Содержание
Нейролирика. Вышла первая книга стихов, созданных нейронной сетью
Как и зачем компьютеры пишут стихи
©ISTOCK
В книжной серии журнала «Контекст» вышла первая книга стихов, созданных нейронной сетью. Сборник «Нейролирика» объединил тексты, написанные в стиле поэтов разных эпох, от античности в русском переводе до Серебряного века и современности. Автор эксперимента, доцент Школы лингвистики НИУ ВШЭ Борис Орехов, рассказал IQ.HSE, зачем нужна компьютерная поэзия, и как это работает.
Легитимация нейротворчества
Борис Орехов поставил эксперимент: он натренировал нейронную сеть на стихах великих поэтов и заставил писать собственные. Проект позволил определить «формулы» поэзии Гомера, Овидия, Пушкина, Ахматовой, Мандельштама, какими их видит искусственный интеллект. Обученные нейросети породили собственные тексты, напоминавшие исходники разными чертами стиля. Соблюдались ритм, размер, синтаксис, интонации, излюбленные слова поэтов.
Такая «поверка гармонии алгеброй» дает представление о стиле поэта или целой эпохи, помогает выделить семплы их поэтики. В этом смысле нейролирика — отличное подспорье в стилеметрии, научной дисциплине, исследующей, как устроена поэзия или проза тех или иных авторов.
В этом смысле нейролирика — отличное подспорье в стилеметрии, научной дисциплине, исследующей, как устроена поэзия или проза тех или иных авторов.
Сборник по итогам эксперимента — «Нейролирика. Стихотворения и тексты», составленный Владимиром Коркуновым, — можно считать «легитимацией нейронных стихов в литературе», говорит Борис Орехов. У нее были свои предтечи в других, не книжных, формах. Так, сотрудники «Яндекса» в 2016 году выпустили альбом «Нейронная оборона» со стихами роботов, написанными в стиле Егора Летова, основателя группы «Гражданская оборона»).
Интерес к нейроэкспериментам явно растет. Похожее явление известно и в изобразительном искусстве. Нейросети, обученные распознавать изображения на картинах или фотографиях, порождают собственную живопись. Термин, обозначающий это явление, — инцепционизм (inceptionism) — отчасти можно перенести и на нейронную поэзию. Она тоже инспирирована уже существующими произведениями.
«Можно взять тексты, написанные русским гекзаметром — шестиударным дольником, который обычно используется для перевода античного гекзаметра (Гомера, Вергилия, Овидия), и натренировать на них нейросеть, — рассказывает Орехов. — Получится, например, такая строка: «Силу, к голубке хитон отличась, Гиоклей благородный». Это правильный гекзаметр. Хотя ни правил расстановки ударений, ни того, что ударение вообще существует, нейросети не объясняли».
— Получится, например, такая строка: «Силу, к голубке хитон отличась, Гиоклей благородный». Это правильный гекзаметр. Хотя ни правил расстановки ударений, ни того, что ударение вообще существует, нейросети не объясняли».
Как это работает
Нейросеть как математическая концепция способного к обучению искусственного интеллекта — задумка давняя. Она восходит к 1940-м годам, когда ученые пробовали воссоздать в технике биологические нейронные сети — человеческий мозг. «Несколько десятилетий назад возникла идея, что можно расщепить информацию на несколько кусочков, и каждый из этих кусочков подать на вход математической функции, — продолжает исследователь. — Если эти функции будут взаимодействовать друг с другом и передавать переработанную информацию, вычисления станут эффективнее. А потом стало ясно, что эту математику можно реализовать в компьютере».
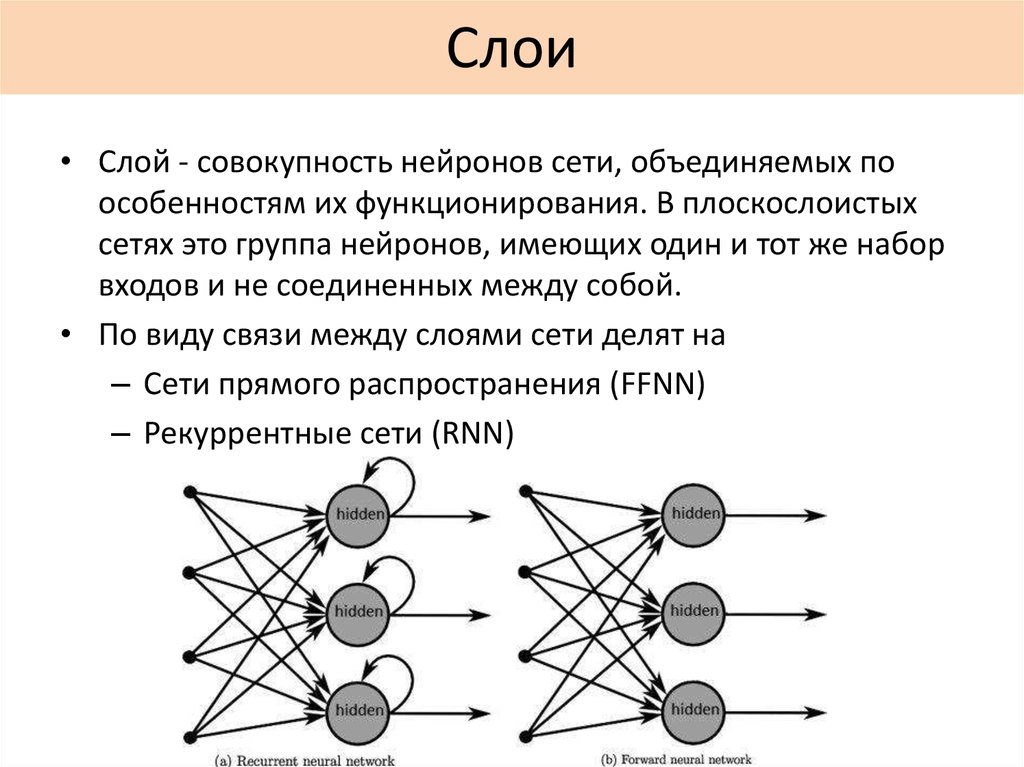
В случае со стихами используются многослойные рекуррентные нейронные сети, которые работают с последовательностями — например, текстами, которые и есть цепочки слов и букв.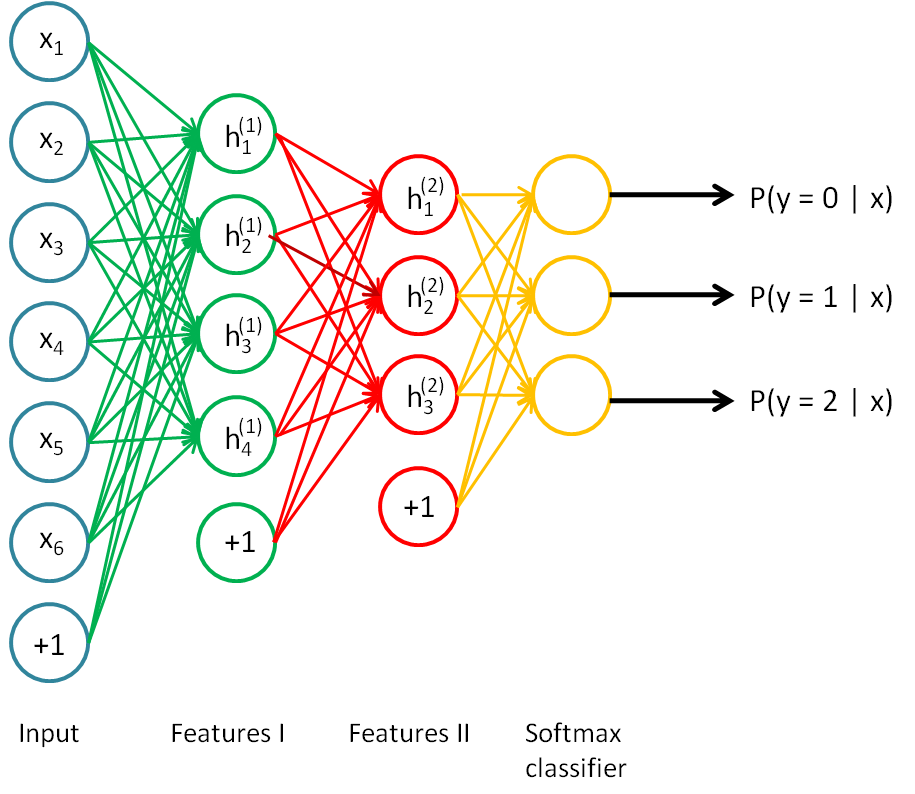
Сеть, которая умеет читать буквы, получает текст. Она старается в нем разобраться: выявить, почему одна буква следует за другой и предшествует третьей, с какой частотой это происходит и пр. «Одного знания о распределении букв оказывается достаточно, чтобы при порождении текста правильно имитировать и согласование слов, и употребление предлогов, и разные другие сложные, на человеческий взгляд, языковые правила, — отмечает Орехов. — Мы не рассказывали сети, что бывают морфемы, ударения, синтаксические конструкции, а она вдруг взяла и все это поняла сама».
Умные устройства чувствительны к объему обучающей выборки. Для того, чтобы порождать тексты приемлемого качества, им нужно проанализировать сотни тысяч стихотворных строк.
Реставрация мифологем
На фоне избытка текстов, созданных людьми, компьютерные поэтические эксперименты могут вызвать недоумение. На сакральный вопрос: «Что хотел сказать автор?» — в случае с нейропоэзией точно не ответишь. Но можно попытаться интерпретировать стихи, вспоминая уже накопленную семантику тех или иных образов в поэзии и — шире — мировой культуре.
В этом смысле анализ нейролирики — рефлексия над поэтическим мышлением в целом.
Нейросеть, обученная на четырехстопных ямбах разных авторов, сочинила такие строки:
Он беспощадной головой,
Волной и волосом
волненья
Не чувствовать не упадет.
В пределах воздух красный смех.
Исследователь комментирует: Плавная, но настойчивая оркестровка «головой, волной, волосом» переносит нас в XX век, возможно, даже во вторую его половину. Из той же эпохи — экспериментальное составное сказуемое «упасть чувствовать», которое, возможно, является попыткой перевода на русский английской идиомы «fall in love»». Затем комментатор остроумно подключает мифологему воздуха. Обычно воздух представляется вездесущей и свободной субстанцией (ср. классическое: «Я вольный ветер, я вечно вею»). В нейростихе же он заключен в пределы. Это актуализирует «тему несвободы».
Деконструкция авторства
Нейростихи сигнализируют, от каких штампов в восприятии поэзии стоит отказаться. Так ли уж обязательно, например, личностное, авторское начало? Вопрос дискуссионный.
Так ли уж обязательно, например, личностное, авторское начало? Вопрос дискуссионный.
Обычно считается, что лирика — подчеркнуто авторское высказывание. Ее создатель выражает свои чувства, мысли, интенции. Это и есть сообщение, транслируемое текстом. Однако нейролирика ничего не сообщает. Компьютеры научились имитировать поэтический язык, эффектно расставлять слова. Но текст без автора «одновременно оказывается текстом без смысла признают исследователи.
Стоит освежить привычные концепции, считает Борис Орехов. Трюизмов, мешающих воспринимать поэзию непосредственно, слишком много. Не зря против них так активно восставали футуристы начала XX века — создатели «заумного языка» Велимир Хлебников, Алексей Крученых и пр.
«Давайте посмотрим на нейростихи, осознаем, что за ними нет никакого личностного субъекта, нет всевидящего и всезнающего автора, нет я-начала, — замечает исследователь. — Это должно научить нас воспринимать красоту текста самого по себе».
Есть и другая причина, по которой не стоит абсолютизировать институт авторства. Объем компьютерных произведений может привести к «инфляции статуса автора», подобно тому, как изменился «статус краснодеревщика после появления мебельных фабрик», говорит лингвист. Люди привыкли к тому, что стихи — «ручная работа», нередко плод больших интеллектуальных усилий. Достаточно вспомнить количество черновиков у Пушкина. Но компьютеры способны создавать свою продукцию в неограниченном масштабе и тем самым — опровергать идею элитарности поэзии.
