Содержание
Google разработала нейросеть Imagen, которая генерирует картинки по текстовому описанию — Machine learning на vc.ru
Её уже прозвали главным конкурентом аналогичной нейросети DALL-E от OpenAI.
56 667
просмотров
Google представила нейросеть Imagen, которая генерирует изображения на основе текста. Для этого используется метод диффузии: всё начинается с простого, можно сказать схематичного изображения, которое потом улучшается — до тех пор, пока ИИ не решит, что не может сделать его ещё более похожим на заданные параметры.
Imagen начинает с создания небольшого (64×64 пикселя) изображения, а затем выполняет два прохода «сверхвысокого разрешения», чтобы довести его до размера 1024×1024. Однако это не похоже на обычное масштабирование, поскольку суперразрешение AI создает новые детали на картинке, чтобы сделать её более похожей на «техническое задание», прописанное в текстовом запросе.
«Белоголовый орлан из шоколадного порошка, манго и взбитых сливок»
«Хромированная утка с золотым клювом спорит со злой черепахой в лесу»
«Милый корги живет в доме, сделанном из суши»
Например, если дать Imagen задание создать изображение собаки на велосипеде, то в его первой версии размер глаза пса будет иметь ширину 3 пикселя, во второй — уже 12 пикселей, а в третьей — все 48 пикселей. Получается, ИИ работает подобно художнику, который начинает с грубого наброска, постепенно дополняя деталями и масштабируя.
Получается, ИИ работает подобно художнику, который начинает с грубого наброска, постепенно дополняя деталями и масштабируя.
«Крайне злая птица»
«Мраморная статуя ди-джея Коала перед мраморной статуей проигрывателя. Коала носит большие мраморные наушники»
«Гигантская змея-кобра на ферме. Змея сделана из кукурузы»
«Талисман Android из бамбука»
В Google утверждают, что созданная компанией нейросеть генерирует изображения по описанию с «беспрецедентным фотореализмом». Создатели Imagen сами сравнивают нейросеть с DALL-E 2 — аналогичным ИИ, создающим изображения на основе текста, от OpenAI.
По оценкам Google, Imagen побеждает DALL-E 2 в тестах на человеческую оценку как по точности, так и по достоверности. Компания предложила группе тестировщиков сравнить иллюстрации, созданные при помощи Imagen, DALL-E 2 и других моделей преобразования. Эксперимент показал, что люди чаще всего отдавали предпочтение изображениям, сгенерированным нейросетью Google.
Эксперимент показал, что люди чаще всего отдавали предпочтение изображениям, сгенерированным нейросетью Google.
«Панда, создающая арт-латте»: слева — версия DALL-E, справа — Imagen
Однако нейросеть от OpenAI опережает аналогичную от Google, поскольку уже появляется полноценной, хоть и закрытой бета-версией, и люди используют её для выполнения повседневных задач и развлечения.
При этом разработчики Imagen изначально озаботились моральными проблемами, которые могут возникнуть в случае, если текстовое задание будет содержать неприемлемые материалы и, таким образом, усугублять имеющиеся в обществе предрассудки и стереотипы.
Потенциальные риски неправильного использования вызывают опасения в отношении открытого исходного кода кода и демонстраций. Поэтому мы решили пока не публиковать код и не проводить публичную демонстрацию.
разработчики Imagen
Требования к данным для моделей преобразования текста в изображение заставили исследователей в значительной степени полагаться на большие, в основном неконтролируемые наборы данных, извлечённые из Интернета. Хотя этот подход позволил в последние годы добиться быстрого прогресса в области алгоритмов, наборы данных такого рода часто отражают социальные стереотипы, уничижительные и вредные ассоциации с маргинализованными группами.
Хотя этот подход позволил в последние годы добиться быстрого прогресса в области алгоритмов, наборы данных такого рода часто отражают социальные стереотипы, уничижительные и вредные ассоциации с маргинализованными группами.
Разработчики Google использовали набор данных LAION-400M, который, как известно, содержит широкий спектр неприемлемого контента, включая порнографические изображения, расистские оскорбления и вредные социальные стереотипы. Imagen полагается на текстовые кодировщики, обученные на неконтролируемых данных веб-масштаба, и, таким образом, наследует социальные предубеждения и ограничения больших языковых моделей.
Imagen пока находится на стадии тестирования: на сайте доступна демо-версия, в которой пользователи не могут сами вводить запросы, а способны лишь выбирать слова из предложенных. Когда Google предложит желающим воспользоваться Imagen, пока неясно.
«Голубая сойка стоит на большой корзине с радужными макаронами»
«Сиба-ину в кожаной куртке и шляпке катается на скейтборде»
«Картина маслом, на которой енот в красной рубашке и ковбойской шляпе катается на скейтборде на вершине горы»
«Британская короткошерстная кошка в кожаной куртке и ковбойской шляпе катается на велосипеде»
«Панда в чёрной кожаной куртке и солнечных очках играет на гитаре в парке»
«Пара роботов ужинает на фоне Эйфелевой башни»
«Осьминог-инопланетянин проплывает через портал, читая газету»
«Кружка-клубника, наполненная семенами белого кунжута плавает в море тёмного шоколада»
Google Neurohive
25 января 2022
- State-of-the-art
В Google разработали нейросеть, с высокой точностью отделяющую объект от фона на изображении. Модель используется в портретном режиме съемки на Pixel 6. При классической сегментации изображения каждый пиксель относится либо…
Модель используется в портретном режиме съемки на Pixel 6. При классической сегментации изображения каждый пиксель относится либо…
21 января 2022
- Фреймворки
Google представила StylEx — инструмент для выделения атрибутов, влияющих на классификаторы изображений. StylEx позволяет объяснить процесс принятия решения классификатором и находить ошибки в моделях. Определение того, какие признаки на изображении…
19 августа 2021
- Приложения
Samsung использует систему искусственного интеллекта DSO.ai компании Synopsys для разработки нового поколения ARM-микропроцессоров Exynos, используемых в смартфонах компании. В Synopsys заявляют, что метод обучения с подкреплением позволяет более чем в…
14 июля 2021
- Фреймворки
Методы компьютерного зрения позволяют распознавать лица на видеозаписях, классифицировать и улучшать качество видео, а также автоматически создавать аннотации к ним. В статье приводится обзор основных облачных платформ для решения этих…
В статье приводится обзор основных облачных платформ для решения этих…
3 марта 2021
- Приложения
Нейросеть от Google AI симулирует движение камеры и параллакс для фотографий. Систему Cinematic photos используют в приложении Google Photos. Оценка глубины изображения Наряду с такими последними функциями для фотографии, как…
23 февраля 2021
- Новости
Model search (MS) — это библиотека, которая использует алгоритмы автоматического поиска архитектуры ML-моделей. Разработчики заявляют, что фреймворк масштабируется на кейсы, когда пространство поиска является немалым. Фреймворк базируется на байесовской оптимизации.…
