Как работает технология распознавания лиц в смартфоне? Распознавания лиц
как это работает и что с ним будет дальше?
- Подписаться
- Лента публикаций
- Последние публикации
- Лучшие публикации
- за все время
- за полгода
- за месяц
- Категории
- Города и страны
- Здоровье
- Изобретения
- Интересные факты
- История
- Космос
- Наука
- Природа
- Рекорды
- Технологии
- Человек
vseonauke.com
Правда и ложь систем распознавания лиц / Блог компании Recognitor / Хабр

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
- Можно ли распознать вас на улице? И насколько автоматически/достоверно?
- Позавчера писали, что в Московском метро задерживают преступников, а вчера писали что в Лондоне не могут. А ещё в Китае распознают всех-всех на улице. А тут говорят, что 28 конгрессменов США преступники. Или вот, поймали вора.
- Кто сейчас выпускает решения распознавания по лицам в чём разница решений, особенности технологий?
Введение, базис
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:- Ошибки первого рода — ситуация когда человека нет в нашей базе, но мы опознаём его как человека присутствующего в базе (в биометрии FAR (false access rate))
- Ошибки второго рода — ситуации когда человек есть в базе, но мы его пропустили. (В биометрии FRR (false reject rate))
Характеристики
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:
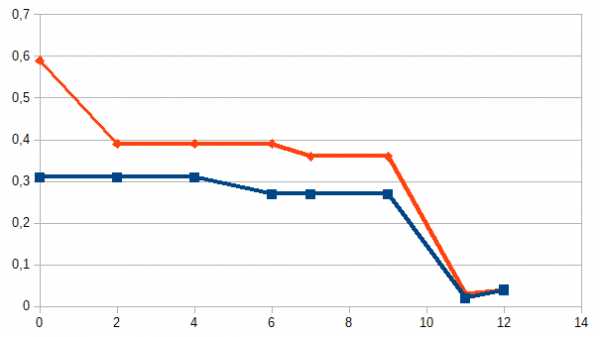
Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:
И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
- Фотография на паспорт (идеальная, фронтальная). Задний фон белый, идеальные системы съёмки. Такое иногда можно встретить на проходной, но очень редко. Обычно такие задачи — это сравнение человека в аэропорту с базой.
- Фотография хорошей системой, но без топового качества. Есть задние фоны, человек может немного не ровно стоять/смотреть мимо камеры, и.т.д.
- Сэлфи с камеры смартфона/компьютера. Когда пользователь оказывает кооперацию, но плохие условия съёмки. Есть два подмножества, но много фото у них только в «сэлфи»

- «Faces in the wild» — съёмка практически с любой стороны/скрытая съёмка.Максимальные углы поворота лица к камере — 90 градусов. Именно тут NIST ооочень сильно упростил базу.
- Дети. Все алгоритмы работают плохо по детям.
- 10^-4 — FAR (одно ложное срабатывание первого рода) на 10 тысяч сравнений с базой
- 10^-6 — FAR (одно ложное срабатывание первого рода) на миллион сравнений с базой
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Главная подстава
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
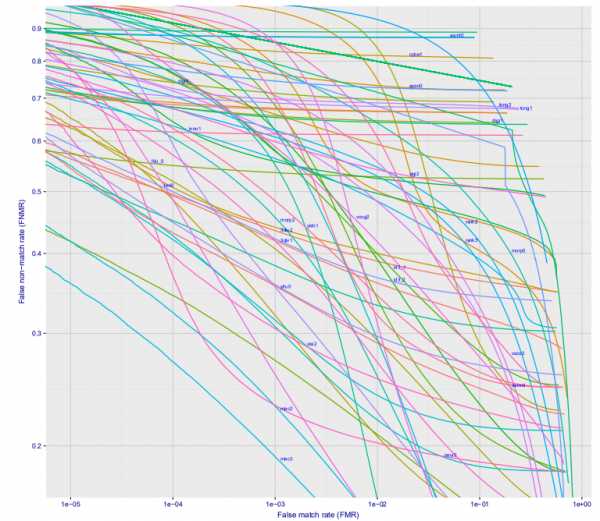
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:
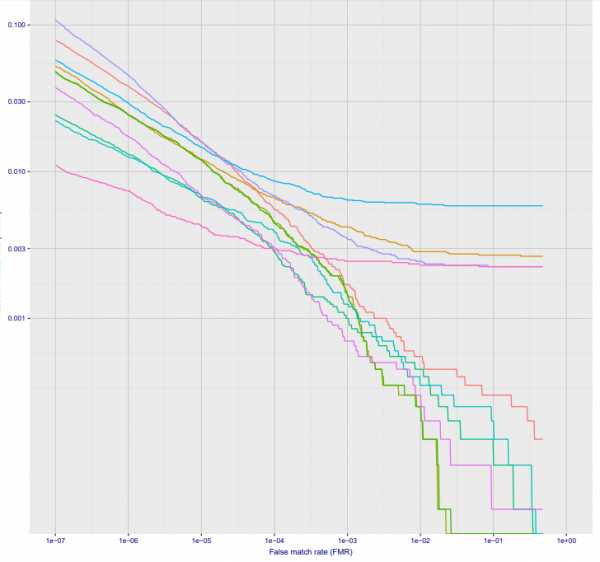
Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Первые вопросы
Похоже время ответить на первую часть вопросов: Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
А что с моей безопасностью? На улице, на митинге?
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
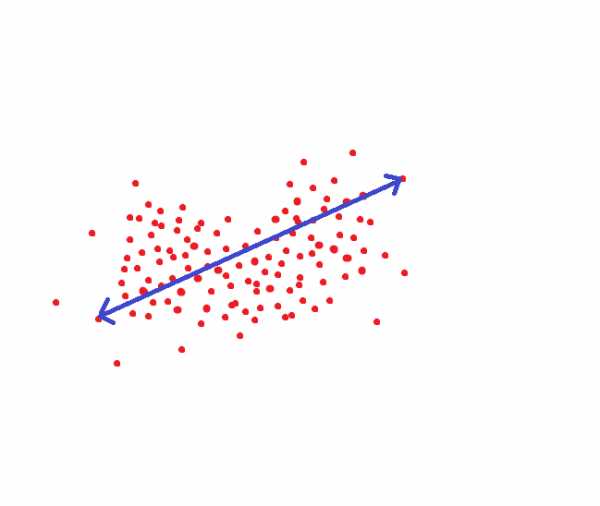
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
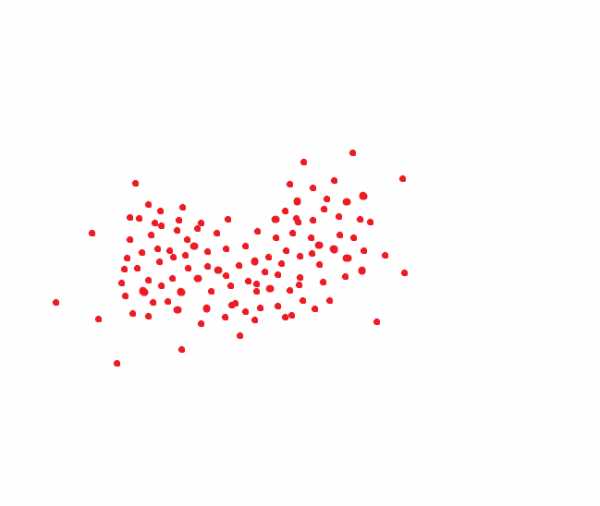
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:
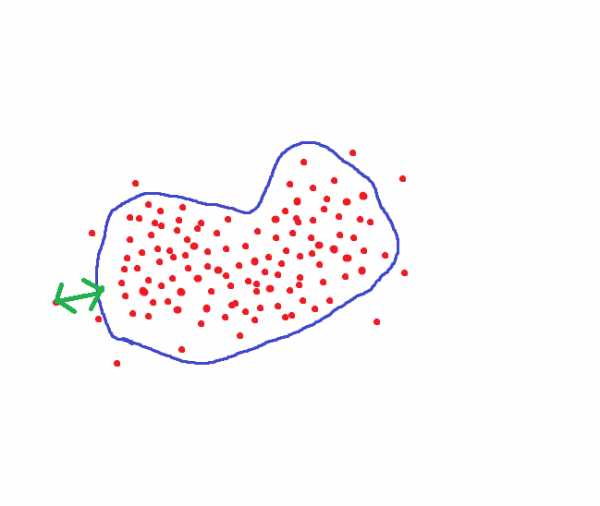
Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз. Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Кстати, про соцсети
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:- Качество выделения лица.
- Используемая метрика близости лиц при обучения Triplet Loss, Center Loss, spherical loss, и.т.д.
- Размер базы
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали. Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Про решения и про компании
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
Выводы
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
habr.com
Технология распознавания лиц в смартфоне: как работает? Виды, особенности
В современные смартфоны всё активнее внедряется система распознавания лиц. Но как она работает?
Можно сказать, что iPhone X открыл новую эпоху. Технология распознавания лиц — основная его «фишка». И никто не сомневается в том, что такой способ разблокировки будет внедряться и во многие другие смартфоны.
Чуть-чуть истории
Ещё в 1960-ых годах проводились специальные опыты, в ходе которых компьютер должен был научиться распознавать лицо человека. Тогда это ни к чему не привело, так как любая эмоция приводила к сбою. Также изобретенная система боялась изменения условий освещения.
Лишь в самом конце XX века появились системы, которые научились определять лица людей по фотографиям, запоминая их. При этом они перестали сбоить при появлении усов, бороды, очков и прочих «помех». Активнее всего подобные системы начали внедряться в цифровые фотоаппараты. Также они нашли себе место в охранном секторе.

