Содержание
Нейронная сеть Google: что нового и какие возможности у сети Гугла?
Нейронная сеть в компании Google используется во многих сервисах. Вообще, нейронная сеть и искусственный интеллект все чаще встречаются в различных приложениях и устройствах. Их частое использование касается не только компании Google, но и других крупных и мелких IT-разработчиков. Нейронная сеть может быть использована практически любым разработчиком. Да, в большинстве случаев это будет не написанная с нуля нейронная сеть, а использование какой-нибудь доступной библиотеки, но все же доступность нейросетей и искусственного интеллекта нельзя отрицать.
Но если присмотреться, то такая доступность ИИ не была бы возможной без крупных IT-игроков, таких как Google, Microsoft, Amazon и др. Ведь именно они вкладывают свои усилия и финансы в развитие библиотек для нейронных сетей, а потом открывают им доступ для всех разработчиков.
Сегодня в статье мы рассмотрим, какими программными продуктами представлена нейронная сеть в Google.
Разбирать все продукты мы не будем, потому что их сотни, но наиболее интересные и значимые — обязательно.
Чем представлена нейронная сеть в Google
Нейронная сеть в Google представлена множеством различных продуктов, но самая главная из всех — это нейронная сеть Bert. Главная, потому что она затрагивает большое количество людей. Ведь именно благодаря этой нейронной сети в 2019 году произошло большое обновление поисковых алгоритмов в Google-поиске. Это обновление так или иначе затронуло всех владельцев собственных сайтов, а около 10% владельцев ресурсов заявили о проблемах после внедрения Bert:
Нейронная сеть Bert от компании Google
Bert — это новейшая нейронная сеть от Google, которая была разработана в 2018 году. Ее основное поле деятельности — это научить компьютеры понимать текст так, как его понимает человек. А это очень сложная задача, ведь в тексте есть много нюансов, которые пока понимает только человек, например: сарказм, подтекст, двусмысленность, недоговоренность, исключение слов из предложений и др.
Поисковая выдача — это лишь одно направление, где работает Bert, но именно здесь она лежит в основе поискового алгоритма. Почему не все веб-мастеры заметили внедрение Берт, а только около 10%? Потому что эта нейронная сеть от Google сфокусирована на анализе длинных поисковых запросов, чтобы выдавать максимально релевантный материал. А основная масса веб-мастеров развивают свои ресурсы с фокусировкой на короткие запросы в 1-3 слова. Такие мастеры не заметили обновление поисковых алгоритмов.
Но нужно понимать, что Bert внедрена в поисковую систему только для более качественной обработки текста, а не для того, чтобы влиять на ранжирование. Именно поэтому специалисты Google после внедрения Bert рекомендовали веб-мастерам ориентироваться на размещение качественного контента на своих ресурсах, а не на внедрении определенного количества ключевых слов.
На сегодняшний день мы имеем следующее: Bert показалась во всей красе в работе с англоязычным контентом. В работе с другими языками, в том числе и с русским, она испытывает небольшие трудности, однако она постоянно обучается. А это означает, что изменения в поисковой выдаче в русскоязычном сегменте можно ожидать в любое время.
Нейронная сеть в других программных продуктах Google
Нейронная сеть в Google представлена не только Bert, но и многими другими продуктами, которые также имеют должную популярность в кругах, где они применяются.
Среди таких продуктов можно выделить:
TensorFlow. Когда-то этот инструмент был просто библиотекой, чуть позже он перерос в целый набор библиотек, но уже сейчас ему придают статус полноценного фреймворка, который можно использовать для обучения собственной нейронной сети.
ML Kit. Это набор библиотек, который необходим для внедрения собственной нейронной сети в мобильный телефон. Например, при помощи этого инструмента можно организовать в своем приложении распознавание языка пользователя и внедрять языковое управление, также можно организовать распознавание объектов, в том числе и QR-код.
AutoFlip. Это система для обработки видео на основе искусственного интеллекта. При помощи этого инструмента можно качественно обрабатывать видео без потери качества, например, можно из альбомной ориентации получить вертикальное видео и наоборот.
Colab. Это инструмент для разработчиков, который сочетает в себе онлайн-редактор кода и компилятор Python.
Cloud AI. Это набор из нескольких инструментов на основе искусственного интеллекта, которые можно внедрять в собственный бизнес для улучшения его показателей.
Cloud AutoML. Это платформа для бизнеса, где можно проводить машинное обучение своих собственных продуктов.
Teachable Machine 2.0. Это платформа для обучения собственных нейронных сетей. Причем это может делать каждый пользователь сети и даже школьники, которые никак не связаны с программированием. Ведь обучать свою нейросеть можно при помощи микрофона и видеокамеры, а потому уже обученную нейросеть можно экспортировать в свои приложения и сайты.
И др.
Заключение
Нейронная сеть и искусственный интеллект понемногу проникают в жизнедеятельность человека благодаря таким компаниям, как Google. Встретить их можно везде: в телефоне, телевизоре, «умном доме», беспилотном автомобиле, в играх, на сайтах, в «умных часах», производственных станках, приложениях и т. д.
Самое важное, что практически любой человек, если ему нужно, может создать и обучить собственную нейросеть, используя наработки и инструменты крупных компаний, опять же, таких как Google.
 Разбирать все продукты мы не будем, потому что их сотни, но наиболее интересные и значимые — обязательно.
Разбирать все продукты мы не будем, потому что их сотни, но наиболее интересные и значимые — обязательно. Эта нейросеть обучена на нескольких миллиардах слов и продолжает постоянно обучаться до сих пор. Основная сфера ее деятельности — это обработка текста в разных ситуациях: начиная от голосовых помощников в пользовательских устройствах и заканчивая внедрением в различные приложения.
