Содержание
Как расшифровывается ДНК – Мир Знаний
Лишь малая часть людей знает как расшифровывается ДНК. Более того, большинство людей (и я не исключение) затрудняются прочитать полное название с первого раза. Хотите попробовать?
Дезоксирибонуклеиновая кислота.
Да уж, словечко не из самых приятных. Нуклеиновые кислоты, такие как дезоксирибонуклеиновая кислота (ДНК) и рибонуклеиновая кислота (РНК) являются химическими переносчиками генетической информации клеток. В клеточной ДНК зашифрована информация, которая будет определять какую роль будет выполнять эта клетка, контролировать её рост и деление, и направлять биосинтез ферментов и белков, необходимых для жизни клетки. В дополнении к нуклеиновым кислотам в «чистом» виде, существуют еще производные нуклеиновых кислот, как например АТФ, которые выполняют не менее важные роли. АТФ являются этакой денежной валютой в мире молекул, поскольку именно она затрачивается при синтезе каких-нибудь сложных соединений.
Нуклеиновые кислоты являются последним из четырех основных классов биологических молекул, о которых мы будем говорить. Возможно, каждый из вас слышал о такой загадочной молекуле ДНК, которая определяет все ваши физические особенности, но вряд ли многие из вас знают что это такое с химической точки зрения.
Так же как белки сделаны из маленьких частичек — аминокислот, нуклеиновые кислоты сделаны из нуклеотидов, соединенных в длинную цепь. Каждый нуклеотид состоит из трех основных частей: углевода, азотистого основания и остатка фосфорной кислоты. В РНК углеводом является рибоза (отсюда и название: рибонуклеиновая кислота), а в ДНК углеводом является производное рибозы, которые называется дезоксирибоза и отличается лишь тем, что в нем находится на один атом кислорода меньше (и отсюда же и название: дезоксирибонуклеиновая кислота). В ДНК содержится четыре основных азотистых основания: аденин, тимин, гуанин и цитозин. В РНК вместо тимина можно встретить довольно похожее основание, которое называется урацил.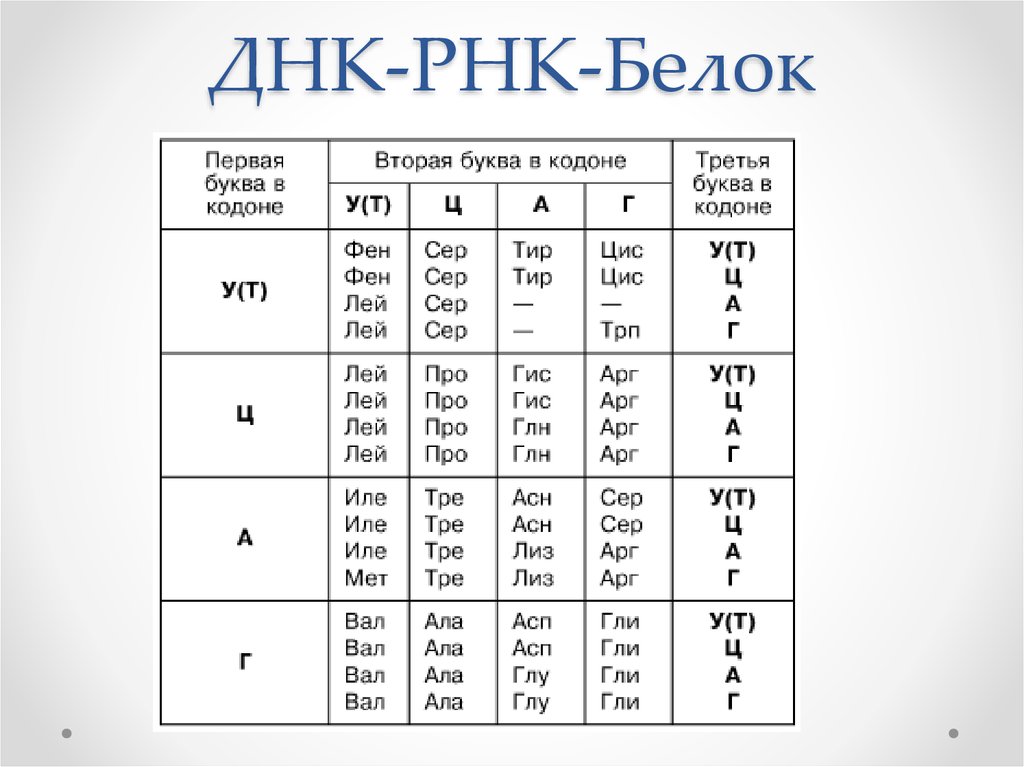
И хоть ДНК и РНК похожи с химической точки зрения, они значительно отличаются по размерам. Молекулы ДНК огромны и содержат около 245 миллионов нуклеотидов, а их молекулярная масса достигает 75 миллиардов грамм на моль. Молекулы РНК в сравнении гораздо меньше, самые маленькие содержат 21 нуклеотид и обладают массой в 7000 грамм на моль.
Несмотря на то, что клетки мозга и клетки кожи обладают совершенно разной структурой и выполняют совершенно разные биологические функции, они обладают совершенно одинаковым генетическим кодом, т.е. одинаковыми молекулами ДНК. При этом, примерно любая человеческая ДНК содержит по 30% аденина и тимина, и по 20% гуанина и цитозина. Более того, феномен равенства количеств тимина и аденина, гуанина и цитозина не является уникальным для человеческого организма. Это повсеместное явление в природе. Но почему?
В 1953 году, Джеймс Уотсон и Фрэнсис Крик обнаружили истинную вторичную структуру молекулы ДНК. Согласно их модели, ДНК состоит из двух цепочек из нуклеотидов, которые сворачиваются в витки двойной спирали, также как винтовые лестницы.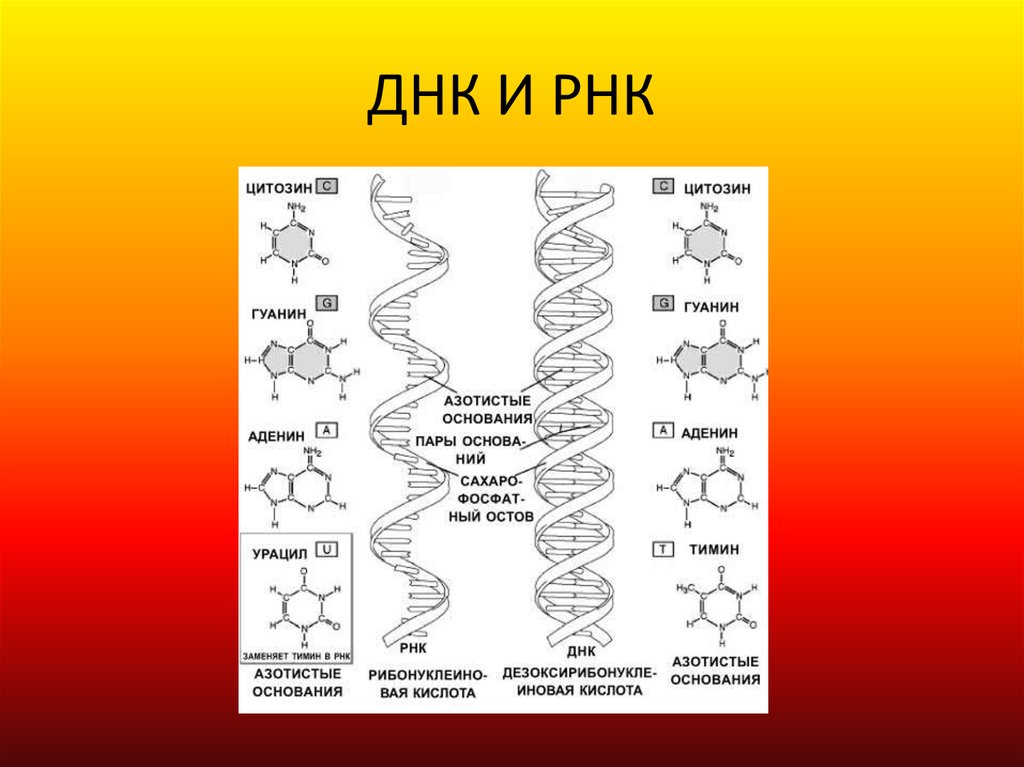 Две цепочки не идентичны, а комплементарны и удерживаются водородными связями. Каждый Аденин (А) связывается с Тимином (Т), а каждый Гуанин (G) связывается с Цитозином (С) и наоборот. То есть, каждый раз как в одной цепочке встречается А, в другой цепочке будет Т. Этот факт обьясняет то, что мы видим одинаковые количества А и Т, G и С в любых живых организмах.