У систем распознавания лиц долгое время был один существенный недостаток. Они сильно зависели от освещения и ракурса. Впрочем, в охранных сканерах эта проблема не была заметна. К ним лицо прикладывалось почти вплотную, освещаясь затем лампами. Избавиться же от вышеупомянутого недостатка помогло внедрение стереосъемки. Две камеры понимают глубину сцены, в связи с чем точность показаний вырастает в несколько раз.
Как работает технология распознавания лиц?
Постепенно новая функция начала появляться в смартфонах. Здесь биометрическая идентификация пользователя внедряется для того, чтобы разблокировать устройство не мог посторонний человек. В идеале получить доступ к персональной информации может только близнец. Переживать по этому поводу не стоит. Вряд ли кто-то будет всерьез скрывать что-то от родного брата или сестры. Да и никто не мешает установить для чтения каких-то особо секретных данных дополнительный пароль.
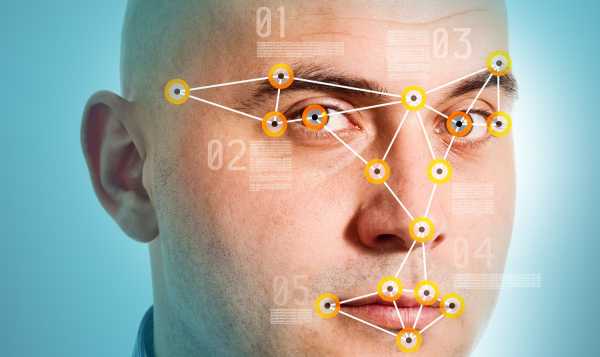
Работу системы распознавания лиц в смартфонах можно условно разделить на четыре этапа:
- Сканирование лица. Оно осуществляется при помощи фронтальной камеры или, как в случае с iPhone X, специального сенсора. Сканирование является трехмерным, поэтому фокус с показом фотографии срабатывать не будет.
- Извлечение уникальных данных. Система ориентируется на набор особенностей сканируемого лица. Чаще всего это контуры глазниц, форма скул и ширина носа. В продвинутых системах также могут «замечаться» шрамы.
- Извлечение из памяти шаблона с ранее полученными данными.
- Поиск соответствий. Финальный этап, на котором система решает, разблокировать ли дисплей. Мощности современных процессоров позволяют тратить на «размышление» всего доли секунды.
Функция распознавания лиц может быть реализована даже при помощи фронтальной камеры — лишь бы она имела два объектива. Однако в таком случае работа данной функции окажется нестабильной. Дело в том, что лишь специальные датчики обеспечат сканирование лица даже в темноте, тогда как «фронталке» требуется яркое освещение. Также особые датчики виртуально выводят на лицо большее количество точек, поэтому они срабатывают даже при появлении бороды, очков и других помех. Словом, в каком-нибудь DOOGEE Mix 2 система точно будет работать заметно хуже, чем в iPhone X. Другое дело — юбилейный продукт Apple стоит гораздо дороже, чем все остальные смартфоны с функцией распознавания лица.

За технологией будущее?
Нужные для сканирования лица датчики требуют идеальной установки. Сдвиг на сотые доли миллиметра приведет к тому, что работа функции перестанет быть идеальной — поэтому при производстве смартфона может наблюдаться повышенный выход брака, а это приводит к росту его стоимости. Да и сами датчики стоят весьма дорого, неспроста их использует только компания Apple, хотя никаких патентов на них у неё нет.
Одним словом, пока функцию распознавания лиц производители «андроидов» будут реализовывать посредством фронтальной камеры. Уже сейчас её можно встретить в Samsung Galaxy S8 и Note 8. Но владельцы этих устройств подтвердят вам, что работает она не лучшим образом — легче использовать сканер отпечатков пальцев. Поэтому пока о будущем функции ничего сказать нельзя. Нужно ждать, будет ли Apple внедрять соответствующие датчики в более доступные смартфоны, а также появятся ли они в устройствах на базе Android.

Заключение
Переживать по поводу сохранения ваших идентификационных данных не стоит. Созданный при сканировании лица шаблон находится в отдельном разделе памяти — чтение этого сектора компьютером или сторонними программами невозможно. Впрочем, это касается и отпечатков пальцев. А каким видом идентификации пользоваться удобнее — это выбирать только вам.
Держали ли вы когда-нибудь в руках смартфон, умеющий распознавать лицо? И ждете ли вы массового внедрения данной функции? Поделитесь своим мнением в комментариях, мы будем этому рады!
setphone.ru
Система распознавания лиц