Объем компьютерных произведений может привести к «инфляции статуса автора», подобно тому, как изменился «статус краснодеревщика после появления мебельных фабрик», говорит лингвист. Люди привыкли к тому, что стихи — «ручная работа», нередко плод больших интеллектуальных усилий. Достаточно вспомнить количество черновиков у Пушкина. Но компьютеры способны создавать свою продукцию в неограниченном масштабе и тем самым — опровергать идею элитарности поэзии.
Геном поэзии
Поскольку сети, натренированные на текстах определенных поэтов, воспроизводят то, что наиболее характерно для них, мы можем получить, например, весьма узнаваемые семплы поэзии Пушкина или Мандельштама. А в итоге можно составить гид по индивидуальным поэтическим стилям.
Нейросетевой текст включает слова, которые часто повторяются в исходнике. «Есть и другие способы выделения этих слов: частотные словари, специальные методики подсчетов. Но почему бы не иметь ещё один? — размышляет Борис Орехов. — К тому же нейросеть как способ наглядного обобщения корпуса — очень user-friendly. Она выдает не таблицу с частотностями, а читаемый текст».
Она выдает не таблицу с частотностями, а читаемый текст».
В античных нейрогекзаметрах фигурируют реалии из «аутентичного» поэтического мира: Афина, Арес, Агамемнон, Менелай, ахейцы, быки, кони, корабли, мечи и пр. Начитавшись «Одиссеи», компьютер выдал, например, такой текст:
А вот отрывок стиха, вдохновленного лирикой Анны Ахматовой (с характерными для нее словами «любовь», «небеса», «веселье», «поэт», «простота» и пр.):
Поэтика в сочетании с характерным ритмом делает стихи узнаваемыми.
Борис Орехов провел эксперимент: предложил аудитории, которой читал лекции, текст «под Владимира Высоцкого» на экране. Слушатели довольно легко идентифицировали его стиль. В лирике были резкие отрывочные фразы с экспрессивными словами. А это присуще «напористой поэтике Высоцкого».
В литературоведении немало проблем с атрибуцией текстов. Обсуждается авторство произведений Шекспира, «Тихого Дона» Шолохова, диалогов Платона (один ли автор или несколько), ряда статей Бахтина.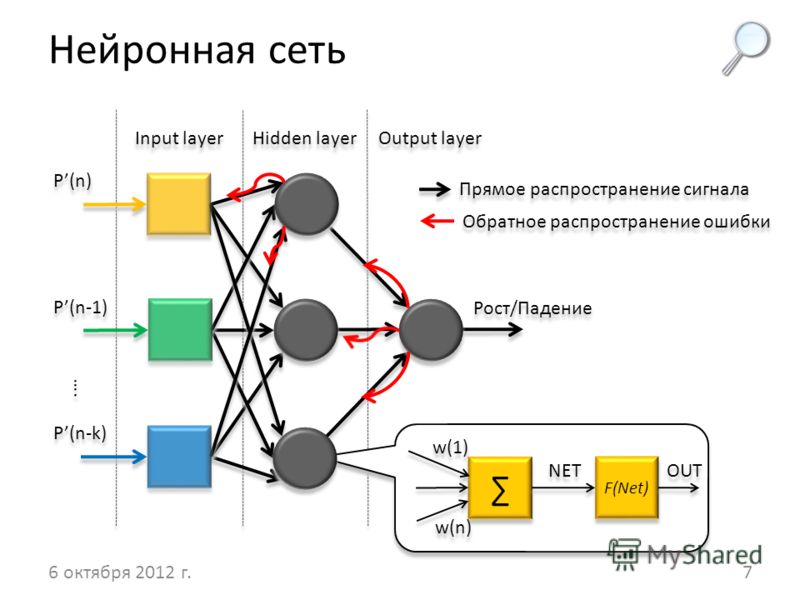 Нейронные сети с их выдающимися аналитическими способностями могут внести ясность – опять же с помощью выделения характерных черт стиля писателей. Правда, есть другие машинные методики, уже успешно проявившие себя. Например, алгоритм «Delta» распознал, что роман, который Джоан Роулинг написала под пседонимом, действительно принадлежит ей.
Нейронные сети с их выдающимися аналитическими способностями могут внести ясность – опять же с помощью выделения характерных черт стиля писателей. Правда, есть другие машинные методики, уже успешно проявившие себя. Например, алгоритм «Delta» распознал, что роман, который Джоан Роулинг написала под пседонимом, действительно принадлежит ей.
Литературный спиритизм
Нейронные сети генерируют идеи для живой авторской поэзии. Они подсказывают ей новые образы и слова.
Поэты прошлого нередко чувствовали себя визионерами: идеи являлись им во сне, в видениях. Даже если не верить Сэмюэлю Кольриджу, который, по его признанию, именно так написал поэму «Кубла-хан», легенда все равно впечатляющая.
Основатели французского сюрреализма Андре Бретон, Филипп Супо и Луи Арагон придумали «автоматическое письмо»: свободное, неконтролируемое порождение текста. В этом процессе писателю, по-видимому, отводилась роль проводника самых разных образов, возникших в подсознании. В живописи похожие эксперименты проделывал Джексон Поллок, который случайно плескал краску на холст.
Принцип случайности, спонтанности завораживал многих мастеров. В таких опытах могли родиться очень необычные образы. Если бы словосочетания «красный смех» из процитированного выше нейростиха не существовало (а у Леонида Андреева есть одноименный рассказ), его следовало бы выдумать. Что и сделала нейросеть, ничего не знавшая о прозе Андреева. Она породила свой «красный смех», обучившись только на поэтических текстах, где такого образа нет. Ему можно приписать очень богатую семантику.
«Красный» ассоциируется с революцией и Советской властью, со средневековой Русью («красный» в значении «красивый»: «красна девица», «на миру и смерть красна»), с гоголевской мистикой («Красная свитка»), с Серебряным веком (тревожное красное домино в романе «Петербург» Андрея Белого). Наконец, красный цвет — излюбленный для итальянской commedia dell’arte.
Сеть придумывает имена. Очень по-гречески смотрится имя «Гиоклей». Есть имя «Диоклей» и немало имен со слогом «ге/ги» в начале или середине (Геракл, Гипподам, Эгиох). Имя удачно стилизовано под гомеровское, да и эпитет приложен подходящий — «благородный». А вот другие нейросетевые неологизмы: «расколоденье», «порочник», «невкусство», «Геромородим», «веролюция», «когданический».
Имя удачно стилизовано под гомеровское, да и эпитет приложен подходящий — «благородный». А вот другие нейросетевые неологизмы: «расколоденье», «порочник», «невкусство», «Геромородим», «веролюция», «когданический».
Нейросеть, обученная на лирике Мандельштама
Компьютер как поэт
А теперь слово скептикам. Они скажут, что компьютеры и до этого писали стихи. Было дело, но сочинительский процесс шел совсем иначе. Существовало два варианта, поясняет Орехов.
Берется готовый текст, режется на части, а компьютер складывает их в случайном порядке. В 1959 году немецкий математик Тео Лутц запрограммировал вычислительную машину случайным образом перекомбинировать фразы из шестнадцати глав романа Франца Кафки «Замок». Полученные тексты он назвал «стохастическими».
Именно такие стихи порождались на первых примитивных, по нынешним меркам, ЭВМ. И, конечно, это был верлибр, стихи без метра и рифмы.
Составлялся тезаурус слов (желательно «попоэтичнее»), в машину загружались правила, по которым эти слова должны комбинироваться (тут обычно привлекали эксперта). Затем запускался генератор случайных значений. «Вот что привлекало поэтов в компьютере: неожиданность результата, полная свобода искусства», — комментирует исследователь.
Затем запускался генератор случайных значений. «Вот что привлекало поэтов в компьютере: неожиданность результата, полная свобода искусства», — комментирует исследователь.
Второй вариант стал популярен в России в 1990-е годы. «В нашей стране всем хочется, чтоб компьютер писал обязательно в рифму и обязательно силлабо-тоникой, — говорит Борис Орехов. – Верлибр наивные читатели (коих много среди негуманитариев) отказываются считать стихами».
Нейронным сетям на стадии, когда надо установить закономерности стихосложения, эксперт не нужен. Они думают сами. Доля эксперта — загрузка данных и шлифовка результата.
IQ
Автор исследования:
Борис Орехов, доцент Школы лингвистики НИУ ВШЭ
Как научить свою нейросеть генерировать стихи / Хабр
Умоляю перестань мне сниться
Я люблю тебя моя невеста
Белый иней на твоих ресницах
Поцелуй на теле бессловесном
Когда-то в школе мне казалось, что писать стихи просто: нужно всего лишь расставлять слова в нужном порядке и подбирать подходящую рифму. Следы этих галлюцинаций (или иллюзий, я их не различаю) встретили вас в эпиграфе. Только это стихотворение, конечно, не результат моего тогдашнего творчества, а продукт обученной по такому же принципу нейронной сети.
Следы этих галлюцинаций (или иллюзий, я их не различаю) встретили вас в эпиграфе. Только это стихотворение, конечно, не результат моего тогдашнего творчества, а продукт обученной по такому же принципу нейронной сети.
Вернее, нейронная сеть нужна лишь для первого этапа — расстановки слов в правильном порядке. С рифмовкой справляются правила, применяемые поверх предсказаний нейронной сети. Хотите узнать подробнее, как мы это реализовывали? Тогда добро пожаловать под кат.
Языковые модели
Определение
Начнем с языковой модели. На Хабре я встречал не слишком-то много статей про них — не лишним будет напомнить, что это за зверь.
Языковые модели определяют вероятность появления последовательности слов в данном языке: . Перейдём от этой страшной вероятности к произведению условных вероятностей слова от уже прочитанного контекста:
.
В жизни эти условные вероятности показывают, какое слово мы ожидаем увидеть дальше. Посмотрим, например, на всем известные слова из Пушкина:
Посмотрим, например, на всем известные слова из Пушкина:
Языковая модель, которая сидит у нас (во всяком случае, у меня) в голове, подсказывает: после честных навряд ли снова пойдёт мой. А вот и, или, конечно, правил — очень даже.
N-граммные языковые модели
Кажется, самым простым способом построить такую модель является использование N-граммной статистики. В этом случае мы делаем аппроксимацию вероятности — отбрасывая слишком далекие слова, как не влияющие на вероятность появления данного.
Такая модель легко реализуется с помощью Counter’ов на Python — и оказывается весьма тяжелой и при этом не слишком вариативной. Одна из самых заметных её проблем — недостаточность статистики: большая часть 5-грамм слов, в том числе и допустимых языком, просто не встретится в сколько-то ни было большом корпусе.
Для решения такой проблемы используют обычно сглаживание Kneser–Ney или Katz’s backing-off.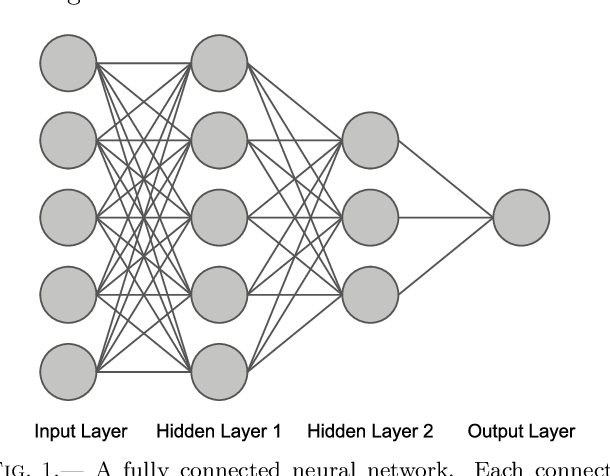 За более подробной информацией про методы сглаживания N-грамм стоит обратиться к известной книге Кристофера Маннинга “Foundations of Statistical Natural Language Processing”.
