Содержание
Как работает искусственный интеллект в области литературного перевода
Когда в 2006 году был запущен Google Translate, он имел в арсенале только два языка перевода. В 2016 году уже было более 103 языков, и он переводил более 100 миллиардов слов в день. Система может не только переводить, но и транскрибировать в режиме реального времени восемь наиболее распространенных языков. Машины учатся, и учатся они очень быстро.
Алана Куллен
Тем не менее, есть некоторые лингвистические коды, которые этим машинам все еще предстоит взломать. Искусственный интеллект продолжает бороться с огромной сложностью человеческого языка, и нигде язык не является таким сложным и значимым, как в литературе. В романах, стихах и пьесах красота слов порою заключается в нюансах и деталях. Машины переводят слово в слово, следуя при этом установленным лингвистикой правилам, поэтому традиционные системы перевода часто не понимают значения литературных текстов. Они не понимают переводимое слово в контексте предложения, параграфа или страницы.
Но есть новая технология, способная разобраться в этом контекстуальном хаосе — Neural Machine Translation (нейронный машинный перевод), сокращенно называемый НМП. Хотя НМП все еще находится в зачаточном состоянии, он уже доказал, что его системы со временем научатся справляться с присущей литературным переводам сложностью. НМП знаменует собой начало новой эры искусственного интеллекта. Он больше не работает по правилам, установленным лингвистами, теперь он создает свои собственные правила и даже свой собственный язык.
НЕЙРОННЫЙ МАШИННЫЙ ПЕРЕВОД (НМП)
НМП появился в 2016 году. На сегодняшний день это самое успешное программное обеспечение для перевода. Помимо того, что он смог снизить погрешность на 60 % — по сравнению со своим предшественником, статистическим машинным переводом (СМП), НМП также значительно быстрее работает.
Улучшения обеспечиваются искусственной нейронной сетью системы. Это значит, что НМП базируется на модели нейронов, созданной по подобию существующей в мозге человека. Эта сеть позволяет программному обеспечению создавать контекстные связи между словами и фразами. Она может создавать эти связи, изучая языковые правила. Она сканирует миллионы блоков из вашей базы данных, определяя общие черты. Затем машина использует заученные правила для создания статистических моделей, которые помогут ей понять, каким образом должно строиться предложение.
Эта сеть позволяет программному обеспечению создавать контекстные связи между словами и фразами. Она может создавать эти связи, изучая языковые правила. Она сканирует миллионы блоков из вашей базы данных, определяя общие черты. Затем машина использует заученные правила для создания статистических моделей, которые помогут ей понять, каким образом должно строиться предложение.
Искусственная нейросеть. Исходный код вводится в сеть, затем отправляется в различные скрытые „слои” сети и выводится на целевом языке. | Алана Куллен | CC-BY-SA
ИСКУССТВЕННЫЙ ЯЗЫК
Новаторской особенностью НМП является создание нового языка чисел, который помогает при переводе.
Как, например, выглядит фраза «To thine own self be true» из шекспировского «Гамлета»? Машина кодирует каждое слово в число, в так называемые векторы: 1, 2, 3, 4, 5, 6. Этот числовой ряд передается в нейронную сеть, как показано по ссылкам. И далее в этих скрытых слоях происходит «магия». Опираясь на изученные языковые правила, система находит подходящие слова в языке перевода. Генерируются числа 7, 8, 9, 10, 11, соответствующие словам целевого предложения. Затем эти числа расшифровываются и в результате преобразуются в предложение: «Быть верным себе».
И далее в этих скрытых слоях происходит «магия». Опираясь на изученные языковые правила, система находит подходящие слова в языке перевода. Генерируются числа 7, 8, 9, 10, 11, соответствующие словам целевого предложения. Затем эти числа расшифровываются и в результате преобразуются в предложение: «Быть верным себе».
По сути, система переводит слова на свой собственный язык, а затем «думает» о том, как, основываясь на том, что она уже знает, она может придать этим словам форму понятного предложения — так, как это сделал бы человеческий мозг.
ПОНИМАНИЕ КОНТЕКСТА
НМП может успешно переводить литературу, поскольку он медленно, но верно понимает контекст. Система фокусируется не только на переводимом слове, но и на словах, стоящих перед ним и за ним.
Как и мозг, расшифровывающий различную информацию, эта искусственная нейронная сеть смотрит на получаемую информацию и генерирует следующее слово на основе предыдущего. Со временем она выучит, на каких словах следует сосредоточиться и, опираясь на существующие примеры, определит, какой контекст имеет основополагающее значение. Этот метод представляет собой один из видов многоуровневого обучения и способствует тому, что система заучивает все больше и больше данных и постоянно совершенствуется. В НМП расшифровка контекста называется «выравниванием», оно происходит с помощью механизма Attention («Внимание»), который занимает в системе промежуточное место между шифрованием и дешифрованием.
Со временем она выучит, на каких словах следует сосредоточиться и, опираясь на существующие примеры, определит, какой контекст имеет основополагающее значение. Этот метод представляет собой один из видов многоуровневого обучения и способствует тому, что система заучивает все больше и больше данных и постоянно совершенствуется. В НМП расшифровка контекста называется «выравниванием», оно происходит с помощью механизма Attention («Внимание»), который занимает в системе промежуточное место между шифрованием и дешифрованием.
Процесс адаптации. Адаптация происходит с помощью механизмов внимания искусственной нейронной сети и делает выводы о контексте слова. | Алана Куллен | CC-BY-SA
Но и машины не совершенны. Когда шекспировская фраза переводится обратно на английский язык, она звучит как «Be true to yourself», что не соответствует тону языка Шекспира и эпохи Тюдоров. Литературный перевод, выполненный слово в слово, звучит как «будь верен своему я», но «живые» переводчики больше склонны переводить эту фразу как «будь верен себе».
