Как выглядят глубокие нейронные сети и почему они требуют так много памяти. Нейронный движок
Нейронный движок Apple будет отвечать за работу искусственного интеллекта следующего iPhone

Компания Apple стремится улучшить быстродействие каждого поколения мобильных процессоров, недавний пример — iPhone 7 и 7 Plus в сентябре были оснащены 4-ядерными чипами A10 Fusion. Но для того, чтобы сохранить конкурентоспособность своих девайсов, в Apple создают вспомогательный процессор, предназначенный для искусственного интеллекта.
Источник сообщил о том, что компания Apple разрабатывает чипы, которые будут использоваться в двух главных сферах, где применяется искусственный интеллект: дополненная реальность и самоуправляемые автомобили. Сейчас девайсы технотитана распределяют обработку связанных с искусственным интеллектом задач между двумя чипами – основным процессором и GPU, но у новой разработки, которую в Apple по неофициальной информации называют нейронным движком, есть собственный модуль, предназначенный для потребностей искусственного интеллекта. Использование отдельного процессора для этих задач также увеличит время работы от батареи.
К сожалению, неизвестно, появится ли чип в этом году. Таким образом, Apple отстаёт от компании Qualcomm с её новейшей версией мобильных процессоров Snapdragon, которые уже используют выделенный для искусственного интеллекта модуль, а также от Google, чей Tensor Processing Unit (TPU) может брать на себя решение задач искусственного интеллекта через облачный сервис.
Компания Apple объявила о создании собственной глубокой нейронной сети на прошлогодней Всемирной конференции для разработчиков на платформах Apple, но подобный вид машинного обучения осуществляется с помощью серверов, а не мобильных процессоров. В отличие от механизмов по защите данных, отправляемых на серверы Apple, процессор нейронного движка позволит девайсам самостоятельно исследовать информацию, что окажется быстрее и снизит нагрузку на батарею точно так же, как это делали отвечающие за распознавание движений процессоры наподобие M7 в 2013 году.
ПОХОЖИЕ ЗАПИСИ
© Gearmix 2013 Права на опубликованный перевод принадлежат владельцам вебсайта gearmix.ru Все графические изображения, использованные при оформлении статьи принадлежат их владельцам. Знак охраны авторского права распространяется только на текст статьи. Использование материалов сайта без активной индексируемой ссылки на источник запрещено.
gearmix.ru
Подробности о сердце iPhone X — чипе A11 Bionic
Одним из самых важных новшеств двухчасовой презентации iPhone X была не столько говорящая какашка, сколько однокристальная система нового поколения с 4,3 млрд транзисторов — A11 Bionic, — с помощью которой такая передовая технология стала возможной. Ну а если серьёзно, то в беседе с журналистами Mashable главный маркетолог Apple Фил Шиллер (Phil Schiller) отметил, что в настоящее время основным новшеством каждого нового поколения продуктов компании являются чипы.
A11 Bionic стал следующим важным шагом Apple по пути вертикальной интеграции продуктов для полного контроля над всеми аспектами своих устройств. Старший вице-президент подразделения аппаратных технологий Apple Джони Сруджи (Johny Srouji) отметил: «Проектирование наших собственных кристаллов началось примерно десять лет назад, потому что это наилучший способ создать по-настоящему оптимизированные с аппаратной и программной сторон продукты Apple».
Он также подчеркнул, что на разработку новых чипов у Apple уходит порядка трёх лет, так что A11 Bionic начал создаваться ещё во времена выхода на рынок смартфона iPhone 6 и чипа A8. Во время этого цикла планы могут несколько корректироваться в соответствии с запросами команды разработчиков продуктов под руководством Джонатана Айва (Jonathan Ive). Но именно три года назад было сделано решение о добавлении на кристалл нейронного движка для ускорения вычислений в области искусственного интеллекта.

Обновлённые ядра CPU на общей площади кристалла A11: 2 высокопроизводительных и 4 энергоэффективных
Разумеется, каждое поколение чипов Apple разрабатывается на основе предыдущих наработок, но некоторые блоки перерабатываются полностью. Например, два высокопроизводительных ядра CPU от A10 Fusion получили небольшое обновление, а количество энергоэффективных ядер было удвоено (в A11 их стало четыре), появилась возможность задействовать от одного до всех шести ядер одновременно. Благодаря этим оптимизациям и новому 10-нм техпроцессу блок CPU в A11 Bionic стал потреблять меньше энергии, чем аналогичный в A10, несмотря на то, что высокопроизводительные ядра теперь на 25 % мощнее, а энергоэффективные — на 70 %.