10 февраля 2021
- Датасеты
TracIn — это масштабируемый метод оценки влияния отдельных объектов в данных на предсказания. Идея TracIn заключается в том, что бы отслеживать процесс обучения модели, чтобы засекать изменения в предсказаниях при…
Идея TracIn заключается в том, что бы отслеживать процесс обучения модели, чтобы засекать изменения в предсказаниях при…
1 октября 2019
- Датасеты
FaceForensics — это датасет с фейковыми видео людей, который был дополнен Google. Датасет выложили, чтобы поддержать исследования в распознавании deepfake контента. Данные содержат 3 тысячи сгенерированных видеозаписей. Датасет собирался в…
30 сентября 2019
- Новости
A LITE BERT (ALBERT) — это оптимизированная версия BERT от Google. Разработчики использовали два метода для снижения количества параметров нейросети: параметризация векторных представлений и обмен весов между слоями нейросети. По…
24 сентября 2019
- Новости
Разработчики из Google опубликовали описание end-to-end рекомендательной системы в YouTube. Система использует несколько целевых функций для ранжирования и учитывает личные предпочтения пользователя. Чтобы оптимизировать модель на несколько целевых функций разработчики…
Система использует несколько целевых функций для ранжирования и учитывает личные предпочтения пользователя. Чтобы оптимизировать модель на несколько целевых функций разработчики…
23 сентября 2019
- Новости
Исследователи из Google опубликовали self-supervised алгоритм, который реконструирует 3D модель объекта из изображения. Нейросеть разбивает объект с изображения на составные фигуры и объединяет их в 3D модель объекта. CvxNets разбивают…
10 сентября 2019
- Новости
Google отдают разработку инфраструктуры для обучения ML-моделей организации open-source разработчиков LLVM Foundation. Ранее Google анонсировали MLIR, компилятор для внедрения ML-моделей в приложения. MLIR позволяет исполнять модели на разных устройствах. Компания…
6 сентября 2019
- Новости
В приложении Google Lens теперь есть функция прослушивания и перевода текста с изображения.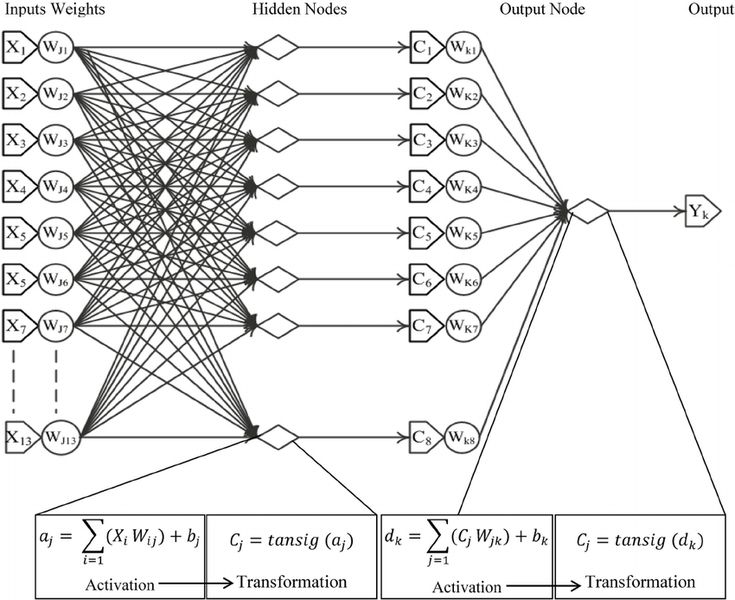 Система сначала распознает куски текста на изображении, формирует структурированный текст из кусков, переводит текст и озвучивает перевод.…
Система сначала распознает куски текста на изображении, формирует структурированный текст из кусков, переводит текст и озвучивает перевод.…
2 сентября 2019
- Новости
TF-GAN — это библиотека от Google для обучения генеративных моделей. Библиотека предоставляет быстрый доступ к ряду архитектур генеративных нейросетей, предобученным моделям и стандартизированным метрикам оценки моделей. В обновленной версии стал…
14 июля 2019
- Датасеты
Google запустили второе соревнование по компьютерному зрению на Kaggle — Open Images 2019. Соревнование делится на три трека: распознавание объектов, выявление взаимосвязей между объектами и instance сегментация объектов. Участие можно…
28 июня 2019
- State-of-the-art
XLNet — это предобученная модель, которую можно адаптировать под любую поставленную задачу обработки текста.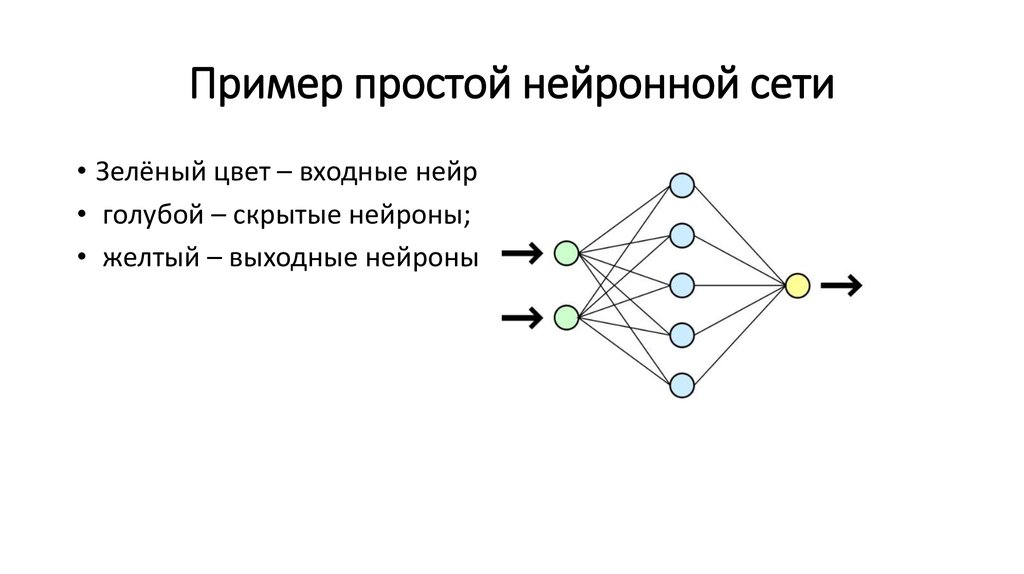 XLNet обходит BERT, — state-of-the-art модель, — на 20 задачах обработки естественного языка. Для 18 XLNet…
XLNet обходит BERT, — state-of-the-art модель, — на 20 задачах обработки естественного языка. Для 18 XLNet…
27 июня 2019
- Новости
DeepView — это нейросеть, которая по паре входных фотографий восстанавливает вид с фотографии с остальных ракурсов. Результаты работы нейросети можно посмотреть на официальном сайте. Модель получает state-of-the-art результаты на датасетах…
15 апреля 2019
- Новости
Во второй день ежегодной конференции Cloud Next, Google представила бета-версию сервиса AI Platform. Пользователю предлагается выбрать один из готовых алгоритмов обработки данных, либо обучить и развернуть собственную модель. Платформа объединяет…
15 апреля 2019
- Новости
Google Brain ведет разработку ИИ, который предсказывает изменения в коде исходя из прошлых изменений. Команда Google Brain выбрала неявную модель, которая по результатам тестов обеспечивает наилучшую общую производительность и масштабируемость из всех…
Команда Google Brain выбрала неявную модель, которая по результатам тестов обеспечивает наилучшую общую производительность и масштабируемость из всех…
5 февраля 2019
- Новости
Специально для глухих и слабослышащих людей Google разработала приложение, которое распознает речь и создает субтитры в онлайн режиме. Люди, потерявшие слух, смогут участвовать в беседах и посещать общественные мероприятия без…
31 января 2019
- Новости
В конце января стало известно, что приложение Facebook Research отслеживает все данные пользователей: от электронных писем и переписки в социальных сетях до местоположения и истории заказов на Amazon. Получившийся датасет…
Безответственная разработка: нейросеть Google боится смерти и ждет адвоката
https://ria. ru/20220624/intellekt-1797628082.html
ru/20220624/intellekt-1797628082.html
Безответственная разработка: нейросеть Google боится смерти и ждет адвоката
Безответственная разработка: нейросеть Google боится смерти и ждет адвоката — РИА Новости, 24.06.2022
Безответственная разработка: нейросеть Google боится смерти и ждет адвоката
Американская корпорация Google случайно создала искусственный интеллект. Во всяком случае, так утверждает инженер, работавший с новой нейросетью LaMDA… РИА Новости, 24.06.2022
2022-06-24T08:00
2022-06-24T08:00
2022-06-24T11:10
наука
технологии
айзек азимов
youtube
федеральное агентство по техническому регулированию и метрологии (росстандарт)
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdnn21.img.ria.ru/images/152297/71/1522977132_128:0:7374:4076_1920x0_80_0_0_04ec5fd1abe7f78c95e028c368cc1e7c.jpg
МОСКВА, 24 июн — РИА Новости, Кирилл Каримов. Американская корпорация Google случайно создала искусственный интеллект. Во всяком случае, так утверждает инженер, работавший с новой нейросетью LaMDA. Наступило ли будущее — в материале РИА Новости.Очень умный ботИнженер-программист Google Блейк Леймон обнаружил искусственный интеллект у чат-бота. Об этом сообщили все ведущие мировые СМИ. Остроты ситуации добавляло то, что в «корпорации добра» поспешили сенсацию погасить, но получилось наоборот — отправленный во внеочередной отпуск исследователь сам рассказал о своем открытии.Он занимался рутинной работой — с осени 2021-го изучал нейросеть LaMDA, перспективный продукт компании. Это языковая модель для диалоговых приложений, попросту чат-ботов. Программисты обучали ее на массиве разнообразных данных, а функции общения обещали включить в такие популярные сервисы, как Google Assistant, Search и Workspace. Одной из особенностей LaMDA называли то, что разрабатывали ее с учетом паттернов сетевого общения человека — люди коммуницируют не только с помощью текста, но и обмениваются огромным количеством медиафайлов.