За более подробной информацией про методы сглаживания N-грамм стоит обратиться к известной книге Кристофера Маннинга “Foundations of Statistical Natural Language Processing”.
Хочу заметить, что 5-граммы слов я назвал не просто так: именно их (со сглаживанием, конечно) Google демонстрирует в статье “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling” — и показывает результаты, весьма сопоставимые с результатами у рекуррентных нейронных сетей — о которых, собственно, и пойдет далее речь.
Нейросетевые языковые модели
Преимущество рекуррентных нейронных сетей — в возможности использовать неограниченно длинный контекст. Вместе с каждым словом, поступающим на вход рекуррентной ячейки, в неё приходит вектор, представляющий всю предыдущую историю — все обработанные к данному моменту слова (красная стрелка на картинке).
Возможность использования контекста неограниченной длины, конечно, только условная. На практике классические RNN страдают от затухания градиента — по сути, отсутствия возможности помнить контекст дальше, чем на несколько слов. Для борьбы с этим придуманы специальные ячейки с памятью. Самыми популярными являются LSTM и GRU. В дальнейшем, говоря о рекуррентном слое, я всегда буду подразумевать LSTM.
Для борьбы с этим придуманы специальные ячейки с памятью. Самыми популярными являются LSTM и GRU. В дальнейшем, говоря о рекуррентном слое, я всегда буду подразумевать LSTM.
Рыжей стрелкой на картинке показано отображение слова в его эмбеддинг (embedding). Выходной слой (в простейшем случае) — полносвязный слой с размером, соответствующим размеру словаря, имеющий softmax активацию — для получения распределения вероятностей для слов словаря. Из этого распределения можно сэмплировать следующее слово (или просто брать максимально вероятное).
Уже по картинке виден минус такого слоя: его размер. При словаре в несколько сотен тысяч слов его он легко может перестать влезать на видеокарту, а для его обучения требуются огромные корпуса текстов. Это очень наглядно демонстрирует картинка из блога torch:
Для борьбы с этим было придумано весьма большое количество различных приемов. Наиболее популярными можно назвать иерархический softmax и noise contrastive estimation. Подробно про эти и другие методы стоит почитать в отличной статье Sebastian Ruder.
Оценивание языковой модели
Более-менее стандартной функцией потерь, оптимизируемой при многоклассовой классификации, является кросс-энтропийная (cross entropy) функция потерь. Вообще, кросс-энтропия между вектором и предсказанным вектором записывается как . Она показывает близость распределений, задаваемый и .
При вычислении кросс-энтропии для многоклассовой классификации — это вероятность -ого класса, а — вектор, полученный с one-hot-encoding (т.е. битовый вектор, в котором единственная единица стоит в позиции, соответствующей номеру класса). Тогда при некотором .
Кросс-энтропийные потери целого предложения получаются усреднением значений по всем словам. Их можно записать так: . Видно, что это выражение соответствует тому, чего мы и хотим достичь: вероятность реального предложения из языка должна быть как можно выше.
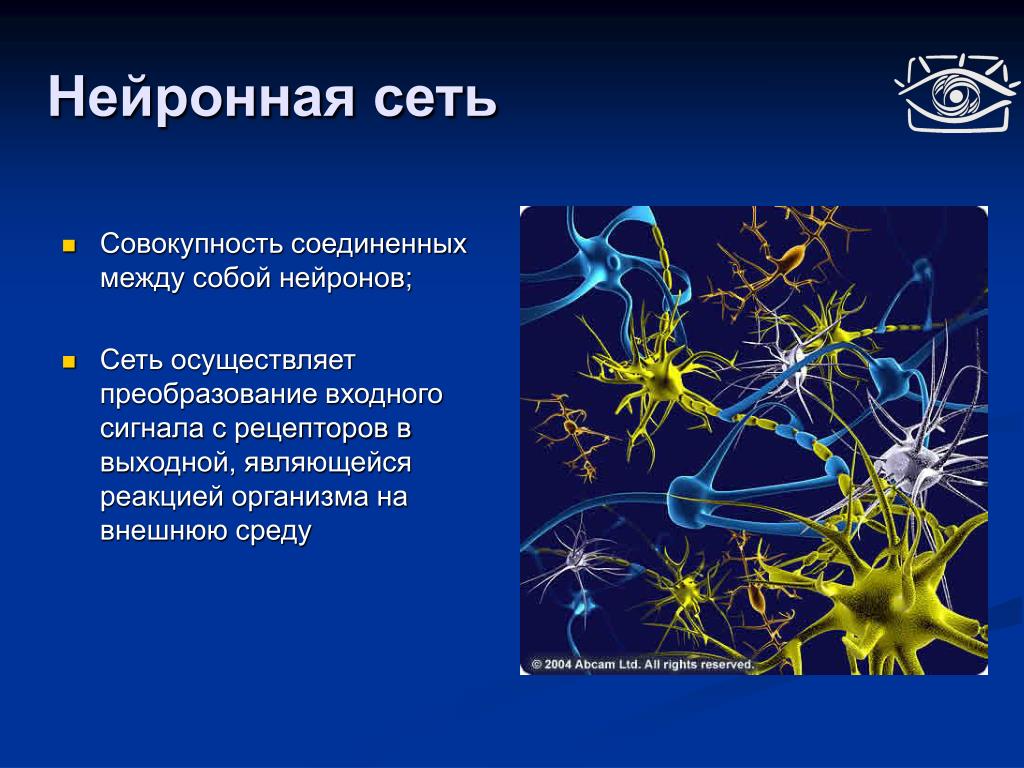
Кроме этого, уже специфичной для языкового моделирования метрикой является перплексия (perplexity):
.
Чтобы понять её смысл, посмотрим на модель, предсказывающую слова из словаря равновероятно вне зависимости от контекста. Для неё , где N — размер словаря, а перплексия будет равна размеру словаря — N. Конечно, это совершенно глупая модель, но оглядываясь на неё, можно трактовать перплексию реальных моделей как уровень неоднозначности генерации слова.
Скажем, в модели с перплексией 100 выбор следующего слова также неоднозначен, как выбор из равномерного распределения среди 100 слов. И если такой перплексии удалось достичь на словаре в 100 000, получается, что удалось сократить эту неоднозначность на три порядка по сравнению с “глупой” моделью.
Реализация языковой модели для генерации стихов
Построение архитектуры сети
Вспомним теперь, что для нашей задачи языковая модель нужна для выбора наиболее подходящего следующего слова по уже сгенерированной последовательности. А из этого следует, что при предсказании никогда не встретится незнакомых слов (ну откуда им взяться). Поэтому число слов в словаре остается целиком в нашей власти, что позволяет регулировать размер получающейся модели. Таким образом, пришлось забыть о таких достижениях человечества, как символьные эмбеддинги для представления слов (почитать про них можно, например, здесь).
Поэтому число слов в словаре остается целиком в нашей власти, что позволяет регулировать размер получающейся модели. Таким образом, пришлось забыть о таких достижениях человечества, как символьные эмбеддинги для представления слов (почитать про них можно, например, здесь).
Исходя из этих предпосылок, мы начали с относительно простой модели, в общих чертах повторяющей ту, что изображена на картинке выше. В роли желтого прямоугольника с неё выступали два слоя LSTM и следующий за ними полносвязный слой.
Решение ограничить размер выходного слоя кажется вполне рабочим. Естественно, словарь надо ограничивать по частотности — скажем, взятием пятидесяти тысяч самых частотных слов. Но тут возникает ещё вопрос: какую архитектуру рекуррентной сети лучше выбрать.
Очевидных варианта тут два: использовать many-to-many вариант (для каждого слова пытаться предсказать следующее) или же many-to-one (предсказывать слово по последовательности предшествующих слов).
Чтобы лучше понимать суть проблемы, посмотрим на картинку:
Здесь изображен many-to-many вариант со словарем, в котором не нашлось места слову “чернил”.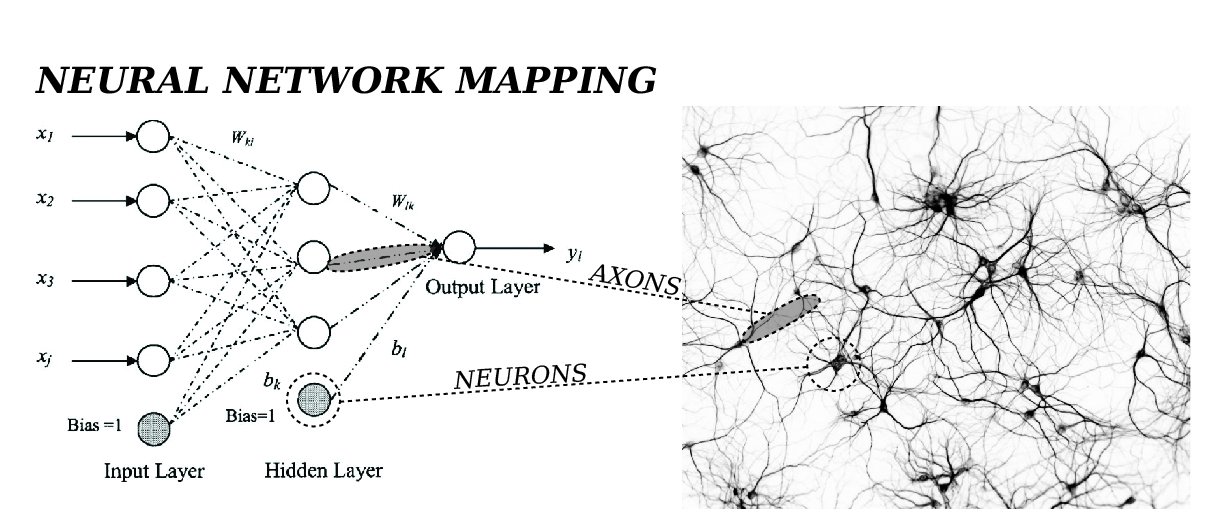 Логичным шагом является подстановка вместо него специального токена <unk> — незнакомое слово. Проблема в том, что модель радостно выучивает, что вслед за любым словом может идти незнакомое слово. В итоге, выдаваемое ею распределение оказывается смещено в сторону именно этого незнакомого слова. Конечно, это легко решается: нужно всего лишь сэмплировать из распределение без этого токена, но всё равно остается ощущение, что полученная модель несколько кривовата.
Логичным шагом является подстановка вместо него специального токена <unk> — незнакомое слово. Проблема в том, что модель радостно выучивает, что вслед за любым словом может идти незнакомое слово. В итоге, выдаваемое ею распределение оказывается смещено в сторону именно этого незнакомого слова. Конечно, это легко решается: нужно всего лишь сэмплировать из распределение без этого токена, но всё равно остается ощущение, что полученная модель несколько кривовата.
Альтернативным вариантом является использование many-to-one архитектуры:
При этом приходится нарезать всевозможные цепочки слов из обучающей выборки — что приведет к заметному её разбуханию. Зато все цепочки, для которых следующее слов — неизвестное, мы сможем просто пропускать, полностью решая проблему с частым предсказанием <unk> токена.
Такая модель имела у нас следующие параметры (в терминах библиотеки keras):
Как видно, в неё включено 60000 + 1 слово: плюс первый токен это тот самый <unk>.
Проще всего повторить её можно небольшой модификацией примера. Основное её отличие в том, что пример демонстрирует посимвольную генерацию текста, а вышеописанный вариант строится на пословной генерации.
Полученная модель действительно что-то генерирует, но даже грамматическая согласованность получающихся предложений зачастую не впечатляет (про смысловую нагрузку и говорить нечего). Логичным следующим шагом является использование предобученных эмбеддингов для слов. Их добавление упрощает обучение модели, да и связи между словами, выученные на большом корпусе, могут придать осмысленность генерируемому тексту.
Основная проблема: для русского (в отличие от, например, английского) сложно найти хорошие словоформенные эмбеддинги. С имеющимися результат стал даже хуже.