Как можно видеть, немалую площадь A11 Bionic занимает процессор обработки изображений
Другим важным новшеством стал существенно более мощный специализированный процессор обработки изображений, который позволяет добиться более качественной цветопередачи камеры, улучшенного шумоподавления при недостатке света, а также ускорить различные эффекты вроде студийного освещения в новом портретном режиме. Благодаря этому новому блоку ISP впервые на рынке смартфонов стала возможна запись видео в разрешении 4K при 60 кадрах/с или 1080p при 240 кадрах/с.
Многие годы Apple использовала в своих однокристальных системах графику Imagination Tecnologies — последним примером стал 6-ядерный ускоритель PowerVR GT7600. Но в A11 компания приняла решение интегрировать спроектированный собственными силами блок GPU. Этот трёхъядерный GPU, по словам Apple, на 30 % мощнее использовавшегося в A10 Fusion блока от Imagination, а при прежней производительности потребляет вдвое меньше энергии. Ускоритель оптимизирован для наилучшей работы с низкоуровневым графическим API Metal 2 и, по словам Apple, позволяет создавать игры консольного класса.
Джони Сруджи отметил, что компания уже 30 лет придерживается принципа, согласно которому в тех областях, где она считает возможным внедрить новации, она старается создавать собственные решения: однокристальная система, CPU, ISP, дисплей и так далее. Следующим шагом в этом направлении стал GPU, благодаря чему Apple теперь может полностью контролировать графику на своих iOS-платформах: начиная от аппаратной части до компиляторов, языков программирования, библиотек и операционной системы. Всё это создаётся, чтобы работать в единой оптимальной связке.

Новый разработанный в недрах Apple графический ускоритель на фоне общей площади кристалла A11
Совершенно новым блоком для ускорения специфических задач стал двухъядерный нейронный движок с производительностью 600 млрд операций в секунду. Он эффективно справляется с задачами матричного умножения и вычислений с плавающей запятой и используется для ускорения специфических алгоритмов, связанных с машинным обучением, вроде Face ID, Animoji, дополненной реальности, студийного освещения при портретной съёмке и многого другого. Создан он для эффективной работы с ИИ-библиотекой Apple Core ML.
Такие ускорители — относительное новшество индустрии. Например, Google лишь в прошлом году представила специальные аппаратные серверные ускорители TPU (Tensor Processor Unit) для вычислений, использующих её ИИ-библиотеку TensorFlow. В этом году она выпустила второе поколение TPU, а также оптимизированную для мобильных устройств версию библиотеки машинного обучения TensorFlowLite. Другие компании тоже двигаются в аналогичном направлении. Например, у Facebook подобная технология называется Caffe2Go — она была представлена в ноябре прошлого года и позволила создать фильтры для фото и видео на основе нейронных сетей, работающих прямо на устройстве пользователя в реальном времени.

Google наверняка планирует реализовать и аппаратные блоки TPU для мобильных устройств, но Apple на этом фронте оказалась впереди и первой интегрировала такой ускоритель в свой чип для смартфонов. До сих пор большинство ИИ-расчётов производились в облаке, но исполнение таких алгоритмов прямо на устройстве позволяет сократить задержки, не требует интернет-соединения и обеспечивает более высокий уровень приватности (ведь данные не покидают устройство).
A11 Bionic включает и массу других блоков вроде цифрового сигнального процессора для качественной обработки звука, различных контроллеров ввода-вывода, специализированных алгоритмов корректирующего кода (ECC) и других блоков, повышающих безопасность и надёжность устройства. За 10 лет команда Apple проделала впечатляющую работу в полупроводниковой области, пройдя путь от 65-нм чипов со 100 млн транзисторов до 10-нм с 4,31 млрд.
Если вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
Нейронный двигатель торговли
Компания из Поднебесной хочет успеть всегда и везде. Это Huawei. Ее неожиданно можно встретить на выставке солнечной энергетики и ожидаемо — в новостях мобильной связи. Иногда компании удается совместить оба информационные фронта. Так и было в Берлине в начале сентября с.г. на IFA 2017: генеральный директор Huawei Consumer BG Ричард Ю (Richard Yu) представил на этой выставке нейронный процессор Kirin 970 – Neural Processing Unit (NPU).
Сей умный чип добавит смартфонам того, чего им явно недостает. Чего же? Что ждут, по авторитетному мнению маркетологов, пользователи интеллектуальных телефонов?
