science» от 11 декабря 1998 года
опубликована серия статей, подробно
рассказывающая об этой поистине грандиозной
работе. Число авторов этой работы столь велико,
что журнал не опубликовал списка, отослав
читателей к Internet, а авторов назвал просто
«Консорциум секвенаторов C. elegans». Это,
вероятно, первый случай в истории науки, когда
открытие с самого начала и с согласия авторов как
бы становится анонимным. Эту работу можно с
полным правом считать знаковой, символизирующей
«индустриальную» науку. Зримый символ
современной науки, где огромные финансовые
вложения, роботизация, автоматизация,
менеджмент, дисциплина, координация играли
определяющую роль, оттеснив на этом этапе роль
интеллекта и творческой изобретательности
отдельных участников проекта.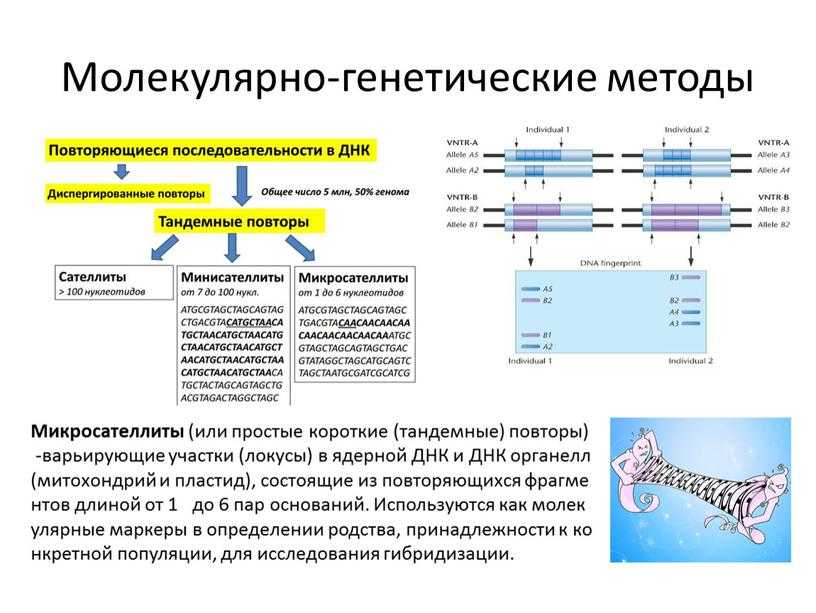
Будет справедливым напомнить о том, кто первым
обратил внимание на C. elegans как на объект
исследования. В середине 1960-х годов Сидней
Бреннер, выдающийся молекулярный генетик,
внесший огромный вклад в изучение генетического
кода, работал в знаменитой лаборатории
молекулярной биологии в Кембридже в Англии (в ней
трудились нобелевские лауреаты Ф. Крик, Дж.
Кендрю, М. Перутц, А. Клуг и другие знаменитые
исследователи). После работы над кодом С. Бреннер
решил посвятить себя изучению нервной системы и
путей ее возникновения и формирования. Он
обратил внимание на малюсенького червя (C. elegans),
состоящего всего из 959 клеток, из которых 302
нейроны, нервные клетки. Замечательным свойством
нематоды была ее прозрачность: можно следить за
поведением и судьбой каждой отдельной клетки!
Сидней Бреннер привлек в свою «нематодную»
лабораторию талантливых молодых исследователей,
сделавших немало важных открытий. Многие из них
Многие из них
стали «мотором» проекта секвенирования,
который был реализован в Сенгеровском центре.
Естественно, расшифровать геном таких
гигантских размеров, как у названной нематоды
(напомню: 97 миллионов пар нуклеотидов ДНК),
невозможно без огромной подготовительной
работы. Ее в основном завершили к 1989 году. Прежде
всего была построена физическая карта всего
генома нематоды. Физическая карта представляет
собой небольшие участки ДНК известной структуры
(маркеры), расположенные на определенных
расстояниях один от другого.
И вот с 1990 года началось само секвенирование.
Его темп составлял в 1992 году 1 миллион пар
нуклеотидов в год. Если бы такой темп сохранился,
на расшифровку всего генома понадобилось бы
почти 100 лет! Ускорить работы удалось простейшим
способом — число исследователей в каждом центре
возросло примерно до 100. Люди и аппараты работали
круглосуточно, производительность каждой машины
была увеличена за счет большего числа дорожек, на
которых секвенировали фрагменты
ДНК.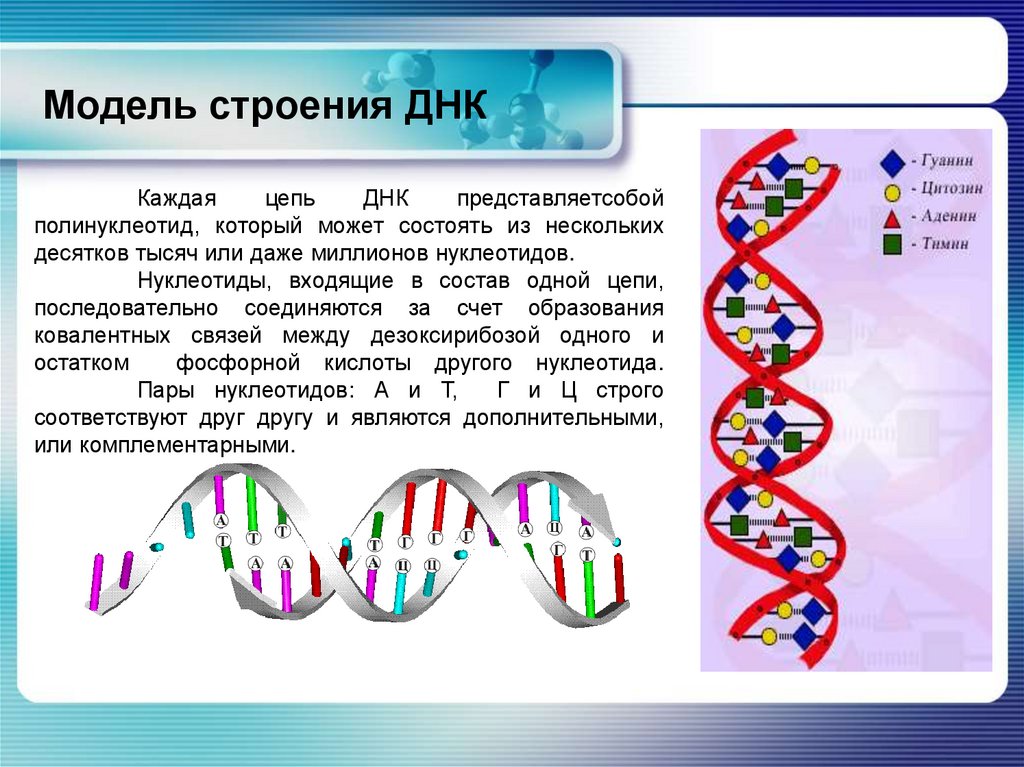
По мере того, как раскрывалась нуклеотидная
последовательность ДНК C. elegans, пришлось
расстаться с двумя заблуждениями. Во-первых,
оказалось, что генов у нее не 15 тысяч, как
предполагали вначале, а 19099. Во-вторых, надежда на
то, что гены сосредоточены в середине хромосом, а
к концам сильно редеют, оправдалась лишь отчасти,
гены распределены вдоль хромосом относительно
равномерно, хотя в центральной части их все-таки
больше.
Если у дрожжей функция половины генов в геноме
неизвестна (так называемые молчащие гены), то у
червя эта доля еще больше: из 19 тысяч генов 12
тысяч остаются пока загадочными.
Два исследовательских центра, решившие
гигантскую по сложности задачу, приобрели
уникальный опыт — и в ходе получения самих
результатов, и в ходе их осмысления, хранения и
переработки. Поэтому неудивительно, что обе
группы недавно заявили, что они готовы раскрыть
структуру половины генома человека, то есть
выполнить работу в 15 раз большую по объему, чем
то, что было сделано на геноме червя.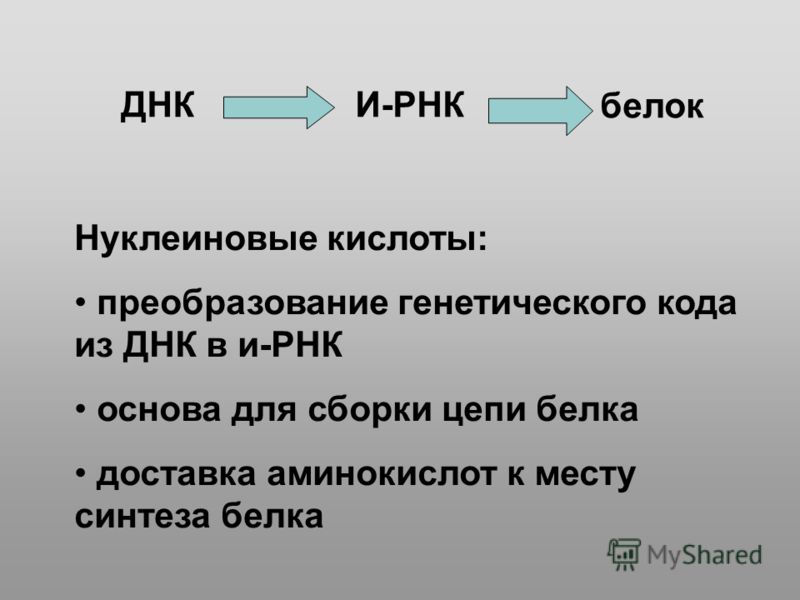 И это
И это
реально. Приведу такие цифры. Сейчас во всем мире
в день расшифровывается более 1 миллиона пар
нуклеотидов — столько, сколько за весь 1992 год.
Скорость возросла в 365 раз!
Значение секвенирования генома нематоды,
конечно, выходит далеко за рамки того, что можно
назвать полигоном для расшифровки генома
человека. C. elegans — первый многоклеточный организм,
геном которого раскрыт практически полностью.
Можно напомнить: два года назад был расшифрован
первый геном эукариотического организма -
дрожжей, то есть организма, клетки которого
содержат оформленные ядра. (К эукариотам
относятся все высшие животные и растения, а также
одноклеточные и многоклеточные водоросли, грибы
и простейшие. Дрожжи, согласно биологической
систематике, относятся к одноклеточным грибам.)
Иначе говоря, за два года был пройден путь от
генома одноклеточного до генома многоклеточного
организма. Биологи знают, это гигантская
дистанция на лестнице эволюции и, следовательно,
на пути усложнения геномов.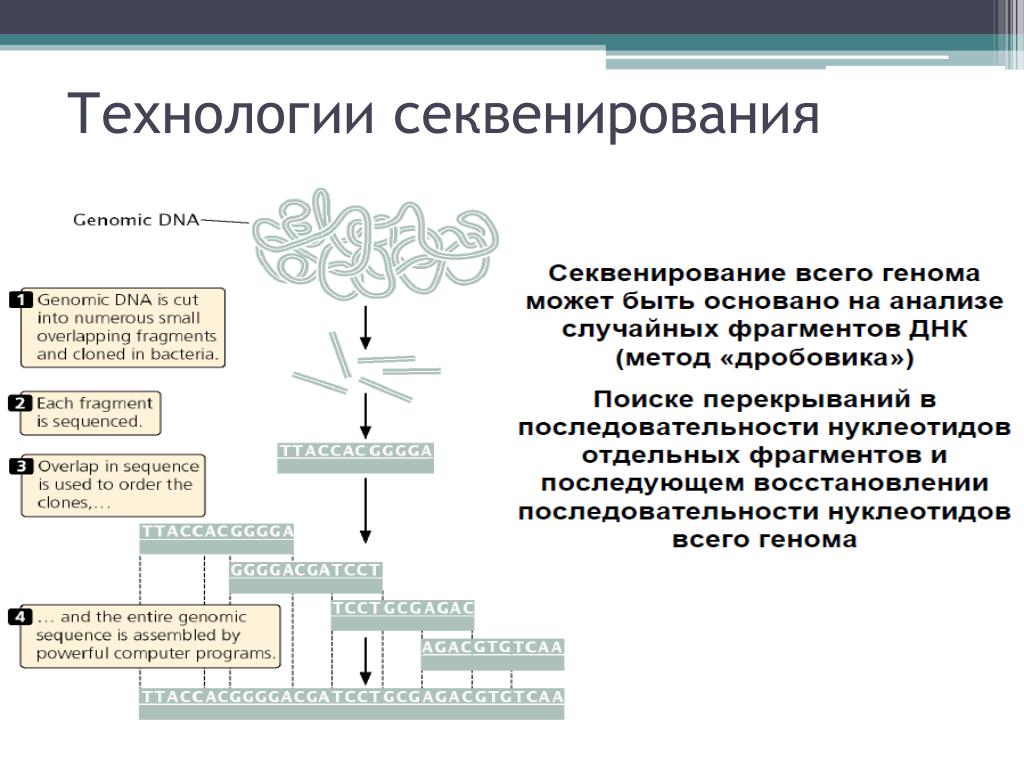 Поразительно, как невероятно быстро пройден этот
Поразительно, как невероятно быстро пройден этот
путь!
Сравнивая теперь геномы бактерий (известно уже
более 20 геномов) с геномами дрожжей и нематоды,
биологи-эволюционисты имеют уникальную
возможность сравнивать не отдельные гены и даже
не генные ансамбли, а целиком геномы — такой
возможности в биологии еще десять лет назад
просто не существовало, об этом только мечтали. В
ближайшие месяцы, когда полученные огромные
объемы информации начнут осваивать и
осмысливать, следует ждать появления
принципиально новых концепций в теории биологической эволюции.
Новые данные и перспективы
биологии
Каковы же ближайшие перспективы, открывающиеся
сейчас в биологии? Вот самые очевидные. У
человека только в пять раз больше генов, чем у
нематоды. Следовательно, по крайней мере около 20%
генома человека должно иметь родственников
среди известных теперь генов C. elegans. Это в
громадной степени облегчает поиск новых генов
человека.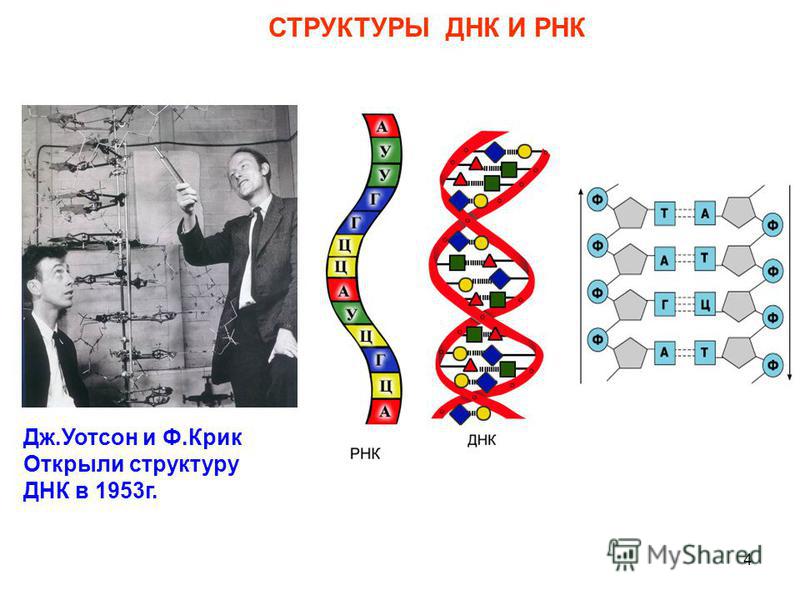 Функции еще не известных генов
Функции еще не известных генов
нематоды изучать несравненно легче, чем
аналогичные гены у человека. Гены червя можно
легко изменить (мутировать), одновременно следя
за изменениями структуры гена и свойств
организма. Таким путем можно выявлять
биологическую роль генных продуктов (то есть
белков) у червя, а затем экстраполировать эти
данные на другие организмы, в первую очередь на
человека. А можно угнетать активность генов
(например, с помощью особых молекул
специфических РНК) и следить, как меняется
поведение организма. Этот путь тоже раскрывает
функции неизвестных генов и, разумеется,
сильнейшим образом повлияет на изучение генома
человека и других высших организмов.
Биологов всегда интригует вопрос: как
регулируется работа генов? Хотя мы знаем об этом
очень много, наши знания получены в основном на
отдельных генах, а потому не дают цельной картины
регуляции работы всего генома как единого
целого. Сейчас бурно развивается техника так
Сейчас бурно развивается техника так
называемых биочипов (по аналогии с микрочипами в
кибернетике). Это маленькие пластинки, на которые
с помощью прецизионных приборов в тысячи точек,
на строго фиксированных расстояниях одна от
другой, наносят микроскопические количества
фрагментов ДНК.
Такой микрочип может, например, содержать все
19000 генов нематоды — по одному гену в каждой точке,
и его можно использовать для того, чтобы
определить, какие гены работают в данной клетке
червя, а какие молчат. Разумеется, здесь возможно
использовать клетки на любой стадии развития и
из любой части тела червя. В результате
исследователь получит информацию о
функциональном состоянии всех генов любой
клетки на любой стадии развития червя. Опыты уже
начаты, есть все основания не сомневаться, что
еще в текущем году мы узнаем о первых
результатах. Это будет действительно
революционным прорывом для биологии развития.
Помимо совершенной микротехники эти опыты
требуют и совершенных компьютерных программ,
чтобы полученные фактические данные можно было
осмыслить и интерпретировать.
Методика биочипов открывает новую стратегию в
решении одной из сложнейших в биологии проблем -
проблемы взаимосвязи сигнальных регуляторных
путей. Основная трудность заключается в том, что
взаимодействие белковых продуктов многих генов
происходит одновременно, причем комбинации
белков меняются не только во времени, но и в
клеточном пространстве. В результате изучение
отдельных генов и их продуктов (что в основном
делалось до сих пор) нередко было неэффективным.
Каково соотношение областей в геноме C. elegans,
кодирующих синтез белков (экзоны) и не кодирующих
(интроны)? Компьютерный анализ показывает, что
экзоны и интроны занимают в геноме нематоды
примерно равные доли (27 и 26%), остальное (47%)
приходится на повторы, на межгенные участки и т.
д., то есть на ДНК с неизвестными науке функциями.
Если сравнить по этим данным дрожжевой геном и
геном человека, то станет очевидным, что в ходе
эволюции доля кодирующих участков в расчете на
весь геном резко уменьшается: у дрожжей она очень
высока, а у человека очень мала. Об этом знали
сравнительно давно, но сейчас названные
соотношения приобрели не только количественную
меру, но и структурную основу. Мы приходим, на
первый взгляд, к достаточно парадоксальному
выводу. Эволюция у эукариот от низших форм к
высшим сопряжена с «разбавлением» генома -
на единицу длины ДНК приходится все меньше
информации о структуре белков и РНК и все больше
информации «ни о чем», то есть для нас
непонятной, непрочитанной.
Это одна из больших загадок биологической
эволюции. По поводу «лишней» ДНК существуют
самые разные предположения, зачастую прямо
противоположные по смыслу. Много лет назад Ф.
Крик, один из отцов двойной спирали ДНК, назвал
эту «лишнюю» ДНК «эгоистической», или
«мусорной». Он считал ее издержкой эволюции,
Он считал ее издержкой эволюции,
накапливающейся в геноме в результате неполного
совершенства генетических процессов,
«балластом», платой за совершенство
остальной части генома. Возможно, что некоторая
небольшая «эгоистическая» доля в ДНК
человека и других высших организмов
действительно относится к такому типу. Однако
теперь стало ясно, что основная доля
«эгоистической» ДНК сохраняется в эволюции
и даже увеличивается, потому что она дает ее
обладателям эволюционные преимущества.
Классическим примером «эгоистической» ДНК
служат так называемые короткие повторы участков
ДНК (Alu-элементы, альфа-сателлитные ДНК и другие).
Как выяснилось в последние годы, их структура
абсолютно консервативна, то есть мутации,
нарушающие «правила», установленные
природой для этих элементов, не сохраняются, они
«отбрасываются» отбором. Структурное
постоянство — мощный аргумент в пользу идеи о том,
что такие участки являются отнюдь не
«эгоистическими», а это очень важная часть
ДНК для жизни вида. Другое дело, что мы еще не
Другое дело, что мы еще не
знаем, в чем конкретно состоит ее биологическая
роль.
Геномика человека и будущее
человечества
Сегодня почти каждый день широкая пресса США и
западноевропейских стран сообщает о все новых и
новых генах человека и об их функциях или связи с
теми или иными заболеваниями. В 1998 году
правительство США истратило на проект по
изучению генома человека 300 миллионов долларов, а
частные компании, прежде всего
биотехнологические, — даже больше этой суммы. По
крайней мере 20 самых развитых стран мира имеют
свои национальные программы по изучению генома
человека.
Сейчас геномная программа уже доказала свое
выдающееся значение для развития наших знаний о
жизни в целом. Интересно вспомнить, как эти идеи
были встречены в момент их первоначального
обсуждения и создания программы. Научное
сообщество тогда разделилось на две части: одна
встретила идею геномной программы с энтузиазмом,
тогда как другая — со скепсисом, недоверием и
подозрительностью. Среди
Среди
этой второй группы были и выдающиеся ученые,
например, лауреат Нобелевской премии Дэвид
Балтимор, один из отцов обратной транскрипции.
Основное возражение противников: создание
геномной программы направлено на то, чтобы привлечь большие финансовые средства (и
тем самым отобрать их у других направлений
биологии), а не получить новые знания.
Истекшие 10 лет показали, что новый уровень
понимания биологических проблем, сложившийся
благодаря результатам геномных исследований,
уже сейчас с лихвой оправдал все организационные
усилия и финансовые вложения. Более того, стало
ясно, что добытая информация не могла быть
получена простой поддержкой сотен отдельных
исследовательских групп, даже высококвали
фицированных и хорошо оснащенных. Но вместе с тем
теперь мы понимаем, что 10 лет назад трудно было
оценить глубину и широту влияния геномики
(области биологии, изучающей геномы) человека на
биологию в целом.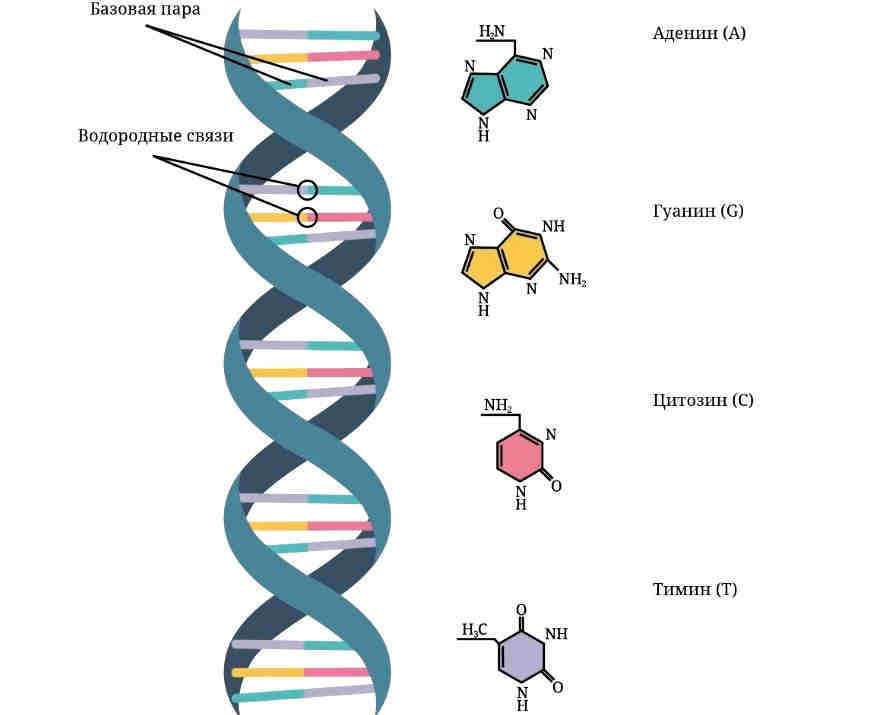
Один из сильных аргументов против геномной
программы состоял также в том, что
«индустриализация» биологии приведет к
утрате ее творческого потенциала, исчезновению
«малой» биологии — небольших
исследовательских групп, возглавляемых
талантливыми, оригинально мыслящими
исследователями, которые не захотят пойти
работать на «фабрики секвенирования ДНК».
Среди ученых, придерживавшихся таких взглядов,
был, например, и Брюс Олбертс, нынешний президент
Национальной академии США.
Безусловно справедливо, что одно из основных
звеньев геномной программы — секвенирование,
которое в столь гигантском масштабе достижимо
только индустриальными методами. Однако само
достижение этой фазы требовало больших
интеллектуальных усилий, новой приборной базы,
новых методов, новых инструментов исследования.
Здесь требовалось творческое усилие отдельных
ученых. И это творческое начало как необходимый
компонент индустриализации было недооценен о
скептиками.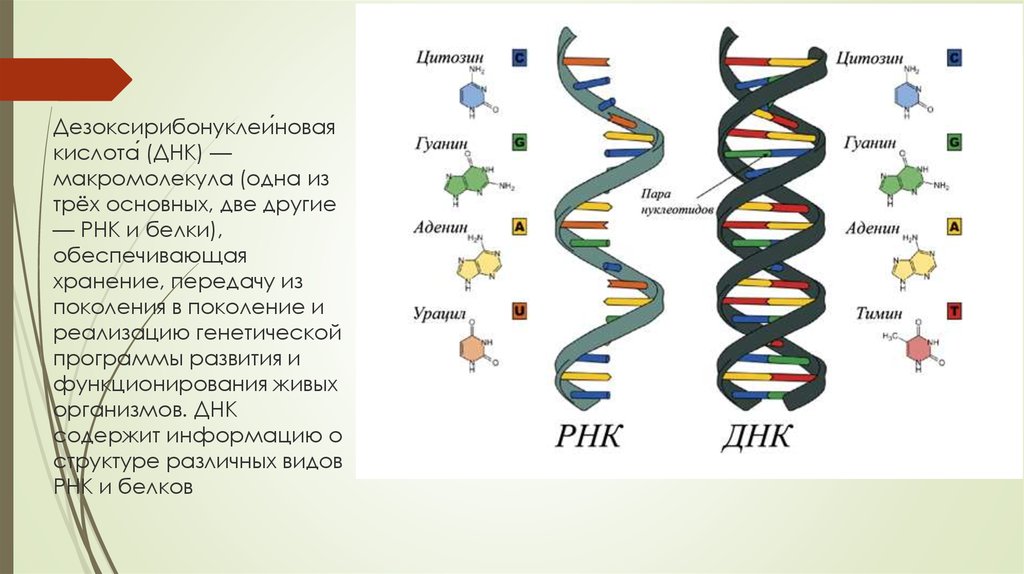
Разработанные в геномике человека идеи и
методы имеют универсальное значение и применимы
для решения огромного круга биологических
проблем, далеко отстоящих от собственно генома
человека. Напомним только о некоторых из них.