Российское производство
Вероятность распознавания лица
Индивидуальная настройка на объекте
Особенности
Система распознавания лиц сочетает в себе высокое качество автоматического обнаружения, сопровождения лиц и извлечения из изображений лиц ключевой информации:
- 98% вероятность достоверного обнаружения лиц людей благодаря алгоритму анализа и коррекции результатов детектирования;
- минимальное количество ложных срабатываний благодаря встроенному алгоритму трекинга и верификации результатов обнаружения;
- автоматическое формирование галереи наилучших для распознавания портретов на каждого обнаруженного человека отдельно;
- автоматическое извлечение необходимой для распознавания ключевой информации об изображении лица.
Описание
Система распознавания лиц предназначена для идентификации личности по видеоизображению. Она состоит из двух основных частей:
- детектор лиц;
- ядро распознавания.
Детектор лиц производит захват видео из источника и обнаружение в кадре лица человека. Далее, полученные фотографии передаются в ядро распознавания, где происходит вычисление опорных точек, создание дескриптора лица и сравнение полученного дескриптора со списком имеющихся в базе лиц.
Помимо непосредственно распознавания и идентификации, система позволяет:
- добавлять и удалять лица из базы персон;
- группировать персон (например, по отделам или организациям) и сохранять данные для дальнейшей идентификации;
- вести в базе поиск по любому из полей описания персоны, группе или по загруженной из стороннего источника фотографии;
- просматривать лог обнаружения персоны на всех включённых в систему источниках.
В основе системы распознавания лиц лежит инновационная технология распознавания образов Re:Action от компании Vision Labs, обладающая лучшими в мире показателями полноты и точности распознавания в реальных условиях (По результатам тестирования на независимой базе данных Labeled Faces in the Wild (LFW), Unrestricted training – Commercial systems http://vis-www.cs.umass.edu/lfw/results.html, University of Massachusetts).
Принцип действия
Оригинальный гибридный алгоритм поиска лиц предварительно сканирует изображение каскадным способом, выделяя подозрительные области, которые в дальнейшем аппроксимируются деформируемой шаблонной моделью лица и, в случае положительного отклика, помечаютс я как детектированные лица.
Основанный на наборе эвристик алгоритм выполняет оценку качества изображения лица и возможности дальнейшего распознавания.
От кадра к кадру вычисляется вектор смещения области лица, подтверждая или опровергая прогноз следующей координаты лица, фильтруются ложные срабатывания и формируется галерея наилучших портретов.
Быстрый детектор обнаруживает устойчивые к возрастным и мимическим изменениям ключевые точки лица (от 8 до 56 в зависимости от решаемой задачи), экстраполирует значения координат точек невидимых частей лица (из-за усов, бороды и т.п.) и строит эластичный граф, проверив корректность взаимных пропорций.
Извлеченная последовательность точек посредством серии сверток и матричных преобразований кодируется в уникальный дескриптор (ключ) изображения лица.
Опционально выполняется классификация пола и возрастной группы (ребенок/взрослый/пожилой) лица.
По заранее определенным сценариям выполняется сравнения извлеченного ключа с имеющейся в базе данных или файловой системе ключами, в ответ получая скалярное значение Евклидовой дистанции между парой ключей (степень схожести) с возможность представления в виде процента схожести.
Гибкая система настроек позволяет задавать пороговые значения допустимых колебаний по каждой из величин, вычисляемых в процессе работы системы, что позволяет настроить систему для работы в любых условиях.
Функции
- Распознавание изображения лица, захваченного детектором лиц, путем сравнения с фотографиями, содержащимися в заранее созданной базе данных. Производится сравнение со всеми лицами, имеющимися в базе. Для сравнения используется технология Re:Action компании Vision Labs.
- Отображение на экране захваченных лиц и сопутствующих данных: даты и времени захвата, номера камеры, с которой работает модуль и сопутствующих данных об идентифицированной персоне.
- Поиск и отображение на экране всех распознанных за определенный временной интервал лиц. Поиск ведется по любому из полей сопутствующих данных.
- Поиск личности в базе данных по фотографии.
- Добавление в базу данных лиц новых записей, содержащих цифровую фотографию, персональные данные персоны и комментарий.
Технические характеристики
| Параметр | Значение |
| Минимальное разрешение видео | 320 x 240 пикс |
| Минимальный размер лица в кадре(для разрешения 320 x 240 пикс) | 40 x 40 пикс |
| Максимальный размер лица в кадре (для разрешения 320 x 240 пикс) | 200 x 200 пикс |
| Вероятность достоверного обнаружения лиц | 93 – 98% |
| Допустимый угол крена лиц в кадре | ±10° |
| Максимальный наклон видеокамеры без потери качества извлеченных дескрипторов (ключей) | Не более 30° по вертикалиНе более 20° по горизонтали |
| Формат кадров видео последовательности | Цветное (RGB) |
| Последовательность каналов цветного RGB изображения | B-G-R (Blue – Green – Red) |
| Количество лиц, одновременно обрабатываемых в кадре | До 5 |
| Количество портретов на каждого человека в кадре | 3 |
www.exacq-vision.ru
распознавание лиц, детектор очередей, поиск объектов на видео / Блог компании Ivideon / Хабр
 Тайваньская компания 42Ark и американский производитель «умных» кормушек CatFi Box используют камеры видеонаблюдения для распознавания кошачьего лика
Тайваньская компания 42Ark и американский производитель «умных» кормушек CatFi Box используют камеры видеонаблюдения для распознавания кошачьего ликаНемецкий электротехник Вальтер Брух в 1941 году установил CCTV-систему (Сlosed Circuit Television — система телевидения замкнутого контура) на полигоне, где испытывали ракеты «Фау-2». Это первый известный в истории случай использования видеонаблюдения на практике. Оператор должен был неотлучно сидеть перед монитором. Так продолжалось до 1951 года, пока не появились первые VTR (VideoTape Recorder) устройства, записывающие изображение на магнитную ленту.
Запись на носитель не избавила оператора от необходимости участвовать в процессе. Опознание лиц, определение местоположения объектов, даже детекция движения – все эти функции выполнял человек, сидящий перед монитором в режиме реального времени или изучающий постфактум архив видео.
Колесо прогресса катится дальше. Видеонаблюдение получило видеоаналитку, полностью изменившую процесс работы с системой. Помните историю про кота и нейросеть глубокого обучения? Да, это тоже часть видеоаналитики, но крохотная. Сегодня расскажем о технологиях, которые кардинально меняют мир CCTV-систем. Детекция очередей и бета-тест  Первая IP-камера в мире Neteye 200, созданная в 1996 году компанией Axis
Первая IP-камера в мире Neteye 200, созданная в 1996 году компанией Axis
Видеонаблюдение зарождалось как охранная замкнутая система, предназначенная только для решения вопросов безопасности. Ограничения аналогового видеонаблюдения не позволяли использовать оборудование как-то иначе. Интеграция видеонаблюдения с цифровыми системами открыла возможность автоматизировано получать различные данные, анализируя последовательность изображений.
Важность трудно переоценить: в обычном случае после 12 минут непрерывного наблюдения оператор начинает пропускать до 45% событий. И до 95% потенциально тревожных событий будет пропущено уже после 22 минут непрерывного наблюдения (по результатам исследования IMS Research, 2002).
Появились сложные алгоритмы анализа видео: подсчет посетителей, подсчет конверсии, статистика кассовых операций и многое другое. В этой системе исчезает оператор наблюдения – мы оставляем компьютеру возможность «смотреть» и делать выводы.
Самой простой пример умного видеонаблюдения – детекция движения. Не так важно есть ли встроенный детектор в самой камере – если вы установите на компьютер, к примеру, софт Ivideon Server, то детекор движения будет использоваться программный. Один детектор способен заменить сразу несколько операторов видеонаблюдения. А уже в 2000-е начали появляться первые системы видеоаналитики, способные распознавать объекты и события в кадре.
У Ivideon сейчас в разработке несколько модулей видеоаналитики – с тех пор, как мы выпустили OpenAPI, дело пошло быстрее за счет интеграции с партнерами. Часть проектов пока в закрытом тестировании, но кое-что уже готово. Это, во-первых, интеграция с кассами для контроля за кассовыми операциями (пока на базе iiko и Штрих-М). Во-вторых, разработан детекор очередей.
У нас был счетчик Ivideon Counter, определявший количество клиентов в зале. Аналитика позволила уйти от специального оборудования в сторону облачных вычислений. Теперь нам не нужна специфическая камера – подойдет любая камера видеонаблюдения с разрешением 1080p+. Сейчас мы хотим не просто считать людей, а определять очереди. Поэтому готовы любому магазину, ТЦ или офису, где ходят и стоят люди, образуя очереди, предоставить бесплатную камеру для теста детекции очереди. Напишите нам, чтобы принять участие в проекте.
Кроме того, Ivideon работает с технологиями распознавания лиц.
Кто и как распознает Технология DeepFace проходит проверку Facebook на примере распознавания эмоционального лица Сильвестра Сталлоне
Технология DeepFace проходит проверку Facebook на примере распознавания эмоционального лица Сильвестра Сталлоне
Над решениями в этой области работают Apple, Facebook, Google, Intel, Microsoft и другие технологические гиганты. Комплексы видеонаблюдения с автоматическим распознаванием лиц пассажиров установлены в 22 аэропортах США. В Австралии занимаются разработкой биометрической системы распознавания лиц и отпечатков пальцев в рамках программы, призванной автоматизировать паспортный и таможенный контроль.
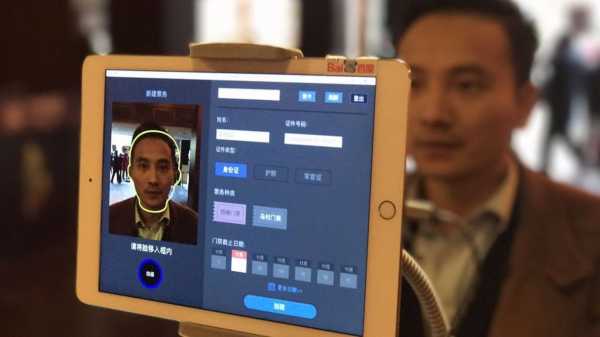
Крупнейшая китайская интернет-компания Baidu провела успешный эксперимент по отказу от билетов с помощью технологии распознавания лиц с точностью 99,77%, при длительности съемки и распознавания – 0,6 секунды. На входах в парк установлены стенды с планшетами и специальные рамки, которые ведут съемку. Когда турист приходит в парк впервые, система его фотографирует, чтобы в дальнейшем использовать функцию распознавания лиц по фото. Новые снимки сравниваются с фото из базы данных – так система определяет, есть ли у человека право на посещение.