Перевод, созданный людьми. Если предложения переведены человеком, соотношения намного сложнее, чем при переводах искусственного интеллекта. Это связано с тем, что люди лучше понимают контекст. | Алана Куллен | CC-BY-SA
Но интересно уже даже то, что Google Translate увидел важность в этом контексте слова «верен». То, что он использовал именно это слово, доказывает, что он смог различить разницу между словами «верный» и «истинный». Многоуровневое обучение означает, что неправильно переведенное предложение может быть переведено правильно, по крайней мере, частично, уже ечерез несколько недель. (Возможно, Google Translate уже исправил свои ошибки к моменту публикации этой статьи.)
Постоянное совершенствование с учетом развития собственного языка означает, что НМП может использоваться для выполнения так называемых переводов Zero-Shot (при отсутствии примеров переводов). Это означает, что он может переводить с одного языка сразу на несколько других языков без использования английского языка в качестве промежуточного варианта. Как и в случае с людьми, к машинам, по-видимому, также применима фраза «Практика приводит к совершенству».
Как и в случае с людьми, к машинам, по-видимому, также применима фраза «Практика приводит к совершенству».
Lost in Translation —
ПОТЕРЯНО ПРИ ПЕРЕВОДЕ
Несмотря на то, что машинный перевод в последние годы уже сделал большие шаги, ему пока не удается достичь литературного стандарта. Генри Джеймс подчеркивал важность понимания текста на языке оригинала, заметив, что идеальным литературным переводчиком должен быть «человек, от которого ничто не ускользает». По крайней мере, в случае с литературой машинам, чтобы соответствовать этому идеалу, предстоит пройти еще очень длинный путь.
При выполнении литературных переводов у НМП возникают проблемы с редкими словами, именами собственными и сложным техническим языком. Только 25-30 % переводов соответствуют литературному стандарту. Соответствующее исследование, посвященное переводу с немецкого на английский язык, показало, что, хотя система и допускала мало синтаксических ошибок, она часто не находила адекватного перевода для многозначных слов. Несмотря на эти ошибки, по мнению исследователей, качество перевода было достаточным, чтобы понять историю и насладиться ею. Другое исследование, посвященное переводам с английского на каталонский язык, показало столь же хороший результат. 25 % носителей языка обнаружили, что качество машинного перевода вполне сопоставимо с переводом, выполненным человеком.
Несмотря на эти ошибки, по мнению исследователей, качество перевода было достаточным, чтобы понять историю и насладиться ею. Другое исследование, посвященное переводам с английского на каталонский язык, показало столь же хороший результат. 25 % носителей языка обнаружили, что качество машинного перевода вполне сопоставимо с переводом, выполненным человеком.
Однако система перевода не всегда добивается таких хороших результатов. В некоторых языковых парах ей приходится бороться с языками с богатой морфологией, в которых серьезную роль играют словоизменение и интонация. И это в первую очередь касается славянских языков. И особенно бросается в глаза, если вы переводите с менее сложного языка на более сложный. Поэтому НМП пока еще не может использоваться в качестве глобального инструмента перевода.
КАК НАЙТИ ПОДХОДЯЩИЙ СТИЛЬ?
Самая большая проблема заключается в том, чтобы найти для переводимого текста правильный стиль и слог. Питер Константин, директор программы литературного перевода в университете Коннектикута, объяснил, что для успешного перевода литературы машины тоже должны найти подходящий стиль.
Питер Константин, директор программы литературного перевода в университете Коннектикута, объяснил, что для успешного перевода литературы машины тоже должны найти подходящий стиль.
«Чему подражает машина? Стремится ли она к блестящей иностранной интерпретации, первоклассно проводящей культурную составляющую? Или язык Чехова покажется таким, как если бы текст был написан десять минут назад в лондонском метро?»
Какой стиль выберет машина? К примеру, рассмотрим обратимся к работам немецкого нобелевского лауреата Томаса Манна. С годами стиль его письма менялся: ранние рассказы были более игривыми, что существенно отличает их слог от поздних, более сложных романов. Если стоит цель уловить точный смысл, машины должны уметь распознавать эти отличия.
ВАЖНАЯ СОВМЕСТНАЯ РАБОТА
Становится ясно, что, несмотря на все свои усилия, учитывая специфическую двусмысленность слов и гибкость литературного языка, машина все еще нуждается в человеческом руководстве.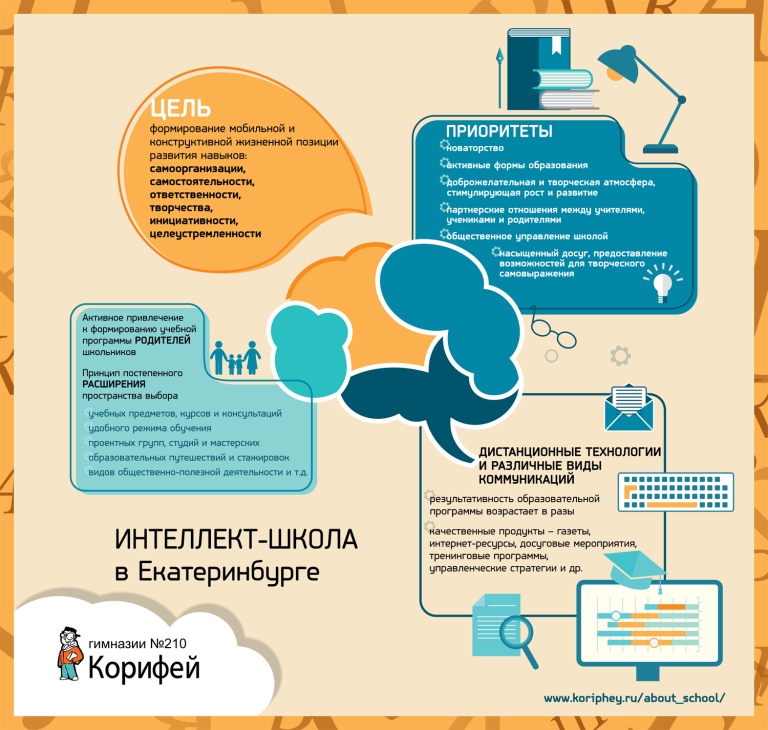 НМП не может заменить живых переводчиков, но может стать полезным инструментом при переводе литературы.