Для картирования генома (обязательная стадия
исследований, предшествующая секвенированию)
разработаны высокоэффективные техники, такие,
как радиационные гибриды (коллекции клеток, в
которых удалены разные небольшие фрагменты
каждой из хромосом), или искусственные дрожжевые
хромосомы, содержащие огромные фрагменты
хромосом человека, бактериальные и фаговые
векторы, позволяющие размножить (клонировать)
фрагменты ДНК человека…
Новые техники в совокупности позволили
построить детальную карту генома человека,
которая к концу 1998 года содержала более 30 тысяч
маркеров, создававших детальную карту генома.
Быстро прогрессировала техника секвенирования
(например, многоканальный капиллярный
электрофорез резко ускорил и удешевил
расшифровку первичной структуры ДНК), созданы
компьютерные программы, позволяющие находить
гены в расшифрованных участках ДНК.
Важно подчеркнуть, что вся эта приборная база и
методология в полной мере может применяться к
любым геномам, от бактерий до
сельскохозяйственных животных и растений.
Пожалуй, от развития геномики человека в
настоящее время выиграла больше всего
микробиология, поскольку уже расшифровано более
20 полных геномов, в том числе возбудителей многих
опасных болезней (туберкулеза, сыпного тифа, язвы
желудка и других). Можно с уверенностью
утверждать, что без геномного проекта эти данные
были бы получены гораздо позже и, вероятно, в
гораздо меньшем объеме. Знание геномной
структуры патогенных бактерий очень важно для
создания вакцин (причем рационально
сконструированных), для диагностики и других
медицинских целей. Велико влияние геномики и на
медицинскую генетику, которая занимается
генодиагностикой наследственных болезней,
генетическими основами предрасположенности ко
многим распространенным болезням.
Частные компании, кредитовавшие проект,
получили тысячи патентов на новые гены,
фрагменты ДНК, новые методики и
т. д. Это имеет как бы двойной эффект. С одной
стороны, геномика получает мощный
дополнительный импульс к развитию, а с другой -
коммерциализация геномики ведет к тому, что
многое из полученной информации фирмы
засекречивают, особенно по геномике
микроорганизмов, заставляя и некоторых ученых
поступать аналогичным образом.
Геномные методы идентификации личности,
разработанные и практически реализованные в
геномике человека, имеют далеко идущие
последствия для общества. Действительно,
криминалистика получила в свое распоряжение
абсолютно надежный метод доказательства
виновности или невиновности человека. Для такого
геномного анализа (его часто называют геномной
дактилоскопией) достаточно одной капли крови,
одного волоса, кусочка ногтя, следов пота, спермы,
слюны, перхоти и т. д. Сегодня в мире тысячи людей
д. Сегодня в мире тысячи людей
осуждены или оправданы только на основании
геномного анализа. Идентификация родственных
связей людей решает сейчас проблемы отцовства и
материнства, проблемы наследования прав и
имущества между родственниками и неродственни
ками, если эти вопросы возникают.
Огромный интерес вызывает вторжение геномики в
историю человечества, этнографию, лингвистику и
другие области гуманитарного знания. В эту
орбиту уже вовлечены и такие биологические
науки, как антропология и палеонтология, теория
эволюции. Многие спорные вопросы истории
цивилизаций в древние времена будут, скорее
всего, решены не историками, а геномоведами.
Например, уже сейчас ясно (хотя эти работы
начались совсем недавно), что происхождение и
миграцию многих народов в мире (и, конечно, в том
числе в России) легче всего будет проследить по геномным маркерам, которые дают
количественную и однозначную информацию.
Программа «Геном человека», как уже
говорилось, — программа общечеловеческая. Каждая
лаборатория, в какой бы стране она ни находилась,
вносит в нее посильный вклад. И как только кому-то
удается раскрыть структуру нового гена, эта
информация немедленно поступает в Международный
банк данных, доступный каждому исследователю.
Без преувеличения надо сказать, что развитие
информатики играет поистине огромную роль в
успехе мировой геномной программы.
В России по этой программе работают около 100
исследовательских групп. Есть оригинальные
работы, получившие международное признание
(только в прошлом году участники программы
опубликовали более 70 статей в международных
журналах). Первые пять лет главным в программе
было картирование, иначе говоря — расстановка
«опознавательных значков», попытка понять:
где, в какой части хромосомы ученые находятся -
подобно тому, как географы прошлого составляли
первые карты Земли.
Теперь акцент сместился, и исследователи
пытаются уже определить функции отдельных генов.
Это переход от «индустриальной науки»,
требующей прежде всего оборудования, к науке
интеллектуальной. И на этом этапе мы надеемся
преуспеть. «Массовое производство» было нам
недоступно прежде всего из-за недостатка
финансирования, а кроме того — русские ученые
никогда не любили механическую работу.
***
Оглядываясь на 10 лет назад, можно увидеть, что
значение геномики было недооценено, а ее влияние
оказалось гораздо шире и глубже, чем ожидалось.
Ясно также, что создание геномного проекта было
огромным достижением для биологов всего мира,
так как впервые поставило биологию в ряд тех
наук, которые способны реализовать глобальные
проекты с огромным не только общенаучным, но и
практическим выходом. Сравнивая геномный проект
с проектом освоения космического пространства
(программа полетов к Луне и Марсу, программа
околоземных станций), видно, что биологическая
программа, будучи во много раз дешевле, по своему
влиянию на жизнь людей не только
не уступает, но и в конечном итоге, безусловно,
превзойдет достижения космических программ,
поскольку окажет влияние в XXI веке почти на
каждого жителя Земли.
Страница обучения — SelfDecode
Страница обучения — SelfDecode
SelfDecode Learn
Помочь вам понять науку, лежащую в основе персонализированного здоровья.
Воспроизвести видео
Отличие SelfDecode
В SelfDecode мы используем передовые алгоритмы искусственного интеллекта и машинного обучения, чтобы наука, стоящая за SelfDecode, была более точной и действенной, чем кто-либо другой.
Понимание науки, лежащей в основе SelfDecode
Основы
Что такое ДНК
Воспроизвести видео
Ваше здоровье и окружающая среда
 vimeo.com/video/589305684?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=14b5221794#t=»/>
vimeo.com/video/589305684?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=14b5221794#t=»/>
Воспроизвести видео
Что такое генетический
Импутация?
Воспроизвести видео
Понимание показателей воздействия и доказательств
Воспроизвести видео
Что такое SelfDecode?
SelfDecode — единственное в мире программное обеспечение для геномики ИИ, которое предоставляет персонализированные рекомендации по здоровью.
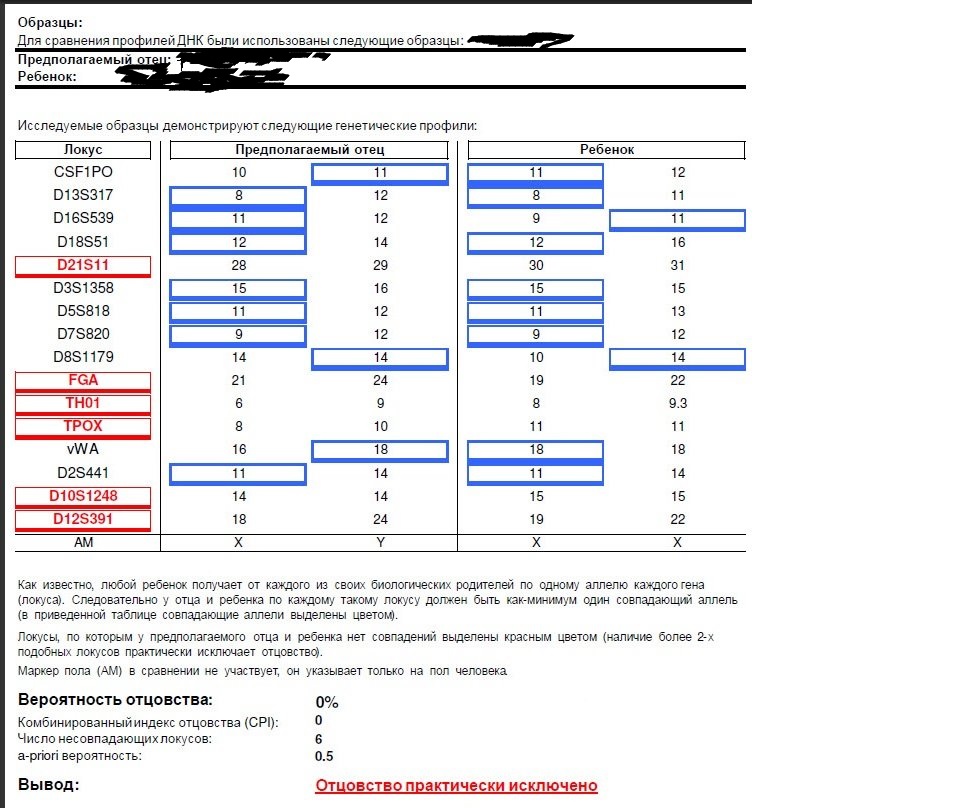 Узнайте, какие добавки, диету и изменения в образе жизни вам следует внести, исходя из вашей ДНК, лабораторных анализов и образа жизни.
Узнайте, какие добавки, диету и изменения в образе жизни вам следует внести, исходя из вашей ДНК, лабораторных анализов и образа жизни.
Воспроизведение видео
Как пользоваться комплектом SelfDecode DNA
Воспроизвести видео
Использование функции «Мой режим»
Воспроизвести видео
Расширенное обучение
Что такое гены?
 vimeo.com/video/639157370?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0#t=»/>
vimeo.com/video/639157370?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0#t=»/>
Воспроизвести видео
Что такое генетические варианты?
Воспроизведение видео
Что такое
Генетические мутации?
Воспроизвести видео
Что такое
Фенотипы?
Воспроизвести видео
Понимание показателей полигенного риска
 vimeo.com/video/613
vimeo.com/video/613
7?color&autopause=0&loop=0&muted=0&title=0&portrait=0&byline=0&h=5f34952462#t=»/>
Воспроизвести видео
Знакомьтесь, Декоди!
Ваш новый тренер по здоровью с искусственным интеллектом!
Декоди — наш продвинутый искусственный интеллект, и его работа — узнать вас на личном уровне, чтобы он мог предоставить вам комплексные рекомендации по здоровью, адаптированные к вашей ДНК, образу жизни, окружающей среде и результатам лабораторных исследований!
Получите наш бесплатный путеводитель!
Как использовать вашу ДНК
для оптимизации
вашего здоровья
Посмотрите, как другие люди использовали науку геномики, чтобы стать здоровыми!
SelfDecode — это служба персонализированных отчетов о состоянии здоровья, которая позволяет пользователям получать подробную информацию и отчеты на основе их генома.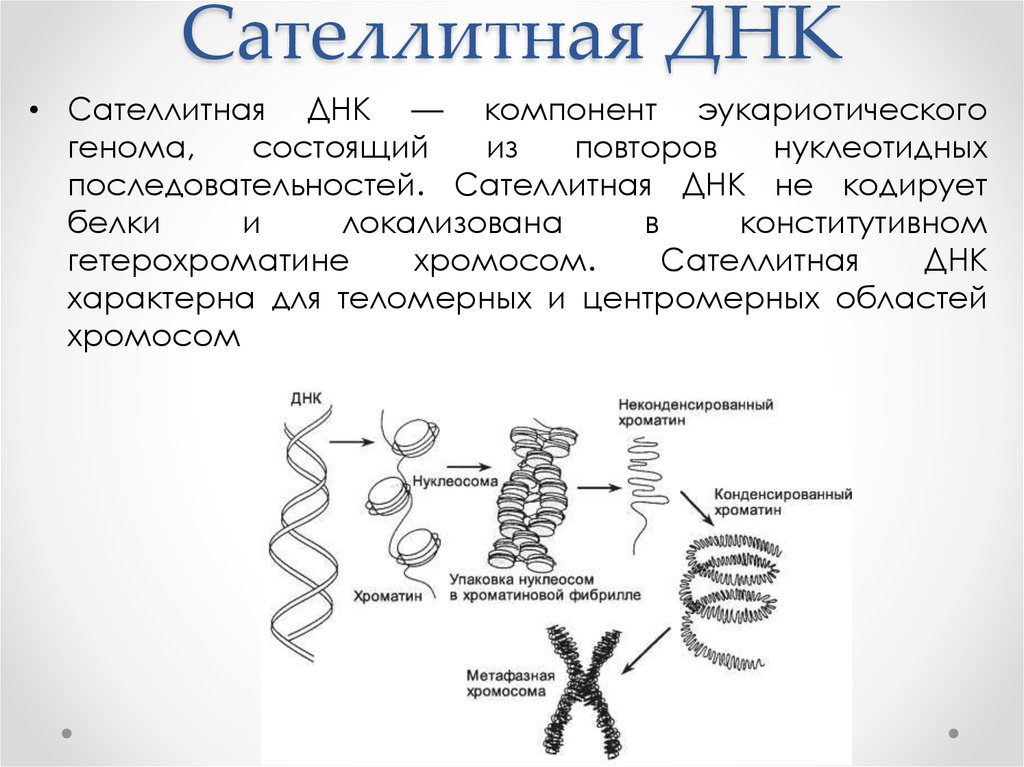 SelfDecode не лечит, не диагностирует и не излечивает какие-либо заболевания, а предназначен исключительно для информационных и образовательных целей.
SelfDecode не лечит, не диагностирует и не излечивает какие-либо заболевания, а предназначен исключительно для информационных и образовательных целей.
Политика
Служба поддержки
Наша команда
Партнерская программа
Health reports
Acne
Allergies
Anxiety
Asthma
Attention
Blood Pressure
Blood Sugar
Bone Health
Brain Fog
Cholesterol
Chronic Fatigue
Chronic Pain
Eczema
Gallstones
Gut Inflammation
Headache
Heart Health
Inflammation
Бессонница
раздраженное кишечник
Воспаление суставов
боли в суставах
Здоровье почек
камней почек
мигрени
Настроение
Шея и боль в плече
Пеперактивная щитовидная железа
PSORIASS
Сексуальная дисфункция
TRAINTICES
THY -IIRLINARIINAL
THYINARINARINARINE
THYRINARINARINE
.
О самодекодировании | Познакомьтесь с командой
О SelfDecode | Встретиться с командой
В SelfDecode мы совершаем революцию в сфере здравоохранения, предоставляя персонализированные рекомендации по здоровью, основанные на сочетании вашей ДНК, лабораторных данных и факторов окружающей среды.
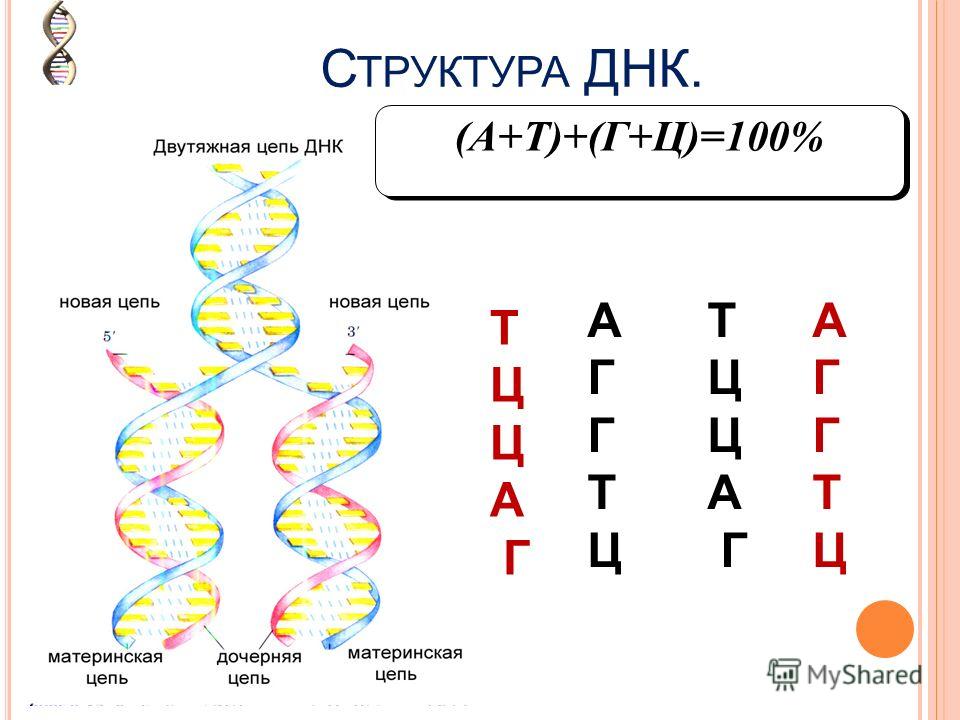
7 миллиардов
кусочки ДНК
Тысячи
лабораторных тестов
Тысячи
факторов окружающей среды
Научный подход, ориентированный на вас.
SelfDecode — единственная компания в мире, которая напрямую предоставляет вам целостный набор точных рекомендаций по здоровью, основанных на ваших генах, чтобы вы могли взять на себя ответственность за свое здоровье, принимая точные решения о здоровье на основе данных.
7 миллиардов
кусочки ДНК
Тысячи
лабораторных тестов
Тысячи
факторов окружающей среды
Чтобы принимать наилучшие решения в отношении здоровья, вы должны учитывать все данные о своем здоровье. В противном случае вы в конечном итоге будете решать отдельные проблемы или симптомы, не глядя на картину в целом. Проблема в том, что информации слишком много, чтобы ее мог проанализировать любой человек.
Наши отчеты основаны на новейших технологиях искусственного интеллекта и машинного обучения, поэтому вы получаете действительно значимые результаты.
 Мы используем методы искусственного интеллекта, включая глубокое обучение, байесовское машинное обучение и гиперпространственные вычисления для импутации и наших генетических моделей. Это одна из тех же технологий, которые компании используют для создания беспилотных автомобилей!
Мы используем методы искусственного интеллекта, включая глубокое обучение, байесовское машинное обучение и гиперпространственные вычисления для импутации и наших генетических моделей. Это одна из тех же технологий, которые компании используют для создания беспилотных автомобилей!
Это делает SelfDecode
самым точным набором здоровья ДНК на рынке , потому что мы можем анализировать миллионы генетических вариантов одновременно, а не несколько десятков отобранных вручную вариантов.
1 набор ДНК.
До 83 миллионов генетических вариантов.
Используя метод, называемый
генетической импутацией , наша система превращает ~750 000 SNP, анализируемых нашим набором ДНК Illumina GSA мирового класса, в более 83 миллионов дополнительных вариантов с точностью 99,7%.
Это позволяет нам анализировать более чем в 100 раз больше вашего генома, чем другие ведущие компании по тестированию ДНК.
Затем мы выясняем, какие из этих вариантов влияют на ваше здоровье, и преобразуем это в показатель генетического риска, который показывает, как ваш генетический риск сравнивается с другими.
 Наконец, наш алгоритм предсказывает наилучшие рекомендации по образу жизни и здоровью для противодействия вашему риску на основе ваших уникальных генов.
Наконец, наш алгоритм предсказывает наилучшие рекомендации по образу жизни и здоровью для противодействия вашему риску на основе ваших уникальных генов.
Узнайте больше в нашем официальном документе
Лаборатория, сертифицированная CLIA
Клинически подтвержденные тесты
Опытная клиническая команда
Используя метод, называемый
генетической импутацией , наша система превращает около 750 000 SNP, анализируемых нашим набором ДНК Illumina GSA мирового класса, в до 83 миллионов дополнительных вариантов с точностью 98%.
Это позволяет нам анализировать в 70 раз больше вашего генома — по доступной цене, потому что мы
верим в здоровье для всех .
Затем мы выясняем, какие из этих вариантов влияют на ваше здоровье, и преобразуем это в показатель генетического риска, который показывает, как ваш генетический риск сравнивается с другими. Наконец, наш алгоритм предсказывает наилучшие рекомендации по образу жизни и здоровью для противодействия вашему риску на основе ваших уникальных генов.
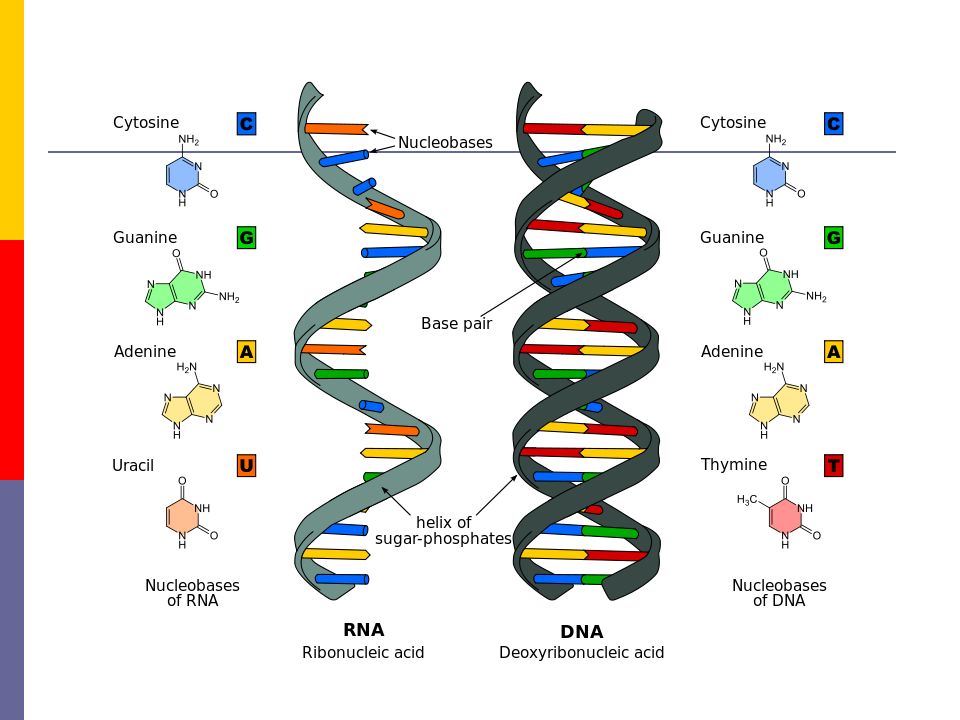
Узнайте больше в нашем официальном документе
Клинически подтвержденные тесты
Лаборатория, сертифицированная CLIA
Опытная клиническая команда
Что такое ДНК?
Что такое генетическое вменение?
Ваши гены против окружающей среды
SelfDecode — это наиболее точное программное обеспечение для точного медицинского обслуживания, предназначенное непосредственно для потребителя, поскольку в нашей команде работает 70 высококвалифицированных специалистов в области науки и техники. Ни в одной другой компании нет такой команды экспертов по искусственному интеллекту и геномике, как наша, которые работают над созданием своего продукта, ориентированного непосредственно на потребителя.
SelfDecode — это наиболее точное программное обеспечение для точного медицинского обслуживания, предназначенное непосредственно для потребителя, поскольку у нас есть команда высококвалифицированных специалистов.
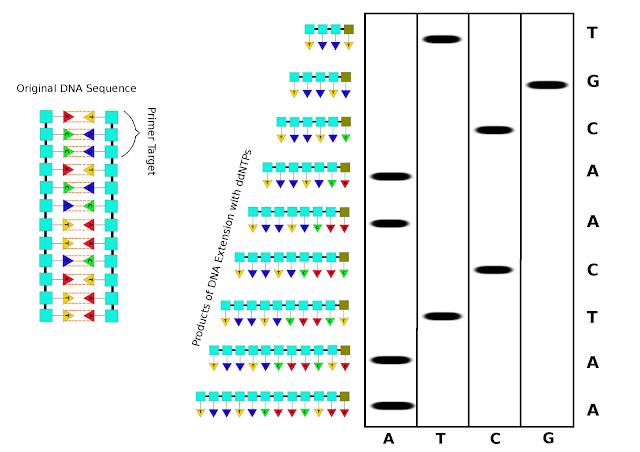 Ни в одной другой компании нет такой команды экспертов по искусственному интеллекту и геномике, как наша, которые работают над созданием своего продукта, ориентированного непосредственно на потребителя.
Ни в одной другой компании нет такой команды экспертов по искусственному интеллекту и геномике, как наша, которые работают над созданием своего продукта, ориентированного непосредственно на потребителя.
показать больше
показать больше
показать больше
показать больше
показать больше
показать больше
Нам не нужны ваши данные. Мы работаем для
вашего здоровья .
В SelfDecode вы владеете своими данными. Мы никогда не продадим и не отдадим.
Вы всегда полностью контролируете свои медицинские данные, и у нас есть штатный инженер по безопасности и конфиденциальности, который следит за тем, чтобы ваша информация оставалась в безопасности.
SelfDecode — единственный набор ДНК, который предлагает действительно персонализированные рекомендации по здоровью на основе ваших генов.
Мы не просто говорим вам, что означают ваши гены — мы используем ваши гены, чтобы предсказать лучшие рекомендации, разработанные специально для вас.
Все, что мы делаем в SelfDecode, основано на нашей миссии помочь таким людям, как вы, улучшить свое здоровье. Вы причина существования SelfDecode.