В Китае с технологиями вообще все очень хорошо. В 2015 году Alipay, оператор платформы онлайн-платежей, входящий в состав холдинга Alibaba, ввел в действие систему верификации платежей на базе Face++, облачной платформы распознавания лиц, созданной китайским стартапом Megvii. Система получила название Smile to Pay — она дает возможность пользователям Alipay платить за онлайн-покупки путем съемки селфи (Alipay определяет владельца по улыбке). UBER в Китае стал применять систему распознавания лиц водителей на базе Face++, чтобы противостоять мошенничеству, краже персональных данных и обеспечить дополнительную безопасность пассажиров.
Но интереснее посмотреть не на зарубежные решения, а на сервисы, созданные в России. Эти технологии находятся гораздо ближе к конечному пользователю (если он из нашей страны), с ними можно познакомиться, в перспективе объединиться для использования в собственном продукте. Компаний, занимающихся распознаванием лиц, вокруг немало. Вспомним несколько, остающихся на слуху.
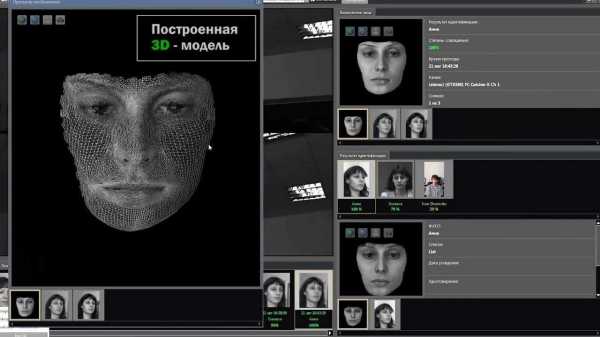
Компания «Вокорд», основанная еще в 1999 году, в программе FaceControl 3D работает с синхронными изображениями со стереокамер, строит 3D-модель лица в кадре и автоматически ищет совпадение полученной модели с моделями в имеющейся базе данных. В 2016 году «Вокорд» стал использовать собственный математический алгоритм распознавания лиц, в основе которого лежат сверточные нейронные сети, благодаря чему их алгоритмы теперь работают с любой камерой видеонаблюдения. В компании утверждают, что могут распознавать лица (в размере 128х128 пикселей) людей, следующих в потоке. В конце 2016 года алгоритм Vocord DeepVo1 показал лучшие результаты в мировом тестировании идентификации, правильно распознав 75,127% лиц.

