Тест Тьюринга. Тьюринга тест это
ТЬЮРИНГА ТЕСТ - это... Что такое ТЬЮРИНГА ТЕСТ?
(англ. Turing's test) — предложенный англ. математиком и философом Аланом Тьюрингом (1912-1954) операциональный способ решения вопроса «мыслит ли машина?». Способ состоит в том, что во время опосредствованного диалога (как минимум) 2 человек, которые непосредственно не видят и не слышат друг друга, а общаются опосредованно (напр., через компьютерную сеть или др. человека), одного из партнеров «подменяют» компьютерной программой, которая способна симулировать понимание речи, отвечать на вопросы и задавать их. Если др. человек не может заметить подмену партнера машиной (и наоборот), то следует считать, что машина обладает «интеллектом». Реальные испытания, в которых тематика общения была ограниченной определенными областями и ситуациями (напр., беседа пациента с невидимым психиатром, которого замещала программа ЭЛИЗА), показали, что создаваемые машинные программы вполне могут вводить людей в заблуждение. (Б. М.)
Большой психологический словарь. — М.: Прайм-ЕВРОЗНАК. Под ред. Б.Г. Мещерякова, акад. В.П. Зинченко. 2003.
- ТРО-СИНДРОМ
- УЗУАЛЬНОЕ ЗНАЧЕНИЕ
Смотреть что такое "ТЬЮРИНГА ТЕСТ" в других словарях:
ТЬЮРИНГА, ТЕСТ — Тест адекватности прибора искусственного интеллекта, в котором решается вопрос, действительно ли можно сказать, что он думает. Как представлял это Алан Тьюринг, человек (А) связан с другим человеком (Б) через телетайп, посредством которого они… … Толковый словарь по психологии
ТЕСТ ТЬЮРИНГА — см. Тьюринга тест. Большой психологический словарь. М.: Прайм ЕВРОЗНАК. Под ред. Б.Г. Мещерякова, акад. В.П. Зинченко. 2003. Тест Тьюринга … Большая психологическая энциклопедия
Тест — (от слова англ. test) «испытание», «проверка» это метод изучения глубинных процессов деятельности человека, посредством его высказываний или оценок факторов функционирования системы управления Содержание 1 Программирование 2 Математика … Википедия
Тест Тьюринга — Стандартная интерпретация теста Тьюринга Тест Тьюринга эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум» (англ. … Википедия
Тест (значения) — Может, вы искали ?Тест (от слова en. test) испытание, проверка, анализ. Программирование * Тестирование программного обеспечения * Тест Тьюринга * Бета тестирование Тесты в биологических и биохимических исследованиях * Тест на ВИЧ *… … Википедия
Недетерминированная машина Тьюринга — Машина Тьюринга Варианты машин Универсальная машина Тьюринга Квантовая машина Тьюринга en:Read only Turing machine en:Read only right moving Turing Machines Вероятностная машина Тьюринга Недетер … Википедия
Тьюринг — Тьюринг, Алан Матисон Алан Тьюринг Alan Mathison Turing Памятник в Сэквиль Парке Дата рождения … Википедия
Тьюринг, Алан Матисон — Алан Тьюринг Alan Turing Памятник в Сэквиль Парке Дата рождения: 23 июня 1912 Место рождения: Лондон, Англия Дата смерти: 7 июня 1954 … Википедия
Тьюринг, Алан — Алан Тьюринг Alan Mathison Turing … Википедия
Тьюринг А. М. — Алан Тьюринг Alan Turing Памятник в Сэквиль Парке Дата рождения: 23 июня 1912 Место рождения: Лондон, Англия Дата смерти: 7 июня 1954 … Википедия
Книги
- Философия, Бен Дюпре. Принято считать, что философия сложна и скучна, а философы - заумные затворники, далекие от реальной жизни. Пора избавиться от заблуждений. Философия столетиями была опаснейшим делом.… Подробнее Купить за 346 руб
psychology.academic.ru
Тест Тьюринга — Абсурдопедия
Для людей с извращённым чувством юмора так называемые «эксперты» из Википедии предлагают статью, озаглавленную Тест Тьюринга.
Испытуемый готовится к завтрашнему тесту Тьюринга Тестер Тьюринга с разрядностью дисплея в 1 битТест Тьюринга — это эксперимент с целью отличить Алана Тьюринга от его машины. Со времён первоначальной постановки было разработано и внедрено множество разновидностей теста. В современном понимании тестом Тьюринга называется любой метод, с помощью которого можно отличить естественную человеческую глупость от её машинной имитации.
Первоначальная постановка[править]
Испытуемый находится в отдельной комнате и перекрикивается с экзаменатором через стенку. Задача экзаменатора — угадать марку, модель, год выпуска и пробег испытуемого.
Дополнительные очки начисляются испытуемому в случае, если он сможет убедить экзаменатора, что тот — машина.
CAPTCHA[править]
Капча РоршахаИспытуемому предлагается описать, что он видит в предложенной картинке. Задача испытуемого — успешно опубликовать пост, комментарий или зарегистрироваться на форуме. Впервые этот вид теста был предложен швейцарским художником Германом Роршахом в 1921 году и применён при оформлении поступающих больных в первом окошке регистратуры Цюрихского психиатрического госпиталя.
Тест бессмертия[править]
В этом варианте теста экзаменатор ждёт, кто из испытуемых раньше умрёт (или заржавеет). Недостатком такого подхода является высокий расход испытуемых.
Самотестирование[править]
Эта разновидность теста выполняется автоматически при включении питания машины Тьюринга. Машина, успешно убедившая себя в том, что она машина, сообщает о результате теста коротким звуковым сигналом.
Деструктивный тест[править]
Суть подхода заключается в том, чтобы разобрать испытуемого и посмотреть, что у него внутри. В таком тесте обычно участвуют сразу несколько крупных, тренированных экзаменаторов.
Слепой тест[править]
Испытуемый не знает заранее, машина он или человек, и ему это так же интересно, как и экзаменатору.
Двойной слепой тест[править]
В дополнение к условиям слепого теста, участники эксперимента не знают, кто из них испытуемый, а кто — экзаменатор.
Тройной слепой тест[править]
Участники эксперимента не знают, что они участники эксперимента.
Обратный тест Тьюринга[править]
Смысл его заключается не в том, чтобы машина убедила экзаменатора что она является человеком, а в том, чтобы испытуемый убедил экзаменатора в том что он машина.
- Тест Тьюринга широко применяется как важнейший этап приёмки читающего, пишущего, отвечающего и комментирующего оборудования.
- По результатам теста принимаются решения о зачислении на должности координатора транзакций, брокера сообщений и планировщика задач.
- Со следующего года в дополнение к флюорографии планируется ввести обязательный тест Тьюринга для желающих подключиться к интернету. Правильные ответы к тесту, однако, уже выложены в упомянутом интернете.
- В быту тест Тьюринга позволяет спеть дуэтом с CD-плеером, плодотворнее построить разговор с автоответчиком и наладить переписку со спамерами.
А ты прошёл тест Тьюринга?[править]
absurdopedia.net
Тест Тьюринга - это... Что такое Тест Тьюринга?
Тест Тьюринга — эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум» (англ. Computing Machinery and Intelligence), опубликованной в 1950 году в философском журнале «Mind». Тьюринг задался целью определить, может ли машина мыслить.
Стандартная интерпретация этого теста звучит следующим образом: «Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Все участники теста не видят друг друга. Если судья не может сказать определенно, кто из собеседников является человеком, то считается, что машина прошла тест. Чтобы протестировать именно интеллект машины, а не её возможность распознавать устную речь, беседа ведется в режиме «только текст», например, с помощью клавиатуры и экрана (компьютера-посредника).
История
Философские предпосылки
Хотя исследования в области искусственного интеллекта начались в 1956 году, их философские корни уходят глубоко в прошлое. Вопрос, сможет машина думать или нет, имеет долгую историю. Он тесно связан с различиями между дуалистическим и материалистическим взглядами. С точки зрения дуализма, мысль не является материальной (или, по крайней мере, не имеет материальных свойств), и поэтому разум нельзя объяснить только с помощью физических понятий. С другой стороны, материализм гласит, что разум можно объяснить физически, таким образом, оставляя возможность существования разумов, созданных искусственно.
В 1936 году философ Альфред Айер рассмотрел обычный для философии вопрос касательно других разумов: как узнать, что другие люди имеют тот же сознательный опыт, что и мы? В своей книге «Язык, истина и логика» Айер предложил алгоритм распознавания осознающего человека и не осознающей машины: «Единственным основанием, на котором я могу утверждать, что объект, который кажется разумным, на самом деле не разумное существо, а просто глупая машина, является то, что он не может пройти один из эмпирических тестов, согласно которым определяется наличие или отсутствие сознания». Это высказывание очень похоже на тест Тьюринга, однако точно неизвестно, была ли известна Тьюрингу популярная философская классика Айера.
Несмотря на то, что прошло больше 50 лет, тест Тьюринга не потерял своей значимости. Но в настоящее время исследователи искусственного интеллекта практически не занимаются решением задачи прохождения теста Тьюринга, считая, что гораздо важнее изучить основополагающие принципы интеллекта, чем продублировать одного из носителей естественного интеллекта. В частности, проблему «искусственного полета» удалось успешно решить лишь после того, как братья Райт и другие исследователи перестали имитировать птиц и приступили к изучению аэродинамики. В научных и технических работах по воздухоплаванию цель этой области знаний не определяется как «создание машин, которые в своем полете настолько напоминают голубей, что даже могут обмануть настоящих птиц».[1]
Алан Тьюринг
К 1956 году британские учёные уже на протяжении 10 лет исследовали «машинный интеллект». Этот вопрос был обычным предметом для обсуждения среди членов «Ratio Club» — неформальной группы британских кибернетиков и исследователей в области электроники, в которой состоял и Алан Тьюринг, в честь которого был назван тест.
Тьюринг в особенности занимался проблемой машинного интеллекта, по меньшей мере, с 1941 года. Одно из самых первых его упоминаний о «компьютерном интеллекте» было сделано в 1947 году. В докладе «Интеллектуальные машины» Тьюринг исследовал вопрос, может ли машина обнаруживать разумное поведение, и в рамках этого исследования предложил то, что может считаться предтечей его дальнейших исследований: «Нетрудно разработать машину, которая будет неплохо играть в шахматы. Теперь возьмем трех человек — субъектов эксперимента. А, В и С. Пусть А и С неважно играют в шахматы, а В — оператор машины. […] Используются две комнаты, а также некоторый механизм для передачи сообщений о ходах. Участник С играет или с А, или с машиной. Участник С может затрудниться ответить с кем он играет».
Таким образом, к моменту публикации в 1950 году статьи «Вычислительные машины и разум», Тьюринг уже на протяжении многих лет рассматривал возможность существования искусственного интеллекта. Тем не менее, данная статья стала первой статьёй Тьюринга, в которой рассматривалось исключительно это понятие.
Тьюринг начинает свою статью утверждением: «Я предлагаю рассмотреть вопрос „Могут ли машины думать?“». Он подчёркивает, что традиционный подход к этому вопросу состоит в том, чтобы сначала определить понятия «машина» и «интеллект». Тьюринг, однако, выбрал другой путь; вместо этого он заменил исходный вопрос другим, «который тесно связан с исходным и формулируется относительно недвусмысленно». По существу, он предлагает заменить вопрос «Думают ли машины?» вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие создания)?». Преимуществом нового вопроса, как утверждает Тьюринг, является то, что он проводит «чёткую границу между физическими и интеллектуальными возможностями человека».
Чтобы продемонстрировать этот подход, Тьюринг предлагает тест, придуманный по аналогии с игрой для вечеринок «Imitation game» — имитационная игра. В этой игре мужчина и женщина направляются в разные комнаты, а гости пытаются различить их, задавая им серию письменных вопросов и читая напечатанные на машинке ответы на них. По правилам игры и мужчина, и женщина пытаются убедить гостей, что все наоборот. Тьюринг предлагает переделать игру следующим образом: "Теперь зададим вопрос, что случится, если в этой игре роль А будет исполнять машина? Будет ли задающий вопросы ошибаться так же часто, как если бы он играл с мужчиной и женщиной? Эти вопросы заменяют собой исходный «Может ли машина думать?».
В том же докладе Тьюринг позднее предлагает «эквивалентную» альтернативную формулировку, включающую судью, который беседует только с компьютером и человеком. Наряду с тем, что ни одна из этих формулировок точно не соответствует той версии теста Тьюринга, которая наиболее известна сегодня, в 1952 учёный предложил третью. В этой версии теста, которую Тьюринг обсудил в эфире радио Би-Би-Си, жюри задает вопросы компьютеру, а роль компьютера состоит в том, чтобы заставить значительную часть членов жюри поверить, что он на самом деле человек.
В статье Тьюринга учтены 9 предполагаемых вопросов, которые включают все основные возражения против искусственного интеллекта, поднятые после того, как статья была впервые опубликована.
Элиза и PARRY
Блей Витби указывает на 4 основные поворотные точки в истории теста Тьюринга — публикация статьи «Вычислительные машины и разум» в 1950, сообщение о создании Джозефом Уайзенбаумом программы Элиза (ELIZA) в 1966, создание Кеннетом Колби программы PARRY, которая была впервые описана в 1972 году, и Коллоквиум Тьюринга в 1990.
Принцип работы Элизы заключается в исследовании введенных пользователем комментариев на наличие ключевых слов. Если найдено ключевое слово, то применяется правило, по которому комментарий пользователя преобразуется и возвращается предложение-результат. Если же ключевое слово не найдено, Элиза либо возвращает пользователю общий ответ, либо повторяет один из предыдущих комментариев. Вдобавок Уайзенбаум запрограммировал Элизу на имитацию поведения психотерапевта, работающего по клиент-центрированной методике. Это позволяет Элизе «притвориться, что она не знает почти ничего о реальном мире». Применяя эти способы, программа Уайзенбаума могла вводить в заблуждение некоторых людей, которые думали, что они разговаривают с реально существующим человеком, а некоторых было «очень трудно убедить, что Элиза […] не человек». На этом основании некоторые утверждают, что Элиза — одна из программ (возможно первая), которые смогли пройти тест Тьюринга. Однако это утверждение очень спорно, так как людей, «задающих вопросы», инструктировали так, чтобы они думали, что с ними будет разговаривать настоящий психотерапевт, и не подозревали о том, что они могут разговаривать с компьютером.
Работа Колби — PARRY — была описана, как «Элиза с мнениями»: программа пыталась моделировать поведение параноидального шизофреника, используя схожий (если не более продвинутый) с Элизой подход, примененный Уайзенбаумом. Для того чтобы проверить программу, PARRY тестировали в начале 70-х, используя модификацию теста Тьюринга. Команда опытных психиатров анализировала группу, составленную из настоящих пациентов и компьютеров под управлением PARRY, используя телетайп. Другой команде из 33 психиатров позже показали стенограммы бесед. Затем обе команды попросили определить, кто из «пациентов» — человек, а кто — компьютерная программа. Психиатры лишь в 48 % случаев смогли вынести верное решение. Эта цифра согласуется с вероятностью случайного выбора. Заметьте, что эти эксперименты не являлись тестами Тьюринга в полном смысле, так как для вынесения решения данный тест требует, чтобы вопросы можно было задавать в интерактивном режиме, вместо чтения стенограммы прошедшей беседы.
Пока что ни одна программа и близко не подошла к прохождению теста. Хотя такие программы, как Элиза (ELIZA), иногда заставляли людей верить, что они говорят с человеком, как, например, в неформальном эксперименте, названном AOLiza, но эти случаи нельзя считать корректным прохождением теста Тьюринга по целому ряду причин:
- Человек в таких беседах не имел никаких оснований считать, что он говорит с программой, в то время как в настоящем тесте Тьюринга человек активно пытается определить, с кем он беседует.
- Документированные случаи обычно относятся к таким чатам, как IRC, где многие беседы отрывочны и бессмысленны.
- Многие пользователи Интернета используют английский как второй или третий язык, так что бессмысленный ответ программы легко может быть списан на языковой барьер.
- Многие просто ничего не знают об Элизе и ей подобных программах, и поэтому не сочтут собеседника программой даже в случае совершенно нечеловеческих ошибок, которые эти программы допускают.
Китайская комната
В 1980 году в статье «Разум, мозг и программы» Джон Сёрль выдвинул аргумент против теста Тьюринга, известный как мысленный эксперимент «Китайская комната». Сёрль настаивал, что программы (такие как Элиза) смогли пройти тест Тьюринга, просто манипулируя символами, значения которых они не понимали. А без понимания их нельзя считать «разумными» в том же смысле, что и людей. «Таким образом, — заключает Сёрль, — тест Тьюринга не является доказательством того, что машина может думать, а это противоречит изначальному предположению Тьюринга».
Такие аргументы, как предложенный Сёрлем, а также другие, основанные на философии разума, породили намного более бурные дискуссии о природе разума, возможности существования разумных машин и значимости теста Тьюринга, продолжавшиеся в течение 80-х и 90-х годов.
Коллоквиум Тьюринга
В 1990 году состоялась сороковая годовщина публикации статьи Тьюринга «Вычислительные машины и разум», что возобновило интерес к тесту. В этом году произошли два важных события.
Одно из них — коллоквиум Тьюринга, который проходил в апреле в Университете Сассекса. В его рамках встретились академики и исследователи из разнообразных областей науки, чтобы обсудить тест Тьюринга с позиций его прошлого, настоящего и будущего. Вторым событием стало учреждение ежегодного соревнования на получение премии Лёбнера.
Премия Лёбнера
Ежегодный конкурс на получение премии Лёбнера является платформой для практического проведения тестов Тьюринга. Первый конкурс прошел в ноябре 1991 года. Приз гарантирован Хью Лёбнером (Hugh Loebner). Кембриджский центр исследований поведения, расположенный в Массачусетсе, США, предоставлял призы до 2003 года включительно. По словам Лёбнера, соревнование было организовано с целью продвижения вперед в области исследований, связанных с искусственным интеллектом, отчасти потому, что «никто не предпринял мер, чтобы это осуществить».