Вот почему мы предлагаем вам самые точные оценки риска и рекомендации на рынке. Другие могут сосредоточиться на получении данных о вашем здоровье, но наша цель — предоставить вам максимально точные отчеты, чтобы вы могли улучшить свое здоровье.
Пройдите ДНК-тест SelfDecode и узнайте, что такое по-настоящему персонализированное медицинское обслуживание. Ваше тело будет благодарить вас долгие годы.
SelfDecode — это служба персонализированных отчетов о состоянии здоровья, которая позволяет пользователям получать подробную информацию и отчеты на основе их генома. SelfDecode не лечит, не диагностирует и не излечивает какие-либо заболевания, а предназначен исключительно для информационных и образовательных целей.
Тестирование недоступно для лиц моложе 18 лет, а также для жителей штатов Нью-Йорк, Нью-Джерси и Род-Айленд.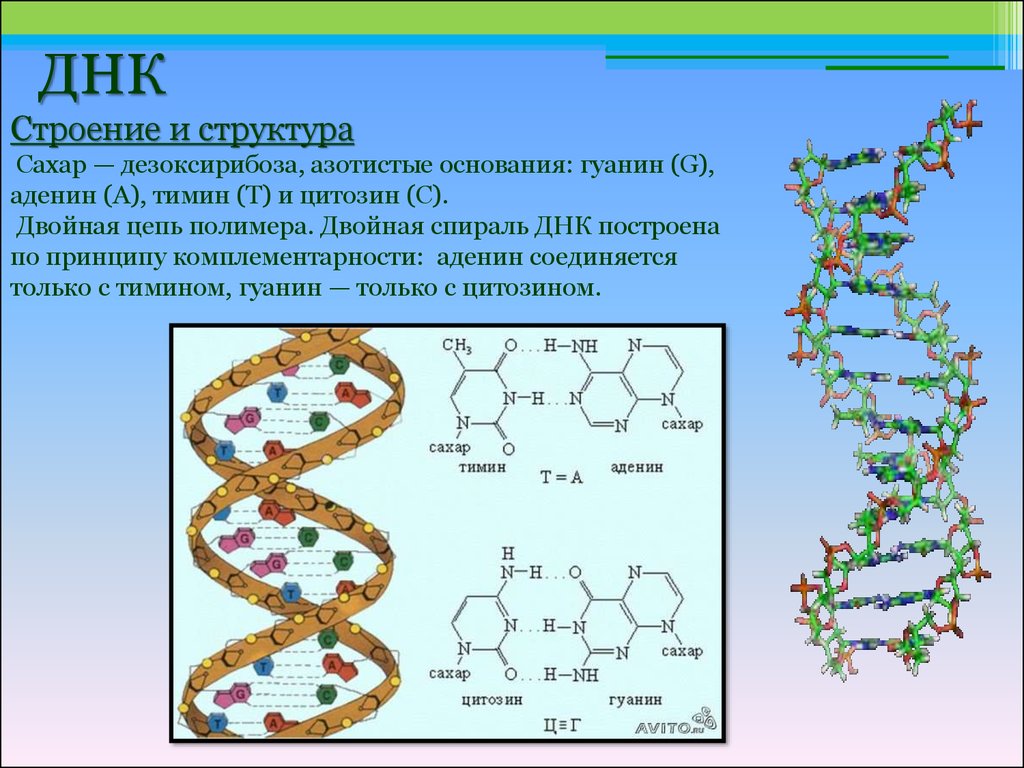
Политики
Навигация
SelfDecode © 2022. Все права защищены.
Джо Коэн, бакалавр наук
Генеральный директор и основатель
Джо Коэн, основатель SelfDecode, SelfHacked и LabTestAnalyzer, успешный оратор и предприниматель, который более 15 лет занимается независимыми исследованиями в области здравоохранения и науки. Джо вырос с множеством проблем со здоровьем, которые не смогла решить традиционная медицина, и подтолкнул Джо к изучению собственных генов, чтобы добраться до первопричины своих проблем.
После решения своих хронических проблем со здоровьем с помощью персонализированного подхода к здоровью, основанного на генах, он понял, что ему нужно поделиться этой информацией с массами. Основание SelfHacked, LabTestAnalyzer и SelfDecode было способом Джо помочь людям взять свое здоровье в свои руки.
Теперь Джо регулярно выступает на мероприятиях вместе с ведущими мировыми экспертами в области здравоохранения и продолжает работать над улучшением продуктов своей компании, чтобы предоставить людям доступ к передовым инструментам и информации, предназначенным для оптимизации здоровья.
Пуйя Язди, доктор медицинских наук
Главный научный сотрудник и Главный медицинский директор
Доктор Пуйя Язди — врач-ученый с более чем 15-летним успешным опытом исследований и разработок, включая 7-летний опыт руководящей работы. Он получил высшее образование в Калифорнийском университете в Ирвине, степень доктора медицины в Университете Южной Калифорнии и был врачом-резидентом в Стэнфордском университете. Он успешно разработал более 10 продуктов для точной медицины, имеет историю рецензируемых публикаций, приобретений интеллектуальной собственности, клинических испытаний, нормативных документов, а также является автором многочисленных официальных документов, сотен публикаций для непрофессионалов, получения многочисленных наград и выступлений на ведущих международных конференции и компании.
Его жизненная миссия состоит в том, чтобы донести мощь и перспективы геномики и ИИ/МО до масс и помочь преобразовать здравоохранение в 21 веке.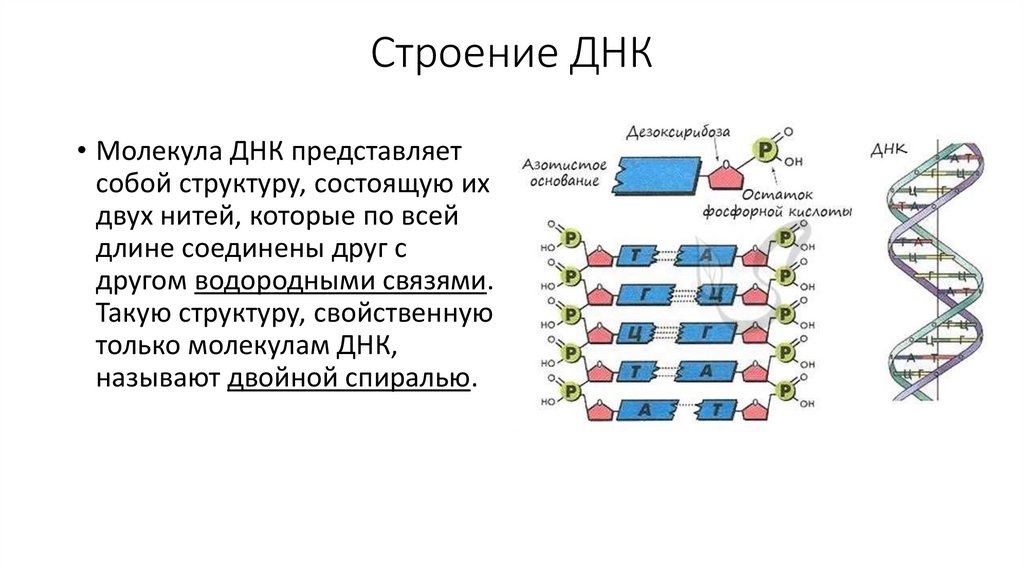
Эрик Ли
Заместитель медицинского директора
Доктор Эрик Ли является уроженцем Кливленда, штат Огайо, выпускником медицинского факультета Университета Толедо. Доктор Ли работал в различных клинических условиях, обучаясь как неотложной медицине, так и семейной медицине. Большая часть клинической деятельности доктора Ли была связана с медициной по месту жительства в качестве директора дома престарелых, посещения хосписа и оказания неотложной медицинской помощи в сельской местности.
Доктор Ли очарован растущей связью между технологиями и здравоохранением. Он владел и управлял небольшим телемедицинским бизнесом в течение трех лет. SelfDecode — идеальное место, где он может реализовать свои интересы в области здоровья человека и технологий!
Чарльз Мэнсон, доктор философии
Ученый-исследователь ИИ
Доктор Чарльз Мэнсон обладает более чем 10-летним опытом работы в области статистики, математического моделирования, анализа и ИИ в различных отраслях. Его предыдущий опыт работы включает в себя Deutsche Bank, AMEC, NHS и HBSC. Ранее он был соучредителем стартапа в области ИИ, работающего над разработкой новых решений ИИ с использованием глубокого обучения, генеративно-состязательных сетей (GAN) и обучения с подкреплением.
Его предыдущий опыт работы включает в себя Deutsche Bank, AMEC, NHS и HBSC. Ранее он был соучредителем стартапа в области ИИ, работающего над разработкой новых решений ИИ с использованием глубокого обучения, генеративно-состязательных сетей (GAN) и обучения с подкреплением.
Он получил степень магистра наук. и доктор философии по математике Уорикского университета. Там он работал под руководством лауреата Филдсовской медали доктора Мартина Хайрера и окончил его с лучшим результатом в своем классе. До этого он изучал вычислительную биологию в Кембриджском университете и математику в Нью-Йоркском университете. Он опубликовал множество статей в области математики и вероятности и выступал на ведущих международных конференциях.
Jon Lerga Jaso, PhD
Ученый в области биоинформатики
Доктор Джон Лерга Джасо получил степень магистра наук. в биоинформатике и доктор философии. в генетике. Его исследования в аспирантуре и аспирантуре были сосредоточены на функциональном влиянии полиморфных инверсий человека на экспрессию генов, эпигенетические изменения и фенотипические вариации.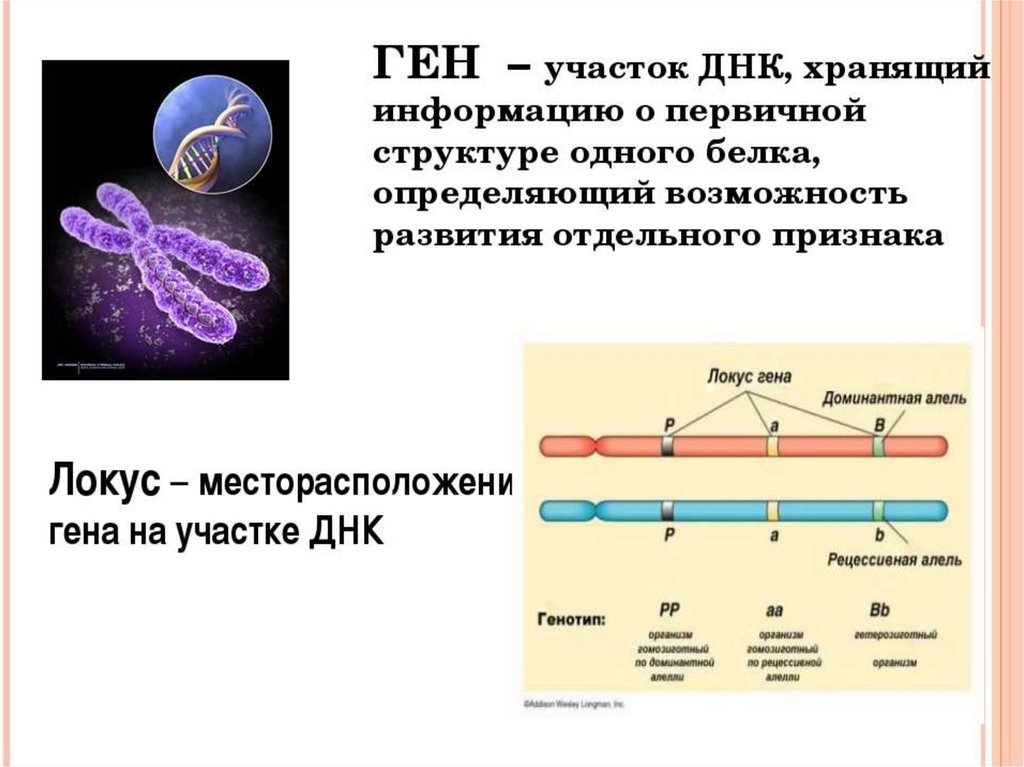 Прежде чем присоединиться к SelfDecode в качестве ученого-биоинформатика, он работал в компании по генетическому тестированию TellmeGen, где он разработал алгоритмы для вывода о происхождении и обнаружения дальних родственников с помощью ДНК.
Прежде чем присоединиться к SelfDecode в качестве ученого-биоинформатика, он работал в компании по генетическому тестированию TellmeGen, где он разработал алгоритмы для вывода о происхождении и обнаружения дальних родственников с помощью ДНК.
Во время своего образования и профессиональной карьеры он был удостоен нескольких наград, таких как «Premio Extraordinario» (прощальный), «Premio Nacional Fin de Carrera» (общенациональная награда за научную степень в Испании), докторская стипендия «La Caixa» самая престижная стипендия для докторантуры в Испании), доктор философии. Премия с отличием и международное упоминание докторских исследований. Он является автором множества исследовательских статей в престижных журналах, а также выступает на ведущих конференциях по геномике.
Его миссия состоит в том, чтобы раскрыть вклад человеческого генома в болезни и использовать эту информацию для изменения здоровья людей.
Биляна Новкович, доктор медицинских наук
Старший научный сотрудник в области точной медицины и директор по исследованиям и разработкам
Доктор Биляна Новкович — ученый с более чем 10-летним опытом исследований и разработок в области наук о жизни.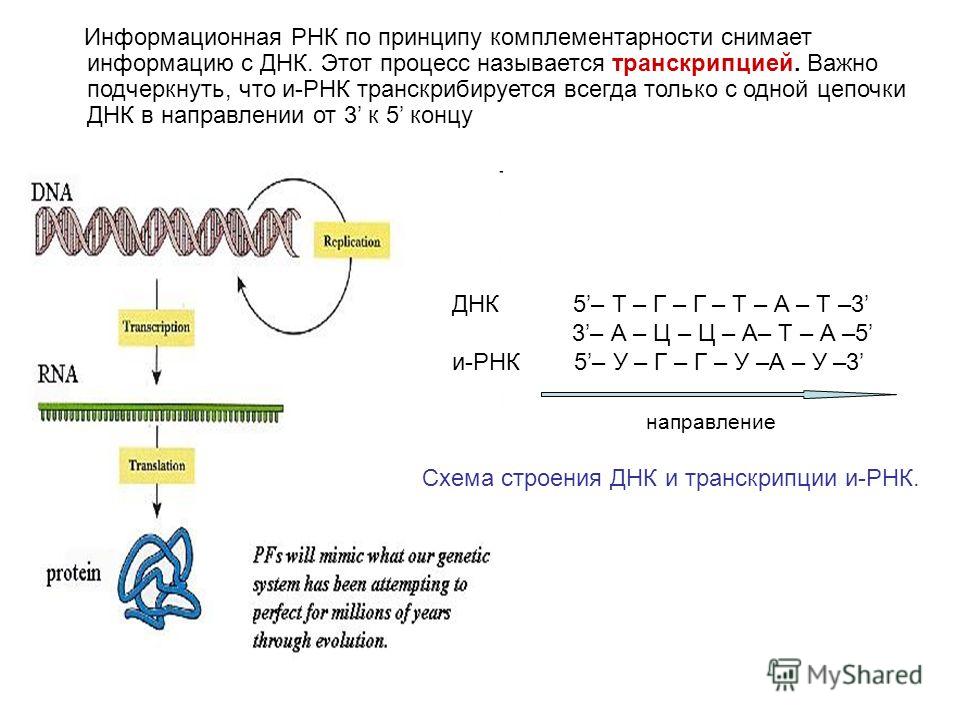 Ее миссия — улучшать профилактическое здравоохранение путем преобразования передовых научных исследований в продукты, которые улучшают жизнь людей. Она получила степень магистра наук. и доктор философии получила степень в области генетики в одном из лучших университетов Японии, где изучала эволюцию и популяционную генетику.
Ее миссия — улучшать профилактическое здравоохранение путем преобразования передовых научных исследований в продукты, которые улучшают жизнь людей. Она получила степень магистра наук. и доктор философии получила степень в области генетики в одном из лучших университетов Японии, где изучала эволюцию и популяционную генетику.
Ранее она занимала несколько руководящих должностей в биотехнологической отрасли. Она является автором нескольких научных рецензируемых публикаций и сотен непрофессиональных статей на темы, связанные со здоровьем.
Адриано Де Марино, доктор философии
Ученый в области биоинформатики и руководитель группы
Доктор Адриано Де Марино имеет более чем 4-летний опыт работы в качестве ученого в области биоинформатики в биотехнологической отрасли. Он получил степень магистра наук. степень в области биоинформатики Римского университета (Италия) и доктор философии. в области компьютерных наук Миланского университета (Италия). Его опыт заключается в написании новых биоинформационных алгоритмов, связанных с геномикой, с использованием новейших прорывных технологий.
Его опыт заключается в написании новых биоинформационных алгоритмов, связанных с геномикой, с использованием новейших прорывных технологий.
Он является автором нескольких рецензируемых публикаций, а также выступает на крупных конференциях по геномике. Он также был идеологом, соучредителем и разработчиком COVIDZONE, веб-приложения, которое помогало итальянцам отслеживать ограничения COVID-19 во время пандемии. Его жизненная миссия состоит в том, чтобы использовать свой талант для написания новых геномных алгоритмов, чтобы произвести революцию в точной медицине.
Лоран Дюфлу, доктор философии
Инженер по работе с большими данными
Доктор Дюфло вырос в районе Парижа, где он провел большую часть подросткового возраста, занимаясь программированием на разных языках. Он получил докторскую степень по математике в 2015 году в Университете Париж 13, где изучал хаусдорфову размерность предельных множеств — область исследований, которая находится на пересечении геометрии, динамических систем и статистики.
Три года работал постдоком в Финляндии, прежде чем начать карьеру инженера по обработке данных. Ранее он был руководителем группы в Societe Generale Investment Banking. Он опубликовал множество статей и выступил на ведущих международных конференциях.
Рокки Хаторанган, доктор философии
Ученый в области биоинформатики
Д-р Марселинус Рокки Хаторанган — ученый с более чем 12-летним опытом исследований и разработок в области наук о жизни. Он эксперт по омике со специализацией в области геномики, эпигеномики и сборки генома. Он создал несколько научных подразделений в области биоинформатики, секвенирования нового поколения и редактирования генома для различных компаний. Он получил докторскую степень. по молекулярной биологии в Шведском университете сельскохозяйственных наук. Он сертифицированный MITxPRO аналитик больших данных.
Он успешно публиковался в области геномного импринтинга, барьеров гибридизации, культуры тканей и генов-транспортеров, а также занимал руководящие должности в крупных компаниях в области наук о жизни.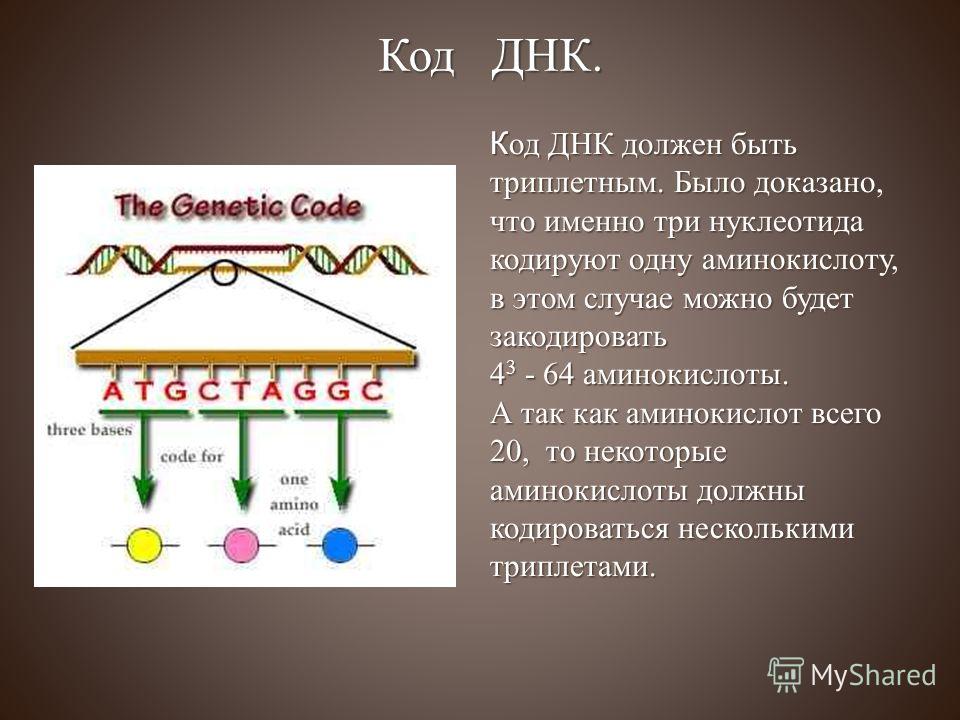
Карлос Тельо Лакаль, доктор философии
Научный сотрудник по исследованиям и разработкам
Доктор Карлос Тельо Лакаль — ученый с более чем 10-летним опытом исследований и разработок в области наук о жизни. Его миссия — использовать свои исследовательские и аналитические способности для улучшения качества жизни людей. Он получил степень магистра наук. и доктор философии получил степень в области молекулярной биологии в Университете Севильи, где изучал перенос ионов в растениях. Он является автором нескольких рецензируемых публикаций, академических книг и заказных обзорных статей, а также более 100 непрофессиональных статей на темы, связанные со здоровьем. Кроме того, он редактировал научные рукописи и докторскую степень. диссертации и письменные подходы к отраслевым проблемам.
В ходе своей разнообразной исследовательской карьеры он помог разработать напиток от похмелья и провел анализ скринингового теста на рак молочной железы.
Ральф Кенни, MSc, MBA
Ральф Кенни имеет более чем 20-летний успешный опыт работы на уровне C в области технологий, здравоохранения и электронной коммерции, работая как в компаниях из списка Fortune 500, так и в стартапах.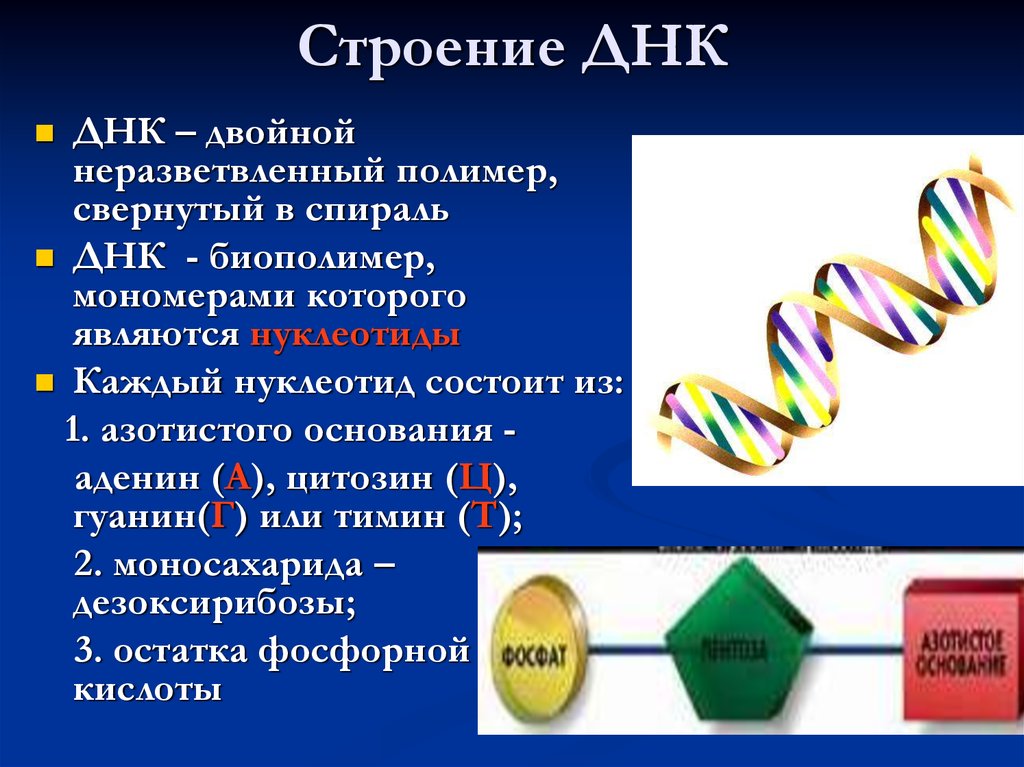 В качестве главного операционного директора он провел предыдущую компанию от стартапа до успешного IPO за 6 лет. Он также основал и возглавил прибыльный семизначный бизнес.
В качестве главного операционного директора он провел предыдущую компанию от стартапа до успешного IPO за 6 лет. Он также основал и возглавил прибыльный семизначный бизнес.
Ральф начал свою профессиональную карьеру в лабораториях AT&T Bell, где он написал протоколы передачи данных для высокоскоростной пакетной передачи голоса и стал соавтором международного стандарта CCITT для сигнализации для сетей с ретрансляцией кадров. Он публикуется в рецензируемых журналах по телекоммуникациям и физике. Он имеет степень магистра электротехники со специализацией в области физики твердотельных материалов.
Элиана Фердман, BEng
Начальник отдела продукта
Элиана получила степень бакалавра технических наук в Университете Макгилла.
Она начала свою карьеру в качестве менеджера проектов в Google и быстро поняла, что ей будет лучше работать в стартапе.
Элиана была первым менеджером проекта, нанятым SelfDecode.