 Ричард Ю, генеральный директор Huawei Consumer BG, не скрывает своего удовлетворения
Ричард Ю, генеральный директор Huawei Consumer BG, не скрывает своего удовлетворения
Не стоит всерьез воспринимать соревнование Kirin 970 с конкурирующими процессорами, как мы это видим в частоколе синтетических тестов. Время таких сравнений уже давно прошло. И хотя пользователи нет-нет, да и заводят разговор о том, что в смартфоне медленно отрабатываются те или иные функции, все понимают, что прирост производительности CPU безжалостно пожирает паразитирующий на одном программном слое другой программный слой. Фактически, идет борьба за отклик смартфона, ибо пользователь, не особо капризничая, готов ждать реакцию мобильной платформы на выполнение сложных функций. Поиска, например.
 Прирост в условных единицах налицо
Прирост в условных единицах налицо
И вот в этот момент мы начинаем понимать, что все эти нервные окончания, проросшие из центрального процессора в периферию смартфона, призваны не для «быстрого набора номера», а для интеллектуализации самого устройства. Поиск по текстовым файлам цифровыми схемами уже освоен, на очереди – поиск по фотографиям, а еще лучше – клипам. Тогда поисковой запрос «Я на море» имеет смысл в фото-галерее смартфона, оснащенного нейронным процессором Kirin 8086.
composter.com.ua
Apple разрабатывает нейронный движок для iPhone
Apple разрабатывает нейронный движок для iPhone
Бутиковa Юлия Дмитриевна
28 Мая , 2017

В компании Apple считают, что юзеры телефонов, получив в руки новейшую модель Apple, поменяют свое представление о мобильных гаджетах. Об этом сообщил авторитетный портал Bloomberg со ссылкой на собственные источники. Чип называется Apple Neural Engine, он создается, чтобы разгрузить основной процессор и графический чип устройства и улучшить его автономность. Сообщается, что разработчикам будет предоставлен доступ к чипу, чтобы чужие приложения тоже могли выполнять задачи AI на особом процессоре. Кроме этого, «нейронный движок» пригодится во время работы с дополненной реальностью — в тех случаях, где необходимо компьютерное зрение.
Вот уже как многие годы Apple активно занимается развитием технологий искусственного интеллекта и машинного обучения. Специалисты считают, что современный чипсет позволит увеличить автономность аппарата, делая его первым в области освоения ИИ посредством установки особого компонента. По утверждению Тима Кука, компания и дальше продолжит улучшение собственных продуктов с целью упрощения качества жизни пользователей.
belrynok.ru
Как выглядят глубокие нейронные сети и почему они требуют так много памяти / Хабр

Сегодня граф – один из самых приемлемых способов описать модели, созданные в системе машинного обучения. Эти вычислительные графики составлены из вершин-нейронов, соединенных ребрами-синапсами, которые описывают связи между вершинами.
В отличие скалярного центрального или векторного графического процессора, IPU – новый тип процессоров, спроектированный для машинного обучения, позволяет строить такие графы. Компьютер, который предназначен для управления графами – идеальная машина для вычислительных моделей графов, созданных в рамках машинного обучения.
Один из самых простых способов, чтобы описать процесс работы машинного интеллекта – это визуализировать его. Команда разработчиков компании Graphcore создала коллекцию таких изображений, отображаемых на IPU. В основу легло программное обеспечение Poplar, которое визуализирует работу искусственного интеллекта. Исследователи из этой компании также выяснили, почему глубокие сети требуют так много памяти, и какие пути решения проблемы существуют.
Poplar включает в себя графический компилятор, который был создан с нуля для перевода стандартных операций, используемых в рамках машинного обучения в высокооптимизированный код приложений для IPU. Он позволяет собрать эти графы воедино по тому же принципу, как собираются POPNN. Библиотека содержит набор различных типов вершин для обобщенных примитивов.
Графы – это парадигма, на которой основывается все программное обеспечение. В Poplar графы позволяют определить процесс вычисления, где вершины выполняют операции, а ребра описывают связь между ними. Например, если вы хотите сложить вместе два числа, вы можете определить вершину с двумя входами (числа, которые вы хотели бы сложить), некоторые вычисления (функция сложения двух чисел) и выход (результат).