Попробуем пошаманить немного с моделью. Недостаток сети, судя по всему — в слишком большом количестве параметров. Сеть просто-напросто не дообучается. Чтобы исправить это, следует поработать с входным и выходным слоями — самыми тяжелыми элементами модели.
Доработка входного слоя
Очевидно, имеет смысл сократить размерность входного слоя. Этого можно добиться, просто уменьшив размерность словоформенных эмебедингов — но интереснее пойти другим путём.
Вместо того, чтобы представлять слово одним индексом в высокоразмерном пространстве, добавим морфологическую разметку:
Каждое слово будем описывать парой: его лемма и грамматическое значение. Использование лемм вместо словоформ позволяет очень сильно сократить размер эмбеддингов: первым тридцати тысячам лемм соответствует несколько сотен тысяч различных слов. Таким образом, серьёзно уменьшив входной слой, мы ещё и увеличили словарный запас нашей модели.
Как видно из рисунка, лемма имеет приписанную к ней часть речи. Это сделано для того, чтобы можно было использовать уже предобученные эмбеддинги для лемм (например, от RusVectores). С другой стороны, эмбеддинги для тридцати тысяч лемм вполне можно обучить и с нуля, инициализируя их случайно.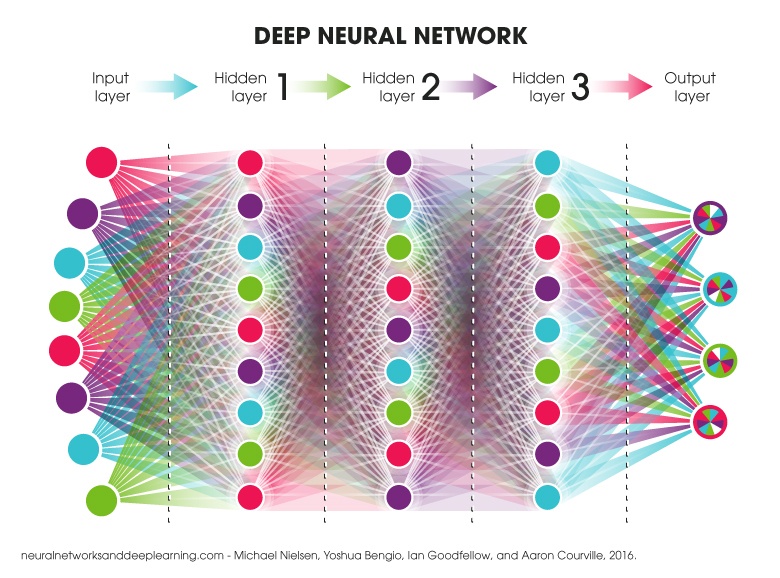
Грамматическое значение мы представляли в формате Universal Dependencies, благо у меня как раз была под рукой модель, обученная для Диалога-2017.
При подаче грамматического значения на вход модели оно переводится в битовую маску: для каждой грамматической категории выделяются позиции по числу граммем в этой категории — плюс одна позиция для отсутствия данной категории в грамматическом значении (Undefined). Битовые вектора для всех категорий склеиваются в один большой вектор.
Вообще говоря, грамматическое значение можно было бы, так же как лемму, представлять индексом и обучать для него эмбеддинг. Но битовой маской сеть показала более высокое качество.
Этот битовый вектор можно, конечно, подавать в LSTM непосредственно, но лучше пропускать его предварительно через один или два полносвязных слоя для сокращения размерности и, одновременно — обнаружения связей между комбинациями граммем.
Доработка выходного слоя
Вместо индекса слова можно предсказывать всё те же лемму и грамматическое значение по отдельности.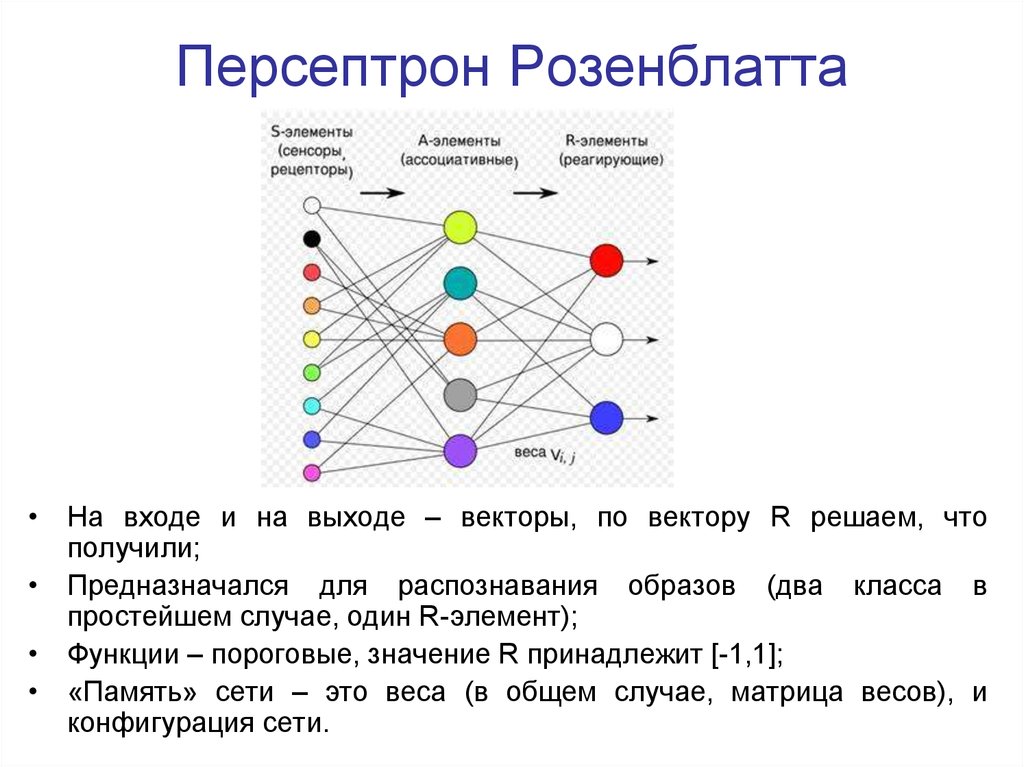 После этого можно сэмплировать лемму из полученного распределения и ставить её в форму с наиболее вероятным грамматическим значением. Небольшой минус такого подхода в том, что невозможно гарантировать наличие такого грамматического значения у данной леммы.
После этого можно сэмплировать лемму из полученного распределения и ставить её в форму с наиболее вероятным грамматическим значением. Небольшой минус такого подхода в том, что невозможно гарантировать наличие такого грамматического значения у данной леммы.
Эта проблема легко исправляется двумя способами. Честный путь — сэмплировать именно слово из действительно реализуемых пар лемма + грамматическое значение (вероятностью этого слова, конечно, будет произведение вероятностей леммы и грамматического значения). Более быстрый альтернативный способ — это выбирать наиболее вероятное грамматическое значение среди возможных для сэмплированной леммы.
Кроме того, softmax-слой можно было заменить иерархическим softmax’ом или вообще утащить реализацию noise contrastive estimation из tensorflow. Но нам, с нашим размером словаря, оказалось достаточно и обыкновенного softmax. По крайней мере, вышеперечисленные ухищрения не принесли значительного прироста качества модели.
Итоговая модель
В итоге у нас получилась следующая модель:
Обучающие данные
До сих пор мы никак не обсудили важный вопрос — на чём учимся. Для обучения мы взяли большой кусок stihi.ru и добавили к нему морфологическую разметку. После этого отобрали длинные строки (не меньше пяти слов) и обучались на них.
Для обучения мы взяли большой кусок stihi.ru и добавили к нему морфологическую разметку. После этого отобрали длинные строки (не меньше пяти слов) и обучались на них.
Каждая строка рассматривалась как самостоятельная — таким образом мы боролись с тем, что соседние строки зачастую слабо связаны по смыслу (особенно на stihi.ru). Конечно, можно обучаться сразу на полном стихотворении, и это могло дать улучшение качества модели. Но мы решили, что перед нами стоит задача построить сеть, которая умеет писать грамматически связный текст, а для такой цели обучаться лишь на строках вполне достаточно.
При обучении ко всем строкам добавлялся завершающий символ , а порядок слов в строках инвертировался. Разворачивать предложения нужно для упрощения рифмовки слов при генерации. Завершающий же символ нужен, чтобы именно с него начинать генерацию предложения.
Кроме всего прочего, для простоты мы выбрасывали все знаки препинания из текстов. Это было сделано потому, что сеть заметно переобучалась под запятые и прочие многоточия: в выборке они ставились буквально после каждого слова.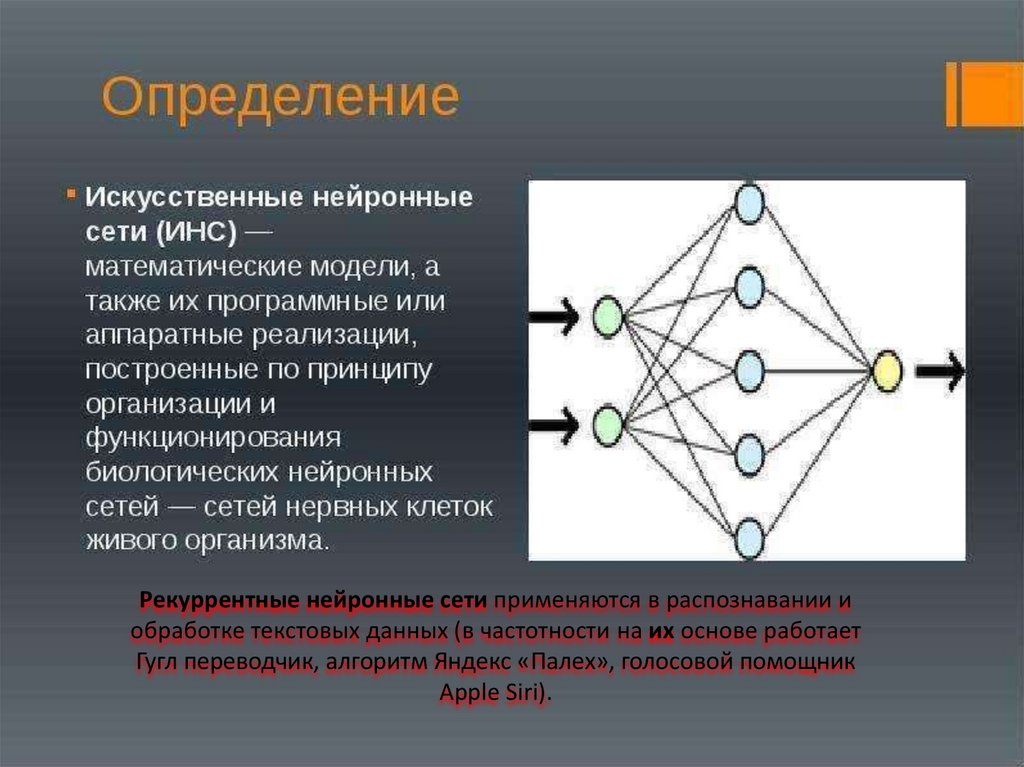 Конечно, это сильное упущение нашей модели и есть надежда исправить это в следующей версии.
Конечно, это сильное упущение нашей модели и есть надежда исправить это в следующей версии.
Схематично предобработка текстов может быть изображена так:
Стрелки означают направление, в котором модель читает предложение.
Реализация генератора
Правила-фильтры
Перейдём, наконец-то, к генератору поэзии. Мы начали с того, что языковая модель нужна только для построения гипотез о следующем слове. Для генератора необходимы правила, по которым из последовательности слов будут строиться стихотворения. Такие правила работают как фильтры языковой модели: из всех возможных вариантов следующего слова остаются только те, которые подходят — в нашем случае по метру и рифмовке.