НМП не может заменить живых переводчиков, но может стать полезным инструментом при переводе литературы.
При этом важно взаимодействие между переводами, выполняемыми машиной и человеком. Одним из ответов на данный вопрос может быть постобработка машинного перевода. В данном случае профессиональные переводчики, разбирающиеся в проблемах машинного перевода, могут отредактировать первичную версию машинного перевода — как более опытные коллеги поддерживают своих не очень опытных коллег. Простая постобработка поможет исправить незначительные орфографические ошибки и улучшить грамматику, а углубленное редактирование позволит решить более серьезные проблемы, такие как структура предложений и стиль речи. В литературных переводах обязательна обработка, позволяющая найти правильный стиль перевода. Одно исследование показало, что этот метод оказался на 31 % быстрее при переводе научно-фантастического романа с гэльского на ирландский язык, чем перевод без использования какого-либо программного обеспечения. Кроме того, производительность переводчиков, которые в качестве отправной точки использовали машинный перевод, выросла на 36 %. С помощью этого метода они генерировали за один час на 182 слова больше.
Кроме того, производительность переводчиков, которые в качестве отправной точки использовали машинный перевод, выросла на 36 %. С помощью этого метода они генерировали за один час на 182 слова больше.
Искусственный интеллект играет все большую роль в нашей жизни, и следует использовать этот инструмент перевода для развития отрасли. Машинный перевод прошел большой путь — от самых азов до отличного вспомогательного инструмента. Программное обеспечение делает мелкую неприятную работу, в то время как переводчики могут посвятить себя чистовой отделке. Это ведет к снятию нагрузки на переводчиков. К тому же, НМП также позволяет переводить с языков, переводы с которых ранее никогда не осуществлялись. Кроме того, НМП может помочь выучить язык. Во время работы мы можем использовать его в качестве обучающего инструмента — ведь он для всех обеспечивает оптимальный доступ к языку и литературе.
Материал является частью проекта Гёте-Института Великобритании, посвящённого искусственному интеллекту и литературному переводу.
Источники:
Brownlee, J. 2017. A Gentle Introduction to Neural Machine Translation. [Accessed 9th July 2020].
Constantine, P. 2019. Google Translate Gets Voltaire: Literary Translation and the Age of Artificial Intelligence. Contemporary French and Francophone Studies. 23(4), pp. 471- 479.
Goldhammer, A. 2016. The Perils of Machine Translation. The Wire. [Accessed 14th July 2020].
Google Brain Team. 2016. A Neural Network for Machine Translation, at Production Scale. [Accessed 9th July 2020].
Gu, J., Wang, Y., Chu, K., Li. V. O. K. 2019. Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations.arXiv. [Accessed 10th July 2020].
Iqram, S. 2020. Now you can transcribe speech with Google Translate. [Accessed 9th July 2020].
Jones, B., Andreas, J., Bauer, D., Hermann, K. M., and Knight, K. 2012. Semantics- Based Machine Translation with Hyperedge Replacement Grammars. Anthology. 12(1083), pp. 1359- 1376.
Anthology. 12(1083), pp. 1359- 1376.
Kravariti, A. 2018. Machine Translation: NMT translates literature with 25% flawless rate. Translate Plus. [Accessed 14th July 2020].
Matusov, E. 2019. The Challenges of Using Neural Machine Translation for Literature. European Association for Machine Translation: Dublin, Ireland.
Maučec, M. S., and Donaj, G. 2019. Machine Translation and the Evaluation of Its Quality Recent Trends in Computational Intelligence. Intech Open.
Shofner, K. 2017. Statistical vs. Neural Machine Translation. ULG’s Language Solutions Blog. [Accessed 10th July 2020].
Systran. 2020. What is Machine Translation? Rule Based Translation vs. Statistical Machine Translation. [Accessed 9th July 202].
Toral, A., Wieling, M., and Way, A. 2018. Post-editing Effort of a Novel with Statistical and Neural Machine Translation. Frontiers in Digital Humanities. 5(9).
Turovsky, B. 2016. Ten years of Google Translate. [Accessed 9th July 2020].
[Accessed 9th July 2020].
Wong, S. 2016. Google Translate AI invents its own language to translate with. New Scientist. [Accessed 11th July].
Yamada, M. 2019. The impact of Google Neural Machine Translation on Post-editing by student translators. The Journal of Specialised Translation. 31, pp. 87- 95.
Zameo, S. 2019. Neural Machine Translation: tips and advantages for your digital translations. Text Master Go Global. [Accessed 14th July 2020].
Как повысить интеллект систем машинного перевода и отучить путать продукты? / Хабр
Всем привет!