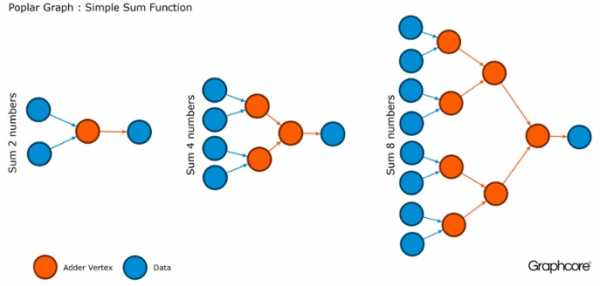
Обычно операции с вершинами гораздо сложнее, чем в описанном выше примере. Зачастую они определяются небольшими программами, называемыми коделетами (кодовыми именами). Графическая абстракция привлекательна, поскольку не делает предположений о структуре вычислений и разбивает вычисления на компоненты, которые процессор IPU может использовать для работы.
Poplar применяет эту простую абстракцию для построения очень больших графов, которые представлены в виде изображения. Программная генерация графика означает, что мы можем адаптировать его к конкретным вычислениям, необходимым для обеспечения наиболее эффективного использования ресурсов IPU.
Компилятор переводит стандартные операции, используемые в машинных системах обучения, в высокооптимизированный код приложения для IPU. Компилятор графов создает промежуточное изображение вычислительного графа, которое разворачивается на одном или нескольких устройствах IPU. Компилятор может отображать этот вычислительный граф, поэтому приложение, написанное на уровне структуры нейронной сети, отображает изображение вычислительного графа, который выполняется на IPU.
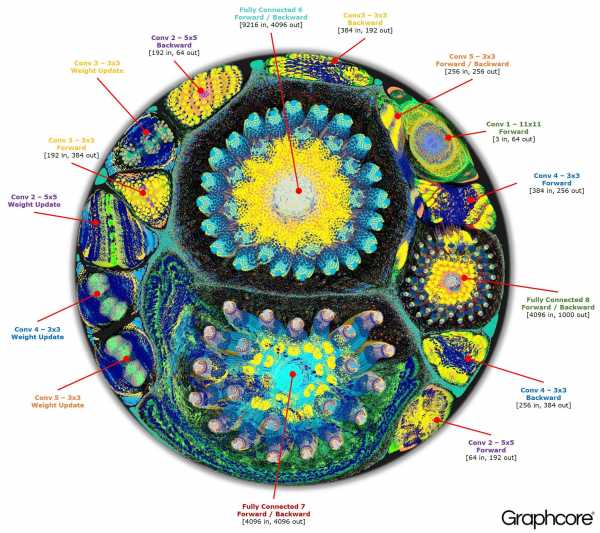 Граф полного цикла обучения AlexNet в прямом и обратном направлении
Граф полного цикла обучения AlexNet в прямом и обратном направлении
Графический компилятор Poplar превратил описание AlexNet в вычислительный граф из 18,7 миллиона вершин и 115,8 миллиона ребер. Четко видимая кластеризация – результат прочной связи между процессами в каждом слое сети с более легкой связью между уровнями.
Другой пример – простая сеть с полной связью, прошедшая обучение на MNIST – простом наборе данных для компьютерного зрения, своего рода «Hello, world» в машинном обучении. Простая сеть для изучения этого набора данных помогает понять графы, которыми управляют приложения Poplar. Интегрируя библиотеки графов с такими средами, как TensorFlow, компания представляет один из простых путей для использования IPU в приложениях машинного обучения.
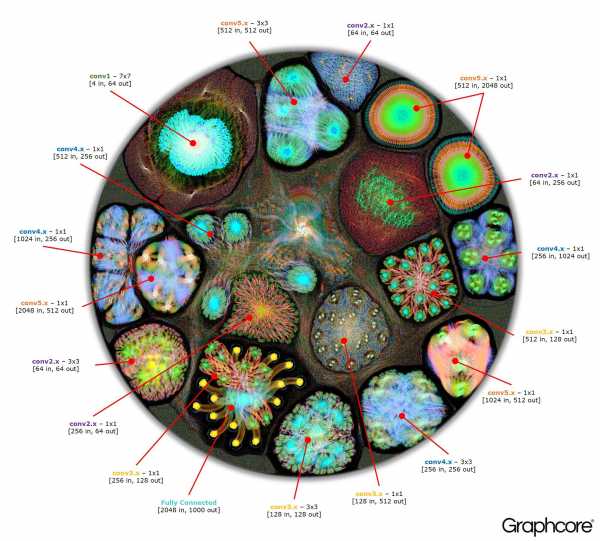
После того, как с помощью компилятора построился граф, его нужно выполнить. Это возможно с помощью движка Graph Engine. На примере ResNet-50 демонстрируется его работа.