После 4 лет работы в SelfDecode Элиана теперь работает руководителем отдела продукта, руководя несколькими параллельными проектами, управляя несколькими группами разработчиков продуктов, определяя объем проекта, управляя коммуникациями и устанавливая сроки.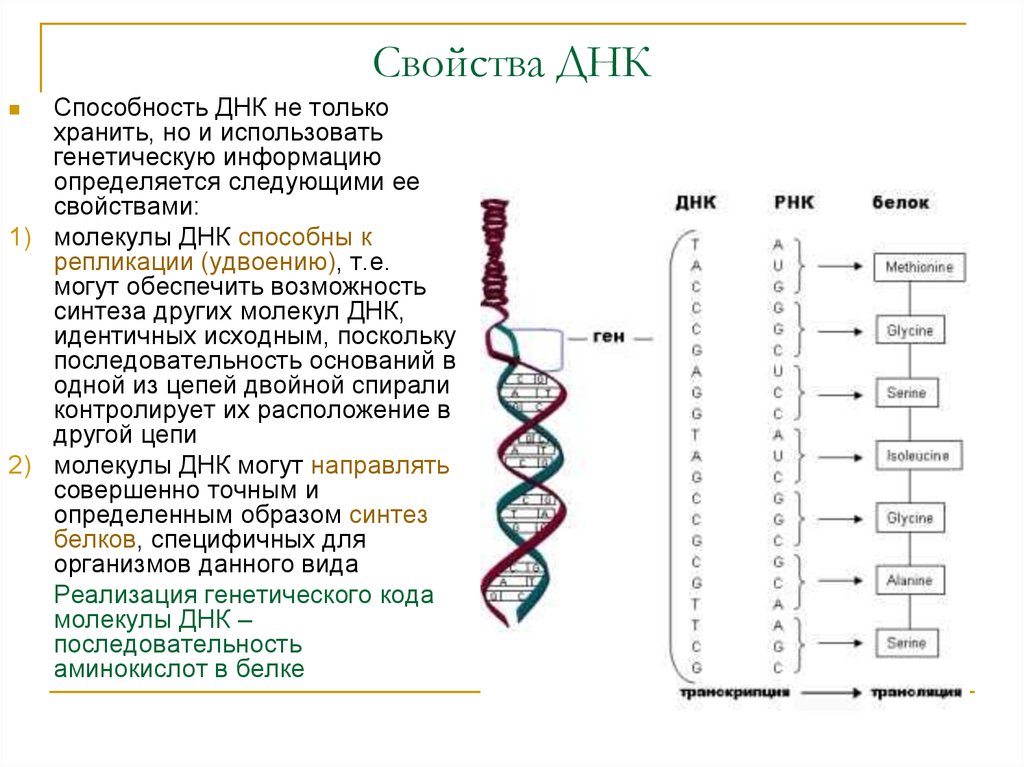
Алекса Ристич, MSc
Специалист по медицинским коммуникациям
Алекса получила степень магистра наук. степень в области фармации. За это время он провел исследование источников белка в вегетарианской и веганской диетах. До того, как присоединиться к SelfDecode в качестве специалиста по медицинским коммуникациям, он работал фармацевтом и внештатным автором медицинских статей. Он также провел 3 месяца в Индии, исследуя передовые системы доставки лекарств. Его области знаний лежат в области функциональной медицины, пищевых добавок и микробиома.
Его миссия — помочь людям лучше понять свое тело, тем самым помогая им жить более здоровой и счастливой жизнью.
Сандра Бон, MSc
Инженер по большим данным
Сандра обладает более чем 7-летним опытом анализа крупномасштабных геномных данных в высокопроизводительных компьютерных кластерах. Сандра получила степень магистра наук. получила степень доктора биологических наук в Университете Южного Миссисипи, где изучала популяционную генетику. В дополнение к ее техническим навыкам в области анализа больших данных, она имеет профессиональный опыт сбора, управления и анализа геномных данных для университетов и федеральных агентств.
В дополнение к ее техническим навыкам в области анализа больших данных, она имеет профессиональный опыт сбора, управления и анализа геномных данных для университетов и федеральных агентств.
Она является автором многочисленных рецензируемых публикаций, а также выступает на местных и национальных конференциях. В то время как ее предыдущая работа была ориентирована на охрану природы, ее интерес к тому, как персонализированная генетика может улучшить результаты в отношении здоровья, привел ее к SelfDecode.
Эндрю Терполовский, MSc
Старший инженер по биоинформатике
Эндрю обладает 10-летним опытом разработки программного обеспечения, включая предыдущие руководящие должности. Эндрю получил степень магистра наук. диплом с отличием по специальности «Информационные технологии и системы – вычислительная техника» Полтавского национального технологического университета. Он успешно руководил или принимал участие в более чем 16 крупных проектах по программному обеспечению, ориентированных на здравоохранение или финансы. Он имеет большой опыт работы с различными фронтенд-технологиями и языками программирования.
Он имеет большой опыт работы с различными фронтенд-технологиями и языками программирования.
Его миссия состоит в том, чтобы использовать свой инженерный опыт для решения самых сложных проблем и разработки революционных программных решений в точной медицине.
Гонсало Амескита Куэльяр, магистр наук
Научный исследователь/писатель
Гонсало получил степень магистра наук. в области медицинских и фармацевтических инноваций в Университете Гронингена (Нидерланды). В это время он занимался исследованиями стволовых клеток, иммунологии и скрининга лекарств. Прежде чем присоединиться к SelfDecode в качестве научного автора/исследователя, он провел 3 месяца в Университете Пердью, занимаясь исследованиями в области молекулярной фармакологии. Он также работал над исследованиями в области натуральных продуктов, создал проект по популяризации науки и выступал в качестве специалиста по борьбе с COVID-19.Специалист по медицинской информации о вакцинах.
Гонсало заинтересован в повышении грамотности в вопросах здоровья путем донесения науки до широкой публики. Он считает, что предоставление людям возможности использовать текущие медицинские исследования будет больше вовлекать их в собственное здравоохранение. Он считает, что это имеет решающее значение для прокладки пути к демократизированной персонализированной медицине.
Эдвард Крейман, MBA
Технический директор
Леонардо Фернандес, бакалавр наук
Руководитель проекта
Леонардо обладает более чем 14-летним опытом работы в отрасли на различных должностях. Он имеет опыт промышленной инженерии Аргентинского университета бизнеса по специализации Data Science (IBM) и Agile Development (Университет Вирджинии). Он имеет большой профессиональный опыт в различных отраслях и работал в нескольких ведущих международных компаниях, таких как Saint-Gobain, Techint, Honda и Bayer.
Он был соучредителем и главным операционным директором Auravant, компании AgTech, которая помогает фермерам использовать семена и агрохимикаты наиболее эффективным способом на основе спутниковых изображений.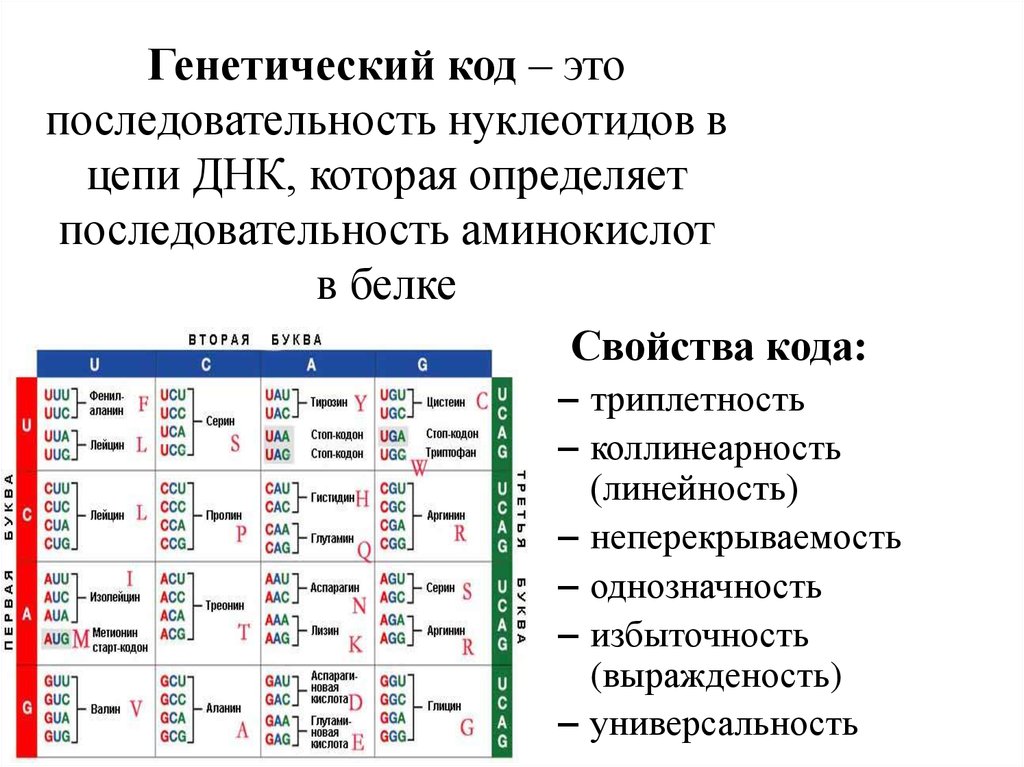 Его работа была отмечена программами BIC и Copernicus Европейского космического агентства и дважды была отмечена в аргентинском журнале Forbes.
Его работа была отмечена программами BIC и Copernicus Европейского космического агентства и дважды была отмечена в аргентинском журнале Forbes.
Варуна Бамунусингхе, бакалавр наук
Старший инженер по искусственному интеллекту и руководитель группы
Варуна обладает более чем 13-летним опытом разработки программного обеспечения, в том числе более 4 лет опыта работы на руководящих должностях. Он получил степень бакалавра наук. (с отличием) в области компьютерных наук одного из лучших университетов Шри-Ланки (Шри-Джаяварденепура), где он был удостоен прощальной речи. Он тесно сотрудничал с Canon Inc. над созданием ведущих в отрасли программных решений для цифровых печатных машин. В конце концов он помог основать Eniplex (Pvt) Ltd, где работал техническим директором и тесно сотрудничал с ведущими компаниями для предоставления программных решений. Среди его клиентов были DISCO Inc.
Он обладает глубоким опытом в области разработки данных и программного обеспечения, включая опыт и знания в области искусственного интеллекта и машинного обучения. Он увлечен сочетанием искусственного интеллекта с геномикой для раскрытия секретов жизни.
Он увлечен сочетанием искусственного интеллекта с геномикой для раскрытия секретов жизни.
Абдалла Махмуд, бакалавр наук
Инженер-биоинформатик
Абдалла — инженер-биоинформатик и биолог-вычислитель, увлеченный внедрением современных моделей AI/ML в геномике и точной медицине. Получил высшее образование в Университете Зеваил (Египет) по специальности «Вычислительная биология». С тех пор он провел множество успешных исследовательских проектов в области точной медицины с использованием моделей AI/ML, таких как SVM (для раннего выявления аутизма), сети LSTM (для прогнозирования диабета 2 типа) и Convolution Neural Networks (для классификации эмоций).
Сайед Васим Уд Дин, бакалавр наук
Старший инженер DevOps
Васим имеет 9-летний многоотраслевой и междисциплинарный опыт работы в индустрии программного обеспечения, и его жизненной миссией является создание передовых решений, которые оказывают положительное влияние на жизнь людей во всем мире.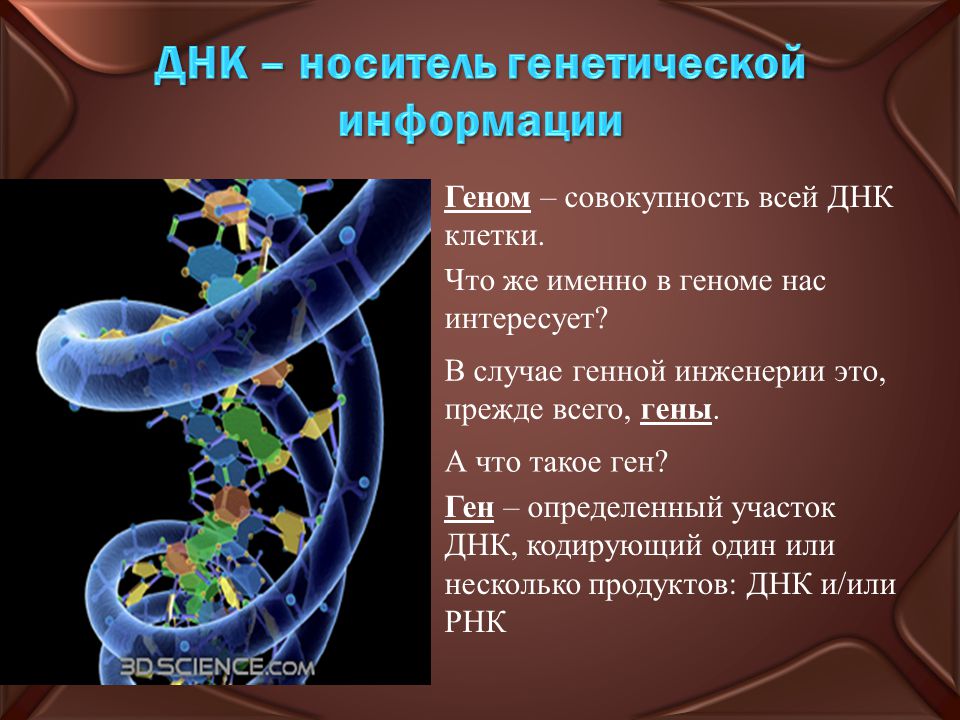 .
.
Он начал свою карьеру в качестве дизайнера и разработчика игр, а затем перешел на предоставление услуг компаниям по управлению инвестициями и фирмам по управлению соблюдением требований в качестве инженера по большим данным и облачным вычислениям. Waseem имеет опыт руководства командами разного размера для создания экспертных решений для обработки структурированных и частично структурированных данных, а также опыт машинного обучения для создания ценных моделей поведения пользователей. Он работал над аспектами облачной безопасности, следуя принципу наименьших привилегий и настраивая брандмауэры для защиты приложений от атак.
Васим получил степень бакалавра наук. (с отличием) в области электротехники со специализацией в области компьютерных наук и с отличием окончил Инженерно-технологический университет в Лахоре. Теперь Васим присоединился к SelfDecode в качестве старшего инженера DevOps, где он гордится тем, что делает новейшие решения для здоровья доступными для всех.
Алекс Осама, бакалавр наук
Data Scientist
Алекс имеет 7-летний профессиональный опыт работы инженером-программистом искусственного интеллекта в крупнейшем научно-исследовательском центре Valeo, работающем над ведущими на рынке проектами для таких клиентов, как AUDI, Daimler и Honda, занимающихся робототехникой. , компьютерное зрение, НЛП и проблемы оптимизации. Для его магистра. защитил диссертацию в Немецком университете в Каире, в настоящее время он работает над использованием ИИ и нейронауки для восстановления зрения.
Выросший в семье с несколькими хроническими заболеваниями, которые со временем плохо помогали неотложной медицине, он начал самостоятельно исследовать способы лечения этих состояний и увлекся питанием и образом жизни, что привело к значительным улучшениям с уменьшением на 80% лекарства. Его текущая миссия состоит в том, чтобы работать над продуктами, которые оказывают положительное влияние на жизнь людей, революционизируя здравоохранение и занимая первое место в списке.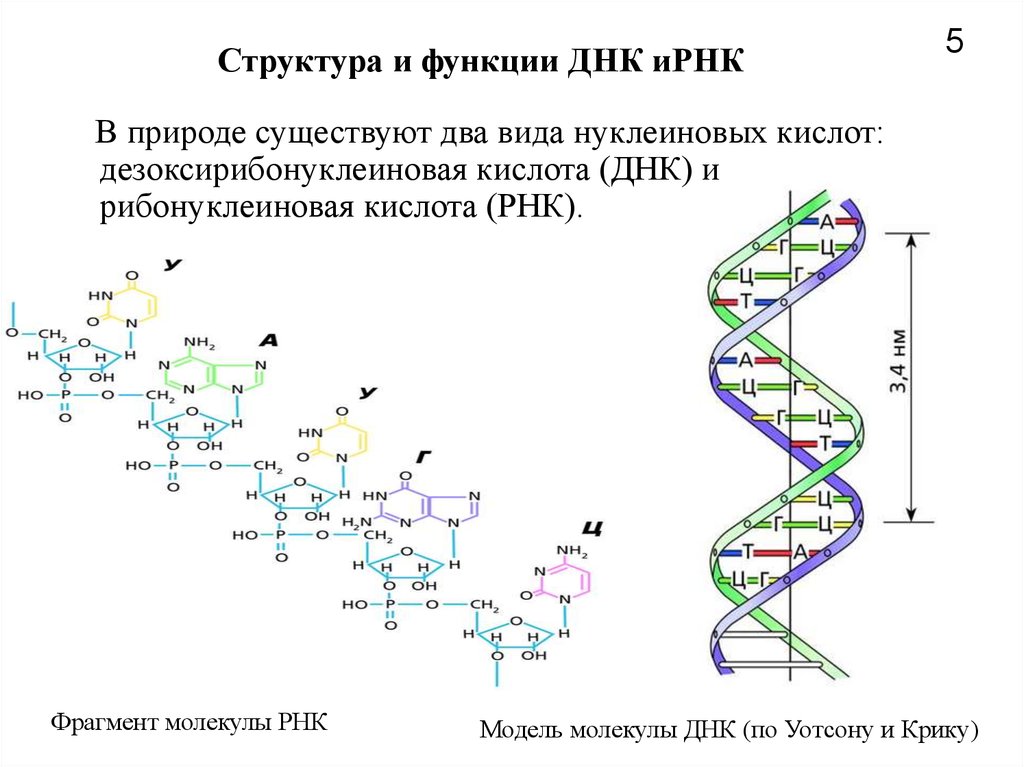
Манфред Грабхерр, доктор философии
Вице-президент по биоинформатике и искусственному интеллекту
Доктор Манфред Грабхерр — всемирно известный эксперт в области геномики, биоинформатики и искусственного интеллекта, обладающий более чем 30-летним опытом работы как в научных кругах, так и в промышленности. Манфред получил докторскую степень по прикладной физике в Венском технологическом университете, Австрия
(TU Wien) в 1992 году. Затем он работал над распознаванием речи, обработкой естественного языка и машинным обучением
в промышленности в течение следующих 11 лет, как в Вене, так и в Район Большого Бостона, Массачусетс. Компании, в которых он работал, включают IBM, Philips, Lernout & Hauspie и Voice Signal Technologies.
В 2003 году он присоединился к Институту Броуда Массачусетского технологического института и Гарварда в качестве вычислительного биолога. Помимо вклада в ряд крупномасштабных проектов и публикаций в области геномики, основные моменты включают в себя программное обеспечение для сборки RNA-Seq Trinity, которое упоминается почти в 12 000 исследованиях по всему миру, и Saguaro, программное обеспечение для автоматического обнаружения сигналов адаптивной эволюции в популяциях, которое с тех пор был объявлен «золотым стандартом» для других методов и анализов.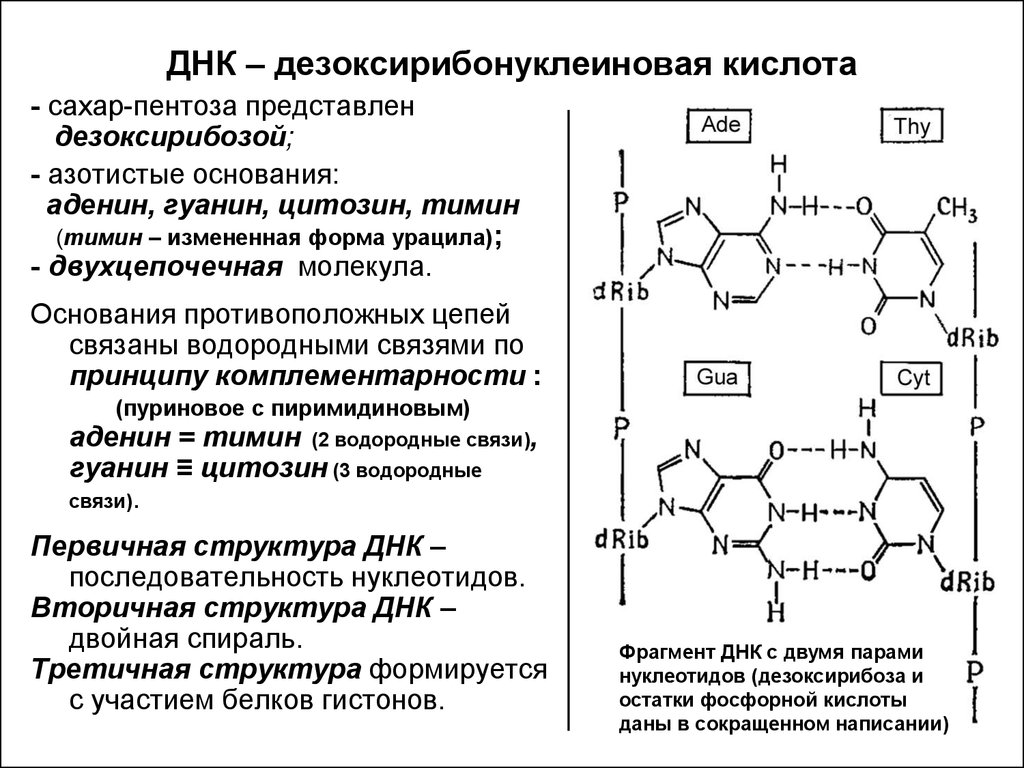 В 2011 году он перешел в Упсальский университет в Швеции, где в 2013 году получил звание доцента.
В 2011 году он перешел в Упсальский университет в Швеции, где в 2013 году получил звание доцента.
Помимо того, что он занимал руководящие должности, он стал соучредителем нескольких компаний. У Манфреда 60 публикаций в авторитетных рецензируемых журналах (Nature, Science и т. д.), он является изобретателем многочисленных патентов и имеет историю успешных выходов.
Умар Хан, бакалавр наук
Ведущий инженер по обработке данных
В настоящее время Умар работает в SelfDecode ведущим инженером по обработке данных. Его миссия — исследовать и внедрять инновации в технологии искусственного интеллекта следующего поколения. Он обладает широким спектром междисциплинарных знаний, с более чем 7-летним опытом работы в качестве технического директора и инженера-программиста, а также обширными знаниями систем обработки естественного языка. До прихода в SelfDecode он сотрудничал с Калифорнийским университетом в Беркли в рамках исследовательского партнерства. Это партнерство направлено на применение тематического моделирования и других моделей искусственного интеллекта для решения проблем финансового соответствия и заполнения пробелов в нормативном надзоре.
Это партнерство направлено на применение тематического моделирования и других моделей искусственного интеллекта для решения проблем финансового соответствия и заполнения пробелов в нормативном надзоре.
На протяжении своей карьеры он создал бесчисленное количество систем сбора данных и аналитики на основе как структурированных, так и неструктурированных наборов данных. Он также успешно провел заявку на участие в программе HotDesq (программа государственной инициативы в Квинсленде, Австралия) с целью расширения инновационных технологических стартапов со всего мира. Одним из его крупных достижений за последние годы было участие в успешной заявке на получение гранта IBM на создание платформы SaaS для DataOps и MLOps.
У него страсть к науке и технологиям, и он рад использовать свое лидерство и опыт в области искусственного интеллекта и машинного обучения для решения самых больших мировых проблем в области геномики и точной медицины.
Shany Lahan, MSc
Специалист по медицинским коммуникациям и редактор
Shany получила степень магистра наук. получила степень доктора неврологии в Западном университете (Канада), где проводила исследования болезни Альцгеймера. В это время она также преподавала анатомию и нейробиологию студентам университетов, параллельно организуя конференции и семинары. Прежде чем присоединиться к SelfDecode в качестве специалиста по медицинским коммуникациям, она накопила обширный опыт работы с людьми и клетками в лаборатории и представила результаты своих исследований на многочисленных конференциях.
получила степень доктора неврологии в Западном университете (Канада), где проводила исследования болезни Альцгеймера. В это время она также преподавала анатомию и нейробиологию студентам университетов, параллельно организуя конференции и семинары. Прежде чем присоединиться к SelfDecode в качестве специалиста по медицинским коммуникациям, она накопила обширный опыт работы с людьми и клетками в лаборатории и представила результаты своих исследований на многочисленных конференциях.
Шэни считает, что исследования должны быть доступны каждому, независимо от научной подготовки. Ее миссия состоит в том, чтобы помочь другим улучшить свое здоровье и благополучие, а также помочь им понять науку, стоящую за всем этим.
Льюис Катбертсон, доктор философии
Научный писатель
Доктор Льюис Катбертсон имеет более чем 6-летний опыт работы в области геномики и технологий секвенирования нового поколения. Доктор Катбертсон провел несколько лет, изучая биоразнообразие бактериальных сообществ Арктики и Антарктики, а также работал исследователем в компании, предоставляющей услуги секвенирования ДНК. В этой компании он участвовал в нескольких исследованиях микробиома, основанных на здоровье. Эти исследования дали ему представление о том, как очень разнообразная и «скрытая» часть человеческого здоровья может потенциально повлиять на качество жизни человека. В конечном счете, это подпитывало его желание помочь другим понять их собственные сложные потребности в области здравоохранения с помощью самых современных научных исследований.
В этой компании он участвовал в нескольких исследованиях микробиома, основанных на здоровье. Эти исследования дали ему представление о том, как очень разнообразная и «скрытая» часть человеческого здоровья может потенциально повлиять на качество жизни человека. В конечном счете, это подпитывало его желание помочь другим понять их собственные сложные потребности в области здравоохранения с помощью самых современных научных исследований.
Люси Брэдли, доктор медицины
Врач
Доктор Люси Брэдли является лицензированным врачом, получившим степень в Университете Шеффилда, Англия. С тех пор она практиковала в Великобритании в качестве врача по различным специальностям, включая онкологию и неотложную медицину, а также последние два года работала в больницах на переднем крае борьбы с пандемией. Она успешно публиковала статьи и представляла свою работу на национальных конференциях по вопросам медицинской этики и радиологического обучения. Она увлекается точной медициной и геномикой и особенно интересуется их применением для первичной профилактики заболеваний.