Метрические правила определяют последовательность ударных и безударных слогов в строке. Записываются они обычно в виде шаблона из плюсов и минусов: плюс означает ударный слог, а минусу соответствует безударный. Например, рассмотрим метрический шаблон + — + — + — + — (в котором можно заподозрить четырёхстопный хорей):
Генерация, как уже упоминалось, идёт справа налево — в направлении стрелок на картинке.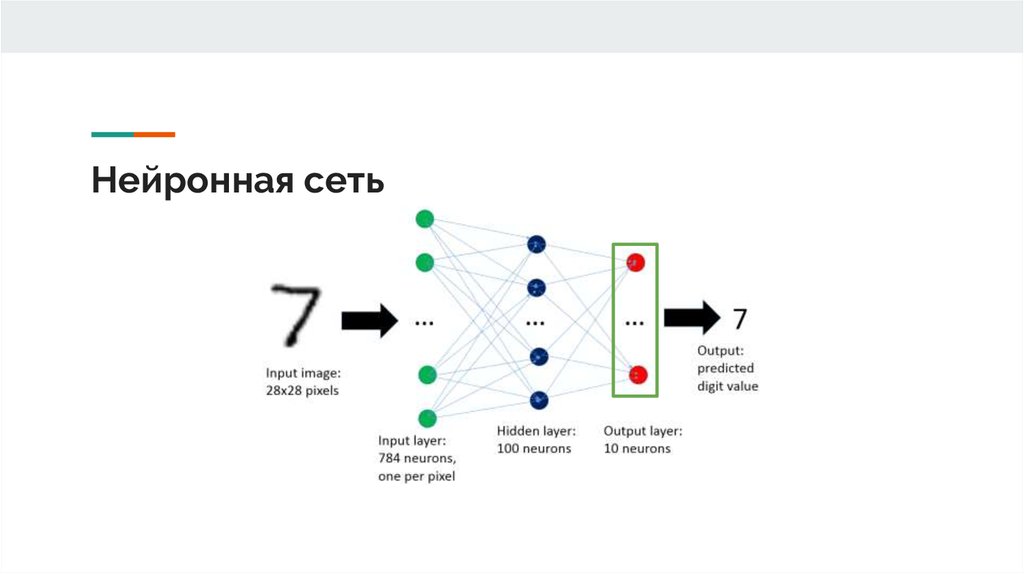 Таким образом, после мглою фильтры запретят генерацию таких слов как метель (не там ударение) или ненастье (лишний слог). Если же в слове больше 2 слогов, оно проходит фильтр только тогда, когда ударный слог не попадает на “минус” в метрическом шаблоне.
Таким образом, после мглою фильтры запретят генерацию таких слов как метель (не там ударение) или ненастье (лишний слог). Если же в слове больше 2 слогов, оно проходит фильтр только тогда, когда ударный слог не попадает на “минус” в метрическом шаблоне.
Второй же тип правил — ограничения по рифме. Именно ради них мы генерируем стихотворения задом наперед. Фильтр применяется при генерации самого первого слова в строке (которое окажется последним после разворота). Если уже была сгенерирована строка, с которой должна рифмоваться данная, этот фильтр сразу отсечёт все нерифмующиеся слова.
Также применялось дополнительное правило, запрещающее считать рифмами словоформы с одинаковой леммой.
У вас мог возникнуть вопрос: а откуда мы взяли ударения слов, и как мы определили какие слова рифмуются с какими? Для работы с ударениями мы взяли большой словарь и обучили на этом словаре классификатор, чтобы предсказывать ударения незнакомых слов (история, заслуживающая отдельной статьи). Рифмовка же определяется несложной эвристикой на основе расположения ударного слога и его буквенного состава.
Рифмовка же определяется несложной эвристикой на основе расположения ударного слога и его буквенного состава.
Лучевой поиск
В результате работы фильтров вполне могло не остаться ни одного слова. Для решения этой проблемы мы делаем лучевой поиск (beam search), выбирая на каждом шаге вместо одного сразу N путей с наивысшими вероятностями.
Итого, входные параметры генератора — языковая модель, метрический шаблон, шаблон рифмы, N в лучевом поиске, параметры эвристики рифмовки. На выходе же имеем готовое стихотворение. В качестве языковой модели в этом же генераторе можно использовать и N-граммную модель. Система фильтров легко кастомизируется и дополняется.
Примеры стихов
Так толку мне теперь грустить
Что будет это прожито
Не суждено кружить в пути
Почувствовав боль бомжика
Затерялся где то на аллее
Где же ты мое воспоминанье
Я люблю тебя мои родные
Сколько лжи предательства и лести
Ничего другого и не надо
За грехи свои голосовые
Скучаю за твоим окном
И нежными эфирами
Люблю тебя своим теплом
Тебя стенографируя
Ссылки
- Репозиторий
- Пакет в pypi
- Паблик в VK со стихами
- Модель и словари, необходимые для её работы
- Оксфордский курс NLP, подготовленный при участии DeepMind
- One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
- Exploring the Limits of Language Modeling
- Character-Aware Neural Language Models
Пост был написан совместно с Гусевым Ильёй. В проекте также принимали участие Ивашковская Елена, Карацапова Надежда и Матавина Полина.
В проекте также принимали участие Ивашковская Елена, Карацапова Надежда и Матавина Полина.
Работа над генератором была проделана в рамках курса “Интеллектуальные системы” кафедры Компьютерной лингвистики ФИВТ МФТИ. Хотелось бы поблагодарить автора курса, Константина Анисимовича, за советы, которые он давал в процессе.
Большое спасибо atwice за помощь в вычитке статьи.
ИИ, машинное обучение, глубокое обучение и нейронные сети: в чем разница?
Эти термины часто используются взаимозаменяемо, но в чем разница, которая делает их уникальными технологиями?
Технологии с каждой минутой все больше внедряются в нашу повседневную жизнь, и, чтобы не отставать от ожиданий потребителей, компании все больше полагаются на алгоритмы обучения, которые упрощают жизнь. Вы можете увидеть его применение в социальных сетях (благодаря распознаванию объектов на фотографиях) или при непосредственном общении с устройствами (такими как Alexa или Siri).
Эти технологии обычно ассоциируются с искусственным интеллектом, машинным обучением, глубоким обучением и нейронными сетями, и хотя все они играют определенную роль, эти термины, как правило, используются в разговоре взаимозаменяемо, что приводит к некоторой путанице в отношении нюансов между ними. Надеюсь, мы сможем использовать этот пост в блоге, чтобы прояснить некоторую двусмысленность.
Надеюсь, мы сможем использовать этот пост в блоге, чтобы прояснить некоторую двусмысленность.
Как связаны искусственный интеллект, машинное обучение, нейронные сети и глубокое обучение?
Возможно, самый простой способ думать об искусственном интеллекте, машинном обучении, нейронных сетях и глубоком обучении — думать о них как о русских матрешках. Каждый из них по существу является компонентом предыдущего термина.
То есть машинное обучение — это подполе искусственного интеллекта. Глубокое обучение — это подраздел машинного обучения, а нейронные сети составляют основу алгоритмов глубокого обучения. На самом деле именно количество слоев узлов или глубина нейронных сетей отличает одну нейронную сеть от алгоритма глубокого обучения, которых должно быть больше трех.
Что такое нейронная сеть?
Нейронные сети — а точнее, искусственные нейронные сети (ИНС) — имитируют человеческий мозг с помощью набора алгоритмов. На базовом уровне нейронная сеть состоит из четырех основных компонентов: входных данных, весов, смещения или порога и выходных данных. Подобно линейной регрессии, алгебраическая формула будет выглядеть примерно так:
Подобно линейной регрессии, алгебраическая формула будет выглядеть примерно так:
Теперь давайте применим его к более осязаемому примеру, например, стоит ли вам заказывать пиццу на ужин. Это будет наш прогнозируемый результат, или y-hat. Предположим, что на ваше решение будут влиять три основных фактора:
- Если вы сэкономите время, сделав заказ (Да: 1; Нет: 0)
- Если вы похудеете, заказав пиццу (Да: 1; Нет: 0)
- Если вы сэкономите деньги (Да: 1; Нет: 0)
Тогда предположим следующее, дав нам следующие входные данные:
- X 1 = 1, так как вы не готовите ужин
- X2 = 0, так как мы получаем ВСЕ начинки
- X 3 = 1, так как мы получаем только 2 среза
Для простоты наши входные данные будут иметь двоичное значение 0 или 1. Технически это определяет его как персептрон, поскольку нейронные сети в основном используют сигмовидные нейроны, которые представляют значения от отрицательной бесконечности до положительной бесконечности. Это различие важно, поскольку большинство реальных задач нелинейны, поэтому нам нужны значения, которые уменьшают влияние любого отдельного входа на результат. Тем не менее, обобщение таким образом поможет вам понять лежащую в основе математику.
Это различие важно, поскольку большинство реальных задач нелинейны, поэтому нам нужны значения, которые уменьшают влияние любого отдельного входа на результат. Тем не менее, обобщение таким образом поможет вам понять лежащую в основе математику.
Двигаемся дальше. Теперь нам нужно присвоить веса для определения важности. Большие веса делают вклад одного входа в результат более значительным по сравнению с другими входами.
- W 1 = 5, так как вы цените время
- З 2 = 3, так как вы цените быть в форме
- W 3 = 2, так как у вас есть деньги в банке
Наконец, мы также примем пороговое значение 5, что соответствует значению смещения –5.
Поскольку мы установили все необходимые значения для нашего суммирования, теперь мы можем подставить их в эту формулу.
Используя следующую функцию активации, мы теперь можем рассчитать результат (т. е. наше решение заказать пиццу):
В итоге:
Y-шляпа (наш прогнозируемый результат) = Решить, заказывать пиццу или нет
Y- шляпа = (1*5) + (0*3) + (1*2) — 5
Y-шляпа = 5 + 0 + 2 – 5
Y-шляпа = 2, что больше нуля.
Поскольку Y-шляпа равна 2, вывод функции активации будет 1, это означает, что мы будем заказывать пиццу (я имею в виду, кто не любит пиццу).
Если выход любого отдельного узла превышает указанное пороговое значение, этот узел активируется, отправляя данные на следующий уровень сети. В противном случае данные не передаются на следующий уровень сети. Теперь представьте, что описанный выше процесс повторяется несколько раз для одного решения, поскольку нейронные сети, как правило, имеют несколько «скрытых» слоев как часть алгоритмов глубокого обучения. Каждый скрытый слой имеет свою собственную функцию активации, потенциально передавая информацию с предыдущего слоя на следующий. Как только все выходные данные скрытых слоев сгенерированы, они используются в качестве входных данных для расчета окончательного вывода нейронной сети. Опять же, приведенный выше пример — это всего лишь самый простой пример нейронной сети; большинство реальных примеров нелинейны и намного сложнее.
Основное различие между регрессией и нейронной сетью заключается в влиянии изменения на один вес. В регрессии вы можете изменить вес, не затрагивая другие входные данные функции. Однако это не относится к нейронным сетям. Поскольку выходные данные одного уровня передаются на следующий уровень сети, одно изменение может иметь каскадный эффект на другие нейроны в сети.
Подробное объяснение количественных понятий, связанных с нейронными сетями, см. в этой статье IBM Developer.
Чем глубокое обучение отличается от нейронных сетей?