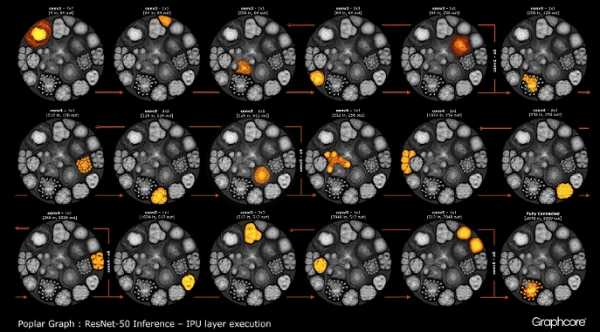 Граф ResNet-50
Граф ResNet-50
Архитектура ResNet-50 позволяет создавать глубокие сети из повторяющихся разделов. Процессору остается только единожды определить эти разделы и повторно вызывать их. Например, кластер уровня conv4 выполняется шесть раз, но только один раз наносится на граф. Изображение также демонстрирует разнообразие форм сверточных слоев, поскольку каждый из них имеет граф, построенный в соответствии с естественной формой вычисления.
Движок создает и управляет исполнением модели машинного обучения, используя граф, созданный компилятором. После развертывания Graph Engine контролирует и реагирует на IPU или устройства, используемые приложениями.
Изображение ResNet-50 демонстрирует всю модель. На этом уровне сложно выделить связи между отдельными вершинами, поэтому стоит посмотреть на увеличенные изображения. Ниже приведены несколько примеров секций внутри слоев нейросети.


Почему глубоким сетям нужно так много памяти?
Большие объемы занимаемой памяти – одна из самых больших проблем глубинных нейронных сетей. Исследователи пытаются бороться с ограниченной пропускной способностью DRAM-устройств, которые должны быть использованы современными системами для хранения огромного количества весов и активаций в глубинной нейронной сети.Архитектуры были разработаны с использованием процессорных микросхем, предназначенных для последовательной обработки и оптимизации DRAM для высокоплотной памяти. Интерфейс между двумя этими устройствами является узким местом, которое вводит ограничения пропускной способности и добавляет значительные накладные расходы в потреблении энергии.
Хотя мы еще не имеем полного представления о человеческом мозге и о том, как он работает, в целом понятно, что нет большого отдельного хранилища памяти. Считается, что функция долговременной и кратковременной памяти в человеческом мозге встроена в структуру нейронов+синапсов. Даже простые организмы вроде червей с нейронной структурой мозга, состоящей из чуть более 300 нейронов, обладают в какой-то степени функцией памяти.
Построение памяти в обычных процессорах – это один из способов обойти проблему узких мест памяти, открыв огромную пропускную способность при гораздо меньшем энергопотреблении. Тем не менее, память на кристалле – дорогая штука, которая не рассчитана на действительно большие объемы памяти, которые подключены к центральным и графическим процессорам, в настоящее время используемым для подготовки и развертывания глубинных нейронных сетей.
Поэтому полезно посмотреть на то, как память сегодня используется в центральных процессорах и системах глубокого обучения на графических ускорителях, и спросить себя: почему для них необходимы такие большие устройства хранения памяти, когда головной мозг человека отлично работает без них?
Нейронным сетям нужна память для того, чтобы хранить входные данные, весовые параметры и функции активации, как вход распространяется через сеть. В обучении активация на входе должна сохраняться до тех пор, пока ее нельзя будет использовать, чтобы вычислить погрешности градиентов на выходе.
Например, 50-слойная сеть ResNet имеет около 26 миллионов весовых параметров и вычисляет 16 миллионов активаций в прямом направлении. Если вы используете 32-битное число с плавающей запятой для хранения каждого веса и активации, то для этого потребуется около 168Мб пространства. Используя более низкое значение точности для хранения этих весов и активаций, мы могли бы вдвое или даже вчетверо снизить это требование для хранения.
Серьезная проблема с памятью возникает из-за того, что графические процессоры полагаются на данные, представляемые в виде плотных векторов. Поэтому они могут использовать одиночный поток команд (SIMD) для достижения высокой плотности вычислений. Центральный процессор использует аналогичные векторные блоки для высокопроизводительных вычислений.