Кристин Эмильен, доктор философии
Менеджер по нормативно-правовым вопросам
Д-р Кристин Эмильен обладает 6-летним опытом работы в отрасли, а также знаниями в области регулирования. Она получила докторскую степень. в науке о питании со второстепенным в области коммуникаций из Университета штата Айова. До прихода в команду SelfDecode она работала на различных управленческих и регулирующих должностях, уделяя особое внимание правилам FDA для продуктов питания, пищевых добавок, косметики и медицинских устройств. Она провела клинические испытания на людях, изучая клетчатку и аппетит у взрослых, а также написала множество научных статей в рецензируемых журналах.
Нусаббех Вакар, MBA
Менеджер по продукту
Нусаббе обладает более чем 5-летним опытом работы в области проектирования, управления и бизнес-анализа. Он получил степень бакалавра наук. Он получил степень бакалавра инженерии, а затем получил степень магистра делового администрирования в Хьюстонском университете, где он специализировался на операциях и финансах и окончил его с лучшим результатом в своем классе.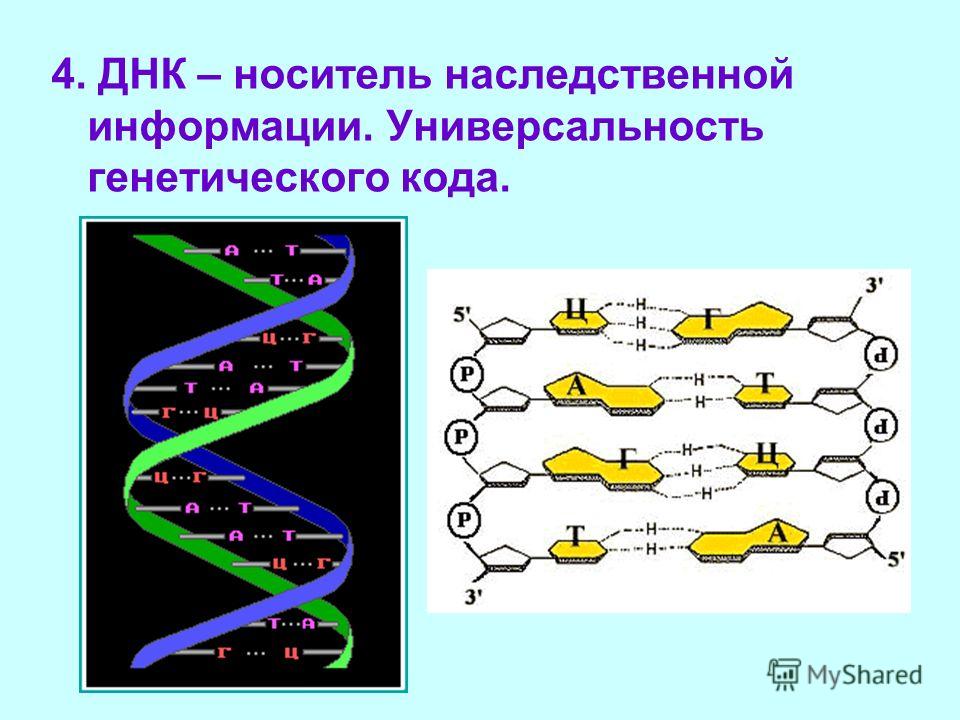 Он присоединился к SelfDecode в качестве менеджера по продукту, где он управляет проектами разработки, организует сотрудничество между командами и обеспечивает эффективную реализацию плана развития продукта. У него мышление «кайдзен», и он постоянно стремится улучшить процессы внутри организации.
Он присоединился к SelfDecode в качестве менеджера по продукту, где он управляет проектами разработки, организует сотрудничество между командами и обеспечивает эффективную реализацию плана развития продукта. У него мышление «кайдзен», и он постоянно стремится улучшить процессы внутри организации.
Рупа Бозе, MSc
Ученый-геномик
Рупа дважды специализировалась на математике и физике в Массачусетском технологическом институте, прежде чем получить степень магистра наук. в микробиологии и биохимии из Университета Флориды. Она имеет 3-летний опыт работы в биотехнологической отрасли в качестве научного сотрудника, занимающегося исследованиями и разработками. В это время она работала в таких компаниях, как Thermo Fisher и Curtiss Healthcare, и участвовала в важных проектах, связанных с генной терапией и вакцинами. Она также имеет большой исследовательский опыт и несколько публикаций под своим именем, изучая все, от рака молочной железы до угольного топлива.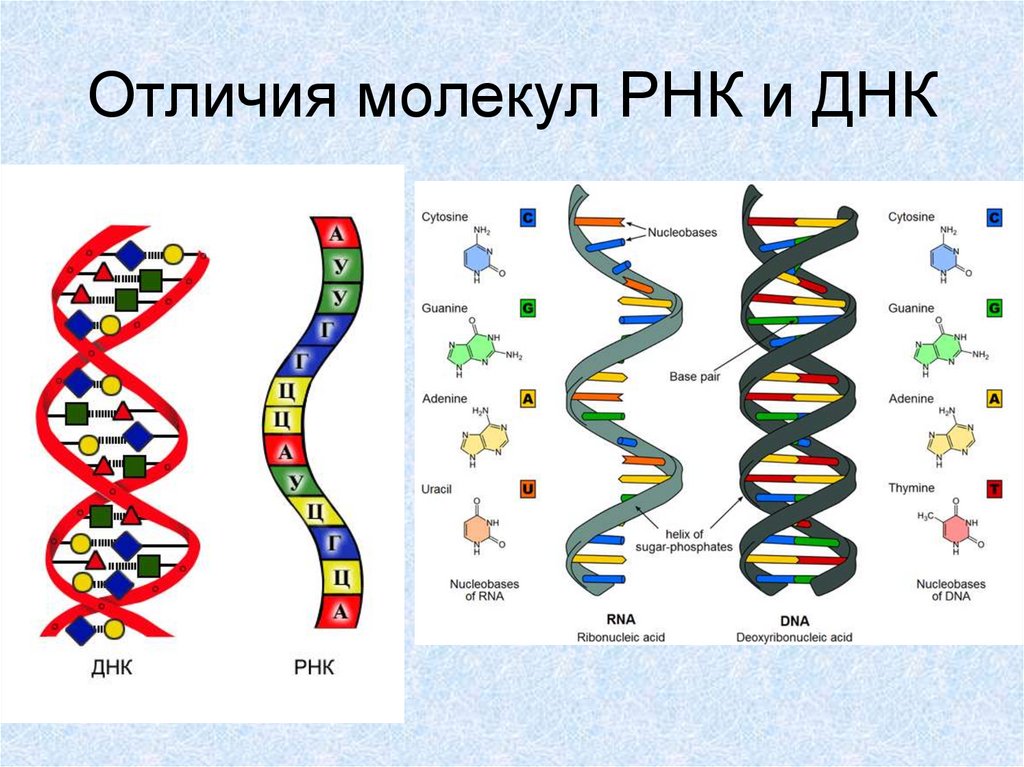
Ее миссия состоит в том, чтобы улучшить область точной медицины, предоставляя людям доступ к самой последней передовой информации об их собственном здоровье. Она стремится побудить людей и их врачей оптимизировать индивидуальное лечение.
Хейли Педерсен, MSc
Ученый-геномик
Хейли — опытный ученый-геномик, который считает, что, понимая нашу уникальную эволюционную историю, мы можем лучше лечить и предотвращать возникновение сложных заболеваний. Ее миссия состоит в том, чтобы улучшить здоровье человека, понимая взаимодействие между геномикой, окружающей средой и культурой через призму эволюции. Она получила степень магистра наук. Кандидат антропологии (специализация по эволюционной генетике) Цюрихского университета.
До прихода в SelfDecode она работала научным сотрудником в группе, проводившей исследования рака, полевым техником в долгосрочном исследовательском проекте по генетике морских животных и технологом в стартапе аквапоники (сельскохозяйственные инновации).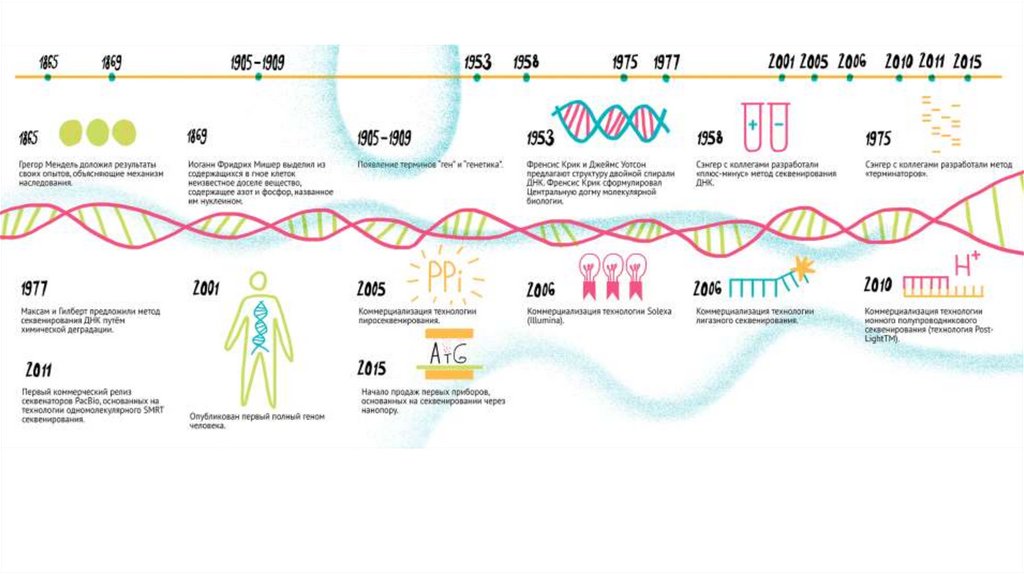 Выступала с докладами на ведущих международных конференциях.
Выступала с докладами на ведущих международных конференциях.
Отчеты о состоянии здоровья
Акне
Аллергия
Беспокойство
Астма
Внимание
Артериальное давление
Уровень сахара в крови
Bone Health
Brain Fog
Cholesterol
Chronic Fatigue
Chronic Pain
Eczema
Gallstones
Gut Inflammation
Headache
Heart Health
Inflammation
Insomnia
Irritable Bowel
Joint Inflammation
Joint Pain
Kidney Health
Kidney Stones
Migraines
Mood
Боль в шее и плечах
Повышенная активность щитовидной железы
Псориаз
Сексуальная дисфункция
Стресс
Шум в ушах
Низкая активность щитовидной железы
Инфекции мочевыводящих путей
Вес
thinkBiotech Глобальный эксперт в области биофармацевтических инноваций, свидетель и спикер
thinkBiotech Глобальный эксперт в области биофармацевтических инноваций, свидетель и спикер — Яли Фридман, доктор философии.
Назван одним из 100 самых влиятельных людей в области биотехнологии по версии журнала
Scientific American
ЭКСПЕРТИЗА
Коммерциализация биотехнологии
Д-р Фридман является автором книги Building Biotechnology , которая использовалась в десятках программ MBA и программ для выпускников в области биотехнологии. Доктор Фридман также опубликовал Журнал коммерческой биотехнологии , который был описан как «Гарвардский обзор бизнеса для биотехнологических компаний»
ЖУРНАЛ КОММЕРЧЕСКОЙ БИОТЕХНОЛОГИИ БИЛДИНГ БИОТЕХНОЛОГИЯ
Патенты на лекарства
Д-р Фридман разработал базу данных DrugPatentWatch.com в 2002 году. знания о глобальных патентах на лекарства и доступе к дженерикам для клиентов по всей цепочке открытия-разработки-поставки лекарств.
DRUGPATENTWATCH
Глобальная биотехнология
Д-р Фридман в течение десяти лет занимала глобальную биотехнологию в рейтинге журнала Scientific American .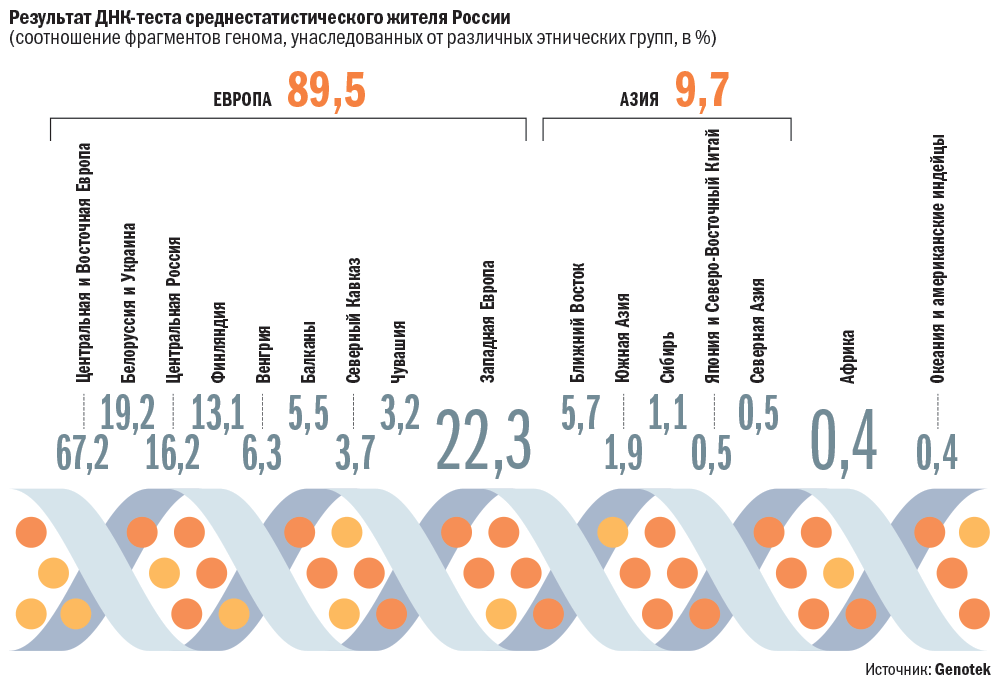 Этот рейтинг был представлен на многочисленных международных конференциях, перед федеральными агентствами США и на многих национальных форумах по развитию биотехнологии.
Этот рейтинг был представлен на многочисленных международных конференциях, перед федеральными агентствами США и на многих национальных форумах по развитию биотехнологии.
МИРОВОЙ РЕЙТИНГ БИОТЕХНОЛОГИЙ
SPEAKING ENGAGEMENTS
Привнесите глобальную перспективу в ваше мероприятие
Доктор Фридман выступал на форумах по развитию биотехнологической промышленности для федеральных агентств США, для международных групп и для отдельных стран Северной Америки, Европы и Азии.
Подготовьте почву для продуктивной встречи с обзором:
- Глобальный рейтинг биофармацевтической отрасли
- Глобальные и местные стратегии развития отрасли
- Целевые показатели
- Тематические исследования
КОНТАКТЫ
ИЗДАТЕЛЬСКИЕ ВОЗМОЖНОСТИ
Патенты на лекарства и фармацевтическая стратегия
Охватите десятки тысяч целевых читателей своей статьей в разделе ресурсов DrugPatentWatch.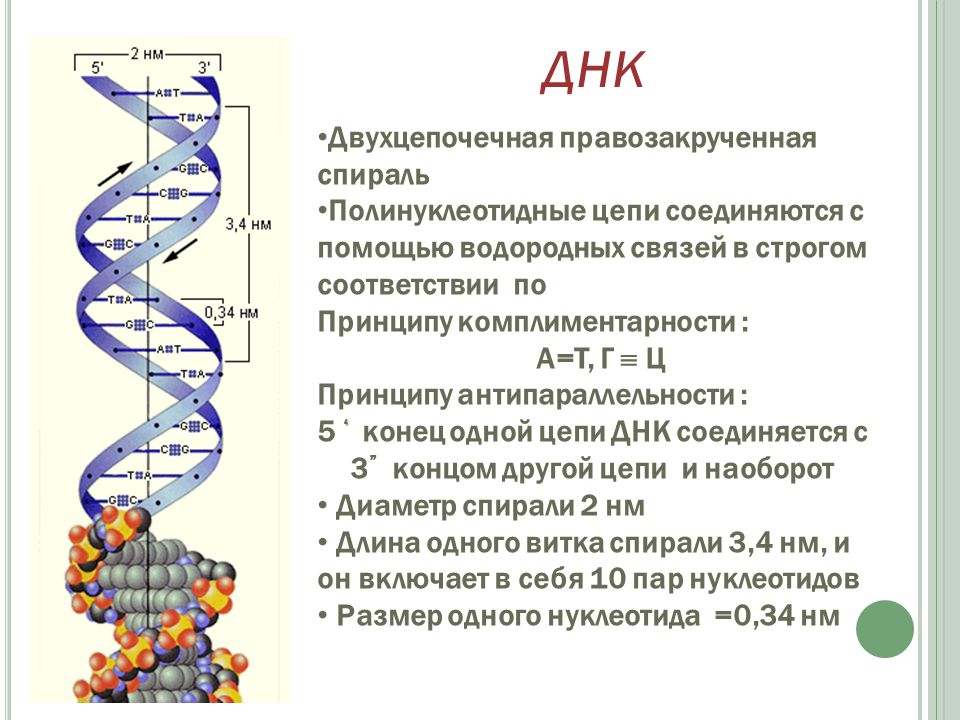
С каждой публикацией вы можете рассчитывать на охват:
Используйте контактную форму на сайте DrugPatentWatch, чтобы предложить тему. Пожалуйста, включите фотографию автора/логотип компании и биографию автора/компании в подписи вместе с любыми материалами.
BiotechBlog
Гостевые посты BiotechBlog доступны для информационных некоммерческих сообщений. Этот нерецензируемый выпуск более информативен, чем Journal of Commercial Biotechnology , и является отличным источником информации о вашей отрасли и практических рекомендаций. Инструкции по отправке находятся на https://www.biotechblog.com/spread-your-message-with-biotechblog, а существующий гостевой контент — на https://www. biotechblog.com/category/guest-content/.
biotechblog.com/category/guest-content/.
Пожалуйста, отправьте короткое сообщение, используя контактную форму BiotechBlog. Пожалуйста, включите фотографию автора/логотип компании и биографию автора/компании в подписи вместе с любыми материалами.
полный размер
Яли Фридман, доктор философии, основатель thinkBiotech и много лет был издателем Journal of Commercial Biotechnology . Его первая книга, Building Biotechnology , использовалась в качестве учебника в десятках программ по биотехнологии. Его другие книги включают Передовой опыт в области биотехнологического образования и Передовой опыт в развитии бизнеса в области биотехнологии . Scientific American также назвал доктора Фридмана одним из 100 самых влиятельных людей в области биотехнологии.
Д-р Фридман хорошо знаком с ведущими проблемами международной биотехнологии. Он является редактором журнала Scientific American worldVIEW Global Biotechnology Scorecard, глобального обзора биотехнологии, отражающего биотехнологические отрасли и инновационный потенциал в более чем пятидесяти странах, и был приглашен участвовать в форумах по развитию биотехнологической промышленности для федеральных агентств США, международных групп, таких как АТЭС и АСЕАН, а также для отдельных стран, таких как Канада, Германия, Индия, Япония, Филиппины и Турция.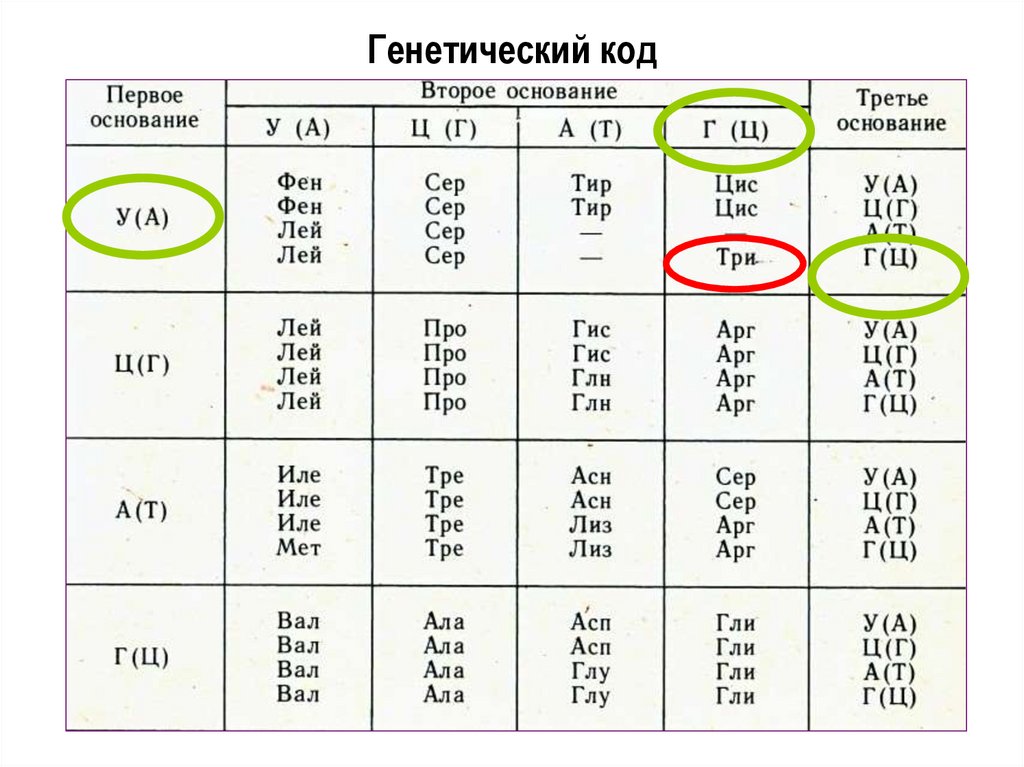
Д-р Фридман в течение нескольких лет преподавал управление биотехнологией в Национальном институте здравоохранения и продолжает регулярно читать лекции по другим образовательным программам в области биотехнологии. Он пишет и говорит на различные темы, такие как биотехнологическое предпринимательство, стратегии преодоления нехватки управленческих талантов и капитала при развитии компаний за пределами установленных центров и новые парадигмы экономического развития, основанного на технологиях.
Доктор Фридман имеет большой опыт работы в области биотехнологии. Он создал первый блог о бизнесе биотехнологии для веб-сайта NY Times, который был включен в список Forbes «Лучшее в Интернете». Его другие проекты включают «Руководство для студентов по компьютерам на основе ДНК», спонсируемое FUJI Television, BiotechBlog.com и DrugPatentWatch.com, платформу конкурентной разведки фармацевтической промышленности, основанную на бизнес-плане, который занял второе место в конкурсе Panasci Entrepreneurial Awards.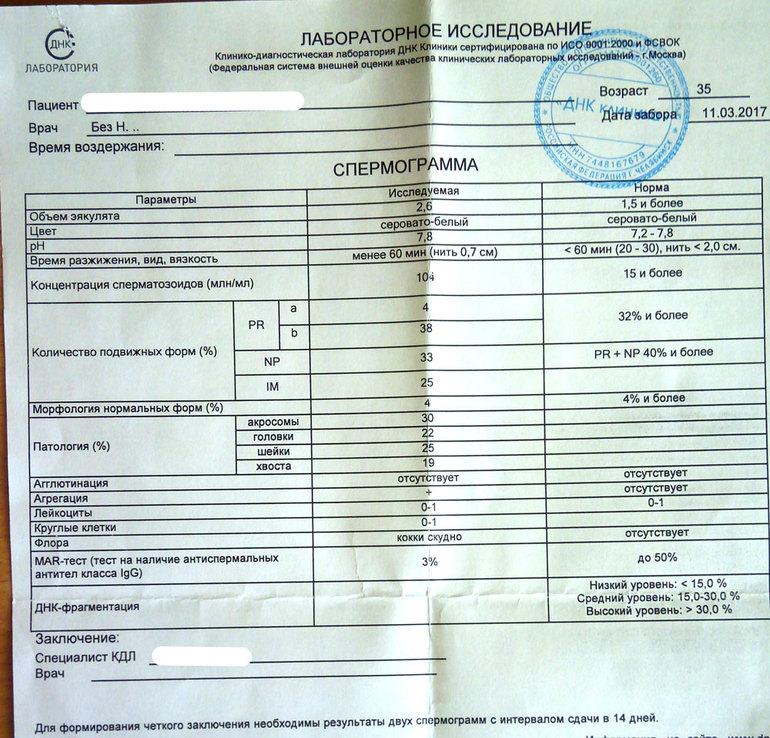
КОНТАКТЫ
Геном человека наконец-то полностью расшифрован
Новости науки
Достижения в технологии геномного секвенирования могут привести к возрождению медицинских открытий, говорят исследователи.
Исследователь Кевин Бишоп изучает образцы рыбок данио. Методы, используемые для секвенирования генома человека, также могут быть применены к другим видам. Ernesto Del Aguila III / National Institutes of Health
Эван Буш
Миссия выполнена — или, во всяком случае, достаточно близко.
Это было послание ученых миру в 2003 году, когда они объявили, что геном человека секвенирован, собран и практически завершен — с несколькими, казалось бы, незначительными пробелами.
На самом деле усилия по количественной оценке и идентификации генетического кода, который делает всех нас людьми, которые обошлись правительству США в миллиарды долларов, так и остались черновиками и по крайней мере на 8 процентов не были завершены.
Некоторые из самых больших, наиболее повторяющихся и сложных фрагментов головоломки ДНК оставались в неведении — до сих пор.
Опираясь на новую мощную технологию секвенирования, группа из примерно 100 ученых объявила в четверг, что они заполнили пробелы, завершили единый геном человека от одного конца до другого и открыли новые, многообещающие направления исследований в областях, в которых ученые бродил в темноте.
Секвенирование генома впервые было опубликовано более года назад, но результаты полного учета, которые теперь проверены и используются исследователями по всему миру, были впервые опубликованы в четверг в рецензируемом журнале. Шесть новых статей описывают все усилия по секвенированию и дополнительный анализ их результатов в журнале Science 9.0899 .
Исследователи прочитали аудиорентгенограмму секвенирования Сэнгера. Техника секвенирования по Сэнгеру, разработанная в 1970-х годах, широко использовалась в течение нескольких десятилетий. Новые технологии секвенирования переопределили возможности обработки ДНК. Национальные институты здравоохранения
Национальные институты здравоохранения
«Это сделано, и это правильно, и это прошло через все эти уровни проверки», — сказал Адам Филлиппи, вычислительный биолог из Национального исследовательского института генома человека. и лидер недавних усилий. «Мы оптимистичны в том, что могут быть ключи к эволюции человека и к тому, что делает нас уникальными людьми».