Серебряная (аудио) и золотая (аудио и зрительная) медали никогда ещё не вручались. Тем не менее, ежегодно из всех представленных на конкурс компьютерных систем судьи награждают бронзовой медалью ту, которая, по их мнению, продемонстрирует «наиболее человеческое» поведение в разговоре. Не так давно программа «Искусственное лингвистическое интернет-компьютерное существо» (Artificial Linguistic Internet Computer Entity — A.L.I.C.E.) трижды завоевала бронзовую медаль (в 2000, 2001 и 2004). Способная к обучению программа Jabberwacky (англ.) побеждала в 2005 и 2006. Её создатели предложили персонализированную версию: возможность пройти имитационный тест, пытаясь более точно сымитировать человека, с которым машина тесно пообщалась перед тестом.
Конкурс проверяет способность разговаривать; победителями становятся обычно чат-боты или «Искусственные разговорные существа» (Artificial Conversational Entities (ACE)s). Правилами первых конкурсов предусматривалось ограничение. Согласно этому ограничению каждая беседа с программой или скрытым человеком могла быть только на одну тему. Начиная с конкурса 1995 года это правило отменено. Продолжительность разговора между судьей и участником была различной в разные годы. В 2003 году, когда конкурс проходил в Университете Суррея, каждый судья мог разговаривать с каждым участником (машиной или человеком) ровно 5 минут. С 2004 по 2007 это время составляло уже более 20 минут. В 2008 максимальное время разговора составляло 5 минут на пару, потому что организатор Кевин Ворвик (Kevin Warwick) и координатор Хьюма Ша (Huma Shah) полагали, что ACE не имели технических возможностей поддерживать более продолжительную беседу. Как ни странно, победитель 2008 года, Elbot (англ.), не притворялся человеком, но всё-таки сумел обмануть трех судей. В конкурсе проведенном в 2010 году, было увеличено время до 25 минут при общении между системой и исследователем, по требованию спонсора. Что только подтверждает, программы подросли в имитации человеку и только лишь при длительной беседе появляются минусы, позволяющие вычислять собеседника. А вот конкурс проведенный 15 мая 2012 года, состоялся впервые в мире с прямой трансляцией беседы, что только поднимает интерес к данному конкурсу.
Появление конкурса на получение премии Лёбнера привело к возобновлению дискуссий о целесообразности теста Тьюринга, о значении его прохождения. В статье «Искусственная тупость» газеты The Economist отмечается, что первая программа-победитель конкурса смогла выиграть отчасти потому, что она «имитировала человеческие опечатки». (Тьюринг предложил, чтобы программы добавляли ошибки в вывод, чтобы быть более хорошими «игроками».) Существовало мнение, что попытки пройти тест Тьюринга просто препятствуют более плодотворным исследованиям.
Во время первых конкурсов была выявлена вторая проблема: участие недостаточно компетентных судей, которые поддавались умело организованным манипуляциям, а не тому, что можно считать интеллектом.
Тем не менее, с 2004 года в качестве собеседников в конкурсе принимают участие философы, компьютерные специалисты и журналисты.
Стоит заметить, что полного диалога с машиной пока не существует, а то что есть больше напоминает общение в кругу друзей когда отвечаешь на вопрос одного, а следом задает вопрос другой или как бы на твой вопрос отвечает совершено посторонний. На этом, в принципе и можно ловить машинную программу, если как по тесту Тьюринга, а в целом очень даже забавно можно скоротать время и попробовать себя в роли судей на конкурсе премии Лёбнера.
Судейство на конкурсе очень строгое. Эксперты заранее готовятся к турниру и подбирают весьма заковыристые вопросы, чтобы понять, с кем же они общаются. Их разговор с программами напоминает допрос следователя. Судьи любят, например, повторять некоторые вопросы через определенное время, так как слабые боты не умеют следить за историей диалога и их можно поймать на однообразных ответах.[2]
Коллоквиум по разговорным системам, 2005
В ноябре 2005 года в Университете Суррея проходила однодневная встреча разработчиков ACE , которую посетили победители практических тестов Тьюринга, проходивших в рамках конкурса на получение премии Лёбнера: Робби Гарнер (Robby Garner), Ричард Уоллес (Richard Wallace), Ролл Карпентер (Rollo Carpenter). В числе приглашенных докладчиков были Дэвид Хэмилл (David Hamill), Хью Лёбнер и Хьюма Ша.
Симпозиум общества AISB по тесту Тьюринга, 2008
В 2008 году наряду с проведением очередного конкурса на получение премии Лёбнера, проходившего в Университете Рединга (University of Reading), Общество изучения искусственного интеллекта и моделирования поведения (The Society for the Study of Artificial Intelligence and Simulation of Behavior — AISB) провело однодневный симпозиум, на котором обсуждался тест Тьюринга. Симпозиум организовали Джон Бенден (John Barnden), Марк Бишоп (Mark Bishop), Хьюма Ша и Кевин Ворвик. В числе докладчиков были директор Королевского института баронесса Сьюзан Гринфилд (Susan Greenfield), Сельмер Брингсорд (Selmer Bringsjord), биограф Тьюринга Эндрю Ходжес (Andrew Hodges) и ученый Оуэн Холланд (Owen Holland). Никакого соглашения о каноническом тесте Тьюринга не появилось, однако Брингсорд предположил, что более крупная премия будет способствовать тому, что тест Тьюринга будет пройден быстрее.
Год Алана Тьюринга и Тьюринг-100 в 2012
В 2012 году будет отмечаться юбилей Алана Тьюринга. На протяжении всего года будет проходить множество больших мероприятий. Многие из них будут проходить в местах, имевших большое значение в жизни Тьюринга: Кембридж, Манчестер и Блетчи Парк. Год Алана Тьюринга курируется организацией TCAC (Turing Centenary Advisory Committee), осуществляющей профессиональную и организационную поддержку мероприятий в 2012 году. Также поддержкой мероприятий занимаются: ACM, ASL, SSAISB, BCS, BCTCS, Блетчи Парк, BMC, BLC, CCS, Association CiE, EACSL, EATCS, FoLLI, IACAP, IACR, KGS и LICS.
Для организации мероприятий по празднованию в июне 2012 года столетия со дня рождения Тьюринга создан специальный комитет, задачей которого является донести мысль Тьюринга о разумной машине, отраженную в таких голливудских фильмах, как «Бегущий по лезвию», до широкой публики, включая детей. В работе комитета участвуют: Кевин Ворвик, председатель, Хьюма Ша, координатор, Ян Бланд (Ian Bland), Крис Чапмэн (Chris Chapman), Марк Аллен (Marc Allen), Рори Данлоуп (Rory Dunlop), победители конкурса на получение премии Лёбнера Робби Гарне и Фред Робертс (Fred Roberts). Комитет работает при поддержке организации «Женщины в технике» (Women in Technology) и Daden Ltd.
На этом конкурсе россияне, имена которых не разглашаются, представили программу «Евгений».[3] В 150 проведённых тестах (а по факту пятиминутных разговорах) участвовали пять новейших программ, которые «затерялись» среди 25 обычных людей. Программа «Евгений», изображавшая 13-летнего мальчика, проживающего в Одессе, стала победителем, сумев в 29,2 % своих ответов ввести экзаменаторов в заблуждение. Таким образом, программа не добрала всего 0,8 % для полного прохождения теста.
Варианты теста Тьюринга
Имитационная игра согласно описанию Тьюринга в статье «Вычислительные машины и разум». Игрок С путем задания серии вопросов пытается определить, кто из двух других игроков — мужчина, а кто — женщина. Игрок А, мужчина, пытается запутать игрока С, а игрок В пытается помочь С. Первоначальный тест на основе имитационной игры, в котором вместо игрока А играет компьютер. Компьютер теперь должен запутать игрока С, в то время как игрок В продолжает пытаться помочь ведущему.Существуют, по крайней мере, три основных варианта теста Тьюринга, два из которых были предложны в статье «Вычислительные машины и разум», а третий вариант, по терминологии Саула Трейджера (Saul Traiger), является стандартной интерпретацией.
Наряду с тем, что существует определенная дискуссия, соответствует ли современная интерпретация тому, что описывал Тьюринг, либо она является результатом неверного толкования его работ, все три версии не считаются равносильными, их сильные и слабые стороны различаются.
Имитационная игра
Тьюринг, как мы уже знаем, описал простую игру для вечеринок, которая включает в себя минимум трех игроков. Игрок А — мужчина, игрок В — женщина и игрок С, который играет в качестве ведущего беседу, любого пола. По правилам игры С не видит ни А, ни В и может общаться с ними только посредством письменных сообщений. Задавая вопросы игрокам А и В, С пытается определить, кто из них — мужчина, а кто — женщина. Задачей игрока А является запутать игрока С, чтобы он сделал неправильный вывод. В то же время задачей игрока В является помочь игроку С вынести верное суждение.
В той версии, которую С. Г. Стеррет (S. G. Sterret) называет «Первоначальный тест на основе имитационной игры» (Original Imitation Game Test), Тьюринг предлагает, чтобы роль игрока А исполнял компьютер. Таким образом, задачей компьютера является притвориться женщиной, чтобы сбить с толку игрока С. Успешность выполнения подобной задачи оценивается на основе сравнения исходов игры, когда игрок А — компьютер, и исходов, когда игрок А — мужчина:
| Теперь мы спросим: «Что произойдёт, если машина выступит в качестве игрока А в этой игре?» Будет ли ведущий принимать неправильные решения, когда игра ведётся таким образом, также часто как если бы в игре принимали участие мужчина и женщина? Эти вопросы заменят наш первоначальный: «Могут ли машины думать?» Оригинальный текст (англ.) We now ask the question, «What will happen when a machine takes the part of A in this game?» Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, «Can machines think?» |
Второй вариант предложен Тьюрингом в той же статье. Как и в «Первоначальном тесте», роль игрока А исполняет компьютер. Различие заключается в том, что роль игрока В может исполнять как мужчина, так и женщина.
«Давайте рассмотрим конкретный компьютер. Верно ли то, что модифицируя этот компьютер с целью иметь достаточно места для хранения данных, увеличивая скорость его работы и задавая ему подходящую программу, можно сконструировать такой компьютер, чтобы он удовлетворительно выполнял роль игрока А в имитационной игре, в то время как роль игрока В выполняет мужчина?», — Тьюринг, 1950, стр. 442.
В этом варианте оба игрока А и В пытаются склонить ведущего к неверному решению.
Стандартная интерпретация
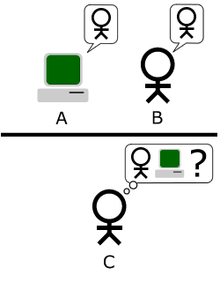
Главной мыслью данной версии является то, что целью теста Тьюринга является ответ не на вопрос, может ли машина одурачить ведущего, а на вопрос, может ли машина имитировать человека или нет. Несмотря на то, что идут споры о том, подразумевался ли этот вариант Тьюрингом или нет, Стеррет считает, что этот вариант Тьюрингом подразумевался и, таким образом, совмещает второй вариант с третьим. В это же время группа оппонентов, включая Трейджера, так не считает. Но это все равно привело к тому, что можно назвать «стандартной интерпретацией». В этом варианте игрок А — компьютер, игрок В — человек любого пола. Задачей ведущего является теперь не определить кто из них мужчина и женщина, а кто из них компьютер, а кто — человек.
Имитационная игра в сравнении со стандартным тестом Тьюринга
Существуют разногласия по поводу того, какой же вариант имел в виду Тьюринг. Стеррет настаивает на том, что из работы Тьюринга следуют два различных варианта теста, которые, согласно Тьюрингу, неэквивалентны друг другу. Тест, в котором используется игра для вечеринок и сравнивается доля успехов, называется Первоначальным тестом на основе имитационной игры, в то время как тест, основанный на беседе судьи с человеком и машиной, называют Стандартным тестом Тьюринга, отмечая, что Стеррет приравнивает его к стандартной интерпретации, а не ко второму варианту имитационной игры.
Стеррет согласен, что Стандартный тест Тьюринга (STT — Standard Turing Test) имеет недостатки, на которые указывает его критика. Но он считает, что напротив первоначальный тест на основе имитационной игры (OIG Test — Original Imitation Game Test) лишен многих из них в силу ключевых различий: в отличие от STT он не рассматривает поведение, похожее на человеческое, в качестве основного критерия, хотя и учитывает человеческое поведение в качестве признака разумности машины. Человек может не пройти тест OIG, в связи с чем есть мнение, что это является достоинством теста на наличие интеллекта. Неспособность пройти тест означает отсутствие находчивости: в тесте OIG по определению считается, что интеллект связан с находчивостью и не является просто «имитацией поведения человека во время разговора». В общем виде тест OIG можно даже использовать в невербальных вариантах.
Тем не менее, другие писатели интерпретировали слова Тьюринга, как предложение считать саму имитационную игру тестом. Причем не объясняется, как связать это положение и слова Тьюринга о том, что тест, предложенный им на основе игры для вечеринок, базируется на критерии сравнительной частоты успехов в этой имитационной игре, а не на возможности выиграть раунд игры.
Должен ли судья знать о компьютере?
В своих работах Тьюринг не поясняет, знает ли судья о том, что среди участников теста будет компьютер, или нет. Что касается OIG, Тьюринг лишь говорит, что игрока А следует заменить машиной, но умалчивает, известно ли это игроку С или нет. Когда Колби, Ф. Д. Хилф (F. D. Hilf), А. Д. Крамер (A. D. Kramer) тестировали PARRY, они решили, что судьям необязательно знать, что один или несколько собеседников будут компьютерами. Как отмечает А. Седжин (A. Saygin), а также другие специалисты, это накладывает существенный отпечаток на реализацию и результаты теста.
Достоинства теста
Ширина темы
Сильной стороной теста Тьюринга является то, что можно разговаривать о чем угодно. Тьюринг писал, что «метод вопросов и ответов кажется подходящим для обсуждения почти любой из сфер человеческих интересов, которую мы хотим обсудить». Джон Хогеленд добавил, что «одного понимания слов недостаточно; вам также необходимо разбираться в теме разговора». Чтобы пройти хорошо поставленный тест Тьюринга, машина должна использовать естественный язык, рассуждать, иметь познания и обучаться. Тест можно усложнить, включив ввод с помощью видео, или, например, оборудовав шлюз для передачи предметов: машине придётся продемонстрировать способность к зрению и робототехнике. Все эти задачи вместе отражают основные проблемы, стоящие перед теорией об искусственном интеллекте.
Уступчивость и простота
Сила и привлекательность теста Тьюринга исходит из его простоты. Философы сознания, психологии в современной неврологии не способны дать определения «интеллект» и «мышление», насколько они являются достаточно точными и вообще применимы к машинам. Без такого определения, в центральных вопросах философии об искусственном интеллекте не может быть ответа. Тест Тьюринга, даже если и несовершенен, но по крайней мере, обеспечивает то, что это действительно может быть измерено. Как таковой, это является прагматическим решением, трудных философских вопросов.
Недостатки теста
Несмотря на все свои достоинства и известность, тест критикуют на нескольких основаниях.
Человеческий разум и разум вообще
Поведение человека и разумное поведениеНаправленность теста Тьюринга ярко выражена в сторону человека (антропоморфизм). Проверяется только способность машины походить на человека, а не разумность машины вообще. Тест неспособен оценить общий интеллект машины по двум причинам:
- Иногда поведение человека не поддается разумному толкованию. В это же время тест Тьюринга требует, чтобы машина была способна имитировать все виды человеческого поведения, не обращая внимания на то, насколько оно разумно. Он также проверяет способность имитировать такое поведение, какое человек за разумное и не посчитает, например, реакция на оскорбления, соблазн соврать или просто большое количество опечаток. Если машина неспособна с точностью до деталей имитировать поведение человека, опечатки и тому подобное, то она не проходит тест, несмотря на весь тот интеллект, которым она может обладать.
- Некоторое разумное поведение не присуще человеку. Тест Тьюринга не проверяет высокоинтеллектуальное поведение, например, способность решать сложные задачи или выдвигать оригинальные идеи. По сути, тест требует, чтобы машина обманывала: какой бы умной ни была машина, она должна притворяться не слишком умной, чтобы пройти тест. Если же машина способна быстро решить некую вычислительную задачу, непосильную для человека, она по определению провалит тест.
Непрактичность
Стюарт Рассел (Stuart Russel) и Питер Норвиг (Peter Norvig) утверждают, что антропоцентризм теста приводит к тому, что он не может быть по-настоящему полезным при разработке разумных машин. "Тесты по авиационному проектированию и строительству, — строят они аналогию, — не ставят целью своей отрасли «создание машин, которые летают точно так же, как летают голуби, что даже сами голуби принимают их за своих». Из-за этой непрактичности прохождение теста Тьюринга не является целью ведущих научных или коммерческих исследований (по состоянию на 2009). Сегодняшние исследования в области искусственного интеллекта ставят перед собой более скромные и специфические цели.
«Исследователи в области искусственного интеллекта уделяют мало внимания прохождению теста Тьюринга», — отмечают Рассел и Норвиг, — с тех пор как появились более простые способы проверки программ, например, дать задание напрямую, а не окольными путями, первой обозначить некоторый вопрос в чат-комнате, к которой подключены и машины, и люди. Тьюринг никогда не предполагал использовать свой тест на практике, в повседневном измерении степени разумности программ; он хотел дать ясный и понятный пример, для поддержки обсуждения философии искусственного интеллекта.