Эта нейросеть обучена на нескольких миллиардах слов и продолжает постоянно обучаться до сих пор. Основная сфера ее деятельности — это обработка текста в разных ситуациях: начиная от голосовых помощников в пользовательских устройствах и заканчивая внедрением в различные приложения.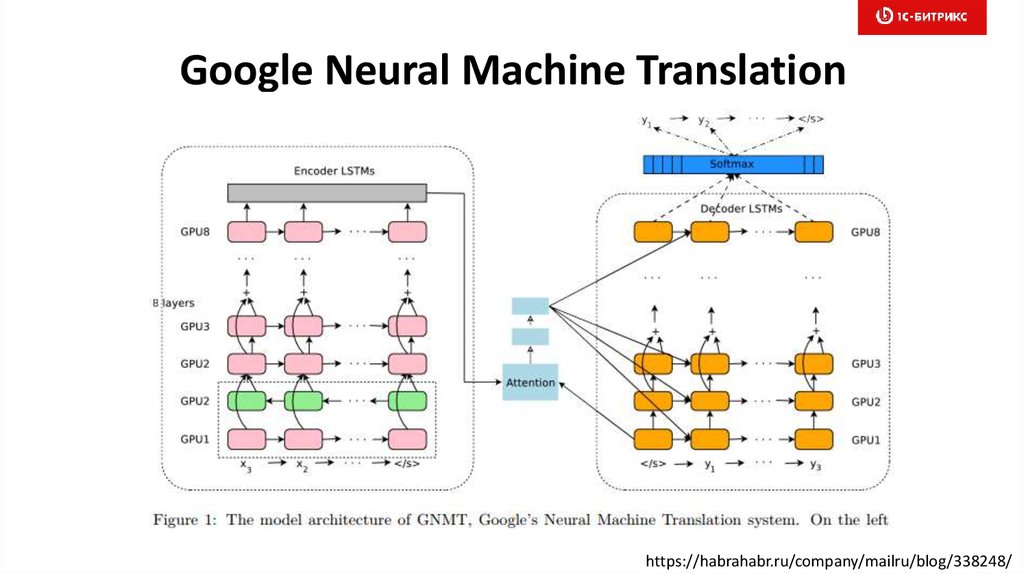 Джон Мюллер на одной пресс-конференции заявил, что умышленная оптимизация контента под Bert невозможна, так как эта нейросеть проверяет текст на естественность, а не на количество вхождений ключевых слов.
Джон Мюллер на одной пресс-конференции заявил, что умышленная оптимизация контента под Bert невозможна, так как эта нейросеть проверяет текст на естественность, а не на количество вхождений ключевых слов.

Новая нейронная сеть Google значительно точнее и быстрее, чем популярные аналоги
3DNews Новости Software Искусственный интеллект, машинное обучен… Новая нейронная сеть Google значительно … Самое интересное в обзорах 30.05.2019 [17:17], Сергей Тверье Свёрточные нейронные сети (англ. Convolutional neural networks — CNN), вдохновлённые биологическими процессами в зрительной коре человека, хорошо подходят для таких задач, как распознавание объектов и лиц, но повышение точности их работы требует утомительной и тонкой настройки. Вот почему учёные из исследовательского отдела Google AI изучают новые модели, которые «масштабируют» CNN «более структурированным» способом. Результат своей работы они опубликовали в статье «EfficientNet: переосмысление масштабирования моделей для свёрточных нейронных сетей», размещённой на научном портале Arxiv. В отличие от стандартных подходов к масштабированию CNN, команда Google AI предлагает метод, который равномерно масштабирует сразу все базовые параметры нейронной сети «Обычная практика масштабирования моделей заключается в произвольном увеличении глубины или ширины CNN, а также использовании большего разрешения входного изображения для обучения и оценки», — пишут штатный инженер-программист Минсинг Тан (Mingxing Tan) и ведущий ученый в Google AI Куок Ли (Quoc V. Le). «В отличие от традиционных подходов, которые произвольно масштабируют параметры сети, такие как ширина, глубина и входящее разрешение, наш метод равномерно масштабирует каждое измерение с фиксированным набором коэффициентов масштабирования». Для дальнейшего повышения производительности исследователи выступают за использование новой базовой сети — мобильной инвертированной свёртки узкого места (англ. В тестах EfficientNets продемонстрировало как более высокую точность, так и лучшую эффективность по сравнению с существующими CNN, на порядок уменьшив требование к размеру параметров и вычислительным ресурсам. Одна из моделей — EfficientNet-B7, продемонстрировала в 8,4 раза меньший размер и в 6,1 раза лучшую производительность, чем известная CNN Gpipe, а также достигла 84,4 % и 97,1 % точности (Топ-1 и Топ-5 результат) в тестировании на наборе ImageNet. По сравнению с популярной CNN ResNet-50, другая модель EfficientNet — EfficientNet-B4, используя аналогичные ресурсы, продемонстрировала точность в 82,6 % против 76,3 % у ResNet-50. Модели EfficientNets хорошо показали себя и на других наборах данных, достигнув высокой точности в пяти из восьми тестов, включая наборы CIFAR-100 (точность 91,7 %) и Flowers (98,8 %). Сравнение размеров модели и точности распознавания для популярных CNN и EfficientNets «Обеспечивая значительные улучшения эффективности нейронных моделей, мы ожидаем, что EfficientNets потенциально может послужить новой основой для будущих задач в области компьютерного зрения», — пишут Тан и Ли. Исходный код и учебные сценарии для облачных тензорных процессоров (TPU) от Google находятся в свободном доступе на Github. Источник: Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER. Материалы по теме Постоянный URL: https://3dnews.ru/988354 Рубрики: Теги: ← В |
 org, а также в публикации в своём блоге. Соавторы утверждают, что семейство систем искусственного интеллекта, получившее название EfficientNets, превосходит точность стандартных CNN и повышает эффективность нейронной сети до 10 раз.
org, а также в публикации в своём блоге. Соавторы утверждают, что семейство систем искусственного интеллекта, получившее название EfficientNets, превосходит точность стандартных CNN и повышает эффективность нейронной сети до 10 раз. mobile inverted bottleneck convolution — MBConv), которая служит основой для семейства моделей EfficientNets.
mobile inverted bottleneck convolution — MBConv), которая служит основой для семейства моделей EfficientNets.