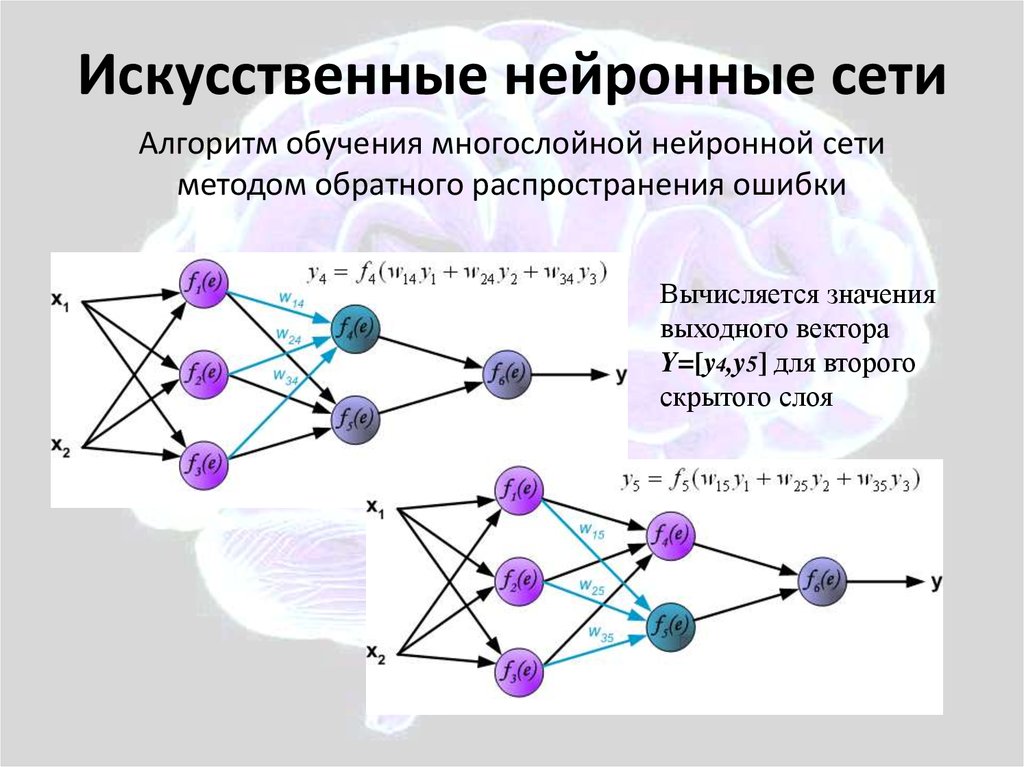
Хотя это подразумевалось в описании нейронных сетей, стоит отметить это более подробно. «Глубокое» в глубоком обучении относится к глубине слоев в нейронной сети. Нейронная сеть, состоящая из более чем трех слоев, включая входные и выходные данные, может считаться алгоритмом глубокого обучения. Обычно это представлено с помощью следующей диаграммы:
Большинство глубоких нейронных сетей имеют прямую связь, то есть они движутся только в одном направлении от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения; то есть двигаться в противоположном направлении от выхода к входу. Обратное распространение позволяет нам рассчитать и атрибутировать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить алгоритм.
Однако вы также можете обучить свою модель с помощью обратного распространения; то есть двигаться в противоположном направлении от выхода к входу. Обратное распространение позволяет нам рассчитать и атрибутировать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить алгоритм.
Чем глубокое обучение отличается от машинного обучения?
Как мы объясняем в нашей статье Learn Hub о глубоком обучении, глубокое обучение — это просто подмножество машинного обучения. Основные различия между ними заключаются в том, как каждый алгоритм обучается и сколько данных использует каждый тип алгоритма. Глубокое обучение автоматизирует большую часть процесса извлечения признаков, устраняя часть необходимого ручного вмешательства человека. Он также позволяет использовать большие наборы данных, за что получил название «масштабируемое машинное обучение» в этой лекции Массачусетского технологического института. Эта возможность будет особенно интересна, когда мы начнем больше изучать использование неструктурированных данных, особенно с 80-9 гг.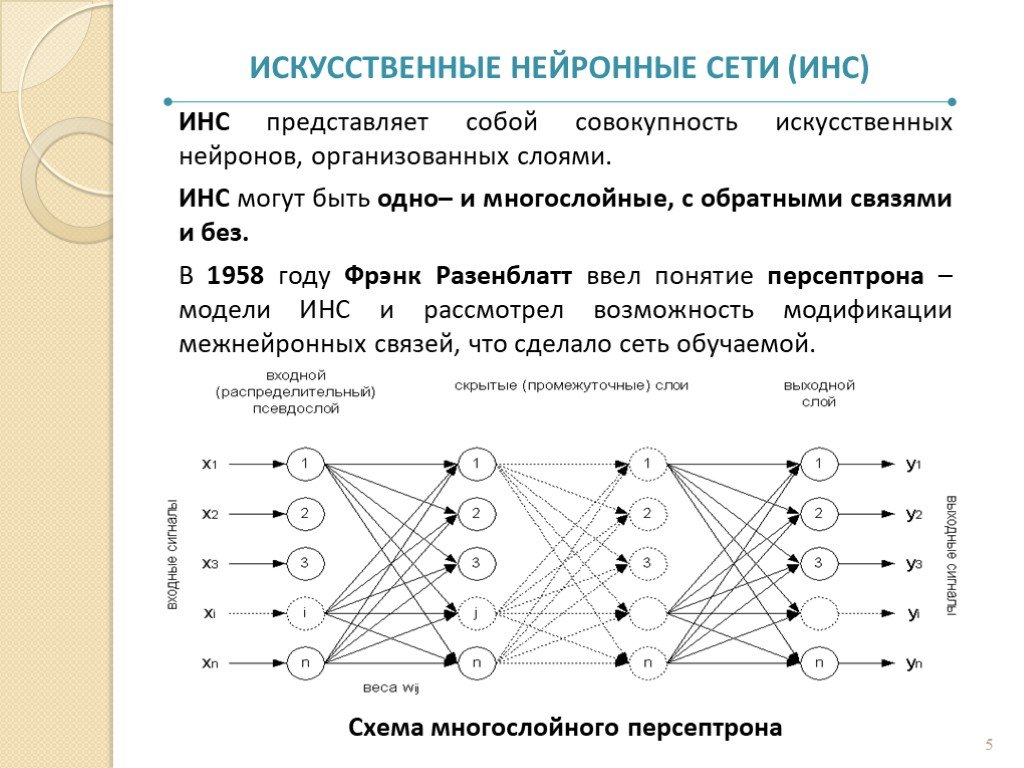 0% данных организации оцениваются как неструктурированные.
0% данных организации оцениваются как неструктурированные.
Классическое или «неглубокое» машинное обучение больше зависит от вмешательства человека. Эксперты-люди определяют иерархию функций, чтобы понять различия между входными данными, обычно требуя более структурированных данных для изучения. Например, предположим, что я должен был показать вам серию изображений различных видов фаст-фуда, «пиццы», «гамбургера» или «тако». Человек-эксперт по этим изображениям должен определить характеристики, которые отличают каждое изображение от определенного типа фаст-фуда. Например, хлеб каждого типа продуктов питания может быть отличительной чертой каждого изображения. В качестве альтернативы вы можете просто использовать ярлыки, такие как «пицца», «бургер» или «тако», чтобы упростить процесс обучения с помощью контролируемого обучения.
«Глубокое» машинное обучение может использовать помеченные наборы данных, также известные как обучение с учителем, для информирования своего алгоритма, но для этого не обязательно требуется помеченный набор данных.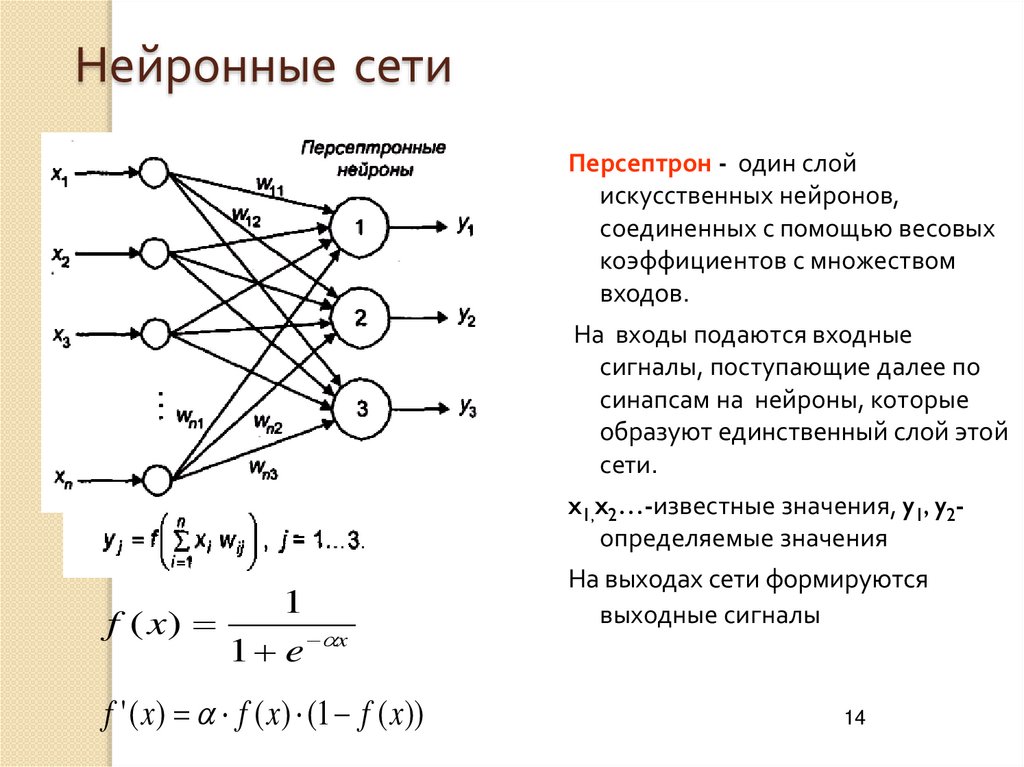 Он может принимать неструктурированные данные в необработанном виде (например, текст, изображения) и автоматически определять набор признаков, отличающих «пиццу», «гамбургер» и «тако» друг от друга.
Он может принимать неструктурированные данные в необработанном виде (например, текст, изображения) и автоматически определять набор признаков, отличающих «пиццу», «гамбургер» и «тако» друг от друга.
Для более подробного ознакомления с различиями между этими подходами ознакомьтесь с разделом «Обучение с учителем и без учителя: в чем разница?»
Наблюдая закономерности в данных, модель глубокого обучения может соответствующим образом группировать входные данные. Взяв тот же пример из предыдущего, мы могли бы сгруппировать изображения пиццы, гамбургеров и тако в соответствующие категории на основе сходств или различий, выявленных на изображениях. С учетом сказанного, модели глубокого обучения потребуется больше точек данных для повышения ее точности, тогда как модель машинного обучения использует меньше данных, учитывая базовую структуру данных. Глубокое обучение в основном используется для более сложных вариантов использования, таких как виртуальные помощники или обнаружение мошенничества.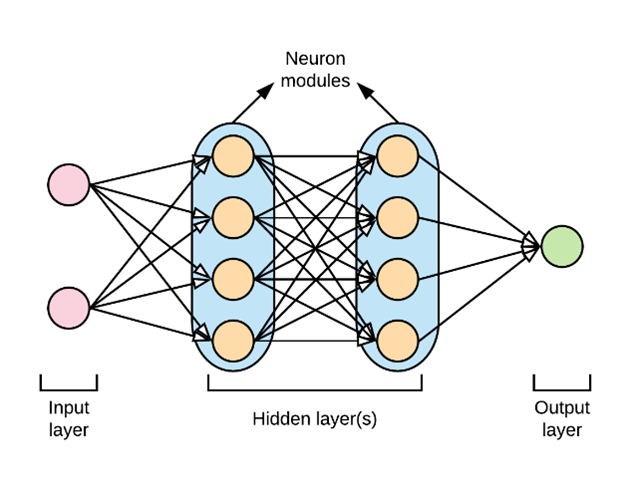
Дополнительные сведения о машинном обучении см. в следующем видео:
Посмотреть видео
Что такое искусственный интеллект (ИИ)?
Наконец, искусственный интеллект (ИИ) — это самый широкий термин, используемый для классификации машин, имитирующих человеческий интеллект. Он используется для прогнозирования, автоматизации и оптимизации задач, которые исторически выполнялись людьми, таких как распознавание речи и лиц, принятие решений и перевод.