Реальный интеллект и имитируемый интеллект
Также тест Тьюринга явно бихевиористичен или функционалистичен: он лишь проверяет, как действует субъект. Машина, проходящая тест, может имитировать поведение человека в разговоре, просто «неинтеллектуально» следуя механическим правилам. Двумя известными контрпримерами, выражающими данную точку зрения являются «Китайская комната» Сёрля (1980) и «Болван» Неда Блока (Ned Block, 1981). По мнению Сёрля основной проблемой является определить, «имитирует» ли машина мышление, или «на самом деле» мыслит. Даже если тест Тьюринга и является годным для определения наличия интеллекта, Сёрль отмечает, что тест не покажет, что у машины есть разум, сознание, возможность «понимать» или иметь цели, которые имеют какой-то смысл (философы называют это целеполаганием).
В своей работе Тьюринг писал по поводу этих аргументов следующее: «Я не хочу создать впечатление, будто я думаю, что у сознания нет никакой загадки. Существует, например, своего рода парадокс, связанный с любой попыткой определить его местонахождение. Но я не думаю, что эти загадки обязательно надо разгадать до того, как мы сможем ответить на вопрос, которому посвящена данная работа».
Предсказания
Тьюринг прогнозировал, что машины, в конце концов, будут способны пройти тест; фактически он ожидал, что к 2000 году, машины с объемом памяти 109 бит (около 119,2 МиБ или 125 МБ) будут способны обманывать 30 % судей по результатам пятиминутного теста. Также он высказал мысль о том, что словосочетание «думающая машина» больше не будет считаться оксюмороном. Далее он предположил, что машинное обучение будет важным звеном в построении мощных машин, что является правдоподобным среди современных исследователей в области искусственного интеллекта.[4]
Экстраполируя экспоненциальный рост уровня технологии в течение нескольких десятилетий, футурист Рэймонд Курцвейл предположил, что машины, способные пройти тест Тьюринга, будут изготовлены, по грубым оценкам, около 2020 года. Это перекликается с законом Мура.
В проект Long Bet Project входит пари стоимостью 20 000 $ между Митчем Капуром (Mitch Kapor — пессимист) и Рэймондом Курцвейлом (оптимист). Смысл пари: пройдет ли компьютер тест Тьюринга к 2029 году? Определены также некоторые условия пари.[5]
Вариации теста Тьюринга
Многочисленные версии теста Тьюринга, включая описанные ранее, уже обсуждаются довольно долгое время.
Обратный тест Тьюринга и CAPTCHA
Модификация теста Тьюринга, в которой цель или одну или более ролей машины и человека поменяли местами, называется обратным тестом Тьюринга. Пример этого теста приведен в работе психоаналитика Уилфреда Биона, который был в особенности восхищен тем, как активизируется мыслительная активность при столкновении с другим разумом.
Развивая эту идею, Р. Д. Хиншелвуд (R. D. Hinshelwood) описал разум как «аппарат, распознающий разум», отметив, что это можно считать как бы «дополнением» к тесту Тьюринга. Теперь задачей компьютера будет определить с кем он беседовал: с человеком или же с другим компьютером. Именно на это дополнение к вопросу и пытался ответить Тьюринг, но, пожалуй, оно вводит достаточно высокий стандарт на то, чтобы определить, может ли машина «думать» так, как мы обычно относим это понятие к человеку.
CAPTCHA — это разновидность обратного теста Тьюринга. Перед тем как разрешить выполнение некоторого действия на сайте, пользователю выдается искаженное изображение с набором цифр и букв и предложение ввести этот набор в специальное поле. Цель этой операции — предотвратить атаки автоматических систем на сайт. Обоснованием подобной операции является то, что пока не существует программ достаточно мощных для того, чтобы распознать и точно воспроизвести текст с искаженного изображения (или они недоступны простым пользователям), поэтому считается, что система, которая смогла это сделать, с высокой вероятностью может считаться человеком. Выводом будет (хотя и не обязательно), что искусственный интеллект пока не создан.
Тест Тьюринга со специалистом
Эта вариация теста описывается следующим образом: ответ машины не должен отличаться от ответа эксперта — специалиста в определенной области знаний. По мере развития технологий по сканированию организма человека, станет возможным копировать необходимую информацию из тела и мозга в компьютер.
Тест бессмертия
Тест бессмертия — это вариация теста Тьюринга, которая определяет, качественно ли передан характер человека, а именно возможно ли отличить скопированный характер от характера человека, послужившего его источником.
Минимальный интеллектуальный Signal-тест (MIST)
MIST предложен Крисом Мак-Кинстри (Chris McKinstry). В этой вариации теста Тьюринга разрешены лишь два типа ответов — «да» и «нет». Обычно MIST используют для сбора статистической информации, с помощью которой можно измерить производительность программ, реализующих искусственный интеллект.
Мета-тест Тьюринга
В этой вариации теста субъект (скажем, компьютер) считают разумным, если он создал нечто, что он сам хочет проверить на разумность.
Премия Хаттера
Организаторы премии Хаттера считают, что сжатие текста на естественном языке является трудной задачей для искусственного интеллекта, эквивалентной прохождению теста Тьюринга.
Тест по сжатию информации имеет определенные преимущества над большей частью вариантов и вариаций теста Тьюринга:
- Его результатом является единственное число, по которому можно судить какая из двух машин «более разумная».
- Не требуется, чтобы компьютер врал судье — учить компьютеры врать считают плохой идеей.
Основными недостатками подобного теста являются:
- С его помощью невозможно протестировать человека.
- Неизвестно какой результат (и есть ли он вообще) эквивалентен прохождению теста Тьюринга (на уровне человека).
Другие тесты интеллекта
Существует множество тестов на уровень интеллекта, которые используют для тестирования людей. Возможно, что их можно использовать для тестирования искусственного интеллекта. Некоторые тесты (например, Си-тест), выведенные из «Колмогоровской сложности», используются для проверки людей и компьютеров.
Тест BotPrize
Двум командам программистов удалось победить в конкурсе BotPrize, который называют "игровой версией" теста Тьюринга. Сообщение о результатах теста приведено на сайте BotPrize, кратко его результаты анализирует NewScientist. Тест BotPrize проходил в виде многопользовательской компьютерной игры (Unreal Tournament 2004), персонажами которой управляли реальные люди или компьютерные алгоритмы[6].
См. также
Ссылки
Литература
Примечания
- ↑ Портал искусственного интеллекта
- ↑ Пройти тест Тьюринга не так-то просто
- ↑ ИТАР-ТАСС : Российские специалисты первыми в мире вплотную приблизились к созданию подлинного искусственного разума
- ↑ Turing, 1950, p. 442
- ↑ Long Bets — By 2029 no computer — or «machine intelligence» — will have passed the Turing Test
- ↑ Две программы прошли "игровую версию" теста Тьюринга
dis.academic.ru
Тест Тьюринга | Virtual Laboratory Wiki
Тест Тьюринга — эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум» (англ. Computing Machinery and Intelligence), опубликованной в 1950 году в философском журнале «Mind». Тьюринг задался целью определить, может ли машина мыслить.
Стандартная интерпретация этого теста звучит следующим образом: «Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Все участники теста не видят друг друга. Если судья не может сказать определенно, кто из собеседников является человеком, то считается, что машина прошла тест. Чтобы протестировать именно интеллект машины, а не её возможность распознавать устную речь, беседа ведется в режиме «только текст», например, с помощью клавиатуры и экрана (компьютера-посредника). Переписка должна производиться через контролируемые промежутки времени, чтобы судья не мог делать заключения исходя из скорости ответов. Во времена Тьюринга компьютеры реагировали медленнее человека. Сейчас это правило необходимо, потому что они реагируют гораздо быстрее, чем человек.
По состоянию на 2009 год ни одна из существующих компьютерных систем не приблизилась к прохождению теста.
Философские предпосылки Править
Хотя исследования в области искусственного интеллекта начались в 1956 году, их философские корни уходят глубоко в прошлое. Вопрос, может машина думать или нет, имеет долгую историю. Он тесно связан с различиями между дуалистическим и материалистическим взглядами. С точки зрения дуализма, мысль не является материальной (или, по крайней мере, не имеет материальных свойств), и поэтому разум нельзя объяснить только с помощью физических понятий. С другой стороны, материализм гласит, что разум можно объяснить физически, таким образом, оставляя возможность существования разумов, созданных искусственно.
В 1936 году философ Альфред Айер рассмотрел обычный для философии вопрос касательно других разумов: как узнать, что другие люди имеют тот же сознательный опыт, что и мы? В своей книге «Язык, истина и логика» Айер предложил алгоритм распознавания сознающего человека и не осознающей машины: «Единственным основанием, на котором я могу утверждать, что объект, который кажется разумным, на самом деле не разумное существо, а просто глупая машина, является то, что он не может пройти один из эмпирических тестов, согласно которым определяется наличие или отсутствие сознания». Это высказывание очень похоже на тест Тьюринга, однако точно неизвестно была ли известна Тьюрингу популярная философская классика Айера.
Алан Тьюринг Править
К 1956 году британские ученые уже на протяжении 10 лет исследовали «машинный интеллект». Этот вопрос был обычным предметом для обсуждения среди членов «Ratio Club» — неформальной группы британских кибернетиков и исследователей в области электроники, в которой состоял и Алан Тьюринг, в честь которого был назван тест.
Тьюринг в особенности занимался проблемой машинного интеллекта, по меньшей мере, с 1941 года. Одно из самых первых его упоминаний о «компьютерном интеллекте» было сделано в 1947 году. В докладе «Интеллектуальные машины» Тьюринг исследовал вопрос, может ли машина обнаруживать разумное поведение, и в рамках этого исследования предложил то, что может считаться предтечей его дальнейших исследований: «Нетрудно разработать машину, которая будет неплохо играть в шахматы. Теперь возьмем трех человек — субъектов эксперимента. А, В и С. Пусть А и С неважно играют в шахматы, а В — оператор машины. […] Используются две комнаты, а также некоторый механизм для передачи сообщений о ходах. Участник С играет или с А, или с машиной. Участник С может затрудниться ответить с кем он играет».
Таким образом, к моменту публикации в 1950 году статьи «Вычислительные машины и разум», Тьюринг уже на протяжении многих лет рассматривал возможность существования искусственного интеллекта. Тем не менее, данная статья стала первой статьей Тьюринга, в которой рассматривалось исключительно это понятие.
Тьюринг начинает свою статью утверждением: «Я предлагаю рассмотреть вопрос „Могут ли машины думать?“». Он подчеркивает, что традиционный подход к этому вопросу состоит в том, чтобы сначала определить понятия «машина» и «интеллект». Тьюринг, однако, выбрал другой путь; вместо этого он заменил исходный вопрос другим, «который тесно связан с исходным и формулируется относительно недвусмысленно». По существу, он предлагает заменить вопрос «Думают ли машины?» вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие создания)?». Преимуществом нового вопроса, как утверждает Тьюринг, является то, что он проводит «четкую границу между физическими и интеллектуальными возможностями человека».
Чтобы продемонстрировать этот подход, Тьюринг предлагает тест, придуманный по аналогии с игрой для вечеринок «Imitation game» — имитационная игра. В этой игре мужчина и женщина направляются в разные комнаты, а гости пытаются различить их, задавая им серию письменных вопросов и читая напечатанные на машинке ответы на них. По правилам игры и мужчина, и женщина пытаются убедить гостей, что все наоборот. Тьюринг предлагает переделать игру следующим образом: "Теперь зададим вопрос, что случится, если в этой игре роль А будет исполнять машина? Будет ли задающий вопросы ошибаться так же часто, как если бы он играл с мужчиной и женщиной? Эти вопросы заменяют собой исходный «Может ли машина думать?».
В том же докладе Тьюринг позднее предлагает «эквивалентную» альтернативную формулировку, включающую судью, который беседует только с компьютером и человеком. Наряду с тем, что ни одна из этих формулировок точно не соответствует той версии теста Тьюринга, которая наиболее известна сегодня, в 1952 ученый предложил третью. В этой версии теста, которую Тьюринг обсудил в эфире радио Би-Би-Си, жюри задает вопросы компьютеру, а роль компьютера состоит в том, чтобы заставить значительную часть членов жюри поверить, что он на самом деле человек.
В статье Тьюринга учтены 9 предполагаемых вопросов, которые включают все основные возражения против искусственного интеллекта, поднятые после того, как статья была впервые опубликована.
Элиза и PARRY Править
Блей Витби указывает на 4 основные поворотные точки в истории теста Тьюринга — публикация статьи «Вычислительные машины и разум» в 1950, сообщение о создании Джозефом Вейзенбаумом программы Элиза в 1966, создание Кеннетом Колби программы PARRY, которая была в первые описана в 1972 году, и Коллоквиум Тьюринга в 1990.
Принцип работы Элизы заключается в исследовании введенных пользователем комментариев на наличие ключевых слов. Если найдено ключевое слово, то применяется правило, по которому комментарий пользователя преобразуется и возвращается предложение-результат. Если же ключевое слово не найдено, Элиза либо возвращает пользователю общий ответ, либо повторяет один из предыдущих комментариев. Вдобавок Вейзенбаум запрограммировал Элизу на имитацию поведения психотерапевта, работающего по клиент-центрированной методике . Это позволяет Элизе «притвориться, что она не знает почти ничего о реальном мире». Применяя эти способы, программа Вейзенбаума могла вводить в заблуждение некоторых людей, которые думали, что они разговаривают с реально существующим человеком, а некоторых было «очень трудно убедить, что Элиза […] не человек». На этом основании некоторые утверждают, что Элиза — одна из программ (возможно первая), которые смогли пройти тест Тьюринга. Однако это утверждение очень спорно, так как людей, «задающих вопросы», инструктировали так, чтобы они думали, что с ними будет разговаривать настоящий психотерапевт, и не подозревали о том, что они могут разговаривать с компьютером.
Работа Колби — PARRY — была описана, как «Элиза с мнениями»: программа пыталась моделировать поведение параноидального шизофреника, используя схожий (если не более продвинутый) с Элизой подход, примененный Вейзенбаумом. Для того чтобы проверить программу, PARRY тестировали в начале 70-х, используя модификацию теста Тьюринга. Команда опытных психиатров анализировала группу, составленную из настоящих пациентов и компьютеров под управлением PARRY, используя телетайп. Другой команде из 33 психиатров позже показали стенограммы бесед. Затем обе команды попросили определить, кто из «пациентов» — человек, а кто — компьютерная программа. Психиатры лишь в 48 % случаев смогли вынести верное решение. Эта цифра согласуется с вероятностью случайного выбора. Заметьте, что эти эксперименты не являлись тестами Тьюринга в полном смысле, так как для вынесения решения данный тест требует, чтобы вопросы можно было задавать в интерактивном режиме, вместо чтения стенограммы прошедшей беседы.
Пока что ни одна программа и близко не подошла к прохождению теста. Хотя такие программы, как Элиза (ELIZA), иногда заставляли людей верить, что они говорят с человеком, как, например, в неформальном эксперименте, названном AOLiza, но эти случаи нельзя считать корректным прохождением теста Тьюринга по целому ряду причин:
- Человек в таких беседах не имел никаких оснований считать, что он говорит с программой, в то время как в настоящем тесте Тьюринга человек активно пытается определить, с кем он беседует.
- Документированные случаи обычно относятся к таким чатам, как IRC, где многие беседы отрывочны и бессмысленны.
- Многие пользователи Интернета используют английский как второй или третий язык, так что бессмысленный ответ программы легко может быть списан на языковый барьер.
- Многие просто ничего не знают об Элизе и ей подобных программах, и поэтому не сочтут собеседника программой даже в случае совершенно нечеловеческих ошибок, которые эти программы допускают.
Китайская комната Править
В 1980 году в статье «Разум, мозг и программы» Джон Сёрль выдвинул аргумент против теста Тьюринга, известный как мысленный эксперимент «Китайская комната». Сёрль настаивал, что программы (такие как Элиза) смогли пройти тест Тьюринга, просто манипулируя символами, значения которых они не понимали. А без понимания их нельзя считать «разумными» в том же смысле, что и людей. «Таким образом, — заключает Сёрль, — тест Тьюринга не является доказательством того, что машина может думать, а это противоречит изначальному предположению Тьюринга».
Такие аргументы, как предложенный Сёрлем, а также другие, основанные на философии разума, породили намного более бурные дискуссии о природе разума, возможности существования разумных машин и значимости теста Тьюринга, продолжавшиеся в течение 80-х и 90-х годов.
Коллоквиум Тьюринга Править
В 1990 году состоялось сороковая годовщина публикации статьи Тьюринга «Вычислительные машины и разум», что возобновило интерес к тесту. В этом году произошли два важных события.
Одно из них — коллоквиум Тьюринга, который проходил в апреле в Университете Суссекса. В его рамках встретились академики и исследователи из разнообразных областей науки, чтобы обсудить тест Тьюринга с позиций его прошлого, настоящего и будущего. Вторым событием стало учреждение ежегодного соревнования на получение премии Лёбнера.
Премия Лёбнера Править
Ежегодный конкурс на получение премии Лёбнера является платформой для практического проведения тестов Тьюринга. Первый конкурс прошел в ноябре 1991 года. Приз гарантирован Хью Лёбнером (Hugh Loebner). Кембриджский центр исследований поведения, расположенный в Масачусетсе, США, предоставлял призы до 2003 года включительно. По словам Лёбнера, соревнование было организовано с целью продвижения вперед в области исследований, связанных с искусственным интеллектом, отчасти потому, что «никто не предпринял мер, чтобы это осуществить».
Серебряная (аудио) и золотая (аудио и зрительная) медали никогда ещё не вручались. Тем не менее, ежегодно из всех представленных на конкурс компьютерных систем судьи награждают бронзовой медалью ту, которая, по их мнению, продемонстрирует «наиболее человеческое» поведение в разговоре. Не так давно программа «Искусственное лингвистическое интернет-компьютерное существо» (Artificial Linguistic Internet Computer Entity — A.L.I.C.E.) трижды завоевала бронзовую медаль (в 2000, 2001 и 2004). Способная к обучению программа Jabberwacky побеждала в 2005 и 2006. Её создатели предложили персонализированную версию: возможность пройти имитационный тест, пытаясь более точно сымитировать человека, с которым машина тесно пообщалась перед тестом.