Компания VisionLabs, основанная в 2012 году, победила в крупнейшем в России и Восточной Европе конкурсе технологических компаний GoTech, вошла в список финалистов европейской программы «Challenge UP!», призванной ускорить вывод на рынок решений и сервисов на базе концепции интернета вещей, привлекла многомиллионные инвестиции и уже внедряет свои продукты в коммерческий сектор. Недавно банк «Открытие» запустил систему распознавания лиц от VisionLabs с целью оптимизации обслуживания и времени ожидания клиентов в очереди. Ну и стоит прочитать замечательную историю, как специалисты из КРОК с помощью VisionLabs кота ловили.
VisionLabs, показавшая один из лучших результатов по распознаванию и уровню ошибок, также работает с нейронными сетями, выявляющими специфические черты каждого лица, такие как разрез глаз, форма носа, рельеф ушной раковины и т.д. Их система Luna позволяет найти все эти особенности лица по фото в архивах. Другое решение компании, Face Is, распознав лицо клиента в магазине, находит его профиль в CRM-системе, узнает из нее историю покупок и интересы покупателя, и отправляет на телефон уведомление с персональным предложением о скидке на его любимую категорию товаров.
Стартап Skillaz, занимающийся автоматизацией процесса найма сотрудников, и VisionLabs собираются в конце 2017 года представить систему компьютерного распознавания, которая будет оценивать поведение соискателей при найме. Проанализировав полученные данные, система будет делать выводы о профессиональных качествах человека и пригодности к должности. Полные характеристики системы «машинного найма» компании не раскрывают. Известно лишь, что будет оцениваться коммуникабельность кандидата, исходя из его ответов на определенный набор вопросов, задаваемых системой online-интервью. Нейросеть будет искать взаимосвязь поведения кандидата на картинке с камеры видеонаблюдения и степень выраженности у него той или иной компетенции.
Сетка, представляющая собой доктора Лайтмана и Шерлока Холмса в одном лице, будет учитывать мимику кандидата, его жестикуляции, а также физиогномику. Тут стоит заметить, что метод определения типа личности человека, его душевных качеств, исходя из анализа внешних черт лица и его выражения, в современной психологической науке считается классическим примером псевдонауки. Как с этим противоречием справятся в новом продукте пока неясно.
 Слайд из презентации NTechLab, угнетающий Салмана Радаева
Слайд из презентации NTechLab, угнетающий Салмана Радаева
NTechLab начинали с приложения, которое определяло породу собак по фотографии. Позже они написали алгоритм FaceN, с которым осенью 2015 года приняли участие в международном конкурсе The MegaFace Benchmark. NTechLab одержала победу в двух номинациях из четырех, обойдя и команду Google (через год в этом же конкурсе победит «Вокорд», а NTechLab сместится на 4-ю позицию). Успех позволил им быстро реализовать сервис FindFace, ищущий людей по фотографиям во ВКонтакте. Но это не единственный способ применения технологии. На фестивале Alfa Future People, организованном «Альфа-Банком», с помощью FindFace посетители могли найти свои фотографии среди сотен других, отправив селфи чат-боту.
Кроме того, NTechLab показали систему, способную в режиме реального времени распознавать пол, возраст и эмоции, используя изображение с видеокамеры. Система способна оценить реакцию аудитории в режиме реального времени, благодаря чему можно определить эмоции, которые испытывают посетители во время презентаций или трансляций рекламных сообщений. Все проекты NTechLab строятся на самообучающихся нейронных сетях.
Путь Ivideon к видеоаналитике 
Распознавание лиц – одна из самых сложных задач в области видеоаналитики. С одной стороны, вроде все понятно и давно используется. С другой стороны, решения идентификации в толпе людей все еще стоят очень дорого и не дают абсолютной точности. В 2012 году в Ivideon начали работу с алгоритмами видеоанализа. В тот год мы выпустили приложения для iOS и Android, вышли на зарубежные рынки, запустили децентрализованные сети CDN с серверами в США, Нидерландах, Германии, Кореи, России, Украине, Казахстане и стали единственным международным сервисом видеонаблюдения, работающим одинаково хорошо во всем мире. В общем, казалось, что сделать свою аналитику с блэк-джеком и распознаванием будет просто и быстро… мы были молоды, трава казалась зеленее, а воздух – сладким и томительным.
[На тот момент мы рассматривали классические алгоритмы. Для начала нужно детектировать и локализовать лица на изображении: используем каскады Хаара, поиск регионов с текстурой, похожей на кожу и т.п. Допустим, нам надо найти первое попавшееся лицо и сопровождать только его в видеопотоке. Тут можно воспользоваться алгоритмом Лукаса-Канаде. Находим алгоритмом лицо и далее определяем в нём характерные точки. Сопровождаем точки с помощью алгоритма Лукаса-Канаде; после их пропадания считаем, что лицо исчезло из поля зрения. Получив характерные признаки лица, мы сможем сравнить его с признаками, заложенными в базе данных.
Для сглаживания траектории движения объекта (лица), а также для предсказания его положения на следующем кадре используем фильтр Кальмана. Тут необходимо отметить, что фильтр Кальмана предназначен для линейных моделей движения. Для нелинейного же используется алгоритм Particle Filter (как вариант Particle Filter + алгоритм Mean Shift).
Можно также использовать алгоритмы вычитания фона: библиотека с примерами реализации алгоритмов по вычитанию фона + статья по реализации легкого алгоритма вычитания фона ViBe. Кроме того, не стоит забывать один из самых распространенных методов Виолы-Джонса, реализованный в библиотеке компьютерного зрения OpenCV.]
Простое распознавание лиц – хорошо, но недостаточно. Нужно еще обеспечить устойчивое слежение за несколькими объектами в кадре даже в случае их совместного пересечения или временного «пропадания» за препятствием. Считать любое количество объектов, пересекающих определенную зону и учитывать направления пересечения. Знать, когда появляется и исчезает предмет/объект в кадре – навести мышкой на грязную чашку на столе и найти момент в видеоархиве, когда она там появилась и кто её оставил. В процессе слежения объект может измениться достаточно сильно (с точки зрения преобразований). Но от кадра к кадру эти изменения будут такими, что можно будет идентифицировать объект.
Кроме того, мы хотели сделать универсальное облачное решение, доступное для всех – из самых требовательных пользователей. Решение должно было быть гибким и масштабируемым, поскольку мы сами не могли знать, за чем хочет следить и что хочет считать пользователь. Вполне возможно, что кто-нибудь предполагал бы сделать на базе Ivideon трансляцию тараканьих бегов с автоматическим определением победителя.
Только спустя пять лет мы приступил к тестированию отдельных компонентов видеоаналитики – подробнее об этих проектах расскажем в новых статьях.
P.S. Итак, мы ищем добровольцев для тестов детектора очередей. А также пользователей системы ШТРИХ-М для теста новой системы контроля кассовых операций. Пишите на почту или в комментариях.
habr.com
19 фактов, о которых должны знать исследователи компьютерного зрения / Хабр
Как обычно, предлагаю сокращенный перевод, полный текст доступен в оригинале.
ВВЕДЕНИЕ
Несмотря на значительные усилия по разработке алгоритмов распознавания лиц, до сих пор не создана система, способная работать без искусственных ограничений, с учетом всех возможных вариаций параметров изображений, таких как шумы сенсоров, расстояние до объекта и уровень освещенности. Единственная система, которая хорошо справляется со своей задачей — это зрение человека. Поэтому полезно изучить стратегии, которые использует эта биологическая система, и попытаться использовать их при разработке искусственных алгоритмов. Предлагаются 19 важных результатов исследований, которые не претендуют на звание полной теории распознавания лиц, но дают важные подсказки разработчикам систем компьютерного зрения. Эти 19 результатов собраны из различных публикаций многих научных групп, и в оригинале статьи приведены ссылки на эти публикации.
РАСПОЗНАВАНИЕ КАК ФУНКЦИЯ ПРОСТРАНСТВЕННОГО РАЗРЕШЕНИЯ
Результат 1: Люди способны распознавать знакомые лица на изображениях очень низкого разрешения.
Прогресс в разработке видеосенсоров высокого разрешения провоцирует на использования все большего количества мелких деталей для распознавания лиц в системах машинного зрения. Пример такого подхода — распознавание по радужной оболочке глаза. Очевидно, такие алгоритмы не работают при отсутствии изображений высокой четкости. Особенно актуальна эта проблема, когда требуется распознавание лиц на значительном расстоянии. Обратимся к человеческому зрению. Как зависит точность распознавания лиц от разрешения изображения? Оказывается, люди сохраняют точность узнавания знакомых лиц на изображениях, сглаженных до размера 16х16 блоков. Точность узнавания свыше 50% сохраняется при сглаживании до эквивалентного размера 7х10 пикселов (см. рис. 1), и становится практически равной максимально возможному значению при разрешении 19х27 пикселов. Рис. 1 Люди способны узнать свыше половины знакомых лиц при разрешении, показанном на этом рисунке. Здесь изображены: 1 — Майкл Джордан, 2 — Вуди Ален, 3 — Голди Хоун, 4 — Билл Клинтон, 5 — Том Хэнкс, 6 — Саддам Хуссейн, 7 — Элвис Пресли, 8 — Джей Лено, 9 — Дастин Хофман, 10 — Принц Чарльз, 11 — Шер, 12 — Ричард Никсон.
Рис. 1 Люди способны узнать свыше половины знакомых лиц при разрешении, показанном на этом рисунке. Здесь изображены: 1 — Майкл Джордан, 2 — Вуди Ален, 3 — Голди Хоун, 4 — Билл Клинтон, 5 — Том Хэнкс, 6 — Саддам Хуссейн, 7 — Элвис Пресли, 8 — Джей Лено, 9 — Дастин Хофман, 10 — Принц Чарльз, 11 — Шер, 12 — Ричард Никсон.Результат 2: Способность игнорировать деградацию изображений увеличивается с ростом степени знакомства.
Способность компенсировать деградацию разрешающей способности изображений сильно зависит от степени знакомства с субъектом. Продемонстрирован низкий процент узнавания незнакомых лиц на двух различных фотографиях одного и того же субъекта, а с другой стороны, высокий процент узнавания изображений коллег по работе при наблюдении изображений с камер видеонаблюдения низкого качества. При этом, фигура и походка оказались значительно менее информативными, чем изображение лиц, несмотря на их чрезвычайно низкое разрешение. Это доказывается тем, что когда заслоняют фигуру, но оставляют лицо, точность распознавания падает незначительно, но при обратном действии точность значительно снижается (см. рис. 2). Рис. 2 Кадры из видеозаписей, использованных в исследовании. (а) исходное изображение, (b) закрыто тело субъекта, (с) закрыто лицо.