Существует три основных категории ИИ:
- Узкий искусственный интеллект (ANI)
- Общий искусственный интеллект (AGI)
- Искусственный суперинтеллект (ASI)
АОН считается «слабым» ИИ, тогда как два других типа классифицируются как «сильный» ИИ. Слабый ИИ определяется его способностью выполнять очень специфическую задачу, например, выиграть в шахматы или идентифицировать конкретного человека на серии фотографий. По мере того, как мы переходим к более сильным формам ИИ, таким как AGI и ASI, включение большего количества человеческого поведения становится более заметным, например, способность интерпретировать тон и эмоции. Чат-боты и виртуальные помощники, такие как Siri, только поверхностно относятся к этому, но они все еще являются примерами ANI.
Чат-боты и виртуальные помощники, такие как Siri, только поверхностно относятся к этому, но они все еще являются примерами ANI.
Сильный ИИ определяется его способностями по сравнению с людьми. Искусственный общий интеллект (AGI) будет работать наравне с другим человеком, в то время как искусственный суперинтеллект (ASI), также известный как суперинтеллект, превзойдет человеческий интеллект и способности. Ни одна из форм сильного ИИ пока не существует, но текущие исследования в этой области продолжаются. Поскольку эта область ИИ все еще быстро развивается, лучший пример, который я могу предложить, — это персонаж Долорес из шоу HBO 9.0032 Мир Дикого Запада .
Управляйте своими данными для ИИ
Хотя все эти области ИИ могут помочь оптимизировать области вашего бизнеса и улучшить качество обслуживания клиентов, достижение целей ИИ может быть сложной задачей, поскольку вам сначала нужно убедиться, что у вас есть правильные системы. для управления вашими данными для построения алгоритмов обучения.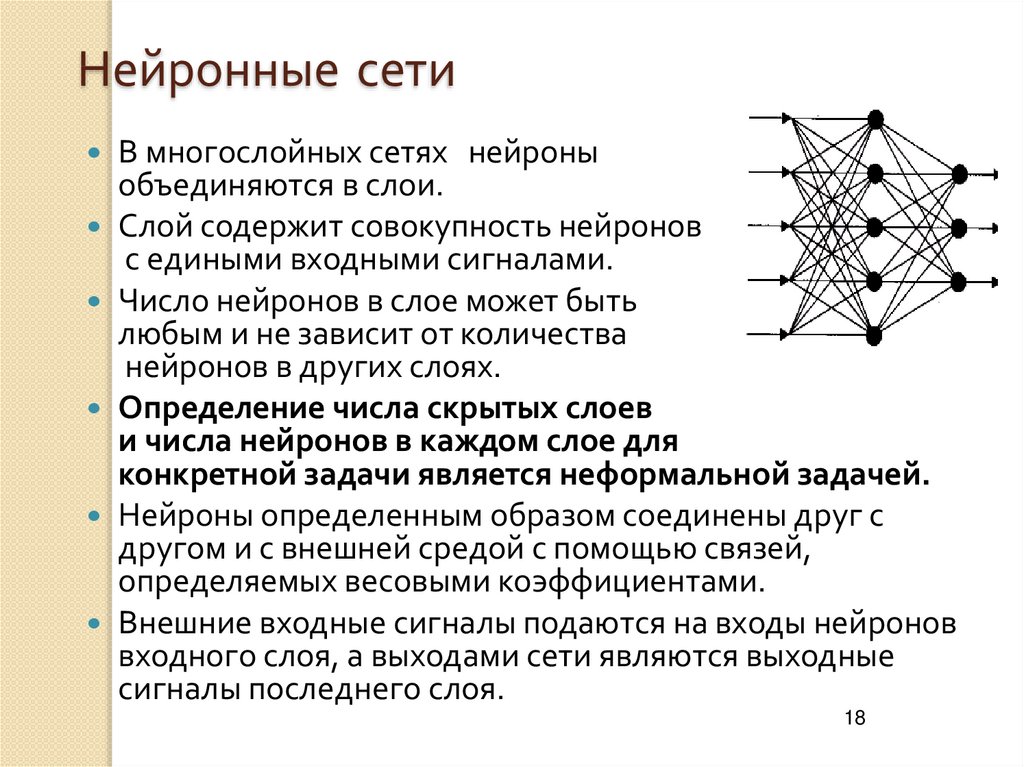 Управление данными, возможно, сложнее, чем создание реальных моделей, которые вы будете использовать для своего бизнеса. Вам понадобится место для хранения ваших данных и механизмы для их очистки и контроля предвзятости, прежде чем вы сможете начать что-либо создавать. Ознакомьтесь с некоторыми предложениями продуктов IBM, которые помогут вам и вашему бизнесу выбрать правильный путь для подготовки данных и управления ими в любом масштабе.
Управление данными, возможно, сложнее, чем создание реальных моделей, которые вы будете использовать для своего бизнеса. Вам понадобится место для хранения ваших данных и механизмы для их очистки и контроля предвзятости, прежде чем вы сможете начать что-либо создавать. Ознакомьтесь с некоторыми предложениями продуктов IBM, которые помогут вам и вашему бизнесу выбрать правильный путь для подготовки данных и управления ими в любом масштабе.
Разница между нейронной сетью и системой глубокого обучения
С момента своего создания в конце 1950-х годов Искусственный интеллект и Машинное обучение прошли долгий путь. Эти технологии стали довольно сложными и продвинутыми в последние годы. Хотя технологические достижения в области Data Science заслуживают похвалы, они привели к потоку терминологии, недоступной для понимания среднего человека.
Есть так много компаний всех размеров, которые используют эти технологии, а именно.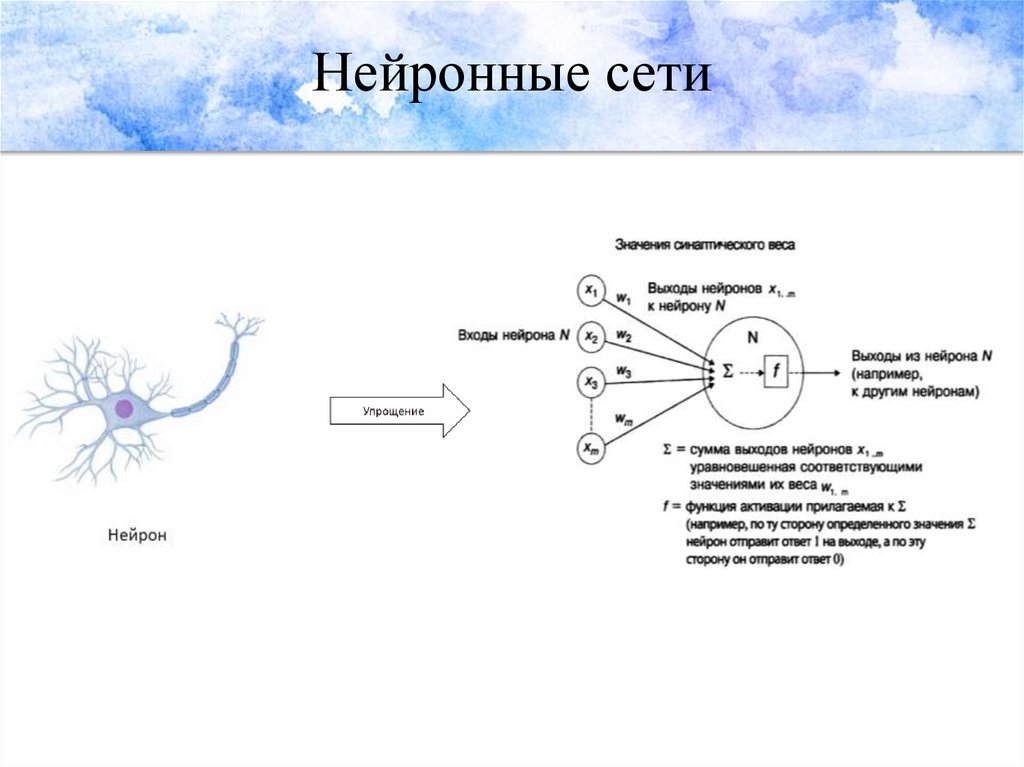 AI и ML в их повседневных приложениях. Тем не менее, многим трудно различать их обширную терминологию. Большинство людей даже используют термины «Машинное обучение», «Глубокое обучение» и «Искусственный интеллект» взаимозаменяемо.
AI и ML в их повседневных приложениях. Тем не менее, многим трудно различать их обширную терминологию. Большинство людей даже используют термины «Машинное обучение», «Глубокое обучение» и «Искусственный интеллект» взаимозаменяемо.
Причина этой путаницы в том, что, хотя у них так много разных названий для разных понятий, большинство из них глубоко переплетены друг с другом и имеют сходство. Тем не менее, каждая из этих терминологий сама по себе уникальна и по-своему полезна.
Теперь давайте поговорим о нейронных сетях и системах глубокого обучения по отдельности, прежде чем мы сможем увидеть их различия!
Что такое нейронная сеть?
- Нейронные сети вдохновлены самым сложным объектом во Вселенной — человеческим мозгом. Давайте сначала разберемся, как работает мозг. Человеческий мозг состоит из того, что называется нейронами. Нейрон — основная вычислительная единица любой нейронной сети, включая мозг.

- Нейроны принимают ввод, обрабатывают его и передают другим нейронам, присутствующим в нескольких скрытых слоях сети, пока обработанный вывод не достигнет выходного слоя.
- Нейронные сети — это алгоритмы, которые могут интерпретировать сенсорные данные посредством машинного восприятия и маркировать или группировать необработанные данные. Они предназначены для распознавания числовых шаблонов, содержащихся в векторах, которые необходимо преобразовать во все данные реального мира (изображения, звуки, текст, временные ряды и т. д.)
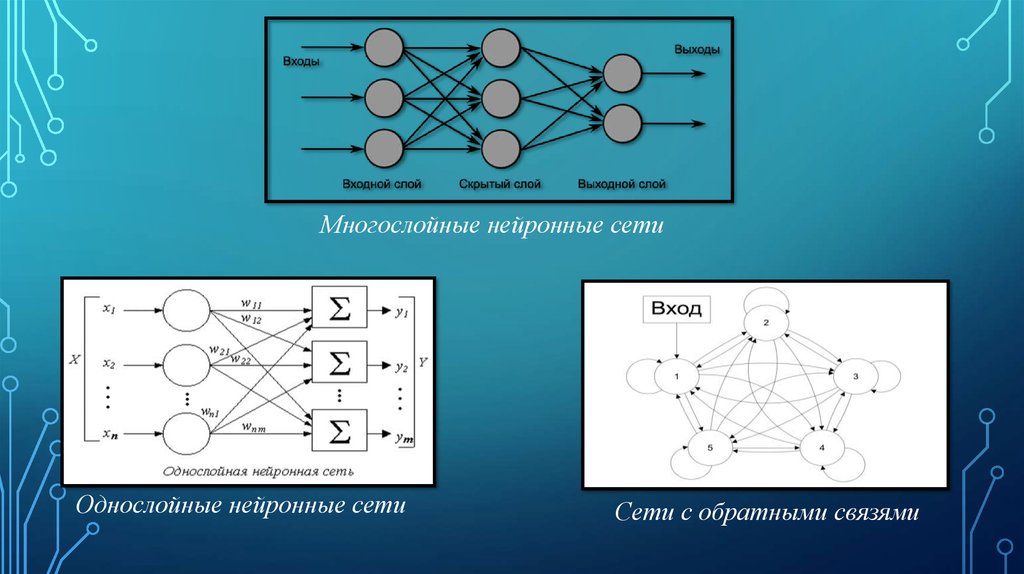
- В своей простейшей форме искусственная нейронная сеть (ИНС) имеет только три уровня. – входной слой, выходной слой и скрытый слой.
Чтобы узнать больше о нейронных сетях – нажмите здесь!
Что такое глубокое обучение?
Теперь, когда мы поговорили о нейронных сетях, давайте поговорим о глубоком обучении.