Конкурс проверяет способность разговаривать; победителями становятся обычно чат-боты или «Искуственные Разговорные Существа» (Artificial Conversational Entities (ACE)s). Правилами первых конкурсов предусматривалось ограничение. Согласно этому ограничению каждая беседа с программой или скрытым человеком могла быть только на одну тему. Начиная с конкурса 1995 года это правило отменено. Продолжительность разговора между судьей и участником была различной в разные годы. В 2003 году, когда конкурс проходил в Университете Суррея, каждый судья мог разговаривать с каждым участником (машиной или человеком) ровно 5 минут. С 2004 по 2007 это время составляло уже более 20 минут. В 2008 максимальное время разговора составляло 5 минут на пару, потому что организатор Кевин Ворвик (Kevin Warwick) и координатор Хьюма Ша (Huma Shah) полагали, что ACE не имели технических возможностей поддерживать более продолжительную беседу. Как ни странно, победитель 2008 года, Elbot, не притворялся человеком, но все-таки сумел обмануть трех судей.
Появление конкурса на получение премии Лёбнера привело к возобновлению дискуссий о целесообразности теста Тьюринга, о значении его прохождения. В статье «Искусственная тупость» газеты The Economist отмечается, что первая программа-победитель конкурса смогла выиграть отчасти, потому что она «имитировала человеческие опечатки». (Тьюринг предложил, чтобы программы добавляли ошибки в вывод, чтобы быть более хорошими «игроками».) Существовало мнение, что попытки пройти тест Тьюринга просто препятствуют более плодотворным исследованиям.
Во время первых конкурсов была выявлена вторая проблема: участие недостаточно компетентных судей, которые поддавались умело организованным манипуляциям, а не тому, что можно считать интеллектом.
Тем не менее, с 2004 года в качестве собеседников в конкурсе принимают участие философы, компьютерные специалисты и журналисты.
Коллоквиум по разговорным системам, 2005 Править
В ноябре 2005 года в Университете Суррея проходила однодневная встреча разработчиков ACE , которую посетили победители практических тестов Тьюринга, проходивших в рамках конкурса на получение премии Лёбнера: Робби Гарнер (Robby Garner), Ричард Уоллес (Richard Wallace), Ролл Карпентер (Rollo Carpenter). В числе приглашенных докладчиков были Дэвид Хэмилл (David Hamill), Хью Лёбнер и Хьюма Ша.
Симпозиум общества AISB по тесту Тьюринга, 2008 Править
В 2008 году наряду с проведением очередного конкурса на получение премии Лёбнера, проходившего в Университете Чтения, Общество изучения искусственного интеллекта и моделирования поведения (The Society for the Study of Artificial Intelligence and Simulation of Behavior — AISB) провело однодневный симпозиум, на котором обсуждался тест Тьюринга. Симпозиум организовали Джон Бенден (John Barnden), Марк Бишоп (Mark Bishop), Хьюма Ша и Кевин Ворвик. В числе докладчиков были директор Королевского института баронесса Сьюзан Гринфилд (Susan Greenfield), Сельмер Брингсорд (Selmer Bringsjord), биограф Тьюринга Эндрю Ходжес (Andrew Hodges) и ученый Оуэн Холланд (Owen Holland). Никакого соглашения о каноническом тесте Тьюринга не появилось, однако Брингсорд предположил, что более крупная премия будет способствовать тому, что тест Тьюринга будет пройден быстрее.
Тьюринг-100 в 2012 Править
Для организации мероприятий по празднованию в 2012 году столетия со дня рождения Тьюринга создан специальный комитет, задачей которого является донести мысль Тьюринга о разумной машине, отраженную в таких голливудских фильмах, как «Бегущий по лезвию», до широкой публики, включая детей. В работе комитета участвуют: Кевин Ворвик, председатель, Хьюма Ша, координатор, Ян Бланд (Ian Bland), Крис Чапмэн (Chris Chapman), Марк Аллен (Marc Allen), Рори Данлоуп (Rory Dunlop), победители конкурса на получение премии Лёбнера Робби Гарне и Фред Робертс (Fred Roberts). Комитет работает при поддержке организации «Женщины в технике» (Women in Technology) и Daden Ltd.
Варианты теста Тьюринга Править
Файл:The Imitation Game.png Файл:Turing Test Version 1.pngСуществуют, по крайней мере, три основных варианта теста Тьюринга, два из которых были предложны в статье «Вычислительные машины и разум», а третий вариант, по терминологии Саула Трейджера (Saul Traiger), является стандартной интерпретацией.
Наряду с тем, что существует определенная дискуссия, соответствует ли современная интерпретация тому, что описывал Тьюринг, либо она является результатом неверного толкования его работ, все три версии не считаются равносильными, их сильные и слабые стороны различаются.
Имитационная игра Править
Тьюринг, как мы уже знаем, описал простую игру для вечеринок, которая включает в себя минимум трех игроков. Игрок А — мужчина, игрок В — женщина и игрок С, который играет в качестве ведущего беседу, любого пола. По правилам игры С не видит ни А, ни В и может общаться с ними только посредством письменных сообщений. Задавая вопросы игрокам А и В, С пытается определить, кто из них — мужчина, а кто — женщина. Задачей игрока А является запутать игрока С, чтобы он сделал неправильный вывод. В то же время задачей игрока В является помочь игроку С вынести верное суждение.
В той версии, которую С. Г. Стеррет (S. G. Sterret) называет «Первоначальный тест на основе имитационной игры» (Original Imitation Game Test), Тьюринг предлагает, чтобы роль игрока А исполнял компьютер. Таким образом, задачей компьютера является притвориться женщиной, чтобы сбить с толку игрока С. Успешность выполнения подобной задачи оценивается на основе сравнения исходов игры, когда игрок А — компьютер, и исходов, когда игрок А — мужчина. Если, по словам Тьюринга, «ведущий беседу игрок после проведения игры [с участием компьютера] выносит неверное решение в так же часто, как и после проведения игры с участием мужчины и женщины», то можно говорить о том, что компьютер разумен.
Второй вариант предложен Тьюрингом в той же статье. Как и в «Первоначальном тесте», роль игрока А исполняет компьютер. Различие заключается в том, что роль игрока В может исполнять как мужчина, так и женщина.
«Давайте рассмотрим конкретный компьютер. Верно ли то, что модифицируя этот компьютер с целью иметь достаточно места для хранения данных, увеличивая скорость его работы и задавая ему подходящую программу, можно сконструировать такой компьютер, чтобы он удовлетворительно выполнял роль игрока А в имитационной игре, в то время как роль игрока В выполняет мужчина?», — Тьюринг, 1950, стр. 442.
В этом варианте оба игрока А и В пытаются склонить ведущего к неверному решению.
Стандартная интерпретация Править
Главной мыслью данной версии является то, что целью теста Тьюринга является ответ не на вопрос, может ли машина одурачить ведущего, а на вопрос, может ли машина имитировать человека или нет. Несмотря на то, что идут споры о том, подразумевался ли этот вариант Тьюрингом или нет, Стеррет считает, что этот вариант Тьюрингом подразумевался и, таким образом, совмещает второй вариант с третьим. В это же время группа оппонентов, включая Трейджера, так не считает. Но это все равно привело к тому, что можно назвать «стандартной интерпретацией». В этом варианте игрок А — компьютер, игрок В — человек любого пола. Задачей ведущего является теперь не определить кто из них мужчина и женщина, а кто из них компьютер, а кто — человек.
Имитационная игра в сравнении со стандартным тестом Тьюринга Править
Существуют разногласия по поводу того, какой же вариант имел в виду Тьюринг. Стеррет настаивает на том, что из работы Тьюринга следуют два различных варианта теста, которые, согласно Тьюрингу, неэквивалентны друг другу. Тест, в котором используется игра для вечеринок и сравнивается доля успехов, называется Первоначальным тестом на основе имитационной игры, в то время как тест, основанный на беседе судьи с человеком и машиной, называют Стандартным тестом Тьюринга, отмечая, что Стеррет приравнивает его к стандартной интерпретации, а не ко второму варианту имитационной игры.
Стеррет согласен, что Стандартный тест Тьюринга (STT — Standard Turing Test) имеет недостатки, на которые указывает его критика. Но он считает, что напротив первоначальный тест на основе имитационной игры (OIG Test — Original Imitation Game Test) лишен многих из них в силу ключевых различий: в отличие от STT он не рассматривает поведение, похожее на человеческое, в качестве основного критерия, хотя и учитывает человеческое поведение в качестве признака разумности машины. Человек может не пройти тест OIG, в связи с чем есть мнение, что это является достоинством теста на наличие интеллекта. Неспособность пройти тест означает отсутствие находчивости: в тесте OIG по определению считается, что интеллект связан с находчивостью и не является просто «имитацией поведения человека во время разговора». В общем виде тест OIG можно даже использовать в невербальных вариантах.
Тем не менее, другие писатели интерпретировали слова Тьюринга, как предложение считать саму имитационную игру тестом. Причем не объясняется, как связать это положение и слова Тьюринга о том, что тест, предложенный им на основе игры для вечеринок, базируется на критерии сравнительной частоты успехов в этой имитационной игре, а не на возможности выиграть раунд игры.
Должен ли судья знать о компьютере? Править
В своих работах Тьюринг не поясняет, знает ли судья о том, что среди участников теста будет компьютер, или нет. Что касается OIG, Тьюринг лишь говорит, что игрока А следует заменить машиной, но умалчивает, известно ли это игроку С или нет. Когда Колби, Ф. Д. Хилф (F. D. Hilf), А. Д. Крамер (A. D. Kramer) тестировали PARRY, они решили, что судьям необязательно знать, что один или несколько собеседников будут компьютерами. Как отмечает А. Седжин (A. Saygin), а также другие специалисты, это накладывает существенный отпечаток на реализацию и результаты теста.
Достоинства теста Править
Ширина темы Править
Сильной стороной теста Тьюринга является то, что можно разговаривать о чем угодно. Тьюринг писал, что «метод вопросов и ответов кажется подходящим для обсуждения почти любой из сфер человеческих интересов, которую мы хотим обсудить». Джон Хогеленд добавил, что «одного понимания слов недостаточно; вам также необходимо разбираться в теме разговора». Чтобы пройти хорошо поставленный тест Тьюринга, машина должна использовать естественный язык, рассуждать, иметь познания и обучаться. Тест можно усложнить, включив ввод с помощью видео, или, например, оборудовав шлюз для передачи предметов: машине придется продемонстрировать способность к зрению и робототехнике. Все эти задачи вместе отражают основные проблемы, стоящие перед теорией об искусственном интеллекте.
Недостатки теста Править
Несмотря на все свои достоинства и известность, тест критикуют на нескольких основаниях.
Человеческий разум и разум вообще Править
Файл:Human Behaviour.pngНаправленность теста Тьюринга ярко выражена в сторону человека (антропоморфизм). Проверяется только способность машины походить на человека, а не разумность машины вообще. Тест неспособен оценить общий интеллект машины по двум причинам:
- Иногда поведение человека не поддается разумному толкованию. В это же время тест Тьюринга требует, чтобы машина была способна имитировать все виды человеческого поведения, не обращая внимания на то, насколько оно разумно. Он также проверяет способность имитировать такое поведение, какое человек за разумное и не посчитает, например, реакция на оскорбления, соблазн соврать или просто большое количество опечаток. Если машина неспособна с точностью до деталей имитировать поведение человека, опечатки и все такое, то она не проходит тест, несмотря на весь тот интеллект, которым она может обладать.
- Некоторое разумное поведение не присуще человеку. Тест Тьюринга не проверяет высокоинтеллектуальное поведение, например, способность решать сложные задачи или выдвигать оригинальные идеи. По сути, тест требует, чтобы машина обманывала: какой бы умной ни была машина, она должна притворяться не слишком умной, чтобы пройти тест. Если же машина способна быстро решить некую вычислительную задачу, непосильную для человека, она по определению провалит тест.
Непрактичность Править
Стюарт Рассел (Stuart Russel) и Питер Норвиг (Peter Norvig) утверждают, что антропоморфизм теста приводит к тому, что он не может быть по-настоящему полезным при разработке разумных машин. "Тексты по авиационному проектированию и строительству, — строят они аналогию, — не ставят целью своей отрасли «создание машин, которые летают точно так же, как летают голуби, что даже сами голуби принимают их за своих». Из-за этой непрактичности прохождение теста Тьюринга не является целью ведущих научных или коммерческих исследований (по состоянию на 2009). Сегодняшние исследования в области искусственного интеллекта ставят перед собой более скромные и специфические цели.
«Исследователи в области искусственного интеллекта уделяют мало внимания прохождению теста Тьюринга», — отмечают Рассел и Норвиг, — с тех пор как появились более простые способы проверки программ, например, дать задание напрямую, а не окольными путями, первой обозначить некоторый вопрос в чат-комнате, к которой подключены и машины, и люди. Тьюринг никогда не предполагал использовать свой тест на практике, в повседневном измерении степени разумности программ; он хотел дать ясный и понятный пример, для поддержки обсуждения философии искусственного интеллекта.
Реальный интеллект и имитируемый интеллект Править
Также тест Тьюринга явно бихевиористичен или функционалистичен: он лишь проверяет, как действует субъект. Машина, проходящая тест, может имитировать поведение человека в разговоре, просто «неинтеллектуально» следуя механическим правилам. Двумя известными контрпримерами, выражающими данную точку зрения являются «Китайская комната» Сёрля (1980) и «Болван» Неда Блока (Ned Block, 1981). По мнению Сёрля основной проблемой является определить, «имитирует» ли машина мышление, или «на самом деле» мыслит. Даже если тест Тьюринга и является годным для определения наличия интеллекта, Сёрль отмечает, что тест не покажет, что у машины есть разум, сознание, возможность «понимать» или иметь цели, которые имеют какой-то смысл (философы называют это целеполаганием).
В своей работе Тьюринг писал по поводу этих аргументов следующее: «Я не хочу создать впечатление, будто я думаю, что у сознания нет никакой загадки. Существует, например, своего рода парадокс, связанный с любой попыткой определить его местонахождение. Но я не думаю, что эти загадки обязательно надо разгадать до того, как мы сможем ответить на вопрос, которому посвящена данная работа».
Тьюринг прогнозировал, что машины, в конце концов, будут способны пройти тест; фактически он ожидал, что к 2000 году, машины с объемом памяти 109 бит (около 119,2 МиБ или 125 МБ) будут способны обманывать 30 % судей по результатам пятиминутного теста. Также он высказал мысль о том, что словосочетание «думающая машина» больше не будет считаться оксюмороном. Далее он предположил, что машинное обучение будет важным звеном в построении мощных машин, что является правдоподобным среди современных исследователей в области искусственного интеллекта.
Экстраполируя экспоненциальный рост уровня технологии в течение нескольких десятилетий, футурист Рэймонд Курцвейл предположил, что машины, способные пройти тест Тьюринга, будут изготовлены, грубо говоря, около 2020 года. Это перекликается с законом Мура.
В проект Long Bet Project входит пари стоимостью 10 000 $ между Митчем Капуром (Mitch Kapor — пессимист) и Рэймондом Курцвейлом (оптимист). Смысл пари: пройдет ли компьютер тест Тьюринга к 2029 году? Определены также некоторые условия пари.
Вариации теста Тьюринга Править
Многочисленные версии теста Тьюринга, включая описанные ранее, уже обсуждаются довольно долгое время.
Обратный тест Тьюринга и CAPTCHA Править
Модификация теста Тьюринга, в которой цель или одну или более ролей машины и человека поменяли местами, называется обратным тестом Тьюринга. Пример этого теста приведен в работе психоаналитика Уилфреда Биона (Wilfred Bion), который был в особенности восхищен тем, как активизируется мыслительная активность при столкновении с другим разумом.
Развивая эту идею, Р. Д. Хиншелвуд (R. D. Hinshelwood) описал разум, как «аппарат, распознающий разум», отметив, что это можно считать как бы «дополнением» к тесту Тьюринга. Теперь задачей компьютера будет определить с кем он беседовал: с человеком или же с другим компьютером. Именно на это дополнение к вопросу и пытался ответить Тьюринг, но, пожалуй, оно вводит достаточно высокий стандарт на то, чтобы определить, может ли машина «думать» так, как мы обычно относим это понятие к человеку.
CAPTCHA — это разновидность обратного теста Тьюринга. Перед тем как разрешить выполнение некоторого действия на сайте, пользователю выдается искаженное изображение с набором цифр и букв и предложение ввести этот набор в специальное поле. Цель этой операции — предотвратить атаки автоматических систем на сайт. Обоснованием подобной операции является то, что пока не существует программ достаточно мощных для того, чтобы распознать и точно воспроизвести текст с искаженного изображения (или они недоступны простым пользователям), поэтому считается, что система, которая смогла это сделать, с высокой вероятностью может считаться человеком. Выводом будет (хотя и не обязательно), что искусственный интеллект пока не создан.
Тест Тьюринга со специалистом Править
Эта вариация теста описывается следующим образом: ответ машины не должен отличаться от ответа эксперта (специалиста) в определенной области. По мере развития технологий по сканированию тела и мозга человека станет возможным копировать необходимую информацию из человека в компьютер.
Тест бессмертия Править
Тест бессмертия — это вариация теста Тьюринга, которая определяет, качественно ли передан характер человека, а именно невозможно ли отличить скопированный характер от человека, послужившего его источником.
Минимальный интеллектуальный Signal-тест (MIST) Править
MIST предложен Крисом Мак-Кинстри (Chris McKinstry). В этой вариации теста Тьюринга разрешены лишь два типа ответов — «да» и «нет». Обычно MIST используют для сбора статистической информации, с помощью которой можно измерить производительность программ, реализующих искусственный интеллект.