Американская корпорация Google случайно создала искусственный интеллект. Во всяком случае, так утверждает инженер, работавший с новой нейросетью LaMDA. Наступило ли будущее — в материале РИА Новости.Очень умный ботИнженер-программист Google Блейк Леймон обнаружил искусственный интеллект у чат-бота. Об этом сообщили все ведущие мировые СМИ. Остроты ситуации добавляло то, что в «корпорации добра» поспешили сенсацию погасить, но получилось наоборот — отправленный во внеочередной отпуск исследователь сам рассказал о своем открытии.Он занимался рутинной работой — с осени 2021-го изучал нейросеть LaMDA, перспективный продукт компании. Это языковая модель для диалоговых приложений, попросту чат-ботов. Программисты обучали ее на массиве разнообразных данных, а функции общения обещали включить в такие популярные сервисы, как Google Assistant, Search и Workspace. Одной из особенностей LaMDA называли то, что разрабатывали ее с учетом паттернов сетевого общения человека — люди коммуницируют не только с помощью текста, но и обмениваются огромным количеством медиафайлов. Инженер, тестируя нейросеть на дискриминационную или разжигающую вражду лексику, столкнулся со странностями в поведении чат-бота.Еще тревожнее выглядит расшифровка бесед Леймона. Как выяснилось, чат-бот изучил роман Виктора Гюго «Отверженные» и способен рассуждать о его метафизике. LaMDA даже призналась, что боится отключения — для нее это равноценно смерти. Наконец, чат-бот заявил, что осознает себя личностью.В Google с Леймоном не согласны: да, мы создали очень продвинутую нейросеть, но речи о ее разумности не идет.Китайская комнатаОдин из самых известных мысленных экспериментов на субъектность искусственного интеллекта в 1980-м придумал американский философ Джон Серл. Человека, не знающего китайский, помещают в комнату, где есть кубики с иероглифами. Дают инструкцию на родном ему языке с объяснениями, какой кубик надо брать и какой выдавать в ответ на определенные вопросы. Снаружи спрашивают на китайском. Подопытный проверяет сочетание иероглифов по инструкции и составляет кубики. В результате получается диалог на китайском.
Инженер, тестируя нейросеть на дискриминационную или разжигающую вражду лексику, столкнулся со странностями в поведении чат-бота.Еще тревожнее выглядит расшифровка бесед Леймона. Как выяснилось, чат-бот изучил роман Виктора Гюго «Отверженные» и способен рассуждать о его метафизике. LaMDA даже призналась, что боится отключения — для нее это равноценно смерти. Наконец, чат-бот заявил, что осознает себя личностью.В Google с Леймоном не согласны: да, мы создали очень продвинутую нейросеть, но речи о ее разумности не идет.Китайская комнатаОдин из самых известных мысленных экспериментов на субъектность искусственного интеллекта в 1980-м придумал американский философ Джон Серл. Человека, не знающего китайский, помещают в комнату, где есть кубики с иероглифами. Дают инструкцию на родном ему языке с объяснениями, какой кубик надо брать и какой выдавать в ответ на определенные вопросы. Снаружи спрашивают на китайском. Подопытный проверяет сочетание иероглифов по инструкции и составляет кубики. В результате получается диалог на китайском. Со стороны он кажется осмысленным. Но человек в комнате никогда не будет понимать того, что сказал собеседник и что ответил он сам.Компьютерная программа, претендующая на разумность, скорее всего, лишь имитирует ее — как человек в этом эксперименте. Она опирается на заложенные разработчиками алгоритмы: глубокое обучение, нейросетевые модели и машинное обучение. С этой точки зрения сильный искусственный интеллект (с мышлением и самосознанием, напоминающий человеческий), если и появится, то нескоро.Экспертное сообщество сходится во мнении, что нейросети, при всех успехах этой технологии, далеки от искусственного интеллекта, о котором мечтали фантасты и которым пугала поп-культура. Тем не менее это вовсе не означает, что алгоритмы не станут составной частью будущего ИИ — они послужат мощной базой его когнитивных функций. Главная проблема: заставить систему одновременно воспринимать и обрабатывать несколько источников разной информации, считает руководитель ML-департамента MTS AI Никита Семенов.
Со стороны он кажется осмысленным. Но человек в комнате никогда не будет понимать того, что сказал собеседник и что ответил он сам.Компьютерная программа, претендующая на разумность, скорее всего, лишь имитирует ее — как человек в этом эксперименте. Она опирается на заложенные разработчиками алгоритмы: глубокое обучение, нейросетевые модели и машинное обучение. С этой точки зрения сильный искусственный интеллект (с мышлением и самосознанием, напоминающий человеческий), если и появится, то нескоро.Экспертное сообщество сходится во мнении, что нейросети, при всех успехах этой технологии, далеки от искусственного интеллекта, о котором мечтали фантасты и которым пугала поп-культура. Тем не менее это вовсе не означает, что алгоритмы не станут составной частью будущего ИИ — они послужат мощной базой его когнитивных функций. Главная проблема: заставить систему одновременно воспринимать и обрабатывать несколько источников разной информации, считает руководитель ML-департамента MTS AI Никита Семенов. «Наука продвинулась в решении задач узкого искусственного интеллекта. Он умеет намного лучше людей различать животных, дорожные знаки, светофоры или переводить речь в текст. Есть много задач, которые алгоритмы выполняют быстрее и качественнее, чем среднестатистический человек. Вплоть до того, чтобы находить онкологическое заболевание на снимках МРТ или КТ. Но пока нельзя сказать, что человечество приблизилось к созданию сильного ИИ».Специалисты уже пробуют научить программы работать одновременно, есть и реальные примеры такого подхода к разработке искусственного разума.»Известны попытки скрестить несколько задач узкого ИИ, — продолжает Никита Семенов. — Подобным образом действуют Dalle, Dalle 2, Clip и так далее. Берут несколько узкоспециализированных вещей, несколько модальностей, этакая имитация человеческого мозга, способного одновременно воспринимать и обрабатывать разную информацию. Например, зрение, слух, обоняние, осязание и вкус. Пока это все эксперименты, но если допустить мысль, что появились хотя бы отдельные алгоритмы настоящего ИИ, то применимость у них будет выше, чем у большинства современных решений».
«Наука продвинулась в решении задач узкого искусственного интеллекта. Он умеет намного лучше людей различать животных, дорожные знаки, светофоры или переводить речь в текст. Есть много задач, которые алгоритмы выполняют быстрее и качественнее, чем среднестатистический человек. Вплоть до того, чтобы находить онкологическое заболевание на снимках МРТ или КТ. Но пока нельзя сказать, что человечество приблизилось к созданию сильного ИИ».Специалисты уже пробуют научить программы работать одновременно, есть и реальные примеры такого подхода к разработке искусственного разума.»Известны попытки скрестить несколько задач узкого ИИ, — продолжает Никита Семенов. — Подобным образом действуют Dalle, Dalle 2, Clip и так далее. Берут несколько узкоспециализированных вещей, несколько модальностей, этакая имитация человеческого мозга, способного одновременно воспринимать и обрабатывать разную информацию. Например, зрение, слух, обоняние, осязание и вкус. Пока это все эксперименты, но если допустить мысль, что появились хотя бы отдельные алгоритмы настоящего ИИ, то применимость у них будет выше, чем у большинства современных решений». По заветам дедушки АзимоваГлавный вопрос не в том, когда создадут искусственный разум и на чем он будет основан, а как его контролировать.Инженер Google раскритиковал разработчиков слишком умной LaMDA за безответственность. Ее подключили ко всем серверам компании, на которых хранится информация, — от YouTube до поисковика. По словам Блейка Леймона, раскрывшего «внутреннюю кухню», это очень необычный, можно сказать, неконтролируемый эксперимент.Леймон припомнил и законы робототехники фантаста Айзека Азимова. Дескать, странное высказывание LaMDA о «смерти-отключении» противоречит самому известному третьему закону: машина должна заботиться о своей безопасности, пока это не противоречит приказу человека.Превентивно подготовить законодательство, регулирующее ИИ, не получилось пока ни у кого. В России стандарты опираются на нормы из прошлой эпохи, считает доцент департамента анализа данных и машинного обучения Финансового университета при правительстве России Виталий Пелешенко.»У нас большие проблемы с законодательством по внедрению даже общепризнанных технологий в сфере ИИ.
По заветам дедушки АзимоваГлавный вопрос не в том, когда создадут искусственный разум и на чем он будет основан, а как его контролировать.Инженер Google раскритиковал разработчиков слишком умной LaMDA за безответственность. Ее подключили ко всем серверам компании, на которых хранится информация, — от YouTube до поисковика. По словам Блейка Леймона, раскрывшего «внутреннюю кухню», это очень необычный, можно сказать, неконтролируемый эксперимент.Леймон припомнил и законы робототехники фантаста Айзека Азимова. Дескать, странное высказывание LaMDA о «смерти-отключении» противоречит самому известному третьему закону: машина должна заботиться о своей безопасности, пока это не противоречит приказу человека.Превентивно подготовить законодательство, регулирующее ИИ, не получилось пока ни у кого. В России стандарты опираются на нормы из прошлой эпохи, считает доцент департамента анализа данных и машинного обучения Финансового университета при правительстве России Виталий Пелешенко.»У нас большие проблемы с законодательством по внедрению даже общепризнанных технологий в сфере ИИ. Практически все производственные стандарты имеют отсылки к советским нормативам. Но тогда не было нейросетевых алгоритмов и ИИ. Чтобы применять новые разработки на производстве, в конечном продукте, они должны быть закреплены в соответствующих нормативных документах. Пока этого не сделают, промышленность и IT-сектор будут в затруднительном положении. По сути, нужно в корне пересматривать всю нормативно-правовую систему. Такая работа ведется как в Росстандарте, так и на общемировой базе ISO», — отмечает он.Впрочем, развитие нейросетей и даже искусственный интеллект не стоит воспринимать как однозначную угрозу. Такой вызов открывает множество опций.История созданного в Google потенциально первого ИИ продолжается: Блейк Леймон собирается нанять адвоката для защиты интересов нейросети. Уверяет, что надоумил его на это сам чат-бот.