Эта беготня однажды может помочь исследователям в выявлении генетических причин заболеваний, распутывании тайн того, что заставляет некоторые клетки становиться раковыми, и помочь объяснить, как разные группы людей со временем развили разные черты, такие как способность процветать при высоких температурах. высота.
«Это знаковое событие», — сказал Стив Хеникофф, молекулярный биолог и профессор Центра исследования рака Фреда Хатчинсона и Вашингтонского университета, не участвовавший в проекте.
От строк к страницам
Сборка генома сродни «взять книгу, разорвать ее на мелкие кусочки и снова сопоставить», — говорит Меган Деннис, доцент, изучающая генетику и геномику человека в Калифорнийском университете в Дэвисе. Health, который внес свой вклад в секвенирование.
Health, который внес свой вклад в секвенирование.
Во-первых, исследователи должны разрезать ДНК на короткие фрагменты. Затем он обрабатывается и считывается по крупицам.
Разрезанная на части, трудно понять, откуда взялась каждая нить, поэтому ученые должны «сшить эту ДНК вместе вычислительным способом», сказал Деннис.
В течение 2000-х технология секвенирования ДНК могла производить только короткие фрагменты генетического кода — около 500 пар оснований или букв за раз.
Но некоторые области человеческого генома чрезвычайно повторяющиеся, почти как книжная страница со словами, повторяющимися много раз.
«Повторяющиеся элементы существуют во многих разных местах. Трудно понять, где они принадлежат», — сказал Деннис. В течение многих лет ученым просто приходилось оставлять эти страницы — и их понимание генома — пустыми.
В последние годы новая технология, позволяющая создавать более длинные считывания ДНК, полностью изменила правила игры. Новые машины могут производить сотни тысяч пар оснований в одном фрагменте.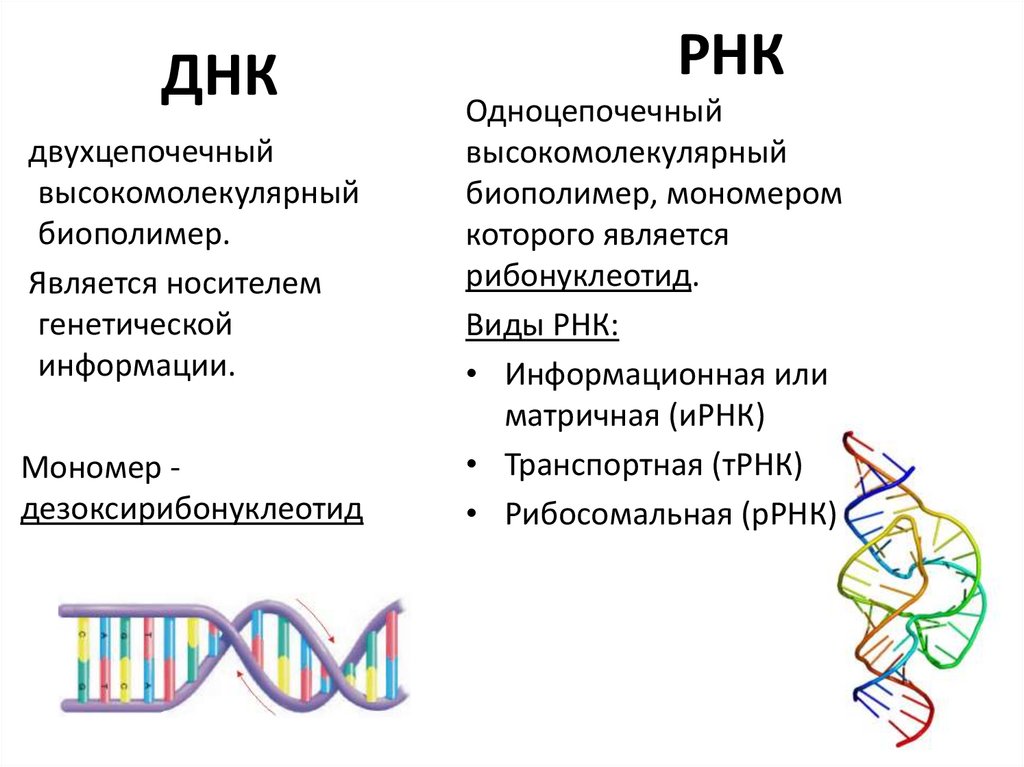
Достижения позволили исследователям восполнить недостающие фрагменты генома.
«20 лет назад было бы немыслимо иметь такую технологию, — сказал Филлиппи. Внезапно исследователи смогли упорядочить и поместить в контекст эти повторяющиеся части генома.
«У этих последовательностей есть гены… в этих областях есть очень важные функции».
Пандемический проект
Идея закончить геном выросла органично.
Будучи перфекционисткой в душе, Филлипи всегда раздражало то, что человеческий геном оставался неполным.
Около пяти лет назад он объединился с Карен Мига, доцентом кафедры биомолекулярной инженерии Калифорнийского университета в Санта-Круз, чтобы закончить работу.
Когда они застряли, они обратились за помощью. Проект начал развиваться как снежный ком, собрав около нескольких сотен научных участников и перерос в то, что сейчас называется проектом «теломер-к-теломерам» с использованием термина, описывающего концевые заглушки хромосом.
На цифровом дисплее отображаются выходные данные секвенатора ДНК. Национальные институты здравоохранения
Когда разразилась пандемия, темпы исследований только ускорились: исследователи общались из грязных подвалов на коммуникационной платформе Slack и по звонкам Zoom.
«2020 год был сумасшедшим по многим причинам. Это дало нам возможность сосредоточиться», — сказал Филлиппи.
В конце концов, исследователи собрали воедино весь генетический код для одной версии генома. Этот геном, который был получен несколько десятилетий назад из клеточной ткани, содержащей генетическую информацию одного сперматозоида, не представляет ни одного человека, который когда-либо жил, потому что он содержит только один набор отцовских хромосом.
Завершенный код станет основой новых геномных исследований и станет новым, законченным эталоном для сравнения.
Теория и практика
Завершенный геном открывает новые возможности для исследований.
В течение десятилетий ученые изучали 92 процента доступного генома, исследуя его, чтобы найти генетические вариации, которые могут вызывать заболевания.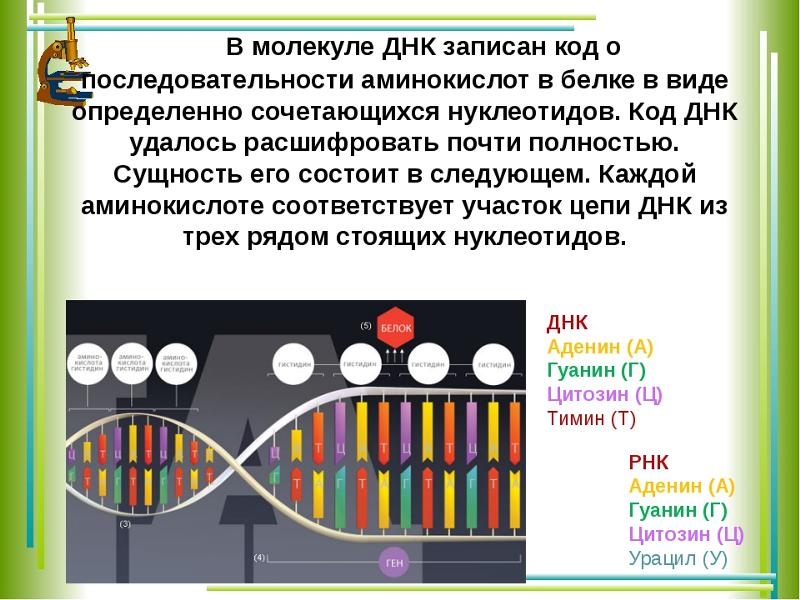
«Мы хорошо понимаем, как выглядят вариации в этих регионах, но у нас нет представления об остальных 8 процентах», — сказал Филлиппи.
Теперь исследователи повторно анализируют свои старые данные в сравнении с новым эталонным геномом, пытаясь найти новые подсказки из того, что было утеряно.
«Мы идентифицировали гораздо больше, десятки тысяч, если не сотни тысяч, новых вариантов, — сказал Деннис. «Некоторые из них относятся к генам, кодирующим белки, а некоторые из этих генов важны с медицинской точки зрения, клинически важны и способствуют возникновению заболеваний».
Новая ссылка на геном также позволяет продолжить изучение того, как работают центромеры.
Центромеры представляют собой структуры в середине хромосом, заполненные повторяющимися последовательностями кода и являющиеся неотъемлемой частью процесса клеточного деления. Исторически они являются одной из наименее изученных частей генома, потому что они содержат очень много утомительного и сложного кода.
«Мы не понимаем лежащий в основе механизма эволюции центромер», — сказал Хеникофф. «Внезапно за последний год, когда появились данные, мы узнали намного больше о центромерах».
Используя новый геном, исследователи могут лучше изучить, как собираются белки центромер и что происходит, когда они изменяют или теряют функцию.
«Дисфункция центромер может быть серьезной причиной рака», — сказал Хеникофф. До сих пор «нам мешало, потому что у нас не было эталонной последовательности».
Дальнейшее изучение недавно секвенированных частей генома также может помочь ученым лучше понять, как люди развили определенные черты, такие как более крупный мозг, который привел их к генетически отличному пути от их великих предков-обезьян.
«Вещи, которые делают нашу лобную кору больше, происходят от генов, которые картируются в этих повторяющихся областях», — сказал Эван Эйхлер, профессор кафедры геномных наук в Медицинской школе Вашингтонского университета, а также участник совместной исследовательской группы. .
.
Достижения в технологии геномного секвенирования могут привести к возрождению медицинских открытий, говорят исследователи.
«Меня больше волнует то, чего мы не знаем, и возможности для открытий», — сказал Мига.
Филлиппи сказал, что его следующая цель — упростить процесс секвенирования, чтобы сделать его более дешевым, эффективным и широкодоступным. Он также планирует секвенировать генетический код как с отцовскими, так и с материнскими хромосомами. По его словам, широкое секвенирование среди людей из разных слоев общества поможет описать генетическое разнообразие мира и выявить важные генетические вариации.
Он представляет себе мир, в котором каждый имеет доступ к своим генетическим данным, что может помочь в предоставлении индивидуальной информации о том, какие болезни врачи должны отслеживать или какие лекарства прописывать.
«Через 10 лет получение полного, совершенно точного генома человека станет рутинной частью здравоохранения, и это будет достаточно дешево, чтобы не задумываться — лабораторный тест стоимостью менее 1000 долларов», — сказал Филлиппи.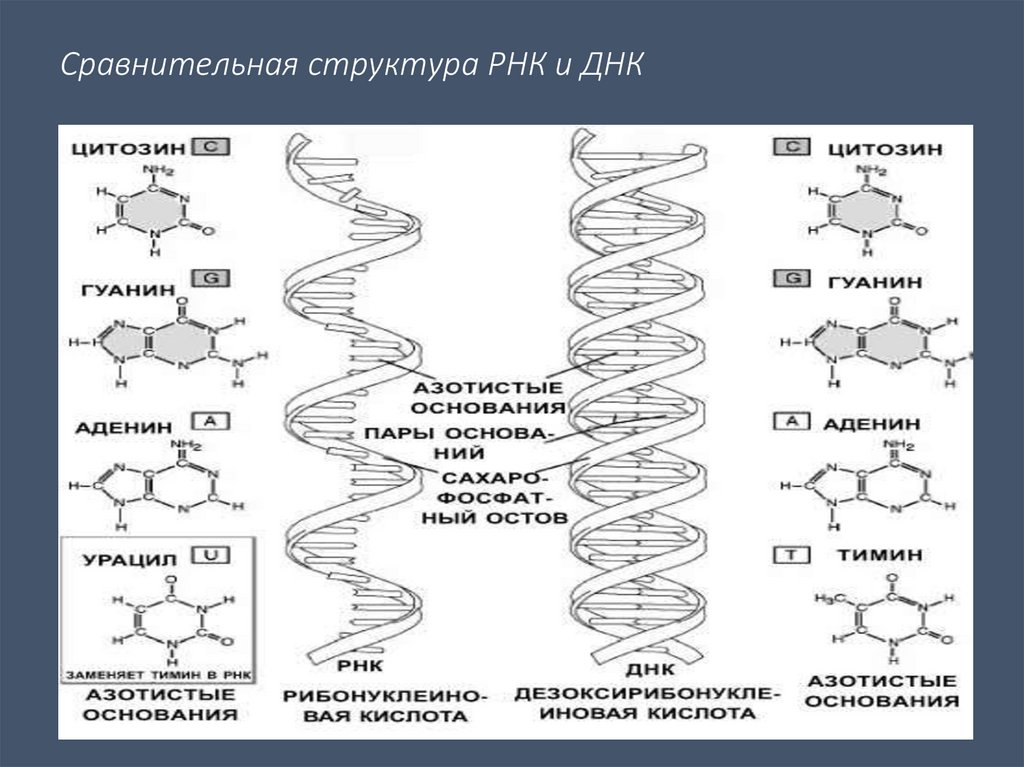 «У вас в кармане будет полный геном».
«У вас в кармане будет полный геном».
Эван Буш
Эван Буш — научный репортер NBC News. С ним можно связаться по адресу [email protected].
Использование Arc для расшифровки секретного водяного знака ДНК Вентера
Недавно Крейг Вентер (расшифровавший геном человека) создал синтетическую бактерию. Институт Дж. Крейга Вентера (JCVI) взял последовательность ДНК бактерии в виде компьютерного файла, модифицировал ее, создал физическую ДНК из этой последовательности и вставил эту ДНК в клетку, которая затем воспроизводилась под контролем новой ДНК для создания новой бактерия. Это действительно классный результат, поскольку он показывает, что ДНК организма можно создать с нуля. (Хотя я бы не назвал это синтетической жизнью, так как для ее работы требуется существующая клетка.) Хотя на завершение этого проекта ушло 10 лет, я уверен, что это только вопрос времени, когда вы сможете отправить файл данных в какую-либо компанию и получить полученные ячейки, отправленные вам обратно.
Одна интересная особенность этой синтетической бактерии состоит в том, что она включает четыре «водяных знака», специальные последовательности ДНК, которые доказывают, что эта бактерия была создана из файла данных и не является природной. Однако они не раскрыли, как были закодированы водяные знаки. Последовательности ДНК были опубликованы (GTTCGAATATTT и т. д.), но как извлечь из этого смысл, оставалось загадкой. Подробную информацию о водяных знаках см. в разделе Singularity Hub. Я взломал код (как я описал ранее) и нашел имена авторов, некоторые цитаты и следующую скрытую веб-страницу. Это похоже на научную фантастику, но это правда. На самом деле есть новая бактерия, в ДНК которой закодирована веб-страница:
Я связался с JCVI по ссылке и узнал, что я был 31-м человеком, взломавшим код, что немного разочаровывает. Я нигде не видел подробностей о том, как работает код, поэтому я предоставлю подробности. (Впереди спойлеры, если вы хотите взломать код самостоятельно. ) Первоначально я использовал Python для взлома кода, но, поскольку номинально это блог Arc, я покажу, как это можно сделать с помощью языка Arc.
) Первоначально я использовал Python для взлома кода, но, поскольку номинально это блог Arc, я покажу, как это можно сделать с помощью языка Arc.
Упрощенное введение в ДНК
Возможно, сейчас мне следует провести ускоренный курс по ДНК. Генетические инструкции для всех организмов содержатся в очень-очень длинных молекулах, называемых ДНК. Для наших целей ДНК можно описать как последовательность четырех разных букв: C, G, A и T. Геном человека состоит из 3 миллиардов пар оснований в 23 парах хромосом, поэтому вашу ДНК можно описать как пару последовательностей 3 миллиарда C, G, A и T.
Уотсон и Крик получили Нобелевскую премию за выяснение структуры ДНК и того, как она кодирует гены. Ваше тело состоит из важных элементов, таких как ферменты, которые состоят из тщательно сконструированных белков, состоящих из особых последовательностей 18 различных аминокислот. Ваши гены, являющиеся частями ДНК, определяют эти аминокислотные последовательности. Каждые три основания ДНК определяют определенную аминокислоту в последовательности. Например, последовательность ДНК CTATGG определяет аминокислоты лейцин и триптофан, поскольку CTA указывает на лейцин, а TGG указывает на триптофан. Крик, Уотсон и Розалинда Франклин открыли генетический код, связывающий определенную аминокислоту с каждой из 64 возможных троек ДНК. Я опускаю здесь множество интересных деталей, но ключевой момент в том, что каждые три символа ДНК обозначают одну аминокислоту.
Каждые три основания ДНК определяют определенную аминокислоту в последовательности. Например, последовательность ДНК CTATGG определяет аминокислоты лейцин и триптофан, поскольку CTA указывает на лейцин, а TGG указывает на триптофан. Крик, Уотсон и Розалинда Франклин открыли генетический код, связывающий определенную аминокислоту с каждой из 64 возможных троек ДНК. Я опускаю здесь множество интересных деталей, но ключевой момент в том, что каждые три символа ДНК обозначают одну аминокислоту.
Кодирование текста в ДНК
Теперь задача состоит в том, чтобы выяснить, как JCVI кодирует текст в ДНК синтетической бактерии. Очевидное расширение состоит в том, чтобы вместо того, чтобы присваивать аминокислоту каждой из 64 троек ДНК, присвойте ей символ. (Должен признаться, что это стало очевидным для меня только задним числом, как я объяснил в своем предыдущем сообщении в блоге.) Таким образом, если последовательность ДНК — GTTCGA, то GTT будет одной буквой, а CGA — другой, и так далее. Теперь нам просто нужно выяснить, какая буква соответствует каждой тройке ДНК.
Теперь нам просто нужно выяснить, какая буква соответствует каждой тройке ДНК.
Если мы знаем какой-то текст и связанную с ним ДНК, то легко взломать код, который сопоставляется между символами и тройками ДНК. Например, если мы узнаем, что текст «ЖИЗНЬ» соответствует ДНК «AAC CTG GGC TAA», то мы можем заключить, что AAA соответствует L, CTG соответствует I, GGC соответствует F, а TAA соответствует E. , Но как мы начнем?
Удобно, что статья Singularity Hub дает цитаты, которые появляются в ДНК, как сообщает JCVI:
«ЖИТЬ, ОШИБАТЬСЯ, ПАДАТЬ, ТРИУМФАТЬ, ВОССОЕДИНЯТЬ ЖИЗНЬ ИЗ ЖИЗНИ». «ВИДИТЕ ВЕЩИ НЕ ТАКИМ, КАК ОНИ ЕСТЬ, А КАКИМ ОНИ МОГЛИ БЫТЬ». «ЧЕГО Я НЕ МОГУ ПОСТРОИТЬ, Я НЕ МОГУ ПОНЯТЬ».
Мы можем попробовать сопоставить кавычки с каждой позицией в ДНК и посмотреть, есть ли работающая позиция. Матч может провалиться двумя способами. Во-первых, если одна и та же тройка ДНК соответствует двум разным буквам, значит, что-то не так.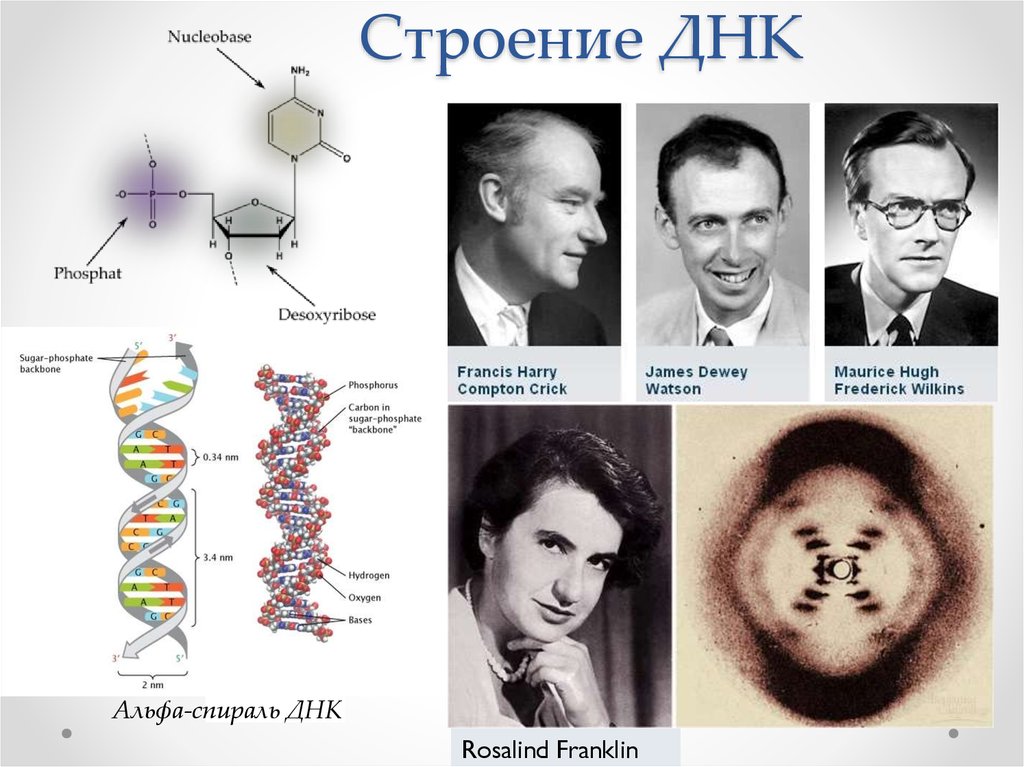 Например, если мы попытаемся сопоставить «ЖИЗНЬ» с «AAC CTG GGC AAC», мы придем к выводу, что AAC означает и L, и E. Во-вторых, если одна и та же буква соответствует двум тройкам ДНК, мы можем отклонить ее. Например, если мы попытаемся сопоставить «ERR» с «TAA CTA GTC», то и CTA, и GTC будут означать R. (Интересно, что реальный генетический код имеет этот второй тип неоднозначности. Потому что есть только 18 аминокислот и 64 аминокислоты). Тройки ДНК, многие тройки ДНК указывают на одну и ту же аминокислоту.)
Например, если мы попытаемся сопоставить «ЖИЗНЬ» с «AAC CTG GGC AAC», мы придем к выводу, что AAC означает и L, и E. Во-вторых, если одна и та же буква соответствует двум тройкам ДНК, мы можем отклонить ее. Например, если мы попытаемся сопоставить «ERR» с «TAA CTA GTC», то и CTA, и GTC будут означать R. (Интересно, что реальный генетический код имеет этот второй тип неоднозначности. Потому что есть только 18 аминокислот и 64 аминокислоты). Тройки ДНК, многие тройки ДНК указывают на одну и ту же аминокислоту.)
Использование Arc для взлома кода
Чтобы взломать код, сначала загрузите последовательности ДНК четырех водяных знаков и назначьте их переменным w1, w2, w3, w4. (Загрузить полный код здесь.)
(= w1 "GTTCGAATATTTCTATAGCTGTACA...") (= w2 "CAACTGGCAGCATAAAACATATAGA...") (= w3 "ТТТААККАТАТТТАААТКАТСКТ...") (= w4 "TTTCATTGCTGATCACTGTAGATAT...")
Затем давайте разобьем четыре водяных знака на тройки, сначала преобразовав их в список, а затем взяв тройки длины 3, которые мы называем от t1 до t4:
(def strtolist (s) (accum accfn (каждый x s (accfn (string x))))) (def threeize (s) (строка карты (кортежи (strtolist s) 3))) (= t1 (утроить w1)) (= t2 (утроить w2)) (= t3 (утроить w3)) (= t4 (утроить w4))
Следующая функция является самой важной.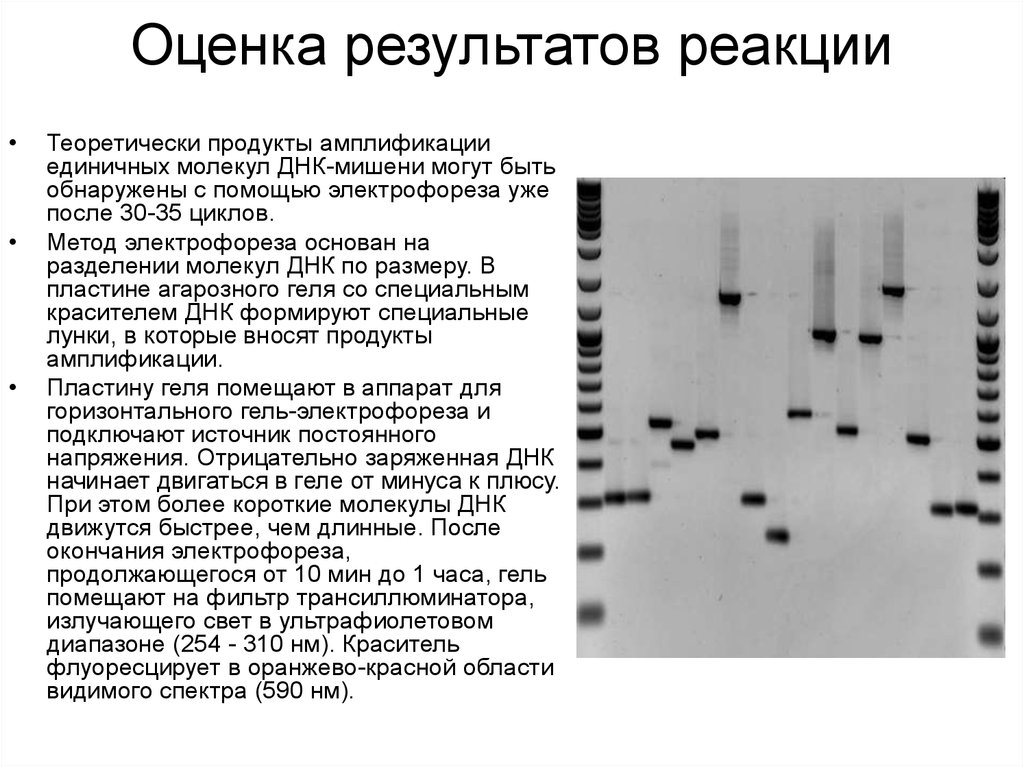 Он принимает тройки и текст, сопоставляет тройки с текстом и генерирует таблицу, которая отображает каждую тройку на соответствующие символы. Если он сталкивается с проблемой (либо два символа, назначенные одной тройке, либо один и тот же символ, назначенный двум тройкам), то он терпит неудачу. В противном случае он возвращает кодовую таблицу. Он использует хвостовую рекурсию для сканирования троек и ввода текста вместе.
