Содержание
Алгоритмы распознавания лиц | Принцип работы и анализа
Всем привет!
Как и обещали в прошлый раз, рассказываем, как оценивать алгоритмы распознавания лиц. Материал подготовлен сотрудниками лаборатории NtechLab.
В последнее время вектор развития распознавания лиц вызывает все больше интереса со стороны коммерческого сектора и государства. Однако корректное измерение точности работы таких систем — задача непростая и содержит массу нюансов. К нам постоянно обращаются с запросами на тестирование нашей технологии распознавания и пилотными проектами на ее основе, и мы заметили, что часто возникают вопросы с терминологией и методами тестирования алгоритмов применительно к бизнес-задачам. В результате для решения задачи могут быть выбраны неподходящие инструменты, что приводит к финансовым потерям или недополученной прибыли. Мы решили опубликовать эту заметку, чтобы помочь людям освоиться в среде специализированных терминов и сырых данных, окружающих технологии распознавания лиц, и упростить их сравнение. Нам хотелось рассказать об основных понятиях в этой области простым и понятным языком, наглядно показать, как работает система распознавания лиц на основе алгоритма. Надеемся, это позволит людям технического и предпринимательского склада говорить на одном языке, лучше понимать сценарии использования распознавания лиц в реальном мире и принимать решения, подтвержденные данными.
Нам хотелось рассказать об основных понятиях в этой области простым и понятным языком, наглядно показать, как работает система распознавания лиц на основе алгоритма. Надеемся, это позволит людям технического и предпринимательского склада говорить на одном языке, лучше понимать сценарии использования распознавания лиц в реальном мире и принимать решения, подтвержденные данными.
Задачи распознавания лиц
Распознаванием лиц часто называют набор различных задач, например, детектирование лица на фотографии или лица в видеопотоке, определение пола и возраста, поиск нужного человека среди множества изображений лиц или проверка того, что на двух изображениях один и тот же человек. В этой статье мы остановимся на последних двух задачах и будем их называть, соответственно, идентификация и верификация. Для решения этих задач из изображений извлекаются специальные дескрипторы лиц, или векторы признаков, необходимые для распознавания лиц. В этом случае задача идентификации сводится к поиску ближайшего вектора признаков, а верификацию можно реализовать с помощью простого порога расстояний между векторами. Комбинируя эти два действия, можно идентифицировать человека среди набора изображений лиц или принимать решение о том, что его нет среди этих изображений. Такая процедура называется open-set identification (идентификацией на открытом множестве), см. Рис. 1.
Комбинируя эти два действия, можно идентифицировать человека среди набора изображений лиц или принимать решение о том, что его нет среди этих изображений. Такая процедура называется open-set identification (идентификацией на открытом множестве), см. Рис. 1.
Рис. 1. Задачи распознавания лиц
Для количественной оценки схожести лиц можно использовать расстояние в пространстве векторов признаков лиц. Часто выбирают евклидово или косинусное расстояние, но существуют и другие, более сложные, подходы к распознаванию. Конкретная функция расстояния часто поставляется в составе продукта по распознаванию лиц. Идентификация и верификация возвращают разные результаты и, соответственно, разные метрики применяются для оценки их качества. Мы подробно рассмотрим метрики качества в последующих разделах. Помимо выбора адекватной метрики, для оценки точности алгоритма понадобится размеченный набор изображений (датасет).
Оценка точности
Датасеты
Почти всё современное ПО на основе лицевой биометрии построено на машинном обучении. Алгоритмы распознавания лиц обучаются на больших датасетах (наборах данных) с размеченными изображениями. И качество, и природа этих датасетов оказывают существенное влияние на точность. Чем лучше исходные данные, тем лучше алгоритм будет справляться с поставленной задачей.
Алгоритмы распознавания лиц обучаются на больших датасетах (наборах данных) с размеченными изображениями. И качество, и природа этих датасетов оказывают существенное влияние на точность. Чем лучше исходные данные, тем лучше алгоритм будет справляться с поставленной задачей.
Естественный способ проверить, как точно работает система распознавания лиц, это измерить точность распознавания на отдельном тестовом датасете. Очень важно правильно выбрать этот датасет. В идеальном случае организации стоит обзавестись собственным набором данных, максимально похожим на те изображения, с которыми система будет работать при эксплуатации. Обратите внимание на камеру, условия съемки, возраст, пол людей, которые попадут в тестовый датасет. Чем более похож тестовый датасет на реальные данные, тем более достоверными будут результаты тестирования. Поэтому часто имеет смысл потратить время и средства для сбора и разметки своего набора данных. Если же это, по какой-то причине, не представляется возможным, можно воспользоваться публичными датасетами, например, LFW иMegaFace. LFW содержит только 6000 пар изображений лиц и не подходит для многих реальных сценариев: в частности, на этом датасете невозможно измерить достаточно низкие уровни ошибок, как мы покажем далее. Датасет MegaFace содержит намного больше изображений и подходит для тестирования алгоритмов распознавания лиц на больших масштабах. Однако и обучающее, и тестовое множество изображений MegaFace’a есть в открытом доступе, поэтому использовать его для тестирования следует с осторожностью.
LFW содержит только 6000 пар изображений лиц и не подходит для многих реальных сценариев: в частности, на этом датасете невозможно измерить достаточно низкие уровни ошибок, как мы покажем далее. Датасет MegaFace содержит намного больше изображений и подходит для тестирования алгоритмов распознавания лиц на больших масштабах. Однако и обучающее, и тестовое множество изображений MegaFace’a есть в открытом доступе, поэтому использовать его для тестирования следует с осторожностью.
Альтернативный вариант заключается в использовании результатов тестирования третьим лицом. Такие тестирования проводятся квалифицированными специалистами на больших закрытых датасетах лиц, и их результатам можно доверять. Одним из примеров может служить NIST Face Recognition Vendor Test Ongoing. Это тест, проводимый Национальным Институтом Стандартов и Технологий (NIST) при Министерстве торговли США. «Минус» данного подхода заключается в том, что датасет организации, проводящей тестирование, может существенно отличаться от интересующего сценария использования.
Переобучение
Как мы говорили, машинное обучение лежит в основе современного ПО для распознавания лиц. Одним из распространенных феноменов машинного обучения является т.н. переобучение. Проявляется он в том, что алгоритм показывает хорошие результаты на лицах, которые использовались при обучении, но результаты распознавания на новых данных получаются значительно хуже.
Рассмотрим конкретный пример: представим себе клиента, который хочет установить лучшую пропускную систему распознавания лиц. Для этих целей он собирает набор фотографий людей, которым будет разрешен доступ, и обучает алгоритм отличать их лица от лиц других людей. На испытаниях система показывает хорошие результаты распознавания и внедряется в эксплуатацию. Через некоторое время список людей с допуском решают расширить и как работает система распознавания лиц? — отказывает новым людям в доступе. Алгоритм тестировался на тех же лицах, что и обучался, и никто не проводил измерения точности на новых фотографиях. Это, конечно, утрированный пример, но он позволяет понять проблему.
Это, конечно, утрированный пример, но он позволяет понять проблему.
Излишне оптимистичная оценка точности работы алгоритма из-за неправильно проведенного тестирования — очень распространенная ошибка. Всегда следует тестировать алгоритм на новых данных, которые ему предстоит обрабатывать в реальном применении, а не на тех данных, на которых проводилось обучение.
Резюмируя вышесказанное, составим список рекомендаций: не используйте фотографии лиц, на которых обучался алгоритм при тестировании, используйте специальный закрытый датасет для тестирования. Если это невозможно и вы собираетесь воспользоваться публичным датасетом, убедитесь, что вендор не использовал его в процессе обучения и/или настройки алгоритма. Изучите датасет перед тестированием, подумайте, насколько он близок к тем данным, которые будут поступать при эксплуатации системы.
Метрики
После выбора датасета следует определиться с метрикой, которая будет использоваться для оценки результатов. В общем случае метрика — это функция, которая принимает на вход результаты работы алгоритма (идентификации или верификации), а на выходе возвращает число, которое соответствует качеству работы алгоритма на конкретном датасете. Использование одного числа для количественного сравнения разных алгоритмов или вендоров позволяет сжато представлять результаты распознавания и облегчает процесс принятия решений. В этом разделе мы рассмотрим метрики, наиболее часто применяемые в распознавании лиц, и обсудим их значение с точки зрения бизнеса.