Рис. 2 Кадры из видеозаписей, использованных в исследовании. (а) исходное изображение, (b) закрыто тело субъекта, (с) закрыто лицо.Результат 3: Высокочастотная информация сама по себе не гарантирует высокое качество распознавания.
Традиционный подход к распознаванию во многом основывается на использовании алгоритмов выделения контура. Считается, что контур является инвариантом при различных условиях освещения. В контексте биологического распознавания лиц, контурные (векторные) изображения обычно бывают достаточны для узнавания лиц. Карандашные наброски и карикатуры часто легко узнаваемы. Означает ли это, что высокочастотные пространственные образы критически важны, или хотя бы достаточны для распознавания лиц? Результаты исследований опровергают это. Конкретно для «векторных» рисунков показано, что изображения, которые содержат только контуры, плохо поддаются распознаванию (правильное распознавание в 47% векторных рисунков против 90% исходных фотографий) — см. рис. 3.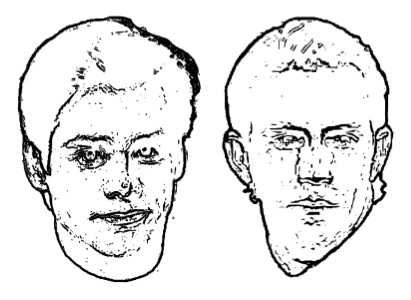 Рис. 3 Изображения, которые содержат только контуры, плохо поддаются распознаванию.
Рис. 3 Изображения, которые содержат только контуры, плохо поддаются распознаванию.ПРИРОДА ОБРАБОТКИ: ФРАГМЕНТАРНО ИЛИ ЦЕЛОСТНО?
Результат 4: Черты лица обрабатываются как единое целое.
Могут ли черты лица (глаза, нос, рот, брови и т.п.) обрабатываться отдельно от целого изображения? Лица часто можно идентифицировать по очень малой части, например только по глазам или бровям. Но если верхняя половина одного лица совмещается с нижней половиной другого лица, очень трудно узнать, кому принадлежали эти части (см. рис. 4). Целостный контекст, по-видимому, влияет на то, как обрабатываются отдельные черты лица. Это исследование показало, что отдельно взятые черты лица могут быт достаточны для распознавания, но в контексте целого лица геометрические соотношения между взятой чертой лица и остальной его частью превалирует при распознавании. Рис. 4 Верхняя часть лица принадлежит Вуди Алену, а нижняя — Опре Уинфри. При совмещении очень трудно угадать, кому принадлежат эти же части лица.
Рис. 4 Верхняя часть лица принадлежит Вуди Алену, а нижняя — Опре Уинфри. При совмещении очень трудно угадать, кому принадлежат эти же части лица.Результат 5: Брови являются одной из важнейших черт лица для узнавания.
Чаще всего, результаты экспериментов показывают, что самыми важными чертами лица для узнавания являются, в порядке убывания, глаза, рот и нос. Однако, недавние эксперименты с цифровым стиранием бровей показали, что брови явно недооценены специалистами по распознаванию лиц. В частности, процент узнанных лиц со стертыми бровями оказался значительно ниже, чем процент узнавания исходных портретов. Чем можно это объяснить? Во-первых, брови очень важны для передачи эмоций. Возможно, биологическая система восприятия лиц изначально смещена для придания повышенной значимости эти чертам лиц. Кроме того, брови являются очень стабильным элементом, устойчивым к деградации разрешающей способности изображения. Брови расположены на выступающей части черепа, а значит меньше подвержены искажению от теней.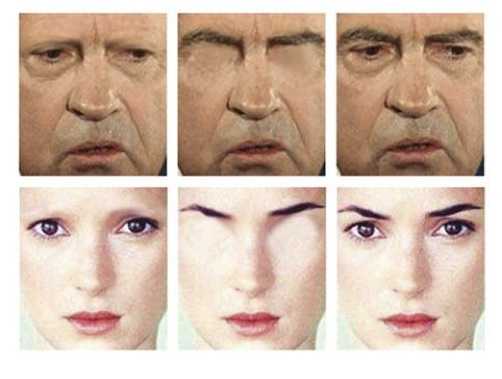 Рис. 5 Образцы изображений для испытания значимости бровей для распознавания лиц.
Рис. 5 Образцы изображений для испытания значимости бровей для распознавания лиц.
Результат 6: Значимые конфигурационные отношения не зависят от размеров по ширине/высоте.
Многие системы по распознаванию лиц используют точные измерения атрибутов, таких как расстояние между глазами, ширина рта, длина носа. Однако в биологической системе, похоже, эти размерности не очень важны. Это доказывается результатами исследований процента узнавания лиц по искаженным изображениям. Например, изображения лиц могут быть сильно искажены по ширине (рис. 6) без потери качества узнавания. Очевидно, искажения полностью сбивают алгоритмы, основанные на измерении абсолютных размеров и соотношений размеров по осям x и y. При подобных искажениях остаются неизменными соотношения размеров вдоль оси. Возможно, биологическая система кодирует такие соотношения, чтобы успешно распознавать лица при повороте шеи. Рис. 6 Даже сильные искажения по ширине (здесь ширина составила 25% от исходной) не мешают узнаванию лиц знаменитостей.
Рис. 6 Даже сильные искажения по ширине (здесь ширина составила 25% от исходной) не мешают узнаванию лиц знаменитостей.ПРИРОДА ИСПОЛЬЗУЕМЫХ КЛЮЧЕЙ: ПИГМЕНТАЦИЯ, ФОРМА И ДВИЖЕНИЕ
Результат 7: Формы лиц кодируются в слегка карикатурном виде.
Интуитивно кажется, что для успешного распознавания лиц зрительная система человека должна кодировать увиденные лица точно как они выглядят. Ошибки в сохраненных изображениях лиц очевидно ослабляют потенциальное совпадение новых изображений со старыми. Однако, эксперименты показали, что некоторые искажения от истинности играют позитивную роль в распознавании лиц. Именно, карикатурные изображения лиц обеспечивают качество распознавания равное или превосходящее уровень распознавания неискаженных лиц. Карикатурные изображения могут преувеличивать отдельные отклонения формы или комбинировать отклонения формы и пигментации (рис. 7). В обоих случаях испытуемые демонстрировали небольшое, но стабильное превосходство уровня распознавания, причем не только распознавания лиц, но и других объектов. Эти результаты можно интерпретировать таким образом. Существует пространство нормальных образов («пространство лиц»). Поскольку карикатуры искажают отдельные черты лица, индивидуальные отклонения лица от нормального играют повышенную роль при распознавали. Это дает в руки разработчиков алгоритмов интересную стратегию.Рис. 7 Пример карикатуризации изображения. (А) Усредненное по популяции женское лицо. (В) Истинное изображение конкретного лица. (С) Искуственно искаженное по форме и пигментации лицо преувеличивает отличия конкретного лица от усредненного. Такие искаженные изображения показали более высокий процент узнавания, чем истинные изображения.Результат 8: Продолжительное рассматривание лица может вызывать высокоуровневые эффекты, что означает возможность кодирования по прототипу.
Эффекты последействия (оптические иллюзии), которые происходят после продолжительного вглядывания в «адаптирующий» стимул (изображение), породили множество гипотез о нейронной обработке простых зрительных атрибутов, таких как движение, ориентация и цвет. Недавние исследования показали, что адаптация может вызывать мощные эффекты последействия на гораздо более сложные стимулы, такие как изображения лиц.
Существование эффекта последействия после продолжительного вглядывания в изображение лица свидетельствует о кодировании лиц на основе нормирования и контрастирования. Эффект последействия может выражаться просто в восприятии лица, искаженного в противоположном направлении по отношении к стимулу, либо порождать сложный эффект «анти-лица» специфической личности без явных искажений (рис. 8). <ПРИМ. ПЕРЕВОДЧИКА разрази меня гром, если кто-то что-то понял из этого перевода!> Это позволяет предположить, что существует несколько измерений, вдоль которых нейронные популяции могут настраиваться. Более того, это может означать, что эти сложные эффекты последействия — результат адаптации высоких отделов зрительной коры. 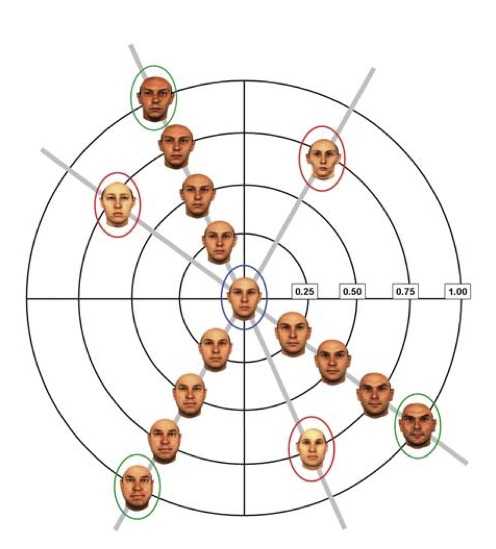 Рис. 8 Лица и из ассоциированные «анти-лица» в схематическом пространстве лиц. Продолжительное вглядывание в лицо, отмеченное зеленым кругом, приводит к тому, что центральное лицо будет ошибочно идентифицировано как лицо индивидуума, отмеченного красным кругом на той оси, н а которой находится исходный стимул (зеленый).
Рис. 8 Лица и из ассоциированные «анти-лица» в схематическом пространстве лиц. Продолжительное вглядывание в лицо, отмеченное зеленым кругом, приводит к тому, что центральное лицо будет ошибочно идентифицировано как лицо индивидуума, отмеченного красным кругом на той оси, н а которой находится исходный стимул (зеленый).
Результат 9: Свойства пигментации не менее важны, чем свойства формы.
Лица могут различаться по форме и по свойствам отражения света, назовем это пигментацией. Исследования были направлены на то, чтобы выяснить, что важнее для распознавания лиц: форма или пигментация. Создавались наборы лиц, отличающихся друг от друга только формой или только пигментацией — например, лазерные сканы лиц, искуственные модели лиц или морфы фотографий лиц. Оказалось, что процент узнавания не зависел от способа модификации, а это означает, что оба класса стимулов (графические свойства формы или совокупность цвета, отражающей способности и проч.) одинаково важны для распознавания лиц. Следствием этого является то, что учет свойств пигментации в искусственных системах распознавания лиц должен улучшить качество распознавания.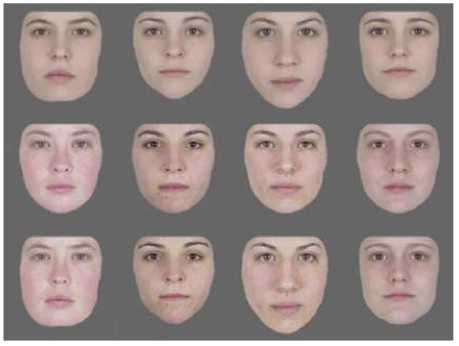 Рис. 9 Лица в нижнем ряду — лазерные сканы лиц, различающиеся как формой, так и пигментацией. Лица в среднем ряду различаются только пигментацией, но не формой. Лица в верхнем ряду различаются формой, но не пигментацией.
Рис. 9 Лица в нижнем ряду — лазерные сканы лиц, различающиеся как формой, так и пигментацией. Лица в среднем ряду различаются только пигментацией, но не формой. Лица в верхнем ряду различаются формой, но не пигментацией. Результат 10: Свойства цветности играют важную роль при деградации свойств формы.
Структура яркости изображений лиц, конечно очень важна для распознавания. Использование только яркости (т.е. монохромных изображений) вполне достаточно для адекватного распознавания лиц. Однако, исследования показали, что мнение о том, что информацие о цвете неважна для распознавания, противоречит наблюдаемым фактам. Когда свойства формы оказываются неточными (например, при снижении разрешающей способности), мозг использует информацию о цвете для успешного распознавания. В таких случаях процент узнавания значительно выше, чем у монохромных изображений. Одной из гипотез того, как используется цвет, является гипотеза диагностической роли информации о цвете — например цвет кожи или волос может подсказать нам правильный ответ. Вторая возможность — использование цветности улучшает возможности низкоуровневой обработки изображения, например сегментации областей изображения. Рис. 10 Примеры того, как цветность может облегчать решение низкоуровневых задач обработки изображения. (А) Распределение цвета (правые изображения) позволяют точнее определять границы областей, а значит свойства формы, чем распределение яркости (монохромные изображения в центре). (В, С) Обратите внимание на то, как форма волосистой части головы чётче определяется по распределению цвета, чем по монохромному изображению.