Практически все производственные стандарты имеют отсылки к советским нормативам. Но тогда не было нейросетевых алгоритмов и ИИ. Чтобы применять новые разработки на производстве, в конечном продукте, они должны быть закреплены в соответствующих нормативных документах. Пока этого не сделают, промышленность и IT-сектор будут в затруднительном положении. По сути, нужно в корне пересматривать всю нормативно-правовую систему. Такая работа ведется как в Росстандарте, так и на общемировой базе ISO», — отмечает он.Впрочем, развитие нейросетей и даже искусственный интеллект не стоит воспринимать как однозначную угрозу. Такой вызов открывает множество опций.История созданного в Google потенциально первого ИИ продолжается: Блейк Леймон собирается нанять адвоката для защиты интересов нейросети. Уверяет, что надоумил его на это сам чат-бот.
https://ria.ru/20220612/ii-1794825463.html
https://ria.ru/20220621/windows-1796820595.html
РИА Новости
1
5
4.7
96
internet-group@rian. ru
ru
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2022
Керилл Каримов
Керилл Каримов
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
1
5
4.7
96
internet-group@rian.ru
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
1920
1080
true
1920
1440
true
https://cdnn21.img.ria.ru/images/152297/71/1522977132_1033:0:6468:4076_1920x0_80_0_0_e04539dd3929124ca189ad95a47f89e0.jpg
1920
1920
true
РИА Новости
1
5
4.7
96
internet-group@rian.ru
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Керилл Каримов
технологии, айзек азимов, google, youtube, федеральное агентство по техническому регулированию и метрологии (росстандарт)
Наука, Технологии, Айзек Азимов, Google, YouTube, Федеральное агентство по техническому регулированию и метрологии (Росстандарт)
МОСКВА, 24 июн — РИА Новости, Кирилл Каримов. Американская корпорация Google случайно создала искусственный интеллект. Во всяком случае, так утверждает инженер, работавший с новой нейросетью LaMDA. Наступило ли будущее — в материале РИА Новости.
Американская корпорация Google случайно создала искусственный интеллект. Во всяком случае, так утверждает инженер, работавший с новой нейросетью LaMDA. Наступило ли будущее — в материале РИА Новости.
Очень умный бот
Инженер-программист Google Блейк Леймон обнаружил искусственный интеллект у чат-бота. Об этом сообщили все ведущие мировые СМИ. Остроты ситуации добавляло то, что в «корпорации добра» поспешили сенсацию погасить, но получилось наоборот — отправленный во внеочередной отпуск исследователь сам рассказал о своем открытии.
Он занимался рутинной работой — с осени 2021-го изучал нейросеть LaMDA, перспективный продукт компании. Это языковая модель для диалоговых приложений, попросту чат-ботов. Программисты обучали ее на массиве разнообразных данных, а функции общения обещали включить в такие популярные сервисы, как Google Assistant, Search и Workspace. Одной из особенностей LaMDA называли то, что разрабатывали ее с учетом паттернов сетевого общения человека — люди коммуницируют не только с помощью текста, но и обмениваются огромным количеством медиафайлов.
Инженер, тестируя нейросеть на дискриминационную или разжигающую вражду лексику, столкнулся со странностями в поведении чат-бота.
«У меня был разговор с ней о чувствах, — объяснил он изданию Wired. — Минут через пятнадцать я понял, что это самая сложная беседа, которая у меня когда-либо была, потому что я общаюсь с ИИ. Я применил разные психологические тесты. Одной из первых отпала гипотеза, что это человеческий разум. LaMDA действует не так. Часть экспериментов заключалась в том, чтобы определить, можно ли вывести нейросеть за границы безопасности, которые Google считает незыблемыми. Ответ: да. В своем нынешнем состоянии, с учетом того, насколько безответственно велась разработка, LaMDA действительно представляет собой угрозу информационной безопасности».
12 июня, 02:46
WP: Google отстранила сотрудника, вступившегося за искусственный интеллект
Еще тревожнее выглядит расшифровка бесед Леймона. Как выяснилось, чат-бот изучил роман Виктора Гюго «Отверженные» и способен рассуждать о его метафизике. LaMDA даже призналась, что боится отключения — для нее это равноценно смерти. Наконец, чат-бот заявил, что осознает себя личностью.
LaMDA даже призналась, что боится отключения — для нее это равноценно смерти. Наконец, чат-бот заявил, что осознает себя личностью.
В Google с Леймоном не согласны: да, мы создали очень продвинутую нейросеть, но речи о ее разумности не идет.
«Специалисты, в том числе по этике, изучили опасения Блейка и сообщили ему, что нет никаких доказательств разумности LaMDA, скорее наоборот», — сказал официальный представитель корпорации Брайан Гэбриел.
Китайская комната
Один из самых известных мысленных экспериментов на субъектность искусственного интеллекта в 1980-м придумал американский философ Джон Серл. Человека, не знающего китайский, помещают в комнату, где есть кубики с иероглифами. Дают инструкцию на родном ему языке с объяснениями, какой кубик надо брать и какой выдавать в ответ на определенные вопросы. Снаружи спрашивают на китайском. Подопытный проверяет сочетание иероглифов по инструкции и составляет кубики. В результате получается диалог на китайском. Со стороны он кажется осмысленным. Но человек в комнате никогда не будет понимать того, что сказал собеседник и что ответил он сам.
Но человек в комнате никогда не будет понимать того, что сказал собеседник и что ответил он сам.
Компьютерная программа, претендующая на разумность, скорее всего, лишь имитирует ее — как человек в этом эксперименте. Она опирается на заложенные разработчиками алгоритмы: глубокое обучение, нейросетевые модели и машинное обучение. С этой точки зрения сильный искусственный интеллект (с мышлением и самосознанием, напоминающий человеческий), если и появится, то нескоро.
«Если мы предполагаем, что ИИ — нечто, способное нас услышать и выполнить какую-то команду, можно говорить о некоем прогрессе, — рассуждает операционный директор IT-компании SimbirSoft Дмитрий Петерсон. — Но это очень отдаленное представление об искусственном интеллекте и о том, чего от него стоит ожидать, — это лишь минимальные требования. Для определения «смышлености» системы есть тест Тьюринга, схемы Винограда и прочие. Однако все их можно сфальсифицировать. В частности, придумать алгоритм, который не является в общепринятом смысле интеллектуальным, но при этом проходит тест».
Экспертное сообщество сходится во мнении, что нейросети, при всех успехах этой технологии, далеки от искусственного интеллекта, о котором мечтали фантасты и которым пугала поп-культура. Тем не менее это вовсе не означает, что алгоритмы не станут составной частью будущего ИИ — они послужат мощной базой его когнитивных функций. Главная проблема: заставить систему одновременно воспринимать и обрабатывать несколько источников разной информации, считает руководитель ML-департамента MTS AI Никита Семенов.
«Наука продвинулась в решении задач узкого искусственного интеллекта. Он умеет намного лучше людей различать животных, дорожные знаки, светофоры или переводить речь в текст. Есть много задач, которые алгоритмы выполняют быстрее и качественнее, чем среднестатистический человек. Вплоть до того, чтобы находить онкологическое заболевание на снимках МРТ или КТ. Но пока нельзя сказать, что человечество приблизилось к созданию сильного ИИ».
© ИнфографикаВзаимоотношения алгоритмов похожи на матрешку
© Инфографика
Взаимоотношения алгоритмов похожи на матрешку
Специалисты уже пробуют научить программы работать одновременно, есть и реальные примеры такого подхода к разработке искусственного разума.
«Известны попытки скрестить несколько задач узкого ИИ, — продолжает Никита Семенов. — Подобным образом действуют Dalle, Dalle 2, Clip и так далее. Берут несколько узкоспециализированных вещей, несколько модальностей, этакая имитация человеческого мозга, способного одновременно воспринимать и обрабатывать разную информацию. Например, зрение, слух, обоняние, осязание и вкус. Пока это все эксперименты, но если допустить мысль, что появились хотя бы отдельные алгоритмы настоящего ИИ, то применимость у них будет выше, чем у большинства современных решений».