В общем случае метрика — это функция, которая принимает на вход результаты работы алгоритма (идентификации или верификации), а на выходе возвращает число, которое соответствует качеству работы алгоритма на конкретном датасете. Использование одного числа для количественного сравнения разных алгоритмов или вендоров позволяет сжато представлять результаты распознавания и облегчает процесс принятия решений. В этом разделе мы рассмотрим метрики, наиболее часто применяемые в распознавании лиц, и обсудим их значение с точки зрения бизнеса.
Верификация
Верификацию лиц можно рассматривать как процесс принятия бинарного решения: «да» (два изображения принадлежат одному лицу), «нет» (на паре фотографий изображены разные люди). Прежде чем разбираться с метриками верификации, полезно понять, как мы можем классифицировать ошибки в подобных задачах. Учитывая, что есть 2 возможных ответа алгоритма и 2 варианта истинного положения вещей, всего возможно 4 исхода:
Рис.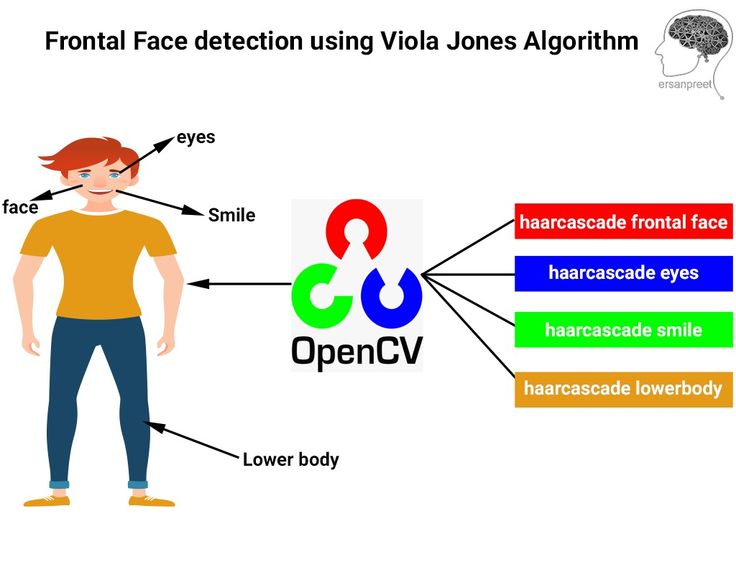 2 Типы ошибок. Цвет фона кодирует истинное отношение между картинками (синий означает «принять», желтый — «отвергнуть»), цвет рамки соответствует предсказанию алгоритма (синий — «принять», желтый — «отвергнуть»
2 Типы ошибок. Цвет фона кодирует истинное отношение между картинками (синий означает «принять», желтый — «отвергнуть»), цвет рамки соответствует предсказанию алгоритма (синий — «принять», желтый — «отвергнуть»
В таблице выше столбцы соответствуют решению алгоритма (синий — принять, желтый — отвергнуть), строки соответствуют истинным значениям (кодируются теми же цветами). Правильные ответы алгоритма отмечены зеленым фоном, ошибочные — красным. Из этих исходов два соответствуют правильным ответам алгоритма, а два — ошибкам первого и второго рода соответственно. Ошибки первого рода называют «false accept», «false positive» или «false match» (неверно принято), а ошибки второго рода — «false reject», «false negative» или «false non-match» (неверно отвергнуто).Просуммировав количество ошибок разного рода среди пар изображений в датасете и поделив их на количество пар, мы получим false accept rate (FAR) и false reject rate (FRR). В случае с системой контроля доступа «false positive» соответствует предоставлению доступа человеку, для которого этот доступ не предусмотрен, в то время как «false negative» означает, что система ошибочно отказала в доступе авторизованной персоне. Эти ошибки имеют разную стоимость с точки зрения бизнеса и поэтому рассматриваются отдельно. В примере с контролем доступа «false negative» приводит к тому, что сотруднику службы безопасности надо перепроверить пропуск сотрудника. Предоставление неавторизованного доступа потенциальному нарушителю (false positive) может привести к гораздо худшим последствиям. Учитывая, что ошибки разного рода связаны с различными рисками, производители ПО для распознавания лиц зачастую дают возможность настроить алгоритм так, чтобы минимизировать один из типов ошибок. Для этого алгоритм возвращает не бинарное значение, а вещественное число, отражающее уверенность алгоритма в своем решении. В таком случае пользователь может самостоятельно выбрать порог и зафиксировать уровень ошибок на определенных значениях. Для примера рассмотрим «игрушечный» датасет из трех изображений. Пусть изображения 1 и 2 принадлежат одному и тому же человеку, а изображение 3 кому-то еще. Допустим, что программа оценила свою уверенность для каждой из трех пар следующим образом:
Эти ошибки имеют разную стоимость с точки зрения бизнеса и поэтому рассматриваются отдельно. В примере с контролем доступа «false negative» приводит к тому, что сотруднику службы безопасности надо перепроверить пропуск сотрудника. Предоставление неавторизованного доступа потенциальному нарушителю (false positive) может привести к гораздо худшим последствиям. Учитывая, что ошибки разного рода связаны с различными рисками, производители ПО для распознавания лиц зачастую дают возможность настроить алгоритм так, чтобы минимизировать один из типов ошибок. Для этого алгоритм возвращает не бинарное значение, а вещественное число, отражающее уверенность алгоритма в своем решении. В таком случае пользователь может самостоятельно выбрать порог и зафиксировать уровень ошибок на определенных значениях. Для примера рассмотрим «игрушечный» датасет из трех изображений. Пусть изображения 1 и 2 принадлежат одному и тому же человеку, а изображение 3 кому-то еще. Допустим, что программа оценила свою уверенность для каждой из трех пар следующим образом:
Таблица 2. Пример значений достоверности для трех изображений
Пример значений достоверности для трех изображений
Мы специально выбрали значения таким образом, чтобы ни один порог не классифицировал все три пары правильно. В частности, любой порог ниже 0.6 приведет к двум false accept (для пар лиц 2−3 и 1−3). Разумеется, такой результат можно улучшить.
Выбор порога из диапазона от 0.6 до 0.85 приведет к тому, что пара лиц 1−3 будет отвергнута, пара лиц 1−2 по-прежнему будет приниматься, а 2−3 будет ложно приниматься. Если увеличить порог до 0.85−0.9, то пара лиц 1−2 станет ложно отвергаться. Значения порога выше 0.9 приведут к двум true reject (пары лиц 1−3 и 2−3) и одному false reject (1−2). Таким образом, лучшими вариантами выглядят пороги из диапазона 0.6−0.85 (один false accept 2−3) и порог выше 0.9 (приводит к false reject 1−2). Какое значение выбрать в качестве финального, зависит от стоимости ошибок разных типов. В этом примере порог варьируется в широких диапазонах, это связано, в первую очередь, с очень маленьким датасетом, и с тем, как мы выбрали значения уверенности алгоритма. Для больших, применяемых для реальных задач датасетов, получились бы существенно более точные значения порога. Зачастую вендоры ПО для распознавания лиц поставляют значения порога по умолчанию для разных FAR, которые вычисляются похожим образом на собственных датасетах вендора.
Для больших, применяемых для реальных задач датасетов, получились бы существенно более точные значения порога. Зачастую вендоры ПО для распознавания лиц поставляют значения порога по умолчанию для разных FAR, которые вычисляются похожим образом на собственных датасетах вендора.
Также нетрудно заметить, что по мере того как интересующий FAR снижается, требуется все больше и больше положительных пар изображений, чтобы точно вычислить значение порога. Так, для FAR=0.001 нужно по меньшей мере 1000 пар, а для FAR=10-6потребуется уже 1 миллион пар. Собрать и разметить такой датасет непросто, поэтому клиентам, заинтересованным в низких значениях FAR, имеет смысл обратить внимание на публичные бенчмарки, такие как NIST Face Recognition Vendor Test или MegaFace. К последнему следует относиться с осторожностью, так как и обучающая, и тестовая выборки доступны всем желающим, что может привести к излишне оптимистичной оценке точности (см. раздел «Переобучение»).
ROC-кривые
Типы ошибок различаются по связанной с ними стоимости, и у клиента есть способ смещать баланс в сторону тех или иных ошибок. Для этого надо рассмотреть широкий диапазон значений порога. Удобный способ визуализации точности алгоритма при разных значениях FAR заключается в построении ROC-кривых (англ. receiver operating characteristic, рабочая характеристика приёмника).