Две цепочки не идентичны, а комплементарны и удерживаются водородными связями. Каждый Аденин (А) связывается с Тимином (Т), а каждый Гуанин (G) связывается с Цитозином (С) и наоборот. То есть, каждый раз как в одной цепочке встречается А, в другой цепочке будет Т. Этот факт обьясняет то, что мы видим одинаковые количества А и Т, G и С в любых живых организмах.
В среднем, каждый виток спирали ДНК содержит около 10 пар оснований (нуклеотидов). Как можно заметить из рисунка: две нити ДНК переплетаются таким образом, что образуются две разных по размерам бороздки: большая (12А в ширину) и малая (6А в ширину), где 1 А в 10 миллиардов раз меньше метра. Большая бороздка немного глубже, и как мы видим на картинке, все азотистые основания складываются в хорошие такие параллельные линии. Все дело в том, что эти основания содержат шестичленные и пятичленные ароматические циклы, которые по форме являются шести- и пятиугольниками. Их называют ароматическими потому, что они а) плоские и б) содержат много двойных связей.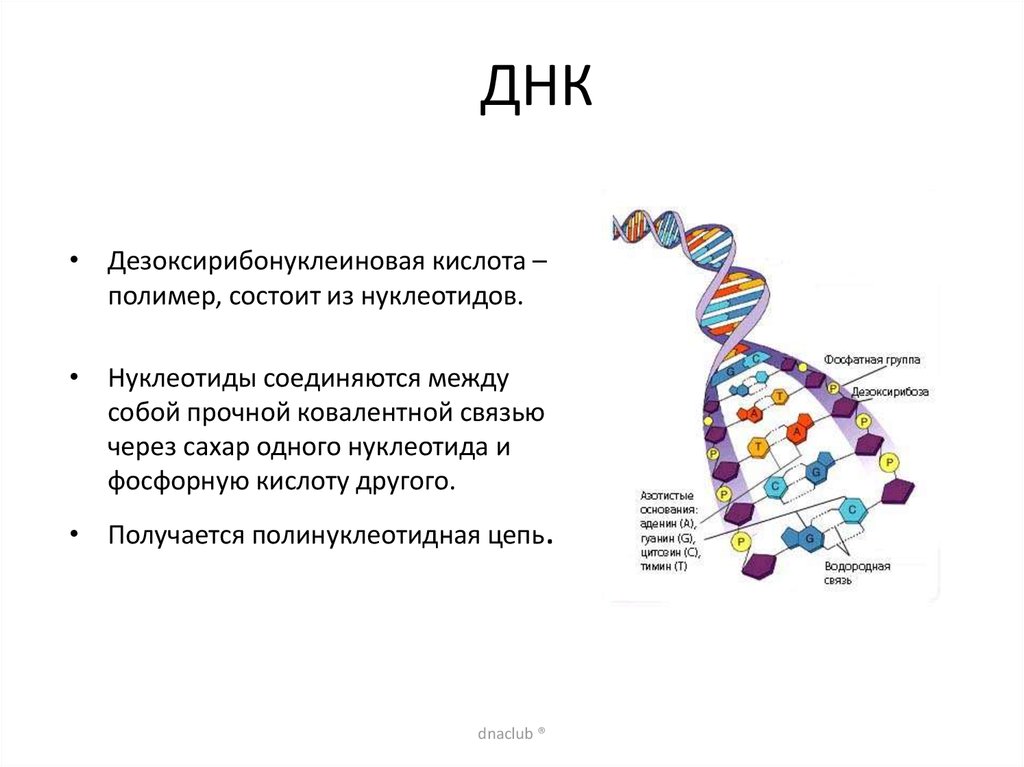 Эти самые двойные связи и могут стабилизировать структуру ДНК если, например, две двойных связи с двух разных ароматических молекул находятся строго параллельно друг под другом. Именно так и происходит в реальной структуре и мы видим параллельно-лежащие молекулы и пространство между ними. Большое количество полициклических ароматических молекул может пролезать в эти пространства, или на научном языке интеркалировать. Многие канцерогены (вещества вызывающие рак) и лекарства от рака функционируют именно взаимодействуя с ДНК методом интеркаляции.
Эти самые двойные связи и могут стабилизировать структуру ДНК если, например, две двойных связи с двух разных ароматических молекул находятся строго параллельно друг под другом. Именно так и происходит в реальной структуре и мы видим параллельно-лежащие молекулы и пространство между ними. Большое количество полициклических ароматических молекул может пролезать в эти пространства, или на научном языке интеркалировать. Многие канцерогены (вещества вызывающие рак) и лекарства от рака функционируют именно взаимодействуя с ДНК методом интеркаляции.
Генетическая информация организма хранится как последовательность нуклеотидов в цепочке ДНК. Все гены, которые определяют наш цвет глаз, наш цвет волос, наш цвет кожи, наши особенности, наш потенциальный рост, наши физические задатки — все это всего лишь последовательность четырех нуклеотидов А, Т, G и С. Ровно как все операционные системы — это лишь последовательности 0 и 1, точно так же ДНК это — последовательности четырех нуклеотидов.
Для того чтобы сохранять генетическую информацию и передавать её следующим поколениям должен существовать механизм для копирования ДНК.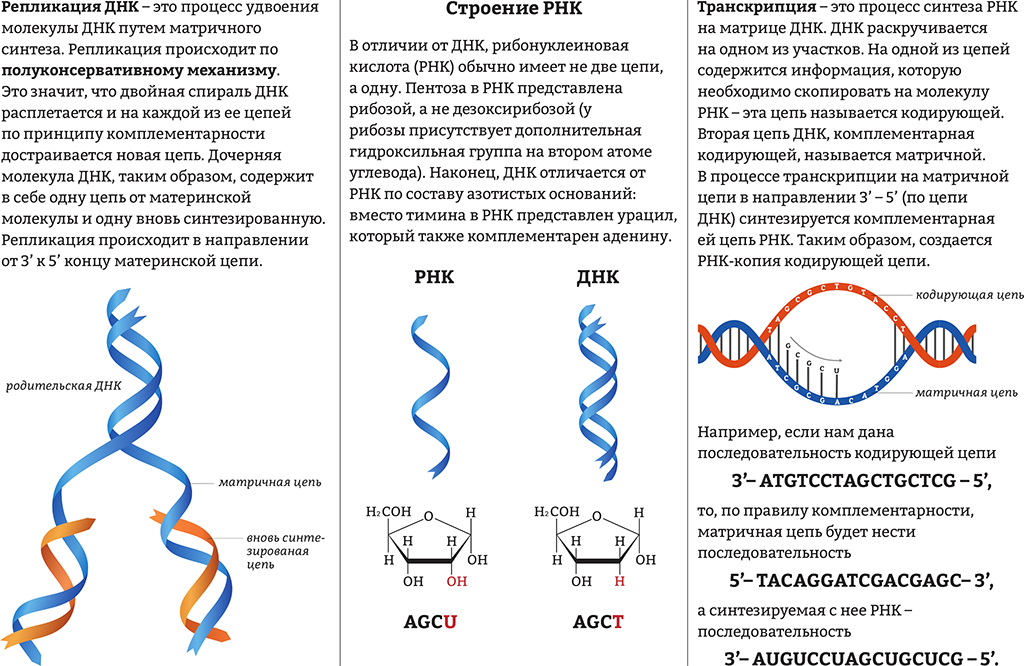 Чтобы использовать эту информацию, должен существовать механизм для расшифровки и использования этого кода. Хорошая новость заключается в том, что эти механизмы более-менее изучены.
Чтобы использовать эту информацию, должен существовать механизм для расшифровки и использования этого кода. Хорошая новость заключается в том, что эти механизмы более-менее изучены.
Однажды, Фрэнсис Крик сформулировал центральную догму молекулярной биологии, которая гласит: функция ДНК заключается в хранении и передаче информации РНК, а функция РНК заключается в чтении, де|шифровке и использование информации из ДНК для создания белков. И хоть такой взгляд может казаться слишком упрощенным, он достаточно хорошо обобщает детали.
Существует три фундаментальных процесса:
- Репликация — процесс по которому создаются идентичные копии ДНК с целью передачи информации потомкам.
- Транскрипция — процесс по которому генетическая информация читается и переносится из ядра клетки к специальным станциям (рибосомам), где происходит синтез белка.
- Трансляция — сам процесс синтеза белка в специальных станциях.