В ходе обсуждения возможных сценариев применения представления смысла документа через действия нам сообщили интересную проблему, с которой сталкиваются пользователи общедоступных систем машинного перевода при работе с не англоязычными текстами. Например, фраза
«Груша мне понравилась больше, чем кислое яблоко, так как она была слаще» переводится на немецкий язык одной из самых известных он-лайн систем так
«Ich mochte die Birne lieber als den sauren Apfel, da er süßer war»
(Мне больше понравилась груша, чем кислое яблоко, так как оно было слаще):
что нарушает смысл и делает яблоко вдобавок еще и сладким – «er süßer war». Разбор проблемы и потенциальное решение — далее.
Разбор проблемы и потенциальное решение — далее.
Проблема
На данный момент к машинному переводу применяются статистический и нейросетевой подходы (согласно материалам на сайте yandex.ru), с помощью которых на массивах данных обучают систему – в какой ситуации какое слово или сочетание что может означать.
Одним из минусов данного подхода, является то, что огромная часть этих массивов данных содержит английский текст, в котором хоть и присутствует разделение слов по родам, но в достаточно ограниченном виде по сравнению с русским, немецким, французским или иными языками.
Учитывая, что за одним и тем же словом, выражающим понятие, в разных языках может быть закреплен разный род, то при обработке местоимений (он/er, она/sie, они/es, его/ihn и т.д.) существует риск возникновения коллизии и искажения смысла.
Из примера выше — «Яблоко», в русском языке отнесенное к среднему роду («оно»), в немецком «Apfel» относится к мужскому («er»).
Вот проиллюстрированный разбор примера из вступления, где цветом обозначены ключевые объекты предложения:
Рис. 1 Иллюстрация перевода
1 Иллюстрация перевода
Таким образом видно, что машинный перевод на основе статистики и весов нейросетей решил присвоить параметр «сладкий» объекту «Яблоко». При этом, семантически корректным переводом была бы фраза
«Ich mochte die Birne lieber als den sauren Apfel, da sie süßer war».
Данный пример не кажется критическим – всего лишь неправильно отнесено свойство. Однако все та же проблема может повлиять на корректность исполнения договоренностей, как в следующем примере:
«В ходе совещания стороны обсудили Программу и Контракт, а также договорились его подписать до 20.01.2021»,
который машинный перевод обработал следующим образом:
«Während des Treffens diskutierten die Parteien das Programm und den Vertrag und vereinbarten auch, diese bis zum 20.01.2021 zu unterzeichnen»
(В ходе встречи стороны обсудили Программу и Контракт и договорились их до 20.01.2021 подписать),
искажая смысл в части итоговой договоренности – в результате перевода должны быть подписаны оба документа, а не только Контракт.
Да, другой известный он-лайн переводчик также допускает ошибку в данной конструкции, но уже предписывает необходимость подписать не Контракт, а Программу
Причина и возможное решение
Причиной происходящего является то, что автоматические переводчики не работают с уровнем понятий переводимого текста, а ограничиваются уровнем слов. Можно сказать, что они не понимают смысла обрабатываемого текста.
Одним из возможных вариантов решения данной проблемы видится применение подхода, обеспечивающего работу не с буквальным представлением документа или предложения, а дополнительно и с его смысловой составляющей.
Например, решение по декомпозиции текста через действия проекта RealAI построит следующую семантическую модель фразы
«Груша мне понравилась больше, чем кислое яблоко, так как она была слаще»
Рис.2 Фрагмент семантической модели фразы
Отнесение местоимения «она» к объекту «Груша» будет произведено семантическим анализатором на основе поиска подходящего по роду и числу объекта из всего перечня выявленных во фразе объектов (Мне(Я), Груша и Яблоко).
В смысловой модели легко увидеть привязку местоимения «она» к существительному «груша», а вовсе не к «яблоку», что позволяет реализовать либо проверку корректности перевода (путем сравнения моделей исходного и целевого языка), либо произвести корректное формирование фразы на целевом языке.
Заключение
Безусловно, практическое внедрение построения семантической модели текста требует на данный момент решения многих задач, в частности по объему базы знаний анализатора и оптимизации производительности, однако без реализации представления в каком-либо виде смысла текста, задача качественного и точного перевода вряд ли может быть решена.
Подход RealAI по декомпозиции текста предлагает один из вариантов представления смысла. Реализованные демо-сценарии (извлечение данных из неформатированного текста, подготовка списка поручений) позволяет говорить о практической реализуемости подхода.
Если хабрапользователи сталкивались с иными проблемами, для которых необходим именно смысл обрабатываемой информации – прошу писать или комментировать для проработки тестовых сценариев.
Влияние искусственного интеллекта на переводческую отрасль
23 декабря 2021 г. | ИИ и машинный перевод, деловой перевод
ИИ быстро меняет наш взгляд на мир и взаимодействие с ним и может изменить наш образ жизни. Один из самых удивительных эффектов искусственного интеллекта проявляется в сфере переводов. Благодаря гаджетам и программному обеспечению с искусственным интеллектом общаться с другими людьми и интерпретировать информацию с разных языков стало намного проще.
По данным Statista, мировой рынок программного обеспечения для искусственного интеллекта вырос на 54 процента в 2021 году. Кроме того, масштабы этой технологии настолько велики, что объем ее рынка достигнет 22,6 миллиарда долларов в период с 2019 по 2025 год. Если вы увлечены языками и хотите узнать больше об использовании ИИ для улучшения качества перевода, читайте дальше, чтобы узнать больше.
Изменит ли ИИ перевод? Самые инновационные гаджеты и программное обеспечение
Развитие технологий означает появление новых устройств и компьютерных программ, упрощающих человеческое общение. Языки и культуры больше не будут иметь многих ограничений. С искусственным интеллектом перевод выполняется быстрее, как для профессиональных переводчиков, так и для туристов. Таковы некоторые из ключевых технологических инноваций в этой области.