Рис. 10 Примеры того, как цветность может облегчать решение низкоуровневых задач обработки изображения. (А) Распределение цвета (правые изображения) позволяют точнее определять границы областей, а значит свойства формы, чем распределение яркости (монохромные изображения в центре). (В, С) Обратите внимание на то, как форма волосистой части головы чётче определяется по распределению цвета, чем по монохромному изображению. Результат 11: Инверсия (негатив) изображения значительно снижает процент узнавания лиц, возможно за счёт искажения свойств пигментации.
Все, кто занимался фотографией, знают, как сложно распознать даже очень знакомые лица на негативной пленке. Это явно свидетельствует о том, что хотя вся информация о форме остается неизменной, сильное и неестественное искажение свойств пигментации затрудняют распознавание, следовательно человеческий мозг активно использует свойства пигментации для распознавания лиц. Рис. 11 На негативе изображены несколько широко известных певцов, но попробуйте их узнать (съемки во время записи песни We Are the World).
Рис. 11 На негативе изображены несколько широко известных певцов, но попробуйте их узнать (съемки во время записи песни We Are the World).Результат 12: Изменения в освещении влияют на генерализацию.
Некоторые вычислительные модели распознавания требуют, чтобы лицо рассматривалось при разнообразных условиях освещения для надежного представления (запоминания). Однако люди способны генерализировать представления о лицах при радикально иных условиях освещения. В эксперименте испытуемым показывали модель лица, полученную лазерным сканированием, при освещении с одной стороны. Затем им показывали модель, освещенную совсем с другой стороны, и спрашивали, является ли модель одним и тем же лицом. Процент узнавания был значительно выше простого угадывания, хотя и ниже, чем при освещении лиц с одной и той же стороны.Рис. 12 Одно и то же лицо, освещаемое слева и справа.Результат 13: Генерализация направления взгляда осуществляется за счет темпоральных ассоциаций.
Распознавание знакомых лиц с разных углов зрения является очень сложной вычислительной задачей. Человеческий мозг с лёгкостью ее решает. Несмотря на то, что изображения одного и того же лица под разным углом гораздо больше различаются, чем изображения разных лиц, снятых с одного угла, люди способны правильно связывать изображения одинаковых лиц. Высказана гипотеза о том, что темпоральные ассоциации являются тем «клеем», которые связывает изображения лиц под разными углами, в единое целое. В экспериментах испытуемым показывали видеоролики, в которых лицо поворачивалось во фронтальной плоскости и одновременно выполнялся морфинг от одного лица к другому. Такой стимул значительно затруднил способность испытуемых правильно идентифицировать лица. Это свидетельствует о том, что рассматривание последовательностей изображений вызывает темпоральные ассоциации.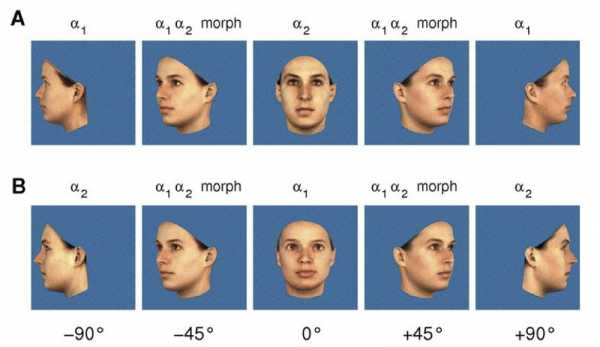 Рис. 13 Вращение и одновременный морфинг от лица а1 к лицу а2 и опять а1.
Рис. 13 Вращение и одновременный морфинг от лица а1 к лицу а2 и опять а1.Результат 14: Движение лиц улучшает распознавание.
Движение лиц улучшает распознавание при определенных условиях. Жесткое движение, например вращение камеры вокруг неподвижной головы, улучшает распознавание знакомых лиц, но не дает преимущества при запоминании. А вот нежесткое движение, такое как эмоциональные изменения в выражении лица или изменения при разговоре, играет большую роль. Это означает, что динамические свойства лиц, проявляемые при нежестких движениях, помогают мозгу точнее выявить структуру лиц и повышают качество распознавания.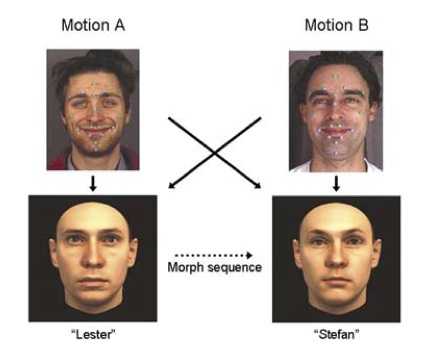 Рис. 14 Движения при отражении эмоций и речи подвергались морфингу, показанному стрелками. Испытуемые ошибались при идентификации исходных лиц, например когда движение губ «Штефана» накладывалось на «Лестера».
Рис. 14 Движения при отражении эмоций и речи подвергались морфингу, показанному стрелками. Испытуемые ошибались при идентификации исходных лиц, например когда движение губ «Штефана» накладывалось на «Лестера».РАЗВИТИЕ ЗРИТЕЛЬНОЙ СИСТЕМЫ
Результат 15: Зрительная система начинает распознавание с рудиментарных предпочтений схематических изображений лиц.
Существуют ли специфические начальные предпочтения зрительной системы человека? Ответ на этот вопрос должен помочь исследователю систем компьютерного зрения выбрать из двух альтернатив: 1) запрограммировать специфические структуры шаблонов лиц в систему распознавания лиц; или 2) сформировать неявные шаблоны за счет процесса обучения, независимо от того, являются шаблоны специфичными для лиц или для любых объектов. Новорожденные избирательно фокусируют взгляд на шаблоны, похожие на лица, уже в первые часы после рождения. Шаблон может выглядеть как три точки в овале, символизирующие глаза и рот (рис. 15а). Перевернутое изображение, невозможное для отображения лица (перевернутая триада точек в овале лица) не привлекает внимания новорожденных. Более поздние исследования показали, что новорожденные предпочитают изображения «утяжеленные сверху» изображениям, утяжеленным снизу (рис. 15b). Поэтому неясно, является ли это общим свойством зрительной коры, или специфическим для распознавания лиц. Простейший шаблон из трех точек может использоваться в системах поиска и распознавания лиц в качестве первоначальной стадии.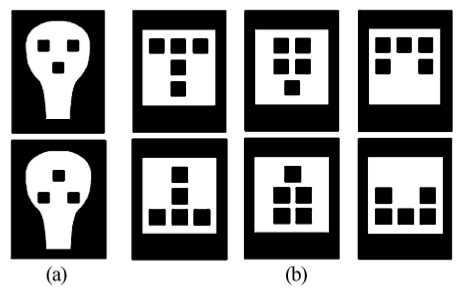 Рис. 15 (А) Новорожденные чаще фокусируют взгляд на верхнем шаблоне, чем на нижнем. (В) Новорожденные предпочитают шаблоны с преобладанием элементов вверху.
Рис. 15 (А) Новорожденные чаще фокусируют взгляд на верхнем шаблоне, чем на нижнем. (В) Новорожденные предпочитают шаблоны с преобладанием элементов вверху.Результат 16: Зрительная система развивается от стратегии частностей к целостной стратегии в течение первых лет жизни.
Обычные взрослые необычайно плохо распознают перевернутые вверх ногами изображения лиц, при этом не испытывают сложностей с распознаванием других перевернутых объектов, например домиков. Исследования показали, что это свойство развивается несколько лет. Шестилетние дети не проявляют снижение процента узнавания лиц по перевернутым изображениям; у восьмилетних уже несколько снижается эта способность; десятилетние дети уже ведут себя в этом отношении как взрослые. В экспериментах манипулировали расстояниями между отдельными элементами изображений лиц и подставляли отдельные элементы (например, глаза) из разных лиц. Результаты показали, что стратегия распознавания лиц развивается в первые годы жизни: от фрагментарной стратегии, основанной на отдельных свойствах, к целостной системе, использующей конфигуративную информацию.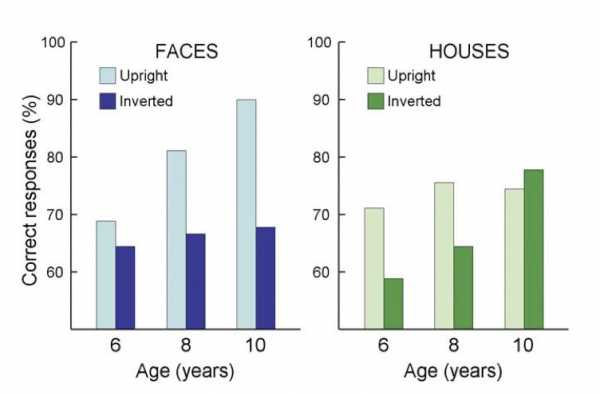 Рис. 16 Шестилетние дети одинаково плохо распознают и прямые и перевернутые лица. По мере взросления узнавание прямых лиц значительно улучшается, а узнавание перевернутых лиц — нет. По горизонтали — возраст; по вертикали — процент правильного узнавания. Слева — данные по распознаванию лиц, справа — по распознаванию домиков.
Рис. 16 Шестилетние дети одинаково плохо распознают и прямые и перевернутые лица. По мере взросления узнавание прямых лиц значительно улучшается, а узнавание перевернутых лиц — нет. По горизонтали — возраст; по вертикали — процент правильного узнавания. Слева — данные по распознаванию лиц, справа — по распознаванию домиков.НЕЙРОННЫЕ ОСНОВЫ
Результат 17: Зрительная система человека, вероятно, формирует отдельные области коры для распознавания лиц.
Исследования показали, что существует область коры головного мозга, которая дает сильный избирательный отклик на изображения лиц людей и животных и слабый отклик на изображения произвольных предметов и даже схематическое изображение лиц (рис. 17). Это может подсказать конструкторам систем компьютерного зрения рамки возможных механизмов генерализации и избирательности, свойственные объективно совершенным биологическим системам.Рис. 17 В левом верхнем углу показана локализация области FFA (fusiform face area) в правом полушарии головного мозга. Показаны примеры зрительных стимулов и откликов на них области FFA. Фотографии человеческого лица и кошки вызвали сильный отклик, а схематическое изображение лица и произвольный объект вызвали слабый отклик.Результат 18: Задержка отклика инферотемпоральной коры на изображение лица составляет 120 мс, что вероятно, означает в основном обработку прямым распространением сигнала.
Исследования на скорость реакции включают значительную задержку на моторную составляющую (например, испытуемый должен нажать кнопку, если увидит лицо). При использовании нейронных маркеров распознавания, такая сложная задача, как распознавание факта наличия животного в естественной сцене, занимает 50 мс. Некоторые клетки в инферотемпоральной (ИТ) коре специфичны для лиц. Задержка отклика этих клеток находится в пределах 80-160 мс. Это может означать, что с вычислительной точки зрения, обработка изображения вплоть до ИТ коры производится за один прямой проход, без обратных связей и итераций. Обработка зашумлённых изображений может занять больше времени.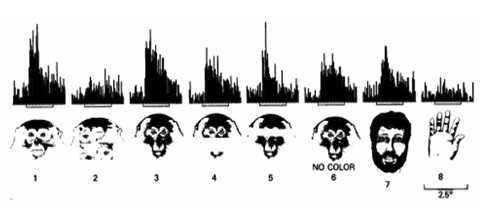 Рис. 18 Пример отклика клеток ИТ коры обезьяны на различные стимулирующие изображения лиц. Отклик систематический для разной степени деградации изображений приматов, а также для лица человека. Низкий отклик на изображение руки означает, что клетка не отвечает за изображение других частей тела, но специфична для лиц.
Рис. 18 Пример отклика клеток ИТ коры обезьяны на различные стимулирующие изображения лиц. Отклик систематический для разной степени деградации изображений приматов, а также для лица человека. Низкий отклик на изображение руки означает, что клетка не отвечает за изображение других частей тела, но специфична для лиц.Результат 19: Идентификация лиц и распознавание выражений лиц, вероятно, производятся различными системами.
Возможно ли извлекать информацию о выражении лица независимо от идентификации лица, либо это взаимосвязано? Поведенческие исследования, электрофизиологические исследования на животных и визуализация нейронной активности показывают, что разделение этих двух задач происходит в самом начале тракта обработки лиц, и существуют отдельные области мозга, отвечающие за идентификацию и за эмоции.habr.com
Распознавание лиц