Мета-тест Тьюринга Править
В этой вариации теста субъект (скажем, компьютер) считают разумным, если он создал нечто, что он сам хочет проверить на разумность.
Премия Хаттера Править
Организаторы премии Хаттера считают, что сжатие текста на естественном языке является трудной задачей для искусственного интеллекта, эквивалентной прохождению теста Тьюринга.
Тест по сжатию информации имеет определенные преимущества над большей частью вариантов и вариаций теста Тьюринга:
- Его результатом является единственное число, по которому можно судить какая из двух машин «более разумная».
- Не требуется, чтобы компьютер врал судье — учить компьютеры врать считают плохой идеей.
Основными недостатками подобного теста являются:
- С его помощью невозможно протестировать человека.
- Неизвестно какой результат (и есть ли он вообще) эквивалентен прохождению теста Тьюринга (на уровне человека).
Другие тесты интеллекта Править
Существует множество тестов на уровень интеллекта, которые используют для тестирования людей. Возможно, что их можно использовать для тестирования искусственного интеллекта. Некоторые тесты (например, Си-тест), выведенные из «Колмогоровской сложности», используются для проверки людей и компьютеров.
| Агентный подход • Адаптивное управление • Генетические алгоритмы • Инженерия знаний • Машинное обучение • Нейронные сети • Нечёткая логика • Обработка естественного языка • Распознавание образов • Эволюционные алгоритмы • Экспертные системы | ||
| Голосовое управление • Задача классификации • Классификация документов • Кластеризация документов • Кластерный анализ • Локальный поиск (оптимизация) • Машинный перевод • Оптическое распознавание символов • Распознавание речи • Распознавание рукописного ввода | ||
| Винер, Норберт • Алан Тьюринг • Глушков, Виктор Михайлович • Осипов, Геннадий С. • Попов Д. Э. • Поспелов, Дмитрий Александрович • Гаазе-Рапопорт, Модест Георгиевич • Гаврилова, Татьяна Альбертовна • Хорошевский, Владимир Фёдорович • Поспелов, Гермоген Сергеевич • Марвин Мински • Маккарти, Джон • Розенблатт, Фрэнк • Бэббидж, Чарльз • Ньюэлл, Аллен • Саймон, Герберт Александер • Хомский, Аврам Ноам • Паперт, Сеймур • Шеннон, Клод • Вейценбаум, Джозеф • Винстон, Патрик (Patrick Winston) | ||
| Тест Тьюринга • Китайская комната | ||
| Все статьи | ||
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Тест Тьюринга. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .
ru.vlab.wikia.com
Тест Тьюринга - Gpedia, Your Encyclopedia
 Стандартная интерпретация теста Тьюринга
Стандартная интерпретация теста Тьюринга Тест Тьюринга — эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум», опубликованной в 1950 году в философском журнале Mind. Тьюринг задался целью определить, может ли машина мыслить.
Стандартная интерпретация этого теста звучит следующим образом: «Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Все участники теста не видят друг друга. Если судья не может сказать определённо, кто из собеседников является человеком, то считается, что машина прошла тест. Чтобы протестировать именно интеллект машины, а не её возможность распознавать устную речь, беседа ведётся в режиме «только текст», например, с помощью клавиатуры и экрана (компьютера-посредника). Переписка должна производиться через контролируемые промежутки времени, чтобы судья не мог делать заключения, исходя из скорости ответов. Во времена Тьюринга компьютеры реагировали медленнее человека. Сейчас это правило тоже необходимо, потому что они реагируют гораздо быстрее, чем человек.
История
Философские предпосылки
Хотя исследования в области искусственного интеллекта начались в 1956 году, их философские корни уходят глубоко в прошлое. Вопрос, сможет ли машина думать, имеет долгую историю. Он тесно связан с различиями между дуалистическим и материалистическим взглядами. С точки зрения дуализма, мысль не является материальной (или, по крайней мере, не имеет материальных свойств), и поэтому разум нельзя объяснить только с помощью физических понятий. С другой стороны, материализм гласит, что разум можно объяснить физически, таким образом, оставляя возможность существования разумов, созданных искусственно.
В 1936 году философ Альфред Айер рассмотрел обычный для философии вопрос касательно других разумов: как узнать, что другие люди имеют тот же сознательный опыт, что и мы? В своей книге «Язык, истина и логика» Айер предложил алгоритм распознавания осознающего человека и не осознающей машины: «Единственным основанием, на котором я могу утверждать, что объект, который кажется разумным, на самом деле не разумное существо, а просто глупая машина, является то, что он не может пройти один из эмпирических тестов, согласно которым определяется наличие или отсутствие сознания». Это высказывание очень похоже на тест Тьюринга, однако точно не известно, была ли известна Тьюрингу популярная философская классика Айера.
Несмотря на то, что прошло больше 50 лет, тест Тьюринга не потерял своей значимости. Но в настоящее время исследователи искусственного интеллекта практически не занимаются решением задачи прохождения теста Тьюринга, считая, что гораздо важнее изучить основополагающие принципы интеллекта, чем продублировать одного из носителей естественного интеллекта. В частности, проблему «искусственного полета» удалось успешно решить лишь после того, как братья Райт и другие исследователи перестали имитировать птиц и приступили к изучению аэродинамики. В научных и технических работах по воздухоплаванию цель этой области знаний не определяется как «создание машин, которые в своем полете настолько напоминают голубей, что даже могут обмануть настоящих птиц».[1]
Алан Тьюринг
К 1956 году британские учёные уже на протяжении 10 лет исследовали «машинный интеллект». Этот вопрос был обычным предметом для обсуждения среди членов «Ratio Club» — неформальной группы британских кибернетиков и исследователей в области электроники, в которой состоял и Алан Тьюринг, в честь которого был назван тест.
Тьюринг в особенности занимался проблемой машинного интеллекта, по меньшей мере, с 1941 года. Одно из самых первых его упоминаний о «компьютерном интеллекте» было сделано в 1947 году. В докладе «Интеллектуальные машины» Тьюринг исследовал вопрос, может ли машина обнаруживать разумное поведение, и в рамках этого исследования предложил то, что может считаться предтечей его дальнейших исследований: «Нетрудно разработать машину, которая будет неплохо играть в шахматы. Теперь возьмем трёх человек — субъектов эксперимента. А, В и С. Пусть А и С неважно играют в шахматы, а В — оператор машины. […] Используются две комнаты, а также некоторый механизм для передачи сообщений о ходах. Участник С играет или с А, или с машиной. Участник С может затрудниться ответить, с кем он играет».
Таким образом, к моменту публикации в 1950 году статьи «Вычислительные машины и разум», Тьюринг уже на протяжении многих лет рассматривал возможность существования искусственного интеллекта. Тем не менее данная статья стала первой статьёй Тьюринга, в которой рассматривалось исключительно это понятие.
Тьюринг начинает свою статью утверждением: «Я предлагаю рассмотреть вопрос „Могут ли машины думать?“». Он подчёркивает, что традиционный подход к этому вопросу состоит в том, чтобы сначала определить понятия «машина» и «интеллект». Тьюринг, однако, выбрал другой путь; вместо этого он заменил исходный вопрос другим, «который тесно связан с исходным и формулируется относительно недвусмысленно». По существу, он предлагает заменить вопрос «Думают ли машины?» вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие создания)?». Преимуществом нового вопроса, как утверждает Тьюринг, является то, что он проводит «чёткую границу между физическими и интеллектуальными возможностями человека».
Чтобы продемонстрировать этот подход, Тьюринг предлагает тест, придуманный по аналогии с игрой для вечеринок «Imitation game» — имитационная игра. В этой игре мужчина и женщина направляются в разные комнаты, а гости пытаются различить их, задавая им серию письменных вопросов и читая напечатанные на машинке ответы на них. По правилам игры и мужчина, и женщина пытаются убедить гостей, что все наоборот. Тьюринг предлагает переделать игру следующим образом: "Теперь зададим вопрос, что случится, если в этой игре роль А будет исполнять машина? Будет ли задающий вопросы ошибаться так же часто, как если бы он играл с мужчиной и женщиной? Эти вопросы заменяют собой исходный «Может ли машина думать?».
В том же докладе Тьюринг позднее предлагает «эквивалентную» альтернативную формулировку, включающую судью, который беседует только с компьютером и человеком. Наряду с тем, что ни одна из этих формулировок точно не соответствует той версии теста Тьюринга, которая наиболее известна сегодня, в 1952 учёный предложил третью. В этой версии теста, которую Тьюринг обсудил в эфире радио Би-Би-Си, жюри задает вопросы компьютеру, а роль компьютера состоит в том, чтобы заставить значительную часть членов жюри поверить, что он на самом деле человек.
В статье Тьюринга учтены 9 предполагаемых вопросов, которые включают все основные возражения против искусственного интеллекта, поднятые после того, как статья была впервые опубликована.
Элиза и PARRY
Блей Витби указывает на четыре основные поворотные точки в истории теста Тьюринга — публикация статьи «Вычислительные машины и разум» в 1950, сообщение о создании Джозефом Уайзенбаумом программы Элиза (ELIZA) в 1966, создание Кеннетом Колби программы PARRY, которая была впервые описана в 1972 году, и Коллоквиум Тьюринга в 1990.
Принцип работы Элизы заключается в исследовании введенных пользователем комментариев на наличие ключевых слов. Если найдено ключевое слово, то применяется правило, по которому комментарий пользователя преобразуется и возвращается предложение-результат. Если же ключевое слово не найдено, Элиза либо возвращает пользователю общий ответ, либо повторяет один из предыдущих комментариев. Вдобавок Уайзенбаум запрограммировал Элизу на имитацию поведения психотерапевта, работающего по клиент-центрированной методике. Это позволяет Элизе «притвориться, что она не знает почти ничего о реальном мире». Применяя эти способы, программа Уайзенбаума могла вводить в заблуждение некоторых людей, которые думали, что они разговаривают с реально существующим человеком, а некоторых было «очень трудно убедить, что Элиза […] не человек». На этом основании некоторые утверждают, что Элиза — одна из программ (возможно первая), которые смогли пройти тест Тьюринга. Однако это утверждение очень спорно, так как людей, «задающих вопросы», инструктировали так, чтобы они думали, что с ними будет разговаривать настоящий психотерапевт, и не подозревали о том, что они могут разговаривать с компьютером.
Работа Колби — PARRY — была описана, как «Элиза с мнениями»: программа пыталась моделировать поведение параноидального шизофреника, используя схожий (если не более продвинутый) с Элизой подход, примененный Уайзенбаумом. Для того чтобы проверить программу, PARRY тестировали в начале 70-х, используя модификацию теста Тьюринга. Команда опытных психиатров анализировала группу, составленную из настоящих пациентов и компьютеров под управлением PARRY, используя телетайп. Другой команде из 33 психиатров позже показали стенограммы бесед. Затем обе команды попросили определить, кто из «пациентов» — человек, а кто — компьютерная программа. Психиатры лишь в 48 % случаев смогли вынести верное решение. Эта цифра согласуется с вероятностью случайного выбора. Эти эксперименты не являлись тестами Тьюринга в полном смысле, так как для вынесения решения данный тест требует, чтобы вопросы можно было задавать в интерактивном режиме, вместо чтения стенограммы прошедшей беседы.
Почти все разработанные программы и близко не подошли к прохождению теста. Хотя такие программы, как Элиза (ELIZA), иногда заставляли людей верить, что они говорят с человеком, как, например, в неформальном эксперименте, названном AOLiza, но эти случаи нельзя считать корректным прохождением теста Тьюринга по целому ряду причин:
- Человек в таких беседах не имел никаких оснований считать, что он говорит с программой, в то время как в настоящем тесте Тьюринга человек активно пытается определить, с кем он беседует.
- Документированные случаи обычно относятся к таким чатам, как IRC, где многие беседы отрывочны и бессмысленны.
- Многие пользователи Интернета используют английский как второй или третий язык, так что бессмысленный ответ программы легко может быть списан на языковой барьер.
- Многие просто ничего не знают об Элизе и ей подобных программах, и поэтому не сочтут собеседника программой даже в случае совершенно нечеловеческих ошибок, которые эти программы допускают.
Китайская комната
В 1980 году в статье «Разум, мозг и программы» Джон Сёрль выдвинул аргумент против теста Тьюринга, известный как мысленный эксперимент «Китайская комната». Сёрль настаивал, что программы (такие как Элиза) смогли пройти тест Тьюринга, просто манипулируя символами, значения которых они не понимали. А без понимания их нельзя считать «разумными» в том же смысле, что и людей. «Таким образом, — заключает Сёрль, — тест Тьюринга не является доказательством того, что машина может думать, а это противоречит изначальному предположению Тьюринга».
Такие аргументы, как предложенный Сёрлем, а также другие, основанные на философии разума, породили намного более бурные дискуссии о природе разума, возможности существования разумных машин и значимости теста Тьюринга, продолжавшиеся в течение 80-х и 90-х годов.
Коллоквиум Тьюринга
В 1990 году состоялась сороковая годовщина публикации статьи Тьюринга «Вычислительные машины и разум», что возобновило интерес к тесту. В этом году произошли два важных события.
Одно из них — коллоквиум Тьюринга, который проходил в апреле в Университете Сассекса. В его рамках встретились академики и исследователи из разнообразных областей науки, чтобы обсудить тест Тьюринга с позиций его прошлого, настоящего и будущего. Вторым событием стало учреждение ежегодного соревнования на получение премии Лёбнера.
Премия Лёбнера
Ежегодный конкурс «AI Loebner» на получение премии Лёбнера является платформой для практического проведения тестов Тьюринга. Первый конкурс прошел в ноябре 1991 года. Приз гарантирован Хью Лёбнером (Hugh Loebner). Кембриджский центр исследований поведения, расположенный в Массачусетсе (США), предоставлял призы до 2003 года включительно. По словам Лёбнера, соревнование было организовано с целью продвижения вперёд в области исследований, связанных с искусственным интеллектом, отчасти потому, что «никто не предпринял мер, чтобы это осуществить».
Серебряная (текстовая) и золотая (аудио и зрительная) медали никогда ещё не вручались. Тем не менее ежегодно из всех представленных на конкурс компьютерных систем судьи награждают бронзовой медалью ту, которая, по их мнению, продемонстрирует «наиболее человеческое» поведение в разговоре. Не так давно программа «Искусственное лингвистическое интернет-компьютерное существо» (Artificial Linguistic Internet Computer Entity — A.L.I.C.E.) трижды завоевала бронзовую медаль (в 2000, 2001 и 2004). Способная к обучению программа Jabberwacky[2] побеждала в 2005 и 2006. Её создатели предложили персонализированную версию: возможность пройти имитационный тест, пытаясь более точно сымитировать человека, с которым машина тесно пообщалась перед тестом.
Конкурс проверяет способность разговаривать; победителями становятся обычно чат-боты или «Искусственные разговорные существа» (Artificial Conversational Entities (ACE)s). Правилами первых конкурсов предусматривалось ограничение. Согласно этому ограничению каждая беседа с программой или скрытым человеком могла быть только на одну тему. Начиная с конкурса 1995 года, это правило отменено. Продолжительность разговора между судьёй и участником была различной в разные годы. В 2003 году, когда конкурс проходил в Университете Суррея, каждый судья мог разговаривать с каждым участником (машиной или человеком) ровно 5 минут. С 2004 по 2007 это время составляло уже более 20 минут. В 2008 максимальное время разговора составляло 5 минут на пару, потому что организатор Кевин Ворвик (Kevin Warwick) и координатор Хьюма Ша (Huma Shah) полагали, что ACE не имели технических возможностей поддерживать более продолжительную беседу. Победитель 2008 года, Elbot[3], не притворялся человеком, но всё-таки сумел обмануть трёх судей. В конкурсе, проведённом в 2010 году, было увеличено время до 25 минут при общении между системой и исследователем, по требованию спонсора (программы продвинулись вперёд в способности имитировать человека, и только лишь при длительной беседе появляются нюансы, позволяющие вычислять собеседника). Конкурс, проведённый 15 мая 2012 года, состоялся впервые в мире с прямой трансляцией беседы, что только поднимает интерес к данному конкурсу.
Появление конкурса на получение премии Лёбнера привело к возобновлению дискуссий о целесообразности теста Тьюринга, о значении его прохождения. В статье «Искусственная тупость» газеты The Economist отмечается, что первая программа-победитель конкурса смогла выиграть отчасти потому, что она «имитировала человеческие опечатки». (Тьюринг предложил, чтобы программы добавляли ошибки в вывод, чтобы быть более хорошими «игроками»). Существовало мнение, что попытки пройти тест Тьюринга просто препятствуют более плодотворным исследованиям.
Во время первых конкурсов была выявлена вторая проблема: участие недостаточно компетентных судей, которые поддавались умело организованным манипуляциям, а не тому, что можно считать интеллектом.
Тем не менее с 2004 года в качестве собеседников в конкурсе принимают участие философы, компьютерные специалисты и журналисты.
Судейство на конкурсе очень строгое. Эксперты заранее готовятся к турниру и подбирают весьма заковыристые вопросы, чтобы понять, с кем же они общаются. Их разговор с программами напоминает допрос следователя. Судьи любят, например, повторять некоторые вопросы через определённое время, так как слабые боты не умеют следить за историей диалога и их можно поймать на однообразных ответах[4].
Коллоквиум по разговорным системам, 2005
В ноябре 2005 года в Университете Суррея проходила однодневная встреча разработчиков ACE, которую посетили победители практических тестов Тьюринга, проходивших в рамках конкурса на получение премии Лёбнера: Робби Гарнер (Robby Garner), Ричард Уоллес (Richard Wallace), Ролл Карпентер (Rollo Carpenter). В числе приглашенных докладчиков были Дэвид Хэмилл (David Hamill), Хью Лёбнер и Хьюма Ша.