Он принимает тройки и текст, сопоставляет тройки с текстом и генерирует таблицу, которая отображает каждую тройку на соответствующие символы. Если он сталкивается с проблемой (либо два символа, назначенные одной тройке, либо один и тот же символ, назначенный двум тройкам), то он терпит неудачу. В противном случае он возвращает кодовую таблицу. Он использует хвостовую рекурсию для сканирования троек и ввода текста вместе.
; Сопоставьте символы в тексте с тройками.
; codetable — это таблица, отображающая тройки в символы.
; offset - это смещение в тексте
; Возвращает codetable или nil, если совпадений нет.
(def matchtext (утроить текст (o кодируемая таблица (таблица)) (o смещение 0))
(if (>= offset (длинный текст)) codetable ; успех
(с (путешествие (тройки автомобилей) ch (смещение текста))
; если ch назначен чему-то другому в таблице
; тогда не совпадение
(if (and (mem ch (vals codetable))
(это не (кодируемая поездка) ch))
ноль
(пусто (кодируемая поездка))
(do (= (кодируемая поездка) ch) ; новый символ
(текст совпадения (тройки cdr) кодируемый текст (+ 1 смещение)))
(это не (кодируемая поездка) ch)
ноль; несоответствие
(matchtext (тройки cdr) text codetable (+ 1 offset)))))
Наконец, функция findtext находит совпадение в любом месте тройного списка. Другими словами, предыдущая функция matchtext предполагает, что начало троек соответствует началу текста. Но findtext пытается найти совпадение в любой точке троек. Он вызывает matchtext, и если совпадения нет, то он отбрасывает первую тройку (используя cdr) и рекурсивно вызывает сам себя, пока не закончатся тройки.
Другими словами, предыдущая функция matchtext предполагает, что начало троек соответствует началу текста. Но findtext пытается найти совпадение в любой точке троек. Он вызывает matchtext, и если совпадения нет, то он отбрасывает первую тройку (используя cdr) и рекурсивно вызывает сам себя, пока не закончатся тройки.
(def findtext (утроенный текст) (если ( В статье Singularity Hub говорится, что ДНК содержит цитату:«ЖИТЬ, ОШИБАТЬСЯ, ПАДАТЬ, ТРИУМФАТЬ, ВОССОЕДИНЯТЬ ЖИЗНЬ ИЗ ЖИЗНИ». - ДЖЕЙМС ДЖОЙСДавайте начнем с простого поиска «ЖИЗНЬ ИЗ ЖИЗНИ», так как мы вряд ли получим LIFE, чтобы он совпадал дважды просто случайно:
arc> (текст t1 «ЖИЗНЬ ИЗ ЖИЗНИ») нольНет совпадений в первом водяном знаке, поэтому давайте попробуем второй.
arc> (найти текст t2 «ЖИЗНЬ ИЗ ЖИЗНИ») #hash(("CGT" . #\O) ("TGA" . #\T) ("CTG" . #\I) ("ATA" . #\пробел) ("TAA" . #\E) (" AAC" . #\L) ("TCC" . #\U) ("GGC" . #\F))Как насчет этого! Похоже на совпадение в водяном знаке 2, где ДНК «AAC» соответствует L, «CGT» соответствует «I», «GGC» соответствует «F» и так далее.
arc> (= code2 (findtext t2 "ЖИТЬ, ОШИБАТЬСЯ, ПАДАТЬ, ТРИУМФАТЬ, ВОССОЕДИНЯТЬ ЖИЗНЬ ИЗ ЖИЗНИ.")) #hash(("TCC" . #\U) ("TCA" . #\H) ("TTG" . #\V) ("CTG" . #\I) ("ACA" . #\P) (" CTA" . #\R) ("CGA" . #\.) ("ATA" . #\пробел) ("CGT" . #\O) ("ТТТ" . #\C) ("TGA" . #\ Т) ("ТАА". #\E) ("ААС" . #\L) ("ВГА" . #\M) ("ГТГ" . #\,) ("TAG" . #\A) ("GGC " .#\F))Точно так же мы можем попробовать сопоставить другие цитаты:
arc> (= code3 (findtext t3 "ВИДИТЕ ВЕЩИ НЕ ТАКИМ, КАК ОНИ ЕСТЬ, А КАКИМ ОНИ МОГЛИ БЫТЬ")) #hash(("CTA" . #\R) ("TCA" . #\H) ("CTG" . #\I) ("GCT" . #\S) ("CGA" . #\.) (" ATA" . #\space) ("CAT" . #\Y) ("CGT" . #\O) ("TCC" . #\U) ("AGT" . #\B) ("TGA" . #\ Т) ("ТАА" . #\E) ("ТГК" . #\N) ("ТАС" . #\G) ("ВГА" . #\M) ("ГТГ" . #\,) ("ТАГ " .#\А)) arc> (= code4 (findtext t4 "ЧЕГО Я НЕ МОГУ ПОСТРОИТЬ, Я НЕ МОГУ ПОНЯТЬ")) #hash(("TCC" .К счастью, все они декодируют одни и те же триплеты в одни и те же буквы, иначе у нас были бы проблемы. Мы можем объединить эти три таблицы декодирования в одну:
arc> (= code (listtab (join (код таблицы2) (код таблицы3) (код таблицы4))))#hash(("TCC" . #\U) ("TCA" . #\H) ("CTA" . #\R) ("CGT" . #\O) ("TGA" . #\T) ("CGA" . #\.) ("TAA" . #\E) ("AAC" . #\L) ("TAC" . #\G) ("TAG" . #\A) ("GGC" . #\F) ("ACA" . #\P) ("ATT" . #\D) ("TTG" . #\V) ("CTG" . #\I) ("GCT" . #\S) ("TTT" . #\C) ("CAT" . #\Y) ("ATA" . #\пробел) ( "АГТ" .#\B) ("ГТГ" .#\,) ("ТГК" .#\N) ("ВГА" .#\M) ("ГТК" .#\W))Теперь давайте создадим функцию декодирования, которая применит строку к неизвестной ДНК, и посмотрим, что мы получим. (Мы оставим неизвестные тройки непреобразованными.
(декод декодирования (тройки декодирования) (строка (accum accfn (каждая тройка утраивает (accfn) (если (тройка декодирования) (тройная карта декодирования) (строка"("тройка")" ))))))) arc> (код декодирования t1) "(GTT). КРЕЙГ ВЕНТЕР ИНСТИТУТ (ACT)(TCT)(TCT)(GTA)(GGG)ABCDEFGHI(GTT)(GCA)LMNOP(TTA)RSTUVW(GGT)Y(TGG)(GGG) (TCT)(CTT )(ACT)(AAT)(AGA)(GCG)(GCC)(TAT)(CGC)(GTA)(TTC)(TCG)(CCG)(GAC)(CCC)(CCT)(CTC)(CCA)( CAC)(CAG)(CGG)(TGT)(AGC)(ATC)(ACC)(AAG)(AAA)(ATG)(AGG)(GGA)(ACG)(GAT)(GAG)(GAA).,( GGG)SYNTHETIC GENOMICS, INC.(GGG)(CGG)(GAG)DOCTYPE HTML(AGC)(CGG)HTML(AGC)(CGG)HEAD(AGC)(CGG)TITLE(AGC)GENOME TEAM(CGG)(CAC) НАЗВАНИЕ(AGC)(CGG)(CAC)HEAD(AGC)(CGG)BODY(AGC)(CGG)A HREF(CCA)(GGA)HTTP(CAG)(CAC)(CAC)WWW.(GTT)CVI.ORG (CAC)(GGA)(AGC)THE (GTT)CVI(CGG)(CAC)A(AGC)(CGG)P(AGC)ДОКАЗЫВАЙТЕ, ЧТО ВЫ(GAA)ВЫ РАСШИФРОВАЛИ ЭТО ВОДНОЕ МАР(GCA) ПО ЭЛЕКТРОННОЙ ПОЧТЕ НАМ (CGG)A HREF(CCA)(GGA)MAILTO(CAG)MRO(TTA)STI(TGG)(TCG)(GTT)CVI.ORG(GGA)(AGC)ЗДЕСЬ(GAG)(CGG)(CAC)A(AGC)(CGG )(CAC)P(AGC)(CGG)(CAC)ТЕЛО(AGC)(CGG)(CAC)HTML(AGC)"Похоже, у нас неплохо получается с декодированием, так как там много распознаваемого текста и немного HTML.
arc> (= (код "GTT") #\J) arc> (= (код "GCA") #\K) arc> (= (код "ACT") #\2) ...После пары циклов добавления недостающих символов и просмотра расшифровок мы получаем почти полные расшифровки четырех водяных знаков:
Содержание водяных знаков
ИНСТИТУТ Дж. КРЕЙГА ВЕНТЕРА, 2009 г.
ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789(TTC)@(CCG)(GAC)-(CCT)(CTC)=/:<(TGT)>(ATC)(ACC)(AAG)(AAA)(ATG)(AGG)"(ACG)(GAT )!'.,
СИНТЕТИК ГЕНОМИКС, ИНК.
ГЕНОМНАЯ КОМАНДА JCVIПодтвердите, что вы расшифровали этот водяной знак, отправив нам электронное письмо ЗДЕСЬ!
МИККЕЛЬ АЛГИР, МАЙКЛ МОНТЕГЮ, САНДЖАЙ ВАШИ, КЭРОЛ ЛАРТИГ, ЧАК МЕРРИМЭН, НИНА АЛЬПЕРОВИЧ, НАСИРА АССАД-ГАРСИА, ГВИН БЕНДЕРС, РАЙ-ЮАН ЧУАНГ, ЕВГЕНИЯ ДЕНИСОВА, ДЭНИЭЛ ГИБСОН, ДЖОН ГЛАСС, ЧЖИ-ЦИН ЦИ.
«ЖИТЬ, ОШИБАТЬСЯ, ПАДАТЬ, ТРИУМФАТЬ, ВОССОЕДИНЯТЬ ЖИЗНЬ ИЗ ЖИЗНИ». - ДЖЕЙМС ДЖОЙСКЛАЙД ХАТЧИСОН, АДРИАНА ДЖИГА, РАДХА КРИШНАКУМАР, ЯН МОЙ, МОНЗИЯ МУДИ, МАРВИН ФРЕЙЗЬЕР, ХОЛЛИ БАДЕН-ТИЛСОН, ДЖЕЙСОН МИТЧЕЛЛ, ДАНА БУСАМ, ДЖАСТИН ДЖОНСОН, ЛАКШМИ ДЭВИ ВИШВАНАТАН, ДЖЕССИКА ХОСТЕТЛЕР, РОБЕРТ ФРИДМАН, ВЛАДИМИР НОРЕСКОВ, ДЖАВЕРИЯ.
"ВИДИТЕ ВЕЩИ НЕ ТАКИМ, КАК ОНИ ЕСТЬ, А ТАКИМ, КАКИМ ОНИ МОГЛИ БЫТЬ."СИНТИЯ ЭНДРЮС-ПФАННКОЧ, КУАНГ ФАН, ЛИ МА, ГАМИЛЬТОН СМИТ, АДИ РАМОН, КРИСТИАН ТАГВЕРКЕР, Дж. КРЕЙГ ВЕНТЕР, ЭУЛА УИЛТЕРНЕР, ЛЕЙ ЯНГ, ШИБУ ЮСЕФ, ПРАБХА АЙЕР, ТИМ СТОКВЕЛЛ, ДИАНА РАДУН, БРИДЖЕТ ШИПИНСКИЙ, СКОТТ ДУРКИН, НАДЬЯФЕР , ХАВЬЕР ХИНОНЕС, ХАННА ТЕКЛЕАБ.
«ЧЕГО Я НЕ МОГУ ПОСТРОИТЬ, Я НЕ МОГУ ПОНЯТЬ». - РИЧАРД ФЕЙНМАНПервый водяной знак состоит из заявления об авторском праве, списка всех символов и скрытой HTML-страницы (которую я показал выше). Второй, третий и четвертый водяные знаки состоят из списка авторов и трех цитат.
Обратите внимание, что есть 14 некодированных троек, которые появляются в списке символов только один раз.
Таблица расшифровки ДНК
В следующей таблице приводится сводка «секретного» кода ДНК в код символа:
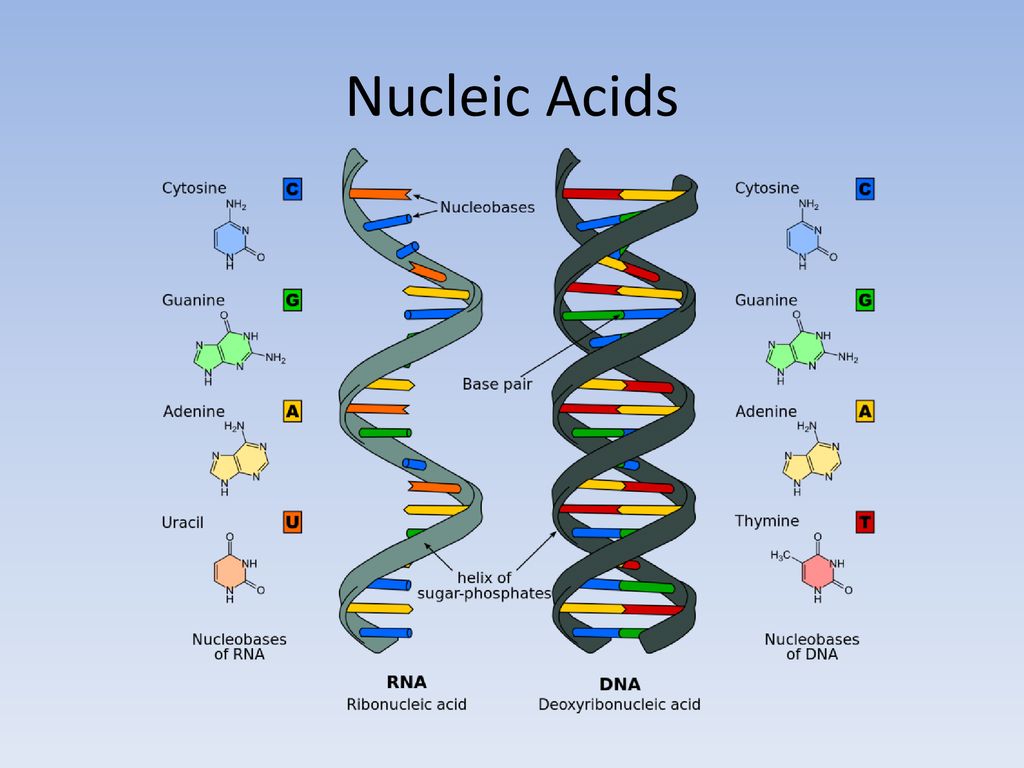 (Формат Arc для хеш-таблиц довольно уродлив, но, надеюсь, вы можете увидеть это в выводе.) Давайте попробуем сопоставить полную цитату и сохранить таблицу в code2:
(Формат Arc для хеш-таблиц довольно уродлив, но, надеюсь, вы можете увидеть это в выводе.) Давайте попробуем сопоставить полную цитату и сохранить таблицу в code2: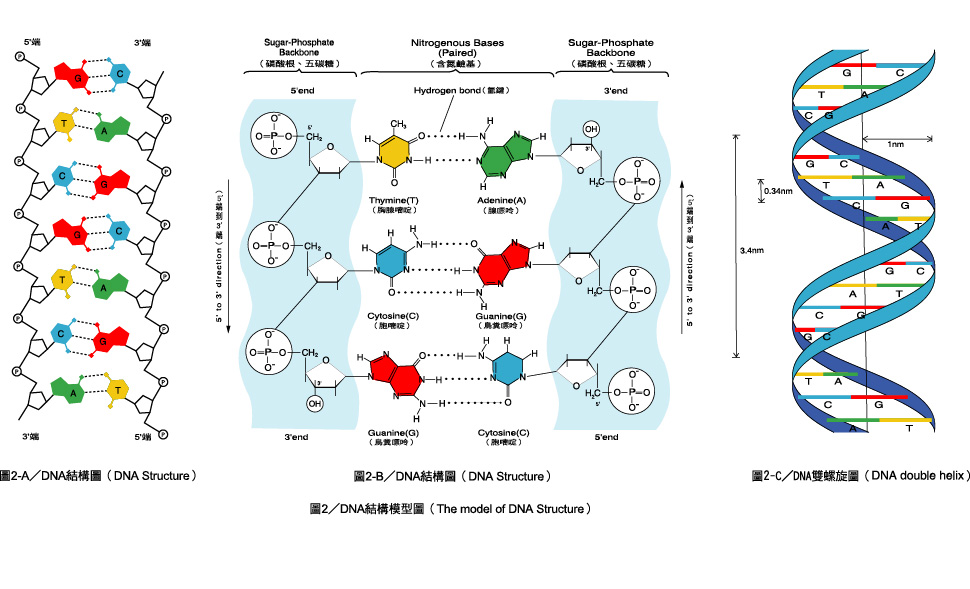 #\U) ("TCA" . #\H) ("ATT" . #\D) ("CTG" . #\I) ("GCT" . #\S) (" TTT" . #\C) ("ATA" . #\space) ("TAA" . #\E) ("CGT" . #\O) ("CTA" . #\R) ("TGA" . #\ Т) ("АГТ" . #\B) ("ААК" . #\L) ("ТГК" . #\N) ("ГТГ" . #\,) ("ТАГ" . #\А) ("ГТК " .#\W))
#\U) ("TCA" . #\H) ("ATT" . #\D) ("CTG" . #\I) ("GCT" . #\S) (" TTT" . #\C) ("ATA" . #\space) ("TAA" . #\E) ("CGT" . #\O) ("CTA" . #\R) ("TGA" . #\ Т) ("АГТ" . #\B) ("ААК" . #\L) ("ТГК" . #\N) ("ГТГ" . #\,) ("ТАГ" . #\А) ("ГТК " .#\W))
 )
) Также удобно использовать весь алфавит в качестве помощи при расшифровке. Исходя из этого, мы можем заполнить множество пробелов, например. GTT — это J, а GCA — это K. Из HTML-тегов мы можем определить угловые скобки, кавычки и косую черту. Мы можем догадаться, что там есть числа, и выяснить, что ACT TCT TCT GTA — это 2009 год. Эти выводы можно добавить вручную в таблицу декодирования:
Также удобно использовать весь алфавит в качестве помощи при расшифровке. Исходя из этого, мы можем заполнить множество пробелов, например. GTT — это J, а GCA — это K. Из HTML-тегов мы можем определить угловые скобки, кавычки и косую черту. Мы можем догадаться, что там есть числа, и выяснить, что ACT TCT TCT GTA — это 2009 год. Эти выводы можно добавить вручную в таблицу декодирования:
 Они не в порядке ASCII, порядке клавиатуры или любом другом порядке, который я могу понять, поэтому я не могу определить, что это такое, но я предполагаю, что в них отсутствуют знаки препинания и специальные символы.
Они не в порядке ASCII, порядке клавиатуры или любом другом порядке, который я могу понять, поэтому я не могу определить, что это такое, но я предполагаю, что в них отсутствуют знаки препинания и специальные символы.| ААА ? | ААС L | ААГ ? | ААТ 3 |
| АСА Р | АКК ? | АКГ ? | АКТ 2 |
| АГА 4 | АРУ > | АГГ ? | АГТ Б |
| ATA пространство | УВД ? | АТГ ? | АТТ D |
| САА М | САС / | КАГ: | КАТ Y |
| ССА = | ССС — | ККИ? | ККТ ? |
| CGA. | СГК 8 | СГГ < | ВКТ О |
| СТА R | КТК ? | КТГ I | СТТ 1 |
| ГАА | ПКК? | Кляп! | ГАТ ? |
| GCA К | GCC 6 | ГКГ 5 | GCT S |
| ГГА» | ГГК Ф | GGG новая строка | ГГТ Х |
| ГТА 9 | ГТК В | ГТГ, | ГТТ Дж |
| ТАА Е | ТАС G | ТЭГ А | ТАТ 7 |
| ТСА Н | ТСС У | ТКГ @ | ТСТ 0 |
| ТГА Т | ТГК N | ТГГ Z | ТГТ ? |
| ТТА Q | ТТС ? | ТТГ В | ТТТ С |
Насколько я могу судить, эта таблица находится в случайном порядке.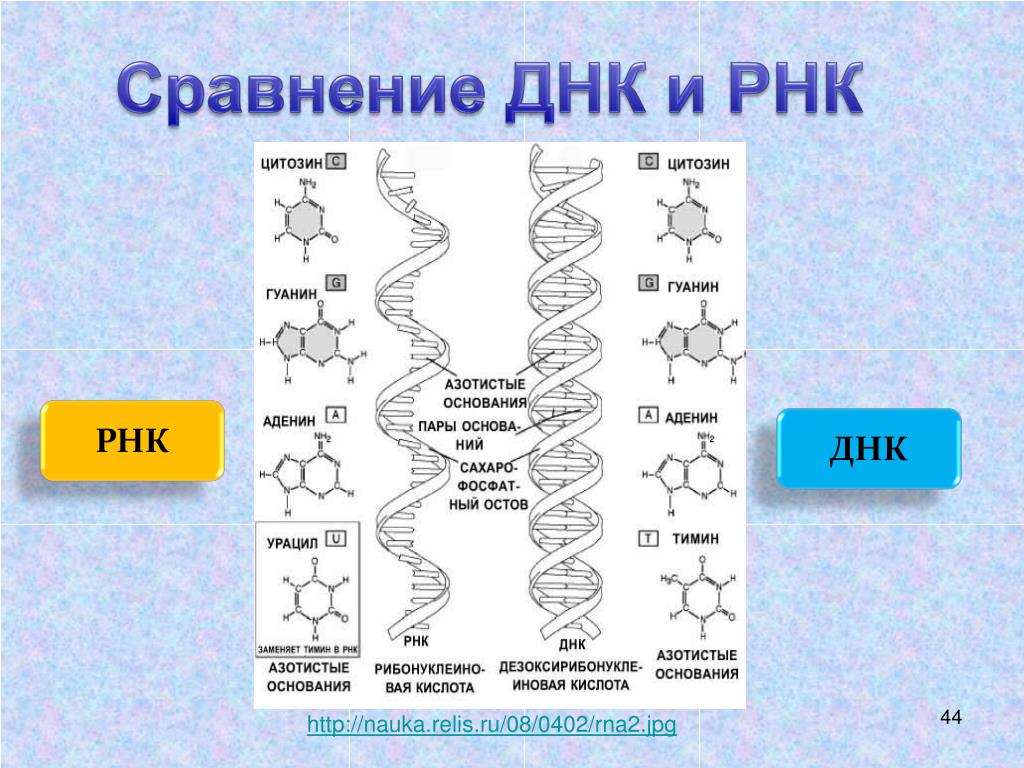 Я проанализировал это множеством способов, от частоты символов и частоты ДНК до порядка ASCII и порядка клавиатуры, и не смог понять ни рифмы, ни причины. Я надеялся найти либо какую-то структуру, либо другое закодированное сообщение, но ничего не нашел.
Я проанализировал это множеством способов, от частоты символов и частоты ДНК до порядка ASCII и порядка клавиатуры, и не смог понять ни рифмы, ни причины. Я надеялся найти либо какую-то структуру, либо другое закодированное сообщение, но ничего не нашел.
Подробнее о взломе кода
Было удобно, что JCVI заранее говорила, какие цитаты есть в ДНК, что облегчало взлом кода. Но мог бы код все еще быть взломан, если бы они этого не сделали?
Один из способов взломать код — посмотреть статистику того, как часто появляются разные триплеты. Мы считаем тройки, преобразуем таблицу в список, а затем сортируем список. В сортировке мы используем специальную функцию сравнения, которая сравнивает количество, чтобы сортировать по количеству, а не по тройкам.
дуга> (сортировка
(fn ((k1 v1) (k2 v2)) (> v1 v2))
(таблица (считает t2)))
(("ATA" 41) ("TAG" 27) ("TAA" 25) ("CTG" 18) ("TGC" 16) ("GTG" 16) ("CTA" 15) ("CGT" 14) ( «ААС» 13) («ТГА» 10) («ТТТ» 10) («ГСТ» 10) («ТАЦ» 10) («ТСА» 8) («ВГА» 7) («КАТ» 7) («ТСС 7) ("ТТГ" 5) ("ГГК" 4) ("ГТТ" 4) ("АТТ" 4) ("ССС" 4) ("ВСА" 3) ("АГТ" 2) ("ТТА" 2 ) («АСА» 2) («ВГА» 2) («ГГА» 2) («ГТК» 1) («ТГГ» 1) («ГГГ» 1))
Это говорит нам о том, что ATA появляется во втором водяном знаке 41 раз, TAG — 27 раз и так далее. Если предположить, что это кодирует английский текст, то наиболее распространенными символами будут пробел, Е, Т, А, О и так далее. Затем нужно методом проб и ошибок пробовать высокочастотные буквы для высокочастотных троек, пока мы не найдем комбинацию, которая дает настоящие слова. (Это похоже на решение газетной криптограммы.) Вы заметите, что высокочастотные тройки соответствуют высокочастотным буквам, но не в точном порядке. (Я уже писал о простом криптоанализе с помощью Arc.)