Репликация ДНК — это реакция, катализируемая ферментами, которая начинается с частичного раскручивания двойной спирали в некоторых местах молекулы ДНК. Раскручивание происходит под действием фермента хеликаза (от английского хеликс — спираль), иными словами приходит фермент и разрывает парочку водородных связей между азотистыми основаниями, тем самым образуя некий пузырь и выворачивая азотистые основания навстречу окружающей среде. При этом, рядом спокойно плавают разные нуклеотиды в свободном виде, и мимо проходя, они подходят к азотистым основаниям ДНК и образуют с ними водородные связи. Таким образом, к каждой из старых двух цепочек ДНК приходят новые нуклеотиды и образуется две молекулы ДНК, каждая из которых содержит по цепочке от начальной молекулы. Нуклеотиды выстраиваются по принципу комплементарности, и поэтому две новые копии идентичны. Размах процесса репликации просто ошеломляет: каждое ядро любой нашей клетки содержит по две копии 22 х хромосом и еще две половые хромосомы (всего 46). Каждая хромосома стоит из одной большой молекулы ДНК, компактно свернутой вокруг специальных белков, называемых гистонами. В целом, оценивается что во всех 46 хромосомах находится в сумме около 3 миллиардов пар оснований, или 6 миллиардов нуклеотидов.
Раскручивание происходит под действием фермента хеликаза (от английского хеликс — спираль), иными словами приходит фермент и разрывает парочку водородных связей между азотистыми основаниями, тем самым образуя некий пузырь и выворачивая азотистые основания навстречу окружающей среде. При этом, рядом спокойно плавают разные нуклеотиды в свободном виде, и мимо проходя, они подходят к азотистым основаниям ДНК и образуют с ними водородные связи. Таким образом, к каждой из старых двух цепочек ДНК приходят новые нуклеотиды и образуется две молекулы ДНК, каждая из которых содержит по цепочке от начальной молекулы. Нуклеотиды выстраиваются по принципу комплементарности, и поэтому две новые копии идентичны. Размах процесса репликации просто ошеломляет: каждое ядро любой нашей клетки содержит по две копии 22 х хромосом и еще две половые хромосомы (всего 46). Каждая хромосома стоит из одной большой молекулы ДНК, компактно свернутой вокруг специальных белков, называемых гистонами. В целом, оценивается что во всех 46 хромосомах находится в сумме около 3 миллиардов пар оснований, или 6 миллиардов нуклеотидов. Несмотря на такой размер генома человека, процесс занимает всего несколько часов, а средняя скорость репликации ДНК составляет 50 нуклеотидов в секунду.
Несмотря на такой размер генома человека, процесс занимает всего несколько часов, а средняя скорость репликации ДНК составляет 50 нуклеотидов в секунду.
Но разве не опасно копировать нашу ДНК так быстро? Случайная ошибка и в ДНК встанет неправильный нуклеотид, а это уже будет означать мутацию всего гена! Если бы мы сознательно копировали нашу ДНК, мы бы перепроверяли каждое основание по несколько раз, никто же не хочет случайных мутаций? Чтобы убедиться в отсутствии ошибок, клетки тоже делают повторное чтение цепочки ДНК и при необходимости исправляют ошибки. В итоге, ошибка может встречаться лишь один раз на каждые 10-100 миллиардов нуклеотидов. При этом, учитывая то, что молекулы ДНК копируются при каждом клеточном делении, а клетки делятся на протяжении всей жизни, всего 60 случайных ошибок (мутаций) передается следующему поколению.
После того как ДНК полностью копируется, образуются две новые копии. Так происходит с каждой хромосомой. В итоге, когда клетка делится на две новые, она передает одну копию одной клетке, а другую другой.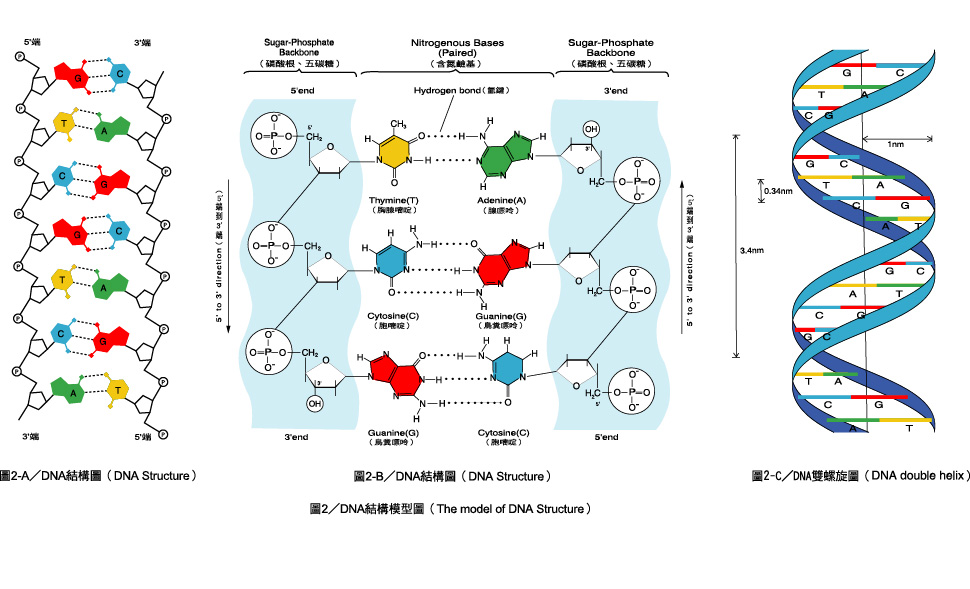 Похожим образом происходит и образование половых клеток, которые участвуют в процессе передачи генетической информации от поколения к поколению.
Похожим образом происходит и образование половых клеток, которые участвуют в процессе передачи генетической информации от поколения к поколению.
Но как же организм может читать информацию зашифрованную в молекуле ДНК? Вернемся к РНК. Ранее мы говорили, что она структурно похожа наиДНК, но содержит рибозу вместо дезоксирибозы, и урацил вместо тимина. В нашем организме есть четыре основных типа РНК: матричная (информационная) — мРНК, рибосомальная — рРНК, транспортная — тРНК, и много маленьких РНК, также называемых функциональными РНК. Последние выполняют большое количество различных функций внутри клетки, например остановка процесса транскрипции или ускорение химической модификации других молекул РНК (катализ).
Генетическая информация в ДНК содержится в определенных сегментах, называемых генами, каждый из которых состоит из специфичной последовательности нуклеотидов, которые кодируют тот или иной белок. Да, да, именно так: все наши гены это просто последовательности нуклеотидов, которые кодируют синтез того или иного белка. При этом, по большей части ДНК хранится в свернутом виде, однако, в разных частях организма развернуты разные части ДНК, будто бы открыты разные страницы одной книги. Именно поэтому, клетки мозга, клетки крови, мышцы, железы обладают одной ДНК но такими разными функциями, которые определяются теми или иными белками в их составе.
При этом, по большей части ДНК хранится в свернутом виде, однако, в разных частях организма развернуты разные части ДНК, будто бы открыты разные страницы одной книги. Именно поэтому, клетки мозга, клетки крови, мышцы, железы обладают одной ДНК но такими разными функциями, которые определяются теми или иными белками в их составе.
Но как же происходит синтез белка? Во-первых, представим что есть определенная последовательность ДНК на цепочке №1, а цепочка ей комплементарная пусть будет №2. Во время транскрипции приходит специальный фермент и опять разворачивает небольшой участок молекулы ДНК. При этом, вместо того, чтобы позволять нуклеотидам присоединяться к обоим цепочкам, фермент удерживает первую (ее еще называют кодирующей), а рибонуклеотиды (именно те, которые входят в состав РНК) присоединяются ко второй цепочке (ее еще называют шаблонной), образуя матричную РНК, которая комплементарна цепочке №2, которая в свою очередь комплементарна цепочке №1. Надеюсь вы еще не запутались. В итоге, мРНК идентична кодирующей цепочке №1, за исключением лишь того, что вместо тимина везде находится урацил.
В итоге, мРНК идентична кодирующей цепочке №1, за исключением лишь того, что вместо тимина везде находится урацил.
Очень часто в природе встречается следующая картина: последовательности ДНК, которые несут какой либо смысл (гены) начинаются в одном месте (называемом экзоном), но периодически прерываются бессмысленными вставками (в том плане, что они не кодируют белок) называемыми интронами. Финальная мРНК появляется только тогда, когда эти интроны вырезаются специальными ферментами, которые называются сплисеосомами. Да, пожалуй к этому моменту вы уже убедились в том, что биологи любят придумывать разные термины. Например, гены кукурузы, которые кодируют фермент триозофосфатизомеразу (отвечает за очень важную стадию в процессе метаболизма углеводов) содержат 8 некодирующих интронов, которые занимают примерно 70% от всей последовательности, и 9 кодирующих экзонов, которые занимают оставшиеся 30%.