Симпозиум общества AISB по тесту Тьюринга, 2008
В 2008 году наряду с проведением очередного конкурса на получение премии Лёбнера, проходившего в Университете Рединга (University of Reading), Общество изучения искусственного интеллекта и моделирования поведения (The Society for the Study of Artificial Intelligence and Simulation of Behavior — AISB) провело однодневный симпозиум, на котором обсуждался тест Тьюринга. Симпозиум организовали Джон Бенден (John Barnden), Марк Бишоп (Mark Bishop), Хьюма Ша и Кевин Ворвик. В числе докладчиков были директор Королевского института баронесса Сьюзан Гринфилд (Susan Greenfield), Сельмер Брингсорд (Selmer Bringsjord), биограф Тьюринга Эндрю Ходжес (Andrew Hodges) и ученый Оуэн Холланд (Owen Holland). Никакого соглашения о каноническом тесте Тьюринга не появилось, однако Брингсорд предположил, что более крупная премия будет способствовать тому, что тест Тьюринга будет пройден быстрее.
Год Алана Тьюринга и Тьюринг-100 в 2012
В 2012 году отмечался юбилей Алана Тьюринга. На протяжении всего года проходило множество больших мероприятий. Многие из них проходили в местах, имевших большое значение в жизни Тьюринга: Кембридж, Манчестер и Блетчи Парк. Год Алана Тьюринга курируется организацией TCAC (Turing Centenary Advisory Committee), осуществляющей профессиональную и организационную поддержку мероприятий в 2012 году. Также поддержкой мероприятий занимаются: ACM, ASL, SSAISB, BCS, BCTCS, Блетчи Парк, BMC, BLC, CCS, Association CiE, EACSL, EATCS, FoLLI, IACAP, IACR, KGS и LICS.
Для организации мероприятий по празднованию в июне 2012 года столетия со дня рождения Тьюринга создан специальный комитет, задачей которого является донести мысль Тьюринга о разумной машине, отраженную в таких голливудских фильмах, как «Бегущий по лезвию», до широкой публики, включая детей. В работе комитета участвуют: Кевин Ворвик, председатель, Хьюма Ша, координатор, Ян Бланд (Ian Bland), Крис Чапмэн (Chris Chapman), Марк Аллен (Marc Allen), Рори Данлоуп (Rory Dunlop), победители конкурса на получение премии Лёбнера Робби Гарне и Фред Робертс (Fred Roberts). Комитет работает при поддержке организации «Женщины в технике» (Women in Technology) и Daden Ltd.
На этом конкурсе россияне, имена которых не разглашались, представили программу «Eugene»[5]. В 150 проведённых тестах (а по факту пятиминутных разговорах) участвовали пять новейших программ, которые «затерялись» среди 25 обычных людей. Программа «Eugene», изображавшая 13-летнего мальчика, проживающего в Одессе, стала победителем, сумев в 29,2 % своих ответов ввести экзаменаторов в заблуждение. Таким образом, программа не добрала всего 0,8 % для полного прохождения теста.
Тест Тьюринга на русском языке, 2015
В 2015 году компания Наносемантика и Фонд Сколково провели конкурс «Тест Тьюринга на русском языке». Независимые судьи из числа посетителей конференции Startup Village в Москве общались с 8 отобранными экспертным советом роботами и 8 волонтёрами-лингвистами. После 3-х минут разговора на русском языке судьи определяли, кто из их собеседников является роботом, а кто нет. Каждый робот провёл по 15 разговоров. В конкурсе победил робот, созданный Иваном Голубевым из Санкт-Петербурга, — «Соня Гусева». 47 % собеседников приняли его за человека[6].
Варианты теста Тьюринга
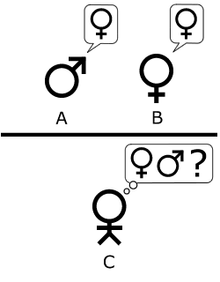 Имитационная игра согласно описанию Тьюринга в статье «Вычислительные машины и разум». Игрок С путём задания серии вопросов пытается определить, кто из двух других игроков — мужчина, а кто — женщина. Игрок А, мужчина, пытается запутать игрока С, а игрок В пытается помочь С.
Имитационная игра согласно описанию Тьюринга в статье «Вычислительные машины и разум». Игрок С путём задания серии вопросов пытается определить, кто из двух других игроков — мужчина, а кто — женщина. Игрок А, мужчина, пытается запутать игрока С, а игрок В пытается помочь С. 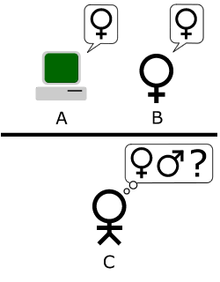 Первоначальный тест на основе имитационной игры, в котором вместо игрока А играет компьютер. Компьютер теперь должен запутать игрока С, в то время как игрок В продолжает пытаться помочь ведущему.
Первоначальный тест на основе имитационной игры, в котором вместо игрока А играет компьютер. Компьютер теперь должен запутать игрока С, в то время как игрок В продолжает пытаться помочь ведущему. Существуют, по крайней мере, три основных варианта теста Тьюринга, два из которых были предложены в статье «Вычислительные машины и разум», а третий вариант, по терминологии Сола Трейджера (Saul Traiger), является стандартной интерпретацией.
Наряду с тем, что существует определённая дискуссия, соответствует ли современная интерпретация тому, что описывал Тьюринг, либо она является результатом неверного толкования его работ, все три версии не считаются равносильными, их сильные и слабые стороны различаются.
Имитационная игра
Тьюринг, как мы уже знаем, описал простую игру для вечеринок, которая включает в себя минимум трех игроков. Игрок А — мужчина, игрок В — женщина и игрок С, который играет в качестве ведущего беседу, любого пола. По правилам игры С не видит ни А, ни В и может общаться с ними только посредством письменных сообщений. Задавая вопросы игрокам А и В, С пытается определить, кто из них — мужчина, а кто — женщина. Задачей игрока А является запутать игрока С, чтобы он сделал неправильный вывод. В то же время задачей игрока В является помочь игроку С вынести верное суждение.
В той версии, которую С. Г. Стеррет (S. G. Sterret) называет «Первоначальный тест на основе имитационной игры» (Original Imitation Game Test), Тьюринг предлагает, чтобы роль игрока А исполнял компьютер. Таким образом, задачей компьютера является притвориться женщиной, чтобы сбить с толку игрока С. Успешность выполнения подобной задачи оценивается на основе сравнения исходов игры, когда игрок А — компьютер, и исходов, когда игрок А — мужчина:
Теперь мы спросим: «Что произойдёт, если машина выступит в качестве игрока А в этой игре?» Будет ли ведущий принимать неправильные решения, когда игра ведётся таким образом, также часто как если бы в игре принимали участие мужчина и женщина? Эти вопросы заменят наш первоначальный: «Могут ли машины думать?» Оригинальный текст (англ.) We now ask the question, «What will happen when a machine takes the part of A in this game?» Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, «Can machines think?» |
Второй вариант предложен Тьюрингом в той же статье. Как и в «Первоначальном тесте», роль игрока А исполняет компьютер. Различие заключается в том, что роль игрока В может исполнять как мужчина, так и женщина.
«Давайте рассмотрим конкретный компьютер. Верно ли то, что модифицируя этот компьютер с целью иметь достаточно места для хранения данных, увеличивая скорость его работы и задавая ему подходящую программу, можно сконструировать такой компьютер, чтобы он удовлетворительно выполнял роль игрока А в имитационной игре, в то время как роль игрока В выполняет мужчина?», — Тьюринг, 1950, стр. 442.
В этом варианте оба игрока А и В пытаются склонить ведущего к неверному решению.
Стандартная интерпретация
Главной мыслью данной версии является то, что целью теста Тьюринга является ответ не на вопрос, может ли машина одурачить ведущего, а на вопрос, может ли машина имитировать человека или нет. Несмотря на то, что идут споры о том, подразумевался ли этот вариант Тьюрингом или нет, Стеррет считает, что этот вариант Тьюрингом подразумевался и, таким образом, совмещает второй вариант с третьим. В это же время группа оппонентов, включая Трейджера, так не считает. Но это все равно привело к тому, что можно назвать «стандартной интерпретацией». В этом варианте игрок А — компьютер, игрок В — человек любого пола. Задачей ведущего является теперь не определить кто из них мужчина и женщина, а кто из них компьютер, а кто — человек.
Имитационная игра в сравнении со стандартным тестом Тьюринга
Существуют разногласия по поводу того, какой же вариант имел в виду Тьюринг. Стеррет настаивает на том, что из работы Тьюринга следуют два различных варианта теста, которые, согласно Тьюрингу, неэквивалентны друг другу. Тест, в котором используется игра для вечеринок и сравнивается доля успехов, называется Первоначальным тестом на основе имитационной игры, в то время как тест, основанный на беседе судьи с человеком и машиной, называют Стандартным тестом Тьюринга, отмечая, что Стеррет приравнивает его к стандартной интерпретации, а не ко второму варианту имитационной игры.
Стеррет согласен, что Стандартный тест Тьюринга (STT — Standard Turing Test) имеет недостатки, на которые указывает его критика. Но он считает, что напротив первоначальный тест на основе имитационной игры (OIG Test — Original Imitation Game Test) лишен многих из них в силу ключевых различий: в отличие от STT он не рассматривает поведение, похожее на человеческое, в качестве основного критерия, хотя и учитывает человеческое поведение в качестве признака разумности машины. Человек может не пройти тест OIG, в связи с чем есть мнение, что это является достоинством теста на наличие интеллекта. Неспособность пройти тест означает отсутствие находчивости: в тесте OIG по определению считается, что интеллект связан с находчивостью и не является просто «имитацией поведения человека во время разговора». В общем виде тест OIG можно даже использовать в невербальных вариантах.
Тем не менее другие писатели интерпретировали слова Тьюринга как предложение считать саму имитационную игру тестом. Причём не объясняется, как связать это положение и слова Тьюринга о том, что тест, предложенный им на основе игры для вечеринок, базируется на критерии сравнительной частоты успехов в этой имитационной игре, а не на возможности выиграть раунд игры.
Должен ли судья знать о компьютере?
В своих работах Тьюринг не поясняет, знает ли судья о том, что среди участников теста будет компьютер, или нет. Что касается OIG, Тьюринг лишь говорит, что игрока А следует заменить машиной, но умалчивает, известно ли это игроку С или нет. Когда Колби, Ф. Д. Хилф (F. D. Hilf), А. Д. Крамер (A. D. Kramer) тестировали PARRY, они решили, что судьям необязательно знать, что один или несколько собеседников будут компьютерами. Как отмечает А. Седжин (A. Saygin), а также другие специалисты, это накладывает существенный отпечаток на реализацию и результаты теста.
Достоинства теста
Ширина темы
Сильной стороной теста Тьюринга является то, что можно разговаривать о чём угодно. Тьюринг писал, что «метод вопросов и ответов кажется подходящим для обсуждения почти любой из сфер человеческих интересов, которую мы хотим обсудить». Джон Хогеленд добавил, что «одного понимания слов недостаточно; вам также необходимо разбираться в теме разговора». Чтобы пройти хорошо поставленный тест Тьюринга, машина должна использовать естественный язык, рассуждать, иметь познания и обучаться. Тест можно усложнить, включив ввод с помощью видео, или, например, оборудовав шлюз для передачи предметов: машине придётся продемонстрировать способность к зрению и робототехнике. Все эти задачи вместе отражают основные проблемы, стоящие перед теорией об искусственном интеллекте.
Уступчивость и простота
Сила и привлекательность теста Тьюринга исходит из его простоты. Философы сознания, психологии в современной неврологии не способны дать определения «интеллект» и «мышление», насколько они являются достаточно точными и вообще применимы к машинам. Без такого определения, в центральных вопросах философии об искусственном интеллекте не может быть ответа. Тест Тьюринга, даже если и несовершенен, но по крайней мере, обеспечивает то, что это действительно может быть измерено. Как таковой, это является прагматическим решением трудных философских вопросов.
Стоит отметить, что в советской психологии Выготский Л. С. и Лурия А. Р. дали вполне четкие определения «интеллекта» и «мышления»[7].
Недостатки теста
Несмотря на все свои достоинства и известность, тест критикуют на нескольких основаниях.
Человеческий разум и разум вообще
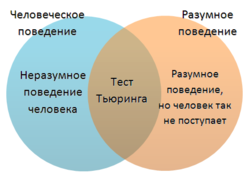 Поведение человека и разумное поведение.
Поведение человека и разумное поведение. Направленность теста Тьюринга ярко выражена в сторону человека (антропоморфизм). Проверяется только способность машины походить на человека, а не разумность машины вообще. Тест неспособен оценить общий интеллект машины по двум причинам:
- Иногда поведение человека не поддается разумному толкованию. В это же время тест Тьюринга требует, чтобы машина была способна имитировать все виды человеческого поведения, не обращая внимания на то, насколько оно разумно. Он также проверяет способность имитировать такое поведение, какое человек за разумное и не посчитает, например, реакция на оскорбления, соблазн соврать или просто большое количество опечаток. Если машина неспособна с точностью до деталей имитировать поведение человека, опечатки и тому подобное, то она не проходит тест, несмотря на весь тот интеллект, которым она может обладать.
- Некоторое разумное поведение не присуще человеку. Тест Тьюринга не проверяет высокоинтеллектуальное поведение, например, способность решать сложные задачи или выдвигать оригинальные идеи. По сути, тест требует, чтобы машина обманывала: какой бы умной ни была машина, она должна притворяться не слишком умной, чтобы пройти тест. Если же машина способна быстро решить некую вычислительную задачу, непосильную для человека, она по определению провалит тест.
Непрактичность
Стюарт Рассел (Stuart Russel) и Питер Норвиг (Peter Norvig) утверждают, что антропоцентризм теста приводит к тому, что он не может быть по-настоящему полезным при разработке разумных машин. «Тесты по авиационному проектированию и строительству, — строят они аналогию, — не ставят целью своей отрасли создание машин, которые летают точно так же, как летают голуби, что даже сами голуби принимают их за своих»[8]. Из-за этой непрактичности прохождение теста Тьюринга не является целью ведущих научных или коммерческих исследований (по состоянию на 2009). Сегодняшние исследования в области искусственного интеллекта ставят перед собой более скромные и специфические цели.
«Исследователи в области искусственного интеллекта уделяют мало внимания прохождению теста Тьюринга, — отмечают Рассел и Норвиг, — с тех пор как появились более простые способы проверки программ, например, дать задание напрямую, а не окольными путями, первой обозначить некоторый вопрос в чат-комнате, к которой подключены и машины, и люди». Тьюринг никогда не предполагал использовать свой тест на практике, в повседневном измерении степени разумности программ; он хотел дать ясный и понятный пример для поддержки обсуждения философии искусственного интеллекта.
Следует подчеркнуть, что Тьюринг не раскрывал в развернутом виде свои цели и идею создания теста. Исходя из условий прохождения можно предположить, что в его время интеллект человека доминировал во всех областях, то есть был сильнее и быстрее любого другого. В настоящее же время некоторые программы, имитирующие интеллектуальную деятельность, настолько эффективны, что превосходят разум среднестатистического жителя Земли в определённых узких областях. Следовательно, при определённых условиях они могут пройти тест.
Реальный интеллект и имитируемый интеллект
Также тест Тьюринга явно бихевиористичен или функционалистичен: он лишь проверяет, как действует субъект. Машина, проходящая тест, может имитировать поведение человека в разговоре, просто «неинтеллектуально» следуя механическим правилам. Двумя известными контрпримерами, выражающими данную точку зрения являются «Китайская комната» Сёрля (1980) и «Болван» Неда Блока (Ned Block, 1981). По мнению Сёрля основной проблемой является определить, «имитирует» ли машина мышление, или «на самом деле» мыслит. Даже если тест Тьюринга и является годным для определения наличия интеллекта, Сёрль отмечает, что тест не покажет, что у машины есть разум, сознание, возможность «понимать» или иметь цели, которые имеют какой-то смысл (философы называют это целеполаганием).
В своей работе Тьюринг писал по поводу этих аргументов следующее: «Я не хочу создать впечатление, будто я думаю, что у сознания нет никакой загадки. Существует, например, своего рода парадокс, связанный с любой попыткой определить его местонахождение. Но я не думаю, что эти загадки обязательно надо разгадать до того, как мы сможем ответить на вопрос, которому посвящена данная работа».
Предсказания
Тьюринг прогнозировал, что машины, в конце концов, будут способны пройти тест; фактически он ожидал, что к 2000 году, машины с объёмом памяти 109 бит (около 119,2 МиБ или 125 МБ) будут способны обманывать 30 % судей по результатам пятиминутного теста. Также он высказал мысль о том, что словосочетание «думающая машина» больше не будет считаться оксюмороном. Далее он предположил, что машинное обучение будет важным звеном в построении мощных машин, что является правдоподобным среди современных исследователей в области искусственного интеллекта[9].
Экстраполируя экспоненциальный рост уровня технологии в течение нескольких десятилетий, футурист Рэймонд Курцвейл предположил, что машины, способные пройти тест Тьюринга, будут изготовлены, по грубым оценкам, около 2020 года. Это перекликается с законом Мура.
В проект Long Bet Project входит пари стоимостью 20 000 $ между Митчем Капуром (Mitch Kapor — пессимист) и Рэймондом Курцвейлом (оптимист). Смысл пари: пройдет ли компьютер тест Тьюринга к 2029 году? Определены также некоторые условия пари[10].
Вариации теста Тьюринга
Многочисленные версии теста Тьюринга, включая описанные ранее, уже обсуждаются довольно долгое время.
Обратный тест Тьюринга и CAPTCHA
Модификация теста Тьюринга, в которой цель или одну или более ролей машины и человека поменяли местами, называется обратным тестом Тьюринга. Пример этого теста приведен в работе психоаналитика Уилфреда Биона, который был в особенности восхищен тем, как активизируется мыслительная активность при столкновении с другим разумом.