Ускорение нейронных сетей на мобильных устройствах и в Интернете с помощью разреженного вывода — блог Google AI
Авторы: Артем Аблаватский и Марат Духан, инженеры-программисты, Google Research
Вывод нейронных сетей на устройстве позволяет использовать различные приложения в реальном времени, такие как оценка позы и размытие фона, с малой задержкой и с учетом конфиденциальности. Используя фреймворки машинного вывода, такие как TensorFlow Lite с библиотекой ускорения XNNPACK ML, инженеры оптимизируют свои модели для работы на различных устройствах, находя оптимальное соотношение между размером модели, скоростью вывода и качеством прогнозов.
Используя фреймворки машинного вывода, такие как TensorFlow Lite с библиотекой ускорения XNNPACK ML, инженеры оптимизируют свои модели для работы на различных устройствах, находя оптимальное соотношение между размером модели, скоростью вывода и качеством прогнозов.
Одним из способов оптимизации модели является использование разреженных нейронных сетей [1, 2, 3], значительная часть весов которых равна нулю. В общем, это желательное качество, поскольку оно не только уменьшает размер модели за счет сжатия, но и позволяет пропустить значительную часть операций умножения-сложения, тем самым ускоряя вывод. Кроме того, можно увеличить количество параметров в модели, а затем разрезать ее, чтобы она соответствовала качеству исходной модели, и в то же время воспользоваться преимуществами ускоренного вывода. Однако использование этого метода в производстве остается ограниченным в основном из-за отсутствия инструментов для разрежения популярных сверточных архитектур, а также из-за недостаточной поддержки выполнения этих операций на устройстве.
Сегодня мы объявляем о выпуске набора новых функций для библиотеки ускорения XNNPACK и TensorFlow Lite, которые обеспечивают эффективный вывод разреженных сетей, а также рекомендации по разрежению нейронных сетей с целью помочь исследователям в разработке собственных разреженных сетей на устройстве. модели. Эти инструменты, разработанные в сотрудничестве с DeepMind, обеспечивают новое поколение опыта живого восприятия, включая отслеживание рук в MediaPipe и фоновые функции в Google Meet, ускоряя скорость вывода с 1,2 до 2,4 раза при одновременном уменьшении размера модели вдвое. В этом посте мы представляем технический обзор разреженных нейронных сетей — от создания разреженности во время обучения до развертывания на устройстве — и предлагаем некоторые идеи о том, как исследователи могут создавать свои собственные разреженные модели.
Сравнение времени обработки плотной ( слева ) и разреженной ( справа ) моделей одинакового качества для фоновых функций Google Meet. Для удобочитаемости показанное время обработки представляет собой скользящее среднее по 100 кадрам. Для удобочитаемости показанное время обработки представляет собой скользящее среднее по 100 кадрам. |
Разрежение нейронной сети
Многие современные архитектуры глубокого обучения, такие как MobileNet и EfficientNetLite, в основном состоят из глубоких сверток с небольшим пространственным ядром и сверток 1×1, которые линейно комбинируют признаки входного изображения. Хотя такие архитектуры имеют ряд потенциальных целей для разреживания, включая полные 2D-свертки, которые часто возникают в начале многих сетей, или глубинные свертки, именно свертки 1×1 являются самыми дорогостоящими операторами с точки зрения времени вывода. Поскольку на них приходится более 65 % всех вычислений, они являются оптимальной целью для разреживания.
| Архитектура | Время вывода |
| Мобильная сеть | 85% |
| МобилнетВ2 | 71% |
| МобилнетВ3 | 71% |
| EfficientNet-Lite | 66% |
Сравнение времени вывода для сверток 1×1 в % для современных мобильных архитектур. |
В современных механизмах логического вывода на устройстве, таких как XNNPACK, реализация сверток 1×1, а также других операций в моделях глубокого обучения опирается на тензорную компоновку HWC, в которой размеры тензора соответствуют высоте, ширине и каналу (например, красный, зеленый или синий) входного изображения. Эта тензорная конфигурация позволяет механизму логического вывода параллельно обрабатывать каналы, соответствующие каждому пространственному местоположению (т. е. каждому пикселю изображения). Однако такое упорядочивание тензора не подходит для разреженного вывода, поскольку оно устанавливает канал как самое внутреннее измерение тензора и делает доступ к нему более затратным с вычислительной точки зрения.
Наши обновления для XNNPACK позволяют ему определять, является ли модель разреженной. Если это так, он переключается со стандартного режима плотного вывода на режим разреженного вывода, в котором используется тензорная компоновка CHW (канал, высота, ширина). Это переупорядочивание тензора позволяет ускорить реализацию разреженного ядра свертки 1×1 по двум причинам: 1) целые пространственные срезы тензора могут быть пропущены, когда соответствующий вес канала равен нулю после единственной проверки условия, вместо попиксельной проверки. тест; и 2) когда вес канала не равен нулю, вычисления можно сделать более эффективными, загрузив соседние пиксели в один и тот же блок памяти. Это позволяет нам обрабатывать несколько пикселей одновременно, а также выполнять каждую операцию параллельно в нескольких потоках. Вместе эти изменения приводят к ускорению от 1,8x до 2,3x, когда по крайней мере 80% весов равны нулю.