Ну вот у нас есть мРНК, которая содержит кодирующую последовательность, но что дальше? мРНК приходит в рибосому (специальную станцию клетки для биосинтеза белка) и там встречается с другими ферментами, в том числе с разными тРНК. Каждые три нуклеотида в мРНК кодируют ту или иную аминокислоту. Например AAA кодирует аминокислоту лизин, a UGC кодирует цистеин. Но почему природа выбрала именно три нуклеотида, не больше и не меньше? Дело в том, что существует лишь 16 разных последовательностей из двух нуклеотидов (при выборе из A,T,G,C), а аминокислот как мы помним 20. Если добавить всего один нуклеотид, количество вариантов возрастает до 64, но теперь одна и та же аминокислота может кодироваться разными последовательностями ДНК. Возвращаясь к кодированию аминокислот: замени хоть один нуклеотид — и ты получишь другую аминокислоту. А вдруг она играла критичную роль? Без нее организм уже становится мутантом.
Каждые три нуклеотида в мРНК кодируют ту или иную аминокислоту. Например AAA кодирует аминокислоту лизин, a UGC кодирует цистеин. Но почему природа выбрала именно три нуклеотида, не больше и не меньше? Дело в том, что существует лишь 16 разных последовательностей из двух нуклеотидов (при выборе из A,T,G,C), а аминокислот как мы помним 20. Если добавить всего один нуклеотид, количество вариантов возрастает до 64, но теперь одна и та же аминокислота может кодироваться разными последовательностями ДНК. Возвращаясь к кодированию аминокислот: замени хоть один нуклеотид — и ты получишь другую аминокислоту. А вдруг она играла критичную роль? Без нее организм уже становится мутантом.
Что мы имеем в итоге? ДНК состоит из последовательностей нуклеотидов. Гены — последовательность нуклеотидов. Три таких нуклеотида называют кодоном и они являются такой буковкой в молекулярном мире. Каждая буковка кодируют какую-либо аминокислоту. Но что же значит кодируют? Дело в том, что существует 61 тРНК, у которых есть участки комплементарные кодонам, а каждая из этих тРНК несет на другом конце одну аминокислоту.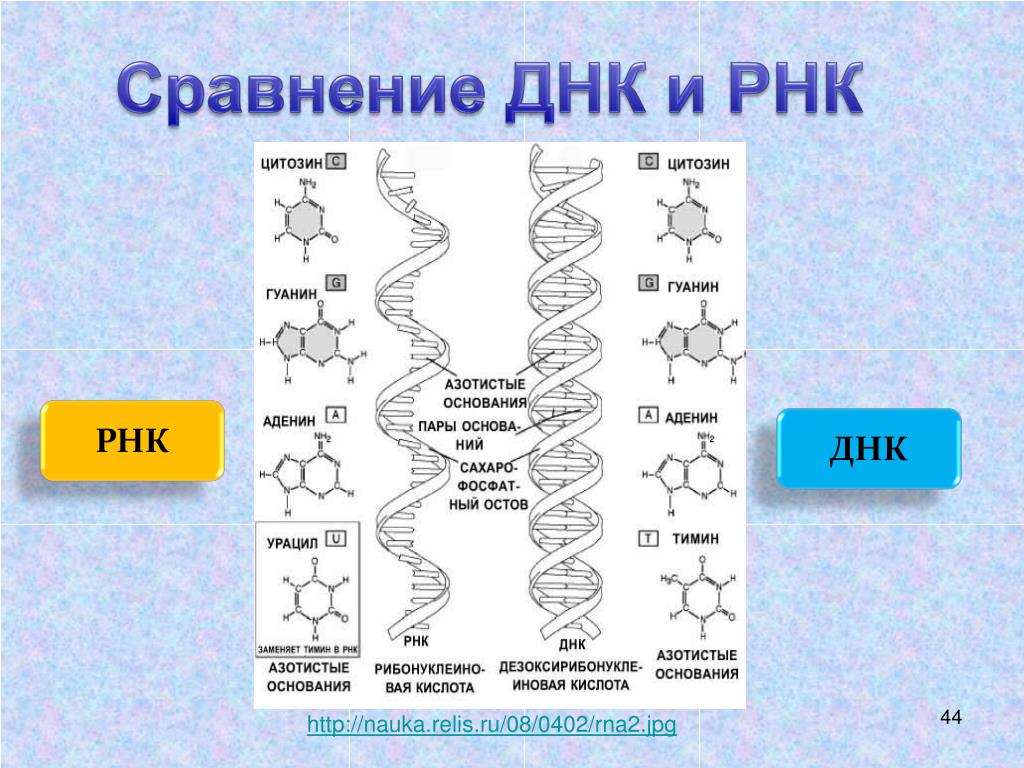 В процессе биосинтеза белков, тРНК присоединяется к комплементарным участкам на мРНК, а ферменты соединяют аминокислоты, которые они несут с другой стороны. Но мы сказали что существует 64 кодона, а тРНК вроде как всего 61, где остальные 3? Остальные 3 тРНК останавливают процесс биосинтеза белка, т.е. в конце любой генетической последовательности есть кодон который говорит организму остановиться. Вот такой вот сложный механизм обеспечивает всю нашу генетическую разнообразность.
В процессе биосинтеза белков, тРНК присоединяется к комплементарным участкам на мРНК, а ферменты соединяют аминокислоты, которые они несут с другой стороны. Но мы сказали что существует 64 кодона, а тРНК вроде как всего 61, где остальные 3? Остальные 3 тРНК останавливают процесс биосинтеза белка, т.е. в конце любой генетической последовательности есть кодон который говорит организму остановиться. Вот такой вот сложный механизм обеспечивает всю нашу генетическую разнообразность.
Скорость расшифровки ДНК увеличили в сотни раз — Наука
ТАСС, 14 сентября. Математики выяснили, что расшифровывать ДНК можно даже на обычном ноутбуке, без привлечения суперкомпьютеров. Для этого механизм расшифровки нужно изменить: разбивать ДНК нужно не на отдельные «буквы»-нуклеотиды, а на часто встречающиеся их комбинации. Описание этой методики опубликовал научный журнал Cell Systems.
«Наш подход работает, даже если в исходном материале содержится до 4% ошибок. Вкупе с удешевлением машин для секвенирования это открывает дорогу для демократизации генетического анализа», – рассказала Бонни Бергер, профессор Массачусетского технологического института и один из авторов исследования.
Вкупе с удешевлением машин для секвенирования это открывает дорогу для демократизации генетического анализа», – рассказала Бонни Бергер, профессор Массачусетского технологического института и один из авторов исследования.
Большинство современых технологий расшифровки ДНК опираются на идею, что большое количество копий нити ДНК можно разбить на множество легко считываемых мелких фрагментов, которые при этом частично пересекаются друг с другом. Благодаря этому их можно много раз считать, а затем «склеить» друг с другом. Этот подход работает очень эффективно, однако для него необходимо много вычислительных ресурсов.
Бергер и ее коллеги придумали, как справиться с этой проблемой. Они создали математическую теорию, с помощью которой геном можно закодировать в виде набора из часто встречающихся последовательностей из нескольких «букв»-нуклеотидов, а не одиночных звеньев.
Эту идею ученые позаимствовали из теории языков и лингвистики. В последние годы в этой обалсти начала набирать популярность идея использования так называемых графов де Брейна. Так математики называют наборы из нескольких пересекающихся последовательностей символов, которые соединены друг с другом множеством направленных связей.
Так математики называют наборы из нескольких пересекающихся последовательностей символов, которые соединены друг с другом множеством направленных связей.
Эти графы используют и при сборке геномов. Однако в результате этого обычно терялось много информации. Бергер и ее коллеги избавились от этих проблем, модифицировав графы де Брейна таким образом, что этот математический инструмент оперировал не отдельными нуклеотидами, а их распространенными комбинациями.
По словам математиков, благодаря этому можно одновременно ускорить поиски и «склеить» частично совпадающие фрагменты ДНК. При для окончательной расшифровки генома нужно гораздо меньше компьютерной памяти. В дополнение к этому, он позволил ученым использовать один и тот же подход для обработки высококачественных данных с минимумом ошибок, а также результатов работы дешевых секвенаторов, некорректно распознающих около 2-4% нуклеотидов.
Для проверки работы алгоритма ученые расшифровали ДНК человека и микробов при помощи двух разных секвенаторов и обработали их при помощи слабого восьмиядерного процессора. Процесс сборки человеческого генома занял всего 10 минут и потребовал около 10 гигабайтов оперативной памяти, тогда как анализ нескольких геномов бактерий завершился за четыре минуты и занял всего гигабайт ОЗУ. Оба этих показателя в десятки и сотни раз меньше времени работы и запросов на память для других подходов.