Языки и культуры больше не будут иметь многих ограничений. С искусственным интеллектом перевод выполняется быстрее, как для профессиональных переводчиков, так и для туристов. Таковы некоторые из ключевых технологических инноваций в этой области.
Google Neural Machine translation
Google Neural Machine — это технология искусственного интеллекта от интернет-компании, которая использует глубокое обучение для получения более качественных переводов. Это программное обеспечение выполняет перевод между двумя разными языками без установления прямого соединения. Интеллектуальная база данных позволяет извлекать шаблоны сравнения для каждого слова.
Ключом к этой программе является нулевая система перевода. С этим элементом перевод выполняется намного быстрее, поскольку он поддерживает словари 100 языков, зарегистрированных в Google Translate.
Voice Translator
Google Translator, самое известное в мире программное обеспечение для перевода, представляет собой платформу с полезной функцией, основанной на искусственном интеллекте. Приложение имеет голосовую команду, которая слушает слова говорящего для перевода длинных предложений. Кроме того, эта опция позволяет транскрибировать любое слово, которое вы говорите, в микрофон вашего смартфона на том же или другом языке.
Приложение имеет голосовую команду, которая слушает слова говорящего для перевода длинных предложений. Кроме того, эта опция позволяет транскрибировать любое слово, которое вы говорите, в микрофон вашего смартфона на том же или другом языке.
Автоматический перевод субтитров
Автоматический перевод субтитров — одно из самых простых технологических нововведений, которое можно использовать для переводов, реализованных с помощью искусственного интеллекта. Платформа SRT — одна из самых популярных систем в Интернете, предназначенная для хранения субтитров к сериалам и фильмам. Универсальность этой системы позволяет переводить субтитры с любого языка на испанский и английский языки.
Google Lens
Устройства виртуальной реальности — главный признак ускорения развития технологий в ближайшие несколько лет. Google Lens — один из самых известных гаджетов в глобальной экспансии искусственного интеллекта. С помощью этого программного обеспечения, среди прочего, вы можете видеть прямой перевод иностранных слов через камеру.
Этот гаджет со встроенным ПО имеет еще одну очень полезную для туристов функцию. Если вы находитесь в другой стране, сфокусируйте камеру на вывесках, плакатах или печатном тексте. Объектив устройства покажет вам мгновенный перевод сообщения на родном языке; Аналогичную технологию Apple представила в iOS 15. Помимо перевода того, что вы видите через камеру, вы также можете копировать и вставлять текст.
DeepL
DeepL — это онлайн-сервис машинного перевода. Система ИИ в этом программном обеспечении имеет большой размах. Вы можете переводить на 21 язык с более чем 72 языковыми комбинациями (немецкий, испанский, французский, английский, итальянский, голландский, польский, португальский и русский). DeepL использует сверточные нейронные сети с базами данных.
Как искусственный интеллект влияет на переводческую отрасль?
- Резкое сокращение рабочей силы: Рост системы образования, основанной на машинном обучении, снизит перспективы профессиональных переводчиков.
 Это нововведение также снижает спрос на услуги переводчика в школах.
Это нововведение также снижает спрос на услуги переводчика в школах. - Создает инклюзивность : Автоматизированные классы с искусственным интеллектом облегчают учащимся поколения Z изучение языков.
- Изменение академического сценария: Выходя за рамки традиционной системы, интерес учащихся к интерактивному методу изучения языков увеличит количество новых учащихся, поступающих в языковые академии.
 Это нововведение также снижает спрос на услуги переводчика в школах.
Это нововведение также снижает спрос на услуги переводчика в школах.Заключение
Искусственный интеллект — мощная, постоянно развивающаяся технология. Его рост будет означать значительное увеличение числа технических рабочих мест, и будет интересно посмотреть на влияние искусственного интеллекта на индустрию переводов, поскольку он помогает миллионам пользователей получить доступ ко многим языкам. Приготовьтесь к встрече и взаимодействию с контентом на любом языке и откройте для себя все, что ИИ и средства коммуникации будут делать в последующие годы.
Искусственный интеллект и технологии перевода
Недавно я задал всем поставщикам технологий перевода, которые пришли мне на ум, этот вопрос:
В каких областях вы видите роль искусственного интеллекта в ваших технологиях и/или в переводе? родственные технологии других производителей?
Зачем спрашивать? Что ж, было много разговоров об искусственном интеллекте (ИИ) в технологиях в целом. В мире перевода мы говорили об этом, в частности, в отношении машинного перевода (МП), но, конечно, об ИИ и переводе можно сказать гораздо больше, чем просто о том, как он связан с МП. Мне было любопытно посмотреть, что находится в авангарде у разработчиков технологии, которую мы с вами используем.
В мире перевода мы говорили об этом, в частности, в отношении машинного перевода (МП), но, конечно, об ИИ и переводе можно сказать гораздо больше, чем просто о том, как он связан с МП. Мне было любопытно посмотреть, что находится в авангарде у разработчиков технологии, которую мы с вами используем.
Кроме того, и это становится очевидным из некоторых ответов, которые я получил, ИИ, с которым мы сегодня сталкиваемся в сценариях реальной жизни, — это не тот ИИ, о котором мечтали (или кошмарили) авторы научной фантастики. ИИ в том виде, в каком мы его знаем, не может иметь какого-либо универсального приложения, в котором он мог бы принимать «решения» в различных областях знаний или областях. ИИ используется для улучшения процесса принятия решений в очень узких областях знаний (таким образом, «узкий ИИ»), и в этом он все больше преуспевает. Возможно, правильнее было бы сказать, что разработчики и пользователи все лучше справляются с использованием такого рода технологий.