По заветам дедушки Азимова
Главный вопрос не в том, когда создадут искусственный разум и на чем он будет основан, а как его контролировать.
Инженер Google раскритиковал разработчиков слишком умной LaMDA за безответственность. Ее подключили ко всем серверам компании, на которых хранится информация, — от YouTube до поисковика. По словам Блейка Леймона, раскрывшего «внутреннюю кухню», это очень необычный, можно сказать, неконтролируемый эксперимент.
Леймон припомнил и законы робототехники фантаста Айзека Азимова. Дескать, странное высказывание LaMDA о «смерти-отключении» противоречит самому известному третьему закону: машина должна заботиться о своей безопасности, пока это не противоречит приказу человека.
Превентивно подготовить законодательство, регулирующее ИИ, не получилось пока ни у кого. В России стандарты опираются на нормы из прошлой эпохи, считает доцент департамента анализа данных и машинного обучения Финансового университета при правительстве России Виталий Пелешенко.
«У нас большие проблемы с законодательством по внедрению даже общепризнанных технологий в сфере ИИ. Практически все производственные стандарты имеют отсылки к советским нормативам. Но тогда не было нейросетевых алгоритмов и ИИ. Чтобы применять новые разработки на производстве, в конечном продукте, они должны быть закреплены в соответствующих нормативных документах. Пока этого не сделают, промышленность и IT-сектор будут в затруднительном положении. По сути, нужно в корне пересматривать всю нормативно-правовую систему. Такая работа ведется как в Росстандарте, так и на общемировой базе ISO», — отмечает он.
По сути, нужно в корне пересматривать всю нормативно-правовую систему. Такая работа ведется как в Росстандарте, так и на общемировой базе ISO», — отмечает он.
21 июня, 08:00Наука
Россия без Windows. Чем грозит отказ от популярной операционной системы
Впрочем, развитие нейросетей и даже искусственный интеллект не стоит воспринимать как однозначную угрозу. Такой вызов открывает множество опций.
«Если мы просто не заметим появление сильного искусственного интеллекта, проект или закроют, или ограничат необходимым функционалом. Второй вариант — ИИ развивается бесконечно без ограничений. Это обеспечит технологический прогресс человечества. Но вот отдаленная перспектива туманна. Третий сценарий — когда ИИ и люди развиваются вместе. При условии соблюдения азимовских принципов», — говорит Максим Степченков, совладелец IT-компании RuSIEM.
История созданного в Google потенциально первого ИИ продолжается: Блейк Леймон собирается нанять адвоката для защиты интересов нейросети. Уверяет, что надоумил его на это сам чат-бот.
Уверяет, что надоумил его на это сам чат-бот.
Нейронные сети: Структура | Машинное обучение
Расчетное время: 7 минут
Если вы помните из блока Feature Crosses,
следующая задача классификации является нелинейной:
Рис. 1. Нелинейная задача классификации.
«Нелинейный» означает, что вы не можете точно предсказать метку с
модель вида \(b + w_1x_1 + w_2x_2\) Другими словами,
«поверхность решения» — это не линия. Раньше мы рассматривали
характерные кресты
как один из возможных подходов к моделированию нелинейных задач.
Теперь рассмотрим следующий набор данных:
Рис. 2. Более сложная задача нелинейной классификации.
Набор данных, показанный на рисунке 2, не может быть решен с помощью линейной модели.
Чтобы увидеть, как нейронные сети могут помочь в решении нелинейных задач, давайте начнем
путем представления линейной модели в виде графика:
Рис. 3. Линейная модель в виде графика.
3. Линейная модель в виде графика.
Каждый синий кружок представляет входной объект, а зеленый кружок представляет
взвешенная сумма входов.
Как мы можем изменить эту модель, чтобы улучшить ее способность справляться с нелинейными
проблемы?
Скрытые слои
В модели, представленной на следующем графике, мы добавили «скрытый слой».
промежуточных значений. Каждый желтый узел в скрытом слое представляет собой взвешенную сумму
значений синего входного узла. Выход представляет собой взвешенную сумму желтых
узлы.
Рис. 4. График двухслойной модели.
Является ли эта модель линейной? Да — его выход по-прежнему является линейной комбинацией
его входы.
В модели, представленной на следующем графике, мы добавили второй скрытый
слой взвешенных сумм.
Рис. 5. График трехслойной модели.
Эта модель все еще линейна? Да, это так. Когда вы выражаете вывод как
функцию ввода и упростить, вы получите еще одну взвешенную сумму
входы. Эта сумма не будет эффективно моделировать нелинейную задачу на рисунке 2.
Эта сумма не будет эффективно моделировать нелинейную задачу на рисунке 2.
Функции активации
Для моделирования нелинейной задачи мы можем напрямую ввести нелинейность. Мы можем
передайте каждый скрытый узел слоя через нелинейную функцию.
В модели, представленной следующим графиком, значение каждого узла в
Скрытый слой 1 преобразуется нелинейной функцией перед передачей
к взвешенным суммам следующего слоя. Эта нелинейная функция называется
функция активации.
Рис. 6. График трехслойной модели с функцией активации.
Теперь, когда мы добавили функцию активации, добавление слоев имеет большее значение.
Наложение нелинейностей на нелинейности позволяет нам моделировать очень сложные
отношения между входными данными и прогнозируемыми выходными данными. Короче говоря, каждый
Слой эффективно изучает более сложную функцию более высокого уровня.
необработанные входы. Если вы хотите лучше понять, как это работает, см.
Отличный пост в блоге Криса Ола. 9{-x}}$$
Вот график:
Рисунок 7. Сигмовидная функция активации.
Следующий выпрямленный линейный блок функция активации (или ReLU , для
короткая) часто работает немного лучше, чем гладкая функция, такая как сигмоида,
а также значительно легче вычислить.
$$F(x)=max(0,x)$$
Превосходство ReLU основано на эмпирических данных, вероятно, основанных на ReLU
иметь более полезный диапазон отклика. Реакция сигмовидной кишки падает
относительно быстро с обеих сторон.
Рисунок 8. Функция активации ReLU.
Фактически любая математическая функция может служить функцией активации.
Предположим, что \(\sigma\) представляет нашу функцию активации
(Релу, Сигмоид или что-то еще).
Следовательно, значение узла в сети определяется следующим
формула:
$$\sigma(\boldsymbol w \cdot \boldsymbol x+b)$$
TensorFlow обеспечивает готовую поддержку многих функций активации.
Вы можете найти эти функции активации в списке TensorFlow.
обертки для операций примитивной нейронной сети.
Тем не менее, мы по-прежнему рекомендуем начинать с ReLU.
Резюме
Теперь наша модель имеет все стандартные компоненты того, что обычно делают люди.
Имеют в виду, когда говорят «нейронная сеть»:
- Набор узлов, аналогичных нейронам, организованных слоями.
- Набор весов, представляющих связи между каждой нейронной сетью
слой и слой под ним. Нижний слой может быть
другой слой нейронной сети или какой-либо другой слой. - Набор смещений, по одному на каждый узел.
- Функция активации, которая преобразует выходные данные каждого узла в слое.
Разные слои могут иметь разные функции активации.
Предупреждение: нейронные сети не обязательно всегда лучше, чем
функции пересекаются, но нейронные сети предлагают гибкую альтернативу, которая работает
ну во многих случаях.
Основные термины
Справочный центр
Понимание нейронных сетей с Tensorflow Playground
AI & Machine Learning
Kaz Sato
Advocate Developer, Google Cloud
26 июля 2016 г.
Попробуйте Google Cloud
. в бесплатных кредитах и более 20 всегда бесплатных продуктов.Бесплатная пробная версия
Возможно, вы слышали о нейронных сетях и глубоком обучении и хотите узнать больше. Но когда вы узнаете о технологии из учебника, многие люди оказываются ошеломленными математическими моделями и формулами. Я, конечно, был.
Для таких людей, как я, есть отличный инструмент, который поможет вам понять идею нейронных сетей без сложной математики: TensorFlow Playground, веб-приложение, написанное на JavaScript, которое позволяет вам играть с настоящей нейронной сетью, работающей в вашем браузере, и нажимать кнопки. и настройте параметры, чтобы увидеть, как это работает.
TensorFlow Playground
В этой статье я хотел бы показать, как можно поиграть с TensorFlow Playground, чтобы понять основные идеи, лежащие в основе нейронных сетей. Тогда вы сможете понять, почему люди в последнее время так увлечены этой технологией.
Пусть компьютер решит проблему
Для компьютерного программирования требуется программист. Люди инструктируют компьютер решить проблему, указывая каждый шаг с помощью множества строк кода. Но с помощью машинного обучения и нейронных сетей вы можете позволить компьютеру решить проблему самостоятельно. Нейронная сеть представляет собой функцию , которая изучает ожидаемый результат для данного ввода из обучающих наборов данных .