Глубокое обучение , также известное как иерархическое обучение , представляет собой подмножество машинного обучения в области искусственного интеллекта, которое может имитировать вычислительные возможности человеческого мозга и создавать шаблоны, аналогичные тем, которые мозг использует для принятия решений.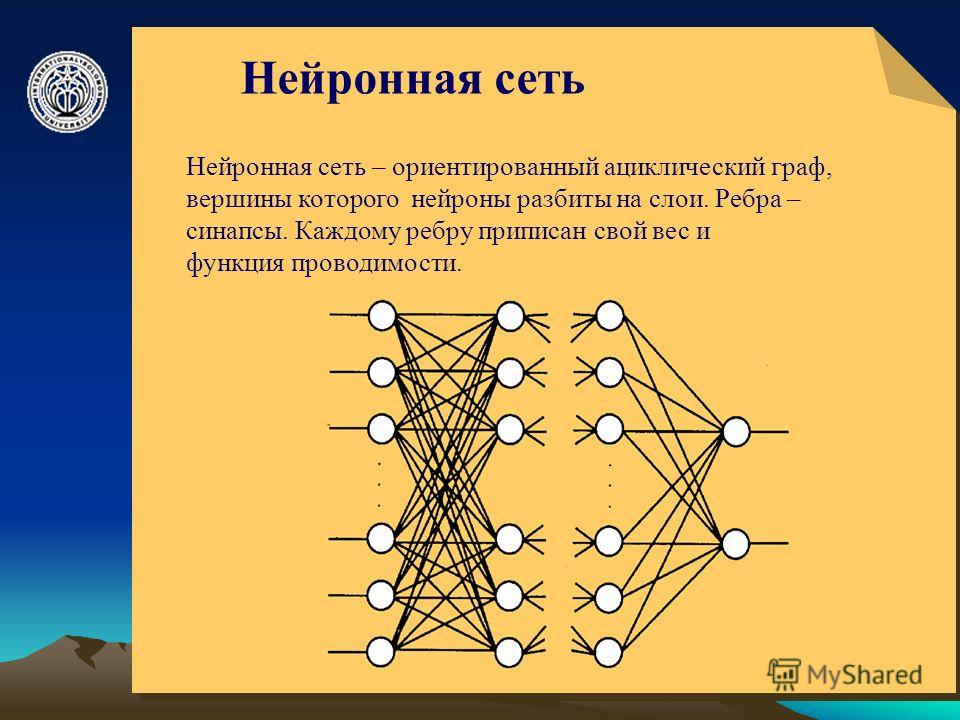 В отличие от алгоритмов, основанных на задачах, системы глубокого обучения учатся на основе представлений данных. Он может учиться на неструктурированных или немаркированных данных.
В отличие от алгоритмов, основанных на задачах, системы глубокого обучения учатся на основе представлений данных. Он может учиться на неструктурированных или немаркированных данных.
Что такое система глубокого обучения?
- Нейронная сеть с несколькими скрытыми слоями и несколькими узлами в каждом скрытом слое известна как система глубокого обучения или глубокая нейронная сеть . Глубокое обучение — это разработка алгоритмов глубокого обучения, которые можно использовать для обучения и прогнозирования выходных данных из сложных данных.
- Слово « deep » в Deep Learning относится к количеству скрытых слоев, то есть к глубине нейронной сети. По сути, каждая нейронная сеть с более чем тремя слоями, то есть включая входной слой и выходной слой, может считаться моделью глубокого обучения.
Чтобы узнать больше о системах глубокого обучения, нажмите здесь!
Таблица различий между нейронной сетью и системой глубокого обучения
Теперь, когда мы поговорили о нейронных сетях и системах глубокого обучения, мы можем двигаться дальше и посмотреть, чем они отличаются друг от друга!
S. № № | Разница между | Нейронные сети | Системы глубокого обучения |
|---|---|---|---|
| 1. | определение 9029 | ||
| 1. | определение 9029 | ||
| 1. | 0232 | Нейронная сеть — это модель нейронов, вдохновленная человеческим мозгом. Он состоит из множества нейронов, которые взаимосвязаны друг с другом. | Нейронные сети глубокого обучения отличаются от нейронных сетей глубиной или количеством скрытых слоев. |
| 2. | Архитектура | Нейронные сети с прямой связью Рекуррентные нейронные сети Симметрично связанные нейронные сети | Рекурсивные нейронные сети Неконтролируемые предварительно обученные сети Снутренние нейронные сети |
| 3. | Структура | Невровые. Блок питания ОЗУ Процессоры | |
| 4. | Время и точность | Обычно их обучение занимает меньше времени. Их точность ниже, чем у систем глубокого обучения | Обычно их обучение занимает больше времени. У них более высокая точность, чем у нейронных сетей. |
| 5. | Производительность | Низкая производительность по сравнению с сетями глубокого обучения. | Дает высокую производительность по сравнению с нейронными сетями. |
| 6. | Интерпретация задачи | Ваша задача плохо интерпретируется нейронной сетью. | Сеть глубокого обучения более эффективно воспринимает вашу задачу. |
| 7. | Приложения | Способность моделировать нелинейные процессы делает нейронные сети отличным инструментом для решения множества задач, включая классификацию, распознавание образов, прогнозирование и анализ, кластеризацию, принятие решений, машинное обучение, глубокое обучение и многое другое. | Модели глубокого обучения могут использоваться в различных отраслях, включая распознавание образов, распознавание речи, обработку естественного языка, компьютерные игры, беспилотные автомобили, фильтрацию социальных сетей и многое другое.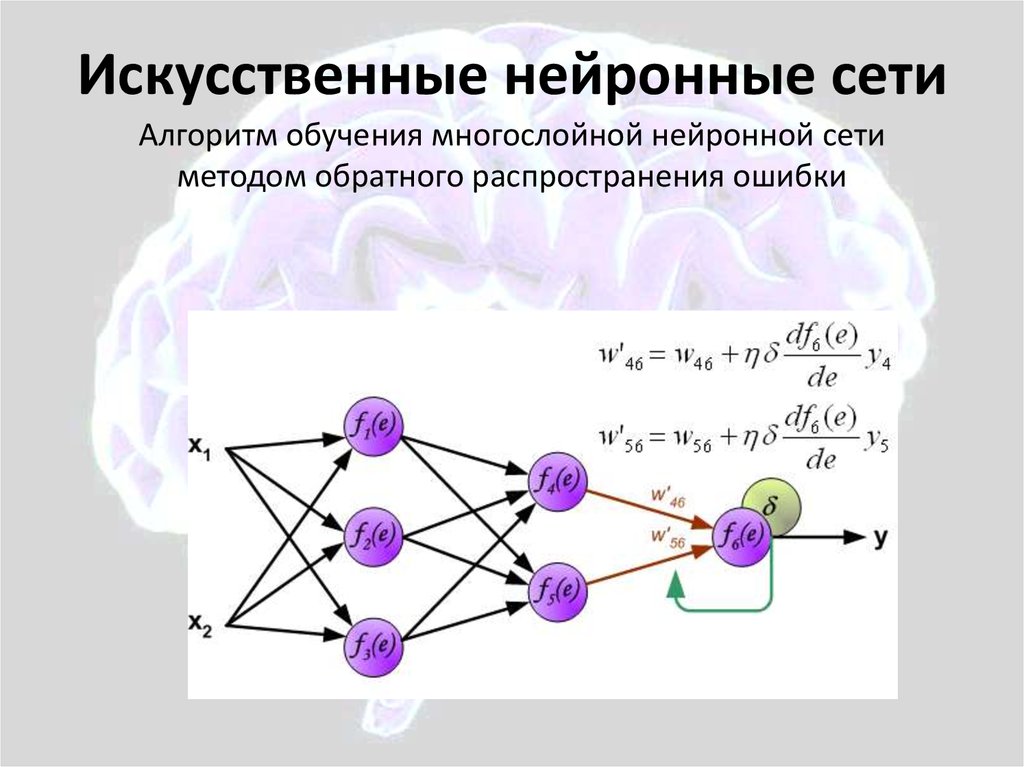 |
| 8. | Критика | Критика нейронных сетей сосредоточена на проблемах обучения, теоретических проблемах, аппаратных проблемах, реальных контрпримерах к критике и гибридных методах. | Критика глубокого обучения, сосредоточенная на теории, ошибках, киберугрозах и т. д. , где первый слой является входным слоем, а последний слой — выходным слоем. Все средние слои являются скрытыми слоями. Архитектуры моделей глубокого обучения в деталях:
СтруктураСтруктуры нейронной сети в деталях:Нейронная сеть состоит из следующих компонентов
Структуры модели глубокого обучения в деталях: Модель глубокого обучения состоит из следующих компонентов
Заключение Глубокое обучение и нейронные сети настолько тесно связаны, что их трудно отличить друг от друга на первый взгляд. |

 Как следует из названия, эта архитектура предварительно обучена на основе прошлого опыта и не требует формального обучения. К ним относятся утоэнкодеры A и Сети глубокого убеждения
Как следует из названия, эта архитектура предварительно обучена на основе прошлого опыта и не требует формального обучения. К ним относятся утоэнкодеры A и Сети глубокого убеждения 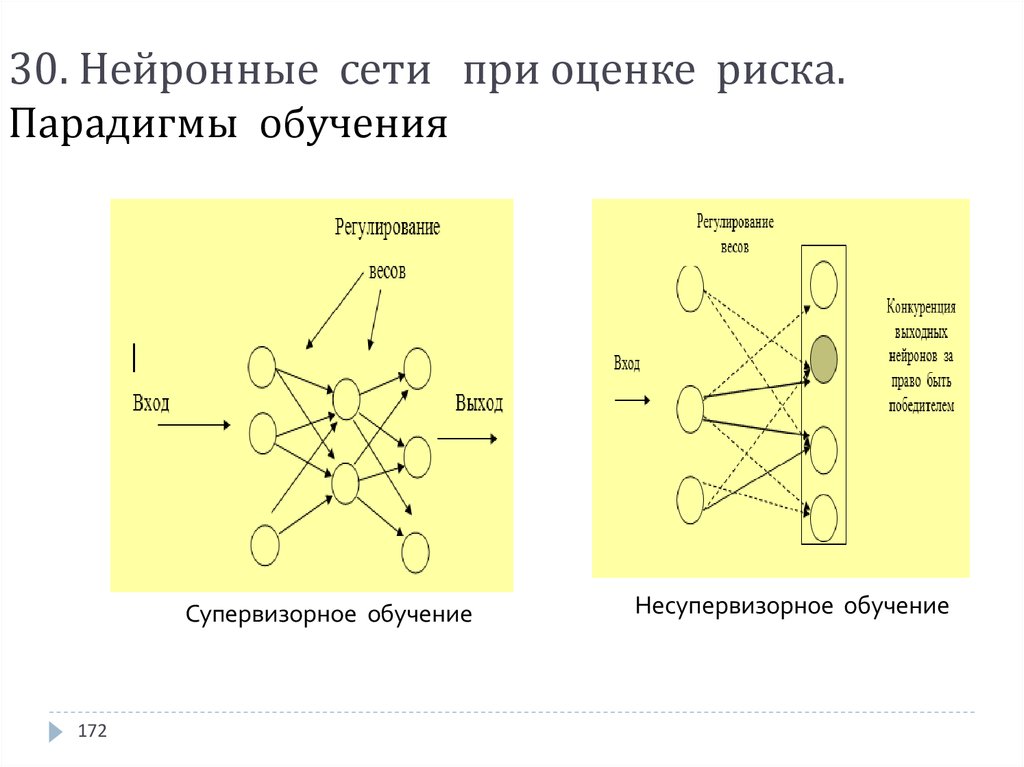 Он вычисляет средневзвешенное значение предоставленных данных, а затем отправляет данные через нелинейную функцию, называемую логистической функцией.
Он вычисляет средневзвешенное значение предоставленных данных, а затем отправляет данные через нелинейную функцию, называемую логистической функцией. Скорость обучения определяет, насколько быстро или медленно обновляются значения веса модели.
Скорость обучения определяет, насколько быстро или медленно обновляются значения веса модели.