В графических процессорах ширина синапса составляет 1024 бит, так что они используют 32-битные данные с плавающей запятой, поэтому часто разбивают их на параллельно работающие mini-batch из 32 образцов для создания векторов данных по 1024 бит. Этот подход к организации векторного параллелизма увеличивает число активаций в 32 раза и потребность в локальном хранилище емкостью более 2 ГБ.
Графические процессоры и другие машины, предназначенные для матричной алгебры, также подвержены нагрузке на память со стороны весов или активаций нейронной сети. Графические процессоры не могут эффективно выполнять небольшие свертки, используемые в глубоких нейронных сетях. Поэтому преобразование, называемое «понижением», используется для преобразования этих сверток в матрично-матричные умножения (GEMM), с которыми графические ускорители могут эффективно справляться.
Дополнительная память также требуется для хранения входных данных, временных значений и инструкций программы. Измерение использования памяти при обучении ResNet-50 на высокопроизводительном графическом процессоре показало, что ей требуется более 7,5 ГБ локальной DRAM.
Возможно, кто-то решит, что более низкая точность вычислений может сократить необходимый объем памяти, но это не так. При переключении значений данных до половинной точности для весов и активаций вы заполните только половину векторной ширины SIMD, потратив половину имеющихся вычислительных ресурсов. Чтобы компенсировать это, когда вы переключаетесь с полной точности до половины точности на графическом процессоре, тогда придется удвоить размер mini-batch, чтобы вызвать достаточный параллелизм данных для использования всех доступных вычислений. Таким образом, переход на более низкую точность весов и активаций на графическом процессоре все еще требует более 7,5ГБ динамической памяти со свободным доступом.
С таким большим количеством данных, которые нужно хранить, уместить все это в графическом процессоре просто невозможно. На каждом слое сверточной нейронной сети необходимо сохранить состояние внешней DRAM, загрузить следующий слой сети и затем загрузить данные в систему. В результате, уже ограниченный пропускной способностью задержкой памяти интерфейс внешней памяти страдает от дополнительного бремени постоянной перезагрузки весов, а также сохранения и извлечения функций активации. Это значительно замедляет время обучения и значительно увеличивает потребление энергии.
Существует несколько путей решения этой проблемы. Во-первых, такие операции, как функции активации, могут выполняться “на местах”, позволяя перезаписывать входные данные непосредственно на выходе. Таким образом, существующую память можно будет использовать повторно. Во-вторых, возможность для повторного использования памяти можно получить, проанализировав зависимость данных между операциями в сети и распределением той же памяти для операций, которые не используют ее в этот момент.
Второй подход особенно эффективен, когда вся нейронная сеть может быть проанализированна на этапе компиляции, чтобы создать фиксированную выделенную память, так как издержки на управление памятью сокращаются почти до нуля. Выяснилось, что комбинация этих методов позволяет сократить использование памяти нейронной сетью в два-три раза. Третий значительный подход был недавно обнаружен командой Baidu Deep Speech. Они применили различные методы экономии памяти, чтобы получить 16-кратное сокращение потребления памяти функциями активации, что позволило им обучать сети со 100 слоями. Ранее при том же объеме памяти они могли обучать сети с девятью слоями.
Объединение ресурсов памяти и обработки в одном устройстве обладает значительным потенциалом для повышения производительности и эффективности сверточных нейронных сетей, а также других форм машинного обучения. Можно сделать компромисс между памятью и вычислительными ресурсами, чтобы добиться баланса возможностей и производительности в системе.
Нейронные сети и модели знаний в других методах машинного обучения можно рассматривать как математические графы. В этих графах сосредоточено огромное количество параллелизма. Параллельный процессор, предназначенный для использования параллелизма в графах, не полагается на mini-batch и может значительно уменьшить объем требуемого локального хранилища.
Современные результаты исследований показали, что все эти методы могут значительно улучшить производительность нейронных сетей. Современные графические и центральные процессоры имеют очень ограниченную встроенную память, всего несколько мегабайт в совокупности. Новые архитектуры процессоров, специально разработанные для машинного обучения, обеспечивают баланс между памятью и вычислениями на чипе, обеспечивая существенное повышение производительности и эффективности по сравнению с современными центральными процессорами и графическими ускорителями.
habr.com
Нейронные сети
23.08.2017

Всем привет!
Буквально вчера нашел книгу Тарика Рашида «Создай свою нейросеть». Книга является бестселлером (топ 1 продаж) в разделе «Искусственный интеллект». Книга свежая, вышла в прошлом году.