Развивая эту идею, Р. Д. Хиншелвуд (R. D. Hinshelwood) описал разум как «аппарат, распознающий разум», отметив, что это можно считать как бы «дополнением» к тесту Тьюринга. Теперь задачей компьютера будет определить с кем он беседовал: с человеком или же с другим компьютером. Именно на это дополнение к вопросу и пытался ответить Тьюринг, но, пожалуй, оно вводит достаточно высокий стандарт на то, чтобы определить, может ли машина «думать» так, как мы обычно относим это понятие к человеку.
CAPTCHA — это разновидность обратного теста Тьюринга. Перед тем как разрешить выполнение некоторого действия на сайте, пользователю выдается искаженное изображение с набором цифр и букв и предложение ввести этот набор в специальное поле. Цель этой операции — предотвратить атаки автоматических систем на сайт. Обоснованием подобной операции является то, что пока не существует программ достаточно мощных для того, чтобы распознать и точно воспроизвести текст с искаженного изображения (или они недоступны рядовым пользователям), поэтому считается, что система, которая смогла это сделать, с высокой вероятностью может считаться человеком. Выводом будет (хотя и не обязательно), что искусственный интеллект пока не создан.
Тест Тьюринга со специалистом
Эта вариация теста описывается следующим образом: ответ машины не должен отличаться от ответа эксперта — специалиста в определённой области знаний.
Тест бессмертия
Тест бессмертия — это вариация теста Тьюринга, которая определяет, качественно ли передан характер человека, а именно возможно ли отличить скопированный характер от характера человека, послужившего его источником.
Минимальный интеллектуальный Signal-тест (MIST)
MIST предложен Крисом Мак-Кинстри (Chris McKinstry). В этой вариации теста Тьюринга разрешены лишь два типа ответов — «да» и «нет». Обычно MIST используют для сбора статистической информации, с помощью которой можно измерить производительность программ, реализующих искусственный интеллект.
Мета-тест Тьюринга
В этой вариации теста субъект (скажем, компьютер) считают разумным, если он создал нечто, что он сам хочет проверить на разумность.
Премия Хаттера
Организаторы премии Хаттера считают, что сжатие текста на естественном языке является трудной задачей для искусственного интеллекта, эквивалентной прохождению теста Тьюринга.
Тест по сжатию информации имеет определённые преимущества над большей частью вариантов и вариаций теста Тьюринга:
- Его результатом является единственное число, по которому можно судить какая из двух машин «более разумная».
- Не требуется, чтобы компьютер врал судье — учить компьютеры врать считают плохой идеей.
Основными недостатками подобного теста являются:
- С его помощью невозможно протестировать человека.
- Неизвестно какой результат (и есть ли он вообще) эквивалентен прохождению теста Тьюринга (на уровне человека).
Другие тесты интеллекта
Существует множество тестов на уровень интеллекта, которые используют для тестирования людей. Возможно, что их можно использовать для тестирования искусственного интеллекта. Некоторые тесты (например, Си-тест), выведенные из «Колмогоровской сложности», используются для проверки людей и компьютеров.
Тест BotPrize
Двум командам программистов удалось победить в конкурсе BotPrize, который называют «игровой версией» теста Тьюринга. Сообщение о результатах теста приведено на сайте BotPrize, кратко его результаты анализирует NewScientist. Тест BotPrize проходил в виде многопользовательской компьютерной игры (Unreal Tournament 2004), персонажами которой управляли реальные люди или компьютерные алгоритмы[11].
Женя Густман
По сообщению Университета Рединга (англ.)русск., в тестировании 6 июня 2014 года, организованном Школой системной инженерии[12] при университете и компаний RoboLaw под руководством профессора Кевина Уорика, полноценный тест Тьюринга впервые в истории был пройден с помощью программы «Eugene Goostman»[13][14], разработанной в Санкт-Петербурге выходцами из России Владимиром Веселовым и Сергеем Уласенем, и выходцем с Украины Евгением Демченко[15][16]. Всего в тестировании участвовали пять суперкомпьютер
www.gpedia.com
Тест Тьюринга
Материал из Seo Wiki - Поисковая Оптимизация и Программирование
Тест Тьюринга — эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум» (англ. Computing Machinery and Intelligence), опубликованной в 1950 году в философском журнале «Mind». Тьюринг задался целью определить, может ли машина мыслить.
Стандартная интерпретация этого теста звучит следующим образом: «Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Все участники теста не видят друг друга. Если судья не может сказать определенно, кто из собеседников является человеком, то считается, что машина прошла тест. Чтобы протестировать именно интеллект машины, а не её возможность распознавать устную речь, беседа ведется в режиме «только текст», например, с помощью клавиатуры и экрана (компьютера-посредника). Переписка должна производиться через контролируемые промежутки времени, чтобы судья не мог делать заключения исходя из скорости ответов. Во времена Тьюринга компьютеры реагировали медленнее человека. Сейчас это правило необходимо, потому что они реагируют гораздо быстрее, чем человек.
По состоянию на 2009 год ни одна из существующих компьютерных систем не приблизилась к прохождению теста.
История
Философские предпосылки
Хотя исследования в области искусственного интеллекта начались в 1956 году, их философские корни уходят глубоко в прошлое. Вопрос, может машина думать или нет, имеет долгую историю. Он тесно связан с различиями между дуалистическим и материалистическим взглядами. С точки зрения дуализма, мысль не является материальной (или, по крайней мере, не имеет материальных свойств), и поэтому разум нельзя объяснить только с помощью физических понятий. С другой стороны, материализм гласит, что разум можно объяснить физически, таким образом, оставляя возможность существования разумов, созданных искусственно.
В 1936 году философ Альфред Айер рассмотрел обычный для философии вопрос касательно других разумов: как узнать, что другие люди имеют тот же сознательный опыт, что и мы? В своей книге «Язык, истина и логика» Айер предложил алгоритм распознавания сознающего человека и не осознающей машины: «Единственным основанием, на котором я могу утверждать, что объект, который кажется разумным, на самом деле не разумное существо, а просто глупая машина, является то, что он не может пройти один из эмпирических тестов, согласно которым определяется наличие или отсутствие сознания». Это высказывание очень похоже на тест Тьюринга, однако точно неизвестно, была ли известна Тьюрингу популярная философская классика Айера.
Алан Тьюринг
К 1956 году британские ученые уже на протяжении 10 лет исследовали «машинный интеллект». Этот вопрос был обычным предметом для обсуждения среди членов «Ratio Club» — неформальной группы британских кибернетиков и исследователей в области электроники, в которой состоял и Алан Тьюринг, в честь которого был назван тест.
Тьюринг в особенности занимался проблемой машинного интеллекта, по меньшей мере, с 1941 года. Одно из самых первых его упоминаний о «компьютерном интеллекте» было сделано в 1947 году. В докладе «Интеллектуальные машины» Тьюринг исследовал вопрос, может ли машина обнаруживать разумное поведение, и в рамках этого исследования предложил то, что может считаться предтечей его дальнейших исследований: «Нетрудно разработать машину, которая будет неплохо играть в шахматы. Теперь возьмем трех человек — субъектов эксперимента. А, В и С. Пусть А и С неважно играют в шахматы, а В — оператор машины. […] Используются две комнаты, а также некоторый механизм для передачи сообщений о ходах. Участник С играет или с А, или с машиной. Участник С может затрудниться ответить с кем он играет».
Таким образом, к моменту публикации в 1950 году статьи «Вычислительные машины и разум», Тьюринг уже на протяжении многих лет рассматривал возможность существования искусственного интеллекта. Тем не менее, данная статья стала первой статьей Тьюринга, в которой рассматривалось исключительно это понятие.
Тьюринг начинает свою статью утверждением: «Я предлагаю рассмотреть вопрос „Могут ли машины думать?“». Он подчеркивает, что традиционный подход к этому вопросу состоит в том, чтобы сначала определить понятия «машина» и «интеллект». Тьюринг, однако, выбрал другой путь; вместо этого он заменил исходный вопрос другим, «который тесно связан с исходным и формулируется относительно недвусмысленно». По существу, он предлагает заменить вопрос «Думают ли машины?» вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие создания)?». Преимуществом нового вопроса, как утверждает Тьюринг, является то, что он проводит «четкую границу между физическими и интеллектуальными возможностями человека».
Чтобы продемонстрировать этот подход, Тьюринг предлагает тест, придуманный по аналогии с игрой для вечеринок «Imitation game» — имитационная игра. В этой игре мужчина и женщина направляются в разные комнаты, а гости пытаются различить их, задавая им серию письменных вопросов и читая напечатанные на машинке ответы на них. По правилам игры и мужчина, и женщина пытаются убедить гостей, что все наоборот. Тьюринг предлагает переделать игру следующим образом: "Теперь зададим вопрос, что случится, если в этой игре роль А будет исполнять машина? Будет ли задающий вопросы ошибаться так же часто, как если бы он играл с мужчиной и женщиной? Эти вопросы заменяют собой исходный «Может ли машина думать?».
В том же докладе Тьюринг позднее предлагает «эквивалентную» альтернативную формулировку, включающую судью, который беседует только с компьютером и человеком. Наряду с тем, что ни одна из этих формулировок точно не соответствует той версии теста Тьюринга, которая наиболее известна сегодня, в 1952 ученый предложил третью. В этой версии теста, которую Тьюринг обсудил в эфире радио Би-Би-Си, жюри задает вопросы компьютеру, а роль компьютера состоит в том, чтобы заставить значительную часть членов жюри поверить, что он на самом деле человек.
В статье Тьюринга учтены 9 предполагаемых вопросов, которые включают все основные возражения против искусственного интеллекта, поднятые после того, как статья была впервые опубликована.
Элиза и PARRY
Блей Витби указывает на 4 основные поворотные точки в истории теста Тьюринга — публикация статьи «Вычислительные машины и разум» в 1950, сообщение о создании Джозефом Вейзенбаумом программы Элиза в 1966, создание Кеннетом Колби программы PARRY, которая была в первые описана в 1972 году, и Коллоквиум Тьюринга в 1990.
Принцип работы Элизы заключается в исследовании введенных пользователем комментариев на наличие ключевых слов. Если найдено ключевое слово, то применяется правило, по которому комментарий пользователя преобразуется и возвращается предложение-результат. Если же ключевое слово не найдено, Элиза либо возвращает пользователю общий ответ, либо повторяет один из предыдущих комментариев. Вдобавок Вейзенбаум запрограммировал Элизу на имитацию поведения психотерапевта, работающего по клиент-центрированной методике . Это позволяет Элизе «притвориться, что она не знает почти ничего о реальном мире». Применяя эти способы, программа Вейзенбаума могла вводить в заблуждение некоторых людей, которые думали, что они разговаривают с реально существующим человеком, а некоторых было «очень трудно убедить, что Элиза […] не человек». На этом основании некоторые утверждают, что Элиза — одна из программ (возможно первая), которые смогли пройти тест Тьюринга. Однако это утверждение очень спорно, так как людей, «задающих вопросы», инструктировали так, чтобы они думали, что с ними будет разговаривать настоящий психотерапевт, и не подозревали о том, что они могут разговаривать с компьютером.
Работа Колби — PARRY — была описана, как «Элиза с мнениями»: программа пыталась моделировать поведение параноидального шизофреника, используя схожий (если не более продвинутый) с Элизой подход, примененный Вейзенбаумом. Для того чтобы проверить программу, PARRY тестировали в начале 70-х, используя модификацию теста Тьюринга. Команда опытных психиатров анализировала группу, составленную из настоящих пациентов и компьютеров под управлением PARRY, используя телетайп. Другой команде из 33 психиатров позже показали стенограммы бесед. Затем обе команды попросили определить, кто из «пациентов» — человек, а кто — компьютерная программа. Психиатры лишь в 48 % случаев смогли вынести верное решение. Эта цифра согласуется с вероятностью случайного выбора. Заметьте, что эти эксперименты не являлись тестами Тьюринга в полном смысле, так как для вынесения решения данный тест требует, чтобы вопросы можно было задавать в интерактивном режиме, вместо чтения стенограммы прошедшей беседы.
Пока что ни одна программа и близко не подошла к прохождению теста. Хотя такие программы, как Элиза (ELIZA), иногда заставляли людей верить, что они говорят с человеком, как, например, в неформальном эксперименте, названном AOLiza, но эти случаи нельзя считать корректным прохождением теста Тьюринга по целому ряду причин:
- Человек в таких беседах не имел никаких оснований считать, что он говорит с программой, в то время как в настоящем тесте Тьюринга человек активно пытается определить, с кем он беседует.
- Документированные случаи обычно относятся к таким чатам, как IRC, где многие беседы отрывочны и бессмысленны.
- Многие пользователи Интернета используют английский как второй или третий язык, так что бессмысленный ответ программы легко может быть списан на языковой барьер.
- Многие просто ничего не знают об Элизе и ей подобных программах, и поэтому не сочтут собеседника программой даже в случае совершенно нечеловеческих ошибок, которые эти программы допускают.
Китайская комната
В 1980 году в статье «Разум, мозг и программы» Джон Сёрль выдвинул аргумент против теста Тьюринга, известный как мысленный эксперимент «Китайская комната». Сёрль настаивал, что программы (такие как Элиза) смогли пройти тест Тьюринга, просто манипулируя символами, значения которых они не понимали. А без понимания их нельзя считать «разумными» в том же смысле, что и людей. «Таким образом, — заключает Сёрль, — тест Тьюринга не является доказательством того, что машина может думать, а это противоречит изначальному предположению Тьюринга».
Такие аргументы, как предложенный Сёрлем, а также другие, основанные на философии разума, породили намного более бурные дискуссии о природе разума, возможности существования разумных машин и значимости теста Тьюринга, продолжавшиеся в течение 80-х и 90-х годов.
Коллоквиум Тьюринга
В 1990 году состоялось сороковая годовщина публикации статьи Тьюринга «Вычислительные машины и разум», что возобновило интерес к тесту. В этом году произошли два важных события.
Одно из них — коллоквиум Тьюринга, который проходил в апреле в Университете Сассекса. В его рамках встретились академики и исследователи из разнообразных областей науки, чтобы обсудить тест Тьюринга с позиций его прошлого, настоящего и будущего. Вторым событием стало учреждение ежегодного соревнования на получение премии Лёбнера.
Премия Лёбнера
Ежегодный конкурс на получение премии Лёбнера является платформой для практического проведения тестов Тьюринга. Первый конкурс прошел в ноябре 1991 года. Приз гарантирован Хью Лёбнером (Hugh Loebner). Кембриджский центр исследований поведения, расположенный в Масачусетсе, США, предоставлял призы до 2003 года включительно. По словам Лёбнера, соревнование было организовано с целью продвижения вперед в области исследований, связанных с искусственным интеллектом, отчасти потому, что «никто не предпринял мер, чтобы это осуществить».
Серебряная (аудио) и золотая (аудио и зрительная) медали никогда ещё не вручались. Тем не менее, ежегодно из всех представленных на конкурс компьютерных систем судьи награждают бронзовой медалью ту, которая, по их мнению, продемонстрирует «наиболее человеческое» поведение в разговоре. Не так давно программа «Искусственное лингвистическое интернет-компьютерное существо» (Artificial Linguistic Internet Computer Entity — A.L.I.C.E.) трижды завоевала бронзовую медаль (в 2000, 2001 и 2004). Способная к обучению программа Jabberwacky побеждала в 2005 и 2006. Её создатели предложили персонализированную версию: возможность пройти имитационный тест, пытаясь более точно сымитировать человека, с которым машина тесно пообщалась перед тестом.
Конкурс проверяет способность разговаривать; победителями становятся обычно чат-боты или «Искусственные разговорные существа» (Artificial Conversational Entities (ACE)s). Правилами первых конкурсов предусматривалось ограничение. Согласно этому ограничению каждая беседа с программой или скрытым человеком могла быть только на одну тему. Начиная с конкурса 1995 года это правило отменено. Продолжительность разговора между судьей и участником была различной в разные годы. В 2003 году, когда конкурс проходил в Университете Суррея, каждый судья мог разговаривать с каждым участником (машиной или человеком) ровно 5 минут. С 2004 по 2007 это время составляло уже более 20 минут. В 2008 максимальное время разговора составляло 5 минут на пару, потому что организатор Кевин Ворвик (Kevin Warwick) и координатор Хьюма Ша (Huma Shah) полагали, что ACE не имели технических возможностей поддерживать более продолжительную беседу. Как ни странно, победитель 2008 года, Elbot, не притворялся человеком, но все-таки сумел обмануть трех судей.
Появление конкурса на получение премии Лёбнера привело к возобновлению дискуссий о целесообразности теста Тьюринга, о значении его прохождения. В статье «Искусственная тупость» газеты The Economist отмечается, что первая программа-победитель конкурса смогла выиграть отчасти, потому что она «имитировала человеческие опечатки». (Тьюринг предложил, чтобы программы добавляли ошибки в вывод, чтобы быть более хорошими «игроками».) Существовало мнение, что попытки пройти тест Тьюринга просто препятствуют более плодотворным исследованиям.
Во время первых конкурсов была выявлена вторая проблема: участие недостаточно компетентных судей, которые поддавались умело организованным манипуляциям, а не тому, что можно считать интеллектом.
Тем не менее, с 2004 года в качестве собеседников в конкурсе принимают участие философы, компьютерные специалисты и журналисты.
Коллоквиум по разговорным системам, 2005
В ноябре 2005 года в Университете Суррея проходила однодневная встреча разработчиков ACE , которую посетили победители практических тестов Тьюринга, проходивших в рамках конкурса на получение премии Лёбнера: Робби Гарнер (Robby Garner), Ричард Уоллес (Richard Wallace), Ролл Карпентер (Rollo Carpenter). В числе приглашенных докладчиков были Дэвид Хэмилл (David Hamill), Хью Лёбнер и Хьюма Ша.