Большинство поставщиков технологий перевода, с которыми я связался, ответили (многие другие ответы перечислены онлайн 1 ). Вы увидите, что ответы ниже (перечисленные в алфавитном порядке в соответствии с поставщиком) встречаются повсюду, но я думаю, что в конечном итоге вы многому научитесь в процессе (я узнал), в том числе о том, что ИИ — это гораздо больше, чем «просто». нейронный машинный перевод. Обратите внимание, что приведенные ниже ответы написаны самими продавцами.
Вы увидите, что ответы ниже (перечисленные в алфавитном порядке в соответствии с поставщиком) встречаются повсюду, но я думаю, что в конечном итоге вы многому научитесь в процессе (я узнал), в том числе о том, что ИИ — это гораздо больше, чем «просто». нейронный машинный перевод. Обратите внимание, что приведенные ниже ответы написаны самими продавцами.
Atril
Применение глубокого обучения к переводу в форме нейронного машинного перевода (NMT), безусловно, является основной ролью, которую ИИ будет играть в сфере перевода в краткосрочной перспективе. Наличие доступных проектов NMT с открытым исходным кодом привело к увеличению количества поставщиков языковых услуг, добавляющих NMT в свой портфель услуг, возможно, как способ продемонстрировать свое техническое мастерство. Тем не менее, учитывая огромное количество обучающих данных, необходимых для обучения высококачественных систем NMT, может пройти некоторое время, прежде чем NMT окажет реальное влияние на отрасль.
В краткосрочной перспективе мы ожидаем, что NMT скоро будет интегрирован в наиболее конкурентоспособные инструменты автоматизированного перевода (CAT), а рабочие процессы переводчика постепенно перейдут на постредактирование. Мы также ожидаем, что другие приложения ИИ будут играть роль в двух других аспектах: а) в сборе и очистке обучающих данных для NMT; и b) в более сложных инструментах обеспечения качества.
Мы также ожидаем, что другие приложения ИИ будут играть роль в двух других аспектах: а) в сборе и очистке обучающих данных для NMT; и b) в более сложных инструментах обеспечения качества.
iLangL
Мы считаем, что искусственный интеллект в сфере переводов можно использовать в следующих областях:
- Оценка качества локализации.
- Помогает быстро выбрать лучшего лингвиста для конкретной работы.
- Анализ загруженности ресурсов и помощь руководителю проекта в управлении и оптимизации пула ресурсов лингвистов.
- Частичная или полная замена менеджера проекта при работе со сложными рабочими процессами локализации.
KantanMT
Существует множество областей, в которых ИИ и машинное обучение будут использоваться для расширения и улучшения рабочих процессов локализации. Что еще более важно, ИИ и машинное обучение будут использоваться для повышения эффективности бизнеса и операций. Это приведет к более быстрому и более интеллектуальному выполнению рабочих процессов локализации с использованием меньшего количества ресурсов и затрат при одновременном повышении рентабельности. Вот несколько областей, которые следует учитывать:
Вот несколько областей, которые следует учитывать:
- Прогнозирование спроса.
- Прогнозное планирование рабочего процесса.
- Механизмы рекомендаций для оптимального выбора рабочего процесса.
- Оповещения и диагностика от мониторинга управления проектами в реальном времени.
- Упреждающее управление работоспособностью рабочего процесса.
- Анализ эффективности проекта.
- Динамическое ценообразование (на основе факторов проекта).
- Шаблон трафика рабочего процесса и управление перегрузками.
- Анализ рисков и регулирование.
- Анализ использования ресурсов.
Хотя большинство людей думают, что ИИ и машинное обучение будут ограничиваться технологическими инновациями, мы твердо верим, что находимся на пороге революции ИИ, которая коренным образом изменит нашу отрасль и заставит нас переосмыслить многие наши подходы к управлению бизнесом в течение последние три десятилетия. Машины на подъеме.
Lilt
Мы думаем о роли ИИ в технологии Lilt с точки зрения дополненного интеллекта. Идея о том, что ИИ каким-то образом может полностью автоматизировать перевод с помощью чистого машинного перевода, ошибочна, особенно для контента, требующего высокого уровня качества. Вы не сможете по-настоящему «решить» машинный перевод, пока не решите искусственный интеллект, который сам по себе является нерешенной проблемой. Нам нужно подумать о том, как мы можем использовать ИИ для повышения качества и скорости человеческого перевода. Перевод — это форма искусства, и Lilt сосредоточена на том, как мы можем продолжать развивать технологию, использующую искусственный интеллект, чтобы переводчики могли выполнять свою работу наилучшим образом. Короче говоря: машины должны работать с людьми-переводчиками и учиться у них.
MateCat
Искусственный интеллект завораживает и пугает. Человеческий язык и, в частности, перевод — это, пожалуй, самые сложные задачи, с которыми сталкиваются машины. Естественный язык — это очень сжатый канал информации, плотно набитый смыслом. Для понимания требуется контекстная информация, выходящая за рамки самих слов.
Естественный язык — это очень сжатый канал информации, плотно набитый смыслом. Для понимания требуется контекстная информация, выходящая за рамки самих слов.
Язык — это величайшая проблема, с которой сталкиваются машины, потому что это самая человеческая вещь, которая существует. Из-за этого системы автоматического перевода развиваются медленно, но они, несомненно, прогрессируют. 2
memoQ
В инструментах переводческой среды ИИ в его воплощении машинного перевода останется, но с явным смещением фокуса. Мы увидим, как технологии и процессы перейдут от постредактирования, где человеческий редактор является второстепенным, к расширенному переводу, где ИИ используется для того, чтобы дать лингвистам сверхспособности. Следующие захватывающие вещи произойдут во взаимодействии человека и машины, а не в моделях машинного перевода как таковых.