Впечатления от первых разделов замечательные. Одно из лучших введений в сферу нейросетей из всех мною виденных. Книга мне так понравилась, что я решил перевести ее на русский язык и выкладывать сюда в виде статей. Часть материала из книги пойдет на улучшение уже существующих глав, часть на следующие.
Перевел уже два первых раздела 1 главы. Вы можете скачать PDF версию этих разделов.
Читайте — наслаждайтесь!
20.08.2017
Всем привет!
Думаю, вы заметили, что сайт выглядит совсем по-другому. Надеюсь, его дизайн вам понравился. Мне пришлось довольно глубоко изучить движок WordPress (на нем работает весь сайт). Зато я сделал свою тему, в которой воплотил все лучшее, что видел на других сайтах.
Теперь это не только сайт-учебник, но и портал, то есть теперь будут регулярно появляться и новости и статьи. А также, к порталу подключен мощный форум. На нем можно задавать вопросы, обсуждать различные темы, делиться своим мнением и выносить идеи на обсуждение.
А теперь моя главная задача — создание интересного и познавательного контента, включая 5 главу 🙂 .
Если кто-то хочет написать новость/статью/главу или просто есть интересная идея, то пишите мне в раздел «Ваши предложения» на форуме.
Надеюсь, вы активно включитесь в обсуждение нейросетей в комментариях и на форуме!
19.08.2017
В предыдущей главе вы усвоили необходимые общие теоретические сведения по ИНС: устройство искусственного нейрона и нейронных сетей, общие подходы к их обучению.
Тема данной главы – простейший вид искусственных нейронных сетей – персептроны. Вы узнаете об их устройстве, научитесь их создавать и обучать.
19.08.2017
В предыдущей главе мы ознакомились с такими понятиями, как искусственный интеллект, машинное обучение и искусственные нейронные сети.
В этой главе я детально опишу модель искусственного нейрона, расскажу о подходах к обучению сети, а также опишу некоторые известные виды искусственных нейронных сетей, которые мы будем изучать в следующих главах.
19.08.2017
В этой главе я в общих чертах расскажу о предмете данного учебника (и сайта) — искусственных нейронных сетях. Что это такое, какими преимуществами они обладают и так далее.
19.08.2017
В этой главе я расскажу, как надо работать с учебником. Требуемый уровень математики, ссылки на главы и разделы, важные места, на которые надо обратить внимание и другие возможности данного учебника описаны в этой главе.
neuralnet.info
иной взгляд на машинное обучение / Блог компании 1cloud.ru / Хабр
Поэтому человечество работает над изобретением новых архитектур, которые бы позволили машинам более эффективно взаимодействовать с окружением. Одним из таких решений стали нейроморфные чипы, о которых мы хотим рассказать в сегодняшнем материале.
 / Flickr / The Preiser Project / CC
/ Flickr / The Preiser Project / CC
Нейроморфные чипы моделируют то, как наш мозг обрабатывает информацию — как миллиарды нейронов и триллионы синапсов реагируют на сигналы от органов чувств. Связи между нейронами также постоянно меняются, реагируя на изображения, звуки и др. Этот процесс мы с вами называем обучением. Идея состоит в том, чтобы заставить чипы делать то же самое.
Даже если нейроморфные чипы будут уступать в «производительности» реальному мозгу, они все равно обгонят современные компьютеры в вопросах обучения и обработки сенсорной информации.
Когнитивные разработки
Сама идея нейроморфных чипов достаточно стара. Профессор Калифорнийского университета Карвер Мид (Carver Mead) ввел этот термин в 1990 году, отметив, что аналоговые чипы, в отличие от бинарных, смогут имитировать мозговую активность, но воплотить идею в жизнь и создать такой чип ему не удалось. Однако сегодня сразу несколько компаний активно занимаются воплощением этой архитектуры в кремнии.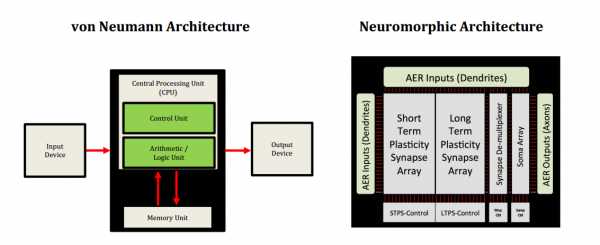 Сравнение обычной архитектуры с нейроморфной (Источник)
Сравнение обычной архитектуры с нейроморфной (Источник)В 2008 году по заказу организации DARPA компания IBM Research начала работу над нейроморфным чипом. И через 6 лет, в 2014 году, ученые представили публике систему TrueNorth, состоящую из 1 млн цифровых нейронов и 256 млн синапсов, заключенных в 4096 синапсных ядер.