Процесс сборки человеческого генома занял всего 10 минут и потребовал около 10 гигабайтов оперативной памяти, тогда как анализ нескольких геномов бактерий завершился за четыре минуты и занял всего гигабайт ОЗУ. Оба этих показателя в десятки и сотни раз меньше времени работы и запросов на память для других подходов.
По словам исследователей, подобное ускорение процесса сборки генома уже сейчас доступно любому желающему, так как Бергер и ее коллеги опубликовали исходный код созданного алгоритма в открытом доступе. Как надеются ученые, его создание и публикация позволят удешевить процесс секвенирования геномов и расширить их применение в научной и медицинской практике
Как клетки читают геном: от ДНК к белку — молекулярная биология клетки
Книжная полка NCBI. Служба Национальной медицинской библиотеки, Национальных институтов здоровья.
Альбертс Б., Джонсон А., Льюис Дж. и др. Молекулярная биология клетки. 4-е издание. Нью-Йорк: Гарланд Наука; 2002.
- По соглашению с издателем эта книга доступна через функцию поиска, но не может быть просмотрена.


Показать детали
Критерий поиска
Только когда в начале 1950-х годов была открыта структура ДНК, стало ясно, как наследственная информация в клетках закодирована в последовательности нуклеотидов ДНК. С тех пор прогресс был поразительным. Пятьдесят лет спустя у нас есть полные последовательности геномов многих организмов, включая человека, и поэтому мы знаем максимальное количество информации, необходимое для создания сложного организма, подобного нам. Ограничения на наследственную информацию, необходимую для жизни, ограничивают биохимические и структурные особенности клеток и ясно показывают, что биология не бесконечно сложна.
В этой главе мы объясним, как клетки расшифровывают и используют информацию, содержащуюся в их геномах. Мы увидим, как много мы узнали о том, как генетические инструкции, записанные в алфавите всего из четырех «букв» — четырех различных нуклеотидов в ДНК — управляют формированием бактерии, плодовой мушки или человека.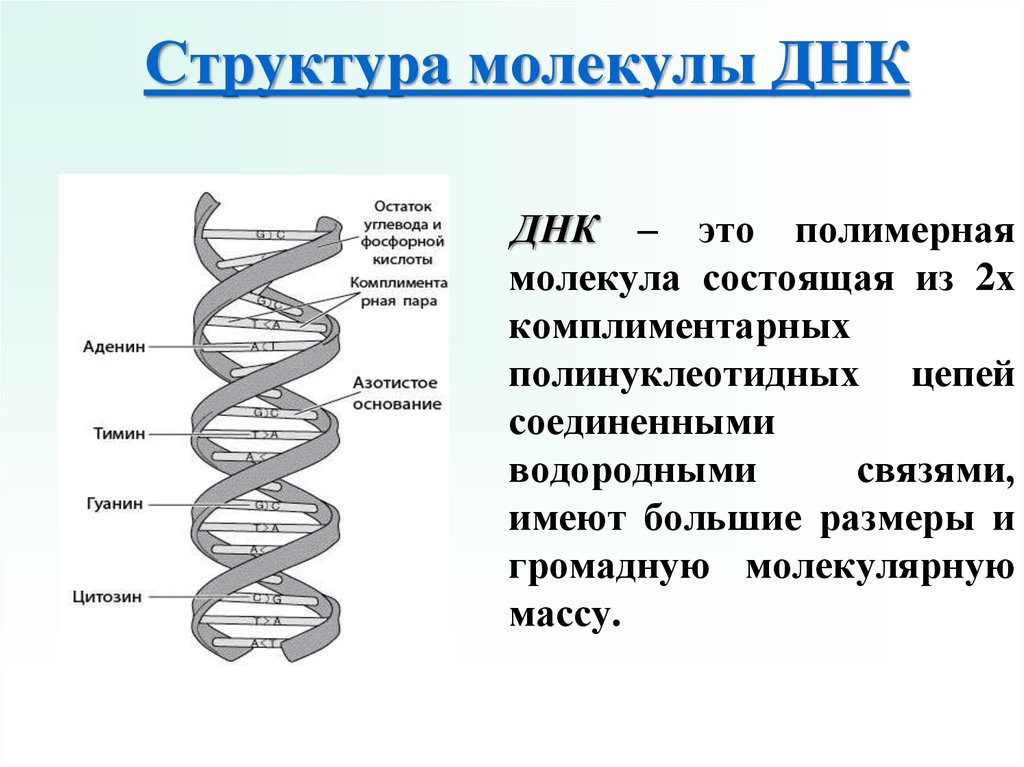 Тем не менее, нам еще предстоит многое узнать о том, как информация, хранящаяся в геноме организма, производит даже простейшую одноклеточную бактерию с 500 генами, не говоря уже о том, как она направляет развитие человека с примерно 30 000 генов. Остается огромное количество невежества; поэтому перед следующим поколением клеточных биологов стоит множество увлекательных задач.
Тем не менее, нам еще предстоит многое узнать о том, как информация, хранящаяся в геноме организма, производит даже простейшую одноклеточную бактерию с 500 генами, не говоря уже о том, как она направляет развитие человека с примерно 30 000 генов. Остается огромное количество невежества; поэтому перед следующим поколением клеточных биологов стоит множество увлекательных задач.
Проблемы, с которыми сталкиваются клетки при расшифровке геномов, можно оценить, рассмотрев небольшую часть генома плодовой мушки Drosophila melanogaster (). Большая часть закодированной в ДНК информации, присутствующей в этом и других геномах, используется для определения линейного порядка — последовательности — аминокислот для каждого белка, производимого организмом. Как описано в главе 3, аминокислотная последовательность, в свою очередь, диктует, как складывается каждый белок, образуя молекулу с отличительной формой и химическим составом. Когда клетка производит определенный белок, соответствующая область генома должна быть точно расшифрована.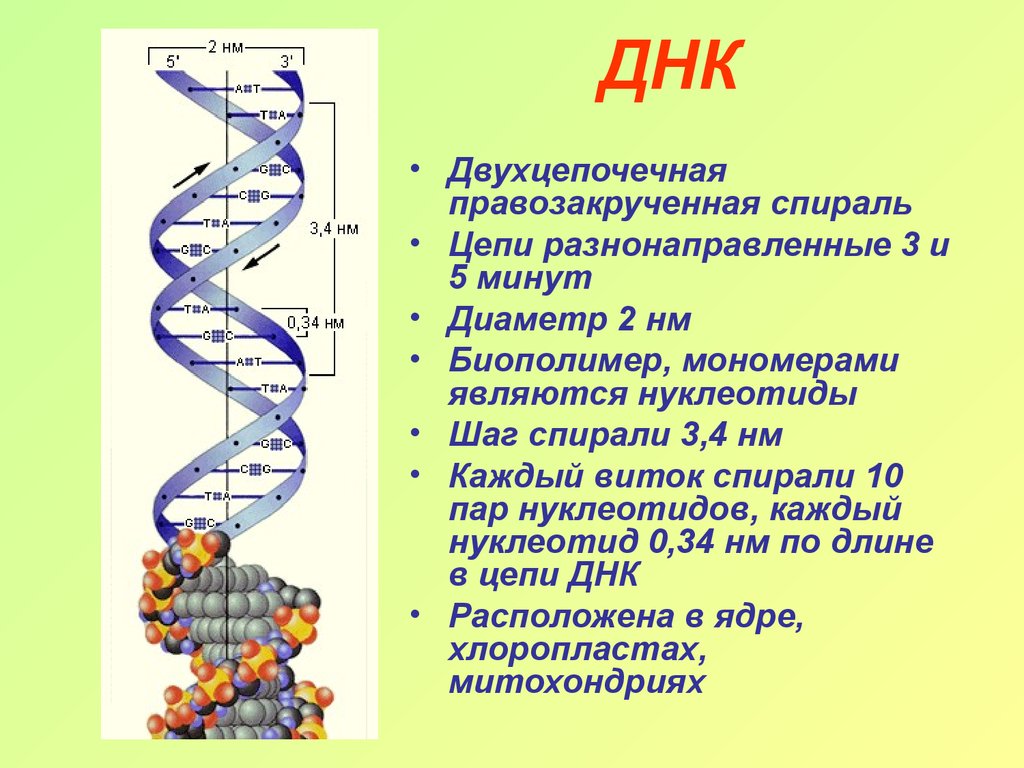 Дополнительная информация, закодированная в ДНК генома, указывает, когда именно в жизни организма и в каких типах клеток каждый ген должен быть экспрессирован в белок. Поскольку белки являются основными составляющими клеток, расшифровка генома определяет не только размер, форму, биохимические свойства и поведение клеток, но и отличительные черты каждого вида на Земле.