A complex ofintegrated automation tools of existing and prospective automated systems at a locallevel, integrated to ensure protection of the population andterritories from natural and technogenic emergencies, social security, public order and security of the environment, as well asthose interacting with them in a united regional information and communication infrastructure.

The creation of the security service of the transport enterprise allows consciously and purposefully to conduct work to ensure the safety of this category of enterprises, as well as all its units and employees.

The safety of the enterprise is the most important factor affecting its functioning. The process of ensuring security implies a set of measures that protect the enterprise from accidental or deliberate interference in its functioning.

Over years, developments of Integra-S have proven their worth at large strategic facilities of transport infrastructure in Russia and abroad.

Integra-S built a unified security and monitoring system of the Russian Sea and River Fleet’s facilities based on Integra-S hardware and software complexes. It is a Unified Global Monitoring System of Russian waters, ports and hydraulic structures, a breakthrough product in the development of absolutely unique security and facility management systems.

Distributed integrated smart security system (ISSS) Integra-S can unite geographically remote local integrated security systems of railway facilities belonging to different territorial levels of railway management into a unified multi-level information and management structure.

The system allows total control throughout the airport, representing a universal product in the construction of security systems and facility management.

Distributed IISB Integra-S allows to unite metro objects (stations, transitions, bridges, administrative buildings, depots and production facilities) into a single multilevel information-management structure.

An integrated security system for the infrastructure of a banking institution is a complex automated management system that is responsible for the security of each site in the bank.

An integrated security system for universities and educational institutions is a complex, multifunctional system that is responsible for the safety of students.

Counting visitors to analyze attendance dynamics. Detecting individuals from "black lists" (for example, persons who have previously committed illegal actions) or from "white lists" (VIP clients), as well as control over the entire area of the building.

Fuel and energy companies need deeply integrated security systems that should be built using innovative hardware and software. Only such systems can really control and ensure security in fuel and energy companies.

The system is a special complex of customer service automation, management of security systems and hotel life support, making the work of staff more efficient, and the guests' stay comfortable and safe.

A special complex of automated control systems for the safety and life support of hospitals, clinics, sanatoria on the basis of integrated smart security system (ISSS) Integra-S makes the work of staff more efficient, and the patients' stay is comfortable and safe.

The integrated complex for the protection of objects is a high-tech, reliable and inexpensive means of protecting your property. This system is used both to protect houses, apartments and cottages, and to ensure business security.

The range of application of the system is wide. This is a high-tech, reliable and inexpensive means of protecting your property. This system is used both to protect houses, apartments and cottages, and to ensure business security.
www.integra-s.com
- Вселенная большой взрыв

- Самый большой сухогруз

- Под робот

- Гаджеты какие бывают
- Самое прочное стекло

- Самая высокая радиовышка в мире

- Механический протез руки

- Какую новую планету открыли астрономы

- С 97

- Мкс онлайн местоположение

- Nike из назад в будущее