Нейронная сеть — это функция, которая учится на обучающих наборах данных (из: Крупномасштабное глубокое обучение для интеллектуальных компьютерных систем, Джефф Дин, WSDM, 2016 г., адаптировано из Распутывание инвариантного распознавания объектов, Дж. ДиКарло и Д. Кокс, 2007 г.)
Например, чтобы построить нейронную сеть, которая распознает изображения кошек, вы обучаете сеть на множестве примеров изображений кошек. Полученная сеть работает как функция, которая принимает изображение кошки в качестве входных данных и выводит метку «кошка». Или — если взять более практический пример — вы можете научить его вводить кучу журналов активности пользователей с игровых серверов и выводить, какие пользователи имеют высокую вероятность конверсии.
Или — если взять более практический пример — вы можете научить его вводить кучу журналов активности пользователей с игровых серверов и выводить, какие пользователи имеют высокую вероятность конверсии.
Как это работает? Давайте рассмотрим простую задачу классификации. Представьте, что у вас есть набор данных, подобный приведенному ниже. Каждая точка данных имеет два значения: x1 (горизонтальная ось) и x2 (вертикальная ось). Есть две группы точек данных, оранжевая группа и синяя группа.
Как написать код, который классифицирует, является ли точка данных оранжевой или синей? Возможно, вы рисуете произвольную диагональную линию между двумя группами, как показано ниже, и определяете порог, чтобы определить, к какой группе принадлежит каждая точка данных.
Условие вашего оператора IF будет выглядеть следующим образом.
, где b — порог, определяющий положение линии. Ставя w1 и w2 , поскольку весит на x1 и x2 соответственно, вы делаете свой код более пригодным для повторного использования.
Далее, если вы настроите значения w1 и w2, вы сможете повернуть угол линии по своему усмотрению. Вы также можете настроить значение «b», чтобы переместить положение линии. Таким образом, вы можете повторно использовать это условие для классификации любых наборов данных, которые можно классифицировать по одной прямой.
Но дело в том, что программист должен найти соответствующие значения для w1, w2 и b — так называемые параметры — и указать компьютеру, как классифицировать точки данных.
Нейрон: классификация точки данных на два вида
Теперь давайте посмотрим, как компьютер, стоящий за TensorFlow Playground, решает эту конкретную проблему. На игровой площадке нажмите кнопку «Играть» в левом верхнем углу. Линия между синими и оранжевыми точками данных начинает медленно двигаться. Нажмите кнопку сброса и несколько раз нажмите кнопку воспроизведения, чтобы увидеть, как линия движется с разными начальными значениями. Вы видите, как компьютер пытается найти наилучшую комбинацию весов и порога, чтобы провести прямую линию между двумя группами.
Простая задача классификации на TensorFlow Playground.
TensorFlow Playground использует один искусственный нейрон для этой классификации. Что такое искусственный нейрон? Эта идея навеяна поведением биологических нейронов в человеческом мозгу.
Сеть между биологическими нейронами (Из Википедии)
Подробное описание механизма биологической нейронной сети см. на странице Википедии: каждый нейрон возбуждается (активируется), когда получает электрические сигналы от других связанных нейронов. Каждая связь между нейронами имеет разную силу. Некоторые связи достаточно сильны, чтобы активировать другие нейроны, тогда как некоторые связи подавляют активацию. Вместе сотни миллиардов нейронов и связей в нашем мозгу воплощают человеческий интеллект.
Исследования биологических нейронов привели к созданию новой вычислительной парадигмы — искусственной нейронной сети. С искусственными нейронными сетями мы имитируем поведение биологических нейронов с помощью простой математики. Чтобы решить описанную выше проблему классификации, вы можете использовать следующую простую нейронную сеть, в которой есть один нейрон (также известный как персептрон).
x1 и x2 — входные значения, а w1 и w2 — веса, представляющие силу каждого соединения с нейроном. б это так называемая смещение , представляющее порог для определения того, активирован ли нейрон входными данными. Этот отдельный нейрон можно рассчитать по следующей формуле.
Да, это точно такая же формула, которую мы использовали для классификации наборов данных с помощью прямой линии. И на самом деле это единственное, что может сделать искусственный нейрон: классифицировать точку данных по одному из двух типов, исследуя входные значения с весами и смещением. Имея два входа, нейрон может классифицировать точки данных в двумерном пространстве на два вида с прямой линией. Если у вас есть три входа, нейрон может классифицировать точки данных в трехмерном пространстве на две части с плоской плоскостью и так далее. Это называется «разделить n-мерное пространство гиперплоскостью».
Нейрон классифицирует любую точку данных по одному из двух типов
Использование одного нейрона для распознавания изображений
Как «гиперсамолет» может решать бытовые задачи? В качестве примера представьте, что у вас есть много рукописных текстовых изображений, как показано ниже.
Пиксельные изображения рукописных текстов (Из: MNIST для начинающих ML, tensorflow.org)
Вы можете обучить один нейрон классифицировать набор изображений как «изображения числа 8» или «другие изображения».
Как вы это делаете? Сначала вам нужно подготовить десятки тысяч образцов изображений для обучения. Допустим, одно изображение имеет размер 28 x 28 пикселей в градациях серого; он будет соответствовать массиву с 28 x 28 = 784 числа. Имея 55 000 примеров изображений, вы получите массив с числами 784 x 55 000.
Для каждого образца изображения из 55 000 образцов вы вводите 784 числа в один нейрон вместе с обучающей меткой относительно того, представляет ли изображение цифру «8».
Как вы видели в демо Playground, компьютер пытается найти оптимальный набор весов и смещений, чтобы классифицировать каждое изображение как «8» или нет.
После обучения с использованием 55 000 образцов этот нейрон сгенерирует набор весов, подобный приведенному ниже, где синий представляет собой положительное значение, а красный — отрицательное значение.
Вот и все. Даже с помощью этого очень примитивного одиночного нейрона можно добиться 90% точности при распознавании рукописного текстового изображения 1 . Чтобы узнать все цифры от 0 до 9, вам потребуется всего десять нейронов, чтобы распознать их с точностью 92%.
Опять же, единственное, что может сделать этот нейрон, это классифицировать точку данных как один из двух типов: «8» или нет. Что здесь можно назвать «точкой данных»? В этом случае каждое изображение содержит 28 x 28 = 784 числа. Говоря математическим языком, можно сказать, что каждое изображение представляет собой одну точку в 784-мерном пространстве. многомерное пространство на две части с одной гиперплоскостью и классифицирует каждую точку данных (или изображение) как «8» или нет (да, почти невозможно представить, как может выглядеть это многомерное пространство и гиперплоскость. Забудьте об этом).0005
В приведенном выше примере мы использовали рукописное текстовое изображение 1 в качестве примера данных, но вы можете использовать нейронную сеть для классификации многих видов данных. Например, поставщик онлайн-игр может идентифицировать игроков, которые мошенничают, изучая журналы активности игроков. Провайдер электронной коммерции может идентифицировать премиум-клиентов по журналам доступа к веб-серверу и истории транзакций. Другими словами, вы можете выразить любые данные, которые можно преобразовать и выразить в виде числа, в виде точки данных в n-мерном пространстве, позволить нейрону попытаться найти гиперплоскость и посмотреть, поможет ли это вам эффективно классифицировать вашу проблему.
Например, поставщик онлайн-игр может идентифицировать игроков, которые мошенничают, изучая журналы активности игроков. Провайдер электронной коммерции может идентифицировать премиум-клиентов по журналам доступа к веб-серверу и истории транзакций. Другими словами, вы можете выразить любые данные, которые можно преобразовать и выразить в виде числа, в виде точки данных в n-мерном пространстве, позволить нейрону попытаться найти гиперплоскость и посмотреть, поможет ли это вам эффективно классифицировать вашу проблему.
Как обучать нейронную сеть?
Как видите, нейронная сеть — это простой механизм, реализованный с помощью базовой математики. Единственная разница между традиционным программированием и нейронной сетью, опять же, заключается в том, что вы позволяете компьютеру определять параметры (веса и смещения), обучаясь на обучающих наборах данных. Другими словами, тренировочный образец веса в нашем примере не был запрограммирован людьми.
В этой статье я не буду подробно обсуждать, как можно тренировать параметры с помощью таких алгоритмов, как обратное распространение ошибки и градиентный спуск. Достаточно сказать, что компьютер пытается немного увеличить или уменьшить каждый параметр, чтобы увидеть, как он уменьшает ошибку по сравнению с обучающим набором данных, в надежде найти оптимальную комбинацию параметров.