Дополнительная информация, закодированная в ДНК генома, указывает, когда именно в жизни организма и в каких типах клеток каждый ген должен быть экспрессирован в белок. Поскольку белки являются основными составляющими клеток, расшифровка генома определяет не только размер, форму, биохимические свойства и поведение клеток, но и отличительные черты каждого вида на Земле.
Рисунок 6-1
Схематическое изображение части хромосомы 2 из генома плодовой мушки Drosophila melanogaster. . Эта цифра составляет примерно 3% от общего генома дрозофилы , расположенного в виде шести непрерывных сегментов. Как указано в ключе, символический (далее…)
Можно было бы предположить, что информация, присутствующая в геномах, будет упорядочена, напоминая словарь или телефонный справочник. Хотя геномы некоторых бактерий кажутся довольно хорошо организованными, геномы большинства многоклеточных организмов, таких как наши Drosophila , например, удивительно беспорядочны. Небольшие фрагменты кодирующей ДНК (то есть ДНК, кодирующей белок) перемежаются с большими блоками кажущейся бессмысленной ДНК. Некоторые участки генома содержат много генов, а другие вообще не содержат генов. Белки, тесно взаимодействующие друг с другом в клетке, часто имеют свои гены, расположенные на разных хромосомах, а соседние гены обычно кодируют белки, которые мало связаны друг с другом в клетке. Следовательно, расшифровка геномов — непростая задача. Даже с помощью мощных компьютеров исследователям все еще трудно точно определить местонахождение начала и конца генов в последовательностях ДНК сложных геномов, не говоря уже о том, чтобы предсказать, когда каждый ген экспрессируется в жизни организма. Хотя последовательность ДНК человеческого генома известна, людям, вероятно, потребуется не менее десяти лет, чтобы идентифицировать каждый ген и определить точную аминокислотную последовательность белка, который он производит. Тем не менее, клетки нашего тела делают это тысячи раз в секунду.
Некоторые участки генома содержат много генов, а другие вообще не содержат генов. Белки, тесно взаимодействующие друг с другом в клетке, часто имеют свои гены, расположенные на разных хромосомах, а соседние гены обычно кодируют белки, которые мало связаны друг с другом в клетке. Следовательно, расшифровка геномов — непростая задача. Даже с помощью мощных компьютеров исследователям все еще трудно точно определить местонахождение начала и конца генов в последовательностях ДНК сложных геномов, не говоря уже о том, чтобы предсказать, когда каждый ген экспрессируется в жизни организма. Хотя последовательность ДНК человеческого генома известна, людям, вероятно, потребуется не менее десяти лет, чтобы идентифицировать каждый ген и определить точную аминокислотную последовательность белка, который он производит. Тем не менее, клетки нашего тела делают это тысячи раз в секунду.
ДНК в геномах не управляет синтезом белка сама по себе, а вместо этого использует РНК в качестве промежуточной молекулы.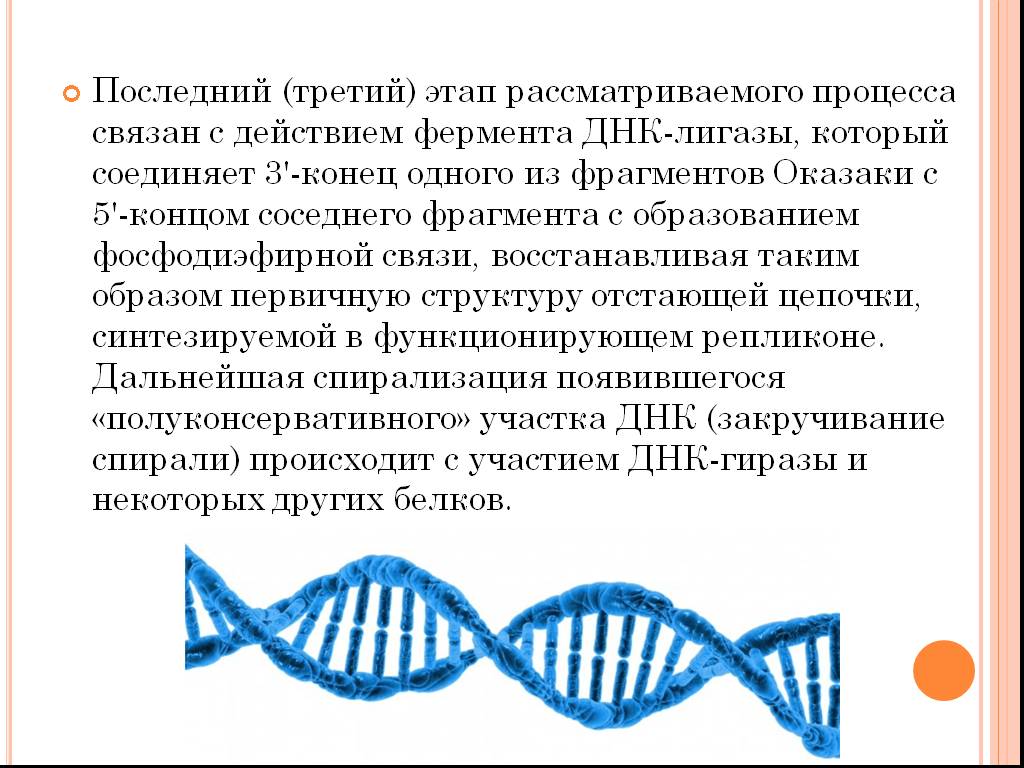 Когда клетке нужен определенный белок, нуклеотидная последовательность соответствующей части чрезвычайно длинной молекулы ДНК в хромосоме сначала копируется в РНК (процесс, называемый транскрипцией ). Именно эти РНК-копии сегментов ДНК используются непосредственно в качестве матриц для управления синтезом белка (процесс, называемый -трансляцией). Таким образом, поток генетической информации в клетках идет от ДНК к РНК и белку (). Все клетки, от бактерий до человека, выражают свою генетическую информацию таким образом — принцип настолько фундаментален, что его называют центральной догмой молекулярной биологии.
Когда клетке нужен определенный белок, нуклеотидная последовательность соответствующей части чрезвычайно длинной молекулы ДНК в хромосоме сначала копируется в РНК (процесс, называемый транскрипцией ). Именно эти РНК-копии сегментов ДНК используются непосредственно в качестве матриц для управления синтезом белка (процесс, называемый -трансляцией). Таким образом, поток генетической информации в клетках идет от ДНК к РНК и белку (). Все клетки, от бактерий до человека, выражают свою генетическую информацию таким образом — принцип настолько фундаментален, что его называют центральной догмой молекулярной биологии.
Рисунок 6-2
Путь от ДНК к белку. Поток генетической информации от ДНК к РНК (транскрипция) и от РНК к белку (трансляция) происходит во всех живых клетках.
Несмотря на универсальность центральной догмы, существуют важные различия в способах передачи информации от ДНК к белку. Главным среди них является то, что транскрипты РНК в эукариотических клетках подвергаются ряду стадий процессинга в ядре, включая сплайсинг РНК до того, как им будет разрешено выйти из ядра и транслироваться в белок.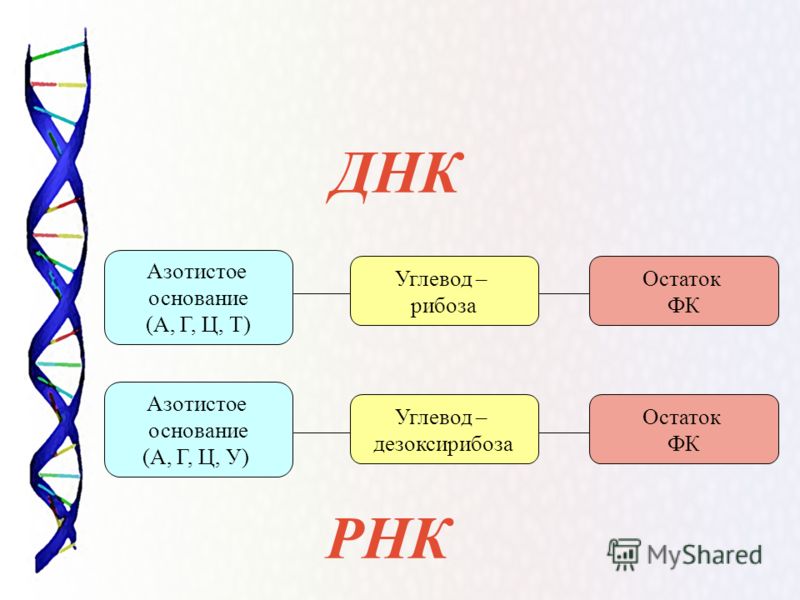 Эти этапы обработки могут критически изменить «значение» молекулы РНК и поэтому имеют решающее значение для понимания того, как эукариотические клетки читают геном. Наконец, хотя в этой главе мы сосредоточимся на производстве белков, кодируемых геномом, мы видим, что для некоторых генов конечным продуктом является РНК. Подобно белкам, многие из этих РНК складываются в четкие трехмерные структуры, которые играют структурную и каталитическую роль в клетке.