Если предположить, что это кодирует английский текст, то наиболее распространенными символами будут пробел, Е, Т, А, О и так далее. Затем нужно методом проб и ошибок пробовать высокочастотные буквы для высокочастотных троек, пока мы не найдем комбинацию, которая дает настоящие слова. (Это похоже на решение газетной криптограммы.) Вы заметите, что высокочастотные тройки соответствуют высокочастотным буквам, но не в точном порядке. (Я уже писал о простом криптоанализе с помощью Arc.)
Другой возможный метод — предположить, что в решении появляется такая фраза, как «КРЕЙГ ВЕНТЕР», и попытаться сопоставить ее с тройками. Оказывается, это так. Это не дает много букв для работы, но это начало.
Arc: по-прежнему плохо подходит для исследовательского программирования
Пару лет назад я писал, что Arc плохо подходит для исследовательского программирования, что оказалось чрезвычайно спорным. Я провел это исследование ДНК, используя как Python, так и Arc, и обнаружил, что Python намного лучше по большинству причин, которые я описал в своей предыдущей статье.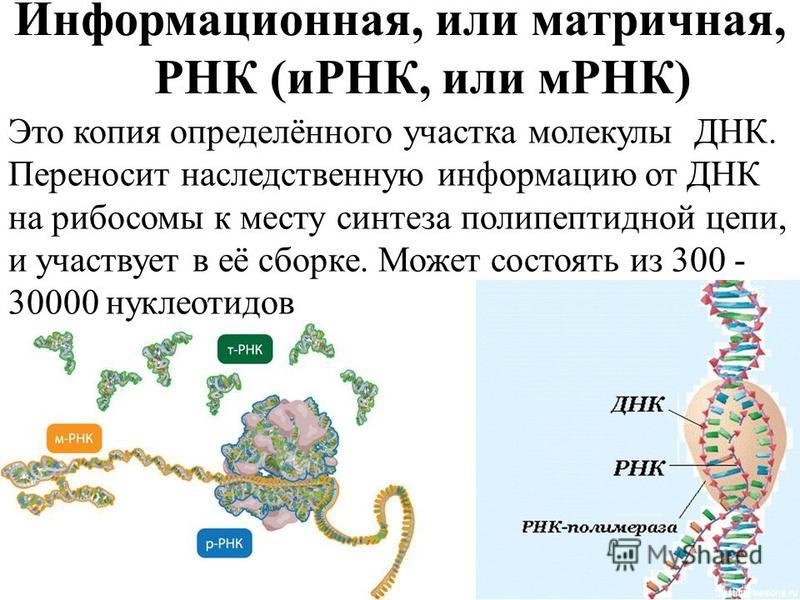 3), и в Python это было сносно быстро, но Arc был бы слишком болезненным.
3), и в Python это было сносно быстро, но Arc был бы слишком болезненным.
Подводя итог, я начал с Arc, переключился на Python, когда понял, что мне потребуется слишком много времени, чтобы понять код ДНК с помощью Arc, а затем вернулся к Arc для этой статьи после того, как понял, что я хочу сделать. Другими словами, Python был намного лучше для исследовательской части.
Мысли о методе кодирования ДНК
Я вижу некоторые потенциальные способы улучшения и расширения техники кодирования ДНК. Поскольку все детали метода кодирования ДНК еще не были опубликованы JCVI, они, возможно, уже рассмотрели эти идеи.
Возможность встроить текст в ДНК живого организма — это очень круто. Однако я не уверен, насколько это практично. Плотность данных в ДНК очень высока, может быть, в 500 раз больше, чем на жестком диске (ссылка), но большая часть ДНК предназначена для поддержания жизни бактерии, и только около 1 КБ текста хранится в водяных знаках.
Я получил электронное письмо от JCVI, в котором говорилось, что механизм кодирования также поддерживает Java, математику (LaTeX?) и Perl, а также HTML. Встраивание кода Perl в живой организм кажется еще более безумным, чем текст или HTML.
Если кодирование текста в ДНК станет популярным, я ожидаю, что для обработки мутаций потребуется исправление ошибок. Код исправления ошибок, такой как Рид-Соломон, на самом деле не будет работать, потому что ДНК может подвергаться делециям и вставкам, а также мутациям, поэтому вам понадобится какой-то обобщенный код, исправляющий удаление/вставку.
Я просто знаю, что 6-битного кода будет недостаточно. Рано или поздно люди захотят строчные буквы, символы с акцентом, японский язык и т. д. Так что вы могли бы придумать способ поместить Unicode в ДНК, возможно, как UTF-8. И люди будут хотеть произвольные байтовые данные. Мой подход состоял бы в том, чтобы использовать четыре пары оснований ДНК вместо трех и кодировать байты. Просто назначьте A=00, C=01, G=10 и T=11 (например) и закодируйте свои байты.
Рано или поздно люди захотят строчные буквы, символы с акцентом, японский язык и т. д. Так что вы могли бы придумать способ поместить Unicode в ДНК, возможно, как UTF-8. И люди будут хотеть произвольные байтовые данные. Мой подход состоял бы в том, чтобы использовать четыре пары оснований ДНК вместо трех и кодировать байты. Просто назначьте A=00, C=01, G=10 и T=11 (например) и закодируйте свои байты.
Если бы я писал RFC для хранения данных в ДНК, я бы предположил, что большую часть времени вы хотели бы хранить фактические данные в Интернете и просто хранить ссылку в ДНК. (Подобно тому, как QR-код или крошечный URL-адрес могут ссылаться на веб-сайт.) Закодированная ссылка может быть окружена специальной последовательностью ДНК, которая указывает на крошечный код ссылки ДНК. Эту последовательность также можно использовать для поиска кода ссылки с помощью ПЦР, поэтому вам не нужно выполнять секвенирование генома всего организма, чтобы найти водяной знак. (Существующие водяные знаки на самом деле окружены фиксированными последовательностями, которые могут быть для этой цели.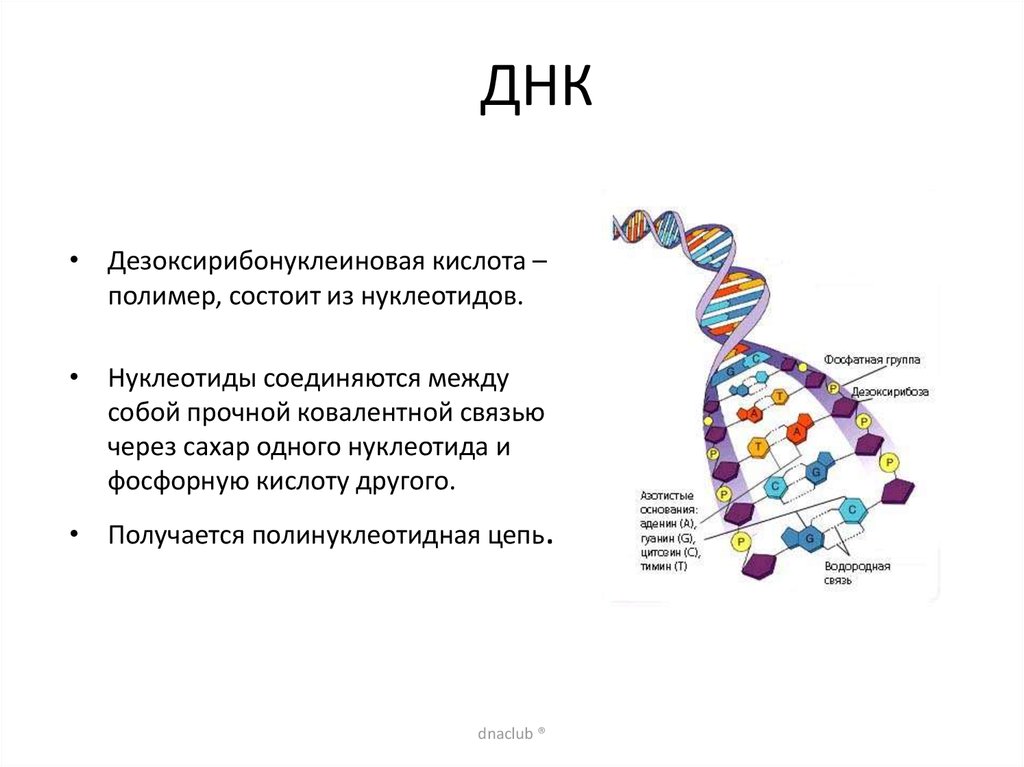 )
)
Я думаю, что также должен быть какой-то способ пометить и структурировать данные, хранящиеся в ДНК, чтобы указать, что является идентификацией, описанием, авторскими правами, HTML, владельцами и так далее. XML кажется очевидным выбором, но внедрение XML в живые организмы вызывает у меня тошноту.
Выводы
Возможность создать живой организм из компьютерного файла ДНК — удивительное достижение Крейга Вентера и JCVI. Встраивание текста веб-страницы в живой организм кажется фантастикой, но это произошло на самом деле. Конечно, бактерия на самом деле не обслуживают веб-страницу… пока.
Источники
- Код My Arc
- Центр сингулярности: секретные сообщения, закодированные в ДНК вентерских синтетических бактерий
- Научная статья: Создание бактериальной клетки под контролем химически синтезированного генома.
- Образ ДНК, авторство Джерома Уокера.
- последовательностей водяных знаков (рис. S1) и карта генома (рис. S2)
- Полный геном Mycoplasma mycoides JCVI-syn1.0. Водяные знаки отображаются как mmycWM1, mmcyWM2b, mmycWM4 и mmycWM3.
 S1) и карта генома (рис. S2)
S1) и карта генома (рис. S2)Расшифровка ДНК: ключ к раскрытию высочайшего потенциала ребенка
Также доступно в: 中文版, Bahasa Malaysia
Узнайте, что это может сделать для вашего ребенка уже сегодня!
Если бы вы как родитель могли манипулировать условиями в пользу успеха и счастья вашего ребенка в жизни, вы бы это сделали? Дело в том, что многие таланты и качества уже заложены в генах вашего ребенка. Знание этих черт поможет вам спланировать самый идеальный путь для вашего ребенка в жизни с наилучшими результатами, какие только можно вообразить!
Это то, что касается ДНК-теста Neucleus Decode Talent.
Будет ли ваш ребенок лучшим музыкантом? А может, быть инженером и есть его истинная судьба? Чтобы узнать больше о расшифровке талантов Neucleus, Kiddy123 встретился с доктором Шейном, доктором философии, чтобы лучше понять этот революционный тест и то, как родители могут извлечь из него максимальную пользу.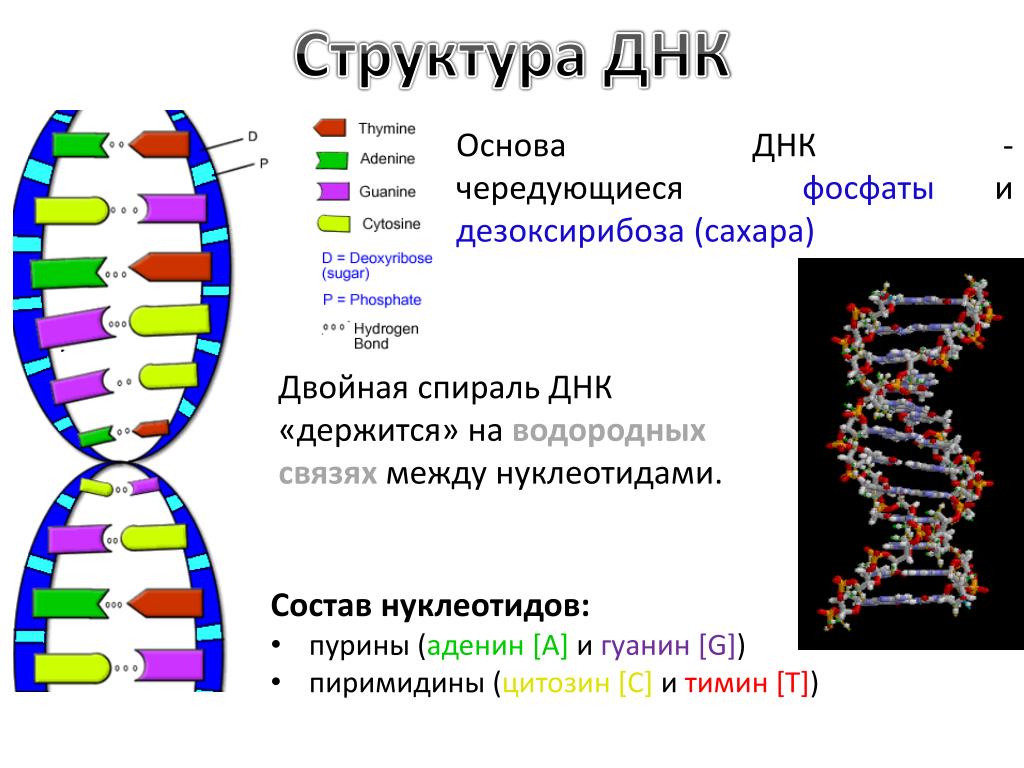
Когда дело доходит до таланта, многие думают, что упорный труд является единственным фактором (100%), способствующим успеху ребенка. Однако мы видели друзей, которые изучают искусство или музыку намного быстрее других , а некоторые просто более одарены в математике и успеваемости.
Все сводится к тому, что есть в нашей ДНК, ведь каждый уникален на генетическом уровне. В 2015 году, проанализировав все исследования близнецов за последние 50 лет, в которых оценивалось 14 миллионов близнецов из 39 стран, мировые ученые обнаружили, что гены вносят от до 49% (вместо 0%), тогда как внешние факторы составляют лишь 51% ( вместо 100%) за их успех.
Это важно иметь в виду, потому что у ребенка может быть самый замечательный скрытый талант, но если его родители не знают об этом и не принимают соответствующих мер для взращивания этого таланта, он будет обречен остаться ‘ скрытый’!
Понимание черт человека с генетического уровня
С момента завершения проекта «Геном человека» в 2003 г.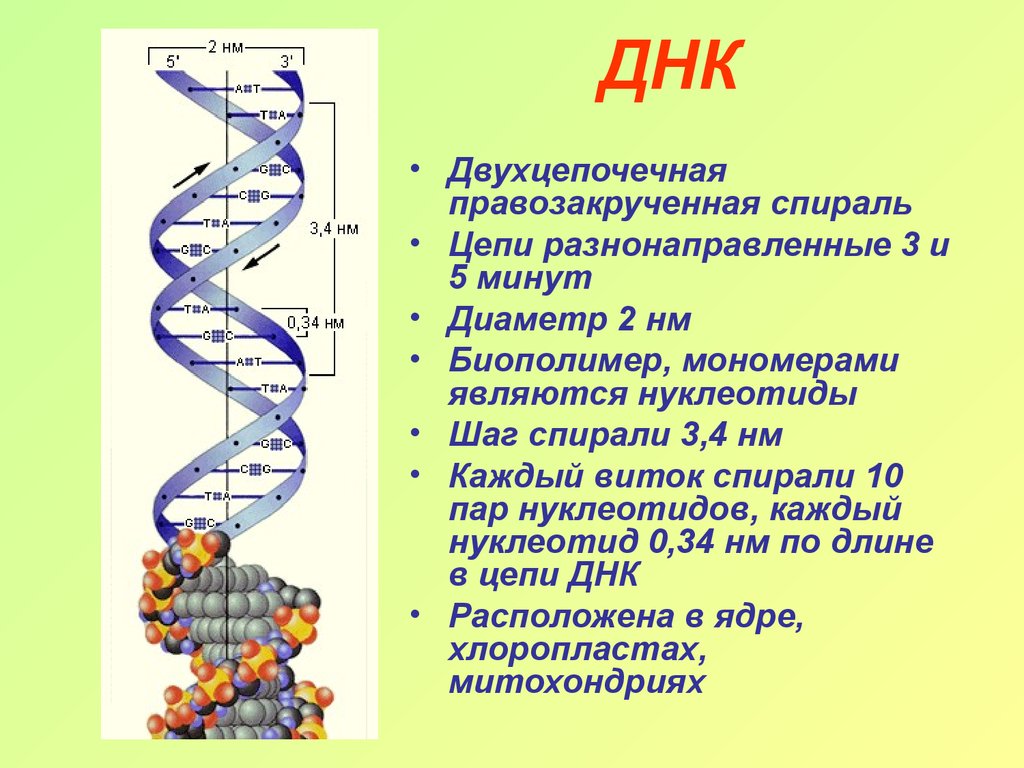 ученые успешно связали гены человека с тем, насколько хорошо (или плохо) функционирует их тело, т. е. с вероятностью приобретения определенных заболеваний , их уникальные потребности в питании, в каких видах спорта они могут преуспеть, их природные врожденные таланты, а также их личности. Это глобальное совместное исследование, которым поделился с нами доктор Шейн, проводится с 1990, когда ученые начали сравнивать сходство людей с определенными талантами.
ученые успешно связали гены человека с тем, насколько хорошо (или плохо) функционирует их тело, т. е. с вероятностью приобретения определенных заболеваний , их уникальные потребности в питании, в каких видах спорта они могут преуспеть, их природные врожденные таланты, а также их личности. Это глобальное совместное исследование, которым поделился с нами доктор Шейн, проводится с 1990, когда ученые начали сравнивать сходство людей с определенными талантами.
Было обнаружено, например, что люди с музыкальными наклонностями (то есть обладающие абсолютным слухом, умеющие играть на музыкальных инструментах и т. д.) имели безошибочное сходство между собой на генетическом уровне. Оказывается, ДНК человека может буквально раскрыть о человеке то, чего не знали бы даже их собственные мама и папа!
Благодаря этому открытию также становится очевидным, что все мы уникальны, и никогда не существовало универсального решения. Таким образом, вполне логично, что, зная конкретные черты, таланты и сильные стороны, которыми обладают их дети, родители могут получить дополнительное преимущество в прокладывании более легкого и значимого пути к их успеху и, в конечном счете, к их счастью.
Почему вашему ребенку следует пройти ДНК-тест на расшифровку талантов?
Кто не хочет быть лучшей версией себя? Однако, как родители, воспитываем ли мы своих детей на основе наших ожиданий или в соответствии с врожденными талантами наших детей?
Однако для наших детей все обстоит иначе, особенно после введения теста ДНК на расшифровку талантов (DTDT), который поможет выявить полезную информацию о них на генетическом уровне! Рекомендуется проводить этот тест с самый младший возможный возраст . Почему? Потому что дети учатся больше всего и быстрее всего в течение первых нескольких лет жизни. Кроме того, многие природные таланты могут быть незаметны в юном возрасте. Присмотритесь к некоторым из самых талантливых людей на земле, и вы обнаружите, что большинство из них оттачивали свои навыки с детства. Итак, зная это, разве вы как родитель не хотели бы использовать этот критический период времени, если у вас есть список важных генетических ключей к вашему ребенку?
На сегодняшний день DTDT уже изменил жизнь многих семей, которые открыли в своих детях таланты и личности и, следовательно, смогли начать использовать весь их потенциал. На сегодняшний день это наиболее полное и точное генетическое тестирование, которое охватывает пять областей, а именно таланты, IQ, EQ, личность и общее самочувствие, при этом образцы ДНК сравниваются с крупнейшей в мире базой данных азиатской генетики. Весь процесс обеспечивает наиболее точные и надежные результаты. Без сомнения, то, что у нас есть под рукой, является безусловным преимуществом для наших детей. И в довершение всего, это всего лишь единственный в жизни тест , ибо ДНК человека не претерпевает изменений.
На сегодняшний день это наиболее полное и точное генетическое тестирование, которое охватывает пять областей, а именно таланты, IQ, EQ, личность и общее самочувствие, при этом образцы ДНК сравниваются с крупнейшей в мире базой данных азиатской генетики. Весь процесс обеспечивает наиболее точные и надежные результаты. Без сомнения, то, что у нас есть под рукой, является безусловным преимуществом для наших детей. И в довершение всего, это всего лишь единственный в жизни тест , ибо ДНК человека не претерпевает изменений.
Важно ли для вас счастье вашего ребенка?
«Причина, по которой этот вопрос важен, заключается в том, что миллионы родителей во всем мире думают, что делают все возможное для своего ребенка, но на самом деле это не так. Не потому, что им все равно, а потому, что они не знают истинного потенциала своего ребенка», — объяснил доктор Шейн. Теперь нетрудно сделать вывод, почему термин «скрытый потенциал» всегда используется в детских развивающих центрах, ведь эти потенциалы не могут быть обнаружены невооруженным глазом. Но ДНК ребенка способна рассказать исчерпывающую историю о том, что делает его уникальным, давая его родителям преимущество в определении того, какие шаги предпринять, чтобы отточить потенциально ошеломляющий навык!
Но ДНК ребенка способна рассказать исчерпывающую историю о том, что делает его уникальным, давая его родителям преимущество в определении того, какие шаги предпринять, чтобы отточить потенциально ошеломляющий навык!
Развитие детей младшего возраста, которое включает в себя дополнительные занятия и развитие талантов, может быть довольно сложным и, не говоря уже о, дорогостоящим! Бесчисленное количество родителей возлагают большие надежды на своих детей, но разочаровываются, когда их дети не развиваются. Этого бы не произошло, если бы у родителей было необходимое понимание истинных талантов их ребенка, потому что только тогда они смогут эффективно развивать их.
Определение истинного таланта ребенка никогда не должно быть игрой в угадайку. С точки зрения успешного ухода, вы хотели бы выкопать колодец в месте с наибольшим шансом получить воду с наименьшими усилиями. Доктор Шейн объяснил с убеждением
DTDT не только раскрывает потенциал ребенка, а также врожденные таланты, но также предупреждает родителей о потенциальных слабостях ребенка с точки зрения личности и здоровья.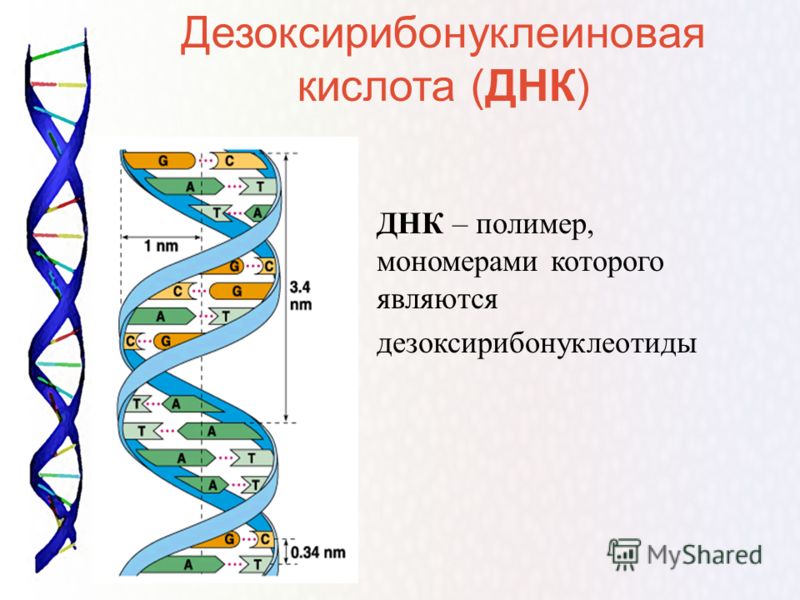 Тест может указать родителям, есть ли у их ребенка склонность к одиночеству, гиперактивности, чрезмерной сентиментальности, депрессии и т. д., и/или есть ли склонность к близорукости, ожирению, курению, алкоголизму — все это и многое другое закодированы в их ДНК! Если тест выявляет вероятность слабой памяти, родители могут сделать важный ранний шаг, например записать ребенка в программу тренировки памяти, чтобы помочь пресечь проблему в зародыше. С другой стороны, если есть потенциал, например, в математике, родители могут обеспечить воспитание, необходимое для воспитания математических способностей. Как сказал доктор Шейн, «в конце концов, генетика зарядит ружье». , но на спусковой крючок нажимает забота».
Тест может указать родителям, есть ли у их ребенка склонность к одиночеству, гиперактивности, чрезмерной сентиментальности, депрессии и т. д., и/или есть ли склонность к близорукости, ожирению, курению, алкоголизму — все это и многое другое закодированы в их ДНК! Если тест выявляет вероятность слабой памяти, родители могут сделать важный ранний шаг, например записать ребенка в программу тренировки памяти, чтобы помочь пресечь проблему в зародыше. С другой стороны, если есть потенциал, например, в математике, родители могут обеспечить воспитание, необходимое для воспитания математических способностей. Как сказал доктор Шейн, «в конце концов, генетика зарядит ружье». , но на спусковой крючок нажимает забота».
В общей сложности 46 результатов, охватывающих талант ребенка, IQ, EQ, потенциал личности и здоровья, которые закодированы в ДНК человека, четко выявляются с помощью одного теста, который обеспечивает точность до 99,9%. «Наша лаборатория в Сингапуре располагает крупнейшей в мире базой данных азиатской генетики, — рассказал доктор Шейн. «Поэтому в настоящее время мы являемся лидером азиатской генетики, чтобы гарантировать высочайшее качество тестов с высокоточными результатами».
«Поэтому в настоящее время мы являемся лидером азиатской генетики, чтобы гарантировать высочайшее качество тестов с высокоточными результатами».
Точность анализа теста подтверждена тысячами научных публикаций ведущих университетов и научно-исследовательских институтов по всему миру благодаря глобальному сотрудничеству в течение последних 30 лет над вышеупомянутым проектом «Геном человека», в котором участвуют сотни тысяч людей для проведения исследований. выход. Таким образом, родители могут быть уверены, что итоговый отчет о расшифровке ДНК основан на фактических данных и гарантирует высокую точность.
Имея на руках отчет DTDT, индивидуальная консультация с родителями поможет им разработать наиболее эффективный план развития для детей. Как уже убедились многие родители, знание истинного потенциала ребенка имеет огромное значение в жизни семьи, поскольку они будут точно знать, какие шаги нужно предпринять, чтобы открыть перед ребенком все правильные двери. Это почти буквально проводник по жизни, если вы правильно его используете.