Это переупорядочивание тензора позволяет ускорить реализацию разреженного ядра свертки 1×1 по двум причинам: 1) целые пространственные срезы тензора могут быть пропущены, когда соответствующий вес канала равен нулю после единственной проверки условия, вместо попиксельной проверки. тест; и 2) когда вес канала не равен нулю, вычисления можно сделать более эффективными, загрузив соседние пиксели в один и тот же блок памяти. Это позволяет нам обрабатывать несколько пикселей одновременно, а также выполнять каждую операцию параллельно в нескольких потоках. Вместе эти изменения приводят к ускорению от 1,8x до 2,3x, когда по крайней мере 80% весов равны нулю.
Чтобы избежать обратного преобразования между тензорной компоновкой CHW, оптимальной для разреженного вывода, и стандартной тензорной компоновкой HWC после каждой операции, XNNPACK обеспечивает эффективные реализации нескольких операторов CNN в компоновке CHW.
Рекомендации по обучению разреженных нейронных сетей
Чтобы создать разреженную нейронную сеть, рекомендации, включенные в этот выпуск, предлагают начать с плотной версии, а затем во время обучения постепенно обнулять часть ее весов. Этот процесс называется обрезкой. Из многих доступных методов сокращения мы рекомендуем использовать сокращение амплитуды (доступно в наборе инструментов оптимизации модели TF) или недавно представленный метод RigL. С небольшим увеличением времени обучения оба они могут успешно разрежать модели глубокого обучения без ухудшения их качества. Полученные разреженные модели могут быть эффективно сохранены в сжатом формате, который уменьшает размер в два раза по сравнению с их плотным эквивалентом.
Этот процесс называется обрезкой. Из многих доступных методов сокращения мы рекомендуем использовать сокращение амплитуды (доступно в наборе инструментов оптимизации модели TF) или недавно представленный метод RigL. С небольшим увеличением времени обучения оба они могут успешно разрежать модели глубокого обучения без ухудшения их качества. Полученные разреженные модели могут быть эффективно сохранены в сжатом формате, который уменьшает размер в два раза по сравнению с их плотным эквивалентом.
На качество разреженных сетей влияют несколько гиперпараметров, включая время обучения, скорость обучения и графики обрезки. TF Pruning API предоставляет отличный пример того, как их выбирать, а также несколько советов по обучению таких моделей. Мы рекомендуем выполнять поиск по гиперпараметрам, чтобы найти лучшее место для вашего приложения.
Приложения
Мы демонстрируем, что можно разрежать задачи классификации, плотную сегментацию (например, Meet с размытием фона) и проблемы регрессии (MediaPipe Hands), что обеспечивает ощутимые преимущества для пользователей. Например, в случае с Google Meet разреженность сократила время вывода модели на 30 %, что обеспечило доступ к более качественным моделям для большего числа пользователей.
Например, в случае с Google Meet разреженность сократила время вывода модели на 30 %, что обеспечило доступ к более качественным моделям для большего числа пользователей.
| Сравнение размеров плотных и разреженных моделей в Мб. Модели были сохранены в 16- и 32-битных форматах с плавающей запятой. |
Описанный здесь подход к разреженности лучше всего работает с архитектурами, основанными на инвертированных остаточных блоках, таких как MobileNetV2, MobileNetV3 и EfficientNetLite. Степень разреженности в сети влияет как на скорость, так и на качество логического вывода. Начиная с плотной сети фиксированной емкости, мы обнаружили скромный прирост производительности даже при разреженности 30%. При увеличении разреженности качество модели остается относительно близким к плотной базовой линии до достижения разреженности 70%, за пределами которой наблюдается более выраженное падение точности. Однако снижение точности при разреженности 70 % можно компенсировать увеличением размера базовой сети на 20 %, что приводит к ускорению времени вывода без ухудшения качества модели. Никаких дополнительных изменений для запуска разреженных моделей не требуется, потому что XNNPACK может распознавать и автоматически включать разреженный вывод.
Однако снижение точности при разреженности 70 % можно компенсировать увеличением размера базовой сети на 20 %, что приводит к ускорению времени вывода без ухудшения качества модели. Никаких дополнительных изменений для запуска разреженных моделей не требуется, потому что XNNPACK может распознавать и автоматически включать разреженный вывод.
| Исследования абляции различных уровней разреженности в отношении времени вывода (чем меньше, тем лучше) и качества, измеренного с помощью Intersection over Union (IoU) для предсказанной маски сегментации. |
Разреженность как автоматическая альтернатива дистилляции
Размытие фона в Google Meet использует модель сегментации, основанную на модифицированной магистрали MobileNetV3 с блоками внимания. Мы смогли ускорить модель на 30%, применив разреженность на 70%, сохранив при этом качество маски переднего плана. Мы изучили прогнозы разреженных и плотных моделей на изображениях из 17 географических субрегионов, не обнаружив существенных различий, и опубликовали подробности в соответствующей карточке модели.
Мы изучили прогнозы разреженных и плотных моделей на изображениях из 17 географических субрегионов, не обнаружив существенных различий, и опубликовали подробности в соответствующей карточке модели.