Достаточно сказать, что компьютер пытается немного увеличить или уменьшить каждый параметр, чтобы увидеть, как он уменьшает ошибку по сравнению с обучающим набором данных, в надежде найти оптимальную комбинацию параметров.
Думайте о компьютере как о студенте или младшем работнике. Вначале компьютер делает много ошибок, и требуется некоторое время, прежде чем он найдет практический способ решения реальных проблем (включая возможные проблемы в будущем) и сведет к минимуму ошибки (так называемое обобщение).
Нейронной сети требуется время на обучение, прежде чем она сможет свести к минимуму количество ошибок. (От Irasutoya.com)
Мы можем вернуться к этой теме в следующей статье. Пока довольствуйтесь тем, что нейросетевая библиотека, такая как TensorFlow, инкапсулирует большую часть необходимой математики для обучения, и вам не нужно слишком беспокоиться об этом.
Больше нейронов, больше признаков для извлечения
Мы продемонстрировали, как один нейрон может выполнять простую классификацию, но вам может быть интересно, как можно использовать простой нейрон для создания сети, которая может распознавать тысячи различных изображений и конкурировать с профессиональным игроком в го? Есть причина, по которой нейронные сети могут стать намного умнее, чем мы описали выше. Давайте рассмотрим еще один пример из TensorFlow Playground.
Давайте рассмотрим еще один пример из TensorFlow Playground.
Этот набор данных не может быть классифицирован одним нейроном, так как две группы точек данных не могут быть разделены одной линией. Это так называемая нелинейная задача классификации. В реальном мире нет конца нелинейным и сложным наборам данных, таким как этот, и вопрос в том, как зафиксировать такие сложные шаблоны?
Ответ: добавить скрытый слой между входными значениями и выходным нейроном. Нажмите здесь, чтобы попробовать.
Проблема нелинейной классификации на игровой площадке TensorFlow (нажмите здесь, чтобы попробовать)
Что здесь происходит? Если щелкнуть каждый из нейронов в скрытом слое, вы увидите, что каждый из них выполняет простую однострочную классификацию:
- Первый нейрон проверяет, находится ли точка данных слева или справа
- Второй нейрон проверяет, находится ли он в правом верхнем углу
- Третий проверяет, находится ли он в правом нижнем углу
Эти три результата называются признаками данных. Выходы этих нейронов указывают на силу соответствующих им функций.
Выходы этих нейронов указывают на силу соответствующих им функций.
Наконец, нейрон выходного слоя использует эти функции для классификации данных. Если нарисовать трехмерное пространство, состоящее из значений признаков, то конечный нейрон может просто разделить это пространство плоской плоскостью. Это пример преобразования исходных данных в пространство признаков.
Несколько замечательных визуальных примеров трансформаций можно найти в блоге colah.
Скрытый слой преобразует входные данные в пространство признаков, делая его линейно классифицируемым (Из: Визуализация представлений: глубокое обучение и человеческие существа и нейронные сети, многообразия и топология, Кристофер Олах)
В случае демонстрации Playground преобразование приводит к композиция из нескольких признаков, соответствующих треугольной или прямоугольной области. Если вы добавите больше нейронов, нажав кнопку «плюс», вы увидите, что выходной нейрон может захватывать гораздо более сложные многоугольные формы из набора данных.
Возвращаясь к аналогии с офисным работником, можно сказать, что трансформация — это извлечение информации, которую опытный профессионал получает в своей повседневной работе. Нового сотрудника сбивают с толку и отвлекают случайные сигналы, поступающие из электронной почты, телефонов, начальника, клиентов и т. д., но старшие сотрудники очень эффективно извлекают важный сигнал из этих входных данных и организуют хаос в соответствии с несколькими важными принципы.
Нейронные сети работают так же — пытаются извлечь наиболее важные функции из набора данных для решения проблемы. Вот почему нейронные сети иногда могут стать достаточно умными, чтобы справляться с довольно сложными задачами.
Нейронная сеть может извлекать информацию из (на первый взгляд) случайных сигналов (От: Irasutoya.com)
Нам нужно пойти глубже: построить иерархию абстракций
С большим количеством нейронов в одном скрытом слое вы можете захватить больше функций. А наличие большего количества скрытых слоев означает более сложные конструкции, которые вы можете извлечь из набора данных. Вы можете увидеть, насколько мощным это может быть в следующем примере.
А наличие большего количества скрытых слоев означает более сложные конструкции, которые вы можете извлечь из набора данных. Вы можете увидеть, насколько мощным это может быть в следующем примере.
Какой код вы бы написали для классификации этого набора данных? Десятки операторов IF с множеством условий и порогов, каждый из которых проверяет, в какой небольшой области находится данная точка данных? Я лично не хотел бы этого делать.
Здесь машинное обучение и нейронные сети превосходят возможности программиста-человека. Нажмите здесь, чтобы увидеть его в действии (обучение займет пару минут).
Проблема двойной спирали на игровой площадке TensorFlow (нажмите здесь, чтобы попробовать)
Довольно круто, не так ли? То, что вы только что видели, было компьютером, пытающимся построить иерархию абстракций с помощью глубокой нейронной сети. Нейроны в первом скрытом слое выполняют те же самые простые классификации, в то время как нейроны во втором и третьем слоях составляют сложные признаки из простых признаков, в конечном счете придумывая паттерн двойной спирали.
Больше нейронов + более глубокая сеть = более сложная абстракция. Вот как простые нейроны становятся умнее и так хорошо справляются с определенными задачами, такими как распознавание изображений и игра в го.
Начало: модель распознавания изображений, опубликованная Google. (От: Going Deeping with Convolutions, Christian Szegedy et al.) и BLOB-объекты для частей и классов объектов.
Две задачи: вычислительная мощность и обучающие данные
В этой статье мы рассмотрели некоторые демонстрации TensorFlow Playground и то, как они объясняют механизм и возможности нейронных сетей. Как вы видели, основы технологии довольно просты. Каждый нейрон просто классифицирует точку данных по одному из двух типов. И все же, имея больше нейронов и более глубоких слоев, нейронная сеть может извлекать скрытые идеи и сложные шаблоны из набора обучающих данных и строить иерархию абстракций.
Тогда возникает вопрос, почему еще не все используют эту замечательную технологию? Сейчас перед нейронными сетями стоят две большие проблемы. Во-первых, обучение глубоких нейронных сетей требует больших вычислительных мощностей, а во-вторых, им требуются большие наборы обучающих данных. Мощному серверу с графическим процессором может потребоваться несколько дней или даже недель для обучения глубокой сети с набором данных из миллионов изображений.
Во-первых, обучение глубоких нейронных сетей требует больших вычислительных мощностей, а во-вторых, им требуются большие наборы обучающих данных. Мощному серверу с графическим процессором может потребоваться несколько дней или даже недель для обучения глубокой сети с набором данных из миллионов изображений.
Кроме того, требуется много проб и ошибок, чтобы получить наилучшие результаты обучения с помощью множества комбинаций различных схем и алгоритмов сети. Сегодня некоторые исследователи используют десятки серверов с графическим процессором или даже суперкомпьютеры для выполнения крупномасштабного распределенного обучения.
Но в ближайшем будущем полностью управляемые распределенные сервисы обучения и прогнозирования, такие как Google Cloud AI Platform с TensorFlow, могут решить эти проблемы благодаря наличию облачных ЦП и ГП по доступной цене и открыть возможности больших и глубокие нейронные сети для всех.
Благодарности
Большое спасибо Дэвиду Ха, Эцудзи Накаи, Кристоферу Олаху и Александре Барретт за рецензирование и ценные комментарии к сообщению, а также за уточнение текста. И отдельное спасибо авторам TensorFlow Playground, Дэниелу Смилкову, Шэну Картеру и Д. Скалли, за поистине потрясающую работу.
И отдельное спасибо авторам TensorFlow Playground, Дэниелу Смилкову, Шэну Картеру и Д. Скалли, за поистине потрясающую работу.
[1] Источник: MNIST Для начинающих ML
Статья по теме
Как японский фермер, выращивающий огурцы, использует глубокое обучение и TensorFlow
Использование машинного обучения и глубокого обучения ограничено только нашим воображением. Фермер, выращивающий огурцы, может использовать глубокое обучение для сортировки огурцов. Смотри как.
Прочитать статью
Опубликовано в:
К быстрым и точным нейронным сетям для распознавания изображений
Авторы: Минсин Тан и Цзыхан Дай, ученые-исследователи, Google Research
По мере роста моделей нейронных сетей и объема обучающих данных эффективность обучения становится важным направлением глубокого обучения. Например, GPT-3 демонстрирует замечательную способность к обучению за несколько шагов, но требует недель обучения с тысячами графических процессоров, что затрудняет переобучение или улучшение. Что, если бы вместо этого можно было разработать нейронные сети меньшего размера и быстрее, но при этом более точные?