Симпозиум общества AISB по тесту Тьюринга, 2008
В 2008 году наряду с проведением очередного конкурса на получение премии Лёбнера, проходившего в Университете Чтения, Общество изучения искусственного интеллекта и моделирования поведения (The Society for the Study of Artificial Intelligence and Simulation of Behavior — AISB) провело однодневный симпозиум, на котором обсуждался тест Тьюринга. Симпозиум организовали Джон Бенден (John Barnden), Марк Бишоп (Mark Bishop), Хьюма Ша и Кевин Ворвик. В числе докладчиков были директор Королевского института баронесса Сьюзан Гринфилд (Susan Greenfield), Сельмер Брингсорд (Selmer Bringsjord), биограф Тьюринга Эндрю Ходжес (Andrew Hodges) и ученый Оуэн Холланд (Owen Holland). Никакого соглашения о каноническом тесте Тьюринга не появилось, однако Брингсорд предположил, что более крупная премия будет способствовать тому, что тест Тьюринга будет пройден быстрее.
Тьюринг-100 в 2012
Для организации мероприятий по празднованию в 2012 году столетия со дня рождения Тьюринга создан специальный комитет, задачей которого является донести мысль Тьюринга о разумной машине, отраженную в таких голливудских фильмах, как «Бегущий по лезвию», до широкой публики, включая детей. В работе комитета участвуют: Кевин Ворвик, председатель, Хьюма Ша, координатор, Ян Бланд (Ian Bland), Крис Чапмэн (Chris Chapman), Марк Аллен (Marc Allen), Рори Данлоуп (Rory Dunlop), победители конкурса на получение премии Лёбнера Робби Гарне и Фред Робертс (Fred Roberts). Комитет работает при поддержке организации «Женщины в технике» (Women in Technology) и Daden Ltd.
Варианты теста Тьюринга
Файл:The Imitation Game.pngИмитационная игра согласно описанию Тьюринга в статье «Вычислительные машины и разум». Игрок С путем задания серии вопросов пытается определить, кто из двух других игроков — мужчина, а кто — женщина. Игрок А, мужчина, пытается запутать игрока С, а игрок В пытается помочь С.
Файл:Turing Test Version 1.pngПервоначальный тест на основе имитационной игры, в котором вместо игрока А играет компьютер. Компьютер теперь должен запутать игрока С, в то время как игрок В продолжает пытаться помочь ведущему.
Существуют, по крайней мере, три основных варианта теста Тьюринга, два из которых были предложны в статье «Вычислительные машины и разум», а третий вариант, по терминологии Саула Трейджера (Saul Traiger), является стандартной интерпретацией.
Наряду с тем, что существует определенная дискуссия, соответствует ли современная интерпретация тому, что описывал Тьюринг, либо она является результатом неверного толкования его работ, все три версии не считаются равносильными, их сильные и слабые стороны различаются.
Имитационная игра
Тьюринг, как мы уже знаем, описал простую игру для вечеринок, которая включает в себя минимум трех игроков. Игрок А — мужчина, игрок В — женщина и игрок С, который играет в качестве ведущего беседу, любого пола. По правилам игры С не видит ни А, ни В и может общаться с ними только посредством письменных сообщений. Задавая вопросы игрокам А и В, С пытается определить, кто из них — мужчина, а кто — женщина. Задачей игрока А является запутать игрока С, чтобы он сделал неправильный вывод. В то же время задачей игрока В является помочь игроку С вынести верное суждение.
В той версии, которую С. Г. Стеррет (S. G. Sterret) называет «Первоначальный тест на основе имитационной игры» (Original Imitation Game Test), Тьюринг предлагает, чтобы роль игрока А исполнял компьютер. Таким образом, задачей компьютера является притвориться женщиной, чтобы сбить с толку игрока С. Успешность выполнения подобной задачи оценивается на основе сравнения исходов игры, когда игрок А — компьютер, и исходов, когда игрок А — мужчина. Если, по словам Тьюринга, «ведущий беседу игрок после проведения игры [с участием компьютера] выносит неверное решение так же часто, как и после проведения игры с участием мужчины и женщины», то можно говорить о том, что компьютер разумен.
Второй вариант предложен Тьюрингом в той же статье. Как и в «Первоначальном тесте», роль игрока А исполняет компьютер. Различие заключается в том, что роль игрока В может исполнять как мужчина, так и женщина.
«Давайте рассмотрим конкретный компьютер. Верно ли то, что модифицируя этот компьютер с целью иметь достаточно места для хранения данных, увеличивая скорость его работы и задавая ему подходящую программу, можно сконструировать такой компьютер, чтобы он удовлетворительно выполнял роль игрока А в имитационной игре, в то время как роль игрока В выполняет мужчина?», — Тьюринг, 1950, стр. 442.
В этом варианте оба игрока А и В пытаются склонить ведущего к неверному решению.
Стандартная интерпретация
Главной мыслью данной версии является то, что целью теста Тьюринга является ответ не на вопрос, может ли машина одурачить ведущего, а на вопрос, может ли машина имитировать человека или нет. Несмотря на то, что идут споры о том, подразумевался ли этот вариант Тьюрингом или нет, Стеррет считает, что этот вариант Тьюрингом подразумевался и, таким образом, совмещает второй вариант с третьим. В это же время группа оппонентов, включая Трейджера, так не считает. Но это все равно привело к тому, что можно назвать «стандартной интерпретацией». В этом варианте игрок А — компьютер, игрок В — человек любого пола. Задачей ведущего является теперь не определить кто из них мужчина и женщина, а кто из них компьютер, а кто — человек.
Имитационная игра в сравнении со стандартным тестом Тьюринга
Существуют разногласия по поводу того, какой же вариант имел в виду Тьюринг. Стеррет настаивает на том, что из работы Тьюринга следуют два различных варианта теста, которые, согласно Тьюрингу, неэквивалентны друг другу. Тест, в котором используется игра для вечеринок и сравнивается доля успехов, называется Первоначальным тестом на основе имитационной игры, в то время как тест, основанный на беседе судьи с человеком и машиной, называют Стандартным тестом Тьюринга, отмечая, что Стеррет приравнивает его к стандартной интерпретации, а не ко второму варианту имитационной игры.
Стеррет согласен, что Стандартный тест Тьюринга (STT — Standard Turing Test) имеет недостатки, на которые указывает его критика. Но он считает, что напротив первоначальный тест на основе имитационной игры (OIG Test — Original Imitation Game Test) лишен многих из них в силу ключевых различий: в отличие от STT он не рассматривает поведение, похожее на человеческое, в качестве основного критерия, хотя и учитывает человеческое поведение в качестве признака разумности машины. Человек может не пройти тест OIG, в связи с чем есть мнение, что это является достоинством теста на наличие интеллекта. Неспособность пройти тест означает отсутствие находчивости: в тесте OIG по определению считается, что интеллект связан с находчивостью и не является просто «имитацией поведения человека во время разговора». В общем виде тест OIG можно даже использовать в невербальных вариантах.
Тем не менее, другие писатели интерпретировали слова Тьюринга, как предложение считать саму имитационную игру тестом. Причем не объясняется, как связать это положение и слова Тьюринга о том, что тест, предложенный им на основе игры для вечеринок, базируется на критерии сравнительной частоты успехов в этой имитационной игре, а не на возможности выиграть раунд игры.
Должен ли судья знать о компьютере?
В своих работах Тьюринг не поясняет, знает ли судья о том, что среди участников теста будет компьютер, или нет. Что касается OIG, Тьюринг лишь говорит, что игрока А следует заменить машиной, но умалчивает, известно ли это игроку С или нет. Когда Колби, Ф. Д. Хилф (F. D. Hilf), А. Д. Крамер (A. D. Kramer) тестировали PARRY, они решили, что судьям необязательно знать, что один или несколько собеседников будут компьютерами. Как отмечает А. Седжин (A. Saygin), а также другие специалисты, это накладывает существенный отпечаток на реализацию и результаты теста.
Достоинства теста
Ширина темы
Сильной стороной теста Тьюринга является то, что можно разговаривать о чем угодно. Тьюринг писал, что «метод вопросов и ответов кажется подходящим для обсуждения почти любой из сфер человеческих интересов, которую мы хотим обсудить». Джон Хогеленд добавил, что «одного понимания слов недостаточно; вам также необходимо разбираться в теме разговора». Чтобы пройти хорошо поставленный тест Тьюринга, машина должна использовать естественный язык, рассуждать, иметь познания и обучаться. Тест можно усложнить, включив ввод с помощью видео, или, например, оборудовав шлюз для передачи предметов: машине придётся продемонстрировать способность к зрению и робототехнике. Все эти задачи вместе отражают основные проблемы, стоящие перед теорией об искусственном интеллекте.
Недостатки теста
Несмотря на все свои достоинства и известность, тест критикуют на нескольких основаниях.
Человеческий разум и разум вообще
Направленность теста Тьюринга ярко выражена в сторону человека (антропоморфизм). Проверяется только способность машины походить на человека, а не разумность машины вообще. Тест неспособен оценить общий интеллект машины по двум причинам:
- Иногда поведение человека не поддается разумному толкованию. В это же время тест Тьюринга требует, чтобы машина была способна имитировать все виды человеческого поведения, не обращая внимания на то, насколько оно разумно. Он также проверяет способность имитировать такое поведение, какое человек за разумное и не посчитает, например, реакция на оскорбления, соблазн соврать или просто большое количество опечаток. Если машина неспособна с точностью до деталей имитировать поведение человека, опечатки и все такое, то она не проходит тест, несмотря на весь тот интеллект, которым она может обладать.
- Некоторое разумное поведение не присуще человеку. Тест Тьюринга не проверяет высокоинтеллектуальное поведение, например, способность решать сложные задачи или выдвигать оригинальные идеи. По сути, тест требует, чтобы машина обманывала: какой бы умной ни была машина, она должна притворяться не слишком умной, чтобы пройти тест. Если же машина способна быстро решить некую вычислительную задачу, непосильную для человека, она по определению провалит тест.
Непрактичность
Стюарт Рассел (Stuart Russel) и Питер Норвиг (Peter Norvig) утверждают, что антропоморфизм теста приводит к тому, что он не может быть по-настоящему полезным при разработке разумных машин. "Тексты по авиационному проектированию и строительству, — строят они аналогию, — не ставят целью своей отрасли «создание машин, которые летают точно так же, как летают голуби, что даже сами голуби принимают их за своих». Из-за этой непрактичности прохождение теста Тьюринга не является целью ведущих научных или коммерческих исследований (по состоянию на 2009). Сегодняшние исследования в области искусственного интеллекта ставят перед собой более скромные и специфические цели.
«Исследователи в области искусственного интеллекта уделяют мало внимания прохождению теста Тьюринга», — отмечают Рассел и Норвиг, — с тех пор как появились более простые способы проверки программ, например, дать задание напрямую, а не окольными путями, первой обозначить некоторый вопрос в чат-комнате, к которой подключены и машины, и люди. Тьюринг никогда не предполагал использовать свой тест на практике, в повседневном измерении степени разумности программ; он хотел дать ясный и понятный пример, для поддержки обсуждения философии искусственного интеллекта.
Реальный интеллект и имитируемый интеллект
Также тест Тьюринга явно бихевиористичен или функционалистичен: он лишь проверяет, как действует субъект. Машина, проходящая тест, может имитировать поведение человека в разговоре, просто «неинтеллектуально» следуя механическим правилам. Двумя известными контрпримерами, выражающими данную точку зрения являются «Китайская комната» Сёрля (1980) и «Болван» Неда Блока (Ned Block, 1981). По мнению Сёрля основной проблемой является определить, «имитирует» ли машина мышление, или «на самом деле» мыслит. Даже если тест Тьюринга и является годным для определения наличия интеллекта, Сёрль отмечает, что тест не покажет, что у машины есть разум, сознание, возможность «понимать» или иметь цели, которые имеют какой-то смысл (философы называют это целеполаганием).
В своей работе Тьюринг писал по поводу этих аргументов следующее: «Я не хочу создать впечатление, будто я думаю, что у сознания нет никакой загадки. Существует, например, своего рода парадокс, связанный с любой попыткой определить его местонахождение. Но я не думаю, что эти загадки обязательно надо разгадать до того, как мы сможем ответить на вопрос, которому посвящена данная работа».
Предсказания
Тьюринг прогнозировал, что машины, в конце концов, будут способны пройти тест; фактически он ожидал, что к 2000 году, машины с объемом памяти 109 бит (около 119,2 МиБ или 125 МБ) будут способны обманывать 30 % судей по результатам пятиминутного теста. Также он высказал мысль о том, что словосочетание «думающая машина» больше не будет считаться оксюмороном. Далее он предположил, что машинное обучение будет важным звеном в построении мощных машин, что является правдоподобным среди современных исследователей в области искусственного интеллекта.
Экстраполируя экспоненциальный рост уровня технологии в течение нескольких десятилетий, футурист Рэймонд Курцвейл предположил, что машины, способные пройти тест Тьюринга, будут изготовлены, грубо говоря, около 2020 года. Это перекликается с законом Мура.
В проект Long Bet Project входит пари стоимостью 20 000 $ между Митчем Капуром (Mitch Kapor — пессимист) и Рэймондом Курцвейлом (оптимист). Смысл пари: пройдет ли компьютер тест Тьюринга к 2029 году? Определены также некоторые условия пари.[1]
Вариации теста Тьюринга
Многочисленные версии теста Тьюринга, включая описанные ранее, уже обсуждаются довольно долгое время.
Обратный тест Тьюринга и CAPTCHA
Модификация теста Тьюринга, в которой цель или одну или более ролей машины и человека поменяли местами, называется обратным тестом Тьюринга. Пример этого теста приведен в работе психоаналитика Уилфреда Биона (Wilfred Bion), который был в особенности восхищен тем, как активизируется мыслительная активность при столкновении с другим разумом.
Развивая эту идею, Р. Д. Хиншелвуд (R. D. Hinshelwood) описал разум как «аппарат, распознающий разум», отметив, что это можно считать как бы «дополнением» к тесту Тьюринга. Теперь задачей компьютера будет определить с кем он беседовал: с человеком или же с другим компьютером. Именно на это дополнение к вопросу и пытался ответить Тьюринг, но, пожалуй, оно вводит достаточно высокий стандарт на то, чтобы определить, может ли машина «думать» так, как мы обычно относим это понятие к человеку.
CAPTCHA — это разновидность обратного теста Тьюринга. Перед тем как разрешить выполнение некоторого действия на сайте, пользователю выдается искаженное изображение с набором цифр и букв и предложение ввести этот набор в специальное поле. Цель этой операции — предотвратить атаки автоматических систем на сайт. Обоснованием подобной операции является то, что пока не существует программ достаточно мощных для того, чтобы распознать и точно воспроизвести текст с искаженного изображения (или они недоступны простым пользователям), поэтому считается, что система, которая смогла это сделать, с высокой вероятностью может считаться человеком. Выводом будет (хотя и не обязательно), что искусственный интеллект пока не создан.
Тест Тьюринга со специалистом
Эта вариация теста описывается следующим образом: ответ машины не должен отличаться от ответа эксперта (специалиста) в определенной области. По мере развития технологий по сканированию тела и мозга человека станет возможным копировать необходимую информацию из человека в компьютер.
Тест бессмертия
Тест бессмертия — это вариация теста Тьюринга, которая определяет, качественно ли передан характер человека, а именно невозможно ли отличить скопированный характер от человека, послужившего его источником.
Минимальный интеллектуальный Signal-тест (MIST)
MIST предложен Крисом Мак-Кинстри (Chris McKinstry). В этой вариации теста Тьюринга разрешены лишь два типа ответов — «да» и «нет». Обычно MIST используют для сбора статистической информации, с помощью которой можно измерить производительность программ, реализующих искусственный интеллект.
Мета-тест Тьюринга
В этой вариации теста субъект (скажем, компьютер) считают разумным, если он создал нечто, что он сам хочет проверить на разумность.
Премия Хаттера
Организаторы премии Хаттера считают, что сжатие текста на естественном языке является трудной задачей для искусственного интеллекта, эквивалентной прохождению теста Тьюринга.
Тест по сжатию информации имеет определенные преимущества над большей частью вариантов и вариаций теста Тьюринга:
- Его результатом является единственное число, по которому можно судить какая из двух машин «более разумная».
- Не требуется, чтобы компьютер врал судье — учить компьютеры врать считают плохой идеей.
Основными недостатками подобного теста являются:
- С его помощью невозможно протестировать человека.
- Неизвестно какой результат (и есть ли он вообще) эквивалентен прохождению теста Тьюринга (на уровне человека).
Другие тесты интеллекта
Существует множество тестов на уровень интеллекта, которые используют для тестирования людей. Возможно, что их можно использовать для тестирования искусственного интеллекта. Некоторые тесты (например, Си-тест), выведенные из «Колмогоровской сложности», используются для проверки людей и компьютеров.
См. также
Ссылки
Литература
Примечания
- ↑ Long Bets - By 2029 no computer - or "machine intelligence" - will have passed the Turing Test
ca:Test de Turing cs:Turingův test da:Turing-test de:Turing-Test en:Turing test eo:Testo de Turing es:Test de Turing et:Turingi test fa:آزمون تورینگ fi:Turingin testi fr:Test de Turing gl:Proba de Turing he:מבחן טיורינג hr:Turingov test hu:Turing-teszt is:Turingpróf it:Test di Turing ja:チューリング・テスト ko:튜링 테스트 lt:Tiuringo testas lv:Tjūringa tests nl:Turing-test no:Turingtest pl:Test Turinga pt:Teste de Turing ro:Testul Turing simple:Turing test sk:Turingov test sr:Тјурингов тест sv:Turingtest th:การทดสอบของทัวริง tr:Turing Testi uk:Тест Тюрінга zh:圖靈試驗
www.sbup.com