Давайте разберемся, как строятся и анализируются ROC-кривые. Уверенность алгоритма (а следовательно, и порог) принимают значения из фиксированного интервала. Другими словами, эти величины ограничены сверху и снизу. Предположим, что это интервал от 0 до 1. Теперь мы можем измерить количество ошибок, варьируя значение порога от 0 до 1 с небольшим шагом. Так, для каждого значения порога мы получим значения FAR и TAR (true accept rate). Далее мы будет рисовать каждую точку так, чтобы FAR соответствовал оси абсцисс, а TAR — оси ординат.
Рис. 3 Пример ROC-кривой
3 Пример ROC-кривой
Легко заметить, что первая точка будет иметь координаты 1,1. При пороге, равном 0, мы принимаем все пары лиц и не отвергаем ни одной. Аналогично, последняя точка будет 0,0: при пороге 1 мы не принимаем ни одной пары лиц и отвергаем все пары. В остальных точках кривая обычно выпуклая. Также можно заметить, что наихудшая кривая лежит примерно на диагонали графика и соответствует случайному угадыванию исхода. С другой стороны, наилучшая возможная кривая образует треугольник с вершинами (0,0) (0,1) и (1,1). Но на датасетах разумного размера такое трудно встретить.
Рис. 4 ROC-кривые NIST FRVT
Можно построить подобие RОС-кривых с различными метриками/ошибками на оси. Рассмотрим, например, рисунок 4. На нем видно, что организаторы NIST FRVT по оси Y нарисовали FRR (на рисунке — False non-match rate), а по оси X — FAR (на рисунке — False match rate). В данном конкретном случае лучшие результаты достигнуты кривыми, которые расположены ниже и смещены влево, что соответствует низким показателям FRR и FAR. Поэтому стоит обращать внимание на то, какие величины отложены по осям.
Поэтому стоит обращать внимание на то, какие величины отложены по осям.
Такой график позволяет легко судить о точности алгоритма при заданном FAR: достаточно найти точку на кривой с координатой Х равной нужному FAR и соответствующее значение TAR. «Качество» ROC-кривой также можно оценить одним числом, для этого надо посчитать площадь под ней. При этом лучшее возможное значение будет 1, а значение 0.5 соответствует случайному угадыванию. Такое число называют ROC AUC (Area Under Curve). Однако следует заметить, что ROC AUC неявно предполагает, что ошибки первого и второго рода однозначны, что не всегда так. В случае если цена ошибок различается, следует обратить внимание на форму кривой и те области, где FAR соответствует бизнес-требованиям.
Идентификация
Второй популярной задачей распознавания лиц является идентификация, или поиск нужного лица среди набора изображений. Результаты поиска по лицам сортируются по уверенности алгоритма, и наиболее вероятные совпадения попадают в начало списка. В зависимости от того, присутствует или нет искомый человек в поисковой базе лиц, идентификацию разделяют на две подкатегории: closed-set идентификация (известно, что искомый человек есть в базе) и open-set идентификация (искомого человека может не быть в базе лиц).
В зависимости от того, присутствует или нет искомый человек в поисковой базе лиц, идентификацию разделяют на две подкатегории: closed-set идентификация (известно, что искомый человек есть в базе) и open-set идентификация (искомого человека может не быть в базе лиц).
Точность (accuracy) является надежной и понятной метрикой для closed-set идентификации. По сути, точность измеряет количество раз, когда нужная персона была среди результатов поиска по лицам.
Как это работает на практике? Давайте разбираться. Начнем с формулировки бизнес-требований. Допустим, у нас есть веб-страница, которая может разместить десять результатов поиска. Нам нужно измерить количество раз, которое искомый человек попадает в первые десять ответов алгоритма. Такое число называется Top-N точностью (в данном конкретном случае N равно 10).
Для каждого испытания мы определяем изображение человека, которого будем искать, и галерею лиц, в которой будем искать, так, чтобы галерея содержала хотя бы еще одно изображение этого человека. Мы просматриваем первые десять результатов работы алгоритма поиска и проверяем, есть ли среди них искомый человек. Чтобы получить точность, следует просуммировать все испытания, в которых искомый человек был в результатах поиска, и поделить на общее число испытаний.
Мы просматриваем первые десять результатов работы алгоритма поиска и проверяем, есть ли среди них искомый человек. Чтобы получить точность, следует просуммировать все испытания, в которых искомый человек был в результатах поиска, и поделить на общее число испытаний.
Рис 5. Пример идентификации. В этом примере искомый человек появляется в позиции 2, поэтому точность Top-1 равна 0, а Top-2 и далее равна 1
Open-set идентификация состоит из поиска людей, наиболее похожих на искомое изображение, и определения, является ли кто-то из них искомым человеком на основании уверенности алгоритма. Open-set идентификацию можно рассматривать как комбинацию closed-set идентификации и верификации, поэтому на этой задаче можно применять все те же метрики, что и в задаче верификации. Также нетрудно заметить, что open-set идентификацию можно свести к попарным сравнениям искомого изображения со всеми изображениями из галереи. На практике это не используется из соображений скорости вычислений. ПО для распознавания лиц часто поставляется с быстрыми алгоритмами поиска, которые могут находить среди миллионов лиц похожие за миллисекунды. Попарные сравнения заняли бы намного больше времени.
ПО для распознавания лиц часто поставляется с быстрыми алгоритмами поиска, которые могут находить среди миллионов лиц похожие за миллисекунды. Попарные сравнения заняли бы намного больше времени.
Практические примеры
В качестве иллюстрации давайте рассмотрим несколько примеров, демонстрирующих измерение качества алгоритмов распознавания лиц для сравнения в реальном сценарии.
Розничный магазин
Допустим, что средний по размеру розничный магазин хочет улучшить свою программу лояльности или уменьшить количество краж. С точки зрения лицевой биометрии это примерно одно и то же. Главная задача этого проекта заключается в том, чтобы как можно раньше идентифицировать постоянного покупателя или злоумышленника по изображению с камеры и передать эту информацию продавцу или сотруднику службы безопасности.
Пусть программа лояльности охватывает 100 клиентов. Данную задачу можно рассматривать как пример open-set идентификации. Оценив расходы, отдел маркетинга пришел в выводу, что приемлемый уровень ошибки — принимать одного посетителя за постоянного покупателя за день. Если в день магазин посещает 1000 посетителей, каждый из которых должен быть сверен со списком 100 постоянных клиентов, то необходимый FAR составит 1 / (1000 * 100) =10-5.
Оценив расходы, отдел маркетинга пришел в выводу, что приемлемый уровень ошибки — принимать одного посетителя за постоянного покупателя за день. Если в день магазин посещает 1000 посетителей, каждый из которых должен быть сверен со списком 100 постоянных клиентов, то необходимый FAR составит 1 / (1000 * 100) =10-5.
Определившись с допустимым уровнем ошибки, следует выбрать подходящий датасет для тестирования. Хорошим вариантом было бы разместить камеру в подходящем месте (вендоры могут помочь с конкретным устройством и расположением). Сопоставив транзакции держателей карт постоянного покупателя с изображениями с камеры и проведя ручную фильтрацию, сотрудники магазина могут собрать набор «позитивных» пар. Также имеет смысл собрать набор изображений случайных посетителей (по одному изображению на человека). Общее количество изображений должно примерно соответствовать количеству посетителей магазина в день. Объединив оба набора, можно получить датасет как «позитивных», так и «негативных» пар.
Для проверки желаемой точности распознавания должно хватить около тысячи «позитивных» пар. Комбинируя различных постоянных клиентов и случайных посетителей, можно собрать около 100 000 «негативных» пар.
Следующим шагом будет запустить (или попросить вендора запустить) ПО и получить уверенность алгоритма для каждой пары из датасета. Когда это будет сделано, можно построить ROC-кривую и удостовериться, что количество правильно идентифицированных постоянных клиентов при FAR=10-5соответствует бизнес-требованиям.
E-Gate в аэропорту
Современные аэропорты обслуживают десятки миллионов пассажиров в год, а процедуру паспортного контроля ежедневно проходит около 300 000 человек. Автоматизация этого процесса позволит существенно сократить расходы. С другой стороны, пропустить нарушителя крайне нежелательно, и администрация аэропорта хочет минимизировать риск такого события. FAR=10-7соответствует десяти нарушителям в год и кажется разумным в этой ситуации. Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями лиц с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
Если при данном FAR, FRR составляет 0.1 (что соответствует результатам NtechLab на бенчмарке NIST visa images), то затраты на ручную проверку документов можно будет сократить в десять раз. Однако для того чтобы оценить точность при данном уровне FAR, понадобятся десятки миллионов изображений. Сбор такого большого датасета требует значительных средств и может потребовать дополнительного согласования обработки личных данных. В результате инвестиции в подобную систему могут окупаться чересчур долго. В таком случае имеет смысл обратиться к отчету о тестировании NIST Face Recognition Vendor Test, который содержит датасет с фотографиями лиц с виз. Администрации аэропорта стоит выбирать вендора на основе тестирования на этом датасете, приняв во внимание пассажиропоток.