Помимо языковой обработки в строгом смысле, машинный перевод начнет появляться в управлении проектами, управлении поставщиками и разработке локализации. В целом, набор инструментов успешного лингвиста будет включать в себя растущее число коммерческих инструментов машинного обучения и анализа данных. Будущее ИИ безрадостно в одной области: обеспечение качества. Если бы инструмент был «достаточно умным», чтобы оценивать качество, он был бы достаточно умным, чтобы лучше выполнять свою работу. Таким образом, мы будем использовать инструмент для выполнения работы, а не обеспечения качества.
В целом, набор инструментов успешного лингвиста будет включать в себя растущее число коммерческих инструментов машинного обучения и анализа данных. Будущее ИИ безрадостно в одной области: обеспечение качества. Если бы инструмент был «достаточно умным», чтобы оценивать качество, он был бы достаточно умным, чтобы лучше выполнять свою работу. Таким образом, мы будем использовать инструмент для выполнения работы, а не обеспечения качества.
Memsource
В Memsource искусственный интеллект нашел свое место в компонентах управления переводами и инструментов перевода. Как правило, мы ищем повторяющиеся задачи, которые необходимо выполнять в масштабе и приносить высокую отдачу от инвестиций. Эти задачи часто являются идеальными кандидатами для ИИ. Например, наша функция оценки качества машинного перевода (MTQE) идентифицирует высококачественный вывод машинного перевода, который не требует постредактирования. Другая функция идентифицирует непереводимый контент. Очень перспективным направлением является сквозная автоматизация рабочего процесса локализации, от настройки правильных параметров проекта до выбора подходящего лингвиста для работы. С другой стороны, ИИ будет бороться с такими задачами, как всесторонний просмотр переведенного контента перед доставкой очень требовательному клиенту. Например, ИИ не будет обнаруживать уникальные или редкие проблемы или проблемы, которых могло не быть в наборе данных, на котором он обучался. В любом случае, это захватывающие времена, и технологии на основе ИИ должны позволить нам сосредоточиться на творческих задачах, которые приносят больше удовольствия.
С другой стороны, ИИ будет бороться с такими задачами, как всесторонний просмотр переведенного контента перед доставкой очень требовательному клиенту. Например, ИИ не будет обнаруживать уникальные или редкие проблемы или проблемы, которых могло не быть в наборе данных, на котором он обучался. В любом случае, это захватывающие времена, и технологии на основе ИИ должны позволить нам сосредоточиться на творческих задачах, которые приносят больше удовольствия.
Plunet
Как система управления бизнесом, управляющая вашими рабочими процессами, Plunet может предусмотреть искусственный интеллект для распределения поставщиков, пытаясь найти наилучший возможный вариант, а затем открываясь для более широкой потенциальной аудитории поставщиков. ИИ также можно использовать для прогнозирования сроков или даже возможных рабочих процессов. Кроме того, мы могли бы предсказать, что
пользователь хочет сделать дальше, и представить ему эти варианты (например, дизайн взаимодействия с пользователем).
В идеальном мире — при наличии достаточного количества метаданных и унаследованной информации — проекты можно было бы полностью автоматизировать: цитирование, настройка проектов, выбор правильного CAT-инструмента, распределение поставщиков и даже некоторая автоматическая обработка исключений.
SDL
Мы видим ИИ в любом сценарии, где речь идет о повышении производительности и автоматизации. Вот несколько примеров:
- Нейронный машинный перевод (ускоритель производительности) в сочетании с памятью переводов (TM), терминологией и сопоставлением фрагментов всегда обеспечивают наилучшее возможное совпадение для начала.
- Распознавание голоса. (Ввиду растущего качества движков на основе ИИ, таких как Google, становится все более и более привлекательной глубокая интеграция со средами CAT.)
- Автоматизация проектов. Например, автоматическая маршрутизация работы путем анализа исходного контента и поиска наиболее подходящих ресурсов (например, TM, терминологических баз и механизмов машинного перевода) и переводчиков/рецензентов с соответствующими навыками.

Имея под рукой этот набор интеллектуальных инструментов, существует определенная вероятность того, что переводчики будут тратить больше времени на надзор и управление процессом перевода, чем начинать перевод с нуля (т. е. переходить от перевода «с нуля» к рецензированию) . Кроме того, нам нравится избегать термина «постредактирование», когда речь идет о NMT. Мы предпочитаем термин «обзор», так как он более точно соответствует типу работы при просмотре результатов хорошо обученного механизма NMT.
Тем не менее, сказав все вышесказанное, язык есть язык, что всегда означает «неожиданные сложности», которые делают ключом к разработке любой технологии таким образом, чтобы переводчики контролировали ресурсы, с которыми они работают, вместо того, чтобы принуждать пользователей к определенному способу работы. Гибкость будет ключевым фактором. В наших фокус-группах пользователи продолжают говорить нам, что это жизненно важный аспект.
Smartcat
Мы используем искусственный интеллект, чтобы сделать переводы и управление переводами простыми и эффективными. Для лингвистов это означает предлагать работу, соответствующую их специализации; адаптация предложений перевода к их стилю и голосу; помощь с утомительными вещами, такими как теги, числовые форматы и непереводимость; обработка счетов, оплата и все, что связано с ведением собственного учета. Эти задачи часто занимают до 30% времени переводчиков, которое они могли бы использовать для перевода, тем самым зарабатывая больше денег и в целом становясь счастливее.