Точно так же MediaPipe Hands прогнозирует ориентиры рук в режиме реального времени на мобильных устройствах и в Интернете, используя модель, основанную на магистрали EfficientNetLite. Эта магистральная модель была вручную получена из большой плотной модели, что является дорогостоящим в вычислительном отношении итеративным процессом. Используя разреженную версию плотной модели вместо дистиллированной, мы смогли сохранить ту же скорость вывода, но без трудоемкого процесса дистилляции из плотной модели. По сравнению с плотной моделью разреженная модель улучшила вывод в два раза, достигнув того же качества ориентира, что и дистиллированная модель. В некотором смысле разреженность можно рассматривать как автоматический подход к неструктурированной дистилляции модели, который может улучшить производительность модели без значительных ручных усилий. Мы оценили разреженную модель в наборе георазнообразных данных и сделали карточку модели общедоступной.
Мы оценили разреженную модель в наборе георазнообразных данных и сделали карточку модели общедоступной.
| Сравнение времени выполнения для плотных ( слева ), дистиллированных ( посередине ) и разреженных ( справа ) моделей одного качества. Время обработки плотной модели в 2 раза больше, чем у разреженных или дистиллированных моделей. Дистиллированная модель взята из официального решения MediPipe. Плотные и разреженные веб-демонстрации общедоступны. |
Будущая работа
Мы считаем, что разрежение является простой, но мощной техникой для улучшения логического вывода ЦП нейронных сетей. Разреженный логический вывод позволяет инженерам запускать более крупные модели без значительных накладных расходов на производительность или размер и предлагает новое многообещающее направление для исследований. Мы продолжаем расширять XNNPACK за счет более широкой поддержки операций в макете CHW и изучаем, как его можно сочетать с другими методами оптимизации, такими как квантование. Мы рады видеть, что вы можете построить с помощью этой технологии!
Мы рады видеть, что вы можете построить с помощью этой технологии!
Благодарности
Особая благодарность всем, кто работал над этим проектом: Картику Равендрану, Эриху Эльсену, Тингбо Хоу, Тревору Гейлу, Сергею Писарчуку, Юрию Картыннику, Юнлу Ли, Утку Эвци, Матсвею Ждановичу, Себастьяну Янссону, Стефану Юло, Майклу Хейс, Юхён Ли, Фан Чжан, Чуо-Лин Чанг, Грегори Карпиак, Тайлер Маллен, Цзюцян Тан, Мин Гуан Юн, Игорь Кибальчич и Матиас Грундманн.
AutoML от Google: преодоление шумихи
Это третья часть серии. Часть 1 здесь, Часть 2 здесь.
Чтобы объявить об AutoML от Google, генеральный директор Google Сундар Пичаи написал: «Сегодня проектирование нейронных сетей занимает чрезвычайно много времени и требует опыта, который ограничивает его использование небольшим сообществом ученых и инженеров. Вот почему мы создали подход под названием AutoML, показывающий, что нейронные сети могут проектировать нейронные сети. Мы надеемся, что AutoML возьмет на себя способность, которой сегодня обладают несколько докторов наук. 0035 позволит сотням тысяч разработчиков через три-пять лет создавать новые нейронные сети для своих конкретных нужд ». (выделено мной)
0035 позволит сотням тысяч разработчиков через три-пять лет создавать новые нейронные сети для своих конкретных нужд ». (выделено мной)
Генеральный директор Google Сундар Пичаи говорит, что нам всем нужно создавать свои собственные нейронные сети.
Когда глава отдела искусственного интеллекта Google Джефф Дин предположил, что 100-кратная вычислительная мощность может заменить потребность в знаниях в области машинного обучения , единственным примером, который он привел, чтобы проиллюстрировать это, был дорогостоящий поиск нейронной архитектуры. (около 23:50 в своем основном докладе TensorFlow DevSummit)
Это поднимает ряд вопросов: нужен ли сотням тысяч разработчиков для «разработки новых нейронных сетей для их конкретных нужд» (цитируя видение Пичаи), или существует ли эффективный способ для нейронных сетей обобщать аналогичные задачи? ? Могут ли большие вычислительные мощности действительно заменить опыт машинного обучения?
При оценке заявлений Google важно помнить, что Google имеет личную финансовую заинтересованность в том, чтобы убедить нас в том, что ключом к эффективному использованию глубокого обучения является увеличение вычислительной мощности , потому что это область, где они явно побеждают остальных из нас. Если это правда, нам всем может понадобиться приобрести продукты Google. Само по себе это не означает, что утверждения Google ложны, но полезно знать, какие финансовые мотивы могут лежать в основе их заявлений.
Если это правда, нам всем может понадобиться приобрести продукты Google. Само по себе это не означает, что утверждения Google ложны, но полезно знать, какие финансовые мотивы могут лежать в основе их заявлений.
В своих предыдущих сообщениях я поделился введением в историю AutoML, определил, что такое поиск нейронной архитектуры, и указал, что для многих проектов машинного обучения проектирование/выбор архитектуры далеко не самое сложное и занимает много времени, или самая болезненная часть проблемы . В сегодняшней статье я хочу конкретно остановиться на AutoML от Google, продукте, получившем большое внимание средств массовой информации, и обратиться к следующему:
.
- Что такое AutoML от Google?
- Что такое трансферное обучение?
- Поиск в нейронной архитектуре и трансферное обучение: два противоположных подхода
- Нужны дополнительные доказательства
- Почему вся эта шумиха вокруг AutoML от Google?
- Как мы можем решить проблему нехватки знаний в области машинного обучения?
Что такое AutoML от Google?