Таргетированная почтовая рассылка
До сих пор мы рассматривали примеры, в которых заказчик был заинтересован в низких FAR, однако это не всегда так. Представим себе оборудованный камерой рекламный стенд в крупном торговом центре. Торговый центр имеет собственную программу лояльности и хотел бы идентифицировать ее участников, остановившихся у стенда. Далее этим лицам можно было бы рассылать таргетированные письма со скидками и интересными предложениями на основании того, что их заинтересовало на стенде.
Торговый центр имеет собственную программу лояльности и хотел бы идентифицировать ее участников, остановившихся у стенда. Далее этим лицам можно было бы рассылать таргетированные письма со скидками и интересными предложениями на основании того, что их заинтересовало на стенде.
Допустим, что эксплуатация такой системы обходится в 10 $, при этом около 1000 посетителей в день останавливаются у стенда. Отдел маркетинга оценил прибыль от каждого таргетированного email в 0.0105 $. Нам хотелось бы идентифицировать как можно больше постоянных покупателей и не слишком беспокоить остальных. Чтобы такая рассылка окупилась, точность должна быть равна затратам на стенд, поделенным на количество посетителей и ожидаемый доход от каждого письма. Для нашего примера точность равна 10 / (1000 * 0.0105) = 95%. Администрация торгового центра могла бы собрать датасет способом, описанным в разделе «Розничный магазин», и измерить точность, как описано в разделе «Идентификация». На основании результатов тестирования можно принимать решение, получится ли извлечь ожидаемую выгоду с помощью системы распознавания лиц.
Применение на практике
Поддержка видео
В этой заметке мы обсуждали преимущественно работу с изображениями и почти не касались потокового видео. Видео можно рассматривать как последовательность статичных изображений, поэтому метрики и подходы к тестированию точности на изображениях применимы и к видео. Стоит отметить, что обработка потокового видео гораздо более затратна с точки зрения производимых вычислений и накладывает дополнительные ограничения на все этапы распознавания лиц. При работе с видео следует проводить отдельное тестирование производительности, поэтому детали этого процесса не затрагиваются в настоящем тексте.
Частые ошибки
В этом разделе мы хотели бы перечислить распространенные проблемы и ошибки, которые встречаются при тестировании ПО для распознавания лиц, и дать рекомендации, как их избежать.
Тестирование на датасете недостаточного размера
Всегда следует быть аккуратным при выборе датасета для тестирования алгоритмов распознавания лиц. Одним из важнейших свойств датасета является его размер. Размер датасета нужно выбирать, исходя из требований бизнеса и значений FAR/TAR. «Игрушечные» датасеты из нескольких изображений лиц людей из вашего офиса дадут возможность «поиграть» с алгоритмом, измерить его производительность или протестировать нестандартные ситуации, но на их основании нельзя делать выводы о точности алгоритма. Для тестирования точности следует использовать датасеты разумных размеров.
Одним из важнейших свойств датасета является его размер. Размер датасета нужно выбирать, исходя из требований бизнеса и значений FAR/TAR. «Игрушечные» датасеты из нескольких изображений лиц людей из вашего офиса дадут возможность «поиграть» с алгоритмом, измерить его производительность или протестировать нестандартные ситуации, но на их основании нельзя делать выводы о точности алгоритма. Для тестирования точности следует использовать датасеты разумных размеров.
Тестирование при единственном значении порога
Иногда люди тестируют алгоритм системы распознавания лиц при одном фиксированном пороговом значении (часто выбранном производителем «по умолчанию») и принимают во внимание лишь один тип ошибок. Это неправильно, так как значения порога «по умолчанию» у разных вендоров различаются или выбираются на основе различных значений FAR или TAR. При тестировании следует обращать внимание на оба типа ошибок.
Сравнение результатов на разных датасетах
Датасеты различаются по размерам, качеству и сложности, поэтому результаты работы алгоритмов на разных датасетах невозможно сравнивать. Можно запросто отказаться от лучшего решения только потому, что оно тестировалось на более сложном, чем у конкурента, датасете.
Можно запросто отказаться от лучшего решения только потому, что оно тестировалось на более сложном, чем у конкурента, датасете.
Делать выводы на основе тестирования на единственном датасете
Следует стараться проводить тестирование на нескольких наборах данных. При выборе единственного публичного датасета нельзя быть уверенным, что он не использовался при обучении или настройке алгоритма. В этом случае точность будет переоценена. К счастью, вероятность этого события можно снизить, сравнив результаты на разных датасетах.
Выводы
В этой заметке мы описали основные составные части тестирования алгоритмов распознавания лиц: наборы данных, задачи, соответствующие метрики и распространенные сценарии.
Конечно, это далеко не всё, что хотелось бы рассказать о тестировании, и наилучший порядок действий может отличаться при многочисленных исключительных сценариях (команда NtechLab с радостью поможет с ними разобраться). Но мы очень надеемся, что этот текст поможет правильно спланировать тестирование, сравнить несколько алгоритмов распознавания лиц, оценить их сильные и слабые стороны и интерпретировать метрики качества с точки зрения бизнес-задач, чтобы в итоге выбрать лучшую систему распознавания лиц.
Но мы очень надеемся, что этот текст поможет правильно спланировать тестирование, сравнить несколько алгоритмов распознавания лиц, оценить их сильные и слабые стороны и интерпретировать метрики качества с точки зрения бизнес-задач, чтобы в итоге выбрать лучшую систему распознавания лиц.
Друзья! Как всегда будем рады вашим комментариям по теме.
Все публикации
Как работает распознавание лиц — Журнал «Код» программирование без снобизма
У вас в телефоне наверняка уже есть технология распознавания лиц. Ещё она есть в городских камерах наблюдения, на заводах и военных объектах, в лабораториях и даже в автомобилях. Посмотрим, как они устроены.
Из чего состоит распознавание лиц
Чтобы машина узнала лицо с помощью камеры, нужны такие компоненты:
- Оптическая камера или лидар, чтобы получить изображение или объёмную карту лица.
- База данных с заранее проанализированными лицами.
- Алгоритм, который находит в кадре лицо.

- Алгоритм приведения лица к какому-то набору векторов.
- Алгоритм сравнения векторов с эталонами.

Теперь посмотрим детали.
Получаем изображение с камеры
Это самая простая часть, которая может даже не зависеть от алгоритма распознавания лиц. Задача компьютера — взять видеопоток с камеры, в реальном времени нарезать его на несколько кадров и эти кадры отправить в алгоритм.
Некоторые алгоритмы используют плоское изображение с камеры. Другие используют лидары — это когда лазерная пушка быстро-быстро стреляет лазером во все стороны и измеряет скорость возвращения лучей. Получается не слишком точная, но в некоторой степени объёмная картинка. Часто её совмещают с изображением основной камеры, чтобы убедиться, что перед нами действительно человек, а не его фотография.
Иногда алгоритм настроен так, чтобы получать только подвижные изображения с меняющейся мимикой — чтобы не сканировали спящих людей или маски.
Некоторые алгоритмы вычисляют трёхмерную модель на основании поворота головы. Прямо говорят: посмотрите налево, посмотрите направо, приблизьтесь, отдалитесь. Так они пытаются построить более точную объёмную модель лица. Всё это — для безопасности.
Пример работы LIDAR-сканера на Айфоне. Это не система распознавания лиц, просто для понимания степени точности скана
Находим лицо в кадре
Перед тем как алгоритм приступит к распознаванию, ему нужно найти лицо на картинке. Для этого он использует метод Виолы — Джонса и специальные чёрно-белые прямоугольники (примитивы Хаара), которые выглядят примерно так:
С помощью этих прямоугольников алгоритм пытается найти на картинке похожие переходы между светлыми и тёмными областями. Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека. Например, вот как с помощью этих примитивов алгоритм находит нос и глаза:
Все примитивы специально подобраны так, чтобы с их помощью можно было найти границы лица и отсечь всё остальное. Поэтому, как только алгоритм находит место скопления таких совпадений, он для проверки сравнивает там остальные прямоугольники:
Если их набирается достаточное количество — это точно лицо. Обычно алгоритмы поиска лиц для контроля обводят рамкой найденную область — она помогает разработчикам понять, всё ли в порядке с логикой программы:
Обычно алгоритмы поиска лиц для контроля обводят рамкой найденную область — она помогает разработчикам понять, всё ли в порядке с логикой программы:
Когда есть алгоритм и достаточно быстрый процессор, находить лица — дело техники. Такие алгоритмы известны, их много, они работают даже на маломощных Raspberry Pi
Строим модель по ключевым точкам
После того как алгоритм нашёл лицо, он строит его цифровую модель. Для этого он:
- Расставляет точки в ключевых местах: нос, рот, глаза, брови и так далее.