TrueNorth — это модульная система, которая состоит из нескольких чипов, представляющих собой нейроны мозга. Соединяя такие чипы между собой, ученые формируют искусственную нейронную сеть. По словам представителей компании, TrueNorth потребляет меньше электроэнергии, чем его «классические» собратья.
Нейрочип с 5,4 млрд транзисторов потребляет 70 мВт энергии, в то время как процессор Intel, в котором транзисторов почти в 4 раза меньше, требует порядка 140 Вт. В планах ученых еще сильнее снизить энергопотребление и размеры последующих версий TrueNorth, чтобы они могли найти применение в мобильных устройствах или часах.
В IBM рассчитывают, что TrueNorth станет новой вехой в развитии компьютерных технологий и будет использоваться высокопроизводительными системами, например в дата-центрах.
Интересно, что для работы с нейромфорными чипами компанией был создан новый язык программирования. В основе языка лежит так называемая концепция корлетов (Corelet) — объектно-ориентированных абстракций нейросинаптических ядер. В программной архитектуре каждый корлет имеет 256 вводов (аксонов) и 256 выводов (нейронов), которые связывают все ядра друг с другом.
«Взаимодействие процессора и памяти в традиционной архитектуре происходит последовательно, — говорит ведущий исследователь проекта SyNAPSE Дхармендра С. Модха. — Наша архитектура — это комплект кубиков LEGO. Каждый корлет имеет различные функции, и вы просто комбинируете их». Например, такая система может использоваться для поиска людей в толпе. Один корлет может искать определенную форму носа, другой — цвет одежды и так далее.
 / Flickr / IBM Research / CC
/ Flickr / IBM Research / CCНо IBM не единственная компания, которая занимается подобными разработками. Среди потенциальных участников рынка числятся такие гиганты, как Google и, что немаловажно, Qualcomm.
Не так давно Qualcomm провели в своей штаб-квартире в Сан-Диего презентацию возможностей нового нейроморфного чипа. Небольшой робот размером с мопса под названием Pioneer подъехал к детской игрушке, а затем начал толкать её в сторону трех невысоких колонн.
Ведущий инженер Qualcomm Иль У Чанг (Ilwoo Chang) указал обеими руками, куда следует разместить фигурку, и Pioneer, распознав жест с помощью встроенной камеры, выполнил задачу. После чего он отправился за другой игрушкой и привез её к той же самой колонне безо всяких подсказок.
Робот оказался способен выполнять задачи, для которых, обычно, нужны мощные специализированные компьютеры. Pioneer уже умеет распознавать новые объекты и расставлять их по сходству с другими предметами, реагируя на команды-жесты.
В компании Qualcomm отмечают, что нейроморфный чип, который управляет роботом, является цифровым, а не аналоговым, однако по-прежнему эмулирует различные аспекты поведения человеческого мозга. Создатели заявили, что их процессор, размещенный в мобильных устройствах, компьютерах и роботах позволит машинам самообучаться.
Проект получил название Zeroth и, по словам представителей компании, первые подобные чипы должны были появиться в продаже в 2014 году, но этого не произошло. Однако в 2015 году компания все же представила одноименную вычислительную платформу.
Новое машинное обучение, но не сегодня
Как было отмечено выше, подобные чипы позволят нашим привычным устройствам самообучаться. Например, медицинские гаджеты научатся распознавать жизненно важные показатели, чтобы превентивно влиять на состояние пациентов. Смартфоны же научатся предсказывать желания своих владельцев.Однако пока еще остаются определенные препятствия, которые предстоит преодолеть. Все еще не решена проблема компоновки нейронов — сложно сопоставить размеры «мозга» с его возможностями. Трудности возникают на всех этапах — сборка, доставка мощности, теплоотвод, управление топологией.
Еще один блок трудностей связывают с абстрактной натурой нейровычислений. Насколько близкую копию нашего мозга необходимо создать, чтобы решить желаемые задачи? И как такие чипы будут взаимодействовать с классической вычислительной техникой?
Практически все проекты сейчас проходят тестирование, и до их использования в смартфонах и часах пока еще далеко. И как ученые справятся с трудностями, покажет только время.
P.S. Дополнительное чтение (новые материалы в нашем блоге)
habr.com