Для лингвистов это означает предлагать работу, соответствующую их специализации; адаптация предложений перевода к их стилю и голосу; помощь с утомительными вещами, такими как теги, числовые форматы и непереводимость; обработка счетов, оплата и все, что связано с ведением собственного учета. Эти задачи часто занимают до 30% времени переводчиков, которое они могли бы использовать для перевода, тем самым зарабатывая больше денег и в целом становясь счастливее.
Для менеджеров проектов это означает предлагать лингвистов, которые лучше всего подходят для конкретных проектов, автоматически устанавливать сроки, выбирать наиболее подходящие механизмы машинного перевода, отслеживать прогресс и уведомлять менеджера проекта, если что-то пойдет не так.
В ближайшем будущем ИИ станет мозгом нескольких интеллектуальных личных помощников для менеджеров проектов и лингвистов в Smartcat, помогая им работать более эффективно и творчески, выполняя повторяющиеся непродуктивные задачи.
Star
Две технологии искусственного интеллекта — семантическое управление информацией и машинное обучение — играют решающую роль в технологиях STAR, а также окажут значительное влияние на развитие этих технологий.
Семантическая информация, представленная в графах знаний и онтологиях, является ключом к открытию «черного ящика контента» в технических коммуникациях, делая контент интерпретируемым. Это обеспечивает интеллектуальные услуги и обработку технических сообщений в оцифрованных процессах. Семантическая информация является основой для интеллектуальных помощников, чат-ботов, голосовых помощников и интеллектуальных сценариев дополненной и виртуальной реальности.
Машинное обучение является основой для машинного перевода и ядром решения STAR MT, которое поддерживает переводчиков, предоставляя машинные предложения по переводу. Нейронные сети на основе машинного обучения также будут поддерживать следующее:
- Интеллектуальное (предиктивное) завершение текста в авторской памяти.
- Более высокая степень автоматизации для обеспечения качества, обнаружения ошибок и исправления в переводах.
- Постредактирование машинных переводов на основе ИИ.
- Оптимизировано распознавание и проверка терминологии в языках с богатой морфологией.
- Более высокая автоматизация коррекции центровки.
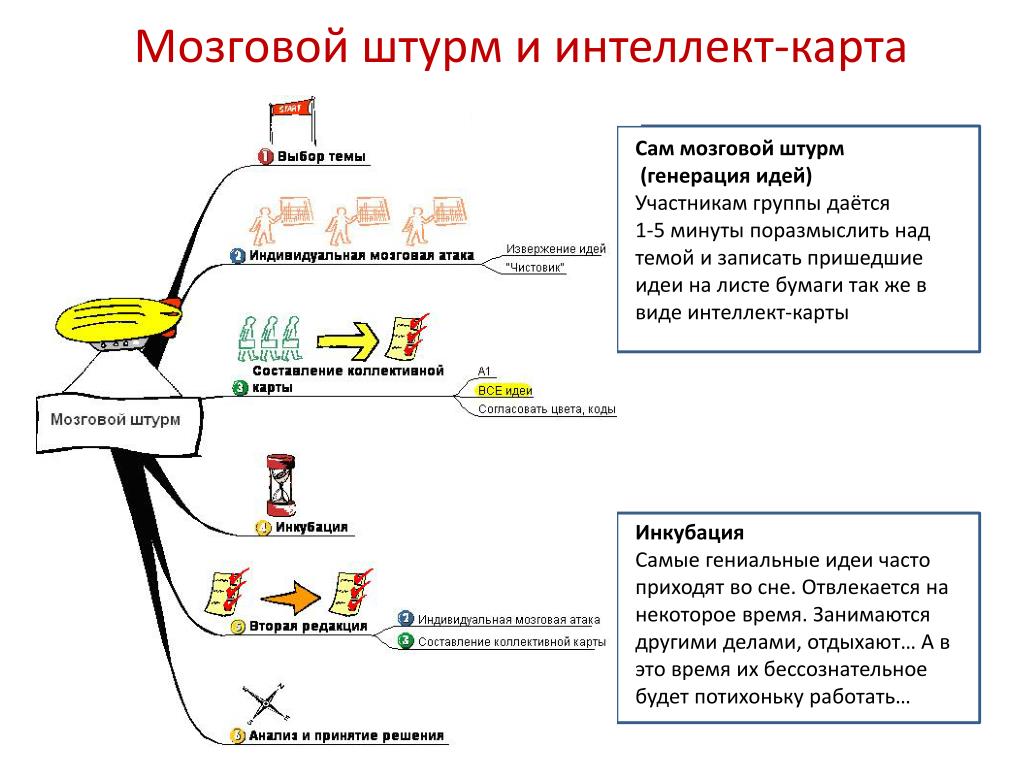
Заключительные мысли
Для меня (Джоста) было очень поучительно узнать, что говорят поставщики технологий. Обратите внимание, что только один (MateCat в своем более длинном ответе, доступном онлайн по ссылке, указанной ниже) ставит под сомнение долговечность мира переводов, каким мы его знаем. Все остальные видят в искусственном интеллекте не только то, что не берет на себя нашу работу, но и то, что дополняет нашу работу в качестве профессиональных переводчиков, редакторов или менеджеров проектов, причем часто очень творчески. И, как я уже много раз говорил в этой колонке, от нас, вероятно, зависит стать еще более изобретательными в общении с поставщиками технологий, какие задачи являются бессмысленными и повторяющимися и, вероятно, должны быть взяты на себя машинами, а какие которые лучше оставить нам.
Примечания
- Полный список ответов см. на странице xl8.link/ToolBoxAI.
- Остальные длинные, но содержательные материалы по этой теме см.