- Считает расстояние между точками.
- По этим расстояниям строит цифровую карту или вектор. Про векторы поговорим ниже.
Ключевые точки, которые расставил алгоритм
От того, как будут расставлены эти точки, зависит точность распознавания, поэтому каждая коммерческая компания держит свой метод в секрете. Чем больше точек — тем выше точность, но минимально нужно проставить 68 точек. Если точек будет меньше, алгоритм может не сработать.
Считаем вектор и сравниваем с базой
Когда все точки найдены, алгоритм считает вектор — математический результат обработки свойств этих точек. Например, он находит расстояние между глазами, форму носа, толщину губ, форму бровей, расстояния между ними и ещё массу других параметров. В результате получается набор чисел, который называется вектором.
Например, он находит расстояние между глазами, форму носа, толщину губ, форму бровей, расстояния между ними и ещё массу других параметров. В результате получается набор чисел, который называется вектором.
Если алгоритм работает в режиме «выучить новое лицо», то он записывает полученный вектор в базу данных с каким-то именем или идентификатором. Условно говоря, в базе это выглядит так:
«Вот здоровенный вектор из 900 чисел — я назову его Мишей»
Распознанные точки на лице и векторы, которые будет считать алгоритм
Другой режим работы алгоритма — сопоставление с эталоном. В базе данных уже есть один или несколько векторов, а задача алгоритма — сравнить их с новым вектором, который посчитали только что по картинке с камеры. Тогда алгоритм считает, насколько новый вектор отличается от тех, которые уже лежат в базе данных. Если этот вектор отличается достаточно мало, считаем, что мы распознали лицо.
На картинке видно, что синий неизвестный вектор, который мы хотим распознать, ближе всех находится к Мише. Если расстояние между векторами будет достаточно маленьким, алгоритм скажет, что человек в кадре — это Миша.
Если расстояние между векторами будет достаточно маленьким, алгоритм скажет, что человек в кадре — это Миша.
У каждого алгоритма свои коэффициенты совпадения: где-то допустимо совпадение только на 98% и выше — тогда алгоритм не будет вас узнавать, если вы в маске или вокруг плохое освещение. Есть алгоритмы, где совпадение может быть меньше — тогда это менее безопасно, но лучше работает. Есть алгоритмы, которые в одном месте требуют точного совпадения, а в других — менее точного (например, глаза должны совпасть точно, а рот может двигаться). Это уже нюансы настройки и подкрутки конкретного алгоритма.
Уточнение векторов и самообучение
Есть алгоритмы, которые уточняются и узнают вас всё лучше со временем. При каждом распознавании лица они видят, что в вас изменилось с прошлого раза, и уточняют свою модель. Например, вы занесли себя в базу данных с бодуна, а на следующий день пришли огурцом. Алгоритм запомнил вас в обоих состояниях.
Что дальше
Теперь, когда мы знаем, как работает эта технология, попробуем повторить это сами — сделаем систему распознавания лиц на Python.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Алексей Сухов
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Виталий Вебер
Как будут работать системы и алгоритмы распознавания лиц в 2022 году?
Создание надежной системы распознавания лиц, свободной от расовой и гендерной предвзятости, — непростая задача. В конце концов, алгоритмы не создают предвзятости. Мы делаем.
Рынок технологий распознавания лиц быстро растет. От аэропортов в Соединенных Штатах, использующих биометрические данные для проверки международных пассажиров, правоохранительных органов, использующих их для поимки преступников, и социальных сетей, использующих их для аутентификации пользователя, технология распознавания лиц является потребностью часа.
Последнее десятилетие было наполнено новыми современными алгоритмами, разработанными ведущими компаниями-разработчиками программного обеспечения, и новаторскими исследованиями в области глубокого обучения. Также были представлены новые алгоритмы компьютерного зрения. Все началось, когда AlexNet, глубокая сверточная нейронная сеть, достигла высокой точности в наборе данных ImageNet (набор данных с более чем 14 миллионами изображений) в 2012 году. Так что же такое программное обеспечение для распознавания лиц? Как это работает?
Также были представлены новые алгоритмы компьютерного зрения. Все началось, когда AlexNet, глубокая сверточная нейронная сеть, достигла высокой точности в наборе данных ImageNet (набор данных с более чем 14 миллионами изображений) в 2012 году. Так что же такое программное обеспечение для распознавания лиц? Как это работает?
Прежде чем мы углубимся в понимание того, как работает технология распознавания лиц, нам нужно понять, как мы распознаем лица.
Что такое система распознавания лиц?
Распознавание лиц — это технологический метод распознавания человеческого лица. Биометрия используется в системе распознавания лиц для сопоставления черт лица с фотографии или видео. Чтобы найти совпадение, он сравнивает информацию с базой данных известных лиц. Распознавание лиц может помочь в проверке личности человека, но также вызывает проблемы с конфиденциальностью.
Ожидается, что к 2022 году рынок распознавания лиц достигнет 7,7 миллиарда долларов по сравнению с 4 миллиардами долларов в 2017 году. Это связано с тем, что распознавание лиц имеет широкий спектр коммерческих приложений. Его можно использовать для различных целей, включая наблюдение и маркетинг.
Это связано с тем, что распознавание лиц имеет широкий спектр коммерческих приложений. Его можно использовать для различных целей, включая наблюдение и маркетинг.
Как люди узнают лицо?
Системы распознавания в нашем мозгу сложны. На самом деле ученые до сих пор пытаются это выяснить. Что мы можем предположить, так это то, что нейроны в нашем мозгу сначала идентифицируют лицо в сцене (от тела человека до его фона), мы извлекаем черты лица и сохраняем их в нашей собственной базе данных. Используя нашу память в качестве базы данных, мы можем затем классифицировать людей в соответствии с их особенностями. Мы прошли обучение на бесконечно большом наборе данных и бесконечно обширной нейронной сети.
Программное обеспечение распознавания лиц в машинах реализовано таким же образом. Во-первых, мы применяем алгоритм обнаружения лиц для обнаружения лиц в сцене, извлекаем черты лица из обнаруженных лиц и используем алгоритм для классификации человека.
Как работает система распознавания лиц?
Рабочий процесс программы распознавания лиц
1
Распознавание лиц
Обнаружение лиц — это специализированная версия Обнаружения объектов, в которой обнаруживается только один объект — Человеческое лицо.
Точно так же, как компромисс между временем и пространством вычислений в информатике, в алгоритмах машинного обучения также существует компромисс между скоростью логического вывода и точностью. Существует множество алгоритмов обнаружения объектов, и разные алгоритмы имеют свои недостатки в скорости и точности.
Мы оценили различные современные алгоритмы обнаружения объектов:
- OpenCV (Хаар-каскад)
- MTCNN
- YoloV3 и Yolo-Tiny
- SSD
- BlazeFace
- ShuffleNet и фейсбоксы
Чтобы создать надежную систему распознавания лиц, нам нужен точный и быстрый алгоритм, который будет работать как на графическом процессоре, так и на мобильном устройстве в режиме реального времени.
Точность
При выводе потокового видео в реальном времени люди могут иметь разные позы, окклюзии и световые эффекты на лице. Важно точно определять лица в различных условиях освещения, а также позы.
Обнаружение лиц в различных позах и при различных условиях освещения Так как эта библиотека написана на языке C. Это очень быстро для логического вывода в системах реального времени.
Минусы: Проблема с этой реализацией заключалась в том, что она не могла обнаружить боковые лица и плохо работала в разных позах и условиях освещения.
MTCNN
Этот алгоритм основан на методах глубокого обучения. Он использует глубокие каскадные сверточные нейронные сети для обнаружения лиц.
Плюсы: Он имел лучшую точность, чем метод OpenCV Haar-Cascade
Минусы: Более высокое время выполнения передовой алгоритм глубокого обучения для обнаружения объектов. Он имеет множество сверточных нейронных сетей, образующих модель Deep CNN. (Глубокий означает, что сложность архитектуры модели огромна).
Оригинальная модель Yolo может обнаруживать 80 различных классов объектов с высокой точностью. Мы использовали эту модель распознавания лиц Yolo для обнаружения только одного объекта — лица.