Эти этапы обработки могут критически изменить «значение» молекулы РНК и поэтому имеют решающее значение для понимания того, как эукариотические клетки читают геном. Наконец, хотя в этой главе мы сосредоточимся на производстве белков, кодируемых геномом, мы видим, что для некоторых генов конечным продуктом является РНК. Подобно белкам, многие из этих РНК складываются в четкие трехмерные структуры, которые играют структурную и каталитическую роль в клетке.
Мы начинаем эту главу с первого шага в расшифровке генома: процесса транскрипции, посредством которого молекула РНК образуется из ДНК гена. Затем мы следим за судьбой этой молекулы РНК в клетке и заканчиваем, когда формируется правильно свернутая молекула белка. В конце главы мы рассмотрим, как нынешняя довольно сложная схема хранения, транскрипции и трансляции информации могла возникнуть из более простых систем на самых ранних стадиях клеточной эволюции.
- От ДНК к РНК
- От РНК к белку
- Мир РНК и происхождение жизни
- Список литературы
По соглашению с издателем эта книга доступна через функцию поиска, но не может быть просмотрена .
Copyright © 2002, Брюс Альбертс, Александр Джонсон, Джулиан
Льюис, Мартин Рафф, Кейт Робертс и Питер Уолтер; Авторское право © 1983,
1989, 1994, Брюс Альбертс, Деннис Брэй, Джулиан Льюис, Мартин Рафф, Кит Робертс,
и Джеймс Д. Уотсон.
ID книжной полки: NBK21050
- Цитировать эту страницу
Запись активности отключена.
Включите запись
Подробнее…
Сможем ли мы полностью расшифровать код жизни?
Вот 12-й отрывок из моей колонки BBC
В 2001 году проект «Геном человека» предоставил нам почти полный черновик из 3 миллиардов букв нашей ДНК. Мы присоединились к элитному клубу видов с последовательностями их геномов, который растет с каждым месяцем.
Эти геномы содержат информацию, необходимую для создания соответствующих владельцев, но эту информацию мы все еще пытаемся разобрать.
На сегодняшний день никто не может взять код из генов организма и предсказать все детали его формы, поведения, развития, физиологии — совокупность признаков, известную как его фенотип. И тем не менее, основа этих деталей есть, и все они запечатлены в отрезках As, Cs, Gs и Ts. «Клетки довольно надежно знают, как это делать», — говорит Леонид Кругляк из Принстонского университета. «Каждый раз, когда вы начинаете с генома курицы, вы получаете курицу, и каждый раз, когда вы начинаете с генома слона, вы получаете слона».По мере развития наших технологий и понимания, сможем ли мы, в конце концов, взглянуть на груду необработанных последовательностей ДНК и собрать всю работу организма, которому они принадлежат? Точно так же, как физики могут использовать законы механики для предсказания движения объекта, могут ли биологи использовать фундаментальные идеи генетики и молекулярной биологии для предсказания черт и недостатков тела исключительно на основе его генов? Можем ли мы поместить геном в черный ящик и распечатать изображение человека? Или муха? Или мышь?
Нелегко.
В сложных организмах некоторые признаки можно проследить до конкретных генов. Если, например, вы смотрите на конкретный вариант гена MC1R, скорее всего, перед вами млекопитающее с рыжими волосами. Действительно, люди предсказали, что некоторые неандертальцы были рыжими именно по этой причине. «Но помимо этого, предсказывая [если что-то] мышь, кит или броненосец, мы все равно не преуспеем», — говорит Кругляк.[Бернхард Палссон из Калифорнийского университета в Сан-Диего соглашается. «Секвенирование шерстистого мамонта не предскажет его свойства», — говорит он. «Но вы могли бы добиться большего успеха с бактериями». С более простыми и меньшими геномами это теоретически должно облегчить предсказание основных особенностей их метаболизма, а также того, растут ли они с использованием кислорода или без него. Несмотря на то, что мы можем секвенировать бактериальный геном менее чем за день и всего за 50 фунтов стерлингов, нам все равно будет сложно определить важные признаки, например, насколько хорошо болезнетворный микроб заражает своего хозяина.
Трудно даже найти все гены в маленьком геноме. Ранее в этом году ученые обнаружили новый ген в вирусе гриппа, геном которого состоит всего из 14 000 букв (достаточно мало, чтобы поместиться в 100 твитов), и его секвенировали снова и снова. Неудивительно, что наш собственный геном с 3 миллиардами букв полон ошибок и пробелов, несмотря на то, что он якобы «полный». В мае другая группа показала, что в эталонном геноме человека отсутствует ген, который, возможно, повлиял на эволюцию нашего большого мозга. «Нет генома, который был бы полностью изучен даже с точки зрения входящих в него генов», — говорит Маркус Коверт из Стэнфордского университета. «Как правило, функция от четвертого до пятого генов неизвестна».
Гены кодируют инструкции по сборке белков, молекулярных машин, которые выполняют жизненно важные функции в наших клетках. Белок представляет собой длинную цепочку аминокислот, и мы можем предсказать эту цепочку с идеальной точностью. Но цепь также складывается, как оригами, в сложную трехмерную форму, и форма диктует все, что делает белок, от химических реакций, которые он ускоряет, до других молекул, к которым он прилипает.
Распознавание этих форм — кропотливая работа, включающая выращивание чистых кристаллов белков и бомбардировку их рентгеновскими лучами. Несмотря на наличие сотен таких структур, даже самые мощные компьютеры с трудом могут точно вычислить форму белка на основе последовательностей ДНК, которые их производят. «Я считаю этот вызов удушающим, — говорит Палссон.Гены, кодирующие белки, составляют всего 1,5 процента нашего генома. Остальное включает в себя много того, что считается бесполезным мусором, не имеющим заметной функции. Но он также содержит регуляторные последовательности, которые контролируют, когда, где и как используются наши гены. Нам нужно определить их, если мы когда-либо собираемся предсказать, как геном приводит к живому, дышащему организму. Технология для этого разрабатывается, и проект ENCODE — Энциклопедия элементов ДНК — нашел ей хорошее применение, составив каталог различных регуляторных последовательностей в нашем собственном геноме. Но в ENCODE участвовало 442 ученых, интенсивно проводивших эксперименты в течение десятилетия, и даже его беспрецедентный каталог неполный.
И даже если у нас есть вся эта информация — каждый ген, структура белка и регуляторная последовательность — нам все равно нужно выяснить, как все это работает вместе и как оно взаимодействует с окружающей средой. Нам потребуются закономерности: когда и где активируются различные гены по мере развития организма. Нам нужны тайминги: как быстро происходят химические реакции в клетке и как белки ускоряют этот процесс.
Здесь наши метафоры подвели нас. Авторы научных статей любят сравнивать геном с учебником или чертежом. Это говорит о том, что он хранит информацию, но приукрашивает его жужжащую, динамичную природу — белки стыкуются и выключаются, чтобы контролировать активность генов, огромные участки ДНК, которые складываются и разворачиваются, открывая или скрывая свои последовательности, паразитические прыгающие гены, которые копируют себя и прыгать по всему геному… Ни один из наших информационных хранилищ — ни ноты, ни книги рецептов — не является таким запутанным.
Это не остановило некоторых ученых от попыток смоделировать эту сложность.
В июле Коверт объявил, что создал грубую симуляцию целого организма — одноклеточного микроба под названием Mycoplasma genitalium. Модель Коверта моделирует, как используются все 525 генов бактерии, белки, которые они производят, как быстро действуют белки, как они взаимодействуют и многое другое. Он не совсем точен, но отражает большую часть образа жизни M.genitalium . Двое коллег написали, что проект «следует похвалить только за его смелость».Тем не менее, стимуляция была достигнута с трудом. При 525 генах M.genitalium имеет наименьший геном за пределами вирусов (для сравнения, у людей 20-25 000 генов), урезанный до крайнего минимализма своей жизнью в качестве паразита. Это может быть одно из самых простых живых существ, которые мы можем себе представить, но для моделирования этого микроба потребовалось около 1900 экспериментов и множество заимствованных знаний. «Примерно половина нашей модели основана на экспериментах, проведенных на других бактериях», — говорит Коверт.
«Не может быть, чтобы [геном] сам по себе был предсказательным».Тайное также необходимо учитывать среду M.genitalium . Он живет только в стабильной среде нашей уретры, без света и при постоянной температуре. «Но даже тогда он иногда видит, как иммунная система идет за ним, и нет никакого способа смоделировать это», — говорит Коверт.