Хотя область AutoML существует уже много лет (включая библиотеки AutoML с открытым исходным кодом, семинары, исследования и конкурсы), в мае 2017 года Google использовала термин AutoML для поиска по нейронной архитектуре. В сообщениях блога, сопровождающих объявления, сделанные на конференции Google I/O, генеральный директор Google Сундар Пичаи написал: «Вот почему мы создали подход под названием AutoML , показывающий, что нейронные сети могут проектировать нейронные сети» и исследователи искусственного интеллекта Google Баррет Зоф и Куок Ле написали : «В нашем подходе (, который мы называем «AutoML» ), нейронная сеть контроллера может предложить «дочернюю» архитектуру модели…»
В сообщениях блога, сопровождающих объявления, сделанные на конференции Google I/O, генеральный директор Google Сундар Пичаи написал: «Вот почему мы создали подход под названием AutoML , показывающий, что нейронные сети могут проектировать нейронные сети» и исследователи искусственного интеллекта Google Баррет Зоф и Куок Ле написали : «В нашем подходе (, который мы называем «AutoML» ), нейронная сеть контроллера может предложить «дочернюю» архитектуру модели…»
Google Cloud AutoML был анонсирован в январе 2018 года как набор продуктов для машинного обучения. Пока он состоит из одного общедоступного продукта, AutoML Vision , API, который идентифицирует или классифицирует объекты на изображениях. Согласно странице продукта, Cloud AutoML Vision опирается на два основных метода: передача обучения и поиск нейронной архитектуры . Поскольку мы уже объяснили поиск в нейронной архитектуре, давайте теперь посмотрим на трансферное обучение и посмотрим, как оно связано с поиском в нейронной архитектуре.
Заголовки лишь нескольких из множества статей, написанных об AutoML и поиске нейронной архитектуры Google.
Примечание. В Google Cloud AutoML также есть продукт машинного обучения с функцией перетаскивания, который все еще находится в стадии альфа-тестирования. Я подал заявку на доступ к нему более 2 месяцев назад, но до сих пор не получил ответа от Google. Я планирую написать пост, как только он выйдет.
Что такое трансферное обучение?
Трансферное обучение — это мощная методика, которая позволяет людям с небольшими наборами данных или меньшей вычислительной мощностью достигать самых современных результатов, используя предварительно обученные модели, которые были обучены на аналогичных больших наборах данных. Поскольку модель, обученная с помощью трансферного обучения, не должна учиться с нуля, она обычно может достигать более высокой точности с гораздо меньшими данными и временем вычислений, чем модели, которые не используют трансферное обучение.
Трансферное обучение — это основная методика, которую мы используем на протяжении всего нашего бесплатного курса «Практическое глубокое обучение для программистов», и которую наши студенты применяют в производстве во всем, от собственных стартапов до компаний из списка Fortune 500. Хотя трансферное обучение считается «менее привлекательным», чем поиск в нейронной архитектуре, оно используется для достижения новаторских академических результатов, таких как применение Джереми Ховардом и Себастьяном Рудером трансферного обучения к НЛП, которое достигло современного состояния. -art на 6 наборах данных и служит основой для дальнейших исследований в этой области в OpenAI.
Поиск в нейронной архитектуре и трансферное обучение: два противоположных подхода
Основная идея трансферного обучения заключается в том, что архитектуры нейронных сетей будут обобщаться для схожих типов задач: например, многие изображения имеют базовые функции (такие как углы, круги, собачьи морды или колеса), которые проявляются во множестве различных виды изображений. Напротив, основная идея продвижения поиска нейронной архитектуры для каждой проблемы противоположна : каждый набор данных имеет уникальную, узкоспециализированную архитектуру, с которой он будет работать лучше всего.
Напротив, основная идея продвижения поиска нейронной архитектуры для каждой проблемы противоположна : каждый набор данных имеет уникальную, узкоспециализированную архитектуру, с которой он будет работать лучше всего.
Примеры Мэтью Зейлера и Роба Фергуса по 4 признакам, полученным с помощью классификаторов изображений: углы, круги, собачьи морды и колеса.
Когда поиск нейронной архитектуры обнаруживает новую архитектуру, вы должны изучить веса для этой архитектуры с нуля, в то время как при переносном обучении вы начинаете с существующих весов из предварительно обученной модели. В этом смысле вы не можете использовать поиск нейронной архитектуры и передачу обучения по одной и той же проблеме: если вы изучаете новую архитектуру, вам нужно будет обучить для нее новые веса; тогда как, если вы используете трансферное обучение на предварительно обученной модели, вы не можете внести существенные изменения в архитектуру.
Конечно, вы можете применить трансферное обучение к архитектуре, изученной с помощью поиска нейронной архитектуры (что, я думаю, хорошая идея!). Для этого требуется лишь, чтобы несколько исследователей использовали поиск по нейронной архитектуре и открывали доступ к найденным моделям. Не обязательно, чтобы все специалисты по машинному обучению самостоятельно использовали нейронную архитектуру для поиска всех проблем , когда вместо этого они могут использовать трансферное обучение. Тем не менее, основной доклад Джеффа Дина, сообщение в блоге Сундара Пичаи, рекламные материалы Google Cloud и освещение в СМИ говорят об обратном: каждый должен иметь возможность напрямую использовать поиск по нейронной архитектуре.
Для этого требуется лишь, чтобы несколько исследователей использовали поиск по нейронной архитектуре и открывали доступ к найденным моделям. Не обязательно, чтобы все специалисты по машинному обучению самостоятельно использовали нейронную архитектуру для поиска всех проблем , когда вместо этого они могут использовать трансферное обучение. Тем не менее, основной доклад Джеффа Дина, сообщение в блоге Сундара Пичаи, рекламные материалы Google Cloud и освещение в СМИ говорят об обратном: каждый должен иметь возможность напрямую использовать поиск по нейронной архитектуре.