Мы использовали эту модель распознавания лиц Yolo для обнаружения только одного объекта — лица.
Мы обучили этот алгоритм на наборе данных WideFace (набор изображений, содержащий 393 703 меток лиц ).
Существует также миниатюрная версия алгоритма Yolo для распознавания лиц, Yolo-Tiny. Yolo-Tiny требует меньше времени для вычислений, ставя под угрозу его точность. Мы обучили модель Yolo-Tiny с тем же набором данных, но результаты граничных рамок не соответствовали друг другу.
Плюсы: Очень точный, без единого изъяна. Быстрее, чем MTCNN.
Минусы: Поскольку он имеет колоссальные уровни глубокой нейронной сети, ему требуется больше вычислительных ресурсов. Таким образом, он медленно работает на процессоре или мобильных устройствах. На графическом процессоре требуется больше видеопамяти из-за большой архитектуры.
SSD
SSD (Single Shot Detector) также является моделью глубокой сверточной нейронной сети, такой как YOLO.
Плюсы: Хорошая точность. Он может обнаруживать в различных позах, освещенности и окклюзиях. Хорошая скорость вывода.
Минусы: Уступает модели YOLO. Хотя скорость логического вывода была хорошей, она по-прежнему не подходила для работы на ЦП, слабом графическом процессоре или мобильных устройствах.
BlazeFace
Как и его название, это невероятно быстрый алгоритм распознавания лиц, выпущенный Google. Он принимает входное изображение размером 128×128. Его время вывода составляет субмиллисекунды. Этот алгоритм оптимизирован для использования в распознавании лиц на мобильных телефонах. Причины, по которым это происходит так быстро:
- Это специализированная модель детектора лиц, в отличие от YOLO и SSD, которые изначально создавались для обнаружения большого количества классов. Таким образом, BlazeFace имеет меньшую архитектуру глубокой сверточной нейронной сети, чем YOLO и SSD.
- Он использует Depthwise Separable Convolution вместо стандартных слоев Convolution, что приводит к меньшему количеству вычислений.
Плюсы: Очень хорошая скорость вывода и точное определение лиц.
Минусы: Эта модель оптимизирована для обнаружения изображений лица с камеры мобильного телефона, поэтому предполагается, что лицо должно занимать большую часть области изображения. Это не работает, когда размер лица маленький. Так что в случае с изображениями с камер видеонаблюдения это работает не очень хорошо.
Faceboxes
Последний используемый нами алгоритм распознавания лиц — Faceboxes. Как и BlazeFace, это глубокая сверточная нейронная сеть с небольшой архитектурой, предназначенная только для одного класса — человеческого лица. Его время вывода в режиме реального времени быстро на ЦП. Его точность сравнима с Yolo для распознавания лиц. Он может точно обнаруживать маленькие и большие лица на изображении.
Плюсы: Высокая скорость вывода и хорошая точность.
Минусы: Выполняется оценка.
2
Извлечение признаков
После обнаружения лиц на изображении мы обрезаем лица и передаем их алгоритму извлечения признаков, который создает встраивание лиц — многомерный (в основном 128 или 512-мерный) вектор, представляющий черты лица.
Мы использовали алгоритм FaceNet для создания вложений лиц.
Векторы встраивания представляют черты лица человека. Таким образом, векторы встраивания двух разных изображений одного и того же человека будут ближе, а другого — дальше. Расстояние между двумя векторами рассчитывается с помощью евклидова расстояния.
3
Классификация лиц
После получения векторов встраивания лиц мы обучили алгоритм классификации K-ближайшего соседа (KNN) для классификации человека по его вектору встраивания.
Предположим, в организации 1000 сотрудников. Мы создаем вложения лиц всех сотрудников и используем векторы встраивания для обучения алгоритма классификации, который принимает векторы встраивания лиц в качестве входных данных и возвращает имя человека.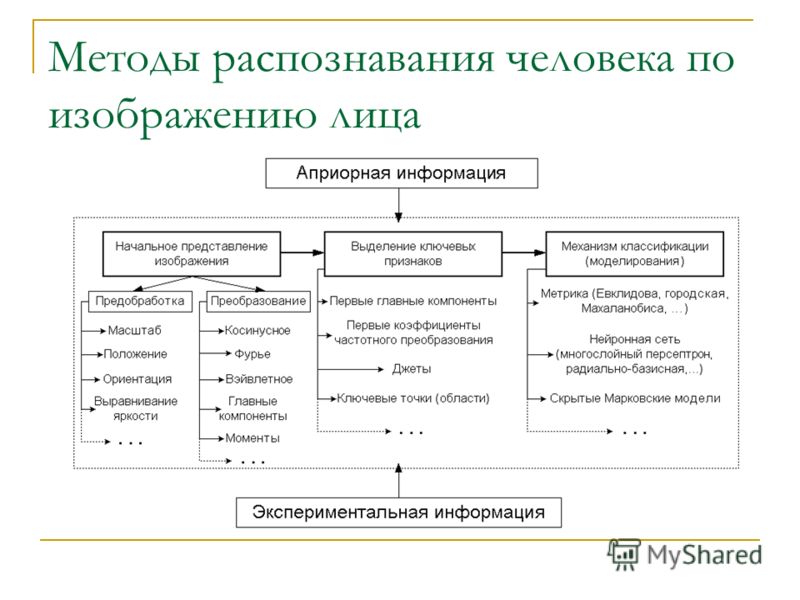
Пользователь может применить фильтр, который изменяет определенные пиксели изображения, прежде чем размещать его в Интернете. Эти изменения незаметны для человеческого глаза, но сбивают с толку алгоритмы распознавания лиц — ThalesGroup
Для чего предназначена система распознавания лиц?
Аэропорты
Людей, входящих и выходящих из аэропортов, можно отслеживать с помощью систем распознавания лиц. Эта технология использовалась Министерством внутренней безопасности для выявления людей, которые просрочили свои визы или находятся под уголовным расследованием.
Компании мобильной связи
Распознавание лиц впервые использовалось Apple для разблокировки iPhone X, а затем эта технология была перенесена на iPhone XS. Face ID подтверждает, что вы тот, за кого себя выдаете, когда получаете доступ к своему телефону. По данным Apple, вероятность того, что случайное лицо разблокирует ваш телефон, составляет один к миллиону.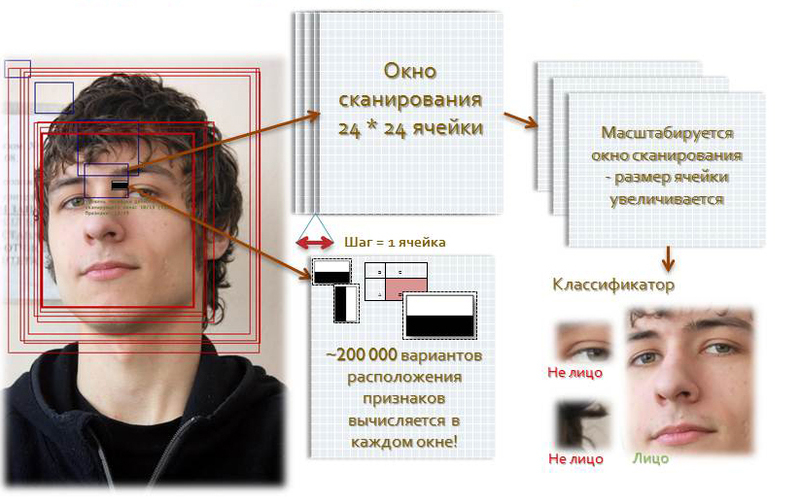
Колледжи и университеты
Фактически, программное обеспечение для распознавания лиц может сыграть свою роль. Ваш профессор может узнать, если вы пропустите урок. Даже не думай о том, чтобы твой сообразительный сосед по комнате сдавал экзамен.
Социальные сети
Когда вы загружаете фото на Facebook, он использует алгоритм для распознавания лиц. Если вы хотите отметить людей на своих фотографиях, компания социальной сети попросит вас об этом. Он может ссылаться на их профили и распознавать лица с точностью до 98%.
Маркетинговые и рекламные кампании
При маркетинге продукта или идеи маркетологи часто учитывают такие факторы, как пол, возраст и этническая принадлежность. Даже на концерте распознавание лиц можно использовать для идентификации конкретной аудитории.
Новые технологии открывают новые возможности
Развитие систем распознавания лиц и компьютерного зрения совершило огромный скачок. Но это только начало технологической революции. Представьте, насколько мощным будет дуэт алгоритмов распознавания лиц и технологии чат-ботов!