Влияние окружающей среды становится еще более важным для более сложных свободноживущих организмов. Температура и кислотность влияют на поведение белков. Пища, которую потребляет организм, поражающие его инфекции и конкуренты, с которыми он взаимодействует, — все это влияет на то, как он развивается и как используются его гены. Многие из этих факторов оставляют следы на самом геноме — «эпигенетические» метки, которые диктуют размещение генов и могут передаваться следующему поколению. Окружение явно имеет значение. Делая предсказания на основе генома, слон в комнате — это комната.
Тем не менее, подход Коверта указывает путь вперед — рассвет виртуальной биологии.
Вы можете секвенировать геном, построить модель или симуляцию, сравнить ее с реальным организмом, устранить недостатки модели и исправить эти недостатки с помощью дальнейших экспериментов. Промыть и повторить. В конце концов, у вас будет зоопарк моделей. Если у вас есть новый геном, начните со сравнения его с одной из существующих симуляций и действуйте исходя из этого. Это не совсем тот черный ящик, который мы себе представляли, но хоть что-то.Если ученые пытаются найти грибы или бактерии, которые могут выполнять определенную работу — скажем, убирать опасные отходы, производить определенные питательные вещества — было бы полезно идентифицировать такие организмы только по их геномам. «Мы можем использовать секвенирование для поиска фенотипов, соответствующих нашей цели», — говорит Нильсен. И если эта цель состоит в искусственном создании новых форм жизни, как пытаются сделать такие люди, как Крейг Вентер, то предсказание становится необходимым, а не желаемым. «Вы будете беспокоиться о побочных эффектах и вам понадобится вычислительный инструмент, который поможет их избежать», — говорит Коверт.
 На сегодняшний день никто не может взять код из генов организма и предсказать все детали его формы, поведения, развития, физиологии — совокупность признаков, известную как его фенотип. И тем не менее, основа этих деталей есть, и все они запечатлены в отрезках As, Cs, Gs и Ts. «Клетки довольно надежно знают, как это делать», — говорит Леонид Кругляк из Принстонского университета. «Каждый раз, когда вы начинаете с генома курицы, вы получаете курицу, и каждый раз, когда вы начинаете с генома слона, вы получаете слона».
На сегодняшний день никто не может взять код из генов организма и предсказать все детали его формы, поведения, развития, физиологии — совокупность признаков, известную как его фенотип. И тем не менее, основа этих деталей есть, и все они запечатлены в отрезках As, Cs, Gs и Ts. «Клетки довольно надежно знают, как это делать», — говорит Леонид Кругляк из Принстонского университета. «Каждый раз, когда вы начинаете с генома курицы, вы получаете курицу, и каждый раз, когда вы начинаете с генома слона, вы получаете слона». В сложных организмах некоторые признаки можно проследить до конкретных генов. Если, например, вы смотрите на конкретный вариант гена MC1R, скорее всего, перед вами млекопитающее с рыжими волосами. Действительно, люди предсказали, что некоторые неандертальцы были рыжими именно по этой причине. «Но помимо этого, предсказывая [если что-то] мышь, кит или броненосец, мы все равно не преуспеем», — говорит Кругляк.
В сложных организмах некоторые признаки можно проследить до конкретных генов. Если, например, вы смотрите на конкретный вариант гена MC1R, скорее всего, перед вами млекопитающее с рыжими волосами. Действительно, люди предсказали, что некоторые неандертальцы были рыжими именно по этой причине. «Но помимо этого, предсказывая [если что-то] мышь, кит или броненосец, мы все равно не преуспеем», — говорит Кругляк.
 Распознавание этих форм — кропотливая работа, включающая выращивание чистых кристаллов белков и бомбардировку их рентгеновскими лучами. Несмотря на наличие сотен таких структур, даже самые мощные компьютеры с трудом могут точно вычислить форму белка на основе последовательностей ДНК, которые их производят. «Я считаю этот вызов удушающим, — говорит Палссон.
Распознавание этих форм — кропотливая работа, включающая выращивание чистых кристаллов белков и бомбардировку их рентгеновскими лучами. Несмотря на наличие сотен таких структур, даже самые мощные компьютеры с трудом могут точно вычислить форму белка на основе последовательностей ДНК, которые их производят. «Я считаю этот вызов удушающим, — говорит Палссон.
 В июле Коверт объявил, что создал грубую симуляцию целого организма — одноклеточного микроба под названием Mycoplasma genitalium. Модель Коверта моделирует, как используются все 525 генов бактерии, белки, которые они производят, как быстро действуют белки, как они взаимодействуют и многое другое. Он не совсем точен, но отражает большую часть образа жизни M.genitalium . Двое коллег написали, что проект «следует похвалить только за его смелость».
В июле Коверт объявил, что создал грубую симуляцию целого организма — одноклеточного микроба под названием Mycoplasma genitalium. Модель Коверта моделирует, как используются все 525 генов бактерии, белки, которые они производят, как быстро действуют белки, как они взаимодействуют и многое другое. Он не совсем точен, но отражает большую часть образа жизни M.genitalium . Двое коллег написали, что проект «следует похвалить только за его смелость». «Не может быть, чтобы [геном] сам по себе был предсказательным».
«Не может быть, чтобы [геном] сам по себе был предсказательным».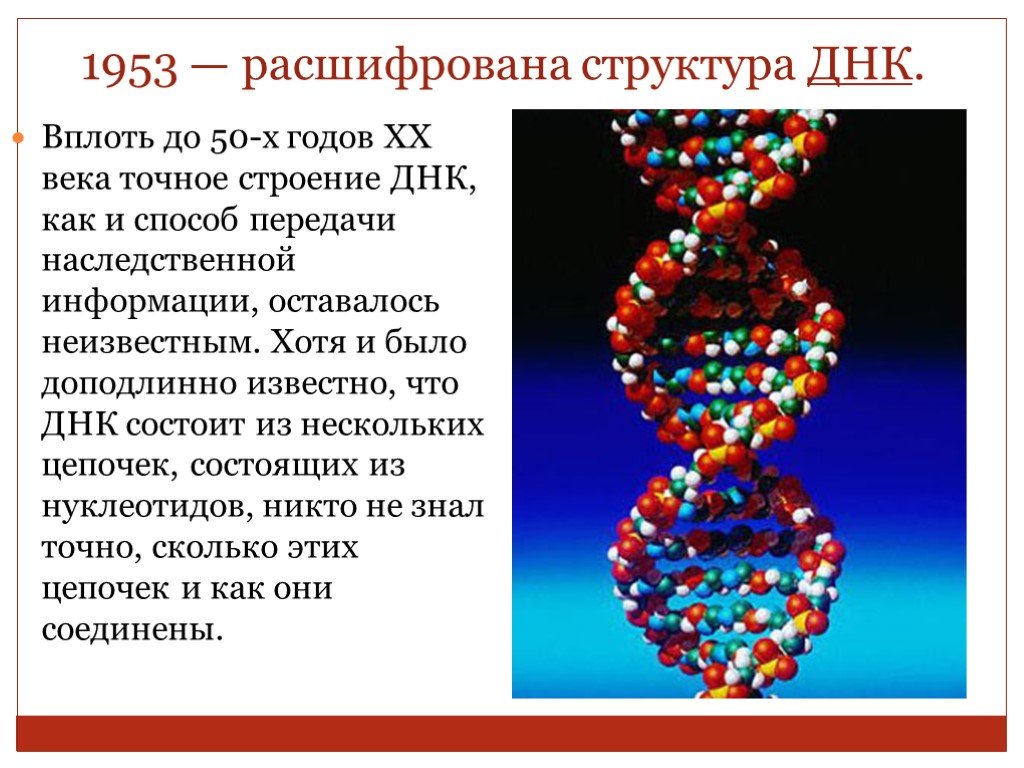 Вы можете секвенировать геном, построить модель или симуляцию, сравнить ее с реальным организмом, устранить недостатки модели и исправить эти недостатки с помощью дальнейших экспериментов. Промыть и повторить. В конце концов, у вас будет зоопарк моделей. Если у вас есть новый геном, начните со сравнения его с одной из существующих симуляций и действуйте исходя из этого. Это не совсем тот черный ящик, который мы себе представляли, но хоть что-то.
Вы можете секвенировать геном, построить модель или симуляцию, сравнить ее с реальным организмом, устранить недостатки модели и исправить эти недостатки с помощью дальнейших экспериментов. Промыть и повторить. В конце концов, у вас будет зоопарк моделей. Если у вас есть новый геном, начните со сравнения его с одной из существующих симуляций и действуйте исходя из этого. Это не совсем тот черный ящик, который мы себе представляли, но хоть что-то.