Чем хорош поиск нейронной архитектуры
Нейронный поиск архитектуры хорош для поиска новых архитектур! AmoebaNet от Google была изучена с помощью поиска по нейронной архитектуре, и (с включением достижений fast.ai, таких как агрессивный график обучения и изменение размера изображения по мере обучения) теперь является самым дешевым способом обучения ImageNet на одной машине !
AmoebaNet не была разработана с функцией вознаграждения, предполагающей возможность масштабирования, поэтому она не масштабировалась так же хорошо, как ResNet, на нескольких машинах, но хорошо масштабируемая нейронная сеть потенциально может быть изучена в будущем, оптимизирована для различных качеств. .
.
Нужны дополнительные доказательства
Мы не видели доказательств того, что каждый набор данных лучше всего моделировать с помощью собственной пользовательской модели, а не тонкой настройки существующей модели. Поскольку для поиска нейронной архитектуры требуется больший обучающий набор, это может стать проблемой для небольших наборов данных. Даже в некоторых собственных исследованиях Google используются переносимые методы вместо поиска новой архитектуры для каждого набора данных, например, NASNet (сообщение в блоге здесь), которая изучила архитектурный строительный блок на Cifar10, а затем использовала этот строительный блок для создания архитектуры для ImageNet. Я пока не знаю каких-либо широкомасштабных соревнований по машинному обучению, которые были бы выиграны с помощью поиска нейронных архитектур.
Кроме того, мы не знаем, является ли подход к поиску по нейронной архитектуре, требующий огромных вычислительных ресурсов, который рекламирует Google, лучшим подходом. Например, в более поздних работах, таких как «Поиск эффективной нейронной архитектуры» (ENAS) и «Поиск дифференциальной архитектуры
Например, в более поздних работах, таких как «Поиск эффективной нейронной архитектуры» (ENAS) и «Поиск дифференциальной архитектуры
» (DARTS), предлагаются значительно более эффективные алгоритмы. DARTS занимает всего 4 GPU-дня , по сравнению с 1800 GPU-днями для NASNet и 3150 GPU-днями для AmoebaNet (все они обучены с одинаковой точностью на Cifar-10). Джефф Дин является автором статьи ENAS, в которой предложена методика с разрешением 1000×9.0035 меньше вычислительных затрат, что кажется несовместимым с его акцентом на TF DevSummit месяц спустя на использовании подходов, которые в 100x больше вычислительных затрат.
Тогда почему вся эта шумиха вокруг AutoML от Google?
Учитывая указанные выше ограничения, почему шумиха вокруг Google AutoML настолько несоразмерна доказанной полезности (по крайней мере, до сих пор)? Я думаю, есть несколько объяснений:
AutoML от Google выделяет некоторые из Опасности академической исследовательской лаборатории, встроенной в коммерческую корпорацию .
Существует искушение попытаться создать продукты на основе интересных академических исследований, не оценивая, удовлетворяют ли они реальную потребность. Это также история многих стартапов в области ИИ, таких как MetaMind или Geometric Intelligence, которые заканчивают тем, что приобретают, так и не выпустив продукт. Мой совет основателям стартапов: избегайте создания своей докторской диссертации и не нанимайте только академических исследователей.Google преуспевает в маркетинге . Искусственный интеллект рассматривается как недоступная и пугающая область для многих посторонних, которые не чувствуют, что у них есть способ оценить претензии, особенно от прославленных компаний, таких как Google. Многие журналисты также становятся жертвами этого и некритически превращают рекламу Google в восторженные статьи. Я периодически общаюсь с людьми, которые не занимаются машинным обучением, но в восторге от различных продуктов Google ML, которыми они никогда не пользовались и не могут ничего объяснить.
Одним из примеров вводящего в заблуждение освещения компанией Google собственных достижений является случай, когда исследователи искусственного интеллекта Google выпустили «технологию глубокого обучения для реконструкции истинного человеческого генома», сравнив свою работу с открытиями, получившими Нобелевскую премию (высокомерие!), и история была Подхватил Wired. Однако Стивен Зальцберг, выдающийся профессор биомедицинской инженерии, компьютерных наук и биостатистики в Университете Джона Хопкинса, опроверг сообщение Google. Зальцберг отметил, что исследование на самом деле не реконструировал геном человека и был «не более чем постепенным улучшением по сравнению с существующим программным обеспечением, а может быть даже меньшим». Ряд других исследователей геномики поддержали Зальцберга.
В Google ведется отличная работа, но ее было бы легче оценить, если бы нам не приходилось просеивать столько вводящей в заблуждение шумихи, чтобы выяснить, что является законным.
DeepVariant от Google «представляет собой не более чем постепенное улучшение существующего программного обеспечения, а может быть и меньше». @StevenSalzberg1
Что думают другие исследователи геномики? https://t.co/vaAECQhvSi
— Рэйчел Томас (@math_rachel) 12 декабря 2017 г.
Google кровно заинтересован в том, чтобы убедить нас в том, что ключом к эффективному использованию глубокого обучения является большая вычислительная мощность , потому что в этой области они явно превзошли остальных. AutoML часто требует очень больших вычислительных ресурсов, например, в примерах Google, использующих 450 графических процессоров K40 в течение 7 дней (что эквивалентно 3150 дням использования графических процессоров) для изучения AmoebaNet.
В то время как инженеры и средства массовой информации часто пускают слюни по поводу мощности «голого железа» и чего-то большего , история показала, что инновации часто рождаются благодаря ограничениям и творчеству.