Представьте, насколько мощным будет дуэт алгоритмов распознавания лиц и технологии чат-ботов!
Никогда не поздно стать частью этого движения.
Алгоритмы распознавания лиц с двумя различными методами
Изображение автора
Компьютерное зрение копирует форму человеческого зрения с помощью компьютерных технологий и алгоритмов, а также мощности данных. Согласно последним разработкам каждого, приложения компьютерного зрения становятся все более популярными и входят в нашу жизнь.
Содержание · Введение
· Пример приложений компьютерного зрения
· Почему Python?
· Алгоритм гистограммы градиентов
∘ Поиск лиц
∘ Поиск ориентиров лица
∘ Коды нахождения ориентиров лица
∘ Рисование линий ориентиров лица
∘ Нумерация лиц
∘ Назовите человека по этим номерам 90 Сравнение лица с ☘ Hog Method
∘ Распознавание лиц в веб-камере
· Алгоритм обнаружения объектов
∘ Что такое Haarcascade?
∘ Важное напоминание: проверка версии
∘ Train-Test Split
∘ Загрузка Haarcascade
∘ Распознавание лиц на изображениях с помощью алгоритма обнаружения объектов
· Заключение
Здравоохранение : В соответствии с увеличением объема данных многие приложения CV были изобретены в отрасли здравоохранения. Примеры: Обнаружение опухоли, Медицинская визуализация, Обнаружение рака, и этот список можно продолжить.
Примеры: Обнаружение опухоли, Медицинская визуализация, Обнаружение рака, и этот список можно продолжить.
Безопасность : Используя распознавание лиц в камерах наблюдения в различных секторах, охранные фирмы и местные органы власти используют преимущества приложений CV.
Автономные транспортные средства : В настоящее время автономные транспортные средства очень популярны. Начиная с Tesla, многие другие компании пытаются разработать свой автономный автомобиль, чтобы идти в ногу с технологиями будущего. Логика, лежащая в основе этих систем, также является одним из приложений CV, которые постоянно работают вокруг автомобиля, пока он находится в автономном режиме.
Распознавание лиц : Распознавание лиц — одно из самых крутых приложений CV.
Если вы используете Facebook или новое имя Meta на каком-то уровне, вы также должны быть знакомы с распознаванием лиц. Одним из популярных приложений для распознавания лиц является тот, который использует Facebook.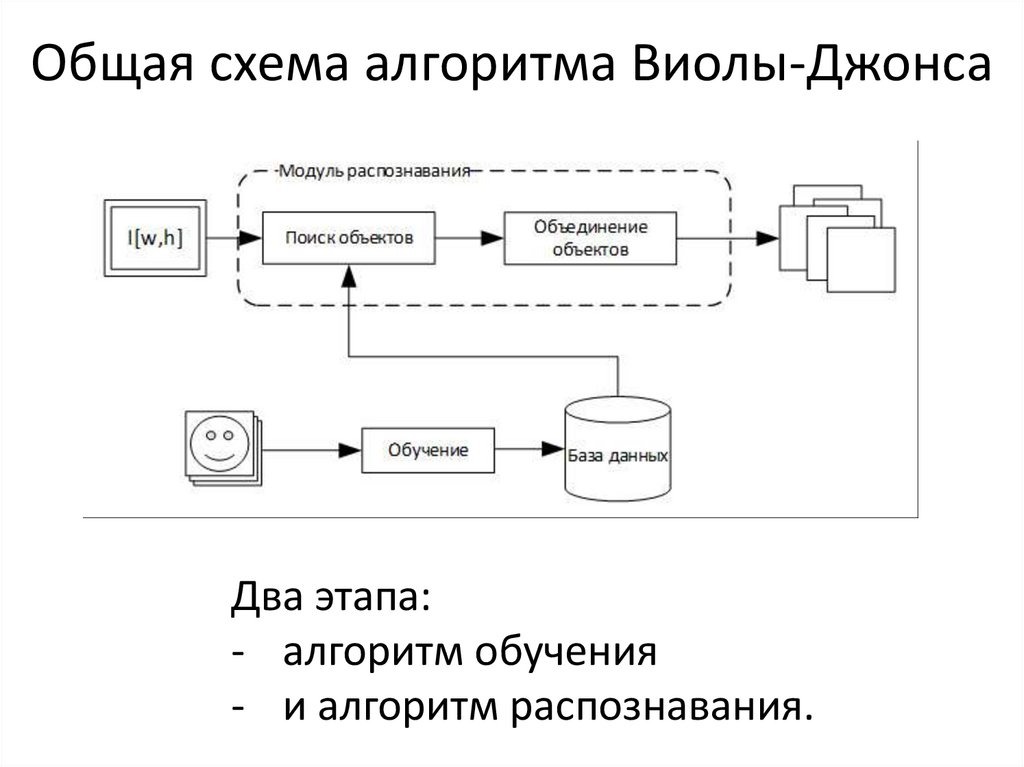
Источник: TechCrunch
Кроме того, эта технология входит в нашу жизнь и через наши телефоны. При использовании библиотеки фотографий на iPhone вы также можете увидеть следующую функцию.
Кредит
Распознавание лиц — популярное приложение компьютерного зрения.
Непонятна логика этих приложений.
В этой статье я объясню вам 2 известных метода распознавания лиц и их применение, коды и важные вещи, на которые следует обратить внимание перед применением этих моделей в Python.
В результате своей растущей популярности и простоты использования Python с течением времени становится все более и более популярным языком программирования.
Вот одно из исследований, проводимых O’Reilly, чтобы показать растущую популярность Python и его сравнение с другими языками.
Ссылка
Гистограмма алгоритма градиентов была создана Навнит Далал и Биллом Триггсом в 2005 году. Этот метод является дескриптором функции и используется в компьютерном зрении для обнаружения объектов.
Теперь делю на 4 раздела приложения HOG в Face Recognition.
- Поиск лиц
- Поиск лицевых ориентиров
- Нумерация лиц
- Назовите человека по этим номерам
Поиск лиц
Чтобы найти лица на изображении, мы рассмотрим каждый пиксель изображения. время.
Для каждого отдельного пикселя. посмотрите на пиксели, которые непосредственно его окружают.
Основная цель — выяснить, в каком направлении изображение становится темнее, и затем провести стрелку к этому пикселю.
Когда вы выполняете это действие снова и снова для каждого пикселя изображения, вы увидите, что каждый пиксель заменяется стрелкой.
Эти стрелки представляют собой «градиенты». Они показывают переход от светлого к темному.
Затем мы взяли по 16×16 пикселей и определили основные стрелки на картинке.
В результате получаем картинку Борова.
Теперь давайте посмотрим на эти примеры как на изображение астронавта Эллен Коллинз, сделанное в виде кабана.
Описание: Визуализация особенностей HOG изображений астронавта Эйлин Коллинз Ссылка
Как превратить ваши фотографии в изображения HOG?
Это легко применить, следуя коду на Python.
После этого по схеме HOG находим лица с картинки.
Источник: Поиск лица. Поиск лица.
. Поиск лицевых ориентиров.
Как видно из этих точек, например, с 36 по 41 виден правый глаз, или с 0 по 16 видна челюсть, или с 27 по 36 нос, полный список;
- Челюсть = 0–16
- Правая бровь = 17–21
- Левая бровь = 22–26
- Нос = 27–35
- Правый глаз = 36–41
- Губы = 61–67
Левый глаз Рот = 48–60
Источник: Ориентиры лица
Коды определения ориентиров лица
Рисование линий ориентиров лица
Источник: Николь Кидман
Нумерация лиц
Для кодирования лиц, во-первых, важно символизировать их кучей цифр. Для этого я использовал библиотека распознавания лиц .
128 Измерения, сгенерированные из изображения.
Источник: Reference
После получения этих измерений мы сравниваем эти результаты, чтобы определить или сравнить лица.
Назовите человека из этих номеров
В этом процессе мы определим человека из кодировок в соответствии с нашим первым определением.
Теперь будет лучше использовать библиотеку Адама Гейтгейса, которая также даст широкое определение этого метода в своей статье.
Источник: Ссылка
Для определения мы применим алгоритм классификации машинного обучения, который является алгоритмом машины опорных векторов.
Если вы знакомы с компьютерным зрением или машинным обучением, вы наверняка знаете алгоритм SVM, который использует для классификации.
Благодаря этому можно различать измерения и можно сказать, относятся ли измерения к данному человеку или нет.
Сравнение лица с методом свиньи
Этот алгоритм даст вам результат сравнения двух разных фотографий.