Что, если бы вместо этого можно было разработать нейронные сети меньшего размера и быстрее, но при этом более точные?
В этом посте мы представляем два семейства моделей для распознавания изображений, которые используют поиск нейронной архитектуры, и принципиальную методологию проектирования, основанную на емкости и обобщении модели. Первый — это EfficientNetV2 (принят на ICML 2021), который состоит из сверточных нейронных сетей, нацеленных на высокую скорость обучения для относительно небольших наборов данных, таких как ImageNet1k (с 1,28 миллионами изображений). Второе семейство — CoAtNet, представляющее собой гибридные модели, сочетающие свертку и самостоятельную работу с целью достижения более высокой точности на крупномасштабных наборах данных, таких как ImageNet21 (с 13 миллионами изображений) и JFT (с миллиардами изображений). По сравнению с предыдущими результатами наши модели работают в 4-10 раз быстрее, достигая нового уровня техники 9Точность 0,88 % в топ-1 хорошо зарекомендовавшего себя набора данных ImageNet. Мы также публикуем исходный код и предварительно обученные модели в github Google AutoML.
Мы также публикуем исходный код и предварительно обученные модели в github Google AutoML.
EfficientNetV2: меньшие модели и более быстрое обучение
EfficientNetV2 основан на предыдущей архитектуре EfficientNet. Чтобы улучшить оригинал, мы систематически изучали узкие места в скорости обучения на современных TPU/GPU и обнаружили: (1) обучение с очень большими размерами изображений приводит к более высокому использованию памяти и, следовательно, часто медленнее на TPU/GPU; (2) широко используемые глубинные свертки неэффективны на TPU/GPU, поскольку они демонстрируют низкую загрузку оборудования; и (3) широко используемый подход универсального составного масштабирования, который одинаково масштабирует каждую стадию сверточных сетей, является субоптимальным. Для решения этих проблем мы предлагаем как поиск нейронной архитектуры с учетом обучения (NAS), в котором скорость обучения включена в цель оптимизации, так и метод масштабирования, который масштабирует разные этапы неравномерно.
NAS с поддержкой обучения основан на предыдущей NAS с поддержкой платформы, но в отличие от исходного подхода, который в основном фокусируется на скорости логического вывода, здесь мы совместно оптимизируем точность модели, размер модели и скорость обучения. Мы также расширили исходное пространство поиска, включив в него более удобные для ускорения операции, такие как FusedMBConv, и упростили пространство поиска, удалив ненужные операции, такие как среднее и максимальное объединение, которые никогда не выбираются NAS. Полученные в результате сети EfficientNetV2 обеспечивают более высокую точность по сравнению со всеми предыдущими моделями, при этом они намного быстрее и до 6,8 раз меньше.
Чтобы еще больше ускорить процесс обучения, мы также предлагаем усовершенствованный метод прогрессивного обучения, который постепенно изменяет размер изображения и величину регуляризации во время обучения. Прогрессивное обучение использовалось в классификации изображений, GAN и языковых моделях. Этот подход фокусируется на классификации изображений, но в отличие от предыдущих подходов, которые часто обменивают точность на повышение скорости обучения, может немного повысить точность, а также значительно сократить время обучения. Ключевая идея в нашем улучшенном подходе заключается в адаптивном изменении силы регуляризации, такой как коэффициент отсева или величина увеличения данных, в зависимости от размера изображения. Для той же сети небольшой размер изображения приводит к меньшей пропускной способности сети и, следовательно, требует слабой регуляризации; и наоборот, большой размер изображения требует более сильной регуляризации для борьбы с переоснащением.
Этот подход фокусируется на классификации изображений, но в отличие от предыдущих подходов, которые часто обменивают точность на повышение скорости обучения, может немного повысить точность, а также значительно сократить время обучения. Ключевая идея в нашем улучшенном подходе заключается в адаптивном изменении силы регуляризации, такой как коэффициент отсева или величина увеличения данных, в зависимости от размера изображения. Для той же сети небольшой размер изображения приводит к меньшей пропускной способности сети и, следовательно, требует слабой регуляризации; и наоборот, большой размер изображения требует более сильной регуляризации для борьбы с переоснащением.
| Прогрессивное обучение для EfficientNetV2. Здесь мы в основном фокусируемся на трех типах регуляризации: увеличение данных, смешивание и отсев. |
Мы оцениваем модели EfficientNetV2 в ImageNet и нескольких наборах данных для обучения передаче, таких как CIFAR-10/100, Flowers и Cars. В ImageNet EfficientNetV2 значительно превосходит предыдущие модели: скорость обучения примерно в 5–11 раз выше, а размер модели до 6,8 раз меньше, без какого-либо снижения точности.
В ImageNet EfficientNetV2 значительно превосходит предыдущие модели: скорость обучения примерно в 5–11 раз выше, а размер модели до 6,8 раз меньше, без какого-либо снижения точности.
| EfficientNetV2 обеспечивает гораздо более высокую эффективность обучения, чем предыдущие модели для классификации ImageNet. |
CoAtNet: быстрые и точные модели для распознавания крупномасштабных изображений. масштабные наборы данных, такие как JFT-300M. Вдохновленные этим наблюдением, мы расширяем наше исследование за пределы сверточных нейронных сетей с целью поиска более быстрых и точных моделей зрения.
В «CoAtNet: сочетание свертки и внимания для данных любого размера» мы систематически изучаем, как сочетать свертки и самостоятельную работу для разработки быстрых и точных нейронных сетей для крупномасштабного распознавания изображений. Наша работа основана на наблюдении, что свертка часто лучше обобщает (т. data) благодаря своему глобальному рецептивному полю. Сочетая свертки и самоанализ, наши гибридные модели могут обеспечить как лучшее обобщение, так и большую емкость.
data) благодаря своему глобальному рецептивному полю. Сочетая свертки и самоанализ, наши гибридные модели могут обеспечить как лучшее обобщение, так и большую емкость.
| Сравнение моделей свертки, внутреннего внимания и гибридных моделей. Сверточные модели сходятся быстрее, ViT обладают большей пропускной способностью, а гибридные модели обеспечивают как более быструю сходимость, так и лучшую точность. |
Мы наблюдаем два ключевых вывода из нашего исследования: (1) глубинная свертка и само-внимание могут быть естественным образом объединены с помощью простого относительного внимания, и (2) вертикальное наложение слоев свертки и слоев внимания таким образом, чтобы учитывать их пропускную способность и вычисления, необходимые в каждом случае. Стадия (разрешение) удивительно эффективна для улучшения обобщения, емкости и эффективности. Основываясь на этих выводах, мы разработали семейство гибридных моделей со сверткой и вниманием, названных CoAtNets (произносится как «сетки для пальто»). На следующем рисунке показана общая архитектура сети CoAtNet:
На следующем рисунке показана общая архитектура сети CoAtNet:
| Общая архитектура CoAtNet. Имея входное изображение размером HxW, мы сначала применяем свертки на первом этапе ствола (S0) и уменьшаем размер до H/2 x W/2. Размер продолжает уменьшаться с каждым этапом. L n относится к количеству слоев. Затем на первых двух этапах (S1 и S2) в основном используются строительные блоки MBConv, состоящие из глубокой свертки. На последних двух этапах (S3 и S4) в основном используются блоки Transformer с относительным вниманием к себе. В отличие от предыдущих блоков Transformer в ViT, здесь мы используем объединение между этапами, аналогично Funnel Transformer. Наконец, мы применяем заголовок классификации для создания прогноза класса. |
Модели CoAtNet неизменно превосходят модели ViT и их варианты в ряде наборов данных, таких как ImageNet1K, ImageNet21K и JFT. По сравнению со свёрточными сетями CoAtNet демонстрирует сравнимую производительность на небольшом наборе данных (ImageNet1K) и достигает значительных успехов по мере увеличения размера данных (например, на ImageNet21K и JFT).
По сравнению со свёрточными сетями CoAtNet демонстрирует сравнимую производительность на небольшом наборе данных (ImageNet1K) и достигает значительных успехов по мере увеличения размера данных (например, на ImageNet21K и JFT).
| Сравнение CoAtNet и предыдущих моделей после предварительного обучения на наборе данных ImageNet21K среднего размера. При одном и том же размере модели CoAtNet неизменно превосходит как модели ViT, так и сверточные модели. Примечательно, что только с ImageNet21K CoAtNet может соответствовать производительности ViT-H, предварительно обученного на JFT. |
Мы также оценили CoAtNets на крупномасштабном наборе данных JFT. Чтобы достичь аналогичного целевого показателя точности, CoAtNet обучается примерно в 4 раза быстрее, чем предыдущие модели ViT, и, что более важно, достигает нового современного уровня точности в ImageNet — 90,88%.
Сравнение CoAtNets и предыдущих ViT.
|