Google работает с максимально возможным объемом данных, используя самые дорогие компьютеры; насколько хорошо этот действительно можно обобщить на проблемы, с которыми остальные из нас сталкиваются , живя в ограниченном мире ограниченных ресурсов?Инновации возникают, когда делаешь что-то по-другому, а не когда делаешь больше. Недавний успех fast.ai в Стэнфордском соревновании DAWNBench является одним из примеров этого.
 Существует искушение попытаться создать продукты на основе интересных академических исследований, не оценивая, удовлетворяют ли они реальную потребность. Это также история многих стартапов в области ИИ, таких как MetaMind или Geometric Intelligence, которые заканчивают тем, что приобретают, так и не выпустив продукт. Мой совет основателям стартапов: избегайте создания своей докторской диссертации и не нанимайте только академических исследователей.
Существует искушение попытаться создать продукты на основе интересных академических исследований, не оценивая, удовлетворяют ли они реальную потребность. Это также история многих стартапов в области ИИ, таких как MetaMind или Geometric Intelligence, которые заканчивают тем, что приобретают, так и не выпустив продукт. Мой совет основателям стартапов: избегайте создания своей докторской диссертации и не нанимайте только академических исследователей.

 Google работает с максимально возможным объемом данных, используя самые дорогие компьютеры; насколько хорошо этот действительно можно обобщить на проблемы, с которыми остальные из нас сталкиваются , живя в ограниченном мире ограниченных ресурсов?
Google работает с максимально возможным объемом данных, используя самые дорогие компьютеры; насколько хорошо этот действительно можно обобщить на проблемы, с которыми остальные из нас сталкиваются , живя в ограниченном мире ограниченных ресурсов?Инновации возникают, когда делаешь что-то по-другому, а не делаешь больше. @jeremyphoward https://t.co/3TJYs8OCbr pic.twitter.com/I55a6gT1OF
— Рэйчел Томас (@math_rachel) 2 мая 2018 г.
Как мы можем решить проблему нехватки знаний в области машинного обучения?
Возвращаясь к проблеме, которую Джефф Дин поднял в своем основном докладе TensorFlow DevSummit о глобальной нехватке специалистов по машинному обучению, возможен другой подход. Мы можем устранить самые большие препятствия на пути использования глубокого обучения несколькими способами:0003
Мы можем устранить самые большие препятствия на пути использования глубокого обучения несколькими способами:0003
- упрощение использования глубокого обучения
- развенчание мифов о том, что нужно для глубокого обучения
- расширение доступа для людей, которым не хватает денег или кредитных карт, необходимых для использования облачного графического процессора
Делаем глубокое обучение проще в использовании
Исследования, направленные на упрощение использования глубокого обучения, имеют огромное значение, позволяя быстрее и проще обучать лучшие сети. Примеры захватывающих открытий, которые теперь стали стандартной практикой:
- Dropout позволяет проводить обучение на небольших наборах данных без переобучения.
- Пакетная нормализация позволяет ускорить обучение.
- Ректифицированные линейные блоки помогают избежать взрыва градиента.
Новые исследования, направленные на повышение простоты использования, включают: — Поиск скорости обучения делает процесс обучения более надежным. — Суперконвергенция ускоряет обучение, требуя меньше вычислительных ресурсов. — «Пользовательские заголовки» для существующих архитектур (например, модификация ResNet, которая изначально была разработана для классификации, чтобы ее можно было использовать для поиска ограничивающих рамок или выполнения переноса стиля) позволяют упростить повторное использование архитектуры для решения ряда задач.
— Суперконвергенция ускоряет обучение, требуя меньше вычислительных ресурсов. — «Пользовательские заголовки» для существующих архитектур (например, модификация ResNet, которая изначально была разработана для классификации, чтобы ее можно было использовать для поиска ограничивающих рамок или выполнения переноса стиля) позволяют упростить повторное использование архитектуры для решения ряда задач.
Ни одно из вышеперечисленных открытий не связано с питанием на «голом железе»; вместо этого все они были творческими идеями о том, как делать что-то по-другому.
Развейте мифы о том, что нужно для глубокого обучения
Еще одним препятствием является множество мифов, которые заставляют людей верить, что глубокое обучение не для них: ложное убеждение, что их данные слишком малы, что у них нет надлежащего образования или опыта, или что их компьютеры невелики. достаточно. Один из таких мифов гласит, что только доктора наук в области машинного обучения способны использовать глубокое обучение, а многие компании, которые не могут позволить себе нанять дорогих специалистов, даже не пытаются. Тем не менее, компании не только могут обучать своих сотрудников, чтобы они стали экспертами в области машинного обучения, это даже предпочтительнее, потому что ваши нынешние сотрудники уже имеют опыт работы в области, в которой вы работаете!
Тем не менее, компании не только могут обучать своих сотрудников, чтобы они стали экспертами в области машинного обучения, это даже предпочтительнее, потому что ваши нынешние сотрудники уже имеют опыт работы в области, в которой вы работаете!
В своем выступлении на конференции по обзору технологий Массачусетского технологического института я рассмотрел 6 мифов, которые заставляют людей ошибочно полагать, что использовать глубокое обучение сложнее, чем оно есть на самом деле.
Для подавляющего большинства людей, с которыми я разговаривал, входные барьеры для глубокого обучения намного ниже, чем они ожидали: один год опыта программирования и доступ к графическому процессору.
Расширение доступа: блокноты Google Colab
Хотя стоимость облачных графических процессоров (около 50 центов в час) находится в пределах бюджета многих из нас, ко мне периодически обращаются студенты со всего мира, которые не могут себе позволить любой GPU вообще использует .