Первое, что мы сделаем, это загрузим изображение и преобразуем его в RGB, потому что мы получаем изображение PGR, и библиотека понимает его в RGB, поэтому мы должны его преобразовать.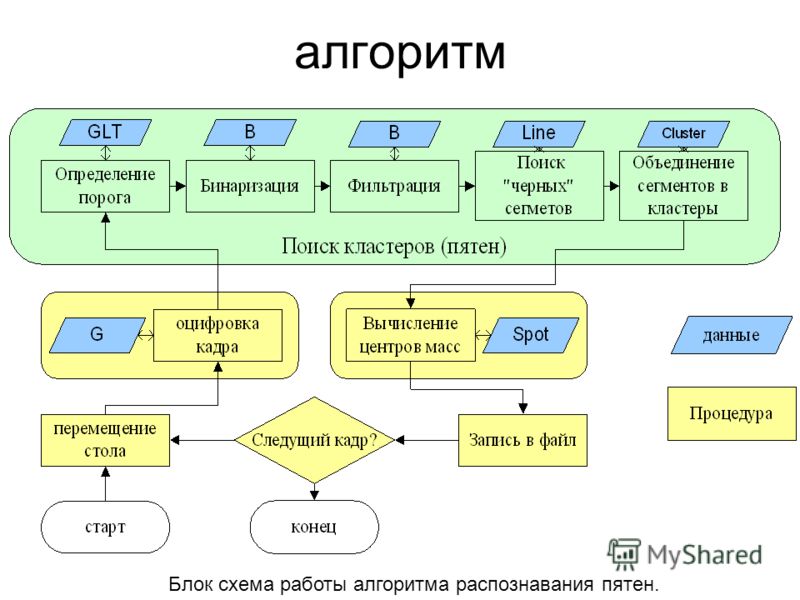
Важное примечание: Не забудьте установить библиотеку dlib 19.18, чтобы было меньше ошибок при применении кодов.
Шаги:
Мы обучим и получим кодировку нашего обычного изображения, затем мы собираемся использовать наше тестовое изображение.
Мы выберем наше изображение, процесс выбора зависит от того, сколько изображений вы загрузите, если у вас есть более одного и выберите его, вы должны использовать слайсер.
Если вы хотите выбрать первый, вы должны использовать обозначение «[0]», чтобы быть уверенным.
Затем мы закодируем обнаруженное лицо.
Далее мы нарисуем прямоугольник вокруг лица, вы можете различать толщину, цвет или размер прямоугольника, изменяя значения кодов.
После того, как мы нашли лица и нарисовали вокруг них прямоугольник, пришло время сравнить лица.
Для этого пришло время применить SVM. Когда расстояние между двумя измерениями невелико, это означает, что они могут быть совпадением, поскольку это указывает на сходство.
Наконец, если вы хотите поместить текст вокруг лиц, которые говорят, что совпадение истинно или ложно, вы можете использовать метод puttext , конечно, вы можете изменить размер или цвет текста в соответствии с вашими пожеланиями.
Полный код;
Теперь пришло время применить коды между двумя известными людьми.
Как мы видим, когда число между двумя картинками увеличивается, это означает, что сходства здесь нет.
Фото предоставлено автором
В отличие от этого, поскольку число уменьшается, это означает, что между двумя фотографиями существует неоспоримое сходство, которое может быть одним и тем же человеком, которого мы видим в примере.
Фото предоставлено автором
Распознавание лиц в веб-камере
Вот полный код распознавания лиц в веб-камере с библиотекой распознавания лиц.
Фото предоставлено автором
Алгоритм использует функции обнаружения границ или линий, созданные Полом Виолой и Майклом Джонсом.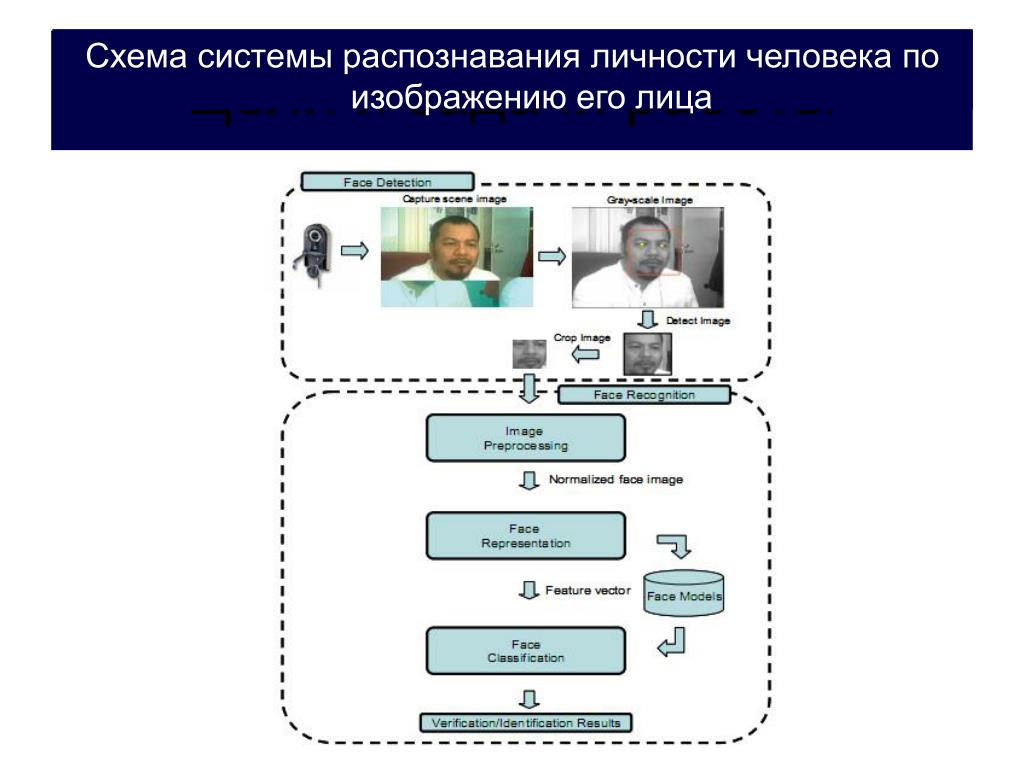
Что такое Haarcascade?
Haarcascade — это алгоритм обнаружения объектов, используемый для распознавания лиц на изображении или видео.
Алгоритм использует функции обнаружения границ или линий, созданные Полом Виолой и Майклом Джонсом в исследовательской статье 9.0003
Важное напоминание: проверка версии
При использовании haarcascade с opencv to face крайне важно загрузить библиотеку opencv_contrib_python, чтобы можно было использовать face.LBPHFaceRecognizer_create.
Поскольку библиотека opencv_python не включает face.LBPHFaceRecognizer_create.
Train-Test Split
Пожалуйста, создайте две папки с картинками в вашем рабочем каталоге, сначала алгоритм будет обучать, а потом тестировать его по результату поезда.
поезд
test
Загрузка Haarcascade
Загрузите haarcascade в формате xml в свой рабочий каталог, если это возможно, для загрузки;
- Откройте его в необработанном формате
- Нажмите Ctrl+A, а затем Ctrl+V или для Mac Command+A и Command+V
- Создайте новый файл в своем каталоге с помощью интерпретатора Python. Я рекомендую Anaconda-Spyder, потому что у меня возникла проблема при загрузке face.LBPHFaceRecongizer.create с помощью PyCharm CE.
- Вставьте его в файл и сохраните.
- Вы будете использовать его в своем коде.
- В более новых версиях OpenCV haarcascades вы можете установить его с помощью
 Я рекомендую Anaconda-Spyder, потому что у меня возникла проблема при загрузке face.LBPHFaceRecongizer.create с помощью PyCharm CE.
Я рекомендую Anaconda-Spyder, потому что у меня возникла проблема при загрузке face.LBPHFaceRecongizer.create с помощью PyCharm CE.Код
Распознавание лиц на изображениях с алгоритмом обнаружения объектов
Это будет немного долго, но я думаю, что это будет намного полезнее, вот полный код и объяснение распознавания лиц на картинках с помощью алгоритма обнаружения объектов.
Фото предоставлено автором
Я провел это исследование в результате данного мне задания относительно одного из моих заявлений о приеме на работу. После этого исследования и моей заявки генеральный директор этой компании лично написал мне по электронной почте и поблагодарил меня за мое исследование, и он сказал, что ему очень понравилось это.
Тогда я подумал, что, возможно, я согласился на эту работу, но, похоже, это была неоплачиваемая стажировка, и поэтому я отказался.